深入浅出 -- 系统架构之单体到分布式架构的演变
一、传统模式的技术改革
在很多年以前,其实没有严格意义上的前后端工程师之分,每个后端就是前端,同理,前端也可以是后端,即Ajax、jQuery技术未盛行前的年代。
起初,大部分前端界面很简单,显示的内容几乎以纯静态的文本和图片为核心,无法动态渲染后台返回的数据到页面,例如:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>静态页面</title>
</head>
<body><h1>我是竹子爱熊猫~</h1>
</body>
</html>
用户能看到的网页内容,只能靠硬编码形式写入到代码里,这就类似于“一张图片”,被制作出来后,就无法进行变更,想要展示不同的内容,只能重新“制作”。
因此,当时为了使得Web页面更加灵活生动,以PHP、JSP、ASP等为代表的动态页面渲染技术相继诞生!所谓的动态页面渲染,则是指“页面”并不是固定写死的,而是提前定义好模板,运行时动态获取数据,并渲染生成页面源码,例如:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>动态渲染页面</title>
</head>
<body><h1>${welcomeMessage}</h1>
</body>
</html>
此时注意看,在上述示例中,通过${welcomeMessage}占位符,表示这里需要动态获取并渲染一句欢迎语。运行时,当出现该页面的请求时,会先执行对应操作动态获取欢迎语(如查库),接着再替换掉前面的占位符,从而动态生成网页源码返回给浏览器展示。
这样,想要改变欢迎语时,就无需重新编写HTML代码,只需改变“数据源”的欢迎语即可(如改库)。凭借着动态页面技术,就可以将最新的欢迎语显示出来,使得页面更加灵活。
OK,从上述背景中不难得知一点,早些年的页面源码,都依靠“后端”来动态生成,比如Java中的JSP技术。正因如此,前后端就没有界限分割,业务逻辑、页面展示都写在一个应用里面,这就是所谓的:单体架构!
1.1,最原始的单机架构

正如上图所示,这是最初的部署模式,前后端代码、静态资源都往同一个包里怼,应用程序、数据库都部署在一台服务器上!优势很明显,因为都是本机环境,内部数据交换非常快;同时运维也简单,只需要关注这一台服务器即可,部署成本非常低。
显然,这种方式虽然成本低,数据交换快,但并不能支撑太大的访问量,当流量增大时,系统很可能因为CPU、内存、带宽、磁盘等各因素出现性能问题,而一旦遇到瓶颈,为了保证系统正常运行,集“前端、后端、运维、测试、售后……”诸多岗位于一身的小竹,只能依靠“升配服务器”来解决。
1.1.1、数据库隔离部署
一味的堆硬件配置,并非长久之计,尤其站在老板角度出发,单机器的配置越高,成本会呈几何倍增长,此时小竹进行了第一次软件架构层面的优化:系统应用与数据库分开部署。
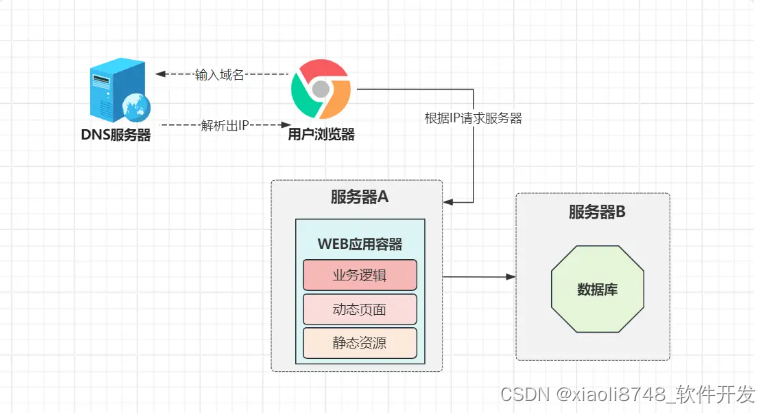
之前一股脑将所有程序部署在一起的做法,会导致业务系统和数据库,这两个不同的程序相互竞争系统资源,在流量较大的情况下,由于系统资源不够,会导致大量请求处于阻塞中;经过拆分后,资源相互隔离,在极大程度上提升了系统整体的性能。同时,就算部署业务程序的机器损坏,也不会丢失系统数据,在一定程度上也提升了系统的抗风险性。
1.1.2、动静分离
随着业务不断增长,小竹没开心几天,原先的系统架构出现了新瓶颈,因为数据库独立部署,而WEB应用服务器,即需要处理业务逻辑,又需要负责动态生成网页,同时还需要处理静态资源请求,日渐一日,系统不堪重负,在某一天下午终于倒下了……
凡事只要有第一次,就会有N多次,迫不得已的情况下,小竹为了保证系统能正常访问,只能通过不断重启来解决问题。但这种方法治标不治本,总不能一天到晚蹲在服务器旁边重启吧?寻找并解决诱发程序频繁宕机的源头,才能真正一劳永逸!于是,小竹踏上了排查之路。
经过一顿操作,此时观测到了问题!因为部署时,所有的静态资源(css、js、图片、模板……),包括运行期间用户上传的文件,统统都放在了WEB容器内托管,这意味着所有静态资源请求,都需要WEB容器来进行处理。
经过三秒钟的观测后,小竹发生这类型的请求,占据了60%以上!导致频繁宕机的原因就在这里,为了解决该问题,新的优化方案是:动静分离。
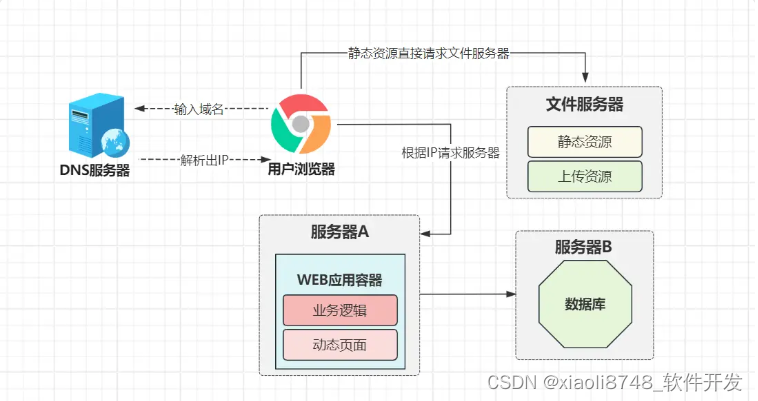
经过动静分离的拆分优化后,所有静态资源的请求都会去到文件服务器,而与业务逻辑相关的请求,则会来到WEB服务器,通过这种动静分流方案,至少能减少WEB服务器60~70%请求,小竹终于可以睡上几天安稳觉了!
1.1.3、动态页面模板化
前面提到过,为了使得网页能动态加载数据,PHP、JSP、ASP等技术曾风靡一时,以Java的JSP技术来说,尽管实现了动态页面的效果,可页面内的数据,都需要依靠Java来动态填充,而渲染页面数据这个工作,放在后端来做,极为耗费时间与资源。
可当时又没有太好的办法解决,直到Ajax、jQuery技术横空出世,前端可以通过Ajax请求,在不刷新、不跳转新页面的情况下,就可以和服务器通信,实现异步获取新的数据,这也意味着:动态页面不再需要依靠后端来生成,前端可以异步请求服务器数据,来实现页面的数据渲染!
放在当时,Ajax技术绝对是WEB领域革命性的突破,也是在这时,IT行业逐渐出现明确的前后端岗位之分,前端可以不懂后端技术,后端同理,两者相互协助,从而完成整个系统的开发。在这期间,为了避免“后端服务渲染动态页面”带来的开销,例如Thymeleaf、FreeMarker、Velocity等各种模板引擎技术蜂拥而至。
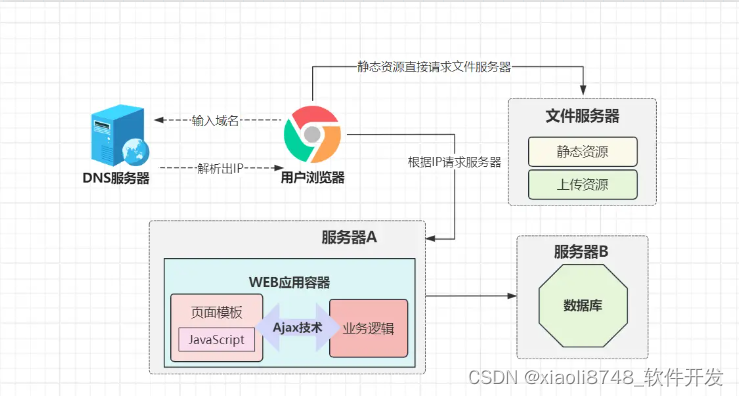
看过Tomcat源码的小伙伴应该清楚,JSP本质上是一个个的Servlet,必须依赖WEB容器才能使用,毕竟要靠Java来生成动态页面。而类似于FreeMarker这种模板引擎技术,可以脱离Servlet容器运行,不再占用JVM内存,很大程度上节省了Java生成动态页面所带来的开销。
1.2,前后端分离架构
随着时代的进步,模板引擎技术仅是昙花一现,很快就被全新的模式完全替代,那就是流行至今的:前后端分离架构!
虽然FreeMarker这类模板引擎技术,可以不再依赖Servlet容器运行,但或多或少会依赖于Java实现渲染,而到了该阶段,前后端的开始正式“分家”,前端涌现了一批又一批的船新技术,如 Angular、React、 Vue等,页面可以完全不依赖Java、PHP这类环境完成动态渲染,Web正式进入2.0时代!
到此时,前端已经可以完全脱离WEB容器运行,这意味着部署时,不再需要将视图相关的代码,和业务逻辑相关的代码一起打包,而是前后端分开部署,HTML、CSS、JavaScript等代码作成前端工程单独部署,处理业务逻辑的Java代码,打包成后端服务单独部署,走出了真正意义上的“前后端分离架构”。
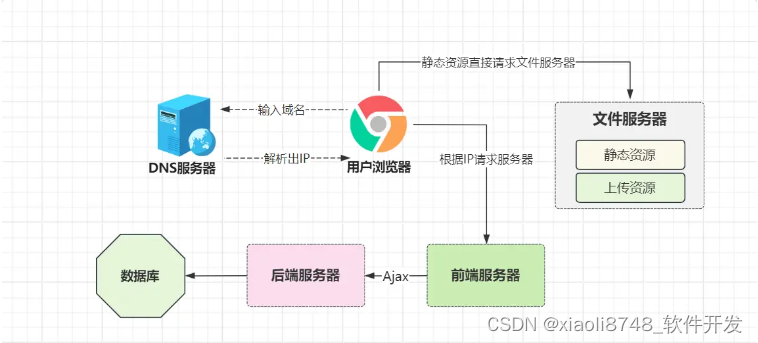
因为前端服务已经独立部署,后端服务器不再会出现“由于生成动态页面,导致资源被耗尽”这类性能瓶颈,此时小竹可以高枕无忧了吗?我们接着往下看。
1.3,集群部署模式
随着日益剧增的访问量,就算已经将系统拆分成了前后端分离架构,但这也远远不够!当用户体量达到一定量级后,会造成大量的并发请求,而此时的后端服务仅有一个节点,并发压力较大时,单节点扛不住外部流量,轻则响应缓慢,重则掉线宕机!
当并发数达到单机器的负载极限,此刻该怎么办?难道又得走上升配的老路吗?答案是No,曾经在《MySQL专栏-分库分表篇》中讲过一个故事,当一匹马拉不动马车时,不要想着去找一匹更强壮的马代替它,而是可以选择再加一匹、两匹……来一起拉车!
同理,当一台服务器扛不住并发请求时,我们可以选择使用多台服务器来部署系统,多个节点均摊处理外部请求,从而保证系统的正常运行,而这种思想则被称为:集群。考虑使用集群来承载更大的流量时,首先得解决一个问题:原本只有一个节点,现在拓展成了多个节点,那出现一个请求时,究竟该落入到那台机器?又该如何分发请求?
为了解决上面提到的问题,此时得引入两个新的概念:请求分发器与负载均衡,而目前80%使用集群模式部署的系统,大多采用Nginx来实现该效果。当然,具体如何做呢?没接触过的小伙伴可参考之前的《Nginx篇》。
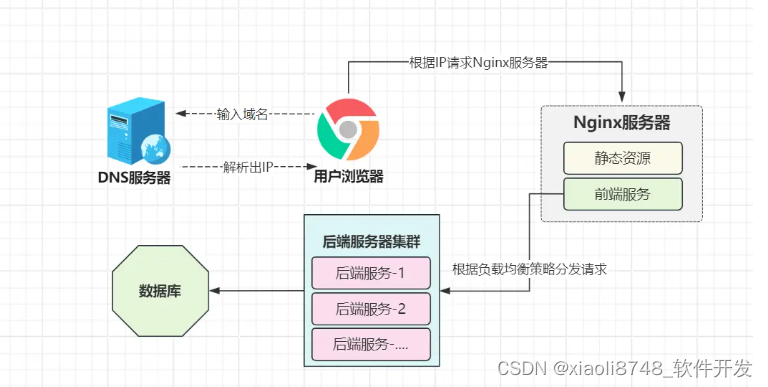
由于Nginx强大的路由匹配模式,如果系统内的静态文件,不需要考虑访问权限控制,那也可以借助Nginx来实现动静分离。当然,Nginx更为重要的是反向代理和负载均衡能力,当系统访问量再次出现增长时,可以线性拓展出N个节点,对外提供更高的吞吐量。
集群化部署的另一个好处在于高可用,之前的单机挂掉后,整个系统会陷入瘫痪,而此时无需担心该问题,就算挂掉部分节点,还有另一部分节点正常工作,系统不会陷入全面瘫痪。终于,精神高度紧绷的小竹松了一口气,心里想着再也不用担心扛不住请求了,大不了再加机器!
二、过渡阶段的技术发展
经过上阶段的集群化部署后,小竹本以为万事大吉,以后再也不用担心系统抗压性跟不上业务增长了!可偏偏理想很丰满,现实很骨感。确实,单从后端层面来说,可以横向拓展服务节点来获取更高的吞吐量,但小竹忽略了另一个致命环节:数据库!
2.1、引入缓存中间件解决读并发
并发请求数越来越大,之前看似游刃有余的数据库,逐渐变的跟不上性能要求,而一套系统中,技术组件之间都有着千丝万缕的关系,一个组件崩溃,就容易带来一系列雪崩结果。以数据库为例,数据库由于并发影响,读取数据越来越慢,所以阻塞在后端服务中等待数据返回的请求越来越多,入站流量远大于出站流量,长此以往,后端服务线程数超负荷,系统再次出现响应缓慢、无返回等严重事故。
好,既然从数据库读取数据较慢,有没有好的办法优化呢?当然有,对于某些热点数据,例如电商中的商品SPU主信息,变动概率小,但访问次数又多。这种情况下,能否把这些短期内不会变更的数据,直接存放在一处能快速读取的位置呢?当然可以,缓存的概念由此而来。
对于计算机来说,从哪里获取数据最快?本机内存,而Java程序而言,从哪里获取数据最快?JVM内存!因此,Ehcache、Caffeine这类进程级缓存框架应运而生。对于热点数据,首次从数据库读取后,直接放入缓存中,对于后续读取相同数据的请求,从缓存中拿出直接返回即可。
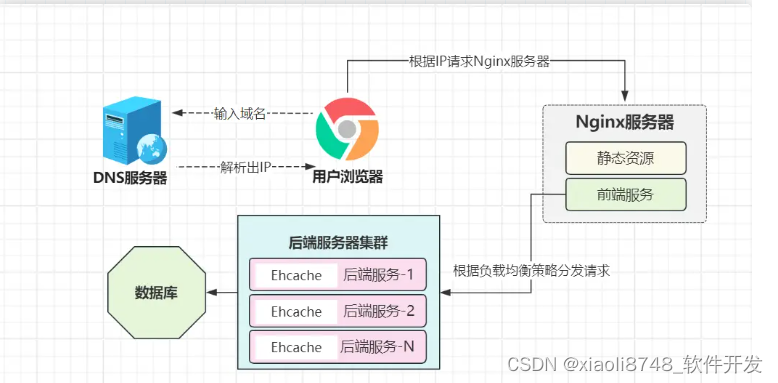
通过进程级缓存技术,在极大程度上减轻了数据库的读取压力,但这种缓存框架,通常会与Java程序共享JVM堆空间,当缓存数据过多时,会造成GC变得更加频繁,熟悉JVM-GC机制的伙伴应该清楚,GC会造成停顿,尤其是次数一多,给用户感受就是系统时不时就要卡一下。
虽然,这些缓存框架提供了参数,允许直接使用本地内存作为缓存区域,但在集群环境下,依旧存在“数据冗余”问题,比如A商品信息,在节点1的缓存中上已存在,可第二个查看A商品的请求,被分发到了节点2,此时又会造成节点2缓存一次,结合具体的业务场景,这时有N个后端节点,就会多出N倍的内存占用。
如何将缓存信息公共化?MemCache、Redis等分布式缓存中间件的出现,完美解决了这个问题。
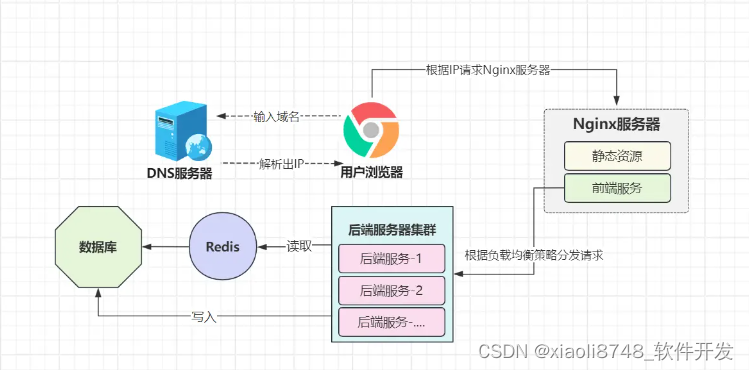
数据库查询慢,首先是因为结构化存储,需要遍历表或索引才能定位数据,其次是基于磁盘读取,本身性能就不咋滴,所以在这些缓存中间件里,基于内存、采用哈希表结构,成为了设计时的基本要素。因为是独立的中间件,读取数据要走网络,虽然没有进程级缓存来的快,但对比数据库而言,性能十分客观~
2.2、通过消息中间件削峰填谷
左眼跳财,右眼跳灾。果然在不久之后,系统再一次出现瓶颈,小竹看着面如黑锅的老板,再次对系统进行观察分析,于是看到了类似下图的流量统计:
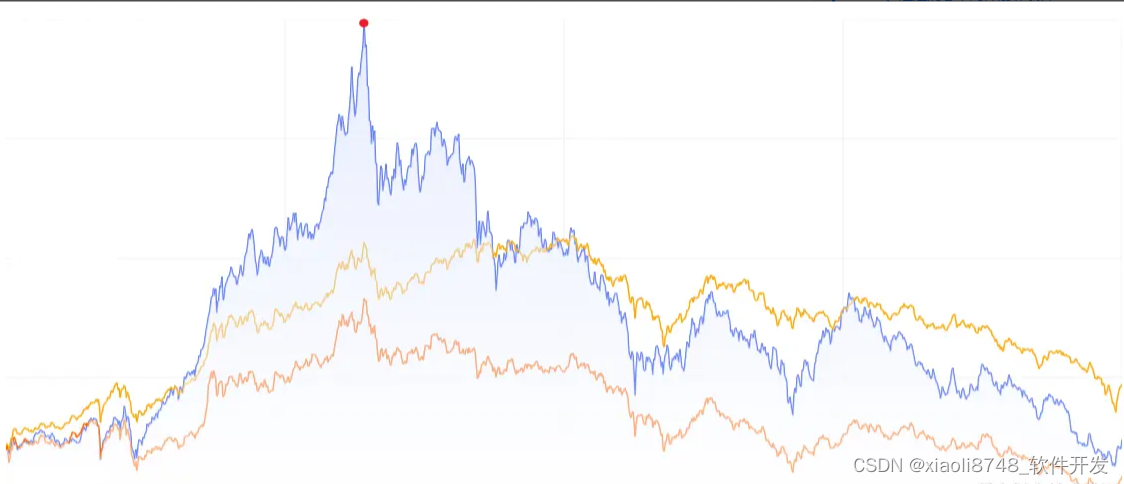
系统在凌晨与深夜,请求数会急剧下降,而在中午时分,请求数屡创新高!小竹盯着这个顶点,心里总有种莫名的熟悉感,怎么回事?仔细一回想,哦,原来是跟自己当初股票的买入点一样……
回归正题,按理说引入Redis后,就算高峰期也能抗住,可为什么系统又不行了?突然闹钟灵光乍现,Redis只能分担读压力,假设此时写并发也非常高,数据库扛不住同样会造成系统瘫痪!
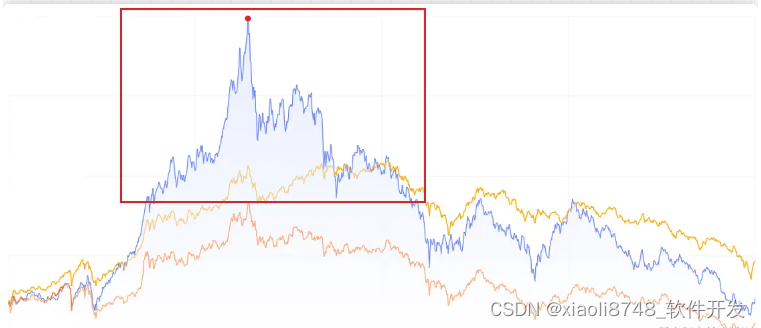
再回过头来观察这张图,很明显,系统流量高峰期只集中在某段时间内(图中框出来的位置),而其余时刻流量正常,特别是凌晨和深晚特别低,流量会进入低谷期。既然系统并不是全天高峰期,那能否想办法把高峰期的流量,放到低谷期来处理呢?这样即不会因为并发过高导致系统瘫痪,同时还能充分利用空闲时间段的机器资源。
上面这个理念特别棒,怎么落地?难道高峰期的用户请求,先记录下来,等到半夜再处理返回吗?显然不可以,因为一个用户中午进行了操作,结果半夜才响应,产品经理能把你砍死……。有更好的方式吗?当然有,消息中间件(MQ)!
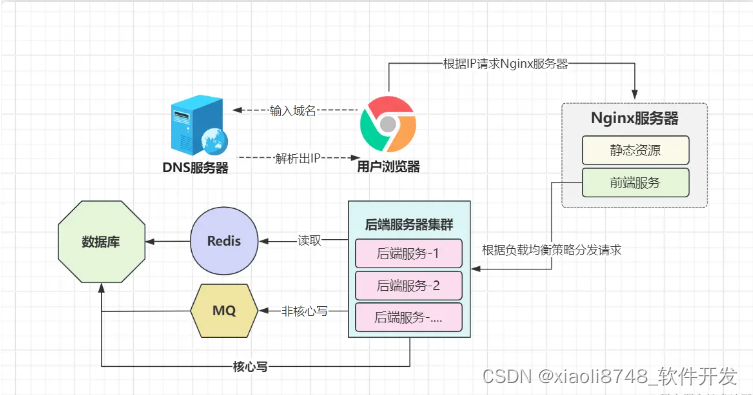
MQ有个核心作用就是削峰填谷,可按前面的模式削峰行不通,到底咋削?想要削的合理,首先得对业务做区分,任何一个功能都可以分为核心步骤与辅助步骤,比如下单链路中,“提交订单、扣减库存”这类属于核心操作,而“推送通知、生成交易快照”这些属于辅助动作,按现有的模式,一个下单请求会将整个链路上的操作都执行一次,这里就会出现四个写操作:插入订单数据、修改库存数据、插入通知数据、插入交易快照数据。
相信到这里大家心里就有数了,削什么?辅助操作,在处理下单请求时,只执行核心操作,非核心操作直接往MQ中丢一/多条消息,等待低谷期再真正执行写入操作。通过这种方式,在目前案例中,就减轻了流量高峰期一半的写入压力!同时,MQ除开能削峰填谷外,还能对业务进行解耦,以及实现异步处理,加快单次请求链路的处理时间,让请求响应速度更快,用户体验感更佳~
2.3、数据库集群
虽然通过Redis减轻了DB的读取压力,通过MQ降低了写入并发,可因为流量越来越大,最终落入到DB的请求还是很多,单库逐渐开始变得吃力,小竹迫于无奈,只能先走上“升配”的老路,同时寻求其他解决之道……
小竹深思一番过后,忽然灵光一动!既然Java应用能做集群,那数据库能否采用相同思想,通过多台机器构建集群呢?好像可以,该怎么做好一点?网上一搜,发现了个概念叫:读写分离,毕竟所有流量都可被分为读、写两种,那能否搞一个节点专门处理写入SQL,另一个节点负责查询SQL呢?当然可以,负责处理读请求的节点,只需及时同步最新写入的数据即可!
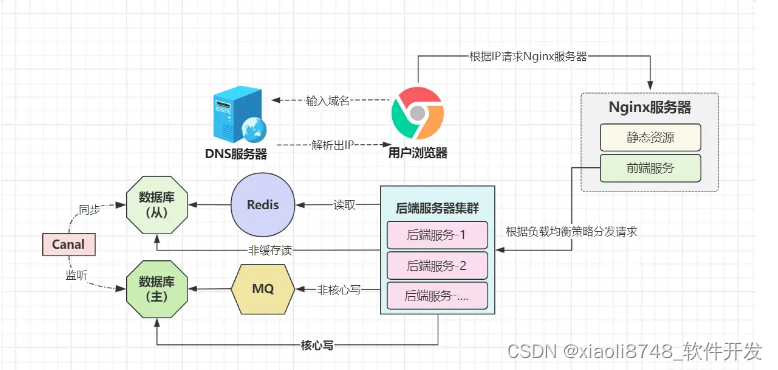
为了保证主从库之间的数据一致性,这里使用Canal来降低同步数据时的延迟(无法保证零延迟),通过这次架构调整后,select语句走从库执行,而写入类型的语句则走主库执行,主从各司其职,数据库的并发吞吐量,爬上了新的阶级。
2.4、按业务划分子系统
经过前面多次架构调整后,系统的架构却没有停止演进,很快便迎来了新挑战,随着业务越来越复杂、团队规模越来越大,Git上的代码分支特别多,搞到最后,代码合并困难,没办法,只能将不同分支的代码独立运行,因此逐渐出现业务分化,在时间的推动下,一个大的系统变成多个子系统共同执行,系统架构变成了如下样貌(以电商平台为例):
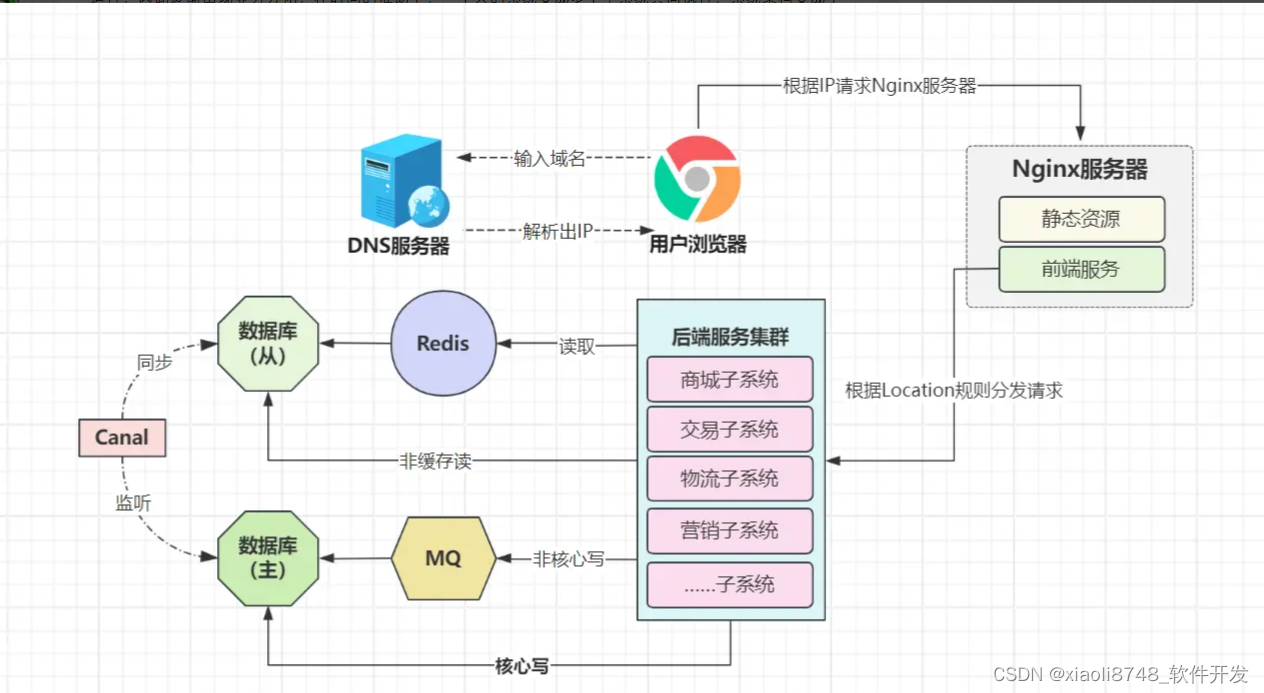
经过不断迭代,小竹最初负责的小电商项目,逐渐演变成了商城子系统、交易子系统、物流子系统、营销子系统……等多个子系统。而进入系统的用户请求,需要在网关配置路由规则,从而实现不同子系统的流量分发,而多个子系统之间通过WebServices、HTTP等方式调用对方接口来配合工作。
通过这种方式,能让团队分工更加明确,并且多个子系统之间互不影响,提升了系统的分区容错性,而且使得系统吞吐量进一步升高(分布式/微服务理念的开始)。
2.5、SOA架构
经过子系统的演变后,其实整个系统已经初步变成了所谓的“分布式系统”,但这种子系统拆分存在致命的缺陷:多个子系统之间,就好似一个项目里的多个模块,产生了强耦合性,系统之间的配合,完全靠写死对方IP地址来完成调用,一旦某个子系统出现故障,依旧存在整个系统全面瘫痪的风险!
同时,这种强耦合的模式下,系统拓展变得十分困难,比如交易子系统扩容节点后,另一个依赖于交易系统的第三方,无法动态感知新节点的加入,有人或许会说,我们可以通过域名完成接口调用呀?这的确是种解决方案,但每次接口调用都需要经过域名解析,进一步加大了接口响应时间,性能堪忧!于是,在多种因素的影响下,小竹必须对系统的整体架构再次进行调整,怎么做?基于SOA架构重构系统。
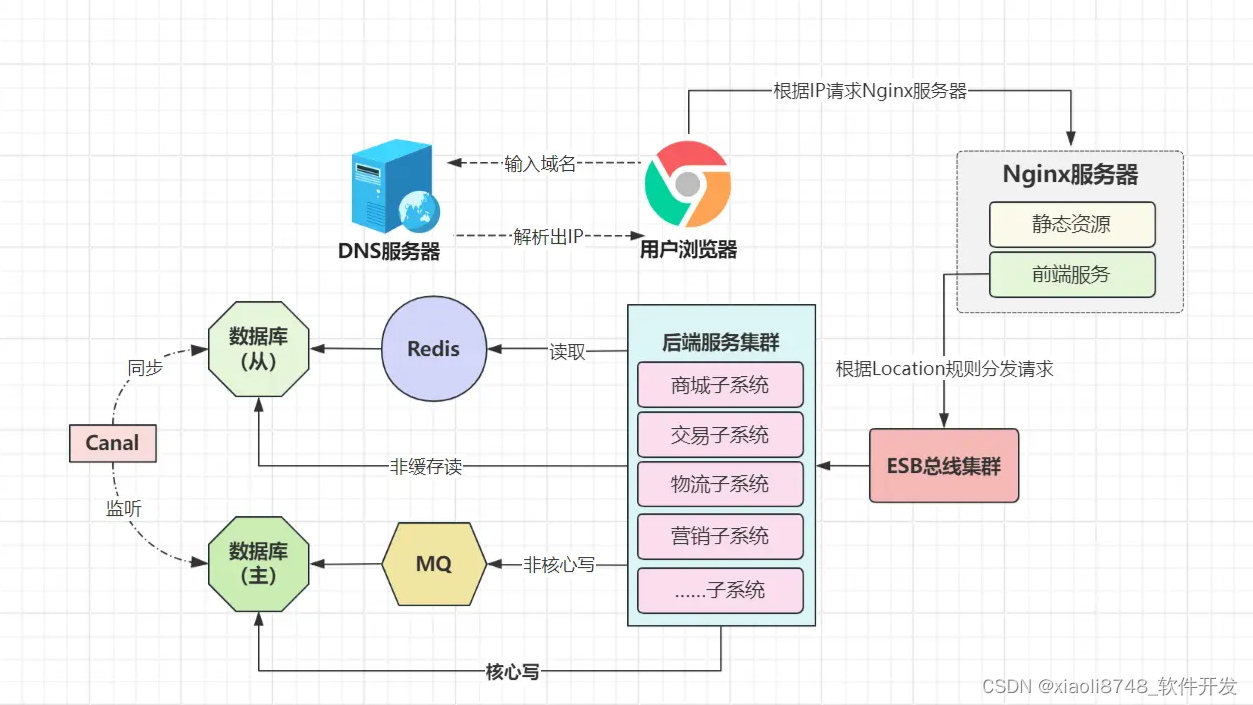
在SOA架构里,有个新的概念:ESB企业服务总线,它是一个可复用的中央基础设施,用于协调各分布式系统中各个服务间的通信和交互,同时能够提供协议转换、消息转换、请求路由、系统集成……等一系列服务。
正是因为ESB总线的存在,它成为了各系统间的粘合剂,就算各系统的接口风格、数据交换格式、使用的协议等不一致,ESB也能完美进行转换,从而使得各系统能很好的交互,并且可以使得各系统接口标准化,各系统更易于维护/迭代。
除此之外,基于SOA架构拆分的项目,在性能出现瓶颈时,各子系统可按需进行横向拓展,比如交易系统承载的访问量较大,可以针对该子系统拓展更大的集群对外提供服务。
2.6、分库分表
随着业务系统的壮大,小竹发现传统模式的数据库再现颓废,虽说能通过主从、多主等模式加以改善,但不足以完全应对越来越大的流量冲击,也无法承载大流量带来的海量数据存储需求,且无法及时响应大表里的查询需求……
综上,数据库架构的改造势在必行!如何改?既然业务系统可以拆成多个子系统,那DB层能否如此?当然可以,我们可以针对不同的子系统,抽出各自的业务表形成专属库,而这就是所谓的:分库分表-垂直分库思想。
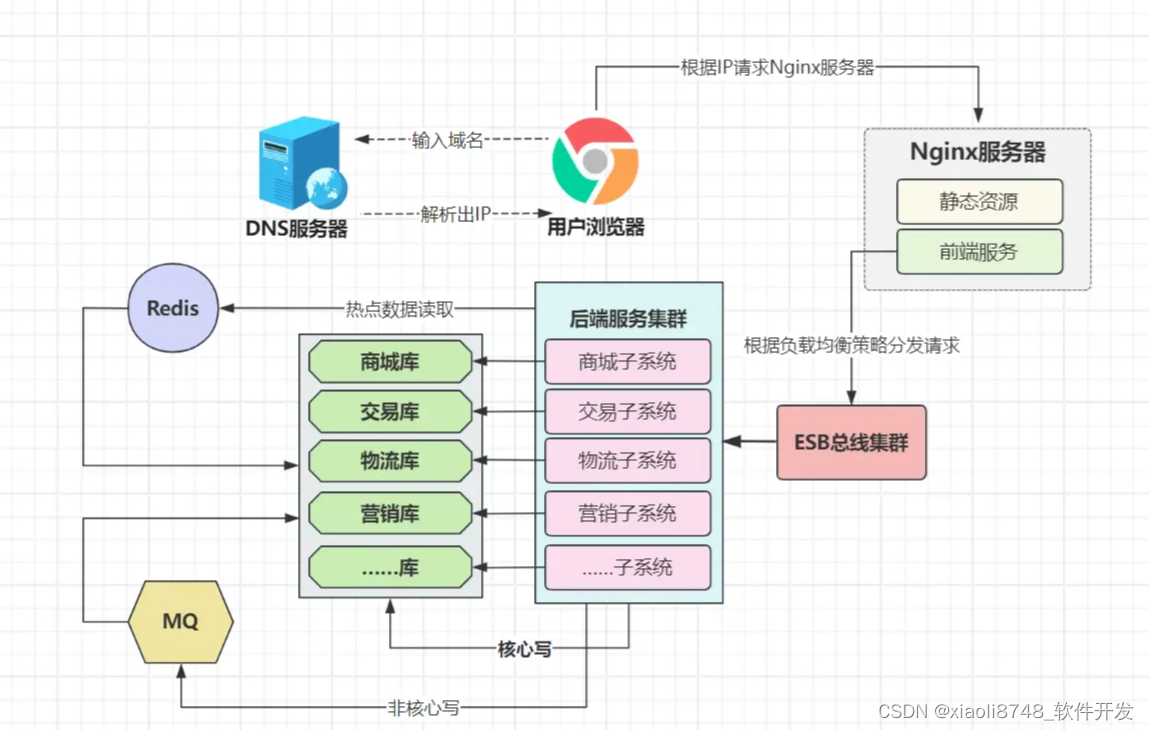
与业务系统一样,如果某个子系统的单个DB节点,无法承载业务量时,依旧可以横向拓展出多个节点对外服务,以此应对随时增长的流量冲击与存储需求。而水平分库时,究竟选择主从、多主,还是分片模式?大家可以根据实际情况来做抉择。
当然,一旦将某业务的数据库,横向拓展出多个节点时,多数据源该怎么协调?读写SQL又该落入哪个节点?这就得引入Sharding-Sphere、MyCat这类分库分表中间件,由它们来负责统一管理(分库分表这里不做展开,感兴趣的伙伴可参考分库分表实战篇)。
分库分表后,并不像传统的单主机数据库一样,所有工作由数据库自身完成,数据库只能在逻辑层被称为一个整体,实际上已经演变成了“分布式数据库”,以Sharding-Sphere里的Sharding-JDBC为例,读写SQL则由Sharding进行分发,写入时,数据会被分散到不同节点存储;查询时,从多节点查询出的数据,也由它来负责汇总聚合。
当然,随着技术的发展,如今也出现了许多例如TiDB、OceanBase……的分布式数据库,它们既支持标准SQL的解析能力,又天然支持分布式场景!执行写入语句时自动分片存储,执行标准查询SQL时,会解析为分布式的执行计划,而后分发到每个节点上并行执行,最终由数据库自身汇总数据返回(感兴趣的自行了解)。
2.7、多层级负载
随着业务系统、数据库架构改造工作的落幕,小竹本以为尘埃落地,可谁曾料到,整个系统的“咽喉要地-网关”竟然出现了问题,Nginx负责接收所有入站流量,并将其转发给内部系统处理,而后处理出站流量,此刻它却显得乏力,面对来势汹汹的入站流量,抗不住只能选择宕机……
好了,如何平稳承接庞大的入站流量?光靠Nginx依然不够,我们可以照葫芦画瓢,选择多负载模式,在Nginx前面再架设一个负载器,预算够可以选择硬件负载均衡器,如F5、A10等;如果预算不足,则可以采用软件层面的负载器,如LVS:
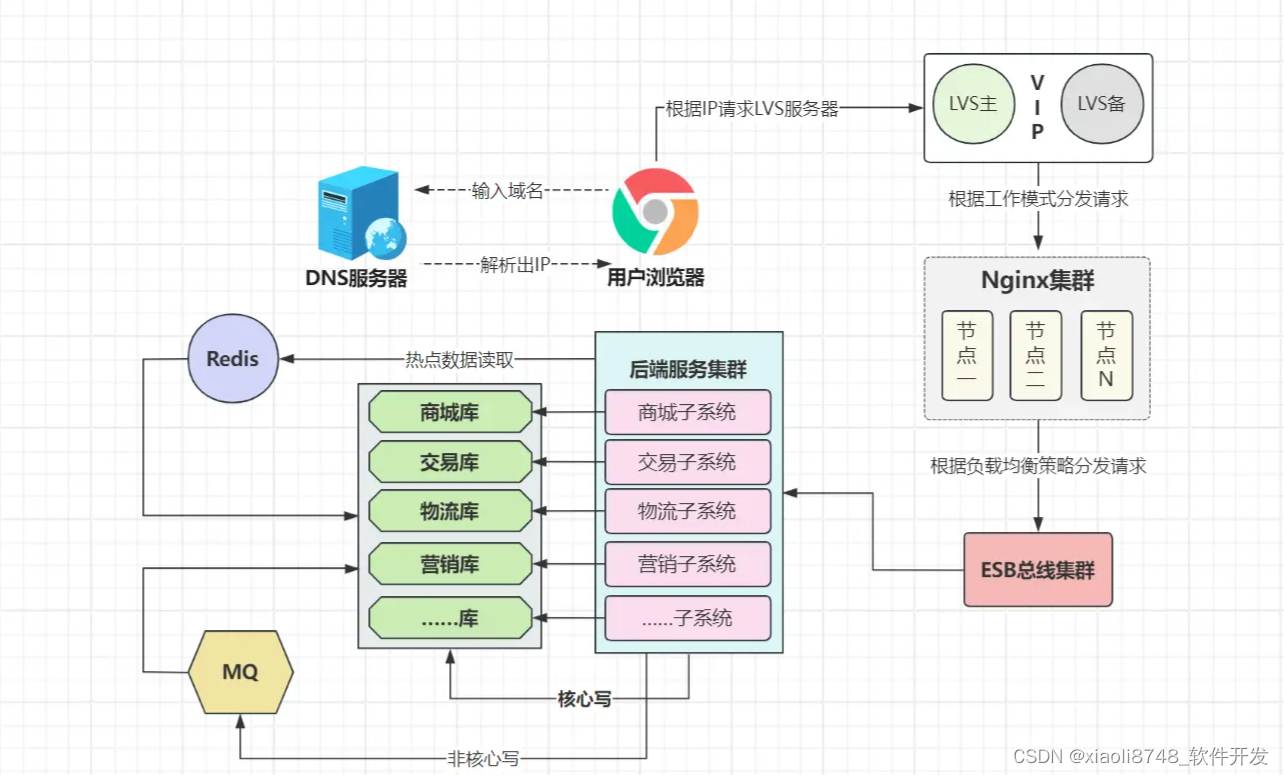
通过LVS,我们可以给Nginx搭建集群,从而提升流量接入层的整体吞吐量,类似于阿里云的SLB(现CLB)负载器,底层亦是使用LVS技术进行构建。当然,接入层还可通过DNS轮询解析、CDN分发等方式进行优化,这里不做展开,感兴趣的可参考之前《流量接入层设计》。
三、微服务云原生时代的演进
流量接入层、DB层的架构趋于平稳后,再次将目光放回业务系统,虽然之前基于SOA架构将整个复杂的系统,拆分成了多个独立的子系统,但是抽取时的粒度较大,随着时间推移,各个子系统又会变得臃肿,彼此间依赖关系变得复杂。同时,因为拆分粒度较大,多个子系统之间会有不少重复功能(如推送消息、权限验证等)。最关键的是,在SOA架构中,ESB总线属于中心,一旦ESB出现故障,会导致整个系统无法正常运转。也正是此时,市面上出现一种新的概念:微服务!
3.1、微服务架构改造
微服务,从它的名称不难看出,它的意思是指将整个业务系统,拆分成一个个独立的微小服务,每个服务专注某个特定的业务功能。而Java因为SpringCloud微服务框架的横空出世,将微服务概念推至巅峰,它继承了SOA架构的理念,提供了API网关、服务治理、服务保护、服务调度、统一配置、RPC调用等一系列基础落地组件!

在微服务架构中,系统内的各项业务,会划分出精细的服务,而一些例如消息、鉴权、支付等基础功能,亦可抽离出可复用的独立服务。此外,非业务类的功能(负载均衡/服务保护/消息转换/请求路由等),不会像SOA架构中那般,由ESB成为独裁者,而是划分更为明确的各个组件,如请求路由交给网关处理、服务保护交给断路器负责、负载均衡交给专门的负载器完成……
粒度更小,代表服务节点数更多,各个服务节点又可做集群拓展,意味着后端架构不再受业务量增长的影响,当业务增长/萎靡时,可以通过动态伸缩节点来提供不同等级的吞吐量,至此,后端的整体架构趋向于稳定。
3.2、多样化存储
随着微服务架构的落地,此时却出现了新的问题,系统体量越来越大,光依靠传统型数据库已无法支撑各种存储需求,比如搜索场景,在体量较小时,咱们可以通过like之类的模糊查询手段实现,而随着数据集变大、搜索场景多样化,之前的手段已不再适用,怎么解决?搜索引擎。
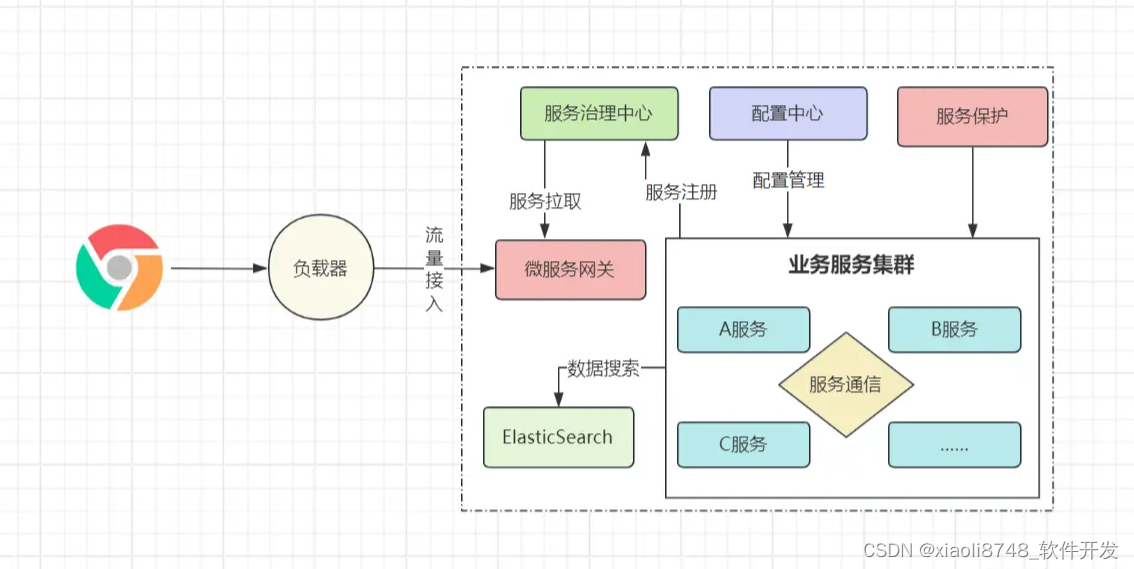
当下较为流行的搜索引擎是ElasticSearch,可以通过它来根据用户输入的关键字,快速检索系统内的海量数据集。当然,ES只是为了解决部分场景下的问题,对于系统多样化的存储需求,可能会用到各类存储组件,如:
- 文档数据库:
MongoDB、Neo4j等; - 时序数据库:
InfluxDB、Druid、Kdb+、Graphite、TimescaleDB等; - 对象/文件存储:云厂商的对象存储服务(
OSS、OBS、COS、S3等)、HDFS、FastDFS、MinIO等; - 大数据套件:
Hadoop、HBase、Cassandra、Hive等;
针对不同的业务场景,可以选用最适合的存储组件,不同组件效果带来的效果差异很大,举个大家都能理解的例子,比如查询热点数据的场景,如果单纯使用MySQL这类关系型数据库,再怎么优化,也很难实现毫秒级响应;但如果选用Redis来存储热点数据,毫秒级的响应速度简直不要太轻松~
3.3、容器化时代
随着各种架构的改革落地,系统内组件越来越多,后端服务数量也越来越多,同时还要考虑高可用,为核心组件/服务搭建集群,小竹很快迎来了新的痛苦,硬件成本实在太太太高了!就算一台机器同时部署几个应用,也需要几十、上百台服务器……
硬件资源开销大是一方面,另一方面是运维困难!几十上百种服务/组件相互交错,代码管理、源码打包、环境部署、版本发布、版本回退、故障恢复……,稍微搞错一步,就会发现整个系统跑不起来,这种体验简直令人痛不欲生,而正是此时,一种新的技术出现在大众视野:虚拟化容器。

虚拟化容器解决了资源问题,而系统部署工作依旧困难,因为流程又多又复杂,光依靠人工很容易出错,此时迫切需要一种自动化部署技术来介入处理,而恰巧正在此时,大名鼎鼎的Kubernetes(K8S)降世!它与Docker形成了完美的互补关系,Docker提供基本的创建、启动、停止和重启等容器化功能,K8S则提供了更高级的功能,如容器的自动部署、自动扩缩、滚动升级、灰度发布、节点自愈等,并支持在多个节点上运行容器,还额外提供了负载均衡、服务发现等功能,面对庞大且复杂的微服务系统,可以使用K8S实现容器的编排和管理!
到这里,系统部署工作依旧没有完全实现自动化,这里缺乏了最关键的一步:代码管理与打包,所有系统并非一开始就能达到“稳定态”,几乎任何一个程序都会经过N多次迭代更新,不可避免的会多次更新代码。如果每次更新后,需要手动打包成镜像,这同样会增加出错风险,这一步能否自动化?答案是可以,有个工具叫:Jenkins。

Jenkins配合Git的触发回调,可以实现代码更新时,自动拉取最新代码并打包生成新镜像,多分支并行开发的情况,开发人员也只需在Jenkins上进行操作,几乎实现了全自动化部署流程。当然,整个完整流程有个专业的叫法:CI/CD(可持续集成/持续部署)。
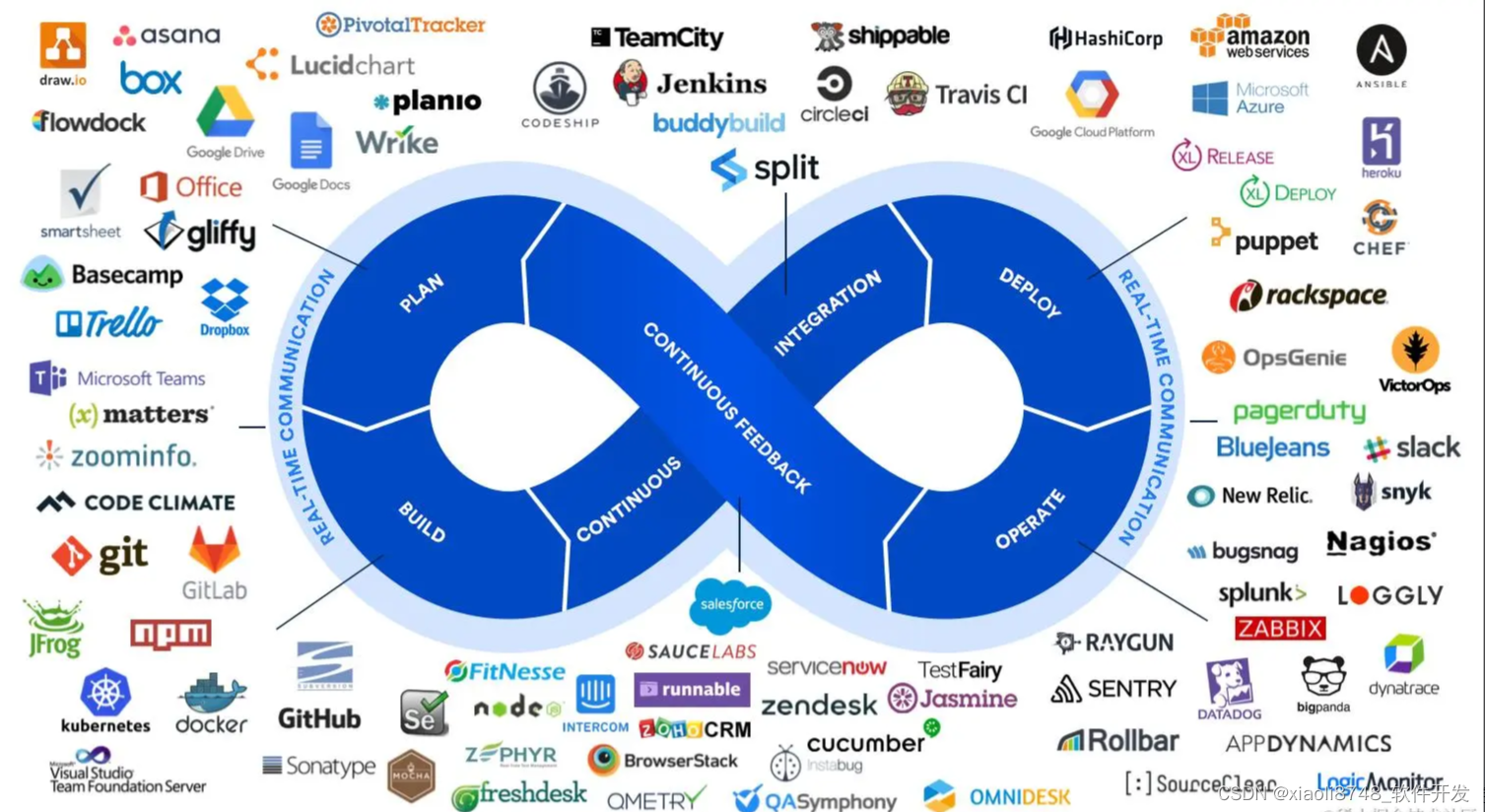
CI/CD的全流程,由Git+Jenkins+Docker+K8S配合实现,四者缺一不可(用类似的产品代替可以),大致的完整流程如下:
- ①开发人员将代码提交到
Git远程仓库,Git上的webhook会触发Jenkins构建; - ②
Jenkins通过Docker构建镜像,完成后并将镜像推送到Docker仓库; - ③
K8S从Docker仓库拉取最新的镜像,并自动部署到系统集群。
越是大型的系统,通过CI/CD技术,更能为开发团队提供高效、自动化的产品开发和部署流程。至此,小竹再也无需担心部署方面的问题。
3.4、云原生时代
上阶段提到的Docker+K8S部署方案,是一种典型的微服务上云的方式,通过这种方式,可以充分利用云计算的优势,通过K8S实现集群管理、自动化部署、动态伸缩、容错处理等功能,从而更好地支持业务的发展和创新。
PS:自己从零搭建私有云的成本很高,所以才出现了各大云厂商,中小项目可以借助这些公有云实现微服务上云,也不需要自行维护云平台本身的问题。并且可以借助云平台的强大功能,满足各场景下的需求,例如中小电商平台,大促活动前可升配资源,活动结束后再降配~
但随着云计算的不断发展,现如今,出现一种名为“云原生”的概念,云原生是一种构建和运行程序的新方法,旨在实现应用与基础设施资源之间的解耦,让开发人员更关注业务本身,这是啥意思呢?
大家想想,如今的微服务架构中,除开我们编写的业务服务外,系统内是不是还会存在许多基础设施?如网关、断路器、负载均衡器、注册中心等等,这些组件是每个微服务开发者需要考虑、甚至介入开发的,而云原生的内在含义是指:开发人员以后老老实实负责写业务就行,像这类基础设施组件,你直接用我提供的!因为云环境中,自身就提供了这些功能(如K8S就有负载均衡、服务发现等功能)。
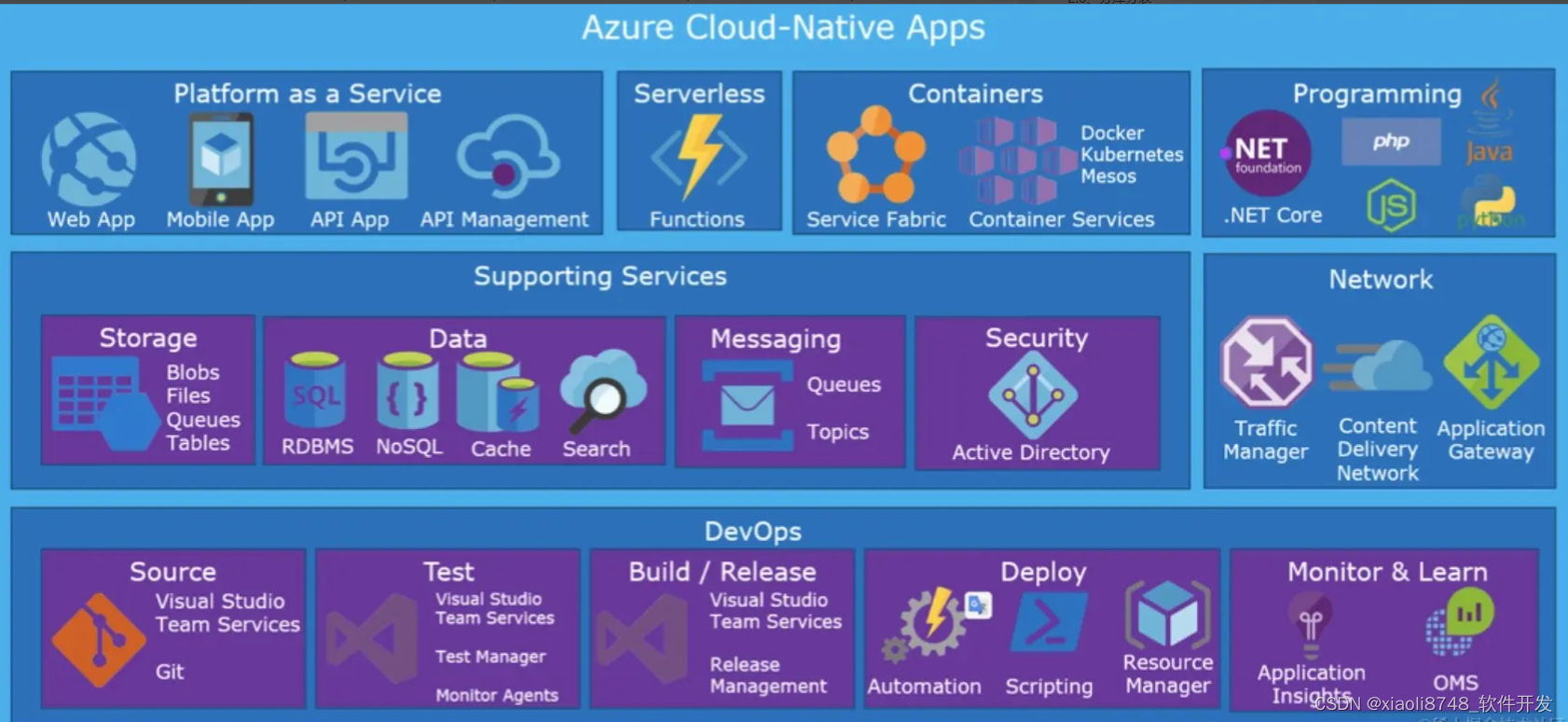
云原生的核心是将应用程序设计成云环境的原生应用,即在系统设计之初,就考虑到应用程序将运行在云环境中,并以后不会脱离云环境独立运行!服务注册、API网关、服务保护……等一系列设施,全都用云环境里自带的,比如直接把服务注册到K8S,不再单独部署Nacos这类组件。
PS:虽然如今很多微服务项目都已经上云了,但很少有项目转到云原生环境,因为想要构建云原生程序,必须全面拥抱云环境,老项目需要推翻之前的架构重新变革,并且后续必须得一直运行在云原生环境中。
3.5、异地多活架构
这里是题外话,异地多活架构是出于高可用、高性能的目的出发,从而衍生出的一种技术架构。正常来说,一个系统不管有多少组件/节点,通常只会部署到一个地区(机房),而早年由于这样的部署模式,机房出现灾难时(如火灾、断电、洪水、断网等),会导致整个系统无法访问,而异地多活架构就因此而来。
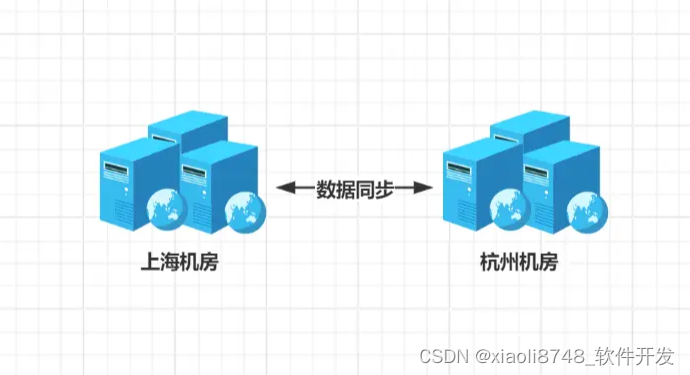
异地多活,指的是在不同城市/地区各自部署一套系统,当某个城市的机房出现故障时,用户请求依旧可以访问另一个地区的服务,从而保证系统达到99.9…%高可用性。同时,还可以借助智能DNS解析技术,实现就近分发,比如上海、杭州两地部署了应用,现实距离上海近的用户,则将请求解析到上海机房处理,杭州同理,这样可以加快用户的访问速度(CDN的原理类似)。
总结
从整篇内容来看,架构的演进似乎是一帆风顺的,每遇到新问题,总有新的技术栈应运而生,巧妙地化解了现有的技术难题。然而,若从历史的角度审视,每次系统面临新的挑战时,解决过程并非如此轻松。许多新技术栈在初期可能鲜有人涉足,需要一步步去踩坑、填坑,直至最终投入生产环境。
如今,我们所面对的众多挑战之所以能有如此丰富的技术栈供选择,是因为历史上有无数“先行者”为我们铺平了道路,是他们帮我们把坑填平了!若有一天你也成为了这样的“先行者”,面对前所未有的问题没有现成的解决方案可以参考时,你或许也需要独自琢磨,甚至可能需要从零开始研发全新的组件来攻克~
其实大家看完这篇文章,也能发现一个技术发展的规律,回顾十年前,曾经风靡一时的“技术栈”,如今却难寻踪影,呈现在我们面前的则是全新技术,为啥?这是因为技术发展会跟随业务,技术为业务提供服务,业务推动技术发展,两者相辅相成,彼此成就。
相关文章:
深入浅出 -- 系统架构之单体到分布式架构的演变
一、传统模式的技术改革 在很多年以前,其实没有严格意义上的前后端工程师之分,每个后端就是前端,同理,前端也可以是后端,即Ajax、jQuery技术未盛行前的年代。 起初,大部分前端界面很简单,显示的…...

每日一题 第七十期 洛谷 [蓝桥杯 2020 省 AB2] 回文日期
[蓝桥杯 2020 省 AB2] 回文日期 题目描述 2020 年春节期间,有一个特殊的日期引起了大家的注意:2020 年 2 月 2 日。因为如果将这个日期按 yyyymmdd 的格式写成一个 8 8 8 位数是 20200202,恰好是一个回文数。我们称这样的日期是回文日期。…...
蓝桥杯第十四届C++A组(未完)
【规律题】平方差 题目描述 给定 L, R,问 L ≤ x ≤ R 中有多少个数 x 满足存在整数 y,z 使得 。 输入格式 输入一行包含两个整数 L, R,用一个空格分隔。 输出格式 输出一行包含一个整数满足题目给定条件的 x 的数量。 样例输入 1 5 样例输出 …...

职场口才提升之道
职场口才提升之道 在职场中,口才的重要性不言而喻。无论是与同事沟通协作,还是向上级汇报工作,亦或是与客户洽谈业务,都需要具备良好的口才能力。一个出色的职场人,除了拥有扎实的专业技能外,还应具备出色…...
【算法练习】28:选择排序学习笔记
一、选择排序的算法思想 弄懂选择排序算法,先得知道两个概念:未排序序列,已排序序列。 原理:以升序为例,选择排序算法的思想是,先将整个序列当做未排序的序列,以序列的第一个元素开始。然后从左…...
【关于窗口移动求和的两种计算方法】
窗口移动计算方法 例子方法1方法2运行结果: 例子 在很多算法中都会涉及到窗口滑动,比如基于新息序列更新的自适应卡尔曼滤波器算法中便会使用到。 已知一个数列:OCV [1;2;3;4;5;6;7;8;9;10;11;12;13;14;15],定义窗口长度为5,每次…...

Win10文件夹共享(有密码的安全共享)(SMB协议共享)
前言 局域网内(无安全问题,比如自己家里wifi)无密码访问,参考之前的操作视频 【电脑文件全平台共享、播放器推荐】手机、电视、平板播放硬盘中的音、视频资源 下面讲解公共网络如办公室网络、咖啡厅网络等等环境下带密码的安全…...

Client sent an HTTP request to an HTTPS server
背景 最近踩坑了 我发现域名:8000可以访问我的服务 但是域名:443却不行,这很反常 结果发现是nginx配置的问题,需要把http改成https! 原因 如果你的后端服务(运行在8000端口上)已经配置了SS…...

Springboot传参要求
Web.java(这里定义了一个实体类交Web) public class Web{ private int Page; public int getPage() {return Page;}public void setPage(int page) {Page page;} } 1、通过编译器自带的getter、Setter传参 。只是要注意参数的名字是固定的,不能灵活改变。 传参的…...

数字乡村创新实践探索:科技赋能农业现代化与乡村治理体系现代化同步推进
随着信息技术的飞速发展,数字乡村作为乡村振兴的重要战略方向,正日益成为推动农业现代化和乡村治理体系现代化的关键力量。科技赋能下的数字乡村,不仅提高了农业生产的效率和品质,也为乡村治理带来了新的机遇和挑战。本文旨在探讨…...

C语言——找单身狗1
题目描述: 在一个整形数组中,只有一个数字出现一次,其他数组都是成对出现的,找出那个只出现一次的数字。 例如: 数组中:1,2,3,4,5,4,3…...

Day82:服务攻防-开发组件安全Solr搜索Shiro身份Log4j日志本地CVE环境复现
目录 J2EE-组件Solr-本地demo&CVE 命令执行(CVE-2019-17558) 远程命令执行漏洞(CVE-2019-0193) Apache Solr 文件读取&SSRF (CVE-2021-27905) J2EE-组件Shiro-本地demo&CVE CVE_2016_4437 Shiro-550Shiro-721(RCE) CVE-2020-11989(身…...
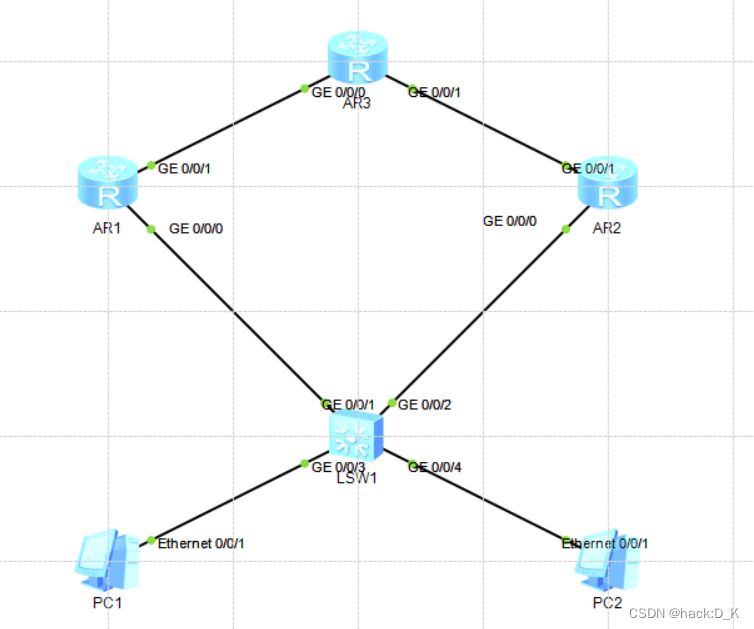
网络协议——VRRP(虚拟路由冗余协议)原理与配置
1. VRRP概述 单网关出现故障后下联业务中断,配置两个及以上的网关时由于IP地址冲突,导致通讯时断时续甚至通信中断。VRRP组播类的网络层协议 2. 协议版本 VRRP v2: 支持认证,仅适用于IPv4网络 VRRP v3: 不支持认证, 适用于IPv4和IPv6两种网…...
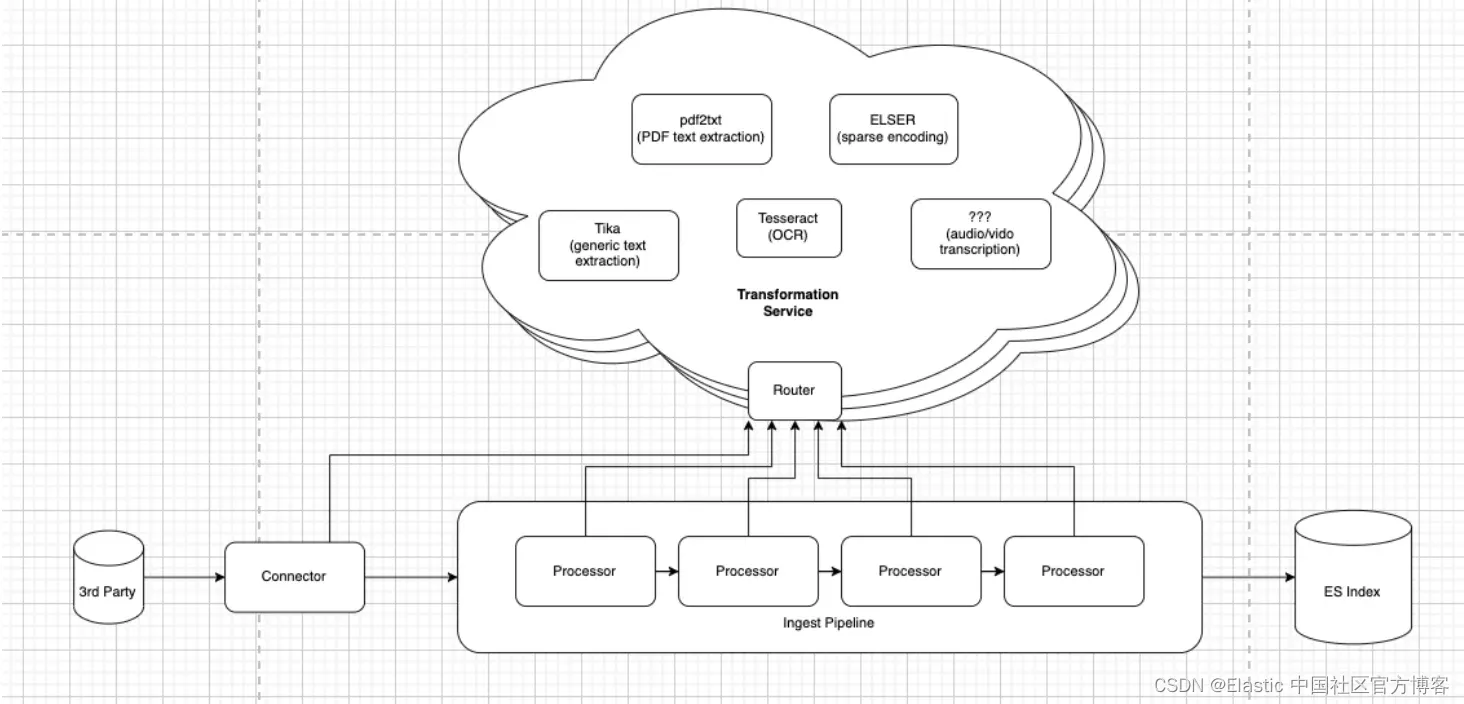
Elasticsearch:我们如何演化处理二进制文档格式
作者:来自 Elastic Sean Story 从二进制文件中提取内容是一个常见的用例。一些 PDF 文件可能非常庞大 — 考虑到几 GB 甚至更多。Elastic 在处理此类文档方面已经取得了长足的进步,今天,我们很高兴地介绍我们的新工具 —— 数据提取服务&…...
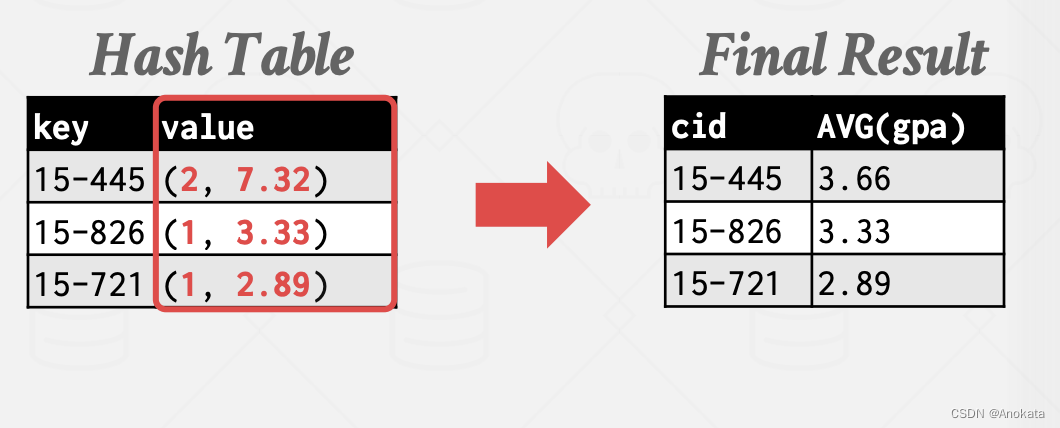
第八讲 Sort Aggregate 算法
我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。 1 查询计划【Query Plan】 我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么? 当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换…...
clickhouse MPPDB数据库--新特性使用示例
clickhouse 新特性: 从clickhouse 22.3至最新的版本24.3.2.23,clickhouse在快速发展中,每个版本都增加了一些新的特性,在数据写入、查询方面都有性能加速。 本文根据clickhouse blog中的clickhouse release blog中,学…...
MATLAB多级分组绘图及图例等细节处理 ; MATLAB画图横轴时间纵轴数值按照不同sensorCode分组画不同sensorCode的曲线
平时研究需要大量的绘图Excel有时候又臃肿且麻烦 尤其是当处理大量数据时可能会拖死Windows 示例代码及数据量展示 因为数据量是万级别的折线图也变成"柱状图"了, 不过还能看出大致趋势! 横轴是时间纵轴是传感器数值图例是传感器所在深度 % data readtable(C:\U…...

20240405,数据类型,运算符,程序流程结构
是我深夜爆炸,不能再去补救C了,真的来不及了,不能再三天打鱼两天晒网了,真的来不及了呜呜呜呜 我实在是不知道看什么课,那黑马吧……MOOC的北邮的C正在进行呜呜 #include <iostream> using namespace std; int…...
Prometheus+grafana环境搭建Nginx(docker+二进制两种方式安装)(六)
由于所有组件写一篇幅过长,所以每个组件分一篇方便查看,前五篇链接如下 Prometheusgrafana环境搭建方法及流程两种方式(docker和源码包)(一)-CSDN博客 Prometheusgrafana环境搭建rabbitmq(docker二进制两种方式安装)(二)-CSDN博客 Prometheusgrafana环…...

贝叶斯逻辑回归
贝叶斯逻辑回归(Bayesian Logistic Regression)是一种机器学习算法,用于解决分类问题。它基于贝叶斯定理,通过建立一个逻辑回归模型,结合先验概率和后验概率,对数据进行分类。 贝叶斯逻辑回归的基本原理是…...

FreeMove:Windows系统磁盘空间智能优化解决方案
FreeMove:Windows系统磁盘空间智能优化解决方案 【免费下载链接】FreeMove Move directories without breaking shortcuts or installations 项目地址: https://gitcode.com/gh_mirrors/fr/FreeMove 当C盘空间告急时,大多数Windows用户面临着一个…...

分布式会话管理实战:Session共享与状态管理的完整方案
分布式会话管理实战:Session共享与状态管理的完整方案 大家好,我是迪哥。分布式系统中,会话管理是一个经典问题。从传统的 Session 复制到 Redis 共享,从 JWT Token 到 OAuth2,我们经历了多种方案的演进。今天就聊聊分…...
)
【ElevenLabs有声书量产指南】:从零到上线的7步闭环流程(含避坑清单+API调优参数)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs有声书量产的底层逻辑与场景定位 ElevenLabs 的有声书量产并非简单调用 TTS API,而是依托其神经语音建模、上下文感知韵律合成与批量异步编排三重能力构建的工业化流水线。其底层…...

量子计算模拟色团阵列振动电子动力学
1. 量子模拟色团阵列振动电子动力学的核心挑战在光合作用等生物过程中,色团阵列(chromophore arrays)的能量转移机制一直是科学家们关注的焦点。传统计算机在模拟这类量子多体系统时面临指数级增长的资源需求,而量子计算为解决这一…...

ClawPaw:将Android手机转化为AI智能体的可编程执行节点
1. 项目概述:ClawPaw,一个将手机变成AI智能体的“手”与“眼” 如果你正在探索AI智能体(Agent)如何与现实世界交互,或者想让你的自动化脚本、个人助手能直接操作你的手机,那么ClawPaw这个项目绝对值得你花…...

光伏产业价值链迁移:从硬件制造到系统服务与金融创新的黄金机遇
1. 光伏行业的价值转移:从硬件制造到系统服务十年前,当我在深圳第一次接触光伏组件生产线时,满眼都是硅料、银浆和层压机,行业里人人谈论的是转换效率又提升了零点几个百分点,或是每瓦成本又降了几分钱。那时候&#x…...

React网格布局终极指南:3步掌握拖拽式界面开发
React网格布局终极指南:3步掌握拖拽式界面开发 【免费下载链接】react-grid-layout A draggable and resizable grid layout with responsive breakpoints, for React. 项目地址: https://gitcode.com/gh_mirrors/re/react-grid-layout React网格布局&#x…...

【Prometheus】如何使用 `promtool` 工具来检查目标端点的指标是否符合规范?
使用 promtool 进行指标合规性验证:从开发到上线的标准化质量门禁 用户问题原文:“如何使用 promtool 工具来检查目标端点的指标是否符合规范?” 在超大规模生产环境中,Prometheus 监控着成千上万个由不同团队、使用不同语言(Java/Spring, Go, Python)开发的服务。一个不…...

终极Element Plus Admin指南:快速构建企业级后台管理系统的完整解决方案
终极Element Plus Admin指南:快速构建企业级后台管理系统的完整解决方案 【免费下载链接】element-plus-admin 基于vitetselementPlus 项目地址: https://gitcode.com/gh_mirrors/el/element-plus-admin 你是否正在寻找一个能够快速搭建企业级后台管理系统的…...

哔哩下载姬DownKyi:你的B站视频下载与处理终极指南
哔哩下载姬DownKyi:你的B站视频下载与处理终极指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...