入门用Hive构建数据仓库
在当今数据爆炸的时代,构建高效的数据仓库是企业实现数据驱动决策的关键。Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以轻松地进行数据存储、查询和分析。本文将介绍什么是 Hive、为什么选择 Hive 构建数据仓库、如何搭建 Hive 环境以及如何在 Hive 中实现数据仓库的分层建模。
本篇文章先做初步讲解,后续会结合数仓建模,Kimball维度建模,从ODS到DWD、DWS、数据集市、ADS等各层进行维度表和事实表的建模。
一、什么是 Hive?
Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以将结构化数据映射到 Hadoop 分布式文件系统(HDFS)上,并提供类似 SQL 的查询语言(HiveQL)来查询和分析数据。Hive 可以处理 PB 级别的数据规模,并提供了高可靠性和扩展性。
二、为什么选择 Hive 构建数据仓库?
易用性: Hive 提供了类似 SQL 的查询语言,使得用户可以轻松地进行数据查询和分析,无需学习复杂的 MapReduce 编程。
扩展性: Hive 可以处理 PB 级别的数据规模,适用于大规模数据存储和分析。
与 Hadoop 生态集成: Hive 可以与其他 Hadoop 生态系统组件(如HDFS、HBase)无缝集成,实现全面的数据管理和分析。
三、如何搭建 Hive 环境?
搭建 Hive 环境通常需要以下步骤:
1.安装 Hadoop:
首先需要安装和配置 Hadoop 分布式文件系统(HDFS)和 YARN(资源管理器)。
2.下载和配置 Hive:
下载并解压缩 Hive 的安装包,根据实际需求配置 Hive 的环境变量和配置文件。
下载 Hive: 访问 Apache Hive 官方网站(https://hive.apache.org/),下载最新版本的 Hive 安装包。
解压安装包: 使用以下命令解压缩安装包到指定目录:
tar -zxvf apache-hive-x.y.z-bin.tar.gz -C /opt配置环境变量: 在用户的环境配置文件(如 ~/.bashrc)中添加以下配置:
export HIVE_HOME=/opt/apache-hive-x.y.z
export PATH=$PATH:$HIVE_HOME/bi
配置 Hive 配置文件: 进入 Hive 安装目录,复制 hive-default.xml.template 文件为 hive-site.xml,并进行必要的配置:
cd /opt/apache-hive-x.y.z/conf
cp hive-default.xml.template hive-site.xml配置 hive-site.xml 文件,根据实际需求设置 Hadoop 的相关参数,如 Hadoop 的 HDFS 地址、YARN 地址等。
3.初始化元数据库:
运行 Hive 的初始化脚本,创建元数据库和初始表。
schematool -initSchema -dbType derby这将在默认的 Derby 数据库中初始化 Hive 的元数据库。如果需要使用其他数据库,可以相应地修改配置文件并初始化。
4.启动 Hive:
启动 Hive 服务,开始使用 Hive 进行数据查询和分析。
hive这将启动 Hive CLI,允许用户使用 HiveQL 进行数据查询和操作。也可以启动 HiveServer2 服务,允许远程连接和提交 Hive 查询。
通过以上步骤,就可以成功搭建 Hive 环境,并开始在其中构建数据仓库和进行数据分析。以下是一个完整的示例代码,演示了如何在 Hive 中创建分区表和分桶表,并进行数据查询和分析。
四、在 Hive 中实现数据仓库的分层建模
Hive 的分区表(Partitioned Table)和分桶表(Bucketed Table)是在数据仓库建模中常用的两种技术,用于提高数据查询和处理的效率。它们在 Hive 中的实现方式和用途略有不同。
1. Hive 分区表(Partitioned Table)
Hive 分区表是按照一个或多个列的值进行逻辑上的划分和存储的表格。通过分区表,可以将数据分散存储在不同的目录中,提高查询性能,同时也更便于数据管理和维护。
特点:
- 按列值分区: 根据一个或多个列的值将数据分区存储。
- 提高查询性能: 可以针对特定的分区进行查询,减少不必要的数据扫描,提高查询效率。
- 便于管理: 可以根据分区进行数据管理和维护,如备份、删除、移动等操作。
示例:
假设有销售数据表 sales,我们可以按照销售日期进行分区存储:
CREATE TABLE sales (product_id INT,sale_date STRING,amount DOUBLE
)
PARTITIONED BY (sale_year INT, sale_month INT);2. Hive 分桶表(Bucketed Table)
Hive 分桶表是将数据根据某一列的哈希值分桶存储的表格。分桶表通过将数据分布到不同的桶中,可以提高数据查询的效率。
特点:
- 按哈希值分桶: 根据某列的哈希值将数据分桶存储。
- 提高查询性能: 可以针对特定的桶进行查询,减少数据扫描,提高查询效率。
- 均匀分布: 数据会被均匀地分布在不同的桶中,避免数据倾斜问题。
示例:
假设有销售数据表 sales,我们可以按照产品ID进行分桶存储:
CREATE TABLE sales_bucketed (
product_id INT,
sale_date STRING,
amount DOUBLE
)
CLUSTERED BY (product_id) INTO 4 BUCKETS;
数据加载示例:
假设有如下的 data.csv 文件包含了销售数据:
product_id,sale_date,amount
101,2022-01-01,100.50
102,2022-01-02,150.75
103,2022-01-03,200.25
104,2022-01-04,180.00我们可以使用以下命令将数据加载到 Hive 表中:
-- 创建分区表
CREATE TABLE sales (product_id INT,sale_date STRING,amount DOUBLE
)
PARTITIONED BY (sale_year INT, sale_month INT);-- 加载数据到分区表
LOAD DATA INPATH '/path/to/data.csv' INTO TABLE sales PARTITION (sale_year=2022, sale_month=1);通过以上示例,可以了解 Hive 分区表和分桶表的概念、特点以及如何加载数据。
3.以下是一个完整的示例代码
演示了如何在 Hive 中创建分区表和分桶表,并进行数据查询:
在 Hive 中建立数据仓库的表并插入数据,然后进行数据查询,通常需要以下步骤:
1). 创建表
在 Hive 中创建表可以使用类似于 SQL 的语法,定义表的结构和属性。
通过以上示例代码,读者可以了解如何在 Hive 中创建分区表和分桶表,并进行数据查询和分析,从而实现数据仓库的分层建模。Hive 提供了强大的数据管理和分析能力,是构建数据仓库的理想选择。
-- 创建用户表
CREATE TABLE users (user_id INT,username STRING,age INT,gender STRING,occupation STRING
);2). 插入数据
在创建好的表中插入数据,可以使用 INSERT INTO 语句或者从外部数据源加载数据。
使用 INSERT INTO 插入数据:
-- 插入数据到用户表
INSERT INTO users VALUES
(1, 'Alice', 30, 'Female', 'Engineer'),
(2, 'Bob', 35, 'Male', 'Manager'),
(3, 'Charlie', 25, 'Male', 'Data Scientist');从外部数据源加载数据:
-- 从外部数据源加载数据到用户表
LOAD DATA INPATH '/path/to/users.csv' OVERWRITE INTO TABLE users;3). 数据查询
在 Hive 中进行数据查询可以使用类似于 SQL 的语法,执行常见的查询操作。
查询所有数据:
-- 查询用户表中所有数据
SELECT * FROM users;条件查询:
-- 查询年龄大于 30 岁的用户
SELECT * FROM users WHERE age > 30;聚合查询:
-- 统计不同职业的用户数量
SELECT occupation, COUNT(*) AS user_count FROM users GROUP BY occupation;通过以上示例代码,可以初步了解如何在 Hive 中创建数据仓库的表、插入数据,并进行常见的数据查询操作。在实际应用中,可以根据具体需求和数据情况编写更复杂的查询语句,实现更多样化的数据分析功能。
更多内容,请关注「同道说」

相关文章:
入门用Hive构建数据仓库
在当今数据爆炸的时代,构建高效的数据仓库是企业实现数据驱动决策的关键。Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以轻松地进行数据存储、查询和分析。本文将介绍什么是 Hive、为什么选择 Hive 构建数据仓库、如何搭建 Hive 环境以及如何在 Hi…...

【计算机网络】会话层
负责维护两个会话主机之间链接的建立、管理和终止,以及数据的交换。 会话控制:决策该由谁来传递数据 令牌管理:禁止双方同时执行一个关键动作 同步功能:在一个长的传输过程中设置一些断点,以便系统崩溃后能恢复至崩…...

springboot实现七牛云的文件上传下载
一:依赖包 <dependency><groupId>com.qiniu</groupId><artifactId>qiniu-java-sdk</artifactId><qiniu-java-sdk.version>7.7.0</qiniu-java-sdk.version></dependency>二:具体实现 RestController RequestMapping…...
- 向量内存一致性模型)
【RISC-V 指令集】RISC-V 向量V扩展指令集介绍(六)- 向量内存一致性模型
1. 引言 以下是《riscv-v-spec-1.0.pdf》文档的关键内容: 这是一份关于向量扩展的详细技术文档,内容覆盖了向量指令集的多个关键方面,如向量寄存器状态映射、向量指令格式、向量加载和存储操作、向量内存对齐约束、向量内存一致性模型、向量…...
Lvgl9 WindowsSimulator Visual Studio2017
因为在操作过程中遇到了一些错误,所以将操作及解决问题的过程记录下来。 一、下载lv_port_pc_visual_studio github链接:GitHub - lvgl/lv_port_pc_visual_studio: Visual Studio projects for LVGL embedded graphics library. Recommended on Windows. Linux su…...
)
【STL】链表(list)
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个…...

node.js常用指令
1、node:启动 Node.js REPL(交互式解释器)。 node 2、node [文件名]:执行指定的 JavaScript 文件。 node app.js 3、npm init:初始化一个新的 Node.js 项目,生成 package.json 文件。 此命令会创建一个…...
Flutter第六弹 基础列表ListView
目标: 1)Flutter有哪些常用的列表组建 2)怎么定制列表项Item? 一、ListView简介 使用标准的 ListView 构造方法非常适合只有少量数据的列表。我们还将使用内置的 ListTile widget 来给我们的条目提供可视化结构。ListView支持…...

【考研经验贴】24考研860软件工程佛系上岸经验分享【丰富简历、初复试攻略、导师志愿、资料汇总】
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文讲解24考研860软件工程佛系上岸经验分享【丰富简历、初复试攻略、导师志愿、资料汇总】,期待与你一同探索、学习、进步,一起卷起来叭! 目…...

15-1-Flex布局
个人主页:学习前端的小z 个人专栏:HTML5和CSS3悦读 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 Flex布局1 Flex容器和Flex项目2 Flex 容器属性2.1 主轴的方向2.2 主轴对齐方式…...

深入浅出 -- 系统架构之负载均衡Nginx的性能优化
一、Nginx性能优化 到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端…...

AI大模型下的策略模式与模板方法模式对比解析
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL应用》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自热榜文章:设计模式深度解析:AI大模型下…...
前端| 富文本显示不全的解决方法
背景 前置条件:编辑器wangEditor vue项目 在pc端进行了富文本操作, 将word内容复制到编辑器中, 进行发布, pc端正常, 在手机端展示的时候 显示不全 分析 根据h5端编辑器内容的数据展示, 看到有一些样式造…...
数据结构——链表
目录 一、链表 1、单向链表 单向链表的遍历方式: 2、循环链表 3、双向链表 二、自行车停放(双向链表) 一、链表 链表是由许多相同数据类型的数据项按特定顺序排列而成的线性表特性:存放的位置是不连续且随机的,动…...

uniapp使用vuex
1、uniapp中使用vuex_uniapp使用vuex-CSDN博客 2、uniapp中使用vuex(store)模块的例子 - 简书 (jianshu.com) 3、vuex介绍及使用指南(面向实战)_vuex 实战应用-CSDN博客...

C++从入门到精通——this指针
this指针 前言一、this指针的引出问题 二、this指针的特性三、例题什么时候会出现编译报错什么时候会出现运行崩溃this指针存在哪里this指针可以为空吗 四、C语言和C实现Stack的对比C语言实现C实现 前言 this指针是一个特殊的指针,在C类的成员函数中使用。它指向调…...
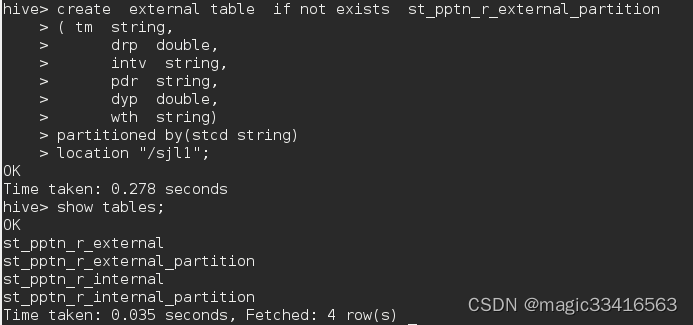
Hive3.0.0建库表命令测试
Hive创建表格格式如下: create [external] table [if not exists] table_name [(col_name data_type [comment col_comment],)] [comment table_comment] [partitioned by(col_name data_type [comment col_comment],)] [clustered by (col_name,col_name,...)…...

一起学习python——基础篇(7)
今天讲一下python的函数。 函数是什么?函数是一段独立的代码块,这块代码是为了实现一些功能,而这个代码块只有在被调用时才能运行。 在 Python 中,使用 def 关键字定义函数: 函数的固定结构就是 def(关键字)函数名字…...
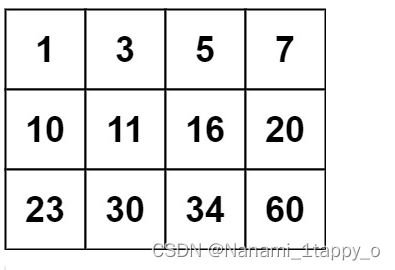
【LeetCode热题100】74. 搜索二维矩阵(二分)
一.题目要求 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,…...

Android OkHttp
目录 1.build.gradle 2.基本使用 3.POST请求 4.Builder构建者 1.build.gradle implementation("com.squareup.okhttp3:okhttp:4.12.0") 2.基本使用 GET同步请求 public void getSync(View view) {new Thread(){Overridepublic void run() {Request request …...

CODESYS硬件平台适配实战:从实时系统到工业控制生态
1. 项目概述:一次工业控制领域的“握手”最近,我们团队完成了一次与CODESYS技术团队的关键联合调测。这次调测的核心,是将我们自主研发的嵌入式硬件平台,与全球领先的工业自动化软件框架CODESYS进行深度适配与验证。对于不熟悉工业…...

如何快速清理Mac残留文件:免费开源工具终极指南
如何快速清理Mac残留文件:免费开源工具终极指南 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的困扰?明明已经…...

你的综述,为什么像文献摘要合集?
相信不少科研人都有过这样的挫败:熬了数个夜晚整理几十篇文献,写出来的综述却被导师批“没有灵魂”——只是把文献摘要简单翻译、拼接,看不到领域的发展脉络,抓不住不同研究间的学术争议,更找不到值得深挖的研究空间&a…...

2个实测免费的AI简历神器,简历回复率翻3倍,顺利过ATS机筛!
当前的求职市场,投简历简直像往海里扔石头。很多同学吐槽:明明自己挺优秀,投了100份简历却连一个面试邀请都没有。 其实,大厂HR第一轮根本不看简历,全是靠ATS(简历筛选系统)关键词过滤。如果你…...

量子退火与模拟退火:工业优化算法对比与应用
1. 量子优化算法概述在工业优化领域,寻找复杂问题的最优解一直是个巨大挑战。量子计算的出现为解决这类问题提供了全新思路。量子退火(Quantum Annealing)和模拟退火(Simulated Annealing)作为两种核心优化方法&#x…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic玩转AirSim仿真(保姆级避坑指南)
告别双系统!用WSL2Ubuntu20.04ROS Noetic玩转AirSim仿真(保姆级避坑指南) 在机器人开发与自动驾驶仿真领域,AirSim与ROS的结合堪称黄金搭档——前者提供高保真物理引擎与视觉渲染,后者则是机器人算法开发的行业标准。…...
)
Altium Designer 22 导出嘉立创SMT文件保姆级教程(附BOM/坐标文件避坑指南)
Altium Designer 22 导出嘉立创SMT文件全流程解析与实战技巧 在电子设计领域,从手工焊接转向SMT贴片生产是一个关键的进阶步骤。对于使用Altium Designer(简称AD)的设计师来说,掌握正确的文件导出方法不仅能节省大量时间ÿ…...

打造丝滑下拉刷新(附Paging3联动实战))
告别传统SwipeRefreshLayout!用Compose的pullRefresh()打造丝滑下拉刷新(附Paging3联动实战)
用Compose的pullRefresh()重构Android下拉刷新体验:从基础封装到Paging3深度集成 下拉刷新作为移动端最基础的用户交互之一,在Jetpack Compose时代迎来了全新的设计范式。传统Android开发中,我们习惯使用SwipeRefreshLayout包裹RecyclerView的…...
:Statement)
JDBC(四):Statement
Statement作用:执行sql1. 执行dml、ddlint excuteUpdate(sql)(1)dml,输出受影响行数(为正,执行成功;为负,执行失败)(2)ddl,可能输出0&…...