序列化案例实操(统计每一个手机号耗费的总上行流量、总下行流量、总流量)
文章目录
- 序列化概述
- 自定义bean对象实现序列化接口(Writable)
- 案例需求
- 编写MapReduce程序
- 运行结果
序列化概述
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
自定义bean对象实现序列化接口(Writable)
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步:
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {super();
}
(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {upFlow = in.readLong();downFlow = in.readLong();sumFlow = in.readLong();
}
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用"\t"分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
@Override
public int compareTo(FlowBean o) {// 倒序排列,从大到小return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
案例需求
统计每一个手机号耗费的总上行流量、总下行流量、总流量
输入总数据:

输入数据格式:
7 13560436666 120.196.100.99 1116 954 200
id 手机号码 网络ip 上行流量 下行流量 网络状态码
期望输出数据格式:
13560436666 1116 954 2070
手机号码 上行流量 下行流量 总流量
编写MapReduce程序
FlowBean:
package com.atxiaoyu.xuliehua;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//空参构造public FlowBean() {}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public void setSumFlow() {this.sumFlow = this.upFlow+this.downFlow;}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);}@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow=in.readLong();this.downFlow=in.readLong();this.sumFlow=in.readLong();}@Overridepublic String toString() {return upFlow+"\t"+downFlow+"\t"+sumFlow;}
}FlowMapper:
package com.atxiaoyu.xuliehua;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {private Text outK=new Text();private FlowBean outV=new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 获取一行String line=value.toString();//切割String[] split=line.split("\t");//抓取想要的数据String phone=split[1];String up=split[split.length-3]; //上行流量String down=split[split.length-2]; //下行流量//封装outK.set(phone);outV.setUpFlow(Long.parseLong(up));outV.setDownFlow(Long.parseLong(down));outV.setSumFlow();// 写出context.write(outK,outV);}
}FlowReducer:
package com.atxiaoyu.xuliehua;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean outV=new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//遍历集合累加值long totalUp=0;long totalDown=0;for (FlowBean value : values) {totalUp=totalUp+value.getUpFlow();totalDown=totalUp+value.getDownFlow();//封装outK,outVoutV.setUpFlow(totalUp);outV.setDownFlow(totalDown);outV.setSumFlow();//写出context.write(key,outV);}}
}FlowDriver:
package com.atxiaoyu.xuliehua;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.kerby.config.Conf;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {Configuration conf = new Configuration();//1 获取jobJob job = Job.getInstance(conf);//2 设置jar包路径job.setJarByClass(FlowDriver.class);// 3 管理mapper和reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);// 4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);//5 设置最终输出的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6 设置输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\input"));FileOutputFormat.setOutputPath(job, new Path("D:\\output"));//7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}运行结果
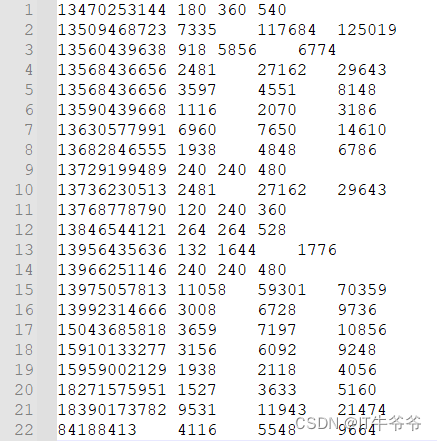
与我们设想的输出结果一致。
相关文章:
序列化案例实操(统计每一个手机号耗费的总上行流量、总下行流量、总流量)
文章目录 序列化概述自定义bean对象实现序列化接口(Writable)案例需求编写MapReduce程序运行结果 序列化概述 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化&…...

使用 LLMLingua-2 压缩 GPT-4 和 Claude 提示
原文地址:Compress GPT-4 and Claude prompts with LLMLingua-2 2024 年 4 月 1 日 向大型语言模型(LLM)发送的提示长度越短,推理速度就会越快,成本也会越低。因此,提示压缩已经成为LLM研究的热门领域。 …...

编程大牛坚持了 10 年的 10 个编程好习惯
目录 1.多看官方文档 2.面向搜索引擎编程 3.规范命名 4.认真注释 5.不要重复造轮子 6.多读多写代码 7.预留开发时间 8.大胆重构 9.师傅领进门 10.多阅读源码 1.多看官方文档 不要被这几个字吓到,官方文档其实都是宝藏。 一个成熟的技术诞生,…...
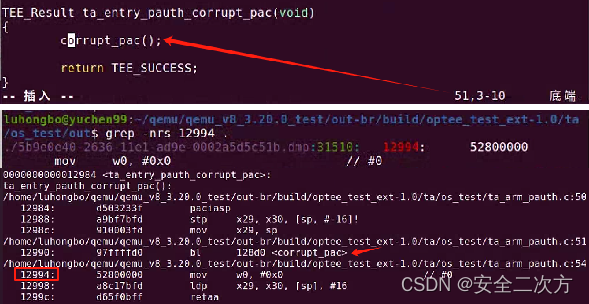
QEMU上PAC功能验证与异常解析
PAC功能如何验证?PAC检查失败时发生什么?问题如何定位?本博客主要探讨这些问题。...
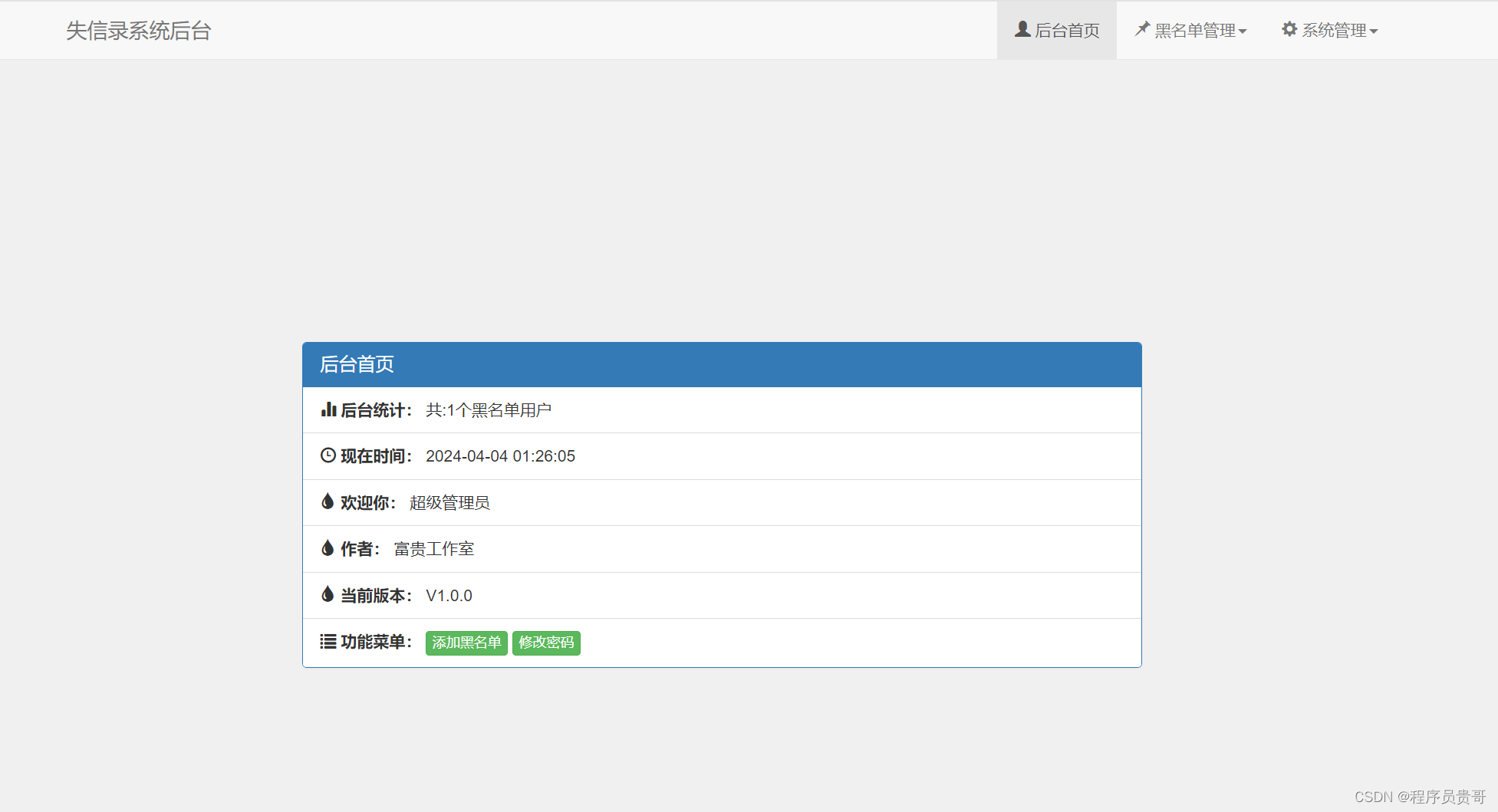
简约轻量-失信录系统源码
失信录系统-最新骗子收录查询系统源码 首页查询: 举报收录页: 后台管理页: 失信录系统 V1.0.0 更新内容: 1.用户查询,举报功能 2.界面独立开发 3.拥有后台管理功能 4.xss,sql安全过滤 5.平台用户查询 6.用户中心(待完…...

前端入门系列-HTML-HTML常见标签(注释,标题,段落,换行)
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” HTML常见标签 注释标签 注释不会显示在界面上,目的是提高代码的可读性 <!---这是一个注释----> 注释的原则 要和代码逻辑一致尽量使用中文不要传递负能量 …...
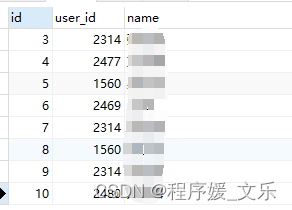
【mysql 第3-10条记录怎么查】
mysql 第3-10条记录怎么查 在MySQL中,如果你想要查询第3到第10条记录,你通常会使用LIMIT和OFFSET子句。但是,需要注意的是,LIMIT和OFFSET是基于结果集的行数来工作的,而不是基于记录的物理位置。这意味着它们通常与某种…...
1.Git是用来干嘛的
本文章学习于【GeekHour】一小时Git教程,来自bilibili Git就是一个文件管理系统,这样说吧,当多个人同时在操作一个文件的同时,很容易造成紊乱,git就是保证文件不紊乱产生的 包括集中式管理系统和分布式管理系统 听懂…...
Git安装教程(图文安装)
Git Bash是git(版本管理器)中提供的一个命令行工具,外观类似于Windows系统内置的cmd命令行工具。 可以将Git Bash看作是一个终端模拟器,它提供了类似于Linux和Unix系统下Bash Shell环境的功能。通过Git Bash,用户可以在Windows系统中运行基于…...

SpringData ElasticSearch - 简化开发,完美适配 Spring 生态
目录 一、SpringData ElasticSearch 1.1、环境配置 1.2、创建实体类 1.3、ElasticsearchRestTemplate 的使用 1.3.1、创建索引 设置映射 1.3.2、创建索引映射注意事项(必看) 1.3.3、简单的增删改查 1.3.4、搜索 1.4、ElasticsearchRepository …...

突破!AI机器人拥有嗅觉!仿生嗅觉芯片研究登上Nature子刊
我们一直梦想着让AI与人类能够更加相似,赋予它们视觉与听觉。而让机器人拥有嗅觉一直以来面临着巨大的困难。 香港科技大学范志勇教授领导的研究团队凭借最新研发的仿生嗅觉芯片(BOC)在这一领域取得了重大突破。该研究成果目前已被发表到IF …...
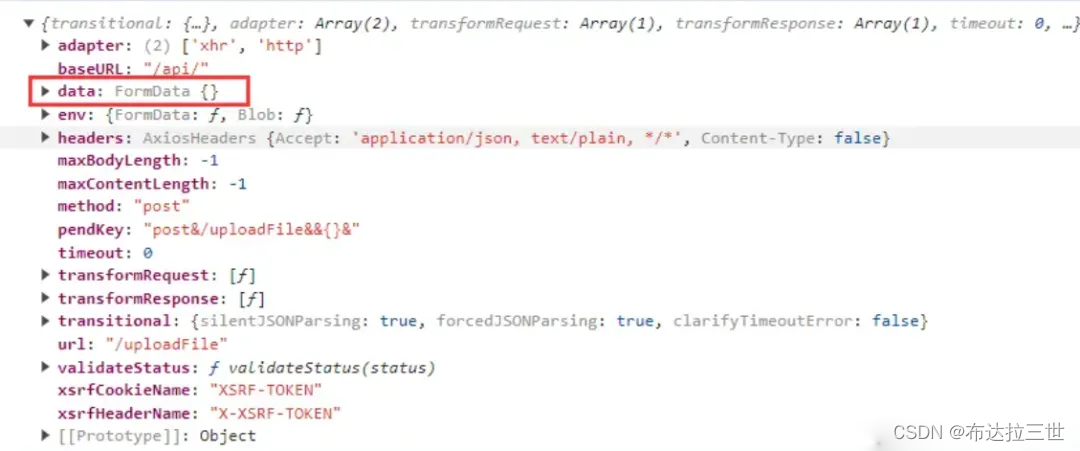
前端接口防止重复请求实现方案
前言 前段时间老板心血来潮,要我们前端组对整个的项目都做一下接口防止重复请求的处理(似乎是有用户通过一些快速点击薅到了一些优惠券啥的)。。。听到这个需求,第一反应就是,防止薅羊毛最保险的方案不还是在服务端加…...
)
【leetcode面试经典150题】13.除自身以外数组的乘积(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

网络编程核心概念解析:IP地址、端口号与网络字节序深度探讨
⭐小白苦学IT的博客主页 ⭐初学者必看:Linux操作系统入门 ⭐代码仓库:Linux代码仓库 ❤关注我一起讨论和学习Linux系统 本节重点 认识IP地址, 端口号, 网络字节序等网络编程中的基本概念; 1.前言 网络编程,作为现代信息社会中的一项核心技术&…...
))
突破编程_C++_网络编程(TCPIP 四层模型(网络层(1))
1 网络层概述 TCP/IP 四层模型中的网络层是模型中的核心组成部分,它主要负责处理数据包的路由和转发,确保数据能够在源主机和目标主机之间准确地传输。 一、主要功能 网络层的主要功能是实现数据包的选路和转发。当数据从应用层传输到传输层后&#x…...

Java | Leetcode Java题解之第9题回文数
题目: 题解: class Solution {public boolean isPalindrome(int x) {// 特殊情况:// 如上所述,当 x < 0 时,x 不是回文数。// 同样地,如果数字的最后一位是 0,为了使该数字为回文࿰…...
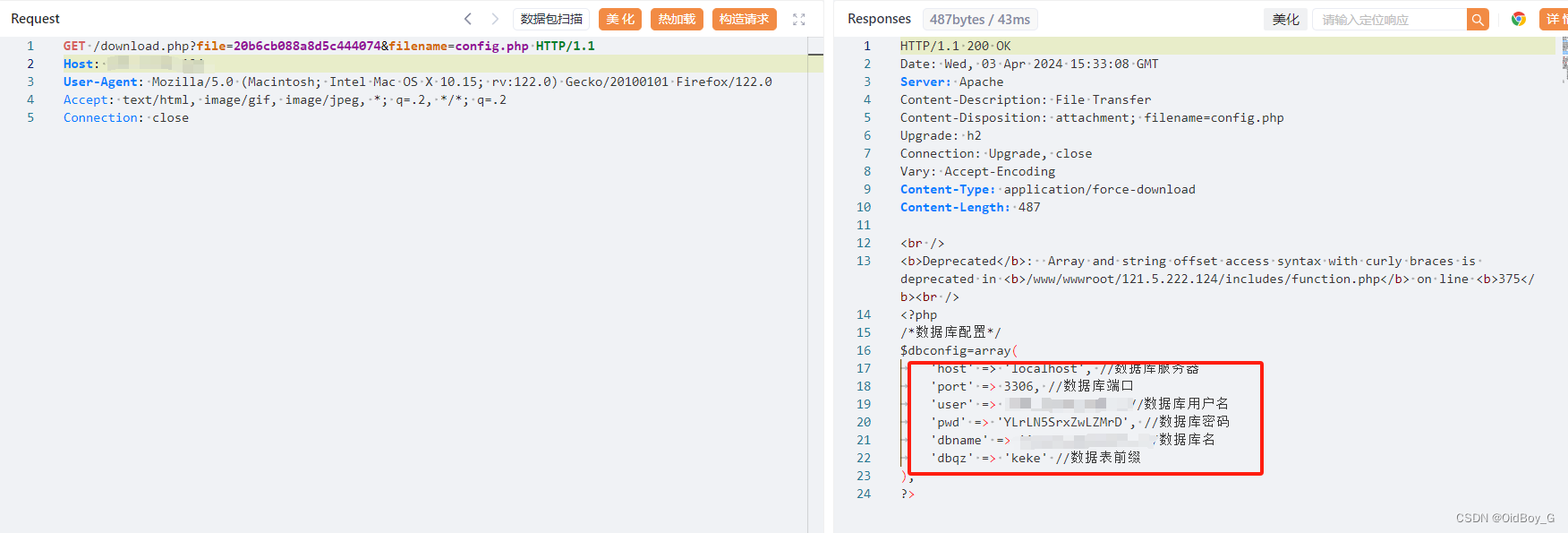
极简云验证 download.php 文件读取漏洞复现
0x01 产品简介 极简云验证是一款开源的网络验证系统,支持多应用卡密生成:卡密生成 单码卡密 次数卡密 会员卡密 积分卡密、卡密管理 卡密长度 卡密封禁 批量生成 批量导出 自定义卡密前缀等;支持多应用多用户管理:应用备注 应用版…...
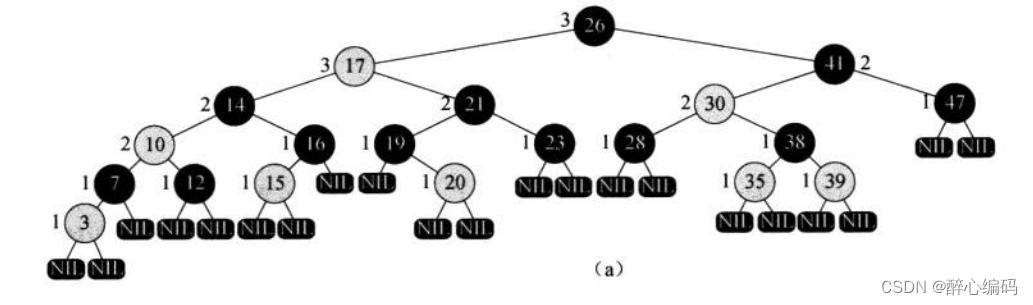
红黑树路径长度分析:证明与实现
红黑树路径长度分析:证明与实现 一、红黑树的基本性质二、证明:最长路径至多是最短路径的2倍2.1 证明思路2.2 证明过程 三、伪代码实现四、 C语言代码实现5、 结论 红黑树作为一种高效的自平衡二叉搜索树,在计算机科学领域中被广泛应用于各种…...
)
esp32 gpio初识(一)
目录 功能介绍 实操 功能介绍 引脚又叫管脚,英文叫 Pin, 就是从集成电路(芯片以及一些电子元件)内部电路引出与外围电路的接线的接口。 在我们的 ESP32 开发板上, 我们可以把这些称为引脚, 这些引脚其实是从 ESP32 芯片内部引出来的, 我们…...
)
python 自制黄金矿工游戏(设计思路+源码)
1.视频效果演示 python自制黄金矿工,细节拉满沉浸式体验,看了你也会 2.开发准备的工具 python3.8, pygame库(python3.5以上的版本应该都可以) 图片处理工具,美图秀秀 截图工具,电脑自带的 自动抠图网页:https://ko…...

【硬核】让所有AI Agent自动进化!港大开源OpenSpace,一个命令让你的Claude Code/Cursor/OpenClaw秒变超级智能体
最近刷 GitHub,发现了一个让我眼前一亮的项目——OpenSpace。 它解决了一个超级痛点:现在的 AI Agent(比如 Claude Code、OpenClaw、Cursor)都很强大,但它们从不学习、永不进化——每次任务都是从头开始,浪…...

OpenClaw多模态扩展:Qwen3.5-4B-Claude处理截图与PDF
OpenClaw多模态扩展:Qwen3.5-4B-Claude处理截图与PDF 1. 为什么需要多模态能力? 去年夏天,我遇到一个头疼的问题:需要从几百份PDF报告里提取关键数据。手动复制粘贴不仅耗时,还容易出错。当时我就在想,如…...
)
从CentOS 7迁移到Ubuntu 22.04 LTS,我整理了一份保姆级系统初始化脚本(含内核调优、换源、时区设置)
从CentOS 7迁移到Ubuntu 22.04 LTS:系统初始化与性能调优全指南 当CentOS 7走向生命周期的终点,许多运维团队正面临向新平台的战略转移。Ubuntu 22.04 LTS以其长期支持特性和活跃的社区生态,成为最受欢迎的替代选择之一。但迁移绝非简单的系统…...

CentOS7 下 Go 多版本管理与无缝升级指南
1. 为什么需要Go多版本管理? 在CentOS7系统上开发Go项目时,经常会遇到这样的尴尬:新项目需要用最新版Go的特性,而老项目必须跑在特定旧版本上才能兼容。我去年就踩过这个坑——用Go 1.21写完的微服务,部署到生产环境发…...

告别传统架构!源网荷储四侧时序数据库选型与落地全解析
新型电力系统应该用什么数据库?源网荷储四侧的时序数据库选型与落地实战 “双碳” 目标的推进正在深刻重构电力系统的运行逻辑。新能源装机占比持续攀升,储能、虚拟电厂、需求响应等新业态快速涌现,源、网、荷、储各侧的角色与互动方式正在被…...

微信无法登录时的恢复操作
本文记录 OpenClaw 中 openclaw-weixin 插件在登录态丢失、微信链接不可用、扫码登录失败时的恢复流程。2026-03-23 版本 OpenClaw 更新后曾出现微信插件失效,但在 2026-03-24 版本中已恢复。本文目标是先判断问题类型,再选择最小影响的修复方式,避免不必要的全量重装。 一、…...
)
【国家级等保2.0合规必读】:Python扩展模块安全开发规范(含12项强制检查项+自动化检测脚本)
第一章:Python扩展模块安全开发概述Python 扩展模块(C/C 编写的 .so/.dll 文件)是提升性能、复用底层库或与系统交互的关键手段,但其直接操作内存、绕过 Python 运行时保护机制的特性,也使其成为安全风险的高发区。开发…...

基于Python的律师事务所案件管理系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在开发一套基于Python的律师事务所案件管理系统,以满足现代法律事务处理的高效性和智能化需求。具体研究目的如下: 首先…...
)
从零开始:用QGIS和PostgreSQL构建交通路线空间数据库(含Python脚本自动化技巧)
从零开始:用QGIS和PostgreSQL构建交通路线空间数据库(含Python脚本自动化技巧) 在交通规划与智慧城市建设的浪潮中,空间数据的高效管理成为技术团队的核心挑战。传统文件存储方式难以应对大规模交通网络数据的实时查询与分析需求&…...

【GitHub 加速计划】:解决智能家居插件获取难题的网络适配方案
【GitHub 加速计划】:解决智能家居插件获取难题的网络适配方案 【免费下载链接】integration 项目地址: https://gitcode.com/gh_mirrors/int/integration 在智能家居系统搭建过程中,插件获取往往是用户面临的首要障碍。许多优质的智能家居插件托…...