SpringData ElasticSearch - 简化开发,完美适配 Spring 生态
目录
一、SpringData ElasticSearch
1.1、环境配置
1.2、创建实体类
1.3、ElasticsearchRestTemplate 的使用
1.3.1、创建索引 设置映射
1.3.2、创建索引映射注意事项(必看)
1.3.3、简单的增删改查
1.3.4、搜索
1.4、ElasticsearchRepository
1.4.1、使用方式
1.4.2、简单的增删改查
1.4.3、分页排序查询
一、SpringData ElasticSearch
1.1、环境配置
a)依赖如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
b)配置文件如下:
spring:elasticsearch:uris: env-base:9200
1.2、创建实体类
a)简单结构如下(后续实例,围绕此结构展开):
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType/*** @shards: 主分片数量* @replicas: 副本分片数量*/
@Document(indexName = "album_info", shards = 1, replicas = 0)
data class AlbumInfoDo(/*** @Id: 表示文档中的主键,并且会在保存在 ElasticSearch 数据结构中 {"id": "", "userId": "", "title": ""}*/@Id@Field(type = FieldType.Keyword)val id: Long? = null,/*** @Field: 描述 Java 类型中的属性映射* - name: 对应 ES 索引中的字段名. 默认和属性同名* - type: 对应字段类型,默认是 FieldType.Auto (会根据我们数据类型自动进行定义),但是建议主动定义,避免导致错误映射* - index: 是否创建索引. text 类型创建倒排索引,其他类型创建正排索引. 默认是 true* - analyzer: 分词器名称. 中文我们一般都使用 ik 分词器(ik分词器有 ik_smart 和 ik_max_word)*/@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")val title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")val content: String,
)
b)复杂嵌套结构如下:
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType@Document(indexName = "album_list")
data class AlbumListDo(@Id@Field(type = FieldType.Keyword)var id: Long,@Field(type = FieldType.Nested) // 表示一个嵌套结构var userinfo: UserInfoSimp,@Field(type = FieldType.Text, analyzer = "ik_max_word")var title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")var content: String,@Field(type = FieldType.Nested) // 表示一个嵌套结构var photos: List<AlbumPhotoSimp>,
)data class UserInfoSimp(@Field(type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")val username: String,@Field(type = FieldType.Keyword, index = false)val avatar: String,
)data class AlbumPhotoSimp(@Field(type = FieldType.Integer, index = false)val sort: Int,@Field(type = FieldType.Keyword, index = false)val photo: String,
)
对于一个小型系统来说,一般也不会创建这种复杂程度的文档,因为会涉及到很多一致性问题, 需要通过大量的 mq 进行同步,给系统带来一定的开销.
因此,一般会将需要进行模糊查询的字段存 Document 中(es 就擅长这个),而其他数据则可以在 Document 中以 id 的形式进行存储. 这样就既可以借助 es 高效的模糊查询能力,也能减少为保证一致性而带来的系统开销. 从 es 中查到数据后,再通过其他表的 id 从数据库中拿数据即可(这点开销,相对于从大量数据的数据库中进行 like 查询,几乎可以忽略).
1.3、ElasticsearchRestTemplate 的使用
1.3.1、创建索引 设置映射
@SpringBootTest(classes = [DataEsApplication::class])
class DataEsApplicationTests {@Resource private lateinit var elasticsearchTemplate: ElasticsearchRestTemplate@Testfun test1() {//创建索引elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).create()//设置映射elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).putMapping(elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).createMapping())}}
效果如下:
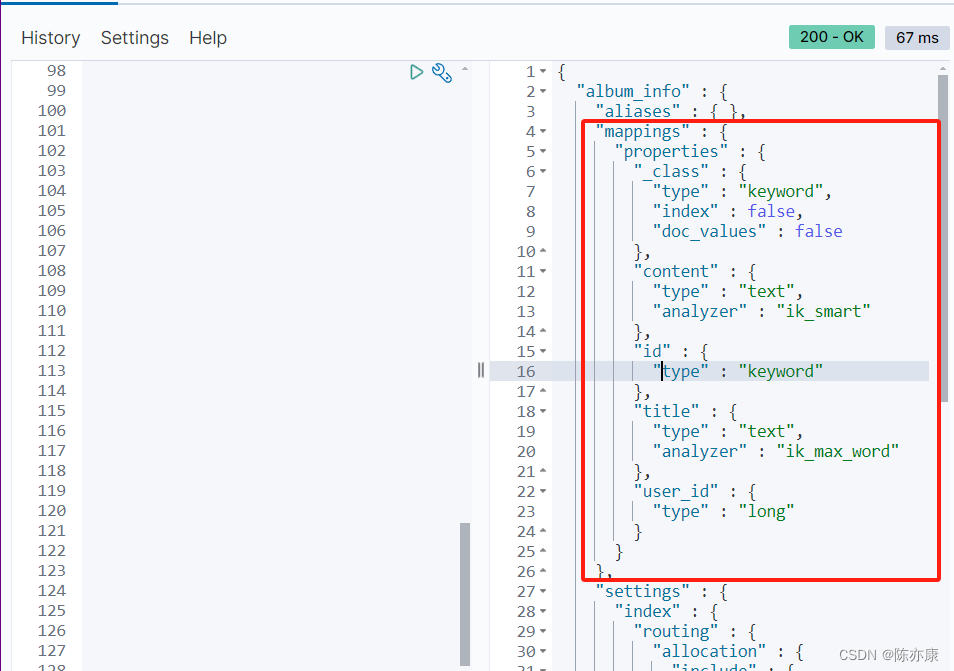
1.3.2、创建索引映射注意事项(必看)
a)在没有创建索引库和映射的情况下,也可以直接向 es 库中插入数据,如下代码:
@Testfun test1() {val o = AlbumListDo(id = 1,userinfo = UserInfoSimp(userId = 1,username = "cyk",avatar = "http:photo1.com"),title = "天气很好的一天",content = "早上起来,我要好好学习,然去公园散步~",photos = listOf(AlbumPhotoSimp(1, "www.photo1"),AlbumPhotoSimp(2, "www.photo2")))val result = esTemplate.save(o)println(result)}
b)即使上述代码中 AlbumListDo 中有各种注解标记,但是不会生效!!! es 会根据插入的数据,自动转化数据结构(无视你的注解).
c)因此,一定要先创建索引库和映射,再进行数据插入!
1.3.3、简单的增删改查
/*** 更新和添加都是这样* 更新的时候会根据 id 进行覆盖*/@Testfun testSave() {//保存单条数据val a1 = AlbumInfoDo(id = 1,userId = 10000,title = "今天天气真好",content = "学习完之后,我要出去好好玩")val result = elasticsearchTemplate.save(a1)println(result)//保存多条数据val list = listOf(AlbumInfoDo(2, 10000, "西安六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumInfoDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumInfoDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多"))val resultList = elasticsearchTemplate.save(list)resultList.forEach(::println)}@Testfun testDelete() {//根据主键删除elasticsearchTemplate.delete("1", AlbumInfoDo::class.java)}@Testfun testGet() {val result = elasticsearchTemplate.get("1", AlbumInfoDo::class.java)println(result)}
补充一个修改:
override fun update(msg: UpdateAlbumInfoMsg): Int {val query = UpdateQuery.builder(msg.albumId.toString()) //指定修改的文档 id.withDocument(org.springframework.data.elasticsearch.core.document.Document.create() //指定修改字段.append("title", msg.title) .append("content", msg.content).append("ut_time", msg.utTime)).build()val result = restTemplate.update(query, IndexCoordinates.of("album_doc")).resultreturn result.ordinal}
1.3.4、搜索
a)一般搜索
import org.cyk.dataes.model.AlbumInfoDo
import org.elasticsearch.index.query.QueryBuilders
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.domain.PageRequest
import org.springframework.data.domain.Sort
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class TemplateTests {@Resource private lateinit var elasticsearchTemplate: ElasticsearchRestTemplate/*** 全文检索查询(match_all)*/@Testfun testMatchAllQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)println("总数为: ${hits.totalHits}")hits.forEach { println(it.content) }}/*** 全文检索查询(match)*/@Testfun testMatchQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "天气")).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 精确查询(term)*/@Testfun testTerm() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.termQuery("user_id", 10001)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 范围查询*/@Testfun testRangeQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.rangeQuery("id").gte(1).lt(4)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 复合查询(bool)*/@Testfun testBoolQuery() {val boolQuery = QueryBuilders.boolQuery()//必要条件: query.must 得到一个集合val mustList = boolQuery.must()mustList.add(QueryBuilders.rangeQuery("user_id").gte(10000).lt(10003))//其他的搜索条件集合的获取方式类似val mustNotList = boolQuery.mustNot()val should = boolQuery.should()//当然,还有一种简化的写法,如下,下述代码相当于 query.should().add(QueryBuilders.matchAllQuery())boolQuery.should(QueryBuilders.matchAllQuery())val query = NativeSearchQueryBuilder().withQuery(boolQuery).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 排序和分页*/@Testfun testSortAndPage() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).withPageable(PageRequest.of(0, 3) //参数一: 页码(从 0 开始),size 每页查询多少条数据.withSort(Sort.by(Sort.Order.desc("id"))) //根据 id 降序排序(这里也可以根据多个字段进行升序降序)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach{ println(it.content) }}/*** 高亮搜索*/@Testfun testHighLight() {//定义高亮字段val field = HighlightBuilder.Field("title")//a) 前缀标签field.preTags("<span style='color:red'>")//b) 后缀标签field.postTags("</span>")//c) 高亮的片段长度(多少个几个字需要高亮,一般会设置的大一些,让匹配到的字段尽量都高亮)field.fragmentSize(10)//d) 高亮片段的数量field.numOfFragments(1)// withHighlightFields(Field... 高亮字段数组)val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "天气")).withHighlightFields(field).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)//注意,hit.content 中本身是没有高亮数据的,因此这里需要手工处理hits.forEach {val result = it.content//根据高亮字段名称,获取高亮数据集合,结果是 List<String>val hList = it.getHighlightField("title")if(hList.size > 0) {//有高亮数据result.title = hList.get(0)}println(result)}}}
b)基于 completionSuggestion 实现自动补全
data 如下:
@Document(indexName = "album_doc")
data class AlbumDocDo (@Id@Field(type = FieldType.Keyword)val id: Long,@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word", copyTo = ["suggestion"])val title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")val content: String,@Field(name = "ct_time", type = FieldType.Long)val ctTime: Long,@Field(name = "ut_time", type = FieldType.Long)val utTime: Long,@CompletionField(maxInputLength = 100, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")val suggestion: Completion? = null,
)
自动补全的字段必须是 completion 类型. 自动补全字段为 title,将他 copy 到了 suggestion 字段,实现自动补全.
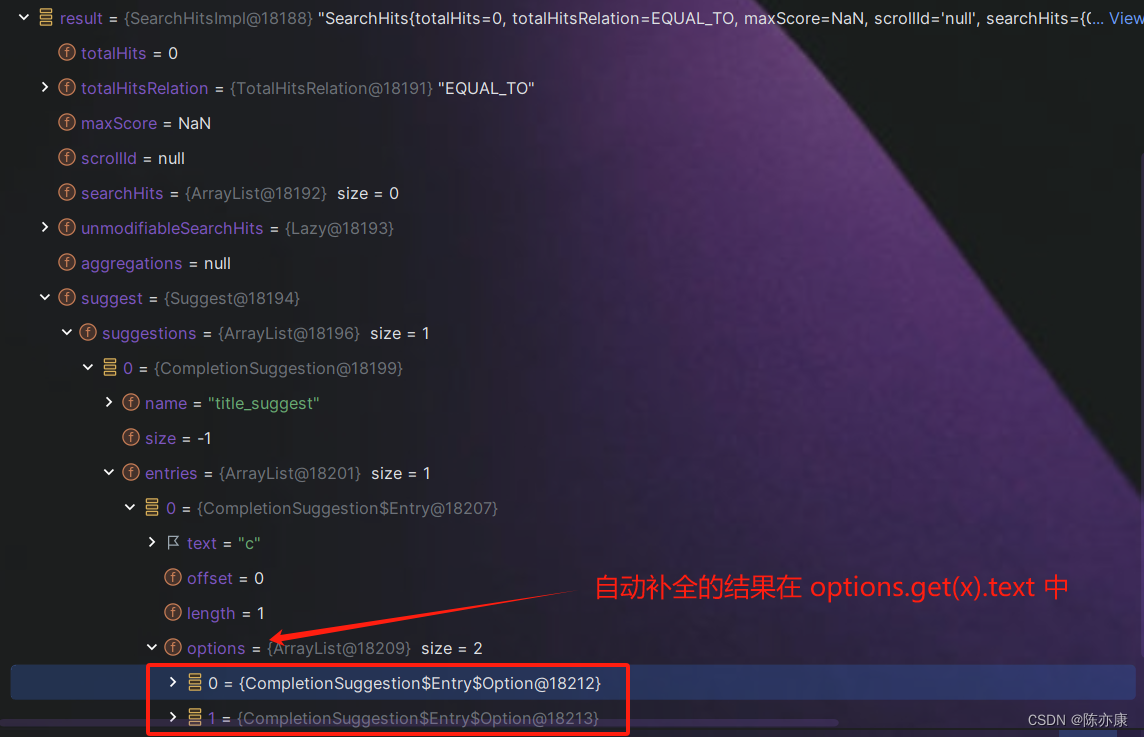
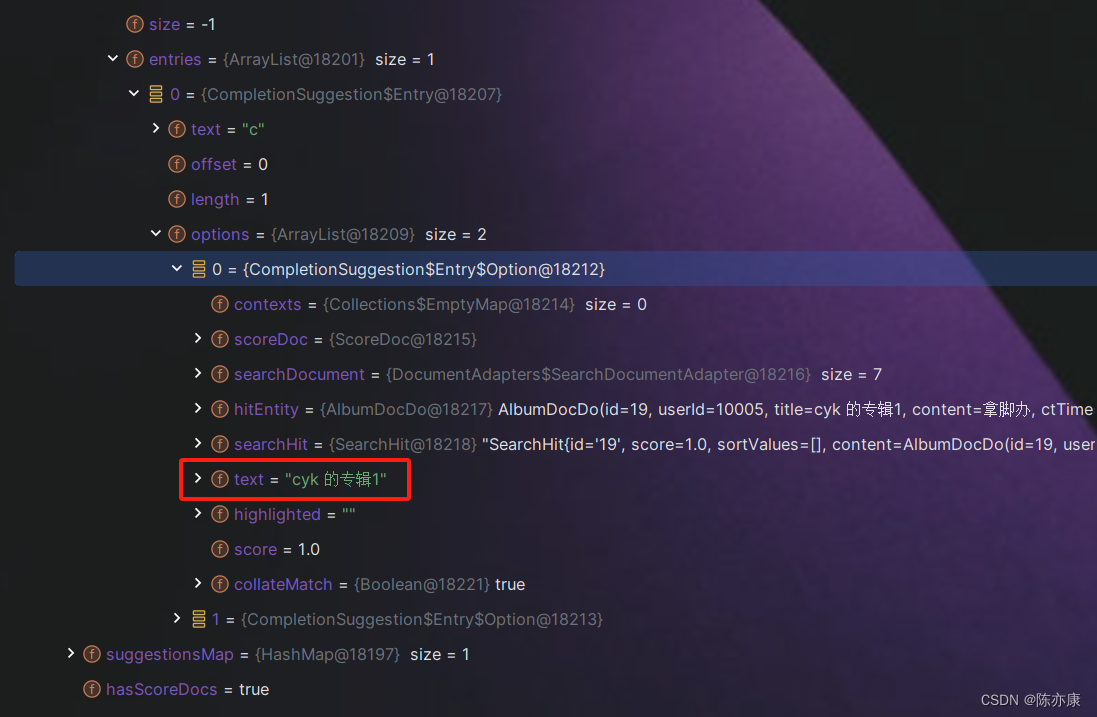
override fun suggestTexts(o: AlbumSuggestDto): List<String> {val suggest = SuggestBuilder().addSuggestion("title_suggest", //自定义补全名SuggestBuilders.completionSuggestion("suggestion") //自动补全时需要查询的字段.prefix(o.text) //要进行补全的值(用户搜索框中输入的).skipDuplicates(true) //如果查询时有重复的词条,是否自动跳过(true 为跳过).size(o.limit) //获取多少个结果)val query = NativeSearchQueryBuilder().withSuggestBuilder(suggest).build()val hits = restTemplate.search(query, AlbumDocDo::class.java)val suggests = hits.suggest?.getSuggestion("title_suggest") //根据自定义补全名获取对应的补全结果集?.entries?.get(0) //结果集(记录了根据什么前缀(prefix)进行自动补全,补全的结果对象...)?.options?.map(::map) ?: emptyList() //补全的结果对象(其中 text 就是自动补全的结果)return suggests}private fun map(hit: Suggest.Suggestion.Entry.Option): String {return hit.text}
例如需要自动补全 "c",result 结构如下
1.4、ElasticsearchRepository
1.4.1、使用方式
这个东西就跟 JPA 的使用方式一样,只不过高版本的 SpringData Elasticsearch 没有给 ElasticsearchRepository 接口提供复杂搜索查询,建议还是使用 ElasticsearchTemplate
自定义一个接口, 继承 ElasticsearchRepository 接口,如下:
import org.cyk.dataes.model.AlbumInfoDo
import org.springframework.data.elasticsearch.repository.ElasticsearchRepositoryinterface AlbumInfoRepo: ElasticsearchRepository<AlbumInfoDo, Long> //<实体类,主键类型>
1.4.2、简单的增删改查
import org.cyk.dataes.model.AlbumInfoDo
import org.cyk.dataes.service.AlbumInfoESRepo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class RepoTests {@Resource private lateinit var albumInfoESRepo: AlbumInfoESRepo@Testfun testSave() {//增加单个val a = AlbumInfoDo(1, 10000, "今天天气真好", "学习完之后,我要出去好好玩")val result = albumInfoESRepo.save(a)println(result)//批量新增val list = listOf(AlbumInfoDo(2, 10000, "西安六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumInfoDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumInfoDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多"))val resultList = albumInfoESRepo.saveAll(list)resultList.forEach(::println)}@Testfun testDel() {//根据 id 删除albumInfoESRepo.deleteById(1)//删除所有albumInfoESRepo.deleteAll()}@Testfun testFind() {//查询所有val resultList = albumInfoESRepo.findAll()resultList.forEach(::println)//根据 id 查询val result = albumInfoESRepo.findById(1)println(result.get())}}
1.4.3、分页排序查询
import org.cyk.dataes.service.AlbumInfoESRepo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.domain.PageRequest
import org.springframework.data.domain.Sort
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class RepoTests2 {@Resourceprivate lateinit var albumInfoESRepo: AlbumInfoESRepo@Testfun testFindPageAndSort() {//从 0 下标开始向后获取 3 个,并根据 id 降序排序val result = albumInfoESRepo.findAll(PageRequest.of(0, 3,Sort.by(Sort.Direction.DESC, "id")))result.content.forEach(::println)}}

相关文章:
SpringData ElasticSearch - 简化开发,完美适配 Spring 生态
目录 一、SpringData ElasticSearch 1.1、环境配置 1.2、创建实体类 1.3、ElasticsearchRestTemplate 的使用 1.3.1、创建索引 设置映射 1.3.2、创建索引映射注意事项(必看) 1.3.3、简单的增删改查 1.3.4、搜索 1.4、ElasticsearchRepository …...

突破!AI机器人拥有嗅觉!仿生嗅觉芯片研究登上Nature子刊
我们一直梦想着让AI与人类能够更加相似,赋予它们视觉与听觉。而让机器人拥有嗅觉一直以来面临着巨大的困难。 香港科技大学范志勇教授领导的研究团队凭借最新研发的仿生嗅觉芯片(BOC)在这一领域取得了重大突破。该研究成果目前已被发表到IF …...
前端接口防止重复请求实现方案
前言 前段时间老板心血来潮,要我们前端组对整个的项目都做一下接口防止重复请求的处理(似乎是有用户通过一些快速点击薅到了一些优惠券啥的)。。。听到这个需求,第一反应就是,防止薅羊毛最保险的方案不还是在服务端加…...
)
【leetcode面试经典150题】13.除自身以外数组的乘积(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

网络编程核心概念解析:IP地址、端口号与网络字节序深度探讨
⭐小白苦学IT的博客主页 ⭐初学者必看:Linux操作系统入门 ⭐代码仓库:Linux代码仓库 ❤关注我一起讨论和学习Linux系统 本节重点 认识IP地址, 端口号, 网络字节序等网络编程中的基本概念; 1.前言 网络编程,作为现代信息社会中的一项核心技术&…...
))
突破编程_C++_网络编程(TCPIP 四层模型(网络层(1))
1 网络层概述 TCP/IP 四层模型中的网络层是模型中的核心组成部分,它主要负责处理数据包的路由和转发,确保数据能够在源主机和目标主机之间准确地传输。 一、主要功能 网络层的主要功能是实现数据包的选路和转发。当数据从应用层传输到传输层后&#x…...

Java | Leetcode Java题解之第9题回文数
题目: 题解: class Solution {public boolean isPalindrome(int x) {// 特殊情况:// 如上所述,当 x < 0 时,x 不是回文数。// 同样地,如果数字的最后一位是 0,为了使该数字为回文࿰…...
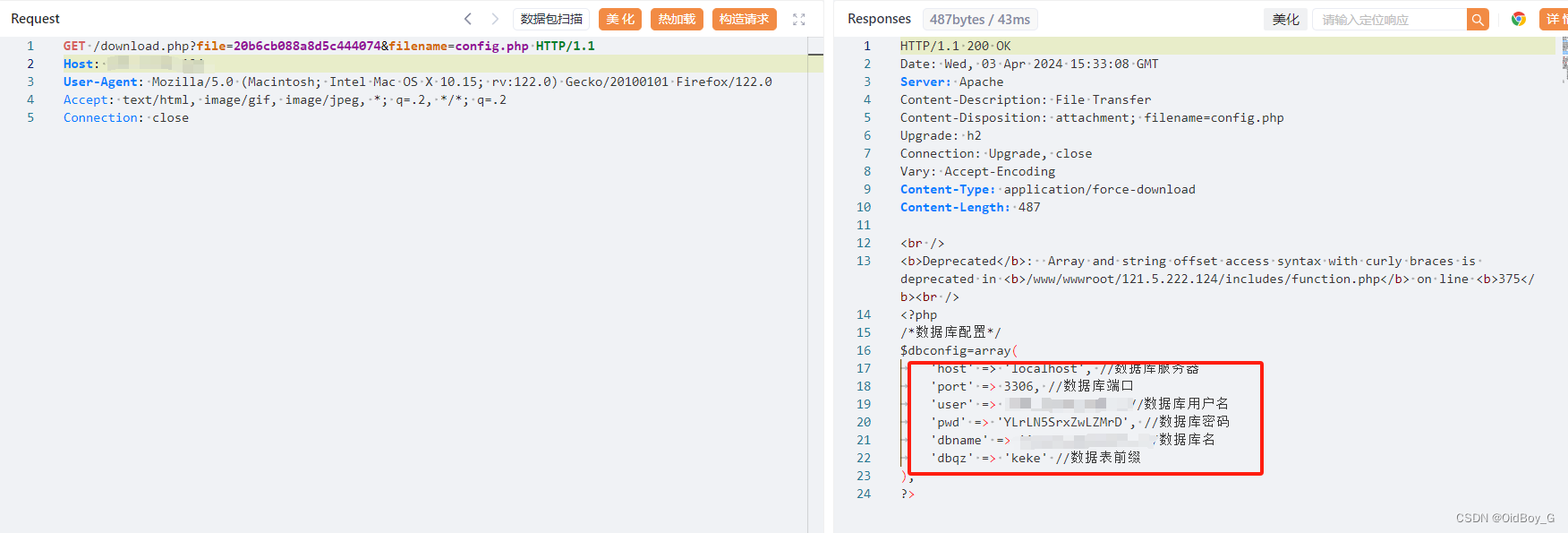
极简云验证 download.php 文件读取漏洞复现
0x01 产品简介 极简云验证是一款开源的网络验证系统,支持多应用卡密生成:卡密生成 单码卡密 次数卡密 会员卡密 积分卡密、卡密管理 卡密长度 卡密封禁 批量生成 批量导出 自定义卡密前缀等;支持多应用多用户管理:应用备注 应用版…...
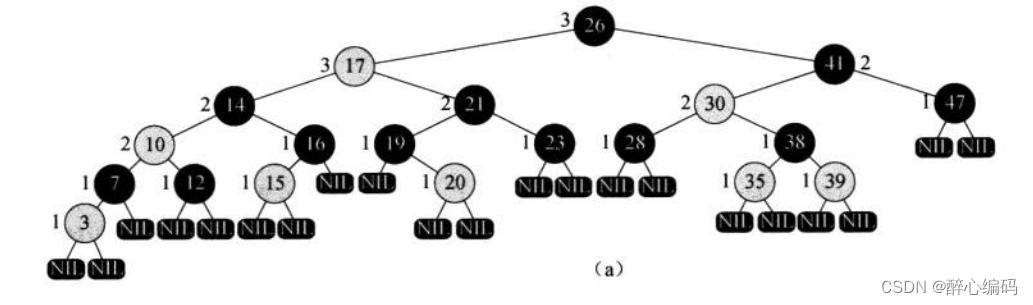
红黑树路径长度分析:证明与实现
红黑树路径长度分析:证明与实现 一、红黑树的基本性质二、证明:最长路径至多是最短路径的2倍2.1 证明思路2.2 证明过程 三、伪代码实现四、 C语言代码实现5、 结论 红黑树作为一种高效的自平衡二叉搜索树,在计算机科学领域中被广泛应用于各种…...
)
esp32 gpio初识(一)
目录 功能介绍 实操 功能介绍 引脚又叫管脚,英文叫 Pin, 就是从集成电路(芯片以及一些电子元件)内部电路引出与外围电路的接线的接口。 在我们的 ESP32 开发板上, 我们可以把这些称为引脚, 这些引脚其实是从 ESP32 芯片内部引出来的, 我们…...
)
python 自制黄金矿工游戏(设计思路+源码)
1.视频效果演示 python自制黄金矿工,细节拉满沉浸式体验,看了你也会 2.开发准备的工具 python3.8, pygame库(python3.5以上的版本应该都可以) 图片处理工具,美图秀秀 截图工具,电脑自带的 自动抠图网页:https://ko…...

Splunk Attack Range:一款针对Splunk安全的模拟测试环境创建工具
关于Splunk Attack Range Splunk Attack Range是一款针对Splunk安全的模拟测试环境创建工具,该工具完全开源,目前由Splunk威胁研究团队负责维护。 该工具能够帮助广大研究人员构建模拟攻击测试所用的本地或云端环境,并将数据转发至Splunk实例…...

OpenCV入门例程:裁剪图片、模糊检测、黑屏检测
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 本例程运行环境为CentOS7&…...

opencv-python库 cv2边界填充resize图片
文章目录 边界填充改变图片大小 边界填充 在OpenCV中,边界填充(Border Padding)是指在图像周围添加额外的像素,以扩展图像的尺寸或满足某些算法(如卷积)的要求。OpenCV提供了cv2.copyMakeBorder()函数来进…...

Java代码基础算法练习-负数个数统计-2024.04.04
任务描述: 从键盘输入任意10个整型数(数值范围-100000~100000),统计其中的负数个数 任务要求: 代码示例: package April_2024;import java.util.Scanner;// 从键盘输入任意10个整型数(数值范围…...

【算法刷题day17】Leetcode:110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和
110.平衡二叉树 文档链接:[代码随想录] 题目链接::110.平衡二叉树 题目: 给定一个二叉树,判断它是否是 平衡二叉树 注意: 判断两棵子树高度差是否大于1 class Solution { public:int result;bool isBalanced(TreeNode…...

C++ | Leetcode C++题解之第10题正则表达式匹配
题目: 题解: class Solution { public:bool isMatch(string s, string p) {int m s.size();int n p.size();auto matches [&](int i, int j) {if (i 0) {return false;}if (p[j - 1] .) {return true;}return s[i - 1] p[j - 1];};vector<…...

职场迷航?MBTI测试为你指明方向,找到最匹配的职业!
MBTI简介 MBTI的全名是Myers-Briggs Type Indicator。它是一种迫选型、自我报告式的性格评估工具,用以衡量和描述人们在获取信息、作出决策、对待生活等方面的心理活动规律和性格类型。 类型指标 美国的凯恩琳布里格斯和她的女儿伊莎贝尔布里格斯迈尔斯研制了迈尔…...
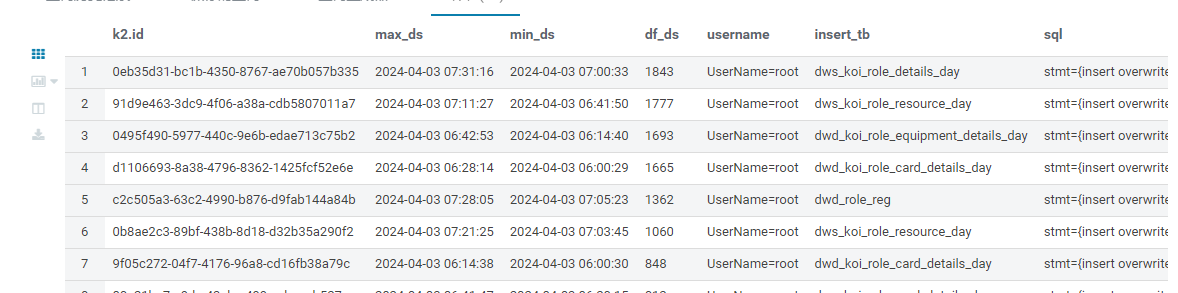
hive 慢sql 查询
hive 慢sql 查询 查找 hive 执行日志存储路径(一般是 hive-audit.log ) 比如:/var/log/Bigdata/audit/hive/hiveserver/hive-audit.log 解析日志 获取 执行时间 执行 OperationId 执行人 UserNameroot 执行sql 数据分隔符为 \001 并写入 hiv…...

Vue - 2( 10000 字 Vue 入门级教程)
一:Vue 1.1 绑定样式 1.1.1 绑定 class 样式 <!DOCTYPE html> <html><head><meta charset"UTF-8" /><title>绑定样式</title><style>......</style><script type"text/javascript" src&…...

前端拖拽交互实现:别再只会用原生拖拽了
前端拖拽交互实现:别再只会用原生拖拽了 毒舌时刻这代码写得跟网红滤镜似的——仅供参考。各位前端同行,咱们今天聊聊前端拖拽交互。别告诉我你还在用原生的HTML5拖拽API,那感觉就像在用诺基亚手机——能打电话,但体验太差。 为什…...

OpenSpec 生成文件说明
proposal.md —— 为什么做、做什么(产品/范围) Why:要解决什么问题、机会是什么。What Changes:会新增/改掉/删掉哪些能力,有没有 BREAKING。Capabilities:会动到哪些能力名(对应后面 specs/&l…...

OpenClaw可视化监控:为nanobot任务添加Web仪表盘
OpenClaw可视化监控:为nanobot任务添加Web仪表盘 1. 为什么需要可视化监控? 去年夏天,我部署了一个基于OpenClaw的nanobot自动化任务,用于定时抓取行业动态并生成日报。最初几周运行良好,直到某天早上发现连续三天的…...
)
Python并发革命进行时:GIL移除后你必须掌握的5种内存序模型(x86/ARM/RISC-V实测对比)
第一章:Python无锁GIL环境下的并发模型架构总览传统CPython解释器受全局解释器锁(GIL)制约,无法真正实现多线程CPU并行。而“无锁GIL环境”并非指移除GIL本身,而是指在GIL被主动释放、绕过或由替代运行时(如…...

利用快马平台十分钟搭建树莓派环境监测系统原型
今天想和大家分享一个快速搭建树莓派环境监测系统的小实验。作为一个硬件爱好者,我经常用树莓派做各种物联网原型开发,但每次从零开始配置环境、写基础代码都很耗时。最近发现InsCode(快马)平台能帮我省去很多重复工作,特别适合快速验证想法。…...

根据您提供的写作范围,我为您总结的标题为:“昆通泰MCGS7.7嵌入版:6车位停车场监控系统仿...
6车位停车场监控系统昆通泰MCGS7.7嵌入版仿真运行带运行效果视频6车位停车场监控系统用昆通泰MCGS7.7嵌入版做仿真,真的是新手友好型项目——不用扛硬件、不用接复杂通讯,靠内部变量和几段脚本就能把核心逻辑跑通,还能直观看到实时效果&#…...

从串口通信到内存总线:手把手拆解‘波特率’、‘比特率’与‘总线带宽’的异同与实战计算
从串口通信到内存总线:深度解析波特率、比特率与总线带宽的实战差异 在嵌入式开发和计算机体系结构领域,数据传输速率的计算是工程师日常工作中无法绕开的基础技能。但令人困惑的是,同样的"速率"概念在不同场景下却有着完全不同的…...

vLLM-v0.17.1详细步骤:vLLM + Triton Ensemble实现多模型协同推理
vLLM-v0.17.1详细步骤:vLLM Triton Ensemble实现多模型协同推理 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的吞吐量和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发,现在已…...

开源风扇控制工具FanControl全攻略:从问题诊断到散热方案优化
开源风扇控制工具FanControl全攻略:从问题诊断到散热方案优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...
两个月搞定)
别再到处找模板了!我用这套软著申请材料(含用户手册+源代码模板)两个月搞定
两个月高效拿下软著:零基础开发者的材料准备实战指南 第一次提交软著申请时,我盯着官网模糊的材料要求整整发呆了半小时——"用户手册需图文并茂"到底要多详细?"源代码前30页后30页"该怎么截取?连续三个晚上搜…...