第八讲 Sort Aggregate 算法
我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。
1 查询计划【Query Plan】
我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么?
当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换成关系的代数表示,需要注意的是,这个代数表示是得到优化过后的。
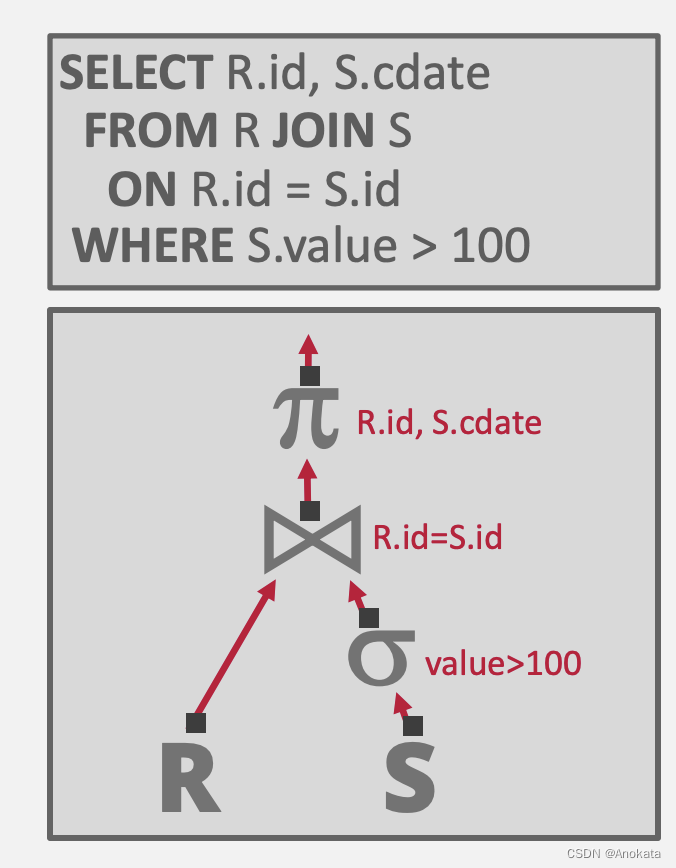
大概解释一下这棵树:
- R 和 S 是两张表,也可以说是两个关系
- 首先对 S 表做查询,条件谓词 value > 100
- 然后将 S 表与 R 表做 join ,连接的条件是 S.id = R.id
- 最后对联表生成的关系做映射,只取R.id和S.cdata两列输出的到结果中
我们得到了用树形表示的查询,树的每一个节点都是一个操作符。数据从树的叶子向上流向根,根节点的输出就是查询的结果。
那么我们想用算法对这些操作符做什么呢??
- 就像不能假设表完全可以被内存容纳下来一样,面向磁盘的 DBMS 也不能假设查询结果(设置时中间结果)可以被内存容纳。
- 我们将使用缓冲池来实现需要溢出到磁盘的算法,即内存不足以承载(中间)结果集时。
- 我们还将更喜欢能够最大化顺序 I/O 量的算法。
2 为什么我们需要排序
关系型模型【Relational model/】/SQL 是无序的【unsorted】。
但是查询【Query】可能要求元组以特定方式排序(ORDER BY)。
但即使查询没有指定顺序,我们可能仍然想要排序来做其他事情:
- 轻松支持重复消除(DISTINCT)。
- 将排序元组【sorted tuples】批量加载到 B+Tree 索引中的速度更快。
- 聚合(GROUP BY)。
3 内存排序
如果内存足以容纳数据,那么我们可以使用标准排序算法,例如快速排序。
大多数数据库系统使用快速排序进行内存排序。
在其他数据平台中,尤其是 Python,默认排序算法是 TimSort。 它是插入排序和二元归并排序的结合。 通常在真实数据上效果很好。
如果内存不足以容纳数据,那么我们需要使用一种能够感知读取和写入磁盘页面成本的技术。
4 排序算法
今天我们主要讲下面几个算法:
- Top-N 堆排序【Top-N Heap Sort】
- 外部归并排序【External Merge Sort】
- 聚合【Aggregations】
4.1 Top-N 堆排序【Top-N Heap Sort】
如果查询【Query】中包含带有 LIMIT 的 ORDER BY,则 DBMS 只需扫描数据一次即可找到前 N 个元素。
堆排序的理想场景:如果 topN 元素适合内存。
- 扫描一次数据,在内存中维护一个排序的优先级队列。
1️⃣ 我们扫描数据
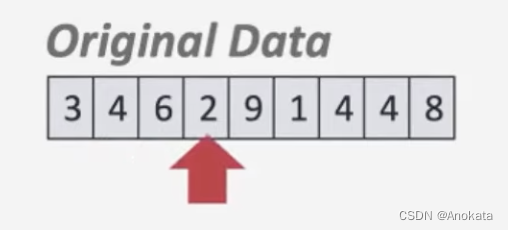
2️⃣ 并将其设置到堆排序的数组中

3️⃣ 当我们扫描到 9 时,由于我们只取最小的 4 个元素,因此9直接在内存中被跳过

4️⃣ 而碰到元素1后,他会改变我们的堆排序数组

4.2 外部归并排序
分而治之算法,将数据分成单独的 runs ,分别对它们进行排序,然后将它们组合成更长的排序了的 runs。
第 1 阶段 – 排序
- 对适合内存的数据块进行排序,然后将排序后的数据块写回到磁盘上的文件中。
第 2 阶段 – 合并
- 将排序后的 runs 合并成更大的 chunks。
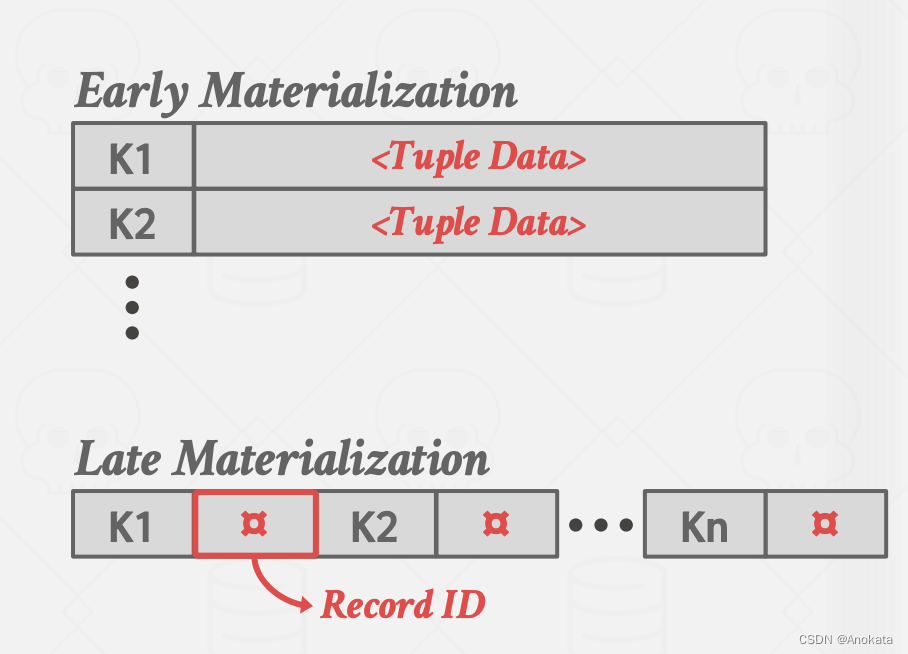
run 是键/值对的列表。
key:用于比较以计算排序顺序的属性【attribute】。
value:有两种选择
- 元组(早期的物化)。
- 记录 ID(后期的物化)。
4.2.1 2路外部归并排序
我们将从 2 路外部归并排序的简单示例开始。
- 其中,“2”是我们每次合并的 run 的数量
数据被分成 N 页。
DBMS 有有限数量的 B 个缓冲池页来保存输入和输出数据。
栗子:
我们有 N 页的数据,而 DBMS 有一个 B 页大小的缓冲池来保存输入和输出数据。
Pass 0
- 将表的所有 B 页【pages】读入内存
- 对页【page】进行排序并将其写回磁盘
Page 2,3,,,
- 递归地将一对 run 合并为两倍长的 run
- 使用三个缓冲区页面(2 个用于输入页面,1 个用于输出页面)
在每次一次传递【Pass】中,我们都要读写每一个页。
总的传递【Pass】数:= 1 + ⌈ log2 N ⌉
总的 IO 花费 = 2N · (# of passes)
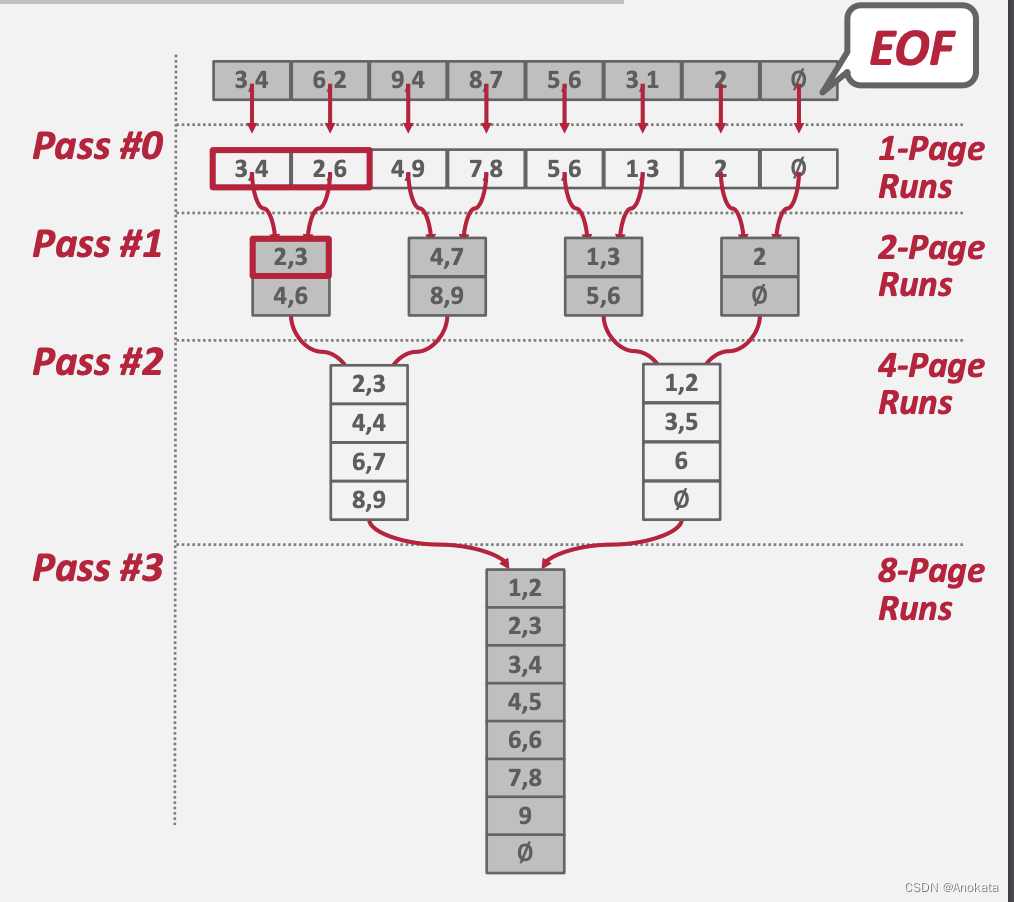
该算法仅需要三个缓冲池页面来执行排序(B=3)。
- 两个输入页面,一个输出页面
但是,即使我们有更多可用 Buffer Pool 空间 (B>3),如果工作线程【worker】必须阻塞磁盘 I/O,那么依然无法有效利用它们。
双缓存优化
当系统处理当前 run 时,在后台预取下一次的 run 并将其存储在第二个缓冲区中。通过持续利用磁盘来减少每个步骤中 I/O 请求的等待时间。
通用外部归并排序
Pass 0
- 使用 B 个 缓冲页
- 产生 ⌈N / B⌉ 个 B 大小的有序 run
Pass #1,2,3,…
- 归并 B-1 个 runs (i.e., K-way merge)
总的传递【Pass】数:= 1 + ⌈ logB-1 ⌈N / B⌉ ⌉
总的 IO 花费 = 2N · (# of passes)
栗子:
确定使用大小为 5 页的 Buffer Pool 来排序占用 108 页的数据,需要经过几次传递【Pass】?
Pass #0: ⌈N / B⌉ = ⌈108 / 5⌉ = 22 个 5 页大小的排好序的 run
Pass #1: ⌈N’ / B-1⌉ = ⌈22 / 4⌉ = 6 个 20 页大小的排好序的 run(最后一个 run 只有3页)
Pass #2: ⌈N’’ / B-1⌉ = ⌈6 / 4⌉ = 2 个排好序的 run ,第一个有 80 页大小,第二个只有 28 页
Pass #3: Sorted file of 108 pages
1+⌈ logB-1⌈N / B⌉ ⌉ = 1+⌈log4 22⌉ = 1+⌈2.229...⌉ = 4 passes
比较优化
方法1:代码特化/硬编码:不要提供比较函数作为排序算法的指针,而是创建特定于键类型的硬编码版本的排序。
方法2:后缀截断:首先比较长 VARCHAR 键【key】的二进制前缀,而不是较慢的字符串比较。 如果前缀相等,则回退到较慢的版本。
4.3 使用 B 树进行排序
如果需要排序的表在排序属性上已经有 B+Tree 索引,那么我们可以使用它来加速排序。
只需遍历树的叶节点所在的页,即可按所需的排序顺序检索元组。
需要考虑下面两种情况:
- 聚簇 B+树
- 非聚集B+树
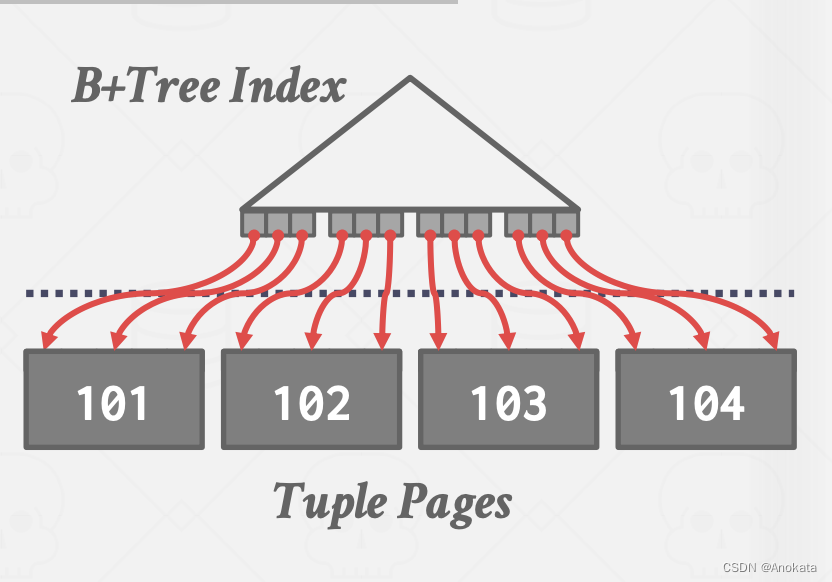
聚簇索引
遍历到最左边的叶节点的页,然后从所有叶节点的页中检索元组。
这种办法总是比外部归并排序更好,因为没有计算成本,并且所有磁盘访问都是顺序的。
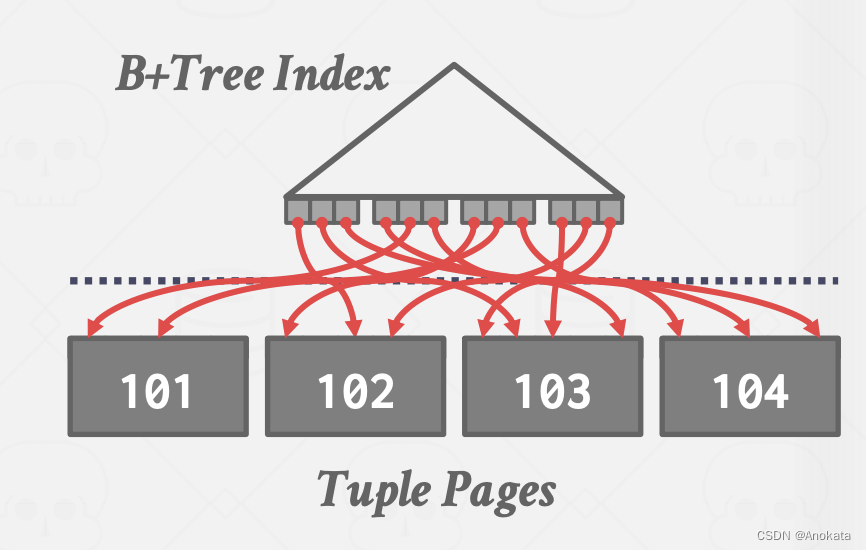
非聚簇索引
这几乎总是一个坏主意。因为在非聚簇索引种,我们需要追踪指向包含数据的页面的每个指针。
一般来说,每个数据记录一个 I/O,这是随机 IO 的灾难。
4.4 聚合
聚合是一种函数【function】,将多个元组中单个属性的值折叠为单个标量值【scalar value】。比如 min / max / sum / count /avg。
当我们要实现这些聚合时,我们需要找到一种方法,让DBMS系统快速找到与我们试图在其上构建聚合的属性具有相同值的元组,这样我们就可以对它们进行分组【grouping】计算我们想要的聚合函数。
两种实现选择:
- 排序
- 哈希,哈希的方案一般是要比排序更好的,尤其是当你的操盘速度很慢时(最小化IO)。
4.4.1 排序聚合
我们以一个栗子开始,这是我们的表:

我们要在该表上查询特定条件下不重复的 cid
SELECT DISTINCT cid
FROM enrolled
WHERE grade IN ('B','C')
ORDER BY cid
首先,我们遍历表,我们要应用 where 子句中的过滤条件,来找到所有成绩为 B 和 C 的元组
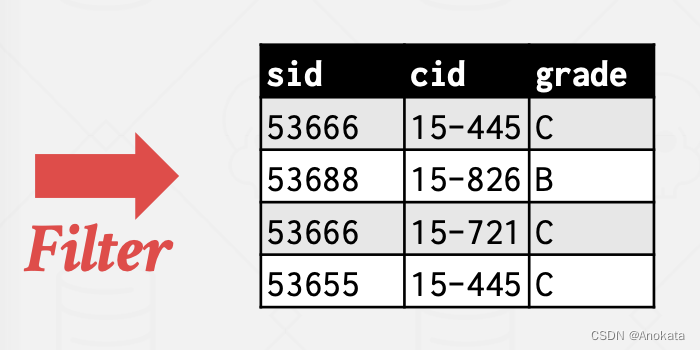
然后我们做一个映射【Projection】,因为我们不需要所有的属性,我们应用映射,只保留 cid

最后,我们对这个单列【column】进行应用排序,现在要生成最终结果,我们只需要扫描排序产生的输出,并跟踪我在光标处看到的最后一个值是什么,然后如果我遇到了和我之前看到的相同的值,那么我知道,它是重复的,我可以把它扔掉。
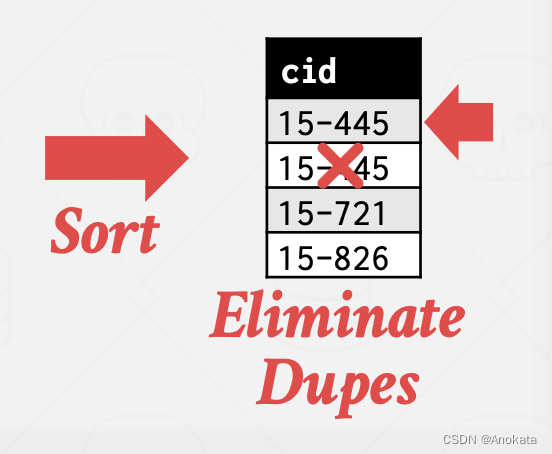
4.4.2 排序的替代方案
如果我们不需要数据有序的话,排序可能并不是最好的方案,那么这该怎么办?
- 在 GROUP BY 中形成组(无顺序)
- 删除 DISTINCT 中的重复项(无顺序)
在这种情况下,哈希散列是更好的选择。
- 只需要去重,无需排序。
- 计算成本比排序更便宜。
4.4.3 哈希聚合
当 DBMS 扫描表时填充临时哈希表。 对于每条记录,检查哈希表中是否已有条目:
- DISTINCT:丢弃重复项
- GROUP BY:执行聚合计算
如果内存足够容纳着一切数据,那么这很容易。
如果 DBMS 必须将数据溢出到磁盘,那么我们需要变得更智能一点。
外部哈希聚合【External Hashing Aggregation】
第 1 阶段 – 分区【Partition】
- 根据哈希键将元组【tuple】划分为桶【bucket】
- 当它们已满时将它们写到磁盘
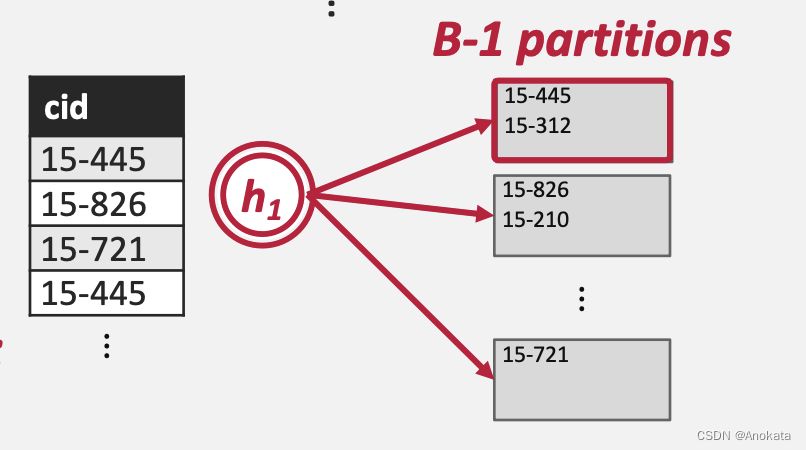
使用哈希函数 h1 将元组拆分为磁盘上的分区【Partition】。
- 分区是包含具有相同哈希值的一组键的一个或多个页面,它是一种逻辑分组
- 分区通过输出缓冲区“溢出”到磁盘
假设我们有 B 个缓冲区。 我们将使用 B-1 个缓冲区用于输出数据,即用于分区【Partition】,1 个缓冲区用于输入数据。
我们继续复用用排序聚合时的栗子:

我们首先对数据做条件过滤没然后只保留满足条件的元组:
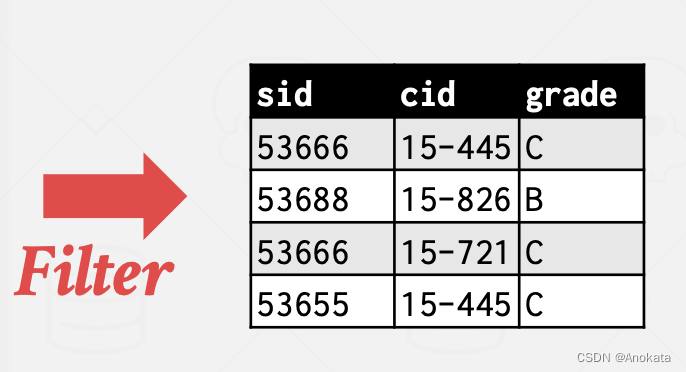
然后通过映射【Projection】删除无用的列

我们对 cid 应用哈希函数
阶段 #2 – ReHash
- 为每个分区构建内存哈希表并计算聚合
对于磁盘上的每个分区:
- 我们要将该分区的所有页面读入内存,逐一扫描它们,并基于第二个哈希函数 h2 构建内存中哈希表。
- 然后遍历该内存哈希表的每个存储桶,以将匹配的元组组合在一起。
我们这里假设每个分区都适合内存大小。
我们继续基于第一阶段产出的分区,进行第二阶段的操作:
1️⃣ 首先我们对每一个分区应用哈希函数 h2,并写入专属于自己分区的哈希表中,需要注意的是,这个哈希表不是简单的原样存储,而是针对聚合函数的特定实现。
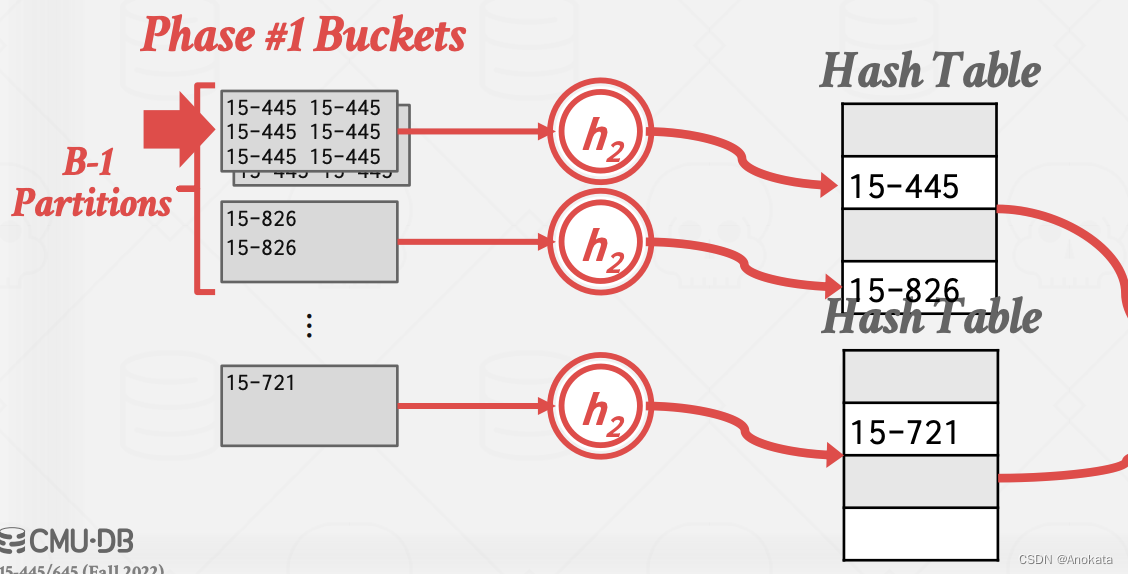
2️⃣ 在将一个分区rehash完,我们再将内存哈希表中的每一个桶中的值,写入到最终结果集中
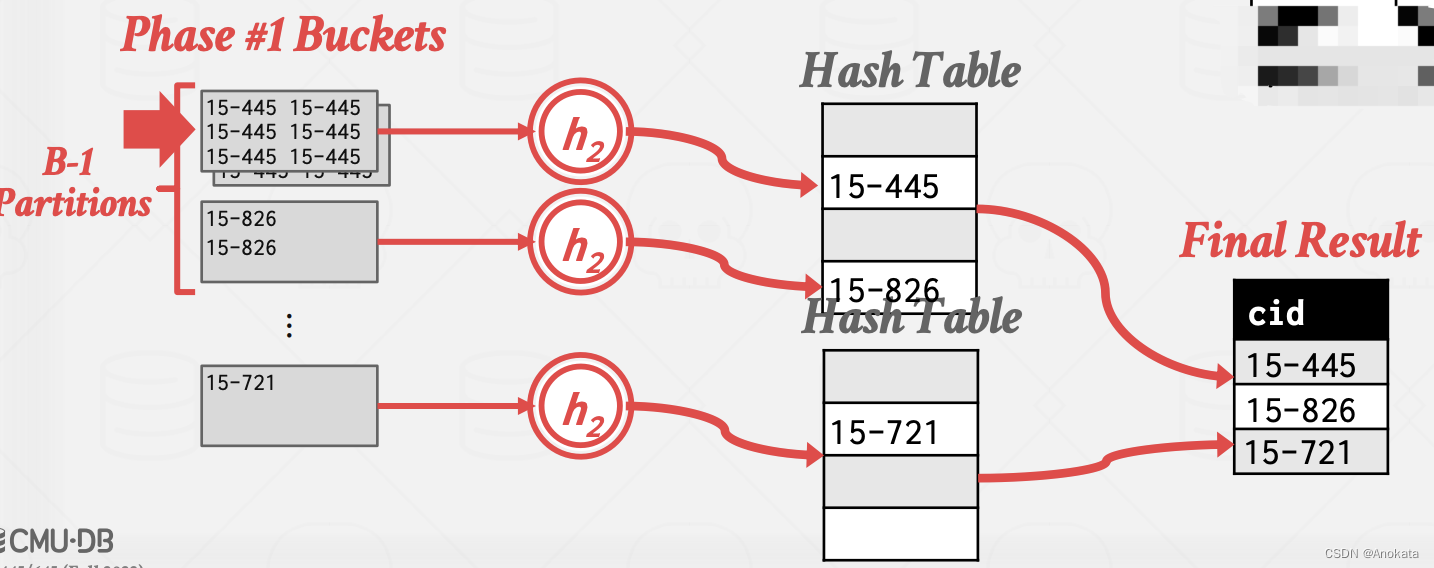
3️⃣ 在一个分区操作完之后,继续执行下一个分区,循环往复,直到所有分区都处理完。
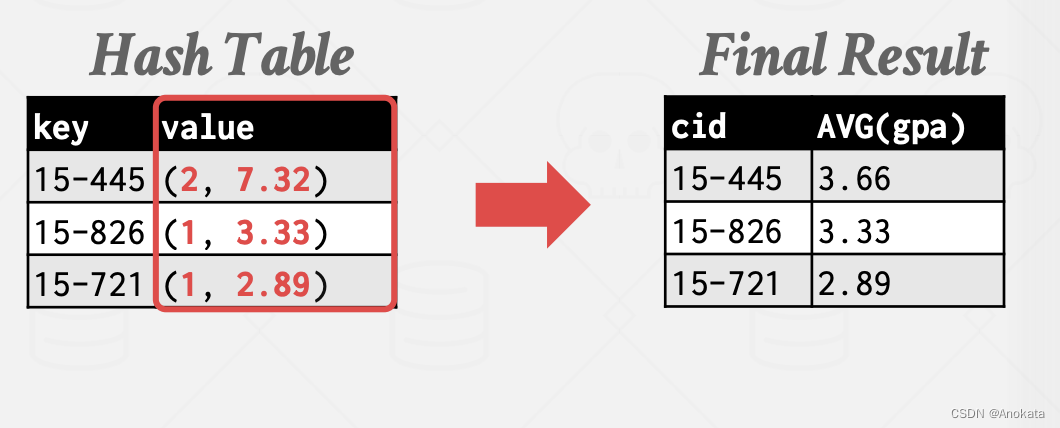
在 ReHash 阶段,存储(GroupKey→RunningVal) 形式的序对【Pair】。
当我们想在哈希表中插入一条新的元组时:
- 如果我们找到匹配的 GroupKey,我们只需要适当的更新RunningVal
- 否则,插入一条 GroupKey→RunningVal
下面我们举个例子来解释一下,我们使用一个新的查询【Query】
SELECT cid, AVG(s.gpa)
FROM student AS s, enrolled AS e
WHERE s.sid = e.sid
GROUP BY cid
1️⃣ 我们先对数据集做分区
2️⃣ 然后应用哈希函数 h2 ,我们聚合函数要的是平均值,因此哈希表的值是关于聚合函数的特定值,它是数量和平均值的一个复合体
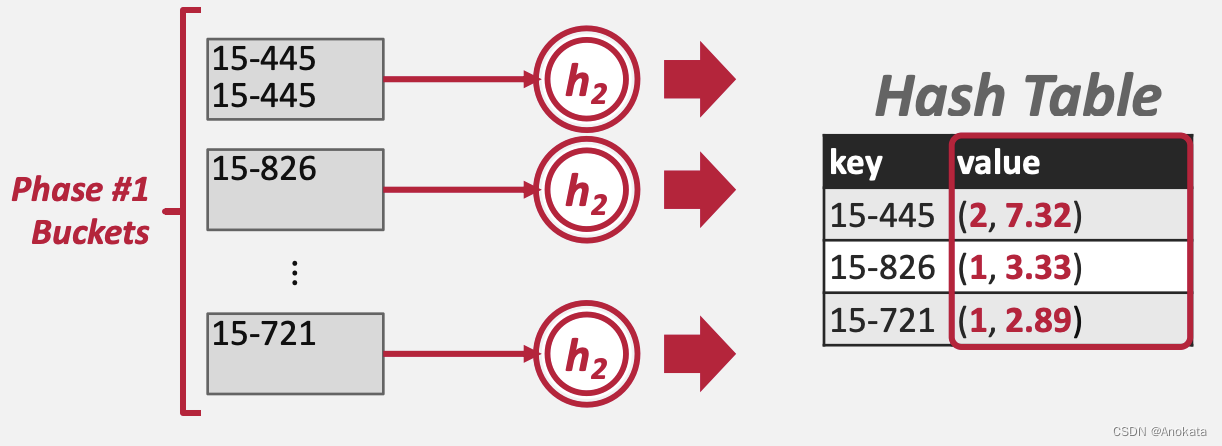 3️⃣ 在rehash完,我们将哈希表写入结果集中
3️⃣ 在rehash完,我们将哈希表写入结果集中
相关文章:
第八讲 Sort Aggregate 算法
我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。 1 查询计划【Query Plan】 我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么? 当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换…...
clickhouse MPPDB数据库--新特性使用示例
clickhouse 新特性: 从clickhouse 22.3至最新的版本24.3.2.23,clickhouse在快速发展中,每个版本都增加了一些新的特性,在数据写入、查询方面都有性能加速。 本文根据clickhouse blog中的clickhouse release blog中,学…...
MATLAB多级分组绘图及图例等细节处理 ; MATLAB画图横轴时间纵轴数值按照不同sensorCode分组画不同sensorCode的曲线
平时研究需要大量的绘图Excel有时候又臃肿且麻烦 尤其是当处理大量数据时可能会拖死Windows 示例代码及数据量展示 因为数据量是万级别的折线图也变成"柱状图"了, 不过还能看出大致趋势! 横轴是时间纵轴是传感器数值图例是传感器所在深度 % data readtable(C:\U…...

20240405,数据类型,运算符,程序流程结构
是我深夜爆炸,不能再去补救C了,真的来不及了,不能再三天打鱼两天晒网了,真的来不及了呜呜呜呜 我实在是不知道看什么课,那黑马吧……MOOC的北邮的C正在进行呜呜 #include <iostream> using namespace std; int…...
Prometheus+grafana环境搭建Nginx(docker+二进制两种方式安装)(六)
由于所有组件写一篇幅过长,所以每个组件分一篇方便查看,前五篇链接如下 Prometheusgrafana环境搭建方法及流程两种方式(docker和源码包)(一)-CSDN博客 Prometheusgrafana环境搭建rabbitmq(docker二进制两种方式安装)(二)-CSDN博客 Prometheusgrafana环…...

贝叶斯逻辑回归
贝叶斯逻辑回归(Bayesian Logistic Regression)是一种机器学习算法,用于解决分类问题。它基于贝叶斯定理,通过建立一个逻辑回归模型,结合先验概率和后验概率,对数据进行分类。 贝叶斯逻辑回归的基本原理是…...

Win10 下 Vision Mamba(Vim-main)的环境配置(libcuda.so文件无法找到,windows系统运行失败)
目录 1、下载NVIDIA 驱动程序、cuda11.8、cudnn8.6.0 2、在Anaconda中创建环境并激活 3、下载gpu版本的torch 4、配置环境所需要的包 5、安装causal_conv1d和mamba-1p1p1 安装causal_conv1d 安装mamba-1p1p1 6、运行main.py失败 请直接拉到最后查看运行失败的原因&am…...

4 万字全面掌握数据库、数据仓库、数据集市、数据湖、数据中台
如今,随着诸如互联网以及物联网等技术的不断发展,越来越多的数据被生产出来-据统计,每天大约有超过2.5亿亿字节的各种各样数据产生。这些数据需要被存储起来并且能够被方便的分析和利用。 随着大数据技术的不断更新和迭代,数据管…...

Leetcode 64. 最小路径和
心路历程: 第一反应像是一个回溯问题,但是看到题目中要求最值,大概率是一道DP问题。并且这里面的递推关系也很明显。 这里面边界条件可以有多种处理方法。 解法:动态规划 class Solution:def minPathSum(self, grid: List[List…...

FANUC机器人故障诊断—报警代码更新(三)
FANUC机器人故障诊断中,有些报警代码,继续更新如下。 一、报警代码(SRVO-348) SRVO-348DCS MCC关闭报警a,b [原因]向电磁接触器发出了关闭指令,而电磁接触器尚未关闭。 [对策] 1.当急停单元上连接了CRMA…...
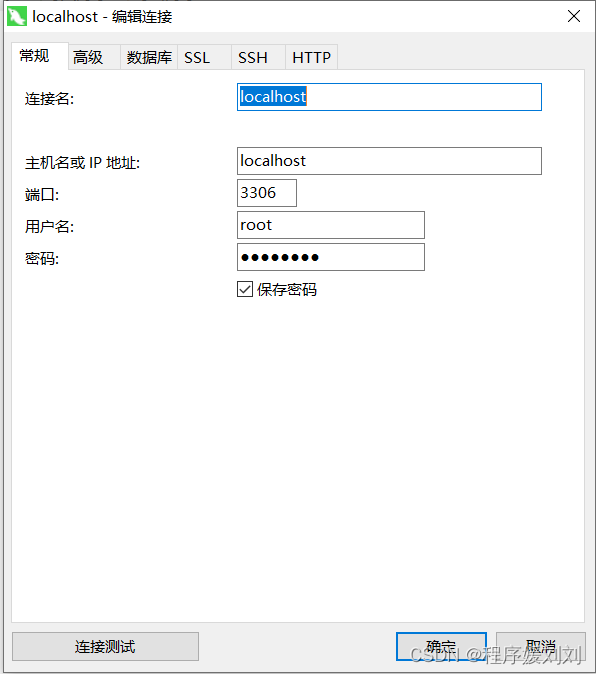
mysql 本地电脑服务部署
前提: 下载mysql 新建配置文档 在安装mysql目录新建 my.ini [mysqld] # 设置3306端口 port3306#设置mysql的安装目录 basedirC:\Program Files\MySQL\MySQL Server 8.3 #切记此处一定要用双斜杠\\,单斜杠我这里会出错,不过看别人的教程,有…...

爬虫学习第一天
爬虫-1 爬虫学习第一天1、什么是爬虫2、爬虫的工作原理3、爬虫核心4、爬虫的合法性5、爬虫框架6、爬虫的挑战7、难点8、反爬手段8.1、Robots协议8.2、检查 User-Agent8.3、ip限制8.4、SESSION访问限制8.5、验证码8.6、数据动态加载8.7、数据加密-使用加密算法 9、用python学习爬…...

labview如何创建2D多曲线XY图和3D图
1如何使用labview创建2D多曲线图 使用“索引与捆绑簇数组”函数将多个一维数组捆绑成一个簇的数组,然后将结果赋值给XY图,这样一个多曲线XY图就生成了。也可以自己去手动索引,手动捆绑并生成数组,结果是一样的 2.如何创建3D图 在…...
)
【华为OD机试】芯片资源限制(贪心算法—JavaPythonC++JS实现)
本文收录于专栏:算法之翼 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-芯片资源限制二.解题思路三.题解代码Python题解代码JAVA题解代码C/C++题解代码JS题解代码四…...

服务器硬件构成与性能要点:CPU、内存、硬盘、RAID、网络接口卡等关键组件的基础知识总结
文章目录 服务器硬件基础知识CPU(中央处理器)内存(RAM)硬盘RAID(磁盘阵列)网络接口卡(NIC)电源散热器主板显卡光驱 服务器硬件基础知识 服务器是一种高性能计算机,用于在…...

STC89C51学习笔记(四)
STC89C51学习笔记(四) 综述:本文讲述了在STC89C51中数码管、模块化编程、LCD1602的使用。 一、数码管 1.数码管显示原理 位选:对74HC138芯片的输入端的配置(P22、P23、P24),来选择实现位选&…...
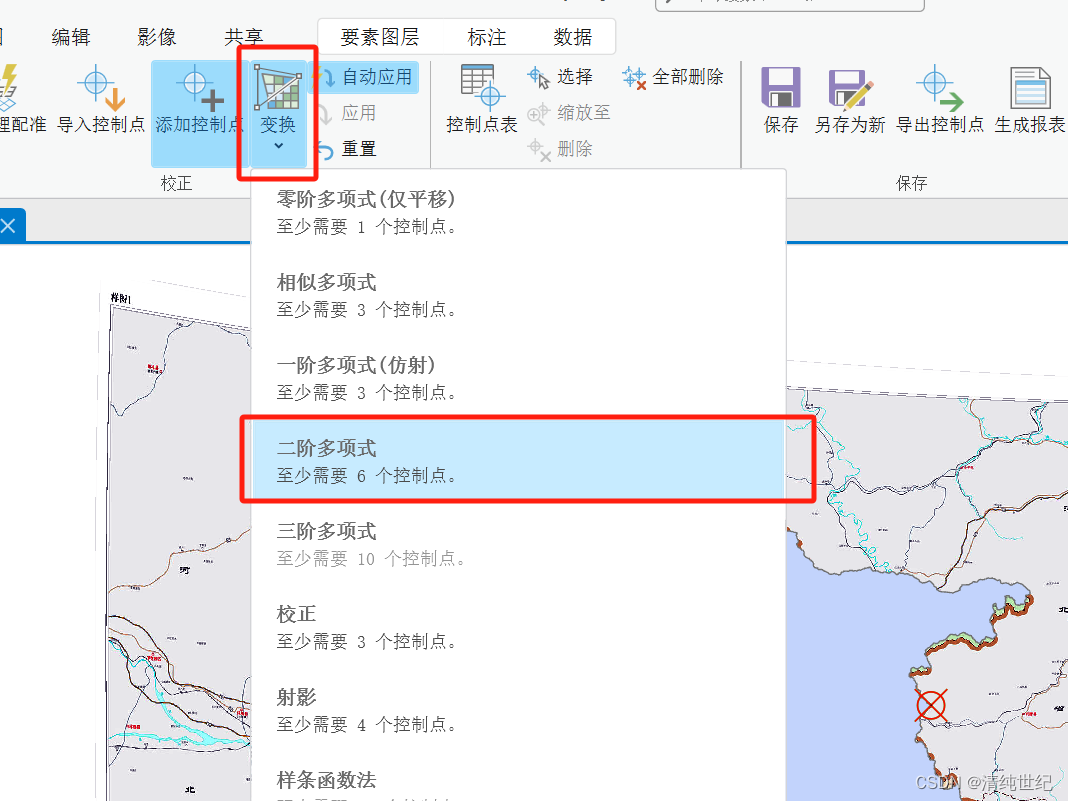
Arcgis Pro地理配准
目录 一、目的 二、配准 1、找到配准工具 2、添加控制点 3、选择控制点 4、添加更多控制点 5、配准完成、保存 三、附录 1、查看控制点或删除控制点 2、效果不好怎么办 一、目的 下面我们将两张地图进行配准,其中一张有地理位置,而另外一张没…...

数字转型新动力,开源创新赋能数字经济高质量发展
应开放原子开源基金会的邀请,软通动力董事、鸿湖万联董事长黄颖基于对软通动力开源战略的思考,为本次专题撰文——数字转型新动力,开源创新赋能数字经济高质量发展。本文首发于2023年12月12日《中国电子报》“开源发展与开发者”专题第8版。以…...
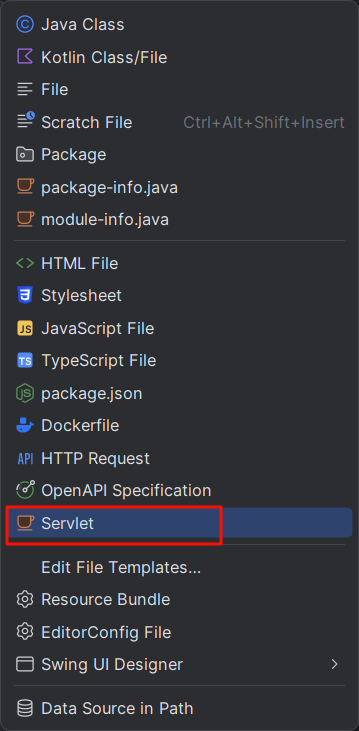
解决JavaWeb中IDEA2023新版本无法创建Servlet的问题
出现问题:IDEA右键创建Servlet时,找不到选项 原因分析:IDEA的2023版的已经不支持Servlet了,如果还要使用的话,需要自己创建模板使用 创建模板 右击设置,选择(File and Code Templates&#x…...

关于oracle切换mysql8总结
最近由于项目换库,特此记录 1.字段类型 number(8) -> int(8) number(16) -> bigint(16) varchar2() -> varchar() 2.导数据 从oracle迁移数据到mysql,除了用专门的数据泵,经常需要用csv导入到mysql; 导出的csv数据如果…...

Motrix WebExtension终极指南:如何让你的浏览器下载速度提升300%
Motrix WebExtension终极指南:如何让你的浏览器下载速度提升300% 【免费下载链接】motrix-webextension A browser extension for the Motrix Download Manager and its forks 项目地址: https://gitcode.com/gh_mirrors/mo/motrix-webextension 你是否厌倦了…...

利用Taotoken统一管理多个AI项目的API密钥与访问权限
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken统一管理多个AI项目的API密钥与访问权限 对于同时维护多个AI应用或为不同客户部署服务的开发者与团队而言,…...
)
从桌面玩具到生产力工具:Dobot Magician机械臂的5个超实用项目实战(含代码)
从桌面玩具到生产力工具:Dobot Magician机械臂的5个超实用项目实战(含代码) 在创客圈里积灰的Dobot Magician机械臂,可能正等待一次真正的觉醒。这款被许多人当作"高级玩具"的六轴机械臂,实际上隐藏着足以改…...

MiGPT小爱音箱AI升级终极指南:5步快速接入ChatGPT和豆包大模型
MiGPT小爱音箱AI升级终极指南:5步快速接入ChatGPT和豆包大模型 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 你是否曾希望家中的小…...
Elsevier Tracker:科研工作者必备的智能投稿状态追踪工具
Elsevier Tracker:科研工作者必备的智能投稿状态追踪工具 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 作为科研工作者,您是否曾因频繁登录Elsevier投稿系统查看审稿进度而感到疲惫&#x…...

对话记忆与上下文管理:Spring AI 实现多轮会话与持久化存储
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 3/10 篇,当前这篇会重点解决:教会读者如何在 Spring AI 中优雅地管理对话上下文,避免重复输入和 Token 浪费。 上一篇回顾:第 2 篇《多模型适配实战:在 Spring AI 中统一管理 OpenAI、…...

一次断电引发的血案:深度复盘CentOS 7 LVM分区下fstab丢失的排查与修复全记录
CentOS 7 LVM环境下fstab丢失的深度修复指南 当服务器遭遇意外断电时,文件系统损坏往往是最令人头疼的问题之一。最近处理的一起CentOS 7系统宕机案例,由于断电导致/etc/fstab文件丢失,系统无法正常启动。本文将详细记录整个排查和修复过程&a…...

HALO框架:硬件感知量化技术优化LLM推理
1. HALO框架:硬件感知量化技术解析在大型语言模型(LLM)的实际部署中,我们常常面临一个核心矛盾:模型规模的指数级增长与硬件算力提升缓慢之间的鸿沟。以LLaMA-65B和GPT-4为例,这些模型的参数量分别达到650亿…...

Dev Containers实战:容器化开发环境配置与团队协作指南
1. 项目概述:一个容器化的开发环境定义仓库如果你和我一样,经常需要在不同的机器上切换工作,或者团队里有新成员加入,那么“环境配置”这件事,绝对能排进程序员最头疼问题的前三名。我经历过无数次这样的场景ÿ…...

修复OpenFDE14缩放窗口时标题栏与应用窗口的宽度不同步的问题
1.问题描述 在OpenFDE 14上缩放应用窗口大小时,会出现标题栏宽度与应用窗口宽度无法保持同步变化的问题,在一些简单布局的应用缩放场景下,同步效果比较好,但对于较复杂布局的应用场景下,不同步的现象就比较明显&#…...