pytest中文使用文档----12缓存:记录执行的状态
- 1.
cacheprovider插件- 1.1.
--lf, --last-failed:只执行上一轮失败的用例 - 1.2.
--ff, --failed-first:先执行上一轮失败的用例,再执行其它的 - 1.3.
--nf, --new-first:先执行新加的或修改的用例,再执行其它的 - 1.4.
--cache-clear:先清除所有缓存,再执行用例 - 1.5. 如果上一轮没有失败的用例
- 1.1.
- 2.
config.cache对象 - 3.
Stepwise
pytest会将本轮测试的执行状态写入到.pytest_cache文件夹,这个行为是由自带的cacheprovider插件来实现的;
注意:
pytest默认将测试执行的状态写入到根目录中的.pytest_cache文件夹,我们也可以通过在pytest.ini中配置cache_dir选项来自定义缓存的目录,它可以是相对路径,也可以是绝对路径;相对路径指的是相对于
pytest.ini文件所在的目录;例如,我们把这一章的缓存和源码放在一起:在
src/chapter-12/pytest.ini中添加如下配置:[pytest] cache_dir = .pytest-cache这样,即使我们在项目的根目录下执行
src/chapter-12/中的用例,也只会在pytest-chinese-doc/src/chapter-12/.pytest_cache中生成缓存,而不再是pytest-chinese-doc/.pytest_cache中;pytest-chinese-doc (5.1.3) λ pytest src/chapter-12
1. cacheprovider插件
在介绍这个插件之前,我们先看一个简单例子:
# src/chapter-12/test_failed.pyimport pytest@pytest.mark.parametrize('num', [1, 2])
def test_failed(num):assert num == 1# src\chapter-12\test_pass.pydef test_pass():assert 1
我们有两个简单的测试模块,首先我们来执行一下它们:
λ pytest -q src/chapter-12/
.F. [100%]
=============================== FAILURES ================================
____________________________ test_failed[2] _____________________________num = 2@pytest.mark.parametrize('num', [1, 2])def test_failed(num):
> assert num == 1
E assert 2 == 1src\chapter-12\test_failed.py:27: AssertionError
1 failed, 2 passed in 0.08s
可以看到一共收集到三个测试用例,其中有一个失败,另外两个成功的,并且两个执行成功的用例分属不同的测试模块;
同时,pytest也在src/chapter-12/的目录下生成缓存文件夹(.pytest_cache),具体的目录结构如下所示:
src
├───chapter-12
│ │ pytest.ini # 配置了 cache_dir = .pytest-cache
│ │ test_failed.py
│ │ test_pass.py
│ │
│ └───.pytest-cache
│ │ .gitignore
│ │ CACHEDIR.TAG
│ │ README.md
│ │
│ └───v
│ └───cache
│ lastfailed
│ nodeids
│ stepwise
现在,我们就结合上面的组织结构,具体介绍一下cacheprovider插件的功能;
1.1. --lf, --last-failed:只执行上一轮失败的用例
缓存中的lastfailed文件记录了上次失败的用例ID,我们可以通过一下--cache-show命令查看它的内容:
--cache-show命令也是cacheprovider提供的新功能,它不会导致任何用例的执行;
λ pytest src/chapter-12/ -q --cache-show 'lastfailed'
cachedir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12\.pytest-cache
--------------------- cache values for 'lastfailed' ---------------------
cache\lastfailed contains:{'test_failed.py::test_failed[2]': True}no tests ran in 0.01s
我们可以看到,它记录了一个用例,为上次失败的测试用例的ID:test_failed.py::test_failed[2];
下次执行时,当我们使用--lf选项,pytest在收集阶段只会选择这个失败的用例,而忽略其它的:
λ pytest --lf --collect-only src/chapter-12/
========================== test session starts ==========================
platform win32 -- Python 3.7.3, pytest-5.1.3, py-1.8.0, pluggy-0.13.0
cachedir: .pytest-cache
rootdir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12, inifile: pytest.ini
collected 2 items / 1 deselected / 1 selected
<Module test_failed.py><Function test_failed[2]>
run-last-failure: rerun previous 1 failure (skipped 2 files)========================= 1 deselected in 0.02s =========================
我们仔细观察一下上面的回显,有一句话可能会让我们有点困惑:collected 2 items / 1 deselected / 1 selected,可我们明明有三个用例,怎么会只收集到两个呢?
实际上,--lf复写了用例收集阶段的两个钩子方法:pytest_ignore_collect(path, config)和pytest_collection_modifyitems(session, config, items);
我们来先看看pytest_ignore_collect(path, config),如果它的结果返回True,就忽略path路径中的用例;
# _pytest/cacheprovider.pydef last_failed_paths(self):"""Returns a set with all Paths()s of the previously failed nodeids (cached)."""try:return self._last_failed_pathsexcept AttributeError:rootpath = Path(self.config.rootdir)result = {rootpath / nodeid.split("::")[0] for nodeid in self.lastfailed}result = {x for x in result if x.exists()}self._last_failed_paths = resultreturn resultdef pytest_ignore_collect(self, path):"""Ignore this file path if we are in --lf mode and it is not in the list ofpreviously failed files."""if self.active and self.config.getoption("lf") and path.isfile():last_failed_paths = self.last_failed_paths()if last_failed_paths:skip_it = Path(path) not in self.last_failed_paths()if skip_it:self._skipped_files += 1return skip_it
可以看到,如果当前收集的文件,不在上一次失败的路径集合内,就会忽略这个文件,所以这次执行就不会到test_pass.py中收集用例了,故而只收集到两个用例;并且pytest.ini也在忽略的名单上,所以实际上是跳过两个文件:(skipped 2 files);
至于pytest_collection_modifyitems(session, config, items)钩子方法,我们在下一节和--ff命令一起看;
1.2. --ff, --failed-first:先执行上一轮失败的用例,再执行其它的
我们先通过实践看看这个命令的效果,再去分析它的实现:
λ pytest --collect-only -s --ff src/chapter-12/
========================== test session starts ==========================
platform win32 -- Python 3.7.3, pytest-5.1.3, py-1.8.0, pluggy-0.13.0
cachedir: .pytest-cache
rootdir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12, inifile: pytest.ini
collected 3 items
<Module test_failed.py><Function test_failed[2]><Function test_failed[1]>
<Module test_pass.py><Function test_pass>
run-last-failure: rerun previous 1 failure first========================= no tests ran in 0.02s =========================
我们可以看到一共收集到三个测试用例,和正常的收集顺序相比,上一轮失败的test_failed.py::test_failed[2]用例在最前面,将优先执行;
实际上,-ff只复写了钩子方法:pytest_collection_modifyitems(session, config, items),它可以过滤或者重新排序收集到的用例:
# _pytest/cacheprovider.pydef pytest_collection_modifyitems(self, session, config, items):...if self.config.getoption("lf"):items[:] = previously_failedconfig.hook.pytest_deselected(items=previously_passed)else: # --failedfirstitems[:] = previously_failed + previously_passed...
可以看到,如果使用的是lf,就把之前成功的用例状态置为deselected,这轮执行就会忽略它们;如果使用的是-ff,只是将之前失败的用例,顺序调到前面;
另外,我们也可以看到lf的优先级要高于ff,所以它们同时使用的话,ff是不起作用的;
1.3. --nf, --new-first:先执行新加的或修改的用例,再执行其它的
缓存中的nodeids文件记录了上一轮执行的所有的用例:
λ pytest src/chapter-12 --cache-show 'nodeids'
========================== test session starts ==========================
platform win32 -- Python 3.7.3, pytest-5.1.3, py-1.8.0, pluggy-0.13.0
cachedir: .pytest-cache
rootdir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12, inifile: pytest.ini
cachedir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12\.pytest-cache
---------------------- cache values for 'nodeids' -----------------------
cache\nodeids contains:['test_failed.py::test_failed[1]','test_failed.py::test_failed[2]','test_pass.py::test_pass']========================= no tests ran in 0.01s =========================
我们看到上一轮共执行了三个测试用例;
现在我们在test_pass.py中新加一个用例,并修改一下test_failed.py文件中的用例(但是不添加新用例):
# src\chapter-12\test_pass.pydef test_pass():assert 1def test_new_pass():assert 1
现在我们再来执行一下收集命令:
λ pytest --collect-only -s --nf src/chapter-12/
========================== test session starts ==========================
platform win32 -- Python 3.7.3, pytest-5.1.3, py-1.8.0, pluggy-0.13.0
cachedir: .pytest-cache
rootdir: D:\Personal Files\Projects\pytest-chinese-doc\src\chapter-12, inifile: pytest.ini
collected 4 items
<Module test_pass.py><Function test_new_pass>
<Module test_failed.py><Function test_failed[1]><Function test_failed[2]>
<Module test_pass.py><Function test_pass>========================= no tests ran in 0.03s =========================
可以看到,新加的用例顺序在最前面,其次修改过的测试用例紧接其后,最后才是旧的用例;这个行为在源码中有所体现:
# _pytest/cacheprovider.pydef pytest_collection_modifyitems(self, session, config, items):if self.active:new_items = OrderedDict()other_items = OrderedDict()for item in items:if item.nodeid not in self.cached_nodeids:new_items[item.nodeid] = itemelse:other_items[item.nodeid] = itemitems[:] = self._get_increasing_order(new_items.values()) + self._get_increasing_order(other_items.values())self.cached_nodeids = [x.nodeid for x in items if isinstance(x, pytest.Item)]def _get_increasing_order(self, items):return sorted(items, key=lambda item: item.fspath.mtime(), reverse=True)
item.fspath.mtime()代表用例所在文件的最后修改时间,reverse=True表明是倒序排列;
items[:] = self._get_increasing_order(new_items.values()) + self._get_increasing_order(other_items.values())保证新加的用例永远在最前面;
1.4. --cache-clear:先清除所有缓存,再执行用例
直接看源码:
# _pytest/cacheprovider.pyclass Cache:... @classmethoddef for_config(cls, config):cachedir = cls.cache_dir_from_config(config)if config.getoption("cacheclear") and cachedir.exists():rm_rf(cachedir)cachedir.mkdir()return cls(cachedir, config)
可以看到,它会先把已有的缓存文件夹删除(rm_rf(cachedir)),再创建一个空的同名文件夹(cachedir.mkdir()),这样会导致上述的功能失效,所以一般不使用这个命令;
1.5. 如果上一轮没有失败的用例
现在,我们清除缓存,再执行test_pass.py模块(它的用例都是能测试成功的):
λ pytest --cache-clear -q -s src/chapter-12/test_pass.py
.
1 passed in 0.01s
这时候我们再去看一下缓存目录:
.pytest-cache
└───v└───cachenodeidsstepwise
是不是少了什么?对!因为没有失败的用例,所以不会生成lastfailed文件,那么这个时候在使用--lf和--ff会发生什么呢?我们来试试:
注意:
如果我们观察的足够仔细,就会发现现在的缓存目录和之前相比不止少了
lastfailed文件,还少了CACHEDIR.TAG、.gitignore和README.md三个文件;这是一个
bug,我已经在pytest 5.3.1版本上提交了issue,预计会在之后的版本修复,如果你有兴趣深入了解一下它的成因和修复方案,可以参考这个:https://github.com/pytest-dev/pytest/issues/6290
luyao@NJ-LUYAO-T460 /d/Personal Files/Projects/pytest-chinese-doc (5.1.3)
λ pytest -q -s --lf src/chapter-12/test_pass.py
.
1 passed in 0.01sluyao@NJ-LUYAO-T460 /d/Personal Files/Projects/pytest-chinese-doc (5.1.3)
λ pytest -q -s --ff src/chapter-12/test_pass.py
.
1 passed in 0.02s
可以看到,它们没有实施任何影响;为什么会这样?我们去源码里找一下答案吧;
# _pytest/cacheprovider.pyclass LFPlugin:""" Plugin which implements the --lf (run last-failing) option """def __init__(self, config):...self.lastfailed = config.cache.get("cache/lastfailed", {})...def pytest_collection_modifyitems(self, session, config, items):...if self.lastfailed:...else:self._report_status = "no previously failed tests, "if self.config.getoption("last_failed_no_failures") == "none":self._report_status += "deselecting all items."config.hook.pytest_deselected(items=items)items[:] = []else:self._report_status += "not deselecting items."
可以看到,当self.lastfailed判断失败时,如果我们指定了last_failed_no_failures选项为none,pytest会忽略所有的用例(items[:] = []),否则不做任何修改(和没加--lf或--ff一样),而判断self.lastfailed的依据是就是lastfailed文件;
继续看看,我们会学习到一个新的命令行选项:
# _pytest/cacheprovider.pygroup.addoption("--lfnf","--last-failed-no-failures",action="store",dest="last_failed_no_failures",choices=("all", "none"),default="all",help="which tests to run with no previously (known) failures.",)
来试试吧:
λ pytest -q -s --ff --lfnf none src/chapter-12/test_pass.py1 deselected in 0.01sλ pytest -q -s --ff --lfnf all src/chapter-12/test_pass.py
.
1 passed in 0.01s
注意:
--lfnf的实参只支持choices=("all", "none");
2. config.cache对象
我们可以通过pytest的config对象去访问和设置缓存中的数据;下面是一个简单的例子:
# content of test_caching.pyimport pytest
import timedef expensive_computation():print("running expensive computation...")@pytest.fixture
def mydata(request):val = request.config.cache.get("example/value", None)if val is None:expensive_computation()val = 42request.config.cache.set("example/value", val)return valdef test_function(mydata):assert mydata == 23
我们先执行一次这个测试用例:
λ pytest -q src/chapter-12/test_caching.py
F [100%]
================================ FAILURES =================================
______________________________ test_function ______________________________mydata = 42def test_function(mydata):
> assert mydata == 23
E assert 42 == 23src/chapter-12/test_caching.py:43: AssertionError
-------------------------- Captured stdout setup --------------------------
running expensive computation...
1 failed in 0.05s
这个时候,缓存中没有example/value,将val的值写入缓存,终端打印running expensive computation...;
查看缓存,其中新加了一个文件:.pytest-cache/v/example/value;
.pytest-cache/
├── .gitignore
├── CACHEDIR.TAG
├── README.md
└── v├── cache│ ├── lastfailed│ ├── nodeids│ └── stepwise└── example└── value3 directories, 7 files
通过--cache-show选项查看,发现其内容正是42:
λ pytest src/chapter-12/ -q --cache-show 'example/value'
cachedir: /Users/yaomeng/Private/Projects/pytest-chinese-doc/src/chapter-12/.pytest-cache
-------------------- cache values for 'example/value' ---------------------
example/value contains:42no tests ran in 0.00s
再次执行这个用例,这个时候缓存中已经有我们需要的数据了,终端就不会再打印running expensive computation...:
λ pytest -q src/chapter-12/test_caching.py
F [100%]
================================ FAILURES =================================
______________________________ test_function ______________________________mydata = 42def test_function(mydata):
> assert mydata == 23
E assert 42 == 23src/chapter-12/test_caching.py:43: AssertionError
1 failed in 0.04s
3. Stepwise
试想一下,现在有这么一个场景:我们想要在遇到第一个失败的用例时退出执行,并且下次还是从这个用例开始执行;
以下面这个测试模块为例:
# src/chapter-12/test_sample.pydef test_one():assert 1def test_two():assert 0def test_three():assert 1def test_four():assert 0def test_five():assert 1
我们先执行一下测试:pytest --cache-clear --sw src/chapter-12/test_sample.py;
λ pytest --cache-clear --sw -q src/chapter-12/test_sample.py
.F
================================= FAILURES =================================
_________________________________ test_two _________________________________def test_two():
> assert 0
E assert 0src/chapter-12/test_sample.py:28: AssertionError
!!!!!! Interrupted: Test failed, continuing from this test next run. !!!!!!!
1 failed, 1 passed in 0.13s
使用--cache-clear清除之前的缓存,使用--sw, --stepwise使其在第一个失败的用例处退出执行;
现在我们的缓存文件中lastfailed记录了这次执行失败的用例,即为test_two();nodeids记录了所有的测试用例;特殊的是,stepwise记录了最近一次失败的测试用例,这里也是test_two();
接下来,我们用--sw的方式再次执行:pytest首先会读取stepwise中的值,并将其作为第一个用例开始执行;
λ pytest --sw -q src/chapter-12/test_sample.py
F
================================= FAILURES =================================
_________________________________ test_two _________________________________def test_two():
> assert 0
E assert 0src/chapter-12/test_sample.py:28: AssertionError
!!!!!! Interrupted: Test failed, continuing from this test next run. !!!!!!!
1 failed, 1 deselected in 0.12s
可以看到,test_two()作为第一个用例开始执行,在第一个失败处退出;
其实,pytest还提供了一个--stepwise-skip的命令行选项,它会忽略第一个失败的用例,在第二个失败处退出执行;我们来试一下:
λ pytest --sw --stepwise-skip -q src/chapter-12/test_sample.py
F.F
=============================== FAILURES ================================
_______________________________ test_two ________________________________def test_two():
> assert 0
E assert 0src\chapter-12\test_sample.py:28: AssertionError
_______________________________ test_four _______________________________def test_four():
> assert 0
E assert 0src\chapter-12\test_sample.py:36: AssertionError
!!!!! Interrupted: Test failed, continuing from this test next run. !!!!! 2 failed, 1 passed, 1 deselected in 0.16s
这个时候,在第二个失败的用例test_four()处退出执行,同时stepwise文件的值也改成了"test_sample.py::test_four";
其实,本章所有的内容都可以在源码的
_pytest/cacheprovider.py文件中体现,如果能结合源码学习,会有事半功倍的效果;
相关文章:

pytest中文使用文档----12缓存:记录执行的状态
1. cacheprovider插件 1.1. --lf, --last-failed:只执行上一轮失败的用例1.2. --ff, --failed-first:先执行上一轮失败的用例,再执行其它的1.3. --nf, --new-first:先执行新加的或修改的用例,再执行其它的1.4. --cache…...
【代码随想录】哈希表
文章目录 242.有效的字母异位词349. 两个数组的交集202. 快乐数1. 两数之和454. 四数相加 II383. 赎金信15. 三数之和18. 四数之和 242.有效的字母异位词 class Solution {public boolean isAnagram(String s, String t) {if(snull || tnull || s.length()!t.length()){return …...

绘图工具 draw.io / diagrams.net 免费在线图表编辑器
拓展阅读 常见免费开源绘图工具 OmniGraffle 创建精确、美观图形的工具 UML-架构图入门介绍 starUML UML 绘制工具 starUML 入门介绍 PlantUML 是绘制 uml 的一个开源项目 UML 等常见图绘制工具 绘图工具 draw.io / diagrams.net 免费在线图表编辑器 绘图工具 excalidr…...

【Vue】 Vue项目中的跨域配置指南
她坐红帐 面带浓妆 唢呐一声唱 明月光 这女子泪眼拜高堂 一拜天地日月 二拜就遗忘这一生 跪三拜红尘凉 庭院 大门锁上 杂乱的眼光 多喧嚷 这女子笑颜几惆怅 余生喜乐悲欢都无关 她眼中已无光 🎵 倪莫问《三拜红尘凉》 在前后端分离的项目开发中…...

跨站脚本攻击XSS
漏洞产生原因: XSS攻击本质上是一种注入攻击,产生原因是Web应用对外部输入参数处理不当,攻击者将恶意代码注入当前Web界面,在用户访问时执行 漏洞攻击手段: 反射型(非持久型)XSS-将payload包…...

C++中的vector与C语言中的数组的区别
C中的vector和C语言中的数组在很多方面都有所不同,以下是它们之间的一些主要区别: 大小可变性: vector是C标准模板库(STL)提供的动态数组容器,它的大小可以动态增长或减少。这意味着你可以在运行时添加或删…...
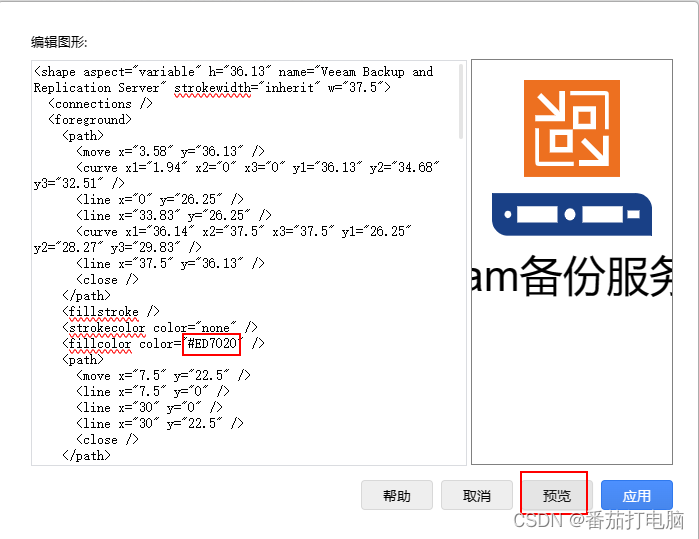
drawio画图编辑图形颜色
drawio画图编辑图形颜色 团队的安全第一图表。将您的存储空间带到我们的在线工具中,或使用桌面应用程序进行本地保存。 1.安装准备 1.1安装平台 多平台 1.2在线使用 浏览器打开网页使用 1.3软件下载 drawio官网github仓库下载 2.在浏览器的网页中使用drawio…...
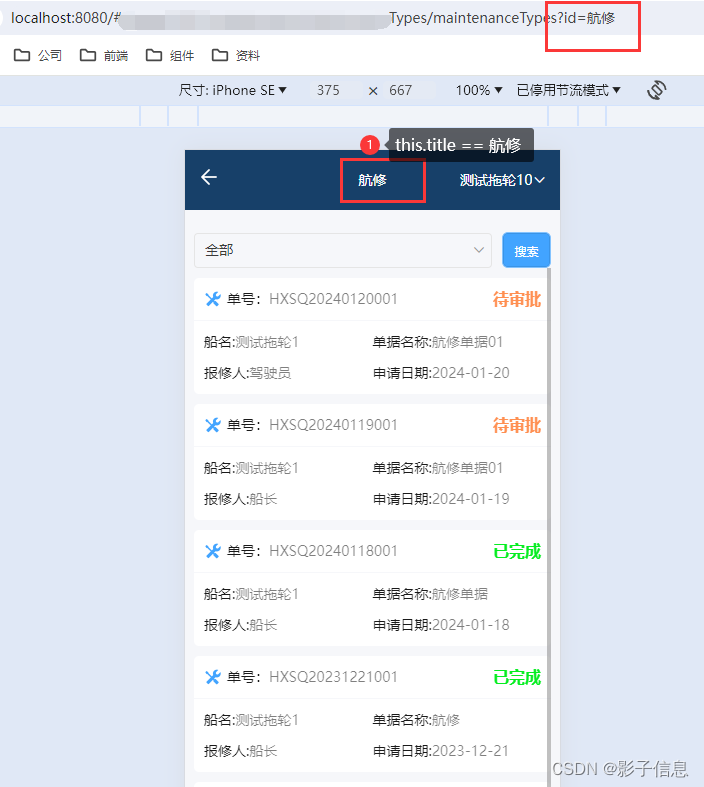
uniapp中uni.navigateTo传递变量
效果展示: 核心代码: uniapp中uni.navigateTo传递变量 methods: {changePages(item) {setDatas("maintenanceFunName", JSON.stringify(item)).then((res) > {uni.navigateTo({url: /pages/PMS/maintenance/maintenanceTypes/maintenanceT…...

Spring Boot 构建war 部署到tomcat下无法在Nacos中注册服务
Spring Boot 构建war 部署到tomcat下无法在Nacos中注册服务 1. 问题2. 分析3. 解决方案参考 1. 问题 使用Nacos作为注册中心的Spring Boot项目,以war包形式部署到服务器上,启动项目发现该服务无法在Nacos中注册。 2. 分析 SpringCloud 项目打 war 包部…...

(2024,Attention-Mamba,MoE 替换 MLP)Jamba:混合 Transformer-Mamba 语言模型
Jamba: A Hybrid Transformer-Mamba Language Model 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 1. 简介 2. 模型架构 3. 收获的好处 3.1 单个 80GB GPU 的 Jamba 实现 …...

“Java泛型” 得所憩,落日美酒聊共挥
本篇会加入个人的所谓鱼式疯言 ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接…...

pdf、docx、markdown、txt提取文档内容,可以应用于rag文档解析
返回的是文档解析分段内容组成的列表,分段内容默认chunk_size: int 250, chunk_overlap: int 50,250字分段,50分段处保留后面一段的前50字拼接即窗口包含下下一段前面50个字划分 from typing import Union, Listimport jieba import recla…...

【Linux系列】“dev-node1“ 运行的操作系统分析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
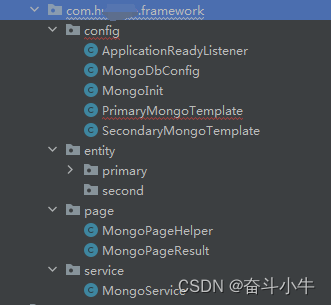
SpriingBoot整合MongoDB多数据源
背景: MongoDB多数据源:springboot为3以上版本,spring-boot-starter-data-mongodb低版本MongoDBFactory已过时, 改为MongoDatabaseFactory。 1、pom引入: <dependency><groupId>org.springframework.boo…...

深入浅出 -- 系统架构之负载均衡Nginx缓存机制
一、Nginx缓存机制 对于性能优化而言,缓存是一种能够大幅度提升性能的方案,因此几乎可以在各处都能看见缓存,如客户端缓存、代理缓存、服务器缓存等等,Nginx的缓存则属于代理缓存的一种。对于整个系统而言,加入缓存带来…...

前端 小程序框架UniApp
小程序框架UniApp uni-app简介uni-app项目结构uni-app开发工具HBuilderXuni-app页面uni-app页面生命周期uni-app组件生命周期uni-app页面调用接口uni-app页面通讯uni-app pages.json 页面路由uni-app组件viewuni-app组件scroll-viewuni-app组件swiperuni-app组件textuni-app组…...
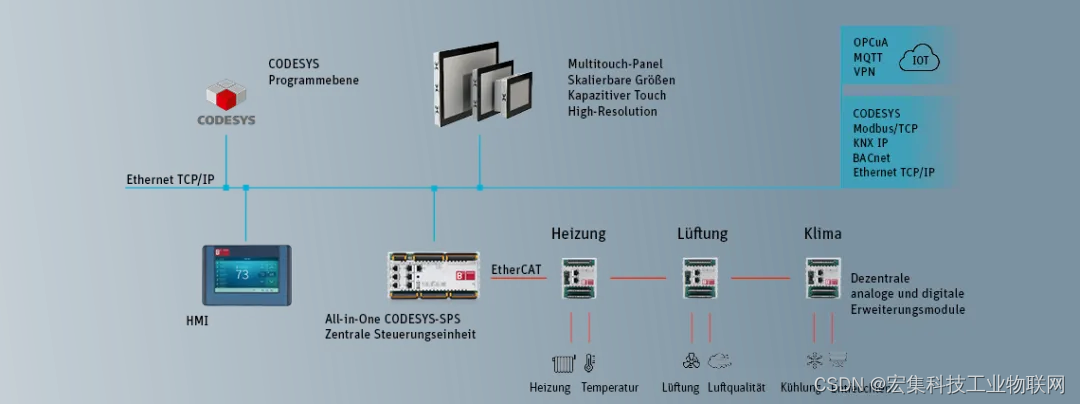
宏集PLC如何为楼宇自动化行业提供空调、供暖与通风的解决方案?
一、应用背景 楼宇自动化行业是通过将先进的技术和系统应用于建筑物中,以提高其运营效率、舒适度和能源利用效率的行业,其目标是使建筑物能够自动监控、调节和控制各种设备和系统,包括照明系统、空调系统、安全系统、通风系统、电力供应系统…...
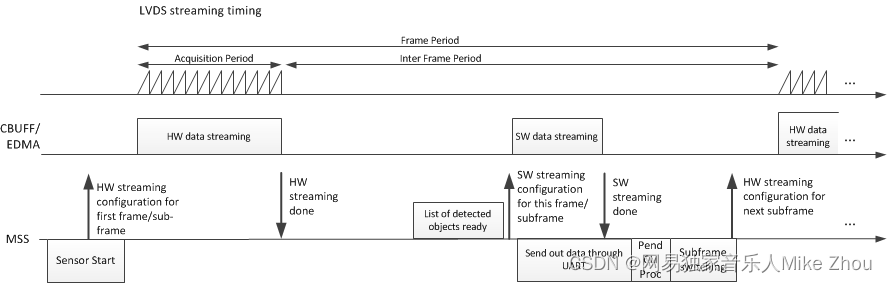
【TI毫米波雷达】官方工业雷达包的生命体征检测环境配置及避坑(Vital_Signs、IWR6843AOPEVM)
【TI毫米波雷达】官方工业雷达包的生命体征检测环境配置及避坑(Vital_Signs、IWR6843AOPEVM) 文章目录 生命体征基本介绍IWR6843AOPEVM的配置上位机配置文件避坑上位机start测试距离检测心跳检测呼吸频率检测空环境测试 附录:结构框架雷达基…...
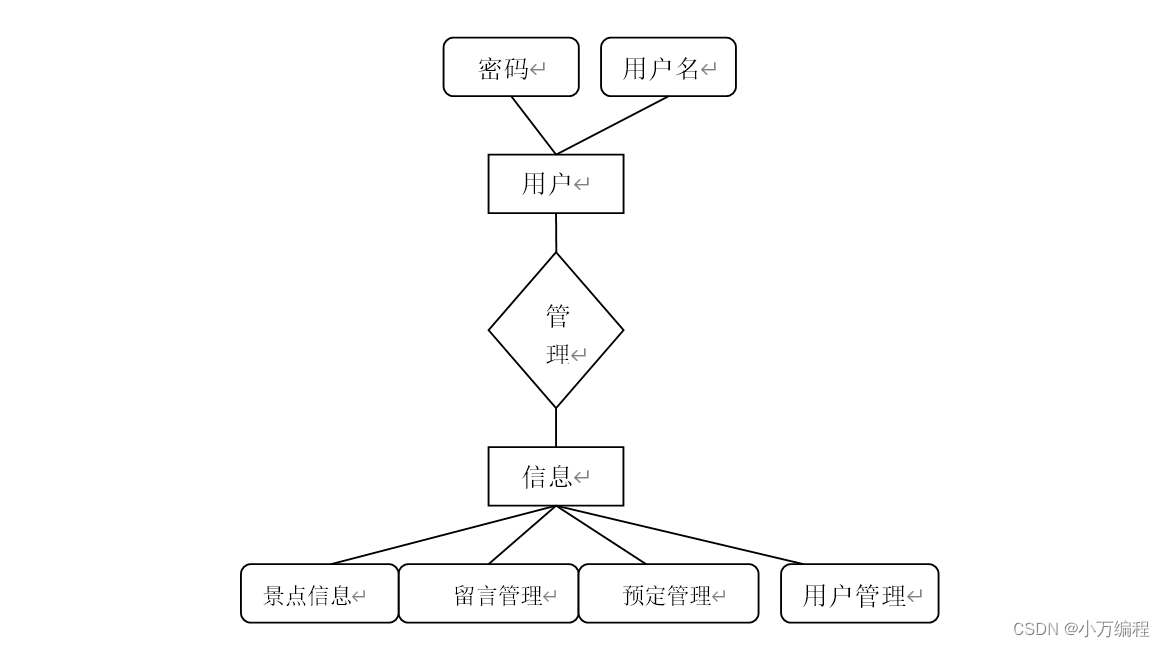
计算机毕业设计选题之基于SSM的旅游管理系统【源码+PPT+文档+包运行成功+部署讲解】
💓项目咨询获取源码联系v💓xiaowan1860💓 🚩如何选题?🍑 对于项目设计中如何选题、让题目的难度在可控范围,以及如何在选题过程以及整个毕设过程中如何与老师沟通,有疑问不清晰的可…...
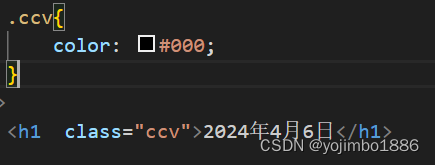
JavaWeb入门——Web前端概述及HTML,CSS语言基本使用
前言: java基础已经学完,开始学习javaWeb相关的内容,整理下笔记,打好基础,daydayup!!! Web Web:全球广域网,也称万维网(www World Wide Web),能够通过浏览器访…...

Qwerty Learner 终极指南:通过打字训练快速掌握英语词汇的免费工具
Qwerty Learner 终极指南:通过打字训练快速掌握英语词汇的免费工具 【免费下载链接】qwerty-learner 项目地址: https://gitcode.com/GitHub_Trending/qw/qwerty-learner 想要在敲击键盘的同时轻松记忆英语单词吗?Qwerty Learner 正是为你设计的…...

Wan2.2-T2V-A5B提示词怎么写?新手快速出效果的实用指南
Wan2.2-T2V-A5B提示词怎么写?新手快速出效果的实用指南 1. 认识Wan2.2-T2V-A5B视频生成模型 Wan2.2-T2V-A5B是一款由通义万相开源的轻量级文本到视频生成模型,拥有50亿参数规模。虽然它生成的视频分辨率是480P,但在时序连贯性和运动推理能力…...

Blazor组件测试工具:BootstrapBlazor测试库完整指南
Blazor组件测试工具:BootstrapBlazor测试库完整指南 【免费下载链接】BootstrapBlazor 项目地址: https://gitcode.com/gh_mirrors/bo/BootstrapBlazor BootstrapBlazor测试库是企业级Blazor UI组件库的质量保障体系,提供了一套完整的组件测试解…...

终极Markdown转换神器:浏览器中的写作革命指南
终极Markdown转换神器:浏览器中的写作革命指南 【免费下载链接】markdown-here Google Chrome, Firefox, and Thunderbird extension that lets you write email in Markdown and render it before sending. 项目地址: https://gitcode.com/gh_mirrors/ma/markdow…...

屠龙刀法35--使用SQL查询器批量生成insert语句
很多网友认为SQL查询器的语句不都是人工输入或者从外面粘贴进去的吗?用查询器批量生成Insert语句感觉有点魔幻哦。的确听起来不太科学,但是对于DBCS来说这个功能的确非常好用。下面我们就举例一步步告诉大家,如何使用这个功能。 第一步&…...

all-MiniLM-L6-v2保姆级教程:Ollama模型卸载、版本回滚与缓存清理指南
all-MiniLM-L6-v2保姆级教程:Ollama模型卸载、版本回滚与缓存清理指南 1. 为什么需要管理你的Ollama模型? 你可能已经用Ollama成功部署了all-MiniLM-L6-v2,体验了它轻量高效的句子嵌入能力。但用久了你会发现,硬盘空间在悄悄减少&…...

7个高级配置技巧:打造极致Markdown预览体验
7个高级配置技巧:打造极致Markdown预览体验 【免费下载链接】vscode-markdown-preview-enhanced One of the "BEST" markdown preview extensions for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-markdown-preview-enhanc…...

从零到一:基于泛微E9开源资源的企业级业务模块二次开发实战指南
1. 为什么选择泛微E9进行二次开发? 泛微E9作为国内领先的OA系统,在企业信息化建设中扮演着重要角色。我接触过不少企业客户,他们选择E9的主要原因很简单:开箱即用的功能已经能满足80%的日常办公需求,而剩下的20%特殊需…...

告别重复造轮子,用快马AI一键生成高复用登录组件提升效率
在开发官网登录入口时,我们常常需要重复处理用户认证、表单验证、状态管理等基础逻辑。这些工作虽然不复杂,但每次从零开始确实会消耗不少时间。最近我发现用InsCode(快马)平台可以快速生成高质量的登录组件,大大提升了开发效率。 组件功能设…...

C# 操作XML
https://blog.csdn.net/2609_95039045/article/details/157469812?fromshareblogdetail&sharetypeblogdetail&sharerId157469812&sharereferPC&sharesourcem0_68206177&sharefromfrom_link 这个写的好 https://blog.csdn.net/lizhenxiqnmlgb/article/det…...