pdf、docx、markdown、txt提取文档内容,可以应用于rag文档解析
返回的是文档解析分段内容组成的列表,分段内容默认chunk_size: int = 250, chunk_overlap: int = 50,250字分段,50分段处保留后面一段的前50字拼接即窗口包含下下一段前面50个字划分
from typing import Union, Listimport jieba
import reclass SentenceSplitter:def __init__(self, chunk_size: int = 250, chunk_overlap: int = 50):self.chunk_size = chunk_sizeself.chunk_overlap = chunk_overlapdef split_text(self, text: str) -> List[str]:if self._is_has_chinese(text):return self._split_chinese_text(text)else:return self._split_english_text(text)def _split_chinese_text(self, text: str) -> List[str]:sentence_endings = {'\n', '。', '!', '?', ';', '…'} # 句末标点符号chunks, current_chunk = [], ''for word in jieba.cut(text):if len(current_chunk) + len(word) > self.chunk_size:chunks.append(current_chunk.strip())current_chunk = wordelse:current_chunk += wordif word[-1] in sentence_endings and len(current_chunk) > self.chunk_size - self.chunk_overlap:chunks.append(current_chunk.strip())current_chunk = ''if current_chunk:chunks.append(current_chunk.strip())if self.chunk_overlap > 0 and len(chunks) > 1:chunks = self._handle_overlap(chunks)return chunksdef _split_english_text(self, text: str) -> List[str]:# 使用正则表达式按句子分割英文文本sentences = re.split(r'(?<=[.!?])\s+', text.replace('\n', ' '))chunks, current_chunk = [], ''for sentence in sentences:if len(current_chunk) + len(sentence) <= self.chunk_size or not current_chunk:current_chunk += (' ' if current_chunk else '') + sentenceelse:chunks.append(current_chunk)current_chunk = sentenceif current_chunk: # Add the last chunkchunks.append(current_chunk)if self.chunk_overlap > 0 and len(chunks) > 1:chunks = self._handle_overlap(chunks)return chunksdef _is_has_chinese(self, text: str) -> bool:# check if contains chinese charactersif any("\u4e00" <= ch <= "\u9fff" for ch in text):return Trueelse:return Falsedef _handle_overlap(self, chunks: List[str]) -> List[str]:# 处理块间重叠overlapped_chunks = []for i in range(len(chunks) - 1):chunk = chunks[i] + ' ' + chunks[i + 1][:self.chunk_overlap]overlapped_chunks.append(chunk.strip())overlapped_chunks.append(chunks[-1])return overlapped_chunkstext_splitter = SentenceSplitter()def load_file(filepath):print("filepath:",filepath)if filepath.endswith(".md"):contents = extract_text_from_markdown(filepath)elif filepath.endswith(".pdf"):contents = extract_text_from_pdf(filepath)elif filepath.endswith('.docx'):contents = extract_text_from_docx(filepath)else:contents = extract_text_from_txt(filepath)return contentsdef extract_text_from_pdf(file_path: str):"""Extract text content from a PDF file."""import PyPDF2contents = []with open(file_path, 'rb') as f:pdf_reader = PyPDF2.PdfReader(f)for page in pdf_reader.pages:page_text = page.extract_text().strip()raw_text = [text.strip() for text in page_text.splitlines() if text.strip()]new_text = ''for text in raw_text:new_text += textif text[-1] in ['.', '!', '?', '。', '!', '?', '…', ';', ';', ':', ':', '”', '’', ')', '】', '》', '」','』', '〕', '〉', '》', '〗', '〞', '〟', '»', '"', "'", ')', ']', '}']:contents.append(new_text)new_text = ''if new_text:contents.append(new_text)return contentsdef extract_text_from_txt(file_path: str):"""Extract text content from a TXT file."""with open(file_path, 'r', encoding='utf-8') as f:contents = [text.strip() for text in f.readlines() if text.strip()]return contentsdef extract_text_from_docx(file_path: str):"""Extract text content from a DOCX file."""import docxdocument = docx.Document(file_path)contents = [paragraph.text.strip() for paragraph in document.paragraphs if paragraph.text.strip()]return contentsdef extract_text_from_markdown(file_path: str):"""Extract text content from a Markdown file."""import markdownfrom bs4 import BeautifulSoupwith open(file_path, 'r', encoding='utf-8') as f:markdown_text = f.read()html = markdown.markdown(markdown_text)soup = BeautifulSoup(html, 'html.parser')contents = [text.strip() for text in soup.get_text().splitlines() if text.strip()]return contentstexts = load_file(r"C:\Users\lo***山市城市建筑外立面管理条例.docx")
print(texts)

相关文章:
pdf、docx、markdown、txt提取文档内容,可以应用于rag文档解析
返回的是文档解析分段内容组成的列表,分段内容默认chunk_size: int 250, chunk_overlap: int 50,250字分段,50分段处保留后面一段的前50字拼接即窗口包含下下一段前面50个字划分 from typing import Union, Listimport jieba import recla…...

【Linux系列】“dev-node1“ 运行的操作系统分析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
SpriingBoot整合MongoDB多数据源
背景: MongoDB多数据源:springboot为3以上版本,spring-boot-starter-data-mongodb低版本MongoDBFactory已过时, 改为MongoDatabaseFactory。 1、pom引入: <dependency><groupId>org.springframework.boo…...

深入浅出 -- 系统架构之负载均衡Nginx缓存机制
一、Nginx缓存机制 对于性能优化而言,缓存是一种能够大幅度提升性能的方案,因此几乎可以在各处都能看见缓存,如客户端缓存、代理缓存、服务器缓存等等,Nginx的缓存则属于代理缓存的一种。对于整个系统而言,加入缓存带来…...

前端 小程序框架UniApp
小程序框架UniApp uni-app简介uni-app项目结构uni-app开发工具HBuilderXuni-app页面uni-app页面生命周期uni-app组件生命周期uni-app页面调用接口uni-app页面通讯uni-app pages.json 页面路由uni-app组件viewuni-app组件scroll-viewuni-app组件swiperuni-app组件textuni-app组…...
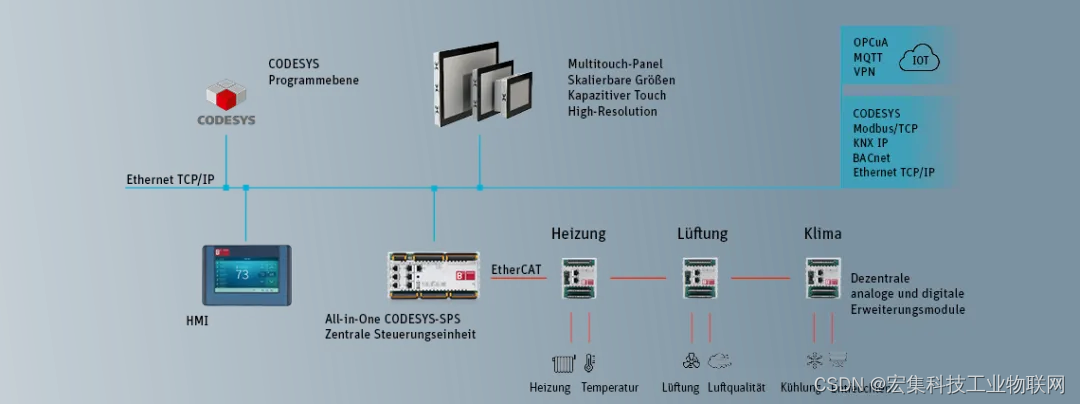
宏集PLC如何为楼宇自动化行业提供空调、供暖与通风的解决方案?
一、应用背景 楼宇自动化行业是通过将先进的技术和系统应用于建筑物中,以提高其运营效率、舒适度和能源利用效率的行业,其目标是使建筑物能够自动监控、调节和控制各种设备和系统,包括照明系统、空调系统、安全系统、通风系统、电力供应系统…...
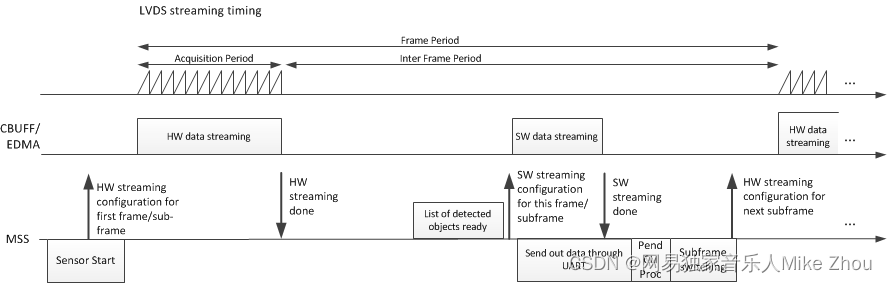
【TI毫米波雷达】官方工业雷达包的生命体征检测环境配置及避坑(Vital_Signs、IWR6843AOPEVM)
【TI毫米波雷达】官方工业雷达包的生命体征检测环境配置及避坑(Vital_Signs、IWR6843AOPEVM) 文章目录 生命体征基本介绍IWR6843AOPEVM的配置上位机配置文件避坑上位机start测试距离检测心跳检测呼吸频率检测空环境测试 附录:结构框架雷达基…...
计算机毕业设计选题之基于SSM的旅游管理系统【源码+PPT+文档+包运行成功+部署讲解】
💓项目咨询获取源码联系v💓xiaowan1860💓 🚩如何选题?🍑 对于项目设计中如何选题、让题目的难度在可控范围,以及如何在选题过程以及整个毕设过程中如何与老师沟通,有疑问不清晰的可…...
JavaWeb入门——Web前端概述及HTML,CSS语言基本使用
前言: java基础已经学完,开始学习javaWeb相关的内容,整理下笔记,打好基础,daydayup!!! Web Web:全球广域网,也称万维网(www World Wide Web),能够通过浏览器访…...
数据结构(3)----栈和队列
目录 一.栈 1.栈的基本概念 2.栈的基本操作 3.顺序栈的实现 •顺序栈的定义 •顺序栈的初始化 •进栈操作 •出栈操作 •读栈顶元素操作 •若使用另一种方式: 4.链栈的实现 •链栈的进栈操作 •链栈的出栈操作 •读栈顶元素 二.队列 1.队列的基本概念 2.队列的基…...

nestjs 全栈进阶--module
视频教程 10_模块Module1_哔哩哔哩_bilibili 1. 模块Module 在 Nest.js 中,Module 是框架的核心概念之一,用于组织和管理应用程序的不同部分,包括服务、控制器、中间件以及其他模块的导入。每个 Nest.js 应用程序至少有一个根模块…...
jupyter python paramiko 网络系统运维
概述 通过使用jupyter进行网络运维的相关测试 设备为H3C 联通性测试 import paramiko import time import getpass import re import os import datetimeusername "*****" password "*****" ip "10.32.**.**"ssh_client paramiko.SSHCli…...

Windows Edge浏览器兼容性问题诊断与修复策略详解
随着Microsoft Edge浏览器的持续迭代与更新,其性能与兼容性已得到了显著提升。然而,在面对互联网上纷繁复杂的网页内容时,仍有可能遇到兼容性问题。本文旨在探讨Edge浏览器在处理网页兼容性问题时的常见场景、原因分析及相应的解决方案&#…...

EXCEL学习笔记
EXCEL学习笔记 小技巧 一键批量添加后缀名词/单词 单元格格式-自定义-通用格式后面输入相应的单位,比如“元”。 输入10000个序号,先输入1,点击开始-填充-序列,选中该列,终止值为10000; 按住shift选取多个…...
)
使用预训练的bert large model实现问答系统源码(本地实现 question answer system)
pre-trained bert model 预训练好的Bert模型 本地实现问答系统 用这条命令将bert下载到本地: model.save_pretrained("path/to/model") 具体代码 如下链接: https://download.csdn.net/download/qqqweiweiqq/89092005...

蓝桥杯 历届真题 杨辉三角形【第十二届】【省赛】【C组】
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 思路: 由于我第一写没考虑到大数据的原因,直接判断导致只得了40分,下面是我的代码: #…...

商务电子邮件: 在WorkPlace中高效且安全
高效和安全的沟通是任何组织成功的核心。在我们关于电子邮件类型的系列文章的第二期中,我们将重点关注商业电子邮件在促进无缝交互中的关键作用。当你身处重要的工作场环境时,本系列的每篇文章都提供了电子邮件的不同维度的视角。 “2024年,全…...

阿里云2024年优惠券领取及使用常见问题
阿里云是阿里巴巴旗下云计算品牌,服务涵盖云服务器、云数据库、云存储、域名注册等全方位云服务和各行业解决方案。为了吸引用户上云,阿里云经常推出各种优惠活动,其中就包括阿里云优惠券。本文将对阿里云优惠券领取及使用常见问题进行解答&a…...
90天玩转Python—05—基础知识篇:Python基础知识扫盲,使用方法与注意事项
90天玩转Python系列文章目录 90天玩转Python—01—基础知识篇:C站最全Python标准库总结 90天玩转Python--02--基础知识篇:初识Python与PyCharm 90天玩转Python—03—基础知识篇:Python和PyCharm(语言特点、学习方法、工具安装) 90天玩转Python—04—基础知识篇:Pytho…...

常见的常见免费开源绘图工具对比 draw.io/Excalidraw/Lucidchart/yEd Graph Editor/Dia/
拓展阅读 常见免费开源绘图工具 OmniGraffle 创建精确、美观图形的工具 UML-架构图入门介绍 starUML UML 绘制工具 starUML 入门介绍 PlantUML 是绘制 uml 的一个开源项目 UML 等常见图绘制工具 绘图工具 draw.io / diagrams.net 免费在线图表编辑器 绘图工具 excalidr…...

Hyprland截图方案:Wayland下高效截图工具配置与优化指南
1. 项目概述与核心价值最近在折腾Hyprland窗口管理器,发现一个痛点:截图。系统自带的工具要么功能单一,要么和Hyprland的Wayland环境配合不佳,用起来总感觉差点意思。直到我发现了nikolai2038/hyprland-screenshoter这个项目&…...
)
从零封装Cesium测量工具:我踩过的3个坑和性能优化心得(鼠标事件、坐标拾取、内存泄漏)
从零封装Cesium测量工具:我踩过的3个坑和性能优化心得 第一次在项目中集成Cesium测量工具时,我天真地以为这不过是调用几个API的简单工作。直到用户反馈地图越来越卡、测量结果偶尔出现诡异偏差时,我才意识到自己掉进了多少陷阱。本文将分享三…...
)
告别混乱搜索:一文搞懂Quartus前仿真的两种玩法(Modelsim调用 vs VWF内嵌)
Quartus前仿真实战指南:Modelsim与VWF的高效选择策略 从Verilog到可靠仿真的关键跨越 当你完成了一段Verilog代码的编写,那种成就感往往伴随着一个迫切的需求:如何快速验证这段代码的行为是否符合预期?在Quartus开发环境中&#x…...

别再只会拖模块了!手把手教你用Simulink封装打造自己的‘智能积木’
从零构建你的Simulink智能积木库:封装技术实战指南 在工程建模领域,Simulink就像数字世界的乐高积木箱,但大多数用户只停留在拖拽现成模块的初级阶段。真正的高手都掌握了一项核心技能——模块封装。这就像把一堆散乱的乐高零件组装成功能完整…...

航空摇篮长岛:从早期飞行到现代航空工业的技术演进与创新集群
1. 项目概述:从长岛的天空回望航空摇篮如果你对航空史感兴趣,或者像我一样,是个对机械、工程和人类如何突破物理极限着迷的工程师,那么“长岛”这个名字绝对绕不开。它不仅仅是纽约市旁边的一个地理名词,在航空史上&am…...

如何用本地OCR工具快速提取视频硬字幕:3步完成专业字幕制作
如何用本地OCR工具快速提取视频硬字幕:3步完成专业字幕制作 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

3步解锁百度网盘满速下载:告别限速困扰的完整方案
3步解锁百度网盘满速下载:告别限速困扰的完整方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的非会员下载速度而烦恼吗?面对100KB/…...

AI编程助手高效协作:Cursor与Claude Code开发者工具箱实战指南
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经从传统的IDE搜索引擎模式,逐渐转向与Cursor、Claude Code等AI编程助手深度协作,那你一定遇到过类似的痛点:每次开启一个新项目&#x…...

嵌入式系统安全设计:挑战、原则与微内核实践
1. 嵌入式系统安全的设计挑战与核心原则在万物互联的时代背景下,嵌入式系统已从封闭的独立设备转变为网络化智能节点。这种转变带来了前所未有的安全挑战——根据工业安全机构的统计,2022年针对工业控制系统的网络攻击同比增加了87%,其中针对…...

DDSP与神经音频合成:AI如何复刻经典合成器音色
1. 项目概述:当AI遇见经典合成器如果你和我一样,是个对复古合成器声音着迷,同时又对现代AI技术充满好奇的音乐制作人或开发者,那么最近在GitHub上出现的martinic/DrMixAISynth项目,绝对值得你花上一个下午的时间好好研…...