Spark-Scala语言实战(13)
在之前的文章中,我们学习了如何在spark中使用键值对中的keys和values,reduceByKey,groupByKey三种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(12)-CSDN博客文章浏览阅读722次,点赞19次,收藏15次。今天开始的文章,我会带给大家如何在spark的中使用我们的键值对方法,今天学习键值对方法中的keys和values,reduceByKey,groupByKey三种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137385224今天的文章开始,我会继续带着大家如何在spark的中使用我们的键值对里的方法。今天学习键值对方法中的fullOuterJoin,zip,combineByKey三种方法。
目录
一、知识回顾
二、键值对方法
1.fullOuterJoin
2.zip
3.combineByKey
拓展-方法参数设置
一、知识回顾
上一篇文章中我们学习了键值对的三种方法,分别是keys和values,reduceByKey,groupByKey。
keys和values分别对应了我们的键与值。
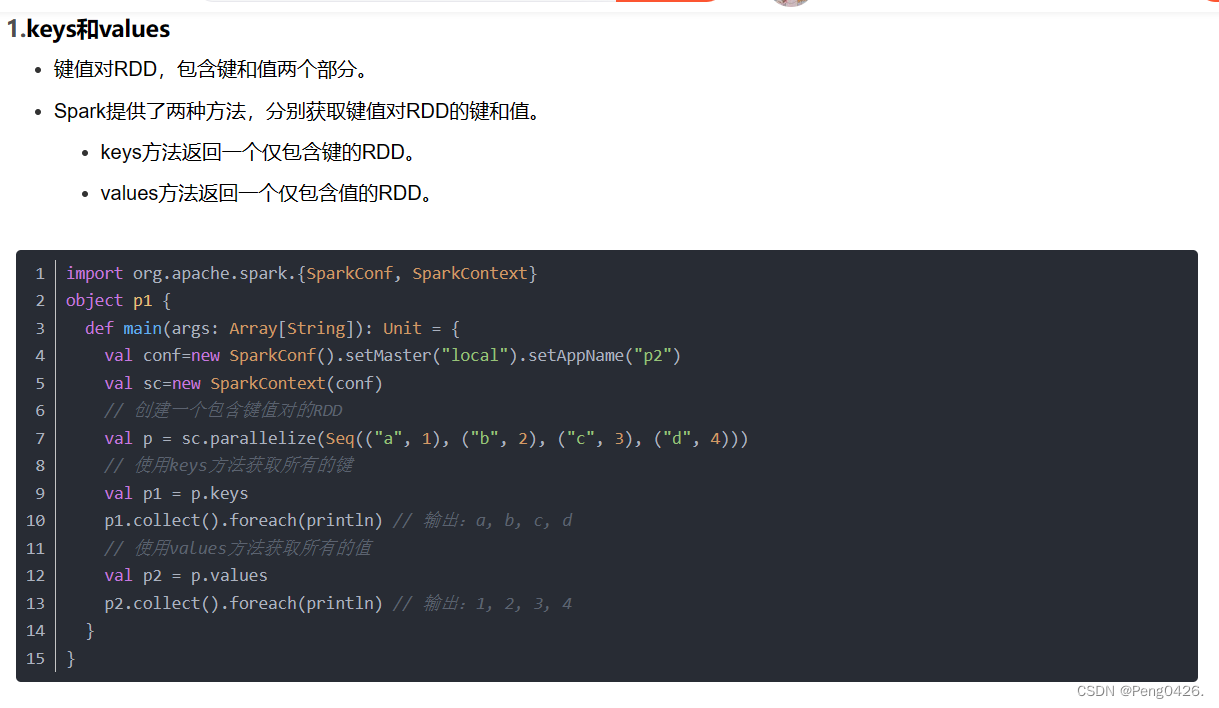
我们可以用它们来创建我们的RDD
reduceByKey可以进行统计,将有相同键的值进行相加,统一输出。
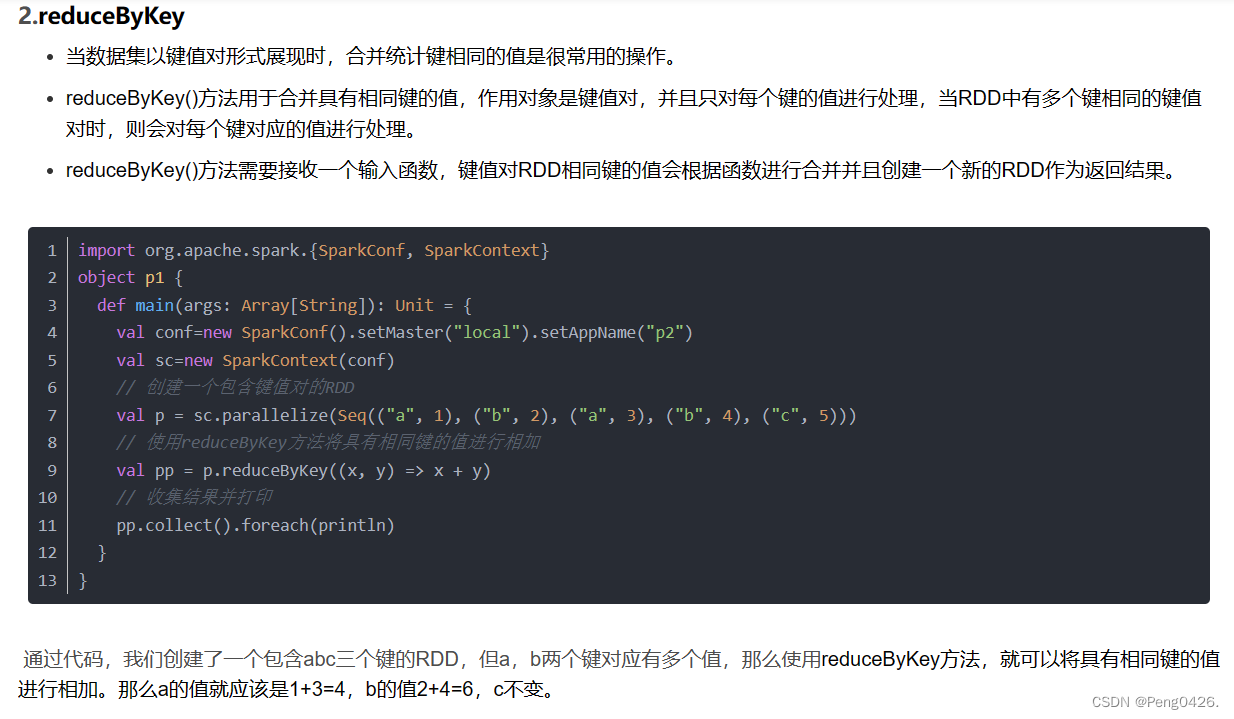
而 groupByKey方法就是对我们的键值对RDD进行分组了
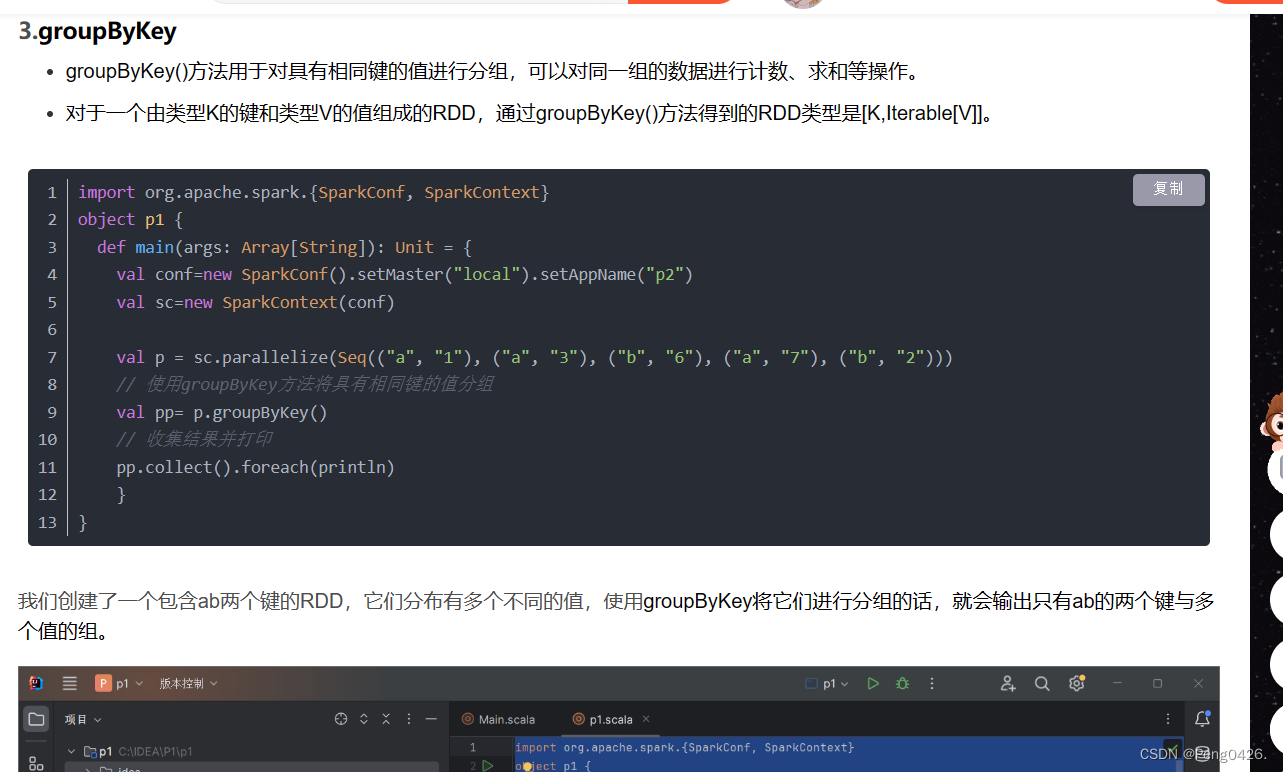
它可以将我们的相同的键,不同的值组合成一个组。
那么,开始今天的学习吧~
二、键值对方法
1.fullOuterJoin
- fullOuterJoin()方法用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)// 创建两个RDD(弹性分布式数据集)val p1 = sc.parallelize(Seq(("a1", "1"), ("a2", "2"), ("a3", "3")))val p2 = sc.parallelize(Seq(("a2", "A"), ("a3", "B"), ("a4", "C")))// 将RDD转换为键值对val pp1 = p1.map { case (key, value) => (key, value) }val pp2 = p2.map { case (key, value) => (key, value) }// 执行fullOuterJoin操作val ppp = pp1.fullOuterJoin(pp2)// 收集结果并打印ppp.collect().foreach(println)}
}我们的代码创建了两个键值对RDD,那么使用 fullOuterJoin方法全外连接那么两个键值对都会连接。
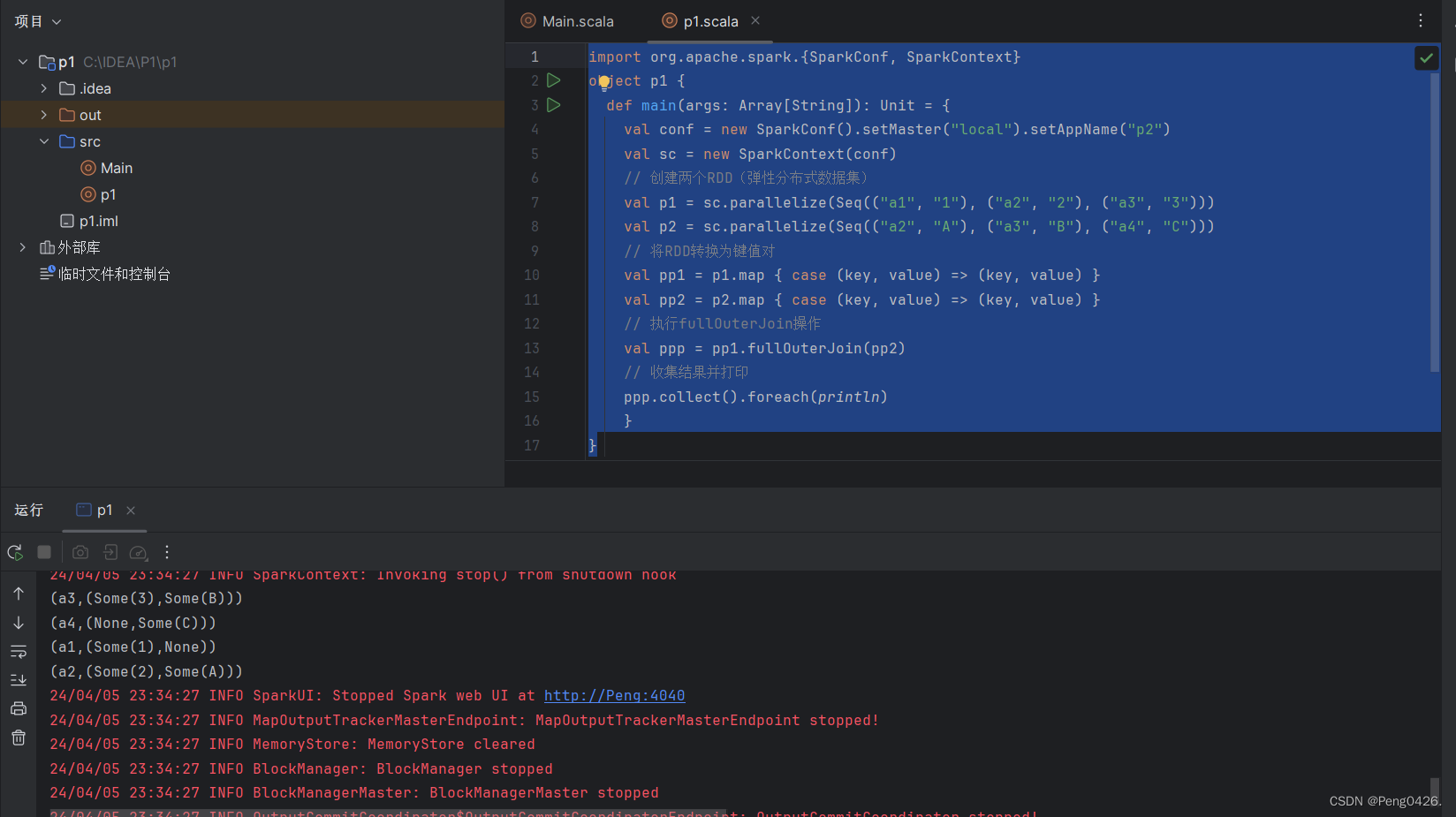
可以看到两个键值对里的键与值都连接上了,互相没有的值即显示None值。
2.zip
- zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。
- 将两个RDD组合成Key/Value形式的RDD,这里要求两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)// 创建两个RDDval p1 = sc.parallelize(Seq(1, 2, 3))val p2 = sc.parallelize(Seq("a", "b", "c"))// 使用zip方法将两个RDD组合在一起val pp1 = p1.zip(p2)val pp2 = p2.zip(p1)// 收集结果并打印pp1.collect().foreach(println)pp2.collect().foreach(println)}
}代码创建了两个不同的RDD键值对,分别使用p1zip方法p2与p2zip方法p1,那么它们输出的结果会是一样的吗?
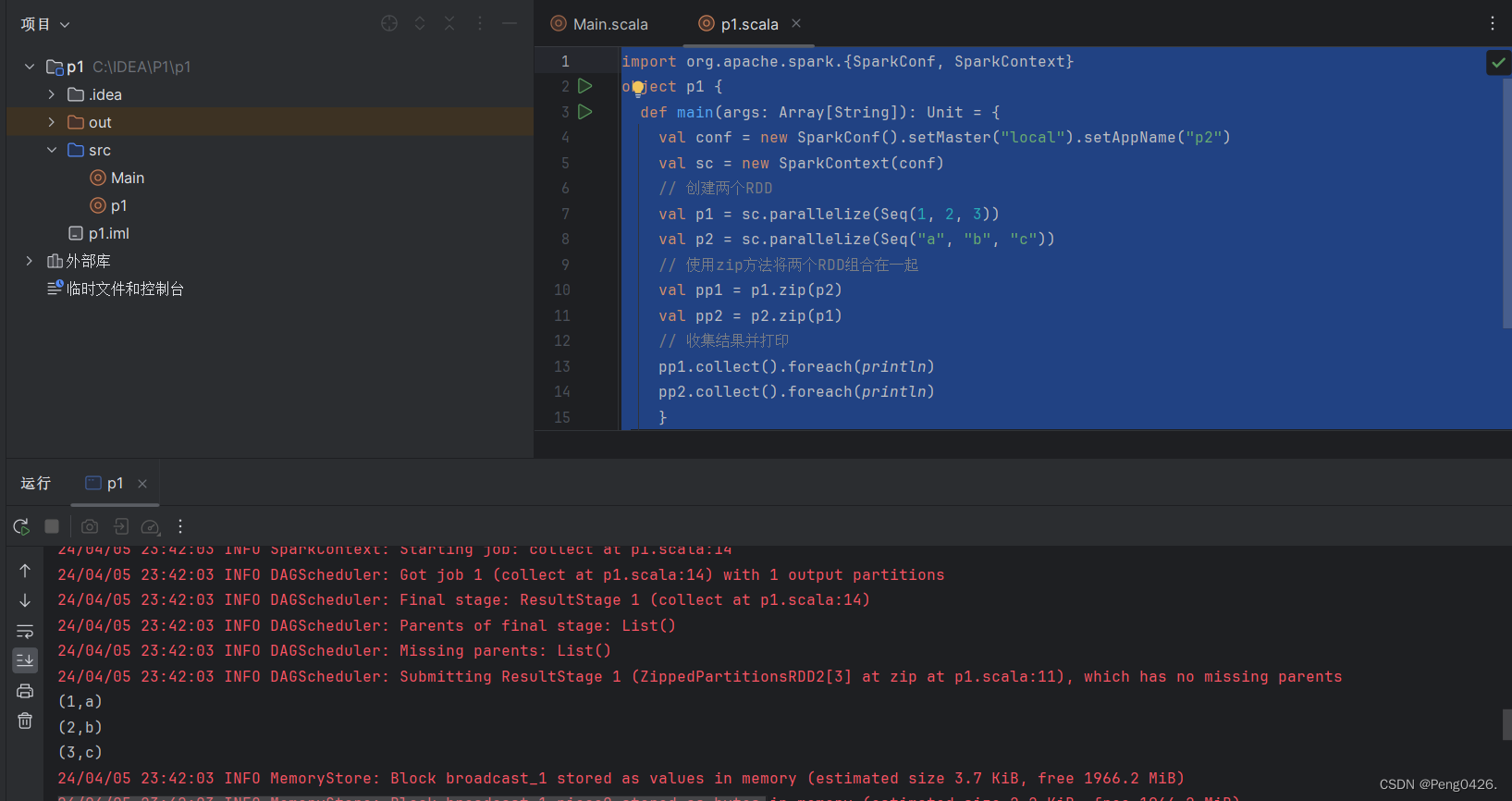
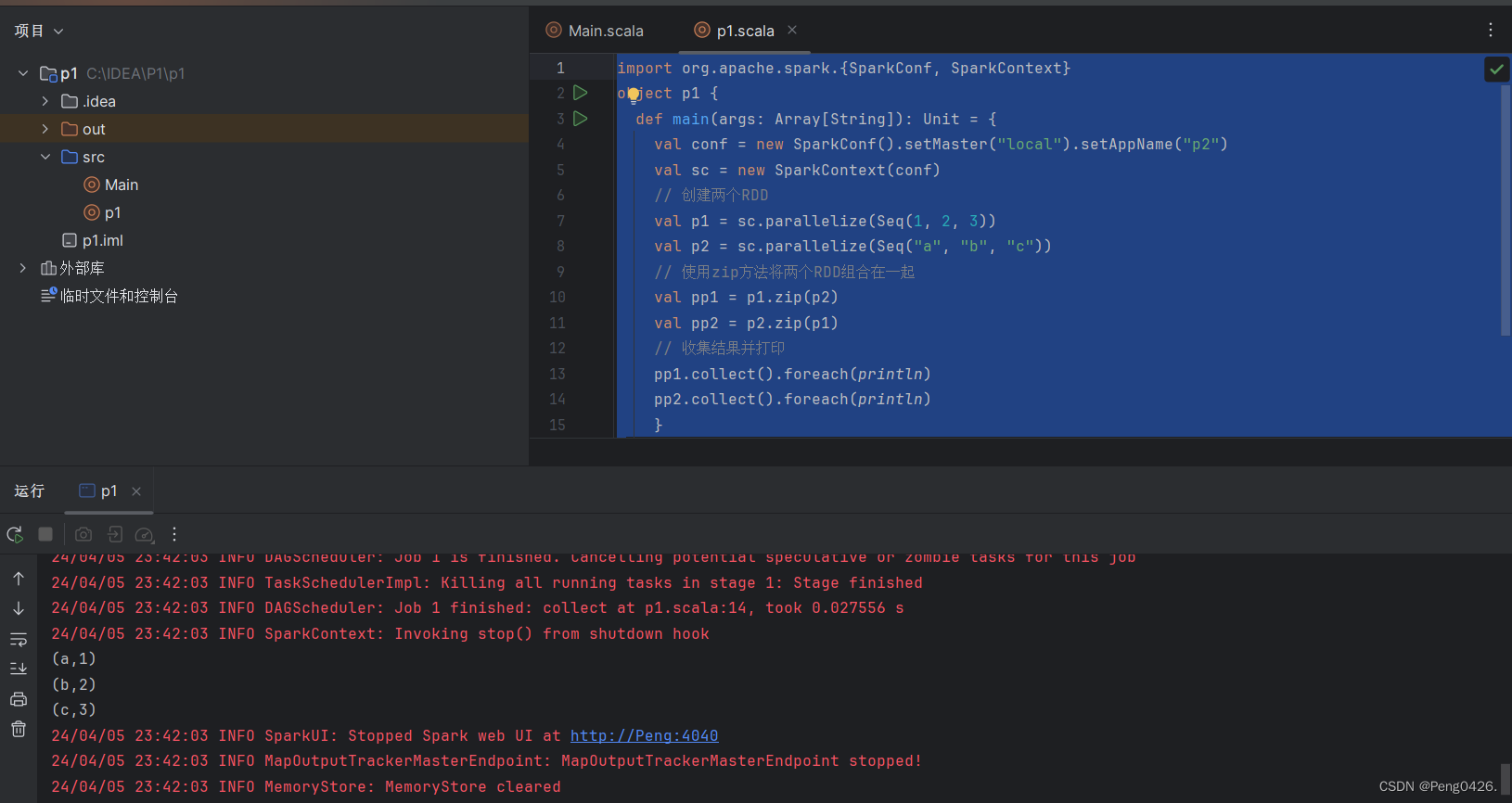
可以看到是不一样的,谁在前面谁就是键,反之是值。
3.combineByKey
- combineByKey()方法是Spark中一个比较核心的高级方法,键值对的其他一些高级方法底层均是使用combineByKey()方法实现的,如groupByKey()方法、reduceByKey()方法等。
- combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。
- combineByKey()方法的使用方式如下。
- combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)val p1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4), ("c", 5)))val p2 = p1.combineByKey(// createCombiner: 将第一个值转换为累加器(v: Int) => v,// mergeValue: 将新的值加到累加器上(c: Int, v: Int) => c + v,// mergeCombiners: 合并两个累加器(c1: Int, c2: Int) => c1 + c2)p2.collect().foreach { case (key, value) =>println(s"Key: $key, Value: $value")}}
}我的代码中:
createCombiner: 这个函数定义了如何将每个键的第一个值转换为初始的累加器值。
代表着每个键,第一个出现的值将作为累加器的初始值。
mergeValue: 这个函数定义了如何将新值与当前的累加器值合并。在我的代码中,我将新值与累加器相加。
代表着每个键的后续值,它们都会被加到当前的累加器值上。
mergeCombiners: 这个函数定义了当两个累加器(对应于同一个键但可能来自不同的分区)需要合并时应该执行的操作。在我的代码中,也是将两个累加器值相加
这确保了无论数据如何在分区之间分布,最终每个键都会得到正确的累加结果。
看看输出效果
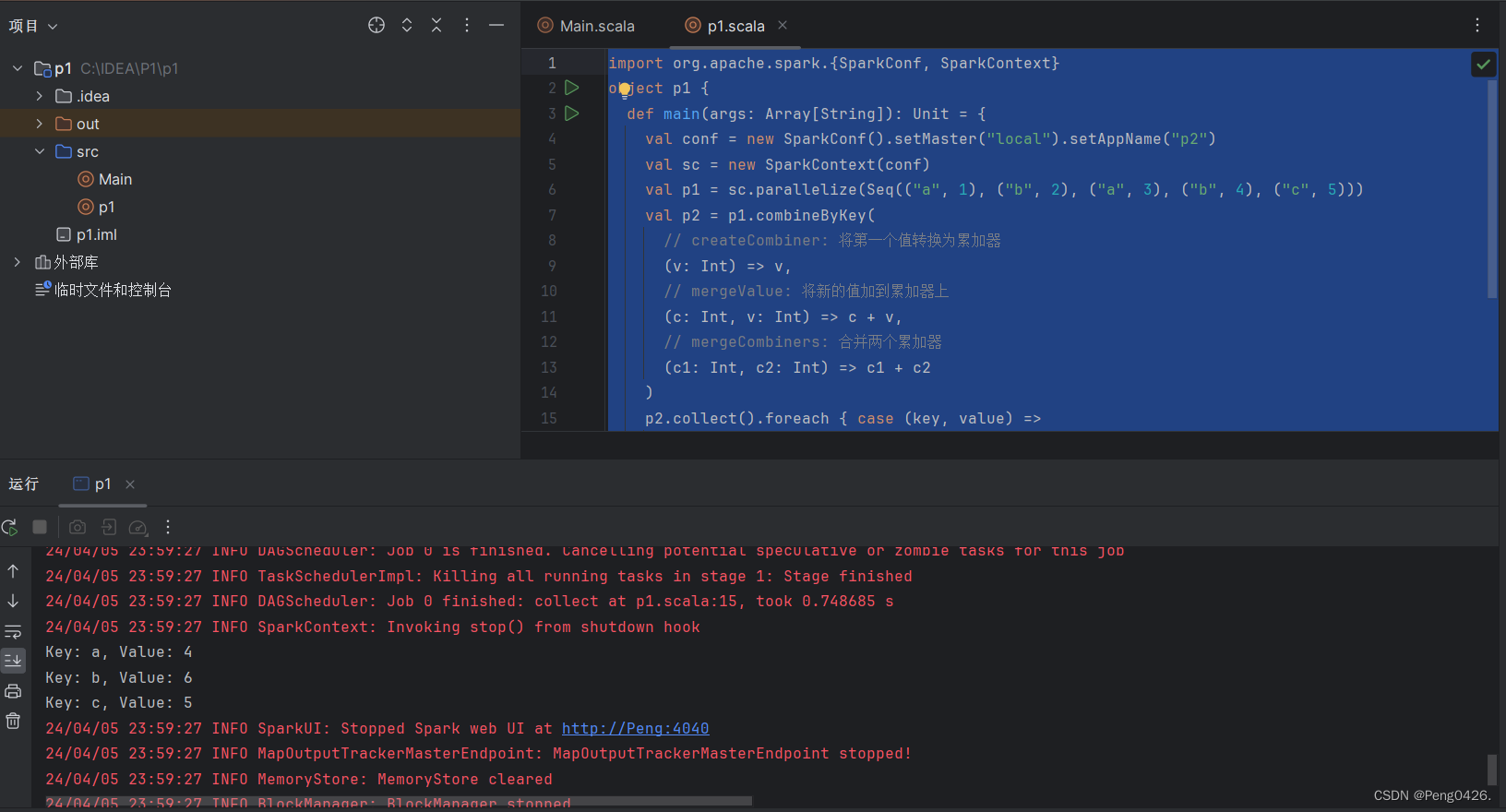
可以看到我们的键值对成功累加。
快去试试吧~
拓展-方法参数设置
| 方法 | 参数 | 描述 | 例子 |
|---|---|---|---|
| fullOuterJoin | otherRDD | 另一个要与之进行全外连接的RDD | rdd1.fullOuterJoin(rdd2) |
| fullOuterJoin | numPartitions | 结果RDD的分区数(可选) | rdd1.fullOuterJoin(rdd2, numPartitions=10) |
| zip | otherRDD | 要与之进行zip操作的另一个RDD | rdd1.zip(rdd2) |
| combineByKey | createCombiner | 处理第一个出现的每个键的值的函数 | lambda v: (v, 1) |
| combineByKey | mergeValue | 合并具有相同键的值的函数 | lambda acc, v: (acc[0] + v, acc[1] + 1) |
| combineByKey | mergeCombiners | 合并两个累积器的函数 | lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]) |
| combineByKey | numPartitions | 结果RDD的分区数(可选) | rdd.combineByKey(createCombiner, mergeValue, mergeCombiners, numPartitions=5) |
相关文章:
Spark-Scala语言实战(13)
在之前的文章中,我们学习了如何在spark中使用键值对中的keys和values,reduceByKey,groupByKey三种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢…...

Android compose 使用指纹验证
基于compose进行指纹验证 点击按钮进行验证 Button(onClick {var passed falseval biometic BiometricPrompt.Builder(applicationContext).setTitle("使用指纹解锁App").setSubtitle("证明你是手机的主人").setNegativeButton("取消验证",…...
开源模型应用落地-chatglm3-6b模型小试-入门篇(一)
一、前言 刚开始接触AI时,您可能会感到困惑,因为面对众多开源模型的选择,不知道应该选择哪个模型,也不知道如何调用最基本的模型。但是不用担心,我将陪伴您一起逐步入门,解决这些问题。 在信息时代…...

C++实现单例模式
#include <iostream> class Singleton { private: static Singleton* instance; // 指向单例实例的指针 Singleton() {} // 私有构造函数 public: // 获取单例对象的唯一全局访问点 static Singleton* getInstance() { if (instance nullpt…...

虚幻UE5智慧城市全流程开发教学
一、背景 这几年,智慧城市/智慧交通/智慧水利等飞速发展,骑士特意为大家做了一个这块的学习路线。 二、这是学习大纲 1.给虚幻UE5初学者准备的智慧城市/数字孪生蓝图开发教程 https://www.bilibili.com/video/BV1894y1u78G 2.UE5数字孪生蓝图开发教学…...
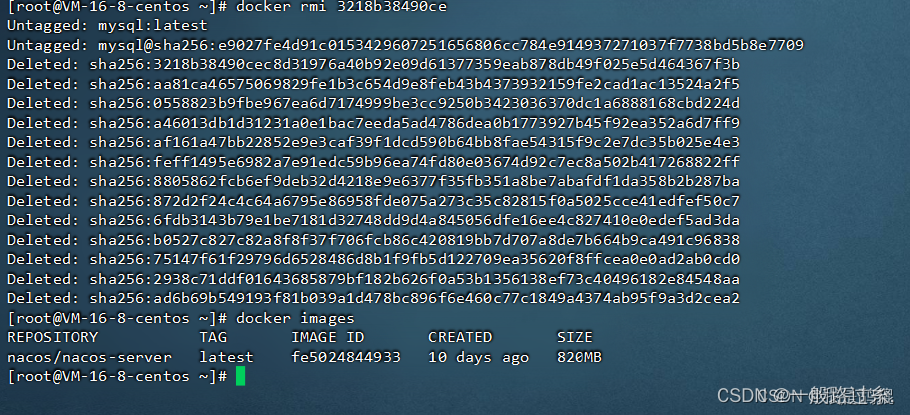
docker的安装及入门指令
目录 一、将docker安装到云服务器步骤 1.更新系统yum版本 2.安装所需依赖 3.添加docker仓库设置(使用的是阿里云) 4.安装docker引擎 5.启动docker并开启自动启动 6. 检查是否安装成功,成功会显示相应版本,否则安装失败 二、docker常用命令 1.从…...

聚能共创下一代智能终端操作系统 软通动力荣膺“OpenHarmony优秀贡献单位”
近日,由开放原子开源基金会指导,以“开源共享未来”为主题的OpenHarmony社区年会在北京成功举办。本次活动汇集OpenHarmony项目群共建单位及生态伙伴等多方力量,旨在对2023年度OpenHarmony年度开源事业全面总结的同时,吸引更多伙伴…...

云服务器ECS租用价格表报价——阿里云
阿里云服务器租用价格表2024年最新,云服务器ECS经济型e实例2核2G、3M固定带宽99元一年,轻量应用服务器2核2G3M带宽轻量服务器一年61元,ECS u1服务器2核4G5M固定带宽199元一年,2核4G4M带宽轻量服务器一年165元12个月,2核…...
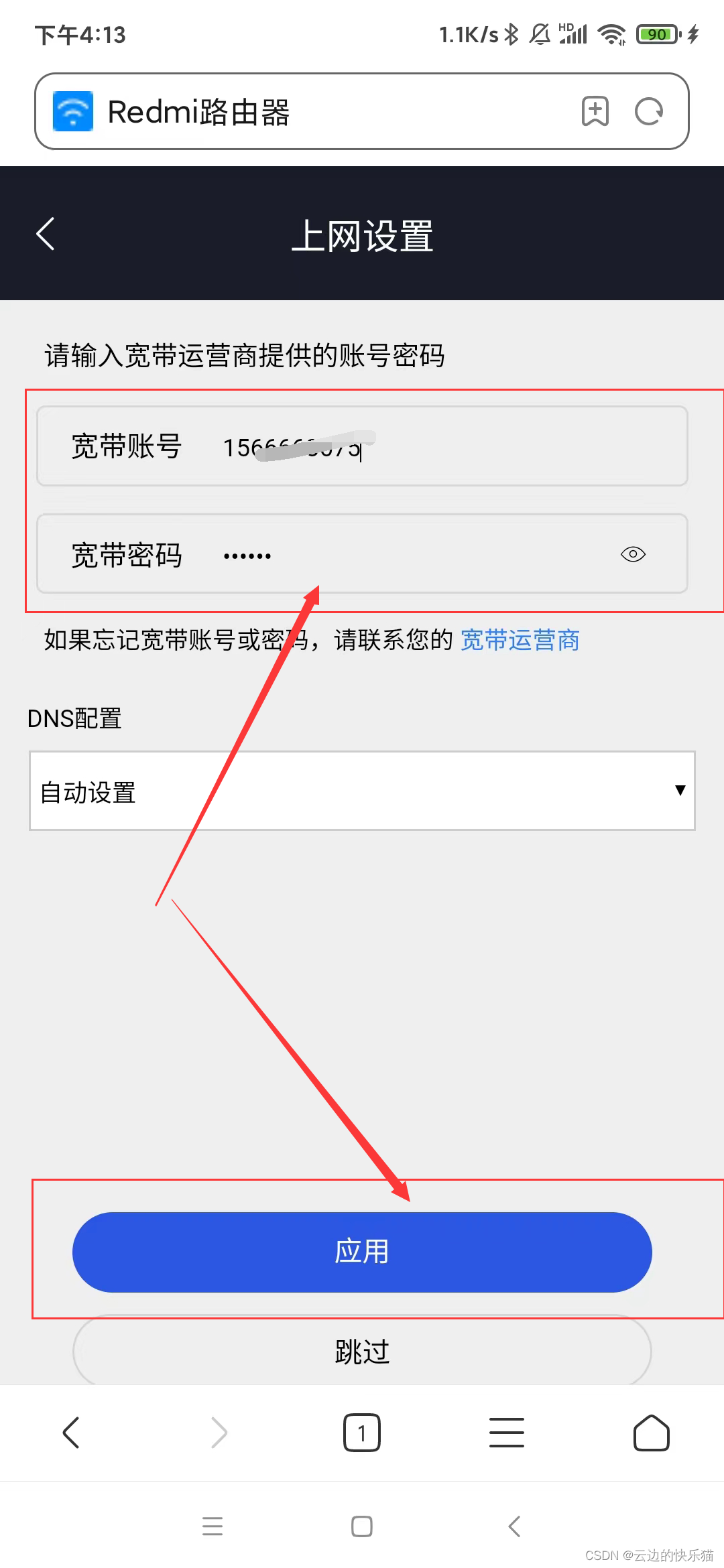
光猫桥接模式详细步骤
目录 一、前言 路由模式 (宽带默认) 桥接模式 二、桥接模式步骤 (一)图片记录备份 设备信息图 网络侧信息 远程管理密码 宽带上网设置 (二)桥接模式开始 光猫设置 路由器设置 一、前言 重点&a…...

构建开源可观测平台
企业始终面临着确保 IT 基础设施和应用程序全年可用的压力。现代架构(容器、混合云、SOA、微服务等)的复杂性不断增长,产生大量难以管理的日志。我们需要智能应用程序性能管理 (APM) 和可观察性工具来实现卓越生产并满足可用性和正常运行时间…...

SketchUp Pro 2024 for mac 草图大师 专业的3D建模软件
SketchUp Pro 2024 for Mac是一款功能强大的三维建模软件,适用于Mac电脑。其简洁易用的界面和强大的工具集使得用户可以轻松创建复杂的3D模型。 软件下载:SketchUp Pro 2024 for mac v24.0.483 激活版下载 SketchUp Pro 2024 for Mac支持导入和导出多种文…...
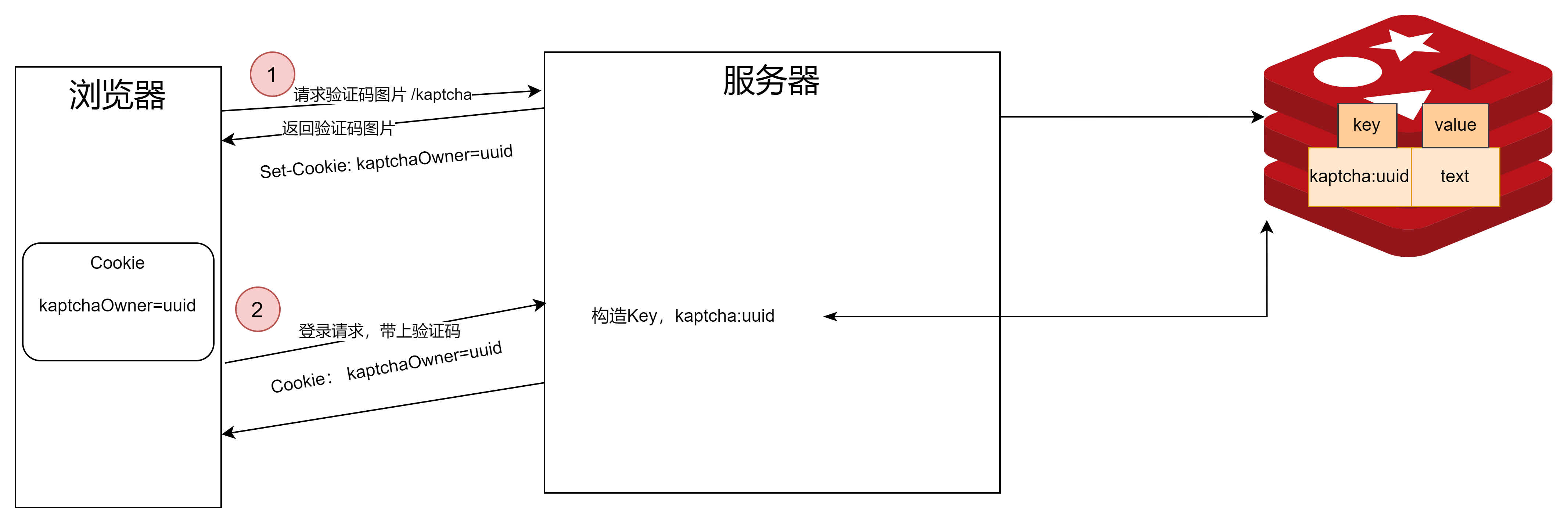
通过 Cookie、Redis共享Session 和 Spring 拦截器技术,实现对用户登录状态的持有和清理(三)
本篇内容对应 “2.4 生成验证码” 小节 和 “4.7 优化登陆模块”小节 视频链接 1 Kaptcha介绍 Kaotcga是一个生成验证码的工具。 你的网站验证码是什么? 在我们这个牛客论坛项目,验证码分为两部分 给用户看的是图片,用户根据图片上显示的…...
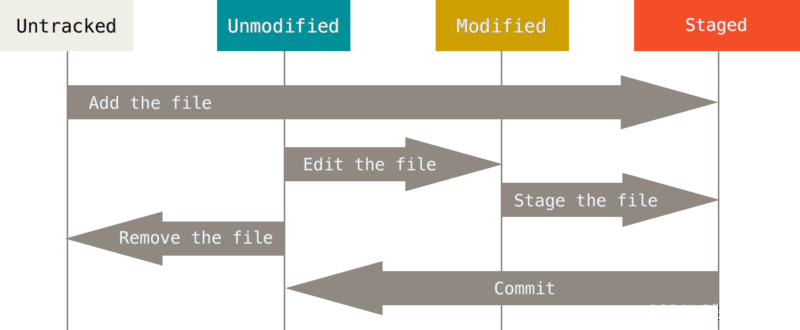
学习 Git 基础知识 - 日常开发任务手册
欢迎来到我关于 Git 的综合指南,Git 是一种分布式版本控制系统,已经在软件开发中彻底改变了协作和代码管理方式。 无论你是经验丰富的开发者还是刚开始编程之旅的新手,理解 Git 对于正确掌控代码、高效管理项目和与他人合作至关重要。 在本…...

pip和conda 设置安装源
pip和conda 设置安装源 conda查看 channels添加 channels移除 channelschannels 配置文件 pip查看 index-url添加 index-url移除 index-urlindex-url 配置文件 常用源 conda 查看 channels conda config --show channels添加 channels conda config --add channels https:/…...

数据分析之Logistic回归分析中的【多元有序逻辑回归】
1、定义 多元有序逻辑回归用于分析有序分类因变量与一个或多个自变量之间的关系。有序逻辑回归适用于因变量具有自然排序但没有固定间距的类别,例如疾病严重程度(轻度、中度、重度)或调查问卷中的满意度评分(非常不满意、不满意、…...
路由器拨号失败解决方法
目录 一、遇到问题 二、测试 三、解决方法 (一)路由器先单插wan口设置 (二)mac地址替换 (三)更改路由器DNS 一、遇到问题 1 .在光猫使用桥接模式,由路由器进行拨号的时候,出现…...
Oracle 中 where 和 on 的区别
1.Oracle 中 where 和 on 的区别 on:会先根据on后面的条件进行筛选,条件为真时返回该行,由于on的优先级高于left join,所以left join关键字会把左表中没有匹配的所有行也都返回,然后生成临时表返回,执行优先级高于…...

NLP学习路线总结
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学领域的一部分,它旨在让计算机能够理解、解释和生成人类语言。NLP学习路线可以大致分为以下几个步骤: 1. 基础知识准备 - 计算机科学知识:…...
AI绘图cuda与stable diffusion安装部署始末与避坑
stable diffusion的安装说起来很讽刺,最难的不是stable diffusion,而是下载安装cuda。下来我就来分享一下我的安装过程,失败了好几次,几近放弃。 一、安装cuda 我们都知道cuda是显卡CPU工作的驱动(或者安装官网的解释…...
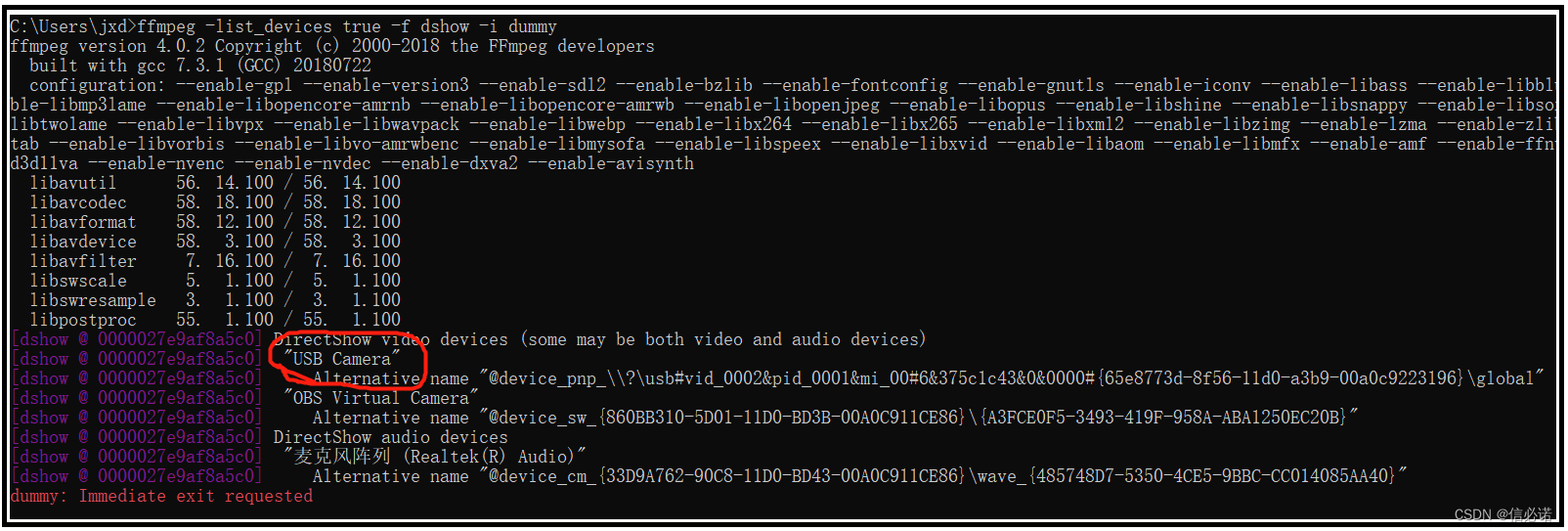
OpenCv —— cv::VideoCapture设置摄像头图像格式为“MJPEG“
背景 今天恰巧同事有台USB摄像头,她想要在Windows系统下通过OpenCV读取该摄像头宽高为1080x768、帧率为60的视频,用来做图像算法处理。但无奈通过网上OpenCV教程 读取的视频对应尺寸的帧率仅为10帧左右,根本无法满足使用要求。于是作者通过本篇文章介绍如何解决,欢迎交流指…...

BilibiliVideoDownload跨平台视频下载工具:从安装到高级配置的完整指南
BilibiliVideoDownload跨平台视频下载工具:从安装到高级配置的完整指南 【免费下载链接】BilibiliVideoDownload Cross-platform download bilibili video desktop software, support windows, macOS, Linux 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibil…...

3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南
3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 你是否曾经因为手头只有AMD显卡,却想运行那些需要CUDA加速的深度学习框架而感到无奈&…...

Matplotlib保存图片尺寸总不对?搞懂bbox_inches=‘tight‘与figsize的‘相爱相杀’,一篇就够了
Matplotlib保存图片尺寸总不对?搞懂bbox_inchestight与figsize的‘相爱相杀’,一篇就够了 当你精心设计了一个数据可视化图表,设置了完美的figsize(10, 8)和dpi100,期待得到一张1000x800像素的精美图片,却在保存时发现…...

热成像与计算机视觉融合:打造免提可穿戴交互新范式
1. 项目概述:从一次“意外”到可穿戴交互新范式 在实验室里摆弄新到的热成像相机,这原本只是一个打发时间的“快乐意外”。我的咖啡杯、显示器,甚至是我自己的脸,在热成像镜头下都呈现出有趣的温度图案。但真正让我停下手中咖啡的…...

芯片原型开发实战指南:从虚拟原型到FPGA的决策与调试
1. 原型决策前的核心考量:一份来自一线的深度清单在硬件和系统设计领域,原型开发是连接构想与现实的桥梁,但这座桥怎么搭、用什么材料、何时能通车,每一步都充满了抉择。很多团队在项目启动时,满腔热情地喊着“先做个原…...

为什么92%的用户调不出正宗120胶片感?揭秘Midjourney底层色彩映射矩阵与胶片光谱响应偏差
更多请点击: https://intelliparadigm.com 第一章:胶片感的视觉本质与数字复现困境 胶片感并非单一参数可定义的视觉效果,而是由卤化银晶体随机分布、显影化学反应非线性响应、颗粒噪点的空间相关性以及动态范围压缩特性共同构成的模拟物理现…...

5分钟终极指南:如何免费激活Windows和Office的完整解决方案
5分钟终极指南:如何免费激活Windows和Office的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统未激活的提示而烦恼吗?或者Office办公软件显…...

Book118文档下载器:3步免费获取完整PDF文档的终极指南
Book118文档下载器:3步免费获取完整PDF文档的终极指南 【免费下载链接】book118-downloader 基于java的book118文档下载器 项目地址: https://gitcode.com/gh_mirrors/bo/book118-downloader 你是否曾在Book118网站上找到急需的学习资料,却发现需…...

Bebas Neue:开源几何无衬线字体的现代设计实践指南
Bebas Neue:开源几何无衬线字体的现代设计实践指南 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue Bebas Neue 是一款基于几何设计的开源无衬线字体,专为标题、标语和视觉层次设计而优化。…...
)
手把手教你给天邑TY1608机顶盒刷机(S905L3B芯片,支持RTL8822CS/MT7668无线模块)
天邑TY1608机顶盒刷机全攻略:从零开始玩转S905L3B芯片 第一次拿到天邑TY1608机顶盒时,你可能被它原厂系统的各种限制所困扰——预装软件无法卸载、广告弹窗频繁出现、存储空间严重不足。这款搭载Amlogic S905L3B芯片的设备,配合RTL8822CS或MT…...