爬虫 新闻网站 并存储到CSV文件 以红网为例 V2.0 (控制台版)升级自定义查询关键词、时间段,详细注释
爬虫:红网网站, 获取指定关键词与指定时间范围内的新闻,并存储到CSV文件 V2.0(控制台版)
爬取目的:为了获取某一地区更全面的在红网已发布的宣传新闻稿,同时也让自己的工作更便捷
对比V1.0升级的内容:可自定义输入查询的关键词、自定义获取的时间段内的新闻,这样大家都可以用
环境:Pycharm2021,Python3.10,
安装的包:requests,csv,bs4,datetime

代码运行结果示例:
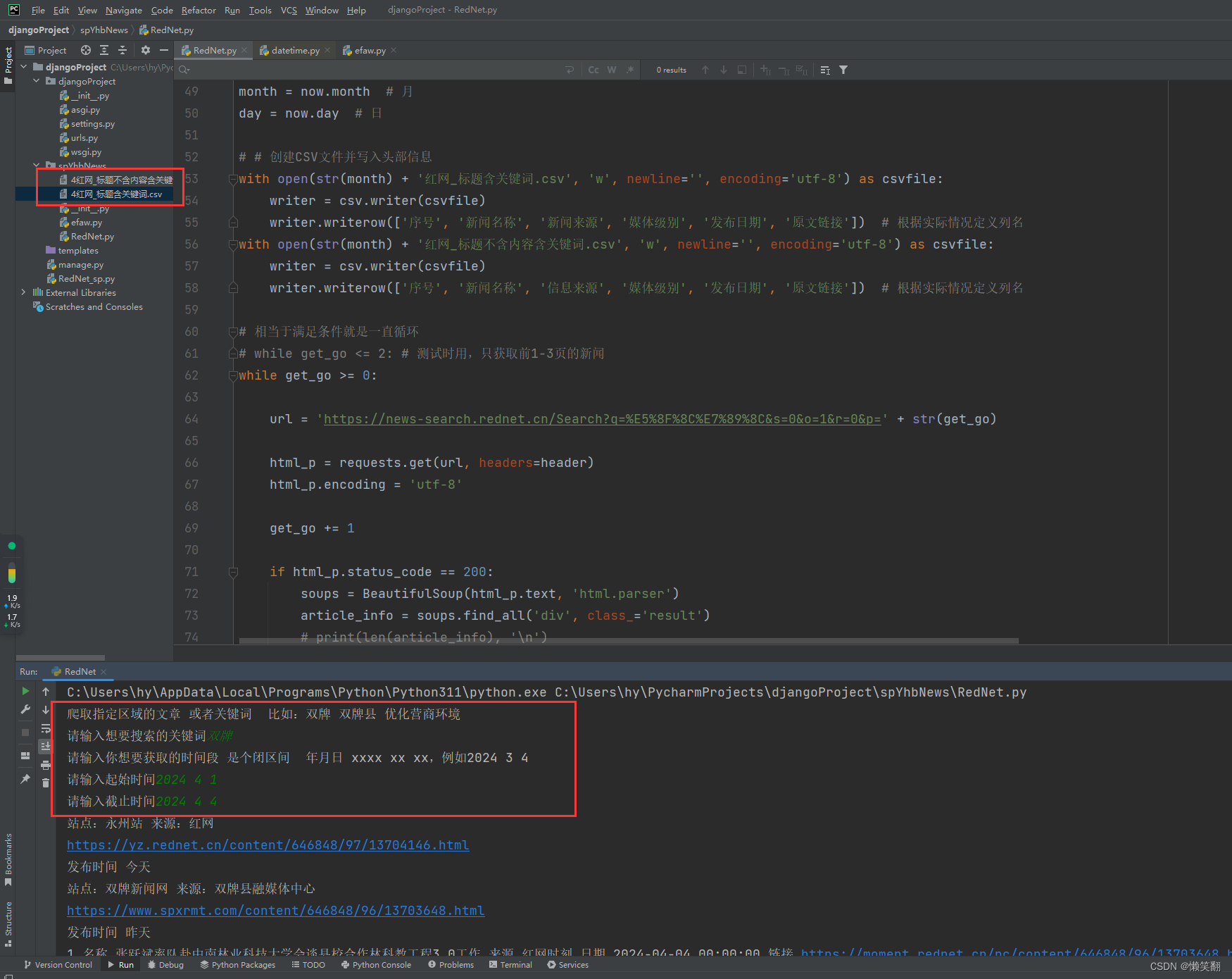
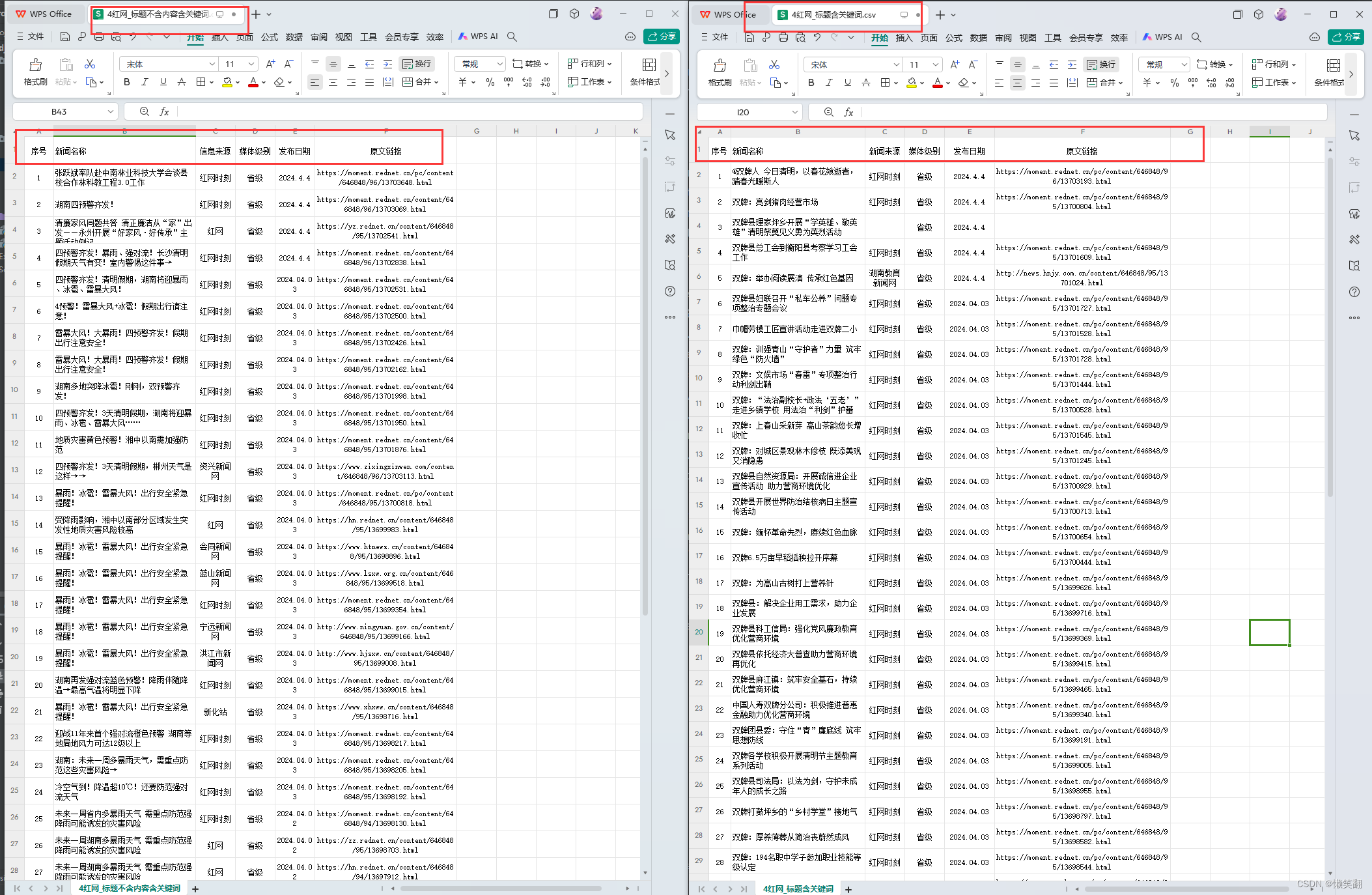
爬虫完整代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/4/4 21:36
# @Author : LanXiaoFang
# @Site :
# @File : RedNet.py
# @Software: PyCharm
import csv
import requests
from bs4 import BeautifulSoup
import datetimeheader = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8','Accept - Encoding': 'gzip, deflate, br',"Accept - Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",'Connection': "keep - alive",'Referer': 'https://news-search.rednet.cn/Search?q=%E5%8F%8C%E7%89%8C','User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0","Cookie": "wdcid=7486a2c50eaf8af8; Hm_lvt_c96b65e9975fa39afbd5e90222af5f39=1711378746,1711528844; Hm_lvt_aaecf8414f59c3fb0127932014cf53c7=1711378746,1711528844; __jsluid_s=56e0acf3607072cce852b9d4fc556f54; Hm_lpvt_c96b65e9975fa39afbd5e90222af5f39=1711528844; Hm_lpvt_aaecf8414f59c3fb0127932014cf53c7=1711528844; __jsl_clearance_s=1711530480.242|1|%2F%2BG2WNMEpLXiwlUgRr2hiMkP%2BMg%3D","Upgrade-Insecure-Requests": "1",
}article_Num_area = 1 # 用于计在标题含指定区域的存储的表中的数据的序号
article_Num = 1 # 用于计在标题不含但内容含指定区域的存储的表中的数据的序号
get_go = 0 # 获取第几页开始的数据,现在是0开始
count = 0 # 用于计算总共爬取的新闻数量"""------Start Set 这一部分是自定义选项 查找自定义新闻------"""
# 爬取指定区域的文章 或者关键词 比如:双牌 双牌县 优化营商环境······
print("爬取指定区域的文章 或者关键词 比如:双牌 双牌县 优化营商环境")
# area = '双牌'
area = input("请输入想要搜索的关键词")# 时间设定
# 想要获取的时间段 是个闭区间 年月日 xxxx-xx-xx
print("请输入你想要获取的时间段 是个闭区间 年月日 xxxx xx xx,例如2024 3 4")
start_time = input("请输入起始时间") # 起始时间(包含起始日期这一天)
start_time = datetime.datetime.strptime(start_time, '%Y %m %d')end_time = input("请输入截止时间") # 截止时间(包含截止日期这一天)
end_time = datetime.datetime.strptime(end_time, '%Y %m %d')
"""------End Set 这一部分是自定义选项 查找自定义新闻------"""# 获取系统时间
now = datetime.datetime.now()
year = now.year # 年
month = now.month # 月
day = now.day # 日# # 创建CSV文件并写入头部信息
with open(str(month) + '红网_标题含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接']) # 根据实际情况定义列名
with open(str(month) + '红网_标题不含内容含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '信息来源', '媒体级别', '发布日期', '原文链接']) # 根据实际情况定义列名# 相当于满足条件就是一直循环
# while get_go <= 2: # 测试时用,只获取前1-3页的新闻
while get_go >= 0:url = 'https://news-search.rednet.cn/Search?q=' + area + '&s=0&o=1&r=0&p=' + str(get_go)html_p = requests.get(url, headers=header)html_p.encoding = 'utf-8'get_go += 1if html_p.status_code == 200:soups = BeautifulSoup(html_p.text, 'html.parser')article_info = soups.find_all('div', class_='result')# print(len(article_info), '\n')for i in article_info:result_info = i.find_all('div', class_='result-info')station_source = result_info[0].select('span') # 选择result_info下的所有span标签station_info = station_source[0].text # 文章发布站点source_info = station_source[1].text # 文章来源print(station_info, source_info)# print(i.find_all('div', class_='title'), '\n')title_info = i.find_all('div', class_='title')# 文章链接article_href = title_info[0].a.get('href')print(article_href)# 升级版2.0,这一部分注释掉了,考虑通过文章链接进入文章详情页面获取: 新闻来源 发布时间,这样可以避免来源分析和计算时间的日期if station_info[3:] == area + "新闻网":# print("双牌新闻网文章链接:", article_href, "---------", "https://moment.rednet.cn/pc" + article_href[22:])article_href = "https://moment.rednet.cn/pc" + article_href[22:]# 修改文章来源为红网时刻if 'rednet' in article_href:source_info = "红网"if 'moment.rednet' in article_href:source_info = "红网时刻"if '来源' in source_info:source_info = station_info[3:]# 文章标题article_title = title_info[0].h3.text# 获取发布时间article_up_time = title_info[0].span.textprint('发布时间', article_up_time)"""本来想直接进入文章详情页面直接获取时间的,但是介于文章来源不同每种网站的时间所在标签也不一样,由此还是决定在这里的时间信息进行处理了"""# 把显示为进入和昨天的时间,改为具体的日期# 要注意 今天对应的昨天,# ---如果是今天是1月1日则昨天的年月日应为上一年的12月31日要注意;# ---如果今天是2-12月的1日则昨天的年月日应为上一月的最后一天if article_up_time == '今天':article_up_time = str(year) + '.' + str(month) + '.' + str(day)elif article_up_time == '昨天':if day == 1:if month == 1:year -= 1month = 12day = 31else:month -= 1if month in [3, 5, 7, 8, 10, 12]:day = 31elif month in [4, 6, 9, 11]:day = 30elif month == 2:if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0): # 闰年2月day = 29else:day = 28article_up_time = str(year) + '.' + str(month) + '.' + str(day - 1)# 修改时间显示格式,-替换为.else:# article_up_time = article_up_time[:4] + '.' + article_up_time[5:7] + '.' + article_up_time[8:10]article_up_time = article_up_time.replace('-', '.')# print(count, '--名称', article_title, '来源', source_info, '日期', article_up_time, '链接', article_href)# 得到这篇文章发布的时间的日期格式date_article_up_time = datetime.datetime.strptime(article_up_time, '%Y.%m.%d')# 现在有个问题怎么退出循环,时间不满足就退出:现在获取到的新闻的时间<开始时间就退出if date_article_up_time < start_time:get_go = -1break# 把满足自定义时间的新闻内容保存到csv表格中if start_time <= date_article_up_time <= end_time:count += 1# date_article_up_time = datetime.datetime.strftime(date_article_up_time, "%Y.%m.%d")print( count, '名称', article_title, '来源', source_info, '日期', date_article_up_time, '链接', article_href)# 把数据存入表格 根据标题或内容 是否含有 #{area} 关键词 分开存储if area in article_title:# 这个是标题含有#{area}的with open(str(month) + '红网_标题含关键词.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([article_Num_area, article_title, source_info, '级', article_up_time, article_href])article_Num_area += 1else:# 这个是标题不含但是内容含有#{area}的with open(str(month) + '红网_标题不含内容含关键词.csv', 'a', newline='',encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([article_Num, article_title, source_info, '级', article_up_time, article_href])article_Num += 1
相关文章:
爬虫 新闻网站 并存储到CSV文件 以红网为例 V2.0 (控制台版)升级自定义查询关键词、时间段,详细注释
爬虫:红网网站, 获取指定关键词与指定时间范围内的新闻,并存储到CSV文件 V2.0(控制台版) 爬取目的:为了获取某一地区更全面的在红网已发布的宣传新闻稿,同时也让自己的工作更便捷 对比V1.0升级的…...
JavaSE-11笔记【多线程2(+2024新)】
文章目录 6.线程安全6.1 线程安全问题6.2 线程同步机制6.3 关于线程同步的面试题6.3.1 版本16.3.2 版本26.3.3 版本36.3.4 版本4 7.死锁7.1 多线程卖票问题 8.线程通信8.1 wait()和sleep的区别?8.2 两个线程交替输出8.3 三个线程交替输出8.4 线程通信-生产者和消费者…...

WebKit是什么?
WebKit是一个开源的浏览器引擎,它用于呈现网页内容在许多现代浏览器中,包括Safari浏览器、iOS内置浏览器、以及一些其他浏览器如Google Chrome的早期版本。以下是一些关于WebKit的重要信息: 起源和发展:WebKit最初是由苹果公司为其…...

谷歌(Google)历年编程真题——接雨水
谷歌历年面试真题——数组和字符串系列真题练习。 接雨水 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:…...

golang 归并回源策略
前言 下面是我根据业务需求画了一个架构图,没有特别之处,很普通,都是我们常见的中间件,都是一些幂等性GET 请求。有一个地方很有意思,从service 分别有10000 qps 请求到Redis,并且它们的key 是一样的。这样…...

【漏洞复现】可视化融合指挥调度平台 dispatch接口处存在任意文件上传漏洞
免责声明:文章来源互联网收集整理,请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该…...

最讨厌这种字符串问题了!!
题目:洛谷P1957口算练习题 题目大意描述: 第一行输入一个整数表示接下来要进行多少次运算,接下来每行输入一个字母c和两个数字x,y(输入的字母为a/b/c,分别表示要进行,-,*运算)或者就输入两个数…...
B-名牌赌王(本人遇到的题,做个笔记)
题解: #include <iostream> #include <queue> //需要用小根堆的优先队列 #include <unordered_map> //用无序映射 using namespace std; bool pai() {int n, m;cin >> n >> m; priority_queue<int, vector<int>, gr…...

博客评论回复03
接着之前写的,之前返回的数据集按道理来说渲染出来还是丑丑的,因此这次我看着抖音的评论样子,自己瞎写了一通,不过也算是模仿出来了虽然肯定没有抖音写的好。 类似与前面几章写的表结构 首先看看抖音评论区是怎么样的?…...
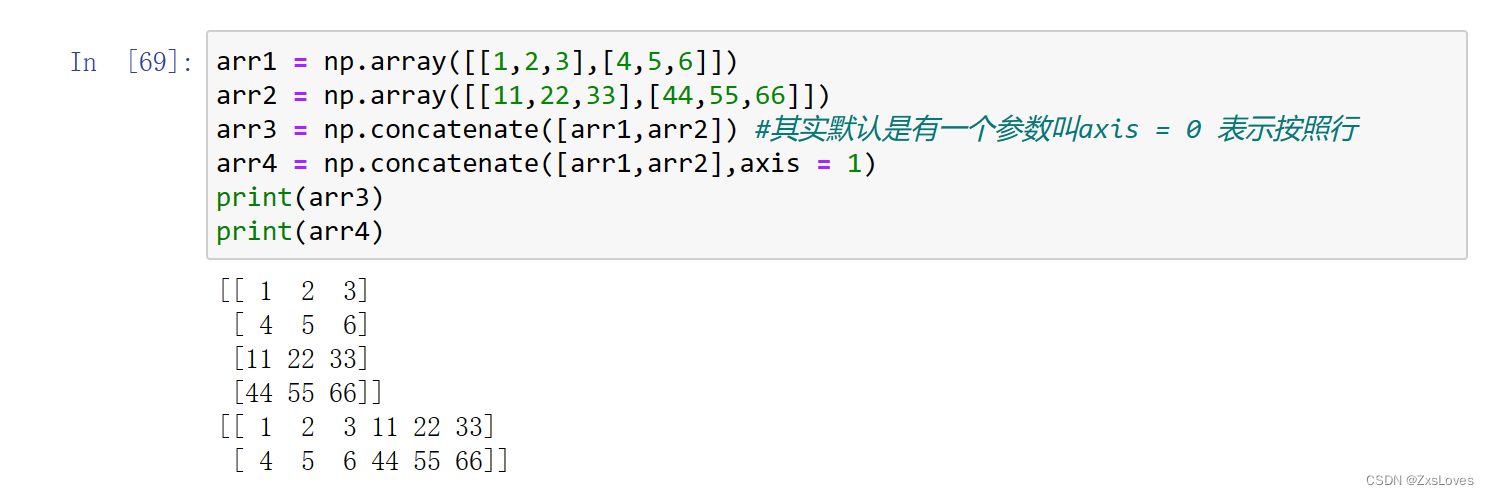
【【萌新的学习之Numpy数组的使用】】
萌新的学习之Numpy数组的使用 先记录一下之前的关于函数的设计 通过创造类的形式 复习完毕之后介绍numpy数组的使用 #整数型数组遇到除法 (即便是除以整数) 不同维度的数组之间 从外形上的本质区别 一维数组用1层中括号 二维数组用2层中括号 三维数…...
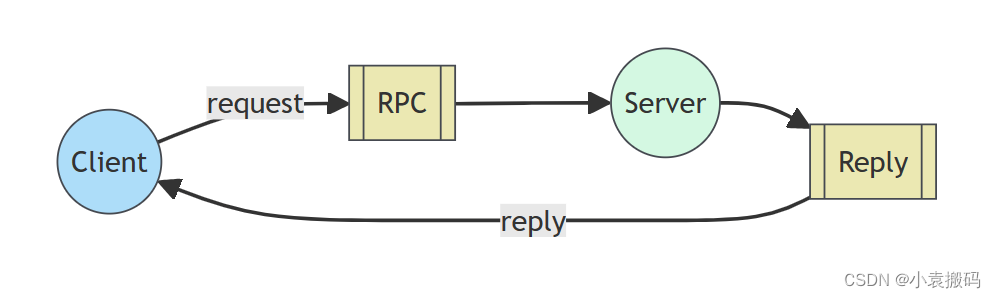
RabbitMQ3.13.x之七_RabbitMQ消息队列模型
RabbitMQ3.13.x之七_RabbitMQ消息队列模型 文章目录 RabbitMQ3.13.x之七_RabbitMQ消息队列模型1. RabbitMQ消息队列模型1. 简单队列2. Work Queues(工作队列)3. Publish/Subscribe(发布/订阅)4. Routing(路由)5. Topics(主题)6. RPC(远程过程调用)7. Publisher Confirms(发布者…...

Android JNI 调用第三方SO
最近一个项目使用了Go 编译了一个so库,但是这个so里面还需要使用第三方so库pdfium, 首先在Android工程把2个so库都放好 在jni中只能使用dlopen方式,其他的使用函数指针的方式来调用,和windows dll类似,不然虽然编译过了但是会崩溃…...
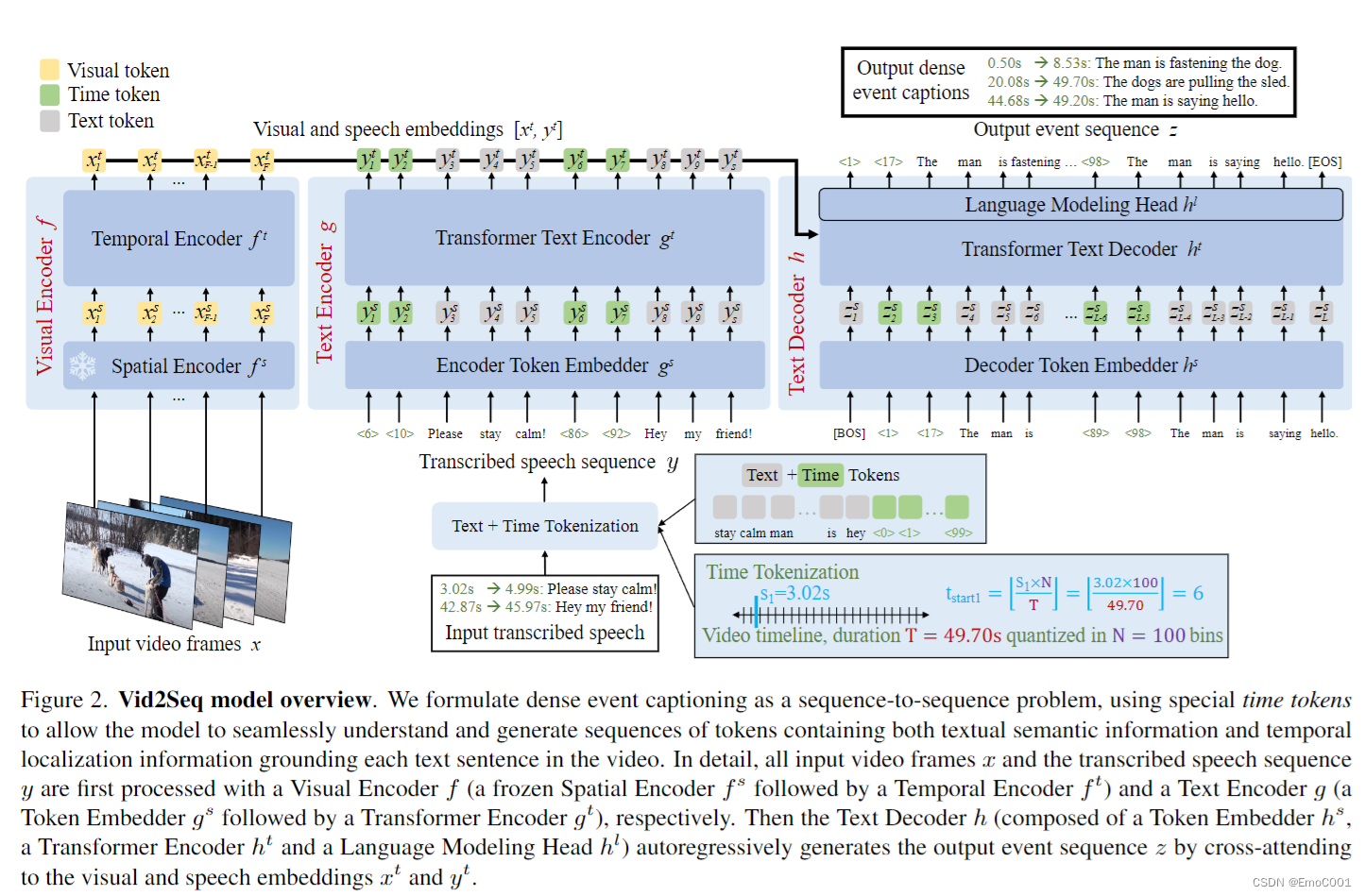
Vid2seq
Vid2Seq 应该是目前为止,个人最中意得一篇能够实际解决对一段视频进行粗略理解得paper了。个人认为它能够真正能解决视频理解是因为它是对一个模型整体做了训练,而不仅仅是通过visual encoders(e.g BLIP/CLIP/…)和 其它multi modal 的encoder直接过了个projection,做一个…...

Opencv人机交互界面设置
Opencv人机交互界面设置 以下是一些常见的OpenCV人机交互界面设置: 窗口交互 显示窗口:可以使用cv2.imshow()函数在屏幕上显示图像。例如,要显示名为“image”的图像,可以使用以下代码: import cv2img cv2.imread…...

蓝桥杯算法心得——字典树考试(贡献度+前缀和)
大家好,我是晴天学长,贡献度的题,找到技巧非常重要,需要的小伙伴可以关注支持一下哦!后续会继续更新的。💪💪💪 1) .字典树考试 字典树考试 问题描述 蓝桥学院最近教学了字典树这一数…...
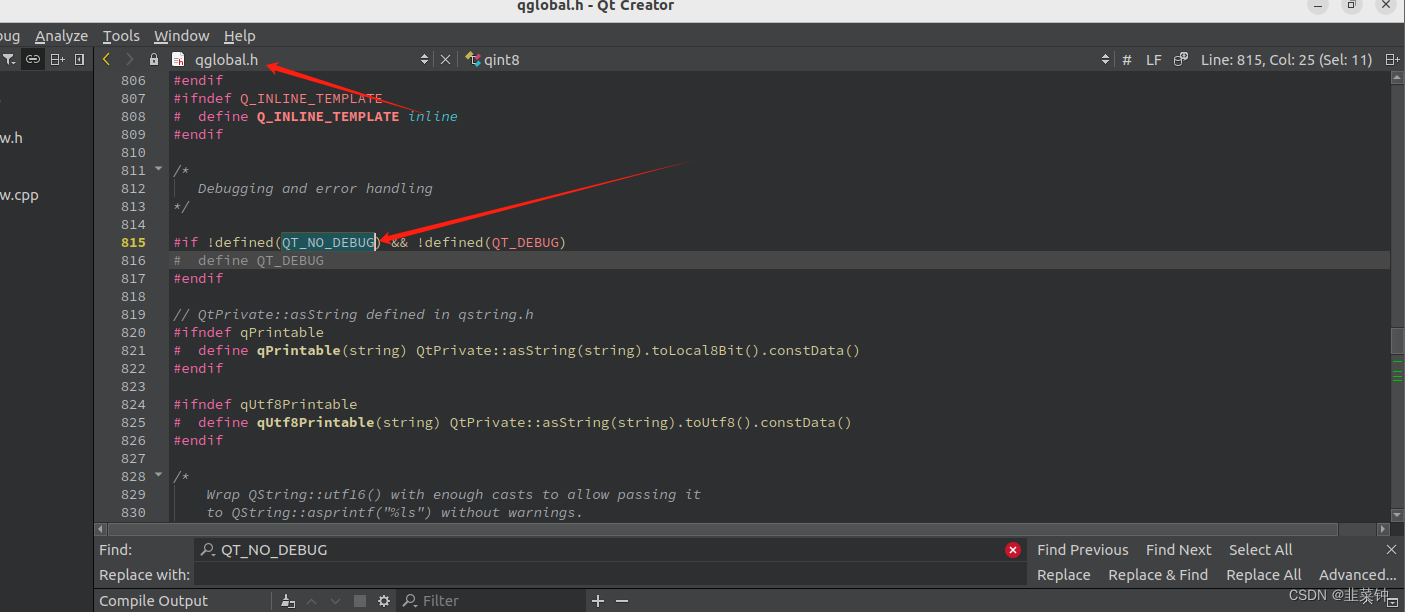
Linux下Qt生成程序崩溃文件
文章目录 1.背景2.Qt编译生成程序2.1.profile模式的本质 3.执行程序,得到core文件4.代码定位4.1.直接使用gdb4.2.使用QtCreator 5.总结6.题外话6.1.profile模式和debug模式的区别 1.背景 在使用Qt时,假如在windows,当软件崩溃时,…...

Go语言中测试和性能
1. 测试:软件开发最重要的方面 测试软件程序可能是软件开发人员能够做的最重要的事情。通过测试代码的功能,开发人员能够在很大程度上确定程序是有效的。另外,每次修改代码后,开发人员都可运行测试,确认没有引入Bug和衰退。通过测试软件,还能够让软件工程师确认程序按期望…...

回归预测 | Matlab基于CPO-GPR基于冠豪猪算法优化高斯过程回归的多输入单输出回归预测
回归预测 | Matlab基于CPO-GPR基于冠豪猪算法优化高斯过程回归的多输入单输出回归预测 目录 回归预测 | Matlab基于CPO-GPR基于冠豪猪算法优化高斯过程回归的多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 Matlab基于CPO-GPR基于冠豪猪算法优化高斯…...

python 日期字符串转换为指定格式的日期
在Python编程中,日期处理是一个常见的任务。我们经常需要将日期字符串转换为Python的日期对象,以便进行日期的计算、比较或其他操作。同时,为了满足不同的需求,我们还需要将日期对象转换为指定格式的日期字符串。本文将详细介绍如…...
day03-Docker
1.初识 Docker 1.1.什么是 Docker 1.1.1.应用部署的环境问题 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题: 依赖关系复杂,容易出现兼容性问题开发、测试、生产环境有差异 例如一个项目中,部署时需要依…...

请教指针初始化:定义指针时,要么直接指向有效内存,要么置为NULL
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

深度实战:如何用League Akari将英雄联盟游戏效率提升300%的终极秘籍
深度实战:如何用League Akari将英雄联盟游戏效率提升300%的终极秘籍 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否经历过在…...

Python实战:三大曲线平滑技术对比与场景选型指南
1. 曲线平滑处理的必要性 当你处理传感器数据、金融时间序列或任何带有噪声的曲线时,原始数据往往像一条暴躁的蚯蚓——上下乱窜让人抓狂。我在处理工业传感器数据时就遇到过这种情况:一条本该平滑的温度曲线,因为电磁干扰变成了"心电图…...

3分钟掌握B站缓存转换:开源m4s-converter工具全攻略
3分钟掌握B站缓存转换:开源m4s-converter工具全攻略 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站下架视频而烦恼吗&…...

智慧工厂与养殖场的一体化光伏监控系统方案
某企业从事乳制品的生产、销售等全流程业务,新增一套分布式光伏发电系统以平衡能耗支出,主要覆盖乳制品生产加工厂、奶牛养殖场及生态观光牧场等场景,实现“自给自足、余电上网”等综合能源目标。现需要对光伏电站进行联网集中监控࿰…...
)
别再瞎猜了!手把手教你算清FPGA Aurora IP核的用户时钟(附8B/10B编码影响)
别再瞎猜了!手把手教你算清FPGA Aurora IP核的用户时钟(附8B/10B编码影响) 当你在Xilinx Vivado中配置Aurora 8B/10B IP核时,是否曾被USER_CLK的计算问题困扰?这个看似简单的参数背后,其实隐藏着线速率、数…...
)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战)
从.axf到.bin:ARM Compiler 6.14链接与格式转换的隐藏细节(Keil MDK实战) 当你在Keil MDK中点击"Build"按钮时,背后发生的远不止简单的代码翻译。对于使用STM32的嵌入式工程师而言,理解从源代码到最终烧录文…...

从‘水管’到‘高速公路’:用‘时延带宽积’重新理解你的网络容量,别再让高带宽‘空转’了
从‘水管’到‘高速公路’:用‘时延带宽积’重新理解你的网络容量 想象一下,你正驾驶一辆满载数据的卡车行驶在数字高速公路上。这条路的车道数(带宽)让你欣喜若狂,但开了半天却发现路上几乎没几辆车——这就是许多工程…...

本地待办清单的革命:为什么My-TODOs让数据隐私与高效任务管理完美融合?
本地待办清单的革命:为什么My-TODOs让数据隐私与高效任务管理完美融合? 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 在云端存储成为主流的今天…...
)
保姆级教程:用Vector CANoe搞定LIN诊断刷写自动化测试(附CAPL脚本思路)
从零构建LIN诊断刷写自动化测试:Vector CANoe实战指南 当汽车电子系统开始全面拥抱OTA升级浪潮时,LIN总线上的控制器也必须具备可靠的远程刷写能力。作为测试工程师,我们面临的挑战是如何在资源有限的LIN网络上,构建一个既能模拟…...