数据结构---顺序表实现
目录
1.顺序表
2.动态顺序表的实现
(4)顺序表初始化
(5)顺序表销毁
(6)顺序表的插入
a.尾插
b.头插
(7)顺序表的删除
a.尾删
b.头删
(8)指定位置之前插入
(9)指定位置删除
(10)顺序表查找数据
3.我的心得体会(可跳过)
4.顺序表完整代码
(1)seqlist.h文件
(2)seqlist.c文件
(3)test.c文件
1.顺序表
数据结构就是计算机存储,组织数据的方式;
顺序表(线性表的一种,线性表是具有相同特性的数据结构的结合)就是一种数据结构,顺序表的本质就是数组;为什么数组存在了,还要有顺序表呢?
因为涉及特殊的操作,增加元素,删除元素,修改元素,插入数据,我们就要先计算数组的元素的个数,再进行相应的操作,顺序表的功能更加全面,含有增删查改的一些方法;
顺序表分为静态顺序表和动态顺序表:
(1)静态:定长的,使用size指定元素的个数;
(2)动态:长度是不确定的,使用size是数组元素的个数,使用capacity记录空间的大小;
静态顺序表是长度确定的,我们给他的空间小了,就会造成数据的丢失,空间给大了,会造成空间的浪费;
动态顺序表,我们可以进行增容,所以我们推荐动态顺序表;
2.动态顺序表的实现
(1)首先我们知道顺序表的本质就是数组,数组里面的元素可以是int,char等等的任意类型,所以我们在定义结构体的时候不能把数组元素的数据类型写死,而是使用宏进行替换,这样当数组的元素的数据类型发生改变的时候,我们就可以直接在宏定义的里面进行修改;
(2)顺序表的英文全称sequense list我们使用sl代表的是顺序表;sldatatype表示的是顺序表里面的数组的数据类型;
(3)为了方便我们的管理,我们新建3个文件,一个是sqlist.h的头文件,一个是sqlist.c的源文件,一个是test.c的源文件,这三个文件的作用是不一样的,头文件负责一些声明和定义,sqlist就是增删查改的具体函数的实现,test.c文件用来测试我们的顺序表的实现;
(4)顺序表初始化
我们首先要在头文件里面定义顺序表,生命我们的初始化的函数:
1.因为源文件里面的函数在使用的时候要包含我们的头文件,第一行的#pragma once就是为了防止头文件被多次包含;
2.我们头文件里面包含stdio.h,stdlib.h(动态内存管理的函数要包含这个文明),头文件里面包含之后,源文件里面包含头文件,就可以不进行包含了;
3.我们定义一个结构体struct seqlist里面的是结构体成员,数组(大小未知),数组元素的个数,空间的大小,因为为了简化我们每次定义结构体变量都要写struct seqlist,我们进行typedef的重定义,定义名字为sl;这样我们定义变量sl s,就相当于struct seqlist s;比较简洁;
4.我们假定数组元素的类型都是int类型,我们进行typedef重定义,如果想要修改为char类型,只需要在第四行进行修改即可;
5.第12行是进行函数的声明,函数的声明和函数的定义第一行是一样的,就是结尾加上了分号;
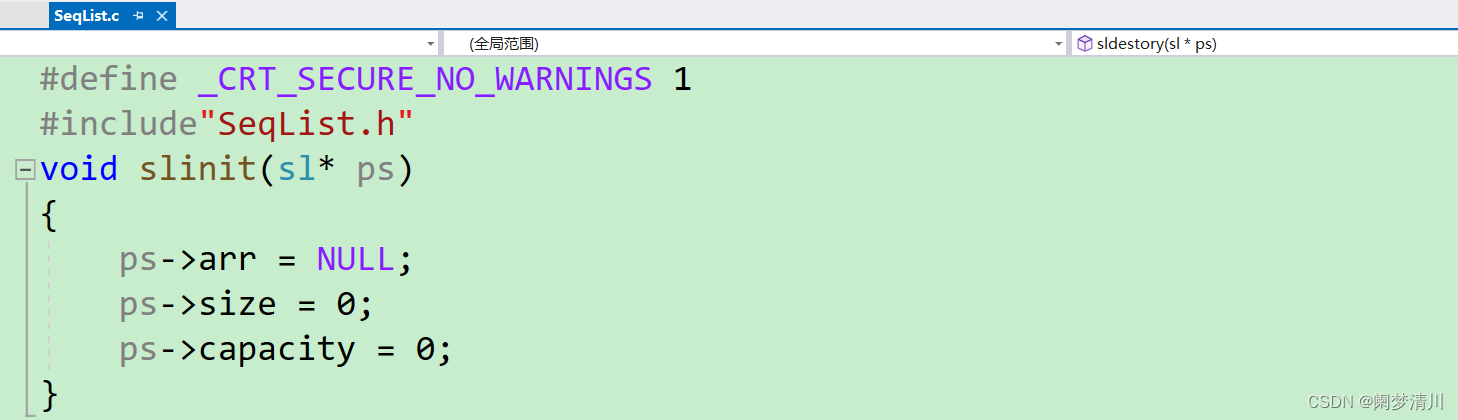
顺序表的源文件:
测试函数的源文件:
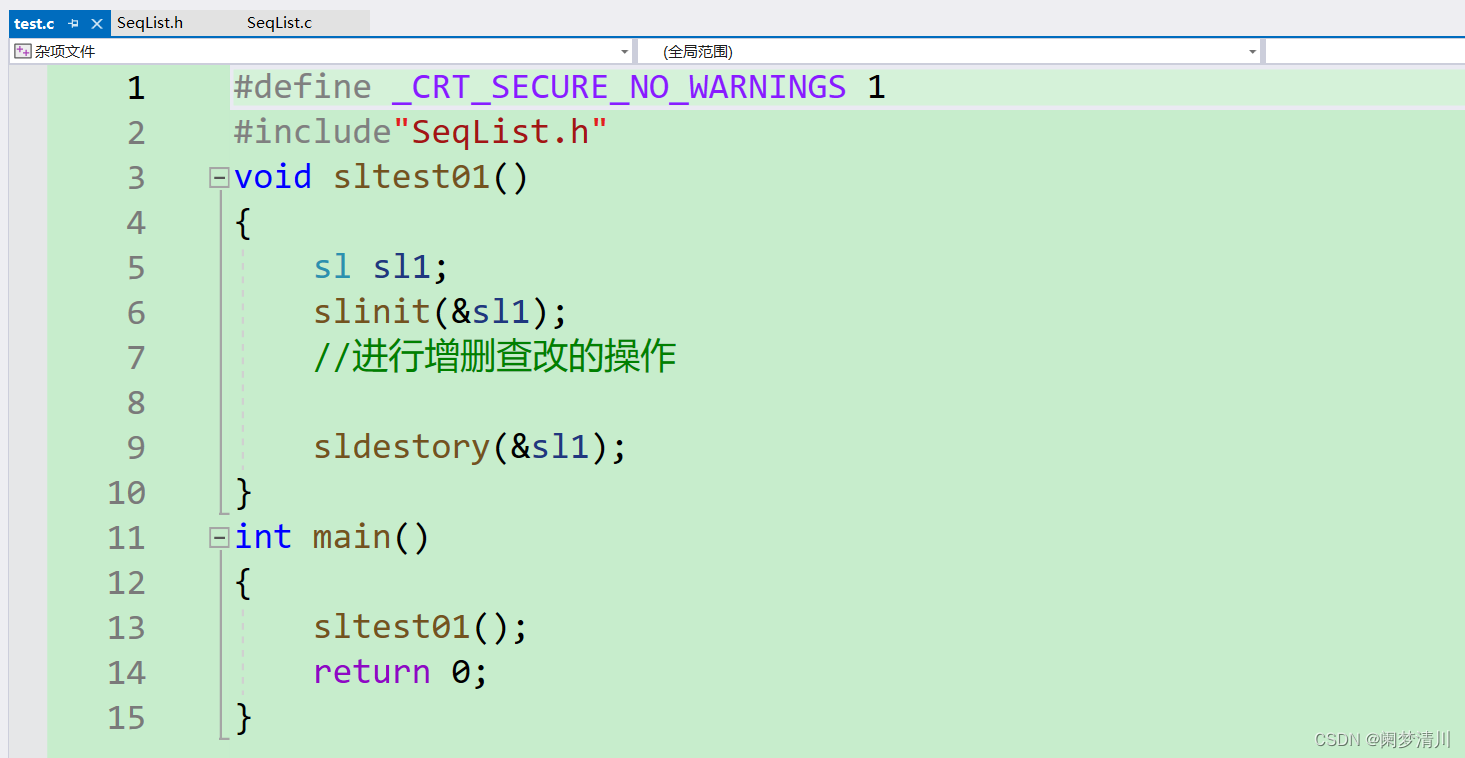
6.可见,两个源文件都包含了头文件,我们在测试的函数里面重新定义了一个sltest01函数,在主函数里面进行调用;
7.我们如果进行传值,达不到真正的初始化的目的,应该传递指针,这样形参的改变才会影响到实参,我们在test01里面先定义了一个结构体的变量,把这个变量的地址传递到顺序表源文件里面进行初始化,初始化的时候,使用结构体成员访问操作符把第一个指针置为空指针,第二个和第三个元素初始化为0;
8.调试观察:
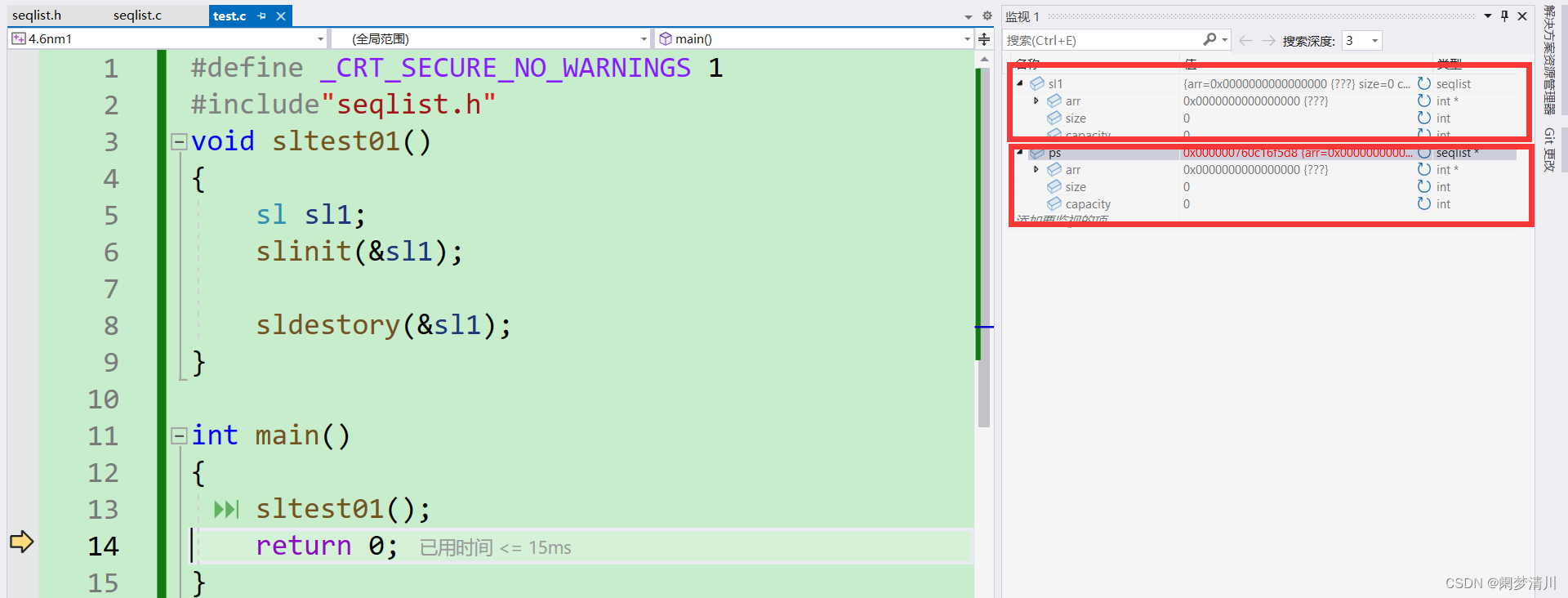 我们进行调试,刚开始我们自己定义的sl1变量是随机值,当初始化完成之后,就可以发现arr变成了空指针,size和capacity都是被初始化为0了,这样就算测试成功,达到我们初始化的目的;
我们进行调试,刚开始我们自己定义的sl1变量是随机值,当初始化完成之后,就可以发现arr变成了空指针,size和capacity都是被初始化为0了,这样就算测试成功,达到我们初始化的目的;
(5)顺序表销毁
初始化之后,我们就要对顺序表填充功能(增删查改),最后进行销毁,我们先看一下如何进行销毁:


顺序表的源文件里面,我们要销毁,就是释放掉数组开辟的空间,然后把arr置为空指针,size和capacity全部赋值为0;

(6)顺序表的插入
顺序表的插入分为头部插入和尾部插入,我们首先看尾部插入(尾插):
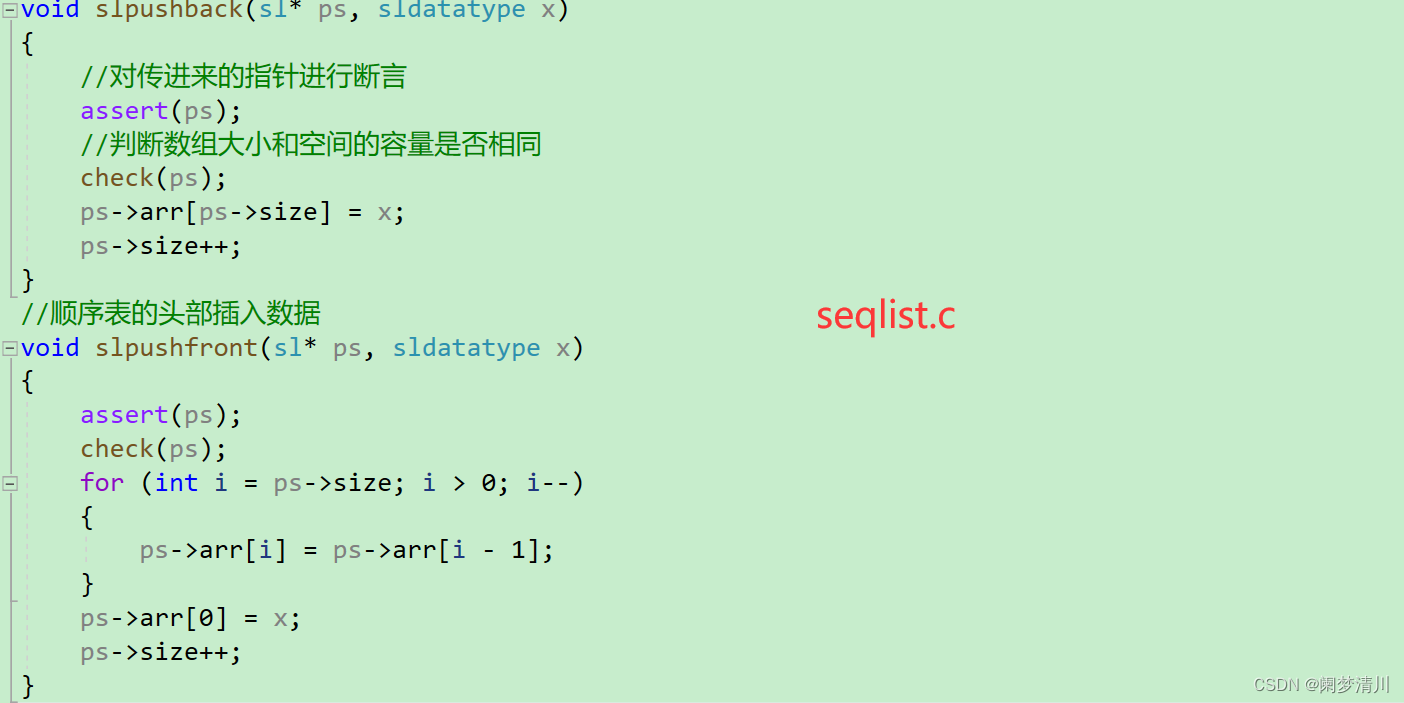
a.尾插

我们上面的举例是数组的空间比较大,我们可以直接插入,当数组元素的个数和我们的空间容量的大小相同时,我们就需要使用动态内存管理的相关的函数开辟内存空间,然后进行数据的插入:
头文件里面进行函数的声明:

顺序表的源文件里面的注意事项比较多,我们一一说明:
1.我们首先能够想到的就是插入数据,然后把size++;
2.我们需要判断是否有空间能够让我们插入数据,否则我们需要进行增容,增容就是使用realloc函数开辟空间,呢么需要开辟多大的空间呢?
这个一次开辟多大的空间需要使用数学里面概率论的知识,我们这里只要记住结论:一次按照原来的两倍进行增容就可以了;
3.但是我们前面进行初始化的时候,capacity==size=0,如果直接进行capacity*2,得到的结果就是0,因此我们需要提前进行设置;
4.怎么进行设置呢,这个地方我们就用到了三目运算符,如果capacity=0,我们就会把空间的容量,设置为4,否则就在原来的基础上面乘以2(这个就是代码里面的三目运算符表达式的含义了);
5.我们不能直接使用ps->arr进行接收,我们应该了解realloc的原理,如果开辟成功,我们就可以使用,如果开辟失败,那么我们原来的数据就没了,因此我们需要定义一个临时的相同的数据类型的指针变量进行接收,如果不是空的,我们在传递给ps->arr;
6.增容之后,我们就需要把新的容量赋值给capacity,实现空间的增大,为了增加代码的健壮性,我们进行断言(防止传递过来的空指针导致程序的崩溃);

测试的源文件里面我们插进去的数字是8,我们也可以多次插入,看看调试的时候的增容的实现过程:

b.头插
尾部插入数据,同样需要判断数组的容量的大小够不够,还是要用到头插里面一样的代码,因此我们可以把代码封装成为一个函数check,这样我们在头插,尾插可以直接进行调用,提高我们的代码的可读性和实用性:

因为,我们顺序表的功能完成之后,我们要进行测试,为了简单起见,我们可以把头插,尾插后的顺序表里面的数组元素打印出来进行验证,因此我们定义了slprint函数:

我们有了这个判断的函数以后,重新实现尾插和头插:
下面的两段代码对比之后就可以发现,异曲同工,都是先进行指针的断言和size的断言,
尾插比较简单:判断之后,直接在size下标的位置加上数字就可以了;
头插相对而言比较复杂:先进行断言和判断,因为是头插,我们呢要后面的一个数据覆盖前面的数据就,然后插入的数据放到0下标就可以了,这个就要用到for循环,最重要的是循环条件的判断,因为最后的覆盖是arr[1]=arr[0],所以循环的终止条件就是i=1,但是不能是0,因此i>0就可以了;
(7)顺序表的删除
a.尾删
尾删也是先进行断言,然后进行减小容量(比较简单,但是不好想明白,我是这样的);
我们就可以理解为原来有1 2 3 4这四个数,我们把size--,size就变为3,这样进行打印的时候,就是以size作为判断的条件的,没有删掉,但是打印结果不会显示,因为那个末尾的数字已经不再我们的范围里了,好像已经“删除”了,(因为本质上就没有删,只不过不打印,不属于我们的范围而已了);

b.头删
头删也是进行的移动覆盖,前面的头插是集体向后移,为第一个数字的插入腾空间,头删就是集体向前移,把最前面的数据给覆盖掉,这里移动的时候同样用到了循环,循环终止条件的判断尤为重要,最后的移动覆盖是arr[size-2]=arr[size-1],同理,1234这四个数字,2覆盖1,3覆盖2,4覆盖3,最后就是2344,其实最后的4覆盖前面之后自己还是存在的,但是我们打印的时候不打印他,因为我们的size--了啊,先当于循环的时候就不会这第二个四这个地方;

(8)指定位置之前插入
先进行断言,范围判断;把指定位置腾出来(循环向后移动),在向这个位置放进去数据,增大size;

(9)指定位置删除
先进行断言,从pos位置开始,循环向前移动数据,把指定位置的数据给覆盖掉,这样就实现指定位置的数据删除,最后size--;

(10)顺序表查找数据

我们使用循环遍历整个数组就可以了;我们这里的返回值是int类型,这个用来显示我们是否找到了,找到了就返回数字的下标,没有就返回无效的下标(因为肯定没有数字的下标是-1);
当然为了让打印的结果更加的直观,我们可以测试的时候对函数的返回值进行判断,有效就说找到了指出下标,没找到就显示未找到。

3.我的心得体会(可跳过)
(1)写到这个位置真正完成了这个全部功能的实现,我也如释重负,但是我知道自己还没有完全掌握,“纸上得来终觉浅,绝知此事要躬行”,只有多多巩固,才能真正的自己写出来;
(2)我自己第一次遇到顺序表的时候,听了一遍也是一头雾水,例如里面的各种重新命名,参数的设置(实参形参),但是当你真正理解一个功能的实现方法之后,其他的就不是问题了,重要的是实现功能的方法逻辑;
(3)现在回想一下,这些功能的实现时候,有许多相似的地方,例如进行断言(指针是否为空指针,空间的容量是否为零,为零的话我们就不能进行删除等操作);
(4)当然他们也有区别,例如在进行循环的时候,循环终止条件的判断,移动覆盖,从前向后移动还是从后向前移动,例如头插就是从后向前移动(腾开位置),头删就是从前向后移动(覆盖掉位置);
(5)我觉得,这个里面比较难的还是循环终止条件的判断,我们不要去用脑子想,要画出来,写出最后一次循环的时候的情况,找出对应的下标和已知的参数的关系,再进行判断;
(6)当然,还有我们进行指定位置之前的插入pos可以等于size的大小,但是进行指定位置指定位置的删除的时候,我们就不能让pos==size了,这个能不能取等,我们也要举例验证;
(7)在test.c文件里面进行测试的时候,例如指定位置的删除,我们要测试3种情况,在第一个位置删除(也就是头删),在中间的位置删除,在最后的位置删除(也就是尾删),对于这样的,既应该满足中间删除的普通情况,也应该满足头删尾删的特殊情况,这几种情况都要进行测试,都通过才证明我们的代码是没有问题的;
(8)感谢你看到这里,听我细细道来,路漫漫其修远兮,we将上下而求索,加油💪!
4.顺序表完整代码
(1)seqlist.h文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int sldatatype;typedef struct seqlist
{sldatatype* arr;int size;int capacity;
}sl;//顺序表的初始化
void slinit(sl* ps);//顺序表的销毁
void sldestory(sl* ps);//顺序表的尾部插入数据
void slpushback(sl* ps, sldatatype x);//顺序表的数组元素的打印
void slprint(sl s);//顺序表的头部插入数据
void slpushfront(sl* ps, sldatatype x);//顺序表的尾删
void slpopback(sl* ps);//顺序表的头删
void slpopfront(sl* ps);//顺序表的打印
void slprint(sl s);//顺序表的指定插入
void slinsert(sl* ps, int pos, sldatatype x);//顺序表的指定删除
void slerase(sl* ps, int pos);//顺序表的数据的查找
int slfind(sl* ps, sldatatype x);
(2)seqlist.c文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"seqlist.h"
void check(sl* ps)
{if (ps->size == ps->capacity){//我们插入数据,需要增大空间,动态内存开辟空间int newcapacity = ps->arr == 0 ? 4 : 2 * ps->capacity;sldatatype* temp = realloc(ps->arr, newcapacity * 2 * sizeof(sldatatype));if (temp == NULL){perror("realloc");exit(1);//直接退出,不再继续执行}ps->arr = temp;ps->capacity = newcapacity;}
}
//顺序表的初始化
void slinit(sl* ps)
{ps->arr = NULL;ps->size = 0;ps->capacity = 0;
}
//顺序表的销毁
void sldestory(sl* ps)
{if (ps->arr != NULL){free(ps->arr);}ps->arr = NULL;ps->size = ps->capacity = 0;
}
//顺序表的尾部插入数据
void slpushback(sl* ps, sldatatype x)
{//对传进来的指针进行断言assert(ps);//判断数组大小和空间的容量是否相同check(ps);ps->arr[ps->size] = x;ps->size++;
}
//顺序表的头部插入数据
void slpushfront(sl* ps, sldatatype x)
{assert(ps);check(ps);for (int i = ps->size; i > 0; i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[0] = x;ps->size++;
}
//顺序表的打印
void slprint(sl s)
{for (int i = 0; i < s.size; i++){printf("%d ", s.arr[i]);}printf("\n");
}
//顺序表的尾删
void slpopback(sl* ps)
{assert(ps);assert(ps->size);//如果我们顺序表本来就没有数据,我们进行减减就会变为-1了,显然不对,进行断言ps->size--;//渐渐就减少了范围,直接把最后的元素删除,就相当于最后一个元素不属于顺序表了
}
//顺序表的头删
void slpopfront(sl* ps)
{assert(ps);assert(ps->size);for (int i = 0; i < ps->size - 1; i++){ps->arr[i] = ps->arr[i + 1];//最后是arr[size-2]=arr[size-1];}ps->size--;
}//顺序表的指定位置之前插入
void slinsert(sl* ps, int pos, sldatatype x)
{assert(ps);assert(pos >= 0 && pos <= ps->size);check(ps);for (int i = ps->size; i > pos; i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[pos] = x;ps->size++;
}//顺序表的指定删除
void slerase(sl* ps, int pos)
{assert(ps);assert(pos >= 0 && pos < ps->size);for (int i = pos; i < ps->size-1; i++){ps->arr[i] = ps->arr[i + 1];}ps->size--;
}//顺序表的数据的查找
int slfind(sl* ps, sldatatype x)
{assert(ps);for (int i = 0; i < ps->size; i++){//找到了if (ps->arr[i] == x){return i;}}//没有找到return -1;//无效的下标
}(3)test.c文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"seqlist.h"
void sltest01()
{sl sl1;//顺序表的初始化slinit(&sl1);//顺序表的尾部插入数据slpushback(&sl1, 8);slpushback(&sl1, 9);slpushback(&sl1, 10);slpushback(&sl1, 11);//尾部插入之后打印slprint(sl1);//顺序表的头部插入数据slpushfront(&sl1, 5);slpushfront(&sl1, 6);//头部插入之后打印slprint(sl1);//顺序表的尾删slpopback(&sl1);slprint(sl1);//顺序表的头删slpopfront(&sl1);slprint(sl1);//顺序表的指定位置之前插入slinsert(&sl1, 1, 0);slprint(sl1);//顺序表的指定删除slerase(&sl1, 1);slprint(sl1);//顺序表的数据的查找int ret = slfind(&sl1, 100);if (ret < 0){printf("没有找到\n");}else{printf("找到了,下标是%d\n", ret);}//顺序表的销毁sldestory(&sl1);
}int main()
{//顺序表的功能测试函数sltest01();return 0;
}相关文章:
数据结构---顺序表实现
目录 1.顺序表 2.动态顺序表的实现 (4)顺序表初始化 (5)顺序表销毁 (6)顺序表的插入 a.尾插 b.头插 (7)顺序表的删除 a.尾删 b.头删 (8)指定位置之…...

python docx 添加动态表格
在Python中,使用python-docx库可以创建Word文档并添加动态表格。以下是一个简单的例子,演示如何创建一个包含动态内容的表格: from docx import Document# 创建一个Word文档 document Document()# 添加一个标题 document.add_heading(动态表…...
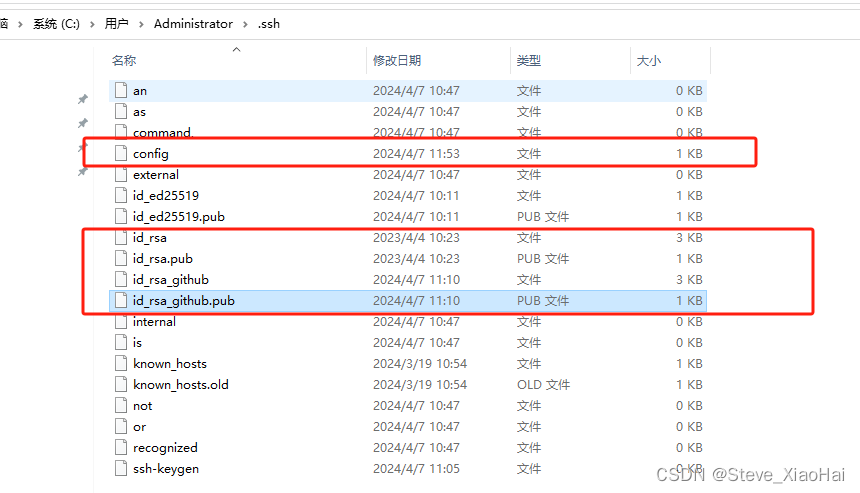
git配置多SSH
目的: 一台电脑可以让github、gitee等账号同时存在,让不同账号配置不同的密钥 第一步:创建不同平台的SSH公钥 执行命令: ssh-keygen -t rsa -C "对应仓库邮箱地址" -f ~/.ssh/id_rsa.github 如果执行上面的命令&…...
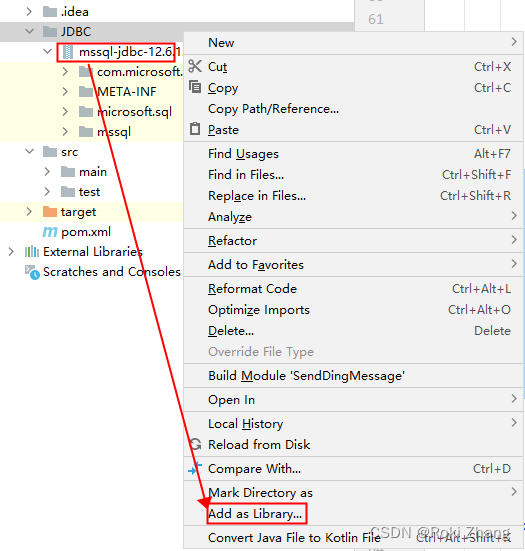
IDEA连接SqlServer数据库
目录 下载jar包 下载sqljdbc_12.6压缩包 解压 导入IDEA 新建文件夹 复制粘贴进JDBC文件夹并设为library 编写类及方法 代码 下载jar包 以sqljdbc_12.6为例 下载sqljdbc_12.6压缩包 最新地址:sqljdbc 官方最新地址 解压 解压即用 导入IDEA 新建文件夹 复制…...
LeetCode 378 有序矩阵中第K小的元素
题目信息 LeetoCode地址: . - 力扣(LeetCode) 题解内容大量转载于:. - 力扣(LeetCode) 题目理解 题意很直观,就是求二维矩阵中所有元素排序后第k小的数。 最小堆写法 该写法不再赘述,维护…...

Vue3(domdiff)最长递归子序列求解简易版(超简单)
Vue3(domdiff)最长递归子序列求解简易版 ⚠️ 关键词(每一个都需要理解)js 代码实现写完感想欢迎关注 ⚠️ 关键词(每一个都需要理解) 动态规划(O(N^2))(不提倡…...

LLaMA-Factory+qwen多轮对话微调
LLaMA-Factory地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md qwen地址:https://huggingface.co/Qwen/Qwen-7B-Chat/tree/main 数据准备 数据样例 [ {"id": "x3959", "conversations": [{&qu…...

邦芒面试:如何在面试中巧妙回答自己的缺点
在面试中,被问及自己的缺点时,如何巧妙回答是一门学问。恰当的回答不仅能够展示你的自我认知,还能让面试官看到你的成长潜力和积极态度。 首先,切忌谈一些看似缺点实则优点的话题,如追求完美、待人接物太客气等。这些…...

Android:身份证识别功能实现
说明: 此文使用华为SDK、百度SDK、百度在线API三种方式实现。 一、使用华为SDK实现身份证识别: 说明:免费,不需要联网。 1.AndroidManifest.xml添加权限:<uses-permission android:name"android.permissio…...

MacOS安装Homebrew教程
安装 Homebrew 是在 macOS 上管理软件包的一种简便方法。以下是安装 Homebrew 的步骤: 打开终端:你可以通过在 Spotlight 搜索栏中输入“终端”并按下回车键来打开 macOS 的终端应用程序。 执行安装命令:在终端中粘贴以下命令并按下回车键执…...

laravel如何通过DB获取一条数据并转成数组
在 Laravel 中,你可以使用原生数据库查询构建器(DB facade)来获取一条数据,并将其转换为数组。这可以通过在查询链的末尾调用 first() 方法后,使用 toArray() 方法来实现。first() 方法会返回一个 StdClass 对象&#…...
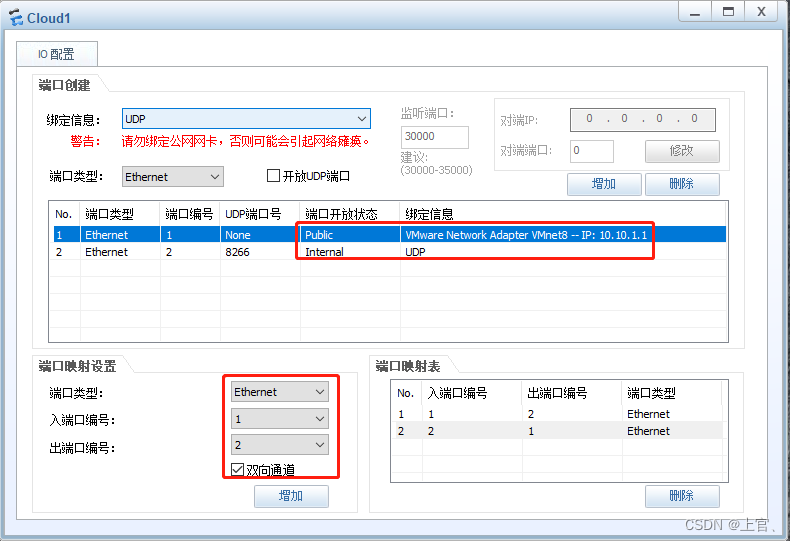
ENSP USG防火墙接入虚拟机;开启Web访问;
1.添加防火墙及云,启动防火墙; 2.配置桥接网卡; 默认账户:admin 默认密码:Admin123 #第一次登陆需修改密码; 默认G0/0/0口为管理口,而在模拟器中进入防火墙的web需如下配置: 配置 …...
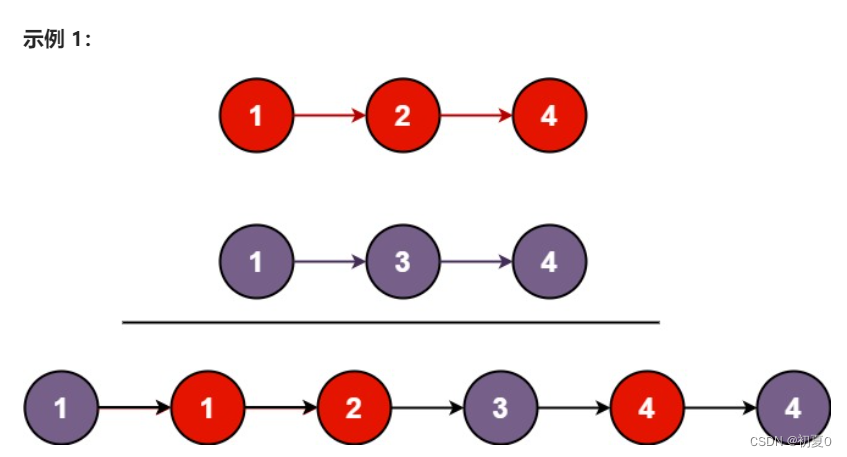
数据结构算法题(力扣)——链表
以下题目建议大家先自己动手练习,再看题解代码。这里只提供一种做法,可能不是最优解。 1. 移除链表元素(OJ链接) 题目描述:给一个链表的头节点 head 和一个整数 val ,删除链表中所有满足值等于 val 的节点…...

LeetCode---391周赛
题目列表 3099. 哈沙德数 3100. 换水问题 II 3101. 交替子数组计数 3102. 最小化曼哈顿距离 一、哈沙德数 简单的模拟题,代码如下 class Solution { public:int sumOfTheDigitsOfHarshadNumber(int x) {int s 0, tmp x;while(tmp){stmp%10;tmp/10;}return x…...

微信小程序的页面交互2
一、自定义属性 (1)定义: 微信小程序中的自定义属性实际上是由data-前缀加上一个自定义属性名组成。 (2)如何获取自定义属性的值? 用到target或currentTarget对象的dataset属性可以获取数据 ÿ…...
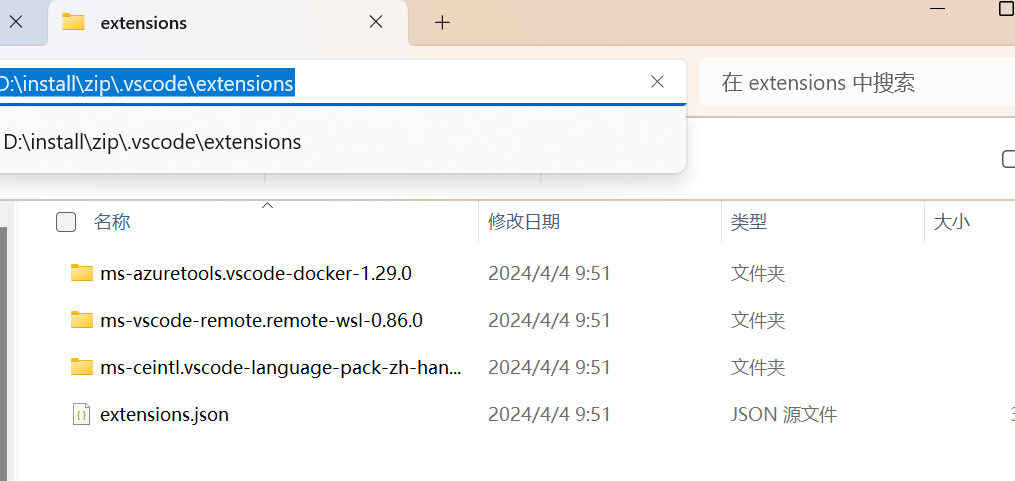
【VSCode】修改插件地址
不想放在原始C盘下面C:\Users\{用户}\.vscode\extensions为了后续存储空间考虑,想通过添加环境变量创建名为VSCODE_EXTENSIONS的环境变量,内容指向vs Code扩展所在目录即可 直接配置环境变量,不要在有空格的文件夹下面 变量名称:…...
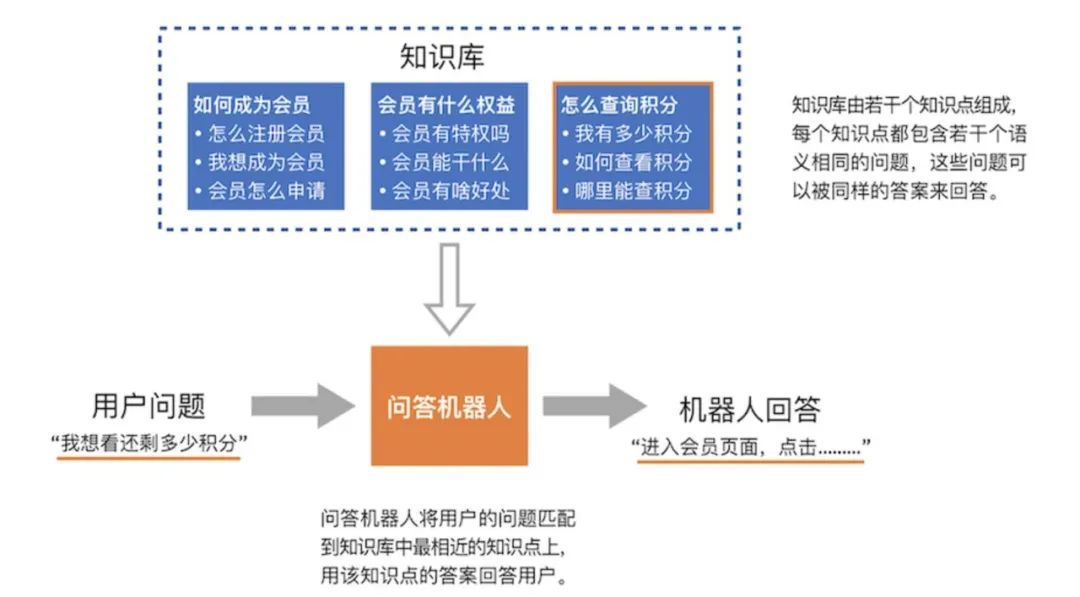
自然语言处理NLP概述
大家好,自然语言处理(NLP)是计算机科学领域与人工智能领域中的一个重要方向,其研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。本文将从自然语言处理的本质、原理和应用三个方面,对其进行概述。 一、NLP的本质 NLP是一种…...

计算机网络——37认证
认证 目标:Bob需要Alice证明他的身份 Protocol ap1.0:Alice说"A am Alice" 可能出现的问题: 在网络上Bob看不到Alice,因此Trudy可以简单的声称他是Alice 认证:重新尝试 Protocol ap2.0:Alice…...

Java中利用BitMap位图实现海量级数据去重
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 目录 前言 什么是BitMap?有什么用? 基本概念 位图的优势 …...

Linux知识点记录
Linux知识点记录 1. 后台运行应用程序方法一:&方法二:nohup & 2. 一个shell脚本中执行多个应用程序3. 2>&14. shell脚本清除日志5. 通过grep查找匹配字符串 1. 后台运行应用程序 参考文章:https://blog.csdn.net/Pan_peter/…...

EDA工具链互操作性:从概念到实践,破解芯片设计数据孤岛
1. 互操作性:一个被误解的工程圣杯 在半导体和电子设计自动化(EDA)这个行当里干了十几年,我听到“互操作性”这个词的频率,可能比听到“摩尔定律”还要高。每次行业巨头们坐下来,宣布要共同制定一个新标准时…...

如何免费获取B站8K高清视频:哔哩下载姬完整使用教程
如何免费获取B站8K高清视频:哔哩下载姬完整使用教程 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...

消息中间件控制平面:统一管理RabbitMQ与Kafka的声明式解决方案
1. 项目概述:一个面向开发者的消息中间件控制平面最近在折腾微服务架构下的消息通信,发现一个挺普遍的问题:虽然像 RabbitMQ、Kafka、RocketMQ 这类消息中间件本身功能强大,但管理起来却是个麻烦事。配置分散在各个服务的代码里&a…...

Prompt工程实战:从CRISPE框架到垂直应用,解锁AI模型高效协作
1. 项目概述与核心价值 如果你正在寻找一套能真正“榨干”ChatGPT、Midjourney、Stable Diffusion等主流AI模型潜力的中文提示词(Prompt)集合,那么你找对地方了。 langgptai/wonderful-prompts 这个开源项目,正是由《ChatGPT中文…...

开关电源传导共模噪声抑制:Y电容原理、安规限制与EMI滤波器设计
1. 项目概述:理解隔离式开关电源中的传导共模噪声在开发离线式开关电源,比如我们常见的手机充电器、笔记本电脑适配器或者工业电源模块时,工程师们常常会遇到一个既棘手又必须解决的难题:传导电磁干扰(Conducted EMI&a…...

ANSYS Workbench网格进阶:巧用‘Face Meshing’与‘Sweep’扫掠,让你的轴承座仿真既快又准
ANSYS Workbench网格进阶:巧用‘Face Meshing’与‘Sweep’扫掠提升轴承座仿真效率 轴承座作为机械传动系统中的关键部件,其应力分布与变形分析的准确性直接影响设备可靠性评估。传统四面体网格虽能快速生成,但在应力集中区域往往需要极高密度…...

OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现
OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 对于拥有2008年至2017年Intel Mac…...

ACE Awards:电子行业年度创新风向标与工程师成长指南
1. 项目概述:一场属于电子工程师的年度庆典如果你在半导体或电子设计行业待过几年,肯定对“EE Times”和“EDN”这两个名字不陌生。它们就像是电子工程师的“行业圣经”,每天刷一刷,看看又有哪些新芯片发布、哪些技术路线在争论&a…...

热间隙填充材料在PCB散热设计中的关键应用与选型
1. 热间隙填充材料在PCB散热设计中的核心作用热间隙填充材料(Thermal Gap Filler)是现代电子散热系统中不可或缺的功能性材料。作为一名经历过数十个散热方案设计的工程师,我深刻理解这类材料在解决"散热器与PCB之间公差累积"问题上…...

告别STM32cubeIDE的路径红波浪线:VSCode配置C/C++插件的保姆级指南
告别STM32cubeIDE的路径红波浪线:VSCode配置C/C插件的保姆级指南 对于习惯了STM32cubeIDE的嵌入式开发者来说,第一次用VSCode打开工程时,满屏的红色波浪线可能会让人瞬间崩溃。别担心,这不是你的代码有问题,而是VSCode…...