Elasticsearch:我们如何演化处理二进制文档格式
作者:来自 Elastic Sean Story
从二进制文件中提取内容是一个常见的用例。一些 PDF 文件可能非常庞大 — 考虑到几 GB 甚至更多。Elastic 在处理此类文档方面已经取得了长足的进步,今天,我们很高兴地介绍我们的新工具 —— 数据提取服务:
- 发布于 8.9 版本,
- 截至目前,没有报告任何错误!
- 截至今天,代码是免费且开放的!
为了将这一切放在其背景下,本博客将带领你了解我们的旅程如何走到了这一步:
从在 Workplace Search 中使用 Apache Tika 作为库开始,具有 20 MB 的下载限制 通过利用 Elasticsearch 附件处理器,绕过此限制,将其提升至 100 MB 通过我们的新工具——数据提取服务,彻底摧毁限制,摄取以 GB 为单位的文件内容 我们对未来发展的愿景
- 首先使用 Apache Tika 作为 Workplace Search 中的库,下载限制为 20 MB
- 利用 Elasticsearch attachment processor 突破此限制并达到 100 MB
- 使用我们的新工具数据提取服务完全消除限制并提取千兆字节的文件内容
- 我们对未来发展的愿望
背景
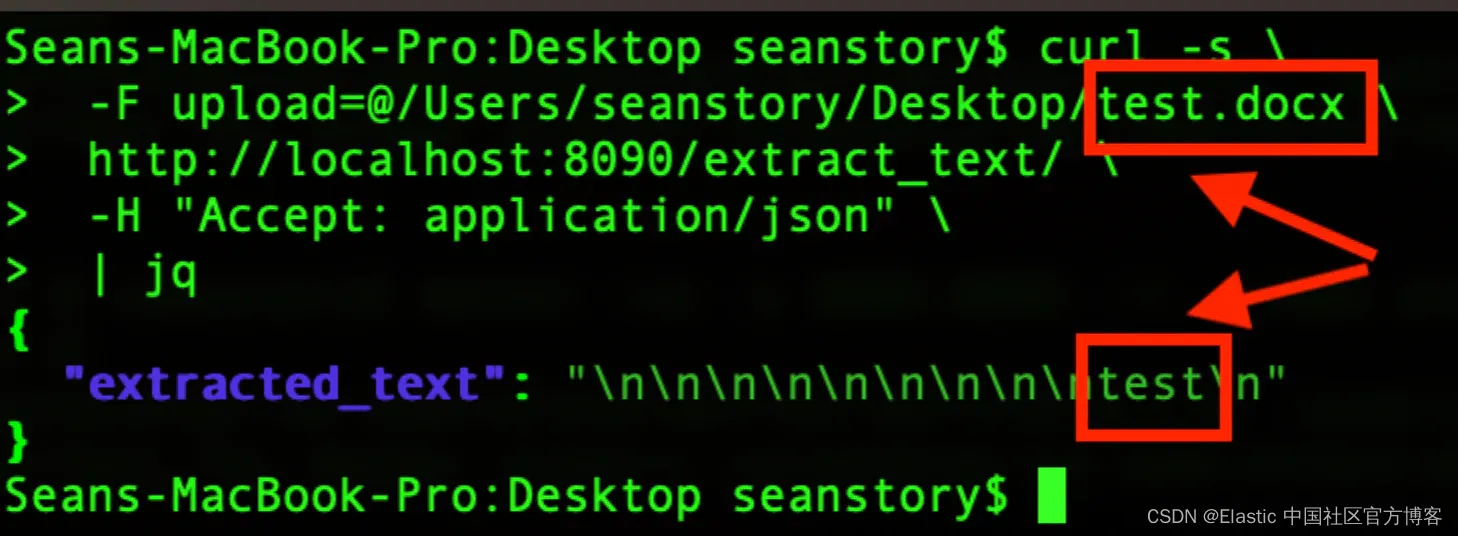
在 Elastic 公司,特别是在搜索团队中,我们长期以来一直致力于从二进制数据格式中提取和检索文本数据。大量企业数据存在于 PDF、Microsoft Word 文档、Powerpoint 演示文稿等格式中。如果你从未尝试过使用 vim、nano 或 cat 打开这些文件,你可能会惊讶地发现,这些文件并不是以人类可读的文本形式存储在你的硬盘上。

上面的图像是当你在 Mac 上使用 TextEdit 应用程序将单词 “test” 保存为 Microsoft Word 2007 (.docx) 文档,并尝试在 nano 中打开时所得到的结果。
与深入研究不同格式及其结构的细节相比,这里要强调的是,当我们谈论 “二进制” 内容时,指的就是这样的内容。这些内容的字节实际上不是人类可读的字符串,与 .txt、.rtf、.md、.html、.csv 等格式的情况不同。
为什么这很重要?

相关性
搜索相关性几乎是我们在 Elastic 所做的一切的核心。 为了使文本搜索具有相关性,Elasticsearch 确实需要文本数据。 虽然我绝对可以对上述 .docx 内容进行 Base64 编码并将其发送到 Elasticsearch,但它们在索引中不会非常有价值,并且对字符串 “test” 的任何查询都不会匹配这样的文档。

因此,如果我们想要在企业数据上实现良好的搜索体验,我们就需要能够从这些二进制格式中提取出纯文本内容。
这就是 Apache Tika 登场的原因。这个开源库一直是文本提取的黄金标准,贯穿了我的整个职业生涯(约自2014年起),尽管它至少从 2007 年就存在了。建立在 JVM 上,Tika 相对容易实现以下功能:
- 判断给定字节序列是否是垃圾数据或与已知格式规范匹配
- 如果匹配任何已知格式,则识别匹配的格式是哪种
- 如果匹配已知格式,则根据该格式解析数据,并提取文本和元数据属性
因此,有一个稳定的、行业标准的工具适用于各种格式。问题在哪里呢?为什么这个主题值得写成博客文章呢?
架构和性能。
在 Elastic,我们重视 speed、scale、relevance。我们已经在注意到在搜索时,与二进制内容相比,文本内容更受青睐时部分解决了相关性的问题。接下来,让我们谈谈规模。
规模
在我上述的 .docx 文件中的 “test” 示例中,文件内容为 3.4KB。同一个 “test” 字符串在 .txt 文件中只有 4B。这是存储大小的 x850 增加!此外,当读入 Java 对象内存模型(Tika 用于解析的)时,这很可能会显著扩展。这意味着,在代表性的数据规模上,内存问题变得非常真实。看到几 MB 大小的 PDF 并不罕见,甚至看到几 GB 大小的 PDF 也并非闻所未闻。所有这些数据都是文本数据吗?几乎可以肯定不是。我最喜欢的一个事实是,托尔斯泰的整部小说《战争与和平》只有大约 3MB 的纯文本。希望没有太多的办公文档超过 60万字。但即使输出的纯文本几乎可以保证只在 MB 级别,这也不保证解析原始文件所需的 RAM 会这么低。根据解析器以及你的代码读取它的智能程度,你可能需要将整个文件保存在内存中,使用 Java 对象模型。你可能还需要它的多个副本。考虑到以上情况,这意味着,在实践中,你通常需要 GB 级别的 RAM(特别是对于 Java/Tika 来说是 “堆”),以确保一个异常的大文件不会导致你的整个进程崩溃。
速度
现在,让我们谈谈速度。如果我有 N 份文档要处理,处理它们的最快方式是 “并行化” —— 同时处理多个(或全部)文档。这在很大程度上受到规模的影响。如果 N=10,而给定文档大约需要 1 秒钟处理时间,那么等待 10 秒可能并不算长。但如果 N=1,000,000,000,那么 31 年很可能就太慢了。因此,在大规模情况下,需要更大的并行化。
然而,当考虑到我们上面讨论的规模的内存成本时,这就加剧了你的内存需求。一次处理一份文档可能只需要几 GB 的内存来应对最糟糕的情况,但如果我试图同时并行处理 1000 份文档,我可能突然发现自己需要 TB 级别的 RAM 来应对最糟糕的情况。
有了这个背景,不难理解为什么 Workplace Search,自 7.6.0 起就是 Elastic 提供的产品之一,始终对从二进制文档中提取文本的并行处理和文档大小设置了相当严格的限制。每个内容源一次只能处理一个二进制文档,将二进制文档的输入大小限制在 20 MB 以内,甚至将输出长度限制在 100KB(默认情况下 - 这是可配置的)。这些限制相当保守,但考虑到处理任何二进制文件的 JVM 是运行 Enterprise Search 服务器及其所有其他后台工作的同一个 JVM,这些限制是有道理的。因此,Workplace Search 必须非常小心,不要消耗超过其份额的资源,或者冒着影响其他 Enterprise Search 功能的风险。
这些保守的限制,连同其他因素,是我们正在努力将客户从 Workplace Search 转移出去的部分原因。(要了解更多关于这种转变的信息,请查看 Workplace Search 的演变博客文章。)在过去几年中,我们看到越来越多的客户需要处理大量文档,像 Workplace Search 那样一次只处理一个文档已经不够用了。
引入附件处理器(Attachment Processor)。最初是作为单独安装的 Elasticsearch 插件,附件处理器也利用 Apache Tika 从二进制文档中提取纯文本。然而,与 Workplace Search 中的文本提取不同,这个工具运行在 Elasticsearch 内部,并且可以在 Elastic Ingest Pipelines 中利用。搜索团队开始在大约 8.3.0 版本时大量使用 Ingest Pipelines,首先是在我们的 App Search Crawler 中,然后是在我们的 Connector Packages 中,最近是在我们的 Native 和 Client Connectors 中。将其用于我们的架构带来了一些好处:
- Elasticsearch 不需要将文档的输入大小限制在区区 20MB。
- Elasticsearch 已经建立了在摄取时进行分布式处理的能力,通过其 Ingest Nodes(这意味着我们可以轻松地水平扩展,并一次处理多于 1 份文档)
- 通过使用 Elasticsearch 的一个功能,我们可以确保我们的文本提取行为与其他 Elastic 使用案例保持一致。
这对我们的新连接器尤其重要,这些新连接器旨在运行在 Enterprise Search 服务器之外,并且不应该被限制在单一生态系统中。通过使用 Elasticsearch 进行文本提取,我们去除了我们的连接器内部需要运行 Tika(记得是 JVM 吗?)的要求,但通过不更换工具,仍然保持了一致的文本提取行为。
这无疑帮助我们提高了摄取速度,并成为我们策略中的一个重要部分,持续了多个版本。在查看附件处理器的一些遥测数据后,很明显,Enterprise Search 使用它的份额是最大的。鉴于我们所有的连接器和爬虫默认使用附件处理器,这并不令人惊讶。它是我们 ent-search-generic-ingestion 管道中的第一个处理器 —— 所有新连接器和爬虫的默认管道。

事实上,附件处理器对我们的用例变得如此重要,以至于我们是将附件插件转换为开箱即用的模块(自动随 Elasticsearch 一起使用)的驱动动机。
然而,这也带来了一些权衡。
首先,虽然 Elasticsearch 没有我们在企业搜索中遇到的同样的 20MB 限制,但它确实有一个最大负载大小的硬性限制为 100MB(由 http.max_content_length 定义)。你可以通过多部分表单数据来绕过这一限制,但 Elasticsearch 核心开发者强烈建议我们不要追求这种思路,因为 100MB 的限制是有其原因的。实际上,虽然这个限制在技术上是可配置的,我们强烈建议不要增加它,因为我们历史上观察到这样做可能会大大降低 Elasticsearch 集群的稳定性。
其次,虽然 Workplace Search 过于积极地处理二进制文件可能导致企业搜索服务器失败,但如果附件处理器被赋予过大的工作量,它可能会威胁到 Elasticsearch 集群的健康。通常情况下,这种情况更糟。虽然 Elasticsearch 能够在摄入时进行分布式处理(CPU)工作负载,但这不是它的主要关注点。Elasticsearch 主要设计用于搜索,其进行分布式处理的能力不是主要焦点。它不应该(也不会)为处理多个大型 PDF 文件的重型工作负载而优化。
相反,我们的团队转向了一种新的方法 —— 构建一个专门用于二进制内容提取的独立服务,该服务在当前的一系列流程之外运行。
介绍:数据提取服务
这项服务是在 Elastic 8.9.0 版本发布时(作为 Beta 版本)推出的。它是一个专用的独立服务器,能够通过 REST API 接收你的二进制文档作为输入,并响应其纯文本内容,以及一些最小的元数据。
通过将该流程与我们的连接器和 Elasticsearch 分离开来,我们创建了一个可以轻松水平扩展的服务。这样,成本和速度之间的权衡就可以轻松控制,你不必为其中一个进行优化而被束缚。
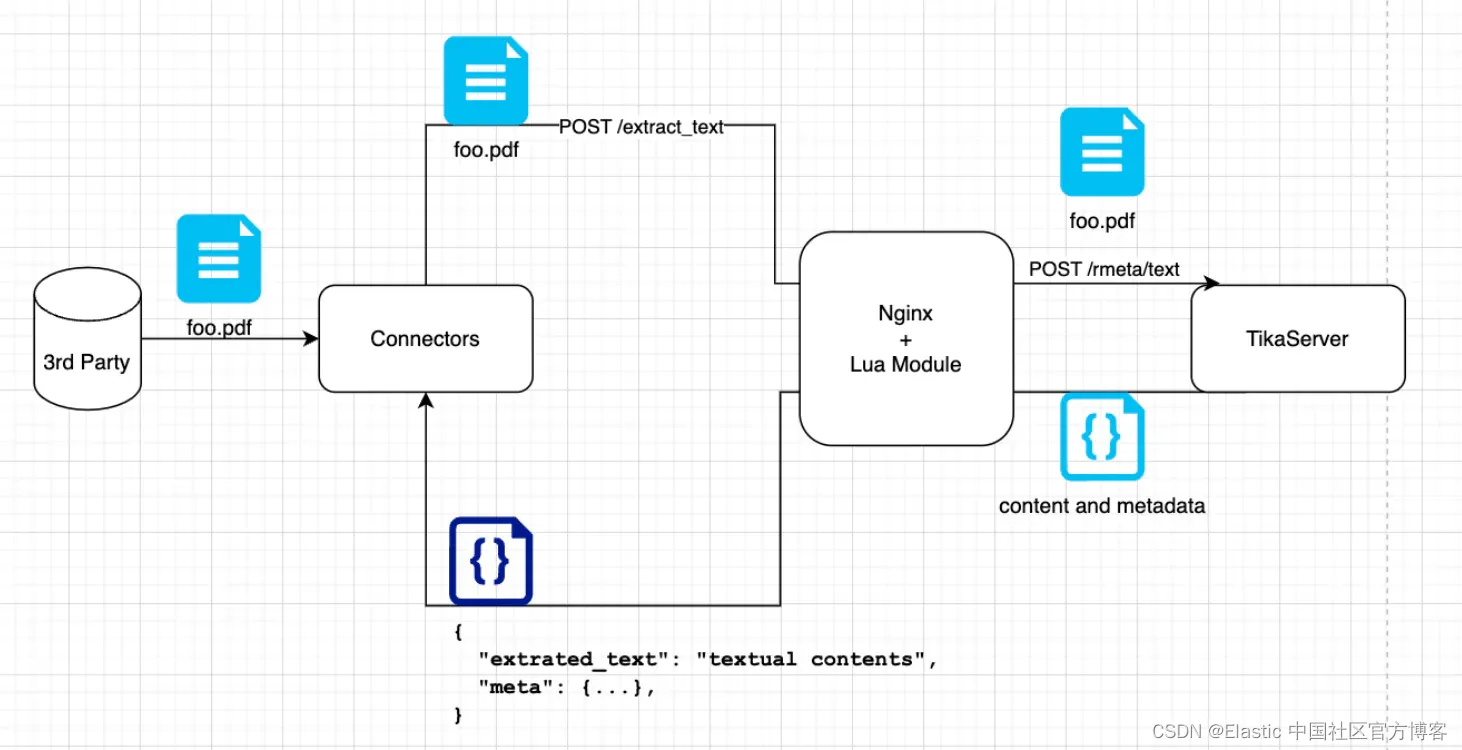
此外,该服务的分离允许你在边缘附近部署它,以避免大型文件负载的额外网络跳跃。通过在连接器和数据提取服务在同一文件系统上共存时利用文件指针,我们可以完全消除从源系统获取文件后通过网络发送文件的需求。
目前,该服务主要只是 Tika Server 的一个包装器。然而,我们希望(有一天)能够对我们如何解析/处理每种文件类型进行细粒度控制。也许对于某些文件类型 X,有些工具比 Tika 更高效。例如,一些个别证据表明,工具 pdf2txt 在解析 PDF 文件时可能比 Tika 更有效率。如果进一步的实验证实了这一点,那么使用最适合工作的工具将有利于我们的产品。
我们通过将数据提取服务构建为一个可以定义自己 REST API 的 Nginx 反向代理,并动态将传入请求路由到各种后端来为此做了架构设计。这是通过一些自定义的 Lua 脚本实现的(这是 Nginx 的一个特性)。
此工具的初步反馈极为正面。到目前为止,我们收到的 “bug” 报告只有:
- 找到它的 Docker 镜像太难了。
- 代码不是开源的。
我们收到的增强功能请求要多得多,我们很兴奋能够优先考虑这些请求,这也显示了人们对这个项目有多少热情。
不过,关于错误,我们已经修复了 docker 映像的歧义,你现在可以在这里轻松浏览我们的所有工件:https://www.docker.elastic.co/r/enterprise-search/data-extraction-service。 关于源代码,我非常高兴地宣布 GitHub 存储库现已公开 - 使数据提取服务代码免费且开放!
接下来呢?
首先,我们希望通过开放代码仓库,进一步吸引我们充满热情的用户社区。我们希望集中处理增强功能请求,并开始征集更多的公开反馈。我们绝对欢迎社区的贡献!我们相信,这是确保这个项目继续有机演进,使所有人受益的最佳方式。
长远愿景是什么?
注意,Elastic 并没有承诺这一点。整个团队甚至可能不会完全同意。但是出于热情的原因,我想与你分享我的个人愿景。
我希望将这项服务发展到不仅仅是从办公文档中提取纯文本。可搜索的数据存在于图像(扫描/复印的文档、图形横幅/幻灯片)、音频文件(音乐、播客、有声书、电话录音、Zoom 音频)和视频文件(电影、电视节目、Zoom 视频)中。即使是纯文本中也包含了嵌入其中的次文本数据,可以通过现代机器学习技术(情感分析、实体识别、语义文本、GenAI)来访问。所有这些都共享着需要大文件和文档处理来实现一流搜索体验的共同问题。它们都将受益于 Elasticsearch 提供的相关搜索,但可能不都适合于需要大量 CPU 的摄入工作负载。所有这些都可能受益于拥有一个专用的、水平可扩展的提取服务,可以位于 “边缘”,以改善大规模摄入速度。
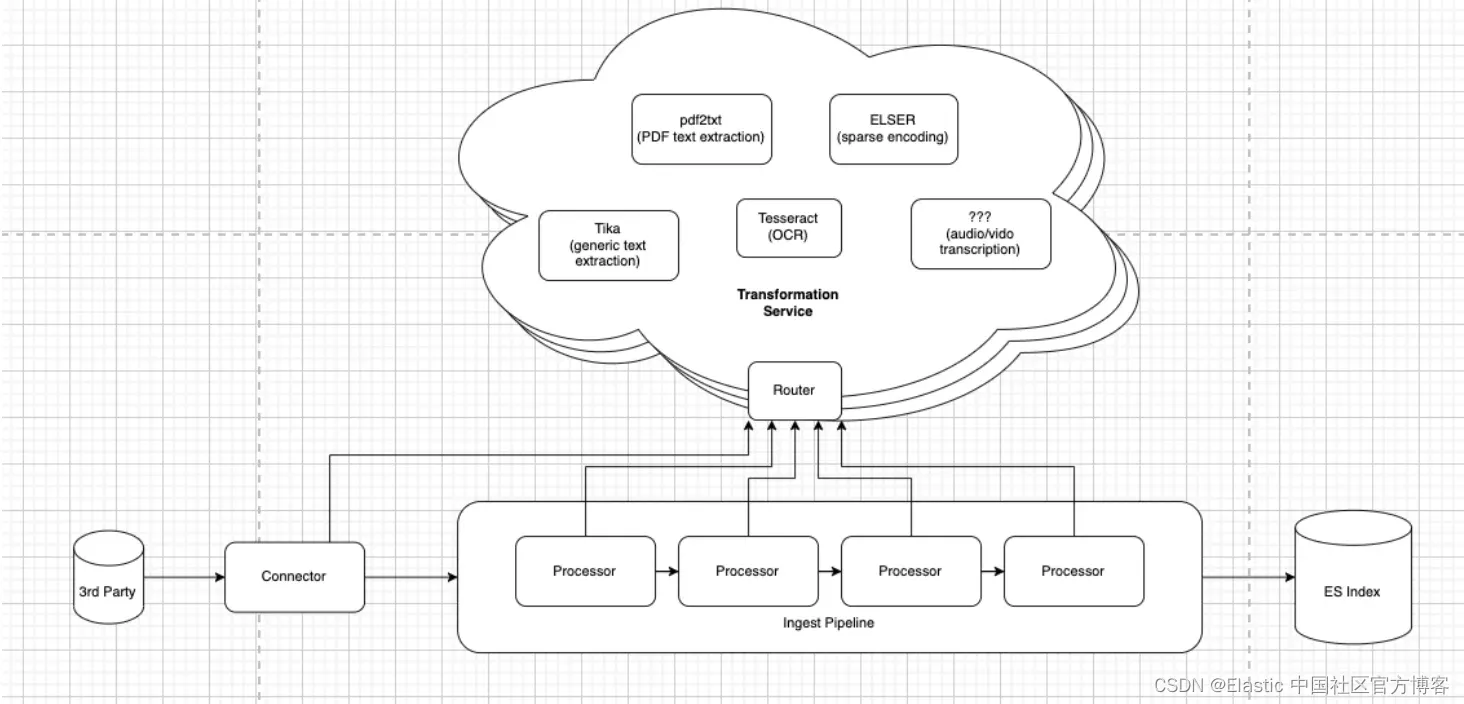
这还不是现实。 这是一个目标。 一颗北极星。 随着我们越来越接近愿景,愿景可能会发生变化,但这不会阻止我们朝着目标迈出战略性的小步骤。
如果你想帮助我们实现这一目标,请访问 https://github.com/elastic/data-extraction-service,并加入该项目。 欢迎新贡献者。
准备好将 RAG 构建到你的应用程序中了吗? 想要尝试使用向量数据库的不同 LLMs?
在 Github 上查看我们的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训!
原文:Evolving How We Ingest Binary Document Formats — Elastic Search Labs
相关文章:
Elasticsearch:我们如何演化处理二进制文档格式
作者:来自 Elastic Sean Story 从二进制文件中提取内容是一个常见的用例。一些 PDF 文件可能非常庞大 — 考虑到几 GB 甚至更多。Elastic 在处理此类文档方面已经取得了长足的进步,今天,我们很高兴地介绍我们的新工具 —— 数据提取服务&…...
第八讲 Sort Aggregate 算法
我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。 1 查询计划【Query Plan】 我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么? 当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换…...
clickhouse MPPDB数据库--新特性使用示例
clickhouse 新特性: 从clickhouse 22.3至最新的版本24.3.2.23,clickhouse在快速发展中,每个版本都增加了一些新的特性,在数据写入、查询方面都有性能加速。 本文根据clickhouse blog中的clickhouse release blog中,学…...
MATLAB多级分组绘图及图例等细节处理 ; MATLAB画图横轴时间纵轴数值按照不同sensorCode分组画不同sensorCode的曲线
平时研究需要大量的绘图Excel有时候又臃肿且麻烦 尤其是当处理大量数据时可能会拖死Windows 示例代码及数据量展示 因为数据量是万级别的折线图也变成"柱状图"了, 不过还能看出大致趋势! 横轴是时间纵轴是传感器数值图例是传感器所在深度 % data readtable(C:\U…...

20240405,数据类型,运算符,程序流程结构
是我深夜爆炸,不能再去补救C了,真的来不及了,不能再三天打鱼两天晒网了,真的来不及了呜呜呜呜 我实在是不知道看什么课,那黑马吧……MOOC的北邮的C正在进行呜呜 #include <iostream> using namespace std; int…...
Prometheus+grafana环境搭建Nginx(docker+二进制两种方式安装)(六)
由于所有组件写一篇幅过长,所以每个组件分一篇方便查看,前五篇链接如下 Prometheusgrafana环境搭建方法及流程两种方式(docker和源码包)(一)-CSDN博客 Prometheusgrafana环境搭建rabbitmq(docker二进制两种方式安装)(二)-CSDN博客 Prometheusgrafana环…...

贝叶斯逻辑回归
贝叶斯逻辑回归(Bayesian Logistic Regression)是一种机器学习算法,用于解决分类问题。它基于贝叶斯定理,通过建立一个逻辑回归模型,结合先验概率和后验概率,对数据进行分类。 贝叶斯逻辑回归的基本原理是…...

Win10 下 Vision Mamba(Vim-main)的环境配置(libcuda.so文件无法找到,windows系统运行失败)
目录 1、下载NVIDIA 驱动程序、cuda11.8、cudnn8.6.0 2、在Anaconda中创建环境并激活 3、下载gpu版本的torch 4、配置环境所需要的包 5、安装causal_conv1d和mamba-1p1p1 安装causal_conv1d 安装mamba-1p1p1 6、运行main.py失败 请直接拉到最后查看运行失败的原因&am…...

4 万字全面掌握数据库、数据仓库、数据集市、数据湖、数据中台
如今,随着诸如互联网以及物联网等技术的不断发展,越来越多的数据被生产出来-据统计,每天大约有超过2.5亿亿字节的各种各样数据产生。这些数据需要被存储起来并且能够被方便的分析和利用。 随着大数据技术的不断更新和迭代,数据管…...

Leetcode 64. 最小路径和
心路历程: 第一反应像是一个回溯问题,但是看到题目中要求最值,大概率是一道DP问题。并且这里面的递推关系也很明显。 这里面边界条件可以有多种处理方法。 解法:动态规划 class Solution:def minPathSum(self, grid: List[List…...

FANUC机器人故障诊断—报警代码更新(三)
FANUC机器人故障诊断中,有些报警代码,继续更新如下。 一、报警代码(SRVO-348) SRVO-348DCS MCC关闭报警a,b [原因]向电磁接触器发出了关闭指令,而电磁接触器尚未关闭。 [对策] 1.当急停单元上连接了CRMA…...
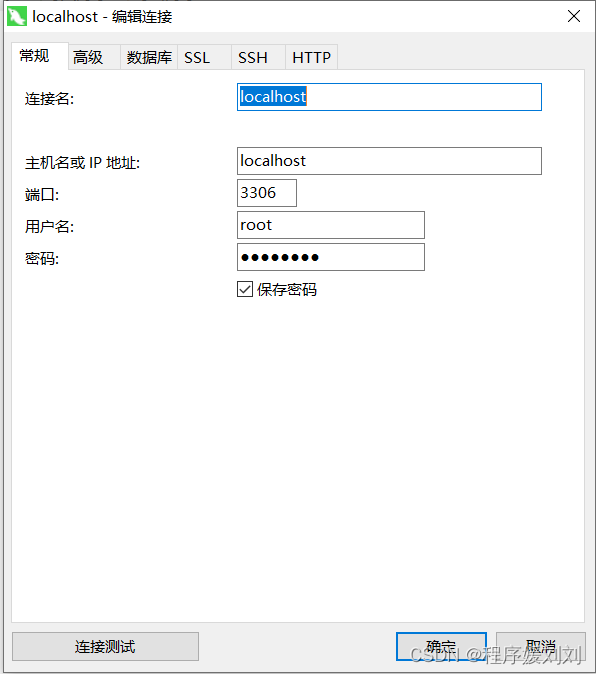
mysql 本地电脑服务部署
前提: 下载mysql 新建配置文档 在安装mysql目录新建 my.ini [mysqld] # 设置3306端口 port3306#设置mysql的安装目录 basedirC:\Program Files\MySQL\MySQL Server 8.3 #切记此处一定要用双斜杠\\,单斜杠我这里会出错,不过看别人的教程,有…...

爬虫学习第一天
爬虫-1 爬虫学习第一天1、什么是爬虫2、爬虫的工作原理3、爬虫核心4、爬虫的合法性5、爬虫框架6、爬虫的挑战7、难点8、反爬手段8.1、Robots协议8.2、检查 User-Agent8.3、ip限制8.4、SESSION访问限制8.5、验证码8.6、数据动态加载8.7、数据加密-使用加密算法 9、用python学习爬…...

labview如何创建2D多曲线XY图和3D图
1如何使用labview创建2D多曲线图 使用“索引与捆绑簇数组”函数将多个一维数组捆绑成一个簇的数组,然后将结果赋值给XY图,这样一个多曲线XY图就生成了。也可以自己去手动索引,手动捆绑并生成数组,结果是一样的 2.如何创建3D图 在…...
)
【华为OD机试】芯片资源限制(贪心算法—JavaPythonC++JS实现)
本文收录于专栏:算法之翼 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-芯片资源限制二.解题思路三.题解代码Python题解代码JAVA题解代码C/C++题解代码JS题解代码四…...

服务器硬件构成与性能要点:CPU、内存、硬盘、RAID、网络接口卡等关键组件的基础知识总结
文章目录 服务器硬件基础知识CPU(中央处理器)内存(RAM)硬盘RAID(磁盘阵列)网络接口卡(NIC)电源散热器主板显卡光驱 服务器硬件基础知识 服务器是一种高性能计算机,用于在…...

STC89C51学习笔记(四)
STC89C51学习笔记(四) 综述:本文讲述了在STC89C51中数码管、模块化编程、LCD1602的使用。 一、数码管 1.数码管显示原理 位选:对74HC138芯片的输入端的配置(P22、P23、P24),来选择实现位选&…...
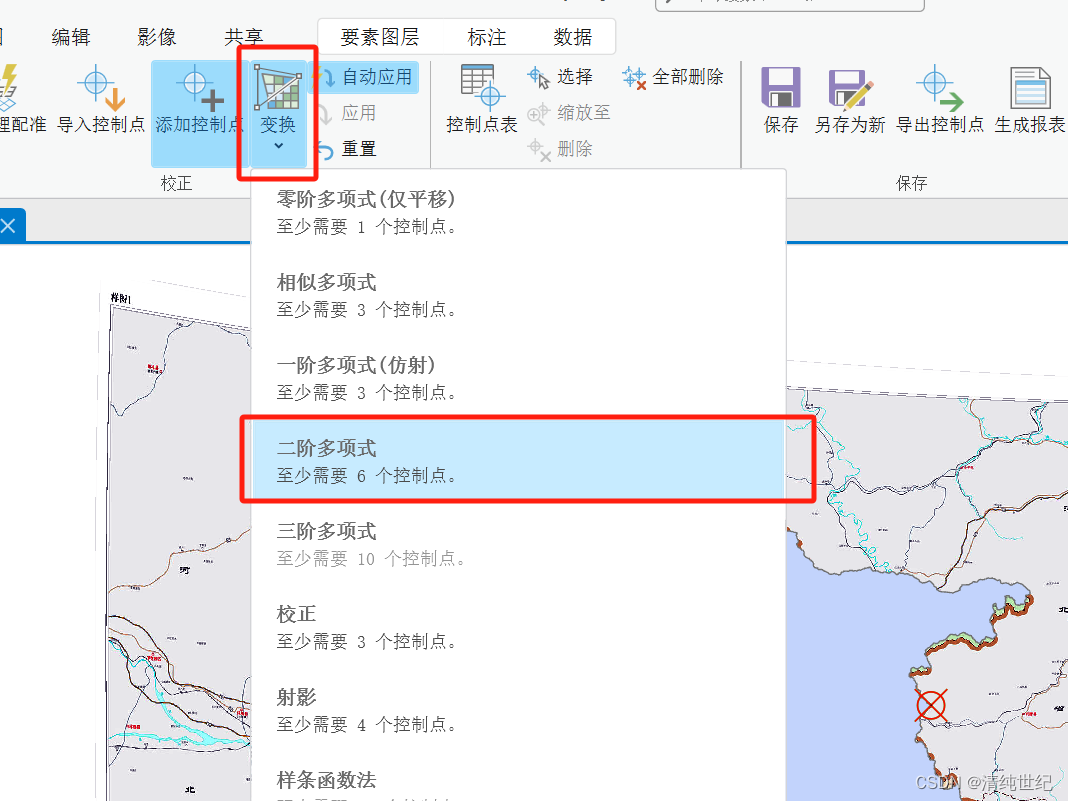
Arcgis Pro地理配准
目录 一、目的 二、配准 1、找到配准工具 2、添加控制点 3、选择控制点 4、添加更多控制点 5、配准完成、保存 三、附录 1、查看控制点或删除控制点 2、效果不好怎么办 一、目的 下面我们将两张地图进行配准,其中一张有地理位置,而另外一张没…...

数字转型新动力,开源创新赋能数字经济高质量发展
应开放原子开源基金会的邀请,软通动力董事、鸿湖万联董事长黄颖基于对软通动力开源战略的思考,为本次专题撰文——数字转型新动力,开源创新赋能数字经济高质量发展。本文首发于2023年12月12日《中国电子报》“开源发展与开发者”专题第8版。以…...
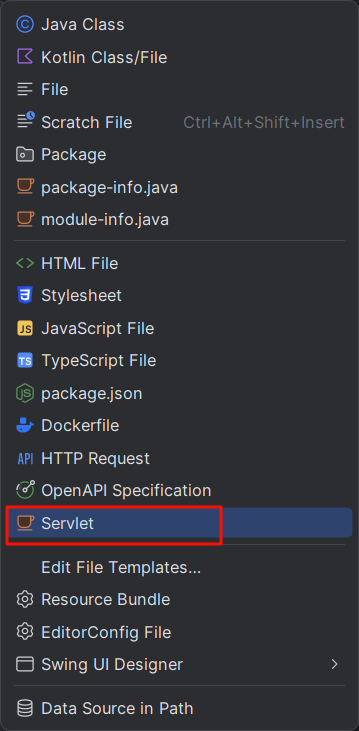
解决JavaWeb中IDEA2023新版本无法创建Servlet的问题
出现问题:IDEA右键创建Servlet时,找不到选项 原因分析:IDEA的2023版的已经不支持Servlet了,如果还要使用的话,需要自己创建模板使用 创建模板 右击设置,选择(File and Code Templates&#x…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...