PyTorch搭建Informer实现长序列时间序列预测
目录
- I. 前言
- II. Informer
- III. 代码
- 3.1 输入编码
- 3.1.1 Token Embedding
- 3.1.2 Positional Embedding
- 3.1.3 Temporal Embedding
- 3.2 Encoder与Decoder
- IV. 实验
I. 前言
前面已经写了很多关于时间序列预测的文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch中利用LSTMCell搭建多层LSTM实现时间序列预测
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
- PyTorch时间序列预测系列文章总结(代码使用方法)
- TensorFlow搭建LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量时间序列预测(负荷预测)
- TensorFlow搭建双向LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- TensorFlow搭建ANN实现时间序列预测(风速预测)
- TensorFlow搭建CNN实现时间序列预测(风速预测)
- TensorFlow搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyG搭建图神经网络实现多变量输入多变量输出时间序列预测
- PyTorch搭建GNN-LSTM和LSTM-GNN模型实现多变量输入多变量输出时间序列预测
- PyG Temporal搭建STGCN实现多变量输入多变量输出时间序列预测
- 时序预测中Attention机制是否真的有效?盘点LSTM/RNN中24种Attention机制+效果对比
- 详解Transformer在时序预测中的Encoder和Decoder过程:以负荷预测为例
- (PyTorch)TCN和RNN/LSTM/GRU结合实现时间序列预测
- PyTorch搭建Informer实现长序列时间序列预测
- PyTorch搭建Autoformer实现长序列时间序列预测
其中有2篇讲分别讲述了如何利用Encoder-Only和Encoder-Decoder的Transformer进行时间序列预测。
然而,Transformer存在一系列的问题,使其不能用于长序列时间序列预测,如和序列长度平方成正比的时间复杂度,高内存使用量和Encoder-Decoder体系结构固有的局限性。为了解决上述问题,文章《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》中提出了一种超越Transformer的长序列时序预测模型Informer。
II. Informer
Informer在Transformer基础上主要做了三点改进:
- Transformer计算self-attention时时间复杂度和序列长度的平方成正比,即 O ( L 2 ) O(L^2) O(L2),为此,Informer中提出了一种ProbSparse self-attention,将时间复杂度和内存使用都压缩到了 O ( L ∗ log L ) O(L*\log L) O(L∗logL)。
- 传统Transformer将多个编码和解码层进行堆叠,带来的复杂度是累加的,这限制了模型在接收长序列输入时的可扩展性。为此,Informer在每个注意力层之间都添加了蒸馏操作,通过将序列的shape减半来突出主要注意力,使得模型可以接受更长的序列输入,并且可以降低内存和时间损耗。
- 传统Transformer的Decoder阶段输出是step-by-step,一方面增加了耗时,另一方面也会给模型带来累计误差。因此Informer提出应该直接得到所有步长的预测结果。
更具体的原理就不做讲解了,网上已经有了很多类似的文章,这篇文章主要讲解代码的使用,重点是如何对作者公开的源代码进行改动,以更好地适配大多数人自身的数据,使得读者只需要改变少数几个参数就能实现数据集的更换。
III. 代码
3.1 输入编码
传统Transformer中在编码阶段需要进行的第一步就是在原始序列的基础上添加位置编码,而在Informer中,输入由三部分组成。我们假设输入的序列长度为(batch_size, seq_len, enc_in),如果用过去96个时刻的所有13个变量预测未来时刻的值,那么输入即为(batch_size, 96, 13)。
3.1.1 Token Embedding
Informer输入的第1部分是对原始输入进行编码,本质是利用一个1维卷积对原始序列进行特征提取,并且序列的维度从原始的enc_in变换到d_model,代码如下:
class TokenEmbedding(nn.Module):def __init__(self, c_in, d_model):super(TokenEmbedding, self).__init__()padding = 1 if torch.__version__ >= '1.5.0' else 2self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,kernel_size=3, padding=padding, padding_mode='circular')for m in self.modules():if isinstance(m, nn.Conv1d):nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='leaky_relu')def forward(self, x):x = self.tokenConv(x.permute(0, 2, 1)).transpose(1, 2)return x
输入x的大小为(batch_size, seq_len, enc_in),需要先将后两个维度交换以适配1维卷积,接着让数据通过tokenConv,由于添加了padding,因此经过后seq_len维度不改变,经过TokenEmbedding后得到大小为(batch_size, seq_len, d_model)的输出。
3.1.2 Positional Embedding
Informer输入的第2部分是位置编码,这点与Transformer无异,代码如下:
class PositionalEmbedding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEmbedding, self).__init__()# Compute the positional encodings once in log space.pe = torch.zeros(max_len, d_model).float()pe.require_grad = Falseposition = torch.arange(0, max_len).float().unsqueeze(1)div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):return self.pe[:, :x.size(1)]
位置编码同样返回大小为(batch_size, seq_len, d_model)的输出。
3.1.3 Temporal Embedding
Informer输入的第3部分是对时间戳进行编码,即年月日星期时分秒等进行编码。作者提出了两种编码方式,我们依次解析。第一种编码方式TemporalEmbedding代码如下:
class TemporalEmbedding(nn.Module):def __init__(self, d_model, embed_type='fixed', freq='h'):super(TemporalEmbedding, self).__init__()minute_size = 4hour_size = 24weekday_size = 7day_size = 32month_size = 13Embed = FixedEmbedding if embed_type == 'fixed' else nn.Embeddingif freq == 't':self.minute_embed = Embed(minute_size, d_model)self.hour_embed = Embed(hour_size, d_model)self.weekday_embed = Embed(weekday_size, d_model)self.day_embed = Embed(day_size, d_model)self.month_embed = Embed(month_size, d_model)def forward(self, x):x = x.long()minute_x = self.minute_embed(x[:, :, 4]) if hasattr(self, 'minute_embed') else 0.hour_x = self.hour_embed(x[:, :, 3])weekday_x = self.weekday_embed(x[:, :, 2])day_x = self.day_embed(x[:, :, 1])month_x = self.month_embed(x[:, :, 0])return hour_x + weekday_x + day_x + month_x + minute_x
TemporalEmbedding的输入要求是(batch_size, seq_len, 5),5表示每个时间戳的月、天、星期(星期一到星期七)、小时以及刻钟数(一刻钟15分钟)。代码中对五个值分别进行了编码,编码方式有两种,一种是FixedEmbedding,它使用位置编码作为embedding的参数,不需要训练参数;另一种就是torch自带的nn.Embedding,参数是可训练的。
更具体的,作者将月、天、星期、小时以及刻钟的范围分别限制在了13、32、7、24以及4。即保证输入每个时间戳的月份数都在0-12,天数都在0-31,星期都在0-6,小时数都在0-23,刻钟数都在0-3。例如2024/04/05/12:13,星期五,输入应该是(4, 5, 5, 13, 0)。注意12:13小时数应该为13,小于等于12:00但大于11:00如11:30才为12。
对时间戳进行编码的第二种方式为TimeFeatureEmbedding:
class TimeFeatureEmbedding(nn.Module):def __init__(self, d_model, embed_type='timeF', freq='h'):super(TimeFeatureEmbedding, self).__init__()freq_map = {'h': 4, 't': 5, 's': 6, 'm': 1, 'a': 1, 'w': 2, 'd': 3, 'b': 3}d_inp = freq_map[freq]self.embed = nn.Linear(d_inp, d_model)def forward(self, x):return self.embed(x)
TimeFeatureEmbedding的输入为(batch_size, seq_len, d_inp),d_inp有多达8种选择。具体来说针对时间戳2024/04/05/12:13,以freq='h’为例,其输入应该是(月份、日期、星期、小时),即(4, 5, 5, 13),然后针对输入通过以下函数将所有数据转换到-0.5到0.5之间:
def time_features(dates, timeenc=1, freq='h'):"""> `time_features` takes in a `dates` dataframe with a 'dates' column and extracts the date down to `freq` where freq can be any of the following if `timeenc` is 0: > * m - [month]> * w - [month]> * d - [month, day, weekday]> * b - [month, day, weekday]> * h - [month, day, weekday, hour]> * t - [month, day, weekday, hour, *minute]> > If `timeenc` is 1, a similar, but different list of `freq` values are supported (all encoded between [-0.5 and 0.5]): > * Q - [month]> * M - [month]> * W - [Day of month, week of year]> * D - [Day of week, day of month, day of year]> * B - [Day of week, day of month, day of year]> * H - [Hour of day, day of week, day of month, day of year]> * T - [Minute of hour*, hour of day, day of week, day of month, day of year]> * S - [Second of minute, minute of hour, hour of day, day of week, day of month, day of year]*minute returns a number from 0-3 corresponding to the 15 minute period it falls into."""if timeenc == 0:dates['month'] = dates.date.apply(lambda row: row.month, 1)dates['day'] = dates.date.apply(lambda row: row.day, 1)dates['weekday'] = dates.date.apply(lambda row: row.weekday(), 1)dates['hour'] = dates.date.apply(lambda row: row.hour, 1)dates['minute'] = dates.date.apply(lambda row: row.minute, 1)dates['minute'] = dates.minute.map(lambda x: x // 15)freq_map = {'y': [], 'm': ['month'], 'w': ['month'], 'd': ['month', 'day', 'weekday'],'b': ['month', 'day', 'weekday'], 'h': ['month', 'day', 'weekday', 'hour'],'t': ['month', 'day', 'weekday', 'hour', 'minute'],}return dates[freq_map[freq.lower()]].valuesif timeenc == 1:dates = pd.to_datetime(dates.date.values)return np.vstack([feat(dates) for feat in time_features_from_frequency_str(freq)]).transpose(1, 0)
当freq为’t’时,输入应该为[‘month’, ‘day’, ‘weekday’, ‘hour’, ‘minute’],其他类似。当通过上述函数将四个数转换为-0.5到0.5之间后,再利用TimeFeatureEmbedding中的self.embed = nn.Linear(d_inp, d_model)来将维度从4转换到d_model,因此最终返回的输出大小也为(batch_size, seq_len, d_model)。
最终,代码中通过一个DataEmbedding类来将三种编码放在一起:
class DataEmbedding(nn.Module):def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1):super(DataEmbedding, self).__init__()# 值编码self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)# 位置编码self.position_embedding = PositionalEmbedding(d_model=d_model)self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type,freq=freq) if embed_type != 'timeF' else TimeFeatureEmbedding(d_model=d_model, embed_type=embed_type, freq=freq)self.dropout = nn.Dropout(p=dropout)def forward(self, x, x_mark):x = self.value_embedding(x) + self.position_embedding(x) + self.temporal_embedding(x_mark)return self.dropout(x)
3.2 Encoder与Decoder
完整的Informer代码如下:
class Informer(nn.Module):def __init__(self, args):super(Informer, self).__init__()self.args = argsself.pred_len = args.pred_lenself.attn = args.attnself.output_attention = Falseself.distil = Trueself.mix = True# Encodingself.enc_embedding = DataEmbedding(args.enc_in, args.d_model, args.embed, args.freq, args.dropout)self.dec_embedding = DataEmbedding(args.dec_in, args.d_model, args.embed, args.freq, args.dropout)# AttentionAttn = ProbAttention if args.attn == 'prob' else FullAttention# Encoderself.encoder = Encoder([EncoderLayer(AttentionLayer(Attn(False, args.factor, attention_dropout=args.dropout,output_attention=self.output_attention), args.d_model, args.n_heads, mix=False),args.d_model,args.d_ff,dropout=args.dropout,activation=args.activation) for l in range(args.e_layers)],[ConvLayer(args.d_model) for l in range(args.e_layers - 1)] if self.distil else None,norm_layer=torch.nn.LayerNorm(args.d_model))# Decoderself.decoder = Decoder([DecoderLayer(AttentionLayer(Attn(True, args.factor, attention_dropout=args.dropout, output_attention=False),args.d_model, args.n_heads, mix=self.mix),AttentionLayer(FullAttention(False, args.factor, attention_dropout=args.dropout, output_attention=False),args.d_model, args.n_heads, mix=False),args.d_model,args.d_ff,dropout=args.dropout,activation=args.activation,)for l in range(args.d_layers)],norm_layer=torch.nn.LayerNorm(args.d_model))# self.end_conv1 = nn.Conv1d(in_channels=label_len+out_len, out_channels=out_len, kernel_size=1, bias=True)# self.end_conv2 = nn.Conv1d(in_channels=d_model, out_channels=c_out, kernel_size=1, bias=True)self.projection = nn.Linear(args.d_model, args.c_out, bias=True)def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):enc_out = self.enc_embedding(x_enc, x_mark_enc)enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)dec_out = self.dec_embedding(x_dec, x_mark_dec)dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)dec_out = self.projection(dec_out)# dec_out = self.end_conv1(dec_out)# dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2)if self.output_attention:return dec_out[:, -self.pred_len:, :], attnselse:return dec_out[:, -self.pred_len:, :] # [B, L, D]
观察forward,主要的输入为x_enc, x_mark_enc, x_dec, x_mark_dec,下边依次介绍:
- x_enc: 编码器输入,大小为
(batch_size, seq_len, enc_in),在这篇文章中,我们使用前96个时刻的所有13个变量预测未来24个时刻的所有13个变量,所以这里x_enc的输入应该是(batch_size, 96, 13)。 - x_mark_enc:编码器的时间戳输入,大小分情况,本文中采用频率freq='h’的TimeFeatureEmbedding编码方式,所以应该输入[‘month’, ‘day’, ‘weekday’, ‘hour’],大小为
(batch_size, 96, 4)。 - x_dec,解码器输入,大小为
(batch_size, label_len+pred_len, dec_in),其中dec_in为解码器输入的变量个数,也为13。在Informer中,为了避免step-by-step的解码结构,作者直接将x_enc中后label_len个时刻的数据和要预测时刻的数据进行拼接得到解码器输入。在本次实验中,由于需要预测未来24个时刻的数据,所以pred_len=24,向前看48个时刻,所以label_len=48,最终解码器的输入维度应该为(batch_size, 48+24=72, 13)。 - x_mark_dec,解码器的时间戳输入,大小为
(batch_size, 72, 4)。
为了方便理解编码器和解码器的输入,给一个具体的例子:假设某个样本编码器的输入为1-96时刻的所有13个变量,即x_enc大小为(96, 13),x_mark_enc大小为(96, 4),表示每个时刻的[‘month’, ‘day’, ‘weekday’, ‘hour’];解码器输入为编码器输入的后label_len=48+要预测的pred_len=24个时刻的数据,即49-120时刻的所有13个变量,x_dec大小为(72, 13),同理x_mark_dec大小为(72, 4)。
为了防止数据泄露,在预测97-120时刻的数据时,解码器输入x_dec中不能包含97-120时刻的真实数据,在原文中,作者用24个0或者24个1来代替,代码如下:
if args.padding == 0:dec_input = torch.zeros([seq_y.shape[0], args.pred_len, seq_y.shape[-1]]).float().to(args.device)
elif args.padding == 1:dec_input = torch.ones([seq_y.shape[0], args.pred_len, seq_y.shape[-1]]).float().to(args.device)
else:raise ValueError('padding must be 0 or 1')
dec_input = torch.cat([seq_y[:, :args.label_len, :], dec_input], dim=1).float()
参数padding 可选,为0则填充0,否则填充1。
IV. 实验
首先是数据处理,原始Informer中的数据处理和我之前写的30多篇文章的数据处理过程不太匹配,因此这里重写了数据处理过程,代码如下:
def get_data(args):print('data processing...')data = load_data()# splittrain = data[:int(len(data) * 0.6)]val = data[int(len(data) * 0.6):int(len(data) * 0.8)]test = data[int(len(data) * 0.8):len(data)]scaler = StandardScaler()def process(dataset, flag, step_size, shuffle):# 对时间列进行编码df_stamp = dataset[['date']]df_stamp.date = pd.to_datetime(df_stamp.date)data_stamp = time_features(df_stamp, timeenc=1, freq=args.freq)data_stamp = torch.FloatTensor(data_stamp)# 接着归一化# 首先去掉时间列dataset.drop(['date'], axis=1, inplace=True)if flag == 'train':dataset = scaler.fit_transform(dataset.values)else:dataset = scaler.transform(dataset.values)dataset = torch.FloatTensor(dataset)# 构造样本samples = []for index in range(0, len(dataset) - args.seq_len - args.pred_len + 1, step_size):# train_x, x_mark, train_y, y_marks_begin = indexs_end = s_begin + args.seq_lenr_begin = s_end - args.label_lenr_end = r_begin + args.label_len + args.pred_lenseq_x = dataset[s_begin:s_end]seq_y = dataset[r_begin:r_end]seq_x_mark = data_stamp[s_begin:s_end]seq_y_mark = data_stamp[r_begin:r_end]samples.append((seq_x, seq_y, seq_x_mark, seq_y_mark))samples = MyDataset(samples)samples = DataLoader(dataset=samples, batch_size=args.batch_size, shuffle=shuffle, num_workers=0, drop_last=False)return samplesDtr = process(train, flag='train', step_size=1, shuffle=True)Val = process(val, flag='val', step_size=1, shuffle=True)Dte = process(test, flag='test', step_size=args.pred_len, shuffle=False)return Dtr, Val, Dte, scaler
实验设置:本次实验选择LSTM以及Transformer来和Informer进行对比,其中LSTM采用直接多输出方式,Transformer又分为Encoder-Only和Encoder-Decoder架构。
使用前96个时刻的所有13个变量预测未来24个时刻的所有13个变量,只给出第一个变量也就是负荷这一变量的MAPE结果:
| LSTM | Encoder-only | Encoder-Decoder | Informer |
|---|---|---|---|
| 10.34% | 8.01% | 8.54% | 7.41% |
由于没有进行调参,实验结果仅供参考。可以发现LSTM在长序列预测上表现不好,而Transformer和Informer表现都比较优秀,其中Informer效果最好。
相关文章:

PyTorch搭建Informer实现长序列时间序列预测
目录 I. 前言II. InformerIII. 代码3.1 输入编码3.1.1 Token Embedding3.1.2 Positional Embedding3.1.3 Temporal Embedding 3.2 Encoder与Decoder IV. 实验 I. 前言 前面已经写了很多关于时间序列预测的文章: 深入理解PyTorch中LSTM的输入和输出(从i…...

firefox切换本地服务和全球服务的方法
方法1:“设置”>“同步">“切换全球/本地服务器” https://jingyan.baidu.com/article/1974b2898523bbb5b1f774e2.html 方法2:地址栏输入about:config,搜索首选项名称里输入identity.fxaccounts.autoconfig.uri,填入…...
Windows下用CMake编译PugiXML及配置测试
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 PugiXML是什么? PugiXML 是一个用于解析和操作 XML 文档的 C 库。它提供了简单易用的接口,能够高效地加载…...

python-基础篇-字符串、列表、元祖、字典-列表
文章目录 2.3.2列表2.3.2.1列表介绍2.3.2.1.1列表的格式2.3.2.1.2打印列表 2.3.2.2列表的增删改查2.3.2.2.1列表的遍历2.3.2.2.1.1使用for循环2.3.2.2.1.2使用while循环 2.3.2.2.2添加元素("增"append, extend, insert)2.3.2.2.2.1append 2.3.2.2.2.2extend2.3.2.2.2…...
)
Qt控件样式设置其一(常见方法及优缺点)
如果你对Qt有基本的了解,应该知道它的一大优点是跨平台,可以在不同的系统中编译运行。但在我看来,Qt还有另外一个优点,就是制作界面比较方便和灵活,能够实现主流静态效果的桌面应用。(如果需要实现比较灵动…...

软件测试(测试用例详解)(三)
1. 测试用例的概念 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合。 测试环境操作步骤测试数据预取结果 测试用例的评价标准: 用例表达清楚,无二义性。。用例可操作性强。用例的输入与输出明确。一条用例只有…...
最优算法100例之33-字符串/数字的排列组合问题
专栏主页:计算机专业基础知识总结(适用于期末复习考研刷题求职面试)系列文章https://blog.csdn.net/seeker1994/category_12585732.html 题目描述 字符串/数字的排列组合问题 void dfs(int deep){if(deep == n){//输出}for(int i = 0; i < n; i++){if(flag[i] == 0){d[d…...

Java面试题:请解释Java中的多线程编程?
Java中的多线程编程允许 concurrently 执行多个线程,从而可以同时执行多个任务,提高程序的效率和响应性。在Java中,线程可以通过以下两种主要方式来实现: 继承 Thread 类实现 Runnable 接口 继承 Thread 类 class MyThread ext…...

acwing算法提高之图论--最小生成树的扩展应用
目录 1 介绍2 训练 1 介绍 本专题用来记录使用最小生成树算法(prim或kruskal)解决的扩展题目。 2 训练 题目1:1146新的开始 C代码如下, #include <iostream> #include <cstring> #include <algorithm>usin…...
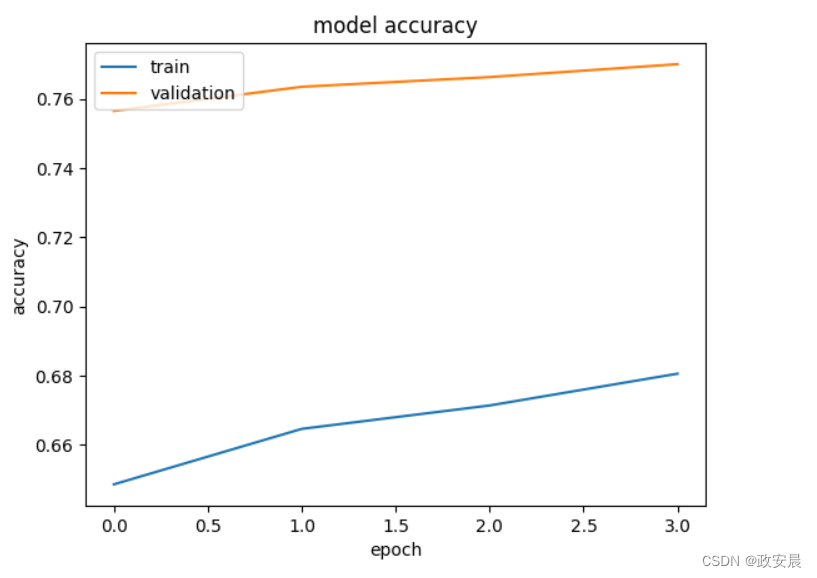
政安晨:【Keras机器学习实践要点】(十七)—— 利用 EfficientNet 通过微调进行图像分类
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras机器学习实战 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文目标: 使用 EfficientNet 和在图…...

wordpress全站开发指南-面向开发者及深度用户(全中文实操)--php函数
php函数 wordpress会封装一部分函数,比如bloginfo该函数的作用是直接调用你设置的你的网站的名称 示例 This is our amazing custom theme <?php echo 22; function myfirstfunction(){ echo 33; echo "<p>Hello ,this is my first function</…...
机制)
Linux 设备驱动管理之内核对象(Kernel Object)机制
Linux 设备驱动管理之内核对象(Kernel Object)机制 Linux内核是一个复杂的系统,它通过一系列的机制和结构体来管理和表示系统中的资源。其中一个关键的概念是“内核对象”(Kernel Object,简称kobject)。本文将深入探讨kobject机制…...

【C语言】关键字选择题
前言 题目一: 题目二: 题目三: 题目四: 题目五: 题目六: 前言 关于C语言关键字相关的选择题 题目一: 用在switch语言中的关键字不包含哪个?( ) A .continue B .break C .defa…...
营销中的归因人工智能
Attribution AI in marketing 归因人工智能作为智能服务的一部分,是一种多渠道算法归因服务,根据特定结果计算客户互动的影响和增量影响。有了归因人工智能,营销人员可以通过了解每个客户互动对客户旅程每个阶段的影响来衡量和优化营销和广告…...

ChatGPT 的核心 GPT 模型:探究其生成式预训练变换架构的革新与应用潜力
GPT(Generative Pre-trained Transformer)模型是一种深度学习模型,由OpenAI于2018年首次提出,并在随后的几年中不断迭代发展,包括GPT-2、GPT-3以及最新的GPT-4。GPT模型在自然语言处理(NLP)领域…...
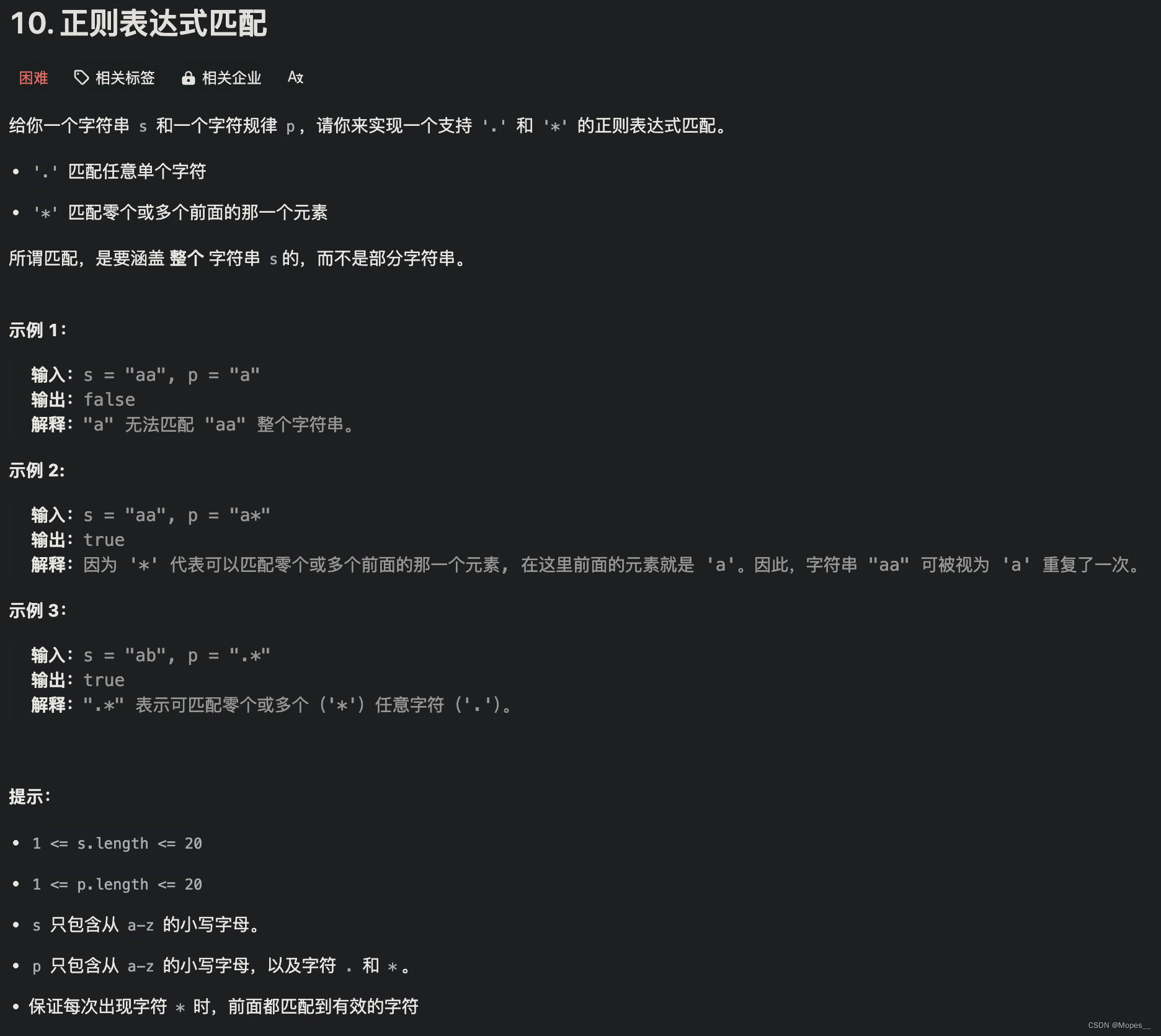
Python | Leetcode Python题解之第10题正则表达式匹配
题目: 题解: class Solution:def isMatch(self, s: str, p: str) -> bool:m, n len(s), len(p)dp [False] * (n1)# 初始化dp[0] Truefor j in range(1, n1):if p[j-1] *:dp[j] dp[j-2]# 状态更新for i in range(1, m1):dp2 [False] * (n1) …...
华大单片机新建工程步骤
1.新建文件夹,比如00_LED 2.拷贝 hc32f460_ddl_Rev2.2.0\driver 到 00_LED 3.拷贝 hc32f460_ddl_Rev2.2.0\mcu\common 到 00_LED 4.拷贝 hc32f460_ddl_Rev2.2.0\example\ev_hc32f460_lqfp100_v2\gpio\gpio_output\source 到 00_LED 5.拷贝 hc32f460_ddl_Rev2.2.…...

设计模式:桥接模式
定义 桥接模式(Bridge Pattern)是一种结构型设计模式,它将抽象与实现分离,使它们可以独立地变化。在桥接模式中,抽象部分(Abstraction)包含对实现部分(Implementor)的引用,实现部分可以通过接口中的方法被抽象部分使用,但是具体的实现细节对于抽象部分来说是隐藏的…...

人脸识别:Arcface--loss+code
之前只接触过传统方法的人脸识别算法,本以为基于深度学习的方法会使用对比损失之类的函数进行训练,但是Arcface算法基于softmax进行了创新,本文未深究其详细的loss公式原理,在大致明白其方向下,运行了代码,…...
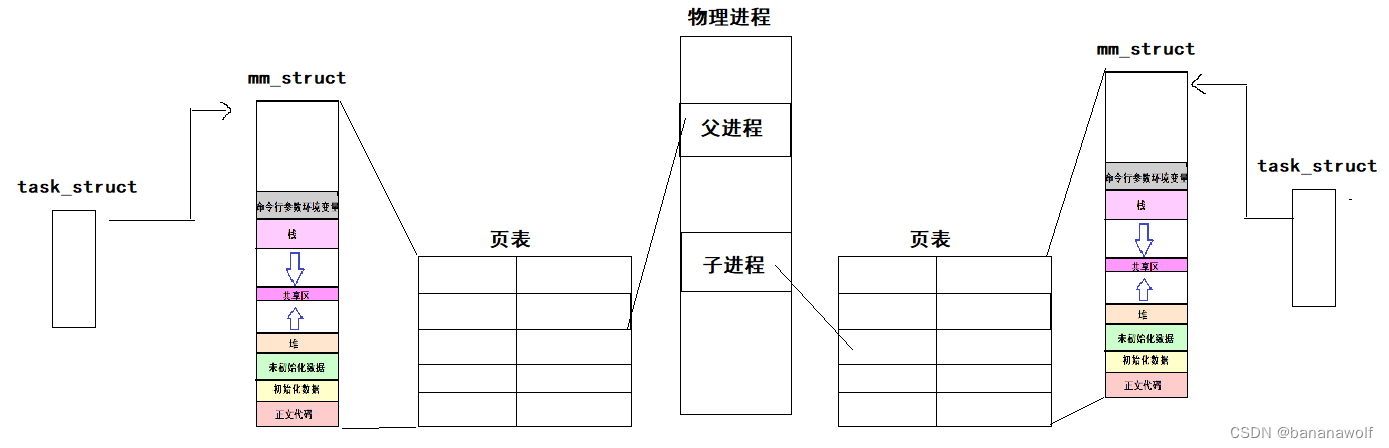
Linux-程序地址空间
目录 1. 程序地址空间分布 2. 两个问题 3. 虚拟地址和物理地址 4. 页表 5. 解决问题 6. 为什么要有地址空间 1. 程序地址空间分布 测试一下: #include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<sys/types.h>int ga…...

二供泵站设备全生命周期管理系统方案
在城镇居民二次供水管理体系中,泵房分散于各小区及大型建筑,管理部门长期面临“监管盲区、故障滞后、运维成本高”的突出矛盾。由于缺乏统一的远程监控手段,水泵运行状态、进出水压力、水箱液位、变频器参数等关键数据无法实时获取࿰…...

AGIAgent框架实践:从LLM到可编程智能体的工程化之路
1. 项目概述:从AGI到AGIAgent的实践跨越最近在GitHub上看到一个挺有意思的项目,叫agi-hub/AGIAgent。光看名字,可能很多朋友会立刻联想到“通用人工智能”或者“AI智能体”,觉得这又是一个宏大叙事下的概念性项目。但实际深入探究…...

Open3D内存检测终极指南:LeakSanitizer的完整应用教程
Open3D内存检测终极指南:LeakSanitizer的完整应用教程 【免费下载链接】Open3D Open3D: A Modern Library for 3D Data Processing 项目地址: https://gitcode.com/gh_mirrors/op/Open3D Open3D作为现代3D数据处理库,在处理大规模点云、网格等数据…...

微服务设计终极指南:从单体到分布式的服务拆分原则与实践
微服务设计终极指南:从单体到分布式的服务拆分原则与实践 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如…...

BilibiliDown实战指南:3大核心功能深度解析与高效下载方案
BilibiliDown实战指南:3大核心功能深度解析与高效下载方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirro…...

The Most Dangerous Writing App 快速入门指南:如何在5秒内开始高效写作
The Most Dangerous Writing App 快速入门指南:如何在5秒内开始高效写作 【免费下载链接】themostdangerouswritingapp If you stop typing for more than five seconds, all progress will be lost. 项目地址: https://gitcode.com/gh_mirrors/th/themostdangero…...

从Arduino AVR到ARM开发板迁移:选型、代码移植与无线通信实战指南
1. 开发板选型:从AVR到ARM的跨越与抉择当你第一次打开Arduino IDE,面对Boards Manager里琳琅满目的选项,是不是有点懵?从经典的Uno R3到各种带“Feather”、“M0”、“M4”后缀的板子,选错了可不是简单的“编译不通过”…...

Zotero插件市场:一站式管理插件的终极解决方案
Zotero插件市场:一站式管理插件的终极解决方案 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 还在为Zo…...

黎巴嫩五大核心港口:贝鲁特港、的黎波里港等
黎巴嫩三大核心港口——贝鲁特港、的黎波里港与赛达港,分工明确、互补发力,承担全国进出口货运重任,是中东航运与区域贸易的关键枢纽。一、贝鲁特港(LBBEY):全国第一大港、中东航运枢纽贝鲁特港位于贝鲁特北…...

出口黎巴嫩必知:清关要求与税费标准
黎巴嫩清关需备齐提单、发票、原产地证等文件,经申报、审查、缴税、查验后放行。关税优惠覆盖旅游、农业、工业投资,助力企业降低成本。黎巴嫩清关流程准备清关文件装货单(Bill of Lading):船运公司签发的货物装船证明…...