pandas(day5)
一. 检测重复值
1.1 检测
data =pd.read_csv("./teacher/订单数据.csv")检测行与行之前是否有重复值
data.drop_duplicates()检测 列是否有重复值出现, keep = first 从前往后判定 , last是从后往前判定data.drop_duplicates(subset=["产品类别","省份"],keep="last")1.2 删除重复值 drop_duplicates
data.drop_duplicates(subset = ["产品类别","省份"],keep="first")二. 时间分组
2.1 时间修饰器
数据类型必须是 datetime64[ns]可以获取年份
data.日期.dt.year获取周几 但是默认周日 是 0 ,用replace 将 0 换成 7
data.日期.dt.weekday.replace({0:7})2.2 将 data 表 的日期 按照 年进行分组
data.groupby(by=[data.日期.dt.year]).agg({"金额":"sum"})用时间修饰器 将 日期 提取年份2.3 将 data 表 的日期 按照 年月 进行分组
- data.日期.dt.strftime("%Y-%m-01")
- strftime 相当于python 中的 f“{}”
data.groupby(by=[data.日期.dt.strftime("%Y-%m-01")]).agg({"金额":"sum"})2.4 下单的时段
- 0-4 : 午夜 5-7 : 凌晨 8-11: 早晨 12-14: 中午 15-18 : 下午 19-21 : 傍晚 22 - 23 : 深夜
定义时段
- map() (是对series 进行循环的)
def func(x):if x<5:return "午夜"elif x<8:return "凌晨"elif x<12:return "早晨"elif x<15:return "中午"elif x<19:return "下午"elif x<22:return "傍晚"else:return "深夜"data["时段"] = data.日期.dt.hour.map(func)data.日期.dt.hour 这里计算出 hour后, 返回到func中,再返回出 相应的时间2.5 下单时间距今差值
计算数据的最大的日期
way1
ds = data.groupby(by=["省份"]).日期.max()Timestamp('2016-07-28 20:12:12')因为ds = data.groupby(by=["省份"]).日期.max() 计算出来的数据类型是时间戳
所有想计算出 天数 需要用 np.timedelta64(1,"D")(datetime(2016,7,29) - ds) / np.timedelta64(1,"D")三 .重采样(resamle)
- 要求日期时间类型的列 必须作为行索引
将 列 日期 转为 行索引
data.set_index(["日期"],inplace=True)data.resample("Y").agg({"金额":"sum"})
这样就会 按照年进行分组金额
日期
2013-12-31 853625
2014-12-31 124443
2015-12-31 1228887
2016-12-31 377721四. 数据分箱 (只能对序列 类型分箱)
- 连续数据类型 : 数字
- 离散数据类型 : 文字
- 一般看的数据表达的含义
- 连续 : 时间类型 可以进行 运算 ,也可以 进行正反推
- 离散 : 当前 时间 范围有限,所以任务 时间 是离散型
数据的分箱 可以 把 连续数据类型 修改成 离散数据类型
- 时间 : 0~23 就是离散类型
4.1 pd.cut() 分箱操作
pd.cut(data.金额,bins=1000)
分箱操作 bins 是分箱的数量三种分箱操作
pd.cut(data.金额,bins=1000) #等分间隔
pd.cut(data.金额,bins=range(0,20001,5000))[(0, 5000] < (5000, 10000] < (10000, 15000] < (15000, 20000]pd.cut(data.金额,bins=[0,500,1500,5000,10000,20000],labels=list("ABCDE"))['A' < 'B' < 'C' < 'D' < 'E']4.2 按照 百分位进行 分箱 , 就是 25% ,50% (pd.qcut)
pd.qcut(data.金额,q=4) 意思是 按照 4 分位进行计算 0.25
[(1.999, 15.75] < (15.75, 40.0] < (40.0, 175.0] < (175.0, 17890.0]]可以用
data.金额.quantile(0),data.金额.quantile(0.25),data.金额.quantile(0.5),data.金额.quantile(0.75),data.金额.quantile(1) 进行验证(2.0, 15.75, 40.0, 175.0, 17890.0)五. 字符修饰器
5.1 contains() 包含...
#包含自行车字样
data.loc[data.产品子类别.str.contains("自行车")].groupby(by=["产品子类别"]).金额.sum()5.2 startswith() 以...开头
data.loc[data.产品子类别.str.startswith("自行车")].groupby(by=["产品子类别"]).金额.sum()5.3 endswith() 以... 结尾
data.loc[data.产品子类别.str.endswith("自行车")].groupby(by=["产品子类别"]).金额.sum()5.4 str.upper(). 大写 str.lower(). 小写 str.title(). 首字母大写 str.swapcase() 大小写转换
data.产品名称.str.upper().str.lower().str.title().str.swapcase()5.5 字符串的分割 与 拼接 str.split(). str.join()
data.产品名称.str.split(" ").str.join("-")以空格分隔 ,再用 - 拼接5.6 指定出现的字符
data.产品名称.str.count("T")5.7 每个字符的长度
data.产品名称.str.len()5.8 编码和解码 encode 编码 decode 解码
data.产品子类别.str.encode("936").str.decode("GB2312")5.9 居中对齐 左对其 右对齐
data.产品子类别.str.center(15) 居中对齐
data.产品子类别.str.ljust(15) 左对齐
data.产品子类别.str.rjust(15) 右对齐6.0 字符长度固定 zfill 和 str.pad()
data.产品子类别.str.zfill(10)0 00000车胎和内胎
1 0000000骑行服
2 00000旅行自行车
3 00000山地自行车
4 00000车胎和内胎data.产品子类别.str.pad(10,side="left",fillchar="-") 左填充 -
0 -----车胎和内胎
1 -------骑行服
2 -----旅行自行车
3 -----山地自行车
6.1 数据类型的判断
s.str.isalpha() #字母s.str.isnumeric() #纯数字组成s.str.isdigit() #数字s.str.istitle() # 开头是大写 其他都小写六 . 时间序列
6.1 获取当前日期时间 datetime.now() .strftime() 就是类似format
#获取当前日期时间
datetime.now().strftime("%Y-%m-%d %H:%M:%S")6.2 时间戳 Timestamp
pd.Timestamp(1234567890,unit="s",tz="Asia/ShangHai")
unit是 时间单位 s是秒 m是月 ,tz是时区把一个序列中的字符 转换成 datetime64
pd.to_datetime([("2015-1-1")])
DatetimeIndex(['2015-01-01'], dtype='datetime64[ns]', freq=None)#Timestamp
pd.Timestamp(datetime(2050,1,1))
Timestamp('2050-01-01 00:00:00')pd.Timestamp("2038-1-1 T23")
#Timestamp('2038-01-01 23:00:00')
#T 是 time 时间
6.3 时间的相关计算
- Timedelta :代表 时间单位
Timedelta :代表 时间单位
pd.Timestamp(2234567890,unit="s") - np.timedelta64(1,"D")np.timedelta64(1,"D") 1 d for day- 一年当中第多少天
pd.Timestamp(2234567890,unit="s").dayofyear #一年当中第多少天- 一年中的第多少周
pd.Timestamp(2234567890,unit="s").weekofyear #一年中的第多少周- 当前月份有多少天
pd.Timestamp("2020-2-2",unit="s").days_in_month七. 内置样式
给空值 高亮
df.style.highlight_null()df.style.highlight_between(subset=["A"],color="#ff10002f")df.style.background_gradient(cmap="rainbow")
梯度背景色格式
df.style.format({"A":"¥{:,.2f}"})"¥" 表示人民币符号。
{:,.2f} 是一个格式说明符,用于格式化浮点数,具体含义如下:
: 表示格式说明符的开始。
, 表示千位分隔符,用于在数字中插入逗号,提高可读性。
.2f 表示保留两位小数的浮点数日期
df1.style.format({"日期":"{:%Y年%m月%d}"})订单ID 日期
0 a01 2015年11月13
1 a02 2015年11月20
2 a03 2015年11月11
3 a04 2015年07月27
4 a05 2015年11月16df1.日期.dt.strftime("%Y年")
0 2015年
1 2015年
2 2015年
3 2015年
4 2015年
Name: 日期, dtype: object相关文章:
)
pandas(day5)
一. 检测重复值 1.1 检测 data pd.read_csv("./teacher/订单数据.csv")检测行与行之前是否有重复值 data.drop_duplicates()检测 列是否有重复值出现, keep first 从前往后判定 , last是从后往前判定data.drop_duplicates(subset["产…...
如何注册midjourney账号
注册Midjourney账号比较简单,准备好上网工具,进入官网 Midjourney访问地址: https://www.midjourney.com/ 目前没有免费使用额度了,会员最低 10 美元/月,一般建议使用30美元/月的订阅方案。了解如何订阅可以查看订阅…...
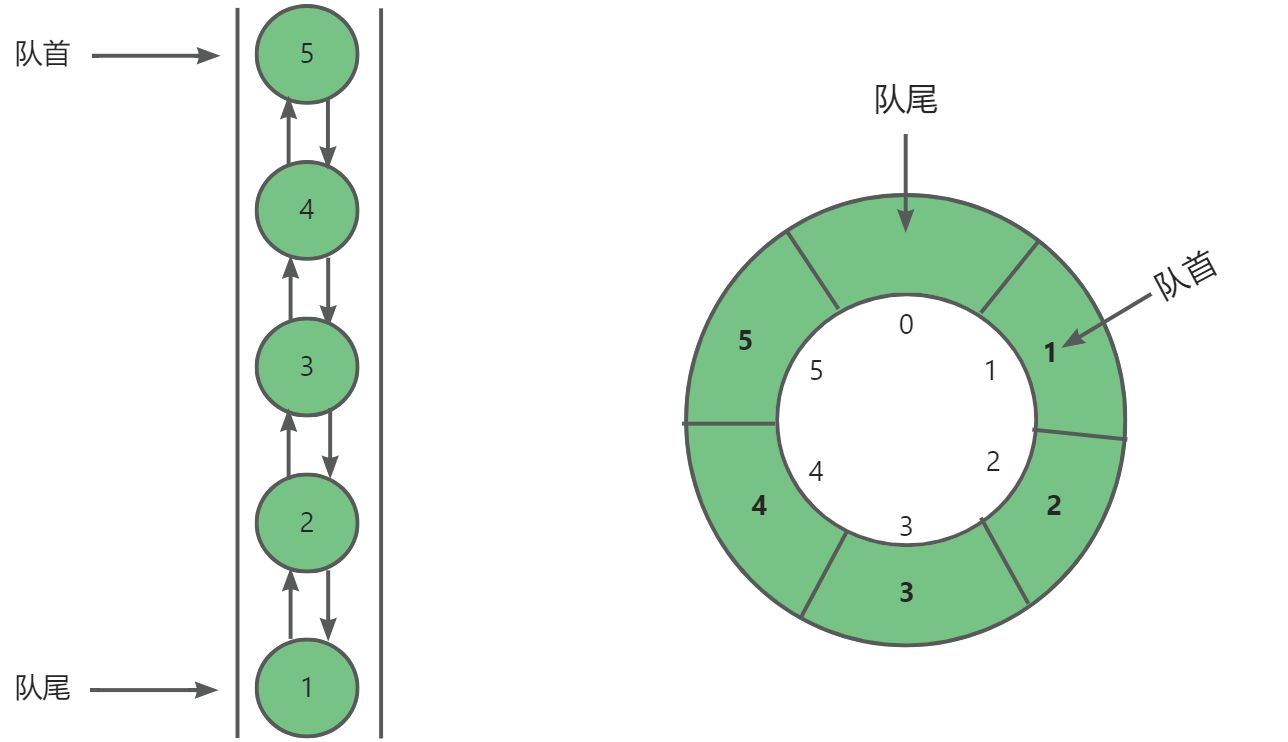
探索数据结构:特殊的双向队列
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:数据结构与算法 贝蒂的主页:Betty’s blog 1. 双向队列的定义 **双向队列(double‑ended queue)**是一种特殊的队列…...

16_I2C库函数
I2C库函数 1.void I2C_DeInit(I2C_TypeDef* I2Cx);2.void I2C_Init(I2C_TypeDef* I2Cx, I2C_InitTypeDef* I2C_InitStruct);3.void I2C_StructInit(I2C_InitTypeDef* I2C_InitStruct);4.void I2C_Cmd(I2C_TypeDef* I2Cx, FunctionalState NewState);5.void I2C_DMACmd(I2C_Type…...

十八、Rust gRPC 多 proto 演示
十八、Rust gRPC 多 proto 演示 网上及各官方资料,基本是一个 proto 文件,而实际项目,大多是有层级结构的多 proto 文件形式,本篇文章 基于此诉求,构建一个使用多 proto 文件的 rust grpc 使用示例。 关于 grpc 的实现…...

【Linux】Linux64位环境下编译32位报错skipping incompatible的解决办法
本文首发于 ❄️慕雪的寒舍 问题 如题,当我尝试在wsl2的ubuntu中使用-m32选项编译32位程序的时候,出现了下面的两种报错 ❯ g -m32 test.cpp -o test1 && ./test1 In file included from test.cpp:1: /usr/include/stdio.h:27:10: fatal error…...

vue指令v-model
<!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>vue指令v-model</title> </head>…...

CentOS安装MySQL数据库
一、更新yum源 #下载对应repo文件 wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo #清除缓存 yum clean all #生成新缓存 yum makecache #更新 yum update -y 二、安装MySQL #获取源 wget http://repo.mysql.com/mysql80-community-release-el7-3.…...

从B2B转向B2B2C模式:工业品牌史丹利百得的转型历程
图片来源:Twitter 在当今数据驱动的营销环境中,企业努力更好了解客户,并在整个客户旅程中提供个性化体验。史丹利百得(Stanley Black & Decker)是一家领先的工具和工业设备供应商,近年来开始重大转型。…...
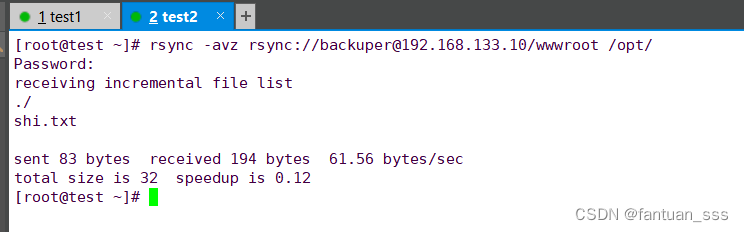
Redis群集模式和rsync远程同步
一、Redis群集模式 1.1 概念 1.2 作用 1.2.1 Redis集群的数据分片 1.2.2 Redis集群的主从复制模型 1.3 搭建Redis 群集模式 1.3.1 开启群集功能 1.3.2 启动redis节点 1.3.3 启动集群 1.3.4 测试群集 二、rsync远程同步 2.1 概念 2.2 同步方式 2.3 备份的方式 2.4…...

JAVA—抽象—定义抽象类Converter及其子类WeightConverter
同样,我们由这道题引出抽象类,抽象方法这个概念。 按下面要求定义类Converter及其子类WeightConverter 定义抽象类:Converter: 定义一个抽象类Converter,表示换算器,其定义的如下: 一个私有…...
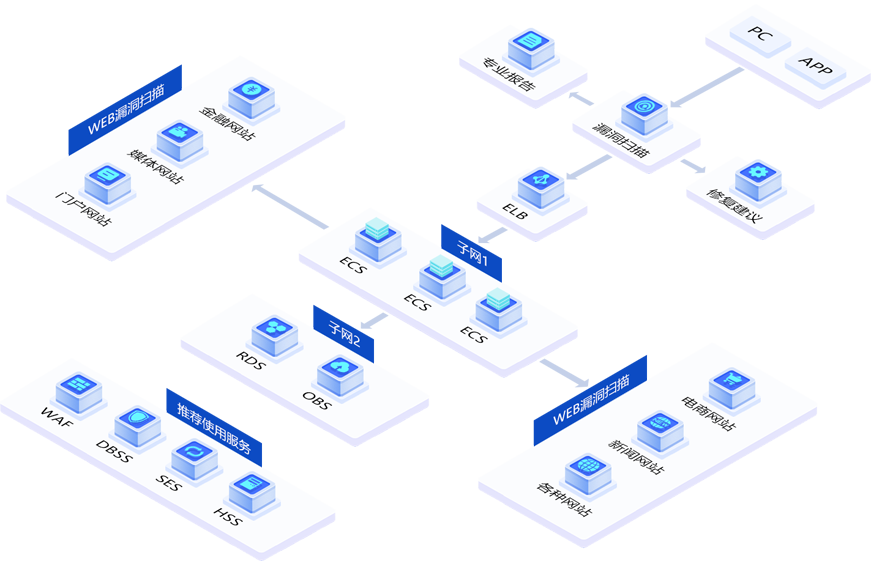
面对复杂多变的网络攻击,企业应如何守护网络安全
企业上云,即越来越多的企业把业务和数据,迁移到云端。随着云计算、大数据、物联网、人工智能等技术的发展,用户、应用程序和数据无处不在,企业之间的业务边界逐渐被打破,网络攻击愈演愈烈,手段更为多。 当前…...

计算机网络练习-计算机网络概述与性能指标
计算机网络概述 ----------------------------------------------------------------------------------------------------------------------------- 1. 计算机网络最据本的功能的是( )。 1,差错控制 Ⅱ.路由选择 Ⅲ,分布式处理 IV.传输控制 …...

vite vue3 ts import.meta在vscode中报错
问题描述:开发使用的框架为vitevue3ts,在开发过程中莫名其妙报仅当“--module”选项为“es2020”、“esnext”或“系统”时才允许使用“import.meta”元属性 问题解决: 通过更改tsconfig.json的module为esnext,es2022等࿰…...
)
Java synchronized(详细)
synchronized 一,介绍 在Java中,synchronized关键字用于解决多线程并发访问共享资源时可能出现的线程安全问题。当多个线程同时访问共享资源时,如果没有合适的同步机制,可能会导致以下问题: 竞态条件(…...

算法设计与分析实验报告python实现(排序算法、三壶谜题、交替放置的碟子、带锁的门)
一、 实验目的 1.加深学生对算法设计方法的基本思想、基本步骤、基本方法的理解与掌握; 2.提高学生利用课堂所学知识解决实际问题的能力; 3.提高学生综合应用所学知识解决实际问题的能力。 二、实验任务 1、排序算法…...

实训问题总结——ajax用get可以成功调用controller方法,用POST就出404错误
因为传输密码时必须用POST。 还有用GET传输参数,说有非法字符,想试试POST是否可以解决。 404错误的三个大致原因,1:找不到对的请求路径,2:请求方式错误,3、请求参数错误。 后来可以调用了。但…...
1、认识MySQL存储引擎吗?
目录 1、MySQL存储引擎有哪些? 2、默认的存储引擎是哪个? 3、InnoDB和MyISAM有什么区别吗? 3.1、关于事务 3.2、关于行级锁 3.3、关于外键支持 3.4、关于是否支持MVCC 3.5、关于数据安全恢复 3.6、关于索引 3.7、关于性能 4、如何…...

微信小程序媒体查询
在微信小程序中,media媒体查询不支持screen关键字,因为小程序页面是再webview中渲染的,而不是在浏览器中渲染的。 在设置样式时,可以使用 wxss 文件中的 media 规则来根据屏幕宽度或高度设置不同的样式。 device-width:设备屏幕…...

前端(动态雪景背景+动态蝴蝶)
1.CSS样式 <style>html, body, a, div, span, table, tr, td, strong, ul, ol, li, h1, h2, h3, p, input {font-weight: inherit;font-size: inherit;list-style: none;border-spacing: 0;border: 0;border-collapse: collapse;text-decoration: none;padding: 0;margi…...

对比直接使用厂商API,Taotoken在路由容灾上的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在路由容灾上的体验差异 1. 引言:服务稳定性的现实挑战 在将大模型能力集成…...

LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制
LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot LeRobo…...

超高清电视普及困境解析:从技术参数到生态系统的完整思考
1. 超高清电视的“非主流”开局:一场始于2013年的行业迷思 如果你在2013年初的拉斯维加斯CES展上,听到关于“Ultra HDTV”(超高清电视,后文简称UHDTV)的喧嚣,感觉就像身处一场盛大的交响乐彩排现场——乐手…...

3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器
3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE SRWE(Simple Runtime Window Editor)是一款革命性的实时窗口编辑器&…...

AI智能体构建实战:从架构设计到工程落地的关键挑战与解决方案
1. 项目概述:揭开AI智能体构建的隐秘面纱 “构建AI智能体”,这听起来像是当下最酷、最前沿的技术话题。无论是科技新闻还是行业论坛,你都能看到无数关于智能体如何自动化工作流、理解复杂指令、甚至自主决策的激动人心的讨论。然而࿰…...

从nano-SIM标准之争看硬件设计:兼容性、防呆与产业博弈
1. 项目概述:一场关于“小卡片”的巨头战争 在消费电子行业,我们常常把目光聚焦在芯片制程、屏幕刷新率或者摄像头传感器尺寸这些“大件”上。但作为一名浸淫硬件设计多年的工程师,我深知,真正决定用户体验和产品成败的࿰…...
)
华为eNSP模拟企业网:用VRRP+MSTP搞定500人公司的网络冗余与隔离(附排错记录)
华为eNSP实战:构建500人企业级网络的高可用架构 当一家企业发展到500人规模时,网络架构的稳定性和可靠性就成为业务连续性的关键保障。作为网络工程师,我们经常面临这样的挑战:如何在有限的预算下,设计出既满足部门隔离…...

从零构建现代桌面应用导航:PyQt-Fluent-Widgets导航组件实战指南
从零构建现代桌面应用导航:PyQt-Fluent-Widgets导航组件实战指南 【免费下载链接】PyQt-Fluent-Widgets A fluent design widgets library based on C Qt/PyQt/PySide. Make Qt Great Again. 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Fluent-Widgets …...

3分钟实现Zotero与Notion双向联动:Notero完整使用指南
3分钟实现Zotero与Notion双向联动:Notero完整使用指南 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 你是否曾为学术研究中的文献管理而烦恼?Zotero中精…...

String、StringBuilder、StringBuffer 学习与深入
1 学习的知识是什么 String:字符串,一旦创建里面的内容就不可变,每次使用拼接都创建一个新的对象而原有的对象依旧存在。 StringBuilder:可变字符串线程不安全,…...