使用向量检索和rerank 在RAG数据集上实验评估hit_rate和mrr
文章目录
- 背景
- 简介
- 代码实现
- 自定义检索器
- 向量检索实验
- 向量检索和rerank 实验
- 代码开源
背景
在前面部分 大模型生成RAG评估数据集并计算hit_rate 和 mrr 介绍了使用大模型生成RAG评估数据集与评估;
在 上文 使用到了BM25 关键词检索器。接下来,想利用向量检索器测试一下在RAG评估数据集上的 hit_rate 和 mrr;
简介
使用 向量检索 和 rerank 在给定RAG评估数据集上的实验计算 hit_rate 和 mrr;
对比了使用 rerank 和 不使用 rerank的实验结果;
步骤:
- 基于RAG评估数据集,构建nodes节点;
- 构建
CustomRetriever自定义的检索器,在检索器中实现 向量检索和 rerank; - 实验评估;
代码实现
from typing import Listfrom llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.base.base_retriever import BaseRetriever
from llama_index.core.evaluation import RetrieverEvaluator
from llama_index.core.indices.postprocessor import SentenceTransformerRerank
from llama_index.core.indices.vector_store import VectorIndexRetriever
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.settings import Settings
from llama_index.legacy.embeddings import HuggingFaceEmbedding
# from llama_index.legacy.schema import NodeWithScore, QueryBundle
from llama_index.core.schema import NodeWithScore, QueryBundle, QueryType, Node
from llama_index.core.evaluation import EmbeddingQAFinetuneDataset
利用数据集中的数据,构建nodes
pg_eval_dataset.json的下载地址: https://www.modelscope.cn/datasets/jieshenai/paul_graham_essay_rag/files
qa_dataset = EmbeddingQAFinetuneDataset.from_json("pg_eval_dataset.json")nodes = []
for key, value in qa_dataset.corpus.items():nodes.append(Node(id_=key, text=value))
m3e 向量编码模型
若想使用其他的编码模型,直接进行修改即可,modelscope和huggingface的编码模型都行;
from modelscope import snapshot_download
model_dir = snapshot_download('AI-ModelScope/m3e-base')
Settings.embed_model = HuggingFaceEmbedding(model_dir)
Settings.llm = None
由于huggingface被墙了,笔者使用的是 modelscope平台,model_dir 为编码模型在本地的绝对路径
自定义检索器
tok_k: 表示召回的节点数量,可自定义设置;
top_k = 10
定义向量检索器,还实现了rerank;
class CustomRetriever(BaseRetriever):"""Custom retriever that performs both Vector search and Knowledge Graph search"""def __init__(self, vector_retriever: VectorIndexRetriever, reranker=None) -> None:"""Init params."""super().__init__()self._vector_retriever = vector_retrieverself.reranker = rerankerdef _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Retrieve nodes given query."""# print(query_bundle, isinstance(QueryBundle))retrieved_nodes = self._vector_retriever.retrieve(query_bundle)if self.reranker != 'None':retrieved_nodes = self.reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodes = retrieved_nodes[:top_k]return retrieved_nodesasync def _aretrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:"""Asynchronously retrieve nodes given query.Implemented by the user."""return self._retrieve(query_bundle)async def aretrieve(self, str_or_query_bundle: QueryType) -> List[NodeWithScore]:if isinstance(str_or_query_bundle, str):str_or_query_bundle = QueryBundle(str_or_query_bundle)return await self._aretrieve(str_or_query_bundle)
eval_results包含每个query的 hit_rate 和 mrr,display_results 计算平均;
import pandas as pd
def display_results(eval_results):"""计算平均 hit_rate 和 mrr"""metric_dicts = []for eval_result in eval_results:metric_dict = eval_result.metric_vals_dictmetric_dicts.append(metric_dict)full_df = pd.DataFrame(metric_dicts)hit_rate = full_df["hit_rate"].mean()mrr = full_df["mrr"].mean()metric_df = pd.DataFrame({"hit_rate": [hit_rate], "mrr": [mrr]})return metric_df
向量检索实验
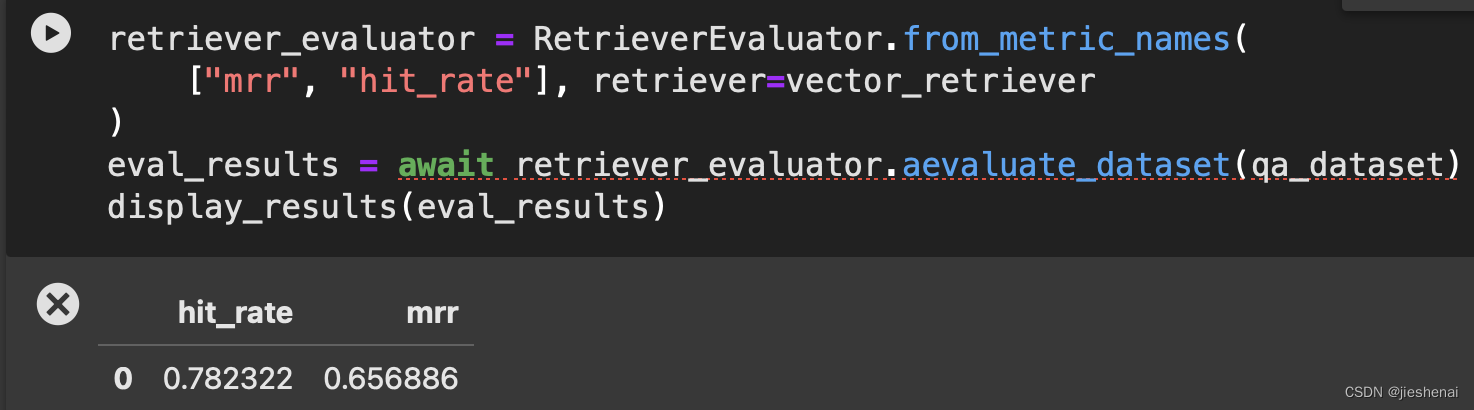
index = VectorStoreIndex(nodes)
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=top_k)
retriever_evaluator = RetrieverEvaluator.from_metric_names(["mrr", "hit_rate"], retriever=vector_retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
display_results(eval_results)
向量检索和rerank 实验
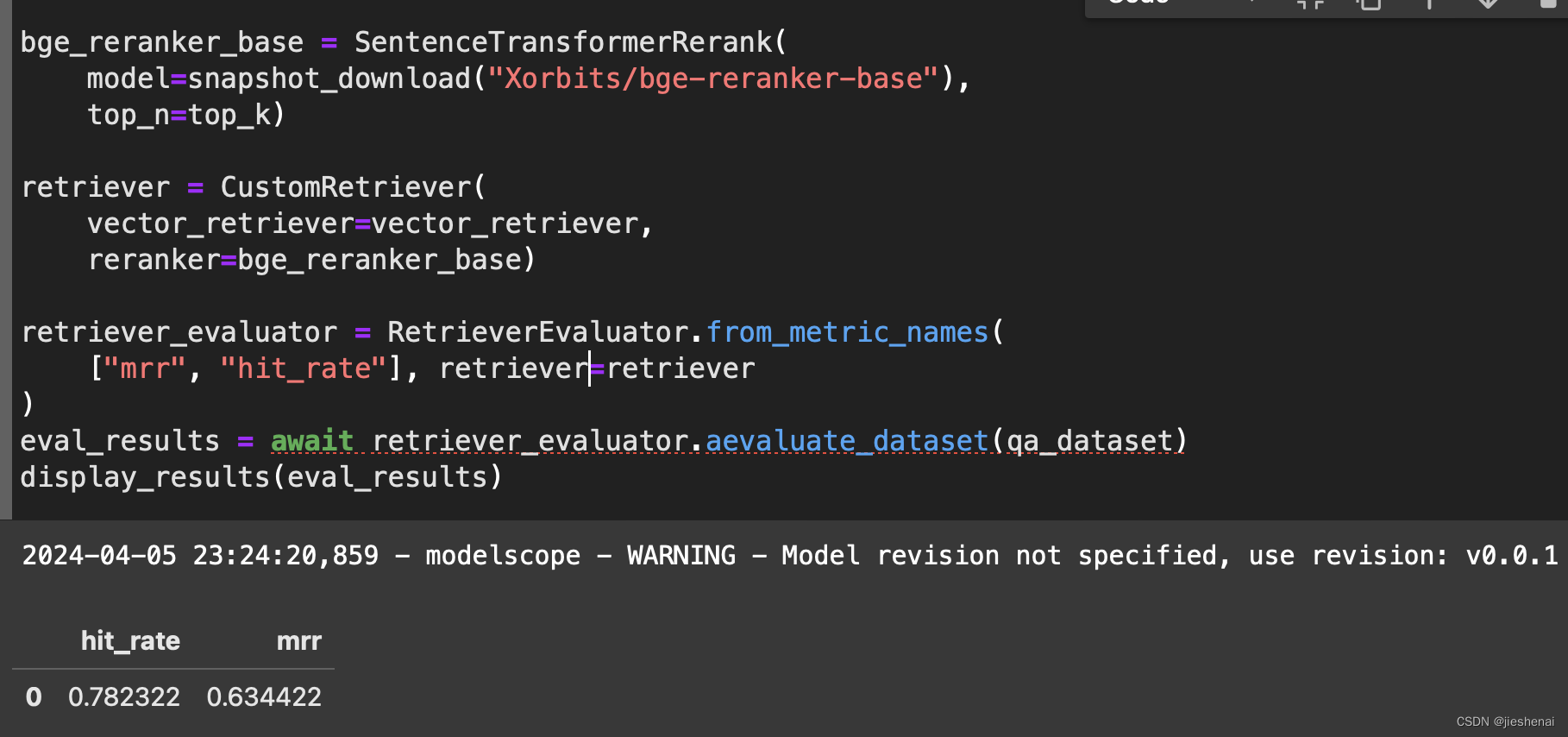
bge_reranker_base = SentenceTransformerRerank(model=snapshot_download("Xorbits/bge-reranker-base"),top_n=top_k)retriever = CustomRetriever(vector_retriever=vector_retriever,reranker=bge_reranker_base)retriever_evaluator = RetrieverEvaluator.from_metric_names(["mrr", "hit_rate"], retriever=retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
display_results(eval_results)
若想使用其他的rerank模型,更换Xorbits/bge-reranker-base;
若使用modelscope平台的rerank模型,直接修改模型名即可;
若使用huggingface 平台的rerank模型,自行修改代码;
上述对比了,在向量检索下,对比了添加rerank和不添加rerank的实验结果;
如上图所示,相比只有向量检索的实验,加了rerank mrr 反而还下降了,这是一个比较反常的实验结果;
这个并不能说明rerank没有用,笔者在其他的RAG数据集测试时,rerank确实能提升mrr;本例子这里的情况大家忽略即可。
在本实验这里仅仅是给读者展示如何使用rerank;这也说明了rerank模型,也并不都能提升所有的mrr;
代码开源
本项目的完整代码,已发布到modelscope平台上;
点击下述链接查看代码:
https://www.modelscope.cn/datasets/jieshenai/paul_graham_essay_rag/file/view/master/vector_rerank_eval.ipynb?status=1
相关文章:
使用向量检索和rerank 在RAG数据集上实验评估hit_rate和mrr
文章目录 背景简介代码实现自定义检索器向量检索实验向量检索和rerank 实验 代码开源 背景 在前面部分 大模型生成RAG评估数据集并计算hit_rate 和 mrr 介绍了使用大模型生成RAG评估数据集与评估; 在 上文 使用到了BM25 关键词检索器。接下来,想利用向…...

Java栈和队列的实现
目录 一.栈(Stack) 1.1栈的概念 1.2栈的实现及模拟 二.队列(Queue) 2.1队列的概念 2.2队列的实现及模拟 2.3循环队列 2.4双端队列(Deque) 一.栈(Stack) 1.1栈的概念 栈:一种特殊的线性表,其 只允许在固定的一端进行插入和删除元素操作…...

我的C++奇迹之旅:内联函数和auto关键推导和指针空值
文章目录 📝内联函数🌠 查看内联函数inline方式🌉内联函数特性🌉面试题 🌠auto关键字(C11)🌠 auto的使用细则🌉auto不能推导的场景 🌠基于范围的for循环(C11)🌠范围for的…...
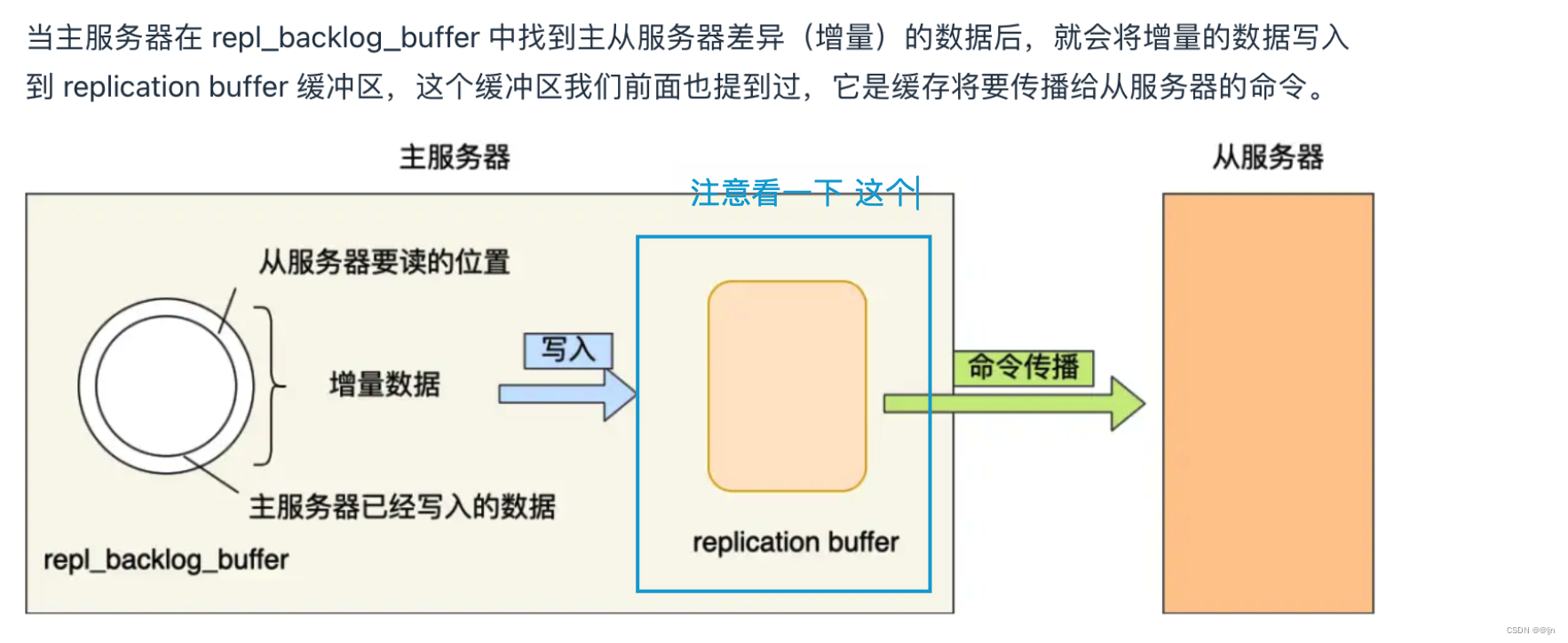
Redis主从集群-主从复制(通俗易懂)
为什么要搭建主从集群? 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据…...

【C++算法竞赛 · 图论】图论基础
前言 图论基础 图的相关概念 图的定义 图的分类 按数量分类: 按边的类型分类: 边权 简单图 度 路径 连通 无向图 有向图 图的存储 方法概述 代码 复杂度 前言 图论(Graph theory),是 OI 中的一样很大…...
Java解析实体类的属性和属性注释
前言 获取某个类的属性(字段)是我们经常都会碰到的,通常我们是通过反射来获取的。 但是有些特殊情况下,我们不仅要获取类的属性,还需要获取属性注释。这种情况下,我们只能通过注解去获取注释。可以自己定…...
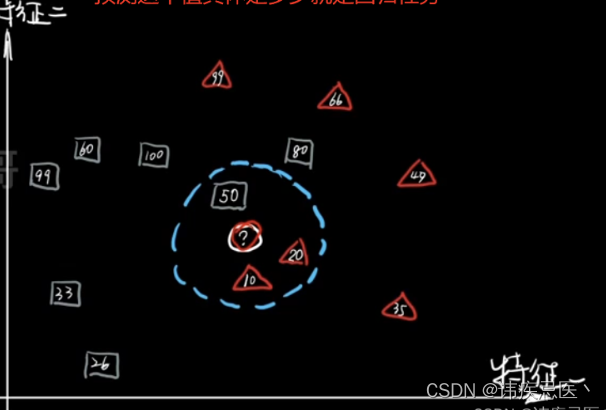
机器学习KNN最邻近分类算法
文章目录 1、KNN算法简介2、KNN算法实现2.1、调用scikit-learn库中KNN算法 3、使用scikit-learn库生成数据集3.1、自定义函数划分数据集3.2、使用scikit-learn库划分数据集 4、使用scikit-learn库对鸢尾花数据集进行分类5、什么是超参数5.1、实现寻找超参数5.2、使用scikit-lea…...
)
分享一个Python爬虫入门实例(有源码,学习使用)
一、爬虫基础知识 Python爬虫是一种使用Python编程语言实现的自动化获取网页数据的技术。它广泛应用于数据采集、数据分析、网络监测等领域。以下是对Python爬虫的详细介绍: 架构和组成:下载器:负责根据指定的URL下载网页内容,常用的库有Requests和urllib。解析器:用于解…...
算法:树形dp(树状dp)
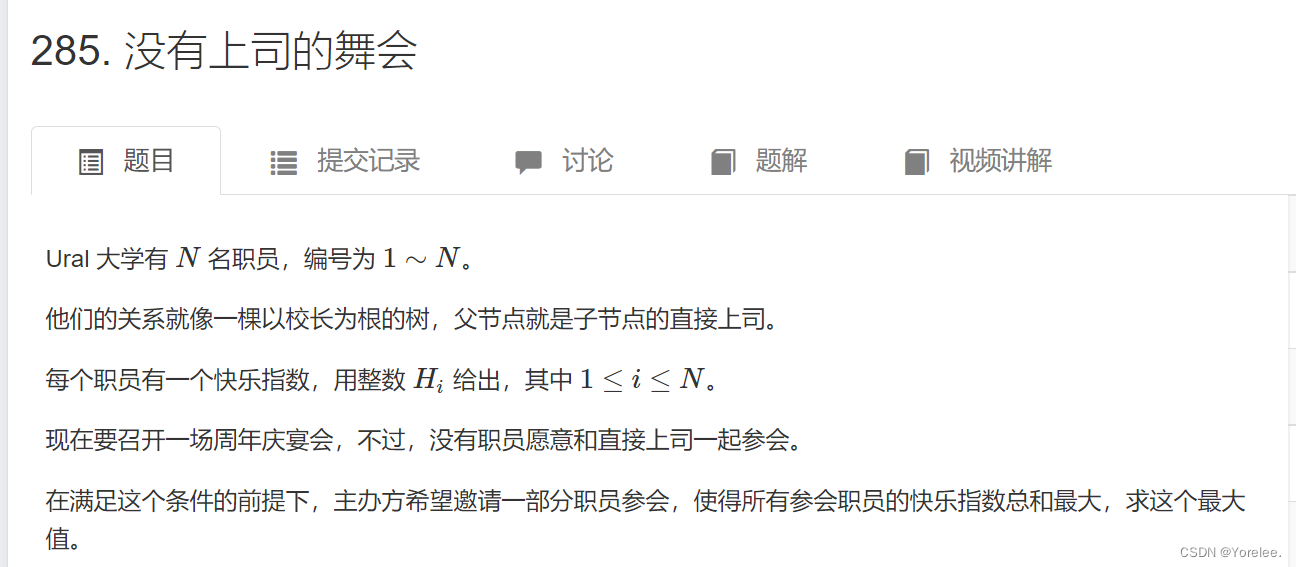
文章目录 一、树形DP的概念1.基本概念2.解题步骤3.树形DP数据结构 二、典型例题1.LeetCode:337. 打家劫舍 III1.1、定义状态转移方程1.2、参考代码 2.ACWing:285. 没有上司的舞会1.1、定义状态转移方程1.2、拓扑排序参考代码1.3、dfs后序遍历参考代码 一…...
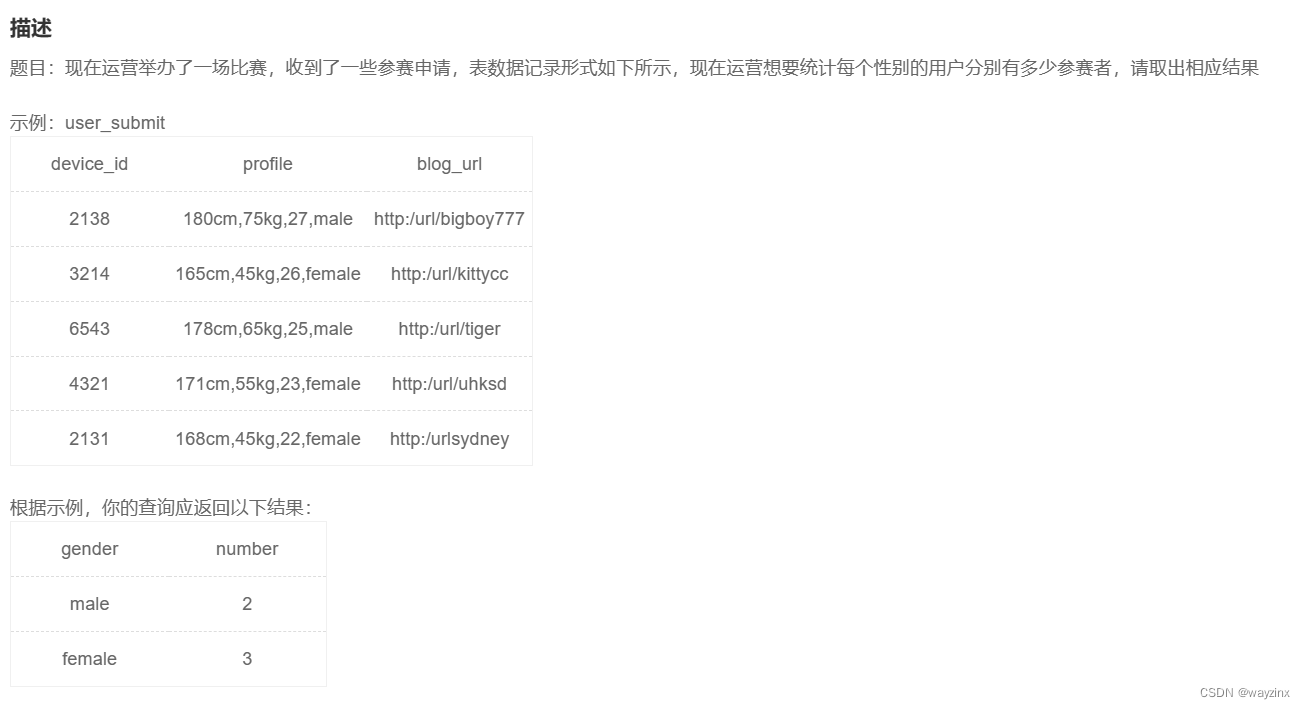
SQL语句学习+牛客基础39SQL
什么是SQL? SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)。 SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。 SQL语法 数据库表 一个…...
动态规划)
竞赛常考的知识点大总结(五)动态规划
DP问题的性质 动态规划(Dynamic Programming,DP)是指在解决动态规划问题时所依赖的一些基本特征和规律。动态规划是一种将复杂问题分解为更小子问题来解决的方法,它适用于具有重叠子问题和最优子结构性质的问题。动态规划问题通常…...
如何在 Mac 上恢复已删除的数据
如果您丢失了 Mac 上的数据,请不要绝望。恢复数据比您想象的要容易,并且有很多方法可以尝试。 在 Mac 上遭受数据丢失是每个人都认为永远不会发生在他们身上的事情之一......直到它发生。不过,请不要担心,因为您可以通过多种方法…...

Java笔试题总结
HashSet子类依靠()方法区分重复元素。 A toString(),equals() B clone(),equals() C hashCode(),equals() D getClass(),clone() 答案:C 解析: 先调用对象的hashcode方法将对象映射为数组下标,再通过equals来判断元素内容是否相同 以下程序执行的结果是: class X{…...
github本地仓库push到远程仓库
1.从远程仓库clone到本地 2.生成SSH秘钥,为push做准备 在Ubuntu命令行输入一下内容 [rootlocalhost ~]# ssh-keygen -t rsa < 建立密钥对,-t代表类型,有RSA和DSA两种 Generating public/private rsa key pair. Enter file in whi…...

Error: TF_DENORMALIZED_QUATERNION: Ignoring transform forchild_frame_id
问题 运行程序出现: Error: TF_DENORMALIZED_QUATERNION: Ignoring transform for child_frame_id “odom” from authority “unknown_publisher” because of an invalid quaternion in the transform (0.0 0.0 0.0 0.707) 主要是四元数没有归一化 Eigen::Quatern…...

Linux从入门到精通 --- 2.基本命令入门
文章目录 第二章:2.1 Linux的目录结构2.1.1 路径描述方式 2.2 Linux命令入门2.2.1 Linux命令基础格式2.2.2 ls命令2.2.3 ls命令的参数和选项2.2.4 ls命令选项的组合使用 2.3 目录切换相关命令2.3.1 cd切换工作目录2.3.2 pwd查看当前工作目录2.4 相对路径、绝对路径和…...
Redis常用命令补充和持久化
一、redis 多数据库常用命令 1.1 多数据库间切换 1.2 多数据库间移动数据 1.3 清除数据库内数据 1.4 设置密码 1.4.1 使用config set requirepass yourpassword命令设置密码 1.4.2 使用config get requirepass命令查看密码 二、redis高可用 2.1 redis 持久化 2.1.1 持…...
二次开发时的错误码)
【记录】海康相机(SDK)二次开发时的错误码
海康相机(SDK)二次开发时的错误码 在进行海康sdk二次开发的时候,经常碰到各种错误,遂结合官方文档和广大网友的一些经验,把这些错误码记录一下,方便查找。笔者使用的SDK版本是HCNetSDKV6.1.9.4。 错误类型…...

端盒日记Day02
JS 本本本本本地存储 localStorage 作用:可以将数据永久存储在本地(用户电脑),除非手动删除,否则关闭页面也会存在 特性:a.可多窗口(页面)共享(同一浏览器可以共享&a…...

考研高数(平面图形的面积,旋转体的体积)
1.平面图形的面积 纠正:参数方程求面积 2.旋转体的体积(做题时,若以x为自变量不好计算,可以求反函数,y为自变量进行计算)...

北京数据恢复公司哪个公司好
在当今数字化时代,数据的重要性不言而喻。无论是个人用户的珍贵照片、文档,还是企业的重要商业数据,一旦丢失,都可能造成巨大的损失。在北京,有众多的数据恢复公司,那么哪家公司才是最好的选择呢࿱…...

对比了8款测试管理平台,最适合中小团队的居然是它
在软件研发的生命周期中,测试用例管理早已不是简单的“记录-执行-通过”的线性流程。随着敏捷开发、DevOps乃至AI辅助测试的全面渗透,测试管理平台承载的职责已扩展至需求追溯、缺陷闭环、自动化集成和质量度量等多个维度。然而,对于中小型测…...

Resolink MCP:基于MCP协议与Playwright的AI浏览器自动化实践
1. 项目概述:当AI助手学会“动手”——Resolink MCP的浏览器自动化革命如果你和我一样,每天在Cursor、Claude这类AI编程助手的陪伴下写代码,那你一定遇到过这样的场景:你正和AI热烈讨论一个技术方案,突然需要去浏览器里…...

BetterGI自动化工具:每天为原神玩家节省2小时
BetterGI自动化工具:每天为原神玩家节省2小时 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 | 自动烹饪 …...

量子计算采购策略与技术路线比较
1. 量子计算采购的现状与挑战 量子计算技术正在经历从实验室研究向实际应用过渡的关键阶段。根据2023年全球量子计算产业报告,量子处理器市场规模预计将从2023年的4.7亿美元增长到2030年的65亿美元,年复合增长率高达45%。然而,面对超导、离子…...
)
告别托盘“隐身术”:Total Commander 9.5 最小化任务栏设置详解(附F12配置技巧)
告别托盘“隐身术”:Total Commander 9.5 最小化任务栏设置详解(附F12配置技巧) 第一次打开Total Commander(以下简称TC)时,许多用户会被它的"消失术"困扰——点击窗口右上角的减号按钮后&#x…...

用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战
用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战 动态模态分解(Dynamic Mode Decomposition, DMD)作为一种数据驱动的建模方法,近年来在复杂系统分析、流体力学和流行病预测等领域展现出强大潜力。本文将带…...

AI科技热点日报 | 2026年5月12日
文章目录AI科技热点日报 | 2026年5月12日一、 行业标准与规范:AI终端迈入“标准化”时代二、 智能体(Agent)与具身智能:从云端走向实战三、 算力与基础设施:产业链的深度重构四、 产业融合与应用探索:AI fo…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置
2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token P…...