爬虫 新闻网站 以湖南法治报为例(含详细注释) V1.0
目标网站:湖南法治报
爬取目的:为了获取某一地区更全面的在湖南法治报已发布的宣传新闻稿,同时也让自己的工作更便捷
环境:Pycharm2021,Python3.10,
安装的包:requests,csv,bs4
v1.0 版本特点:获取指定页数的新闻数据,筛选出含有想要查找的的关键词的新闻内容,并存储起来。
1 首先分析网页
(查看数据返回方式,发现网站不用像红网那样设置各种headers了,可以直接爬)
发现在这个页面只有文章标题和发布时间,以及文章链接的信息(当然文章有图片的就还有图片信息)


2 再看文章内容页面
(像我就只要文字部分就行了,不需要图片)
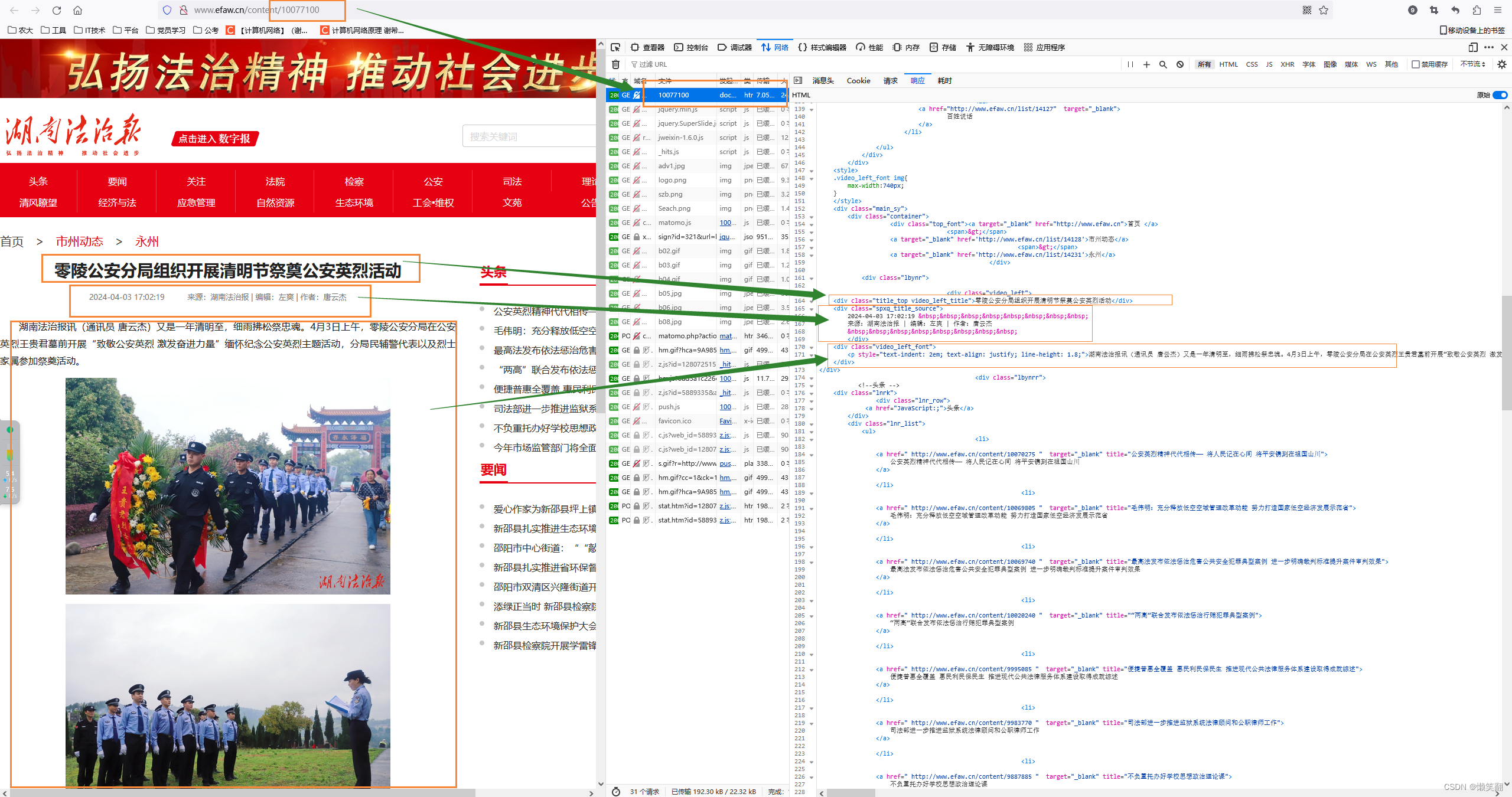
3 运行结果:
爬虫 新闻网站 以湖南法治报为例 V1.0
4 具体分析和实现请看代码(含详细注释):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/4/4 21:36
# @Author : LanXiaoFang
# @Site :
# @File : efaw.py
# @Software: PyCharm
import csv
import requests
from bs4 import BeautifulSoup# 由于发现湖南法治报没有设置反爬机制,因为我们不用反反爬了,可以直接爬数据了
# 市州动态 下的对应市州的编号
szId = {"长沙": "14129", "株洲": "14130", "湘潭": "14223", "衡阳": "14224", "邵阳": "14225", "岳阳": "14226", "常德": "14227","张家界": "14228", "益阳": "14229", "郴州": "14230", "永州": "14231", "怀化": "14232", "娄底": "14233", "湘西": "14234"}# 输入你想要获取的湖南省下的哪一市州的新闻 比如 湖南省下的永州市,直接输入 永州 即可
sz = "永州"
# 根据输入的湖南省下的市州 得到对应的市州编号 再拼接入链接
url = "http://www.efaw.cn/list/" + szId[sz]
# 输入你想要的关键词 比如 双牌、蓝山、宁远、新田、零陵
search_keyword = '双牌'
# 标题就含有关键词的计数器
title_Yes_Num = 0
# 标题不含有关键词但是内容含有关键词的计数器
title_No_Num = 0
# 新闻来源级别
level = "省级"
"""
爬虫思路:
首先最开始是打开要爬取的网站,然后分析怎样获取需要的数据最完整和便捷
一开始看到搜索其实是想直接搜关键词获取新闻的,但是发现通过搜索框获得到新闻数据不如市州动态下的全面,所以还是打算一条一条新闻比对是否符合自定义关键词
1 首先进入市州动态获取到某市州动态下的所有新闻数据
2 根据具体新闻链接进入新闻页面,获取到新闻信息
"""# # 创建CSV文件并写入头部信息
with open(search_keyword + '湖南法治报_标题含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源']) # 根据实际情况定义列名
with open(search_keyword + '湖南法治报_标题不含内容含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源']) # 根据实际情况定义列名# http://www.efaw.cn/list/14231?page=1
page = 1
while page <= 20: # 从这里修改数字以控制要多少页的新闻内容,,page<=20page从1开始一直到20# 拼接出每一页的urlurl_page = url + "?page=" + str(page)html_all = requests.get(url_page)html_all.encoding = 'utf-8'print(page, '页', url_page)if html_all.status_code == 200:soups = BeautifulSoup(html_all.text, 'html.parser')article_info = soups.find_all('ul', class_='list_content')for i in article_info:result_info = i.find_all('div')for art in result_info:article_href = art.a.get('href') # 文章链接print(article_href)article_title = art.a.get('title') # 文章标题article_time = art.i.text # 文章发布时间 显示为:发布时间:2024-04-02 10:08:03# 因为只要年月日部分的时间,因此把一些不需要的字符去掉article_time = article_time[2+article_time.index('间:'):]article_time = article_time[:article_time.index(':')-2]# 从文章内容中获取到来源html_article_info_sk = requests.get(article_href)html_article_info_sk.encoding = 'utf-8'if html_article_info_sk.status_code == 200:soups_sk = BeautifulSoup(html_article_info_sk.text, 'html.parser')article_info_sk = soups_sk.find_all('div', class_='video_left')# 其实在这里我想获取到具体的来源,这一段因为在新闻详情页面,如果 来源 为 双牌县优化办 ,那么这条新闻就是优化办推过去的spxq_title_source = soups_sk.find('div', class_='spxq_title_source').text# 文章信息来源 显示为: 来源:湖南法治报atricle_source = spxq_title_source[spxq_title_source.index('来源:')+3:spxq_title_source.index('|')]# 在这里可以从标题判断是否含有搜索的关键词search_keyword,如果有则可以直接存储这条新闻信息,如果没有则继续查看新闻内容,看是否含有关键词信息if search_keyword in article_title: # 标题判断含有搜索的关键词search_keywordtitle_Yes_Num += 1with open(search_keyword + '湖南法治报_标题含关键词.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_Yes_Num, article_title, "湖南法治报", level, article_time, article_href, atricle_source])print("Yes Tile have SK !!!!!", title_Yes_Num)print(title_Yes_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href, 'source:', atricle_source)else: # 标题判断不含搜索的关键词search_keywordif search_keyword in article_info_sk:title_No_Num += 1with open(search_keyword + '湖南法治报_标题不含内容含关键词.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_No_Num, article_title, "湖南法治报", level, article_time, article_href, atricle_source])print("Yes Content have SK !!!!!", article_info_sk)print(title_No_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href, 'source:', atricle_source)page += 1
相关文章:
爬虫 新闻网站 以湖南法治报为例(含详细注释) V1.0
目标网站:湖南法治报 爬取目的:为了获取某一地区更全面的在湖南法治报已发布的宣传新闻稿,同时也让自己的工作更便捷 环境:Pycharm2021,Python3.10, 安装的包:requests,csvÿ…...

物联网实战--入门篇之(十)安卓QT--后端开发
目录 一、项目配置 二、MQTT连接 三、数据解析 四、数据更新 五、数据发送 六、指令下发 一、项目配置 按常规新建一个Quick空项目后,我们需要对项目内容稍微改造、规划下。 首先根据我们的需要在.pro文件内添加必要的模块,其中quick就是qml了&…...
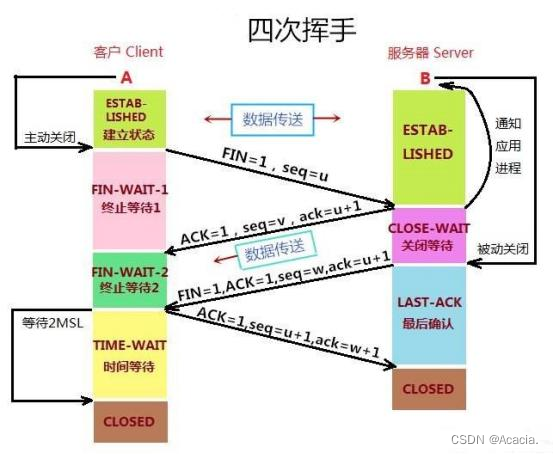
[Java]网络编程
网络编程概述 计算机网络: 把分布在不同地理区域的具有独立功能的计算机,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。 Java是 Internet 上的语言,它从语言级上提供了对网络应用程序的支持,程序…...

重读Java设计模式: 适配器模式解析
引言 在软件开发中,经常会遇到不同接口之间的兼容性问题。当需要使用一个已有的类,但其接口与我们所需的不兼容时,我们可以通过适配器模式来解决这一问题。适配器模式是一种结构型设计模式,它允许接口不兼容的类之间进行合作。本…...

MySQL面试题系列-9
MySQL是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的RDBMS (Relational Database Management System,关系数据…...

书生·浦语训练营二期第二次笔记
文章目录 1. 部署 InternLM2-Chat-1.8B 模型进行智能对话1.1 配置环境1.2 下载 InternLM2-Chat-1.8B 模型 2. 实战:部署实战营优秀作品 八戒-Chat-1.8B 模型2.1 配置基础环境2.2 使用 git 命令来获得仓库内的 Demo 文件:2.3 下载运行 Chat-八戒 Demo 3. …...

python_3
文章目录 题目运行结果模式A模式B模式C模式D 题目 mode input("请选择模式:") n int(input("请输入数字:"))if mode "A" or mode "a":# 模式A n:输入的层数 i:当前的层数# 每行数字循环次数 ifor i in range(1, n 1):for j in r…...

【Python】 使用Apache Tika和Python实现zip、csv、xls等多格式文件文本内容提取
时间的电影 结局才知道 原来大人已没有童谣 最后的叮咛 最后的拥抱 我们红着眼笑 我们都要把自己照顾好 好到遗憾无法打扰 好好的生活 好好的变老 好好假装我 已经把你忘掉 🎵 五月天《好好》 在进行数据分析、搜索引擎优化或任何需要处理大量…...

C语言如何将多维数组名作为函数参数?
一、问题 ⼦函数执⾏时,整个多维数组是由主函数决定的,这时就要把多维数组的数组名作为函数参数传递给⼦函数。那么在C程序中,怎样将多维数组名作函数参数进⾏传递? 二、解答 以⼆维数组为例,其格式如下。 形参定义&…...

2013年认证杯SPSSPRO杯数学建模C题(第二阶段)公路运输业对于国内生产总值的影响分析全过程文档及程序
2013年认证杯SPSSPRO杯数学建模 C题 公路运输业对于国内生产总值的影响分析 原题再现: 交通运输作为国民经济的载体,沟通生产和消费,在经济发展中扮演着极其重要的角色。纵观几百年来交通运输与经济发展的相互关系,生产水平越高…...
)
《LeetCode力扣练习》代码随想录——二叉树(合并二叉树---Java)
《LeetCode力扣练习》代码随想录——二叉树(合并二叉树—Java) 刷题思路来源于 代码随想录 617. 合并二叉树 二叉树-前序遍历 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode…...

openstack云计算(二)——使用Packstack安装器安装一体化OpenStack云平台
初步掌握OpenStack快捷安装的方法。掌握OpenStack图形界面的基本操作。 一【准备阶段】 (1)准备一台能够安装OpenStack的实验用计算机,建议使用VMware虚拟机。 (2)该计算机应安装CentOS 7,建议采用CentO…...

Flutter Don‘t use ‘BuildContext‘s across async gaps.
Flutter提示Don‘t use ‘BuildContext‘s across async gaps.的解决办法—flutter里state的mounted属性...
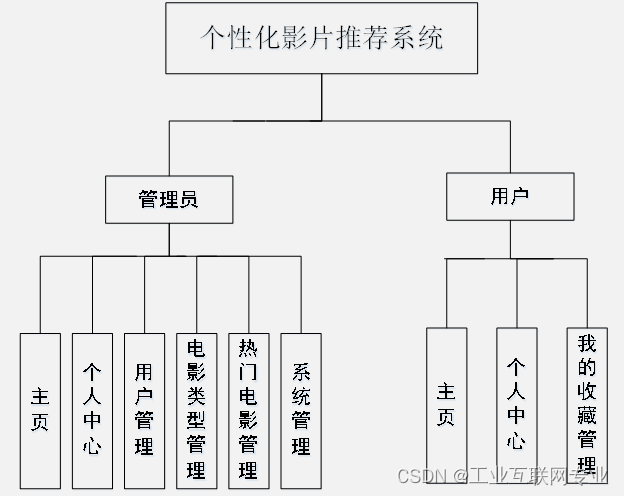
基于SSM+Jsp+Mysql的个性化影片推荐系统
开发语言:Java框架:ssm技术:JSPJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包…...
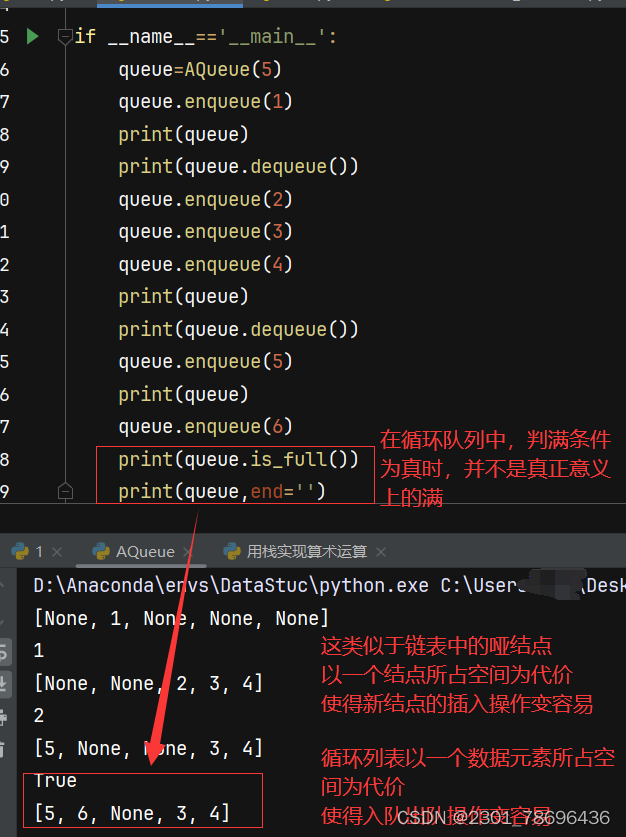
循环队列的实现及应用——桶排序bucket_sort、基数排序radix_sort
一、循环队列的实现 代码解释 1、完成初始化 2、定义方法 3、测试实例 4、完整代码 class AQueue:def __init__(self, size=10):self.__mSize = sizeself.__front=0self.__rear = 0self.__listArray = [None] * size#清空元素def clear(self):self.__front = 0self.__rear =…...

ubuntu16如何使用高版本cmake
1.引言 最近在尝试ubuntu16.04下编译开源项目vsome,发现使用apt命令默认安装cmake的的版本太低。如下 最终得知,ubuntu16默认安装确实只能到3.5.1。解决办法只能是源码安装更高版本。 2.源码下载3.20 //定位到opt目录 cd /opt 下载 wget https://cmak…...

电商-广告投放效果分析(KMeans聚类、数据分析-pyhton数据分析
电商-广告投放效果分析(KMeans聚类、数据分析) 文章目录 电商-广告投放效果分析(KMeans聚类、数据分析)项目介绍数据数据维度概况数据13个维度介绍 导入库,加载数据数据审查相关性分析数据处理建立模型聚类结果特征分析…...
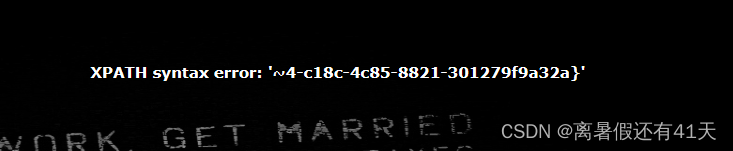
练习 16 Web [极客大挑战 2019]LoveSQL
extractvalue(1,concat(‘~’, (‘your sql’) ) )报错注入,注意爆破字段的时候表名有可能是table_name不是table_schema 有登录输入框 常规尝试一下 常规的万能密码,返回了一个“admin的密码”: Hello admin! Your password is…...
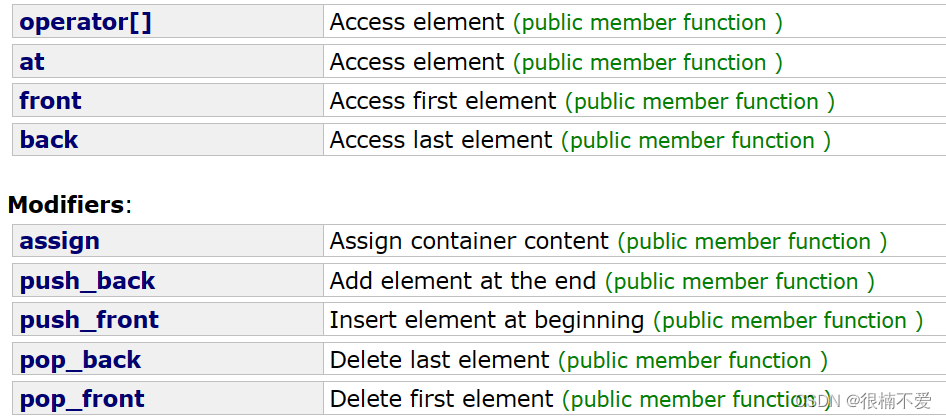
C++——栈和队列容器
前言:这篇文章我们将栈和队列两个容器放在一起进行分享,因为这两个要分享的知识较少,而且两者在结构上有很多相似之处,比如栈只能在栈顶操作,队列只能在队头和队尾操作。 不同于前边所分享的三种容器,这篇…...

Java集合(个人整理笔记)
目录 1. 常见的集合有哪些? 2. 线程安全的集合有哪些?线程不安全的呢? 3. Arraylist与 LinkedList 异同点? 4. ArrayList 与 Vector 区别? 5. Array 和 ArrayList 有什么区别?什么时候该应 Array而不是…...

番茄小说下载神器:3步轻松打造个人数字图书馆
番茄小说下载神器:3步轻松打造个人数字图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为找不到心仪的小说资源而烦恼吗?还在为阅读体验不佳…...

多模式MRI数据融合显示帕金森病患者抑郁的结构、功能和神经化学相关
论文总结1、研究问题:帕金森病中抑郁症非常常见,但机制复杂,既涉及脑结构异常,也涉及脑功能异常,还可能涉及多种神经递质系统。且现有研究大多是基于单模态,只看结构或者只看功能,很少研究“结构…...

Bose-Hubbard模型与量子Gibbs态模拟技术解析
1. Bose-Hubbard模型与量子模拟基础在量子多体物理研究中,Bose-Hubbard模型作为描述玻色子在周期性势场中行为的标准模型,已成为连接理论预测与实验验证的关键桥梁。这个看似简单的模型却能展现出丰富的物理现象,从超流态到Mott绝缘态的量子相…...

LangGraph多智能体系统运维:从部署到监控的自动化方案
LangGraph多智能体系统运维:从部署到监控的全链路自动化方案 一、引言 钩子:你是否也踩过LangGraph上线的这些坑? 上周接到某企业AI团队的紧急求助:他们基于LangGraph搭建的客户服务多智能体系统上线仅3小时就全线崩溃,1.2万条用户咨询全部卡住,技术团队排查了2个小时才…...

【最新版】Windows 环境OpenClaw 本地 AI 智能体搭建指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建数字员工 在开源 AI 智能体快速普及的当下,OpenClaw(小龙虾)凭借本地运行 零代码操控 自动执行任务的能力,收获大量用户关注&#x…...

5分钟掌握视频号批量下载:res-downloader高效操作指南
5分钟掌握视频号批量下载:res-downloader高效操作指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容…...

Versal AI Engine加速椭圆曲线密码学计算实践
1. 项目概述:Versal AI Engine加速椭圆曲线密码学计算在当今的数字安全领域,椭圆曲线密码学(ECC)因其高安全性和计算效率成为主流方案。其中,多标量乘法(MSM)作为ECC的核心运算,在零…...

【AI】短期记忆:会话上下文管理与实现
短期记忆:会话上下文管理与实现 📝 本章学习目标:本章深入探讨记忆机制,这是AI Agent持续执行的关键能力。通过本章学习,你将全面掌握"短期记忆:会话上下文管理与实现"这一核心主题。 一、引言&a…...

Git Conflict Resolution
1. 这篇文章解决什么问题? Git 冲突不是异常情况,而是多人协作和分支开发里的正常现象。 常见问题包括: 1. 为什么会产生冲突? 2. 冲突文件里的 <<<<<<<、、>>>>>>> 是什么?…...

CSS 视图过渡完全指南
CSS 视图过渡完全指南 引言 CSS 视图过渡(View Transitions)是一个强大的新特性,它允许开发者创建平滑的页面过渡动画。本文将深入探讨视图过渡的各种用法和高级技巧。 基础概念回顾 什么是视图过渡 视图过渡 API 允许你在 DOM 状态变化时创建…...