爬虫学习第一天
爬虫-1
- 爬虫学习第一天
- 1、什么是爬虫
- 2、爬虫的工作原理
- 3、爬虫核心
- 4、爬虫的合法性
- 5、爬虫框架
- 6、爬虫的挑战
- 7、难点
- 8、反爬手段
- 8.1、Robots协议
- 8.2、检查 User-Agent
- 8.3、ip限制
- 8.4、SESSION访问限制
- 8.5、验证码
- 8.6、数据动态加载
- 8.7、数据加密-使用加密算法
- 9、用python学习爬虫,需要用到 request模块
- 10、函数
- 11、requests模块
- 11.3、玩一下
- 12、玩一玩豆瓣读书
爬虫学习第一天
1、什么是爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
通俗来讲,假如你需要互联网上的信息,如商品价格,图片视频资源等,但你又不想或者不能自己一个一个自己去打开网页收集,这时候你便写了一个程序,让程序按照你指定好的规则去互联网上收集信息,这便是爬虫,我们熟知的百度,谷歌等搜索引擎背后其实也是一个巨大的爬虫。
2、爬虫的工作原理
爬虫的基本工作流程通常包括以下几个步骤:
- 发起请求:爬虫首先向目标网站发送HTTP请求,请求特定的网页内容1。
- 获取响应:服务器处理这些请求后,会返回相应的网页内容,爬虫接收这些内容1。
- 解析内容:爬虫对获取的网页内容进行解析,提取有用信息。这通常涉及到HTML、CSS和JavaScript的解析。
- 提取数据:解析后的内容中,爬虫会根据预设的规则提取所需的数据,如文本、图片、链接等。
- 存储数据:提取的数据会被存储到数据库或文件中,以便后续的分析和使用。
- 发现新链接:在解析内容的过程中,爬虫会发现新的链接地址,这些链接将被加入到待爬取的队列中,循环执行上述步骤。
3、爬虫核心
-
**爬取网页:**爬取整个页面,包含了网页中所有的内容
-
**解析数据:**将网页中你得到的数据,进行解析,获取需要的数据
-
**存储数据:**将解析后的数据保存到数据库、文件系统或其他存储介质中,以便后续的访问和使用。
-
**分析数据:**对存储的数据进行统计、挖掘和分析,提取有价值的信息或洞察,为决策提供支持。
-
**可视化数据:**将分析结果通过图表、图形等形式直观展现出来,帮助用户更好地理解和利用数据。
4、爬虫的合法性
爬虫技术本身是中立的,其合法性取决于使用爬虫的目的和方式。一般来说,只要爬虫的行为不影响网站的正常运行,并且不是出于商业目的,大多数网站只会采取技术手段限制爬虫,如封禁IP或账号,而不涉及法律风险1。此外,许多网站通过
robots.txt文件声明了哪些内容可以被抓取,哪些不可以,这是一种行业约定,虽然没有法律约束力,但遵守这些规则是一种良好的网络道德行为1。
5、爬虫框架
随着爬虫技术的发展,出现了一些成熟的爬虫框架,如Scrapy。这些框架提供了一套完整的解决方案,包括请求管理、数据解析、数据存储等,使得开发者能够更专注于爬虫逻辑的实现。
6、爬虫的挑战
爬虫在实际应用中可能会遇到一些挑战,如网站的反爬策略、动态加载的内容、登录认证等。这些挑战需要爬虫开发者具备一定的技术能力,包括但不限于JavaScript逆向、模拟登录、使用代理IP等。
7、难点
- 爬虫和反爬虫之间的博弈
- 爬虫会加大系统负载!并发(每秒访问的人数100)爬虫1000
- 什么是反爬虫
- 阻止非正常用户来访问我的系统
- 登录站点=》输入验证码(图片,手机)
- 刷新太快
8、反爬手段
8.1、Robots协议
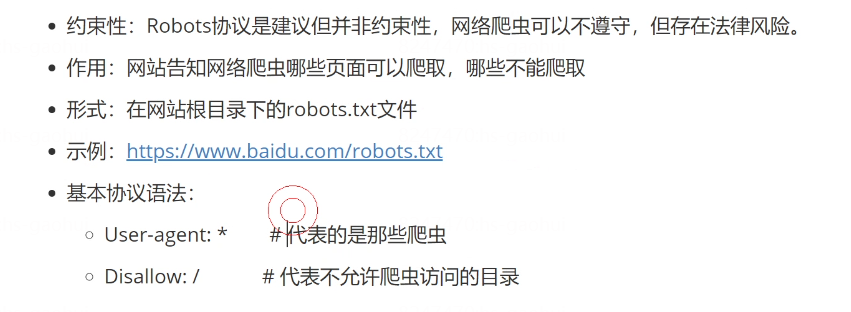
8.2、检查 User-Agent

8.3、ip限制
- 通过对访问频率进行限制,如果某个IP地址在单位时间内请求次数过多,则可能暂时或永久封禁该IP地址。

8.4、SESSION访问限制

8.5、验证码

8.6、数据动态加载

8.7、数据加密-使用加密算法

9、用python学习爬虫,需要用到 request模块
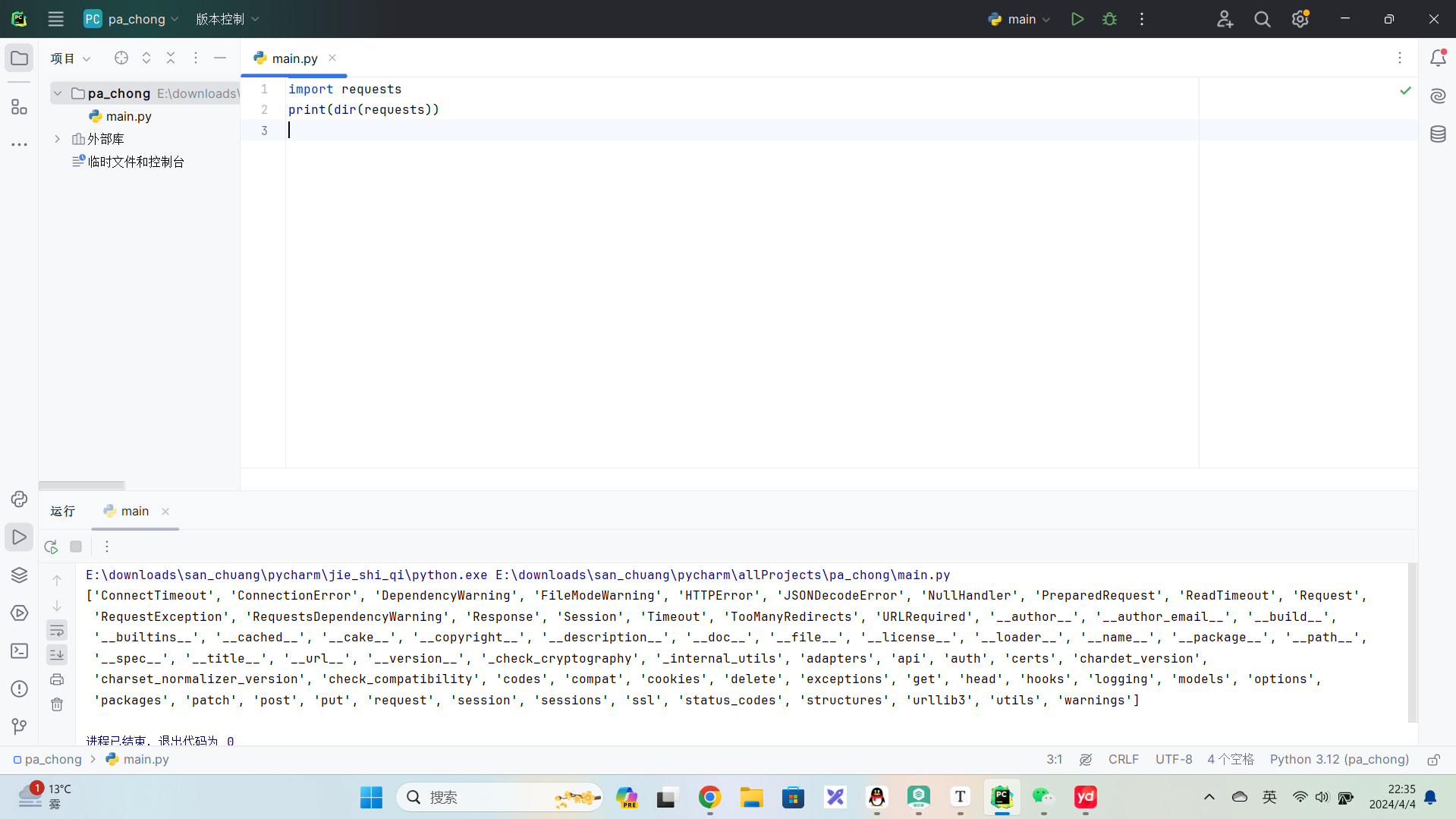
通常先用dir或者help来查看怎么使用
Requests is an HTTP library, written in Python, for human beings.
Requests是一个HTTP库,用Python编写,供人类使用。
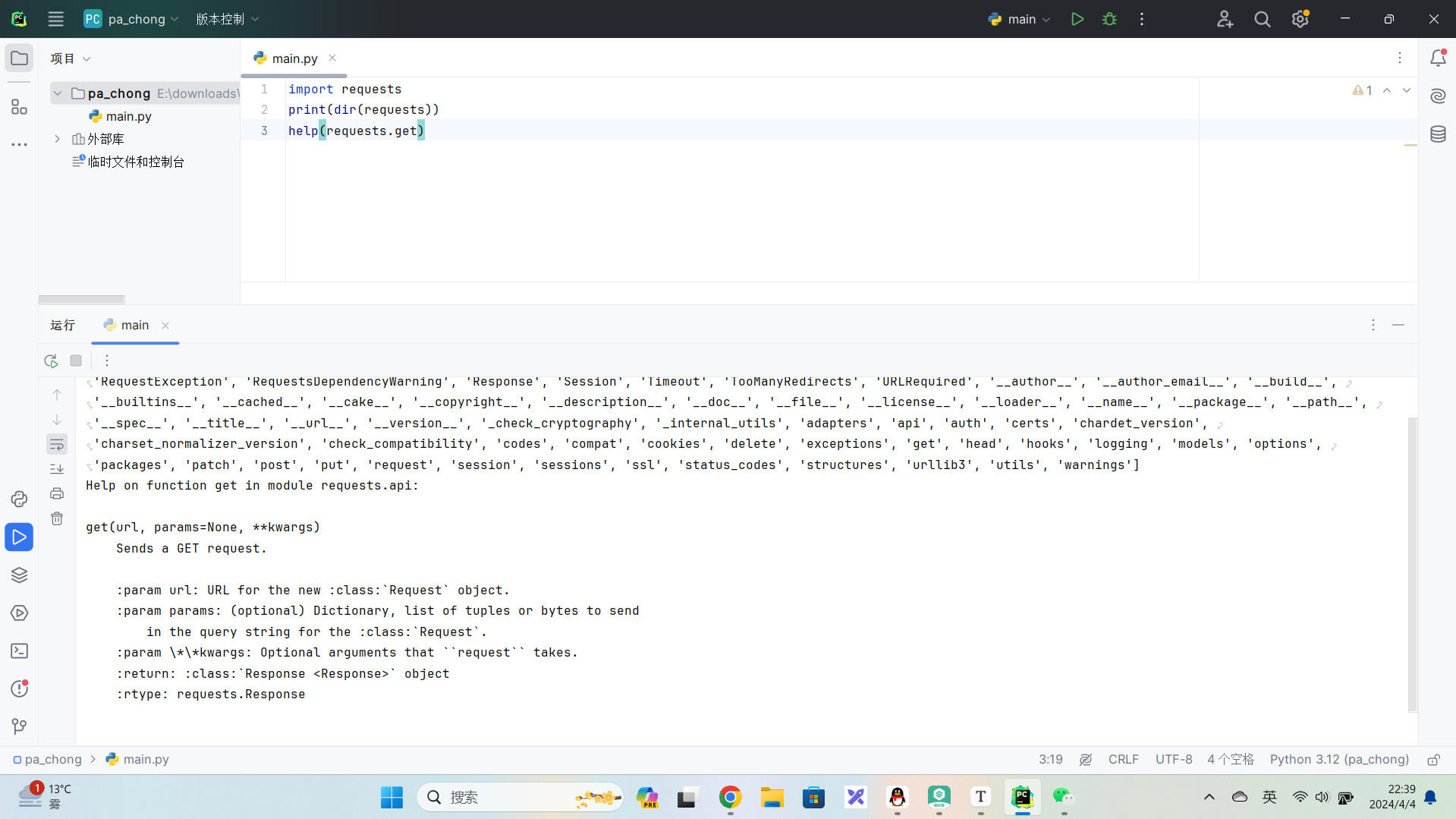
这段文本是Python中`requests`库的一个函数文档字符串,描述了`get`函数的用途和参数。`requests`是一个非常流行的HTTP库,用于发送HTTP请求并处理返回的响应。下面是对这段文档的详细解释:### 函数名称
`get` - 这是`requests`库中的一个函数,用于发送HTTP GET请求。### 参数
- `url`: 这是必须提供的参数,表示要发送GET请求的目标URL。这个URL可以是完整的,也可以是相对路径,如果是相对路径,它会基于当前的URL上下文进行解析。
- `params`: 这是一个可选参数,用于传递查询字符串。它可以是一个字典、列表或元组,也可以是字节串。这个参数中的数据会被添加到URL的查询字符串中。例如,当你想要传递查询参数如`page=1`和`limit=10`时,你可以这样做:`params={'page': 1, 'limit': 10}`。
- `**kwargs`: 这是Python中的参数字典,它允许你传递任意数量的其他参数给函数。在`get`函数中,这可以用来传递`requests`库中`Request`对象支持的其他参数,比如`headers`、`cookies`、`auth`等。### 返回值
- `Response`对象 - 当GET请求发送并接收到服务器响应后,`get`函数会返回一个`Response`对象。这个对象包含了服务器返回的所有信息,包括状态码、响应头、以及响应体(通常是HTML、JSON或其他格式的数据)。### 示例代码
```python
import requests# 发送GET请求
response = requests.get('https://api.example.com/data', params={'page': 1, 'limit': 10})# 打印响应状态码
print(response.status_code)# 打印响应内容
print(response.text)
```在这个示例中,我们使用`requests.get`函数向`https://api.example.com/data`发送了一个GET请求,并且传递了查询参数`page=1`和`limit=10`。然后,我们打印出响应的状态码和响应的内容。总的来说,`requests.get`函数是一个非常方便的工具,用于发送HTTP GET请求并处理响应。通过这个函数,你可以轻松地与Web服务进行交互,获取或提交数据。
10、函数
get(url,params=None,**kwargs)
括号中的变量叫函数的参数
-
url=>位置参数(有顺序,按位置依次给数据)
-
params=None =>默认参数(如果你没有传递会给一个默认值)
-
*args => 可变长位置参数
-
**kwargs => 可变长关键字参数

位置参数的使用:
# 定义一个函数,实现摄氏度转华氏度
# 32°F + 摄氏度 × 1.8def Celsius_To_Fahrenheit(a):b=(a*1.8)+32print(f"{a}°C 转换成 华氏度 为:{b:.2f}°F")Celsius_To_Fahrenheit(44.5)
更好的写法:

# get(url, params=None, **kwargs)
# 括号中的变量叫函数的参数
# url => 必选位置参数(有顺序,按位置依次给数据)
# => 注意按顺序传递参数
# params=None => 默认参数(如果你没有传递会给一个默认值)
# *args => 可变长位置参数
# **kwargs => 可变长关键字参数# 调用:requests.get("test", "http://www.baidu.com") X 位置参数调用
# requests.get(params="test", url="http://www.baidu.com") J 关键字参数调用# def 函数名(参数列表<0-n>):
# 函数体
# return value =>返回值
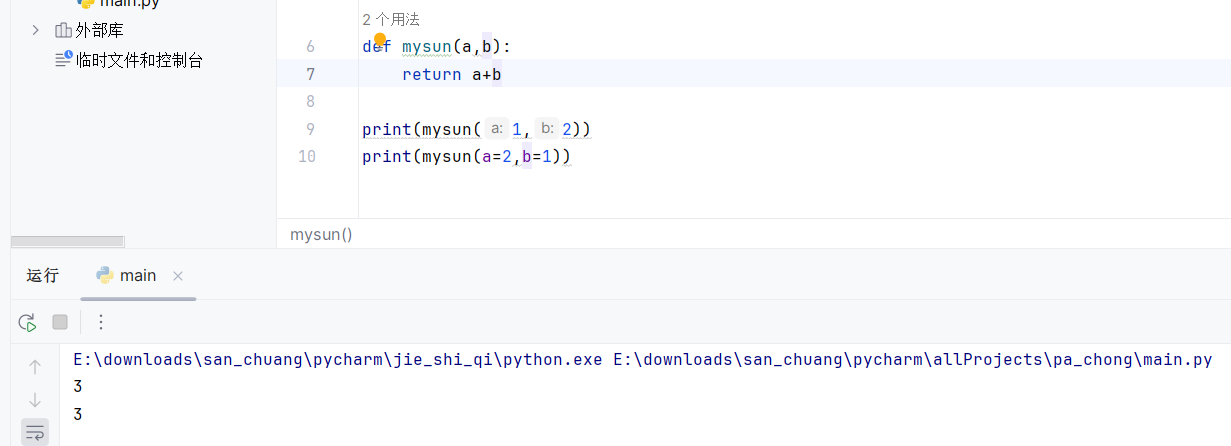
def mysum(a, b):return a+b
# a = 1
# b = 2
# 位置参数的调用
print(mysum(1,2))
# 关键字参数的调用
print(mysum(a=1, b=2))
print(mysum(b=2, a=1))
# TypeError: mysum() missing 1 required positional argument: 'b'
# mysum(1)# 定义一个函数,实现摄氏度转华氏度
# 32°F+ 摄氏度 × 1.8
# 传递一个摄氏温度 -> 返回一个华氏度温度# 参数名:数据类型 => 告诉调用者,该函数需要是什么类型的!
# =>类型声明是可写可不写的
# -> 数据类型 => 函数的返回值
# return 接返回值 => 函数如果没有return语句,表示返回None
# 文档注释(document string)和类型注解(type hint)都是可选的def ctof(celsius:int) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""result = 32+celsius*1.8return result
# pass => 占位符 => 什么也不做 => 保持语法完整print(ctof(10))# 定义一个函数,实现摄氏度转华氏度
# 如果没有传温度过来,当作计算 0摄氏度对应的华氏度
# 默认参数
def ctof(celsius:int=0) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""result = 32+celsius*1.8return result
print(ctof())# 默认参数的推荐写法:先给它一个默认值为None,在函数体中处理默认
def ctof(celsius=None) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""if celsius is None:celsius = 0result = 32+celsius*1.8return result
import requests
# print(dir(requests))
help(requests.get)# get(url, params=None, **kwargs)
# 括号中的变量叫函数的参数
# url => 必选位置参数(有顺序,按位置依次给数据)
# => 注意按顺序传递参数
# params=None => 默认参数(如果你没有传递会给一个默认值)
# *args => 可变长位置参数
# **kwargs => 可变长关键字参数# 调用:requests.get("test", "http://www.baidu.com") X 位置参数调用
# requests.get(params="test", url="http://www.baidu.com") J 关键字参数调用# def 函数名(参数列表<0-n>):
# 函数体
# return value =>返回值
def mysum(a, b):return a+b
# a = 1
# b = 2
# 位置参数的调用
print(mysum(1,2))
# 关键字参数的调用
print(mysum(a=1, b=2))
print(mysum(b=2, a=1))
# TypeError: mysum() missing 1 required positional argument: 'b'
# mysum(1)# 定义一个函数,实现摄氏度转华氏度
# 32°F+ 摄氏度 × 1.8
# 传递一个摄氏温度 -> 返回一个华氏度温度# 参数名:数据类型 => 告诉调用者,该函数需要是什么类型的!
# =>类型声明是可写可不写的
# -> 数据类型 => 函数的返回值
# return 接返回值 => 函数如果没有return语句,表示返回None
# 文档注释(document string)和类型注解(type hint)都是可选的def ctof(celsius:int) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""result = 32+celsius*1.8return result
# pass => 占位符 => 什么也不做 => 保持语法完整print(ctof(10))# 定义一个函数,实现摄氏度转华氏度
# 如果没有传温度过来,当作计算 0摄氏度对应的华氏度
# 默认参数
def ctof(celsius:int=0) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""result = 32+celsius*1.8return result
print(ctof())# 默认参数的推荐写法:先给它一个默认值为None,在函数体中处理默认
def ctof(celsius=None) -> float:""" document string 文档注释 => 直接用作帮助文档:param celsius: 传递一个int类型的摄氏温度:return: 返回一个float类型的华氏度温度"""if celsius is None:celsius = 0result = 32+celsius*1.8return result# *args => 可变长位置参数 => 接受多个(位置)参数
# **kwargs => 可变长关键字参数 => 接受多个(关键字)参数# 实现一个mysum函数,可以接收多个数据,计算这个数据的和
# args => arguments
# kw =>keyword
def mysum2(*args, **kwargs) ->int :"""计算出所有传进来的数据之和:param args::param kwargs::return:"""print("args:", args, type(args))print("kwargs:", kwargs, type(kwargs))mysum2(1,2,3,4, a=1, b=2, c=3)
# 注意 : SyntaxError: positional argument follows keyword argument
# 位置参数必须写在关键字参数的前面
mysum2(1, 2, a=1, b=2)
#!/usr/bin/env python
# @FileName :1.python函数.py
# @Time :2024/3/10 14:59
# @Author :wenyao# 4月底 => 爬虫+数据分析+数据可视化
# requests => dir哪些功能, help函数具体怎么用
# requests.get函数# get(url, params=None, **kwargs)
"""
# 注意参数类型的顺序
def 函数名(位置参数,默认参数,可变长位置参数,可变长关键字参数) -> 返回值类型:passreturn 返回值
def function(a:int, b:int=0, *args, **kwargs) -> int:return a
如果函数没有返回值,相当于return None
"""def sum(*args, **kwargs)->int:# args => 保存调用时传的所有的位置参数# kwargs => 保存调用时传的所有的关键字参数(如:a=1)print(args) # tupleprint(kwargs) # dicts = 0for i in args:s+=ifor key in kwargs:s+=kwargs[key]return s# 什么情况下需要return => 如果算出来的结果还有其他用途print(sum(1,2,3,a=4,b=5,c=6))"""
1. 函数定义参数的类型4类(注意顺序)
2. 函数调用参数类型2类(注意顺序)
3. 注释:文档注释(写的一些帮助信息->help时可以看到),类型注解(给参数和返回值做类型声明) 类型注解在高版本中是否有强制类型限制
4. 返回值: return =>如果结果还需要用(一般情况建议返回)
"""import requests
help(requests.get)
11、requests模块
11.3、玩一下
#获取百度首页信息
import requestsurl = "https://www.baidu.com"
response = requests.get(url)
print(response,type(response))
# requests模块功能
# 相当于一个模块浏览器,发送网络请求,获取数据import requests
# 获取百度首页的数据
url="http://www.baidu.com"
response = requests.get(url)
print(response, type(response))
# status_code => 200 OK
# => 用代码的方式告诉你,你的请求是否正确
# =>2XX 成功
# =>4XX 客户端错误
# =>5XX 服务端错误
# => $? => 0 成功,其他错误
# 取出当前响应的状态码
print(response.status_code)
# 获取当前的网页数据
# text => string
print(response.text[:100])
# content => bytes
print(response.content[:100])
# 获取请求的url
print(response.url)
# 获取响应头信息
print(response.headers)
print(dir(response))
# 获取编码方式 UTF8(全球),GBK(中文)
print(response.encoding)
# 推荐!
print(response.apparent_encoding)
12、玩一玩豆瓣读书
import requestsdef download(url:str) -> str:"""这个函数用来获取url的数据,返回网页的string:param url: 这应该提供一个网址:return: 返回网页的string类型的数据"""response = requests.get(url)if response.status_code == 200:return response.textelse:return Noneprint(download("http://www.baidu.com"))def download(url: str) -> str | None:"""这个函数用来获取url的数据,返回网页的string:param url: 这应该提供一个网址:return: 返回网页的string类型的数据"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:return Noneprint(download("https://book.douban.com/"))
大佬写的:
import requests
import time# def download(url:str) -> str:
# """
# 这个函数数用来获取url的数据,返回网页的string
# :param url: 应该提供一个网址
# :return: 返回网页的string类型的数据
# """
# response = requests.get(url)
# if response.status_code == 200:
# # 指定正确的网页编码
# response.encoding = response.apparent_encoding
# return response.text
# else:
# return ""# try...except
def download(url:str) -> str:"""这个函数数用来获取url的数据,返回网页的string:param url: 应该提供一个网址:return: 返回网页的string类型的数据"""# 反爬虫1:添加user-agentheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}response = requests.get(url, headers=headers)# 如果没有获取到网页或者获取到网页了,但状态码不对,那么请报异常# 4xx , 5xx 都会抛出异常response.raise_for_status()# 指定正确的网页编码response.encoding = response.apparent_encoding# 反爬虫2:增加sleeptime.sleep(1)return response.text# print(download("http://www.baidu3sdf.com"))
# print(download("https://gitee.com/asdfasdf"))# 1. 获取数据
data = download("https://book.douban.com/top250")
# 2. 提取数据
# re模块:正则表达式,速度最快,使用难度最高
# lxml(xpath): 速度较快,使用难度一般
# BeautifulSoup: 慢,最简单
PS E:\downloads\san_chuang\pycharm\allProjects\pa_chong> pip install beautifulsoup4
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting beautifulsoup4Downloading https://pypi.tuna.tsinghua.edu.cn/packages/b1/fe/e8c672695b37eecc5cbf43e1d0638d88d66ba3a44c4d321c796f4e59167f/beautifulsoup4-4.12.3-py3-none-any.whl (147 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 147.9/147.9 kB 1.1 MB/s eta 0:00:00
Collecting soupsieve>1.2 (from beautifulsoup4)Downloading https://pypi.tuna.tsinghua.edu.cn/packages/4c/f3/038b302fdfbe3be7da016777069f26ceefe11a681055ea1f7817546508e3/soupsieve-2.5-py3-none-any.whl (36 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.12.3 soupsieve-2.5
PS E:\downloads\san_chuang\pycharm\allProjects\pa_chong>
相关文章:
爬虫学习第一天
爬虫-1 爬虫学习第一天1、什么是爬虫2、爬虫的工作原理3、爬虫核心4、爬虫的合法性5、爬虫框架6、爬虫的挑战7、难点8、反爬手段8.1、Robots协议8.2、检查 User-Agent8.3、ip限制8.4、SESSION访问限制8.5、验证码8.6、数据动态加载8.7、数据加密-使用加密算法 9、用python学习爬…...

labview如何创建2D多曲线XY图和3D图
1如何使用labview创建2D多曲线图 使用“索引与捆绑簇数组”函数将多个一维数组捆绑成一个簇的数组,然后将结果赋值给XY图,这样一个多曲线XY图就生成了。也可以自己去手动索引,手动捆绑并生成数组,结果是一样的 2.如何创建3D图 在…...
)
【华为OD机试】芯片资源限制(贪心算法—JavaPythonC++JS实现)
本文收录于专栏:算法之翼 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-芯片资源限制二.解题思路三.题解代码Python题解代码JAVA题解代码C/C++题解代码JS题解代码四…...

服务器硬件构成与性能要点:CPU、内存、硬盘、RAID、网络接口卡等关键组件的基础知识总结
文章目录 服务器硬件基础知识CPU(中央处理器)内存(RAM)硬盘RAID(磁盘阵列)网络接口卡(NIC)电源散热器主板显卡光驱 服务器硬件基础知识 服务器是一种高性能计算机,用于在…...

STC89C51学习笔记(四)
STC89C51学习笔记(四) 综述:本文讲述了在STC89C51中数码管、模块化编程、LCD1602的使用。 一、数码管 1.数码管显示原理 位选:对74HC138芯片的输入端的配置(P22、P23、P24),来选择实现位选&…...
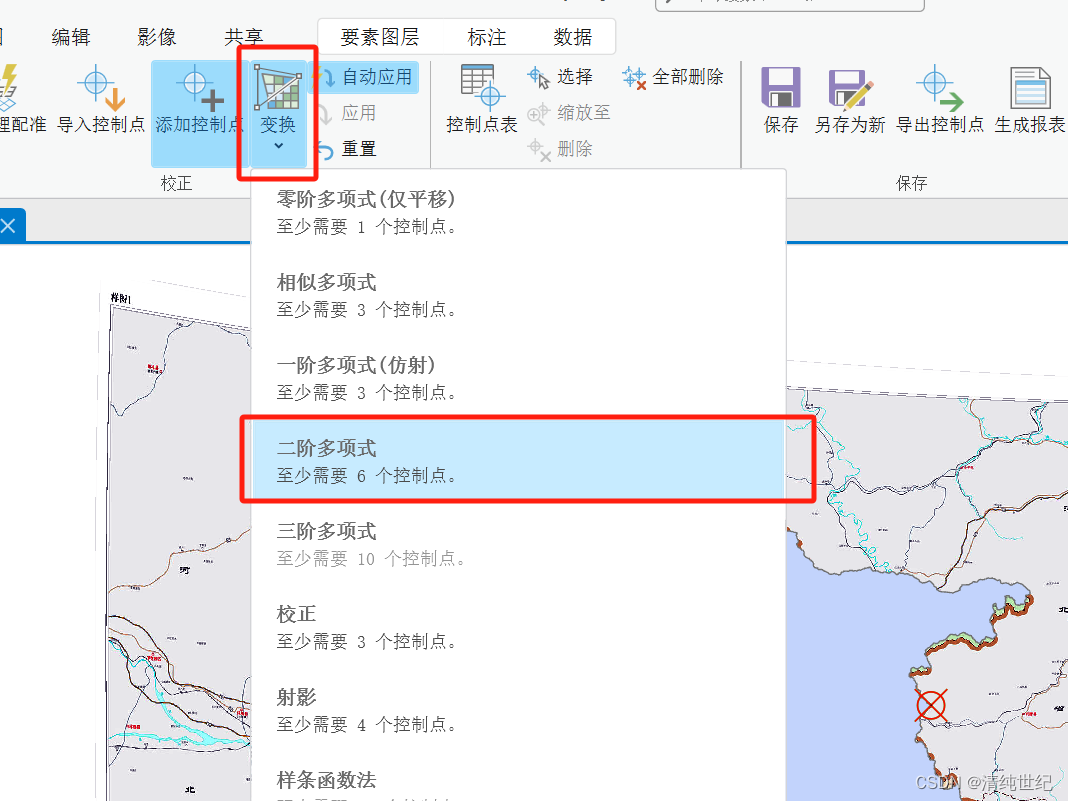
Arcgis Pro地理配准
目录 一、目的 二、配准 1、找到配准工具 2、添加控制点 3、选择控制点 4、添加更多控制点 5、配准完成、保存 三、附录 1、查看控制点或删除控制点 2、效果不好怎么办 一、目的 下面我们将两张地图进行配准,其中一张有地理位置,而另外一张没…...

数字转型新动力,开源创新赋能数字经济高质量发展
应开放原子开源基金会的邀请,软通动力董事、鸿湖万联董事长黄颖基于对软通动力开源战略的思考,为本次专题撰文——数字转型新动力,开源创新赋能数字经济高质量发展。本文首发于2023年12月12日《中国电子报》“开源发展与开发者”专题第8版。以…...
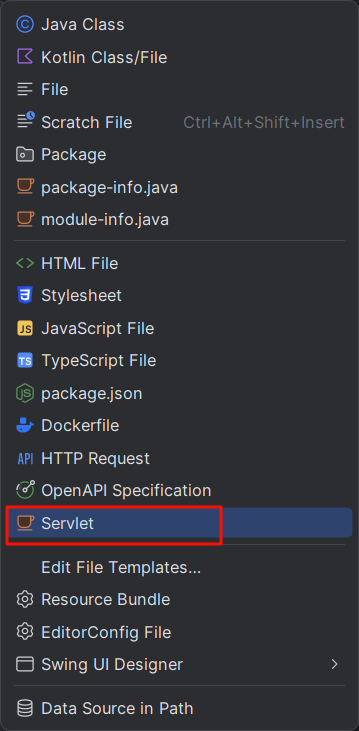
解决JavaWeb中IDEA2023新版本无法创建Servlet的问题
出现问题:IDEA右键创建Servlet时,找不到选项 原因分析:IDEA的2023版的已经不支持Servlet了,如果还要使用的话,需要自己创建模板使用 创建模板 右击设置,选择(File and Code Templates&#x…...

关于oracle切换mysql8总结
最近由于项目换库,特此记录 1.字段类型 number(8) -> int(8) number(16) -> bigint(16) varchar2() -> varchar() 2.导数据 从oracle迁移数据到mysql,除了用专门的数据泵,经常需要用csv导入到mysql; 导出的csv数据如果…...
Docker 容器编排技术解析与实践
探索了容器编排技术的核心概念、工具和高级应用,包括 Docker Compose、Kubernetes 等主要平台及其高级功能如网络和存储管理、监控、安全等。此外,文章还探讨了这些技术在实际应用中的案例,提供了对未来趋势的洞见。 一、容器编排介绍 容器编…...

微信小程序 ---- 慕尚花坊 订单列表
订单列表 本章节为课堂作业 01. 封装订单列表接口 API 思路分析: 为了方便后续进行商品管理模块的开发,我们在这一节将商品管理所有的接口封装成接口 API 函数 落地代码: ➡️ api/orderpay.js /*** description 获取订单列表* returns …...
Tuxera2023 NTFS for Mac下载,安装和序列号激活
对于必须在Windows电脑和Mac电脑之间来回切换的Mac朋友来说,跨平台不兼容一直是一个巨大的障碍,尤其是当我们需要使用NTFS格式的硬盘在Windows和macOS之间共享文件时。因为Mac默认不支持写入NTFS磁盘。 为了解决这一问题,很多朋友会选择很便捷…...

移动Web学习04-移动端订单结算页PC端个人中心页面
5、电商结算页面案例 css body{background-color: #F2F2F2; } * {box-sizing: border-box;margin: 0;padding: 0; }.main{padding: 12px 11px 80px; }.pay{display: flex;height: 80px;background-color: #fff;bottom: 0;width: 100%;border-top: 1px solid #ededed;position:…...
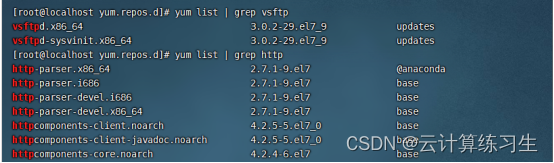
Linux基础篇:Linux网络yum源——以配置阿里云yum源为例
Linux网络yum源——以阿里云为例 一、网络yum源介绍 Linux中的YUM(Yellowdog Updater, Modified)源是一个软件包管理器,它可以自动处理依赖关系并安装、更新、卸载软件包。YUM源是一个包含软件包的远程仓库,它可以让用户轻松地安…...

2024.2.10力扣每日一题——二叉树的中序遍历
2024.2.10 题目来源我的题解方法一 递归方式方法二 非递归方式 题目来源 力扣每日一题;题序:94 我的题解 方法一 递归方式 使用递归实现,结果List也可以定义为一个类变量。 按照访问左子树——根节点——右子树的方式遍历这棵树࿰…...

MVP惊现神秘买家,或疑为华尔街传奇投资人?
随着距离美国总统大选已不足240天,全球都开始聚焦这次具有历史意义的重大事件,作为全球唯一的超级大国,美国大选的最终结果,将会更深远的影响世界的走向。 除了我们熟知的全球性安全问题,美国这次大选更是一次意识形态…...
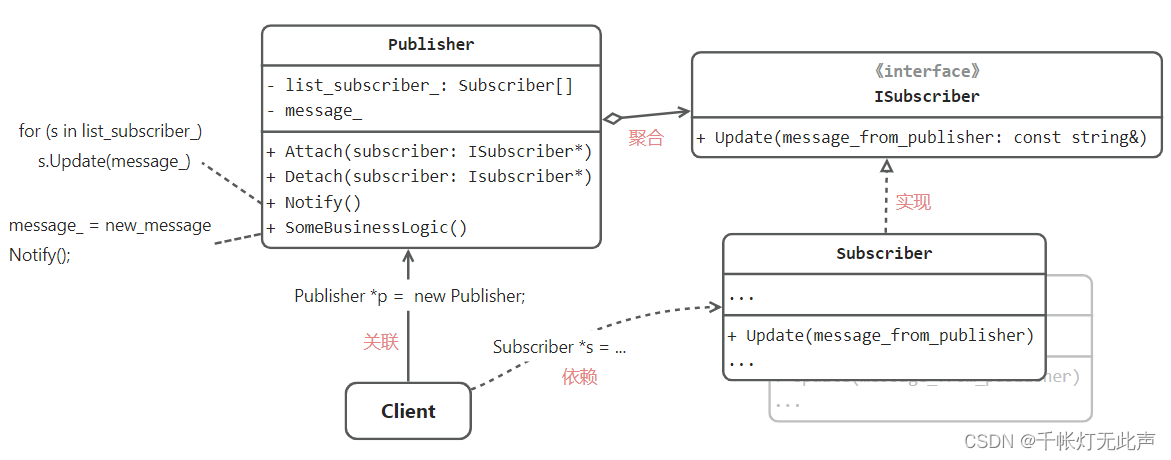
观察者模式 C++
👂 Honey Honey - 孙燕姿 - 单曲 - 网易云音乐 目录 🌼前言 🌼描述 🎂问题 💪解决方案 🈲现实场景 代码 场景1 -- 报纸发行 场景 解释 代码 场景2 -- 气象资料发布 场景3 -- 过红绿灯 &#x…...

每日一题 --- 删除字符串中的所有相邻重复项[力扣][Go]
删除字符串中的所有相邻重复项 题目:1047. 删除字符串中的所有相邻重复项 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反复执行重复项删除操作,直到无法继续删除。 在完成所…...

前端三剑客 —— CSS (第四节)
目录 内容回顾: 1.常见样式 2.特殊样式 特殊样式 过滤效果 动画效果 动画案例: 渐变效果 其他效果: 多列效果 字体图标(icon) 内容回顾: 1.常见样式 text-shadow x轴 y轴 阴影的模糊程度 阴影的…...
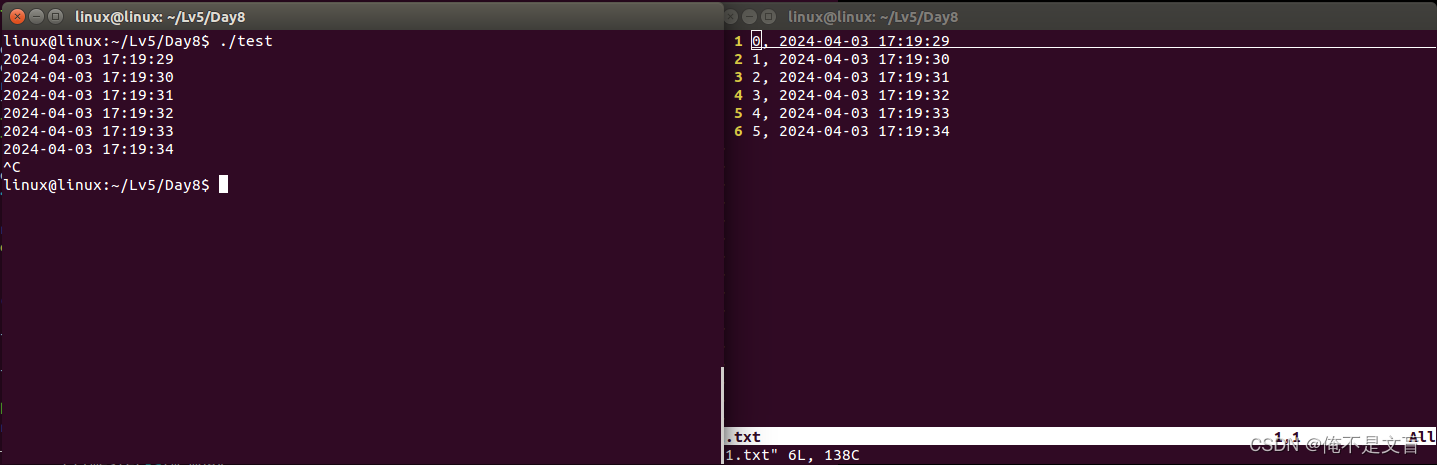
Linux文件IO(3):使用文件IO进行文件的打开、关闭、读写、定位等相关操作
目录 1. 文件IO的概念 2. 文件描述符概念 3. 函数介绍 3.1 文件IO-open函数 3.2 文件IO-close函数 3.3 文件IO-read函数 3.4 文件IO-write函数 3.5 文件IO-lseek函数 4. 代码练习 4.1 要求 4.2 具体实现代码 4.3 测试结果 5. 总结 1. 文件IO的概念 posix(可移植操作系统接…...
TranslucentTB中文界面完整设置指南:5分钟掌握Windows任务栏美化终极技巧
TranslucentTB中文界面完整设置指南:5分钟掌握Windows任务栏美化终极技巧 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB Tra…...

让普通鼠标在macOS上超越触控板的智能解决方案
让普通鼠标在macOS上超越触控板的智能解决方案 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否厌倦了在macOS上使用第三方鼠标时那种生硬…...

Tauri + Next.js 桌面应用开发:从架构到部署的完整实践指南
1. 项目概述:一个现代桌面应用开发的“瑞士军刀” 最近在折腾一个桌面端的小工具,需要把Web前端那套东西打包成一个独立的桌面应用。一开始想着用Electron,毕竟生态成熟,但一想到那动辄上百兆的安装包和不算低的内存占用…...

RT-Thread Smart下基于74LV595的KSZ8081网卡复位与驱动移植实战
1. 硬件连接与复位逻辑解析 第一次拿到i.MX6ULL开发板时,我发现KSZ8081网卡的复位引脚竟然接在了74LV595芯片上,这和常见的直接连接GPIO的设计完全不同。这种设计虽然节省了GPIO资源,但给驱动开发带来了新挑战。 74LV595是典型的串行输入并行…...

LoRA微调工程化2026:从实验到生产的完整落地指南
LoRA(Low-Rank Adaptation)已经成为大模型微调的工业标准。不是因为它最先进,而是因为它在成本、效果、灵活性之间取得了最好的平衡。本文从工程实践角度,覆盖LoRA微调的完整流程——从数据准备、训练配置到生产部署。 LoRA的工程…...

Java微服务全解:快速上手SpringCloud+SpringCloudAlibaba!
SpringCloud想必每一位Java程序员都不会陌生,很多人一度把他称之为“微服务全家桶”,它通过简单的注解,就能快速地架构微服务,这也是SpringCloud的最大优势。但是最近有去面试过的朋友就会发现,现在面试你要是没有Spri…...

工资到账前,先把个税摸个底
工资到账前,先把个税摸个底 什么是个税 「个税」通常指个人所得税。对大多数上班族来说,最常见的是工资薪金所得:公司发你税前工资,按规定预扣预缴一部分税款交给税务;你到手的「实发」已经扣过税了。除此之外&#…...

Cursor Pro破解工具:简单5步实现AI编程助手永久免费使用
Cursor Pro破解工具:简单5步实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

一次断电引发的血案:深度复盘CentOS 7 LVM分区下fstab丢失的排查与修复全记录
CentOS 7 LVM环境下fstab丢失的深度修复指南 当服务器遭遇意外断电时,文件系统损坏往往是最令人头疼的问题之一。最近处理的一起CentOS 7系统宕机案例,由于断电导致/etc/fstab文件丢失,系统无法正常启动。本文将详细记录整个排查和修复过程&a…...

Cursor AI Pro破解工具2025:终极免费方案解决试用限制问题
Cursor AI Pro破解工具2025:终极免费方案解决试用限制问题 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...