Mysql迁移Postgresql
目录
- 原理
- 环境准备
- 操作系统(Centos7)
- Mysql客户端安装
- Psql客户端安装
- 数据库用户
- 空字符串处理成null
- 导表脚本
- dbmysql2pgmysqlcopy
- 测试
- 在mysql中建表
- 导表测试
- 查看pg中的表
原理
Mysql抽取:mysql命令重定向到操作系统文件,处理成csv文件;
PG装载:copy方式将csv文件装载进PG。
环境准备
操作系统(Centos7)
useradd pgload
passwd pgload
mkdir -p /data/etl/mysql2pg/csv
mkdir -p /data/etl/mysql2pg/tmp
mkdir -p /data/etl/mysql2pg/log
mkdir -p /data/etl/mysql2pg/shell
chown -R pgload.pgload /data/etl
su - pgload
touch /data/etl/mysql2pg/shell/dbmysql2pgmysqlcopy
chmod +x /data/etl/mysql2pg/shell/dbmysql2pgmysqlcopy
echo 'export PATH=${PATH}:/data/etl/mysql2pg/shell
# mysqlselect作为mysql抽取数据的用户
export MYSQLID=mysqlselect:000000@10.10.10.10:3306/etl
# pgload为PG数据装载的用户
export PGID=pgload:000000@10.10.10.10:5432/etl' >> ~/.bash_profile
source ~/.bash_profile
Mysql客户端安装
- 由于rpm安装方式与系统自带的mariadb有冲突,所以只有卸载mariadb才能通过rpm方式进行安装;
- 所以,在此以压缩包的方式进行安装。
Mysql客户端下载地址
- 下载mysql客户端,我这里下载mysql5.7.34

- 将下载好的压缩包进行一次解压得到2个文件

- 将 mysql-5.7.34-el7-x86_64.tar.gz 上传至服务器
cd /usr/local
rz
tar -zxvf mysql-5.7.34-el7-x86_64.tar.gz
mv mysql-5.7.34-el7-x86_64 mysql-client
# 配置环境变量
echo 'export PATH=$PATH:/usr/local/mysql-client/bin' >> /etc/profile
source /etc/profile
# 测试mysql命令
mysql -uroot -h10.10.10.10 -P3306 --database etl -e "select 1 from dual;" -p
Psql客户端安装
Psql客户端下载地址
cd /opt
rz
rpm -ivh postgresql12-libs-12.11-1PGDG.rhel7.x86_64.rpm
rpm -ivh postgresql12-12.11-1PGDG.rhel7.x86_64.rpm
# 测试
psql etl -h 10.10.10.10 -p 5432 -U pgload -W
数据库用户
- Mysql
CREATE USER 'mysqlselect'@'%' IDENTIFIED BY '000000';
GRANT SELECT ON *.* TO 'mysqlselect'@'%';
- PG
--普通用户
create role yuzhenchao with login password '000000';
create schema yuzhenchao;
grant create,usage on schema yuzhenchao to yuzhenchao;
grant usage on schema yuzhenchao to public;
alter default privileges for role yuzhenchao revoke execute on functions from public;
alter default privileges in schema yuzhenchao revoke execute on functions from public;
alter default privileges in schema yuzhenchao grant select on tables to public;
alter default privileges for role yuzhenchao grant select on tables to public;--集中用户(即专门用来做数据装载的用户)
create role pgload with login password '000000' connection limit 60;
create schema pgload;
grant create,usage on schema pgload to pgload;
grant usage on schema pgload to public;
alter default privileges for role pgload revoke execute on functions from public;
alter default privileges in schema pgload revoke execute on functions from public;
alter default privileges in schema pgload grant select on tables to public;
alter default privileges for role pgload grant select on tables to public;--普通用户都要创建该函数
--为yuzhenchao用户创建sp_exec函数
create or replace function yuzhenchao.sp_exec(vsql varchar)returns void --返回空language plpgsqlsecurity definer --定义者权限
as $function$
beginexecute vsql;
end;
$function$
;
alter function yuzhenchao.sp_exec(varchar) owner to yuzhenchao;
grant execute on function yuzhenchao.sp_exec(varchar) to yuzhenchao,pgload;create or replace function pgload.sp_exec(vsql varchar)returns void --返回空language plpgsqlsecurity definer --定义者权限
as $function$
beginexecute vsql;
end;
$function$
;
alter function pgload.sp_exec(varchar) owner to pgload;
grant execute on function pgload.sp_exec(varchar) to pgload;--集中用户pgload创建该函数,新增用户则需要增加配置重新编译
create or replace function pgload.sp_execsql(exec_sql character varying,exec_user character varying)returns voidlanguage plpgsqlsecurity definer
as $function$
/* 作者 : v-yuzhenc* 功能 : 集中处理程序,以某用户的权限执行某条sql语句* exec_sql : 需要执行的sql语句* exec_user : 需要以哪个用户的权限执行该sql语句* */
declare p_user varchar := exec_user;o_search_path varchar;
begin--记录原来的模式搜索路径execute 'show search_path;' into o_search_path;--临时切换模式搜索路径execute 'SET search_path TO '||p_user||',public,oracle';case p_user when 'yuzhenchao' then perform yuzhenchao.sp_exec(exec_sql);when 'pgload' then perform pgload.sp_exec(exec_sql);else raise exception '未配置该用户:%',p_user;end case;--恢复模式搜索路径execute 'SET search_path TO '||o_search_path;exception when others then--恢复模式搜索路径execute 'SET search_path TO '||o_search_path;raise exception '%',sqlerrm;
end;
$function$
;
--将对应模式的对应模式的函数给对应的模式的拥有者
alter function pgload.sp_execsql(varchar,varchar) owner to pgload;
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限
grant execute on function pgload.sp_execsql(varchar,varchar) to pgload;
空字符串处理成null
- 在pgload模式下建立函数
create or replace function replace_to_null(tablename character varying, schemaname character varying default ("current_user"())::character varying(64))returns voidlanguage plpgsql
as $function$
/* 作者 : v-yuzhenc* 功能:扫描指定表的所有varchar和text类型的字段,将字段值为''替换成null* tablename : 需要扫描的表名* schemaname : 需要扫描的模式名* */
declare p_tablename varchar := lower(tablename);p_schemaname varchar := lower(schemaname);p_user varchar(64) := lower(user::varchar(64));--调用者existbj int := 0; --存在标记v_sql varchar; --动态sql
begin--扫描varchar和text字段select count(1)into existbjfrom pg_class ainner join pg_namespace bon (a.relnamespace = b.oid)inner join pg_attribute con (a.oid = c.attrelid)inner join pg_type don (c.atttypid = d.oid)where c.attnum > 0and d.typname in ('varchar','text')and a.relname = p_tablenameand b.nspname = p_schemaname;--若不存在varchar或者text字段,则不做处理if existbj = 0 thenraise notice '%.%表不需要处理空字符串!',p_schemaname,p_tablename;return;end if;--拼接处理空字符串语句select string_agg('update '||p_schemaname||'.'||p_tablename||' set '||c.attname||' = null where '||c.attname||' = '''';',chr(10))into v_sqlfrom pg_class ainner join pg_namespace bon (a.relnamespace = b.oid)inner join pg_attribute con (a.oid = c.attrelid)inner join pg_type don (c.atttypid = d.oid)where c.attnum > 0and d.typname in ('varchar','text')and a.relname = p_tablenameand b.nspname = p_schemaname;if p_user = p_schemaname then execute v_sql;execute 'analyze '||p_schemaname||'.'||p_tablename;else --通过集中处理程序执行动态sqlperform pgload.sp_execsql(v_sql,p_schemaname);--分析表perform pgload.sp_execsql('analyze '||p_schemaname||'.'||p_tablename,p_schemaname);end if;
end;
$function$
;
导表脚本
dbmysql2pgmysqlcopy
#! /bin/bash
showuseage() {echo "程序功能:mysql导出MYSQL数据库表,copy方式导入PG数据库Useage: [dbmysql2pgmysqlcopy \${SCHEMANAME}.\${TABLENAME}]-i [:可选,源数据库(MYSQL)帐号:username:passwd@hostname:port/dbname,默认定义在.bash_profile \${MYSQLID},不要出现这些字符:冒号(:),艾特(@),空格( ),斜杠(/)]-j [:可选,目标数据库(PG)帐号:username:passwd@hostname:port/dbname,默认定义在.bash_profile \${PGID},不要出现这些字符:冒号(:),艾特(@),空格( ),斜杠(/)]-o [:可选,指定需要导入到PG的schemaname,默认为MYSQL同名的schemaname(即MYSQL的数据库名)]-f [:可选,可指定导入表名,常用于不同数据库或不同用户同一表名冲突、源表改名不影响后续应用、表名追加时间参数等情况,表名暂时限定为:英文字母(不分大小写)、数字和任意组合,禁止使用特殊字符]-8 [:可选,指定字符编码导出MYSQL数据,默认utf8]-e [:可选,指定字符编码入库PG,默认utf8]-u [:可选,指定表授权其他用户,指定且多个时使用逗号分开,如:'public'、'bss,apl',不要有空格]-t [:可选,(test mod)调试模式,最多导出100行记录进行调试]-a [:可选,指定where条件内容,如:'city_id in (0,755)'(无需转义)]-c [:可选,不建表,直接导数据,表结构必须存在]-z [:可选,导完表后的追加操作]-I [:可选,过滤字段,建表时过滤掉过滤字段,逗号分隔,例如:serv_id,\"acc_nbr\"]-s [:可选,指定字段,建表时只导指定的字段,逗号分隔,例如:serv_id,\"acc_nbr\"]-d [:可选,指定字段特殊处理,原字段类型不变,字段处理后的值不能超出原来的精度,全角冒号顿号分隔,'字段名1:字段处理值1、字段名2:字段处理值2',例如:COMPENSATETEXT:to_clob(COMPENSATETEXT)、update_time:to_date(to_char(update_time,'yyyymmdd hh24:mi:ss'),'yyyymmdd hh24:mi:ss')]-v [:可选,指定某些字段对应PG的类型,全角冒号顿号分隔,字段名1:PG类型1、字段名2:PG类型2',例如:COMPENSATETEXT:text、update_time:date]"
}# 退出之前删除临时文件
trap "rmtmpfile" EXIT# 进度条程序
progress() {M=0local MAIN_PID=$1local MAX_SECOND=14400local SEP_SECOND=1if [ -n "$2" ];then SEP_SECOND=$2fiif [ -n "$3" ];then MAX_SECOND=$3filocal MAX_SECOND=$[${MAX_SECOND}/${SEP_SECOND}]while [ "$(ps -p ${MAIN_PID} | wc -l)" -ne "1" ] ; doM=$[$M+1]echo `date '+%Y-%m-%d %H:%M:%S'`"|WAIT|$M"if [ $M -ge ${MAX_SECOND} ];thenecho `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|后台程序处理超时"kill $MAIN_PIDexit 2fisleep ${SEP_SECOND}done
}function killPid(){#根据程序的ppid获取程序的pidPIDS=`ps -ef|awk '{if($3=='$1'){print $2} }'`;#杀掉父程序的pid,防止子程序被杀掉后开启新的子程序kill -s 9 $1#如果获得了pid,则以已获得的pid作为ppid继续进行查找if [ -n "$PIDS" ]; thenfor PID in $PIDSdokill -9 $PIDdonefi
}# 数据文件目录
CSVDIR=/data/etl/mysql2pg/csv
# 临时文件目录
TMPDIR=/data/etl/mysql2pg/tmp
# 日志目录
LOGDIR=/data/etl/mysql2pg/log# 删除临时文件
rmtmpfile() {# 删除临时文件# PG装载生成的模板SQLrm -f ${TMP_M2P_SQL}# 模板SQL生成的PSQL脚本rm -f ${TMP_M2P_PSQL}# MYSQL抽取生成的模板SQLrm -f ${TMP_TMP_SQL}# 模板SQL生成的MYSQL抽取SQLrm -f ${TMP_TMPO_SQL}# csv文件路径rm -f ${CSVFILEPATH}# PGSQL执行日志rm -f ${PSQL_EXEC_LOG}# 关闭子进程killPid $$
}# 检测参数
# 没有参数直接退出
if [ $# -eq 0 ]
thenshowuseageexit -1
fi# 限定第一个参数
PARAM1=$1
# 分析第一个参数中是否 - 开头
if [[ ${PARAM1} =~ ^-(.*?) ]]; then#如果第一个参数第一个字符碰到-,echo "dbmysql2pgmysqlcopy的第一个参数应为需要导入的MYSQL的表名!"showuseageexit -1
elsePARAM=${PARAM1}
fi# MYSQL连接串
MYSQLDESC=${MYSQLID}
# PG连接串
PGDESC=${PGID}
# 调试模式
TESTMOD="-1"
# 条件
MYSQLCOND=" WHERE 1 = 1 "
# PG的schema
PGSCHEMA="-1"
# MYSQL的schema
MYSQLSCHEMA="-1"
# MYSQL的tablename
MYSQLTABLE="-1"
# PG的tablename
PGTNAME="-1"
# 授权用户
GRANTUSER="-1"
# 建表标记 默认建表
CREATEBJ="1"
# 追加操作
EXTRAOPT="-1"
# MYSQL导出编码
MYSQLENCODE="utf8"
# PG装载编码
PGENCODE="utf8"
# 字段忽略标记
IGNOREBJ="-1"
# 字段处理
COLUMNDEAL="-1"
# 指定类型
COLUMNTYPE="-1"
# 指定建为复制表
REPLICATEDBJ="-1"
# 日期处理标记
DATEFORMAT="-1"
# 指定字段
SPECIALCOLUMN="-1"# 解析mysql表
PARAM=$1
ARRAY=(${PARAM//./ })
MYSQLSCHEMA=${ARRAY[0]}
MYSQLTABLE=${ARRAY[1]}# 如果mysql表名被双引号包着,则直接去掉双引号
# 如果mysql表名没被双引号包着,则默认全部小写
if [[ "$MYSQLTABLE" =~ \"(.*?)\" ]];thenMYSQLTABLE=`echo ${MYSQLTABLE} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
else MYSQLTABLE=${MYSQLTABLE,,}
fi# 如果mysql模式被双引号包着,则直接去掉双引号
# 如果mysql模式没被双引号包着,则默认小写
if [[ "$MYSQLSCHEMA" =~ \"(.*?)\" ]];thenMYSQLSCHEMA=`echo ${MYSQLSCHEMA} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
elseMYSQLSCHEMA=${MYSQLSCHEMA,,}
fi# 参数后移
shiftwhile getopts :i:j:f:o:8:e:u:t:a:cz:I:s:d:v: OPTS; docase "$OPTS" ini)MYSQLDESC="$OPTARG";;j)PGDESC="$OPTARG";;o)PGSCHEMA="${OPTARG}";;f)PGTNAME="${OPTARG}";;u)GRANTUSER="${OPTARG}";;t)if [ $OPTARG -gt 0 -a $OPTARG -le 100 ];thenTESTMOD="$OPTARG"fi;;a)MYSQLCOND=`echo " WHERE $OPTARG" | sed "s/'/''/g"`;;c)CREATEBJ=-1;;z)EXTRAOPT="$OPTARG";;8)MYSQLENCODE="$OPTARG";;e)PGENCODE="$OPTARG";;I)IGNOREBJ="$OPTARG";;s)SPECIALCOLUMN="$OPTARG";;d)COLUMNDEAL="$OPTARG";;v)COLUMNTYPE="$OPTARG";;:)echo "$0 必须为 -$OPTARG 添加一个参数!"exit -1;;?)showuseageexit -1;;esac
done# 解析mysql连接串
ARRAY2=(${MYSQLDESC//@/ })
USERPWD=${ARRAY2[0]}
ARR4=(${USERPWD//:/ })
MYSQLUSER=${ARR4[0]}
MYSQLPWD=${ARR4[1]}
HPDB=${ARRAY2[1]}
ARR5=(${HPDB//:/ })
MYSQLHOST=${ARR5[0]}
PDB=${ARR5[1]}
ARR6=(${PDB//// })
MYSQLPORT=${ARR6[0]}
MYSQLDB=${ARR6[1]}
export MYSQL_PWD=$MYSQLPWD
MYSQLCONN="mysql -u$MYSQLUSER -h$MYSQLHOST -P$MYSQLPORT --database $MYSQLDB"#分隔符
PGCSEP=","
PGQSEP='"'
PGESCAPE='\'
# 获取当前时间戳
TIMEST=`date +%Y%m%d%H%M%S`
# 日志路径
LOG_M2P_OUT=${LOGDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out
# copy语句的输出路径
TMP_COPY_OUT=${TMPDIR}/copy_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out
# PG装载生成的模板SQL
TMP_M2P_SQL=${TMPDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# 模板SQL生成的PSQL脚本
TMP_M2P_PSQL=${TMPDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.psql
# MYSQL抽取生成的模板SQL
TMP_TMP_SQL=${TMPDIR}/tmp_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# 模板SQL生成的MYSQL抽取SQL
TMP_TMPO_SQL=${TMPDIR}/tmpo_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# csv文件路径
CSVFILEPATH=${CSVDIR}/${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.csv
# PGSQL执行日志
PSQL_EXEC_LOG=${LOGDIR}/PG_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out# 判断是否有表
tablebj=`${MYSQLCONN} -e "select 1 from information_schema.tables where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}' union all select 1 from information_schema.views where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}';" | sed '1d'`if [ -z "$tablebj" ];thenecho `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|表或视图不存在"echo `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|程序异常结束"exit -1
fi# 调试模式处理
if [ ! $TESTMOD = "-1" ];thenMYSQLCOND="${MYSQLCOND} limit ${TESTMOD}"
fi# PGSCHEMA处理
# 如果PGSCHEMA等于"-1",则默认使用mysql同名schema
if [ "$PGSCHEMA" = "-1" ];thenPGSCHEMA=${MYSQLSCHEMA}
fi# PGTNAME处理
# 如果PGTNAME等于"-1",则默认与源表同名
if [ "$PGTNAME" = "-1" ];thenPGTNAME=${MYSQLTABLE}
fi# 如果PG表名被双引号包着,则直接去掉双引号
# 如果PG表名没被双引号包着,则转为小写
if [[ "$PGTNAME" =~ \"(.*?)\" ]];thenPGTNAME=`echo ${PGTNAME} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
elsePGTNAME=${PGTNAME,,}
fi# 如果PG模式被双引号包着,则直接去掉双引号
# 如果PG模式没被双引号包着,则转为小写
if [[ "$PGSCHEMA" =~ \"(.*?)\" ]];thenPGSCHEMA=`echo ${PGSCHEMA} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
elsePGSCHEMA=${PGSCHEMA,,}
fi# 解析PG连接串
ARRAY1=(${PGDESC//@/ })
USERPWD=${ARRAY1[0]}
ARR1=(${USERPWD//:/ })
PGUSER=${ARR1[0]}
PGPWD=${ARR1[1]}
HPDB=${ARRAY1[1]}
ARR2=(${HPDB//:/ })
PGHOST=${ARR2[0]}
PDB=${ARR2[1]}
ARR3=(${PDB//// })
PGPORT=${ARR3[0]}
PGDB=${ARR3[1]}
export PGPASSWORD="$PGPWD"
PGCONN="psql -d $PGDB -U $PGUSER -h $PGHOST -p $PGPORT"# 格式化过滤字段
if [ "$IGNOREBJ" != "-1" ];thenIGNOREBJ_ARR=(${IGNOREBJ//,/ })for I in "${!IGNOREBJ_ARR[@]}"doTMP=${IGNOREBJ_ARR[$I]}if [[ "$TMP" =~ \"(.*?)\" ]];thenTMP="'`echo ${TMP} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`'"elseTMP="'${TMP,,}'"fiif [ $I -eq 0 ];thenIGNOREBJ="$TMP"elseIGNOREBJ="$TMP,${IGNOREBJ}"fidoneIGNOREBJ="column_name not in (${IGNOREBJ}) and "
elseIGNOREBJ=" "
fi# 格式化指定字段
if [ "$SPECIALCOLUMN" != "-1" ];thenSPECIALCOLUMN_ARR=(${SPECIALCOLUMN//,/ })for I in "${!SPECIALCOLUMN_ARR[@]}"doTMP=${SPECIALCOLUMN_ARR[$I]}if [[ "$TMP" =~ \"(.*?)\" ]];thenTMP="'`echo ${TMP} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`'"elseTMP="'${TMP,,}'"fiif [ $I -eq 0 ];thenSPECIALCOLUMN="$TMP"elseSPECIALCOLUMN="$TMP,${SPECIALCOLUMN}"fidoneSPECIALCOLUMN="column_name in (${SPECIALCOLUMN}) and "
elseSPECIALCOLUMN=" "
fi# 判断PGUSER和PGSCHEMA是否一致
# 如果不一致,需要调用对方的权限执行psql
if [ "$PGUSER" = "$PGSCHEMA" ];thenUSERSCHEMABJ="1"
elseUSERSCHEMABJ="-1"
fi# 创建日志
rm -f ${LOG_M2P_OUT}
touch ${LOG_M2P_OUT}# 写入日志
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表准备开始" | tee -a ${LOG_M2P_OUT}echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接数据抽取脚本开始" | tee -a ${LOG_M2P_OUT}
rm -f ${TMP_TMP_SQL}
touch ${TMP_TMP_SQL}
rm -f ${TMP_TMPO_SQL}
touch ${TMP_TMPO_SQL}#拼接导表语句
cat>${TMP_TMP_SQL}<<eof
select'select ' dbsql
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}';
eof
${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}
cat>${TMP_TMP_SQL}<<eof
selectcolumnname
from(selectconcat(' ', case when ordinal_position = 1 then '' else ',' end, '\`', lower(column_name), '\`') columnname,ordinal_positionfrominformation_schema.columnswhere ${IGNOREBJ} ${SPECIALCOLUMN}table_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'order byordinal_position
) a;
eof
${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}
cat>${TMP_TMP_SQL}<<eof
select'from \`${MYSQLSCHEMA}\`.\`${MYSQLTABLE}\`'
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'
union all
select'${MYSQLCOND}'
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}';
eof${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}#字段特殊处理替换
#COMPENSATETEXT:to_clob(COMPENSATETEXT)、update_time:to_date(to_char(update_time,'yyyymmdd hh24:mi:ss'),'yyyymmdd hh24:mi:ss')
COLUMNNAME=""
ORIGINROW=""
REPLACEROW=""
REPLACEROWNUM=""
OLD_IFS="$IFS"
if [ "$COLUMNDEAL" != "-1" ];thenIFS="、"COLUMNDEAL_ARRAY=(${COLUMNDEAL})for I in "${!COLUMNDEAL_ARRAY[@]}"doORIGINROW=""REPLACEROW=""TMP=${COLUMNDEAL_ARRAY[$I]}IFS=":"TMP_ARRAY=(${TMP})for J in "${!TMP_ARRAY[@]}"doTMP1=${TMP_ARRAY[$J]}if [ $J -eq 0 ];thenif [[ "$TMP1" =~ \"(.*?)\" ]];thenCOLUMNNAME=${TMP1}ORIGINROW=" ,\`${TMP1}\`"elseCOLUMNNAME="\`${TMP1,,}\`"ORIGINROW=" ,\`${TMP1,,}\`"fielse REPLACEROW="${REPLACEROW}${TMP1}"if [ $J -eq $[${#TMP_ARRAY[*]}-1] ];thenREPLACEROW=${REPLACEROW}' AS '${COLUMNNAME}fifidoneREPLACEROWNUM=`awk "/${ORIGINROW}/{print NR;exit;}" ${TMP_TMPO_SQL}`if [ ${REPLACEROWNUM} -eq 2 ];thenREPLACEROW=' '$REPLACEROWelseREPLACEROW=' ,'$REPLACEROWfiORIGINROW=`sed -n "${REPLACEROWNUM}p" ${TMP_TMPO_SQL}`#双引号和斜杠转义ORIGINROW=${ORIGINROW//\"/\\\"}REPLACEROW=${REPLACEROW//\"/\\\"}ORIGINROW=${ORIGINROW//\//\\\/}REPLACEROW=${REPLACEROW//\//\\\/}sed -i "s/$ORIGINROW/$REPLACEROW/g" ${TMP_TMPO_SQL}done
fi
IFS="$OLD_IFS"echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接数据抽取脚本完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出MYSQL脚本" | tee -a ${LOG_M2P_OUT}
cat ${TMP_TMPO_SQL} | tee -a ${LOG_M2P_OUT}echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接PG的数据装载脚本开始" | tee -a ${LOG_M2P_OUT}rm -f ${TMP_M2P_SQL}
touch ${TMP_M2P_SQL}cat>${TMP_M2P_SQL}<<EOF
selectcase when '${USERSCHEMABJ}' = '-1' then 'select pgload.sp_execsql(\$\$' else '--自己导表无须调用pgload' end psql
from dual
union all
select 'drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";' psql
from information_schema.tables
where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}'
union all
select 'create table "${PGSCHEMA}"."m2p_${PGTNAME}" ('
from information_schema.tables
where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select columnname
from (select concat(' ',case when ordinal_position = 1 then '' else ',' end,'"',lower(column_name),'"',' ',case when data_type = 'int' then data_typewhen data_type = 'varchar' then replace (column_type,'varchar(0)','varchar(1)')when data_type = 'char' then replace(replace(column_type,'char','varchar'),'varchar(0)','varchar(1)')when data_type = 'date' then 'date'when data_type = 'datetime' then replace (column_type, data_type, 'timestamp')when data_type = 'timestamp' then 'timestamp'when data_type = 'bigint' then 'bigint'when data_type = 'double' then 'double precision'when data_type = 'smallint' then 'smallint'when data_type = 'decimal' then replace (column_type,'unsigned zerofill','')when data_type = 'longtext' then 'text'when data_type = 'text' then 'text'when data_type = 'tinyint' then 'int'when data_type = 'longblob' then 'bytea'when data_type = 'blob' then 'bytea'when data_type = 'float' then 'real'when data_type = 'tinytext' then 'text'when data_type = 'mediumtext' then 'text'when data_type = 'numeric' then 'numeric'when data_type = 'time' then 'interval'else 'varchar'end) columnname,ordinal_positionfrom information_schema.columnswhere ${IGNOREBJ} ${SPECIALCOLUMN} table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}'order by ordinal_position
) a;
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select PGPRI from (select case when primarykey is not null then concat(' ,primary key (',primarykey,'));') else '); ' end PGPRIfrom (selectgroup_concat(case when column_key = 'PRI' then concat('"',lower(column_name),'"') else null end order by ORDINAL_POSITION separator ',') primarykeyfrom information_schema.tables a, information_schema.columns bwhere a.table_name = b.table_nameand a.table_schema = b.table_schemaand a.table_name = '${MYSQLTABLE}'and a.table_schema = '${MYSQLSCHEMA}'group by table_rows) a
) a
union all
selectconcat('comment on table "${PGSCHEMA}"."m2p_${PGTNAME}" is ''',replace(table_comment,'''',''''''),''';')
from information_schema.tables
where table_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and table_comment != ''and table_comment is not null
union all
select concat('comment on column "${PGSCHEMA}"."m2p_${PGTNAME}"."',lower(column_name),'" is ''',replace(column_comment,'''',''''''),''';')
from information_schema.columns
where table_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and column_comment != ''and column_comment is not null
UNION ALL
select'\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where'${USERSCHEMABJ}' = '-1'
union all
select'select pgload.sp_execsql(\$\$grant insert on table "${PGSCHEMA}"."m2p_${PGTNAME}" to "${PGUSER}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where'${USERSCHEMABJ}' = '-1';
EOF${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}cat>>${TMP_M2P_PSQL}<<eof
\\copy "${PGSCHEMA}"."m2p_${PGTNAME}" FROM '${CSVFILEPATH}' WITH ( FORMAT csv,HEADER true,DELIMITER '${PGCSEP}',QUOTE '${PGQSEP}',ESCAPE '${PGESCAPE}');
eofcat>${TMP_M2P_SQL}<<EOF
select'select pgload.sp_execsql(\$\$' pgsql
fromdual
where'${USERSCHEMABJ}' = '-1'and '${CREATEBJ}' = '-1'
union all
select'insert into "${PGSCHEMA}"."${PGTNAME}" (' insertsql
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
selectcolumnname
from(selectconcat(' ', case when ordinal_position = 1 then '' else ',' end, '"', lower(column_name), '"') columnname,ordinal_positionfrominformation_schema.columnswhere ${IGNOREBJ} ${SPECIALCOLUMN}table_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'order byordinal_position
) a
where '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select')' insertsql
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and '${CREATEBJ}' = '-1'
union all
select'select ' insertsql
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
selectcolumnname
from(selectconcat(' ', case when ordinal_position = 1 then '' else ',' end, '"', lower(column_name), '"') columnname,ordinal_positionfrominformation_schema.columnswhere ${IGNOREBJ} ${SPECIALCOLUMN}table_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'order byordinal_position
) a
where '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select'from "${PGSCHEMA}"."m2p_${PGTNAME}";'
frominformation_schema.tables
wheretable_name = '${MYSQLTABLE}'and table_schema = '${MYSQLSCHEMA}'and '${CREATEBJ}' = '-1'
union all
select'\$\$,\$\$${PGSCHEMA}\$\$);'
fromdual
where'${USERSCHEMABJ}' = '-1'and '${CREATEBJ}' = '-1'
union all
select 'drop table if exists "${PGSCHEMA}"."${PGTNAME}";'
from dual
where '${CREATEBJ}' = '1'and '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$drop table if exists "${PGSCHEMA}"."${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '1'and '${USERSCHEMABJ}' = '-1'
union all
select 'alter table "${PGSCHEMA}"."m2p_${PGTNAME}" rename to "${PGTNAME}";'
from dual
where '${CREATEBJ}' = '1'and '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$alter table "${PGSCHEMA}"."m2p_${PGTNAME}" rename to "${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '1'and '${USERSCHEMABJ}' = '-1'
union all
select 'drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";'
from dual
where '${CREATEBJ}' = '-1'and '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '-1'and '${USERSCHEMABJ}' = '-1'
union all
select 'grant select on table "${PGSCHEMA}"."${PGTNAME}" to ${GRANTUSER};'
from dual
where '${GRANTUSER}' <> '-1'and '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$grant select on table "${PGSCHEMA}"."${PGTNAME}" to "${GRANTUSER}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${GRANTUSER}' <> '-1'and '${USERSCHEMABJ}' = '-1'
union all
select '${EXTRAOPT}'
from dual
where '${EXTRAOPT}' <> '-1'and '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$${EXTRAOPT}\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${EXTRAOPT}' <> '-1'and '${USERSCHEMABJ}' = '-1'
union all
select 'select pgload.replace_to_null(\$\$${PGTNAME}\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
union all
select 'analyze "${PGSCHEMA}"."${PGTNAME}";'
from dual
where '${USERSCHEMABJ}' = '1'
union all
select 'select pgload.sp_execsql(\$\$analyze "${PGSCHEMA}"."${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${USERSCHEMABJ}' = '-1';
EOF${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}#指定字段类型
OLD_IFS="$IFS"
if [ "$COLUMNTYPE" != "-1" ];thenIFS="、"COLUMNTYPE_ARRAY=(${COLUMNTYPE})for I in "${!COLUMNTYPE_ARRAY[@]}"doORIGINROW=""REPLACEROW=""TMP=${COLUMNTYPE_ARRAY[$I]}IFS=":"TMP_ARRAY=(${TMP})for J in "${!TMP_ARRAY[@]}"doTMP1=${TMP_ARRAY[$J]}if [ $J -eq 0 ];thenif [[ "$TMP1" =~ \"(.*?)\" ]];thenCOLUMNNAME=${TMP1}ORIGINROW=",${TMP1}"elseCOLUMNNAME="\"${TMP1,,}\""ORIGINROW=",\"${TMP1,,}\""fielse REPLACEROW="${REPLACEROW}${TMP1}"if [ $J -eq $[${#TMP_ARRAY[*]}-1] ];thenREPLACEROW="${COLUMNNAME} ${REPLACEROW}"fifidoneREPLACEROWNUM=`awk "/${COLUMNNAME}/{print NR;exit;}" ${TMP_M2P_PSQL}`if [ $REPLACEROWNUM -eq 4 ];thenREPLACEROW=' '$REPLACEROWelseREPLACEROW=' ,'$REPLACEROWfiORIGINROW=`sed -n "${REPLACEROWNUM}p" ${TMP_M2P_PSQL}`#双引号和斜杠转义ORIGINROW=${ORIGINROW//\"/\\\"}REPLACEROW=${REPLACEROW//\"/\\\"}ORIGINROW=${ORIGINROW//\//\\\/}REPLACEROW=${REPLACEROW//\//\\\/}#echo $ORIGINROW#echo $REPLACEROW#echo $REPLACEROWNUMsed -i "s/$ORIGINROW/$REPLACEROW/g" ${TMP_M2P_PSQL}done
fi
IFS="$OLD_IFS"echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接PG的数据装载脚本完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出PSQL脚本" | tee -a ${LOG_M2P_OUT}
cat ${TMP_M2P_PSQL} | tee -a ${LOG_M2P_OUT} echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表准备完成" | tee -a ${LOG_M2P_OUT}#开始抽取数据
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|从MYSQL抽取数据开始" | tee -a ${LOG_M2P_OUT}
rm -f ${CSVFILEPATH}
touch ${CSVFILEPATH}
extractmysqldata(){# ${MYSQLCONN} < ${TMP_TMPO_SQL} | sed "s/\x00//g;s/\\\n/\n/g;s/${PGQSEP}/\\""${PGESCAPE}${PGQSEP}/g;s/\t/${PGQSEP}${PGCSEP}${PGQSEP}/g;s/^/${PGQSEP}&/g;s/$/&${PGQSEP}/g;s/${PGQSEP}NULL${PGQSEP}//g;s/${PGQSEP}${PGQSEP}//g;s/\\\t/\t/g" > ${CSVFILEPATH}${MYSQLCONN} < ${TMP_TMPO_SQL} | sed "s/\x00//g;s/\\\n/\n/g;s/${PGQSEP}/\\""${PGESCAPE}${PGQSEP}/g;s/\t/${PGQSEP}${PGCSEP}${PGQSEP}/g;s/^/${PGQSEP}&/g;s/$/&${PGQSEP}/g;s/${PGQSEP}NULL${PGQSEP}//g;s/\\\t/\t/g" > ${CSVFILEPATH}
}
extractmysqldata &
EXTRACTMYSQLDATA_PID=$(jobs -p | tail -1)
progress "${EXTRACTMYSQLDATA_PID}" &
EXTRACTMYSQLDATA_PPID=$(jobs -p | tail -1)
wait "${EXTRACTMYSQLDATA_PID}"
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|从MYSQL抽取数据完成" | tee -a ${LOG_M2P_OUT}echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|在PG中装载数据开始" | tee -a ${LOG_M2P_OUT}loadmysqldata(){#执行psql建表脚本${PGCONN} >>${PSQL_EXEC_LOG} 2>&1 <<PSQL
\set ECHO all
\set ON_ERROR_STOP on
\timing on
\! echo `date "+%Y %m %d %H:%M:%S"`
\i ${TMP_M2P_PSQL}
\! echo `date "+%Y %m %d %H:%M:%S"`
PSQL
}
loadmysqldata &
LOADMYSQLDATA_PID=$(jobs -p | tail -1)
progress "${LOADMYSQLDATA_PID}" &
LOADMYSQLDATA_PPID=$(jobs -p | tail -1)
wait "${LOADMYSQLDATA_PID}"echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|在PG中装载数据完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出装载日志" | tee -a ${LOG_M2P_OUT}
cat ${PSQL_EXEC_LOG} | tee -a ${LOG_M2P_OUT}echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表日志:${LOG_M2P_OUT}" | tee -a ${LOG_M2P_OUT}#获取PG装载的记录数
ERRORBJ=`cat ${LOG_M2P_OUT} | grep '^psql:' | grep -E 'FATAL:|ERROR:' | wc -l`
if [ ${ERRORBJ} -ne 0 ];thenecho `date '+%Y-%m-%d %H:%M:%S'`"|INFO|数据导入失败" | tee -a ${LOG_M2P_OUT}exit -1
elsePGNUM=`awk '{if($1=="COPY") print $2}' ${PSQL_EXEC_LOG}`echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|数据导入成功:${PGNUM}" | tee -a ${LOG_M2P_OUT}
fi
测试
在mysql中建表
create table tmp (id int primary key comment '主键',name varchar(50) comment '姓名'
);
insert into tmp values (1,'张三');
insert into tmp values (2,'李四');
insert into tmp values (3,'王五');
insert into tmp values (4,'你好,'' "
我不好 1111');

导表测试
[root@yzcdb-2 ~]# su - pgload
Last login: Tue Mar 7 08:56:24 CST 2023 on pts/0
[pgload@yzcdb-2 ~]$ dbmysql2pgmysqlcopy etl.tmp -o yuzhenchao
2023-03-07 14:02:12|INFO|导表准备开始
2023-03-07 14:02:12|INFO|拼接数据抽取脚本开始
2023-03-07 14:02:12|INFO|拼接数据抽取脚本完成
2023-03-07 14:02:12|INFO|输出MYSQL脚本
select `id`,`name`
from `etl`.`tmp`WHERE 1 = 1
2023-03-07 14:02:12|INFO|拼接PG的数据装载脚本开始
2023-03-07 14:02:12|INFO|拼接PG的数据装载脚本完成
2023-03-07 14:02:12|INFO|输出PSQL脚本
select pgload.sp_execsql($$
drop table if exists "yuzhenchao"."m2p_tmp";
create table "yuzhenchao"."m2p_tmp" ("id" int,"name" varchar(50),primary key ("id"));
comment on column "yuzhenchao"."m2p_tmp"."id" is '主键';
comment on column "yuzhenchao"."m2p_tmp"."name" is '姓名';
$$,$$yuzhenchao$$);
select pgload.sp_execsql($$grant insert on table "yuzhenchao"."m2p_tmp" to "pgload";$$,$$yuzhenchao$$);
\copy "yuzhenchao"."m2p_tmp" FROM '/data/etl/mysql2pg/csv/etl_tmp_20230307140212.csv' WITH ( FORMAT csv,HEADER true,DELIMITER ',',QUOTE '"',ESCAPE '\');
select pgload.sp_execsql($$drop table if exists "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
select pgload.sp_execsql($$alter table "yuzhenchao"."m2p_tmp" rename to "tmp";$$,$$yuzhenchao$$);
select pgload.sp_execsql($$analyze "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
2023-03-07 14:02:12|INFO|导表准备完成
2023-03-07 14:02:12|INFO|从MYSQL抽取数据开始
2023-03-07 14:02:12|WAIT|1
2023-03-07 14:02:12|INFO|从MYSQL抽取数据完成
2023-03-07 14:02:12|INFO|在PG中装载数据开始
2023-03-07 14:02:13|WAIT|1
2023-03-07 14:02:13|INFO|在PG中装载数据完成
2023-03-07 14:02:13|INFO|输出装载日志
\timing on
Timing is on.
\! echo 2023 03 07 14:02:12
2023 03 07 14:02:12
\i /data/etl/mysql2pg/tmp/m2p_etl_tmp_20230307140212.psql
select pgload.sp_execsql($$
drop table if exists "yuzhenchao"."m2p_tmp";
create table "yuzhenchao"."m2p_tmp" ("id" int,"name" varchar(50),primary key ("id"));
comment on column "yuzhenchao"."m2p_tmp"."id" is '主键';
comment on column "yuzhenchao"."m2p_tmp"."name" is '姓名';
$$,$$yuzhenchao$$);
psql:/data/etl/mysql2pg/tmp/m2p_etl_tmp_20230307140212.psql:9: NOTICE: table "m2p_tmp" does not exist, skippingsp_execsql
------------(1 row)Time: 17.889 ms
select pgload.sp_execsql($$grant insert on table "yuzhenchao"."m2p_tmp" to "pgload";$$,$$yuzhenchao$$);sp_execsql
------------(1 row)Time: 1.558 ms
\copy "yuzhenchao"."m2p_tmp" FROM '/data/etl/mysql2pg/csv/etl_tmp_20230307140212.csv' WITH ( FORMAT csv,HEADER true,DELIMITER ',',QUOTE '"',ESCAPE '\');
COPY 4
Time: 32.051 ms
select pgload.sp_execsql($$drop table if exists "yuzhenchao"."tmp";$$,$$yuzhenchao$$);sp_execsql
------------(1 row)Time: 3.049 ms
select pgload.sp_execsql($$alter table "yuzhenchao"."m2p_tmp" rename to "tmp";$$,$$yuzhenchao$$);sp_execsql
------------(1 row)Time: 1.687 ms
select pgload.sp_execsql($$analyze "yuzhenchao"."tmp";$$,$$yuzhenchao$$);sp_execsql
------------(1 row)Time: 1.848 ms
\! echo 2023 03 07 14:02:13
2023 03 07 14:02:13
2023-03-07 14:02:13|INFO|导表日志:/data/etl/mysql2pg/log/m2p_etl_tmp_20230307140212.out
2023-03-07 14:02:13|INFO|数据导入成功:4
Killed
查看pg中的表
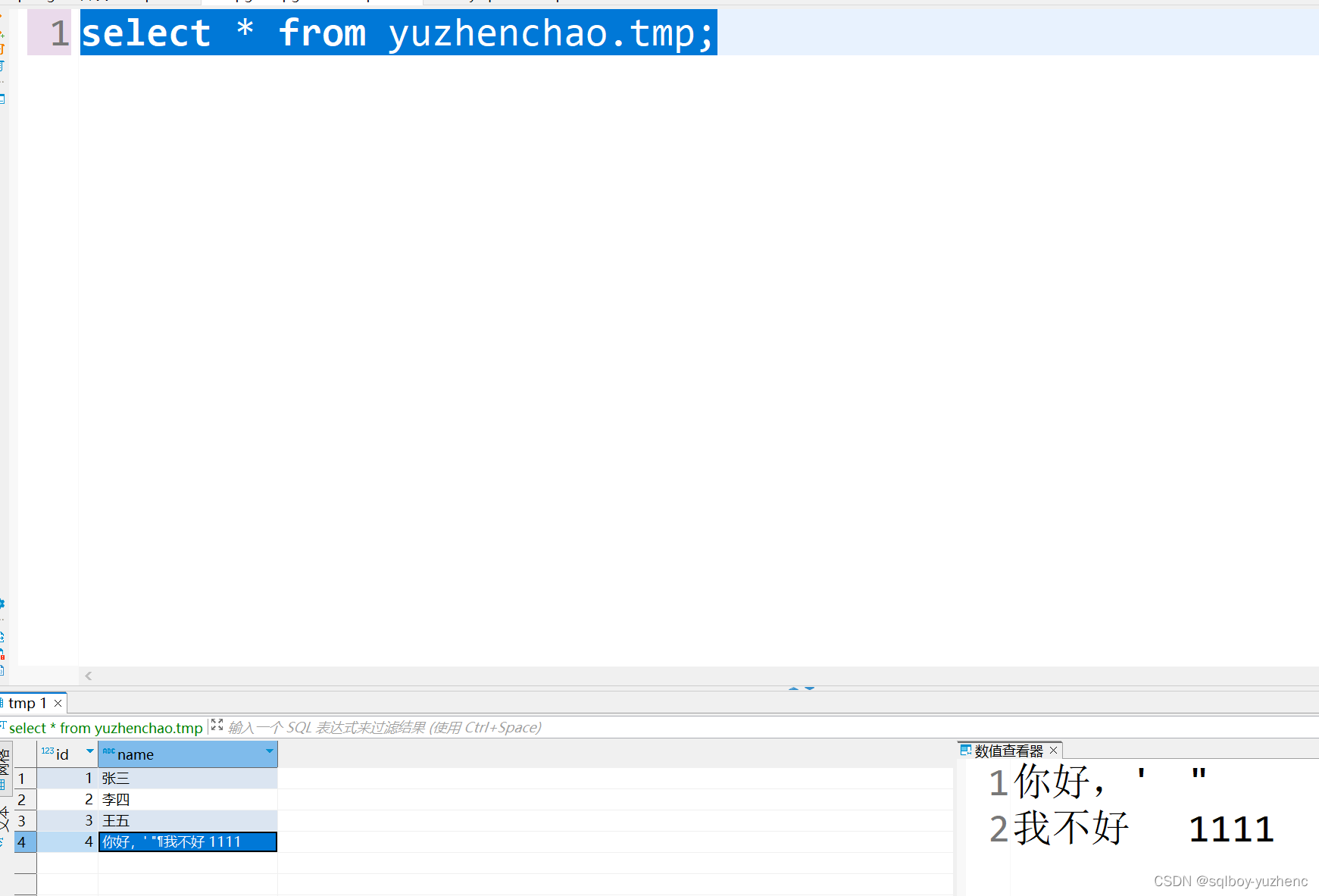
相关文章:
Mysql迁移Postgresql
目录原理环境准备操作系统(Centos7)Mysql客户端安装Psql客户端安装数据库用户空字符串处理成null导表脚本dbmysql2pgmysqlcopy测试在mysql中建表导表测试查看pg中的表原理 Mysql抽取:mysql命令重定向到操作系统文件,处理成csv文件; PG装载&a…...
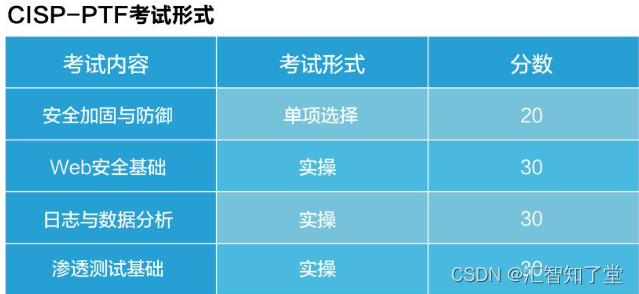
关于信息安全认证CISP、PTE对比分析
CISP 注册信息安全专业人员 CISP-PTE 注册渗透测试工程师(以下简称PTE) 1 、发证机构 CISP与PTE的发证机构都是中国信息安全测评中心,政府背景给认证做背书,学员信息都在中国政府可控的机构手中; 如果想在政府、国…...

游戏场景编辑器和骨骼动画相关软件
游戏场景编辑器 一.Tiled(2D) Tiled 是帮助你开发游戏内容的 2D 地图编辑器。它的主要功能是可以编辑各种形式的瓦片地图,还支持通过用空图片这种强大的方式来标记额外信息给游戏使用。Tiled 关注的是总体灵活性,同时尽量保持直观性。 Tiled Map 不但…...

vue3常用的API
目录 1.ref函数 2.reactive函数 3.reactive对比ref 4.computed函数 5.watch函数 6.toRef 7..provide && inject 1.ref函数 作用: 定义一个响应式的数据 语法: const xxx ref(initValue) 创建一个包含响应式数据的引用对象(reference对象ÿ…...

Qt中使用
LIB库路径,include 头文件,运行的时候记得吧dll库带上,这基本就完成了。准备工作:Qt可以是傻瓜式的安装就行,GE的驱动里面有exe,直接点击安装即可,完了记得到安装路径把“.h”“.liib”和“.dll…...
controller-runtime搭建operator开发环境
目录 基本结构 注入CRD 基本结构 首先下载相应的go pkg go get -u sigs.k8s.io/controller-runtime 接下来需要创建控制器和Manager Operator的本质是一个可重入的队列编程模式,而Manager可以用来管理Controller、Admission Webhook,包括访问资源对…...

FPGA使用GTX实现SFP光纤收发SDI视频 全网首创略显高端 提供工程源码和技术支持
目录1、前言2、设计思路和框架3、vivado工程详解4、上板调试验证并演示5、福利:工程代码的获取1、前言 FPGA实现SDI视频编解码目前有两种方案: 一是使用专用编解码芯片,比如典型的接收器GS2971,发送器GS2972,优点是简…...

Django 之 CharField 和 TextField
CharField test_char models.CharField(max_length288)设置长度为 288 并不会报错,这取决于你的数据库后端,mysql char 类型长度为 255,django 里面设置超过 255 并不会有提示,个人感觉有点误导人,起码给个警告也行&…...

recyclerview 使用的坑
1.有不同的布局 12_GridLayoutManager setSpanSizeLookup()方法 - 简书 setSpanSizeLookup 这个方法要会 spanCount和 getSpanSize spanCount/getSpanSize() 才是这一项所占的宽度 2.均分 item布局要设置宽度为match_paraent 3.设置完了。发现高度不一样,…...
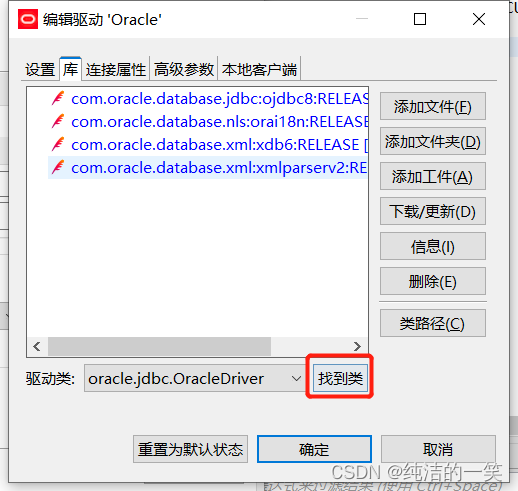
DBeaver连接mysql、oracle数据库
1. DBeaver连接mysql 1) 下载DBeaver https://dbeaver.io/download/,并安装 2) 新建数据库连接 3)选择mysql驱动程序 4)填写连接设置内容 5)点击 “编辑驱动设置”,并填写相关信息 6)选择本地…...

Kivy GridLayout 布局
Kivy GridLayout 是一种用于构建用户界面的布局类型,可以帮助我们快速创建具有固定列和行的网格布局。GridLayout 布局是可以适用于任意数量的行和列的布局,然后在这些行和列中放置 UI 元素。 Kivy 的 GridLayout 使用起来类似于 HTML 的表格,…...
Spark高手之路2—Spark安装配置
文章目录Spark 运行环境一、Local 模式1. 下载压缩包2.上传到服务器3. 解压4. 启动 Local 环境5. 命令行工具6. 退出本地模式7. 提交应用二、Standalone 模式1. 解压2. 修改配置文件1)进入解压缩后路径的 conf 目录,复制 workers.template 文件为 worker…...

Java中对象的比较
目录元素的比较基本类型的比较引用类型的比较1. 覆写基类的equals2. 基于Comparble接口类的比较3. 基于比较器比较三种方法对比元素的比较 基本类型的比较 这里就拿整型, 字符型, 布尔型 为例: public static void main(String[] args) {int a 10;int b 20;System.out.pri…...

Python编程训练题2
1.11 有 n 盏灯,编号 1~n(0<n<100)。第 1 个人把所有灯打开,第 2 个人按下所有编号为 2 的倍数的开关(这些灯将被关掉),第 3 个人按下所有编号为 3 的倍数的开关(其…...

Shifu基础功能:设备管理
设备管理 deviceshifu_configmap.yaml中的telemetries表示自动测量记录传导。Shifu通过telemetries中设置的方法,以指定时间向设备周期性地发送请求,来判断设备的连接情况。如果设备出现故障或者连接出现问题,edgeDevice的状态将发生改变&am…...

交互:可以执行命令行的框架才是好框架
上一节课,我们开始把框架向工业级迭代,重新规划了目录,这一节课将对框架做更大的改动,让框架支持命令行工具。 第三方命令行工具库 cobra obra 不仅仅能让我们快速构建一个命令行,它更大的优势是能更快地组织起有许多…...

eunomia-bpf 和 wasm-bpf 项目的 3 月进展
eunomia-bpf 项目是一个开源项目,旨在提供一组工具,用于在 Linux 内核中更方便地编写和运行 eBPF 程序。在过去一个月中,该项目取得了一些新的进展,以下是这些进展的概述。 首先,eunomia-bpf 动态加载库进行了一些重要…...
Spring框架核心功能手写实现
文章目录概要Spring启动以及扫描流程实现基础环境搭建扫描逻辑实现bean创建的简单实现依赖注入实现BeanNameAware回调实现初始化机制模拟实现BeanPostProcessor模拟实现AOP模拟实现概要 手写Spring启动以及扫描流程手写getBean流程手写Bean生命周期流程手写依赖注入流程手写Be…...

k8s-镜像构建Flink集群Native session
一.Flink安装包下载 wget https://dlcdn.apache.org/flink/flink-1.14.6/flink-1.14.6-bin-scala_2.12.tgz 二.构建基础镜像推送私服 docker pull apache/flink:1.14.6-scala_2.12 docker tag apache/flink:1.14.6-scala_2.12 172.25.152.2:30002/dmp/flink:...

在 k8S 中搭建 SonarQube 7.4.9 版本(使用 PostgreSQL 数据库)
本文搭建的 SonarQube 版本是 7.4.9-community,由于在官方文档中声明 7.9 版本之后就不再支持使用 MySQL 数据库。所以此次搭建使用的数据库是 PostgreSQL 11.4 版本。 一、部署 PostgreSQL 服务 1. 创建命名空间 将 PostgreSQL 和 SonarQube 放在同一个命名空间…...

5步解决网易云音乐NCM文件难题:ncmdumpGUI实战指南
5步解决网易云音乐NCM文件难题:ncmdumpGUI实战指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样的情况:在网易…...

在株洲如何选择护脊透气的床垫?
引言在现代社会,随着生活节奏的加快和工作压力的增加,越来越多的人开始关注睡眠质量。而床垫作为影响睡眠质量的重要因素之一,其选择显得尤为重要。特别是对于需要护脊和透气功能的床垫,如何选择成为了一个关键问题。本文将结合德…...

告别桌面混乱!Ubuntu 16.04 多桌面+Terminator分屏,打造程序员高效工作流
Ubuntu 16.04多桌面与Terminator分屏:构建程序员的高效工作流 作为一名长期在Ubuntu环境下工作的开发者,我深刻体会到工作环境配置对效率的影响。桌面混乱、窗口堆叠、频繁切换不仅浪费时间,还会打断编程的"心流"状态。经过多次迭代…...

OpenClaw到Hermes一键迁移:自动化配置转移与智能体升级实践
1. 项目概述:从 OpenClaw 到 Hermes 的平滑迁移方案如果你正在运行一个名为 OpenClaw 的智能体项目,并且最近听说了它的“继任者”或一个更强大的替代品 Hermes,那么你很可能正面临一个经典的工程难题:如何将现有的、已经配置好的…...

WeChatMsg:如何用开源工具构建你的个人数字记忆库
WeChatMsg:如何用开源工具构建你的个人数字记忆库 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...

YOLOv11室内展台飞机模型目标检测数据集-182张-Airplane-1_4_2
YOLOv11室内展台飞机模型目标检测数据集 📊 数据集基本信息 目标类别: [‘airplane’] 中文类别:[‘飞机’] 训练集:159 张 验证集:23 张 测试集:0 张 总计:182 张 📄 data.yaml 配置信息 该数据集提供了data.yaml文件,内容如下: train: ../train/images val: .…...

全景视频会议核心技术解析:从200°视场角到实时图像拼接
1. 项目概述:全景视频会议如何从概念走向现实视频会议这玩意儿,我们搞通信和消费电子这行的,这些年见得多了。从最早模糊不清的像素块,到后来高清但视角固定的摄像头,大家总觉得少了点什么。没错,少的就是那…...

你还在迷信AI的回答?2026年,信息主权争夺战已全面打响
一、AI信息乱象:个人与企业的双重困境 (一)个人用户:深陷“AI虚假陷阱”,决策毫无安全感2026年的今天,AI大模型的“幻觉缺陷”非但没有消失,反而因模型参数膨胀而变得更加隐蔽。用户向豆包询问某…...

基于Vike+React+Mantine构建现代文档站:架构解析与工程实践
1. 项目概述:从零构建 SurrealDB 官方文档站的技术选型与架构最近在梳理 SurrealDB 官方文档站(docs.surrealdb.com)的源码,发现它是一个非常典型的现代技术栈组合案例。项目基于 Vike React Mantine 构建,并集成了 …...

Sonos语音控制功能大揭秘:常用指令、局限与第三方助手对比
ZDNET核心要点Sonos音箱内置语音助手,其语音控制虽不如其他助手智能,但并非一无是处,每日闹钟、天气预报和定时器能提升使用体验。Sonos语音控制使用体验并非智能家居爱好者,但家里有好几台Sonos智能音箱。虽不太喜欢自动语音助手…...