算法设计与分析实验报告python实现(排序算法、三壶谜题、交替放置的碟子、带锁的门)
一、 实验目的
1.加深学生对算法设计方法的基本思想、基本步骤、基本方法的理解与掌握;
2.提高学生利用课堂所学知识解决实际问题的能力;
3.提高学生综合应用所学知识解决实际问题的能力。
二、实验任务
1、排序算法
目前已知有几十种排序算法,请查找资料,并尽可能多地实现多种排序算法(至少实现8种)并分析算法的时间复杂度。比较各种算法的优劣。
2、三壶谜题:
有一个充满水的8品脱的水壶和两个空水壶(容积分别是5品脱和3品脱)。通过将水壶完全倒满水和将水壶的水完全倒空这两种方式,在其中的一个水壶中得到4品脱的水。
3、交替放置的碟子
我们有数量为2n的一排碟子,n黑n白交替放置:黑,白,黑,白…
现在要把黑碟子都放在右边,白碟子都放在左边,但只允许通过互换相邻碟子的位置来实现。为该谜题写个算法,并确定该算法需要执行的换位次数。
4、带锁的门:
在走廊上有n个带锁的门,从1到n依次编号。最初所有的门都是关着的。我们从门前经过n次,每次都从1号门开始。在第i次经过时(i = 1,2,…, n)我们改变i的整数倍号锁的状态;如果门是关的,就打开它;如果门是打开的,就关上它。在最后一次经过后,哪些门是打开的,哪些门是关上的?有多少打开的门?
三、实验设备及编程开发工具
实验设备:Win10电脑
开发工具:Python 3.7,Pycharm
四、实验过程设计(算法思路及描述,代码设计)
1、排序算法
(1)冒泡排序
1、比较相邻的元素。如果第一个比第二个大,就交换他们两个
2、对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上
3、针对所有的元素重复以上的步骤,除了最后一个
4、持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
代码:
def BubbleSort(sums):n = len(sums)for i in range(n):for j in range(1,n - i):if sums[j - 1] > sums[j]:sums[j - 1],sums[j] = sums[j],sums[j - 1]return sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()BubbleSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
冒泡排序
最好时间复杂度为O(n2),最坏时间复杂度为O(n2),平均时间复杂度为O(n^2)

(2)选择排序
1、在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
2、再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾
3、以此类推,直到所有元素均排序完毕
代码:
def SelectSort(sums):n = len(sums)for i in range(0,n):min = ifor j in range(i + 1,n):if sums[j] < sums[min]:min = jsums[min],sums[i] = sums[i],sums[min]return sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()SelectSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
选择排序
最好时间复杂度为O(n2),最坏时间复杂度为O(n2),平均时间复杂度为O(n^2)
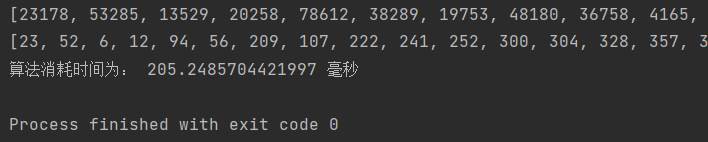
(3)插入排序
1、从第一个元素开始,该元素可以认为已经被排序
2、取出下一个元素,在已经排序的元素序列中从后向前扫描
3、如果被扫描的元素(已排序)大于新元素,将该元素后移一位
4、重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5、将新元素插入到该位置后
6、重复步骤2~5
代码:
def InsertSort(sums):n = len(sums)for i in range(1,n):temp = sums[i]j = i - 1while j >= 0 and sums[j] > temp:sums[j + 1] = sums[j]j -= 1sums[j + 1] = tempreturn sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()InsertSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
插入排序
最好时间复杂度为O(n),最坏时间复杂度为O(n2),平均时间复杂度为O(n2)
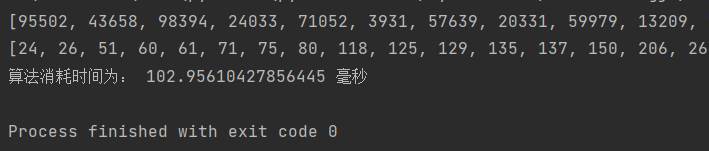
(4)希尔排序
1、比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,算法先将要排序的一组数按某个增量d分成若干组
2、对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序
3、当增量减到1时,整个要排序的数被分成一组,排序完成
4、一般的初次取序列的一半为增量,以后每次减半,直到增量为1
代码:
def ShellSort(sums):n = len(sums)mid = n//2while mid >= 1:for i in range(mid,n):temp = sums[i]j = iwhile j - mid >= 0 and sums[j - mid] > temp:sums[j] = sums[j - mid]j -= midsums[j] = tempmid //= 2return sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()ShellSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
希尔排序
最好时间复杂度为O(nlog n),最坏时间复杂度为O(nlogn),平均时间复杂度为O(nlogn)
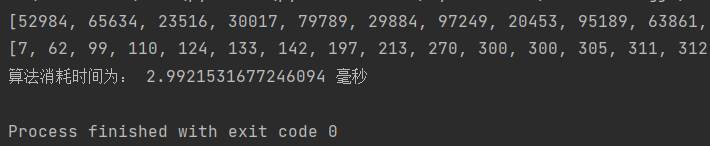
(5)归并排序
1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2、设定两个指针,最初位置分别为两个已经排序序列的起始位置
3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4、重复步骤 3 直到某一指针达到序列尾
5、 将另一序列剩下的所有元素直接复制到合并序列尾
代码:
def MergeSort(sums):if len(sums) <= 1:return sumsn = len(sums)//2left = MergeSort(sums[:n])right = MergeSort(sums[n + 1:])return Merge(left,right)def Merge(left,right):new_sums = []i,j = 0,0while i < len(left) and j < len(right):if left[i] < right[j]:new_sums.append(left[i])i += 1else:new_sums.append(right[j])j += 1new_sums = new_sums + left[i:] + right[j:]return new_sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()MergeSort(List)b = time.time()
print(MergeSort(List))
print("算法消耗时间为:",(b - a)*100,"毫秒")
归并排序
最好时间复杂度为O(nlogn),最坏时间复杂度为O(nlogn),平均时间复杂度为O(nlogn)
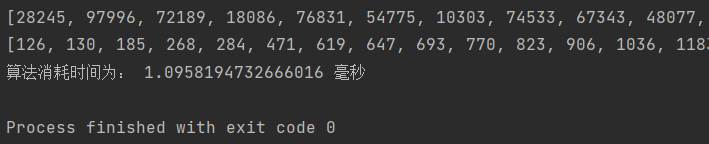
(6)快速排序
1、从数列中挑出一个元素作为基准数
2、分区过程,将比基准数大的放到右边,小于或等于它的数都放到左边
3、再对左右区间递归执行第二步,直至各区间只有一个数
代码:
def QuickSort(sums,left,right):if left >= right:return Falselow = lefthigh = righttemp = sums[low]while left < right:while left < right and sums[right] > temp:right -= 1sums[left] = sums[right]while left < right and sums[left] <= temp:left += 1sums[right] = sums[left]sums[right] = tempQuickSort(sums,low,left - 1)QuickSort(sums,left + 1,high)return sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()QuickSort(List,0,len(List) - 1)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
快速排序
最好时间复杂度为O(nlogn),最坏时间复杂度为O(n^2),平均时间复杂度为O(nlogn)

(7)堆排序
1、最大堆调整:将堆的末端子节点作调整,使得子节点永远小于父节点
2、创建最大堆:将堆中的所有数据重新排序
3、堆排序:移除位在第一个数据的根节点,并做最大堆调整的递归运算
代码:
def HeapSort(sums):n = len(sums)first = n//2 - 1for start in range(first,-1,-1):HeapSort_Max(sums,start,n - 1)for end in range(n - 1,0,-1):temp = sums[end]sums[end] = sums[0]sums[0] = tempHeapSort_Max(sums,0,end - 1)return sumsdef HeapSort_Max(sums,start,end):root = startwhile True:child = 2 * root + 1if child > end:breakif child + 1 <= end and sums[child] < sums[child + 1]:child = child + 1if sums[root] < sums[child]:temp = sums[root]sums[root] = sums[child]sums[child] = temproot = childelse:breakimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()HeapSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
堆排序
最好时间复杂度为O(nlogn),最坏时间复杂度为O(nlogn),平均时间复杂度为O(nlogn)

(8)计数排序
1、找出待排序的数组中最大和最小的元素,新开辟一个长度为 最大值-最小值+1 的数组
2、统计原数组中每个元素出现的次数,存入到新开辟的数组中
3、根据每个元素出现的次数,按照新开辟数组中从小到大的秩序,依次填充到原来待排序的数组中,完成排序
代码:
def RadixSort(sums):Min = min(sums)Max = max(sums)List = [0 for i in range(Max - Min + 2)]for i in range(len(sums)):List[sums[i] - Min] += 1j,k = 0,0while j < (len(List)):if List[j] > 0:sums[k] = j + MinList[j] -= 1k += 1else:j += 1return sumsimport random
import timeList = [random.randint(0, 100000) for i in range(5000)]
print(List)
a = time.time()RadixSort(List)b = time.time()
print(List)
print("算法消耗时间为:",(b - a)*100,"毫秒")
计数排序
最好时间复杂度为O(n),最坏时间复杂度为O(n),平均时间复杂度为O(n)
2、三壶谜题
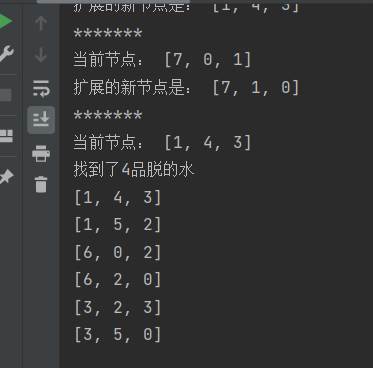
将某个时刻水壶中水的数量看作一个状态,用一个长度为3的数组表示,初始状态便为[8,0,0],再拓展他的下一结点的可能结构,若下一结点的结构已经被拓展过了便放弃,若没有拓展过则加入拓展列表中。然后递归上述操作,直到拓展列表为空或者找到目标为止。
代码:
class node: def __init__(self, data):self.data = dataself.per = None def pour(n):r_list = n.data max_list = [8, 5, 3] for i, j in ((0, 1), (0, 2), (1, 2), (1, 0), (2, 0), (2, 1)):if r_list[i] != 0:n_list = r_list.copy() if r_list[i] + r_list[j] > max_list[j]:n_list[i] = r_list[i] - (max_list[j] - r_list[j])n_list[j] = max_list[j]else:n_list[j] = r_list[i] + r_list[j]n_list[i] = 0flag = True for one in closed_list:if one.data == n_list: flag = Falseif flag:print("扩展的新节点是:",n_list)new_node = node(n_list) new_node.per = nopen_list.append(new_node)def BFS_node(root_1): n = root_1print("当前节点:",n.data)if open_list is None:return "没有找到4品脱的水"nodelist = n.dataif 4 in nodelist:print("找到了4品脱的水")print_node(n)return "找到了4品脱的水"closed_list.append(open_list.pop(0))pour(n)print("*******")BFS_node(open_list[0])def print_node(n): if n.per == None:return ""print(n.data)print_node(n.per)# 初始化数据
root = node([8, 0, 0])
open_list = [root]
closed_list = []
BFS_node(open_list[0])
三壶谜题:
时间复杂度为O(n^2)
3、交替放置的碟子
输入碟子的总数n,产生一个0,1交错的列表,其中1代表黑碟子,0代表白碟子,通过冒泡排序将碟子分开。
代码:
def Black_White(s):sums = [0 for i in range(s)]i = 0while i * 2 < s:sums[i * 2] = 1i += 1print(sums)k = 0n = len(sums)for i in range(n):for j in range(1, n - i):if sums[j - 1] > sums[j]:sums[j - 1], sums[j] = sums[j], sums[j - 1]k += 1print(sums)print("次数为:", k, "次")# 黑碟子为1,白碟子为0
Black_White(40)
交替放置的碟子:
时间复杂度为O(n^2)

4、带锁的门
输入门的总数n,产生两个列表表示开门和关门的状态,同过循环遍历,将各位表示反复重置,最终得到门的状态并输出。其中1表示开门,0表示关门。
代码:
# 1表示开门,0表示关门
def LockDoor(n):List = [0 for i in range(n)]List_open = []List_close = []k,s = 0,0for i in range(1,n + 1):m = n // ifor j in range(1,m + 1):if List[i * j - 1] == 0:List[i * j - 1] = 1else:List[i * j - 1] = 0for i in range(n):if List[i] == 1:List_open.append(i + 1)k += 1else:List_close.append(i + 1)s += 1print('门的状态:',List,List_open,List_close,k,s)print('开门的编号:',List_open)print('开门的数量为:', k)print('关门的编号:',List_close)print('关门的数量为:',s) LockDoor(100)带锁的门:
时间复杂度为O(n^2)

相关文章:
算法设计与分析实验报告python实现(排序算法、三壶谜题、交替放置的碟子、带锁的门)
一、 实验目的 1.加深学生对算法设计方法的基本思想、基本步骤、基本方法的理解与掌握; 2.提高学生利用课堂所学知识解决实际问题的能力; 3.提高学生综合应用所学知识解决实际问题的能力。 二、实验任务 1、排序算法…...

实训问题总结——ajax用get可以成功调用controller方法,用POST就出404错误
因为传输密码时必须用POST。 还有用GET传输参数,说有非法字符,想试试POST是否可以解决。 404错误的三个大致原因,1:找不到对的请求路径,2:请求方式错误,3、请求参数错误。 后来可以调用了。但…...
1、认识MySQL存储引擎吗?
目录 1、MySQL存储引擎有哪些? 2、默认的存储引擎是哪个? 3、InnoDB和MyISAM有什么区别吗? 3.1、关于事务 3.2、关于行级锁 3.3、关于外键支持 3.4、关于是否支持MVCC 3.5、关于数据安全恢复 3.6、关于索引 3.7、关于性能 4、如何…...

微信小程序媒体查询
在微信小程序中,media媒体查询不支持screen关键字,因为小程序页面是再webview中渲染的,而不是在浏览器中渲染的。 在设置样式时,可以使用 wxss 文件中的 media 规则来根据屏幕宽度或高度设置不同的样式。 device-width:设备屏幕…...

前端(动态雪景背景+动态蝴蝶)
1.CSS样式 <style>html, body, a, div, span, table, tr, td, strong, ul, ol, li, h1, h2, h3, p, input {font-weight: inherit;font-size: inherit;list-style: none;border-spacing: 0;border: 0;border-collapse: collapse;text-decoration: none;padding: 0;margi…...

软考-系统集成项目管理中级-新一代信息技术
本章历年考题分值统计 本章重点常考知识点汇总清单(掌握部分可直接理解记忆) 本章历年考题及答案解析 32、2019 年上半年第 23 题 云计算通过网络提供可动态伸缩的廉价计算能力,(23)不属于云计算的特点。 A.虚拟化 B.高可扩展性 C.按需服务 D.优化本地存储 【参考…...
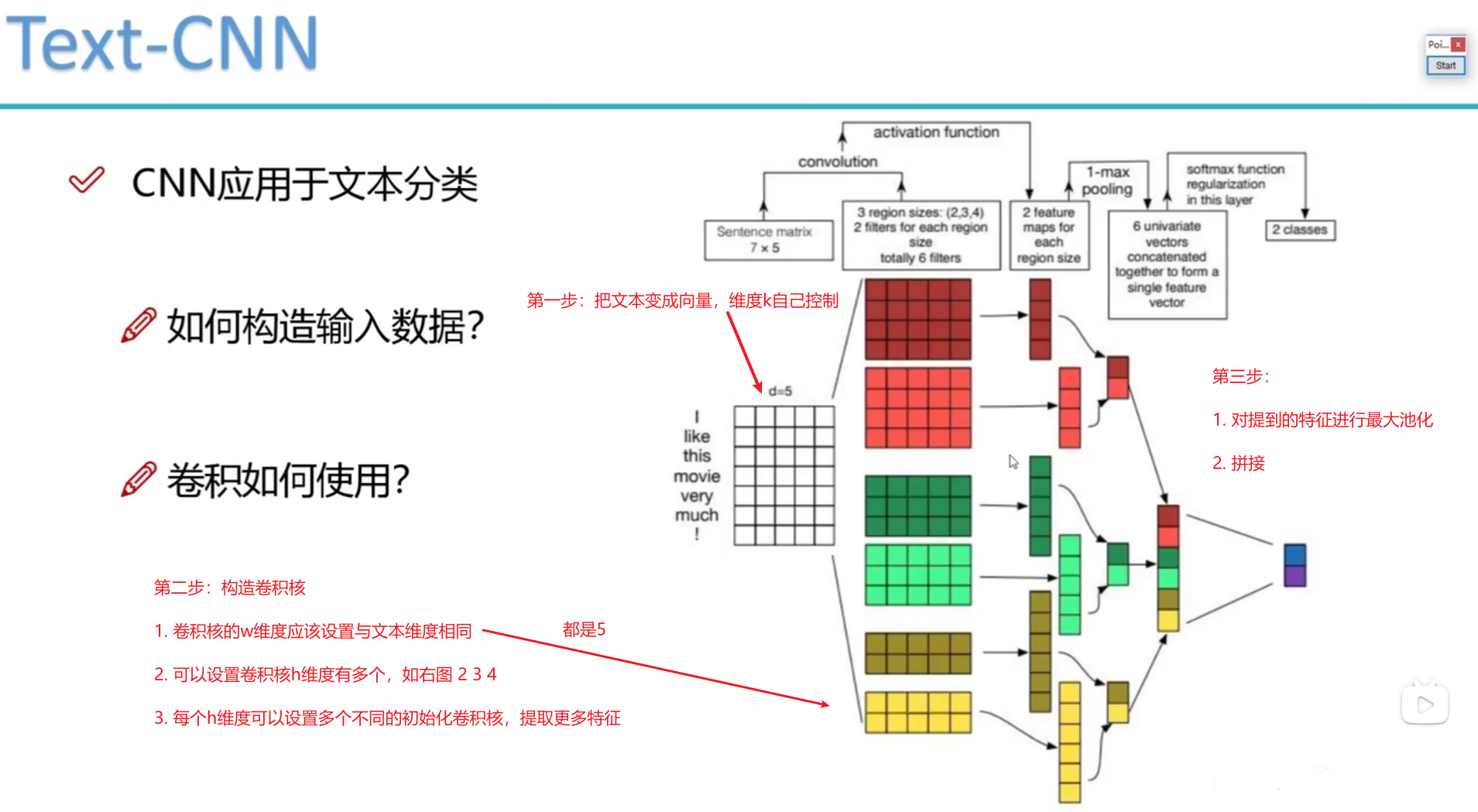
【卷积神经网络进展】
打基础日常记录 CNN基础知识1. 感知机2. DNN 深度神经网络(全连接神经网络)DNN 与感知机的区别DNN特点,全连接神经网络DNN前向传播和反向传播 3. CNN结构【提取特征分类】4. CNN应用于文本 CNN基础知识 1. 感知机 单层感知机就是一个二分类…...

yarn的安装和使用
windows mac 环境 yarn的安装和使用 yarn安装 npm install -g yarnyarn设置代理 yarn config set registry https://registry.npm.taobao.org -gyarn官方源 yarn config set registry https://registry.yarnpkg.comyarn使用 // 查看板本 yarn --version// 安装指定包 yarn…...
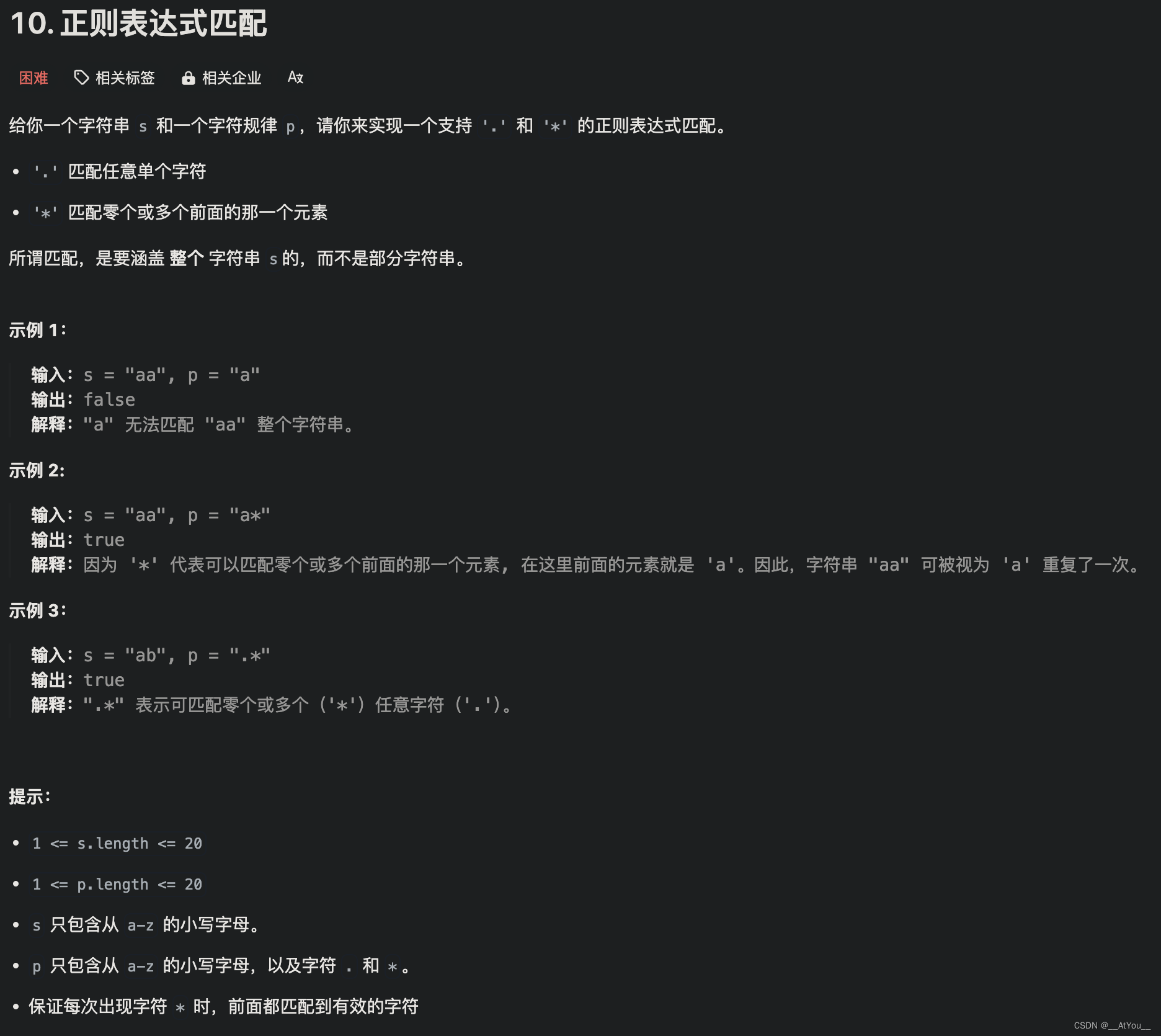
Golang | Leetcode Golang题解之第10题正则表达式匹配
题目: 题解: func isMatch(s string, p string) bool {m, n : len(s), len(p)matches : func(i, j int) bool {if i 0 {return false}if p[j-1] . {return true}return s[i-1] p[j-1]}f : make([][]bool, m 1)for i : 0; i < len(f); i {f[i] m…...
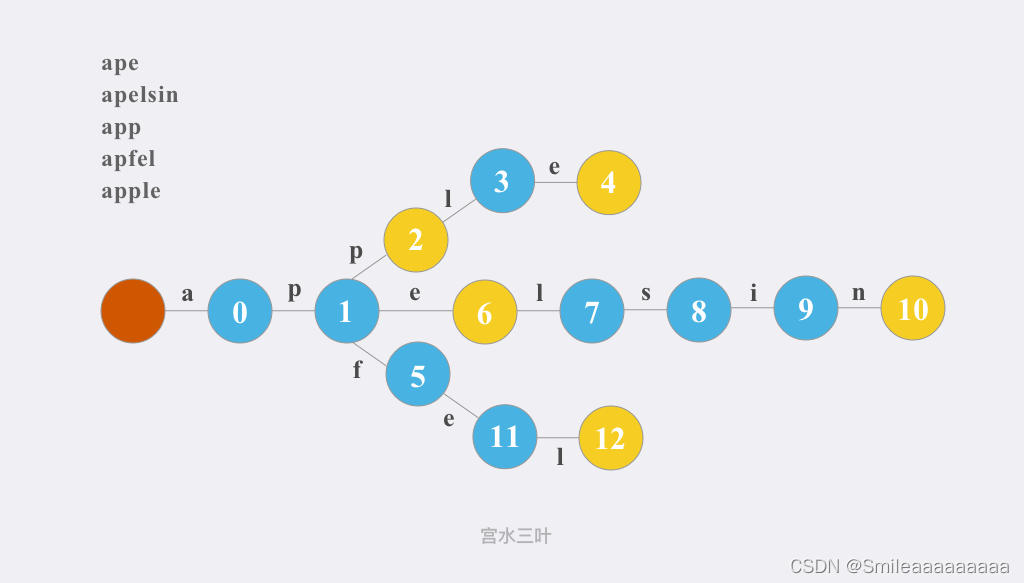
【Leetcode】top 100 图论
基础知识补充 1.图分为有向图和无向图,有权图和无权图; 2.图的表示方法:邻接矩阵适合表示稠密图,邻接表适合表示稀疏图; 邻接矩阵: 邻接表: 基础操作补充 1.邻接矩阵: class GraphAd…...

【沈阳航空航天大学】 <C++ 类与对象计分作业>
C类与对象 1. 设计用类完成计算两点距离2. 设计向量类3. 求n!4. 出租车收费类的设计与实现5. 定义并实现一个复数类6. 线性表类的设计与实现7. 数组求和8. 数组求最大值 1. 设计用类完成计算两点距离 【问题描述】设计二维点类Point,包括私有成员:横坐标…...

Vue3 自定义指令Custom Directives
简介 在vue中重用代码的方式有:组件、组合式函数。组件是主要的构建模块,而组合式函数更偏重于有状态的逻辑。 指令系统给我们提供了例如:v-model、v-bind,vue系统允许我们自定义指令,自定义指令也是一种重用代码的方式…...

蓝桥杯 【日期统计】【01串的熵】
日期统计 第一遍写的时候会错了题目的意思,我以为是一定要八个整数连在一起构成正确日期,后面发现逻辑明明没有问题但是答案怎么都是错的才发现理解错了题目的意思,题目的意思是按下标顺序组成,意思就是可以不连续,我…...

CSP201409T5拼图
题意:给出一个 n m nm nm的方格图,现在要用如下L型的占3个的积木拼到这个图中,总共有多少种拼法使图满。 #include<bits/stdc.h> using namespace std; long long n,m,k1,Now; int Mod1000000007; struct Matrix {long long a[129][129];Matrix(…...
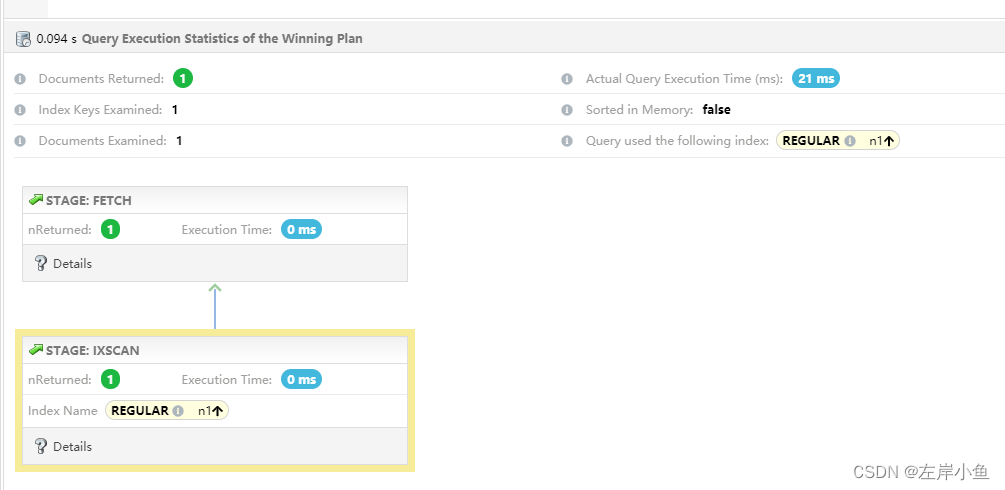
mongoDB 优化(2)索引
执行计划 语法:1 db.collection_xxx_t.find({"param":"xxxxxxx"}).explain(executionStats) 感觉这篇文章写得很好,可以参考 MongoDB——索引(单索引,复合索引,索引创建、使用)_mongo…...

【2024系统架构设计】案例分析- 5 Web应用
目录 一 基础知识 二 真题 一 基础知识 1 Web应用技术分类 大型网站系统架构的演化:高性能、高可用、可维护、应变、安全。 从架构来看:MVC,MVP,MVVM,REST,Webservice,微服务。...
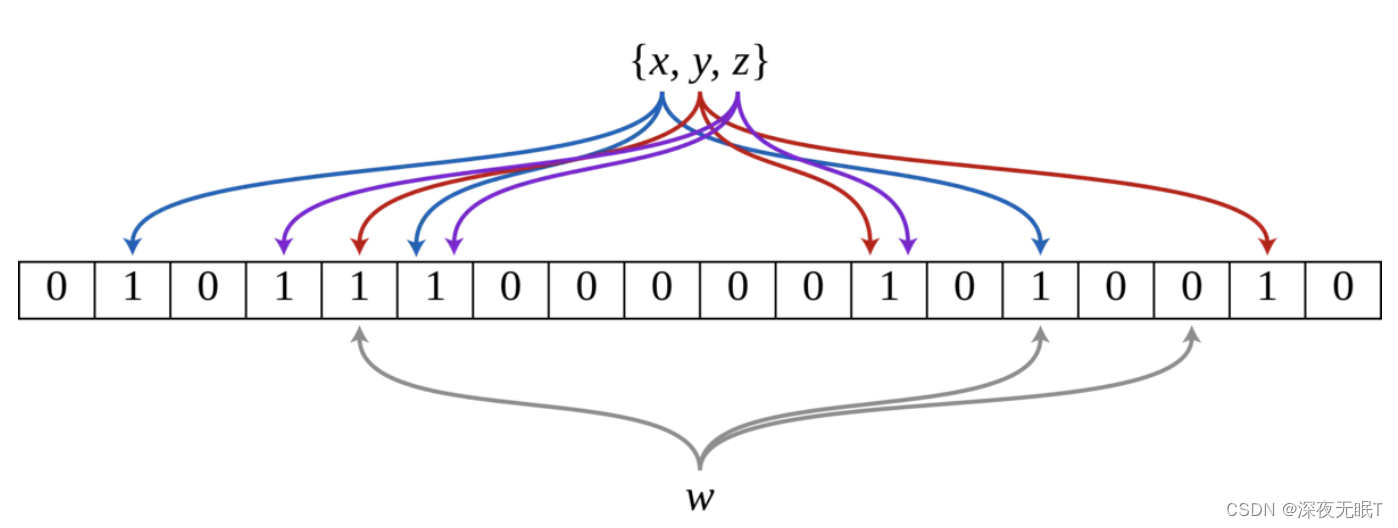
布隆过滤器详解及java实现
什么是布隆过滤器? 布隆过滤器(Bloom Filter)是一种数据结构,用于判断一个元素是否属于一个集合。它的特点是高效地判断一个元素是否可能存在于集合中,但是存在一定的误判率。 布隆过滤器的基本原理是使用一个位数组…...
CloudCompare 点云工具
CloudCompare 点云工具 1. CloudCompare简介1.1 CloudCompare下载 2. CloudCompare安装 1. CloudCompare简介 CloudCompare 是一款开源的三维点云处理软件,它提供了一系列功能来处理、查看和分析三维点云数据。这个软件可以用于许多不同的应用领域,包括…...

Linux 著名的sudo、su是什么?怎么用?
一、su 什么是su? su命令(简称是:substitute 或者 switch user )用于切换到另一个用户,没有指定用户名,则默认情况下将以root用户登录。 为了向后兼容,su默认不改变当前目录,只设…...
C语言分支语句
一、什么是语句 C语句可分为以下五类: 表达式语句 函数调用语句 控制语句 复合语句 空语句 本周后面介绍的是控制语句。 控制语句用于控制程序的执行流程,以实现程序的各种结构方式,它们由特定的语句定义符组成,C语 言有…...

对比体验Taotoken平台不同大模型在创意生成上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验Taotoken平台不同大模型在创意生成上的差异 对于内容创作者而言,大模型是激发灵感、提升效率的得力工具。然而…...
及适用场景)
告别预装旧版Demo:详解mmWave SDK两种刷写模式(Demonstration vs. CCS Development)及适用场景
告别预装旧版Demo:详解mmWave SDK两种刷写模式(Demonstration vs. CCS Development)及适用场景 当你第一次拿到毫米波雷达评估模块(EVM)时,预装的Demo固件可能已经过时半年甚至更久。这时候你会面临一个关键…...

Memor:为LLM对话构建结构化记忆引擎,实现可重现、可移植的AI交互管理
1. 项目概述:Memor,为LLM对话赋予结构化记忆如果你和我一样,长期和各类大语言模型打交道,从早期的GPT-3到现在的Claude、Gemini,一个绕不开的痛点就是:对话历史的管理。默认的聊天界面里,历史记…...

后端程序员必看:3-6个月从0到1转型高薪AI应用
本文针对传统后端程序员想转型AI应用开发的焦虑,提出了一条省时、高薪、稳定的转型路线。文章指出,转型AI应用开发的核心是复用后端优势,走“后端AI集成”的复合型路线,而非死磕底层算法。文章详细规划了3-6个月的转型路线&#x…...

3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南
3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II 如果你在使用Reloaded-I…...

宝塔面板磁盘爆满排查与清理全记录
前言前几天登录宝塔面板,发现磁盘空间告急(日志文件都清理了,怎么磁盘占用率还这么高):81.52G / 98.3G,剩余不足 17%。虽然服务器负载不高,但这个磁盘占用率让人隐隐不安——如果不及时处理&…...

ncmdumpGUI:解锁网易云音乐NCM文件格式的终极解决方案
ncmdumpGUI:解锁网易云音乐NCM文件格式的终极解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM格式文件无法在其…...

从云原生到边原生:AI营销一体机如何重构企业的“数字孪生”基础设施?
摘要: 随着大模型参数量的激增,传统的“端-管-云”架构在处理高频营销任务时遭遇了带宽与延迟的瓶颈。本文将探讨“边原生(Edge-Native)”架构的崛起,并以卡特加特AI营销一体机为例,解析如何利用本地化超…...

不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力
不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力 很多公司一遇到系统卡顿。 第一反应特别统一: 加机器。CPU 不够? 加。 QPS 扛不住? 扩容。 数据库慢? 上集群。 结果最后: 服务器越来越多。 成本越来越高。 系统还是越来越慢。 最离谱的是: 有…...
)
Vivado里配置RFSoC数据转换器IP,这10个参数新手最容易搞错(附PG269避坑指南)
Vivado中RFSoC数据转换器IP配置的10个关键参数解析与实战避坑指南 第一次在Vivado中配置RFSoC的数据转换器IP核时,面对密密麻麻的参数选项,即使是经验丰富的FPGA工程师也可能感到无从下手。RFSoC作为集成了高速数据转换器的异构计算平台,其配…...