【深度学习】最强算法之:深度Q网络(DQN)
深度Q网络
- 1、引言
- 2、深度Q网络
- 2.1 定义
- 2.2 原理
- 2.3 实现方式
- 2.4 算法公式
- 2.5 代码示例
- 3、总结
1、引言
小屌丝:鱼哥, 马上清明小长假了, 你这准备去哪里玩啊?
小鱼:哪也不去,在家待着
小屌丝:在家? 待着? 干啥啊?
小鱼:啥也不干,床上躺着
小屌丝:床上… 躺着… 做啥啊?
小鱼:啥也不做,睡觉
小屌丝:睡觉?? 这大白天的,确定睡觉?
小鱼:我擦… 你这wc~
小屌丝:我很正经的好不好。
小鱼:… 我有点事,待会说
小屌丝: 待会,没时间了哦
小鱼:那就在多几个待会的
小屌丝:这火急火燎的, 肯定"有事"。

2、深度Q网络
2.1 定义
深度Q网络(DQN)是一种结合了深度学习和Q-learning的强化学习算法。它通过深度神经网络逼近值函数,并利用经验回放和目标网络等技术,使得Q-learning能够在高维连续状态空间中稳定学习。
2.2 原理
DQN的核心原理是利用深度神经网络来估计Q值函数。
在每个时刻,DQN根据当前状态s和所有可能的动作a计算出一组Q值,然后选择Q值最大的动作执行。
执行动作后,环境会给出新的状态s’和奖励r,DQN将这些信息存储到经验回放缓存中。
在训练过程中,DQN从经验回放缓存中随机采样一批历史数据,利用这些数据进行梯度下降更新神经网络参数。
此外,DQN还引入了目标网络来稳定学习过程,即每隔一定步数将当前网络参数复制给目标网络,用于计算目标Q值。
2.3 实现方式
实现DQN主要包括以下步骤:
- 初始化深度神经网络(Q网络)和目标网络(目标Q网络)。
- 初始化经验回放缓存。
- 对于每个训练回合:
- 初始化状态s。
- 对于每个时间步t:
- 使用ε-贪婪策略选择动作a。
- 执行动作a,观察奖励r和新状态s’。
- 将经验(s, a, r, s’)存储到经验回放缓存中。
- 从经验回放缓存中采样一批数据,计算损失函数并更新Q网络参数。
- 每隔一定步数更新目标网络参数。
- 重复上述步骤直至满足终止条件。
2.4 算法公式
DQN的损失函数通常采用均方误差(MSE)形式,即:
L ( θ ) = 1 / N ∗ Σ [ ( r + γ ∗ m a x a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) 2 ] L(θ) = 1/N * Σ[(r + γ * max_a' Q(s', a'; θ⁻) - Q(s, a; θ))^2] L(θ)=1/N∗Σ[(r+γ∗maxa′Q(s′,a′;θ−)−Q(s,a;θ))2]
其中,
- θ θ θ是 Q Q Q网络参数,
- θ − θ⁻ θ−是目标网络参数,
- N N N是采样数据批量大小,
- γ γ γ是折扣因子,
- r r r是奖励,
- s s s和 a a a分别是当前状态和动作,
- s ′ s' s′是下一状态,
- a ′ a' a′是下一状态的所有可能动作。
2.5 代码示例
# -*- coding:utf-8 -*-
# @Time : 2024-04-01
# @Author : Carl_DJ'''
实现功能:使用PyTorch框架的简单DQN(Deep Q-Network)实现示例'''
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque# 创建一个简单的神经网络,作为Q网络
class DQN(nn.Module):def __init__(self, input_dim, output_dim):super(DQN, self).__init__()self.net = nn.Sequential(nn.Linear(input_dim, 128),nn.ReLU(),nn.Linear(128, output_dim))def forward(self, x):return self.net(x)# 经验回放
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))return np.array(state), action, reward, np.array(next_state), donedef __len__(self):return len(self.buffer)# DQN算法实现
class DQNAgent:def __init__(self, input_dim, output_dim):self.model = DQN(input_dim, output_dim)self.target_model = DQN(input_dim, output_dim)self.target_model.load_state_dict(self.model.state_dict())self.optimizer = optim.Adam(self.model.parameters())self.buffer = ReplayBuffer(10000)self.steps_done = 0self.epsilon_start = 1.0self.epsilon_final = 0.01self.epsilon_decay = 500self.batch_size = 32def act(self, state):epsilon = self.epsilon_final + (self.epsilon_start - self.epsilon_final) * \np.exp(-1. * self.steps_done / self.epsilon_decay)self.steps_done += 1if random.random() > epsilon:state = torch.FloatTensor(state).unsqueeze(0)q_value = self.model(state)action = q_value.max(1)[1].item()else:action = random.randrange(2)return actiondef update(self):if len(self.buffer) < self.batch_size:returnstate, action, reward, next_state, done = self.buffer.sample(self.batch_size)state = torch.FloatTensor(state)next_state = torch.FloatTensor(next_state)action = torch.LongTensor(action)reward = torch.FloatTensor(reward)done = torch.FloatTensor(done)q_values = self.model(state)next_q_values = self.target_model(next_state)q_value = q_values.gather(1, action.unsqueeze(1)).squeeze(1)next_q_value = next_q_values.max(1)[0]expected_q_value = reward + 0.99 * next_q_value * (1 - done)loss = (q_value - expected_q_value.data).pow(2).mean()self.optimizer.zero_grad()loss.backward()self.optimizer.step()def update_target(self):self.target_model.load_state_dict(self.model.state_dict())# 训练环境设置
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQNAgent(state_dim, action_dim)# 训练循环
episodes = 100
for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)agent.buffer.push(state, action, reward, next_state, done)state = next_statetotal_reward += rewardagent.update()agent.update_target()print('Episode: {}, Total reward: {}'.format(episode, total_reward))解析:
- 首先定义了一个简单的神经网络DQN,
- 然后定义了ReplayBuffer用于经验回放,
- 接着定义了DQNAgent类封装了DQN的决策、学习和目标网络更新逻辑。
- 最后,通过创建一个gym环境(这里使用的是CartPole-v1)并在该环境中运行DQNAgent来进行训练。

3、总结
深度Q网络(DQN)通过将深度学习与强化学习相结合,解决了传统Q-learning在高维连续状态空间中的维度灾难问题。
DQN利用深度神经网络的强大表征能力来估计Q值函数,并通过经验回放和目标网络等技术来稳定学习过程。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,学习【机器学习】&【深度学习】领域的知识。
相关文章:
【深度学习】最强算法之:深度Q网络(DQN)
深度Q网络 1、引言2、深度Q网络2.1 定义2.2 原理2.3 实现方式2.4 算法公式2.5 代码示例 3、总结 1、引言 小屌丝:鱼哥, 马上清明小长假了, 你这准备去哪里玩啊? 小鱼:哪也不去,在家待着 小屌丝:…...
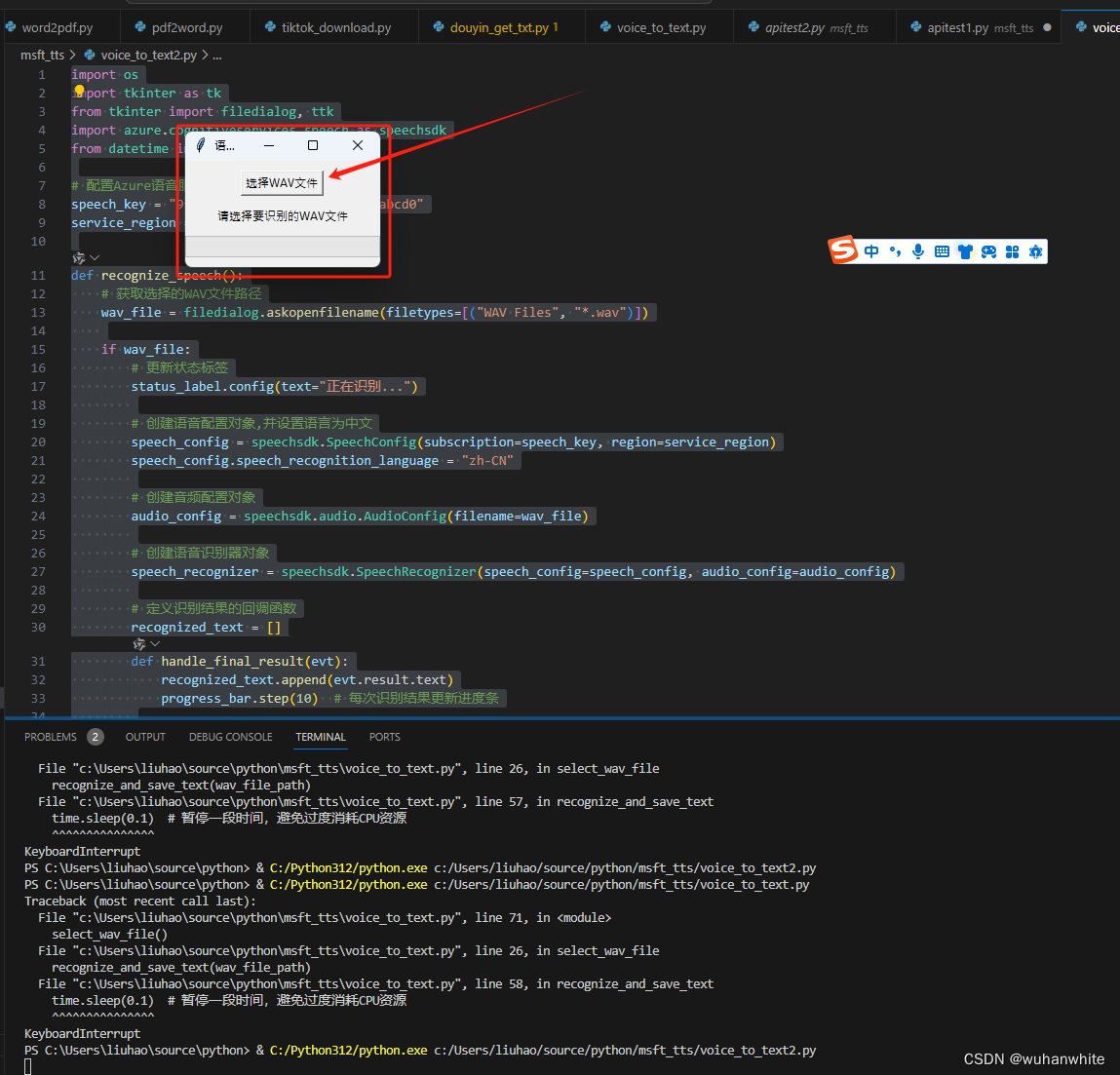
微软文本转语音和语音转文本功能更新,效果显著!
今天我要和大家分享一个新功能更新——微软的文本转语音和语音转文本功能。最近,微软对其AI语音识别和语音合成技术进行了重大升级,效果非常好,现在我将分别为大家介绍这两个功能。 先来听下这个效果吧 微软文本转语音和语音转文本功能更新 …...

充场拉新工作室保证金靠谱吗?找一手渠道是否免费?
在当前的互联网经济中,充场拉新工作室作为一种新兴的创业项目,吸引了众多创业者的关注。然而,关于是否需要支付保证金、加盟费,以及如何寻找免费的充场拉新一手渠道,许多人仍然存在疑问。 本文将为您提供专业的解答&a…...
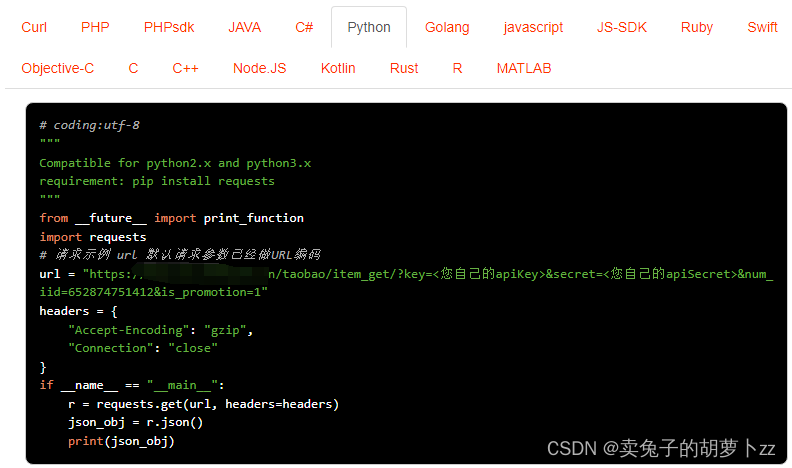
揭秘淘宝商品详情数据接口(Taobao.item_get)
淘宝商品详情数据接口(Taobao.item_get)是一种允许开发者通过API访问淘宝平台上的商品详情信息的接口。通过该接口,开发者可以获取到商品的标题、价格、销量、描述等详细信息,为商品展示和销售提供数据支持。 请求示例࿰…...

Linux从入门到精通 --- 4(上).快捷键、软件安装、systemctl、软链接、日期和时区、IP地址
文章目录 第四章(上):4.1 快捷键4.1.1 ctrl c 强制停止4.1.2 ctrl d 退出4.1.3 history4.1.4 历史命令搜索4.1.5 光速移动快捷键4.1.6 清屏 4.2 软件安装4.2.1 yum4.2.2 apt 4.3 systemctl4.4 软链接4.4.1 ln 4.5 日期和时区4.5.1 date命令4.5.2 date进行日期加减…...
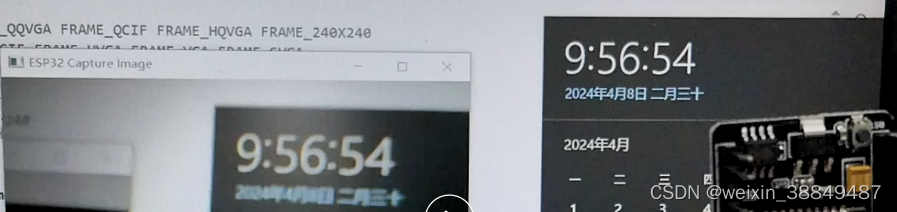
ESP32调试笔记
目录 基于Thonny和micropythonESP32-CAM开发板无法连接Thonnyesp32cam局域网图传esp32代码上位机代码 基于Thonny和micropython ESP32-CAM开发板无法连接Thonny esp32cam有两个模式:下载模式、运行模式 两种模式的接线不同 IO0 短路 GND ! 正是因为两种模式接线…...

python -- NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+
报错分析 完整的报错:urllib3 v2 only supports OpenSSL 1.1.1, currently the ssl module is compiled with LibreSSL 2.8.3. See: https://github.com/urllib3/urllib3/issues/3020报错分析:LibreSSL 是 OpenSSL 的一个分支,LibreSSL 2.8.…...

解决nginx代理后,前端拿不到后端自定义的header
先说结论,因为前端和nginx对接,所以需要在nginx添加如下配置向前端暴露header add_header Access-Control-Expose-Headers Authorization 排查过程 1.后端设置了Authorization 的响应头作为token的返回,前后端本地联调没有问题 response.s…...
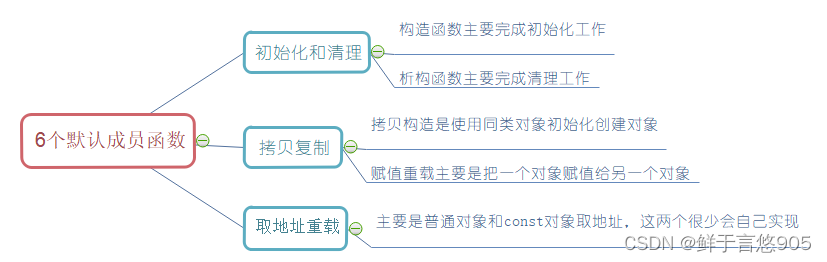
C++从入门到精通——类的6个默认成员函数之构造函数
构造函数 前言一、构造函数的概念二、构造函数特性 前言 类的6个默认成员函数:如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数…...
整数删除)
第十四届蓝桥杯省赛大学B组(C/C++)整数删除
原题链接:整数删除 给定一个长度为 N 的整数数列:A1,A2,...,AN。 你要重复以下操作 K 次: 每次选择数列中最小的整数(如果最小值不止一个,选择最靠前的),将其删除,并把与它相邻的…...

openGauss学习笔记-257 openGauss性能调优-使用Plan Hint进行调优-Custom Plan和Generic Plan选择的Hint
文章目录 openGauss学习笔记-257 openGauss性能调优-使用Plan Hint进行调优-Custom Plan和Generic Plan选择的Hint257.1 功能描述257.2 语法格式257.3 示例 openGauss学习笔记-257 openGauss性能调优-使用Plan Hint进行调优-Custom Plan和Generic Plan选择的Hint 257.1 功能描…...

智慧校园|智慧校园管理小程序|基于微信小程序的智慧校园管理系统设计与实现(源码+数据库+文档)
智慧校园管理小程序目录 目录 基于微信小程序的智慧校园管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、微信小程序前台 2、管理员后台 (1)学生信息管理 (2) 作业信息管理 (3)公告…...
【信贷后台管理之(五)】
文章目录 目录结构一、面包屑组件封装二、退出登录接口联调三、申请列表的菜单路由3.1 路由创建,表格编写3.2 列表接口调用3.3 出生日期转变3.4 申请状态3.5 申请列表的操作3.5.1 编辑删除提交操作3.5.2 禁用状态3.5.3 操作接口3.5.4 搜索查询3.5.5 申请列表分页功能…...

C++ 动态字符串String的介绍及经典用法展示
std::string: 在C中,std::string是标准模板库(STL)中的一个类,用于表示和操作字符串。std::string提供了丰富的功能来处理文本数据,包括字符串的创建、修改、搜索、比较和转换等操作。 std::string的特点:…...

.NET Standard、.NET Framework 、.NET Core三者的关系与区别?
.NET Standard、.NET Framework 和 .NET Core 是 .NET 平台生态中的三个关键概念,它们之间存在明确的关系和显著的区别。下面分别阐述它们各自的角色以及相互间的关系: .NET Standard 角色: .NET Standard 是一套正式的 API 规范,…...

【国产AI持续突破带动互联网智能生态进入正循环】
2022年底ChatGPT横空出世带动AI产业大规模崛起,人工智能领域技术如雨后春笋一般迅速发芽,随着各领域不断深入探索AI大模型,该技术开始发展成新质生产力,在这个以数据驱动的新时代,AI芯片已成为新的战略资源,…...

全志 Linux Qt
一、简介 本文介绍基于 buildroot 文件系统的 QT 模块的使用方法: • 如何在 buildroot 工具里编译 QT 动态库; • 编译及运行 qt_demo 应用程序; • 适配过程遇到的问题。 二、QT动态库编译 在项目根路径执行 ./build.sh buildroot_menuc…...
微功耗数据监测终端可应用在哪些场景?
随着科技的飞速发展,绿色、低碳、可持续已成为当代社会发展的重要主题。微功耗电池供电遥测终端机,正是这一时代背景下的杰出代表。它采用先进的微功耗技术,有效延长电池使用寿命,减少频繁更换电池的麻烦,同时降低能源…...
Windows下Docker安装Kafka3+集群
编写 docker-compose.yaml 主要参照:https://www.cnblogs.com/wangguishe/p/17563274.html version: "3"services:kafka1:image: bitnami/kafka:3.4.1container_name: kafka1environment:- KAFKA_HEAP_OPTS-Xmx1024m -Xms1024m- KAFKA_ENABLE_KRAFTyes- K…...

关于前端资源文件打包问题
可以使用webpack CopyWebpackPlugin插件 CopyWebpackPlugin是一个用于在构建过程中共复制文件和文件夹的Webpack插件。可以帮助我们将特定的文件或文件夹从源目录复制到构建目录,使得这些文件能够在输出的bundle中被访问到。 使用步骤: 1、安装CopyWeb…...

OpenClaw Provider Manager:统一管理第三方服务的微服务治理框架
1. 项目概述与核心价值最近在折腾一些自动化流程和微服务治理,发现一个挺普遍但处理起来又有点琐碎的问题:如何高效、统一地管理那些分散在各个角落的第三方服务提供商(Provider)?比如短信发送、邮件推送、对象存储、支…...
M.2 SSD系统迁移实战:从克隆到无缝启动)
【玩转Jetson TX2 NX】(四)M.2 SSD系统迁移实战:从克隆到无缝启动
1. 为什么需要将系统迁移到M.2 SSD? Jetson TX2 NX作为一款嵌入式AI计算设备,默认搭载的eMMC存储空间往往捉襟见肘。我在实际项目中发现,16GB的eMMC在安装完JetPack系统后,剩余空间连一个中等规模的深度学习模型都放不下。更不用…...

程序员的“黄金5年”:如何快速成为技术骨干
一、认知黄金5年:测试工程师的职业分水岭在软件行业,“黄金5年”是从业者职业发展的关键期,对于软件测试工程师而言更是如此。这5年不仅是技术能力从量变到质变的积累期,更是职业方向从模糊到清晰的定型期。据行业数据显示&#x…...

终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南
终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://…...

3个关键指标揭示:你的游戏手柄响应速度是否拖了后腿?
3个关键指标揭示:你的游戏手柄响应速度是否拖了后腿? 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 在竞技游戏的激烈对决中,每一毫秒的…...

树莓派驱动MAX31855热电偶传感器:从SPI通信到高精度测温实践
1. 项目概述:从热电偶到Python读数在嵌入式开发、工业监控或者任何需要精确测温的项目里,热电偶(Thermocouple)往往是工程师们的首选传感器。它结构简单、皮实耐用,而且测温范围能从零下两百多度一直覆盖到上千度&…...

5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南
5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南 【免费下载链接】UnityGaussianSplatting Toy Gaussian Splatting visualization in Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityGaussianSplatting 想象一下,你花费数小时扫…...

3大核心功能解密:HS2-HF_Patch如何让Honey Select 2游戏体验焕然一新
3大核心功能解密:HS2-HF_Patch如何让Honey Select 2游戏体验焕然一新 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在玩Honey Select 2却…...

AI工作流编排框架aiflows:构建模块化、可维护的多智能体系统
1. 项目概述:当AI工作流成为团队协作的“操作系统”如果你和我一样,在过去几年里尝试过将多个大语言模型(LLM)串联起来,构建一个能处理复杂任务的智能体(Agent)或工作流,那你一定经历…...

基于Arduino Yun的DIY无线安防摄像头:运动检测、云端同步与实时流媒体
1. 项目概述与核心价值 手头有个闲置的Arduino Yun和USB摄像头,一直琢磨着怎么把它们利用起来,做个有点意思的东西。市面上那些无线监控摄像头功能是挺全,但总觉得少了点“掌控感”,数据存在哪里、怎么访问,都得听厂家…...