PyTorch示例——使用Transformer写古诗
文章目录
- PyTorch示例——使用Transformer写古诗
- 1. 前言
- 2. 版本信息
- 3. 导包
- 4. 数据与预处理
- 数据下载
- 先看一下原始数据
- 开始处理数据,过滤掉异常数据
- 定义 词典编码器 Tokenizer
- 定义数据集类 MyDataset
- 测试一下MyDataset、Tokenizer、DataLoader
- 5. 构建模型
- 位置编码器 PositionalEncoding
- 古诗 Transformer 模型
- 6. 开始训练
- 7. 推理
- 直接推理
- 为推理添加随机性
- 8. 更多学习资料
PyTorch示例——使用Transformer写古诗
1. 前言
- 很早、很早以前,在TensorFlow2 学习——RNN生成古诗词_rnn古诗生成头词汇是 “ 日 、 红 、 山 、 夜 、 湖、 海 、 月 。-CSDN博客中已使用TensorFlow+RNN的方式实现过写古诗的功能,现在来个Pytorch+Transformer的示例😄
- 数据处理逻辑和前面博文中大致相似,本文中就不再赘述
- Kaggle Notebook地址: PyTorch示例-使用Transformer写古诗x
2. 版本信息
- PyTorch:
2.1.2 - Python:
3.10.13
3. 导包
import math
import numpy as np
from collections import Counter
import torch
from torch import nn
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import tqdm
import random
import sysprint("Pytorch 版本:", torch.__version__)
print("Python 版本:", sys.version)
Pytorch 版本: 2.1.2
Python 版本: 3.10.13 | packaged by conda-forge | (main, Dec 23 2023, 15:36:39) [GCC 12.3.0]
4. 数据与预处理
数据下载
- 度盘: https://pan.baidu.com/s/1HIROi4mPMv0RBWHIHvUDVg,提取码:b2pp
- Kaggle:https://www.kaggle.com/datasets/alionsss/poetry
先看一下原始数据
# 数据路径
DATA_PATH = '/kaggle/input/poetry/poetry.txt'# 先看下原始数据,每一行格式为"诗的标题:诗的内容"
with open(DATA_PATH, 'r', encoding='utf-8') as f:lines = f.readlines()for i in range(0, 5):print(lines[i])print(f"origin_line_count = {len(lines)}")
首春:寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。初晴落景:晚霞聊自怡,初晴弥可喜。日晃百花色,风动千林翠。池鱼跃不同,园鸟声还异。寄言博通者,知予物外志。初夏:一朝春夏改,隔夜鸟花迁。阴阳深浅叶,晓夕重轻烟。哢莺犹响殿,横丝正网天。珮高兰影接,绶细草纹连。碧鳞惊棹侧,玄燕舞檐前。何必汾阳处,始复有山泉。度秋:夏律昨留灰,秋箭今移晷。峨嵋岫初出,洞庭波渐起。桂白发幽岩,菊黄开灞涘。运流方可叹,含毫属微理。仪鸾殿早秋:寒惊蓟门叶,秋发小山枝。松阴背日转,竹影避风移。提壶菊花岸,高兴芙蓉池。欲知凉气早,巢空燕不窥。origin_line_count = 43030
开始处理数据,过滤掉异常数据
# 单行诗最大长度
MAX_LEN = 64
MIN_LEN = 5
# 禁用的字符,拥有以下符号的诗将被忽略
DISALLOWED_WORDS = ['(', ')', '(', ')', '__', '《', '》', '【', '】', '[', ']', '?', ';']# 一首诗(一行)对应一个列表的元素
poetry = []# 按行读取数据 poetry.txt
with open(DATA_PATH, 'r', encoding='utf-8') as f:lines = f.readlines()
# 遍历处理每一条数据
for line in lines:# 利用正则表达式拆分 标题 和 内容fields = line.split(":")# 跳过异常数据if len(fields) != 2:continue# 得到诗词内容(后面不需要标题)content = fields[1]# 过滤数据:跳过内容过长、过短、存在禁用符的诗词if len(content) > MAX_LEN - 2 or len(content) < MIN_LEN:continueif any(word in content for word in DISALLOWED_WORDS):continuepoetry.append(content.replace('\n', '')) # 最后要记得删除换行符
for i in range(0, 5):print(poetry[i])print(f"current_line_count = {len(poetry)}")
寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。
晚霞聊自怡,初晴弥可喜。日晃百花色,风动千林翠。池鱼跃不同,园鸟声还异。寄言博通者,知予物外志。
夏律昨留灰,秋箭今移晷。峨嵋岫初出,洞庭波渐起。桂白发幽岩,菊黄开灞涘。运流方可叹,含毫属微理。
寒惊蓟门叶,秋发小山枝。松阴背日转,竹影避风移。提壶菊花岸,高兴芙蓉池。欲知凉气早,巢空燕不窥。
山亭秋色满,岩牖凉风度。疏兰尚染烟,残菊犹承露。古石衣新苔,新巢封古树。历览情无极,咫尺轮光暮。
current_line_count = 24375
- 过滤掉出现频率较低的字符串,后面统一当作 UNKNOWN
# 最小词频
MIN_WORD_FREQUENCY = 8# 统计词频,利用Counter可以直接按单个字符进行统计词频
counter = Counter()
for line in poetry:counter.update(line)
# 过滤掉低词频的词
tokens = [token for token, count in counter.items() if count >= MIN_WORD_FREQUENCY]
# 打印一下出现次数前5的字
for i, (token, count) in enumerate(counter.items()):print(token, "->",count)if i >= 4:break;
寒 -> 2612
随 -> 1036
穷 -> 482
律 -> 118
变 -> 286
定义 词典编码器 Tokenizer
class Tokenizer:"""词典编码器"""UNKNOWN = "<unknown>"PAD = "<pad>"BOS = "<bos>" EOS = "<eos>" def __init__(self, tokens):# 补上特殊词标记:开始标记、结束标记、填充字符标记、未知词标记tokens = [Tokenizer.UNKNOWN, Tokenizer.PAD, Tokenizer.BOS, Tokenizer.EOS] + tokens# 词汇表大小self.dict_size = len(tokens)# 生成映射关系self.token_id = {} # 映射: 词 -> 编号self.id_token = {} # 映射: 编号 -> 词for idx, word in enumerate(tokens):self.token_id[word] = idxself.id_token[idx] = word# 各个特殊标记的编号id,方便其他地方使用self.unknown_id = self.token_id[Tokenizer.UNKNOWN]self.pad_id = self.token_id[Tokenizer.PAD]self.bos_id = self.token_id[Tokenizer.BOS]self.eos_id = self.token_id[Tokenizer.EOS]def id_to_token(self, token_id):"""编号 -> 词"""return self.id_token.get(token_id)def token_to_id(self, token):"""词 -> 编号,取不到时给 UNKNOWN"""return self.token_id.get(token, self.unknown_id)def encode(self, tokens):"""词列表 -> <bos>编号 + 编号列表 + <eos>编号"""token_ids = [self.bos_id, ] # 起始标记# 遍历,词转编号for token in tokens:token_ids.append(self.token_to_id(token))token_ids.append(self.eos_id) # 结束标记return token_idsdef decode(self, token_ids):"""编号列表 -> 词列表(去掉起始、结束标记)"""tokens = []for idx in token_ids:# 跳过起始、结束标记if idx != self.bos_id and idx != self.eos_id:tokens.append(self.id_to_token(idx))return tokensdef __len__(self):return self.dict_size
定义数据集类 MyDataset
class MyDataset(TensorDataset):def __init__(self, data, tokenizer, max_length=64):self.data = dataself.tokenizer = tokenizerself.max_length = max_length # 每条数据的最大长度def __getitem__(self, index):line = self.data[index]word_ids = self.encode_pad_line(line)return torch.LongTensor(word_ids)def __len__(self):return len(self.data)def encode_pad_line(self, line):# 编码word_ids = self.tokenizer.encode(line)# 如果句子长度不足max_length,填充PADword_ids = word_ids + [tokenizer.pad_id] * (self.max_length - len(word_ids))return word_ids
测试一下MyDataset、Tokenizer、DataLoader
- 使用 MyDataset、Tokenizer
# 实例化 Tokenizer
tokenizer = Tokenizer(tokens)
print("tokenizer_len: ",len(tokenizer))# 实例化MyDataset
my_dataset = MyDataset(poetry, tokenizer)
one_line_id = my_dataset[0].tolist()
print("one_line_id: ", one_line_id)# 解码
poetry_line = tokenizer.decode(one_line_id)
print("poetry_line: ","".join([w for w in poetry_line if w != Tokenizer.PAD]))
tokenizer_len: 3428
one_line_id: [2, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 9, 21, 22, 23, 24, 25, 15, 26, 27, 28, 29, 30, 9, 31, 32, 33, 34, 35, 15, 36, 37, 16, 38, 39, 9, 40, 41, 42, 43, 44, 15, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
poetry_line: 寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。
- 使用 DataLoader
# 读取一批数据,并解码
temp_dataloader = DataLoader(dataset=my_dataset, batch_size=8, shuffle=True)one_batch_data = next(iter(temp_dataloader))for poetry_line_id in one_batch_data.tolist():poetry_line = tokenizer.decode(poetry_line_id)print("".join([w for w in poetry_line if w != Tokenizer.PAD]))
曲江春草生,紫阁雪分明。汲井尝泉味,听钟问寺名。墨研秋日雨,茶试老僧<unknown>。地近劳频访,乌纱出送迎。
旧隐无何别,归来始更悲。难寻白道士,不见惠禅师。草径虫鸣急,沙渠水下迟。却将波浪眼,清晓对红梨。
举世皆问人,唯师独求己。一马无四蹄,顷刻行千里。应笑北原上,丘坟乱如蚁。
海燕西飞白日斜,天门遥望五侯家。楼台深锁无人到,落尽春风第一花。
良人犹远戍,耿耿夜闺空。绣户流宵月,罗帷坐晓风。魂飞沙帐北,肠断玉关中。尚自无消息,锦衾那得同。
天涯片云去,遥指帝乡忆。惆怅增暮情,潇湘复秋色。扁舟宿何处,落日羡归翼。万里无故人,江鸥不相识。
宝鸡辞旧役,仙凤历遗墟。去此近城阙,青山明月初。
夜帆时未发,同侣暗相催。山晓月初下,江鸣潮欲来。稍分扬子岸,不辨越王台。自客水乡里,舟行知几回。
5. 构建模型
位置编码器 PositionalEncoding
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=2000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)# 初始化Shape为(max_len, d_model)的PE (positional encoding)pe = torch.zeros(max_len, d_model)# 初始化一个tensor [[0, 1, 2, 3, ...]]position = torch.arange(0, max_len).unsqueeze(1)# 这里就是sin和cos括号中的内容,通过e和ln进行了变换div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))# 计算PE(pos, 2i)pe[:, 0::2] = torch.sin(position * div_term)# 计算PE(pos, 2i+1)pe[:, 1::2] = torch.cos(position * div_term)# 为了方便计算,在最外面在unsqueeze出一个batchpe = pe.unsqueeze(0)# 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来,这个时候就可以用register_bufferself.register_buffer("pe", pe)def forward(self, x):"""x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128"""# 将x和positional encoding相加。x = x + self.pe[:, : x.size(1)].requires_grad_(False)return self.dropout(x)
古诗 Transformer 模型
class PoetryModel(nn.Module):def __init__(self, num_embeddings = 4096, embedding_dim=128):super(PoetryModel, self).__init__()# Embedding层self.embedding = nn.Embedding(num_embeddings=num_embeddings, embedding_dim=embedding_dim)# 定义Transformerself.transformer = nn.Transformer(d_model=embedding_dim, num_encoder_layers=3, num_decoder_layers=3, dim_feedforward=512)# 定义位置编码器self.positional_encoding = PositionalEncoding(embedding_dim, dropout=0)# 线性层输出需要和原始词典的字符编号范围对应self.predictor = nn.Linear(embedding_dim, num_embeddings)def forward(self, src, tgt):# 生成 Masktgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size()[-1]).to(DEVICE)src_key_padding_mask = PoetryModel.get_key_padding_mask(src).to(DEVICE)tgt_key_padding_mask = PoetryModel.get_key_padding_mask(tgt).to(DEVICE)# 编码src = self.embedding(src)tgt = self.embedding(tgt)# 增加位置信息src = self.positional_encoding(src)tgt = self.positional_encoding(tgt)# 喂数据给 Transformer# permute(1, 0, 2) 切换成 批次 在中间维度的形式,因为没有设置batch_firstout = self.transformer(src.permute(1, 0, 2), tgt.permute(1, 0, 2),tgt_mask=tgt_mask,src_key_padding_mask=src_key_padding_mask,tgt_key_padding_mask=tgt_key_padding_mask)# 训练和推理时的行为不一样,在该模型外再进行线性层的预测return out@staticmethoddef get_key_padding_mask(tokens):key_padding_mask = torch.zeros(tokens.size())key_padding_mask[tokens == Tokenizer.PAD] = float('-inf')return key_padding_mask
6. 开始训练
- 准备参数、数据、模型
# 参数配置
EPOCH_NUM = 50
BATCH_SIZE = 64 # 内存不够的话,就把BATCH_SIZE调小点
DICT_SIZE = len(tokenizer)
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# 数据
my_dataset = MyDataset(poetry, tokenizer)
train_dataloader = DataLoader(dataset=my_dataset, batch_size=BATCH_SIZE, shuffle=True)# 模型
model = PoetryModel(num_embeddings=DICT_SIZE).to(DEVICE)
criteria = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4)print(model)
PoetryModel((embedding): Embedding(3428, 128)(transformer): Transformer((encoder): TransformerEncoder((layers): ModuleList((0-2): 3 x TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=512, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)))(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True))(decoder): TransformerDecoder((layers): ModuleList((0-2): 3 x TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=512, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False)))(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)))(positional_encoding): PositionalEncoding((dropout): Dropout(p=0, inplace=False))(predictor): Linear(in_features=128, out_features=3428, bias=True)
)
- 训练
for epoch in range(1, EPOCH_NUM + 1):model.train()total_loss = 0data_progress = tqdm.tqdm(train_dataloader, desc="Train...")for step, data in enumerate(data_progress, 1):data = data.to(DEVICE)# 随机选一个位置,拆分src和tgte = random.randint(1, 20)src = data[:, :e]# tgt不要最后一个token,tgt_y不要第一个的tokentgt, tgt_y = data[:, e:-1], data[:, e + 1:]# 进行Transformer的计算,再将结果送给最后的线性层进行预测out = model(src, tgt)out = model.predictor(out)# 使用view时,前面的数据必须是在内存连续的(即is_contiguous()为true)# 使用permute后,会导致数据不是内存连续的(即is_contiguous()为false),需要先调用contiguous(),才能继续使用viewloss = criteria(out.view(-1, out.size(-1)), tgt_y.permute(1, 0).contiguous().view(-1))optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()# 更新训练进度data_progress.set_description(f"Train... [epoch {epoch}/{EPOCH_NUM}, loss {(total_loss / step):.5f}]")
Train... [epoch 1/50, loss 3.66444]: 100%|██████████| 381/381 [00:10<00:00, 35.40it/s]
Train... [epoch 2/50, loss 3.35216]: 100%|██████████| 381/381 [00:09<00:00, 39.61it/s]
Train... [epoch 3/50, loss 3.27860]: 100%|██████████| 381/381 [00:09<00:00, 39.44it/s]
Train... [epoch 4/50, loss 3.15286]: 100%|██████████| 381/381 [00:09<00:00, 39.10it/s]
Train... [epoch 5/50, loss 3.05621]: 100%|██████████| 381/381 [00:09<00:00, 39.32it/s]
Train... [epoch 6/50, loss 2.97613]: 100%|██████████| 381/381 [00:09<00:00, 39.42it/s]
Train... [epoch 7/50, loss 2.91857]: 100%|██████████| 381/381 [00:09<00:00, 38.83it/s]
Train... [epoch 8/50, loss 2.88052]: 100%|██████████| 381/381 [00:09<00:00, 39.59it/s]
Train... [epoch 9/50, loss 2.78789]: 100%|██████████| 381/381 [00:09<00:00, 39.19it/s]
Train... [epoch 10/50, loss 2.77379]: 100%|██████████| 381/381 [00:09<00:00, 38.24it/s]
......
Train... [epoch 41/50, loss 2.25991]: 100%|██████████| 381/381 [00:09<00:00, 39.89it/s]
Train... [epoch 42/50, loss 2.24437]: 100%|██████████| 381/381 [00:09<00:00, 39.72it/s]
Train... [epoch 43/50, loss 2.23779]: 100%|██████████| 381/381 [00:09<00:00, 39.09it/s]
Train... [epoch 44/50, loss 2.25092]: 100%|██████████| 381/381 [00:09<00:00, 39.16it/s]
Train... [epoch 45/50, loss 2.23653]: 100%|██████████| 381/381 [00:09<00:00, 39.90it/s]
Train... [epoch 46/50, loss 2.20175]: 100%|██████████| 381/381 [00:09<00:00, 39.51it/s]
Train... [epoch 47/50, loss 2.22046]: 100%|██████████| 381/381 [00:09<00:00, 39.83it/s]
Train... [epoch 48/50, loss 2.20892]: 100%|██████████| 381/381 [00:09<00:00, 39.84it/s]
Train... [epoch 49/50, loss 2.22276]: 100%|██████████| 381/381 [00:09<00:00, 39.35it/s]
Train... [epoch 50/50, loss 2.20212]: 100%|██████████| 381/381 [00:09<00:00, 39.75it/s]
7. 推理
直接推理
model.eval()
with torch.no_grad():word_ids = tokenizer.encode("清明时节")src = torch.LongTensor([word_ids[:-2]]).to(DEVICE)tgt = torch.LongTensor([word_ids[-2:-1]]).to(DEVICE)# 一个一个词预测,直到预测为<eos>,或者达到句子最大长度for i in range(64):out = model(src, tgt)# 预测结果,只需最后一个词predict = model.predictor(out[-1:])# 找出最大值的indexy = torch.argmax(predict, dim=2)# 和之前的预测结果拼接到一起tgt = torch.cat([tgt, y], dim=1)# 如果为<eos>if y == tokenizer.eos_id:breaksrc_decode = "".join([w for w in tokenizer.decode(src[0].tolist()) if w != Tokenizer.PAD])print(f"src = {src}, src_decode = {src_decode}")tgt_decode = "".join([w for w in tokenizer.decode(tgt[0].tolist()) if w != Tokenizer.PAD])print(f"tgt = {tgt}, tgt_decode = {tgt_decode}")
src = tensor([[ 2, 403, 235, 293]], device='cuda:0'), src_decode = 清明时
tgt = tensor([[ 197, 9, 571, 324, 571, 116, 14, 15, 61, 770, 158, 514,934, 9, 228, 293, 493, 1108, 44, 15, 3]],device='cuda:0'), tgt_decode = 节,一夜一枝开。不是无人见,何时有鹤来。
为推理添加随机性
def predict(model, src, tgt):out = model(src, tgt)# 预测结果,只需最后一个词# 取3:,表示预测结果不要UNKNOWN、PAD、BOS_probas = model.predictor(out[-1:])[0, 0, 3:]_probas = torch.exp(_probas) / torch.exp(_probas).sum() # softmax,让概率高的变得更高,便于待会儿按概率抽取时更容易抽取到概率高的# 取前10,再按概率分布抽取1个(提高诗词随机性)values, indices = torch.topk(_probas, 10, dim=0)target_index = torch.multinomial(values, 1, replacement=True)y = indices[target_index]# +3,因为之前移除掉了UNKNOWN、PAD、BOSreturn y + 3
def generate_random_poem(tokenizer, model, text):"""随机生成一首诗、自动续写"""if text == None or text == "":text = tokenizer.id_to_token(random.randint(4, len(tokenizer)))model.eval()with torch.no_grad():word_ids = tokenizer.encode(text)src = torch.LongTensor([word_ids[:-2]]).to(DEVICE)tgt = torch.LongTensor([word_ids[-2:-1]]).to(DEVICE)# 一个一个词预测,直到预测为<eos>,或者达到句子最大长度for i in range(64):y = predict(model, src, tgt)# 和之前的预测结果拼接到一起tgt = torch.cat([tgt, y.view(1, 1)], dim=1)# 如果为<eos>if y == tokenizer.eos_id:break# src_decode = "".join([w for w in tokenizer.decode(src[0].tolist()) if w != Tokenizer.PAD])# print(f"src = {src}, src_decode = {src_decode}")# tgt_decode = "".join([w for w in tokenizer.decode(tgt[0].tolist()) if w != Tokenizer.PAD])# print(f"tgt = {tgt}, tgt_decode = {tgt_decode}")result = torch.cat([src, tgt], dim=1)result_decode = "".join([w for w in tokenizer.decode(result[0].tolist()) if w != Tokenizer.PAD])return result_decodefor i in range(0, 5):poetry_line = generate_random_poem(tokenizer, model, "清明")print(poetry_line)
清明日已长安,不独为君一病身。唯有诗人知处在,更愁人夜月明。
清明月在何时,夜久山川有谁。今日不知名利处,一枝花落第花枝。
清明月上,风急水声。山月随人远,天河度陇平。水深秋月在,江远夜砧迎。莫问东楼兴,空怀不可情。
清明夜夜月,秋月满池塘。夜坐中琴月,空阶下菊香。风回孤枕月,月冷一枝香。惆怅江南客,明朝是此中。
- 生成藏头诗的代码,请参考之前写的文章 TensorFlow2 学习——RNN生成古诗词_rnn古诗生成头词汇是 “ 日 、 红 、 山 、 夜 、 湖、 海 、 月 。-CSDN博客
8. 更多学习资料
- 相关文章
- https://blog.csdn.net/zhaohongfei_358/article/details/126019181
- https://blog.csdn.net/zhaohongfei_358/article/details/122861751
- https://zhuanlan.zhihu.com/p/554013449
- 相关视频
- https://www.bilibili.com/video/BV1Wv411h7kN?p=38
- https://www.bilibili.com/video/BV1Wv411h7kN/?p=49
- PyTorch官方
- https://pytorch.org/tutorials/beginner/transformer_tutorial.html
相关文章:
PyTorch示例——使用Transformer写古诗
文章目录 PyTorch示例——使用Transformer写古诗1. 前言2. 版本信息3. 导包4. 数据与预处理数据下载先看一下原始数据开始处理数据,过滤掉异常数据定义 词典编码器 Tokenizer定义数据集类 MyDataset测试一下MyDataset、Tokenizer、DataLoader 5. 构建模型位置编码器…...
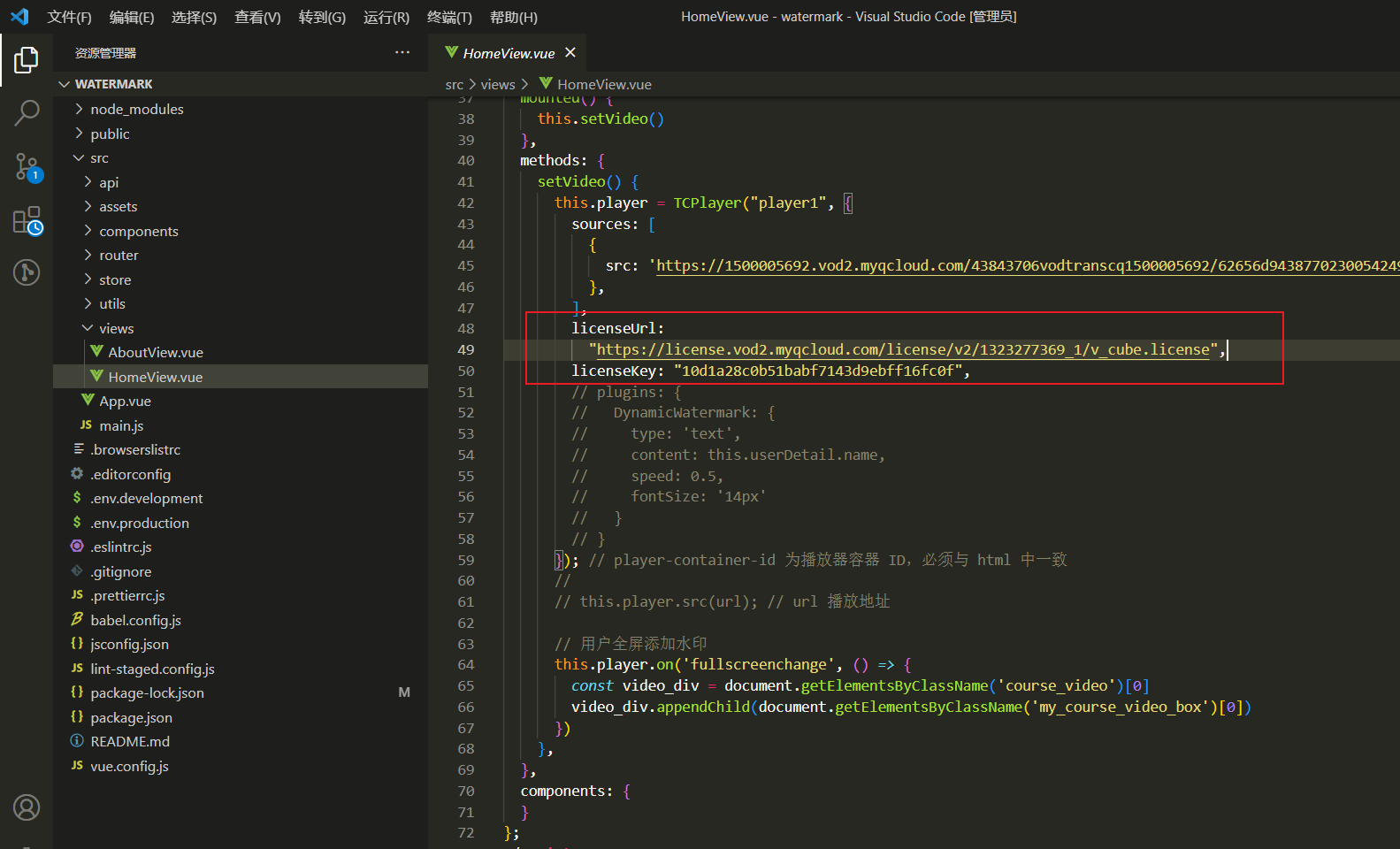
vue 视频添加水印
1.需求背景 其实腾讯云点播的api也支持视频水印,但是只有单个水印,大概效果是这样子的,不满足我们的需求,我们的需求是需要视频中都是水印。 腾讯云点播水印 项目需求的水印(主要是防录屏,最后的实现效果是这样&…...
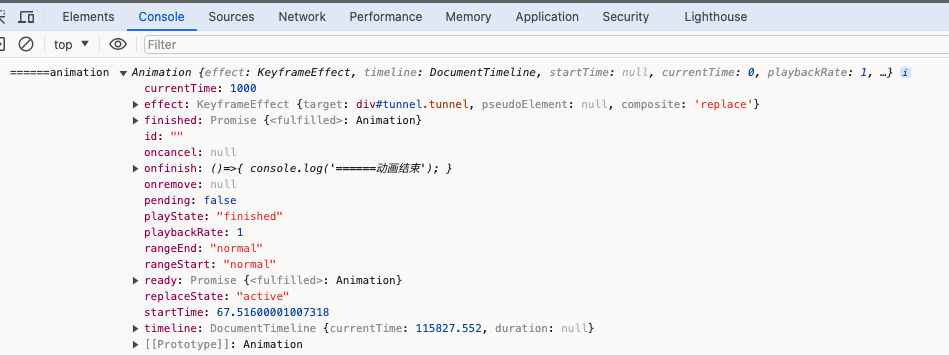
Web Animations API 动画
Element.animate() dom.animate动画可以避免污染dom原有的css动画 参考资料 Element.animate() - Web API 接口参考 | MDN Element: getAnimations() method - Web APIs | MDN .tunnel{width:200px;height:200px;background-color:#38f;}<div class"tunnel" …...
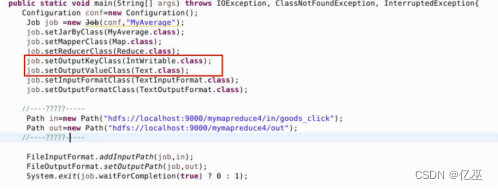
【大数据存储】实验五:Mapreduce
实验Mapreduce实例——排序(补充程序) 实验环境 Linux Ubuntu 16.04 jdk-8u191-linux-x64 hadoop-3.0.0 hadoop-eclipse-plugin-2.7.3.jar eclipse-java-juno-SR2-linux-gtk-x86_64 实验内容 在电商网站上,当我们进入某电商页面里浏览…...

日志服务 HarmonyOS NEXT 日志采集最佳实践
作者:高玉龙(元泊) 背景信息 随着数字化新时代的全面展开以及 5G 与物联网(IoT)技术的迅速普及,操作系统正面临前所未有的变革需求。在这个背景下,华为公司自主研发的鸿蒙操作系统(…...
 (C dp D前缀和优化倍数关系dp))
Educational Codeforces Round 133 (Rated for Div. 2) (C dp D前缀和优化倍数关系dp)
A:能用3肯定用三,然后分类讨论即可 #include<bits/stdc.h> using namespace std; const int N 2e510,M2*N,mod998244353; #define int long long typedef long long LL; typedef pair<int, int> PII; typedef unsigned long long ULL; usi…...

【讲解下如何Stable Diffusion本地部署】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
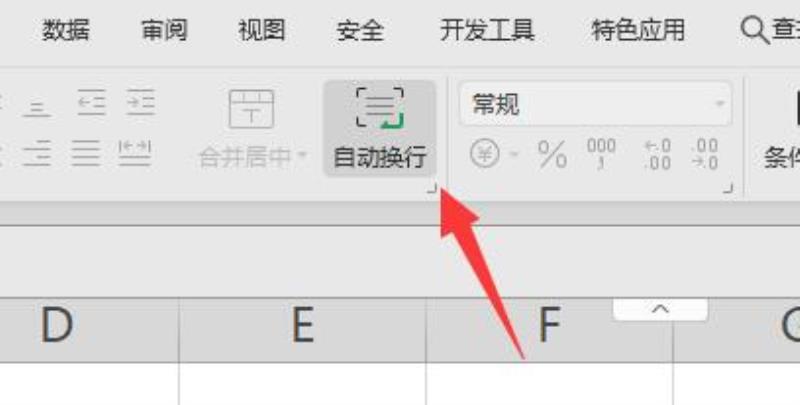
wps斜线表头并分别打字教程
wps斜线表头怎么做并分别打字: 1、首先选中我们想要设置的表头。 2、接着右键选中它,点击“设置单元格格式” 3、然后点击上方“边框”选项卡。 4、随后选择图示的斜线,点击“确定” 5、设置完成后,我们只要在其中打字就可以在斜…...

2024第八届全国青少年无人机大赛暨中国航空航天科普展览会
2024第八届全国青少年无人机大赛暨中国航空航天科普展览会 邀请函 主办单位: 中国航空学会 重庆市南岸区人民政府 招商执行单位: 重庆港华展览有限公司 为更好的培养空航天产业人才,汇聚航空教育产业创新科技,丰富和完善航…...

fastadmin学习08-查询数据渲染到前端
index.php查询,这个是前台的index.php public function index() {$slideImgs Db::name("slideimg")->where("status",,normal)->limit(5)->order(sort,desc)->select();$productList Db::name("product")->where(…...

实验报告答案
基本任务(必做) 先用普通用户(自己的姓名拼音)登录再操作 编程有代码截图和执行过程结果截图 代写获取: https://laowangall.oss-cn-beijing.aliyuncs.com/studentall.pdf 1. Linux的Shell编程 (1&am…...

PDF编辑和格式转换工具 Cisdem PDFMaster for Mac
Cisdem PDFMaster for Mac是一款功能强大的PDF编辑和格式转换工具。它为用户提供了直观且易于使用的界面,使常用功能触手可及,从而帮助用户轻松管理、编辑和转换PDF文件。 软件下载:Cisdem PDFMaster for Mac v6.0.0激活版下载 作为一款完整的…...

E-魔法猫咪(遇到过的题,做个笔记)
题解: 来自学长们思路: 其中一种正解是写单调队列。限制队列内的数单调递增,方法为每当新来的数据比当前队尾数据小时队 尾出列,直到能够插入当前值,这保证了队头永远是最小值。因此总体思路是队尾不断插入新值的同时 …...
keil创建工程 芯源半导体CW32F003E4P7
提前下载keil 安装步骤 1、下载CW32F003固件库 芯源半导体官网下载固件库 下载好后右键解压 CW32F003_StandardPeripheralLib_V1.5\IdeSupport\MDK 进入MDK文件夹 双击WHXY.CW32F003_DFP.1.0.4.pack安装固件库 点击next然后finish安装结束 keil创建工程 点击new uVision P…...
学习鸿蒙基础(12)
目录 一、网络json-server配置 (1)然后输入: (2)显示下载成功。但是输入json-server -v的时候。报错。 (3)此时卸载默认的json-server (4)安装和nodejs匹配版本的js…...

HTML5和CSS3笔记
一:网页结构(html): 1.1:页面结构: 1.2:标签类型: 1.2.1:块标签: 1.2.2:行内标签: 1.2.3:行内块标签: 1.2.4:块标签与行…...

MHA高可用-解决MySQL主从复制的单点问题
目录 一、MHA的介绍 1.什么是 MHA 2.MHA 的组成 2.1 MHA Node(数据节点) 2.2 MHA Manager(管理节点) 3.MHA 的特点 4. MHA工作原理总结如下: 二、搭建 MySQL MHA 实验环境 …...
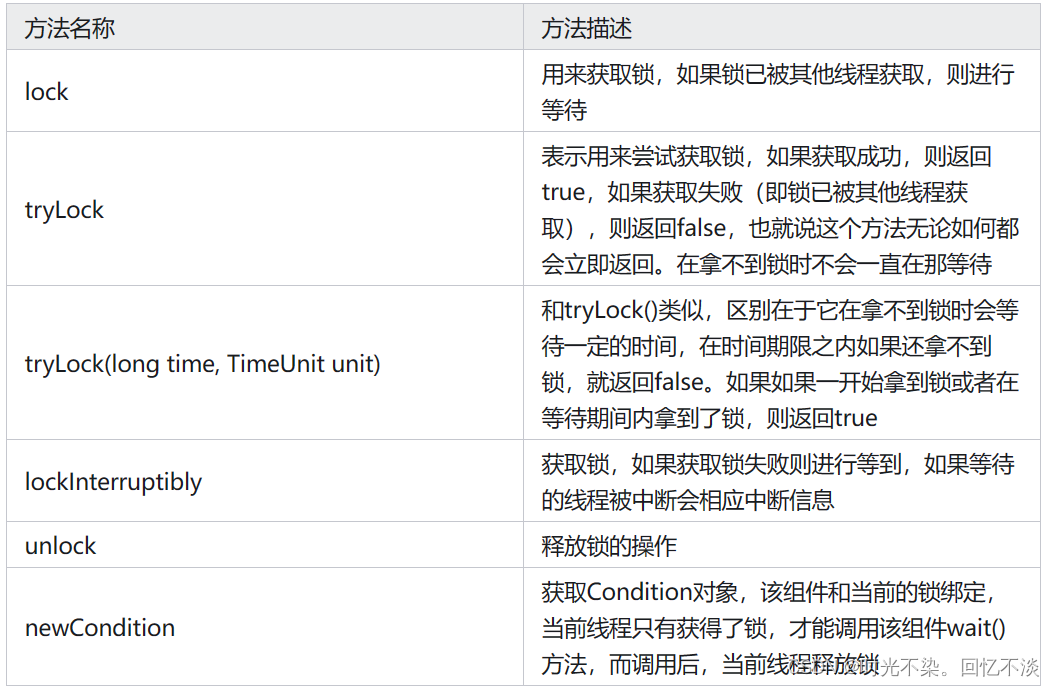
【多线程】震惊~这是我见过最详细的ReentrantLock的讲解
一.与synchronized相比ReentrantLock具有以下四个特点: 可中断:synchronized只能等待同步代码块执行结束,不可以中断,强行终断会抛出异常, 而reentrantlock可以调用线程的interrupt方法来中断等待,继续执行下面的代码。 在获取锁…...
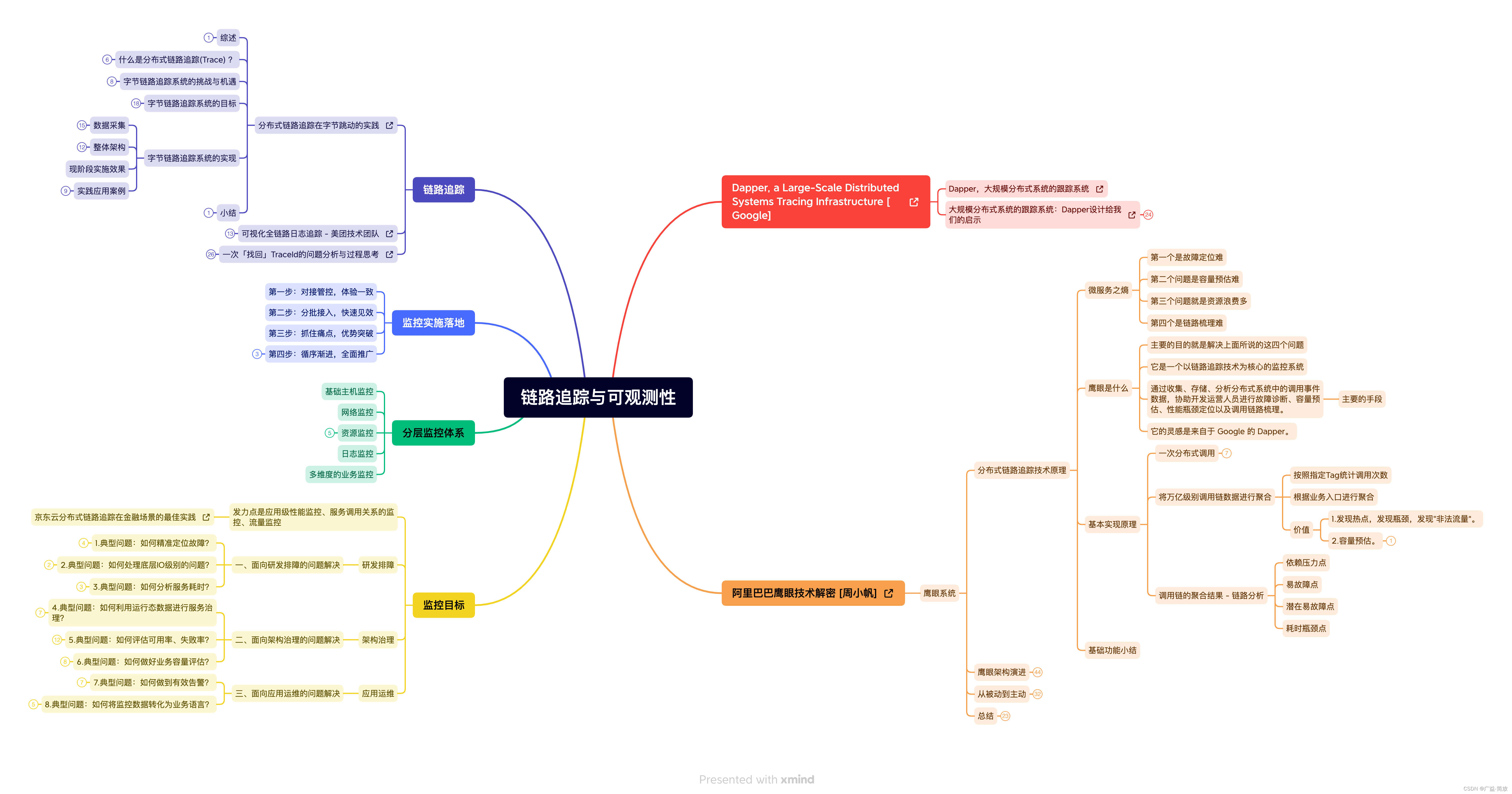
分布式链路追踪与云原生可观测性
分布式链路追踪系统历史 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure - Google Dapper,大规模分布式系统的跟踪系统大规模分布式系统的跟踪系统:Dapper设计给我们的启示 阿里巴巴鹰眼技术解密 - 周小帆京东云分布式链路追踪在金…...
CSS3新增的语法(三)【2D,3D,过渡,动画】
CSS3新增的语法(三)【2D,3D,过渡,动画】 10.2D变换10.1. 2D位移10.2. 2D缩放10.3. 2D旋转10.4. 2D扭曲(了解)10.5. 多重变换10.6. 变换原点 11. 3D变换11.1. 开启3D空间11.2. 设置景深11.3. 透视点位置11.4. 3D 位移11…...

知识图谱与量化LLM协同架构解析与应用
1. 知识图谱与量化LLM协同架构解析在自然语言处理领域,知识图谱(KG)与大型语言模型(LLM)的协同正展现出独特价值。这种架构的核心在于发挥两者的互补优势:KG提供结构化、可验证的语义网络,而LLM…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...

Android本地AI智能家居框架:ZeroClaw架构设计与工程实践
1. 项目缘起与核心愿景几年前,我还在为一个智能家居项目焦头烂额,试图让家里的灯光、空调和音箱能听懂人话,而不是只会执行预设的“回家模式”或“睡眠模式”。当时市面上主流的方案,要么是依赖某个封闭的云平台,所有指…...
✅)
计算机毕业设计:Python医疗文本挖掘与可视化决策平台 Flask框架 随机森林 机器学习 疾病数据 智慧医疗 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
)
C语言打印三角形别再只会用*了!用字母、数字、符号玩出新花样(附完整代码)
C语言打印三角形:用字母、数字和符号玩转循环艺术 在C语言入门阶段,打印三角形几乎是每个初学者必经的练习。但你是否已经厌倦了千篇一律的星号(*)图案?今天,我们将打破常规,探索如何用字母、数字和各种符号来创造独特…...

从Simulink模型到C代码:Assignment模块的‘Index Mode’选Zero还是One?一个影响深远的决定
从Simulink模型到C代码:索引模式选择的工程实践指南 在嵌入式软件开发中,模型与代码的协同设计一直是提高开发效率的关键环节。当Simulink模型工程师将算法模型转换为C代码时,一个看似简单的参数配置——Assignment模块的"Index Mode&q…...
服务启停、远程连接与基础排查)
国产化服务器运维笔记:手把手搞定MariaDB/PostgreSQL(瀚高)服务启停、远程连接与基础排查
国产化环境数据库运维实战:MariaDB与瀚高数据库深度管理指南 在信息技术应用创新背景下,国产服务器与开源数据库的组合已成为企业基础架构的重要选择。面对复杂的生产环境,掌握数据库服务的精细化管理能力,是每位运维工程师的必备…...

用LDAP Browser连接OpenLDAP时,这3个配置细节坑了我一整天
用LDAP Browser连接OpenLDAP时,这3个配置细节坑了我一整天 第一次用LDAP Browser连接OpenLDAP服务器时,我本以为照着教程五分钟就能搞定,结果硬是折腾了一整天。明明服务端已经正常启动,客户端工具也装好了,但就是连不…...

Simulink代码生成实战指南:从模型配置到嵌入式部署
1. Simulink代码生成的核心价值 第一次接触Simulink代码生成功能时,我完全被它的自动化程度震惊了。想象一下,你花了几个月精心设计的控制算法模型,只需要点几下鼠标就能变成可以直接烧录到ECU的C代码,这简直就像魔术一样。不过在…...

揭秘SITS 2026调度内核:如何用1个轻量CRD替代3类Operator+2个Admission Webhook,实现离线推理任务零配置交付?
更多请点击: https://intelliparadigm.com 第一章:AI原生批处理优化:SITS 2026离线推理任务调度策略 SITS 2026(Scalable Intelligent Task Scheduler)是专为AI原生工作负载设计的离线推理调度引擎,其核心…...