性能优化-如何爽玩多线程来开发
前言
多线程大家肯定都不陌生,理论滚瓜烂熟,八股天花乱坠,但是大家有多少在代码中实践过呢?很多人在实际开发中可能就用用@Async,new Thread()。线程池也很少有人会自己去建,默认的随便用用。在工作中大家对于多线程开发,大多是用在异步,比如发消息,但是对于提效这块最重要的优势却很少有人涉及。因此本篇文章会结合我自己的工作场景带大家去发掘项目中的多线程场景,让你的代码快如闪电。
最后会有我对自己三个多月来写的十篇原创文章的个人总结,希望读者大大能耐心看完本篇,一定会有所收获。
多线程普及
多线程解决了什么问题?带来了什么问题?
Cpu为了均衡与内存的速度差异,增加了缓存–导致了可见性问题
操作系统增加了进程和线程,分时复用CPU,进而均衡CPU与IO设备的速度差异–导致了原子性问题
编译程序优化指令排序(JVM指令重排序)–导致了有序性问题
可见性问题–线程A修改共享变量,修改后CPU缓存中的数据没有及时同步到内存,线程B读取了内存中老数据
原子性问题–多个线程增加数据,有几个线程挂了,这数据就少了
有序性问题–经典的对象创建三步,堆中分配内存–>初始化–>变量指向内存地址,如果排序重排会出现132,导致没有初始化的对象被创建
JVM提供了什么工具去解决线程不安全问题?Java代码有哪些实现思路?
JVM提供了三个关键词,synchronized、volatile、final和JMM(线程操作内存规范,例如8个happen before原则)
Java代码实践可从三方面入手
- 同步:synchronized和ReentrantLock
- 非同步:CAS(CPU原语,依赖硬件)
- 线程安全:局部变量(虚拟机栈或者本地方法栈,线程私有)和ThreadLocal(本地线程变量副本,空间换安全,每个线程一份)
如何开启线程?
基础的Thread、runable、callable,进阶的ThreadExecutor和Future,以及JDK8的终极武器CompletableFuture
线程间如何协作?
基础
- volatile和synchronized关键字
- volatile关键字用来修饰共享变量,保证了共享变量的可见性,任何线程需要读取时都要到内存中读取(确保获得最新值)。
- synchronized关键字确保只能同时有一个线程访问方法或者变量,保证了线程访问的可见性和排他性。
- 等待/通知机制–指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B 调用了对象O的notify()或者notifyAll()方法,线程A收到通知后从对象O的wait()方法返回,进而 执行后续操作
- 管道输入/输出流
- 管道输入/输出流和普通的文件输入/输出流或者网络输入/输出流不同之处在于,它主要 用于线程之间的数据传输,而传输的媒介为内存。
- 管道输入/输出流主要包括了如下4种具体实现:PipedOutputStream、PipedInputStream、 PipedReader和PipedWriter,前两种面向字节,而后两种面向字符。
- join()方法–如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才 从thread.join()返回。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时 时间里没有终止,那么将会从该超时方法中返回。
- ThreadLocal–即线程本地变量(每个线程都有自己唯一的一个哦),是一个以ThreadLocal对象为键、任意对象为值的存储结构。底层是一个ThreadLocalMap来存储信息,key是弱引用,value是强引用,所以使用完毕后要及时清理(尤其使用线程池时)。
进阶
有JDK5开始提供的Semaphore(信号量)、CyclicBarrier、CountDownLatch以及JDK8的CompletableFuture
场景实战
多线程处理场景
并行聚合处理数据
以下案例主要运用CompletableFuture.allOf()方法,将原本串行的操作改为并行。本案例相对比较常规,算是CompletableFuture的基本操作,其他特性就不一一介绍了。
AtomicReference<List<SellOrderList>> orderLists = new AtomicReference<>();
AtomicReference<List<InternationalSalesList>> salesLists = new AtomicReference<>();
AtomicReference<Map<String, BigDecimal>> productMap = new AtomicReference<>();
.........
//逻辑A
CompletableFuture<Void> orderListCom =CompletableFuture.runAsync(() -> {orderLists.set(sellOrderListService.lambdaQuery().ge(SellOrderList::getOrderCreateDate, startDate).le(SellOrderList::getOrderCreateDate, endDate).eq(SellOrderList::getIsDelete, 0).list());});
CompletableFuture<Void> productCom = CompletableFuture.runAsync(() -> {//逻辑B});
CompletableFuture<Void> euLineCom = CompletableFuture.runAsync(() -> {//逻辑C});
//汇总线程操作
CompletableFuture.allOf(orderListCom, productCom, euCloudCom).handle((res, e) -> {if (e != null) {log.error("客户订单定时任务聚合数据异常", e);} else {try {//获取全部数据后处理数据aggregateData(customerList, saleMonth, orderLists, salesLists, productMap, euLineList, asLineList,euCloudList, asCloudList, itemMap, deliveryMap, parities);} catch (Exception ex) {log.error("客户订单处理数据异常", ex);}}return null;
});
修改for循环为并行操作
这里借鉴了parallelStream流的思路,将串行的for循环分割成多个集合后,对分割后的集合进行循环。这应该是最普遍的多线程应用场景了,需要注意的是线程池需要自定义大小、不安全的集合例如ArrayList并行add时需要加锁,加好日志就完事了。
@Autowired
@Qualifier("ioDenseExecutor")
private ThreadPoolTaskExecutor ioDense;
//自建线程池,ForkJoinPool默认的太小,一般是逻辑CPU数量-1
int logicCpus = Runtime.getRuntime().availableProcessors();
ForkJoinPool forkJoinPool = new ForkJoinPool(logicCpus * 80);
//指定集合大小,避免频繁扩容
List<RedundantErpSl> slAddList = new ArrayList<>(50000);
//谷歌提供工具类切分集合--import com.google.common.collect.Lists;
List<List<SlErpDTO>> partition = Lists.partition(slErpList, 1000);
int finalLastStatus = lastStatus;
CompletableFuture<Void> handle = CompletableFuture.allOf(partition.stream().map(addPartitionList ->CompletableFuture.runAsync(() -> {for (SlErpDTO slErp : addPartitionList) {//TODO 逻辑处理synchronized (slAddList) {//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失slAddList.add(sl);}}}, ioDense)).toArray(CompletableFuture[]::new)).whenComplete((res, e) -> {if (e != null) {log.error("多线程组装数据失败", e);} else {try {//进一步处理循环后的结果slService.batchSchedule(versionNum, slAddList);} catch (Exception ex) {log.error("批量插入失败", ex);}}});
handle.join();
List转Map解除嵌套循环
一个常见的场景,当我们需要判断当前数据的唯一值是否在数据库存在从而判断是新增还是修改时,常规做法是:
for(X x:待新增或者修改的数据){String xKey=x.getKey();//key为当前数据的唯一值for(Y y:数据库中的数据){if(Objects.equals(xKey,yKey)){update;//相等就修改 }else{add;//不等就新增 }}
}
循环套循环,时间复杂度O(n²),性能肯定是比较差的,那怎么改造呢?如果能确定key是唯一值,就拿优化神器Map来操作,算法里面常见的优化手段。我们把唯一值key作为键,输出对象作为值那么上面的代码就可以改造为:
public Map<String, SafeRule> list2Map() {List<SafeRule> ruleList = lambdaQuery().eq(SafeRule::getIsDelete, 0).list();return ruleList.stream().collect(Collectors.toMap(e -> e.getBigClass() + e.getSmallClass(),
Function.identity()));
}
for(X x:待新增或者修改的数据){String xKey=x.getKey();//key为当前数据的唯一值Map<String, SafeRule> map=list2Map();if(map.get(xKey)!=null){update;//相等就修改 }else{add;//不等就新增 }}
}
引入Map之后,第二个嵌套的循环就干掉了,换成了单次循环来组装Map,时间复杂度降为O(n)。此方法仅适用于每行数据拥有唯一值,不然stream在组装时会提示重复key。
修改Map遍历为并行操作
既然for循环能转换,那么map遍历必然也能通过多线程改造。
/*** 将map切成段--工具类** @param splitMap 被切段的map* @param splitNum 每段的大小*/
public static <k, v> List<Map<k, v>> mapSplit(Map<k, v> splitMap, int splitNum) {if (splitMap == null || splitNum <= 0) {List<Map<k, v>> list = new ArrayList<>();list.add(splitMap);return list;}Set<k> keySet = splitMap.keySet();Iterator<k> iterator = keySet.iterator();int i = 1;List<Map<k, v>> total = new ArrayList<>();Map<k, v> tem = new HashMap<>();while (iterator.hasNext()) {k next = iterator.next();tem.put(next, splitMap.get(next));if (i == splitNum) {total.add(tem);tem = new HashMap<>();i = 0;}i++;}if (!CollectionUtils.isEmpty(tem)) {total.add(tem);}return total;
}
//代码示例
Map<String, List<BudgetErpDTO>> materialMap = materialList.parallelStream().collect(Collectors.groupingBy(e -> e.getInvOrgId() + "-" + e.getItemId() + "-" + e.getVendorId()));List<Map<String, List<BudgetErpDTO>>> mapList = MapUtil.mapSplit(materialMap, 50);CompletableFuture<Void> handle =CompletableFuture.allOf(mapList.stream().map(splitMap -> CompletableFuture.runAsync(() -> {splitMap.forEach((identity, list) -> {//业务操作});}, ioDense)).toArray(CompletableFuture[]::new)).exceptionally(e -> {log.error("多线程组装数据失败", e);return null;});
上面提供了一个切分的工具类,以及Map改造的代码,总体还是非常简单,思路和for循环的改造是差不多的
多线程新增
我个人在开发中会使用一些小工具来提高开发效率,接下来公开一个我常用的批量插入的小工具,这个小工具最开始是同事给我的,然后我做了优化和扩充,主要是扩充了多线程以及service块的代码。
总览
该工具类用于生成复制可用的代码,这里需要提前指定一些固定变量。除了entity和serviceName需要根据实际情况变化之外,方法名和参数名可以不变。生成了四个方法,分别是mapper类中的方法、mapper.xml中的foreach批量插入代码、普通无事务的多线程批量插入代码、多线程事务代码
//批量方法名,对应mapper和xml中id
String methodName = "batchSchedule";
//mapper参数名称
String paramName = "addList";
//实际代码里面的service命名
String serviceName = "baseInfoService";
Class<?> entity = BudgetBase.class;
//批量插入
printMapper(entity.getSimpleName(), methodName, paramName);
printXml(entity, methodName, paramName);
//普通多线程批量插入,无事务
printSave(entity.getSimpleName(), serviceName, paramName, 1000);
//多线程事务,慎用
printAddTransaction(entity.getSimpleName(), paramName, 1000);
mapper方法

xml批量插入语句
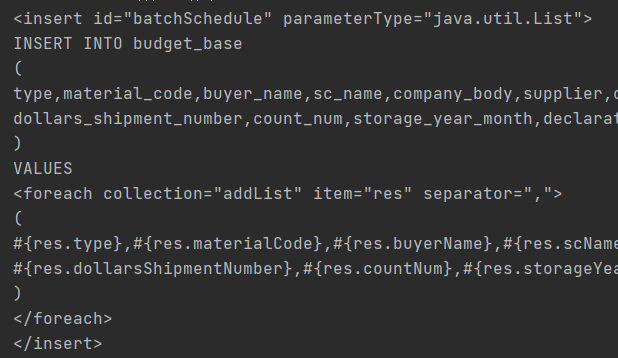
多线程批量插入
这个多线程插入其实就是我上面多线程处理场景中for循环改造的变种,将集合拆分进行并行批量插入
if (CollectionUtils.isNotEmpty(addList)) {List<List<BudgetBase>> partition = Lists.partition(addList, 1000);CompletableFuture.allOf(partition.stream().map(addPartitionList ->CompletableFuture.runAsync(() -> baseInfoService.getBaseMapper().batchSchedule(addPartitionList))).toArray(CompletableFuture[]::new)).exceptionally(e -> {log.error("多线程处理异常", e);return null;});}
花里胡哨-多线程事务提交
这个才是本文的重点,接下来我会详细介绍我在开发中遇到的坑和知识点,敲黑板了啊,重点来了!
我写的这个多线程事务本质就是根据2PC理论手写了一个分布式事务,涉及到多线程、Spring事务、ThreadLocal、LockSupport这些知识点,在线上一定要慎重使用,最好不用,可作炫技用,秀就完了。
深刻理解Spring事务、ThreadLocal
从头说起,既然是多线程事务,那自然不能使用注解@Transactional去开启事务,Spring事务采用ThreadLocal来做线程隔离,ThreadLocalMap内部key为当前线程的ThreadLocal对象,也可以当作以当前线程为key,value也是个map,看源码可以知道,map里面key为数据源,value为数据库连接。
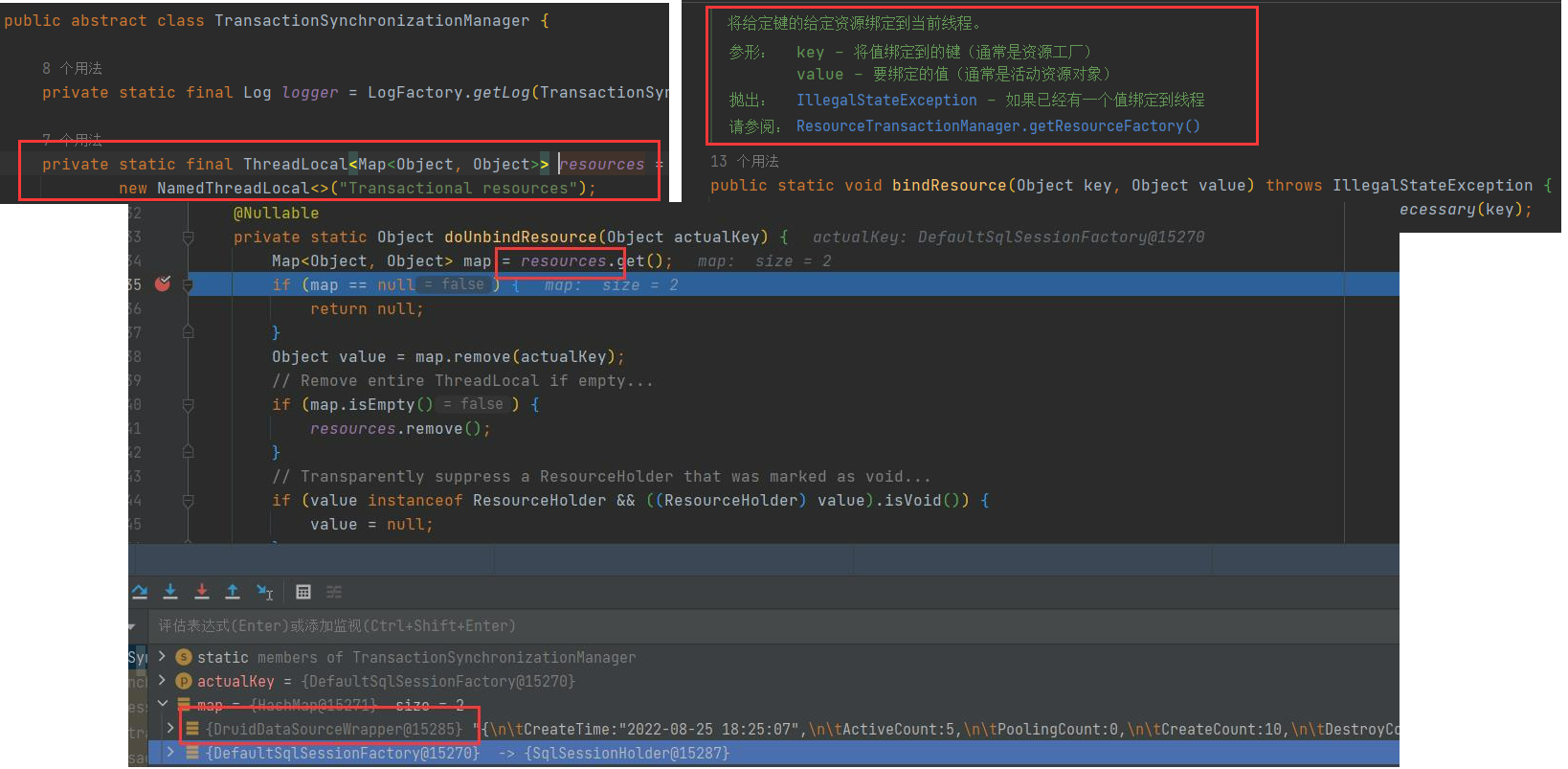
当然上来看源码,肯定认识不够深刻,接下来是一段错误代码示范,充分展示了理解上面那段话的重要性。我的第一次失败就是如下一段代码,首先肯定是能运行的,不能运行的例子我就不给了,先来看看这段代码。
//存储事务集合
List<TransactionStatus> traStatusList = new ArrayList<>();
//最外部更新或者删除时手动创建一个新事务
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
def.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);
TransactionStatus statusStart = transactionManager.getTransaction(def);
traStatusList.add(statusStart);
//外部DML操作
lambdaUpdate().set(RedundantErpSl::getIsDelete, 1).set(RedundantErpSl::getUpdateTime, new Date()).eq(RedundantErpSl::getVersionNum, versionNumber).eq(RedundantErpSl::getIsDelete, 0).update();
List<List<RedundantErpSl>> partition = Lists.partition(RedundantErpSlList, 1000);
try {CompletableFuture<Void> future = CompletableFuture.allOf(partition.stream().map(addPartitionList ->CompletableFuture.runAsync(() -> {//Spring事务内部由ThreadLocal存储事务绑定信息,因此需要每个线程新开一个事务DefaultTransactionDefinition defGo = new DefaultTransactionDefinition();defGo.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);defGo.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);TransactionStatus statusGo = transactionManager.getTransaction(defGo);//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失synchronized (traStatusList) {traStatusList.add(statusGo);}getBaseMapper().batchSchedule(addPartitionList);})).toArray(CompletableFuture[]::new)).exceptionally(e -> {log.error("批量导入出现异常", e);//向外抛出异常,确保最外面catch回滚throw new PtmException(e.getMessage());});future.join();for (TransactionStatus status : traStatusList) {transactionManager.commit(status);}
} catch (Exception e) {log.error("批量导入出现异常回滚开始", e);for (TransactionStatus status : traStatusList) {transactionManager.rollback(status);}
}
先说说这个错误例子我当时开发的思路,手动开启事务后,在每个线程操作开始的时候都创建一个事务,Spring事务传播级别用的TransactionDefinition.PROPAGATION_REQUIRES_NEW,即默认创建新事务。隔离级别一开始没改,然后我就尝试着操作了一下,好家伙批量新增的时候直接锁了。
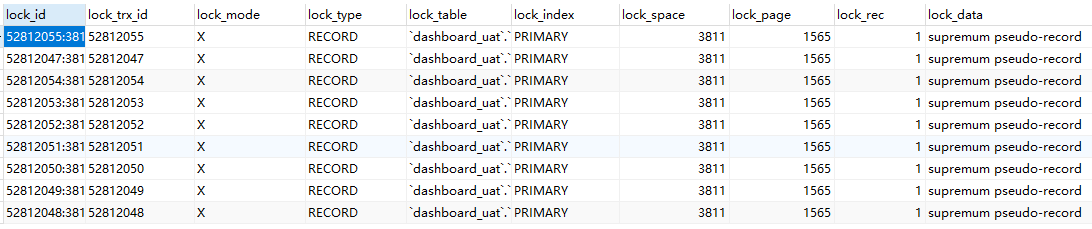
查看正在锁的事务 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
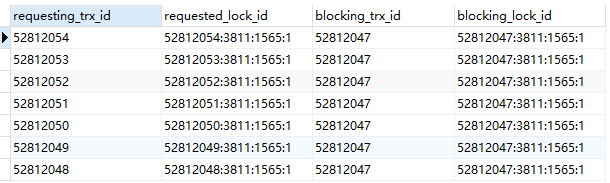
查看等待锁的事务 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
异常如下图,锁超时异常

第一次看见下图这个错的时候,我是疑惑的,没有当回事,以为是多数据源的问题。我项目里有直连Oracle和MySQL两种关系型数据库,当时怀疑是多数据源事务没有正确解绑导致的问题。
:::info
PS:事实上这个坑给足了我提示,根本原因就是多线程事务解绑失败,但是我理解出现了偏差,为后文埋下了伏笔。
:::

我当时一看有锁,这我能惯着,马上修改事务隔离级别为TransactionDefinition.ISOLATION_READ_COMMITTED读已提交(MySQL默认事务隔离级别为可重复读,这里下调了一级,总共四级)。顺利插入但还是报上面这个错,错误位置是下面这个循环提交时报的,第二次循环的时候一定会报错。
for (TransactionStatus status : traStatusList) {transactionManager.commit(status);
}
当时一度以为是多数据源的问题,但是Debug后发现resource里面只有一个数据源key,解绑一次后就没了,第二个循环解绑的时候就报上面这个错,因为找不到可以解绑的key了。我就很疑惑,为啥就一个数据源key,我不是在别的线程开了事务嘛,按理说开了多少个线程就有多少个事务,这个问题困扰了我大概一天左右的时间。然后我想到了Spring事务的实现原理ThreadLocal,然后联想到我的多线程开启事务,再看到我在主线程里面进行傻叉循环解绑,我瞬间为梦想窒息。
所以破案了,我在主线程是操作不了子线程事务,这也是代码报key找不到的原因,因为用主线程做key在ThreadLocal里肯定是拿不到子线程信息的,只能拿到主线程自己的。
多线程事务提交方案
因此解决方案就很简单,子线程的事务自己操作,那么多线程事务处理哪家强,JDK里找CompletableFuture!当然这里使用CountDownLatch也是可行的,网上也有案例。多线程事务在处理逻辑上其实和分布式事务很像,因此我这里采用2PC的思想,一阶段所有子线程全部开启事务并执行SQL,然后阻塞等待,二阶段判断是否全部成功,是就唤醒所有线程提交事务,否就全部回滚。
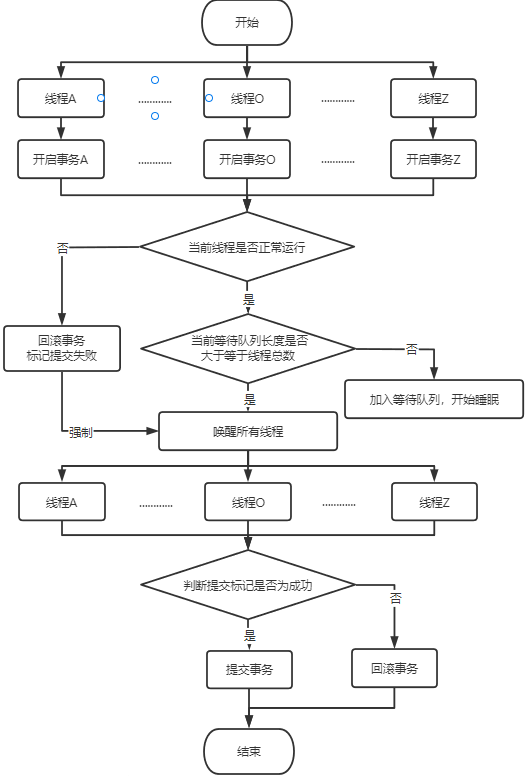
-----------需要注入Bean,一个是Spring Boot事务管理,一个是线程池-----------
@Autowired
private PlatformTransactionManager transactionManager;
@Autowired
@Qualifier("ioDenseExecutor")
private ThreadPoolTaskExecutor ioDense;
-----------多线程事务新增操作-----------
private void batchSchedule(List<BudgetBase> addList) {if (!CollectionUtils.isEmpty(addList)) {//定义局部变量,是否成功、顺序标识、等待线程队列AtomicBoolean isSuccess = new AtomicBoolean(true);AtomicInteger cur = new AtomicInteger(1);List<Thread> unfinishedList = new ArrayList<>();//切分新增集合List<List<BudgetBase>> partition = Lists.partition(addList, 1000);int totalSize = partition.size();//多线程处理开始CompletableFuture<Void> future =CompletableFuture.allOf(partition.stream().map(addPartitionList -> CompletableFuture.runAsync(() -> {//Spring事务内部由ThreadLocal存储事务绑定信息,因此需要每个线程新开一个事务DefaultTransactionDefinition defGo = new DefaultTransactionDefinition();defGo.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);TransactionStatus statusGo = transactionManager.getTransaction(defGo);int curInt = cur.getAndIncrement();try {log.info("当前是第{}个线程开始启动,线程名={}", curInt, Thread.currentThread().getName());baseInfoService.getBaseMapper().batchSchedule(addPartitionList);log.info("当前是第{}个线程完成批量插入,开始加入等待队列,线程名={}", curInt, Thread.currentThread().getName());//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失synchronized (unfinishedList) {unfinishedList.add(Thread.currentThread());}log.info("当前是第{}个线程已加入队列,开始休眠,线程名={}", curInt, Thread.currentThread().getName());notifyAllThread(unfinishedList, totalSize, false);LockSupport.park();if (isSuccess.get()) {log.info("当前是第{}个线程提交,线程名={}", curInt, Thread.currentThread().getName());transactionManager.commit(statusGo);} else {log.info("当前是第{}个线程回滚,线程名={}", curInt, Thread.currentThread().getName());transactionManager.rollback(statusGo);}} catch (Exception e) {log.error("当前是第{}个线程出现异常,线程名={}", curInt, Thread.currentThread().getName(), e);transactionManager.rollback(statusGo);isSuccess.set(false);notifyAllThread(unfinishedList, totalSize, true);}}, ioDense)).toArray(CompletableFuture[]::new));future.join();}}
private void notifyAllThread(List<Thread> unfinishedList, int totalSize, boolean isForce) {if (isForce || unfinishedList.size() >= totalSize) {log.info("唤醒当前所有休眠线程,线程数={},总线程数={},是否强制={}", unfinishedList.size(), totalSize, isForce);for (Thread thread : unfinishedList) {log.info("当前线程={}被唤醒", thread.getName());LockSupport.unpark(thread);}}}
方案详解
为什么用LockSupport的park()和unpark()而不用Thread.sleep()、Object.wait()、Condition.await()?
- 更简单,不需要获取锁,能直接阻塞线程。
- 更直观,以thread为操作对象更符合阻塞线程的直观定义;
- 更精确,可以准确地唤醒某一个线程(notify随机唤醒一个线程,notifyAll唤醒所有等待的线程);
- 更灵活 ,unpark方法可以在park方法前调用。
第4点很重要,如果不能提前使用unpark()的话,按照代码逻辑最后一个线程会被永久阻塞。
为什么要自建线程池?
CompletableFuture默认的线程池ForkJoinPool.commonPool()偏向于计算密集型任务处理,核心线程数和逻辑CPU数少1,对于多线程事务这种IO密集型任务来说核心线程数偏少。并且上述方法在操作中都是阻塞线程,无法一次性开启全部线程的话,会导致notifyAllThread方法无法执行,老线程阻塞新线程无法开启,就尬住了。
ForkJoinPool基于工作窃取算法,所以最适合的是计算密集型任务,这里我们开启一个参数调整为IO密集型(多核心少队列)的ThreadPoolTaskExecutor线程池即可。
注意MySQL/Druid等数据库的最大连接数
使用多线程的时候也别忘了调整其他组件的最大连接数。Druid线程池这个代码配置可以调,MySQL5.7默认151得用配置文件调整。MySQL最大连接数调整的方法之前从零开始的SQL修炼手册-实战篇有讲解过,欢迎读者们翻翻我之前写的干货。
真实的批量提交
Mybatis与JDBC批量插入MySQL数据库性能测试及解决方案
先贴一个大佬的文章,里面大概讲了Mybatis批量插入和JDBC批量+手动事务的优劣,结论就是小于1W用Mybatis,小于10W且大于1W用JDBC,大于10W必须数据分批。当然我上面多线程做的分批导入肯定是不安全的操作,如果要一次性导入的话根据数据量判断用大佬文章中的代码案例即可。
多线程事务提交方案–使用须知

如果此时数据库连接池配置较小,比如spring.datasource.druid.max-active=10(Druid配置最大连接数为10)。但是我在使用多线程提交时,分批次数为20,那么开了10个之后达到上线就会一直卡住,原因是老的线程挂起不会释放,新的线程因为线程池满了无法创建。因此在使用该方案时一定要估算数据量,分好合适的大小,连接池和数据库的最大连接数也要注意是否匹配。
相关文章:
性能优化-如何爽玩多线程来开发
前言 多线程大家肯定都不陌生,理论滚瓜烂熟,八股天花乱坠,但是大家有多少在代码中实践过呢?很多人在实际开发中可能就用用Async,new Thread()。线程池也很少有人会自己去建,默认的随便用用。在工作中大家对…...
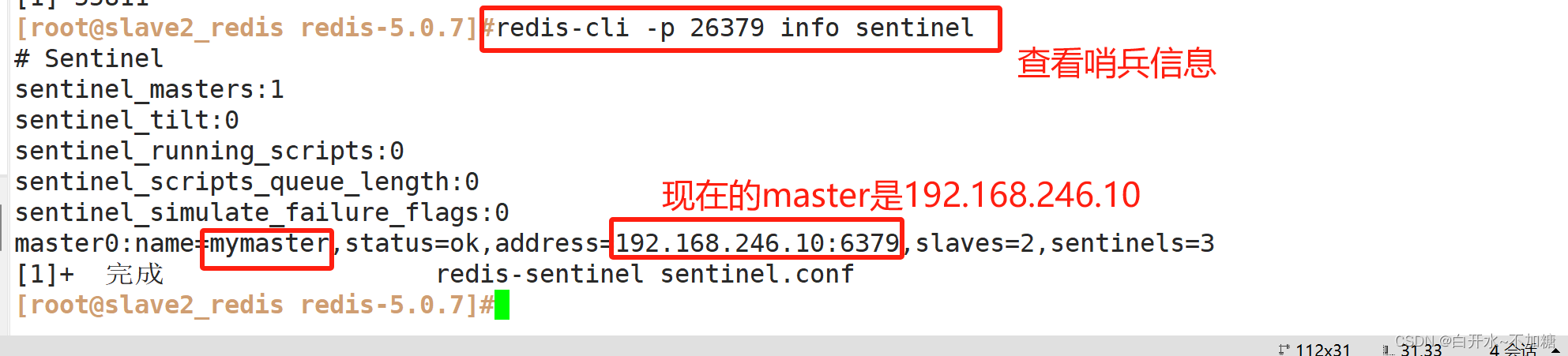
非关系型数据库-----------Redis的主从复制、哨兵模式
目录 一、redis群集有三种模式 1.1主从复制、哨兵、集群的区别 1.1.1主从复制 1.1.2哨兵 1.1.3集群 二、主从复制 2.1主从复制概述 2.2主从复制的作用 ①数据冗余 ②故障恢复 ③负载均衡 ④高可用基石 2.3主从复制流程 2.4搭建redis主从复制 2.4.1环境准备 2.4…...

使用docx4j转换word为pdf处理中文乱码问题
word转pdf 实现方法 mavendocx4j版本自己酌情升级 实现方法 import org.docx4j.Docx4J; import org.docx4j.fonts.IdentityPlusMapper; import org.docx4j.fonts.Mapper; import org.docx4j.fonts.PhysicalFonts; import org.docx4j.openpackaging.packages.WordprocessingMLP…...

【引子】C++从介绍到HelloWorld
C从介绍到HelloWorld 一、C的介绍1. 简介2. 应用场景3. C的标准4. C的运行过程 二、Visual Studio的安装1. 什么是Visual Studio2. Visual Studio的安装 三、完成HelloWorld1.…...
Django检测到会话cookie中缺少HttpOnly属性手工复现
一、漏洞复现 会话cookie中缺少HttpOnly属性会导致攻击者可以通过程序(JS脚本等)获取到用户的cookie信息,造成用户cookie信息泄露,增加攻击者的跨站脚本攻击威胁。 第一步:复制URL:http://192.168.43.219在浏览器打开,…...

2024数字城市建设博览会:一站式平台,满足多元需求
2024数字城市建设博览会:引领未来城市发展的风向标 2024年,一场前所未有的盛会——数字城市建设博览会暨交流大会,将在雄安这座未来之城拉开帷幕。本次大会不仅是数字经济全产业链的精英集结,更是一场汇聚了众多优质项目和丰富客…...
iOS 17.5系统或可识别并禁用未知跟踪器,苹果Find My技术应用越来越合理
苹果公司去年与谷歌合作,宣布将制定新的行业标准来解决人们日益关注的跟踪器隐私问题。苹果计划在即将发布的 iOS 17.5 系统中加入这项提升用户隐私保护的新功能。 科技网站 9to5Mac 在苹果发布的 iOS 17.5 开发者测试版内部代码中发现了这项反跟踪功能的蛛丝马迹…...

关于搭建elk日志平台
我这边是使用docker compose进行的搭建 所以在使用的时候 需要自行提前安装docker以及dockercompose环境 或者从官网下载对应安装包也可以 具体文章看下一章节:【ELK】搭建elk日志平台(使用docker-compose),并接入springboot项目...
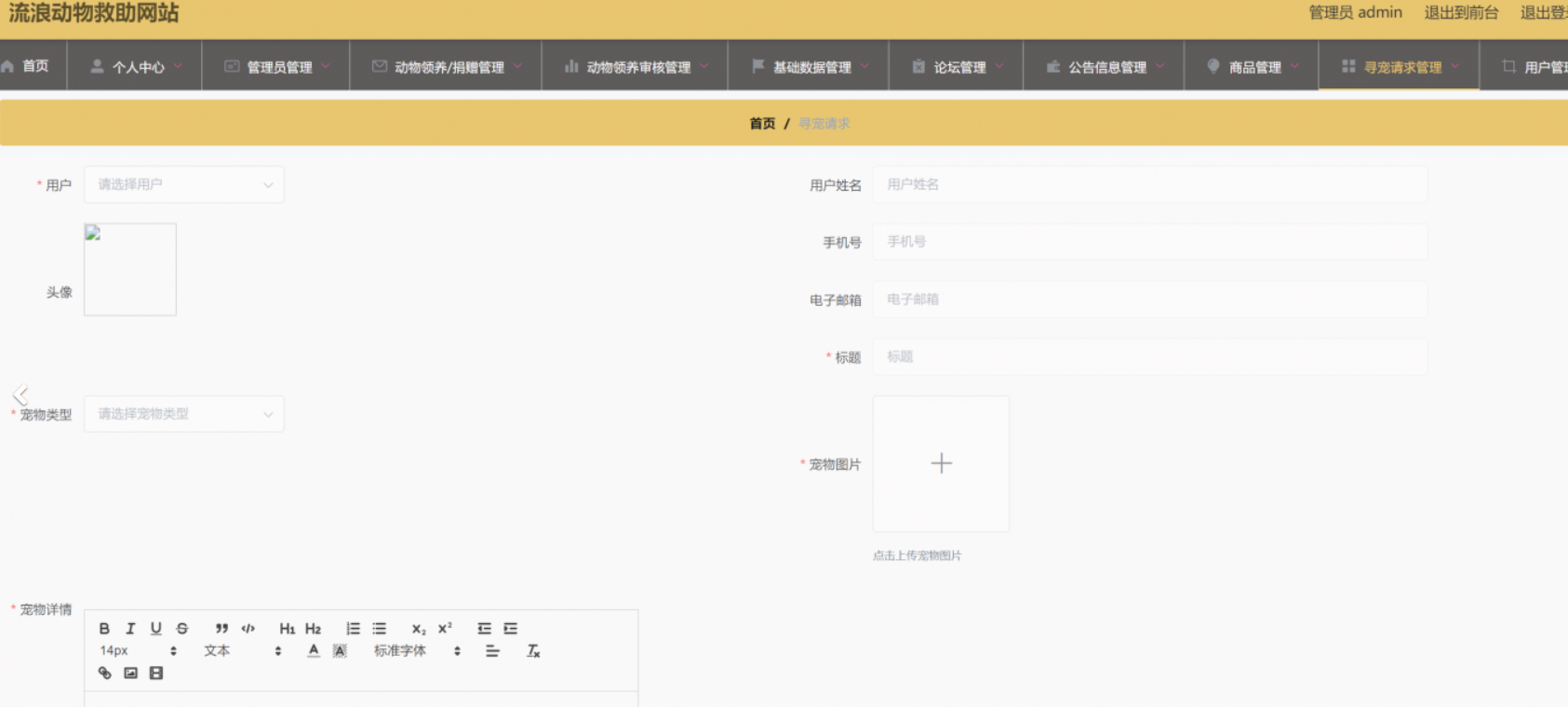
【全套源码教程】基于SpringBoot+MyBatis+Vue的流浪动物救助网站的设计与实现
目录 前言 需求分析 可行性分析 技术实现 后端框架:Spring Boot 持久层框架:MyBatis 前端框架:Vue.js 数据库:MySQL 功能介绍 前台界面功能介绍 动物领养及捐赠 宠物论坛 公告信息 商品页面 寻宠服务 个人中心 购…...
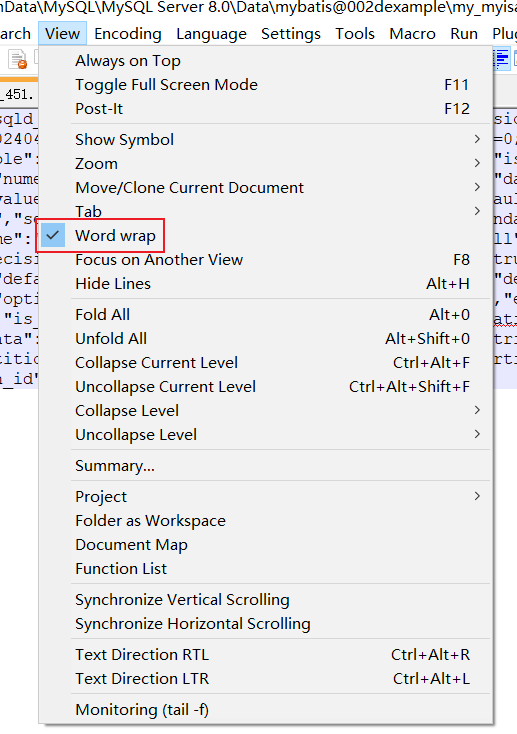
Word wrap在计算机代表的含义(自动换行)
“Word wrap”是一个计算机术语,用于描述文本处理器在内容超过容器边界时自动将超出部分转移到下一行的功能。在多种编程语言和文本编辑工具中,都有实现这一功能的函数或选项。 在编程中,例如某些编程语言中的wordwrap函数,能够按…...

室友打团太吵?一条命令让它卡死
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:更多干货,请关注专栏《网络安全自学教程》 SYN Flood 1、hping3实现SYN Flood1.1、主机探测1.2、扫描端…...

RabbitMQ3.13.x之八_RabbitMQ中数据文件和目录位置
RabbitMQ3.13.x之_RabbitMQ中数据文件和目录位置 文章目录 RabbitMQ3.13.x之_RabbitMQ中数据文件和目录位置1. 概述2. 覆盖位置1. 路径和目录名称限制2.所需的文件和目录权限 3. 环境变量4. Linux、macOS、BSD上的默认位置5. Windows上的默认位置6. 通用二进制构建默认值 1. 概…...
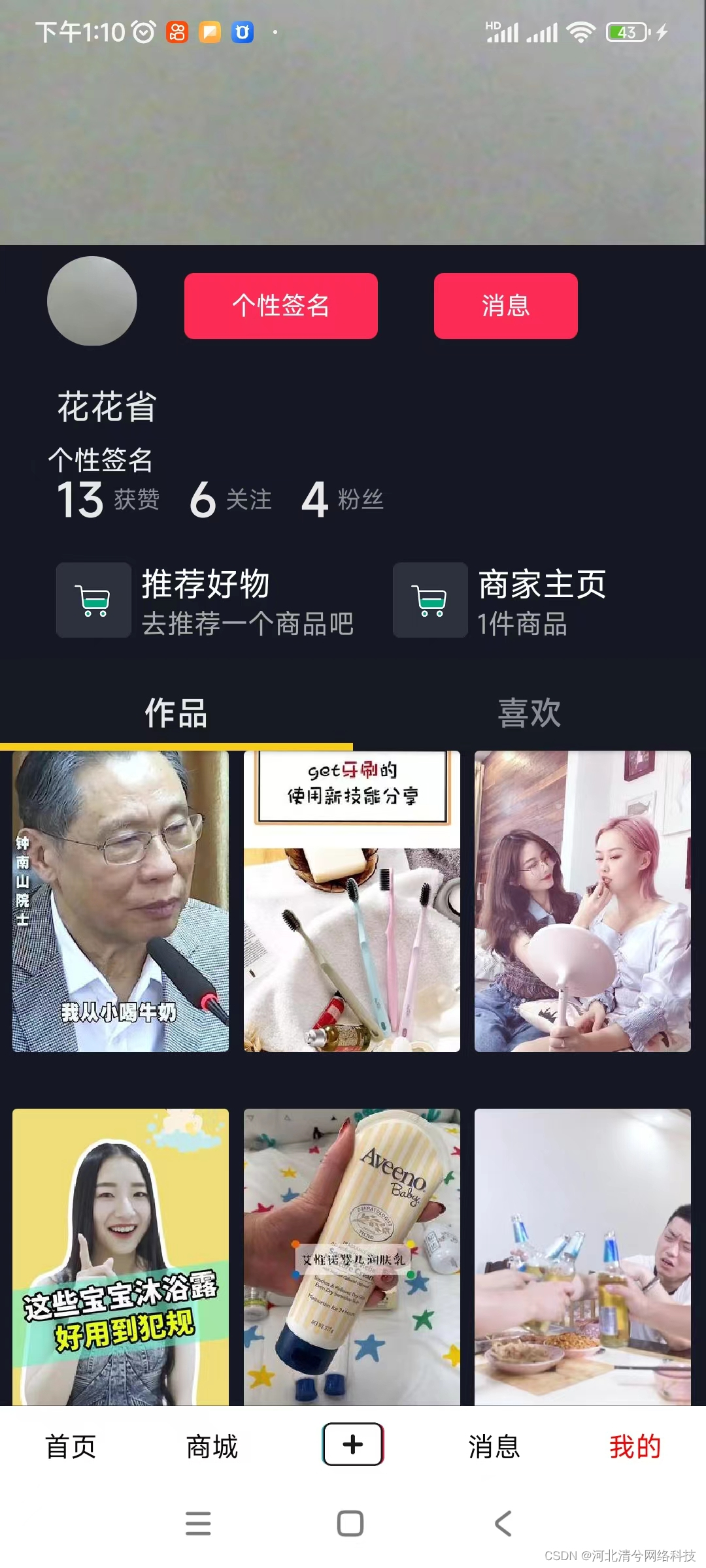
仿抖音短视频直播带货刷一刷商城社交电商源码系统小程序APP开发
系统功能介绍 一、短视频与社交功能 短视频浏览与互动 用户可以浏览仿抖音风格的短视频,包括评论、点赞、进入视频发布者的主页,以及加关注等功能。系统会显示用户关注的好友列表,方便用户快速查看好友发布的视频。用户还可以浏览同城视频&…...

Vue - 你知道Vue组件中的data为什么是一个函数吗
难度级别:中高级及以上 提问概率:80% 在Vue项目中,App.vue下的每个子组件都会生成一个单独的Vue实例对象,但这些子对象都是通过通过vue.extend方法创建而来的,也就是说我们平时在项目中所定义的Vue组件,都有一个相同的父类对象。这样也就…...
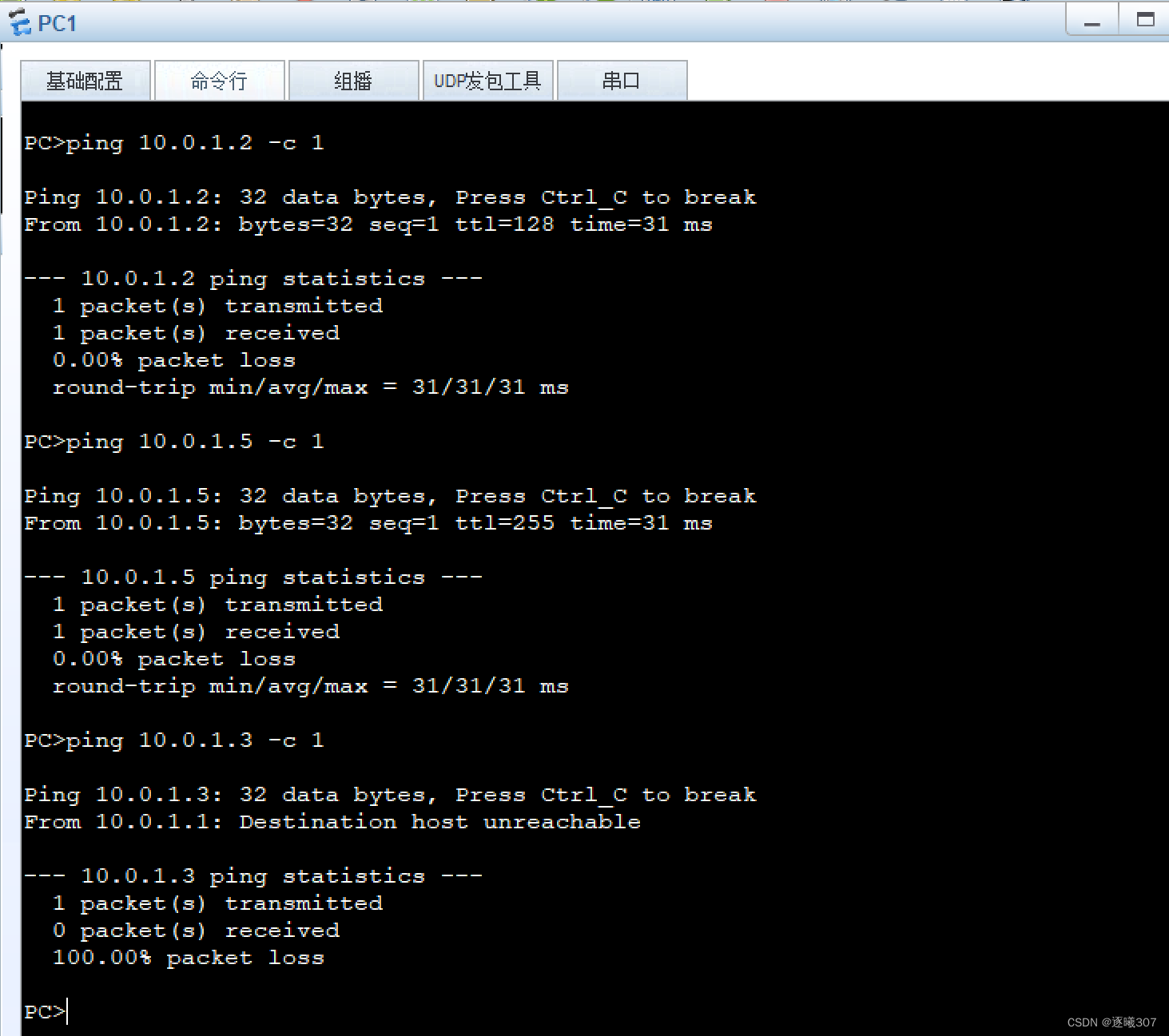
MUX VLAN
目录 原理概述 实验目的 实验内容 实验拓扑 1.基本配置 2.使用Hybrid端口实现网络需求 3.使用Mux VLAN实现网络需求 原理概述 在实际的企业网络环境中,往往需要所有的终端用户都能够访问某些特定的服务器,而用户之间的访问控制规则则比较复杂。在…...

漫谈:“标准”是一种幻觉 C++语言标准的意义
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 “标准”这个词很迷惑…...

【Wbpack原理】基础流程解析,实现 mini-webpack
【Wbpack原理】基础流程解析,实现 mini-webpack ⛄:webpack 对前端同学来说并不陌生,它是我们学习前端工程化的第一站,在最开始的 vue-cli 中我们就可以发现它的身影。我们的 vue/react 项目是如何打包成 js 文件并在浏览器中运行…...

Debian 安装 python 3.9.6
安装相关依赖 sudo apt update sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev curl libbz2-dev 下载Python 源码 wget https://mirrors.aliyun.com/python-release/source/Py…...

搜索二维矩阵2 合并两个有序链表
240. 搜索二维矩阵 II - 力扣(LeetCode) class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int i matrix.size() - 1, j 0;while(i > 0 && j < matrix[0].size()){if(matrix[i][j…...

深入Tauri开发——从环境搭建到项目构建
深入Tauri开发——从环境搭建到项目构建 开启你的Tauri桌面应用开发之旅(续) 经过上一篇文章的基础介绍,现在让我们更进一步,详细阐述如何在Windows和macOS平台上顺利搭建Tauri应用所需的开发环境,并指导您从创建项目…...
)
【算法题攻略】位运算总结(含习题解析)
文章目录一、位运算总结1. 位操作符 和 移位操作符(含原码、反码、补码介绍)2. 给一个数n,确定它的二进制表示中的第 x 位是 0 还是 13. 给一个数n,将它的二进制表示中的第 x 位修改成 1(或 0)4. 提取一个数…...

基于Unsloth与LoRA的高效大语言模型微调工程化实践指南
1. 项目概述:一个为Unsloth优化的AI开发伴侣 如果你最近在折腾大语言模型(LLM)的微调,尤其是想在自己的消费级显卡上跑起来,那你大概率听说过或者正在用Unsloth。这个开源库通过一系列巧妙的优化(比如融合…...
)
第12期:综合优化与结业项目(工程落地与量产调优)
一、本期课程简介本期为整套TinyML嵌入式实战课程的收官总结阶段,旨在帮助学员打通技术壁垒,完成从零散知识点积累到系统化工程落地能力的蜕变。课程将全面梳理前序所有实战项目技术栈,涵盖传感器数据采集、数据集预处理、神经网络模型轻量化…...

第一卷第4章:接口而非实现编程
第一卷第4章:接口而非实现编程 目录介绍 00.先回答上篇思考题 0.1 上篇遗留三道题 0.2 云迁移6万行代码 0.3 五次反转补锅 0.4 灵魂五连问 01.从一个搬迁切入 1.1 上云搬迁案例...

SmartDock:让Android设备拥有桌面级生产力的智能启动器
SmartDock:让Android设备拥有桌面级生产力的智能启动器 【免费下载链接】smartdock A user-friendly desktop mode launcher that offers a modern and customizable user interface 项目地址: https://gitcode.com/gh_mirrors/smar/smartdock 你是否曾经想过…...

FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题
FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题 在嵌入式系统开发中,多任务并发访问共享资源是一个常见且棘手的问题。想象一下这样的场景:你的STM32设备上有两个任务需要向同一个串口发送数据——一个高优先…...

把 Key User 自定义字段纳入 abapGit 管理,让扩展交付真正可追踪
在 SAP S/4HANA Cloud 的扩展项目里,Key User Extensibility 很容易被误解成一种只属于业务顾问的配置能力。打开 Custom Fields 应用,创建字段,选择 business context,启用 UI、报表、API 或表单相关用途,发布字段,业务界面上就多了一个可用字段。这个体验很轻,几乎不像…...

BLE扫描器开发实战:从原始字节解析到IN100设备高效调试
1. 项目概述:从芯片到应用,一个BLE扫描器的诞生去年五月,我们团队独立开发的NanoBeacon™ BLE扫描器移动应用在应用宝正式上架了。这件事本身可能不算惊天动地,但对我们这些从底层芯片一路摸爬滚打上来的工程师来说,意…...

告别手动标注!R语言ggplot2+ggannotate高效绘制组间差异柱状图保姆级教程
R语言科研绘图革命:ggplot2ggannotate自动化差异标注全攻略 科研图表的美观程度直接影响论文的第一印象,而统计显著性标注更是数据可视化的灵魂所在。传统手动添加p值和星号的方式不仅效率低下,还容易出错——标注位置偏移、字体大小不一、连…...

MATLAB浮动许可利用率低:软件许可浪费,提高周转率
说实话,MATLAB浮动许可利用率低这个问题,我真的被老板问爆了。咱们实验室有50个许可,但系统显示平均不到20%在用,剩下的40%天天躺在服务器上吃灰。这事儿让我悟了:软件许可不是你买了就赚了,它要像现金流一…...