大语言模型上下文窗口初探(下)
由于篇幅原因,本文分为上下两篇,上篇主要讲解上下文窗口的概念、在LLM中的重要性,下篇主要讲解长文本能否成为LLM的护城河、国外大厂对长文本的态度。
3、长文本是护城河吗?
毫无疑问,Kimi从一开始就用“长文本”占领了用户心智,它能否像去年的Claude 一样,凭借着上下文长度形成一条稳定的护城河?在去年,这个答案也许是肯定的,但进入2024年,这项技术本身已经很难说的上是护城河了。当下,已经有越来越多成熟的手段去处理上下文的问题。
上下文扩展的问题之所以这么难解决,主要原因还是Transformer这个基础框架本身。
它最核心的问题有三个:
1)对文本长度记忆非常死板,超过训练集最大长度就无法处理:Transformer为输入序列的每个token的位置都映射了一个固定长度的向量。这是一个绝对的位置信息,导致模型对文本长度的记忆非常死板。一旦你给了模型超出训练集最大长度的信息时,这些超出的位置他就定位不了,也就读取和理解不了。很可惜的是,根据Sevice Now的研究员Harm de Vries的技术博客分析,现在模型训练用的主要素材之一公开可用的互联网抓取数据集CommonCrawl中,95%以上的语料数据文件的token数少于2k,并且实际上其中绝大多数的区间在1k以下。也就是说,它在训练这个过程中就是很难拓展到2k以上的文本长度。
2)注意力机制占据资源,耗费算力:因为自注意力机制需要计算每个token与其他所有token之间的相对注意力权重,所以token越长,计算量就越大,耗时越长。而且算出来的结果,还要储存成注意力得分矩阵,大量矩阵会占据巨大的存储空间,快速存储能力不足也不行。而且大部分 token之间其实就没啥关系,非要这么来回算一遍纯粹浪费资源。
3)不擅长处理远端信息:深度学习的基本逻辑之一是梯度下降,它通过不断地调整模型参数来最小化与结果差异的损失函数,从而使模型的预测能力得到提高。另一个逻辑就是反向传播,将梯度传播到更高的神经网络层级中,从而使模型能识别更复杂的模式和特征。当序列较长时,梯度在反向传播过程中可能变得非常小(梯度消失)或非常大(梯度爆炸),这导致模型无法学习到长距离的依赖关系。而且注意力机制本身就倾向于近距离词汇,远距离依赖关系对它来说优先级不高。
这三大难题其实已经有非常多的手段去规避。学界把增加上下文的方法主要归类为外推(Extrapolation)和内插(Interpolation)。一般都会并行使用。
外推负责解决训练外资料无法编码的问题,并保证长文本处理的能力。用通俗的语言来解释我们有一个巨大的语言模型,就像一个超级大脑,它通过阅读大量的书籍和文章来学习理解人类的语言和知识。但是,如果给它一段新的长文本,它可能会遇到一些之前没有接触过的内容,这时候它就需要一种特殊的能力来理解这些新信息。这种能力就是所谓的“外推”。
为了让这个语言模型能够处理超长的文章,我们需要给它一种特殊的编码方式,就像给这个超级大脑安装了一副可以看得更远的眼镜。这副眼镜就是“位置编码”,比如ALiBi和RoPE这样的编码方式,它们帮助语言模型理解更长的文本。
但是,长文本不仅长,还很复杂,需要语言模型快速而且准确地理解。为了解决这个问题,我们发明了一种叫做“稀疏注意力”的技术,它就像是给这个超级大脑装了一个高效的信息处理系统,让它可以快速聚焦在重要的信息上,而不是被无关的细节分散注意力。
还有一个问题,就是语言模型的“记忆”问题。就像电脑如果开太多程序会卡顿一样,语言模型处理太多信息也会遇到问题。这时候,我们有了像Transformer-XL这样的技术,它就像是给语言模型加了一个超级大的内存,让它可以记住更多的东西。而环注意力(Ring Attention)这个新技术,就像是给语言模型的大脑做了一个升级,让它在处理信息的时候更加高效,不会忘记重要的事情。
除了处理长文本,我们还需要让语言模型能够更好地理解它已经学过的内容,这就是“内插”。我们通过调整它的注意力机制,让它可以更轻松地找到信息之间的联系,就像是给这个超级大脑装了一个更聪明的搜索系统。
通过这些技术的提升,我们的语言模型变得越来越强大,虽然还不是完美无缺,但已经能够处理很多复杂的问题了。最近,微软的研究人员还发明了一种新的方法,叫做LongRoPE,它就像是给这个超级大脑的超能力做了一个升级,让它可以处理更多的信息,而且不需要重新训练或者更多的硬件支持。
本身这个方法略微复杂,会使用到1000步微调,但效果绝对值得这么大费周章。直接连重新训练和额外的硬件支持都不需要就可以把上下文窗口拓展到200万水平。从学术的角度看,上下文似乎已经有了较为明确的突破路径。而业界头部公司模型的进化也说明了这一点。
4、长文本难担大模型的下一步?
早在Kimi引发国内大模型“长文本马拉松竞赛”的4个月前,美国大模型界就已经赛过一轮了。参赛的两名选手是OpenAI的GPT4-Turbo和Antrophric的Claude。在去年11月,OpenAI在Dev Day上发布了GPT4-Turbo, 最高支持128k上下文长度的输入,这一下打到了Claude的命门。在能力全面落后GPT4的基础上,唯一的优势也被超越,Antrophric顿时陷入了危机。在14天后,Antrophric紧急发布Claude 2.1,在其他能力没有显著增强的情况下,仅把上下文支持从100k提升到了200k来应对挑战。而在今年2月发布的Geminni 1.5更是直接把上下文窗口推到了100万的水位,这基本上是哈利波特全集的长度和1小时视频的量级。
这说明全球第一梯队的三个大模型,在去年都突破了长文本的限制。
这其中还有一个小插曲,Claude 2.1发布后,完全没想到行业人士这么快就对它进行了探针测试,可以用简单的概念来理解,就是大海捞针。
探针测试的逻辑是向长文章的不同位置中注入一些和文章完全不相关的话语,看它能不能找出来。能就说明它真的懂了,不能就说明它只是支持了这样的长度,但并没有记住。Claude 2.1探针综合召回率只有20%,可以说基本没记住,而对比GPT4 Turbo放出的论文中,128k长文本的召回率足有97%。
在这场公关战中落于下风的Claude紧急打了补丁,在12月6日放出更新,探针召回率大幅提升,而且按Antrophic官方的说法,他们只是加了个Prompt就解决了这个问题。


一个Prompt就能解决上下文拓展中出现的严重问题。如果不是Claude 本身在故意隐藏底牌,只能说到了去年12月份,这个护城河已经略浅了。而到了今年3月份,中文大模型的这场最新版本的长文本战争时,其他厂商的快速跟上,更为“护城河略浅”加了些注脚。
5、国外为什么不卷长文本了?
全球三大模型的长文本之战最终“高开低走”。GPT4-Turbo 128k直到今天仍然仅对API用户(主要是专业开发者及公司)开放,一般用户只能用32 k的GPT4版本。在今年3月发布的号称超越GPT4的Claude 3依然只支持到200K的上下文限制。
突然他们都不卷了。这是为什么?
首先是因为不划算。在上文提及注意力机制的时候,我们讲到因为其内生的运作逻辑,上下文越长需要计算的量级越大。上下文增加32倍时,计算量实际会增长大约1000倍。虽然靠着稀疏注意力等减负措施,时机运算量并没有那么巨大,但对模型来讲依然是非常大的负担。这从大模型的反应时间可以一窥:根据目前的测试反馈,Gemini在回答36万个上下文时需要约30秒,并且查询时间随着token数量呈非线性上升。而当在Claude 3 Opus中使用较长文本的上下文时,反应时间也会加长。其间Claude还会弹出提示,表示在长上下文的情况下,应答时间会显著变长,希望你耐心等待。
较大的计算量就意味着大量的算力和相应的成本。
GPT-4 128k版本之所以开放给API用户,是因为他们按输入token数量结算,自己承担这部分算力成本。对于20美元一个月的一般用户而言,这个并不划算。Claude 3 会员版本最近也开始限制同一时间段内的输入次数,预计也是在成本上有所承压。虽然未来算力和模型速度都会变得越来越快,成本和用户体感都会进一步上升。但现在,如果长上下文的需求能够在当下支持框架下获得满足,大模型提供商何必“再卷一步”呢?
其次,长上下文的扩充在一定限度以后对模型整体能力的提升有限。前文提到,上下文对模型能力会有一定提升,尤其是处理长内容的连贯能力和推理能力上有所提升。在早期谷歌进行的较弱模型实验中,我们确实可以看到这样的明显正向关系。
但我们现在评价模型的角度实际上更综合,核心还是希望它能有更好的常识能力和推理能力。GPT4一直都不是支持上下文长度最长的模型,但其综合能力一直一骑绝尘了半年多时间。当上下文够用后,把时间花在优化模型的其他方面似乎更为合理。
在Langchain最近的研究中,他们设置了多个探针后发现,即使是支持长上下文的模型,在探针越多的情况下,其正确召回率仍然会衰退,而且对探针的推理能力衰退的更明显。所以,当前的方法下大模型可能能记住很长上下文,但懂多少,能用多少还是存疑的。

最后,有更便宜的,更有拓展性的解决方法,为什么死磕这条路?
在杨植麟过往的采访中,他曾经指出一种拓展上下文的模式是蜜蜂模式,属于一种走捷径的模式,不能真正的影响到模型的能力。这种模式就是RAG,也就是检索增强生成(RAG)。其基本逻辑就是在模型外部设置一个存储器,通过切片方法将我们输入给模型的长文本切成模型有能力识别的短文本小块,在取用时通过索引让大模型找到具体的分块。它和蜂巢一样一块块的所以被称作蜜蜂模式。
通过RAG,大模型可以考仅处理索引涉及到的小段落就可以,所以反馈速度很快,也更便宜。但它的问题正如杨植麟所说,因为是分块的,只能窥一斑难见长文本的一豹。
GPT4用的就是这样的模式,所以在32k的长度下也可以接受更大的文本进行阅读,但问题确实很多,它会经常返回说明明在文章里有的东西它找不到。
但这个问题最近也被攻破了。今年2月发布BGE Landmark embedding的论文也阐述了一种利用长上下文解决信息不完整检索的方法。通过引入无分块的检索方法,Landmark embedding能够更好地保证上下文的连贯性,并通过在训练时引入位置感知函数来有限感知连续信息段中最后一个句子,保证嵌入依然具备与Sentence Embedding相近的细节。这种方法大幅提升了长上下文RAG的精度。
另外,就像当下的数据库一样,因为我们日常生活工作中真正用到的上下文不仅包含了长文本、图片等非结构化数据,更包含了复杂的结构化数据,比如时间序列数据、图数据、代码的变更历史等等,处理这些数据依然需要足够高效的数据结构和检索算法。
100万token这个上下文长度,在文本,代码为主的场景下,已经足够满足99%我们当下的上下文用例了。再卷,对用户而言毫无价值。当然,因为看一个五分钟的视频可能就需要10万以上的token,在多模态模型实装时代中,各个模型供应商还是有再往上卷的理由。但在当下的算力成本之下,它的大规模应用应该还很难。
关于长文本本身有多大可扩展空间,杨植麟的回答是:“非常大。一方面是本身窗口的提升,有很长路要走,会有几个数量级。另一方面是,你不能只提升窗口,不能只看数字,今天是几百万还是多少亿的窗口没有意义。你要看它在这个窗口下能实现的推理能力、the faithfulness的能力(对原始信息的忠实度)、the instruction following的能力(遵循指令的能力)——不应该只追求单一指标,而是结合指标和能力。”
如果这两个维度持续提升,人类下达一个几万字、几十万字的复杂指令,大模型都能很好地、准确地执行,这确实是巨大的想象空间。到了那个时候,可能没有人会纠结,这家公司的核心竞争力究竟是长文本,还是别的什么。
相关文章:
大语言模型上下文窗口初探(下)
由于篇幅原因,本文分为上下两篇,上篇主要讲解上下文窗口的概念、在LLM中的重要性,下篇主要讲解长文本能否成为LLM的护城河、国外大厂对长文本的态度。 3、长文本是护城河吗? 毫无疑问,Kimi从一开始就用“长文本”占领…...

Java整合ElasticSearch8.13
1、引入Jar包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> 2、配置ES连接信息 spring:elasticsearch:# 地址uris: http://xxx:9200# 用户…...
2.网络编程-HTTP和HTTPS
目录 HTTP介绍 HTTP协议主要组成部分 GET 和 POST有什么区别 常见的 HTTP 状态码有哪些 http状态码100 HTTP1.1 和 HTTP1.0 的区别有哪些 HTTPS 和 HTTP 的区别是什么 HTTP2 和 HTTP1.1 的区别是什么 HTTP3 和 HTTP2 的区别是什么 HTTPS的请求过程 对称加密和非对称…...
MTK i500p AIoT解决方案
一、方案概述 i500p是一款强大而高效的AIoT平台,专为便携式、家用或商用物联网应用而设计,这些应用通常需要大量的边缘计算,需要强大的多媒体功能和多任务操作系统。该平台集成了Arm Cortex-A73 和 Cortex-A53 的四核集群,工作频…...

ES入门十四:分词器
我们存储到ES中数据大致分为以下两种: 全文本,例如文章内容、通知内容精确值,如实体Id 在对这两类值进行查询的时候,精确值类型会比较它们的二进制,其结果只有相等或者不想等。而对全文本类型进行等值比较是不太实现…...

汇编——SSE打包整数
SSE也可以进行整数向量的加法,示例如下: ;sse_integer.asm extern printfsection .datadummy db 13 align 16pdivector1 dd 1dd 2dd 3dd 4pdivector2 dd 5dd 6dd 7dd 8fmt1 db "Packed Integer Vector 1: %d, %d, %d, %d",…...
)
动态规划(2)
动态规划(2) 文章目录 动态规划(2)1、聪明的寻宝人2、基因检测3、药剂稀释4、找相似串 1、聪明的寻宝人 #include <iostream> using namespace std; void MaxValue(int values[], int weights[], int n, int m) {int dp[21…...

JetBrains IDE 2024.1 发布 - 开发者工具
JetBrains IDE 2024.1 (macOS, Linux, Windows) - 开发者工具 CLion, DataGrip, DataSpell, Fleet, GoLand, IntelliJ IDEA, PhpStorm, PyCharm, Rider, RubyMine, WebStorm 请访问原文链接:JetBrains IDE 2024.1 (macOS, Linux, Windows) - 开发者工具࿰…...

C++ 构造函数中的参数顺序
描述: 未初始化的参数必须在初始化参数之前 正确 ✓ 写法: mother(const char* food, const char* lastName"无姓", const char* firstName "无名" ); 错误❌写法: mother(const char* lastName"无姓", …...

Git Flow困境逃脱指南
本来来自极狐GitLab 资源中心,原文链接:https://resources.gitlab.cn/articles/020183ba-cfc0-4917-b901-248acdcfc92f。 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab ÿ…...

MySQL的sql_mode模式简介
前言 今天同事使用数据库时报错,排查问题时发现配置文件里的sql_mode配置被人注释了,所以通过查询资料对这个配置进行了下了解。 介绍 mysql为了支持在不同的环境下运行,允许我们给它设置不同的运行模式(sql_mode)。 不同的运行模式&#…...

性能优化-如何爽玩多线程来开发
前言 多线程大家肯定都不陌生,理论滚瓜烂熟,八股天花乱坠,但是大家有多少在代码中实践过呢?很多人在实际开发中可能就用用Async,new Thread()。线程池也很少有人会自己去建,默认的随便用用。在工作中大家对…...
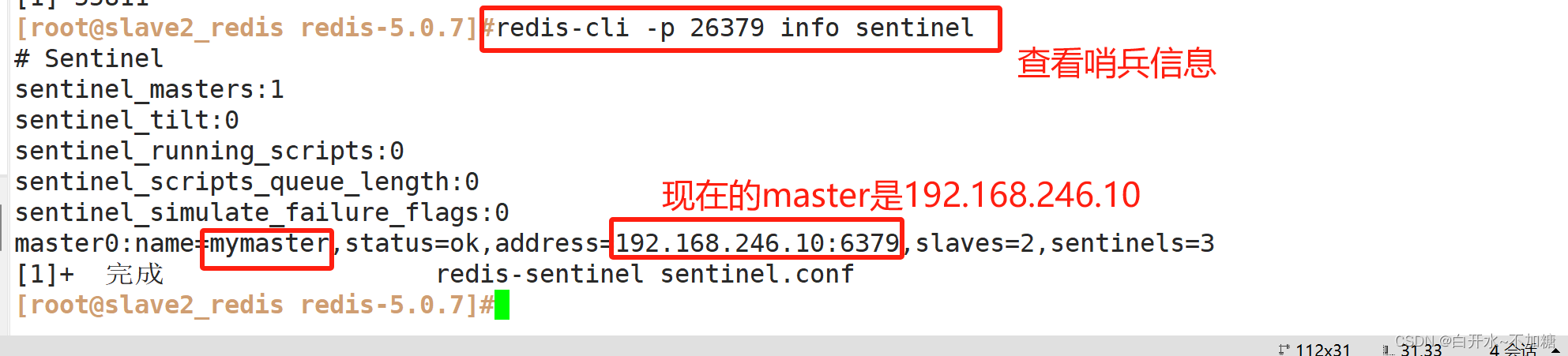
非关系型数据库-----------Redis的主从复制、哨兵模式
目录 一、redis群集有三种模式 1.1主从复制、哨兵、集群的区别 1.1.1主从复制 1.1.2哨兵 1.1.3集群 二、主从复制 2.1主从复制概述 2.2主从复制的作用 ①数据冗余 ②故障恢复 ③负载均衡 ④高可用基石 2.3主从复制流程 2.4搭建redis主从复制 2.4.1环境准备 2.4…...

使用docx4j转换word为pdf处理中文乱码问题
word转pdf 实现方法 mavendocx4j版本自己酌情升级 实现方法 import org.docx4j.Docx4J; import org.docx4j.fonts.IdentityPlusMapper; import org.docx4j.fonts.Mapper; import org.docx4j.fonts.PhysicalFonts; import org.docx4j.openpackaging.packages.WordprocessingMLP…...

【引子】C++从介绍到HelloWorld
C从介绍到HelloWorld 一、C的介绍1. 简介2. 应用场景3. C的标准4. C的运行过程 二、Visual Studio的安装1. 什么是Visual Studio2. Visual Studio的安装 三、完成HelloWorld1.…...
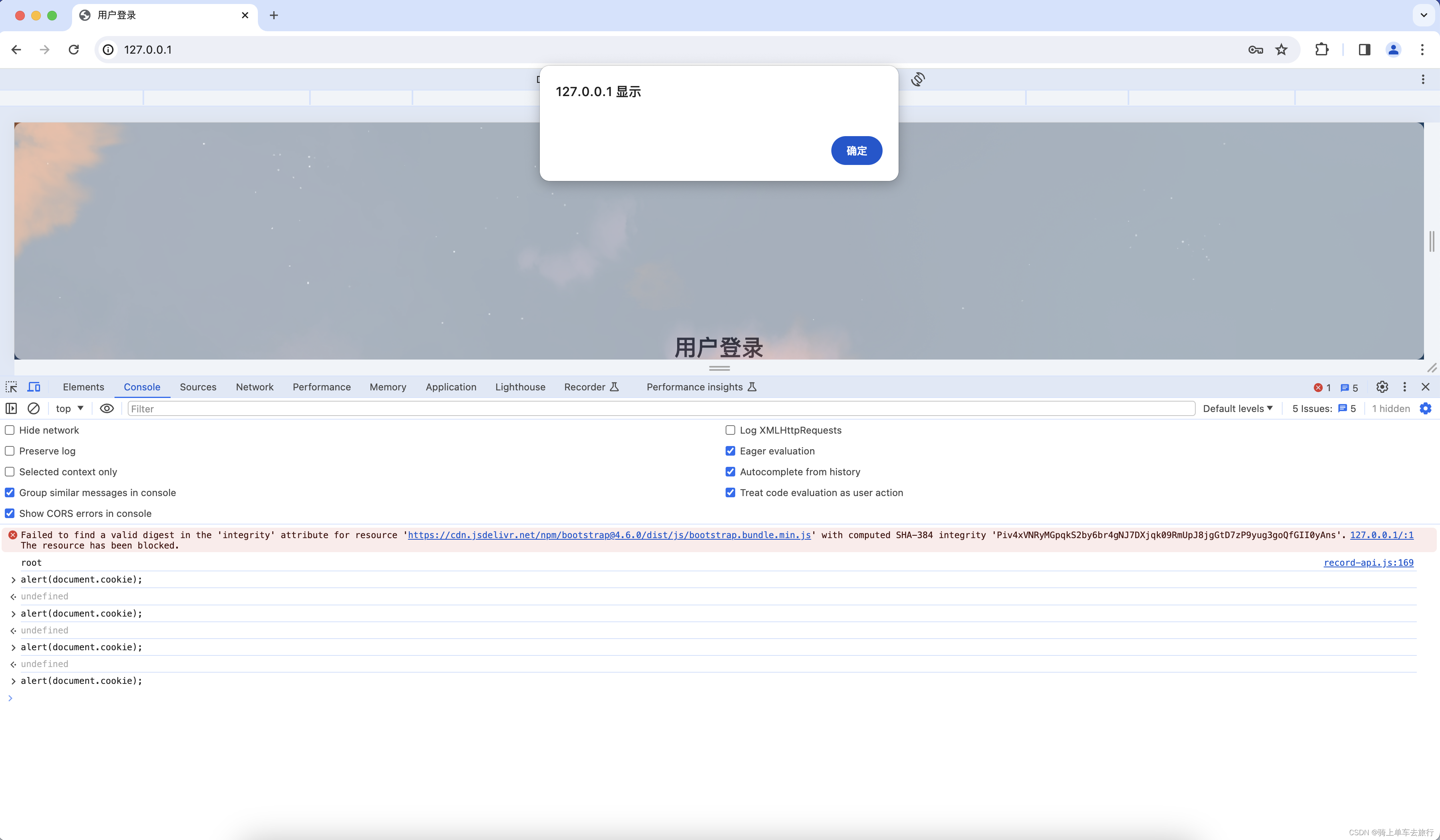
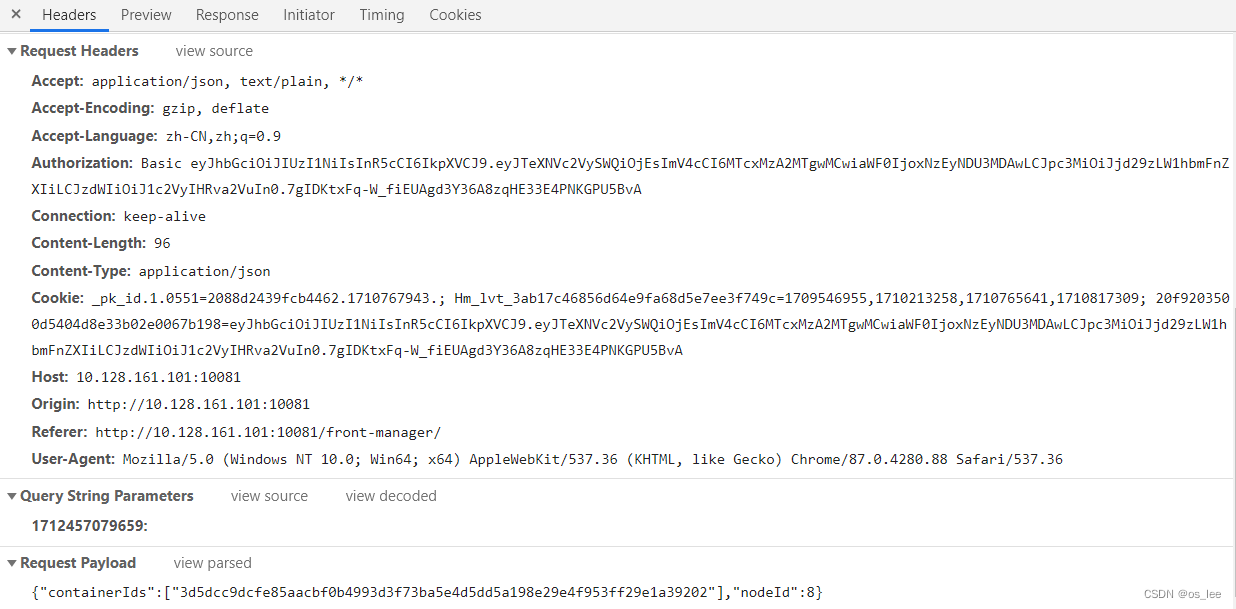
Django检测到会话cookie中缺少HttpOnly属性手工复现
一、漏洞复现 会话cookie中缺少HttpOnly属性会导致攻击者可以通过程序(JS脚本等)获取到用户的cookie信息,造成用户cookie信息泄露,增加攻击者的跨站脚本攻击威胁。 第一步:复制URL:http://192.168.43.219在浏览器打开,…...

2024数字城市建设博览会:一站式平台,满足多元需求
2024数字城市建设博览会:引领未来城市发展的风向标 2024年,一场前所未有的盛会——数字城市建设博览会暨交流大会,将在雄安这座未来之城拉开帷幕。本次大会不仅是数字经济全产业链的精英集结,更是一场汇聚了众多优质项目和丰富客…...
iOS 17.5系统或可识别并禁用未知跟踪器,苹果Find My技术应用越来越合理
苹果公司去年与谷歌合作,宣布将制定新的行业标准来解决人们日益关注的跟踪器隐私问题。苹果计划在即将发布的 iOS 17.5 系统中加入这项提升用户隐私保护的新功能。 科技网站 9to5Mac 在苹果发布的 iOS 17.5 开发者测试版内部代码中发现了这项反跟踪功能的蛛丝马迹…...

关于搭建elk日志平台
我这边是使用docker compose进行的搭建 所以在使用的时候 需要自行提前安装docker以及dockercompose环境 或者从官网下载对应安装包也可以 具体文章看下一章节:【ELK】搭建elk日志平台(使用docker-compose),并接入springboot项目...
【全套源码教程】基于SpringBoot+MyBatis+Vue的流浪动物救助网站的设计与实现
目录 前言 需求分析 可行性分析 技术实现 后端框架:Spring Boot 持久层框架:MyBatis 前端框架:Vue.js 数据库:MySQL 功能介绍 前台界面功能介绍 动物领养及捐赠 宠物论坛 公告信息 商品页面 寻宠服务 个人中心 购…...

基于Adafruit与CircuitPython的交互式光剑:从硬件选型到3D打印全流程解析
1. 项目概述:打造一把会“呼吸”的交互式光剑几年前,当我第一次在游戏里挥动《塞尔达传说》中的大师之剑时,就被那种兼具力量感与神圣感的视觉效果深深吸引。作为一个硬件创客,我一直在想,能不能把这种虚拟的体验带到现…...
的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”))
面向对象分析(OOA)的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”)
面向对象分析(OOA)的第一个步骤是识别问题域中的对象和类(也称为“识别对象与类”或“确定问题域中的概念类”)。 这一步要求分析师深入理解用户需求和现实世界的问题背景,通过用例分析、领域建模、名词提取等方法&…...
)
【程序源代码】校园论坛仿知乎贴吧微信小程序系统(含源码)
关键字:发帖,搜索,校园社区,Vue,服务,系统,管理,springboot,java,h2项目名称:校园论坛(仿知乎贴吧)微信小程序系统微信小程序校园论坛(仿知乎贴吧)系统是基于SpringBoot框架开发的一款轻量化校园论坛&#…...

NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案 NotebookLM 作为 Google 推出的 AI 增强型笔记工具,其“共享链接即协作”的默认机制在提升效率的同…...

NotebookLM权限审计日志难追溯?手把手教你启用VPC Service Controls + Cloud Logging Query Builder构建实时越权预警看板
更多请点击: https://intelliparadigm.com 第一章:NotebookLM权限控制设置 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 辅助理解与生成的实验性工具,其权限模型默认采用 Google 账户体系集成,但需主动配置以满足团队协…...

Linux文本管道效率异常定位实战
Linux文本管道效率异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在文本管道效率,重点讨论管道组合、文本过滤和执行开销。在真实生产环境中,文本管道效率相关问题往往不会以单一错误形式出现,而是混杂在日志、权…...

算法工程师简历封神指南:项目细节 + 论文 / 竞赛成果缺一不可
引言:算法岗简历的“死亡三连”,你中了吗? “熟悉CNN、Transformer、大模型微调,掌握PyTorch、TensorFlow”——当面试官第88次看到这句“算法词典式”技能描述时,已经开始默默划走简历。2026年算法岗卷到什么程度?智联招聘数据显示,硕士学历算法岗平均竞争比达300:1,…...

Thanos剪枝算法:高效压缩大型语言模型的技术解析
1. 项目概述:Thanos剪枝算法解析在深度学习领域,大型语言模型(LLM)的参数量已突破千亿级别,这对计算资源和内存提出了极高要求。模型剪枝技术通过移除神经网络中的冗余连接,能在保持模型性能的同时显著降低…...

企业邮箱代理:谷歌企业邮箱安全防护架构与合规应用解析
前言谷歌企业邮箱凭借全球通用 IP 信誉、海外节点覆盖广等优势,成为外贸企业对接欧美、东南亚海外客户的首选办公邮箱。但国内企业直接使用,容易出现登录卡顿、邮件发送延迟、大批量开发信被限制等问题,做好针对性优化,才能最大化…...
)
告别仿真报错!手把手教你用Quartus II 21.1和ModelSim 2022.1创建Testbench(附完整代码)
Quartus II与ModelSim联合仿真实战:从零构建高可靠性Testbench 在数字电路设计领域,仿真验证环节往往决定着项目成败。据统计,超过60%的FPGA开发时间消耗在功能验证阶段,而其中近半问题源于Testbench编写不当或仿真环境配置错误。…...