SpringBoot整合ELK8.1.x实现日志中心教程
目录
背景
环境准备
环境安装
1.JDK安装
2.安装Elasticsearch
3.安装zookeeper
4.安装Kafka
5.安装logstash
6.安装file beat
解决方案场景
1.日志采集
1.1 应用日志配置
1.1.1 创建logback-spring.xml文件
1.1.2 创建LoggerFactory
1.1.3 trace日志的记录用法
1.1.4 dap-trace日志的记录用法
1.2 应用日志采集
2.日志缓冲
3.日志分析
4.日志存储
5.小总结
6.日志查看
背景
最近公司需要把产品中用到的组件做一下升级,从6.x升级到8.x,本人负责做升级,搞完之后一顿空虚,感觉总少点什么没完成,没错,忘记写点什么了,因此记录下从应用产生日志、filebeat收集日志、发送日志到kafka、logstash完成对日志的结构整理、最终入库es完整链路的方案以及一些配置的说明,希望能帮助到有需求的童鞋们,如果是入门的童鞋,照着本教程一步一步来的话,不出意外的话肯定是能手搓出一套ELK的日志中心的方案出来的;整理不易,望诸君高台贵手,点赞支持。
环境准备
应用:Springboot、Springcloud应用,版本不限
jvm:1.8、17,因为从es8.0.x之后就不支持jdk1.8.x了,本文选的版本是8.1.x,所以需要准备jdk17的环境,但是有些组件还是不能够支持17,因此还需要1.8的环境,具体支持下面会做详细介绍
filebeat、logstash、elasticsearch:8.1.2
filebeat下载地址:Past Releases of Elastic Stack Software | Elastic![]() https://www.elastic.co/cn/downloads/past-releases#filebeat
https://www.elastic.co/cn/downloads/past-releases#filebeat
logstash下载地址:Past Releases of Elastic Stack Software | Elastic![]() https://www.elastic.co/downloads/past-releases#logstash
https://www.elastic.co/downloads/past-releases#logstash
es下载地址:Past Releases of Elastic Stack Software | Elastic![]() https://www.elastic.co/downloads/past-releases#elasticsearch
https://www.elastic.co/downloads/past-releases#elasticsearch
kafka:2.5.1;filebeat8.1.2支持的版本是0.8.2.0 and 2.6.0之间的所有版本,因此选择的版本是2.5.1,也就是2.6.0之前的最后一个release版本,具体支持的详细说明请移步官网介绍:Configure the Kafka output | Filebeat Reference [8.12] | Elastic
下载地址:Apache Kafka
zookeeper:2.5.8,kafka2.5.1对应的zk版本就是2.5.8,如何通过kafka确定zk的对应版本,本人有个方式:去官网下载Kafka的源码:以-src.tgz结尾的就是源码,下载完之后解压,打开解压目录下的/gradle目录,然后打开dependencies.gradle文件,然后搜索zookeeper,你就会看到有个配置如下:"zookeeper":"2.5.8" 这个就是当前kafka版本对应的zk的版本。
zookeeper下载地址:Index of /dist/zookeeper (apache.org) 注意:下载-bin.tar.gz结尾的文件,这个是编译好的介质,不带-bin的是源码,需要自己编译。
sky walking:9.3.0 为什么选择这个版本,因为从9.3.0开始才支持es8.x,之前的版本都只能支持最高到7.x,因此选择这个版本,当然也可以选择更高的版本,本文选择的是9.3.0版本。
下载地址:Downloads | Apache SkyWalking
自此所需要的介质以及对应版本都ok了,接下来就开始安装服务了,先从es开始安装,因为它是最底层环节,别人都需要靠它才能完成最终安装。
环境安装
1.JDK安装
官网下载jdk17,小版本随意,下载完之后上传至服务器,或者直接用wget命令也行,随意
解压完之后,按照如下命令进行全局变量配置
vim /etc/profile
export JAVA_HOME=/usr/lib/jdk17/jdk-17.0.10
export CLASSPATH=.:$JAVA_HOME/lib/
export PATH=.:$JAVA_HOME/bin:$PATH
# 生效
source /etc/profile2.安装Elasticsearch
先新建一个用户(出于安全考虑,elasticsearch默认不允许以root账号运行)
# 创建组
groupadd es
# 创建用户
useradd -m -g es es
# 设置密码 如果提示密码过于简单或少于8个字符则可将密码设置的复杂一点
passwd es新建目录/opt/elk/es,然后上传介质并解压到指定目录 tar -zxvf elasticsearch-8.1.2-linux-x86_64.tar.gz -C /opt/elk/es
解压后目录结构如下:
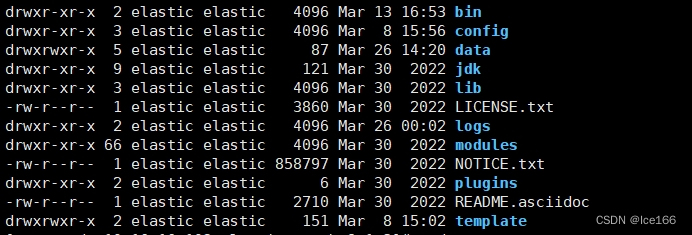
修改Elasticsearch配置文件 文件路径{安装位置}/config/elasticsearch.yml,8.1.2默认是开启了ssl的,所以如果关闭则需要在配置文件中关闭,具体配置如下:
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
xpack.security.http.ssl.enabled: false# 修改es的ip地址
network.host:{安装机器IP}
node.name: node-1
cluster.initial_master_nodes: ["node-1"]如果需要开启ssl则只需要配置下面三个配置即可,接下来就是JVM参数的调优,因为es比较吃cpu和内存,如果你的机器够大,建议设置一下jvm的参数,在{安装位置}/config/jvm.options文件中,增加:
-Xms10g
-Xmx10g启动Elasticsearch
# 进入bin目录
cd {安装位置}/bin
# 启动Elasticsearch
./elasticsearch -d验证:访问ip:9200 看到如下返回,则启动成功,到此es初步安装完成,后面等所有环境安装完成之后还会根据业务场景对ELK各组件进行设置调整
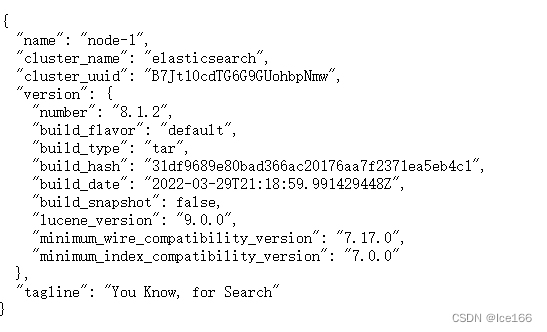
3.安装zookeeper
注:2.5.8版本的zk还不支持jdk17,因此zk以及后面的kafka都不能安装在jdk17的环境下,本人选择的是jdk1.8,因此童鞋们注意下。
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz 解压介质,解压完之后是这样
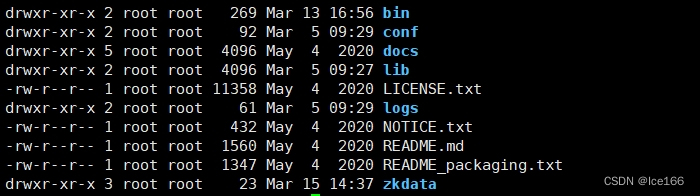
解压完之后进入到{解压目录}/conf目录
cd {安装目录}/conf
#修改conf目录下的zoo_sample.cfg 改成zoo.cfg
mv zoo_sample.cfg zoo.cfg
#修改dataDir配置为自定义目录
vi zoo.cfg 启动zookeeper,进入zookeeper/bin目录
我的建议是不要配置环境变量,因为zookeeper本来就是个特定场景下的组件,感觉没什么必要配置全局环境变量,我看很多博主都是直接告诉人家配置全部变量,没必要
# 启动
sh zkServer.sh start
# 查看状态
sh zkServer.sh status
#停止
sh zkServer.sh stop 执行查看状态,能看到下面信息则表示启动成功
Mode: standalone4.安装Kafka
Kafka一样,2.5.1同样不支持jdk17(3.1.0开始才支持jdk17),本文选择的是jdk1.8
tar -zxvf kafka_2.12-2.5.1.tgz 解压完之后,进行配置修改
# 编辑{安装位置}/config/server.properties文件
# 修改server.properties文件中以下内容,配置kafka监听端口及ip地址
listeners=PLAINTEXT://{安装机器IP}:9092
advertised.listeners=PLAINTEXT://{安装机器IP}:9092
# 修改zookeeper地址
zookeeper.connect=127.0.0.1:2181/kafka
#修改日志文件路径
log.dirs=/tmp/kafka-logs启动kafka
#进入kafka/bin目录,执行以下命令
nohup sh kafka-server-start.sh -daemon ../config/server.properties >>/dev/null 2>&1 &5.安装logstash
注意,8.1.x版本的logstash需jdk17的环节;直接解压介质
tar -zxvf logstash-8.1.2-linux-x86_64.tar.gz
到此安装已经完成了,哈哈,当然是开玩笑的,如果仅仅是安装,确实已经完成了,但是离我们想要的logstash还差一步:配置,具体配置请参考下面的日志分析章节,这里就不重复介绍了
6.安装file beat
file beat同logstash一样,这里暂时跳过,因为filebeat的配置要紧密结合业务来做对应配置的,所以等后面节合场景来具体说明
解决方案场景
本文所解决的业务场景就是:采集各应用产生的本地日志数据,进行汇总,可以进行应用日志查看,检索,链路分析,大致分为这几个步骤:1.日志采集;2.日志缓冲;3.分析日志;4.日志存储;5.日志查看。
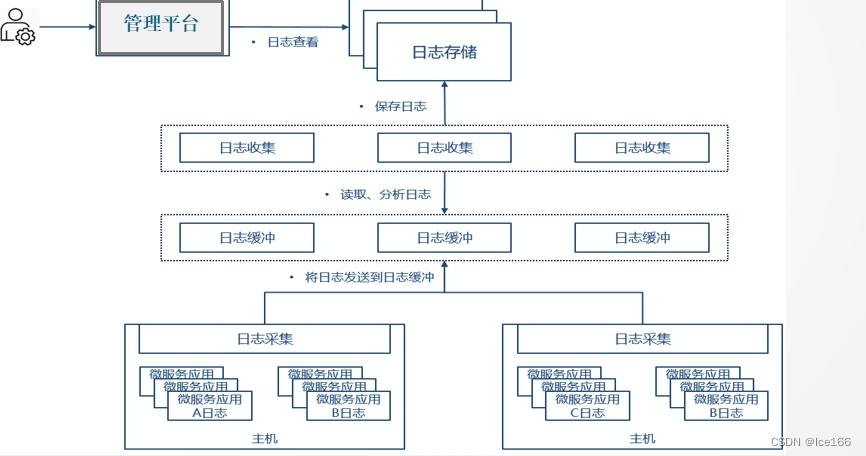
1.日志采集
这章节的重点不是讲如何开发一个spring boot应用,而且从实际场景出发,一个真实的应用所产生的不同类型的日志是如何被file beat采集到的,从而完成日志中心的第一步:日志采集。
1.1 应用日志配置
在实际应用开发中,一个应用所产生的日志可能根据业务需求或者场景会分为很多种,需要记录的日志也随之有很多种,比如:应用程序本身日志-sys.log,应用的跟踪日志-trace.log,应用的sql日志-sql.log等等,这些日志根据类型不同所记录的日志内容肯定也是不一样的,那我们首先要做的第一步就是制定这些日志的格式,以便我们可以根据日志类型在后续logstash里面通过一系列filter生成不通的message和属性,最终生成不同的es索引存储在es中,方便我们做查询,当前这些都是后话,我们先把第一步搞定。
在这里,我们就假设应用需要生成3种类型日志,分别是:
app-sys.log:应用系统日志,记录程序本身的一些日志,包括spring框架、正常代码中自己记录的一些logger、异常等等信息
app-trace.log:应用内部service之间调用关系跟踪日志,记录service内部method的调用、出参入参等,方便查看应用本身的调用逻辑,以便能快速定位问题
app-dap-trace.log:微服务之间的调用日志,记录每个应用之间的调用,以便能查看一个业务场景的整个调用链,能快速知悉业务具体涉及的应用等。
根据这三种类型日志,那么就需要设计对应的日志记录的信息结构,那么我就根据日志的不通性质来定义一些通用的一些属性。当然,在实际开发中,每个人每个公司都有自己的业务,肯定跟着自己的业务来定,我这里只是做一个demo仅供参考。
既然设计已经初步完成了,那么接下来就是怎么实现了;在spring里面通常大家都是用logback来作为日志框架,那么我们就用logback来举例如何生成这三种类型的日志。
1.1.1 创建logback-spring.xml文件
logback文件主要是用来定义每个日志的结构、策略等等,在这里我就不对log back文件做详细的标签介绍了,以下logback-spring.xml 可直接复制即用,只需要修改里面的某些东西即可,具体见如下代码:
<?xml version="1.0" encoding="UTF-8"?><configuration><!-- Spring 自身日志配置 对应APP-SYS --><springProperty scope="context" name="appCode" source="spring.application.name" defaultValue=""/><springProperty scope="context" name="appInstId" source="application.app-inst-id" defaultValue=""/><conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/><conversionRule conversionWord="wex"converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/><conversionRule conversionWord="wEx"converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/><property name="APP_LOG_PATTERN_CONSOLE"value="${APP_LOG_PATTERN_CONSOLE:-%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} %5p [${appCode:-},${appInstId:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-B3-ParentSpanId:-}] ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/><property name="APP_LOG_PATTERN_FILE"value="${APP_LOG_PATTERN_FILE:-%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} %5p [${appCode:-},${appInstId:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-B3-ParentSpanId:-}] ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/><property name="APP_LOG_LEVEL" value="${APP_LOG_LEVEL:-INFO}"/><property name="APP_LOG_FILE_MAX_SIZE" value="${APP_LOG_FILE_MAX_SIZE:-100MB}"/><property name="APP_LOG_FILE_MAX_HISTORY" value="${APP_LOG_FILE_MAX_HISTORY:-100}"/><property name="APP_LOG_FILE_TOTAL_SIZE" value="${APP_LOG_FILE_TOTAL_SIZE:-0}"/><property name="APP_LOG_FILE"value="./logs/app-sys.log}"/><!--配置APP-SYS到控制台--><appender name="APP_LOG_APPENDER_CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${APP_LOG_PATTERN_CONSOLE}</pattern></encoder></appender><!--配置APP-SYS到文件--><appender name="APP_LOG_APPENDER_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder><pattern>${APP_LOG_PATTERN_FILE}</pattern></encoder><file>${APP_LOG_FILE}</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${APP_LOG_FILE}.%d{yyyy-MM-dd}.%i</fileNamePattern><maxFileSize>${APP_LOG_FILE_MAX_SIZE}</maxFileSize><maxHistory>${APP_LOG_FILE_MAX_HISTORY}</maxHistory><totalSizeCap>${APP_LOG_FILE_TOTAL_SIZE}</totalSizeCap></rollingPolicy></appender><!-- 复制自 spring boot org/springframework/boot/logging/logback/defaults.xml --><logger name="org.apache.catalina.startup.DigesterFactory" level="ERROR"/><logger name="org.apache.catalina.util.LifecycleBase" level="ERROR"/><logger name="org.apache.coyote.http11.Http11NioProtocol" level="WARN"/><logger name="org.apache.sshd.common.util.SecurityUtils" level="WARN"/><logger name="org.apache.tomcat.util.net.NioSelectorPool" level="WARN"/><logger name="org.eclipse.jetty.util.component.AbstractLifeCycle" level="ERROR"/><logger name="org.hibernate.validator.internal.util.Version" level="WARN"/><!-- APP-TRACE 日志配置 --><property name="APP_TRACE_LOG_PATTERN"value="[${appCode:-},${appInstId:-},%X{X-B3-TraceId:-}] [%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}] %m%n"/><property name="APP_TRACE_LOG_FILE" value="./logs/app-trace.log}"/><property name="APP_TRACE_LOG_LEVEL" value="${APP_TRACE_LOG_LEVEL:-INFO}"/><!--APP-TRACE to file--><appender name="APP_TRACE_LOG_APPENDER_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder><pattern>${APP_TRACE_LOG_PATTERN}</pattern><charset>UTF-8</charset></encoder><file>${APP_TRACE_LOG_FILE}</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${APP_TRACE_LOG_FILE}.%d{yyyy-MM-dd}.%i</fileNamePattern><maxFileSize>${APP_TRACE_LOG_FILE_MAX_SIZE:-100MB}</maxFileSize><maxHistory>${APP_TRACE_LOG_FILE_MAX_HISTORY:-100}</maxHistory><totalSizeCap>${APP_TRACE_LOG_FILE_TOTAL_SIZE:-0}</totalSizeCap></rollingPolicy></appender><!--DAP-TRACE 日志配置--><conversionRule conversionWord="dapTraceJsonMsg"converterClass="com.testlog.wx.testspringlog.LogJSONMessageConverter"/><property name="DAP_TRACE_LOG_FILE"value="./logs/app-dap-trace.log}"/><property name="DAP_TRACE_LOG_LEVEL" value="${DAP_TRACE_LOG_LEVEL:-INFO}"/><property name="DAP_TRACE_LOG_FILE_MAX_SIZE" value="${DAP_TRACE_LOG_FILE_MAX_SIZE:-100MB}"/><property name="DAP_TRACE_LOG_FILE_MAX_HISTORY" value="${DAP_TRACE_LOG_FILE_MAX_HISTORY:-100}"/><property name="DAP_TRACE_LOG_FILE_TOTAL_SIZE" value="${DAP_TRACE_LOG_FILE_TOTAL_SIZE:-0}"/><!--DAP-TRACE to console--><appender name="DAP_TRACE_LOG_APPENDER_CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%dapTraceJsonMsg</pattern><charset>UTF-8</charset></encoder></appender><!--DAP-TRACE to file--><appender name="DAP_TRACE_LOG_APPENDER_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder><pattern>%dapTraceJsonMsg</pattern><charset>UTF-8</charset></encoder><file>${DAP_TRACE_LOG_FILE}</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${DAP_TRACE_LOG_FILE}.%d{yyyy-MM-dd}.%i</fileNamePattern><maxFileSize>${DAP_TRACE_LOG_FILE_MAX_SIZE}</maxFileSize><maxHistory>${DAP_TRACE_LOG_FILE_MAX_HISTORY}</maxHistory><totalSizeCap>${DAP_TRACE_LOG_FILE_TOTAL_SIZE}</totalSizeCap></rollingPolicy></appender><!--日志开关--><root level="${APP_LOG_LEVEL}"><appender-ref ref="APP_LOG_APPENDER_CONSOLE"/><appender-ref ref="APP_LOG_APPENDER_FILE"/></root><logger name="app-trace" additivity="false" level="${APP_TRACE_LOG_LEVEL}"><appender-ref ref="APP_TRACE_LOG_APPENDER_FILE"/></logger><logger name="app-dap-trace" additivity="false" level="${DAP_TRACE_LOG_LEVEL}"><appender-ref ref="DAP_TRACE_LOG_APPENDER_CONSOLE"/><appender-ref ref="DAP_TRACE_LOG_APPENDER_FILE"/></logger></configuration>1.1.2 创建LoggerFactory
LoggerFactory的作用是为了给程序员更方便的创建不通的logger,我们在这里就封装app-trace和dap-trace logger的创建,app-sys用系统日志即可,无需额外创建,具体代码如下:
package com.testlog.wx.testspringlog;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;/*** @Description TODO* @Author wx * @Date 2024/3/28*/
public class DemoTraceLoggerFactory {public static final String TRACE_LOGGER_NAME_PREFIX = "app-trace.";public static final String DAP_TRACE_LOGGER_NAME_PREFIX = "app-dap-trace.";public static Logger getTraceLogger(Class<?> clazz) {return LoggerFactory.getLogger(TRACE_LOGGER_NAME_PREFIX + clazz.getName());}public static Logger getDapTraceLogger(Class<?> clazz) {return LoggerFactory.getLogger(DAP_TRACE_LOGGER_NAME_PREFIX + clazz.getName());}}
1.1.3 trace日志的记录用法
app-trace的作用是用来记录应用内部不同service.method的调用链,因此我们编写一个demo,两个service来做一个演示具体app-trace的记录效果;
首先新建 IDemoService 以及实现类 DemoServiceImpl
IDemoService:
package com.testlog.wx.testspringlog;/*** @Description TODO* @Author wx520* @Date 2024/3/28*/
public interface IDemoService {String sayHi(String name);}
DemoServiceImpl:
package com.testlog.wx.testspringlog;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;/*** @Description TODO* @Author wx* @Date 2024/3/28*/
@Service
public class DemoServiceImpl implements IDemoService {@Autowiredprivate IDemoService2 demoService2;@Overridepublic String sayHi(String name) {System.out.println(name);demoService2.test11();return "hello word";}}
再新建IDemoService2以及实现类DemoServiceImpl2
IDemoService2:
package com.testlog.wx.testspringlog;/*** @Description TODO* @Author wx520* @Date 2024/3/28*/
public interface IDemoService2 {void test11();}
DemoServiceImpl2:
package com.testlog.wx.testspringlog;import org.springframework.stereotype.Service;/*** @Description TODO* @Author wx * @Date 2024/3/28*/
@Service
public class DemoServiceImpl2 implements IDemoService2 {@Overridepublic void test11() {System.out.println("test");}}
建完service之后那么就开始写记录trace日志的逻辑,我们用aspect来对@Service做拦截,用@Aroud来进行记录请求在进入method之前和之后的日志信息,具体实现如下:
package com.testlog.wx.testspringlog;import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;import java.util.UUID;/*** @Description TODO* @Author wx* @Date 2024/3/28*/
@Aspect
@Component
public class SpringTraceLoggerMethodInterceptor {private Logger traceLogger = DemoTraceLoggerFactory.getTraceLogger(getClass());@Around("@within(org.springframework.stereotype.Service)")public Object around(ProceedingJoinPoint joinPoint) throws Throwable {Class clazz = joinPoint.getTarget().getClass();String beanClassName = clazz.getName();MethodSignature signature = (MethodSignature) joinPoint.getSignature();String methodName = signature.getName();String message = "Spring Bean " + beanClassName + "#" + methodName;String[] argNames = signature.getParameterNames();Object[] parameters = joinPoint.getArgs();traceLogger.info(entry(message, buildParams(argNames, parameters)));Object result = joinPoint.proceed();traceLogger.info(exit(message, buildResult(result)));return result;}private String buildResult(Object result) {StringBuffer sb = new StringBuffer();sb.append("{");sb.append("result:").append(JsonUtil.toJson(result));sb.append("}");return sb.toString();}private String buildParams(String[] argNames, Object[] parameters) {StringBuffer sb = new StringBuffer();sb.append("{");for (int i = 0; i < argNames.length; i++) {sb.append("" + argNames[i] + ":").append("" + JsonUtil.toJson(parameters[i]) + "");if (i != argNames.length - 1) sb.append(",");}sb.append("}");return sb.toString();}/*** 测试代码 写的不够严谨 不能作为正式开发使用** @param message*/private String entry(String message, String params) {String traceId = MDC.get("X-B3-TraceId");if (StringUtils.isEmpty(traceId)) {MDC.put("X-B3-TraceId", UUID.randomUUID().toString());}return getFormatSysLoggerMessages(message, params, " invoker start.", "Begin");}private String exit(String message, String params) {return getFormatSysLoggerMessages(message, params, " invoker end.", "End");}/*** 测试代码 写的不够严谨 不能作为正式开发使用** @param message* @param params* @param action* @return*/private String getFormatSysLoggerMessages(String message, String params, String action, String loggerType) {StringBuffer sb = new StringBuffer();sb.append("[");sb.append(loggerType).append("]");sb.append("[").append(message).append("]");sb.append("[").append(params).append("]");sb.append("[Spring Bean ").append(message).append(action).append("]");return sb.toString();}}
最后建一个controller用来做远程调用入口
package com.testlog.wx.testspringlog;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import static org.springframework.http.MediaType.ALL_VALUE;/*** @Description TODO* @Author wx * @Date 2024/3/28*/
@RestController
@RequestMapping(value = "/demo", consumes = ALL_VALUE)
public class DemoController {@Autowiredprivate IDemoService demoService;@GetMapping("/sayHi/{name}")public String sayHi(@PathVariable("name") String name) {return demoService.sayHi(name);}}
效果:
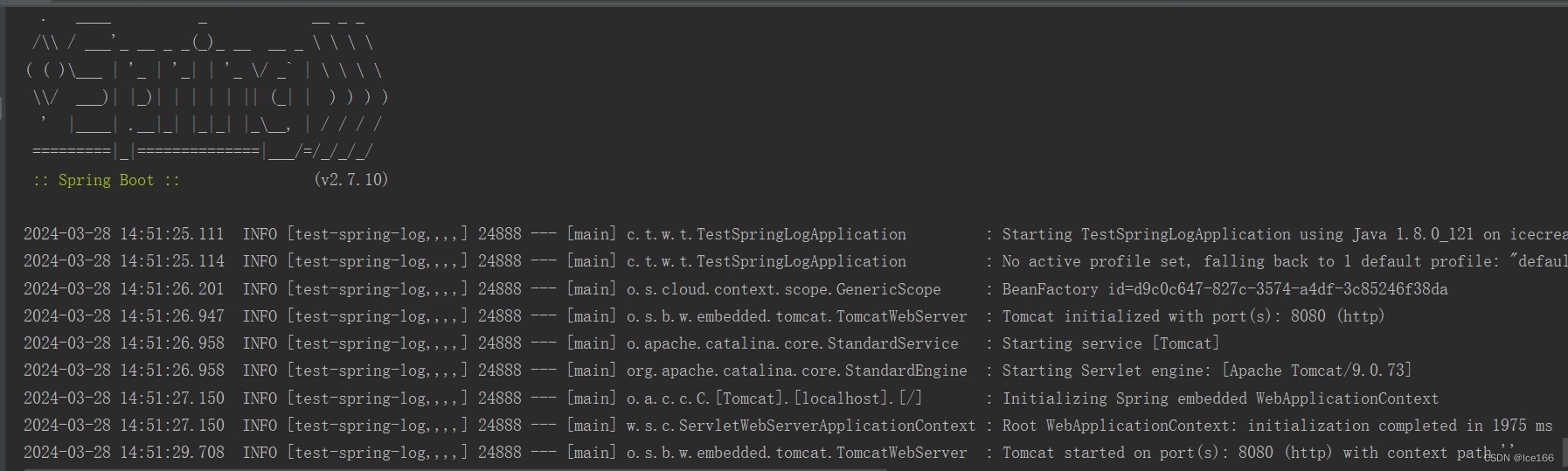
开发工具直接启动应用,我们会发现控制台输入的日志信息就跟我们在logback-spring.xml里面配置的app-sys日志格式是一样的,同时,在当前应用的根目录/logs目录下会生成一个app-sys.log的日志文件;
app-sys.log 控制台效果如下:
app-sys.log 文件内容效果如下:
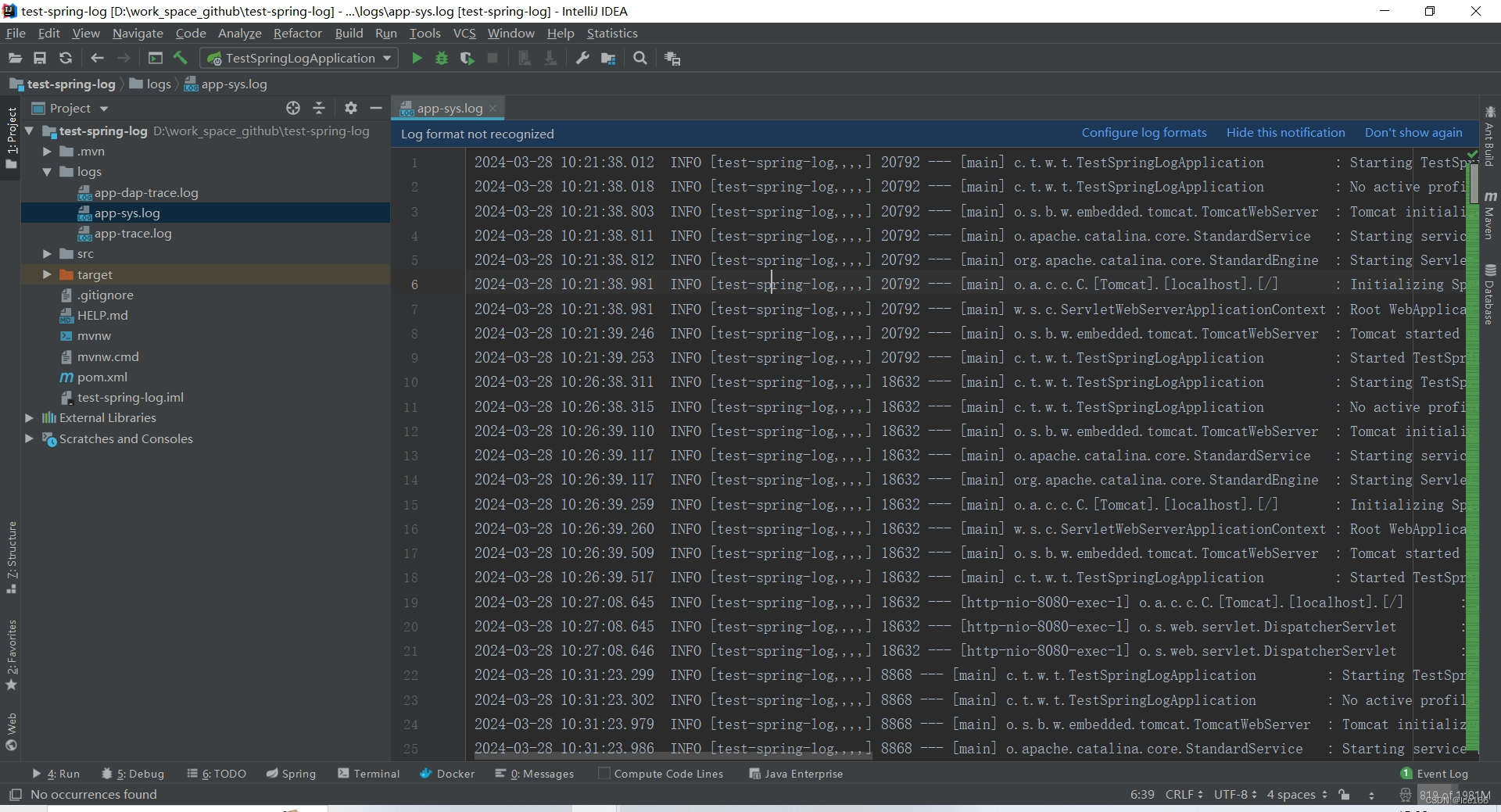
那么我们接下来浏览器直接访问controller接口或者用其他工具都可,访问成功之后会在/logs目录生成app-trace.log日志文件,具体内容如下:
[test-spring-log,,e00cc8a5-fcc0-46d5-b694-eccc8e129bc7] [2024-03-28 14:41:50.636] [Begin][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi][{name:"aa"}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi invoker start.]
[test-spring-log,,e00cc8a5-fcc0-46d5-b694-eccc8e129bc7] [2024-03-28 14:41:50.642] [Begin][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11][{}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11 invoker start.]
[test-spring-log,,e00cc8a5-fcc0-46d5-b694-eccc8e129bc7] [2024-03-28 14:41:50.645] [End][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11][{result:null}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11 invoker end.]
[test-spring-log,,e00cc8a5-fcc0-46d5-b694-eccc8e129bc7] [2024-03-28 14:41:50.645] [End][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi][{result:"hello word"}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi invoker end.]
[test-spring-log,,daa999c2-49d1-40e0-83c6-b33781926185] [2024-03-28 14:51:33.048] [Begin][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi][{name:"aa"}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi invoker start.]
[test-spring-log,,daa999c2-49d1-40e0-83c6-b33781926185] [2024-03-28 14:51:33.055] [Begin][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11][{}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11 invoker start.]
[test-spring-log,,daa999c2-49d1-40e0-83c6-b33781926185] [2024-03-28 14:51:33.059] [End][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11][{result:null}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl2#test11 invoker end.]
[test-spring-log,,daa999c2-49d1-40e0-83c6-b33781926185] [2024-03-28 14:51:33.059] [End][Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi][{result:"hello word"}][Spring Bean Spring Bean com.testlog.wx.testspringlog.DemoServiceImpl#sayHi invoker end.]
你会发现我们日志中一个完整的traceId包含四条日志信息:service1.sayHi begin---》service2.test11 begin ---->service2.tes11 end ---> service1.sayHi end;这就是app-trace日志记录的一个请求的一条完成trace链路。
1.1.4 dap-trace日志的记录用法
dap-trace比较特殊,因为它的作用是用来记录每个微服务实例之间的调用链路的,本来考虑这里加入sky walking一起讲的,但是感觉这样篇幅就收不住了就打住了,后期有时间会整理一套应用节合sky walking以及节合业务属性来做追踪的方案,因此这里就直接使用sleuth来做trace跟踪,
还有一个需要注意的地方就是:前面两种日志都是自定义的常规格式,因此dap-trace日志楼主就想用个特殊格式-json 来做记录,这样也方便大家有这个需求:怎么用logback记录json格式的日志,什么格式这里都有,无需再去查找资料了
pom文件添加sleuth依赖:版本自定 无需跟本文一致
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><version>3.1.7</version></dependency>既然是记录dap-trace日志,那么肯定是要在请求进来应用后以及响应之前做日志记录,那么楼主推荐大家使用spring的OncePreRequestFilter来做拦截,这个filter的作用和原理我就不说了,望名知意,具体大家可以去官网看文档介绍,代码如下:
package com.testlog.wx.testspringlog;import org.slf4j.Logger;
import org.slf4j.MarkerFactory;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import org.springframework.web.servlet.HandlerMapping;import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;/*** @Description TODO* @Author wx* @Date 2024/3/28*/
@Component
public class DapTraceLoggerFilter extends OncePerRequestFilter implements Ordered {private Logger dapTraceLogger = DemoTraceLoggerFactory.getDapTraceLogger(getClass());@Overridepublic int getOrder() {return HIGHEST_PRECEDENCE + 10;}@Overrideprotected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {//这里用来记录dap-tracelong start = System.nanoTime();logRequest(request);filterChain.doFilter(request, response);logResponse(start, response, request);}private void logResponse(long start, HttpServletResponse response, HttpServletRequest request) {Map<String, Object> map = new HashMap<>();map.put("comp", "SPRING_WEB");map.put("r_event", "SS");map.put("hsc", response.getStatus());map.put("api_path", request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE));map.put("etime", TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start));dapTraceLogger.info(MarkerFactory.getMarker("//@args-json-formatter"), null, map);}private void logRequest(HttpServletRequest request) {Map<String, Object> map = new HashMap<>();map.put("comp", "SPRING_WEB");map.put("r_event", "SR");map.put("hurl", request.getRequestURL().toString());map.put("hm", request.getMethod());map.put("hra", request.getRemoteAddr());
//使用该Marker时, 如果日志参数里有Map类型参数, 则会将Map变成json结构dapTraceLogger.info(MarkerFactory.getMarker("//@args-json-formatter"), null, map);}
}
因为是需要json格式的日志,楼主这里就没有用常规方式去配置,也就是在logback里面配置一大堆属性,这个方式我感觉有点不方便,既然是json,那属性肯定都是动态或者自定义的,方便后期扩展,否则每次新增属性都要去修改logback就很麻烦,不利于迭代和维护,具体代码如下:
package com.testlog.wx.testspringlog;import ch.qos.logback.classic.pattern.ThrowableHandlingConverter;
import ch.qos.logback.classic.spi.ILoggingEvent;
import org.slf4j.MDC;
import org.slf4j.MarkerFactory;import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;/*** @Description TODO* @Author wx * @Date 2024/3/28*/
public class LogJSONMessageConverter extends ThrowableHandlingConverter {private static final ThreadLocal<SimpleDateFormat> SDF = new ThreadLocal<SimpleDateFormat>() {protected SimpleDateFormat initialValue() {return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");}};@Overridepublic String convert(ILoggingEvent le) {Map<String, Object> map = new HashMap<>();String traceId = MDC.get("traceId");String spanId = MDC.get("spanId");String psid = MDC.get("parentId");//skywalking 相关代码暂时去掉 有感兴趣的同学也可以自己打开注释
// String swTraceId = MDC.get("swTraceId");
// if (StringUtils.isEmpty(swTraceId) || StringUtils.equals("N/A", swTraceId)) {
// swTraceId = TraceContext.traceId();
// }map.put("time", SDF.get().format(new Date(le.getTimeStamp())));map.put("app", LoggerProperties.INSTANCE.getAppCode());map.put("tid", traceId);map.put("sid", spanId);map.put("psid", psid);
// map.put("sw_tid", swTraceId);if (le.getMarker() == MarkerFactory.getMarker("//@args-json-formatter")) {Object[] array = le.getArgumentArray();if (array != null && array.length > 0) {for (int i = 0, len = array.length; i < len; i++) {Object item = array[i];// 只处理 Map类型 这个根据自己的模型来就是了if (item instanceof Map) {for (Map.Entry<?, ?> entry : ((Map<?, ?>) item).entrySet()) {map.put(String.valueOf(entry.getKey()), entry.getValue());}}}}}return JsonUtil.toJson(map) + System.lineSeparator();}
}
效果:
同样的,访问刚刚的controller接口,会在控制台以及/logs目录生成app-dap-trace.log日志文件,具体效果如下:
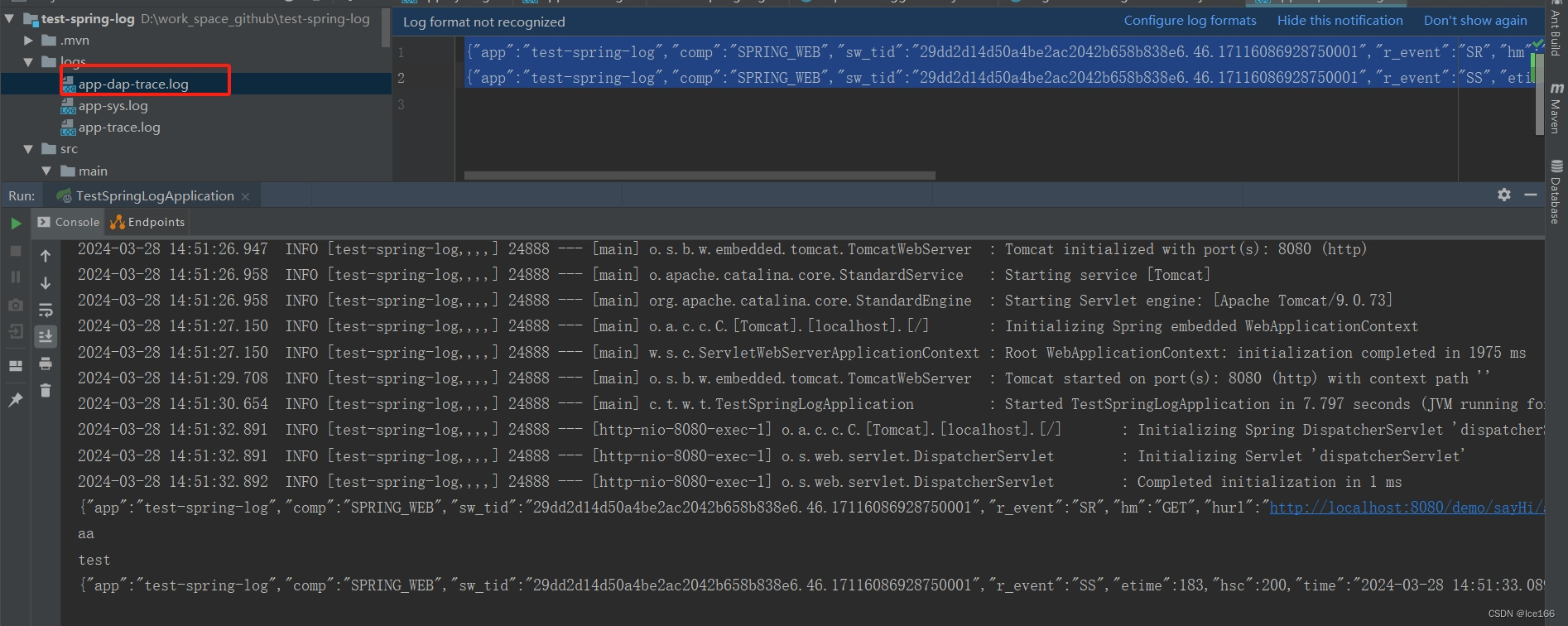
{"app":"test-spring-log","comp":"SPRING_WEB","sw_tid":"29dd2d14d50a4be2ac2042b658b838e6.46.17116086928750001","r_event":"SR","hm":"GET","hurl":"http://localhost:8080/demo/sayHi/aa","hra":"0:0:0:0:0:0:0:1","time":"2024-03-28 14:51:32.907","tid":"60c5cfdc3694eb1b","sid":"60c5cfdc3694eb1b"}
{"app":"test-spring-log","comp":"SPRING_WEB","sw_tid":"29dd2d14d50a4be2ac2042b658b838e6.46.17116086928750001","r_event":"SS","etime":183,"hsc":200,"time":"2024-03-28 14:51:33.089","api_path":"/demo/sayHi/{name}","tid":"60c5cfdc3694eb1b","sid":"60c5cfdc3694eb1b"}
同样的,一次请求会记录SR和SS两条日志,全局跟踪链的话就用tid(也就是traceId)来做跟踪。
自此,应用日志配置已经全部完成,接下来就是日志到底如何采集的。
1.2 应用日志采集
日志采集这块就交给file beat了,但是我们有三套日志文件,想要file beat能识别不同格式的日志以便能正确采集到日志信息,就得需要对应配置好file beat,,进入{安装目录}/,新建test-filebeat.yml配置文件进行配置,具体配置如下:
filebeat.inputs:# -----
# app-dap-trace-log
# -----
- type: filestream id: app-dap-trace-log-idenabled: truepaths: - /opt/elk/test-logs/app-dap-trace.log*- /opt/elk/test-logs/app-dap-trace.log*- /opt/elk/test-logs/app-dap-trace.log*- /opt/elk/test-logs/app-dap-trace.log*encoding: UTF-8 fields:app-topic-name: app-logapp-log-type: app-dap-trace-log prospector.scanner.exclude_files: [".gz$"]parsers: #因为我们的dap-trace日志是json格式的,所以需要用的file beat的ndjson来做解析- ndjson:target: ""add_error_key: trueoverwrite_keys: true# -----
# app-sys-log
# -----
- type: filestreamid: app-sys-log-idenabled: truepaths: - /opt/elk/test-logs/app-sys.log*- /opt/elk/test-logs/app-sys.log*- /opt/elk/test-logs/app-sys.log*encoding: UTF-8 fields:app-topic-name: app-logapp-log-type: app-sys-logprospector.scanner.exclude_files: [".gz$"]parsers:- multiline:type: patternpattern: '^\d{4}\-\d{2}\-\d{2}' negate: truematch: aftermax_lines: 500# -----
# app-trace-log
# -----
- type: filestreamid: app-log-idenabled: truepaths: - /opt/elk/test-logs/app-trace.log*encoding: UTF-8 fields:app-topic-name: app-logapp-log-type: app-trace-logprospector.scanner.exclude_files: [".gz$"]parsers:- multiline:type: patternpattern: '^\[[^,]+,[^,]+,'negate: truematch: aftermax_lines: 500# -----
# output
# -----
output.kafka:enabled: truehosts: ["localhost:9092"]topic: '%{[fields.app-topic-name]}'max_retries: 3bulk_max_size: 2048timeout: 30broker_timeout: 10channel_buffer_size: 256keep_alive: 60compression: gzipmax_message_bytes: 100000000required_acks: 1client_id: 'app-filebeats'# -----
# 8.x版本logstash会用event做字段,冲突 不想改原本的日志结构 这里做一下rename
# -----
processors:- rename:fields:- from: "event"to: "r_event"ignore_missing: falsefail_on_error: true
配置解析:
官方文档: Configure inputs | Filebeat Reference [8.12] | Elastic 版本选择8.1.2
| scope | 属性 | 值 | 说明 |
| inputs配置 | type | filestream | 老版本为log,新版本统一用filestream |
| id | 自定义 | 多个filestream需要用id来区分 | |
| paths | 路径 | 配置当前filestream要采集的日志路径,数组格式,可配置多个 | |
| fields | 字段 | 可自定义添加当前采集的数据的字段属性,比如本文中用添加了app-log-type和app-topic-name用来给后续用 | |
| parsers | ndjson | 解析器 可多配 | |
| target | 解析json的时候放在哪个属性下,为空就是放在跟目录,老版本是keys_under_root | ||
| multiline | 处理多行数据 | ||
| type | pattern | 正则匹配多行数据 | |
| pattern | 正则表达式 | 匹配上的数据才会采集 | |
| output | kafka | 输出 | |
| topic | 输出到kafka的topic | 节合业务定义对应的topic,logstash那边读取对应的topic数据,各行其职 | |
| processors | rename | 修改属性字段名称 | |
| fields | |||
| from | 原属性 | ||
| to | 目标属性 |
在这里为什么要单独列一下processors配置呢,因为开头也说了,楼主因为是升级ELK,但是应用日志模板升级的时候你肯定是不能改的,一改,日志结构就没法兼容了,所以大家也有可能会遇到楼主同样的问题,因为之前楼主公司的trace日志里面有个属性叫:event,是String,记录是输入还是输出类型的,但是8.1.x版本的logstash会把event当作它自己的属性,而且还是个Object类型,一升级,就会导致日志在logstash那边没办法识别,从而存进es的时候就会发现存的索引不对,这个时候file beat的这个rename处理就有大作用了,我可以不用修改应用的日志结构从而兼容升级之前的日志数据,而且file beat还有很多其他的处理器,大家在遇到问题的时候建议多去看看官方文档找找,总有解决办法的。
到此,日志采集环节就已经完成了,接下来就是日志缓冲。
2.日志缓冲
这里加上kafka的主要作用是用来做缓冲,不过这一块看具体业务,有些业务量小的,数据没那么夸张就感觉没必要上,那有些业务非常频繁,数据量很大,如果直接从beat到logstash很大概率会讲logstash压垮,或者是导致logstash非常吃资源,这样就有点得不偿失。
说白了,日志数据并不像其他业务数据一样需要时效性以及100%准确性,只需要在特定的时间完成处理即可,所以kafka就派上用场了。
在这一环节,大家回过头来看上面file beat的配置,大家会发现我们配置了一个自定义的fields:app-topic-name,所以在kafka这里我们也要将这个topic创建出来,具体命令如下:
#进入到kafka安装目录/bin目录下执行命令
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181/kafka --replication-factor 1 --partitions 1 --topic app-log
3.日志分析
现在整个ELK环节从file beat采集--->kafka缓冲--->已经来到了logstash分析整理了,logstash在这里的主要作用就是通过读取kafka推送过来的日志数据,然后分析日志结构,整理成我们和es都想要的格式存进es,进入到{安装目录}/config目录,新建一个test-logstash.conf文件,然后进行配置,具体配置如下:
input {kafka {bootstrap_servers => ["127.0.0.1:9092"]topics_pattern => "app-.*"group_id => "app-logstash"client_id => "app-logstash"auto_offset_reset => "earliest"codec => json {charset => "UTF-8"}consumer_threads => 3decorate_events => true}
}filter {# -----# pre process [fields][app-log-type]# -----if ![fields][app-log-type] and [log][file][path] {grok {match => { "[log][file][path]" => "%{GREEDYDATA}(\\|\/)%{DATA:log-file-name}\."}}mutate {add_field => { "[fields][app-log-type]" => "%{[log-file-name]}-log" } }}# -----# parse log message as json field# -----# app-sys-log is log generated by app8 if [fields][app-log-type] =~ "app-sys-log" {grok {match => { "message" => "%{TIMESTAMP_ISO8601:time}\s+%{LOGLEVEL:level}\s+\[%{DATA:app},%{DATA:inst},%{DATA:tid},%{DATA:sid},%{DATA:psid}\]%{GREEDYDATA:msg}" }}}else if [fields][app-log-type] =~ "app-trace-log" {grok {match => { "message" => "\[%{DATA:app},%{DATA:inst},%{DATA:tid}\]\[%{TIMESTAMP_ISO8601:time}\]%{GREEDYDATA:msg}" }}}# -----# replace logstash @timestamp with log timestamp, and output.elasticsearch create index use this time# -----date {match => [ "time", "yyyy-MM-dd HH:mm:ss.SSS", "ISO8601" ]locale => "cn"timezone => "Asia/Shanghai"}
}output {elasticsearch {hosts => ["127.0.0.1:9200"]index => "%{[fields][app-log-type]}-%{+YYYY.MM.dd}"}
}
这里为什么只做了两种日志type的分析,因为dap-trace本身就是json格式的,无需再处理了,而其他两种的日志为什么不也生成json格式的呢,这就涉及到一个开发习惯了,相信绝大数人看日志的话肯定还是习惯于像spring框架产生的那种格式的日志,因为大多数人第一次接触开发,从成功启动第一个应用到看到控制台输出日志,看到的日志就是类似
2024-03-28 10:21:38.803 INFO [test-spring-log,,,,] 20792 --- [main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
这种格式的,这种格式日志也方便大家查看信息定位问题,尤其是堆栈信息,而dap-trace日志不同,它是记录应用之间的调用链的,一般这种日志都是通过第三方工具或者节合业务需求来查看的,所以一般都是记录的json格式数据。
在这里做日志分析的目的就是从日志数据中解析出我们想要的属性,这样存进es的时候方便后续通过某些自定义的一些业务属性进行条件查询,比如,按照日志记录时间查询某时间段的sys日志;比如按照应用appCode来查找不同应用的sys日志,如果你只是一股脑把数据放进es,查是能查,查出来的数据就不一定是你想要的了,就不贴合业务场景了
这里我就不过多介绍logstash配置文件里的那些配置具体作用了,感兴趣的同学可去官方文档查看: Logstash Reference [8.13] | Elastic
4.日志存储
这一环节有两个方面需要思考:
1.怎么存
2.怎么查
在上一个环节:日志分析章节我们可以看到,我们根据日志的类型去单独解析出具体日子内容,然后解析出来我们需要的属性,然后在根据日志生成的时间+日志类型作为es的索引构成一个完整的日志索引模型,那这个环节我们要做的就是匹配logstash过来的数据,然后按照我们设计好的日志索引模板来存储索引数据,所以我们首先要做的就是:制定好对应的日志类型的索引模板;那么索引模板定好了,所有的数据都会按照我们设计的模型存储到es中,查自然就不在话下了。
针对我们设计的三种日志类型我分别设计了三个对应的日志索引模板,具体如下:
app-sys、app-trace日志索引模板:
{"index_patterns": ["*app-trace-log*","*app-sys-log*"],"priority": 1,"template": {"mappings": {"properties": {"time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"},"app": {"type": "keyword"},"inst": {"type": "keyword"},"tid": {"type": "keyword"},"sid": {"type": "keyword"},"psid": {"type": "keyword"}}}}
}app-dap-trace日志索引模板:
{"index_patterns": ["*app-dap-trace-log*"],"priority": 3,"template": {"mappings": {"properties": {"time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"},"app": {"type": "keyword"},"inst": {"type": "keyword"},"tid": {"type": "keyword"},"sid": {"type": "keyword"},"psid": {"type": "keyword"},"comp": {"type": "keyword"},"r_event": {"type": "keyword"},"sw_tid": {"type": "keyword"},"api_path": {"type": "keyword"}}}}
}接下来就是让日志模板在es生效,将上述模板分别保存为app-sys-trace-log-template.json、app-dap-trace-log-template.json文件,然后将文件上传至es安装目录,然后执行如下命令:
curl -H "Content-Type:application/json" -XPUT 'http://ip:9200/_index_template/app-sys-trace-log' -d @app-sys-trace-log-template.json
curl -H "Content-Type:application/json" -XPUT 'http://ip:9200/_index_template/app-dap-trace-log' -d @app-dap-trace-log-template.json命令解析:
1. 创建索引模板的接口格式是ip:port/_index_template/{模板名称},模板名称可换成你们自定义的名称。
2. -d @后面的是对应的模板文件名称,我这个命令是在模板所在的目录执行的,如果你是要在其他地方执行,请带上完整路径。
3. 模板里面的priority属性一定要注意:多个模板存在的情况,一定要修改值,不能存在相同priority的模板,这个属性其实就是order的作用,新版本es不允许模板的order存在相同配置。
或者可以直接用postman请求es创建索引模板接口也行,接口还是上面命令里面的接口,body直接复制上面模板内容即可。
创建完模板之后,验证一下我们刚刚创建的索引有没有成功,请求接口:http://ip:9200/_index_template/{模板名称} 查询索引模板的接口,然后查看有没有我们刚刚创建的索引模板,如下所示:
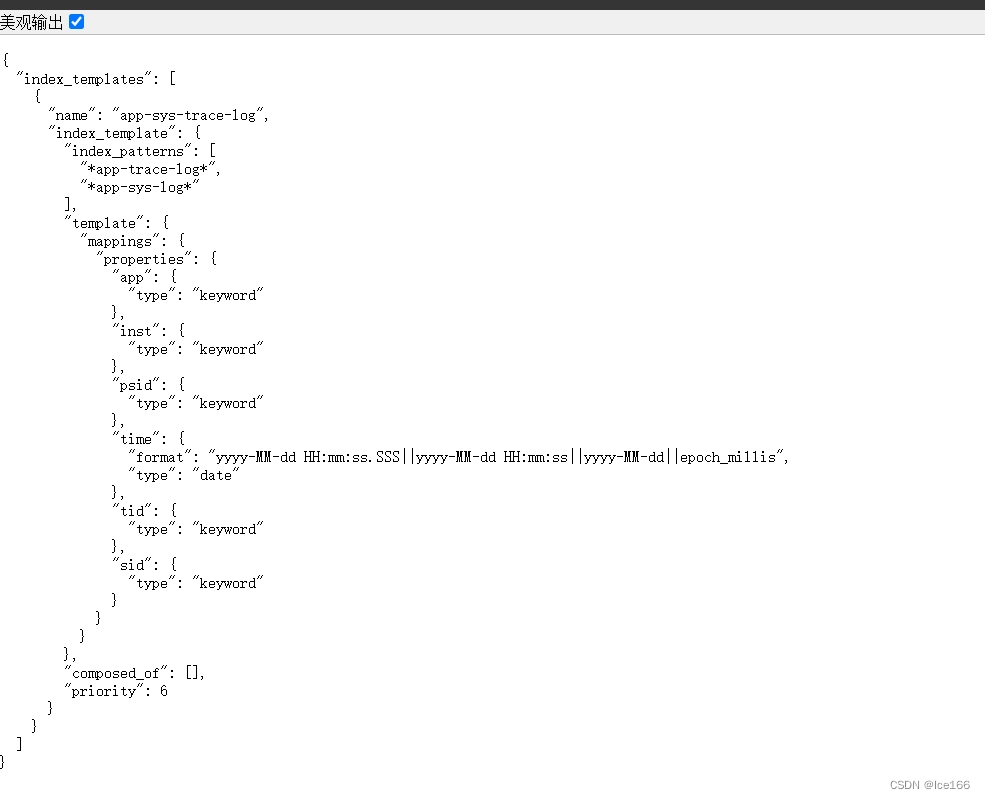
或者查看响应:{"acknowledged":true} 则表示成功
5.小总结
到这里,我们再来捋一下整体流程:
1.首先在开发之前先大家讨论制定好日志类型、日志格式
2.接下来就是定好日志框架,包括日志配置、日志的输入输出等
3.根据前两步对file beat进行配置,能够正确采集到我们应用产生的日志文件内的数据
4.file beat配置好日志特定的topic,然后采集的数据输出到kafka
5.kafka进行日志专属topic的创建
6.logstash通过读取kafka-日志topic中的日志数据对日志进行分析、整理,最后生成es索引所需要的特定格式数据,并输出到es中
7.es制定好日志对应所需要的索引模板,然后创建模板,等待数据从logstash输入。
捋完流程我们再来回过头来将流程跑一遍看看效果如何,日志是否能按照我们所设计的完美进入es中,请按照以下流程来启动各组件(ps:因为各个组件有严格的上下游关系,所以我们一般都是从最底层开始);
1.启动我们的应用,确保有日志输出(随便访问下接口让日志产生)
2.check一下es有没有添加我们的索引模板,check方式请看上面,索引模板ok的话,我们启动es,执行如下命令:
# 进入{es安装目录/bin目录}
nohup sh elasticsearch -d >> ../logs/out.log 2>&1 &3.启动zookeeper,执行如下命令:
# j进入{安装目录}/bin目录 启动
sh zkServer.sh start
# 查看状态
sh zkServer.sh status
#停止
sh zkServer.sh stop 4.启动kafka,执行如下命令:
#启动kafka
nohup sh kafka-server-start.sh -daemon ../config/server.properties >>/dev/null 2>&1 &## 初始化topic
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181/kafka --replication-factor 1 --partitions 1 --topic app-log5.启动logstash,执行如下命令
#进入{安装目录}/bin目录
nohup sh logstash -f ../config/test-logstash.conf >> ../logs/out.log 2>&1 &6.启动file beat,执行如下命令
#进入{安装目录}
nohup ./filebeat -e -c test-filebeat.yml >/dev/null 2>&1 &7.验证日志是否正确输出到es
先查看是否有正确按照我们的配置生成索引,请浏览器直接访问接口:
http://ip:9200/_cat/indices?v ,不出意外的话我们就能看到返回的数据有我们定义的索引数据存在。
然后我们查看一下具体某个索引里面的数据,看下结构数据跟我们设定的模板对不对的上,
用远程工具,比如postman访问接口:
post请求:http://ip:9200/{索引名称}/_search?ignore_unavailable=true ,正常情况下会返回如下格式的数据:
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 5760,"relation": "eq"},"max_score": 1.0,"hits": [{"_index": "app-dap-trace-log-2024.03.02","_id": "J1DEQI4BgHvBZxO0CTeC","_score": 1.0,"_ignored": ["event.original.keyword"],"_source": {"input": {"type": "filestream"},"hra": "127.0.0.1","host": {"name": "node-127-0-0-1"},"hurl": "http://127.0.0.1:14083/api/demo/aa","@version": "1","sw_tid": "","comp": "SPRING_WEB","inst": "127.0.0.1:test-spring-log:14083","app": "test-spring-log","ecs": {"version": "8.0.0"},"r_event": "SR","@timestamp": "2024-03-02T17:57:05.056Z","hm": "POST","log": {"offset": 415082,"file": {"path": "/opt/elk/test-logs/app-dap-trace.log.2024-03-03.0"}},"agent": {"name": "node-127-0-0-1","version": "8.1.2","ephemeral_id": "5ff7d980-129a-4af5-bade-85c656a63fec","id": "d72a0d75-7491-4ebf-9bdd-f461f84dd7bc","type": "filebeat"},"event": {"original": "{\"@timestamp\":\"2024-03-15T06:18:58.222Z\",\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"_doc\",\"version\":\"8.1.2\"}}"},"time": "2024-03-03 01:57:05.056","sid": "2bdf6a3a87116341","tid": "2bdf6a3a87116341","fields": {"app-topic-name": "app-log","app-log-type": "app-dap-trace-log"}}}]}
}其中,hits.hits._source中的数据就是所存进去的该类型的日志数据以及结构,我们可以看到_source下面的一些key都是我们在模板里面定好的,没有定的就是logstash本身的属性字段,这就是一个我们所需要的一个完整的es索引结构,将来做条件查询的时候这些字段会有大用处。
如果你按照本文来一步一步走下来,得到的数据结构和上面的示例一样,就说明你已经成功了。
6.日志查看
这一块其实有点不大好讲,因为涉及到实际业务场景,每个人所运用的场景都不一样,我就按照我现在做的来给大家讲一讲思路,归根结底,日志中心最后展现给人的就是这个环节:日志查看。用户也是最关心这一点,其他的包括采集、存储什么什么的用户是不关心的,他们只需要一个符合他们的结果就行,其他你们程序员搞定就行(~!~),所以日志查看最核心的就是节合业务场景,那本文所采用的方案就是将业务字段存储进es索引中,节合日志查看系统进行业务场景条件查询日志,这样的话日志和业务就能紧密节合在一起了,如何将业务字段存储进es中,前面已经很详细的描述了,接下来就是如何查询,这里我只是讲一下大致的实现思路细节,给大家提供一个可参考的方向,具体如下:
Rest apis
es已经提供了一套rest api,无论大家是使用java es client还是其他方式,底层都是rest api,所以直接使用rest api,再节合业务场景进行查询es即可,我就列举一些常见的查询示例
根据索引名称条件查询日志信息
POST:http://10.16.16.103:9200/{index_name}/_search
body:
{"from" : 0, "size" : 300,"query":{"bool":{"filter":[{"range":{"time":{"gte":"2024-04-02 10:31:23.000", "lt":"2024-04-03 10:31:23.000"}}}, {"term": {"app": "appName"}}, {"term": {"inst": "应用实例id"}} //todo 也可以加其他业务字段 只要是你日志里面对应有的]}},"sort": { "time": { "order": "asc" }}
}这样我们就可以在body里面自定义添加我们业务上需要的查询条件进行search,日志系统也可以自行节合业务场景然后封装自己的rest api进行查询即可,虽然现在es也自己提供了java client,但是我感觉这个适合那种场景:应用需要自行操作es,比如将es当作应用本身的存储来交互;这种的就比较适合使用client来进行操作,但是日志系统并不需要其他的,只需要查询而已,所以为了不强依赖es,我们可以节合业务场景自行封装rest api。
自此,一个完整的springboot整合ELK的日志中心DEMO方案就算是初步完成了,如有更好的方案,欢迎交流,点个赞吧~
相关文章:
SpringBoot整合ELK8.1.x实现日志中心教程
目录 背景 环境准备 环境安装 1.JDK安装 2.安装Elasticsearch 3.安装zookeeper 4.安装Kafka 5.安装logstash 6.安装file beat 解决方案场景 1.日志采集 1.1 应用日志配置 1.1.1 创建logback-spring.xml文件 1.1.2 创建LoggerFactory 1.1.3 trace日志的记录用法 …...

计算机网络:数据链路层 - 封装成帧 透明传输 差错检测
计算机网络:数据链路层 - 封装成帧 & 透明传输 & 差错检测 数据链路层概述封装成帧透明传输差错检测 数据链路层概述 从数据链路层来看,主机 H1 到 H2 的通信可以看成是在四段不同的链路上的通信组成的,所谓链路就是从一个节点到相邻…...

Open3D (C++) 计算点云的特征值特征向量
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 针对整个点云 P = { p i } i...

Java | Leetcode Java题解之第8题字符串转换整数atoi
题目: 题解: class Solution {public int myAtoi(String str) {Automaton automaton new Automaton();int length str.length();for (int i 0; i < length; i) {automaton.get(str.charAt(i));}return (int) (automaton.sign * automaton.ans);} …...

BL200耦合器数据采集模块
BL200耦合器数据采集模块是一个数据采集和控制系统,基于强大的32 位ARM926EJ-S™ 微处理器设计,采用Linux操作系统,支持Modbus TCP协议,可以快速接入现场PLC、MES、Ignition和SCADA以及ERP系统,同时也能快速连接到AWS云…...

基于Uni-app的体育场馆预约系统的设计与实现
个人介绍 hello hello~ ,这里是 code袁~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 🦁作者简介:一名喜欢分享和记录学习的…...
1.Spring Boot框架整合
Spring Boot项目创建(约定大于配置) 2.1.3.RELEASE版本示例 idea创建 从官网下载(https://start.spring.io/)单元测试默认依赖不对时,直接删除即可 Web支持(SpringMVC) <dependency>&…...

如何在 Debian VPS 上添加、删除和授予用户 sudo 权限
简介 当你启动一个新的服务器时,会创建一个名为 root 的默认账户。这个用户拥有完全的系统访问权限,应该仅用于管理任务。作为 root 用户,你基本上可以对系统做任何操作,这很强大,但也极其危险。Linux 没有“撤销”按…...

openlayers 入门教程(九):overlay 篇
还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas,webgl,ech…...

基于Python的高考志愿辅助填报系统
基于Python的高考志愿辅助填报系统是一个利用数据分析和机器学习技术帮助高考生进行志愿填报决策的工具。该系统可以根据考生的分数、兴趣、专业偏好、历史录取数据等因素,为考生提供科学合理的志愿填报建议。以下是设计这样一个系统的步骤和要点。 ### 1. 数据收集…...

使用CMake搭建简单的Qt程序
目录结构 代码 CMakeLists.txt: cmake_minimum_required(VERSION 3.15)set(CMAKE_AUTOUIC ON) set(CMAKE_AUTOMOC ON) set(CMAKE_AUTORCC ON)# set the project name project(xxx)# 设置Qt的路径 # 例如 E:/Qt/Qt/aaa/msvc2019_64 # aaa 为Qt的版本号 set(QT_PATH…...
Qt + VS2017 创建一个简单的图片加载应用程序
简介: 本文介绍了如何使用Qt创建一个简单的图片加载应用程序。该应用程序可以打开图片文件并在界面上显示选定的图片,并保存用户上次选择的图片路径。 1. 创建项目: 首先,在VS中创建一个新的Qt Widgets应用程序项目,并…...

Linux文件搜索工具(gnome-search-tool)
opensuse下安装: sudo zypper install gnome-search-tool 操作界面:...
c++20协程详解(三)
前言 前面两节我们已经能够实现一个可用的协程框架了。但我们一定还想更深入的了解协程,于是我们就想尝试下能不能co_await一个协程。下面会涉及到部分模板编程的知识,主要包括(模板偏特化,模板参数列表传值,模板函数…...

LLM--提示词Propmt的概念、作用及如何设计提示词
文章目录 1. 什么是提示词?2. 提示词的作用3. 如何设计提示词?3.1. 提供详细的信息3.2. 指定角色3.3. 使用分隔符和特殊符号3.4. 提供示例3.5. 少量示例的思维链(COT)模型3.6. 思维树(TOT)模型3.7. 自洽性 …...

59 使用 uqrcodejs 生成二维码
前言 这是一个最近的一个来自于朋友的需求, 然后做了一个 基于 uqrcodejs 来生成 二维码的一个 demo package.json 中增加以依赖 "uqrcodejs": "^4.0.7", 测试用例 <template><div class"hello"><canvas id"qrcode&qu…...

Leetcode 3097. Shortest Subarray With OR at Least K II
Leetcode 3097. Shortest Subarray With OR at Least K II 1. 解题思路2. 代码实现 题目链接:3097. Shortest Subarray With OR at Least K II 1. 解题思路 这一题是题目3095的一个进阶版本,但也就是增加了序列的复杂度而已,要求我们能够在…...
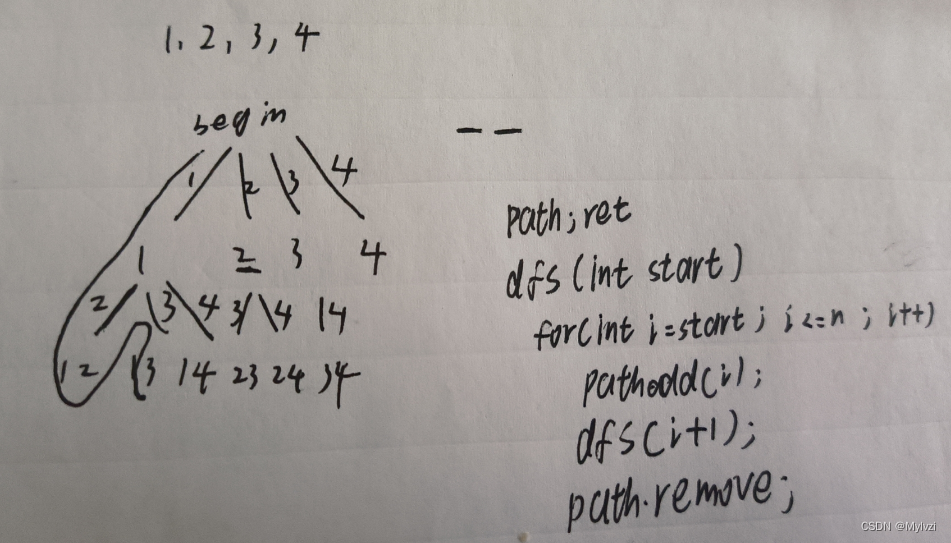
算法系列--递归,回溯,剪枝的综合应用(2)
💕"对相爱的人来说,对方的心意,才是最好的房子。"💕 作者:Lvzi 文章主要内容:算法系列–递归,回溯,剪枝的综合应用(2) 大家好,今天为大家带来的是算法系列--递归,回溯,剪枝的综合应用(2) 一.括号…...

Docker搭建LNMP环境实战(09):安装mariadb
1、编写mariadb部署配置文件 在文件夹:/mnt/hgfs/dockers/test_site/compose下创建文件:test_site_mariadb.yml,内容如下: version: "3.5" services:test_site_mariadb:container_name: test_site_mariadbimage: mari…...
基于Python的微博舆论分析,微博评论情感分析可视化系统,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

降AI提示词够用吗?降AI工具比prompt强在哪?嘎嘎降AI双降!
降AI提示词够用吗?降AI工具比prompt强在哪?嘎嘎降AI双降! 用 AI 写论文的同学经常纠结一件事:0 元的降 AI 提示词够用吗?还是非得花钱买降 AI 工具不可? 直接给结论: 如果你 AI 写得不多、整体 …...

FPGA动态电压调节技术与PMBus控制路径设计
1. FPGA动态电压调节技术概述 在当今计算密集型应用中,FPGA因其可重构性和并行处理能力而广受欢迎,但随之而来的功耗问题也日益突出。动态电压调节技术(Dynamic Voltage Scaling, DVS)作为一种有效的功耗优化手段,允许系统根据工作负载实时调…...

STM32的DAC玩出花:双通道独立波形生成与相位差控制的保姆级配置指南
STM32双通道DAC相位控制实战:从定时器触发到波形同步的工程实现 在工业控制、音频合成和通信系统仿真等领域,精确控制两路模拟信号之间的相位关系是常见需求。STM32系列微控制器内置的12位DAC配合定时器与DMA,能够实现双通道独立波形生成与微…...

终极Dell G15温度控制解决方案:开源软件TCC-G15完整指南
终极Dell G15温度控制解决方案:开源软件TCC-G15完整指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为你的Dell G15笔记本高温发烫而烦恼吗…...

DDrawCompat完整教程:Windows 11上经典游戏DirectDraw兼容性修复终极指南
DDrawCompat完整教程:Windows 11上经典游戏DirectDraw兼容性修复终极指南 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh…...

如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存
如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

Switch大气层系统:从零开始掌握自定义固件的完整指南
Switch大气层系统:从零开始掌握自定义固件的完整指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 大气层系统(Atmosphere)是任天堂Switch平台上最强大…...

iOS 27 开放 AI 生态,长距高清传输新引擎 @ACP#GSV5800 筑牢 iPhone AI 显示后端底座
一、iOS 27 开放 AI:引爆高清长距传输与多接口扩展刚需苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 一跃成为全球最大 AI 交互与视觉输出入口。这一变革直接引爆AI 扩展…...
终极指南:3分钟掌握Translumo实时屏幕翻译工具,游戏外语学习两不误
终极指南:3分钟掌握Translumo实时屏幕翻译工具,游戏外语学习两不误 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr…...

GTA5线上小助手:解锁洛圣都无限可能的游戏增强神器
GTA5线上小助手:解锁洛圣都无限可能的游戏增强神器 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 你是否曾在《侠盗猎车手5》线上模式中感到力不从心?面对繁琐的任务、漫长的通…...