KingbsaeES数据库分区表的详细用法
数据库版本:KingbaseES V008R006C008B0014
简介
分区表是一种将大型数据库表拆分为更小、更可管理的部分的技术。它通过将表数据分散存储到多个物理存储单元中,可以提高查询和数据维护的性能,并优化对大型数据集的处理。本篇文章以kingbase为例介绍分区表的用法。
文章目录如下
1. 基本语法
1.1. 语法一
1.1.1. 一级分区
1.1.2. 二级分区
1.2. 语法二
1.2.1. 一级分区
1.2.2. 二级分区
2. 分区类型
2.1. 范围分区
2.1.1. 按金额范围分区
2.1.2. 按日期分区
2.1.3. 自动创建日期分区
2.1.4. 自动创建整数分区
2.2. 列表分区
2.2.1. 按日志级别分区
2.2.2. 按地区分区
2.3. 哈希分区
2.3.1. 按用户ID分区
2.3.2. 按订单号分区
2.3.3. 自定义hash模
3. 应用场景
3.1. 利用EXTRACT提取年份
3.2. 分区表性能对比
1. 基本语法
1.1. 语法一
1.1.1. 一级分区
创建分区表有2种语法,第1种:在创建普通表后面加上指定的分区信息。
CREATE TABLE 表名
(列名1 数据类型,列名2 数据类型,...
)
PARTITION BY RANGE (分区键) --要分区的列名
(PARTITION 分区名1 VALUES LESS THAN (分区值), --存储的范围PARTITION 分区名2 VALUES LESS THAN (分区值), --存储的范围...
);
举个例子:创建一张列表分区,将性别分区存储
CREATE TABLE p1 (id int,name varchar(64),sex varchar(4))
PARTITION BY LIST(sex) --指定sex列分区(PARTITION boy VALUES ('男'), --sex为男的数据存储到该分区PARTITION girl VALUES ('女') --sex为女的数据存储到该分区);
创建完成后包含一张分区表和n张子分区表。
此时向分区表插入3条数据
INSERT INTOp1
VALUES(1, '小李', '男'),(2, '小张', '女'),(3, '小王', '男');查询主表:存在3条数据
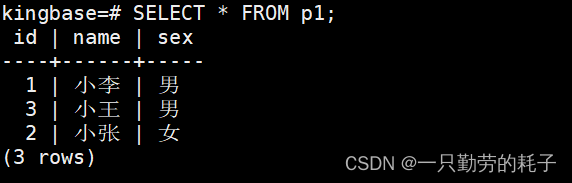
查询分区表p1_boy:存储性别为"男"的数据

查询分区表p1_girl:存储性别为"女"的数据

总结
分区表利用不同的列数据来分别存储,插入数据后不同的子分区根据自己的规则存储不同的数据。主分区可以查询所有数据,子分区只包含规则内的数据。
1.1.2. 二级分区
《目录1.1》描述了如何创建一个分区表(一级分区),而真实场景会使得一级分区覆盖度远远不够,所以需要使用二级分区,语法如下:
CREATE TABLE 表名(列名 数据类型
)
PARTITION BY RANGE (一级分区键) --指定一级分区
SUBPARTITION BY RANGE (二级分区键) --指定二级分区
(PARTITION 一级分区名 VALUES LESS THAN (分区值)(SUBPARTITION 二级分区名 VALUES LESS THAN (分区值))
);- PARTITION BY:普通分区语法
- SUBPARTITION BY:子分区语法
注意:KingbasES的MySQL、Oracle模式最大支持二级分区,PG模式无限层级。
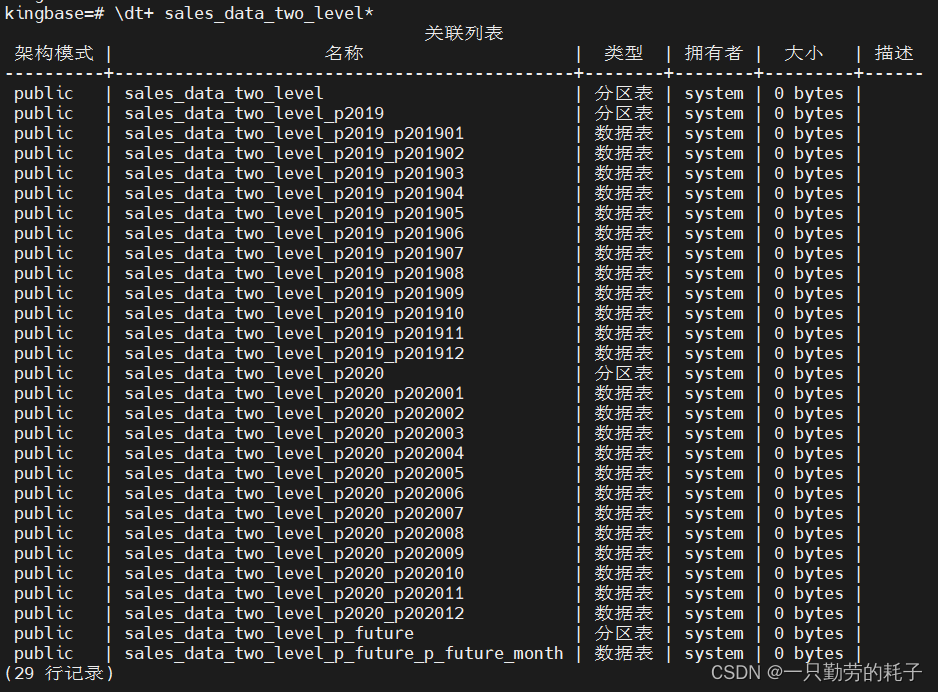
举个例子,年份作为一级分区、月份作为二级分区
CREATE TABLE sales_data_two_level (sale_date DATE, --销售日期amount DECIMAL(10,2) --销售金额
)
PARTITION BY RANGE (sale_date) --将销售日期分区
SUBPARTITION BY RANGE (sale_date) --作一级分区
(/*一级分区为2020-01-01以前*/PARTITION p2019 VALUES LESS THAN ('2020-01-01')(/*二级分区,按月份分区*/SUBPARTITION p201901 VALUES LESS THAN ('2019-02-01'),SUBPARTITION p201902 VALUES LESS THAN ('2019-03-01'),SUBPARTITION p201903 VALUES LESS THAN ('2019-04-01'),SUBPARTITION p201904 VALUES LESS THAN ('2019-05-01'),SUBPARTITION p201905 VALUES LESS THAN ('2019-06-01'),SUBPARTITION p201906 VALUES LESS THAN ('2019-07-01'),SUBPARTITION p201907 VALUES LESS THAN ('2019-08-01'),SUBPARTITION p201908 VALUES LESS THAN ('2019-09-01'),SUBPARTITION p201909 VALUES LESS THAN ('2019-10-01'),SUBPARTITION p201910 VALUES LESS THAN ('2019-11-01'),SUBPARTITION p201911 VALUES LESS THAN ('2019-12-01'),SUBPARTITION p201912 VALUES LESS THAN ('2020-01-01')),/*一级分区,2020-01-01 ~ 2020-12-31*/PARTITION p2020 VALUES LESS THAN ('2021-01-01')(/*二级分区,按月份分区*/SUBPARTITION p202001 VALUES LESS THAN ('2020-02-01'),SUBPARTITION p202002 VALUES LESS THAN ('2020-03-01'),SUBPARTITION p202003 VALUES LESS THAN ('2020-04-01'),SUBPARTITION p202004 VALUES LESS THAN ('2020-05-01'),SUBPARTITION p202005 VALUES LESS THAN ('2020-06-01'),SUBPARTITION p202006 VALUES LESS THAN ('2020-07-01'),SUBPARTITION p202007 VALUES LESS THAN ('2020-08-01'),SUBPARTITION p202008 VALUES LESS THAN ('2020-09-01'),SUBPARTITION p202009 VALUES LESS THAN ('2020-10-01'),SUBPARTITION p202010 VALUES LESS THAN ('2020-11-01'),SUBPARTITION p202011 VALUES LESS THAN ('2020-12-01'),SUBPARTITION p202012 VALUES LESS THAN ('2021-01-01')),/*一级分区,存储2020-12-31以后的数据*/PARTITION p_future VALUES LESS THAN (MAXVALUE)(SUBPARTITION p_future_month VALUES LESS THAN (MAXVALUE))
);
1.2. 语法二
1.2.1. 一级分区
- 这种语法来自于PG语法,与上述类似,将分区表和子分区分开创建。
创建范围分区
--创建范围分区表
CREATE TABLE t1(id int
) PARTITION BY RANGE(id);--创建子分区,将1~4的数值存储到t1_p1
CREATE TABLE t1_p1 PARTITION OF t1 FOR VALUES FROM(1) TO (5);
--创建子分区,将大于4的数值存储到t1_max
CREATE TABLE t1_max PARTITION OF t1 FOR VALUES FROM(5) TO (maxvalue);
创建列表分区
--创建列表分区表
CREATE TABLE t1(id int,sex varchar(4)
) PARTITION BY LIST(sex);--创建子分区,将性别为男存储到t1_boy
CREATE TABLE t1_boy PARTITION OF t1 FOR VALUES IN ('男');
--创建子分区,将性别为女存储到t1_girl
CREATE TABLE t1_girl PARTITION OF t1 FOR VALUES IN ('女');
创建哈希分区
--创建列表分区表
CREATE TABLE t1(id int
) PARTITION BY HASH(id);--创建子分区,存储模为3余数为0的数据
CREATE TABLE t1_h1 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 0);
1.2.2. 二级分区
二级分区在一级分区的基础上增加
CREATE TABLE p1 (id int,name varchar(64),sex varchar(4))
PARTITION BY LIST(sex); --指定sex列分区--创建一级子分区,将id列指定为范围分区
CREATE TABLE p1_boy PARTITION OF p1 FOR VALUES IN ('男') PARTITION BY RANGE(id);--创建二级子分区,目标表为p1_boy(作为它的二级分区),分区数据为id列1~10
CREATE TABLE p1_boy_id10 PARTITION OF p1_boy FOR VALUES FROM (1) TO (11) ;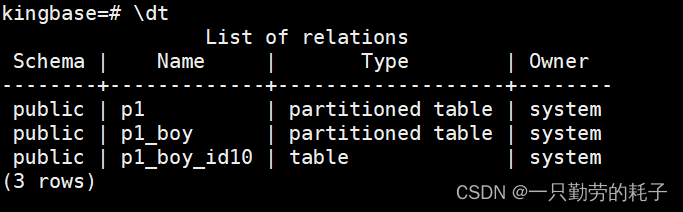
创建多个子分区根据上述语法继续写,例如:
--创建一级子分区
CREATE TABLE p1_girl PARTITION OF p1 FOR VALUES IN ('女') PARTITION BY RANGE(id);--创建二级子分区
CREATE TABLE p1_girl_id10 PARTITION OF p1_girl FOR VALUES FROM (1) TO (11) ;--创建二级子分区
CREATE TABLE p1_girl_id_max PARTITION OF p1_girl FOR VALUES FROM (11) TO (MAXVALUE) ;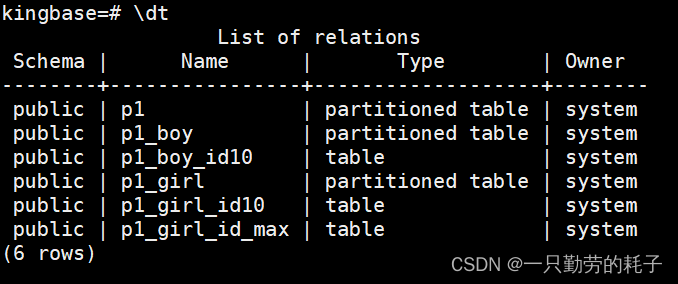
2. 分区类型
在目录1中理解了如何创建分区,那么分区的类型在这一目录介绍,包括:
- 范围分区:数值范围、日期范围等。
- 列表分区:固定列表值,如['北京', '上海']。
- 哈希分区:基于用户指定分区键上的哈希算法,自动将各个分区中均匀分布。
它们的语法在 PARTITION BY 后面
PARTITION BY RANGE(分区键) --范围分区
PARTITION BY LIST(分区键) --列表分区
PARTITION BY HASH(分区键) --哈希分区
2.1. 范围分区
范围分区是根据列的范围值将表数据分布到不同的分区中,常见的日期范围、数值范围等。
语法:
PARTITION BY RANGE (列名)(PARTITION 分区名 VALUES LESS THAN (范围)
)2.1.1. 按金额范围分区
CREATE TABLE orders1 (order_id INT PRIMARY KEY, --订单IDorder_date DATE, --订单日期customer_id INT, --客户IDtotal_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (total_amount) ( --将总金额分区PARTITION p_1 VALUES LESS THAN (1000), --存储<1000PARTITION p_2 VALUES LESS THAN (10000), --存储<1wPARTITION p_3 VALUES LESS THAN (100000), --存储<10wPARTITION p_max VALUES LESS THAN (MAXVALUE) --存储>=10w
);p_1范围:0~999
p_2范围:1000~9999
p_3范围:10000~99999
p_max范围:100000~最大值
2.1.2. 按日期分区
CREATE TABLE sales_orders (order_id INT PRIMARY KEY, --订单IDorder_date DATE, --订单日期customer_id INT, --客户IDtotal_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (order_date) ( --将订单日期分区PARTITION p2019 VALUES LESS THAN ('2020-01-01'),PARTITION p2020 VALUES LESS THAN ('2021-01-01'),PARTITION p2021 VALUES LESS THAN ('2022-01-01'),PARTITION p2022 VALUES LESS THAN ('2023-01-01'),PARTITION p_max VALUES LESS THAN (MAXVALUE)
);p2019范围:2020以前
p2020范围:2020年日期
p2021范围:2021年日期
p2022范围:2022年日期
p_max范围:2023年~以后
2.1.3. 自动创建日期分区
CREATE TABLE sales_orders (order_id INT PRIMARY KEY, --订单IDorder_date DATE, --订单日期customer_id INT, --客户IDtotal_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (order_date) INTERVAL('3 MONTH'::INTERVAL) --自动创建
(PARTITION p1 VALUES LESS THAN ('2020-01-01') --小于等于2020-01-01存储到p1
);p1存储2020-01-01以前的数据,后面插入的数据每隔3个月自动创建分区
- '1 YEAR':每隔1年创建一个分区
- '1 MONTH':每个1个月创建一个分区
- '1 DAY':每个1天创建一个分区
2.1.4. 自动创建整数分区
CREATE TABLE sales_orders (order_id INT PRIMARY KEY, -- 订单IDorder_date DATE, -- 订单日期customer_id INT, -- 客户IDtotal_amount DECIMAL(10, 2) -- 总金额
)
PARTITION BY RANGE (order_id)INTERVAL('1000'::BIGINT) --自动创建
(PARTITION p0 VALUES LESS THAN (0) --小于等于0存储到p0
);- '1000'::BIGINT:数字每增长1000自动创建1个分区,也就是说插入 order_id 列 2000 后自动创建1个分区,3000、4000...同理。
2.2. 列表分区
列表分区不同于范围,而是将每个分区基于列值的列表。比如指定列表为 ('aa', 'bb'),那么只会将该列为 aa 或 bb 值存储到指定分区中。
语法:
PARTITION BY LIST (列名)(PARTITION 分区名 VALUES ('固定值1', '固定值2'),
)2.2.1. 按日志级别分区
CREATE TABLE log_entries (log_id SERIAL PRIMARY KEY, --日志IDlog_message TEXT, --日志信息log_date TIMESTAMP, --日志日期log_type VARCHAR(50) --日志类型
)
PARTITION BY LIST (log_type) --将日志类型分区
(PARTITION type_error VALUES ('ERROR', 'CRITICAL'),PARTITION type_warning VALUES ('WARNING'),PARTITION type_info VALUES ('INFO', 'DEBUG')
);- 将 'ERROR'、'CRITICAL' 存储到 type_error 中
- 将 'WARNING' 存储到 type_warning
- 将 'INFO'、'DEBUG' 存储到 type_info 中
- 其他类型无法插入
2.2.2. 按地区分区
CREATE TABLE sales_orders (order_id SERIAL PRIMARY KEY, --订单IDorder_date DATE, --订单日期customer_id INT, --客户IDtotal_amount DECIMAL(10, 2), --总金额region VARCHAR(50) --地区
)
PARTITION BY LIST (region)
(PARTITION First_tier VALUES ('北京', '上海', '广州', '深圳'),PARTITION second_tier VALUES ('天津', '南京', '杭州', '成都'),PARTITION third_tier VALUES ('哈尔滨', '福州', '长春', '石家庄')
);- 将一线城市分区到 First_tier
- 将二线城市分区到 second_tier
- 将三线城市分区到 third_tier
2.3. 哈希分区
哈希分区是基于用户指定分区键上的哈希算法,数据库自动将各个分区中均匀分布,可用于划分大表,提高可管理性。当查询需要扫描整个表时,数据在各个分区上分布均匀,可以有效地利用并行查询来加速查询操作,提高查询性能。例如:将一张频繁更新的表创建为哈希分区,一张表被分为几个部分后,则这几个分区可以被同时更新,以减少锁冲突次数。
语法:
PARTITION BY HASH (列名) PARTITIONS 分区数;
2.3.1. 按用户ID分区
CREATE TABLE users (user_id INT PRIMARY KEY, --用户IDusername VARCHAR(50), --用户名email VARCHAR(100) --用户邮箱
) PARTITION BY HASH (user_id) PARTITIONS 4; --将用户ID分4个区- PARTITIONS 4:表示分4个区
2.3.2. 按订单号分区
CREATE TABLE product_orders (order_id INT PRIMARY KEY, --订单IDproduct_id INT, --产品IDquantity INT, --产品数量order_date DATE --订单日期
) PARTITION BY HASH (order_id) PARTITIONS 8; --将订单ID分8个区- PARTITIONS 8:表示分8个区
2.3.3. 自定义hash模
CREATE TABLE t1(id INT
) PARTITION BY HASH (id);CREATE TABLE t1_hash_m3_r0 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 0);
CREATE TABLE t1_hash_m3_r1 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 1);
CREATE TABLE t1_hash_m3_r2 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 2);创建完成后会存在如下4张表:

向 t1 表插入数值 3。按正常来讲 3 的模是0,应该插入到 t1_hash_m3_r0,实际上插入在 t1_hash_m3_r1 中
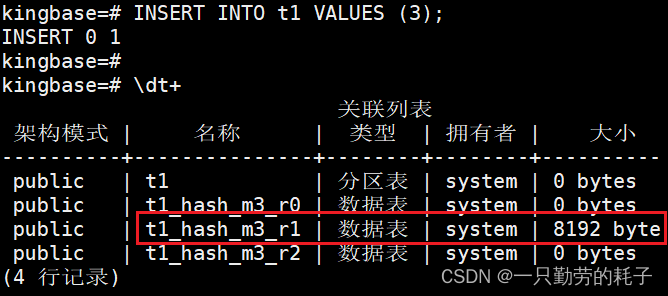
这里的模并不是平时数学中的模,是通过哈希算法得出的结果:
SELECT ora_hash(3, 3);
3. 应用场景
3.1. 利用EXTRACT提取年份
正常情况下创建一个日期分区
CREATE TABLE sales (id SERIAL PRIMARY KEY, --销售IDsale_date DATE --销售日期
) PARTITION BY RANGE (sale_date);CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
CREATE TABLE sales_2020 PARTITION OF sales FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
CREATE TABLE sales_2021 PARTITION OF sales FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');- 自动将sale_date列2019年的数据存储到sales_2019表
- 自动将sale_date列2020年的数据存储到sales_2020表
- 自动将sale_date列2021年的数据存储到sales_2021表
利用EXTRACT函数创建年份分区(在创建子分区时可以简写)
CREATE TABLE sales (id SERIAL PRIMARY KEY, --销售IDsale_date DATE --销售日期
) PARTITION BY RANGE (EXTRACT(YEAR FROM sale_date));CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM (2019) TO (2020);
CREATE TABLE sales_2020 PARTITION OF sales FOR VALUES FROM (2020) TO (2021);
CREATE TABLE sales_2021 PARTITION OF sales FOR VALUES FROM (2021) TO (2022);- 存储信息与案例一相同,写法不同
EXTRACT的各种用法
EXTRACT(类型 FROM 列名)
类型如下:/*YEAR:提取年份部分QUARTER:提取季度部分MONTH:提取月份部分DAY:提取日期中的天部分HOUR:提取小时部分MINUTE:提取分钟部分SECOND:提取秒部分 */提取年份、季度、月份,在创建子分区时直接使用数值
CREATE TABLE sales (id SERIAL PRIMARY KEY, --销售IDsale_date DATE --销售日期
) PARTITION BY RANGE (EXTRACT(YEAR FROM sale_date), --年份EXTRACT(QUARTER FROM sale_date), --季度EXTRACT(MONTH FROM sale_date) --月份
);/*2020年子分区*/
CREATE TABLE sales_2020_q1_m1 PARTITION OF sales FOR VALUES FROM (2020, 1, 1) TO (2020, 1, 2);
CREATE TABLE sales_2020_q1_m2 PARTITION OF sales FOR VALUES FROM (2020, 1, 2) TO (2020, 1, 3);
CREATE TABLE sales_2020_q1_m3 PARTITION OF sales FOR VALUES FROM (2020, 1, 3) TO (2020, 1, 4);
CREATE TABLE sales_2020_q2_m4 PARTITION OF sales FOR VALUES FROM (2020, 2, 4) TO (2020, 2, 5);
CREATE TABLE sales_2020_q2_m5 PARTITION OF sales FOR VALUES FROM (2020, 2, 5) TO (2020, 2, 6);
CREATE TABLE sales_2020_q2_m6 PARTITION OF sales FOR VALUES FROM (2020, 2, 6) TO (2020, 2, 7);
CREATE TABLE sales_2020_q3_m7 PARTITION OF sales FOR VALUES FROM (2020, 3, 7) TO (2020, 3, 8);
CREATE TABLE sales_2020_q3_m8 PARTITION OF sales FOR VALUES FROM (2020, 3, 8) TO (2020, 3, 9);
CREATE TABLE sales_2020_q3_m9 PARTITION OF sales FOR VALUES FROM (2020, 3, 9) TO (2020, 3, 10);
CREATE TABLE sales_2020_q4_m10 PARTITION OF sales FOR VALUES FROM (2020, 4, 10) TO (2020, 4, 11);
CREATE TABLE sales_2020_q4_m11 PARTITION OF sales FOR VALUES FROM (2020, 4, 11) TO (2020, 4, 12);
CREATE TABLE sales_2020_q4_m12 PARTITION OF sales FOR VALUES FROM (2020, 4, 12) TO (2021, 1, 1);/*2021年子分区*/
CREATE TABLE sales_2021_q1_m1 PARTITION OF sales FOR VALUES FROM (2021, 1, 1) TO (2021, 1, 2);
CREATE TABLE sales_2021_q1_m2 PARTITION OF sales FOR VALUES FROM (2021, 1, 2) TO (2021, 1, 3);
CREATE TABLE sales_2021_q1_m3 PARTITION OF sales FOR VALUES FROM (2021, 1, 3) TO (2021, 1, 4);
CREATE TABLE sales_2021_q2_m4 PARTITION OF sales FOR VALUES FROM (2021, 2, 4) TO (2021, 2, 5);
CREATE TABLE sales_2021_q2_m5 PARTITION OF sales FOR VALUES FROM (2021, 2, 5) TO (2021, 2, 6);
CREATE TABLE sales_2021_q2_m6 PARTITION OF sales FOR VALUES FROM (2021, 2, 6) TO (2021, 2, 7);
CREATE TABLE sales_2021_q3_m7 PARTITION OF sales FOR VALUES FROM (2021, 3, 7) TO (2021, 3, 8);
CREATE TABLE sales_2021_q3_m8 PARTITION OF sales FOR VALUES FROM (2021, 3, 8) TO (2021, 3, 9);
CREATE TABLE sales_2021_q3_m9 PARTITION OF sales FOR VALUES FROM (2021, 3, 9) TO (2021, 3, 10);
CREATE TABLE sales_2021_q4_m10 PARTITION OF sales FOR VALUES FROM (2021, 4, 10) TO (2021, 4, 11);
CREATE TABLE sales_2021_q4_m11 PARTITION OF sales FOR VALUES FROM (2021, 4, 11) TO (2021, 4, 12);
CREATE TABLE sales_2021_q4_m12 PARTITION OF sales FOR VALUES FROM (2021, 4, 12) TO (2022, 1, 1);

3.2. 分区表性能对比
- 简介中说到了分区表性能比普通表更好,这里直接举例说明
1、创建一张分区表,数据100w行,每个分区存储1w行,共100分区
--创建一个按数值自动分区的分区表,每1w行自动分1个区
CREATE TABLE t1 (c1 INT,c2 TEXT
)
PARTITION BY RANGE (c1)INTERVAL('10000'::BIGINT)
(PARTITION p0 VALUES LESS THAN (0)
);--插入100w行数据
INSERT INTO t1 VALUES(generate_series(1, 1000000), md5(random()));
2、创建一张普通表,数据100w行,结构与分区表一样
CREATE TABLE t2 (c1 INT,c2 TEXT
);
INSERT INTO t2 VALUES(generate_series(1, 1000000), md5(random()));
执行t1和t2的查询语句
explain analyze select * from t1 where c1 = 900000;
explain analyze select * from t2 where c1 = 900000;结果如下:
kingbase=# explain analyze select * from t1 where c1 = 900000;QUERY PLAN
---------------------------------------------------------------------------------------------------Seq Scan on t1_p91 (cost=0.00..210.00 rows=1 width=37) (actual time=0.020..0.777 rows=1 loops=1)Filter: (c1 = 900000)Rows Removed by Filter: 9999Planning Time: 28.207 msExecution Time: 0.895 ms
(5 rows)kingbase=# explain analyze select * from t2 where c1 = 900000;QUERY PLAN
------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..14612.43 rows=1 width=37) (actual time=94.872..120.737 rows=1 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on t2 (cost=0.00..13612.33 rows=1 width=37) (actual time=31.346..35.375 rows=0 loops=3)Filter: (c1 = 900000)Rows Removed by Filter: 333333Planning Time: 0.150 msExecution Time: 120.775 ms
(8 rows)如上:分区表成本 0.777,普通表成本 120.737。从100w数据耗时看,分区表性能是普通表的155倍,那么为什么性能提升这么多呢?
从t1表的扫描结果来看,查询的是 t1_p91 表,这张表仅存储1w行数据。而普通表t2扫描的是全表(100w行),相较之下,分区表自然快得多。
需要注意的是,这个例子没有索引,当加上索引后若非超大数据,分区表与普通表性能相差无几。
相关文章:
KingbsaeES数据库分区表的详细用法
数据库版本:KingbaseES V008R006C008B0014 简介 分区表是一种将大型数据库表拆分为更小、更可管理的部分的技术。它通过将表数据分散存储到多个物理存储单元中,可以提高查询和数据维护的性能,并优化对大型数据集的处理。本篇文章以kingbase为…...
MySQL 索引底层探索:为什么是B+树?
MySQL 索引底层探索:为什么是B树? 1. 由一个例子总结索引的特点2. 基于哈希表实现的哈希索引3. 高效的查找方式:二分查找4. 基于二分查找思想的二叉查找树5. 升级版的BST树:AVL 树6. 更加符合磁盘特征的B树7. 不断优化的B树&#…...

XML HTTP传输 小结
what’s XML XML 指可扩展标记语言(eXtensible Markup Language)。 XML 被设计用来传输和存储数据,不用于表现和展示数据,HTML 则用来表现数据。 XML 是独立于软件和硬件的信息传输工具。 应该掌握的基础知识 HTMLJavaScript…...

相机标定——四个坐标系介绍
世界坐标系(Xw,Yw,Zw) 世界坐标系是一个用于描述和定位三维空间中物体位置的坐标系,通常反映真实世界下物体的位置和方向。它是一个惯性坐标系,被用作整个场景或系统的参考框架。在很多情况下,世界坐标系被认为是固定不变的,即它…...
)
C++:MySQL数据库的增删改(三)
1、相关API 执行所有的sql语句都是mysql_query或者mysql_real_query mysql_query无法处理带有特殊字符的sql语句(如:反斜杠0)mysql_real_query则可以避免,一般使用这个。 mysql_affected_rows:获取sql语句执行结果影响…...

golang - 简单实现linux上的which命令
本文提供了在环境变量$PATH设置的目录里查找符合条件的文件的方法。 实现函数 import ("fmt""os""path""strings" )// 实现 unix whtich 命令功能 func Which(cmd string) (filepath string, err error) {// 获得当前PATH环境变量en…...

推荐一个好用的数据库映射架构
SqlSugar ORM 优点: SqlSugar 是 .NET 开源 ORM 框架,由 Fructose 大数据技术团队维护和更新,是开箱即用最易用的 ORM 优点: 【低代码】【高性能】【超简单】【功能综合】【多数据库兼容】【适用产品】 支持 .NET .NET framework.net core3.1.ne5.net6.net7.net8 .net…...
window的Idea运行程序 Amazon java.nio.file.AccessDeniedException)
(013)window的Idea运行程序 Amazon java.nio.file.AccessDeniedException
解决方法一 在资源管理器中删除该目录, 在程序中使用代码,重新建立该目录: if (!FileUtil.exist(destinationPath)){FileUtil.mkdir(destinationPath); }解决方法二 JDK 的版本有问题,换个JDK。 解决方法三 网络不好…...

LeetCode 1684. 统计一致字符串的数目
解题思路 首先用set把allowed中的字符保存,然后一一判断。 相关代码 class Solution {public int countConsistentStrings(String allowed, String[] words) {Set<Character> set new HashSet<>();int reswords.length;for(int i0;i<allowed.len…...

uniapp-设置UrlSchemes从外部浏览器H5打开app
需求:外部浏览器H5页面,跳转到uniapp开发的原生app内部。 1、uniapp内部的配置: (1)打开manifest->App常用其他设置,如下,按照提示输入您要设置的urlSchemes: (2&am…...

校园圈子小程序,大学校园圈子,三段交付,源码交付,支持二开
介绍 在当今的数字化时代,校园社交媒体和在线论坛成为了学生交流思想、讨论问题以及分享信息的常用平台。特别是微信小程序,因其便捷性、用户基数庞大等特点,已逐渐成为构建校园社区不可或缺的一部分。以下是基于现有资料的校园小程序帖子发…...
基于kmeans的聚类微博舆情分析系统
第一章绪论 1.1研究背景 如今在我们的生活与生产的每个角落都可以见到数据与信息的身影。自从上十世纪八十年代的中后期开始,我们使用的互联网技术已经开始快速发展,近些年来云计算、大数据和物联网等与互联网有相领域的发展让互联网技术达到了史无前例…...
】)
【Docker常用命令(四)】
目录 Docker常用命令(四)注意 Docker常用命令(四) docker pause docker pause 命令用于暂停容器中的所有进程。docker pause CONTAINER [CONTAINER...]常用子命令和选项:无特定常用选项。docker port docker port 命令…...

黑豹程序员-Spring Task实现定时任务
定时任务 项目中,我们有一个特殊的要求,无需人为去触发,而是自动去触发程序。通常有一定的频率,每天,某时等。 实现的四种方式 1、java自身提供定时任务java.util.Timer类,但太过简单,几乎无…...

云原生安全当前的挑战与解决办法
云原生安全作为一种新兴的安全理念,不仅解决云计算普及带来的安全问题,更强调以原生的思维构建云上安全建设、部署与应用,推动安全与云计算深度融合。所以现在云原生安全在云安全领域越来受到重视,云安全厂商在这块的投入也是越来…...
)
Qt——Qt实现数据可视化之QChart的使用总结(使用QChart画出动态显示的实时曲线)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》...
(React生命周期)前端八股文修炼Day8
一 React的生命周期有哪些 React组件的生命周期可以分为三个主要阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting)。React类组件的生命周期方法允许你在组件的不同阶段执行代码。 挂载…...
考研||考公||就业||其他?-------愿不再犹豫
大三下了,现在已经开学一个多月了,在上个学期的时候陆陆续续吧周围有的行动早的人已经开始准备考研了,当然这只是下小部分人吧,也有一部分人是寒假可能就开始了,更多的则是开学的时候,我的直观感受是图书馆…...
)
使用 Selenium 和 OpenCV 识别验证码(使用 Java)
验证码的自动识别对于爬虫来说是一个常见的挑战。在这篇文章中,我们将展示如何使用 Selenium 和 OpenCV,结合 Java,来自动化识别网站上的验证码。 配置 Maven 依赖 首先,我们需要在 Maven 项目中添加 Selenium 和 OpenCV 的依赖。…...

什么是数据库?如何安装SQL Server(超详细版)
文章目录 什么是数据库数据库与数据库管理系统数据库系统之间的区别和联系数据库在生活中的应用 安装SQL Server数据库系统要求 安装步骤(超详细)安装前的准备 安装SSMS 什么是数据库 数据库,顾名思义,是存储数据的“仓库”。它不仅仅是简单的数据存储&…...

PC市场转型:从性能竞赛到价值回归的产业变革
1. 市场格局的深层演变:从“性能至上”到“够用就好”如果你在2012年前后关注过PC市场,应该能清晰地感受到一股寒流。那几年,行业里最热门的话题不再是英特尔又发布了多快的处理器,或者英伟达的显卡性能提升了多少百分比ÿ…...

QMCDecode:Mac上最简单的QQ音乐加密音频解密工具
QMCDecode:Mac上最简单的QQ音乐加密音频解密工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南
如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法获得心仪角色和皮肤而烦恼…...

告别IDEA编译警告:深入解析JDK版本过时问题与多维度解决方案
1. 当IDEA开始"抱怨":那些烦人的编译警告从哪来? 每次打开老项目,总能看到那个熟悉的黄色警告:"Warning:java: 源值1.5已过时,将在未来所有发行版中删除"。这个提示就像个唠叨的老朋友,…...


英雄联盟专业视频编辑器:用League Director制作电影级游戏录像的完整指南
英雄联盟专业视频编辑器:用League Director制作电影级游戏录像的完整指南 【免费下载链接】leaguedirector League Director is a tool for staging and recording videos from League of Legends replays 项目地址: https://gitcode.com/gh_mirrors/le/leaguedir…...

坐北朝南教育集团
在教育行业不断发展的当下,家长和学生在选择教育机构时常常面临诸多困扰,寻找一家口碑好、教学质量高的教育集团成为了关键。坐北朝南教育集团作为辽沈地区知名的综合教育航母,在解决教育领域痛点方面表现出色,成为众多家长和学生…...

原来市面上这些匹克球装备制造厂,都有啥独特之处?
匹克球运动近年来愈发火热,市面上的匹克球装备制造厂也如雨后春笋般涌现,每个品牌都有其独特的优势和特点。下面为你介绍其中一部分具有代表性的厂家及其独特之处。凯瑞麟体育用品:科技与文化的融合凯瑞麟体育用品成立于2025年11月࿰…...

从SPICE到Q-SPICE:四阶累积量如何重塑阵列信号处理的超分辨能力
1. 从SPICE到Q-SPICE:为什么我们需要四阶累积量? 我第一次接触SPICE算法是在处理雷达信号的时候。当时团队遇到一个头疼的问题:在强噪声环境下,传统算法就像近视眼观察星空,明明知道那里有信号,却怎么也分辨…...

JimuReport积木报表 — 实战API数据源动态参数与分页优化
1. 为什么API分页总让人头疼? 做过报表开发的朋友应该都遇到过这样的场景:后台接口明明提供了分页参数,但报表工具里就是没法正常翻页。要么点了下一页数据没变化,要么直接报错。我在第一次用JimuReport对接API数据源时࿰…...