Pytorch实用教程:TensorDataset和DataLoader的介绍及用法示例
TensorDataset
TensorDataset是PyTorch中torch.utils.data模块的一部分,它包装张量到一个数据集中,并允许对这些张量进行索引,以便能够以批量的方式加载它们。
当你有多个数据源(如特征和标签)时,TensorDataset能够让你把它们打包成一个数据集,这在训练模型时非常有用。
介绍
TensorDataset接收任意数量的张量作为输入,前提是这些张量的第一维度大小(也就是数据点的数量)相同。
每个张量的第一维被视为数据的长度。当对TensorDataset进行索引时,它会返回一个元组,其中包含每个张量在对应索引处的数据。
用法示例
下面是一个使用TensorDataset的简单示例,包括如何创建它,以及如何与DataLoader结合使用,以便于批量加载数据。
首先,你需要有一些数据。在这个例子中,我们将创建一些随机数据来模拟特征(X)和标签(y)。
import torch
from torch.utils.data import TensorDataset, DataLoader
import numpy as np# 假设我们有一些随机数据作为特征和标签
X = np.random.random((100, 10)) # 100个样本,每个样本10个特征
y = np.random.randint(0, 2, (100,)) # 100个样本的二分类标签# 将NumPy数组转换为PyTorch张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.long)# 创建TensorDataset
dataset = TensorDataset(X_tensor, y_tensor)# 使用DataLoader来批量加载数据
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 遍历数据集
for features, labels in dataloader:print(features, labels)# 在这里进行训练的步骤,比如将features和labels送入模型等
在上面的代码中:
- 我们首先创建了特征
X和标签y的NumPy数组,然后将它们转换为PyTorch张量。 - 使用这些张量创建了一个
TensorDataset实例。 - 接着,我们创建了一个
DataLoader实例来定义数据的批量大小和是否需要打乱。 - 最后,我们遍历了
DataLoader,它每次迭代会返回一批数据(由features和labels组成),这些数据可以直接用于模型的训练过程。
通过使用TensorDataset和DataLoader,可以非常灵活地处理数据的加载和迭代,这对于训练深度学习模型来说是非常必要的。
DataLoader
DataLoader是PyTorch中用于加载数据的一个非常重要的工具,它提供了一个简便的方式来迭代数据。
这对于训练模型时批量处理数据,以及在训练过程中对数据进行洗牌(shuffle)和并行处理非常有帮助。
介绍
DataLoader封装了一个数据集,并提供了多种功能,使得数据加载变得更加灵活和高效。它的主要功能包括:
- 批量加载:允许你指定
每次迭代加载的数据数量。 - 洗牌:在每个训练周期开始时,可以选择
是否打乱数据,这有助于模型的泛化能力。 - 并行加载:可以利用多个进程来
加速数据的加载过程,特别是当数据预处理比较耗时时这一点非常有用。 - 自定义数据抽样:通过定义一个
Sampler,你可以控制数据的加载顺序,或者实现一些复杂的抽样策略。
用法示例
以下是一个简单的示例,展示如何使用DataLoader来加载一个TensorDataset。
import torch
from torch.utils.data import DataLoader, TensorDataset# 假设我们有一些数据张量
features = torch.tensor([[1, 2], [3, 4], [5, 6], [7, 8]], dtype=torch.float32)
labels = torch.tensor([0, 1, 0, 1], dtype=torch.float32)# 创建TensorDataset
dataset = TensorDataset(features, labels)# 创建DataLoader
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)# 使用DataLoader进行迭代
for batch_idx, (features, labels) in enumerate(dataloader):print(f"Batch {batch_idx}:")print("Features:\n", features.numpy())print("Labels:\n", labels.numpy())
在这个示例中,我们首先创建了一个包含特征和标签的TensorDataset。接着,我们使用DataLoader来定义如何加载这些数据,包括设置批量大小和是否打乱数据。最后,我们通过迭代DataLoader来按批次获取数据,并打印出来。
这个过程展示了DataLoader在数据加载中的基本使用,特别是在处理批量数据和进行迭代训练时。在实际应用中,你可以根据需要调整DataLoader的参数,比如批量大小、是否洗牌以及使用的进程数等,以最适合你的训练流程。
相关文章:

Pytorch实用教程:TensorDataset和DataLoader的介绍及用法示例
TensorDataset TensorDataset是PyTorch中torch.utils.data模块的一部分,它包装张量到一个数据集中,并允许对这些张量进行索引,以便能够以批量的方式加载它们。 当你有多个数据源(如特征和标签)时,TensorD…...
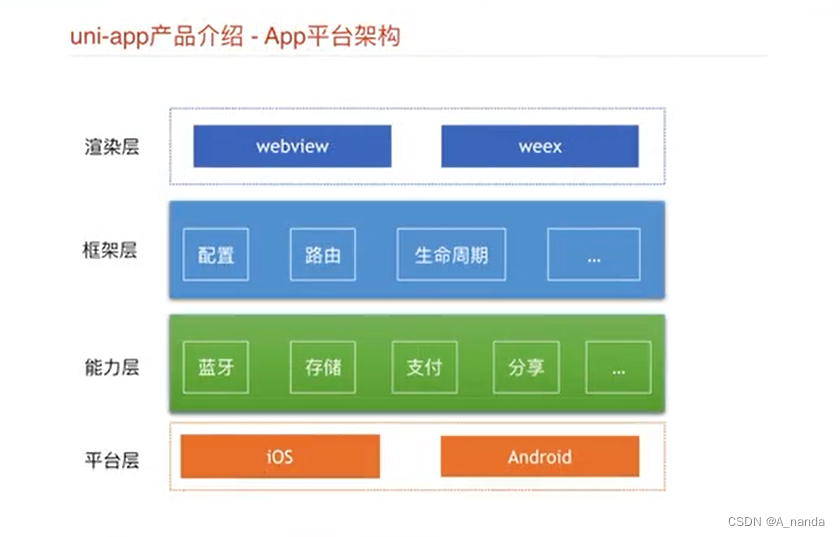
uni-app如何实现高性能
这篇文章主要讲解uni-app如何实现高性能的问题? 什么是uni-app? 简单说一下什么是uni-app,uni-app是继承自vue.js,对vue做了轻度定制,并且实现了完整的组件化开发,并且支持多端发布的一种架构,…...

docker 应用部署
参考:docker 构建nginx服务 环境 Redhat 9 步骤: 1、docker部署MySQL 安装yum 工具包 [rootadmin ~]# yum -y install yum-utils.noarch 正在更新 Subscription Management 软件仓库。 无法读取客户身份本系统尚未在权利服务器中注册。可使用 subscription-…...

java.awt.FontFormatException: java.nio.BufferUnderflowException
Font awardFont Font.createFont(Font.TRUETYPE_FONT, awardFontFile).deriveFont(120f).deriveFont(Font.BOLD);使用如上语句创建字体时出现问题。java.awt.FontFormatException: java.nio.BufferUnderflowException异常表明在处理字体数据时出现了缓冲区下溢(Buf…...

C++ 枚举类型 ← 关键字 enum
【知识点:枚举类型】● 枚举类型(enumeration)是 C 中的一种派生数据类型,它是由用户定义的若干枚举常量的集合。 ● 枚举元素作为常量,它们是有值的。C 编译时,依序对枚举元素赋整型值 0,1,2,3,…。 下面代…...

MySQL故障排查与优化
一、MySQL故障排查 1.1 故障现象与解决方法 1.1.1 故障1 1.1.2 故障2 1.1.3 故障3 1.1.4 故障4 1.1.5 故障5 1.1.6 故障6 1.1.7 故障7 1.1.8 故障8 1.1.9 MySQL 主从故障排查 二、MySQL优化 2.1 硬件方面 2.2 查询优化 一、MySQL故障排查 1.1 故障现象与解决方…...

如何做一个知识博主? 善用互联网检索
Google 使用引号: 使用双引号将要搜索的短语括起来,以便搜索结果中只包含该短语。例如,搜索 "人工智能" 将只返回包含该短语的页面。 排除词汇: 在搜索中使用减号 "-" 可以排除特定词汇。例如,搜索 "苹果 -手机" 将返回关于苹果公司的结果,但…...
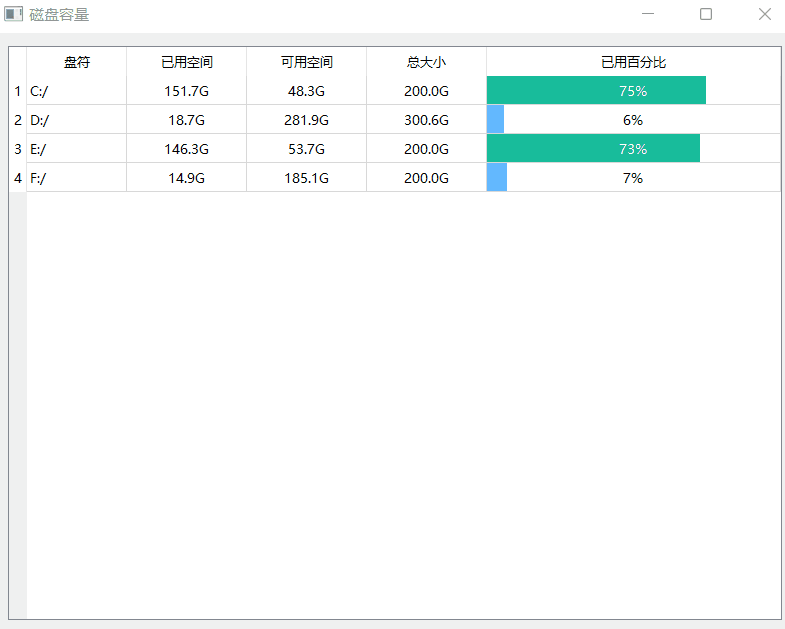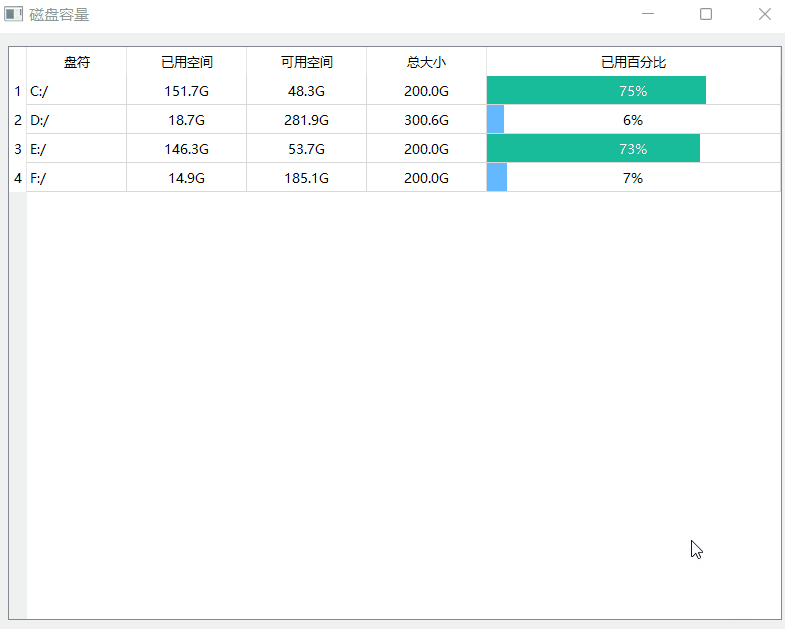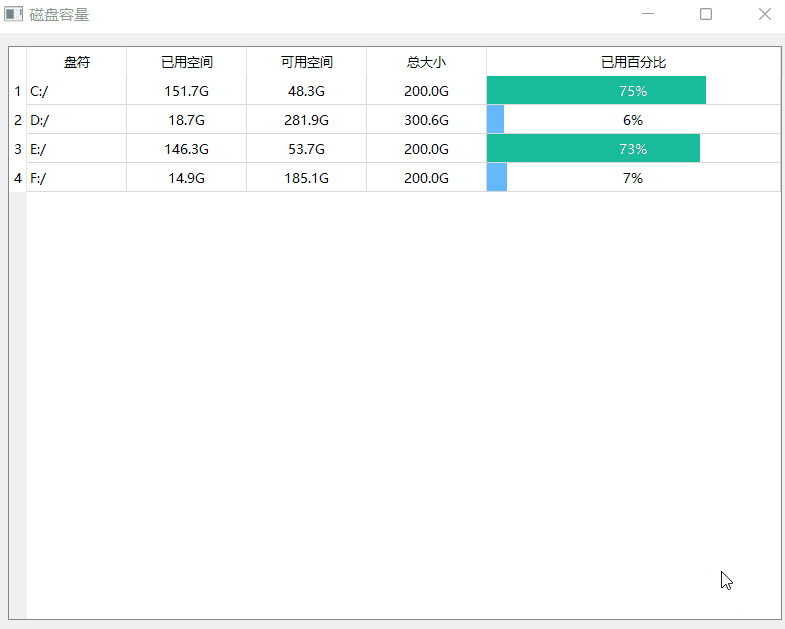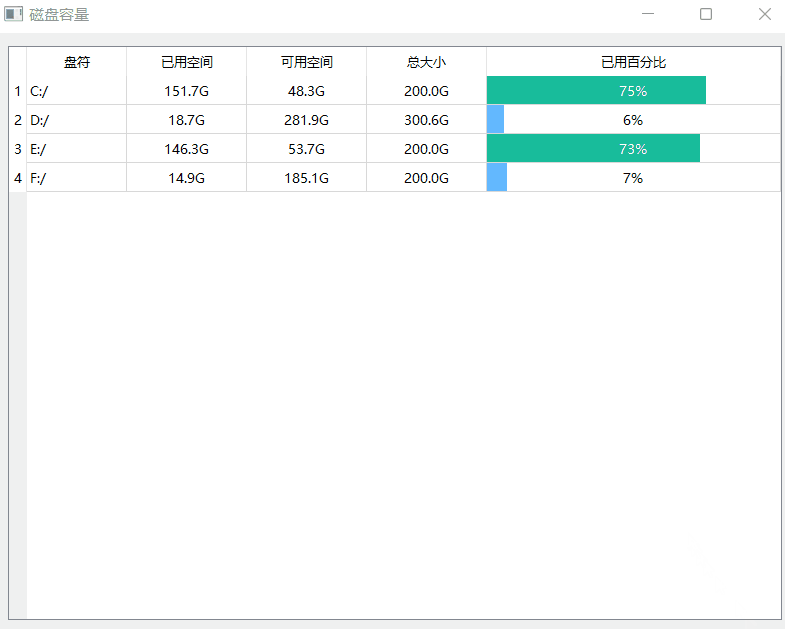
《QT实用小工具·十》本地存储空间大小控件
1、概述 源码放在文章末尾 本地存储空间大小控件,反应电脑存储情况: 可自动加载本地存储设备的总容量/已用容量。进度条显示已用容量。支持所有操作系统。增加U盘或者SD卡到达信号。 下面是demo演示: 项目部分代码如下: #if…...

作为一个初学者该如何学习kali linux?
首先你要明白你学KALI的目的是什么,其次你要了解什么是kali,其实你并不是想要学会kali你只是想当一个hacker kali是什么: 只是一个集成了多种渗透工具的linux操作系统而已,抛开这些工具,他跟常规的linux没有太大区别。…...

多线程学习-线程池
目录 1.线程池的作用 2.线程池的实现 3.自定义创建线程池 1.线程池的作用 当我们使用Thread的实现类来创建线程并调用start运行线程时,这个线程只会使用一次并且执行的任务是固定的,等run方法中的代码执行完之后这个线程就会变成垃圾等待被回收掉。如…...
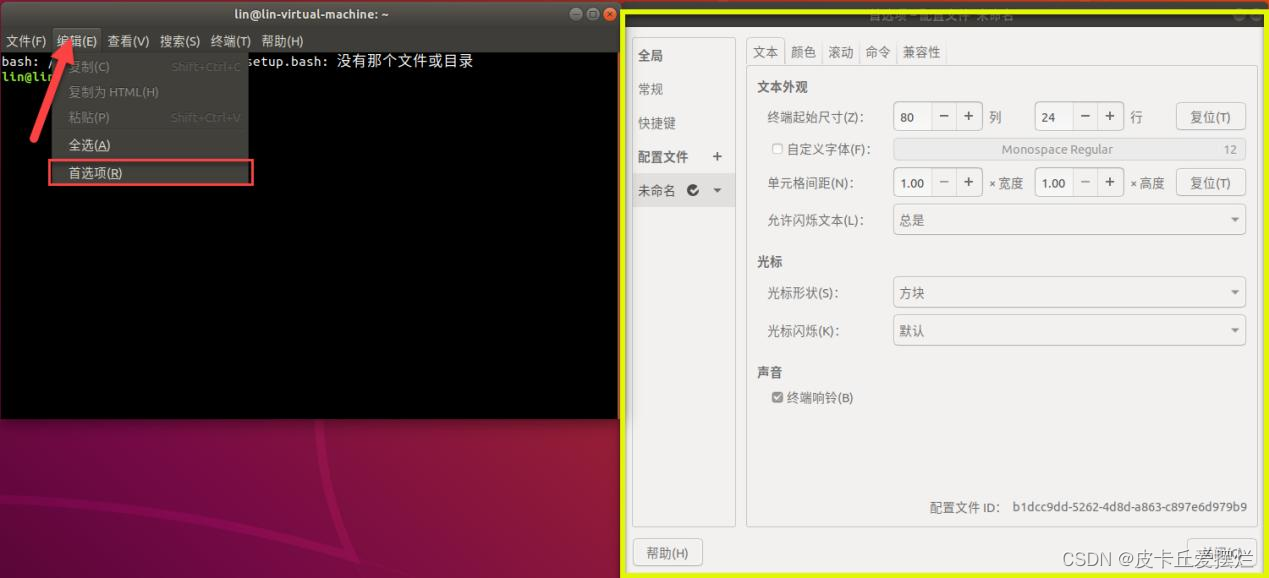
Linux第4课 Linux的基本操作
文章目录 Linux第4课 Linux的基本操作一、图形界面介绍二、终端界面介绍 Linux第4课 Linux的基本操作 一、图形界面介绍 本节以Ubuntu系统的GUI为例进行说明,Linux其他版本可自行网搜。 图形系统进入后,左侧黄框内为菜单栏,右侧为桌面&…...

堆排序解读
在算法世界中,排序算法一直是一个热门话题。推排序(Heap Sort)作为一种基于堆这种数据结构的有效排序方法,因其时间复杂度稳定且空间复杂度低而备受青睐。本文将深入探讨推排序的原理、实现方式,以及它在实际应用中的价…...

docker + miniconda + python 环境安装与迁移(详细版)
本文主要列出从安装dockerpython环境到迁移环境的整体步骤。windows与linux之间进行测试。 简化版可以参考:docker miniconda python 环境安装与迁移(简化版)-CSDN博客 目录 一、docker 安装和测试 二、docker中拉取minicondaÿ…...

蓝桥杯刷题第八天(dp专题)
这道题有点像小学奥数题,解题的关键主要是: 有2种走法固走到第i级阶梯,可以通过计算走到第i-1级和第i-2级的走法和,可以初始化走到第1级楼梯和走到第2级楼梯。分别为f[1]1;f[2]1(11)1(2)2.然后就可以循环遍历到后面的状态。 f[i…...

【WEEK6】 【DAY1】DQL查询数据-第一部分【中文版】
2024.4.1 Monday 目录 4.DQL查询数据(重点!)4.1.Data Query Language查询数据语言4.2.SELECT4.2.1.语法4.2.2.实践4.2.2.1.查询字段 SELECT 字段/* FROM 表查询全部的某某查询指定字段 4.2.2.2.给查询结果或者查询的这个表起别名(…...
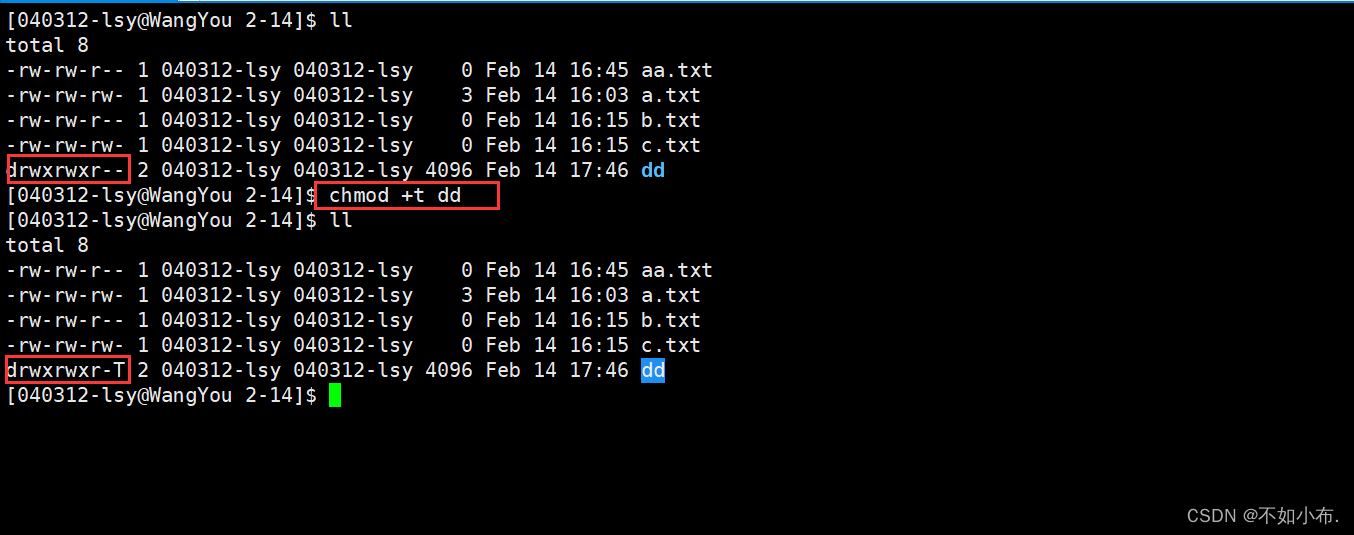
Linux:权限篇
文章目录 前言1.用户2.文件的权限管理2.1 修改文件的权限2.2 修改文件的拥有者2.3 修改文件的所属组 3.file指令4.umask指令4.目录的权限管理总结 前言 Linux权限在两个地方有所体现,一种是使用用户:分为root超级用户员与普通用户。另一个是体现在文件的…...
Lua热更新(xlua)
发现错误时检查是否:冒号调用 只需要导入asset文件夹下的Plugins和Xlua这两个文件即可,别的不用导入 生成代码 和清空代码 C#调用lua using Xlua; 需要引入命名空间 解析器里面执行lua语法 lua解析器 LuaEnv 单引号是为了避免引号冲突 第二个参数是报错时显示什么提示…...
)
并查集(基础+带权以及可撤销并查集后期更新)
并查集 并查集是一种图形数据结构,用于存储图中结点的连通关系。 每个结点有一个父亲,可以理解为“一只伸出去的手”,会指向另一个点,初始时指向自己。一个点的根节点是该点的父亲的父亲的..的父亲,直到某个点的父亲…...
)
基于 Java 的数据结构和算法 (不定期更新)
JavaIsBestLang 数据结构 Collection 是 Java 中的接口,被多个泛型容器接口所实现。在这里,Collection 是指代存放对象类型的数据结构。 ArrayList 函数名功能size()返回 this 的长度add(Integer val)在 this 尾部插入一个元素add(int idx, Integer …...

考研回忆录【二本->211】
备考时长差不多快一年半,从22年的11月底开始陆陆续续地准备考研,因为开始的早所以整个备考过程显得压力不是很大,中途还去一些地方旅游,我不喜欢把自己绷得太紧。虽然考的不是很好,考完我甚至都没准备复试,…...

GitHub企业版MCP服务器:为AI助手集成私有化GitHub工作流
1. 项目概述:一个为开发者定制的GitHub企业版MCP服务器如果你是一名重度依赖GitHub Enterprise进行团队协作的开发者,并且正在探索如何将AI助手(比如Claude、Cursor等)无缝集成到你的日常开发工作流中,那么你很可能已经…...

第10期| 空间算法入门--GeoAI核心算法拆解,不用啃论文,通俗看懂原理
大家好,我是你们的地理信息工程师朋友,专注GIS与AI的实战落地。 第上一期期我们聊了GeoAI的应用场景,很多朋友留言说“想入门,但论文太晦涩,代码看不懂”。这期实战笔记就精准解决这个痛点——不啃晦涩论文,…...

原生TypeScript待办清单:纯前端架构、观察者模式与拖拽排序实践
1. 项目概述:一个由AI辅助构思的现代化待办清单最近在整理个人项目时,我重新审视了一个之前用TypeScript写的待办清单应用。这个项目的初衷很简单:我需要一个极简、快速、完全由我掌控的待办工具,它不需要登录,数据就存…...

多品牌技高速存储卡术拆解分析实测:如何同时满足企业级监控与创作两不误?
一、开篇:当监控连续记录与影视创作相遇——存储卡的双重使命在企业级安防监控与专业影像创作的交汇点上,存储卡不再仅仅是数据的载体,而是工作流中不可绕过的风险控制节点。安防监控要求724小时不间断写入,对持续写入稳定性和数据…...

清华系团队造出能“边听边说、边看边想“的AI耳朵MiniCPM-o 4.5
这项由清华大学自然语言处理实验室(THUNLP)主导、OpenBMB开源社区联合推出的研究成果,于2026年4月30日以预印本形式发布在arXiv平台,编号为arXiv:2604.27393。感兴趣的读者可通过这个编号检索到完整论文。**一场关于"耳朵和嘴…...
:8大核心维度,适配信创+全行业场景)
2026设备管理系统选型标准(技术向):8大核心维度,适配信创+全行业场景
对于企业IT运维、采购人员而言,设备管理系统选型需兼顾技术适配、合规要求、落地效率与长期扩展性。本文从技术与实践角度,梳理出8大核心选型标准,重点覆盖独享云部署、Excel导入能力、自定义扩展、信创适配等关键维度,为技术选型…...

2026届学术党必备的六大降重复率平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 令AI精确执行任务的基础,是下达精准的指令,此即降AI指令。降AI指令专…...

从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束
从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束 在ZYNQ7000系列开发中,EMIO引脚的正确分配与约束是实现PS与PL协同工作的关键环节。许多工程师在初次接触ZYNQ架构时,往往会被MIO、EMIO和AXI_GPIO的关系所困扰ÿ…...

告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南
告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南 在独立游戏开发中,角色往往是玩家情感投射的核心载体。一个缺乏生命力的角色模型,即使建模精度再高,也会让玩家产生"纸片人"的疏…...

基于GAN的端到端ISP:用AI学习从RAW到RGB的图像处理革命
1. 项目概述:从“拍”到“算”的ISP革命在计算机视觉和图像处理领域,图像信号处理器(ISP)一直扮演着“幕后英雄”的角色。它负责将相机传感器捕捉到的原始、未经处理的RAW Bayer数据,转换为我们手机相册里那些色彩鲜艳…...