深入浅出 -- 系统架构之分布式多形态的存储型集群
一、多形态的存储型集群
在上阶段,我们简单聊了下集群的基本知识,以及快速过了一下逻辑处理型集群的内容,下面重点来看看存储型集群,毕竟这块才是重头戏,集群的形态在其中有着多种多样的变化。
逻辑处理型的应用,部署集群架构是为了解决单点故障、获得更高的吞吐量,集群内各节点之间没有依赖关系,同时遵循着“去中心化思想”,即多个节点里没有所谓的“老大”。
反观存储型的应用,需要保存数据、记录会话数据、用户认证信息、事务状态等信息,如果要搭建集群架构,则需要考虑各节点之间的数据一致性和完整性,来看个例子:

假设现在数据库使用三个节点组成集群,如果和业务系统集群一样,多个节点之间地位平等,此时客户端读写数据时,究竟该去到哪个节点呢?包含多个操作的事务如何保证落到同一节点?用户在A节点登录后,如何把登录态(连接信息)同步给B、C节点?
正是因为上述一堆的问题,存储型集群里的节点必须要划分等级,一定要有一个等级更高的节点,来承担客户端的写操作。因此,在很长一段时间内,涉及到数据存储的应用,集群方案都是以主从模式为主。
趣事:主从模式对应的英文是
Master/Slave,不过大家会发现,后来许多技术的主从模式,都叫Leader/Follower,这是为啥?因为Master/Slave代表的是“主人/奴隶”,再加上集群存在选举机制,所以在西方被痛斥为“此命名的政治思想不正确”,于是许多技术栈都经历过“语言净化”(如Redis)……
好了,上面提到主从集群,下面来展开聊聊存储型应用的集群方案,粗分下来也是两大类:
主从模式:集群内的节点区分等级,可以有一或多个主节点,具备完整的读写能力;也允许拥有多个从节点,但能力方面有所阉割,只具备处理读取请求的能力。
分片模式:集群内节点地位平等,各节点都具备数据读写能力,但每个节点只负责一部分数据,完整数据分散在各节点上。
1.2、主从架构
主从集群,这个概念所有人都熟悉,它的身影在各种技术栈随处可见,如主从集群、镜像集群、复制集群、副本集群……,尽管在不同技术栈的叫法不同,可本质上都是同一个东西。
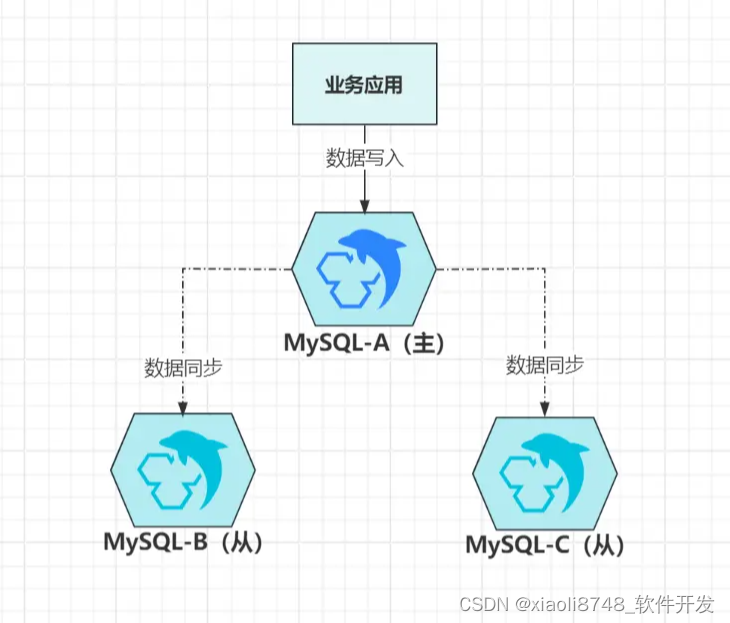
上图是经典的一主多从架构,客户端的写请求,都会落到主节点A上,而后再给同步给B、C这两个从节点,这就是大名鼎鼎的“主从复制技术”,数据同步有三种方案:
- 同步复制:等数据写入集群所有节点后,再给客户端返回写入成功;
- 半同步复制:等集群内一半数量以上的节点写入数据成功后,给客户端返回写入成功;
- 异步复制:数据在主节点上写入成功后,立即给客户端返回写入成功。
大多数支持主从复制的技术栈,几乎都上面三种同步方案,从数据一致性角度看:同步复制>半同步复制>异步复制,而从性能角度出发则完全相反:异步复制>半同步复制>同步复制。
如今大多数技术栈默认的复制方案都是第三种,虽然有数据丢失的风险,可是它的性能最好,何况“主节点写入完数据,正好就发生故障”的这种几率很小。当然,如果你的系统更在乎数据一致性和安全性,那就可以选择半同步模式,如果完全不在乎性能,则可以切换成同步复制模式。
1.2.1、读写分离
在主从架构中,因为从节点被阉割掉了处理写请求的能力,所以在大部分时间里,如果从节点只作为数据副本而存在,显然会造成很大的资源浪费。为了充分利用从节点的资源,一种名为“读写分离”的技术曾风靡一时。
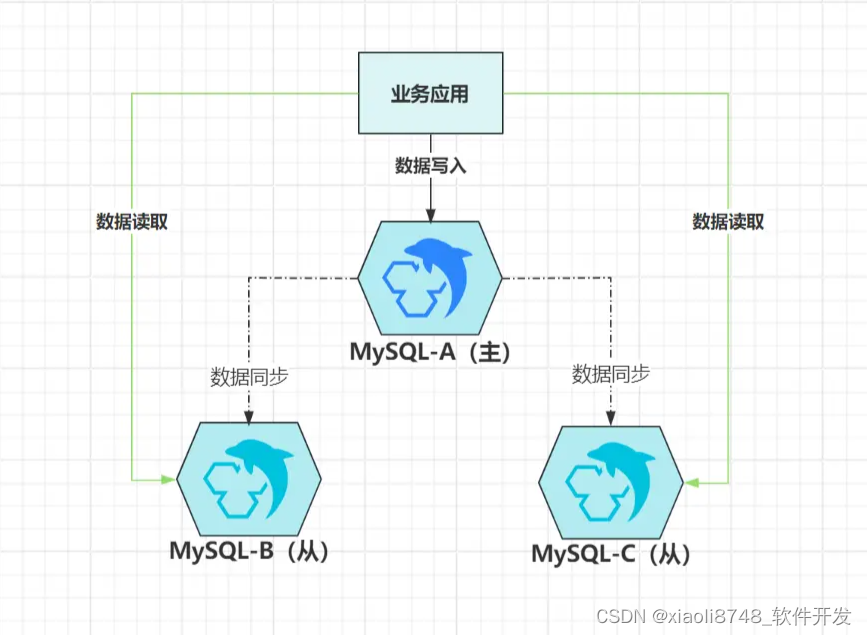
虽然从节点没有处理写请求的能力,可是它会把主节点写入的所有数据都同步过来,为此,它具备“一定程度”的读请求处理能力,此时就可以将读取数据的请求分发给从机,既能充分利用空闲资源,又能减轻主节点的访问压力。
PS:从节点只具备“一定程度”的读请求处理能力,注意里面用引号标出的“一定程度”,这啥意思?
因为主从复制技术,都依靠网络来同步数据,而网络并不可靠,也必然存在延迟性。在异步复制的模式下,当一个数据写入到主节点,立马出现读请求到从节点读取,此时有可能读不到最新的数据。
1.2.2、故障转移
本文开篇提到的集群四大优势,其中一条则是保证了高可用,解决了单点故障问题,可实际上部分技术栈,虽然支持主从集群,但却只提供了基本的主从复制功能(如MySQL),并不具备故障转移能力。
所谓的故障转移,通常是针对主节点而言的,即:当主节点发生故障时,集群能自动推选出新主节点,并将流量自动转移到新主处理。大家熟知的MySQL,它并不具备自动故障转移功能,当原本设定的主节点故障后,必须通过人工介入、或第三方工具(如MHA),又或者自己研发的组件实现故障转移。
当然,也有很多技术栈,官方就实现了故障转移机制,比如Redis的Sentinel哨兵、MongoDB的Arbiter仲裁者、Kafka的Controller控制器……,这些中间件的主从集群,在主节点发生故障时,都能实现无人力介入、自动转移效果。
这种自动故障转移机制,它们内部是如何实现的?其实原理大同小异,故障转移的第一步,是需要能检测出故障的节点,有两种方案可选:
- ①探测模式:负责故障处理的节点,每隔一段时间向集群所有节点发送探测包(
ping),没有回复的节点说明已经故障; - ②上报模式:集群内所有节点,主动向负责故障处理的节点发送存活信息(心跳),当一个节点没有心跳时说明陷入故障。
不过为了兼容网络分区问题,通常会组合起来使用,正常情况下,集群节点主动发送心跳包,当某个节点没有心跳后,故障处理节点会主动发起探测请求,如果还是没有回复,则会认为该节点陷入故障。考虑到网络分区的影响,故障处理节点也可能陷入了分区,因此也会向其他故障处理节点,发出二次确认的请求,以此进一步确认对应节点是否故障。
PS:上述概念类似于
Redis哨兵里的主观下线、客观下线,同时也不仅仅只有故障处理节点,具备故障检测能力,集群内的节点也拥有该能力,如从节点去拉数据时,也可以检测出主节点的健康状态。
如果本次检测出的故障节点是主节点,则会进入新主选举流程,选举一般是通过投票机制实现,新主上任的前提是“节点数一半以上的票数”;而投票机制的内在逻辑则是数据POS点,即谁的数据更新则更有机会成为新主,总体流程如下:
- ①故障检测:当感知到某个节点不可用时,会先发起通信向其他可用节点进行二次确认;
- ②故障处理:如果检测到主节点不可用,从节点会将自己转换为候选人,并向其他成员宣布;
- ③选举开始:轮次号加一,开启一轮新的选举,每个候选人节点开始向其他成员发送拉票请求;
- ④投票开始:在一个新的选举轮次中,每个节点只能投一票,可以投给自己或者其他节点;
- ⑤投票结束:所有节点已投票,或抵达本轮选举的时间限制后,将获得大多数投票的节点立为新主;
- ⑥主从切换:新主会向其他节点发送“上位”消息,其他节点更新自己的配置,接受新主上位;
- ⑦数据同步:完成主从切换后,从节点以新主为数据基准,校验自身数据是否完整,有缺失则同步。
上面只是大概流程,但几乎所有技术栈实现的思路都是这样,因为它们都遵循着Paxos、Raft等协议制定的标准,本文对此不做展开,后续会单开篇章来聊。
1.2.3、级联复制
级联复制是主从架构的变种,其本质还是主从模型,主要用于一主多从的结构中,如:
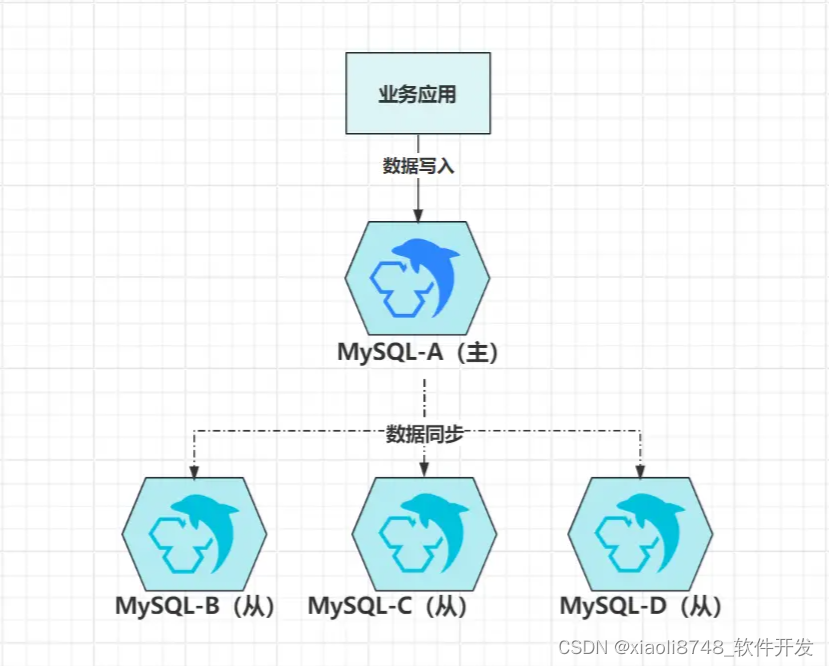
在主从架构中,想要实现数据同步有两种方式:
- 主节点推送:当主节点出现数据变更时,主动向自身注册的所有从节点推送新数据写入。
- 从节点拉取:从节点定期去询问一次主节点是否有数据更新,有则拉取新数据写入。
但不管是哪种方式,都会存在一个问题:主节点同步数据的压力,会随着从节点的数量呈线性增长!啥意思?因为不管是推还是拉,数据都需要从主节点出站。
对主节点来说,数据同步会对磁盘、内存、带宽、CPU带来不小压力,此时多一个从节点,自然多出一倍的压力,数据量较大时,特别容易把主节点的资源占满,从而造成主节点无法处理客户端的请求,级联复制的出现,就是为了解决此问题。
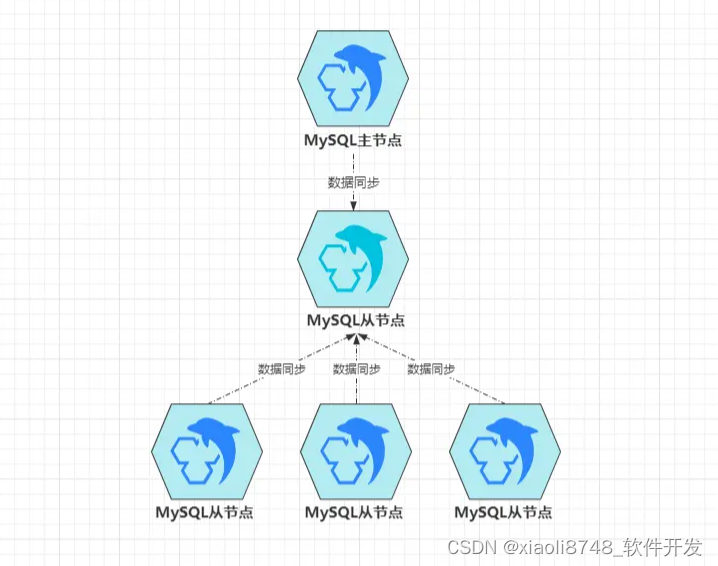
级联复制模式中,只有一个从节点B挂在主节点A下面,其余的从节点都会成为B的从节点,数据由B先同步到自身,其余节点再从B去同步数据,这样就解决前面的问题,可此时又会带来新问题:
- 数据延迟:本身主从复制就存在延迟性,而新加入一层后,数据延迟性会更高;
- 级联节点故障:负责同步主节点数据的
B一旦故障,会导致其余从节点无法同步数据。
凡事有利必有弊,虽然级联复制能解决原本的问题,可是也会带来新问题,这时就需要处理新的问题,或者把新问题的影响降到最低。
PS:用来同步数据的
Canal中间件,就类似于级联复制的思想。当然,除开小部分特殊的项目,一般很少用到级联复制模式。
1.2.4、多主热备
虽然可以通过读写分离、级联复制,减轻主节点的部分压力,可对于写请求,都必须得落到主节点上处理,而主节点再强悍,总有扛不住的时候,这时又出现了变种集群:双主/多主模式。
多主模式也是建立在主从复制的基础之上,比如双主模式时,两个节点互为主从,各自都具备完整的读写能力,客户端的写请求,可以落入任意节点上处理。不管数据落到哪个节点,另一个节点都会将数据同步过去,此时客户端的读取请求,在任意节点上都能读到数据。
通过这种方案,可以将写入性能翻个倍,并且可以继续拓展出更多的主节点,组成多主集群。不过一般是双主,因为大部分技术栈支持的主从集群,仅允许为一个从节点配置一个主节点,在这个限制下,想要实现多主,则只能组成环形多主集群:
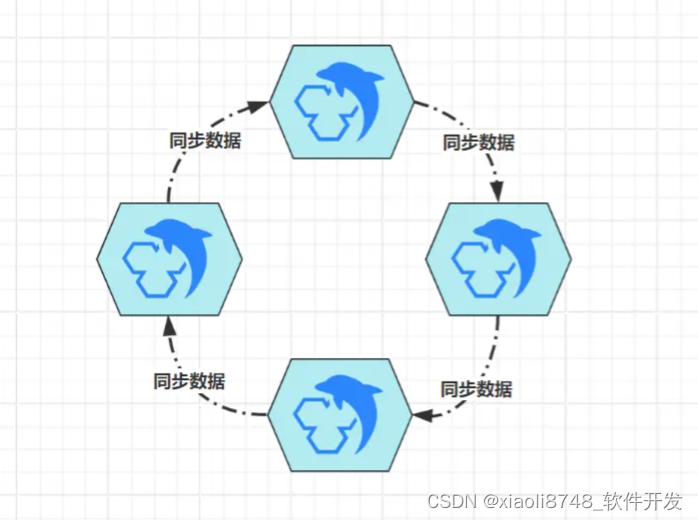
这种环形多主架构,由于每个节点都支持写入数据,所以能极大提升写入吞吐量,但成也萧何败也萧何,一个节点写入新数据后,需要经过N次(节点数量-1)复制,才能将数据同步给所有节点,集群内的延迟性很高,这也是为什么一般只搭建双主的根本原因。
PS:多主集群除开能提升写入吞吐量外,只要客户端略加适配,就可以实现“客户端版故障转移”,即客户端检测到一个节点不可用后,自动切换到其他节点上读写数据。
1.3、分片架构
不管是开始提到的横向集群,还是上面聊到的主从集群,本质上都是“克隆”多个具备完整功能的单机节点组合部署,尽管主从里的从节点功能有所阉割,可整体上还是属于主节点的复制体。
对业务系统这类应用而言,用多个克隆体组成集群没任何问题,这也是集群概念的标准思想,但对于存储型应用来说,就会出现三个致命问题:
- 木桶效应:三个节点的磁盘容量为
512G、1T、1T,集群最大容量则为512G; - 写入受限:传统的主从集群,写入的吞吐量受单个主节点限制,写入的并发很难提升;
- 容量危机:主从集群通过升配存储
GB、TB级数据,但上升到PB甚至更高量级时无力。
为了解决木桶效应,必须保证集群所有节点的资源配置一致,否则同步数据时存不下;为了解决写入受限,可以搭建另类的多主集群,可这种模式数据延迟太大;为了存储海量数据,只能不断加硬件资源带来更大的存储空间……
主从集群有着天然的弊端,虽然可以通过特殊手段环境,但无法根治“先天性的劣势”,这种传统型的集群方案,不再适用于增长迅猛的系统(无法处理高并发与海量数据存储)。正因如此,存储型应用在设计集群模式时,做出了一个违背祖宗的决定:将数据分区存储,既然一台机子存不下,那我就用多台机子存!
1.3.1、分片式集群
分区存储,就是目前大数据存储领域大名鼎鼎的分布式存储技术,也叫:分片式集群,我们再来好好聊聊这块知识~
之前的单体模式也好,主从集群也罢,数据其实都是集中式存储,即所有数据都存储在一起。分区存储,就相当于把原本的一缸水,分到不同的桶子里,如下:
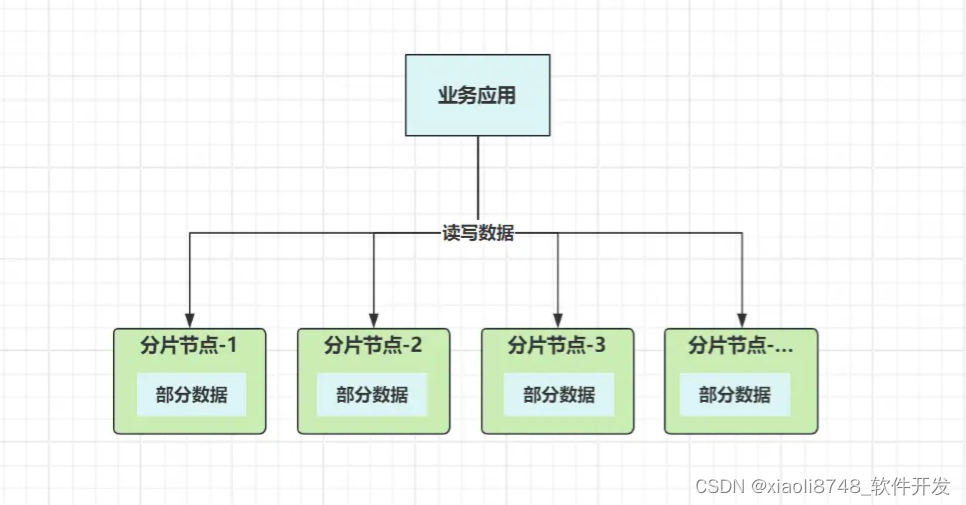
每个分片节点,都具备读写数据的能力,这样就从根本上解决了写入瓶颈,并且数据分散到多个节点独立存储,这并不受木桶效应的影响,解决了PB级数据存储造成的容量危机。
分片集群的好处很多,但想要实现分片式存储,首先要解决的就是数据路由问题,写入时能自动根据规则落到某个分片节点存储,读取时能精准找到存储的分片节点获取数据。这和前面聊的请求分发算法类似,只不过数据分发时,需要保证同一数据的写入/读取落入相同的节点。
数据路由到具体的分片节点,有两个核心点,一是分片(路由)算法,二是分片(路由)键。数据分发和请求分发不同,因为要保证同一数据读写都在相同节点操作,光靠分发算法无法实现,所以每条数据需要有个标识,这个标识就是路由键,以ID字段作为路由键来举例:
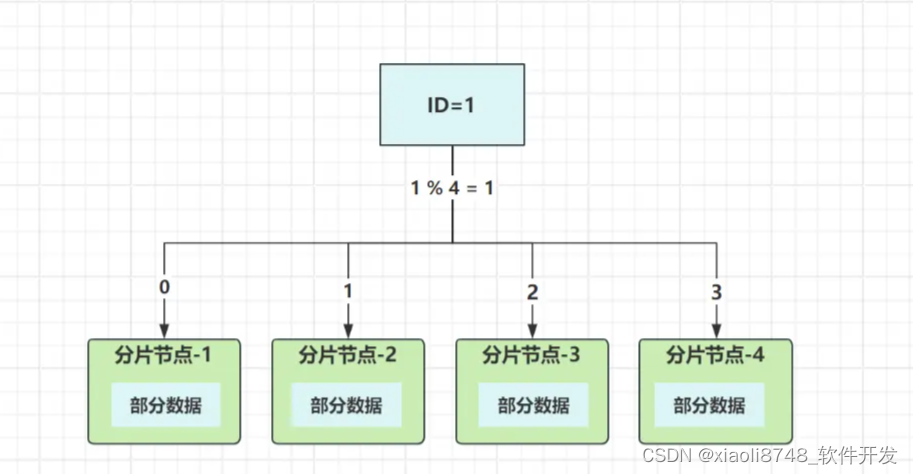
集群有四个节点,选用取模分发算法,根据ID值取模节点数量,计算出数据最终要落入的节点。来看实际过程,假设要操作ID=1这条数据:
- 写入:路由键
ID取模四:1%4,结果为1,数据落入分片节点2; - 读取:路由键
ID取模四:1%4=1,从分片节点2中读取数据。
通过这种方式,就保证了读写数据的节点一致,避免“写入成功,无法读取”的尴尬现象发生。不过除了取模分发外,还有其他一些分发算法,如范围分发、哈希取模、一致性哈希、哈希槽……,像Redis-cluster集群中,就采用CRC16算法计算Key(Key即路由键),并结合哈希槽模式实现数据分发。
解决了数据分发问题后,分片架构其实还存在一系列问题,好比多节点的数据如何聚合等等。如果当前分片的存储组件属于关系型数据库,如何兼容事务机制?多表联查如何关联?如何实现多字段维度查询?当然,其实还有一系列头疼的问题,这里不做展开,感兴趣可参考《分库分表副作用篇》。
经过上面的阐述后,大家一定对分片式集群有了基本认知,现在来聊聊分片集群的类型,总体可分两种:中心代理分片集群、去中心化分片集群。
1.3.2、中心化分片集群
中心化分片集群,意味着集群中又存在不同的角色节点,最少有两种:
- 中心节点:负责路由规则、数据节点的管理工作,以及处理数据分发请求,自身不存储分片数据;
- 数据节点:具体存储数据的分片节点,负责处理中心节点分发过来的写入/读取数据请求。
上面的中心节点,就类似于之前的”负载均衡器“,负责管理集群所有节点,以及具体的分发工作,这种模式也是早期最主流的分片集群方案,即:代理式分片集群。
代理式分片,可以在官方不支持分片集群的情况下,自己来搭建分片集群,以传统关系型数据为例,MySQL官方并不支持分片存储,怎么办?如果工作年限较长的小伙伴一定清楚,之前有个大名鼎鼎的中间件叫:MyCat,示意图如下:

尽管MySQL不支持分片架构,但通过上述方案,可以将一个个独立的MySQL节点,组合成一个逻辑上的大整体,每个独立的MySQL节点,则代表着具体要存储数据的分片节点。MyCat则是负责节点管理与数据分发的中心节点,所有要操作MySQL的客户端,都会连接到MyCat,读写请求交给MyCat做具体分发。
PS:实际
MyCat就是伪装成了一台MySQL,业务系统依旧和往常一样连接即可,屏蔽了客户端对分片集群的感知。
除开MyCat外,如同类型的Sharding-Proxy,又或者早期Redis的TwemProxy、Codis等等,这都是代理式分片理念的产物。究其根本,还是由于早期官方并不支持分片式架构,因此部分业务庞大的企业迫于无奈,只能在更高的维度上,架设中心节点来分发数据到不同的节点中存储。
这种中心化分片集群的思想,直到现在依旧在使用,只不过如今很少有代理中间件,基本都由官方自己实现,如MongoDB分片集群,依靠路由节点mongos进行数据分发。
为啥我称呼这类分片集群为“中心化分片集群”呢?其实站在数据/分片节点的角度出发,节点之间相互平等,不存在之前主从架构里的Master概念。可是,虽然没有了Master,但在数据节点之上有了一种更高维度的节点,所有数据节点都得“听”它安排,这就是一种另类的中心化体现。
中心化分片集群有何劣势?特别明显,不管是第三方实现的代理中间件,还是官方自身研发的“高等级节点”,毕竟所有请求都需经过“中心节点”,为此,一旦这类节点故障,必然会造成整个分片集群不可用。
中心化分片集群,为了解决中心节点的单点故障问题,一般都需要对中心节点做高可用建设,如
mongos集群式部署、MyCat做热备等等。
1.3.3、去中心化分片集群
与上阶段提到的中心化分片集群相反的,则是去中心化分片集群,典型的例子就是Redis3.x推出的Redis-Cluster集群,这是一种完全意义上的去中心化集群,所有负责读写数据的节点地位平等,并且没有“中心化”的路由节点。
相反,Redis-Cluster中采用了哈希槽的概念,总计16384个槽位,集群初始化时会平均分给每个节点负责管理(支持手动设置),比如现在有四个节点,哈希槽的默认分配如下:
A节点:0~4095槽位;B节点:4096~8191槽位;C节点:8192~12287槽位;D节点:12288~16384槽位;
类似于之前0~15这16个默认的库一样,每个槽中都可以存放多个Key,同时配备CRC16哈希算法,最终实现数据的分发,例如下述命令:
set name zhuzi
则会使用CRC16算法对name这个键名进行哈希,接着取模总槽数16384,从而得出具体要落入的槽位。假设name对应的哈希值是185272,最终落入槽位则是5047(185272%16384-1),即落入到B节点中存储。
既然没有中心化的路由节点,那CRC16+取模运算的工作谁来完成?集群内的所有节点!在Redis-Cluster中,任意节点都具备CRC16取模的能力,来看个场景:
如果一个本该落入
A节点的Key,在set时去到了C节点,那么C节点在经过CRC16计算后,会不会把该Key转发到A节点去呢?
答案是不会,而是会向客户端会返回一个重定向错误的消息,其中指示了正确的节点位置,告诉客户端去连接对应节点写入数据即可。
PS:实际项目中,并不会把
CRC16+取模的工作交给Redis来做,因为这样有可能会出现一次重定向,通常都是客户端计算,而后直连正确的节点写入数据(如Java中主流的Redis客户端框架,都有实现CRC16的逻辑)。
好了,上述便是去中心化的大体逻辑,相信大家一定明白为啥叫去中心化分片集群,因为不存在中心节点,各个节点自身就具备数据分发计算的能力,即使集群内部分节点宕机,也只会影响部分数据,保证了BASE理论中的基本可用思想,并不会像中心化分片集群那样,一旦中心节点故障,就会造成分片集群不可用。
PS:分库分表领域的
Sharding-JDBC,也是一种去中心化分片存储的体现,即各个客户端具备数据分发的能力,不需要依赖MyCat这类中间件实现数据路由。
相较于传统的主从集群,分片式集群的维度显然更高,当应对数据量级、并发规模非常大的系统时,分片式集群能够利用多台机器的共同满足数据需求,它能充分利用集群中每一台机器的资源,实现数据读写的并行处理,以及海量数据的分区存储。也正因如此,早期想实现分片式存储,需要自己研发中间件,反观如今,随着分布式各领域技术的发展,分片式集群成为了新趋势,官方基本都开始支持分片架构。
二、集群篇总结
OK,看到这里,我们一步步阐述了集群中的常用知识,也对集群的形态有了全面认知,但本文并没有涵盖集群的方方面面,实际上,不同类型的集群架构,总会带来各种各样的问题,而这些问题并未做展开,也包括集群与云平台的结合,本文也未曾说明,这些就留给诸位自行去探索啦~
相信看到这里的小伙伴,对集群方面的知识应该建立出了系统化、结构化的认知体系,不过经常阅读我文章的小伙伴会发现,本文中的很多概念,在以往的文章里都有提及,看起来会感觉异常熟悉,为啥?这就是我经常说的那句话:技术学到最后都是共通的,不同技术之间最后都能串起来。
不管是业务系统,还是注册中心、定时任务、Redis、MQ、MySQL、ES……等各种组件,在实现集群方案时,底层逻辑都大差不差,本文则是各种技术栈集群方面的共通知识,当你在学不同技术栈的集群技术时,就会发现这些技术之间的共通性。
最后,也希望大家不管在学习什么技术,不要只把目光集中在表层的应用,闲暇之余,记得看看内层的实现思想,这样方能做到一通百通,才能让大家真正成为技术领域的“高手”。
相关文章:
深入浅出 -- 系统架构之分布式多形态的存储型集群
一、多形态的存储型集群 在上阶段,我们简单聊了下集群的基本知识,以及快速过了一下逻辑处理型集群的内容,下面重点来看看存储型集群,毕竟这块才是重头戏,集群的形态在其中有着多种多样的变化。 逻辑处理型的应用&…...
STL —— list
博主首页: 有趣的中国人 专栏首页: C专栏 本篇文章主要讲解 list模拟实现的相关内容 1. list简介 列表(list)是C标准模板库(STL)中的一个容器,它是一个双向链表数据结构,…...

申请SSL证书
有很多方法可以确保您的网站安全。添加SSL证书可针对恶意攻击提供额外且关键的保护层。 即使网站不接受交易,您仍然需要保护用户的登录详细信息、地址和其他个人信息。 没有SSL证书的网站使用HTTP(一种基于文本的协议),这意味着…...
深入浅出 -- 系统架构之负载均衡Nginx环境搭建
引入负载均衡技术可带来的收益: 系统的高可用:当某个节点宕机后可以迅速将流量转移至其他节点。系统的高性能:多台服务器共同对外提供服务,为整个系统提供了更高规模的吞吐。系统的拓展性:当业务再次出现增长或萎靡时…...

notepad++绿色版添加右键菜单
解压路径 D:\Green\notepad_v8.0_x64_绿色版 添加右键菜单.reg 新建nodepad添加右键菜单.reg文件 Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\*\shell\NotePad] "Edit with &Notepad" "Icon""D:\\Green\\notepad_v8.0_x64_绿色版…...
7 个 iMessage 恢复应用程序/软件可轻松恢复文本
由于误操作、iOS 升级中断、越狱失败、设备损坏等原因,您可能会丢失 iPhone/iPad 上的 iMessages。意外删除很大程度上增加了这种可能性。更糟糕的是,这种情况经常发生在 iDevice 缺乏备份的情况下。 (iPhone消息消失还占用空间?&…...

DockerFile启动jar程序
1.创建Dockerfile 在项目的根目录下创建一个名为Dockerfile的文件,并使用文本编辑器打开它。Dockerfile的内容如下: # 基础镜像 FROM openjdk:8-jre # 创建目录 RUN mkdir -p /usr/app/ # 设置工作目录 WORKDIR /usr/app # 将JAR文件复制到容器中,注:…...
基于R、Python的Copula变量相关性分析及AI大模型应用
在工程、水文和金融等各学科的研究中,总是会遇到很多变量,研究这些相互纠缠的变量间的相关关系是各学科的研究的重点。虽然皮尔逊相关、秩相关等相关系数提供了变量间相关关系的粗略结果,但这些系数都存在着无法克服的困难。例如,…...

鸿蒙组件学习_Tabs组件
说明 该组件从API Version 7 开始支持。 子组件 仅可包含子组件TabContent 参数 barPosition 设置Tabs的页签位置,默认值: BarPosition.StartStart vertical属性方法设置为true时,页签位于容器左侧;vertical属性方法设置为false时,页签位于容器顶部。End vertic…...
BabyAGI:根据气候变化自动制定鲜花存储策略)
【LangChain学习之旅】—(19)BabyAGI:根据气候变化自动制定鲜花存储策略
【LangChain学习之旅】—(19)BabyAGI:根据气候变化自动制定鲜花存储策略 AutoGPTBaby AGIHuggingGPTLangChain 目前是将基于 CAMEL 框架的代理定义为 Simulation Agents(模拟代理)。这种代理在模拟环境中进行角色扮演,试图模拟特定场景或行为,而不是在真实世界中完成具体…...
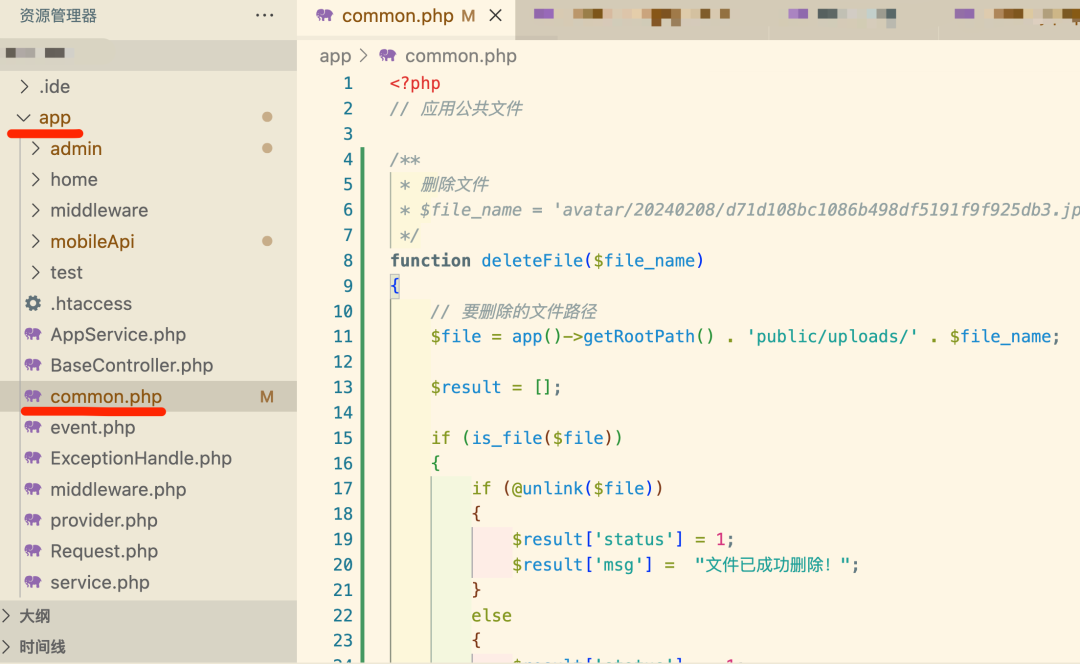
thinkphp6入门(21)-- 如何删除图片、文件
假设文件的位置在 /*** 删除文件* $file_name avatar/20240208/d71d108bc1086b498df5191f9f925db3.jpg*/ function deleteFile($file_name) {// 要删除的文件路径$file app()->getRootPath() . public/uploads/ . $file_name; $result [];if (is_file($file)) {if (unlin…...

虚拟内存知识详解
虚拟内存 单片机的 CPU 是直接操作内存的「物理地址」 在这种情况下,要想在内存中同时运行两个程序是不可能的 操作系统是如何解决这个问题呢? 关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的。 可以把进程所使用的…...
数据结构初阶:顺序表和链表
线性表 线性表 ( linear list ) 是 n 个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使 用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串 ... 线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的, 线性…...
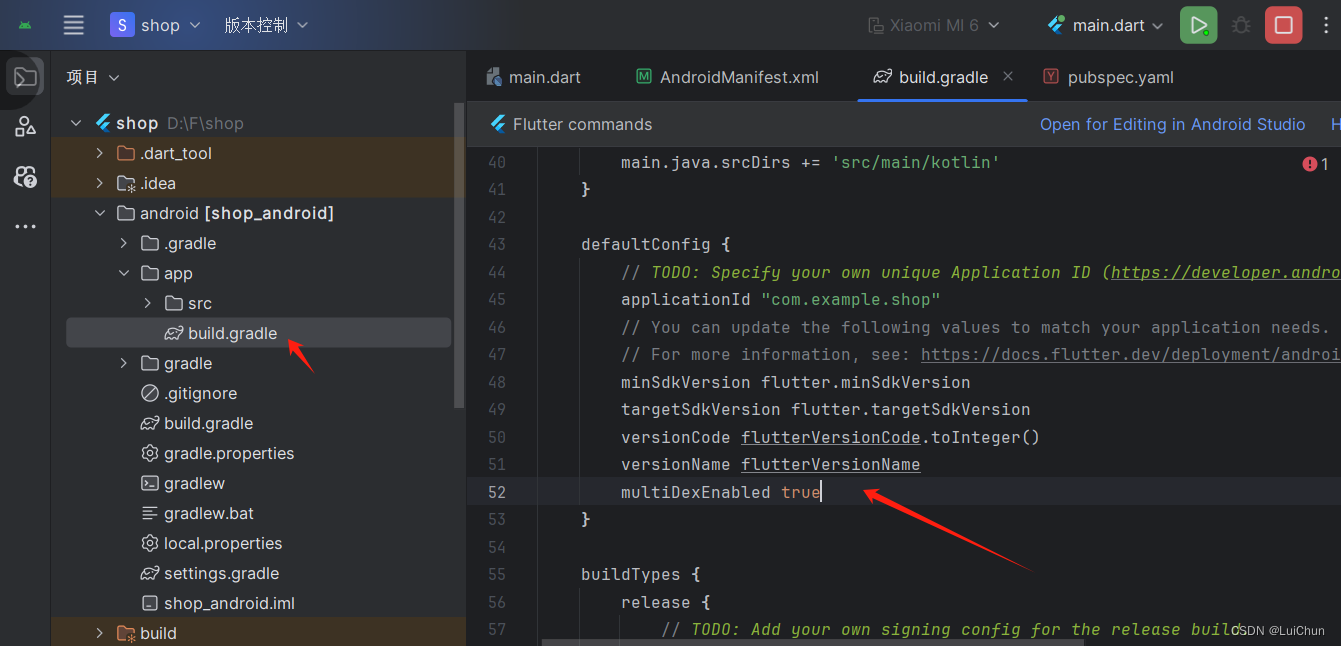
在flutter中添加video_player【视频播放插件】
添加插件依赖 dependencies:video_player: ^2.8.3插件的用途 在Flutter框架中,video_player 插件是一个专门用于播放视频的插件。它允许开发者在Flutter应用中嵌入视频播放器,并提供了一系列功能来控制和定制视频播放体验。这个插件对于需要在应用中展…...

golang微服务框架特性分析及选型
目录 一、微服务框架特性(10个)包括:Istio、go-zero、go-kit、go-kratos、go-micro、rpcx、kitex、goa、jupiter、dubbo-go、tarsgo 1、特性及使用场景2、比较 二、web框架特性(7个)包括:gin、fiber、beego…...
苹果cmsV10 MXProV4.5自适应PC手机影视站主题模板苹果cms模板mxone pro
演示站:http://a.88531.cn:8016 MXPro 模板主题(又名:mxonepro)是一款基于苹果 cms程序的一款全新的简洁好看 UI 的影视站模板类似于西瓜视频,不过同对比 MxoneV10 魔改模板来说功能没有那么多,也没有那么大气,但是比较且可视化功…...

GPU的了解
3D动画揭秘显卡的GPU是如何工作的_哔哩哔哩_bilibili 位于显卡中。 与CPU区别: 100名小学生和1位数学博士 做100道非常简单的算术题,小朋友一个人一道题,比博士快。 做1道非常复杂的数学问题,只有博士可以做出来。 CPU主要用于快…...

鸿蒙实战开发-如何使用Stage模型卡片
介绍 本示例展示了Stage模型卡片提供方的创建与使用。 用到了卡片扩展模块接口,ohos.app.form.FormExtensionAbility 。 卡片信息和状态等相关类型和枚举接口,ohos.app.form.formInfo 。 卡片提供方相关接口的能力接口,ohos.app.form.for…...
)
蓝桥杯刷题 前缀和与差分-[2128]重新排序(C++)
问题描述 给定一个数组 A 和一些查询 L**i, R**i,求数组中第 L**i 至第 R**i 个元素之和。 小蓝觉得这个问题很无聊,于是他想重新排列一下数组,使得最终每个查询结果的和尽可能地大。小蓝想知道相比原数组,所有查询结果的总和最多…...
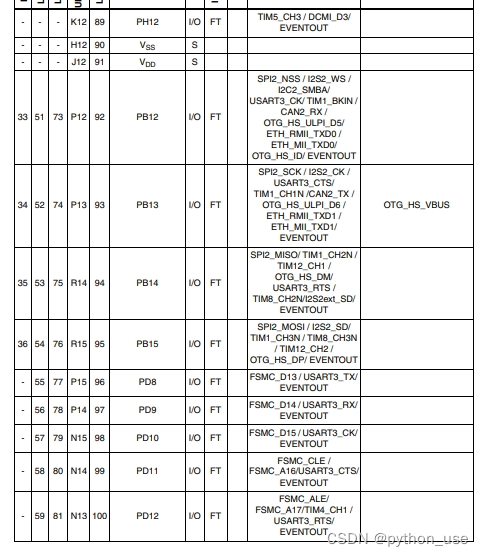
STM32重要参考资料
stm32f103c8t6 一、引脚定义图 二、时钟树 三、系统结构图 四、启动配置 (有时候不小心短接VCC和GND,芯片会锁住,可以BOOT0拉高试试(用跳线帽接)) 五、最小系统原理图 可用于PCB设计 六、常见折腾人bug…...
)
【Nature期刊精准捕获术】:基于Perplexity语义图谱的跨学科文献溯源方法论(附2024最新验证数据集)
更多请点击: https://intelliparadigm.com 第一章:【Nature期刊精准捕获术】:基于Perplexity语义图谱的跨学科文献溯源方法论(附2024最新验证数据集) 传统关键词检索在跨学科高影响力期刊(如 Nature、Scie…...

macOS桌面歌词终极解决方案:LyricsX 2.0完整指南
macOS桌面歌词终极解决方案:LyricsX 2.0完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾经在听音乐时,想要跟着歌词一起唱却发现…...

5分钟极速指南:免费将Word文档完美转换为LaTeX的终极工具docx2tex
5分钟极速指南:免费将Word文档完美转换为LaTeX的终极工具docx2tex 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 还在为Word文档转换LaTeX格式而烦恼吗?每次手动调整公…...

上午题_程序设计语言
编译程序和解释程序...

Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件
Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾好奇NDS游戏内部藏着什么秘密?想要提取…...

开源自托管看板工具:基于Preact+Hono+SQLite的零云依赖方案
1. 项目概述:一个为自托管与AI协作而生的看板应用如果你正在寻找一个可以完全掌控在自己手里、没有订阅费用、又能无缝集成到你自己产品中的看板工具,那么clawnify/open-kanban这个项目值得你花时间深入研究。它不是一个玩具,而是一个生产就绪…...

使用curl命令直接调试Taotoken大模型聊天接口的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型聊天接口的详细步骤 对于需要在底层进行调试、验证或是在无特定SDK环境中工作的开发者而言&am…...

AI大模型学习路线!手把手带你入门_AI大模型学习路线及相关资源推荐
本文详细介绍了AI大模型的基础信息、主要特点、类型,并提供了完整的学习路线图及丰富资源。内容涵盖数学、编程、机器学习、深度学习、自然语言处理等基础知识,以及Transformer模型、预训练模型等核心技术。此外,还强调了理论学习、实践操作和…...

动物森友会岛屿设计终极指南:用Happy Island Designer轻松规划你的梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer轻松规划你的梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会…...

终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略
终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略 【免费下载链接】sqlc Generate type-safe code from SQL 项目地址: https://gitcode.com/gh_mirrors/sq/sqlc sqlc是一个强大的工具,能够从SQL生成类型安全的代码,帮…...