TensorBoard可视化+Confustion Matrix Drawing
for later~
代码阅读
1. 加载trainset
import argparse
import logging
import os
import numpy as npimport torch
from torch import distributed
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom backbones import get_model
from dataset import get_dataloader
from face_fc_ddp import FC_ddp
from utils.utils_callbacks import CallBackLogging, CallBackVerification
from utils.utils_config import get_config
from utils.utils_distributed_sampler import setup_seed
from utils.utils_logging import AverageMeter, init_loggingfrom utils.utils_invreg import env_loss_ce_ddp, assign_loss
from utils.utils_feature_saving import concat_feat, extract_feat_per_gpu
from utils.utils_partition import load_past_partitionassert torch.__version__ >= "1.9.0", "In order to enjoy the features of the new torch, \
we have upgraded the torch to 1.9.0. torch before than 1.9.0 may not work in the future."import datetimeos.environ["NCCL_BLOCKING_WAIT"] = "1"try:world_size = int(os.environ["WORLD_SIZE"])rank = int(os.environ["RANK"])distributed.init_process_group("nccl", timeout=datetime.timedelta(hours=3))
except KeyError:world_size = 1rank = 0distributed.init_process_group(backend="nccl",init_method="tcp://127.0.0.1:12584",rank=rank,world_size=world_size,)def main(args):cfg = get_config(args.config)setup_seed(seed=cfg.seed, cuda_deterministic=False)torch.cuda.set_device(args.local_rank)os.makedirs(cfg.output, exist_ok=True)init_logging(rank, cfg.output)summary_writer = (SummaryWriter(log_dir=os.path.join(cfg.output, "tensorboard"))if rank == 0else None)##################### Trainset definition ###################### only horizon-flip is used in transformstrain_loader = get_dataloader(cfg.rec,args.local_rank,cfg.batch_size,False,cfg.seed,cfg.num_workers,return_idx=True)
3. 定义backbone model,加载权重,并行化训练
##################### Model backbone definition #####################backbone = get_model(cfg.network, dropout=cfg.dropout, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()if cfg.resume:if rank == 0:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"))backbone.load_state_dict(dict_checkpoint["state_dict_backbone"])del dict_checkpointbackbone = torch.nn.parallel.DistributedDataParallel(module=backbone, broadcast_buffers=False, device_ids=[args.local_rank], bucket_cap_mb=16,find_unused_parameters=True)backbone.train()backbone._set_static_graph()
4. 分类函数+损失定义
##################### FC classification & loss definition ######################if cfg.invreg['irm_train'] == 'var':reduction = 'none'else:reduction = 'mean'module_fc = FC_ddp(cfg.embedding_size, cfg.num_classes, scale=cfg.scale,margin=cfg.cifp['m'], mode=cfg.cifp['mode'], use_cifp=cfg.cifp['use_cifp'],reduction=reduction).cuda()if cfg.resume:if rank == 0:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"))module_fc.load_state_dict(dict_checkpoint["state_dict_softmax_fc"])del dict_checkpointmodule_fc = torch.nn.parallel.DistributedDataParallel(module_fc, device_ids=[args.local_rank])module_fc.train().cuda()opt = torch.optim.SGD(params=[{"params": backbone.parameters()}, {"params": module_fc.parameters()}],lr=cfg.lr, momentum=0.9, weight_decay=cfg.weight_decay)##################### Train scheduler definition #####################cfg.total_batch_size = cfg.batch_size * world_sizecfg.num_image = len(train_loader.dataset)n_cls = cfg.num_classescfg.warmup_step = cfg.num_image // cfg.total_batch_size * cfg.warmup_epochcfg.total_step = cfg.num_image // cfg.total_batch_size * cfg.num_epochassert cfg.scheduler == 'step'from torch.optim.lr_scheduler import MultiStepLRlr_scheduler = MultiStepLR(optimizer=opt,milestones=cfg.step,gamma=0.1,last_epoch=-1)start_epoch = 0global_step = 0if cfg.resume:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"),map_location={'cuda:0': f'cuda:{rank}'})start_epoch = dict_checkpoint["epoch"]global_step = dict_checkpoint["global_step"]opt.load_state_dict(dict_checkpoint["state_optimizer"])del dict_checkpoint
- dict_checkpoint是 检查点的信息,用字典存储
5. 评估定义
##################### Evaluation definition #####################callback_verification = CallBackVerification(val_targets=cfg.val_targets, rec_prefix=cfg.val_rec, summary_writer=summary_writer)callback_logging = CallBackLogging(frequent=cfg.frequent,total_step=cfg.total_step,batch_size=cfg.batch_size,start_step=global_step,writer=summary_writer)loss_am = AverageMeter()amp = torch.cuda.amp.grad_scaler.GradScaler(growth_interval=100)updated_split_all = []for key, value in cfg.items():num_space = 25 - len(key)logging.info(": " + key + " " * num_space + str(value))loss_weight_irm_init = cfg.invreg['loss_weight_irm']
6. 训练迭代
##################### Training iterations #####################if cfg.resume:callback_verification(global_step, backbone)for epoch in range(start_epoch, cfg.num_epoch):if cfg.invreg['loss_weight_irm_anneal'] and cfg.invreg['loss_weight_irm'] > 0:cfg.invreg['loss_weight_irm'] = loss_weight_irm_init * (1 + 0.09) ** (epoch - 5)if epoch in cfg.invreg['stage'] and cfg.invreg['loss_weight_irm'] > 0:cfg.invreg['env_num'] = cfg.invreg['env_num_lst'][cfg.invreg['stage'].index(epoch)]save_dir = os.path.join(cfg.output, 'saved_feat', 'epoch_{}'.format(epoch))if os.path.exists(os.path.join(save_dir, 'final_partition.npy')):logging.info('Loading the past partition...')updated_split_all = load_past_partition(cfg, epoch)logging.info(f'Total {len(updated_split_all)} partition are loaded...')else:if os.path.exists(os.path.join(save_dir, 'feature.npy')):logging.info('Loading the pre-saved features...')else:# extract features for each gpuextract_feat_per_gpu(backbone, cfg, args, save_dir)if rank == 0:_, _ = concat_feat(cfg.num_image, world_size, save_dir)distributed.barrier()emb = np.load(os.path.join(save_dir, 'feature.npy'))lab = np.load(os.path.join(save_dir, 'label.npy'))# conduct partition learninglogging.info('Started partition learning...')from utils.utils_partition import update_partitionupdated_split = update_partition(cfg, save_dir, n_cls, emb, lab, summary_writer,backbone.device, rank, world_size)del emb, labdistributed.barrier()updated_split_all.append(updated_split)if isinstance(train_loader, DataLoader):train_loader.sampler.set_epoch(epoch)for _, (index, img, local_labels) in enumerate(train_loader):global_step += 1local_embeddings = backbone(img)# cross-entropy lossif cfg.invreg['irm_train'] == 'var':loss_ce_tensor, acc = module_fc(local_embeddings, local_labels, return_logits=False)loss_ce = loss_ce_tensor.mean()loss = loss_ceelif cfg.invreg['irm_train'] == 'grad':loss_ce, acc, logits = module_fc(local_embeddings, local_labels, return_logits=True)loss = loss_ce# IRM lossif len(updated_split_all) > 0:if cfg.invreg['irm_train'] == 'grad':loss_irm = env_loss_ce_ddp(logits, local_labels, world_size, cfg, updated_split_all, epoch)elif cfg.invreg['irm_train'] == 'var':import dist_all_gatherloss_total_lst = dist_all_gather.all_gather(loss_ce_tensor)label_total_lst = dist_all_gather.all_gather(local_labels)loss_total = torch.cat(loss_total_lst, dim=0)label_total = torch.cat(label_total_lst, dim=0)loss_irm_lst = []for updated_split in updated_split_all:n_env = updated_split.size(-1)loss_env_lst = []for env_idx in range(n_env):loss_env = assign_loss(loss_total, label_total, updated_split, env_idx)loss_env_lst.append(loss_env.mean())loss_irm_lst.append(torch.stack(loss_env_lst).var())loss_irm = sum(loss_irm_lst) / len(updated_split_all)else:print('Please check the IRM train mode')loss += loss_irm * cfg.invreg['loss_weight_irm']if rank == 0:callback_logging.writer.add_scalar(tag='Loss CE', scalar_value=loss_ce.item(),global_step=global_step)if len(updated_split_all) > 0:callback_logging.writer.add_scalar(tag='Loss IRM', scalar_value=loss_irm.item(),global_step=global_step)if cfg.fp16:amp.scale(loss).backward()amp.unscale_(opt)torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)amp.step(opt)amp.update()else:loss.backward()torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)opt.step()opt.zero_grad()if cfg.step[0] > cfg.num_epoch:# use global iteration as the stepslr_scheduler.step(global_step)else:lr_scheduler.step(epoch=epoch)with torch.no_grad():loss_am.update(loss.item(), 1)callback_logging(global_step, loss_am, epoch, cfg.fp16, lr_scheduler.get_last_lr()[0], amp, acc)if global_step % cfg.verbose == 0 and global_step > 0:callback_verification(global_step, backbone)if rank == 0:path_module = os.path.join(cfg.output, f"model_{epoch}.pt")torch.save(backbone.module.state_dict(), path_module)if cfg.save_all_states:checkpoint = {"epoch": epoch + 1,"global_step": global_step,"state_dict_backbone": backbone.module.state_dict(),"state_dict_softmax_fc": module_fc.module.state_dict(),"state_optimizer": opt.state_dict(),"state_lr_scheduler": lr_scheduler.state_dict()}torch.save(checkpoint, os.path.join(cfg.output, f"checkpoint_{epoch}.pt"))callback_verification(global_step, backbone)if rank == 0:path_module = os.path.join(cfg.output, f"model_{epoch}.pt")torch.save(backbone.module.state_dict(), path_module)# convert model and save itfrom torch2onnx import convert_onnxconvert_onnx(backbone.module.cpu().eval(), path_module, os.path.join(cfg.output, "model.onnx"))distributed.destroy_process_group()
Run it with “main” f
if __name__ == "__main__":torch.backends.cudnn.benchmark = Trueparser = argparse.ArgumentParser(description="Distributed Training of InvReg in Pytorch")parser.add_argument("config", type=str, help="py config file")parser.add_argument("--local_rank", type=int, default=0, help="local_rank")main(parser.parse_args())
相关文章:

TensorBoard可视化+Confustion Matrix Drawing
for later~ 代码阅读 1. 加载trainset import argparse import logging import os import numpy as npimport torch from torch import distributed from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriterfrom backbones import get_…...
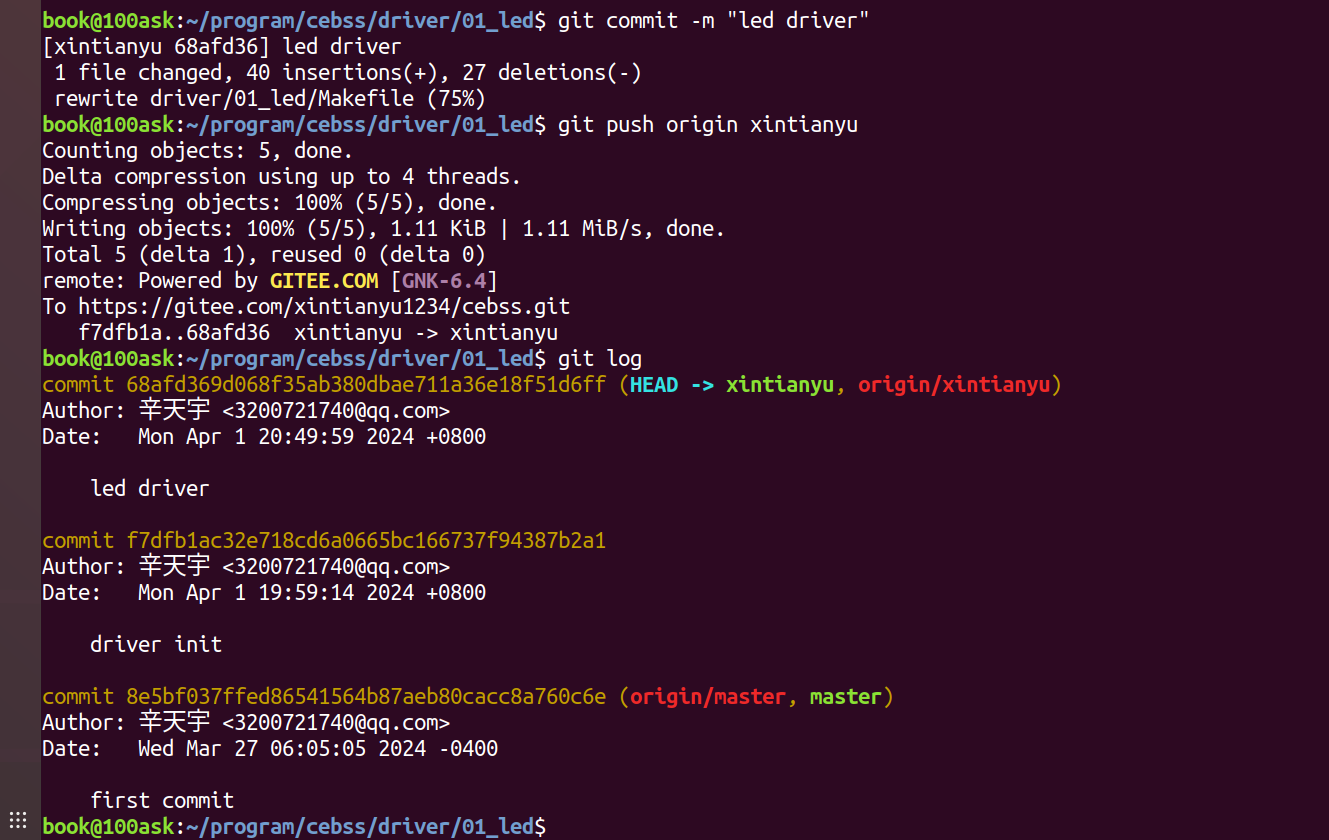
012——LED模块驱动开发(基于I.MX6uLL)
目录 一、 硬件原理图 二、 驱动程序 三、 应用程序 四、 Makefile 五、操作 一、 硬件原理图 又是非常经典的点灯环节 ,每次学新语言第一步都是hello world,拿到新板子或者学习新的操作系统,第一步就是点灯。 LED 的驱动方式࿰…...

基于springboot实现房屋租赁管理系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现房屋租赁系统演示 摘要 房屋是人类生活栖息的重要场所,随着城市中的流动人口的增多,人们对房屋租赁需求越来越高,为满足用户查询房屋、预约看房、房屋租赁的需求,特开发了本基于Spring Boot的房屋租赁系统。 …...

168.乐理基础-中古调式概述
如果到这五线谱还没记住还不认识的话去看102.五线谱-高音谱号与103.五线谱-低音谱号这两个里,这里面有五线谱对应的音名,对比着看 如果不认识调号去看112.五线谱的调号(一)、113.五线谱的调号(二)、114.快…...
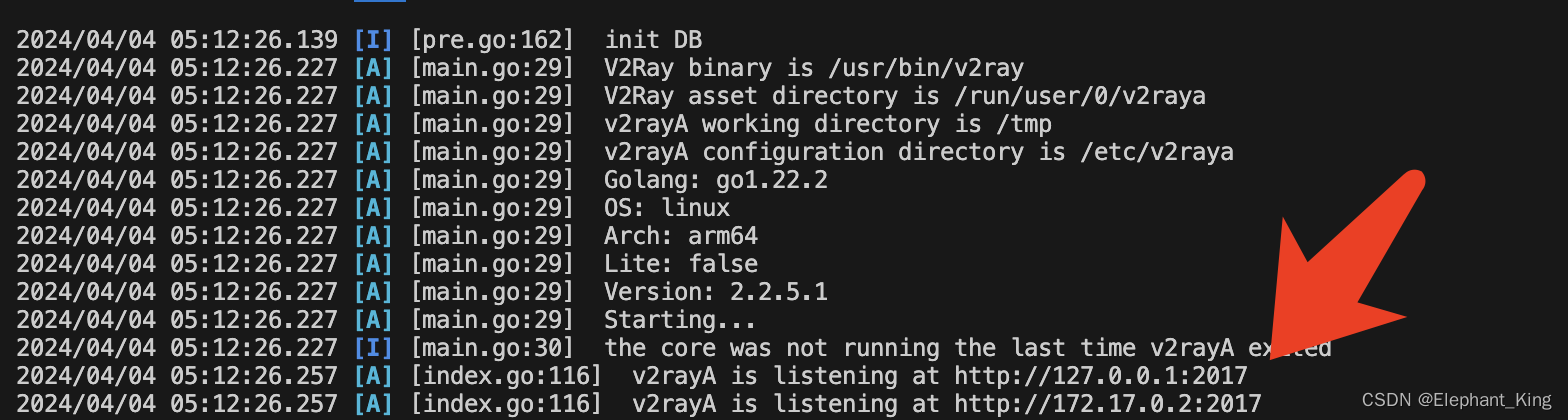
【项目实战】【Docker】【Git】【Linux】部署V2rayA项目
今天着手了一个全新领域的项目,从完全没有头绪到成功运行,记录一下具体的部署流程 github项目链接V2rayA 一开始拿到以后完全没有抓手,去阅读了一下他的帮助文档 写着能用docker运行,就去下载了一个Docker配置了一下 拉取代码到…...

mac 切换 jdk
查看 mac 上都有哪些版本 /usr/libexec/java_home -V看准版本切换 按前缀切换 比如 export JAVA_HOME/usr/libexec/java_home -v 1.8这样会随机一个 1.8 的 如果想再确定一个比如 openjdk export JAVA_HOME/usr/libexec/java_home -v 1.8.0_292这个方式是临时的,…...

MD5加密返回32位密文字符串
前言: 项目中需要调用其他系统的 api 接口,接口使用的是按一定规则生成 MD5 密文作为签名来进行身份验证,本文仅记录 32 位 MD5 密文的生成方式,仅供参考。 什么是MD5 加密? MD5 加密是一种加密算法,MD5…...

npm常用命令技巧
NPM (Node Package Manager) 是 JavaScript 的包管理工具,广泛用于管理项目中的依赖。无论是前端项目还是Node.js后端项目,NPM 都扮演着重要的角色。本文将介绍 NPM 中常用的几个命令,并提供相应的代码示例。 1. 初始化项目:npm …...

intellij idea 使用git撤销(取消)commit
git撤销(取消) 未 push的 commit Git,选择分支后,右键 Undo Commit ,会把这个 commit 撤销。 git撤销(取消) 已经 push 的 commit 备份分支内容: 选中分支, 新建 分支,避免后续因为操作不当,导…...
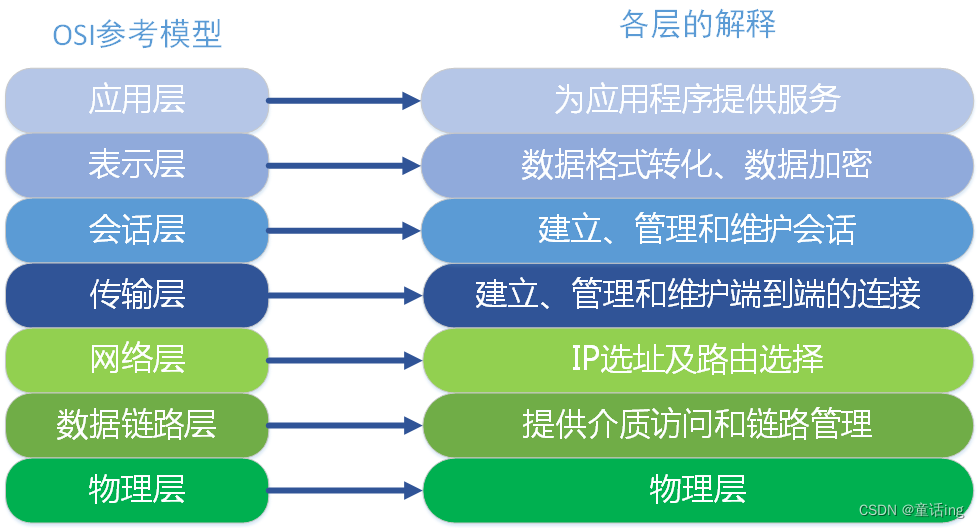
【计算机网络】四层负载均衡和七层负载均衡
前言 1、分层方式 首先我们知道,在计算机网络中,常用的协议分层方式:OSI和TCP/IP,以及实际生产中使用的协议划分方式。 在OSI中,各层的职责如下: 应用层:对软件提供接口以使程序能使用网络服…...

IP-guard WebServer 任意文件读取漏洞复现
0x01 产品简介 IP-guard是由溢信科技股份有限公司开发的一款终端安全管理软件,旨在帮助企业保护终端设备安全、数据安全、管理网络使用和简化IT系统管理。 0x02 漏洞概述 由于IP-guard WebServer /ipg/static/appr/lib/flexpaper/php/view.php接口处未对用户输入的数据进行严…...

【IoTDB 线上小课 01】我们聊聊“金三银四”下的开源
关于 IoTDB,关于物联网,关于时序数据库,关于开源...你是否仍有很多疑问? 除了自己钻研文档,群里与各位“大佬”的沟通,你是否还希望能够有个学习“捷径”? 天谋科技发起社区小伙伴,正…...

2024053期传足14场胜负前瞻
2024053期售止时间为4月6日(周六)21点00分,敬请留意: 本期深盘多,1.5以下赔率1场,1.5-2.0赔率8场,其他场次是平半盘、平盘。本期14场难度中等。以下为基础盘前瞻,大家可根据自身判断…...

C语言------冒泡法排序
一.前情提要 1.介绍 冒泡法排序法: 1)冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历要排序的列表,一次比较相邻的两个元素,并且如果它们的顺序错误就将它们交换过来。重复这个过程直到没有需…...
学习笔记_Enum枚举类型【十三】)
C#(C Sharp)学习笔记_Enum枚举类型【十三】
什么是枚举类型 枚举类型(Enum) 是由基础整型数值类型的一组命名常量定义的值类型。枚举包含自己的值,但不能继承或传递继承。 语法 // enum enum_name // enum_name variable enum_name.enum_value// 定义一个枚举类型——例如: enum enum_name {va…...
乐知付-如何制作html文件可双击跳转到指定页面?
标题: 乐知付-如何制作html文件可双击跳转到指定页面? 标签: [乐知付, 乐知付加密, 密码管理] 分类: [网站,html] 为了便于买家理解使用链接进行付费获取密码;现开发个小工具,将支付链接转为浏览器可识别的文件,双击打开即可跳转到…...

电工技术学习笔记——直流电路及其分析方法
一、直流电路 电路的组成 1. 电压和电流的参考方向 电压(Voltage):电压是电场力对电荷产生的作用,表示为电荷单位正电荷所具有的能量。在电路中,电压通常被定义为两点之间的电势差,具有方向性,…...

详解python中的迭代
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。 在Python中,迭代是通过for ... in来完成的,而很多语言比如C语言,迭代list是通过下标完…...
)
机器学习模型——集成算法(三)
前面我们说了bagging算法和Boosting算法 接下来我们学习Adaboost算法 Adaboost基本概念: AdaBoost (Adaptive Boosting,自适应提升): 算法原理是将多个弱学习器进行合理的结合,使其成为一个强学习器。 Adaboost采用…...
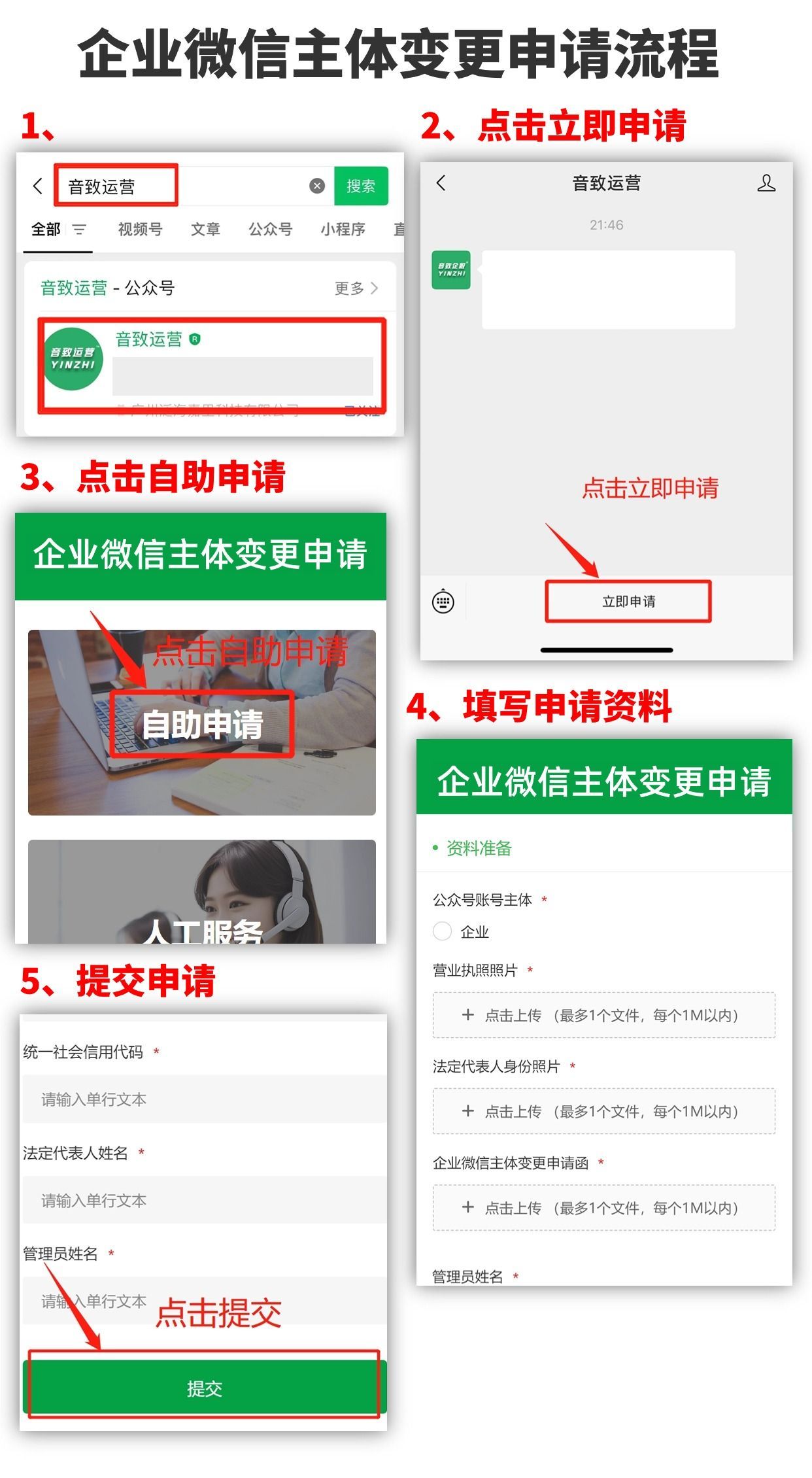
企业微信企业主体变更认证介绍
企业微信变更主体有什么作用? 说一个自己亲身经历的事情,当时我在一家教育公司做运营,公司所有客户都是通过企业微信对接的。后来行业整顿,公司不得不注销,换了营业执照打算做技能培训,但发现注销后原来的企…...
)
32_AI短片实战第五弹:飞跃峡谷——高潮镜头的“放手”哲学与首帧脑补策略(附提示词)
文章目录 一、第十一镜:飞跃峡谷——从精确控制到主动放手 镜头设定 前期准备:多角度参考图 第一轮生成:比例失控 第二轮生成:视角偏差 关键转折:主动移除参考图 最终获得 二、关键策略:首帧脑补 vs. 首尾帧控制 传统思路:首尾帧控制 本片的策略:首帧脑补 经验法则 三、…...

终极键盘打字练习指南:Qwerty Learner 免费高效学习方案
终极键盘打字练习指南:Qwerty Learner 免费高效学习方案 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://g…...

3分钟快速上手:免费AI语音修复工具VoiceFixer终极指南 [特殊字符]
3分钟快速上手:免费AI语音修复工具VoiceFixer终极指南 🎤 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 你是否曾经因为录音质量不佳而烦恼?会议录音充满杂音、珍…...

从井下挖煤到改变高考:他用选择题终结“人情分“
1983年之前,中国的高考试卷上还没有选择题。那年春天,北京师范大学心理学教授郑日昌带着团队做了一项调查。他们从全国随机抽取了5套高考试卷,复印后分发给不同省市的评卷教师打分。结果出来后,所有人都傻眼了:同一份理…...

探索Taotoken模型广场如何帮助开发者快速选型与切换模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 探索Taotoken模型广场如何帮助开发者快速选型与切换模型 当启动一个需要集成大语言模型的新项目时,开发者面临的首要问…...

不想花百元订阅 Microsoft 365?三种免费使用方法来了!
ZDNET 核心要点Microsoft 365 需要订阅才能解锁全部功能,不过,仍可免费使用 Word 和 Excel 等应用程序,免费使用方式包括网页版和移动应用程序。无论处于学习或职业生涯的哪个阶段,可能时不时仍需使用 Microsoft 365(前…...

MAX86150 ECG/PPG数据采集实战:基于STM32F103的FIFO配置与多传感器数据融合解析
MAX86150 ECG/PPG数据采集实战:基于STM32F103的FIFO配置与多传感器数据融合解析 在可穿戴健康监测设备的开发中,如何高效处理多通道生物信号是工程师面临的核心挑战。MAX86150作为一款集成了ECG(心电图)和PPG(光电容积…...

TegraRcmGUI完整指南:Windows上最简单的Switch注入工具终极教程
TegraRcmGUI完整指南:Windows上最简单的Switch注入工具终极教程 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Windows系…...

GitHub加速插件:让国内开发者告别龟速下载的终极解决方案
GitHub加速插件:让国内开发者告别龟速下载的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub…...

Go语言技能树工具goskill:构建与管理技术团队知识图谱
1. 项目概述:一个Go语言技能树的构建与管理工具最近在整理团队内部的技术栈和成员技能时,发现了一个挺普遍的问题:我们很难清晰地知道谁擅长什么,某个技术方向(比如微服务、数据库优化)的深度如何ÿ…...