【数据结构】考研真题攻克与重点知识点剖析 - 第 6 篇:图
前言
- 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。
- 此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术有限,最终数据清洗结果不够理想,相关CSDN文章便没有发出。
(考研真题待更新)
欢迎订阅专栏:408直通车
请注意,本文中的部分内容来自网络搜集和个人实践,如有任何错误,请随时向我们提出批评和指正。本文仅供学习和交流使用,不涉及任何商业目的。如果因本文内容引发版权或侵权问题,请通过私信告知我们,我们将立即予以删除。
文章目录
- 前言
- 第六章 图
- 图的定义及基本术语
- 概念
- 基本术语
- 小结
- 图的存储结构
- 邻接矩阵法
- 小结
- 邻接表法
- 十字链表法(有向图)
- 邻接多重表(无向图)
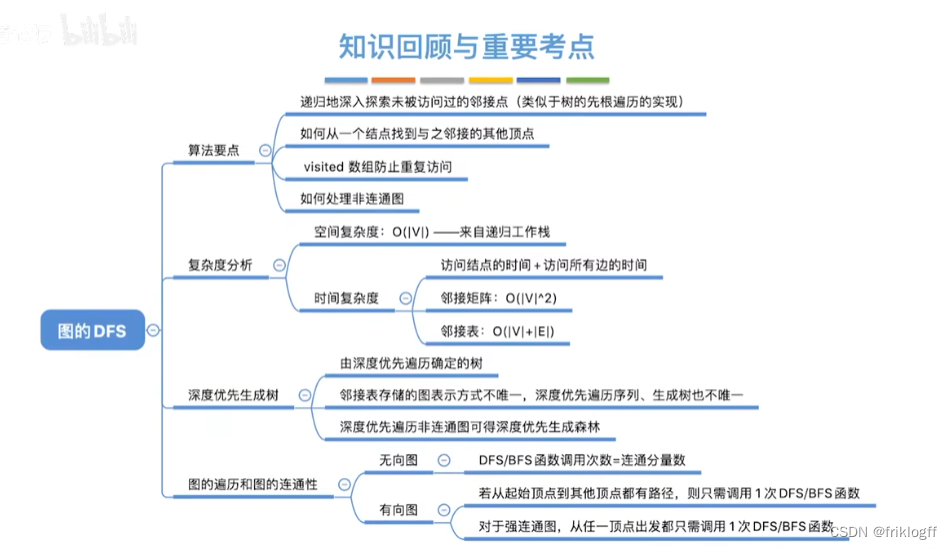
- 图的遍历
- 广度优先搜索
- 小结
- 深度优先搜索
- 小结
- 图的应用
- 最小生成树
- 最短路径
- BFS求无权图的单源最短路径
- Dijkstra算法(两点间最短路径)
- Floyd算法(各顶点之间最短路径)
- 小结
- 有向无环图的应用
- 有向无环图描述表达式
- 拓扑排序(AOV网)
- 逆拓扑排序(AOV网)
- 小结
- 关键路径(AOE网)
- 小结
- 代码
- 图的存储结构
- 图的遍历
- 最短路径问题导图
- 最小生成树与二分图导图
第六章 图
图的定义及基本术语
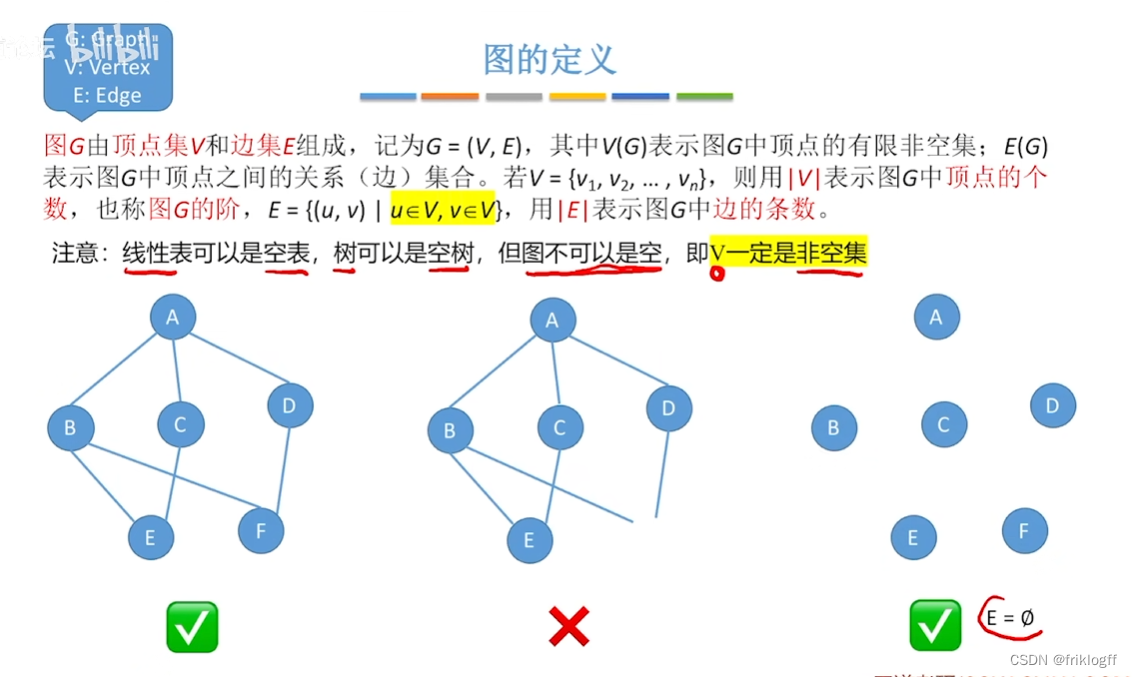
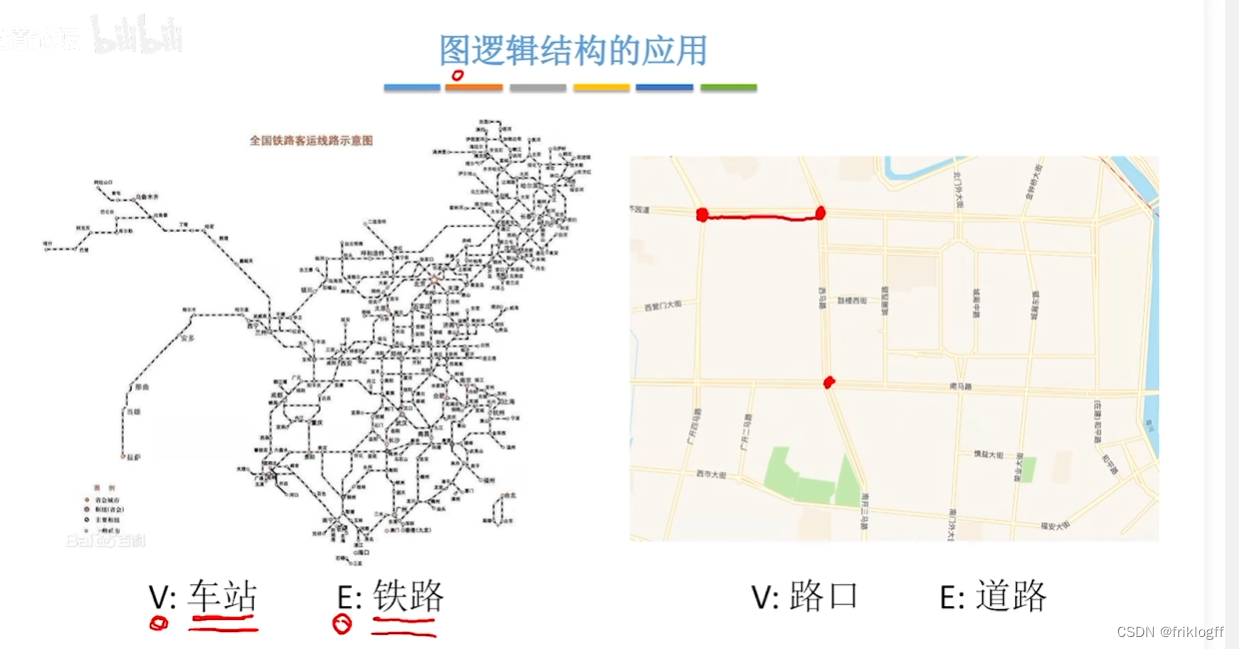
概念
- 图G由顶点集V和边集E组成,记G=(V, E),其中V(G)表示图G中顶点的有限非空集;E(G)表示图G中顶点之间的关系(边)集合
基本术语
-
关系及路径术语
-
邻接:有边/弧相连的两个顶点之间的关系(无向图的边:(vi, vj),有向图的边:<vi, vj>)
-
关联(依附):边/弧与顶点之间的关系
-
顶点的度:与该顶点相关联的边的数目,记为TD(v)
有向图中,顶点的度等于该顶点的入度和出度之和
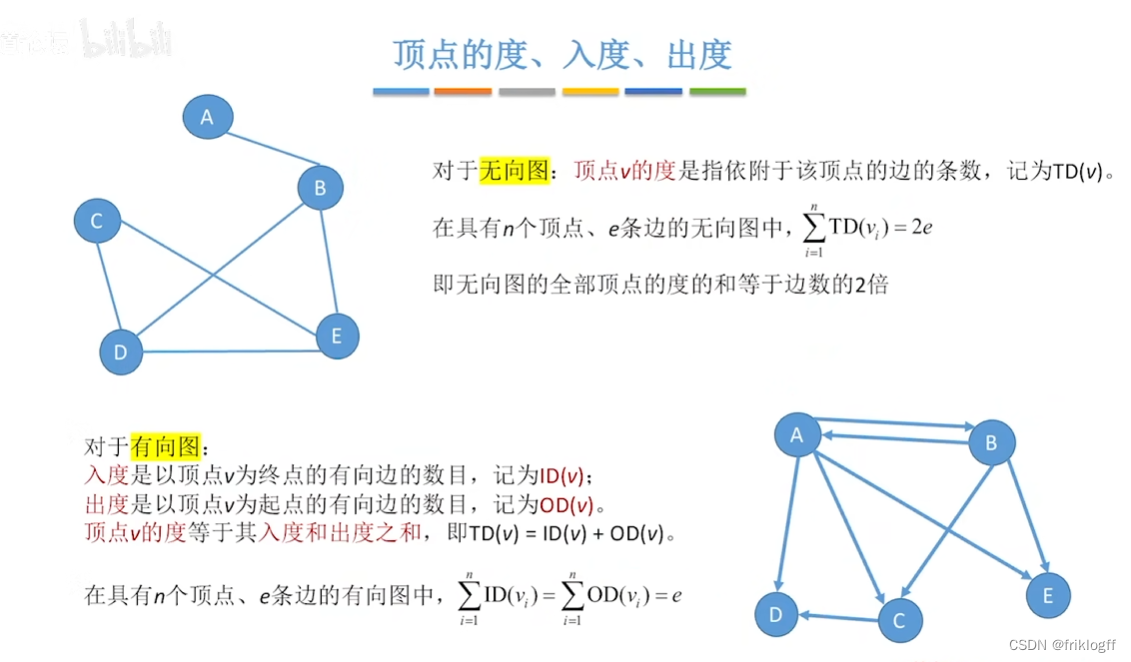
-
路径:连续的边构成的顶点序列
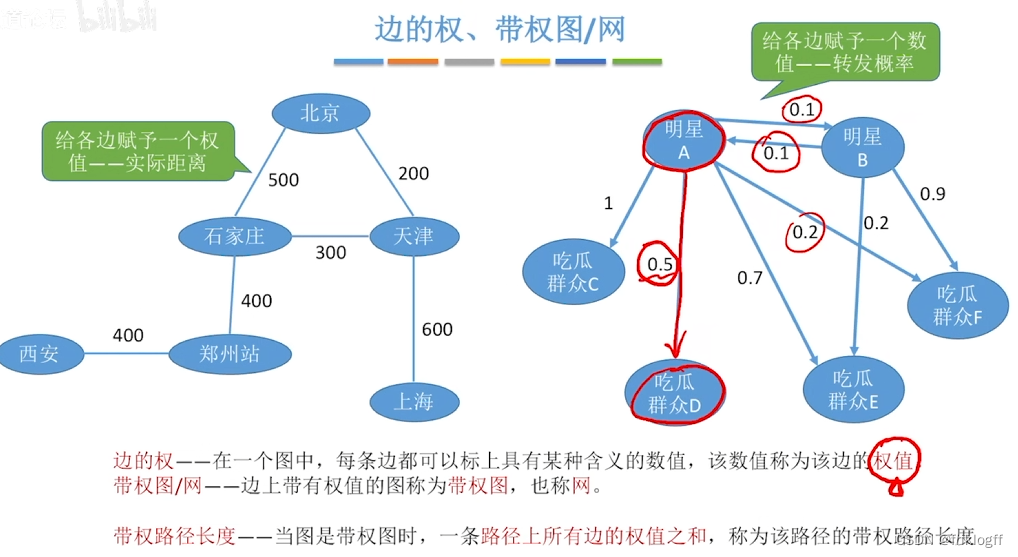
路径长度:路径上边或弧的数目/权值之和 -
回路(环):第一个顶点和最后一个顶点相同的路径
-
简单路径:除路径起点和终点可以相同外,其余顶点均不相同的路径
简单回路(简单环):除路径起点和终点相同外,其余顶点均不相同的路径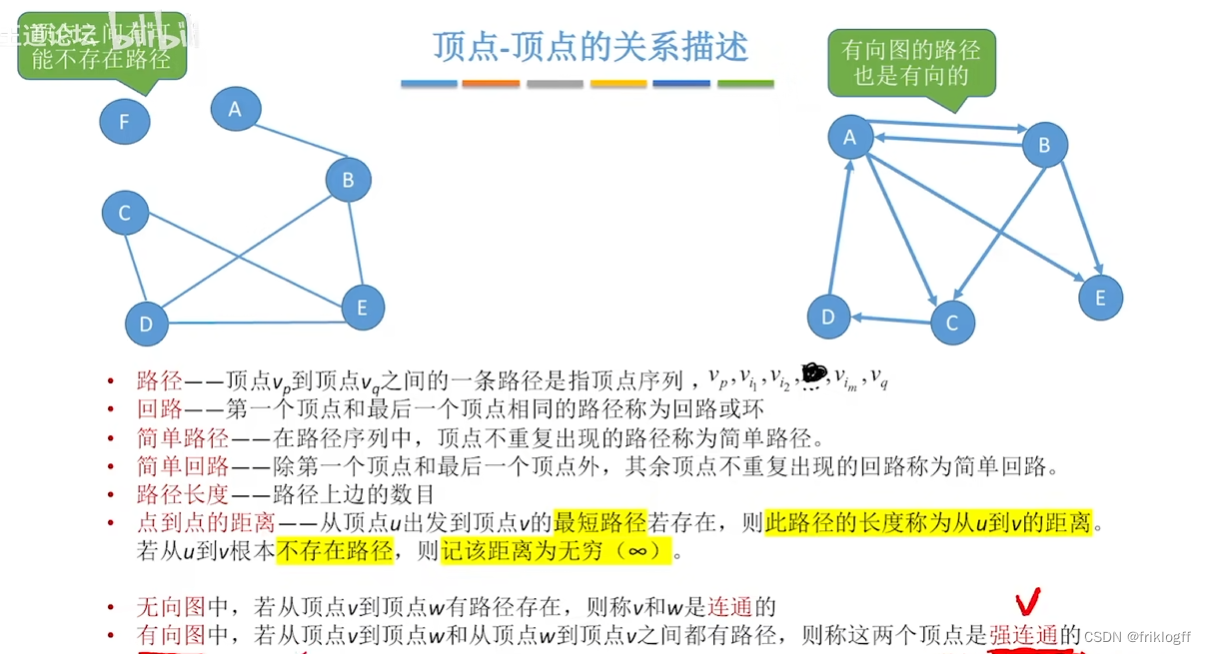
-
-
图的术语
-
无向图:每条边都是无方向的
有向图:每条边都是有方向的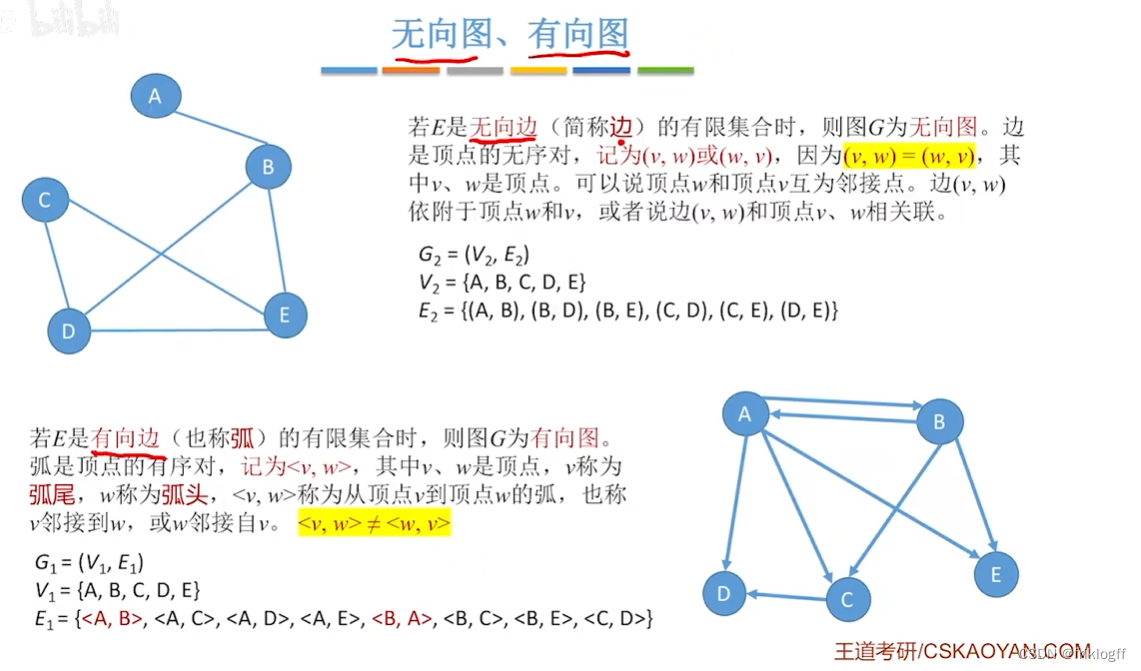
-
简单图:不存在重复边,不存在顶点到自身的边
多重图:反之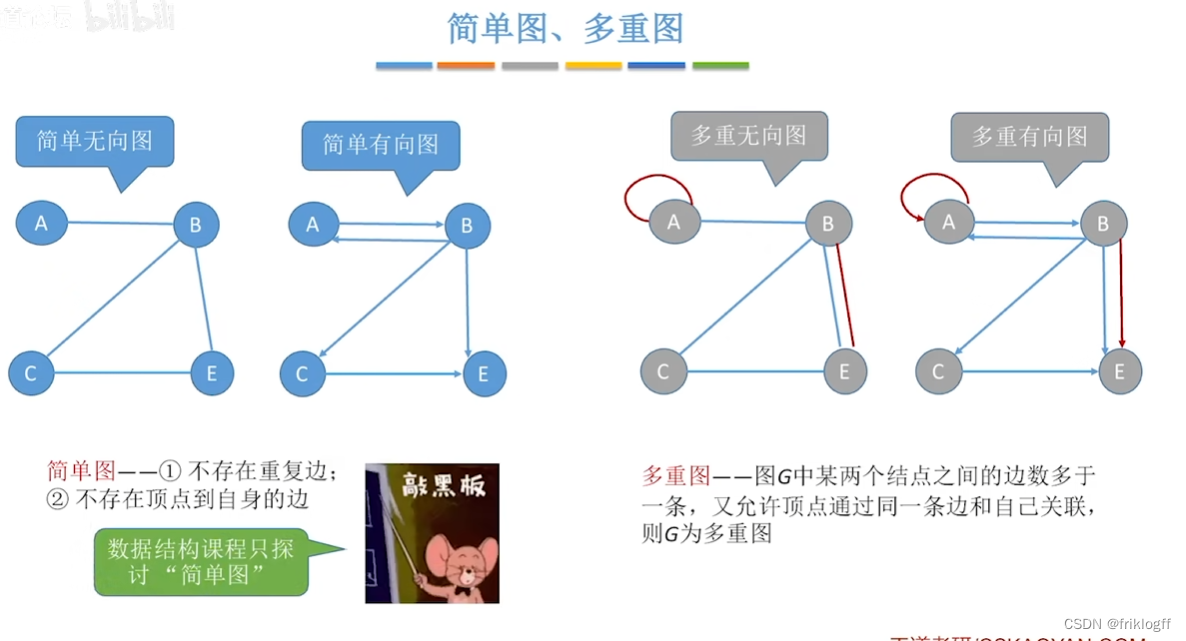
-
子图:设有两个图G=(V, E)和G’=(V’, E’),若V’是V的子集,且E’是E的子集,则称G’是G的子图
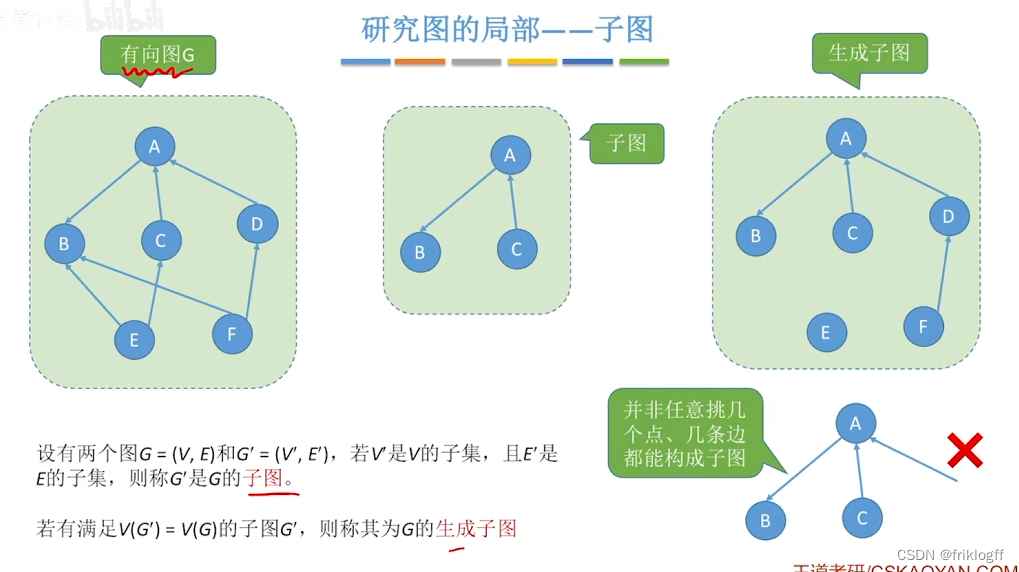
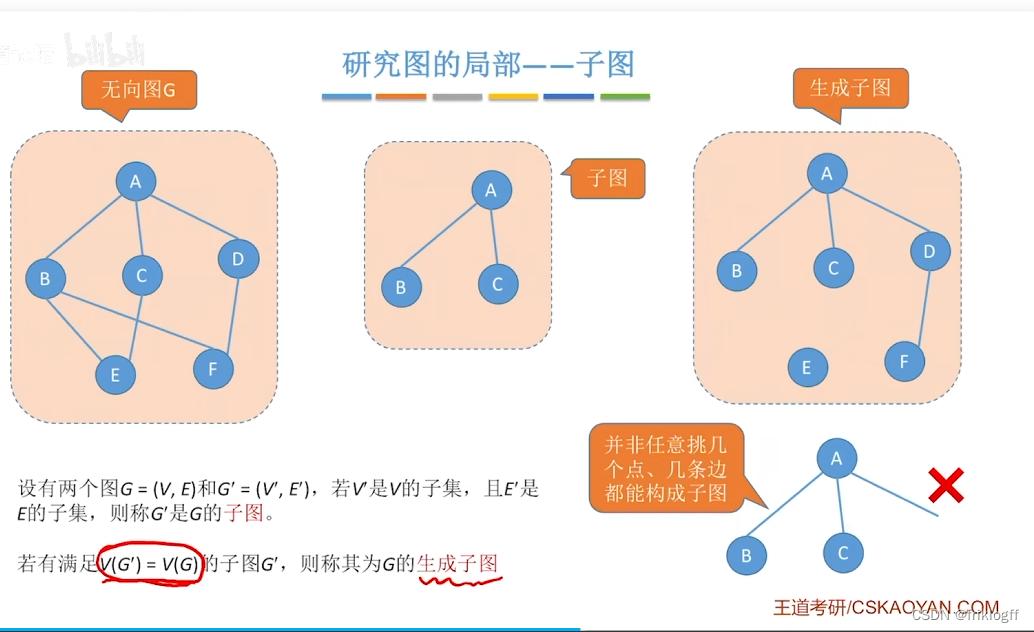
-
网:边/弧带权的图
-
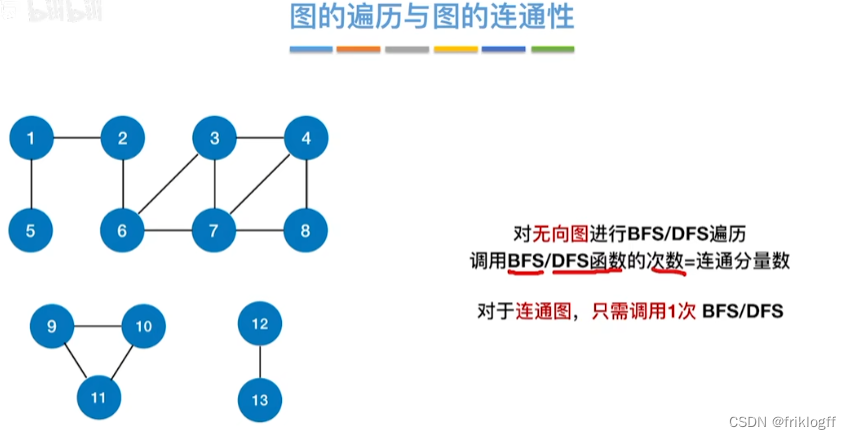
连通图(强连通图):在无(有)向图中,若对任何两个顶点v,u都存在从v到u的路径,则G是连通图(强连通图)
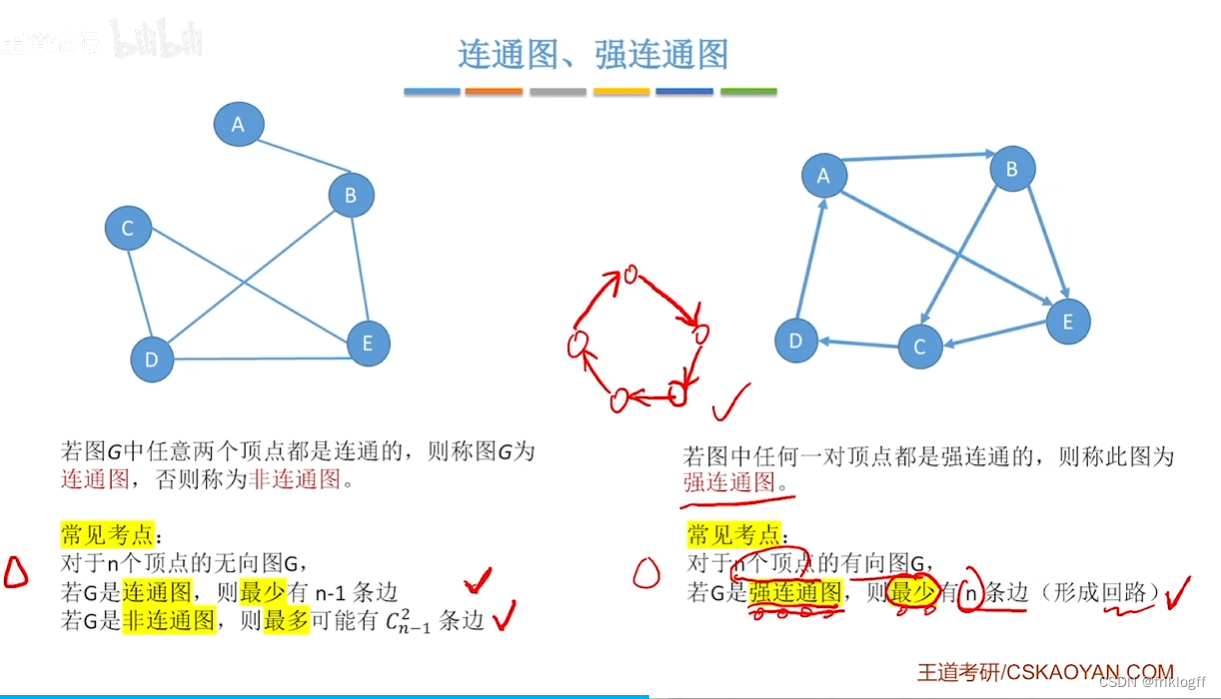
-
-
子图相关术语
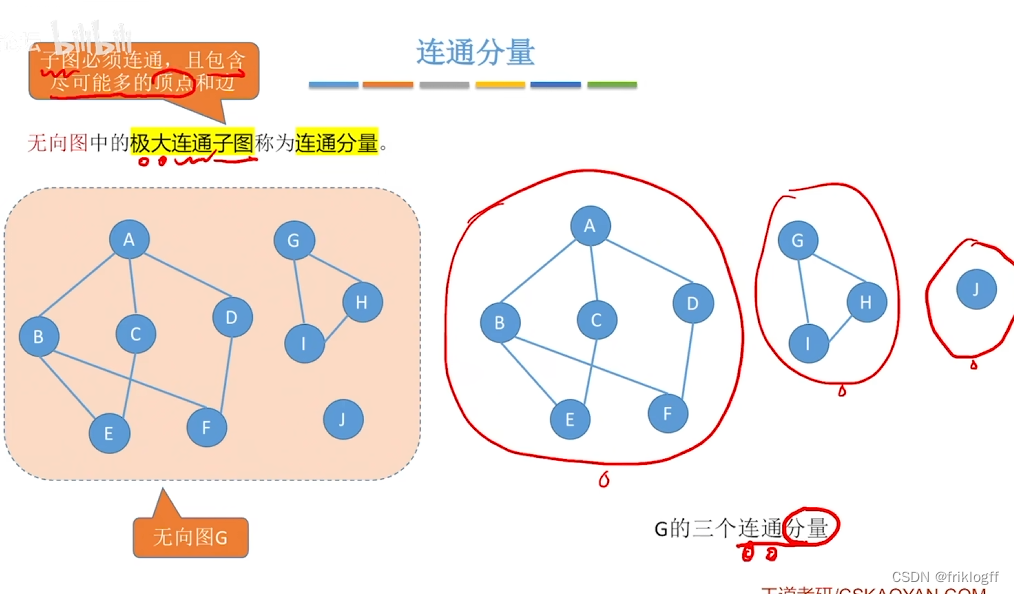
-
连通分量/极大连通子图:该子图是G连通子图,将G的任何不在该子图的顶点加入,子图不再连通
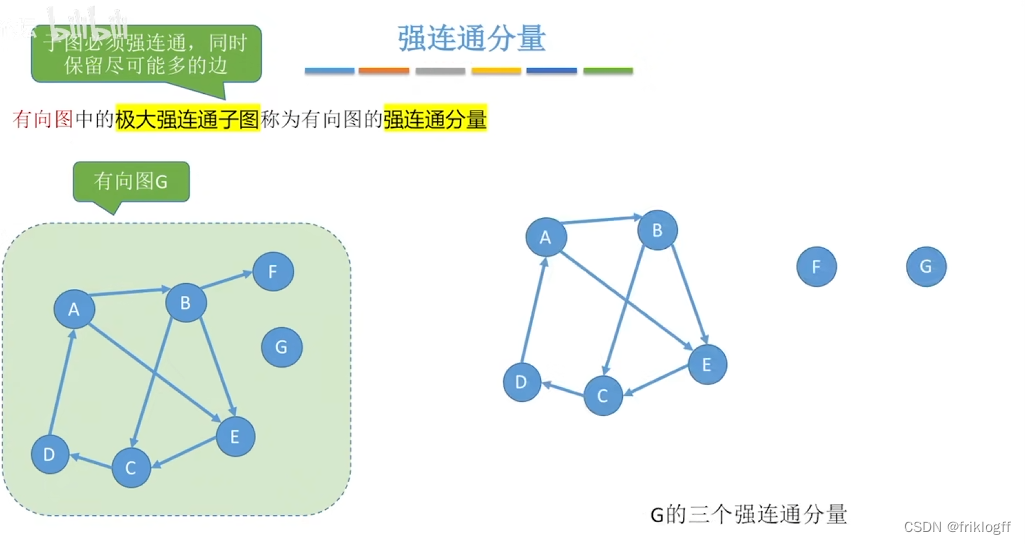
强连通分量/极大强连通子图:该子图是G强连通子图,将G的任何不在该子图的顶点加入,子图不再强连通
-
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边,子图不再连通
-
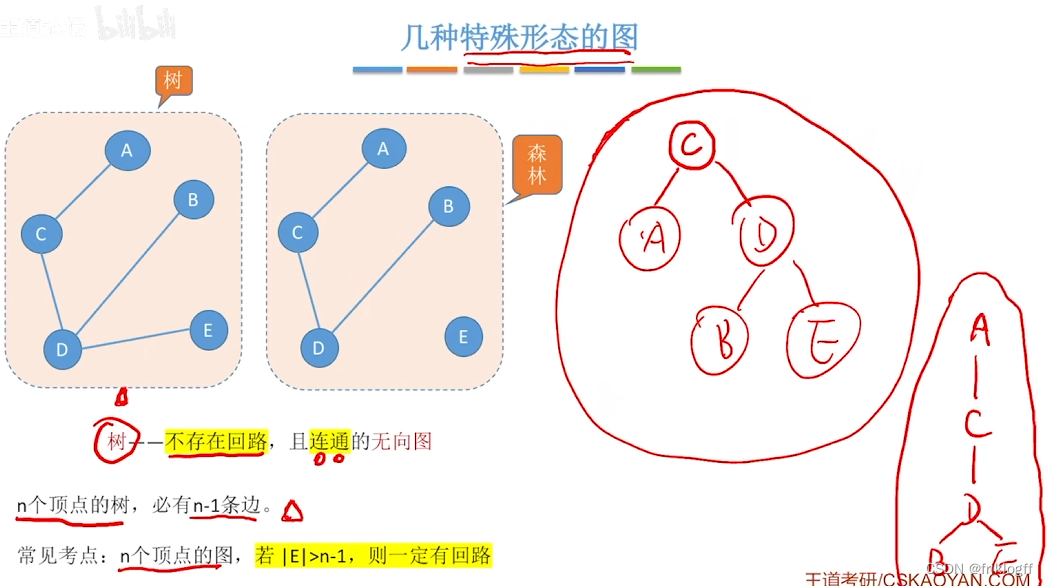
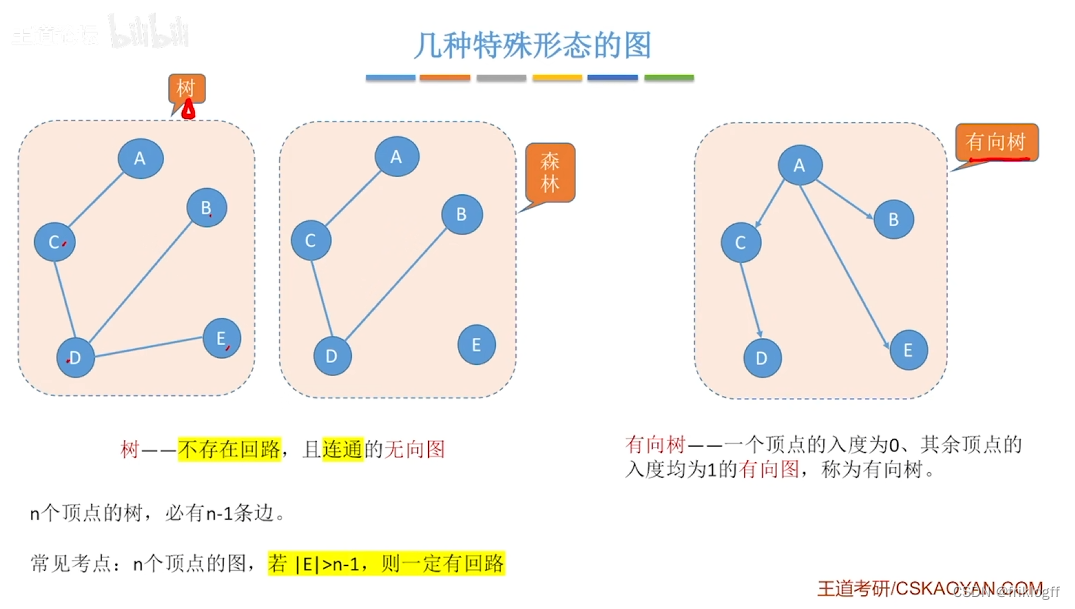
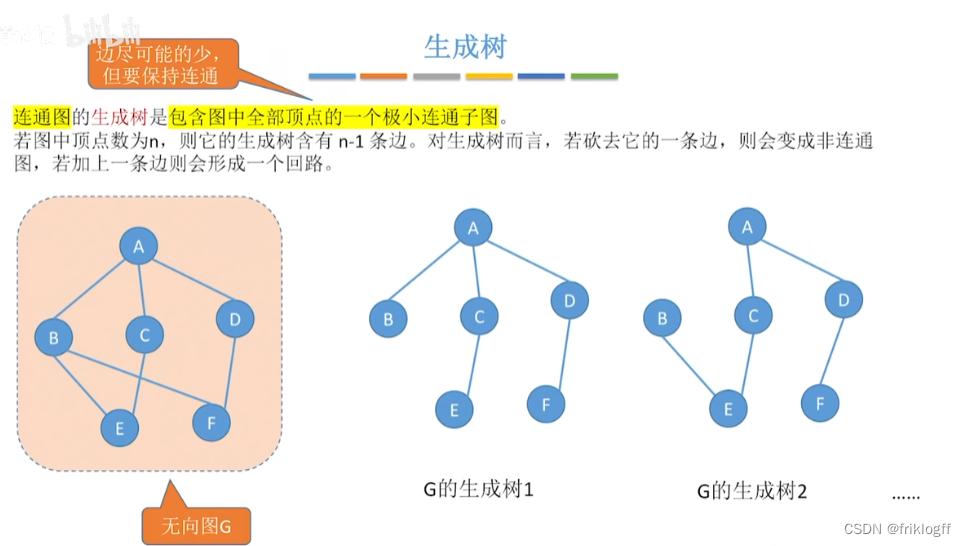
生成树:包含无向图G所有顶点的极小连通子图
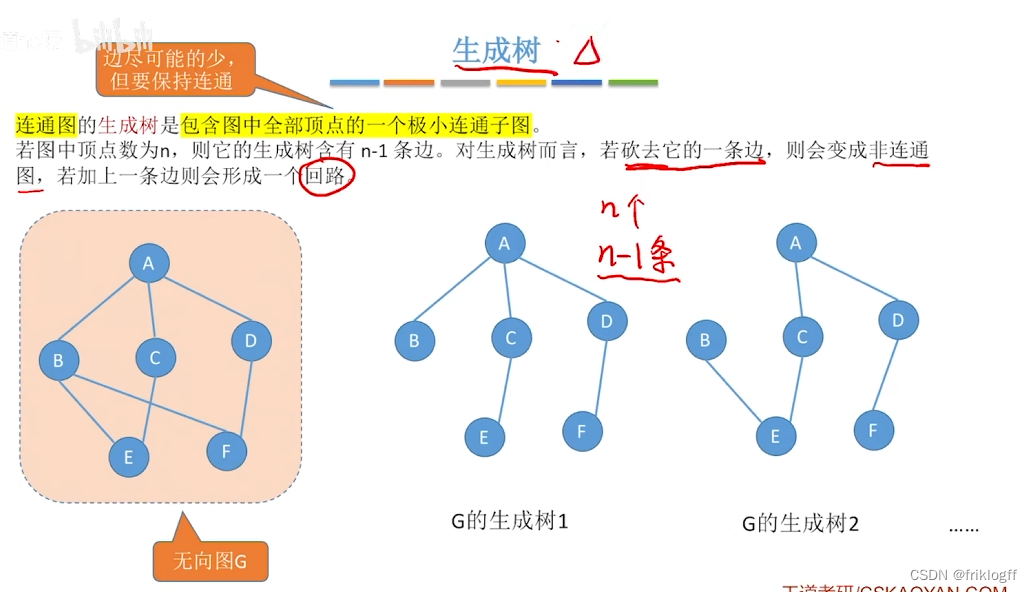
-
生成森林,对非连通图,由各个连通分量的生成树的集合
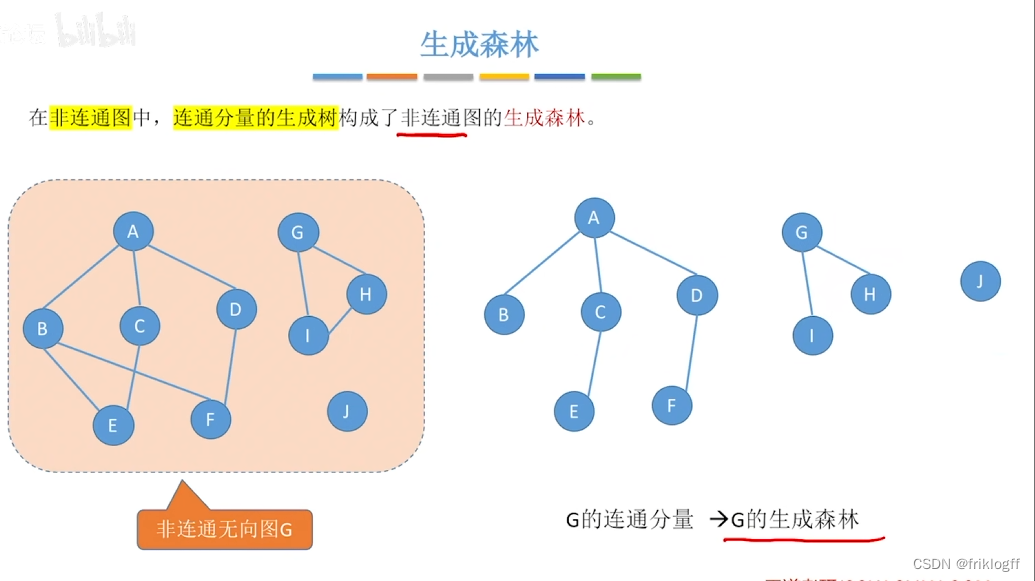
-
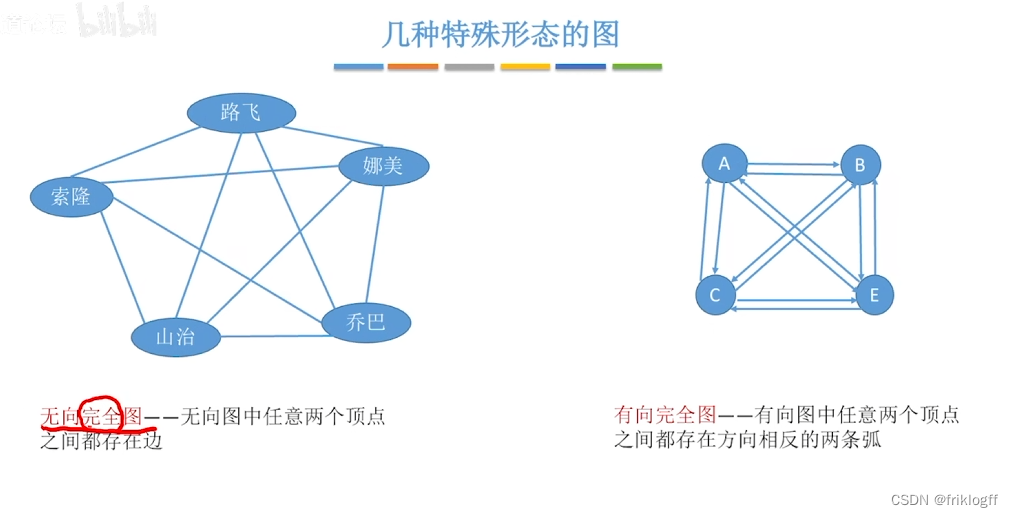
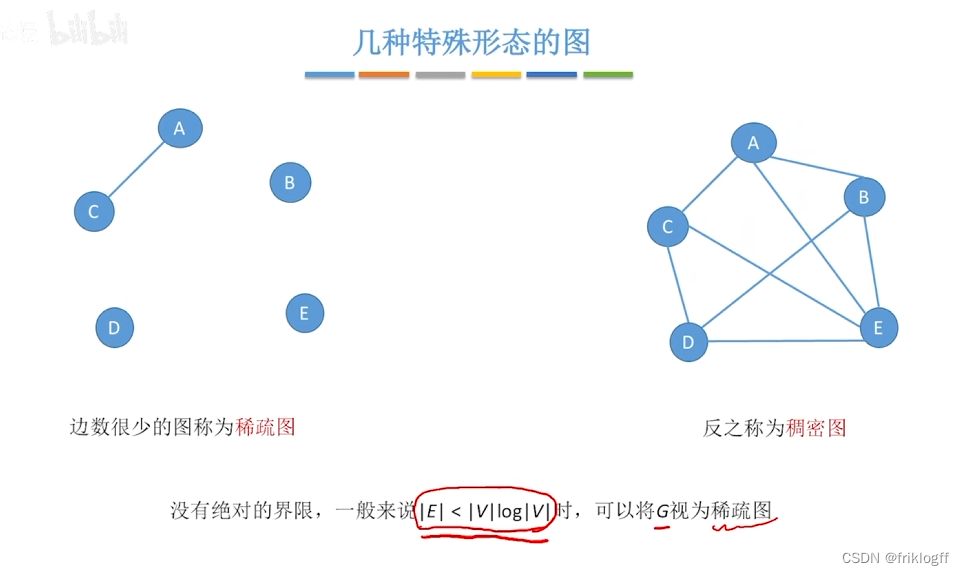
- 无向完全图:任意两个点都有一条边
- 有向完全图:任意两个点都有两条边
- 稀疏图:有很少边或弧的图(e<nlogn)
- 稠密图:有较多边或弧的图
小结

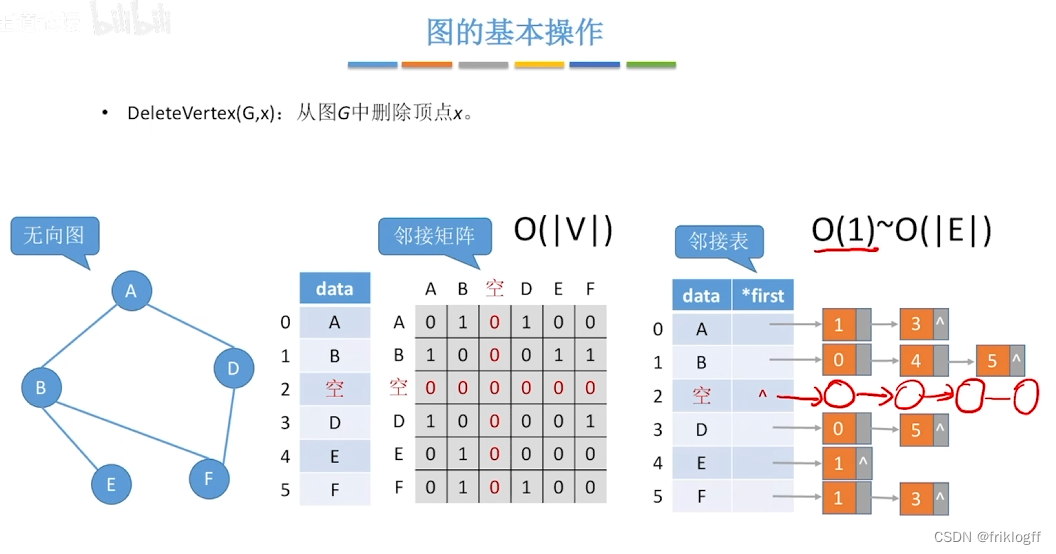
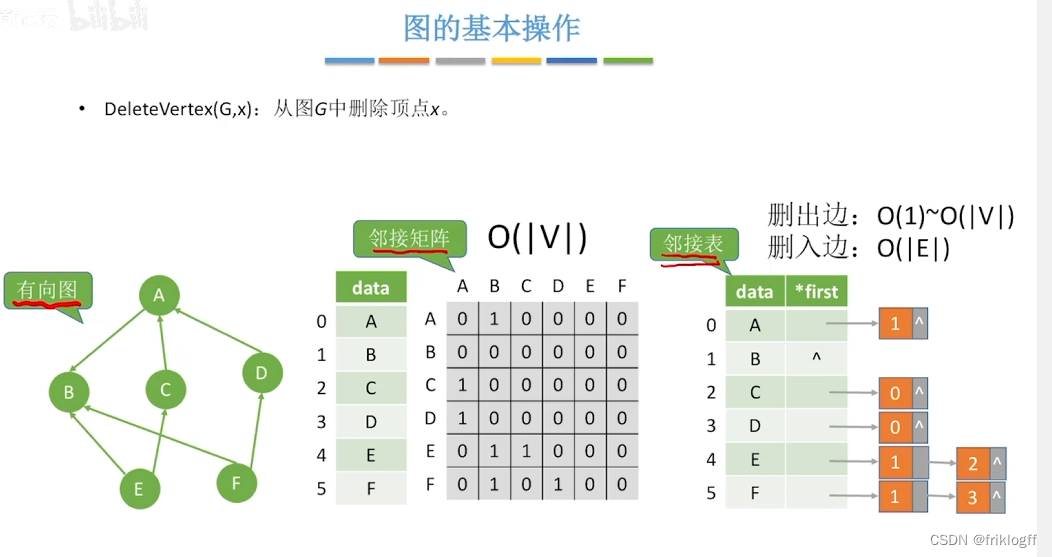
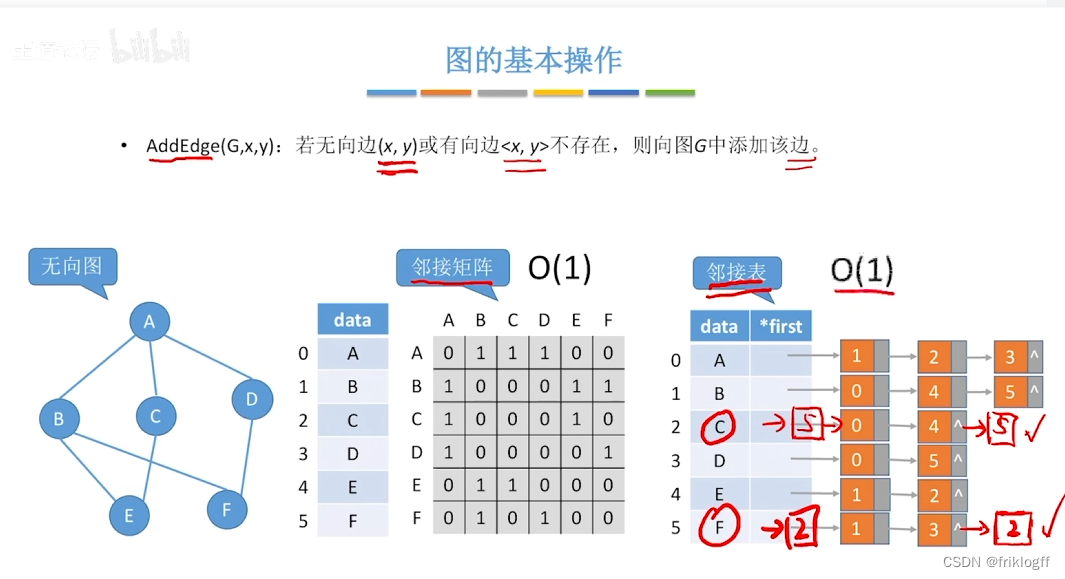
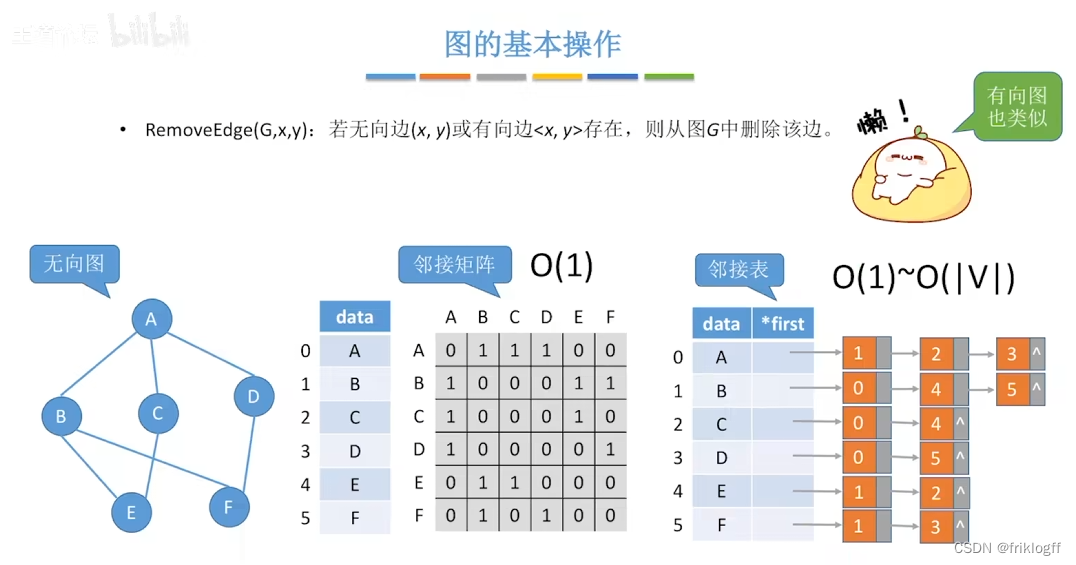
图的存储结构
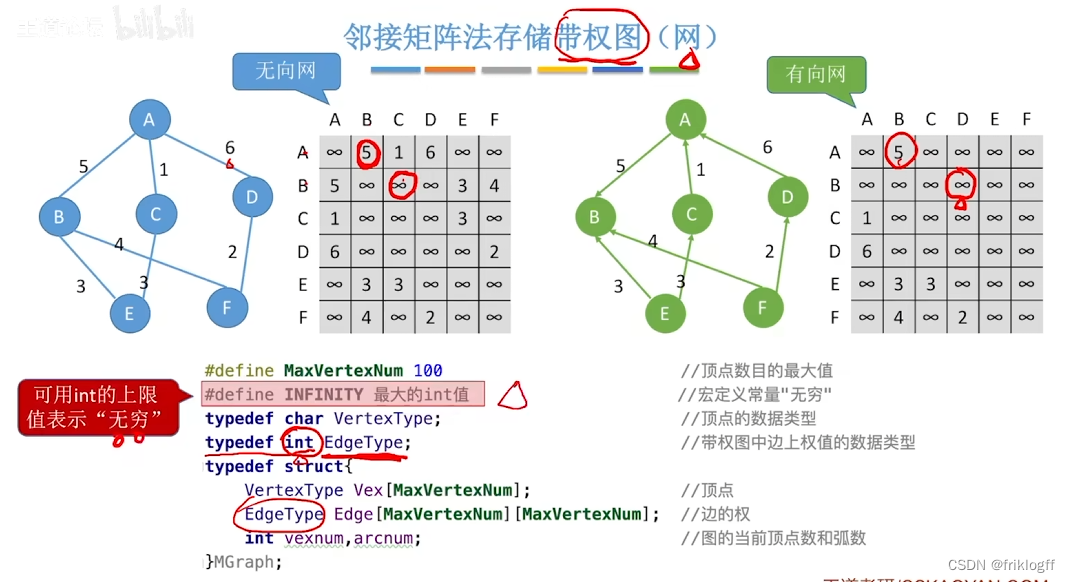
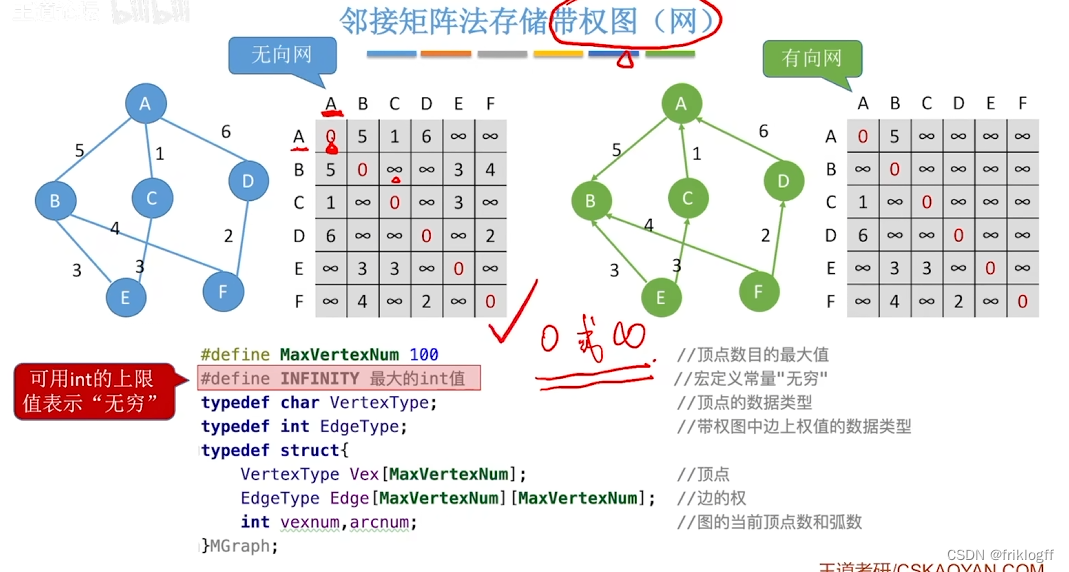
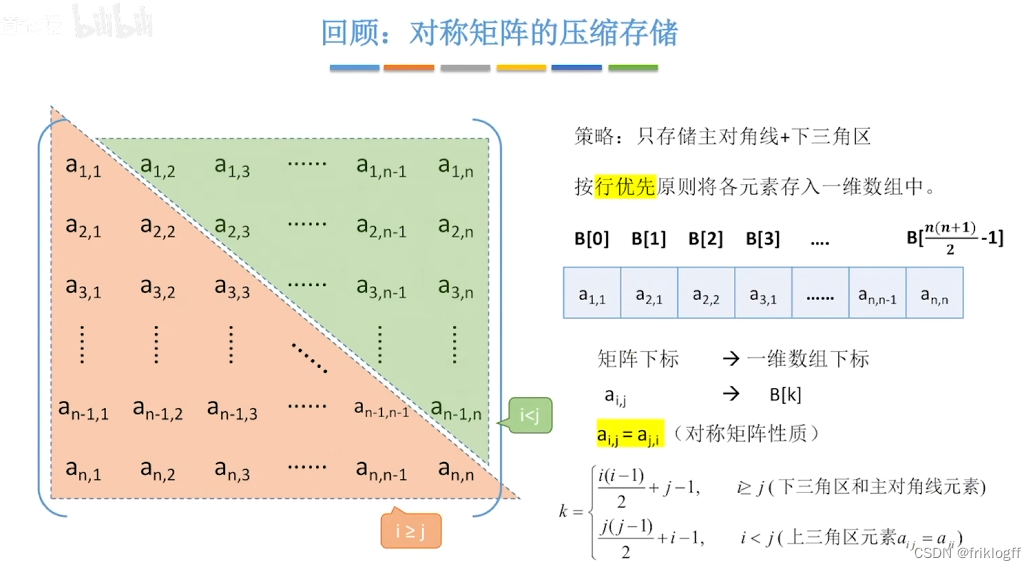
邻接矩阵法
-
概念
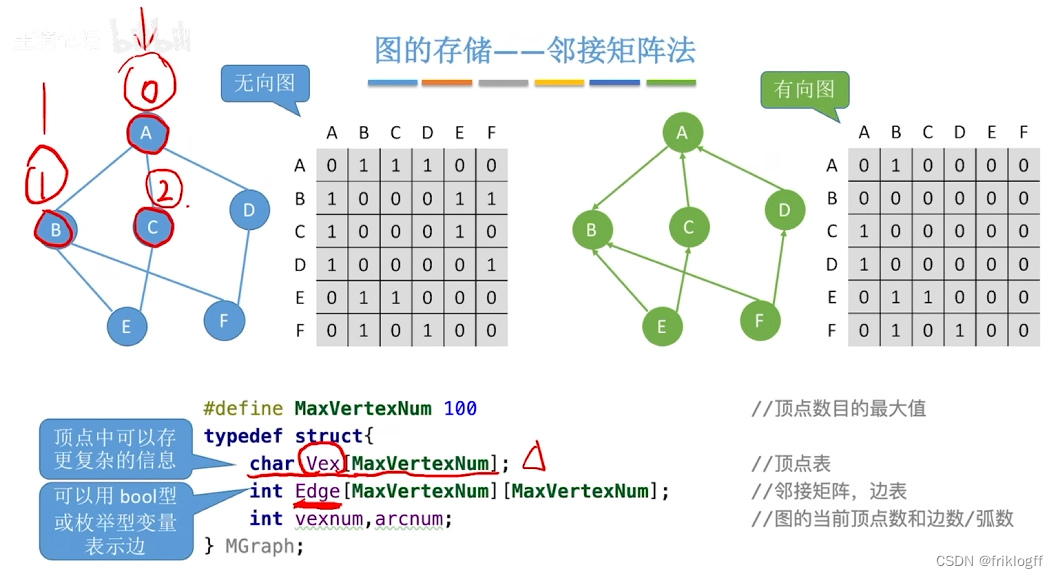
- 是指用一个一位数组存储图中顶点的信息,用一个二维数组存储图中边的信息(邻接关系),二维数组即邻接矩阵
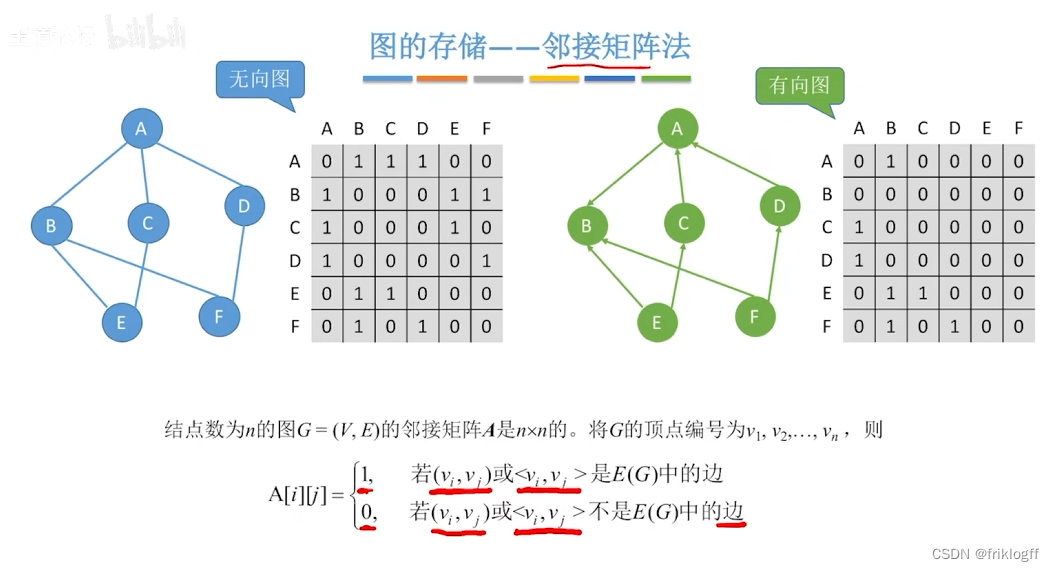
- 是指用一个一位数组存储图中顶点的信息,用一个二维数组存储图中边的信息(邻接关系),二维数组即邻接矩阵
-
无向图
-

-
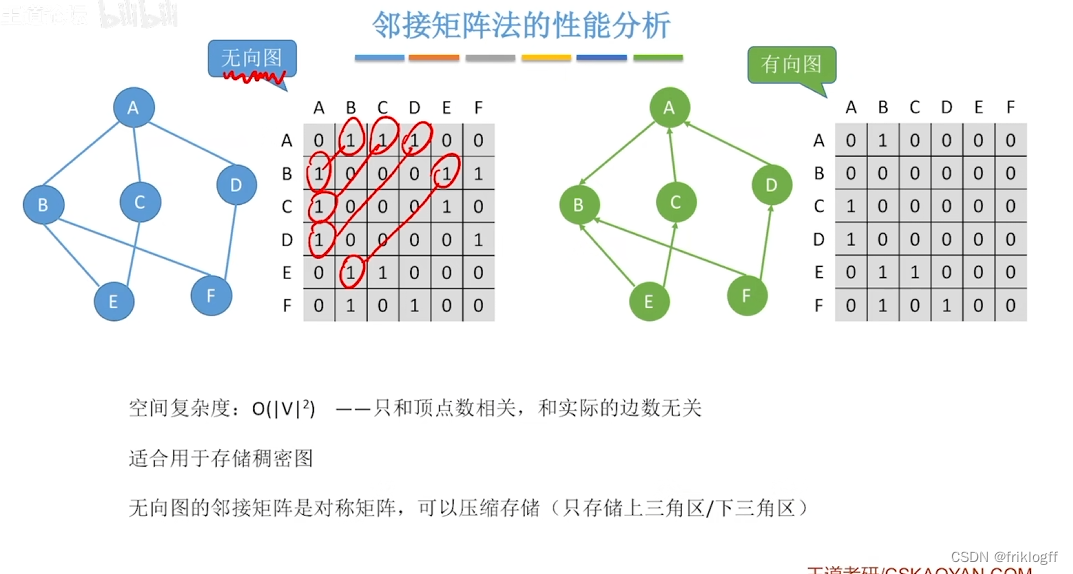
无向图的邻接矩阵是对称的
-
顶点i的度=第i行(或第i列)中1的个数
-
-
-
有向图
-
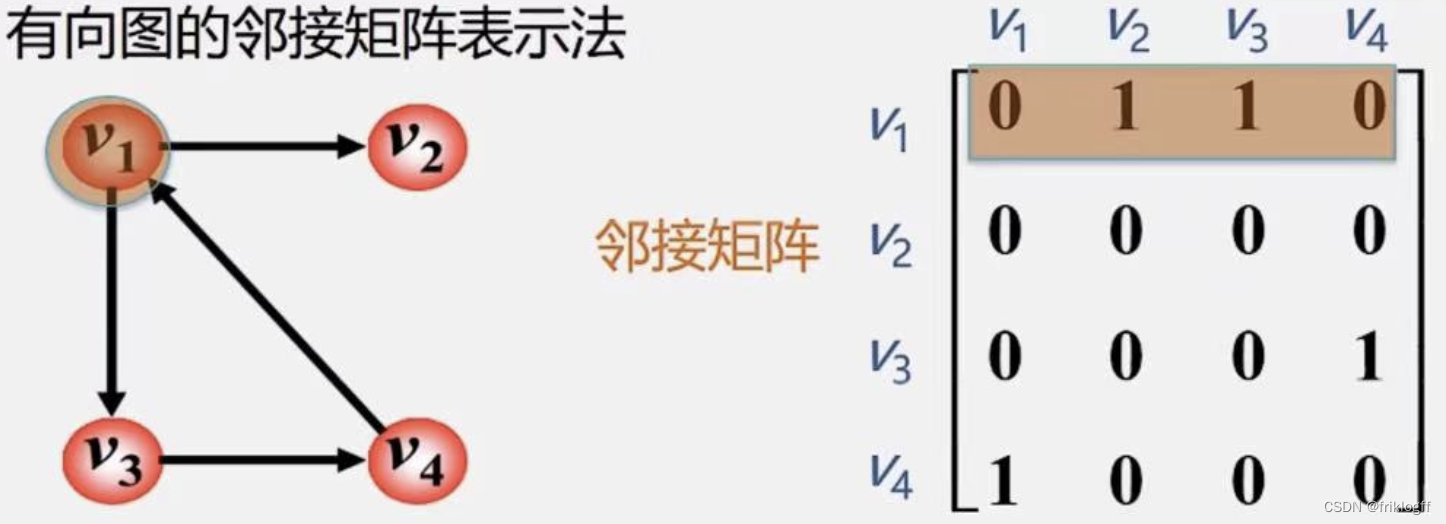
-
有向图的邻接矩阵可能是不对称的
-
顶点的出度 = 第i行元素之和
-
顶点的入度 = 第i列元素之和
-
-
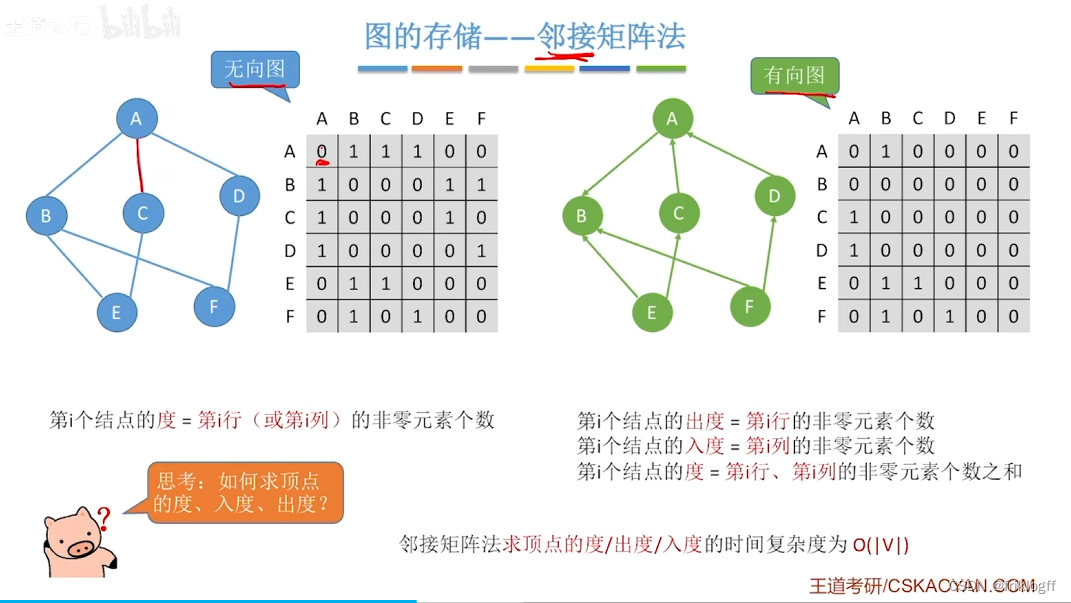
- 有向网
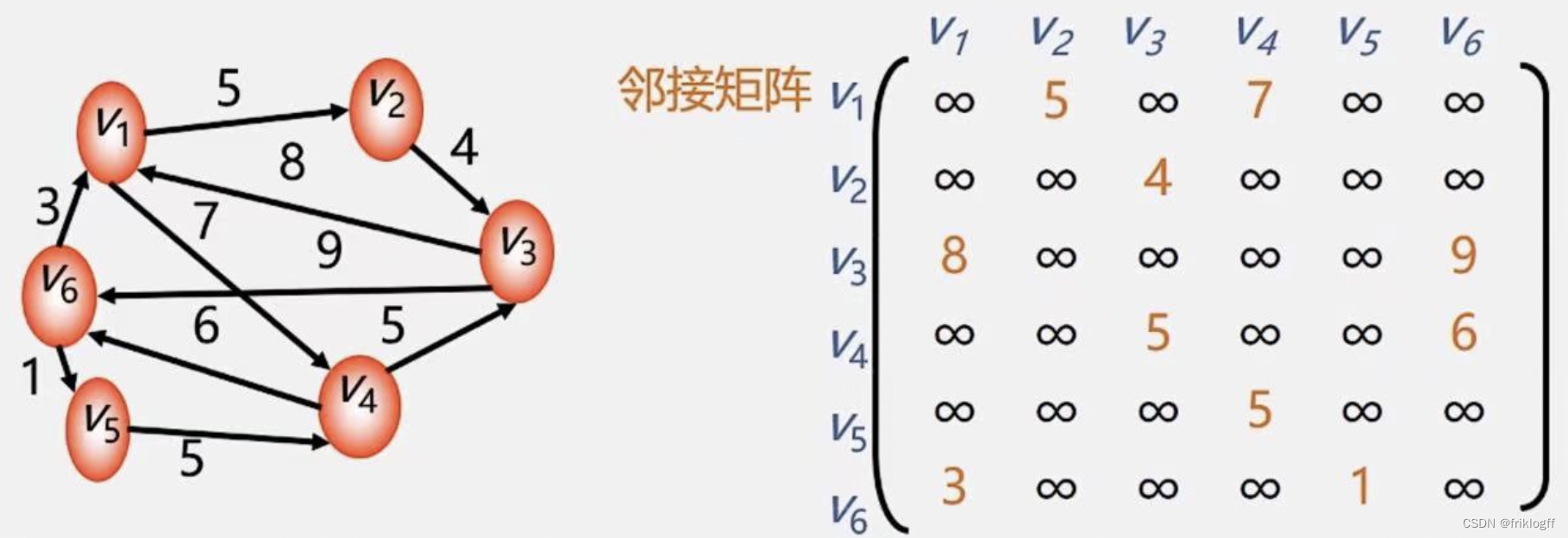

-
缺点
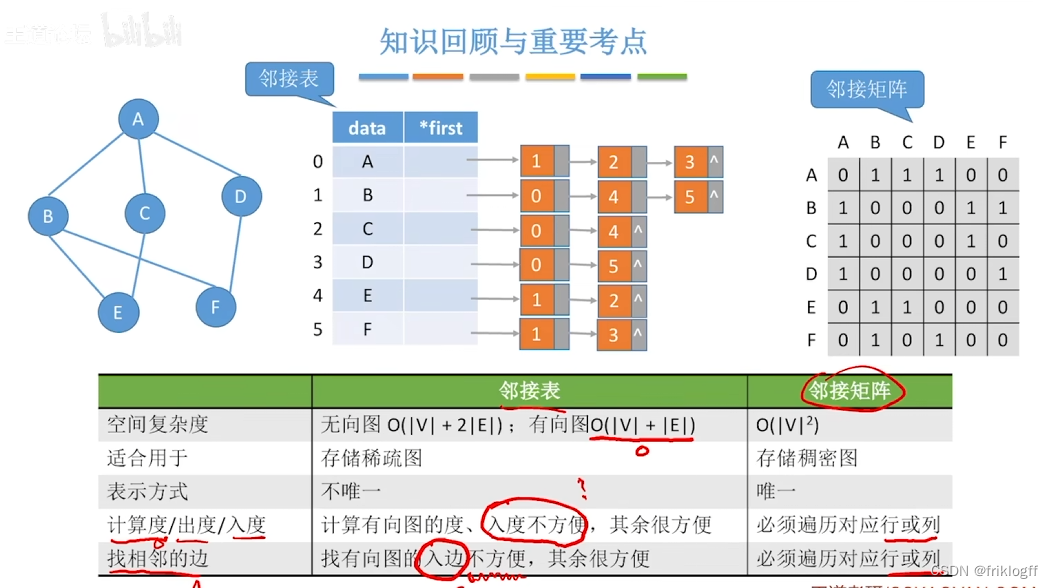
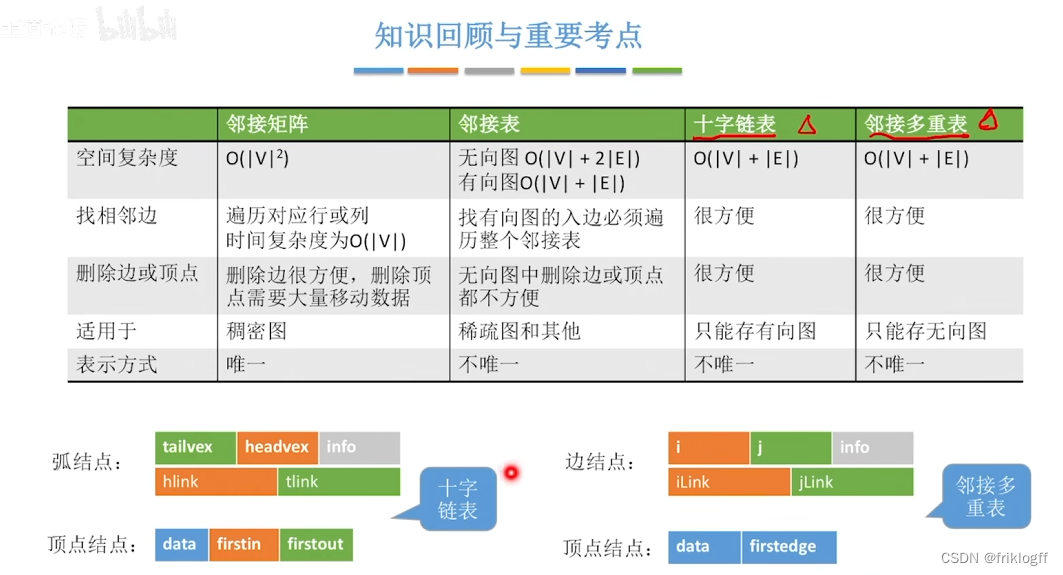
- 不便于增加和删除结点、存稀疏图浪费大量空间(O(n^2))、统计一共有多少条边浪费时间
- 不便于增加和删除结点、存稀疏图浪费大量空间(O(n^2))、统计一共有多少条边浪费时间
-
补充
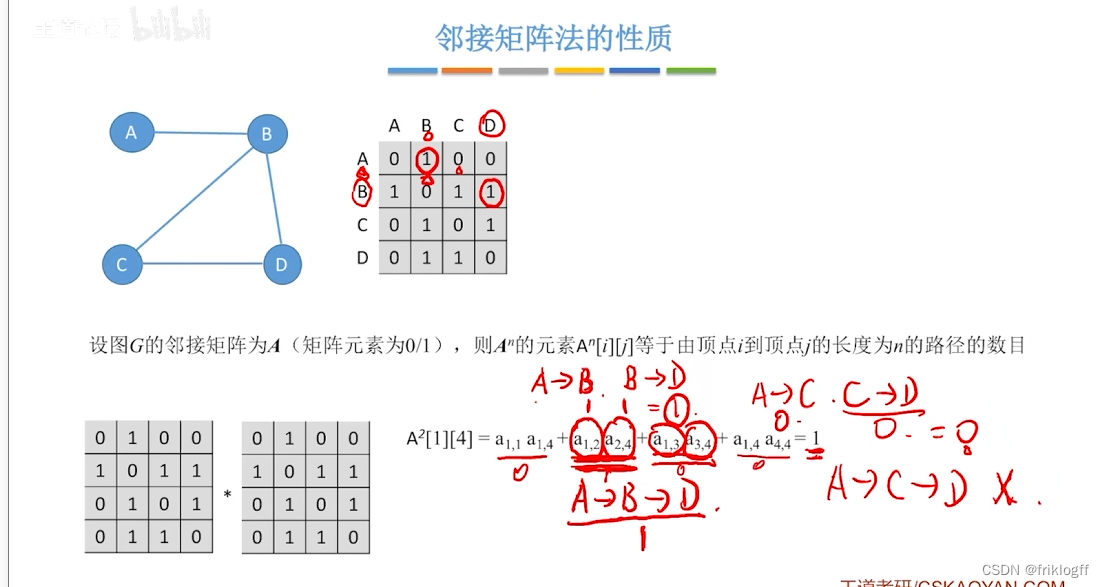
- 邻接矩阵A的A^n[i][j]等于由顶点i到j的长度为n的路径数量
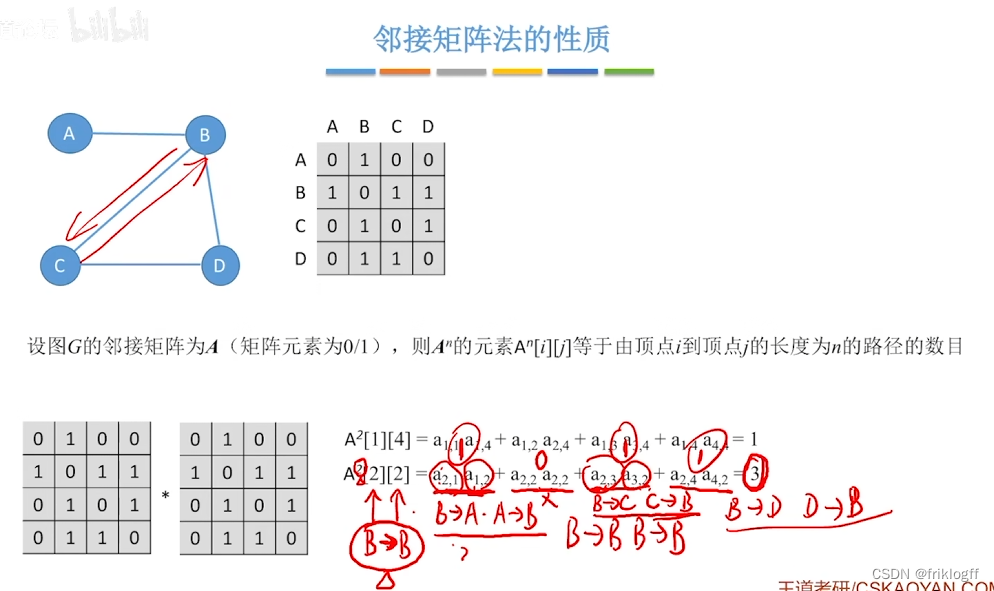
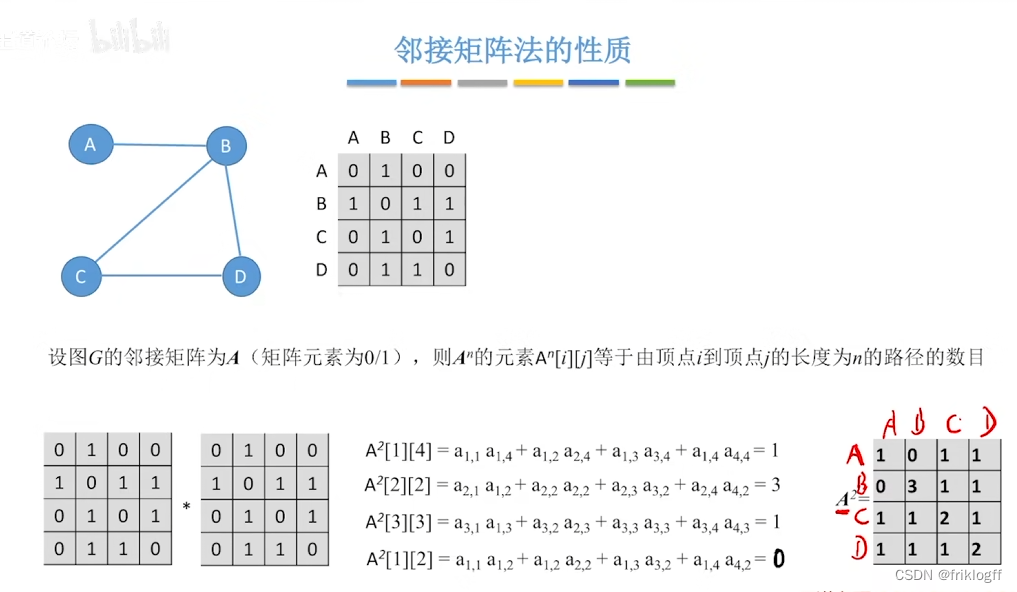
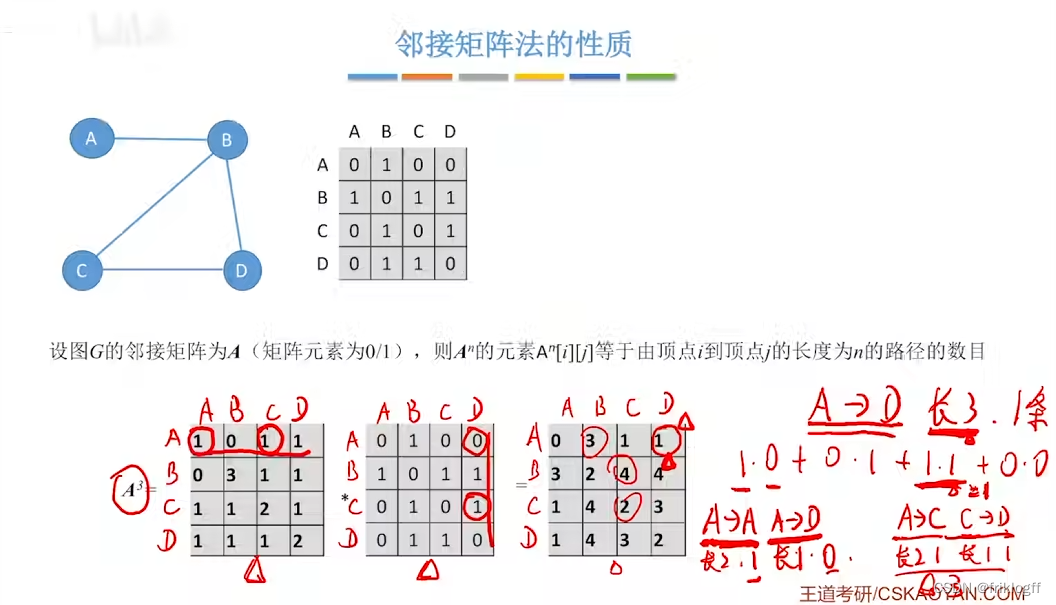
- 邻接矩阵A的A^n[i][j]等于由顶点i到j的长度为n的路径数量
小结

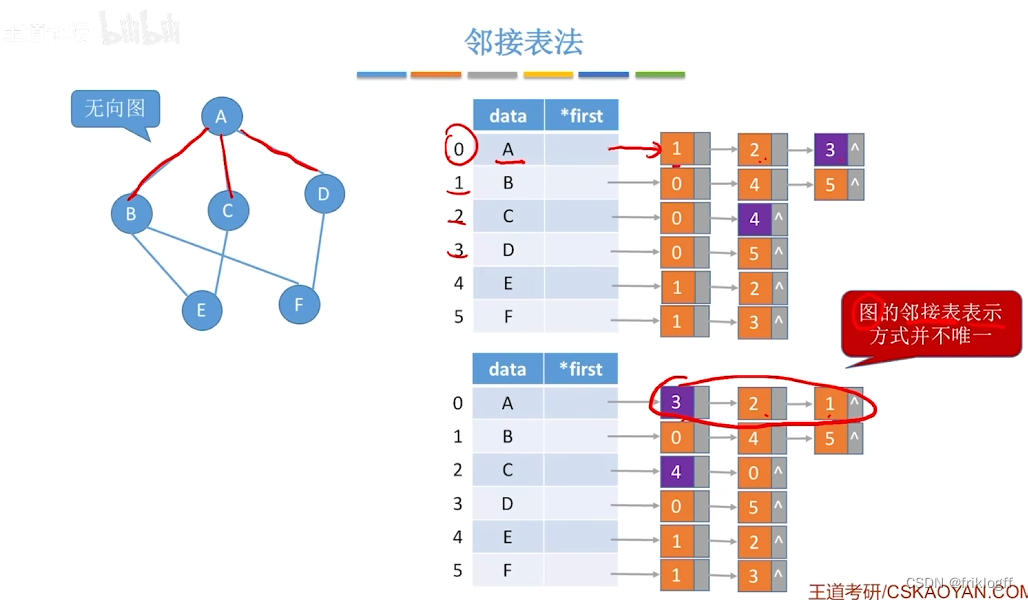
邻接表法
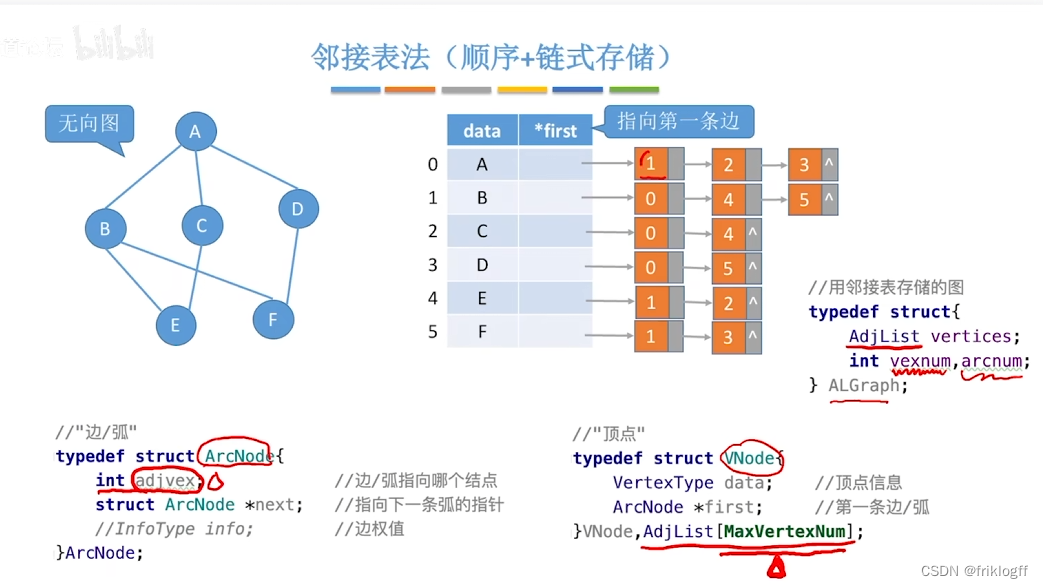
-
概念
-
图中顶点用一个一维数组存储,元素包含指向第一个邻接点的指针,存储顶点和头指针的一维数组叫顶点表
-
每个顶点的所有邻接点构成一个单链表
-
-
结构
-
-
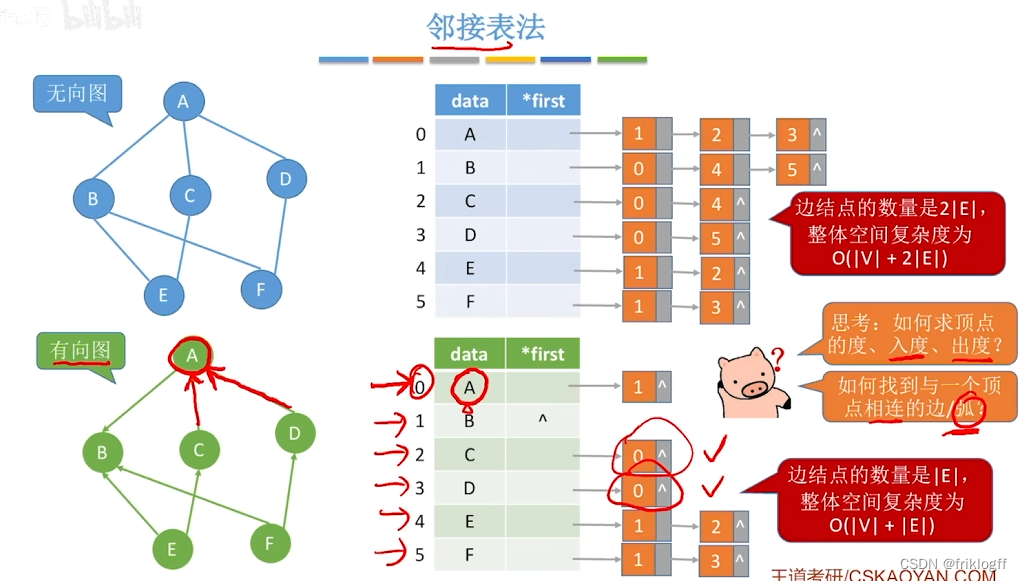
若为无向图,则需要存储两倍的边,存储空间为O(|V|+2|E|)
-
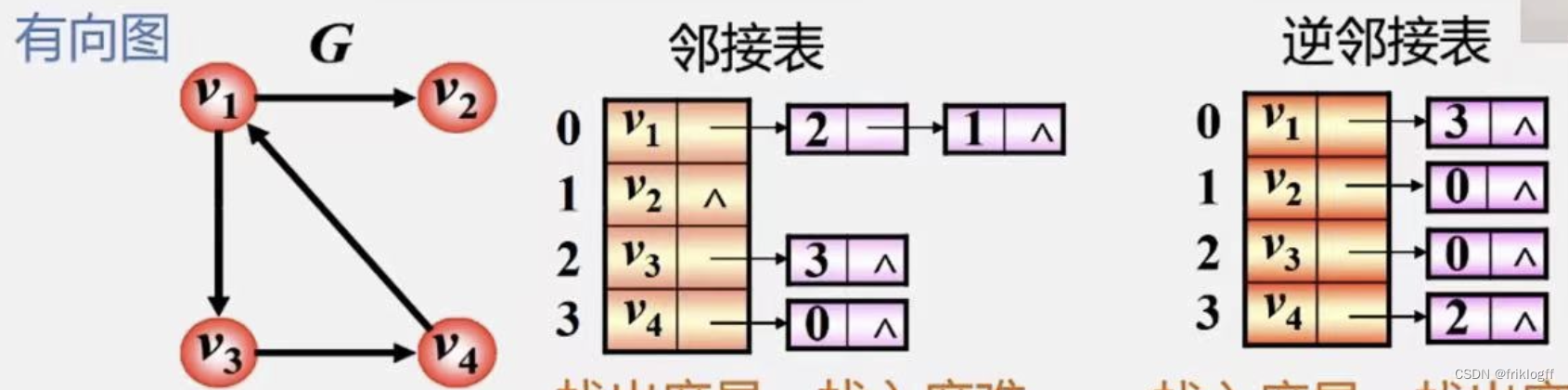
若为有向图,存储空间为O(|V|+|E|),若采用邻接表法则找出度易,找入度难;若采用逆邻接表则找入度易,找出度难
-
有向图邻接表法中,顶点vi出度为第i个单链表中结点个数;入度为整个单链表中邻接点域值是i-1的结点个数
-
图的邻接表表示不唯一
-
-
-
实现

-

-
顶点表结点:顶点域+边表头指针
-
边表结点:邻接点域+指针域+权值(若为网)
-
-
-
缺点
- 若不构建逆邻接表则找入度麻烦、不方便检查任意一对顶点之间是否存在边
-
领接表

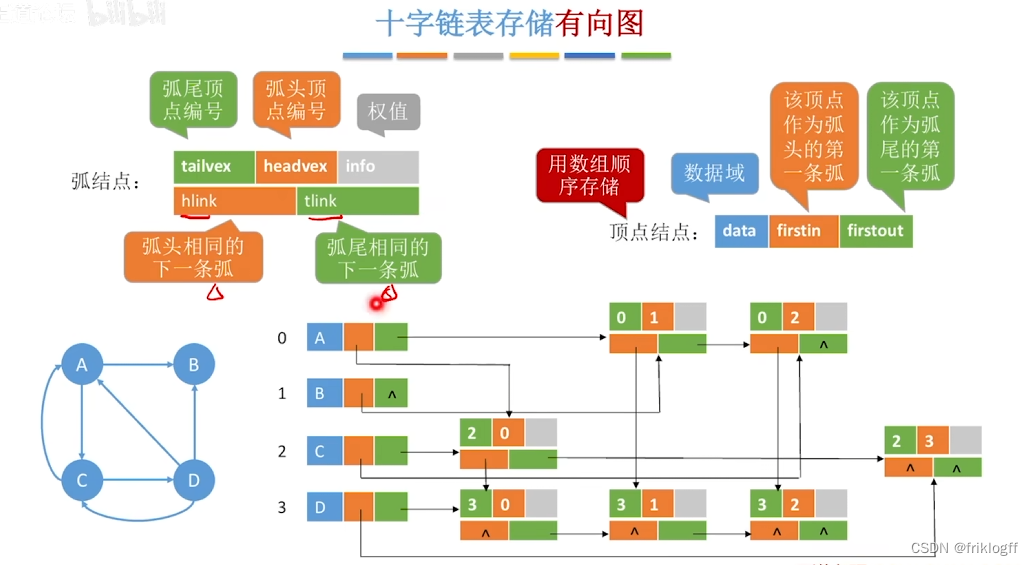
十字链表法(有向图)
-
概念
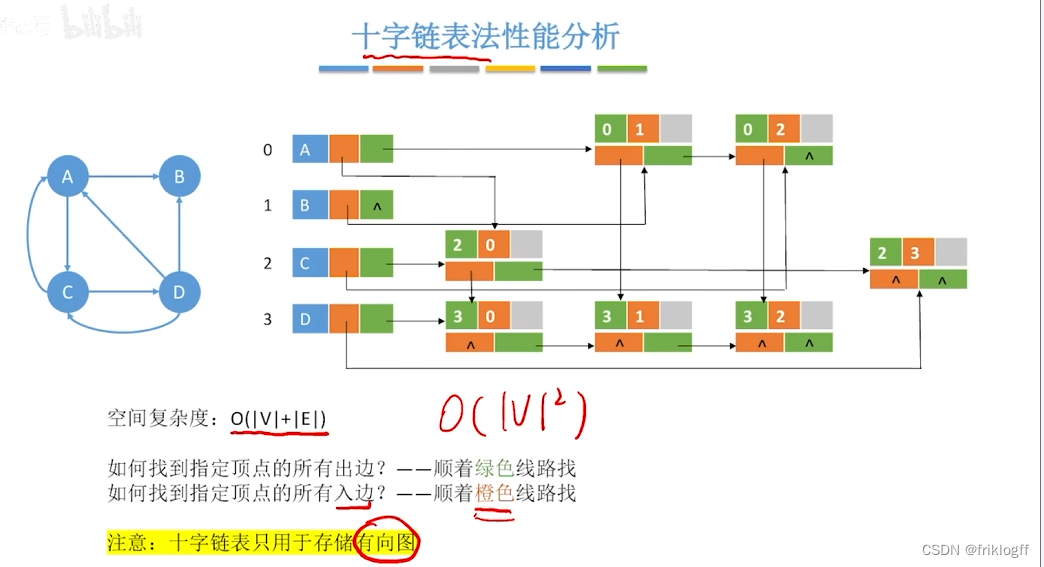
- 十字链表时针对有向图的存储方式,对应于有向图中的每条弧有一个结点,对应于每个顶点也有一个结点(有向图的邻接表与逆邻接表的结合)
-
结构
-
-
顶点结点域结构
- data域(存放顶点数据信息) + firstin域 + firstout域(分别指向以该顶点为弧头或弧尾的第一个弧结点)
-
弧结点域结构
- 尾域(弧尾)+ 头域(弧头)+ hlink域(指向弧头相同的下一条弧)+ tlink域(指向弧尾相同的下一条弧)+ info域(弧相关信息)
-
-
-
图的十字链表不唯一,但一个十字链表表示确定一个图
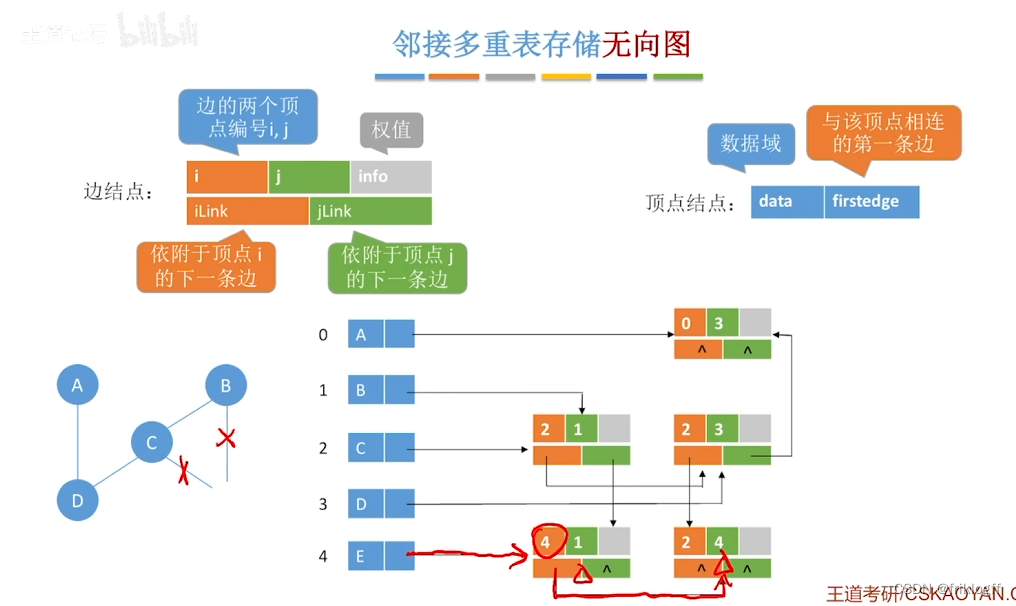
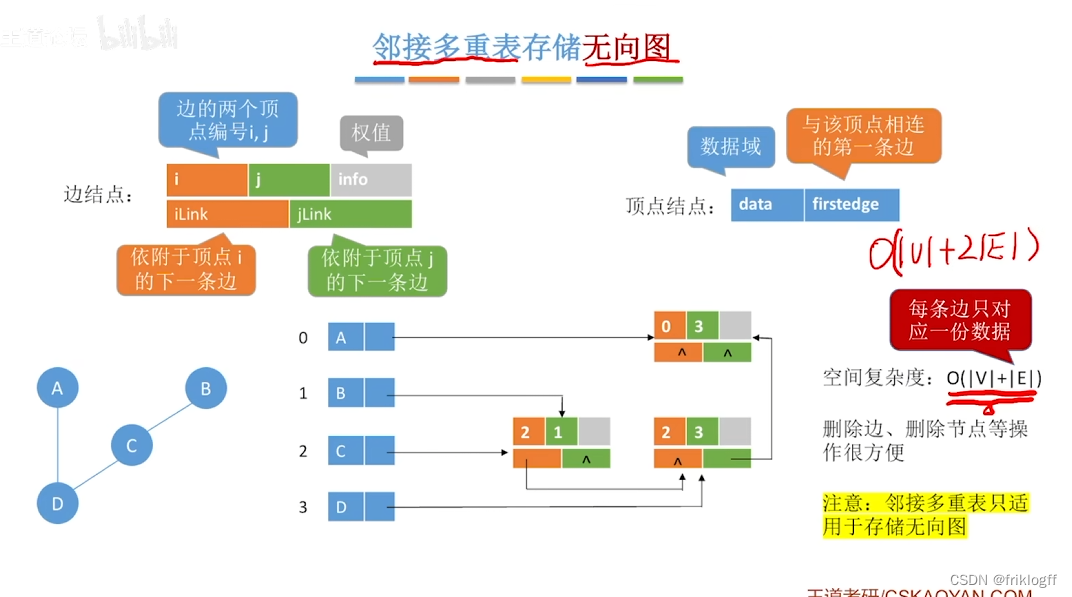
邻接多重表(无向图)
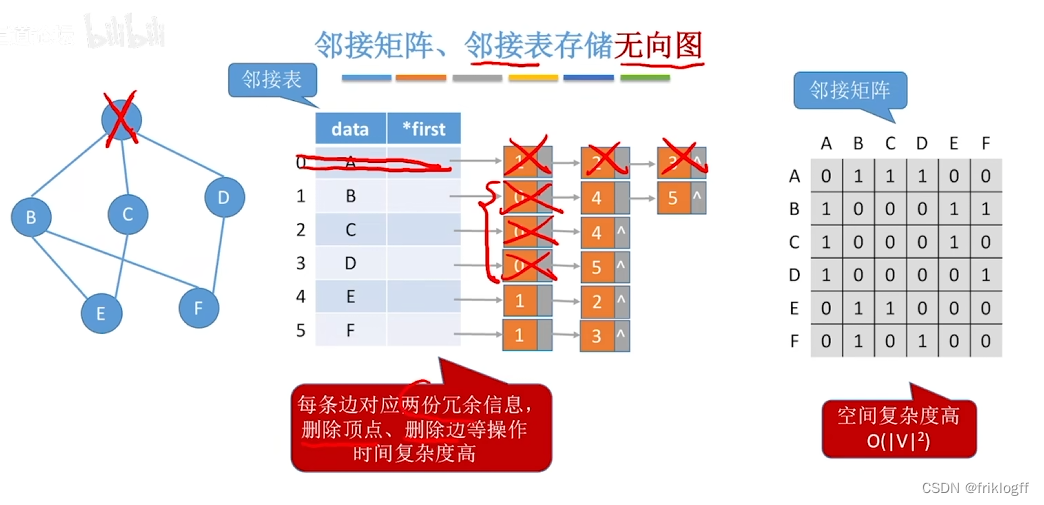
-
概念
- 对邻接表的边表进行改造,得到专门针对存储无向图的邻接多重表
-
结构
-
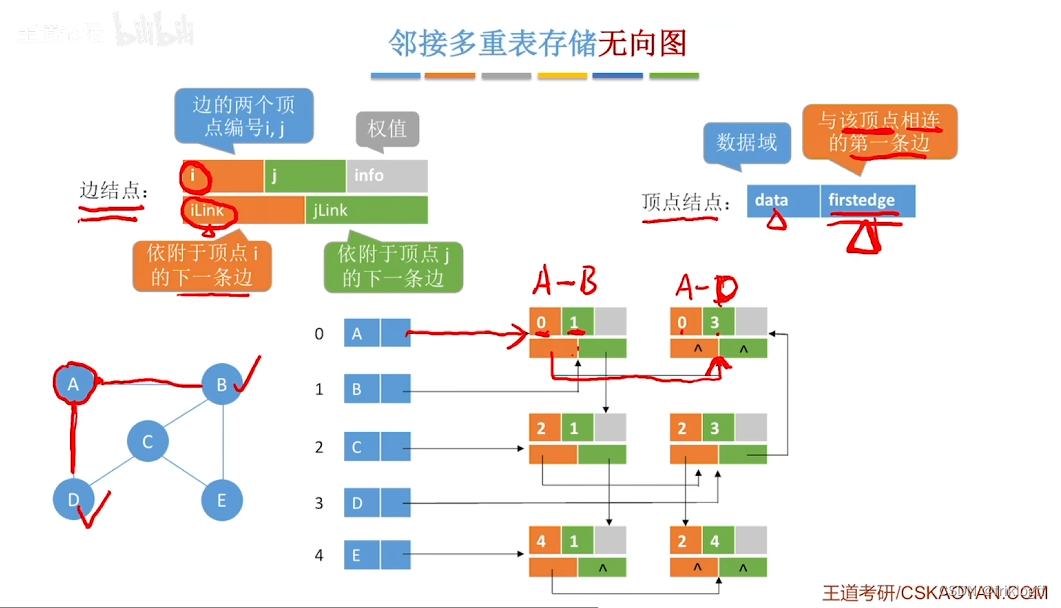
-
顶点结点域结构
- data域(存储该顶点的信息)+ firstedge域(指示第一条依附于该顶点的边)
-
弧结点域结构
- 标志域(标记该边是否被搜索过)+ ivex域 + jvex域(该边依附的两个顶点在图中位置)+ ilink域 + jlink域(分别指向下一条依附于顶点ivex、jvex的边)+ info域(弧相关信息)
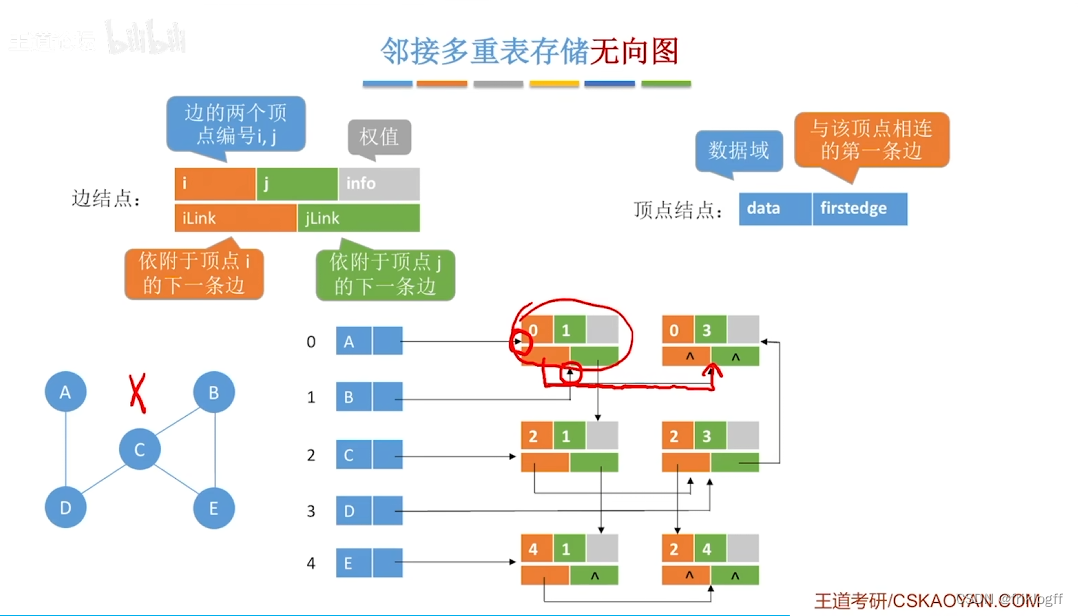
- 标志域(标记该边是否被搜索过)+ ivex域 + jvex域(该边依附的两个顶点在图中位置)+ ilink域 + jlink域(分别指向下一条依附于顶点ivex、jvex的边)+ info域(弧相关信息)
-
-
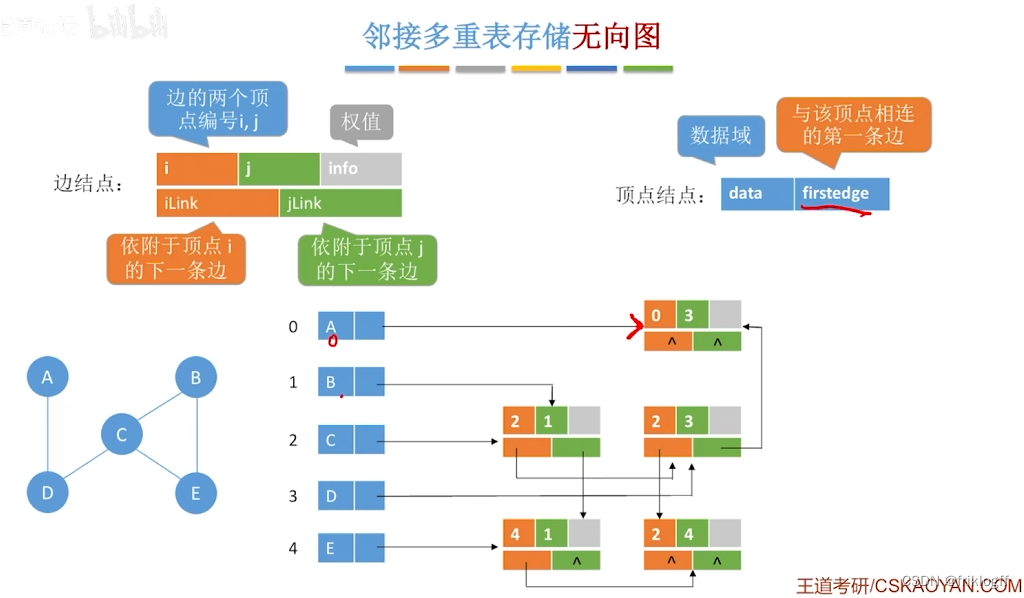
图的遍历

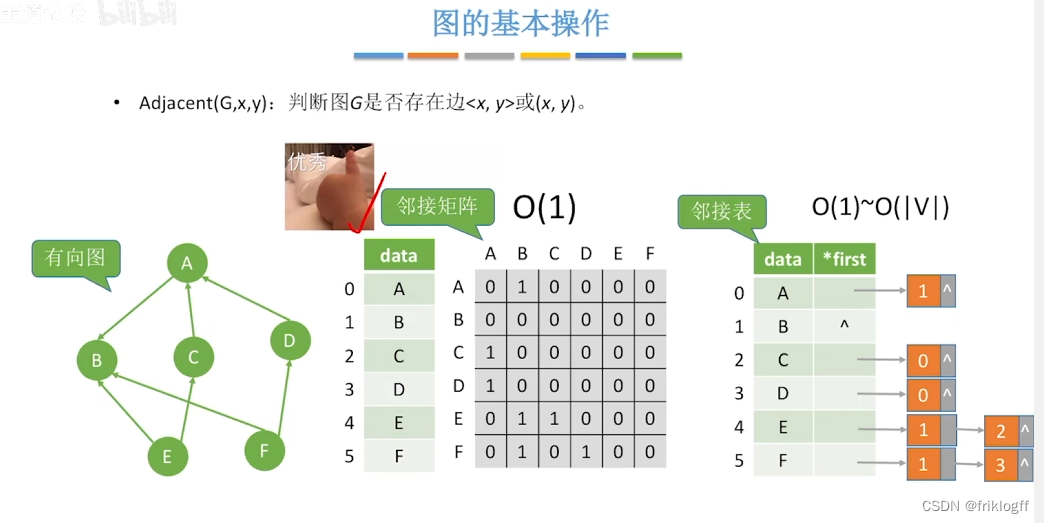
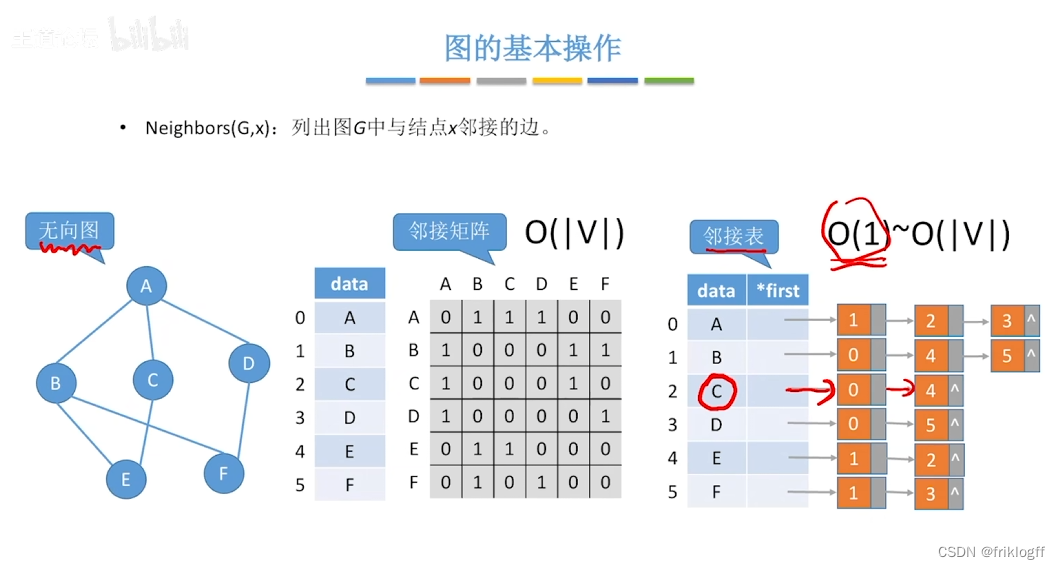
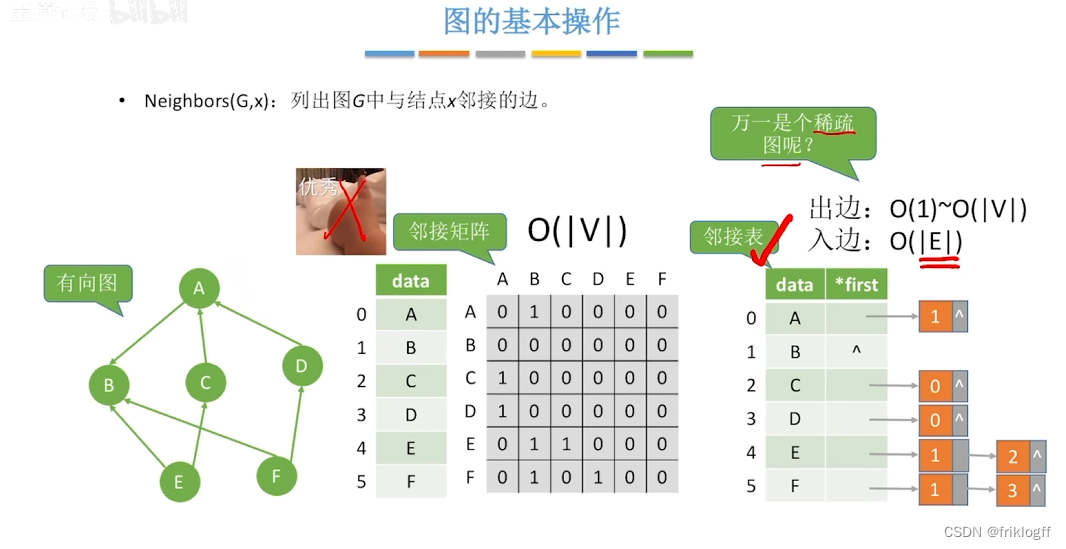
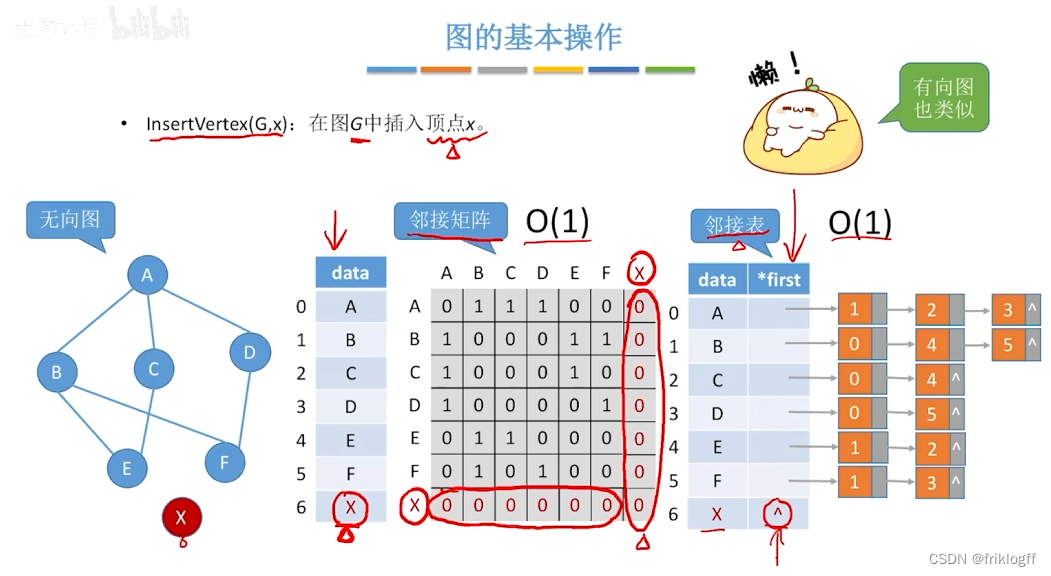
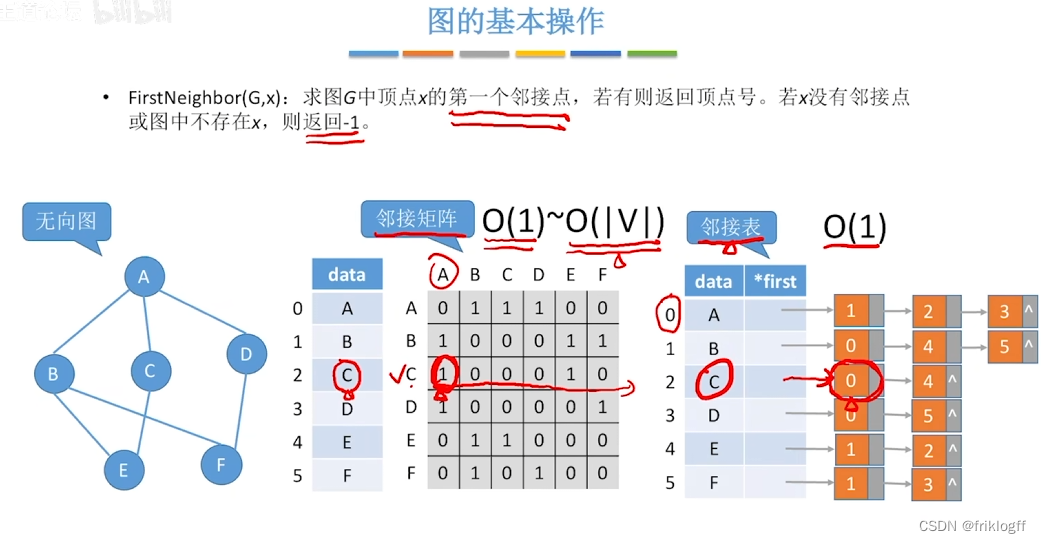
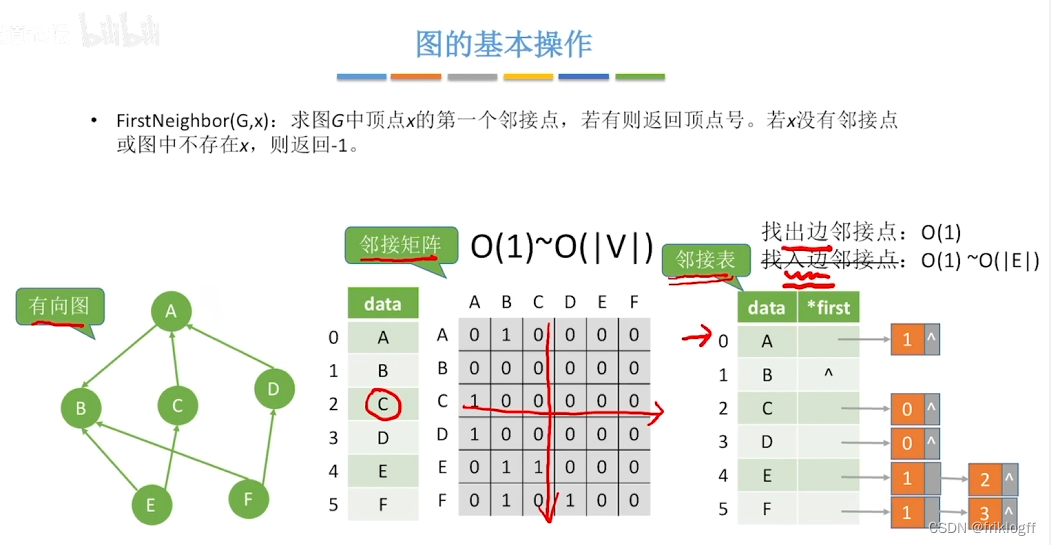
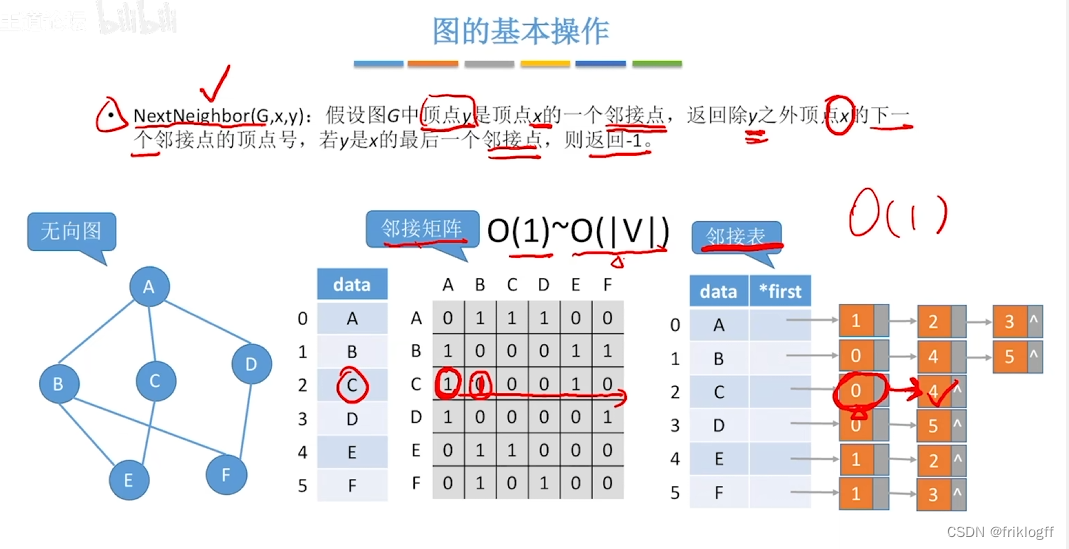
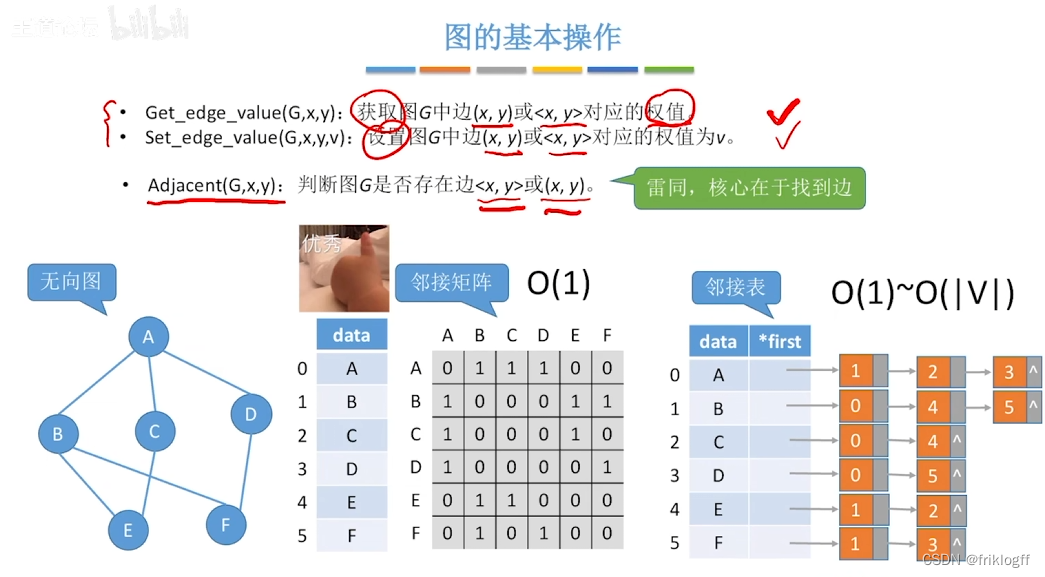

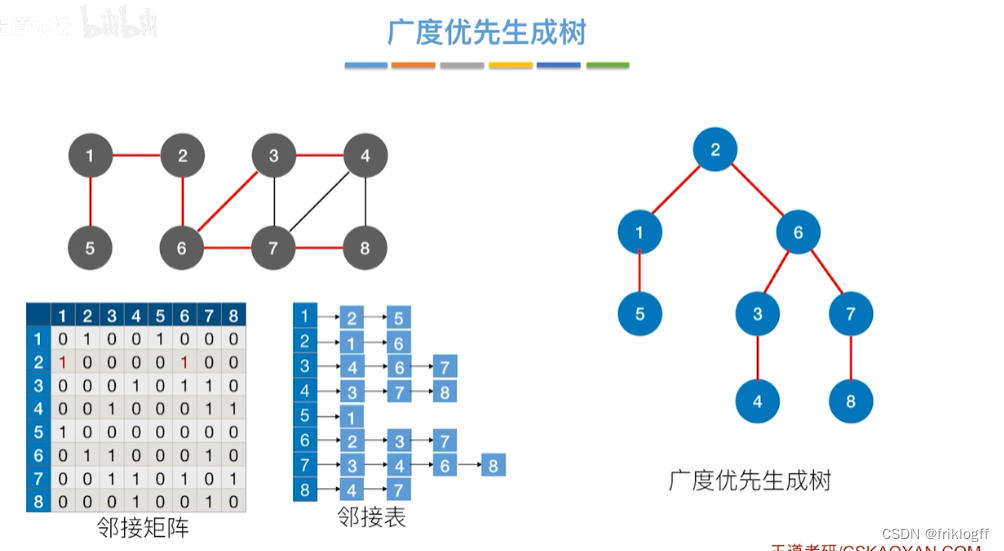
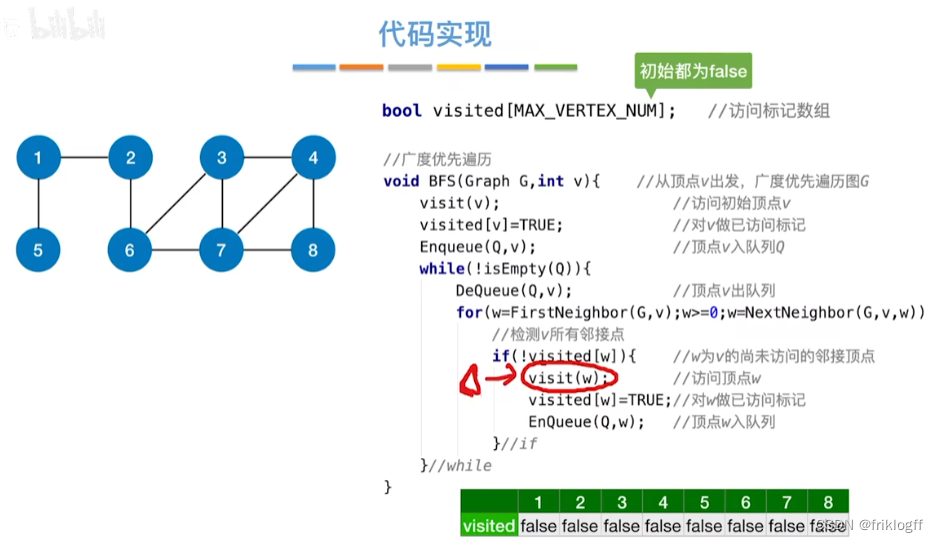
广度优先搜索
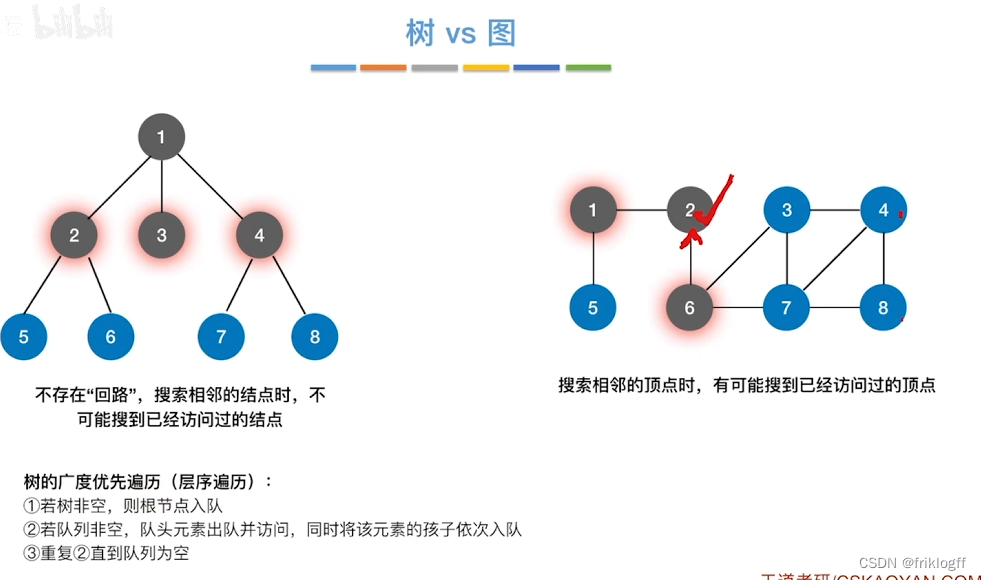
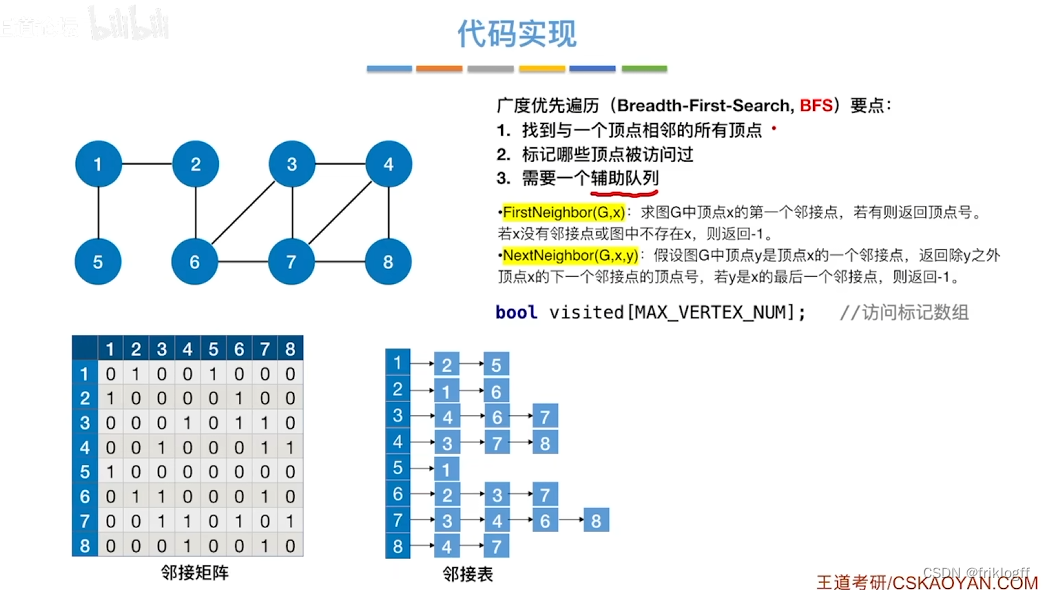
-
概念
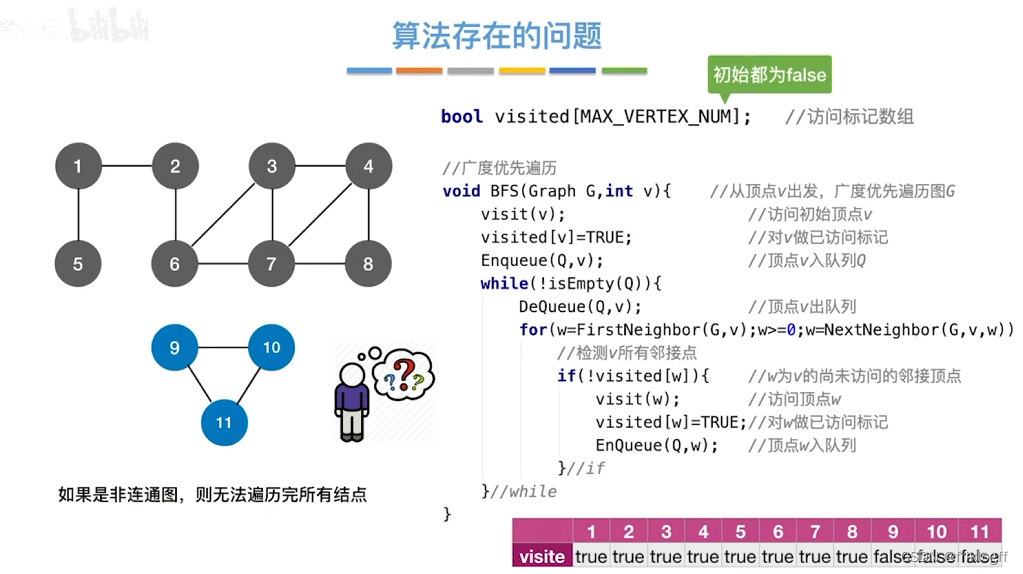
- 类似于二叉树的层序遍历算法,多了标记数组,用于确定已访问的结点
-
算法思想
-
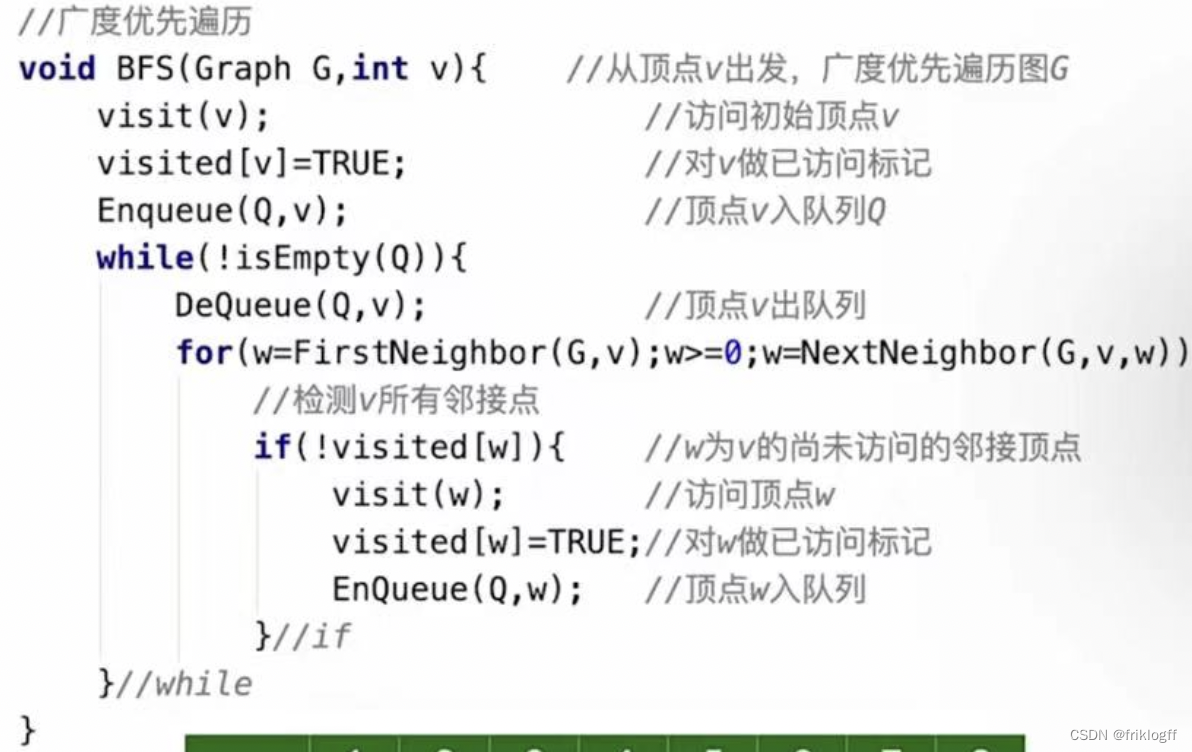
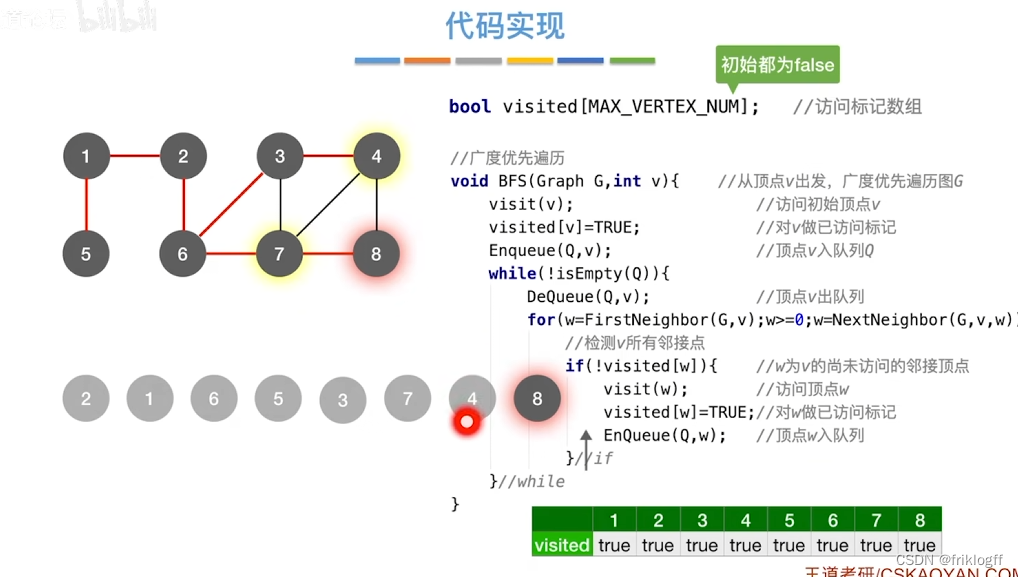
-
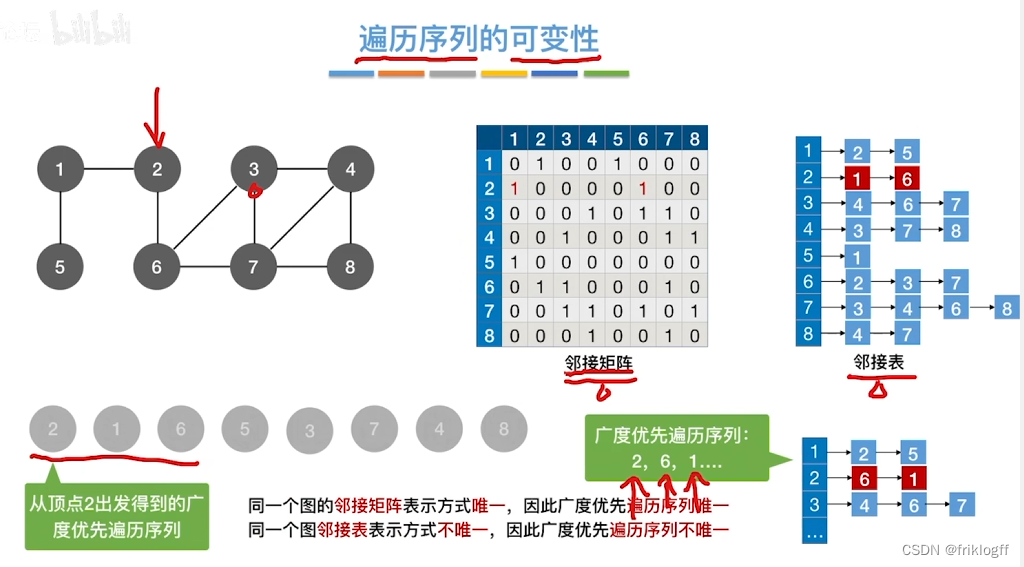
首先访问起始顶点v(进队列),由v出发,依次访问v的各个未访问过的邻接顶点w1,w2,…,wi(都加入队列,起始顶点pop掉)
-
然后依次访问w1,w2,…,wi的所有未访问过的邻接顶点(加入队列,并pop访问过的顶点)
-
再从这些顶点出发,访问所有未被访问过的邻接顶点,直到遍历完成(利用队列实现)
-
-
-
性能分析
-
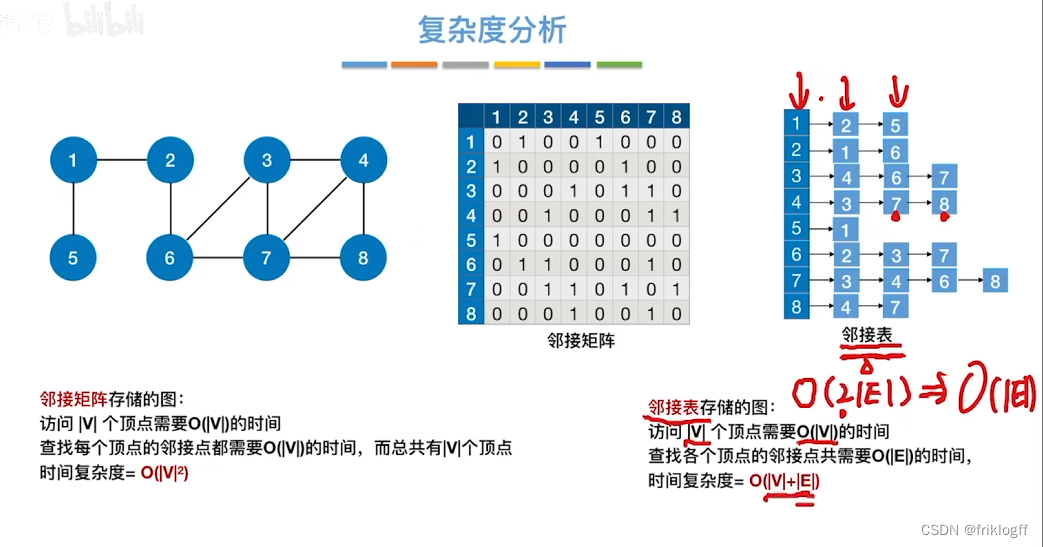
时间复杂度
-
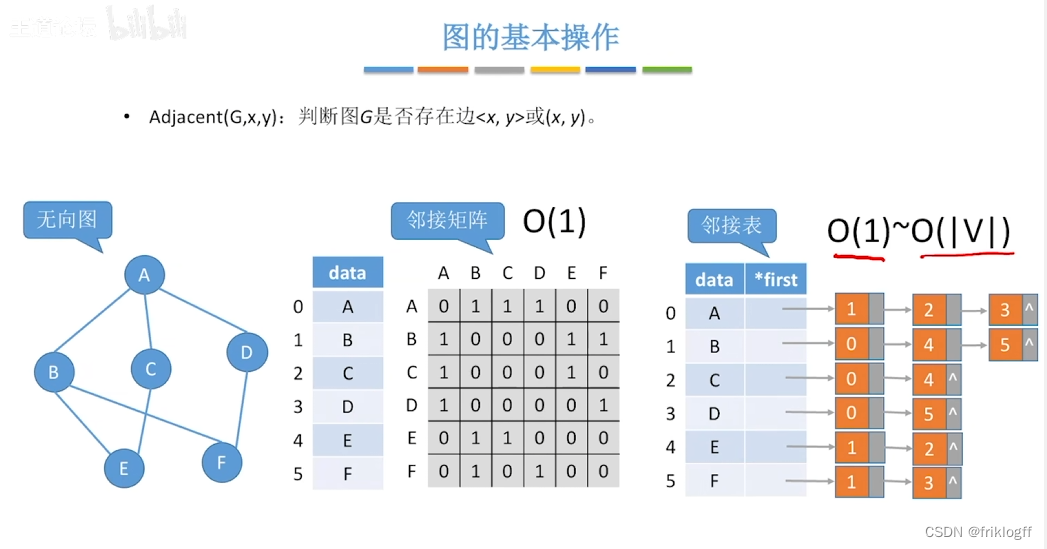
邻接矩阵存储方式:O(|V|^2)
-
邻接表存储方式:O(|V|+|E|)
-
-
空间复杂度
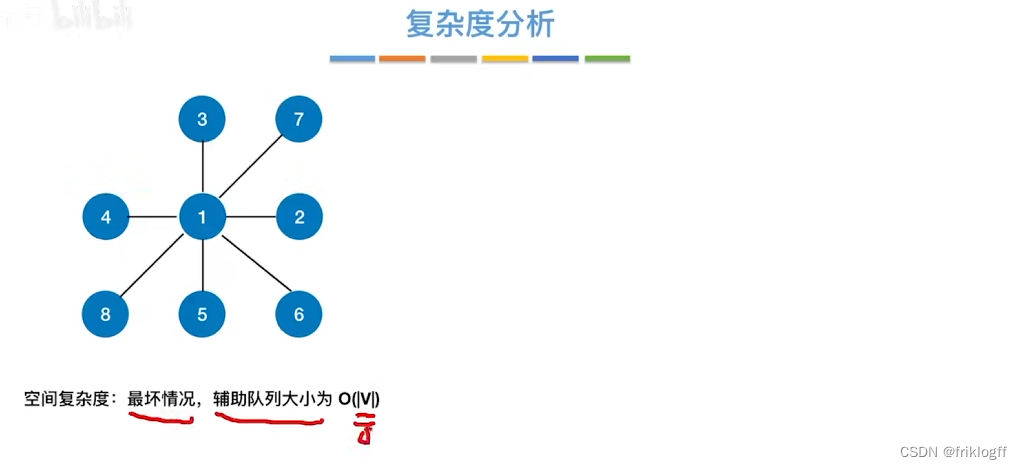
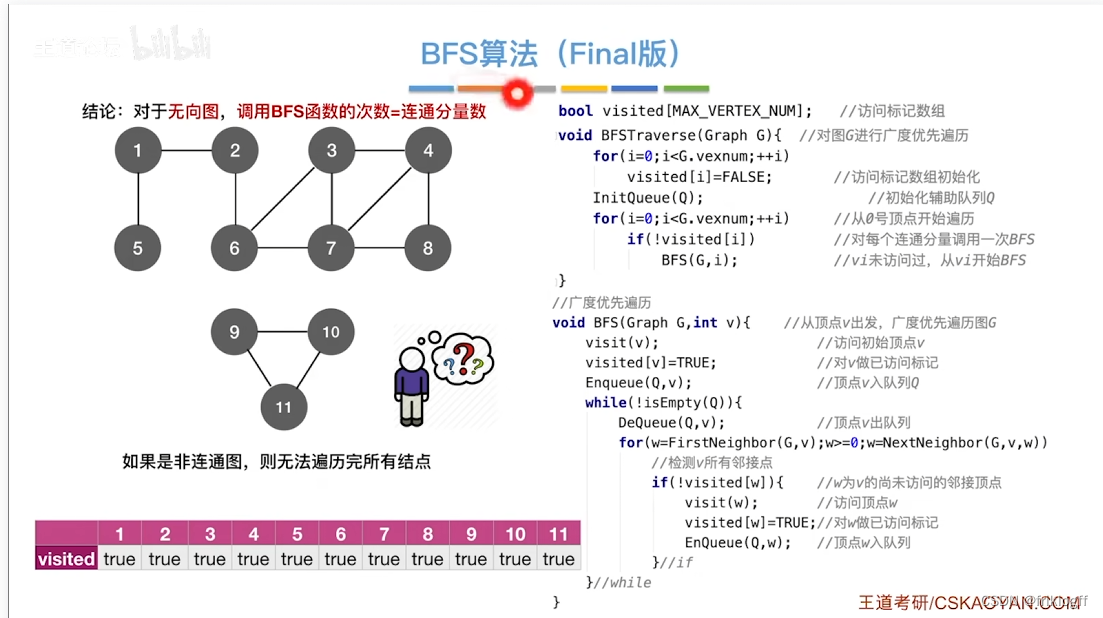
- BFS需要借助一个队列,n个顶点均需要入队一次,所以最坏情况下n个顶点在队列,O(|V|)
-
-
基于邻接矩阵的遍历BFS序列是唯一的,基于邻接表的遍历所得到的BFS序列是不唯一的
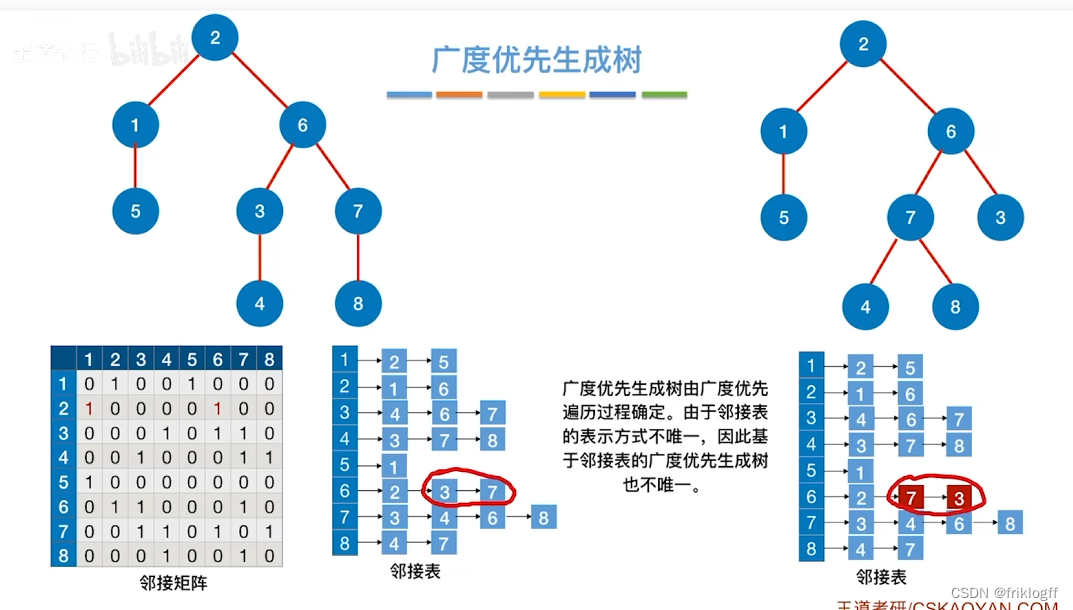
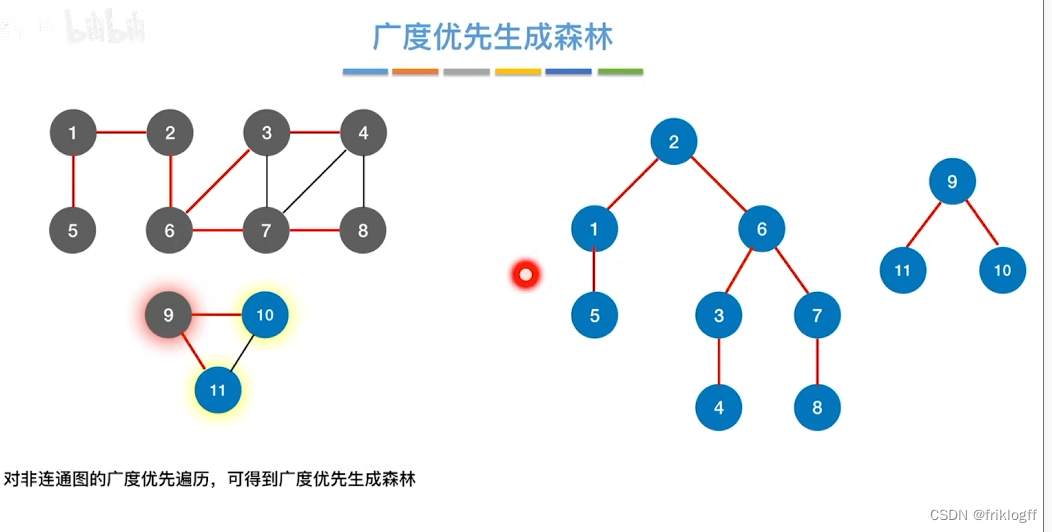
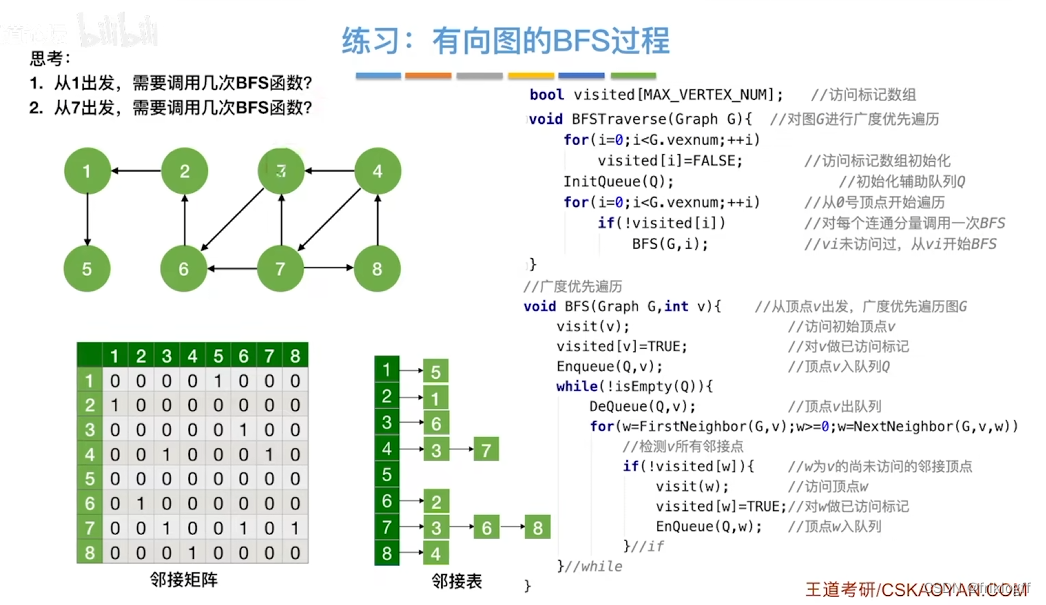
小结
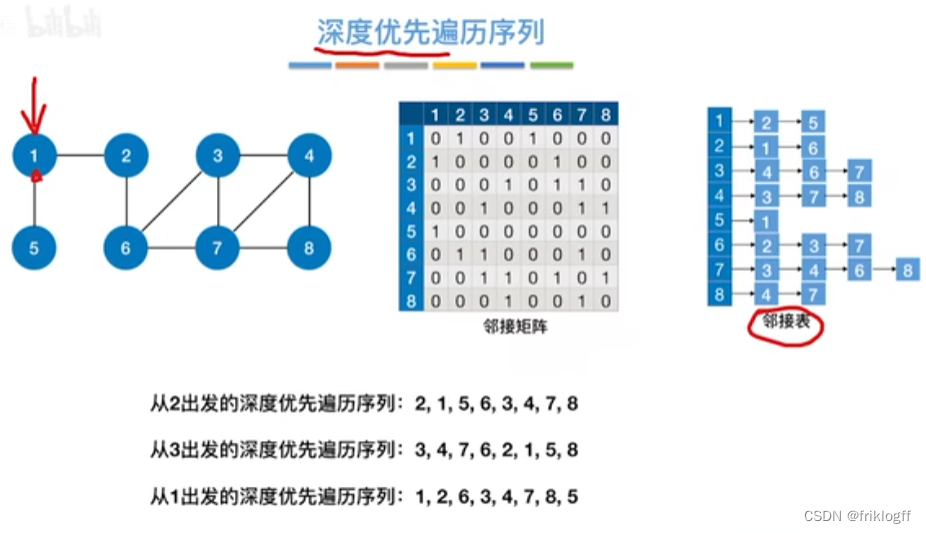
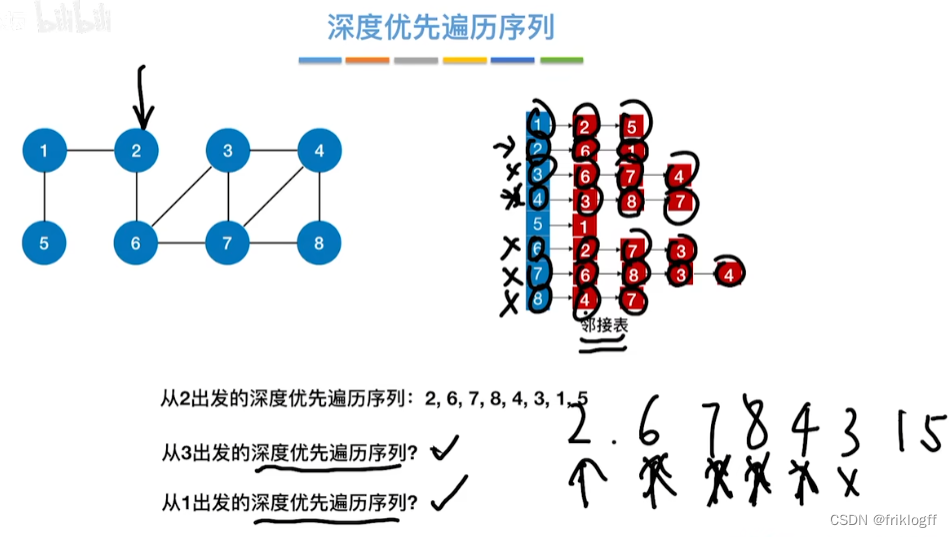
深度优先搜索
-
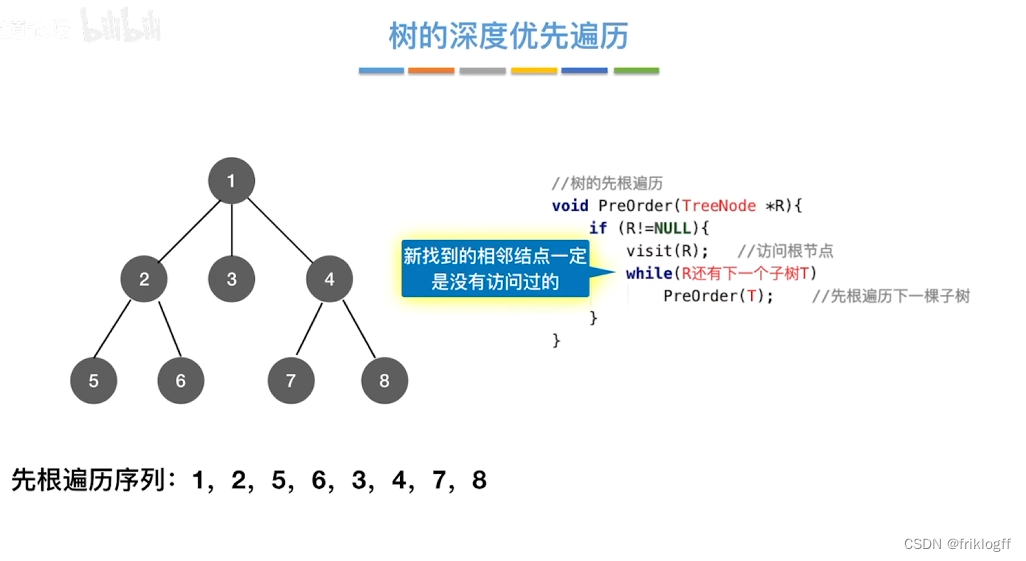
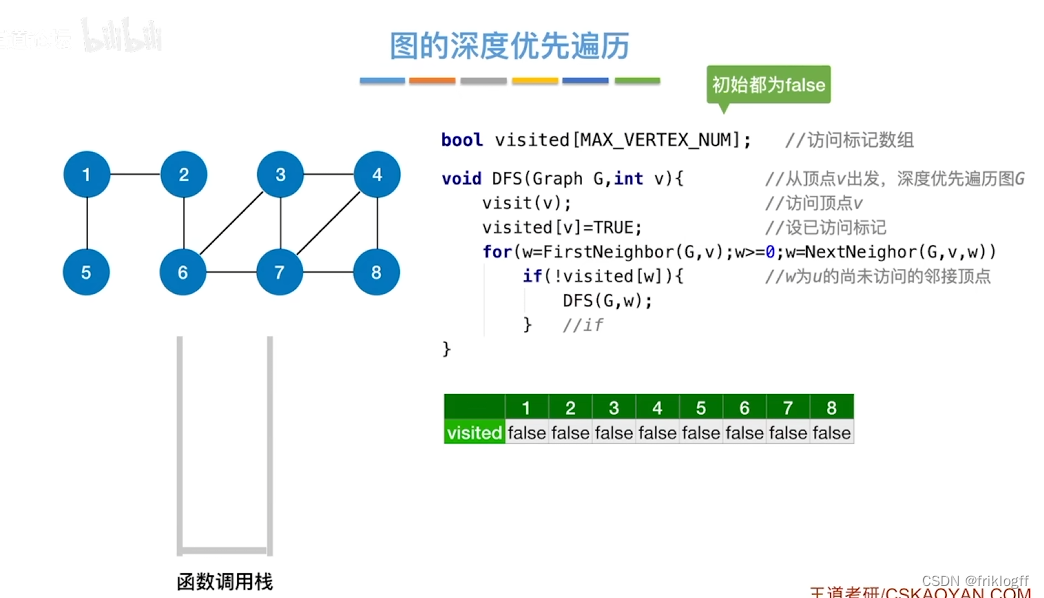
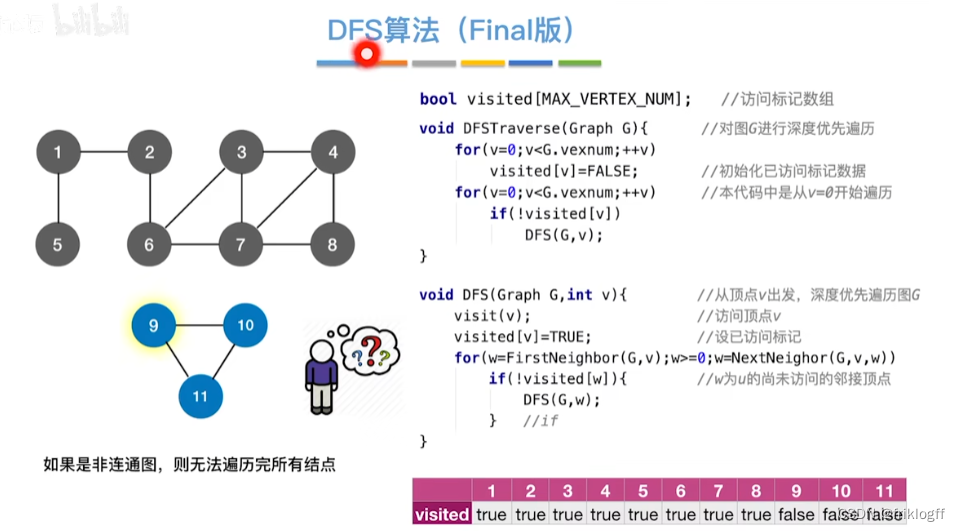
概念
- 类似于树的先序遍历,搜索策略是尽可能深地搜索一个图
-
算法思想
-

-
首先访问图中某个起始顶点v,由v出发,访问与v邻接且未被访问的任一顶点w1,再访问与w1邻接且未访问的任一顶点,重复
-
当不能继续向下访问,则依次退回到最近被访问的顶点,若还有邻接顶点未被访问,则从该点继续DFS,直到所有顶点均被访问为止(用递归实现)
-
-
-
性能分析
-
时间复杂度
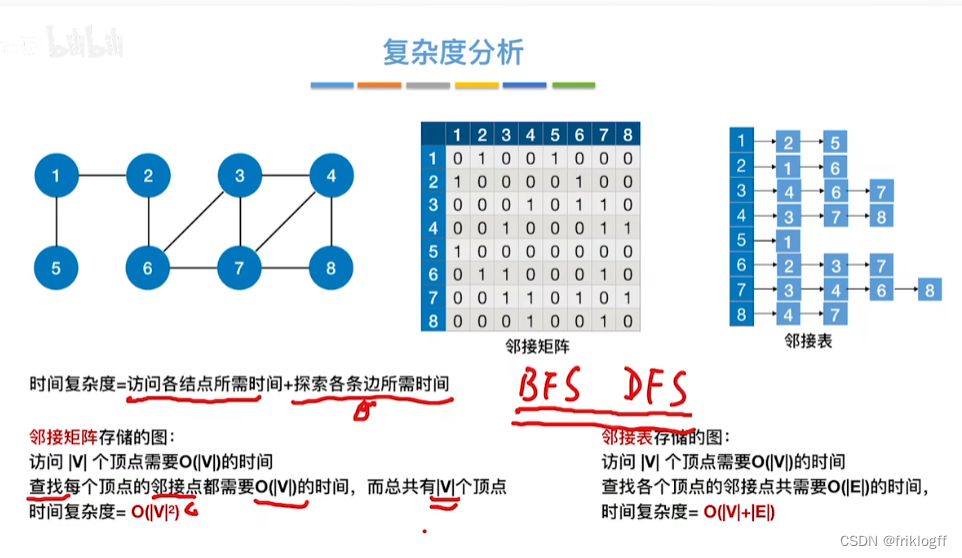
-
邻接矩阵存储方式:O(|V|^2)
-
邻接表存储方式:O(|V|+|E|)
-
-
空间复杂度
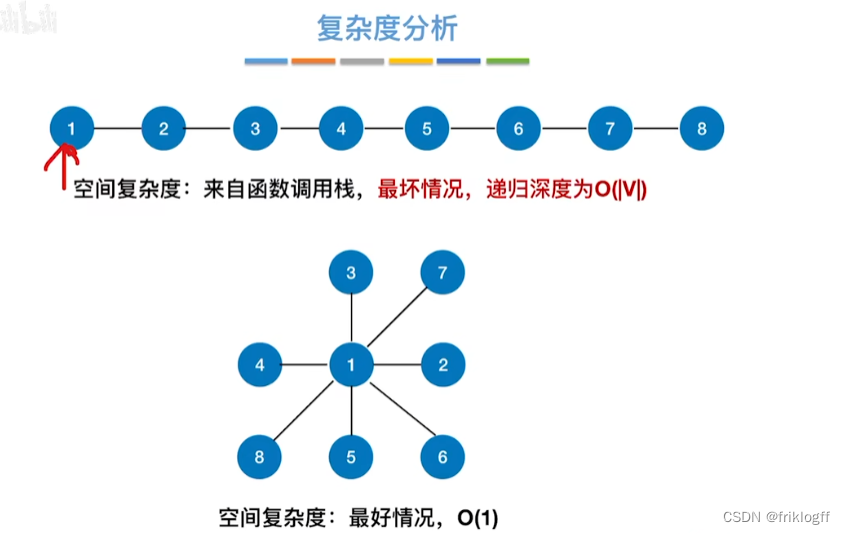
- DFS是一个递归算法,需要工作栈辅助,最多需要图中所有顶点进栈,O(|V|)
-
-
基于邻接矩阵的遍历DFS序列是唯一的,基于邻接表的遍历所得到的DFS序列是不唯一的
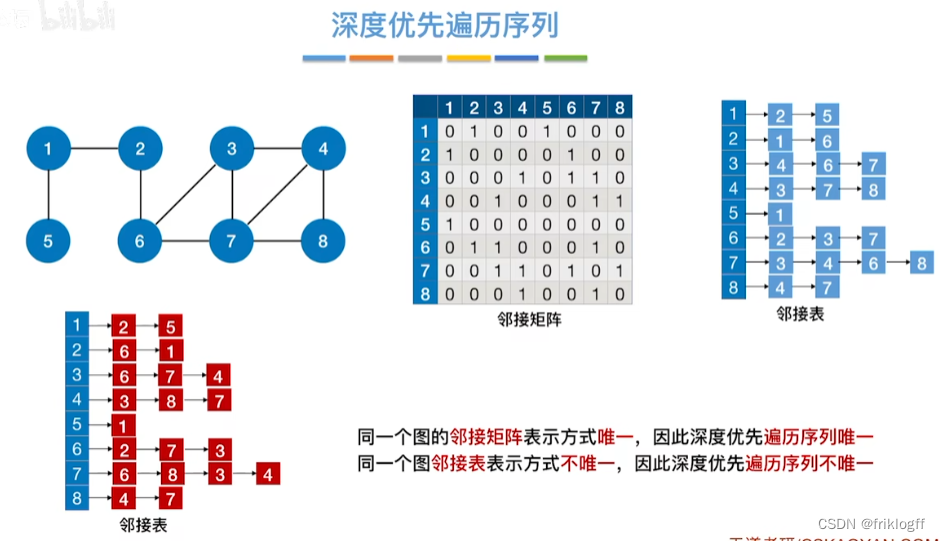
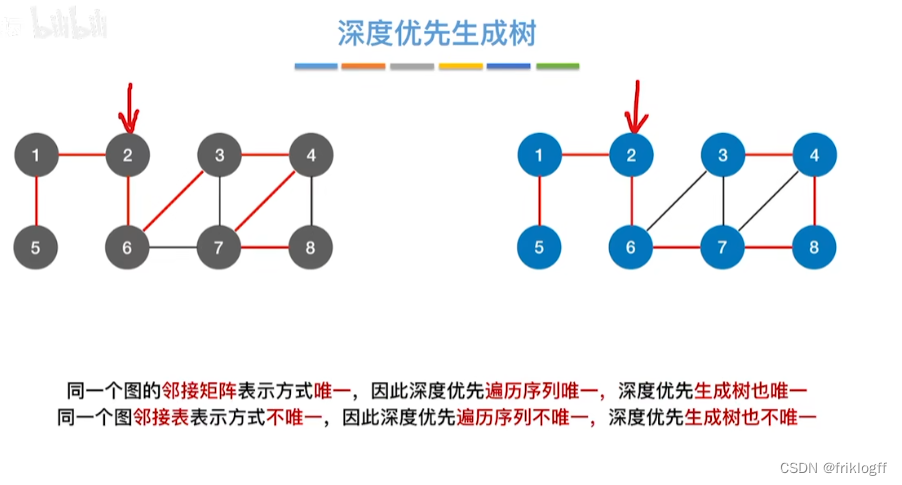
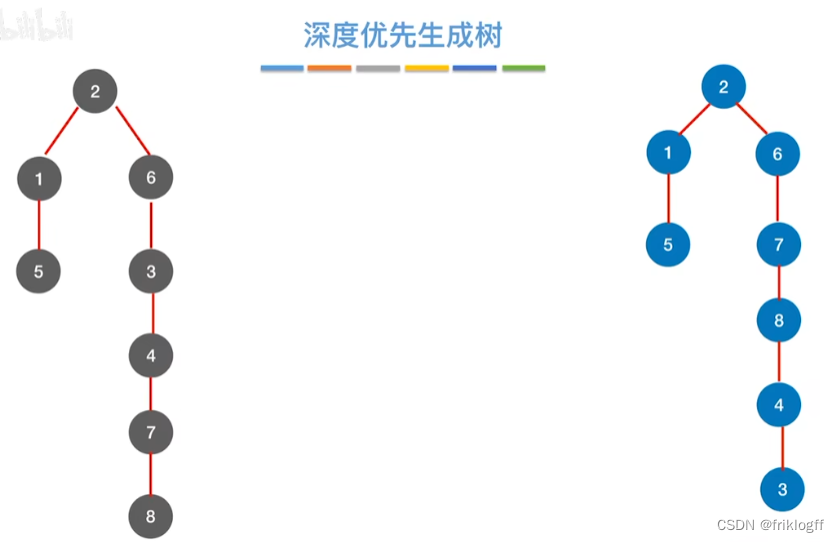
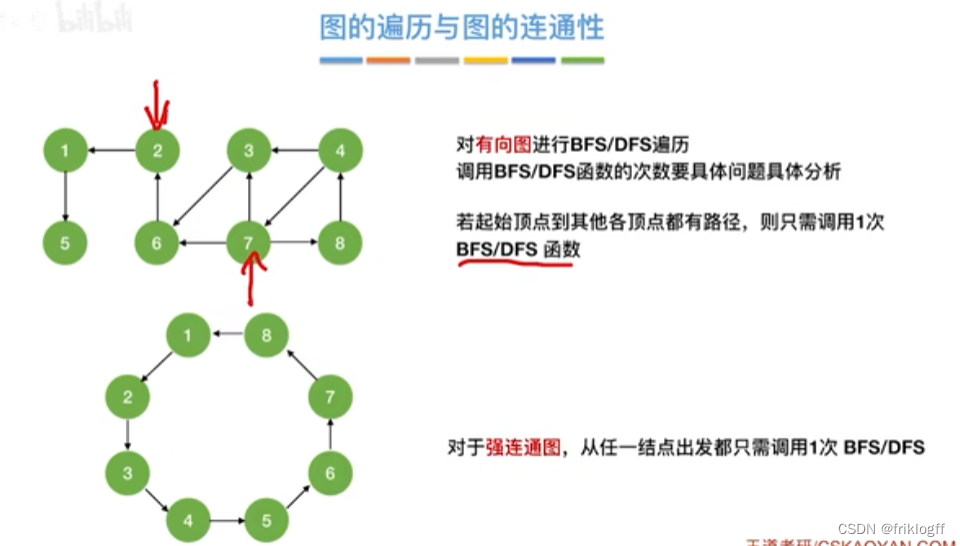
小结
图的应用
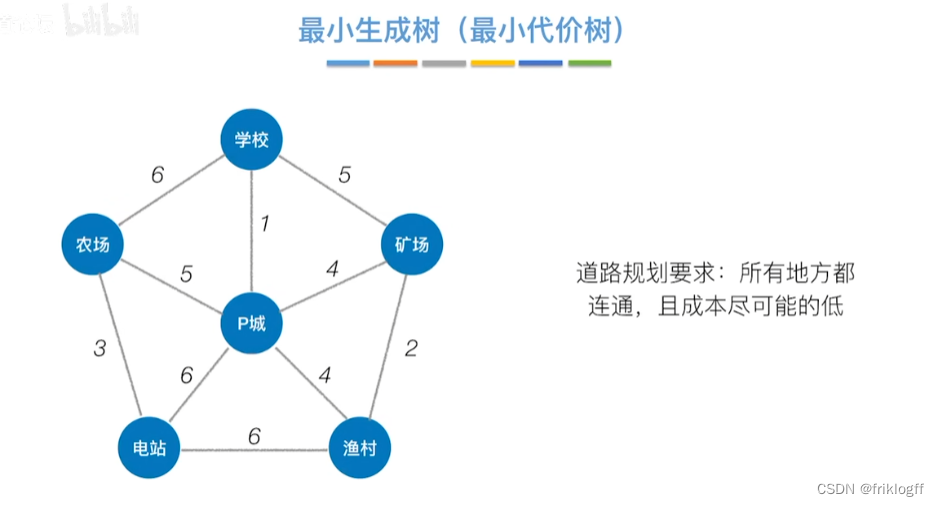
最小生成树
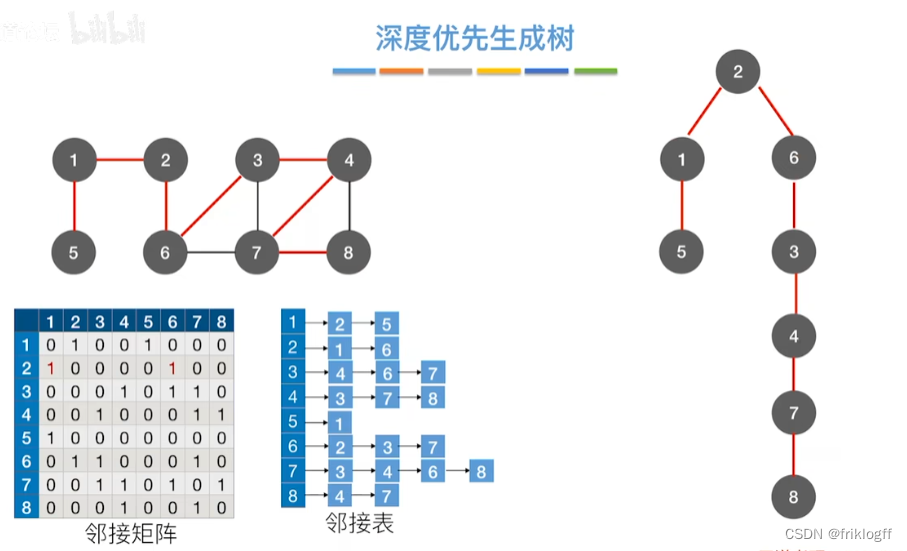
-
概念
-
生成树:所有顶点均由边连接在一起,但不存在回路的图
-
最小生成树:权值之和最小的那棵生成树
-
-
性质
-
最小生成树不是唯一的
-
其对应的边的权值之和总是唯一的,且是最小的
-
最小生成树的边数=顶点数-1
-
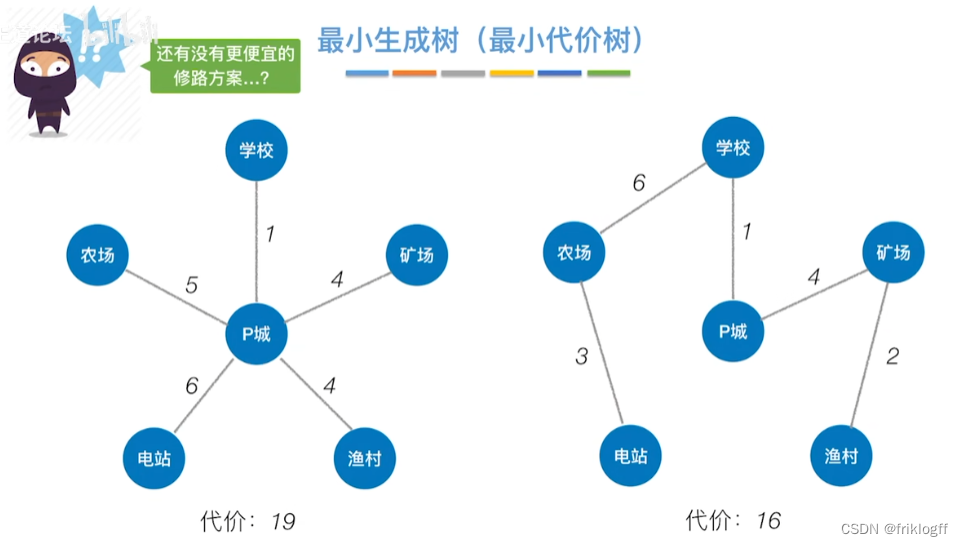
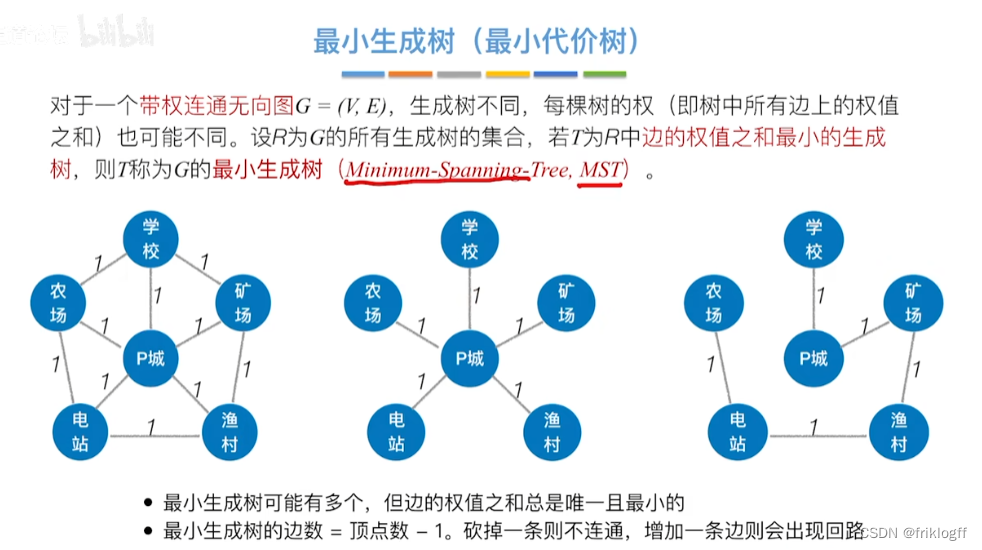
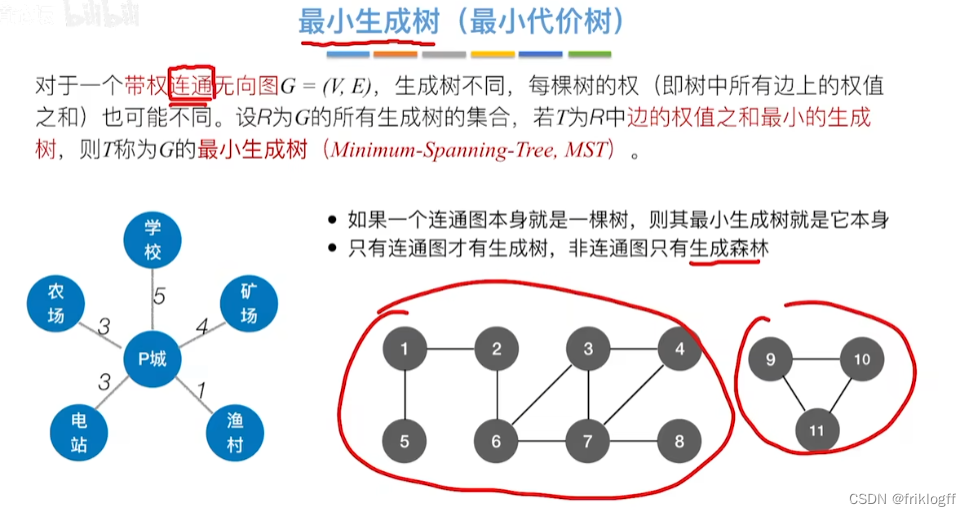

-
算法
-
算法基于MST性质
- 性质解释:n个顶点分属已经在生成树上的顶点集U和未在生成树上的顶点集V-U,接下来应在连通U和V-U的边中选取权值最小的边
-
Prim算法
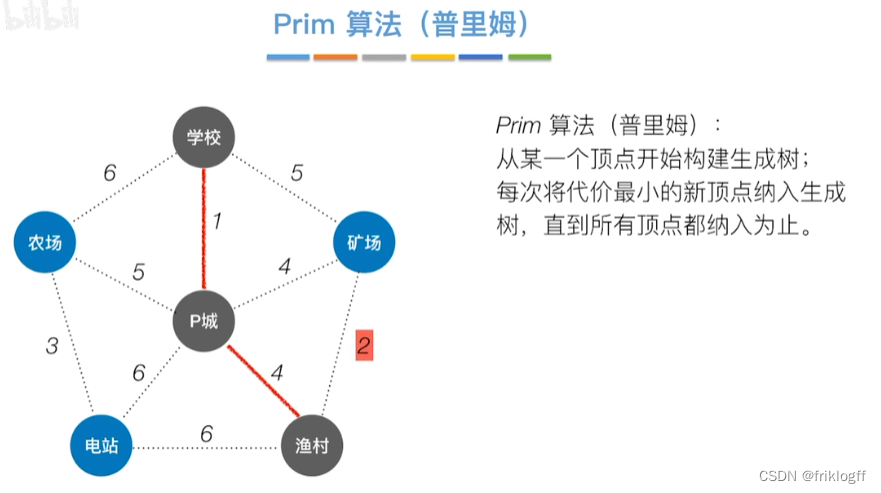
-
概述
- 每次将代价最小的新顶点加入生成树
-
实现
-
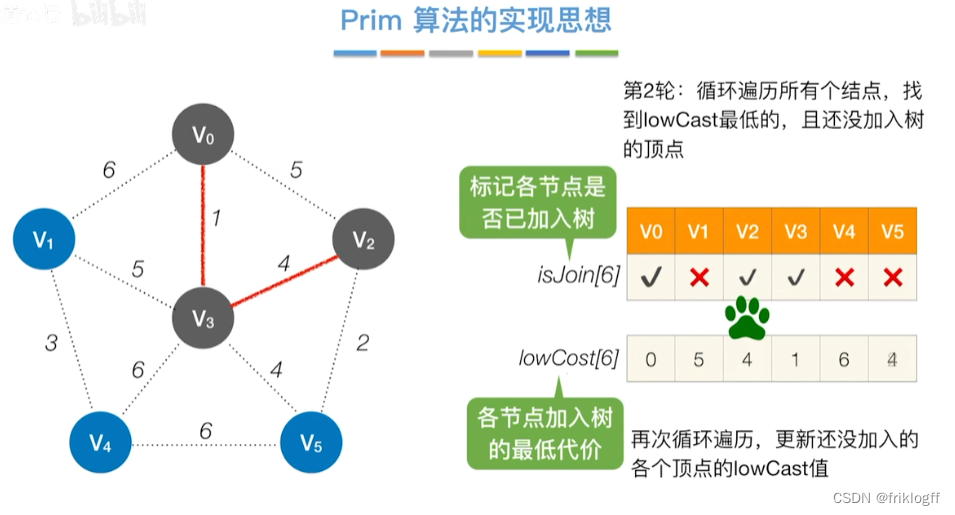
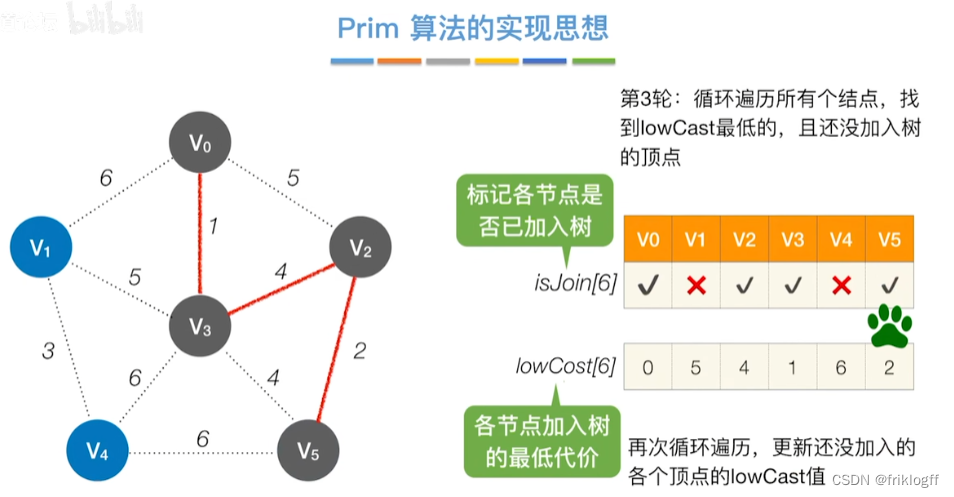
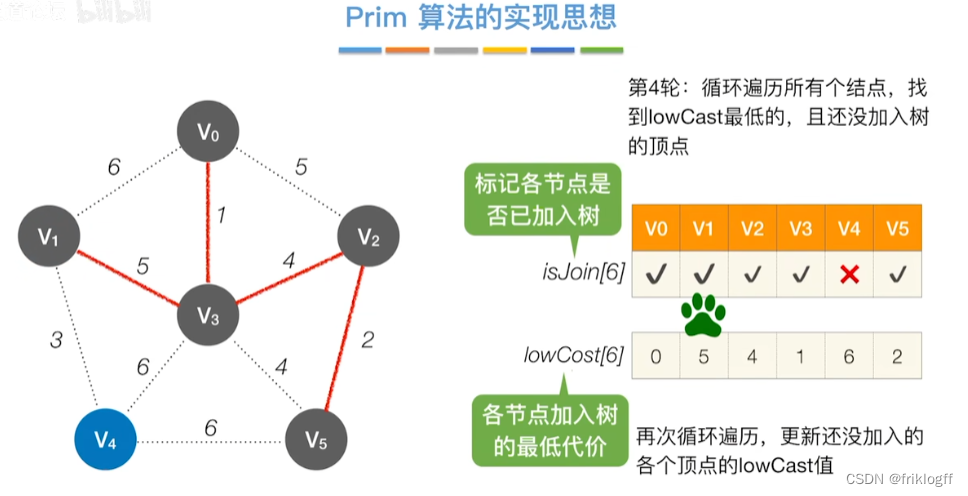
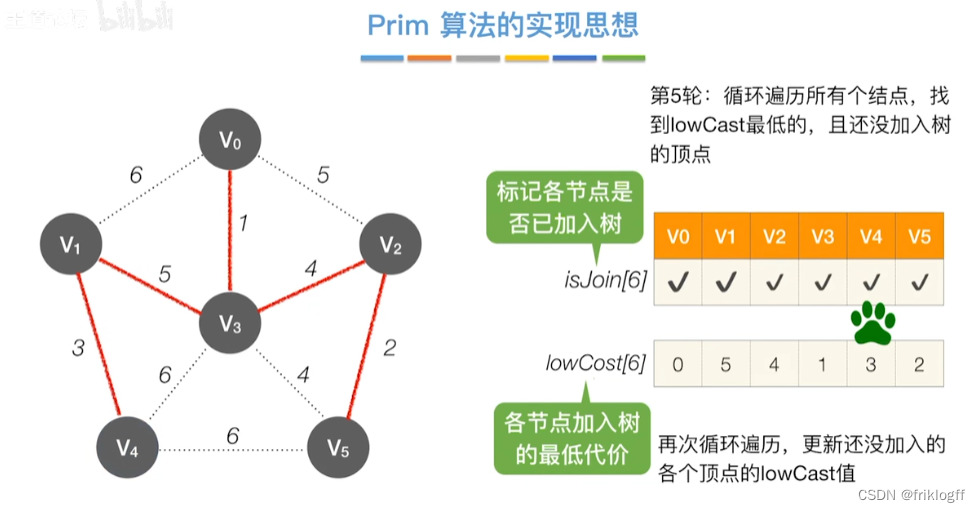
开始时从图中任取一个顶点加入树T
-
之后选择一个与当前T中顶点集合距离最近的顶点,将该点和对应边加入T,每次操作后T中顶点数和边数都+1
-
以此类推,当所有点加入T,必然有n-1条边,即T就是最小生成树
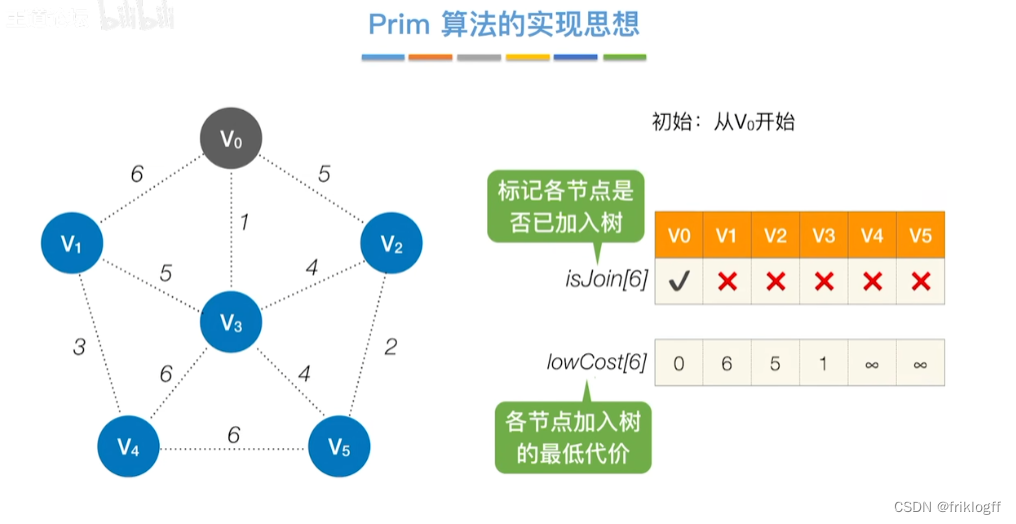
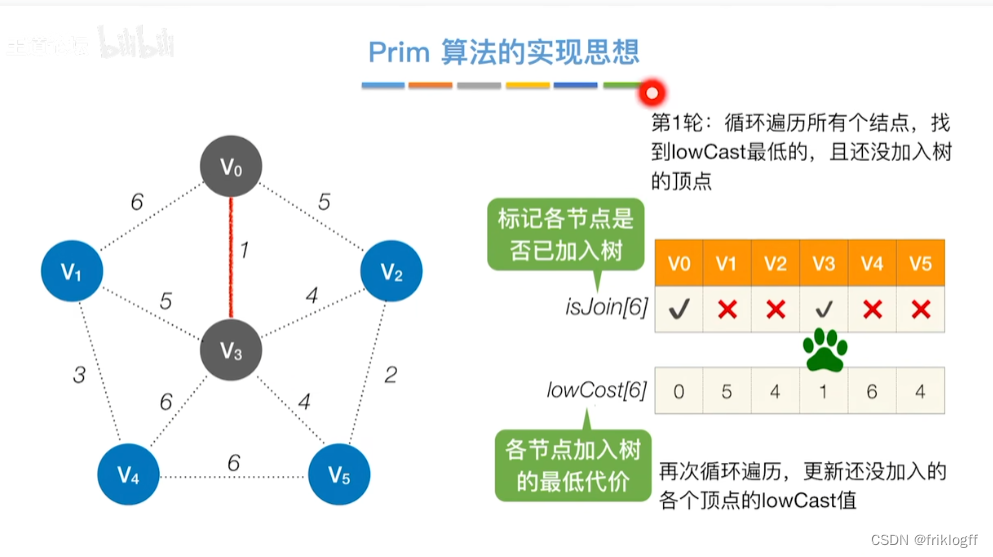
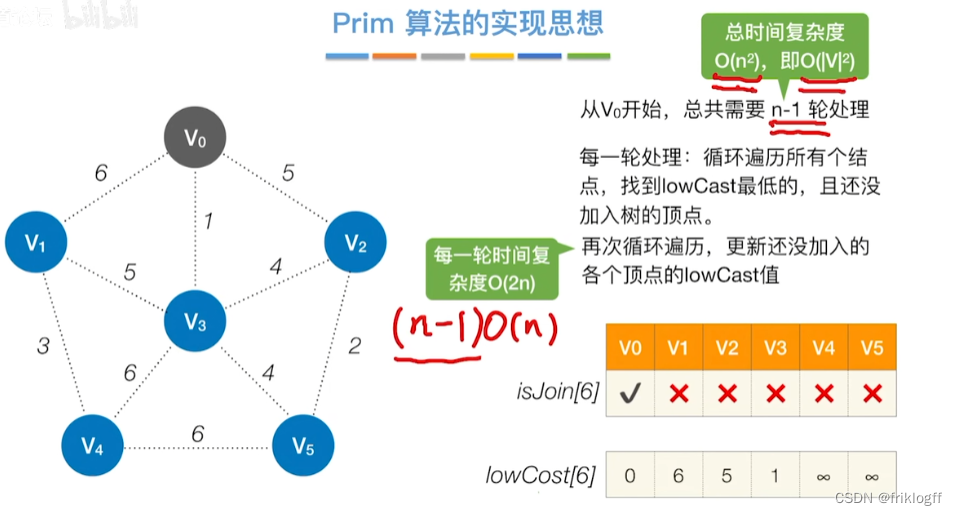
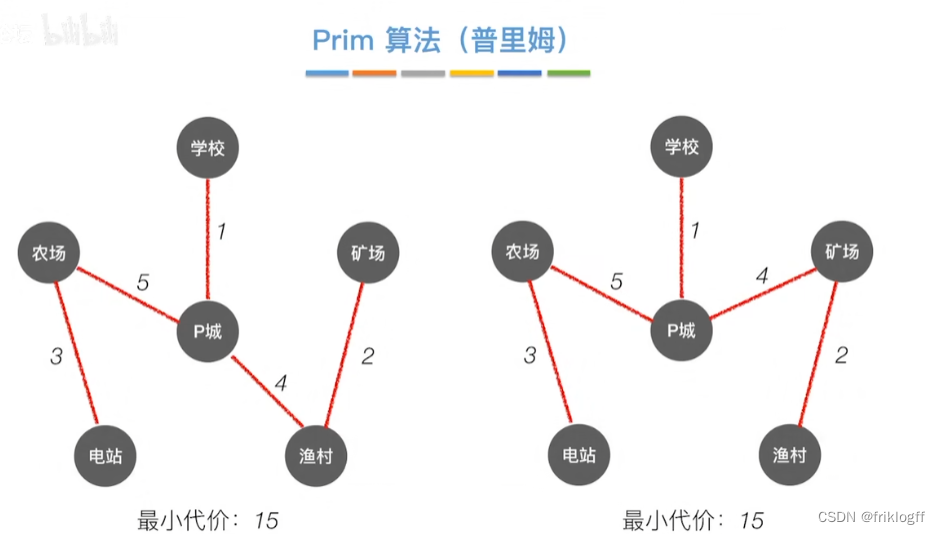
-
-
-
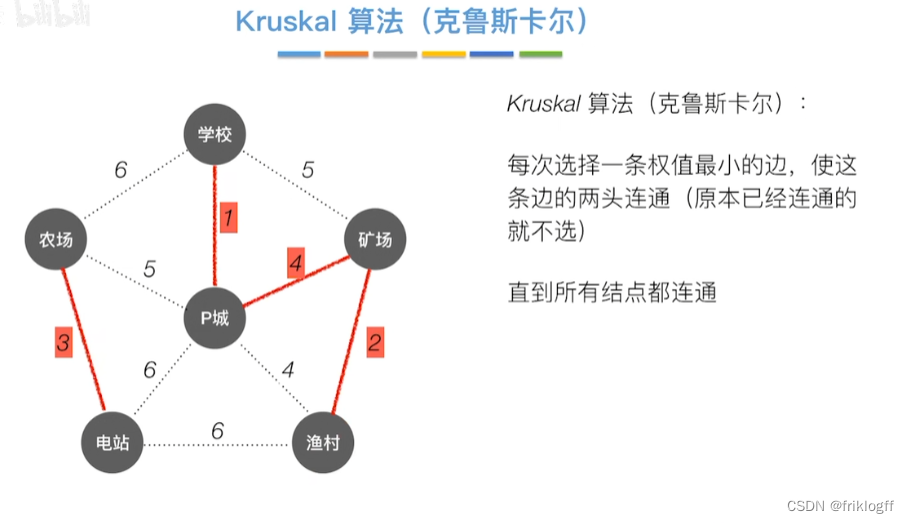
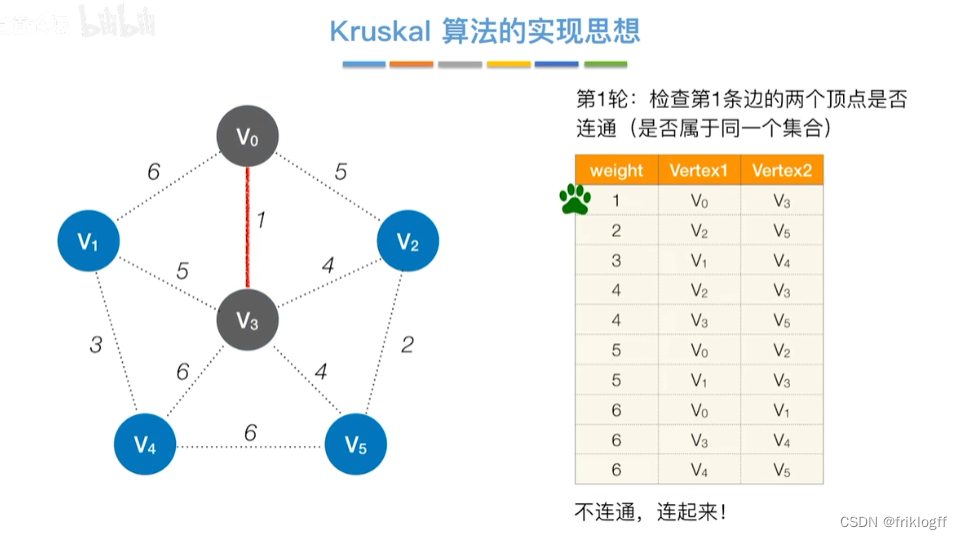
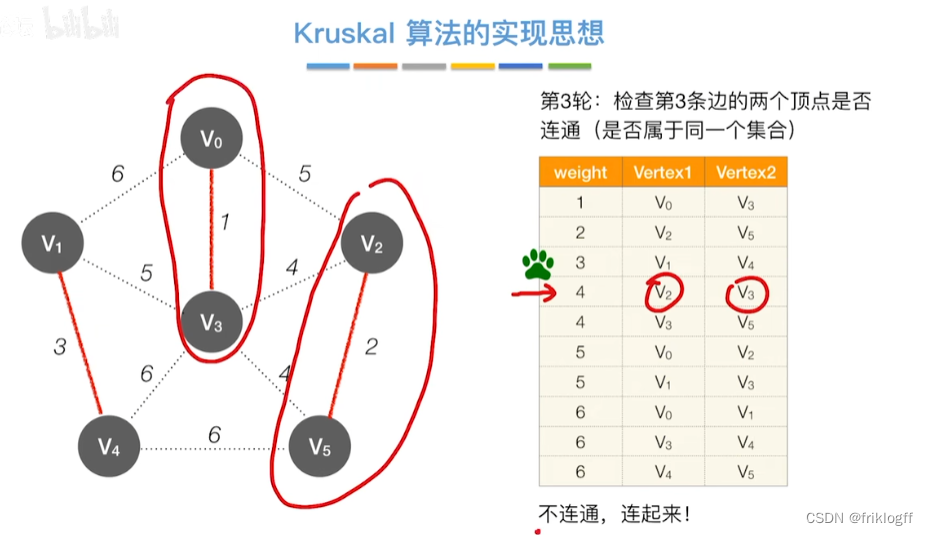
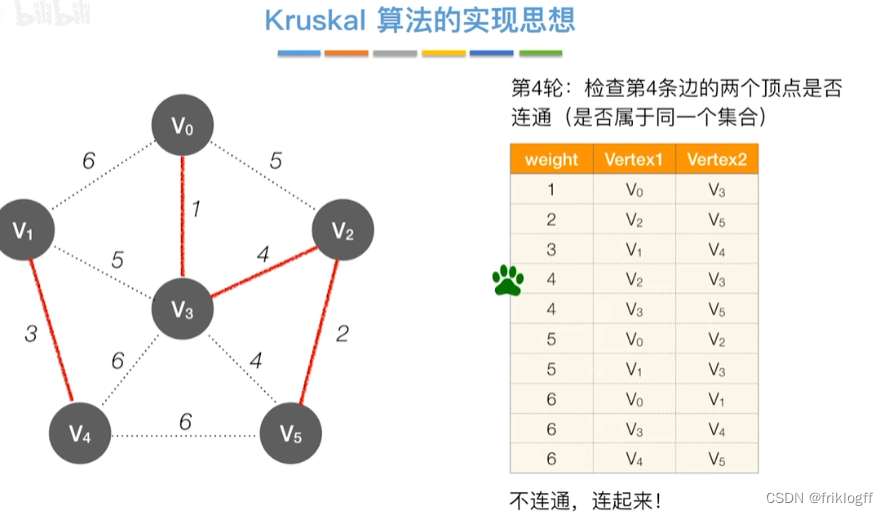
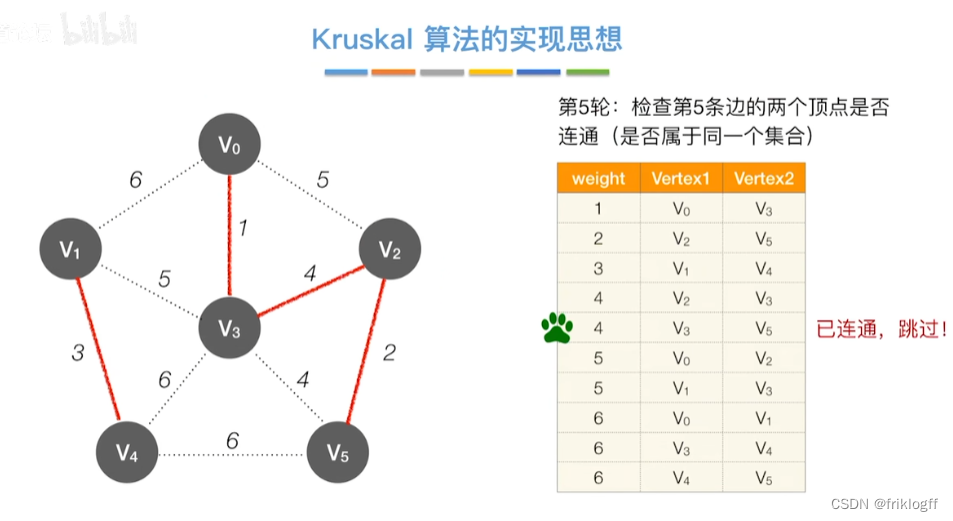
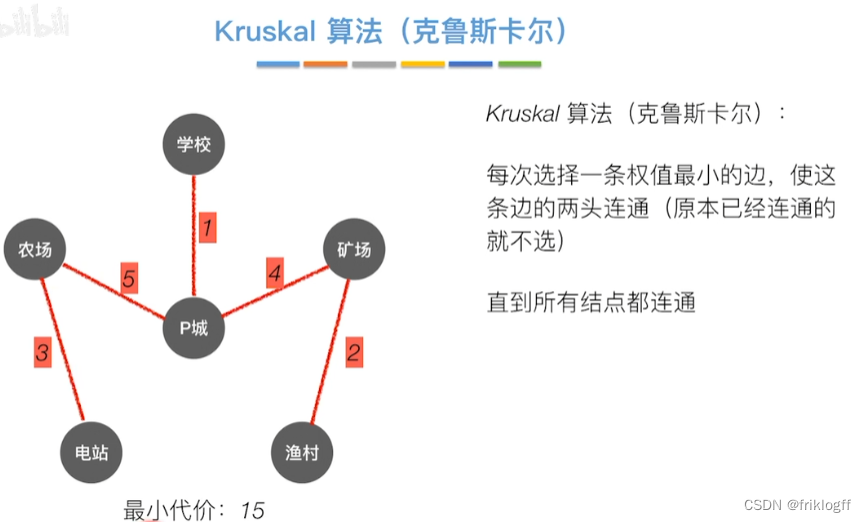
Kruskal算法
-
概述
- 每次选一条权值最小的边(边按权值排序),使其连通(用并查集判断并实现)
-
实现
-
开始时为只有n个顶点而无边的非连通图T={V,{}},每个顶点自成一个连通分量
-
然后按照边的权值由小到大,不断选取当前未被选取过且权值最小的边
-
若该边依附的顶点在两个连通分量上,则将边加入T,否则继续选取下一条边
-
以此类推,直到T中所有顶点都在一个连通分量上
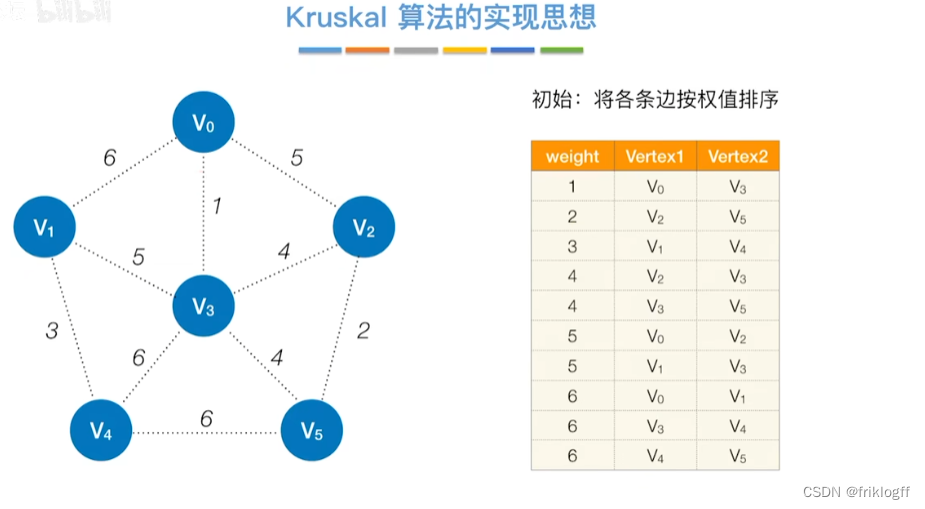
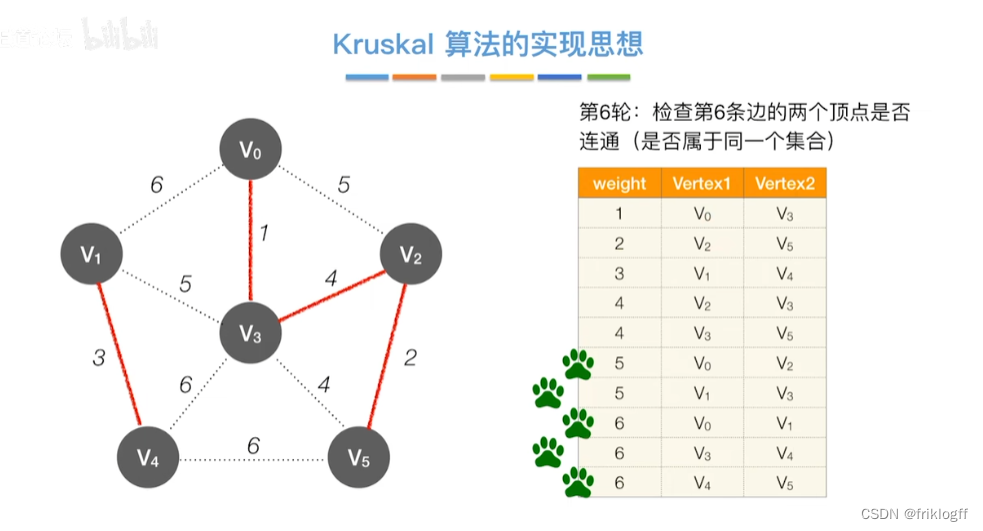
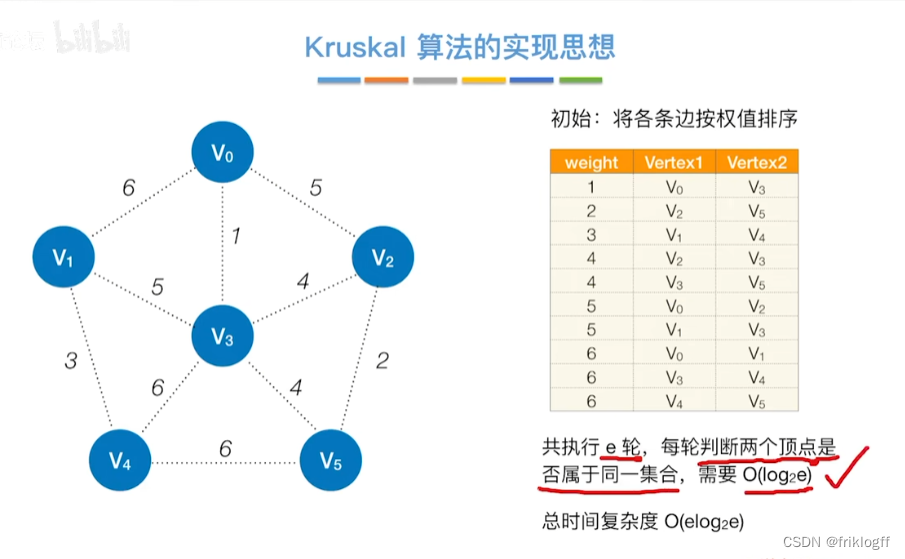
-
-
-
比较


-
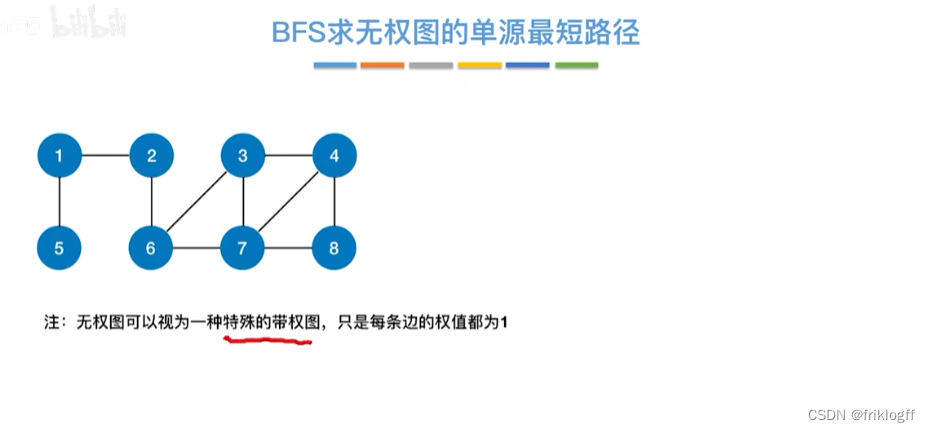
最短路径
- 在有向网中A点(源点)到达B点(终点)的多条路径中,找到一条各边权值之和最小的路径
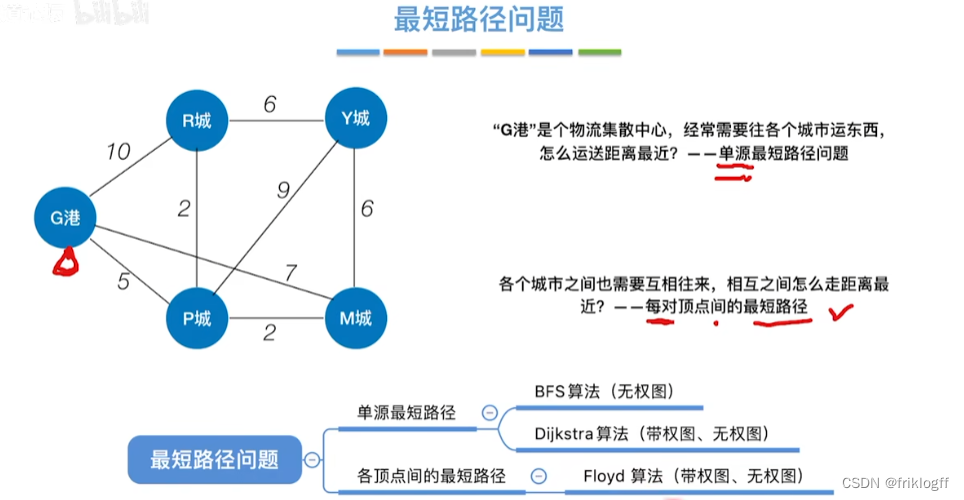
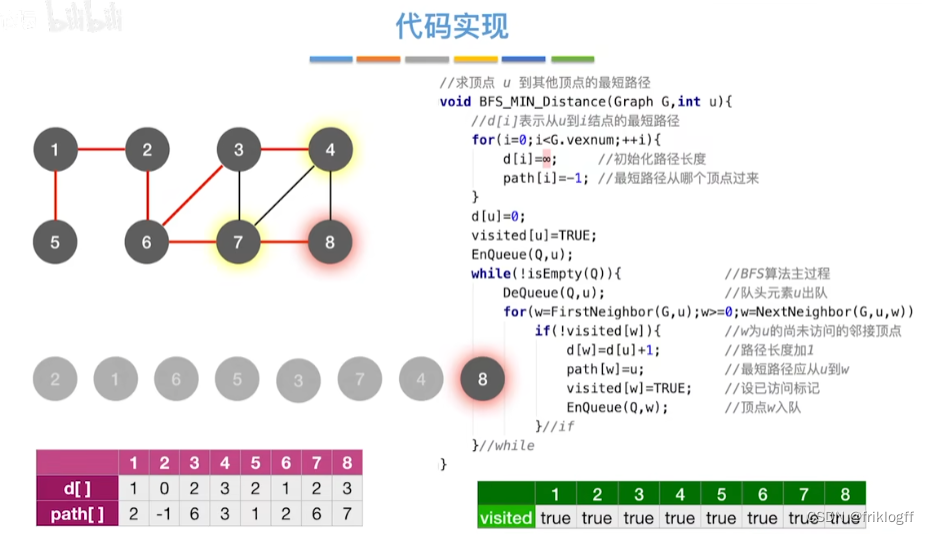
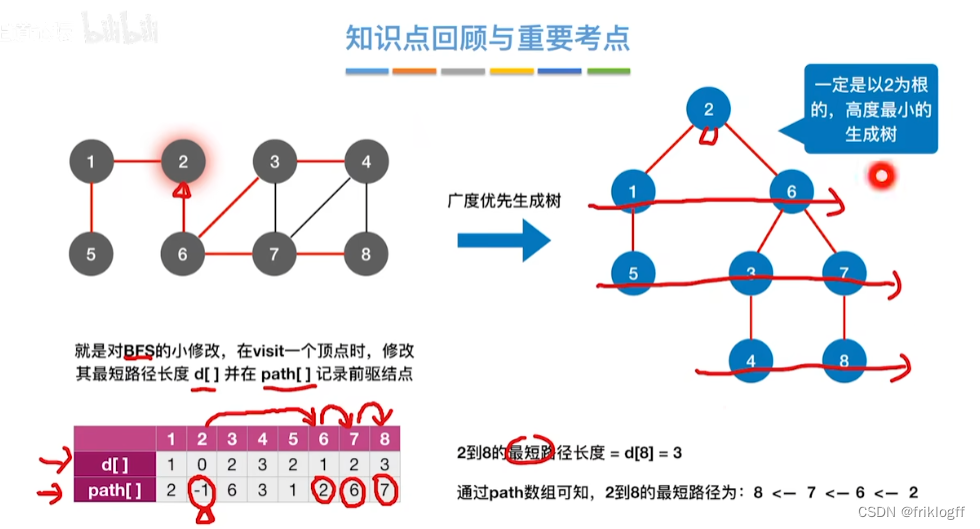
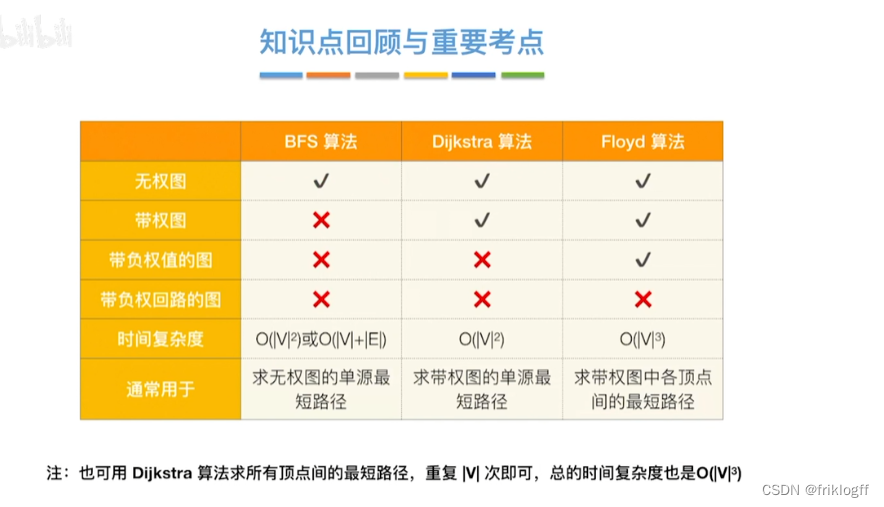
BFS求无权图的单源最短路径
Dijkstra算法(两点间最短路径)

-
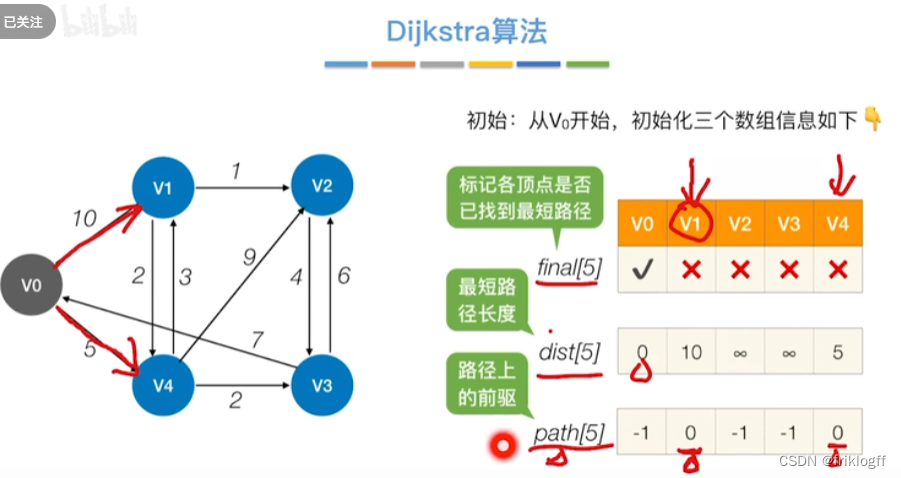
概述
-
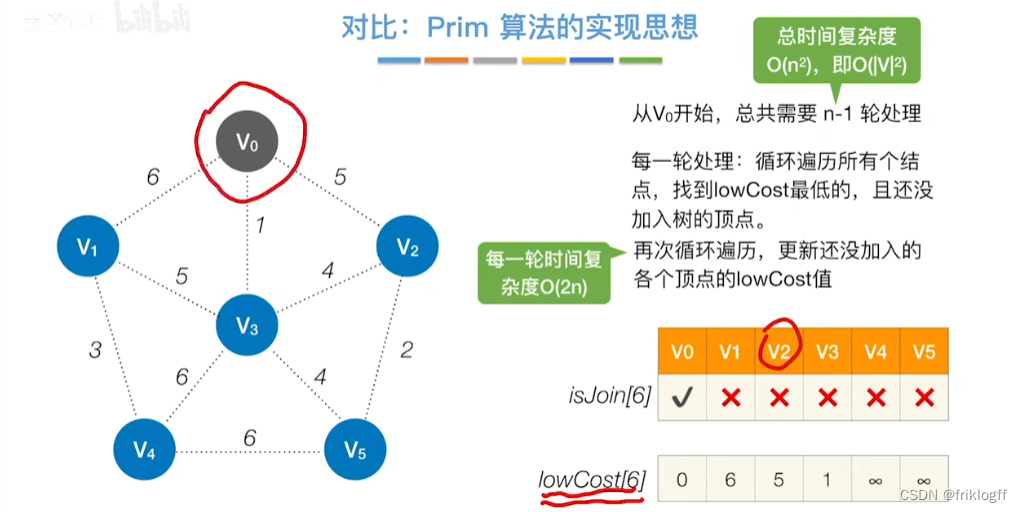
维护一个最短路径数组,每次选取最短的顶点加入,更新加入后的最短路径,直到所有顶点都访问
-
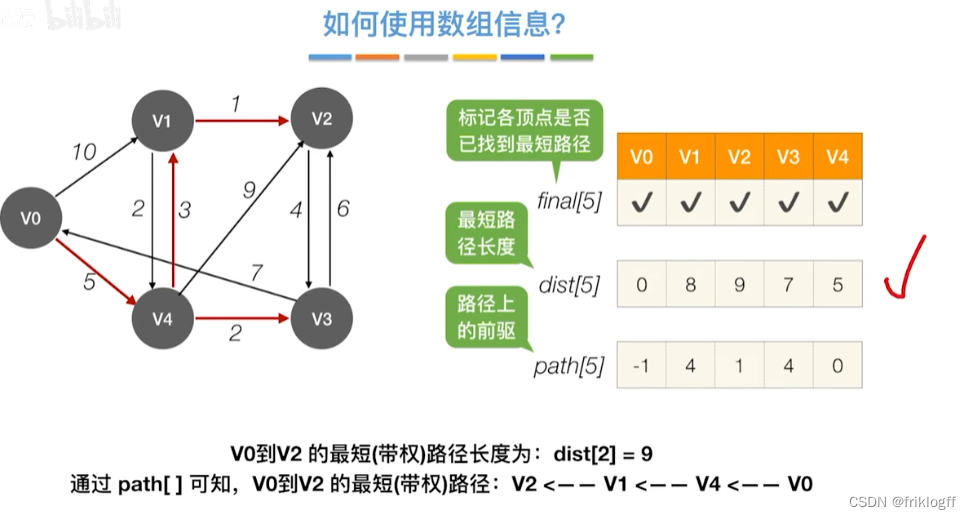
s[]记录是否访问,dist[]记录源地到各点最短路径,path[]记录前驱结点
-
-
过程
-
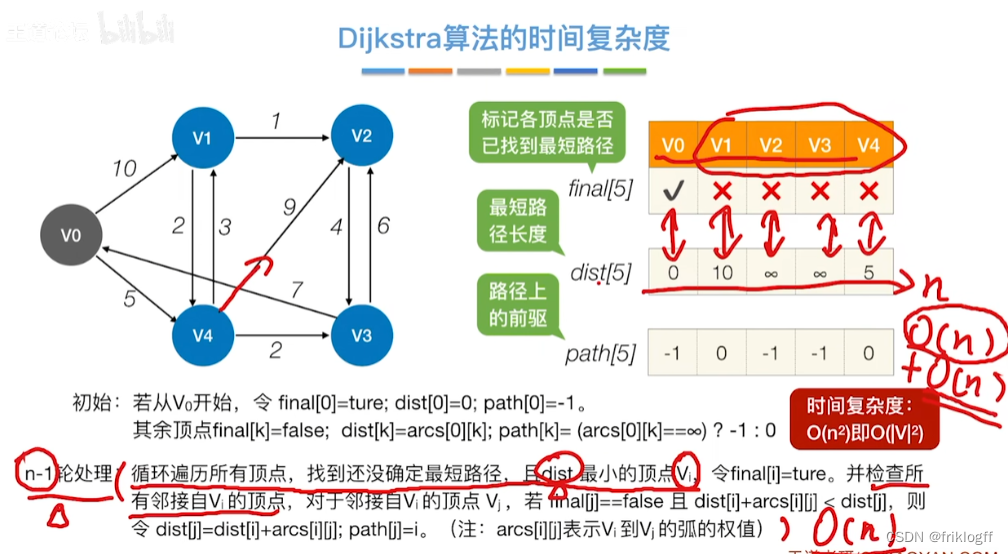
初始化:集合S初始为{0}(源点入集合),dist[]初始值dist[i]=arcs[0][i](与源点距离)
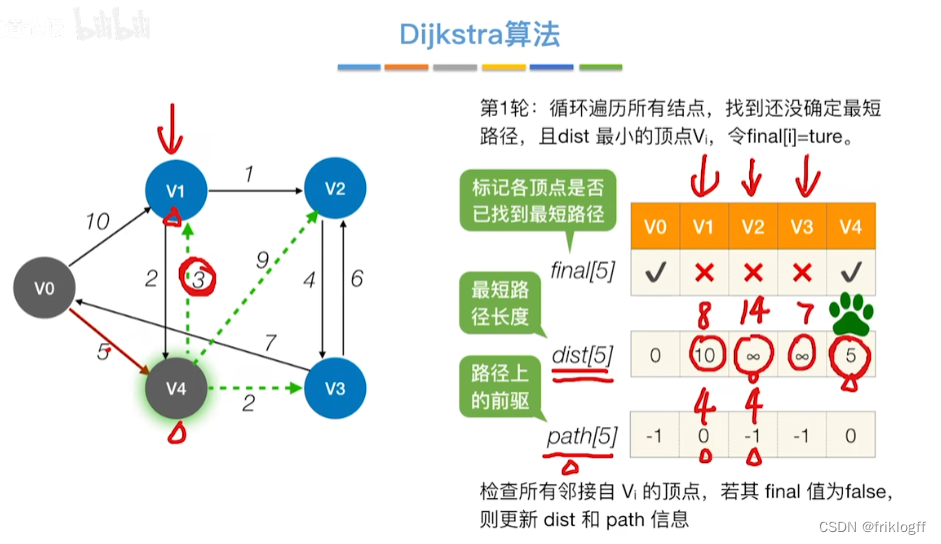
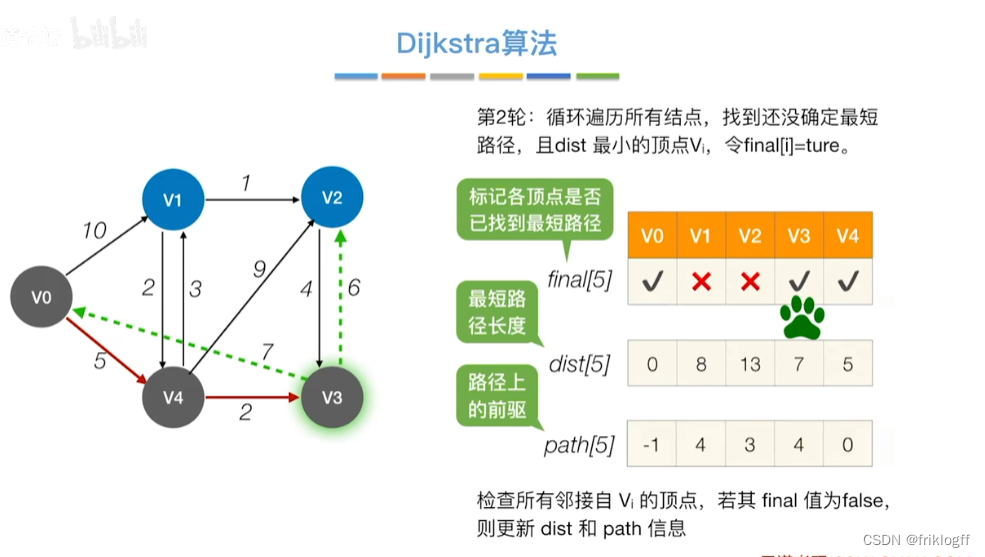
-
从顶点集合V-S中选出dist[]数组值最小的,即选最近的点加入
-
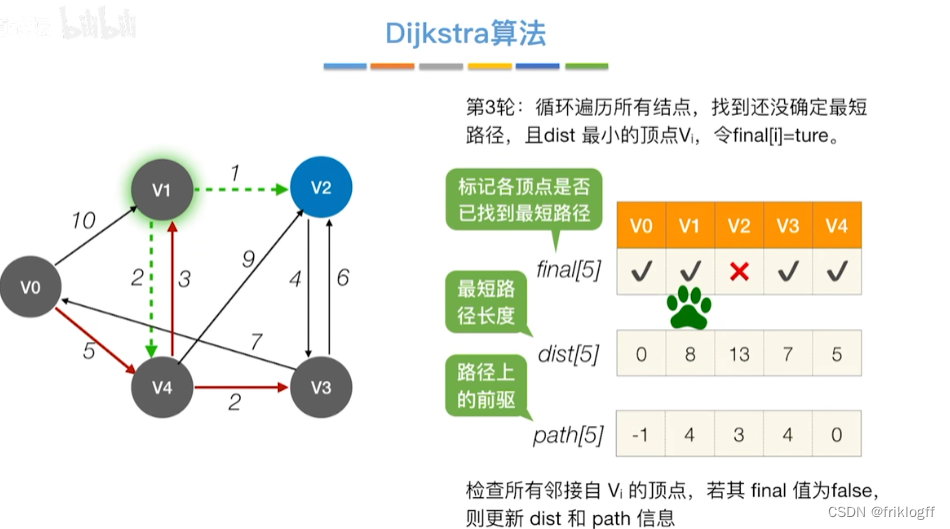
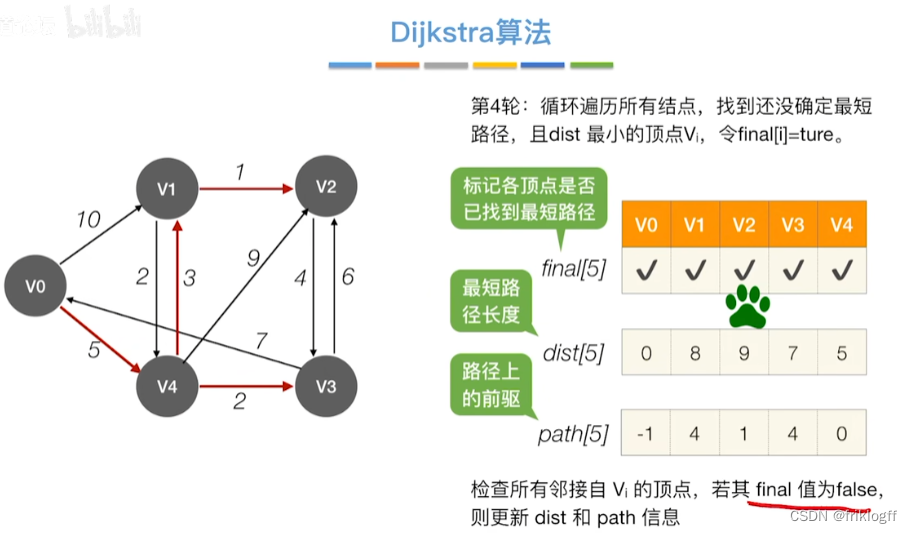
修改V0出发到集合V-S上任一顶点最短路径长度:若dist[j]+arcs[j][k]<dist[k],则更新dist[k]=dist[j]+arcs[j][k]
-
重复步骤2-3,n-1次,直到所有顶点都包含在S中
-
-
时间复杂度
- O(|V|^2)
- O(|V|^2)
-
注意
- 适合稠密图,无负权值
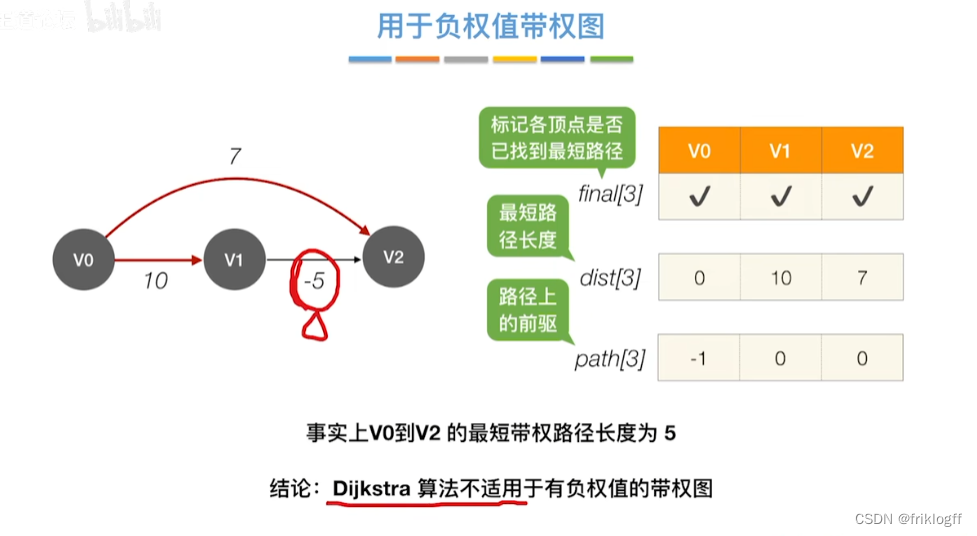
- 适合稠密图,无负权值
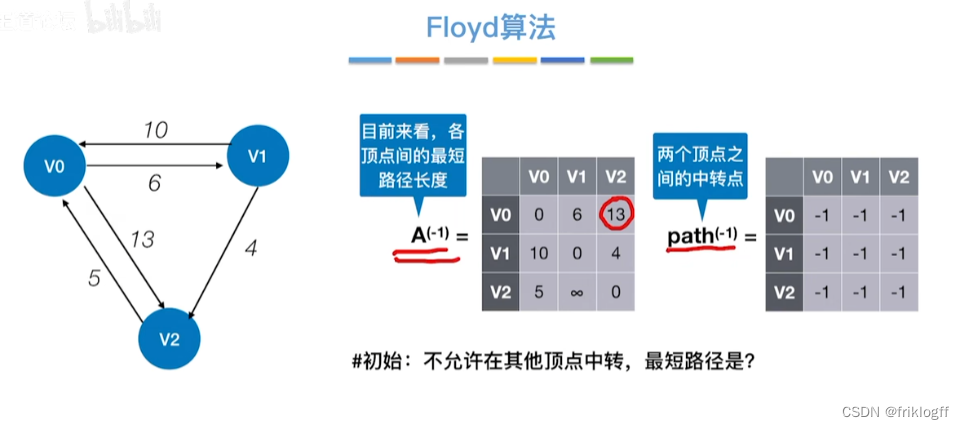
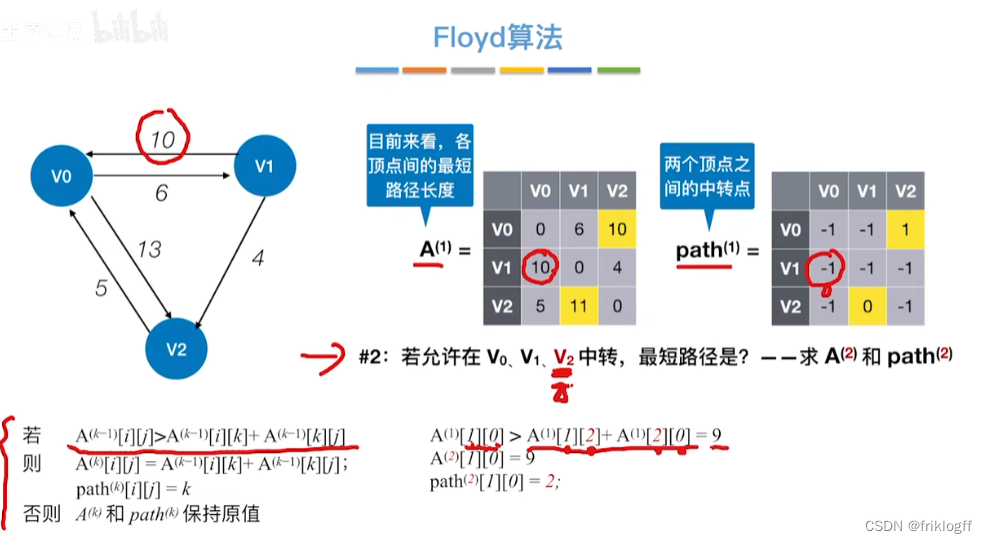
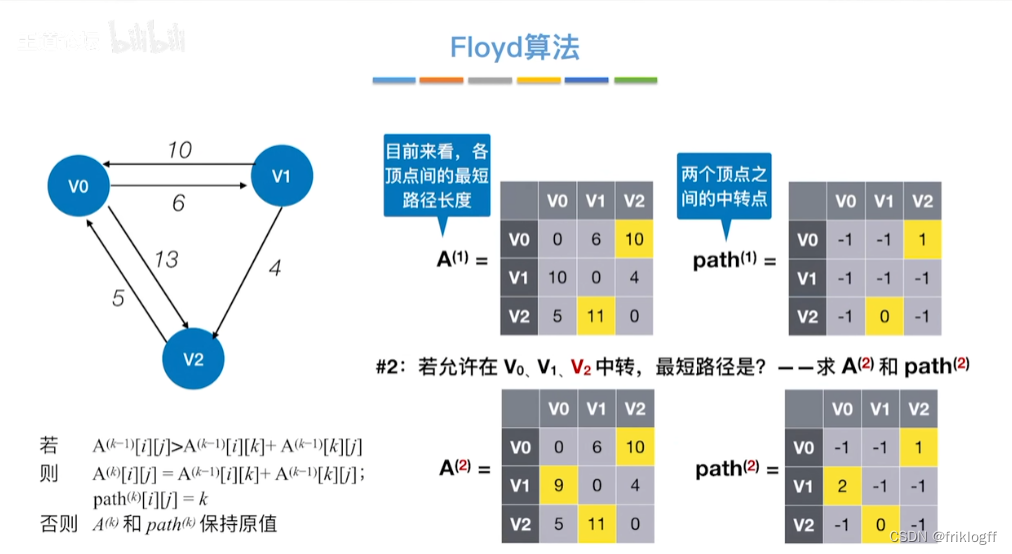
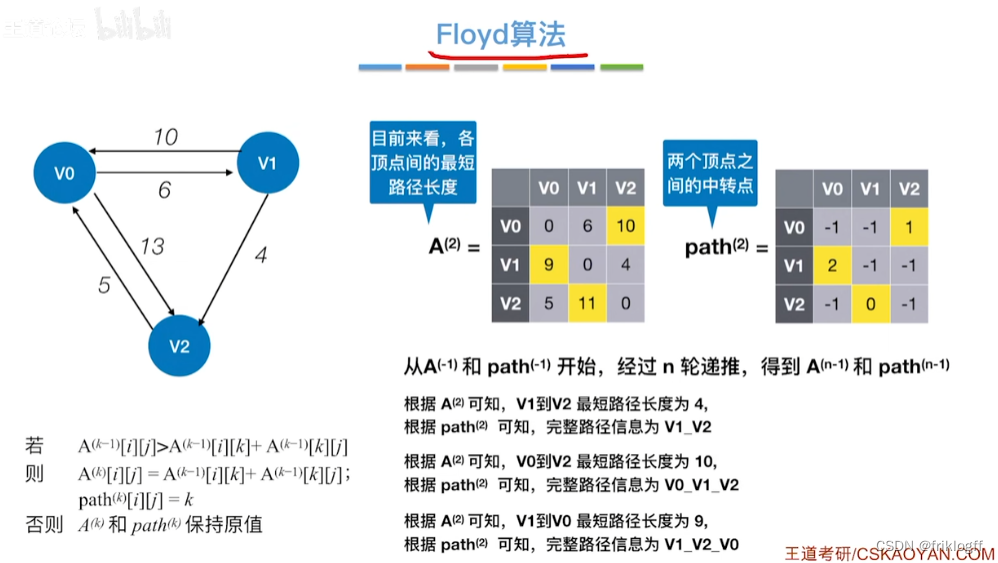
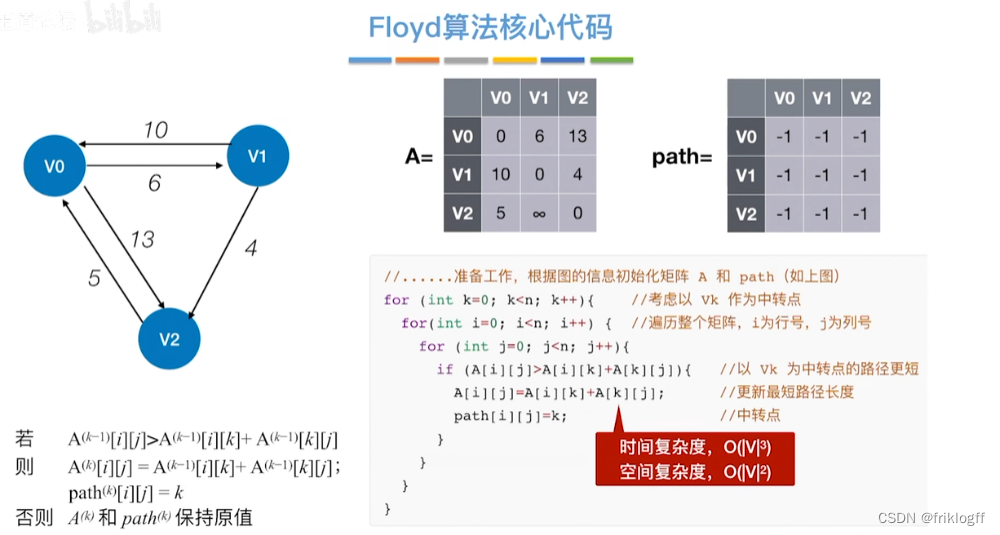
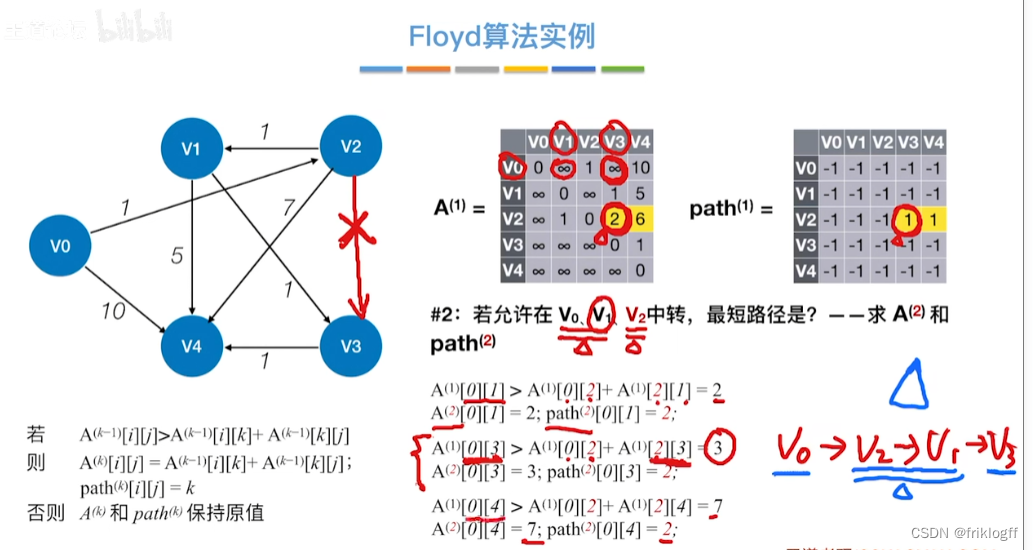
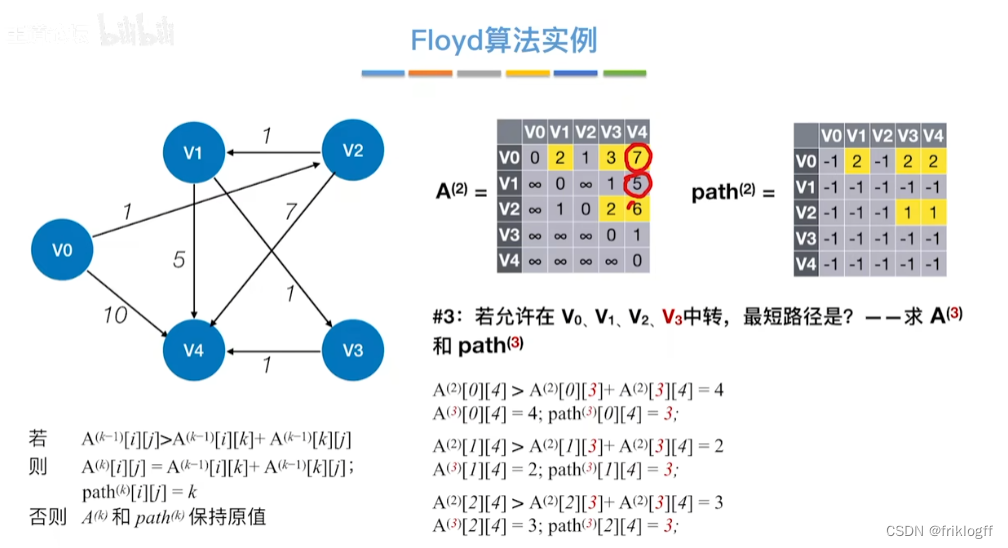
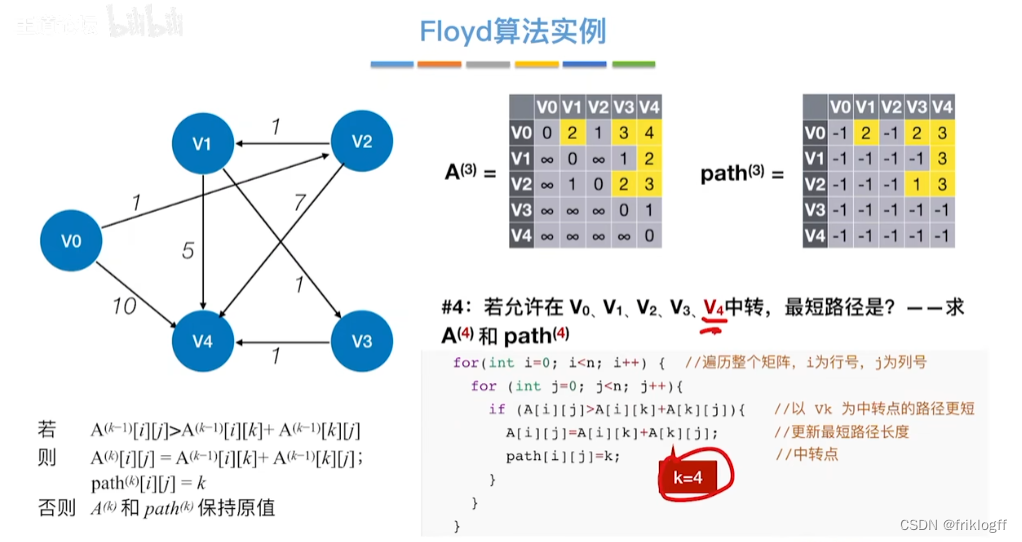
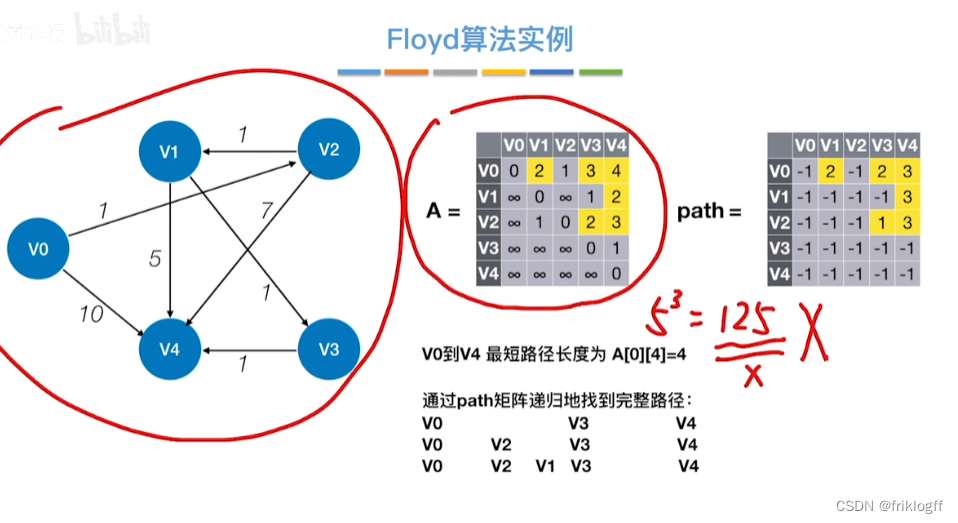
Floyd算法(各顶点之间最短路径)
-
概述
- 维护一个各顶点间最短路径二维数组,不断试探加入中间结点,是否缩短距离(三重循环)

- 维护一个各顶点间最短路径二维数组,不断试探加入中间结点,是否缩短距离(三重循环)
-
过程
-
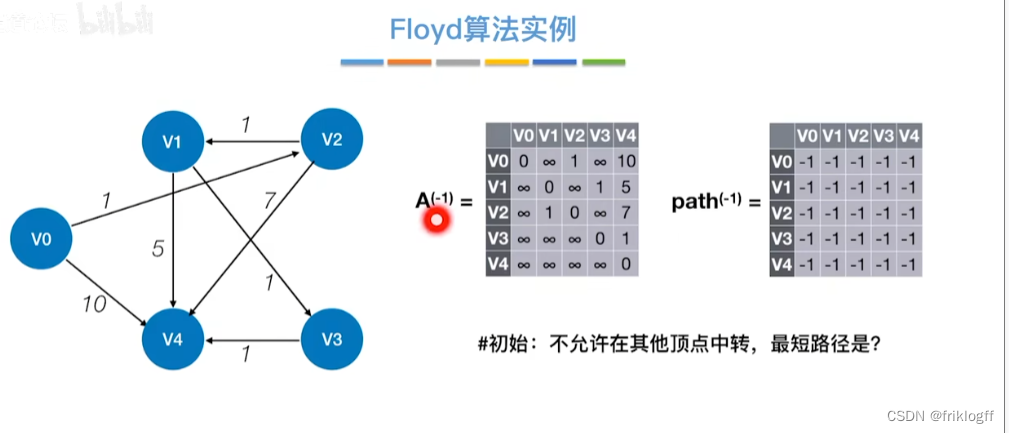
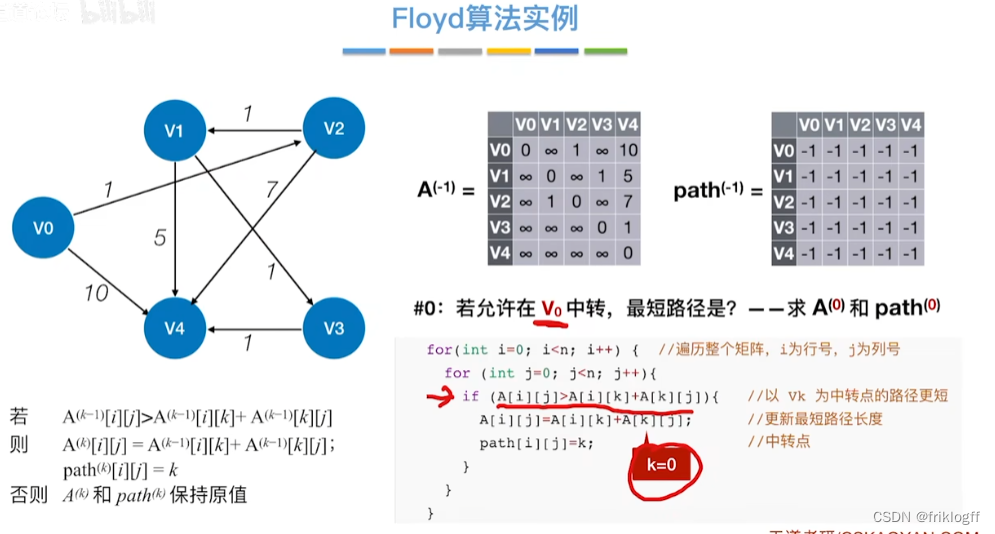
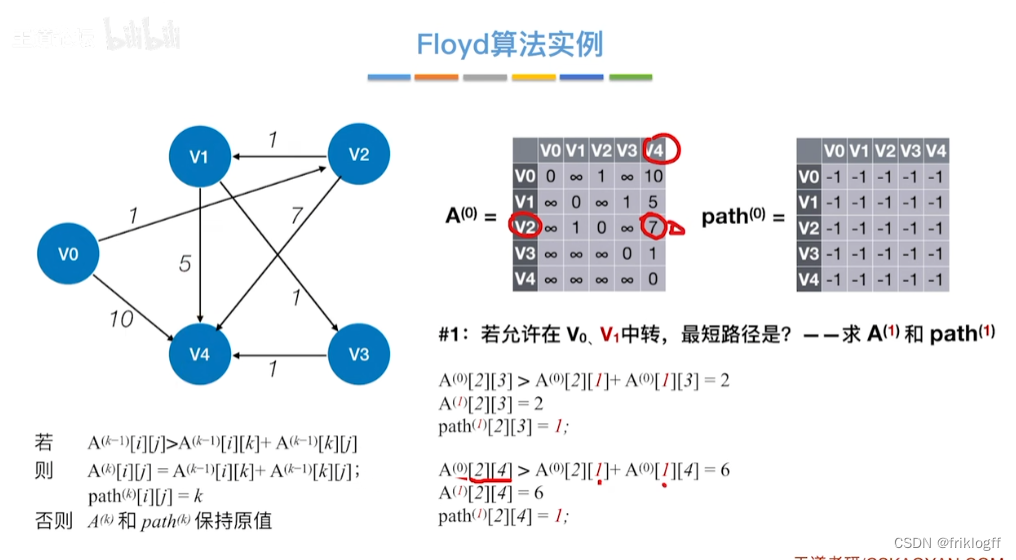
初始化:对任意两个顶点vi和vj,若存在边,则二维数组上最短路径为权值(不存在则最短路径为无穷)
-
逐步尝试在原路径上加入顶点k(k = 0,1,…,n-1)为中间结点
-
若更新后得到路径比原本路径长度短,则新路径代替原本路径
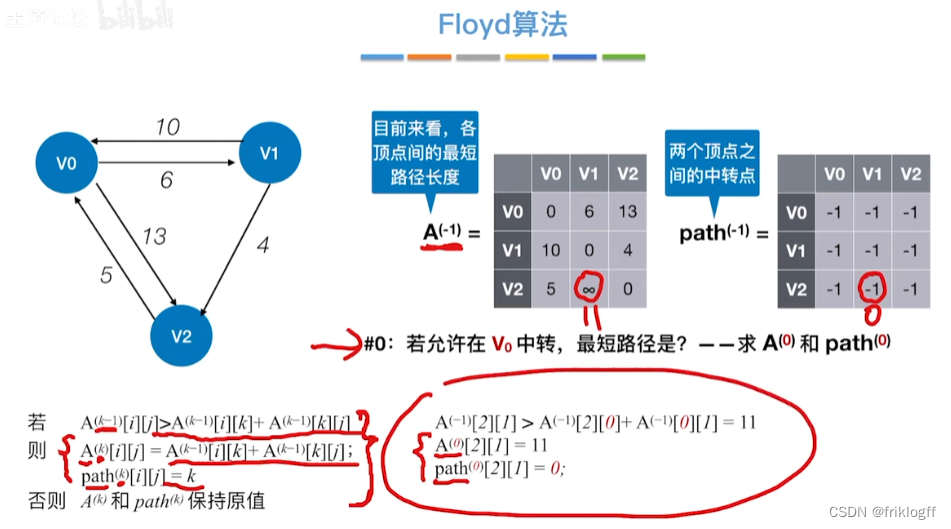
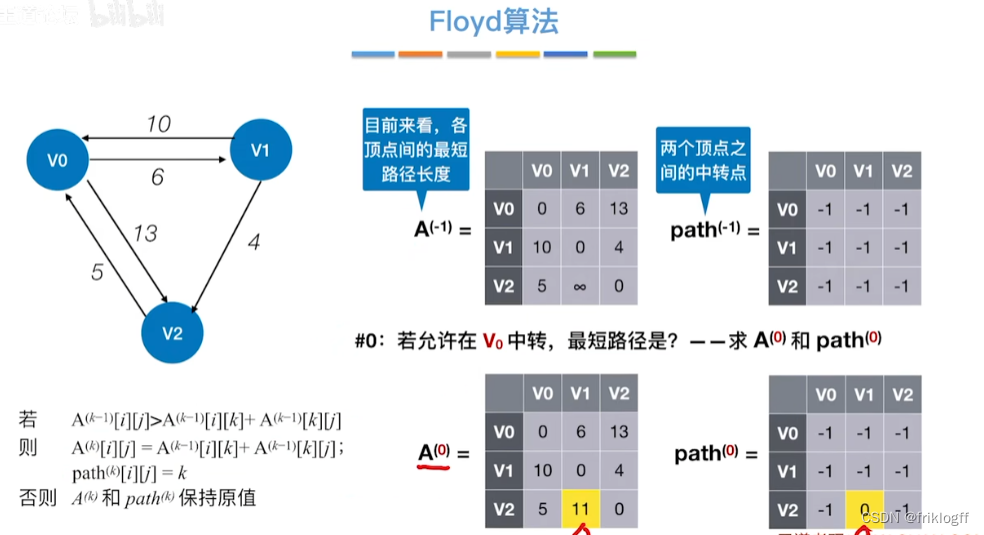
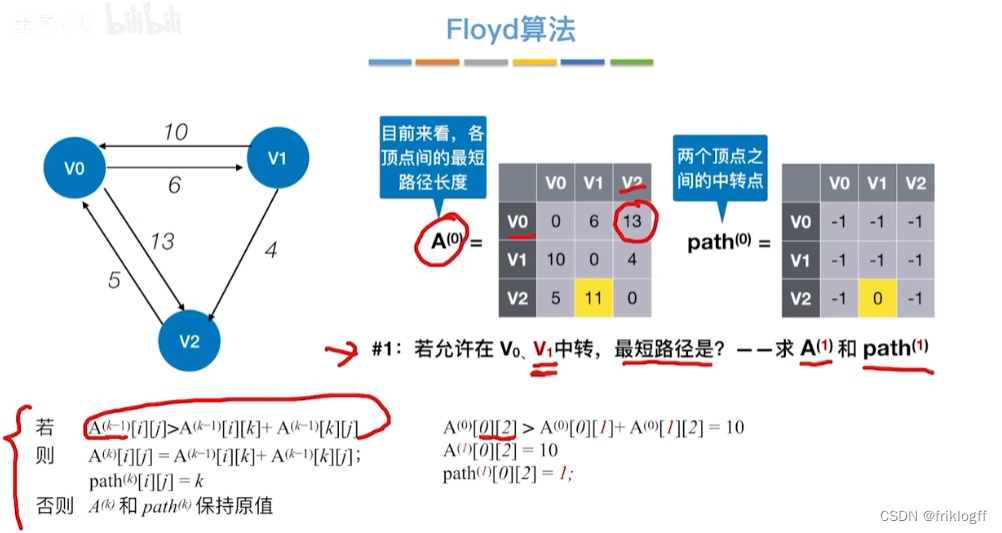
-
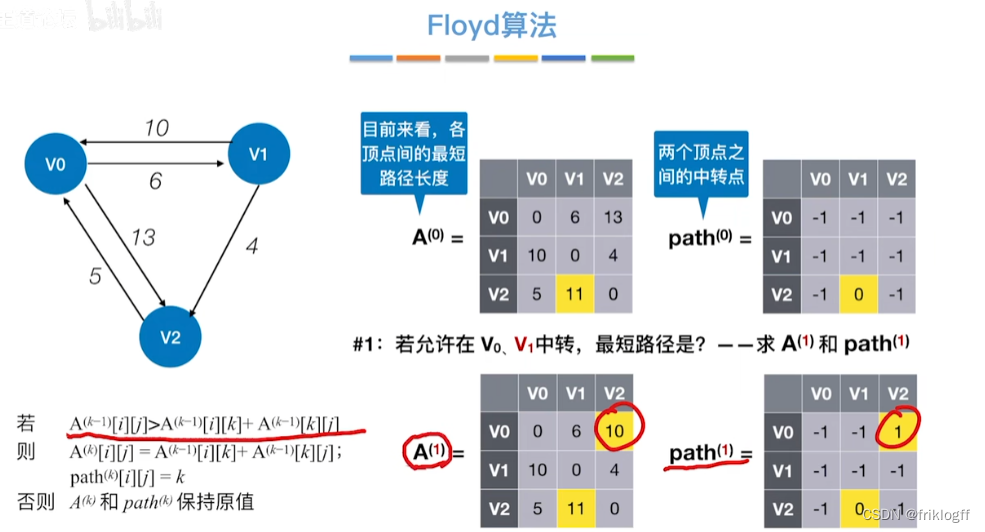
-
时间复杂度
-
O(|V|^3)
-
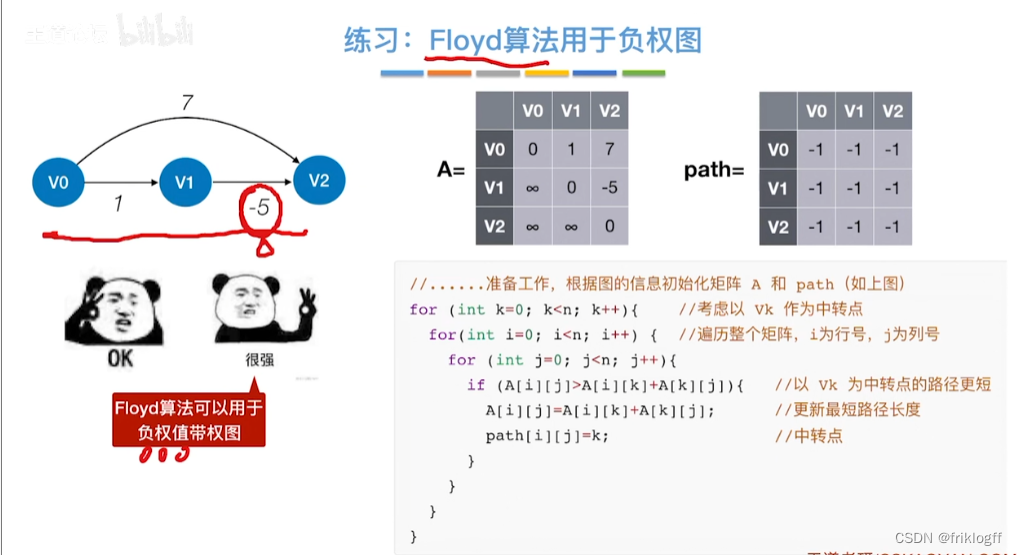
注意
-
允许图中有带父权值的边,但不允许有包含带负权值的边组成回路
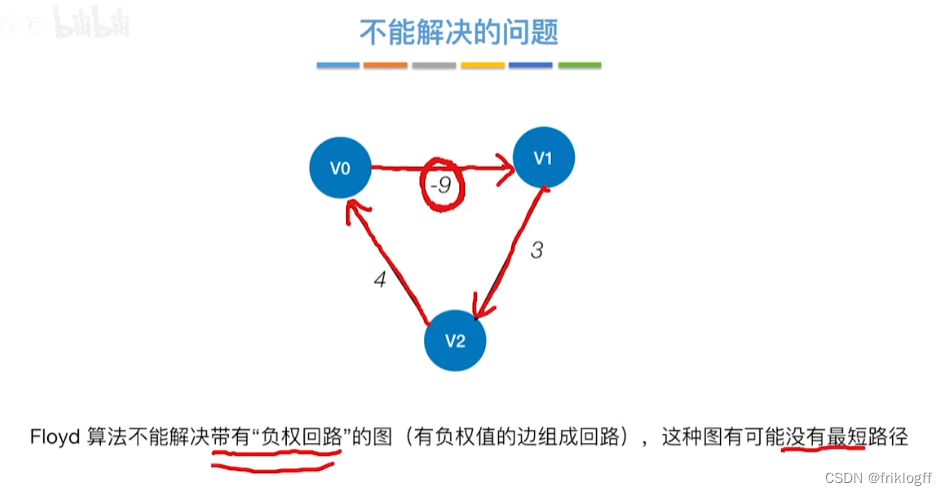
-
适用于带权无向图
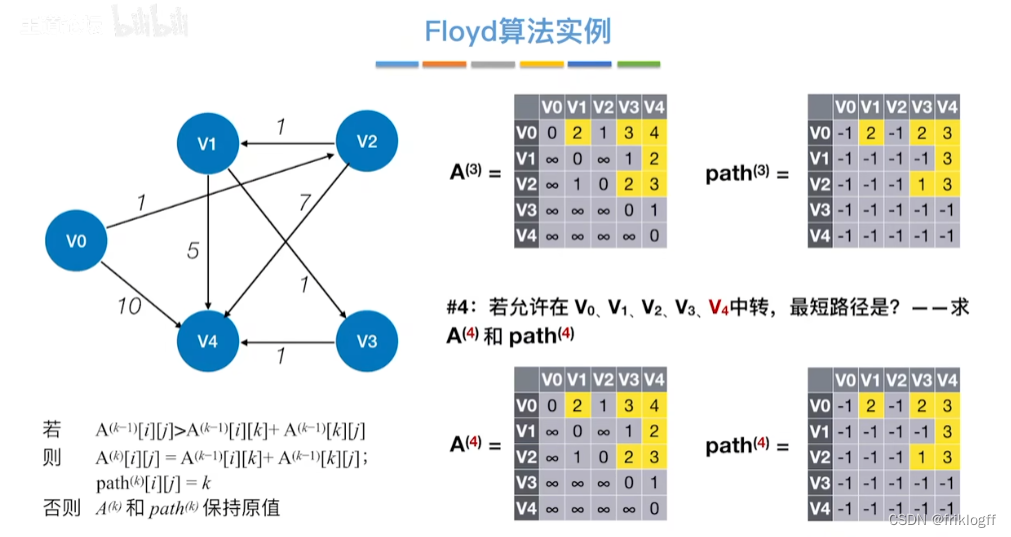
小结
有向无环图的应用
-
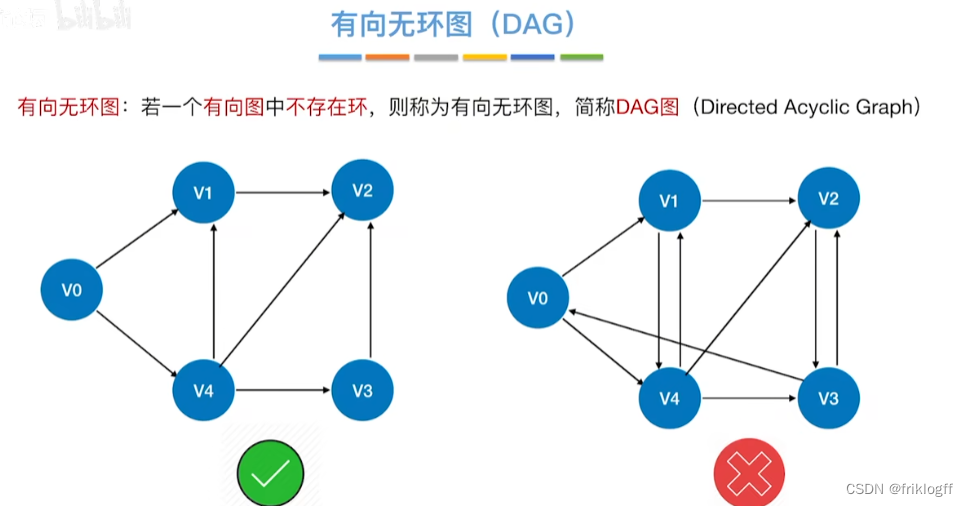
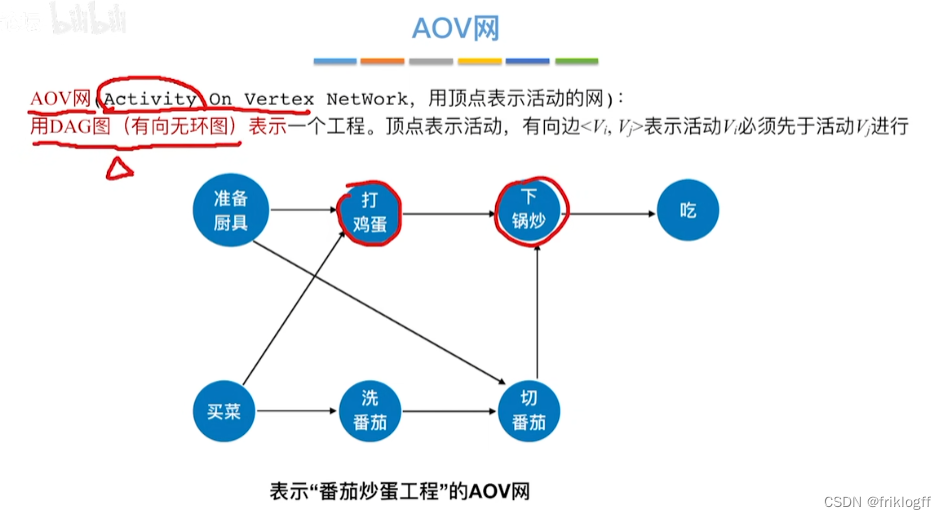
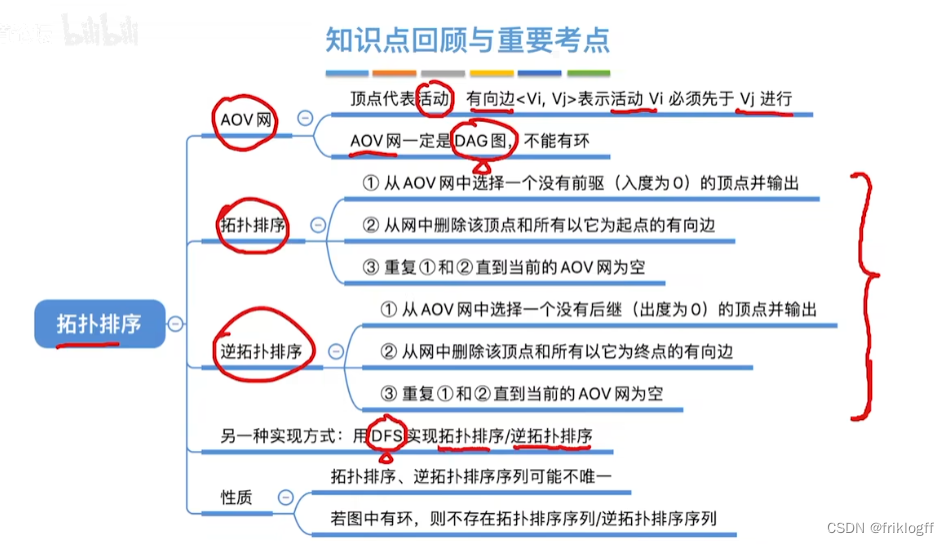
有向无环图:无环的有向图,简称DAG图
-
用一个有向图表示一个工程的各子工程及其互相制约关系
-
AOV网:顶点表示活动,弧表示活动之间的优先制约关系
-
AOE网:弧表示活动,以顶点表示活动的开始或结束事件
-
有向无环图描述表达式
-
-
28题为例
-
操作数在最下层排成一排
-
按生效顺序,加入运算符(分层)
-
从底向上检查同层能否合并
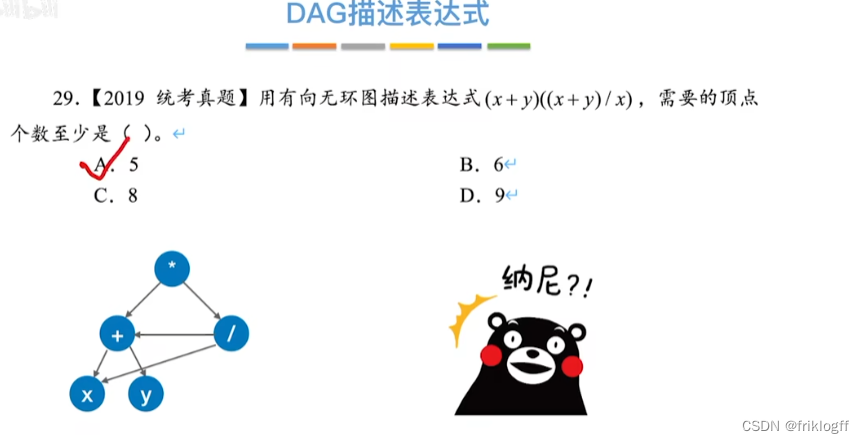
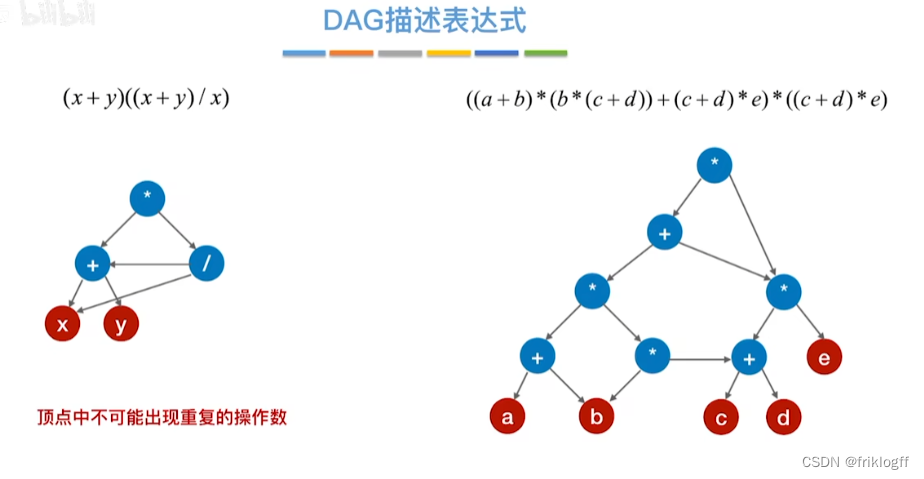
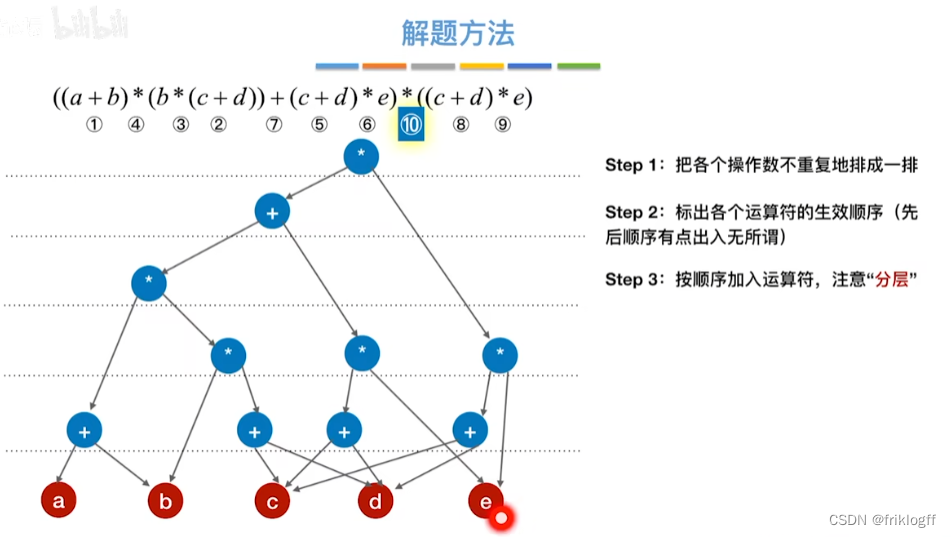
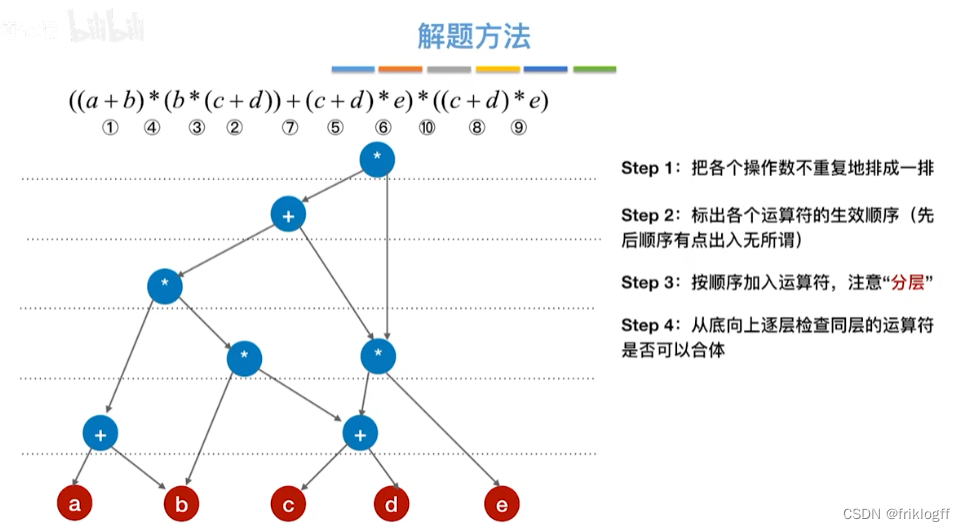
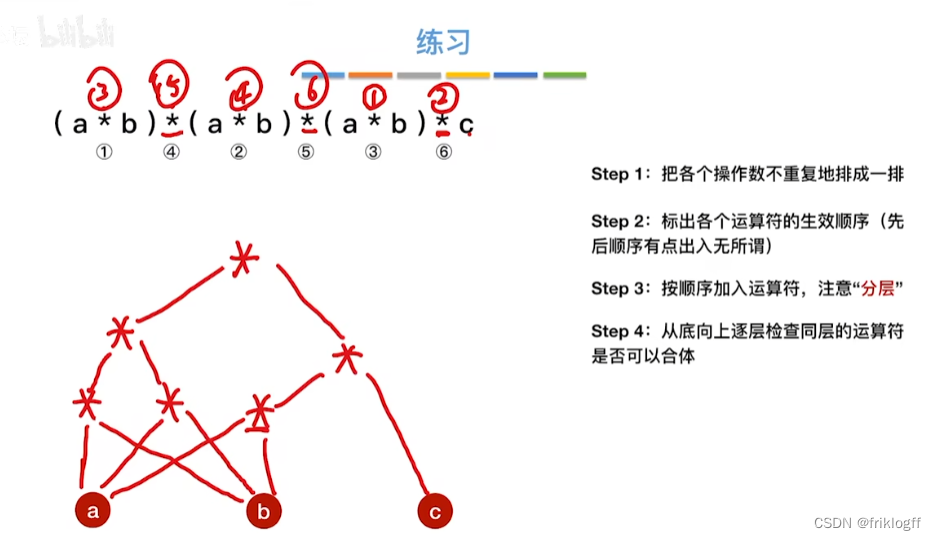
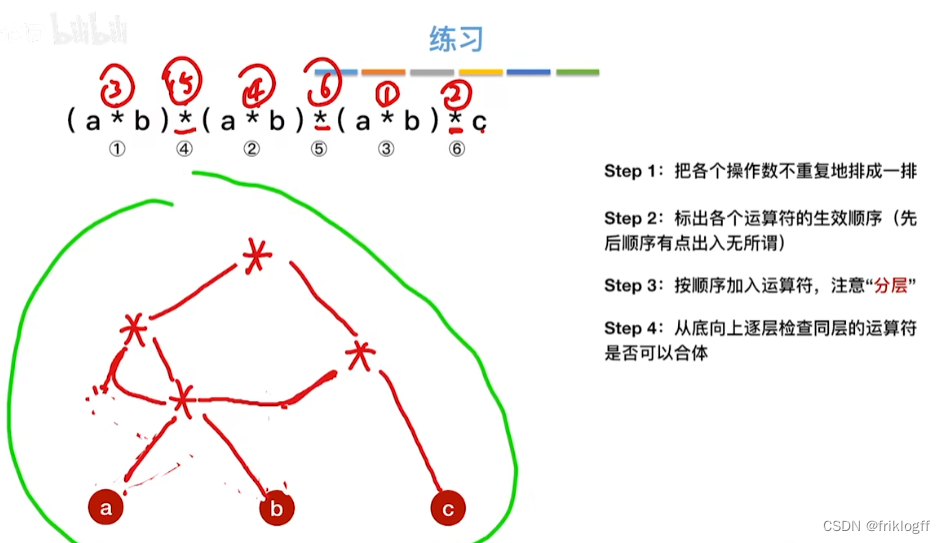
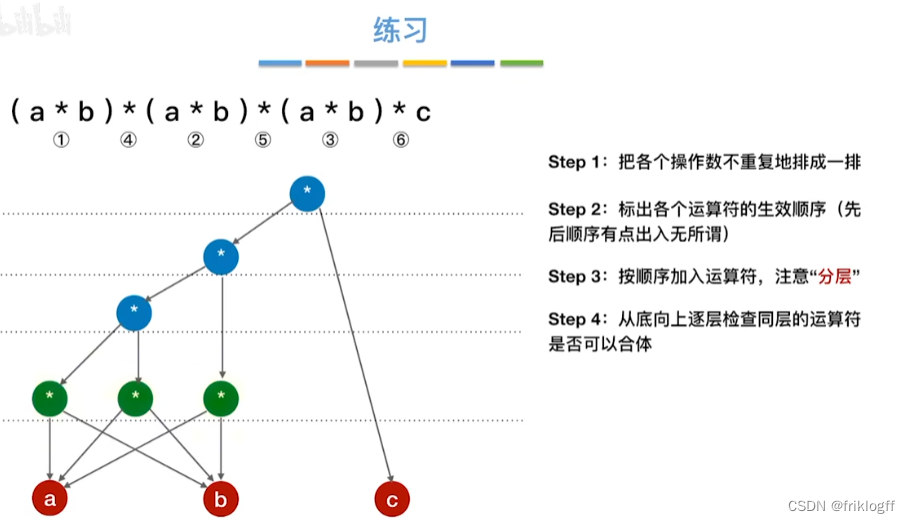
-
-
拓扑排序(AOV网)
-
概述
-
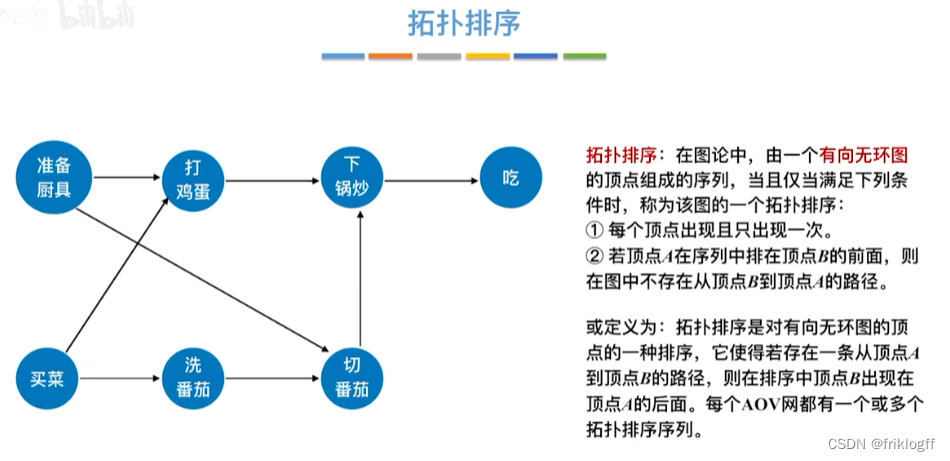
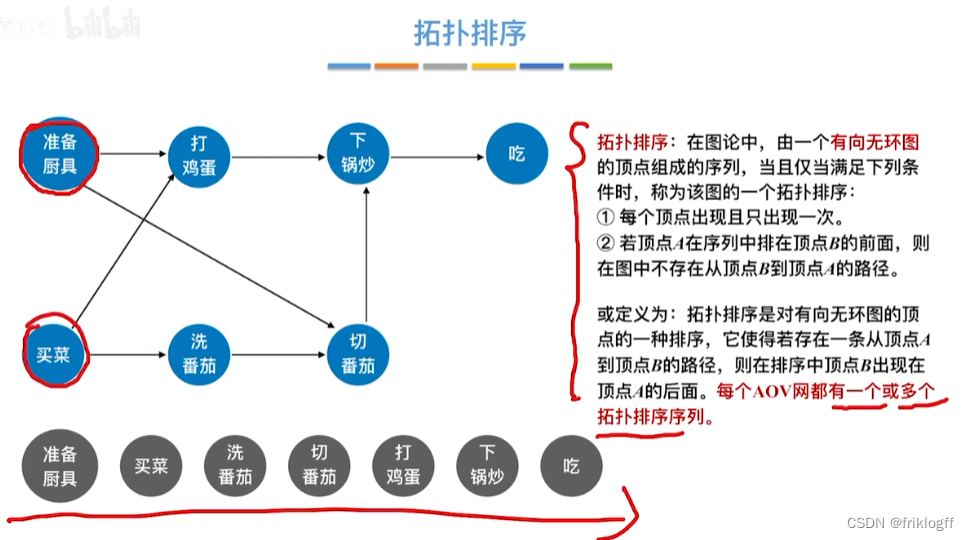
拓扑序列
- 拓扑序列是对图中所有的顶点,如果存在一条从顶点A到顶点B的路径,那么在排序中顶点A出现在顶点B的前面
-
拓扑排序
- 对一个有向图构造拓扑序列的过程

- 对一个有向图构造拓扑序列的过程
-
-
过程
-
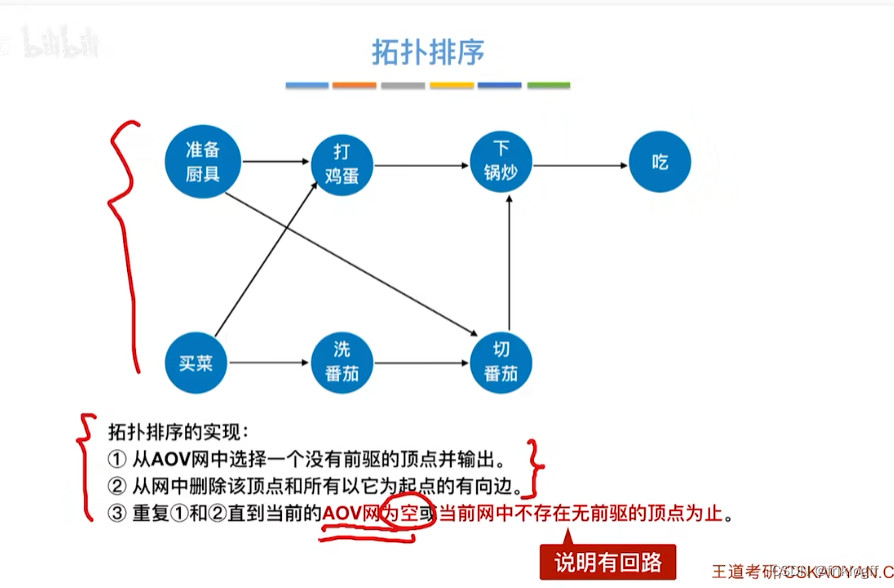
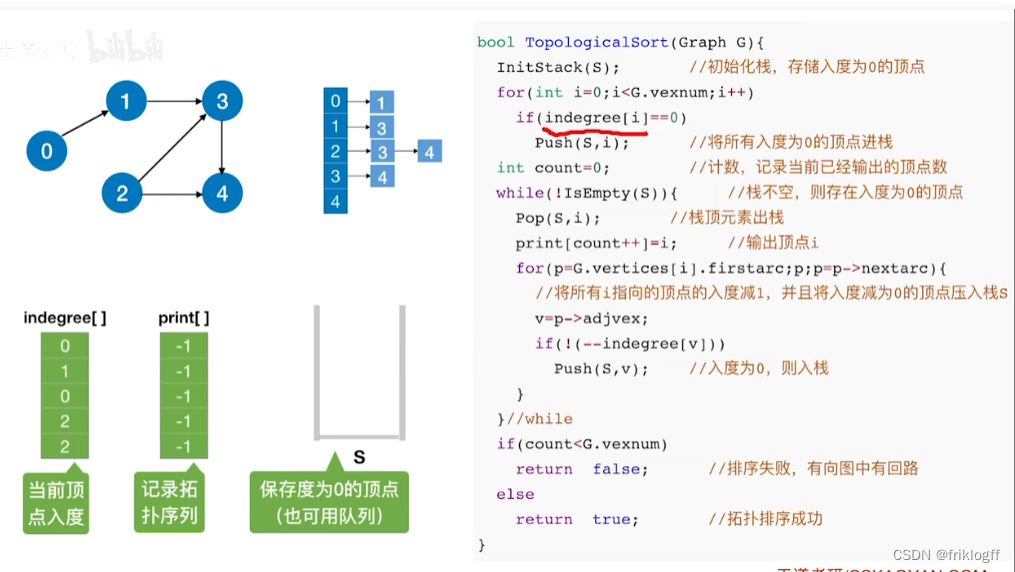
从AOV网中选择一个没有前驱的顶点并输出
-
从网中删除该顶点和所有以它为起点的有向边
-
重复前两个步骤,直到当前的AOV网为空或当前网中不存在无前驱的顶点为止(后者说明有向图中存在环)

-
-
时间复杂度
-
邻接矩阵存储,O(|V|^2)
-
邻接表存储,O(|V|+|E|)
-
-
注意
-
若一个顶点有多个直接后继,则拓扑排序通常不唯一(若每个顶点有唯一前驱后继,则唯一)
-
若图的邻接矩阵是三角矩阵,则存在拓扑排序,反之不一定成立
-
逆拓扑排序(AOV网)

-
实现
- DFS算法

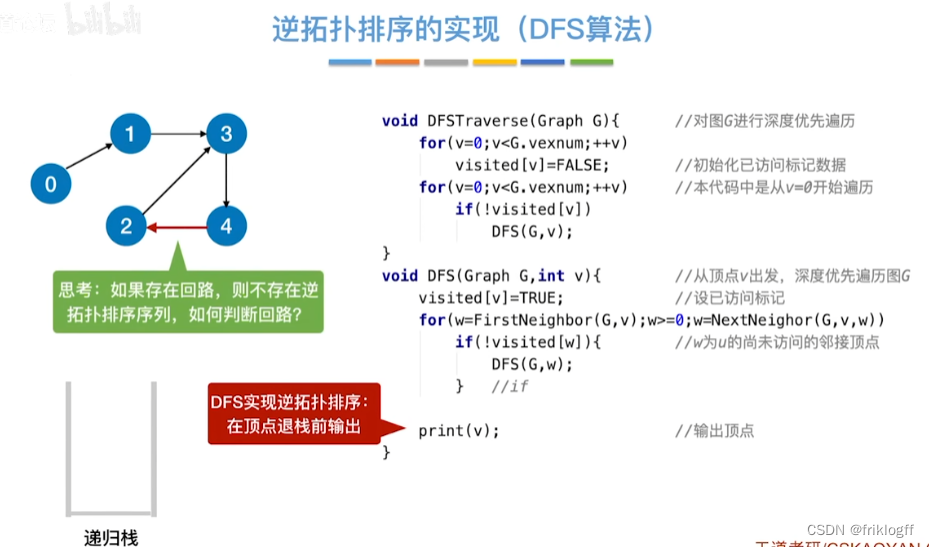
- DFS算法
-
过程
-
从AOV网中选择一个没有后继的顶点并输出
-
从网中删除该顶点和所有以它为终点的有向边
-
重复前两个步骤,直到当前的AOV网为空
-
小结
关键路径(AOE网)
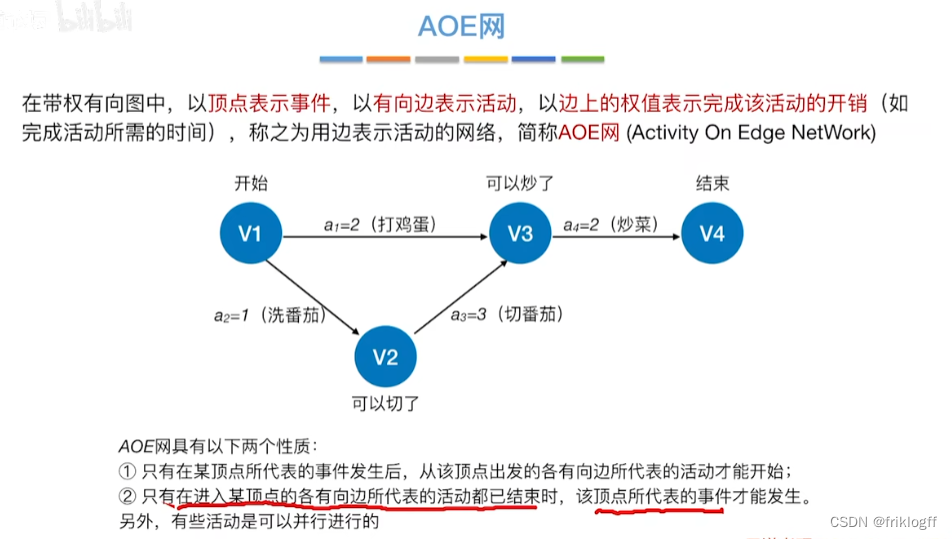
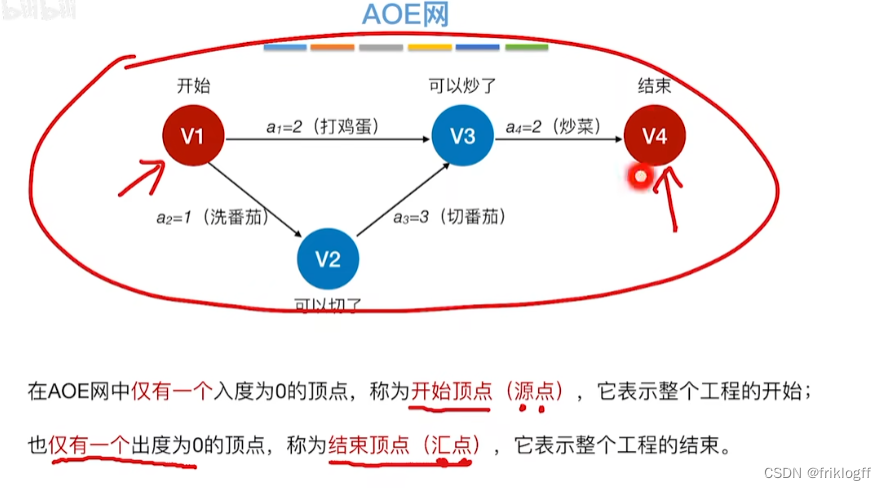
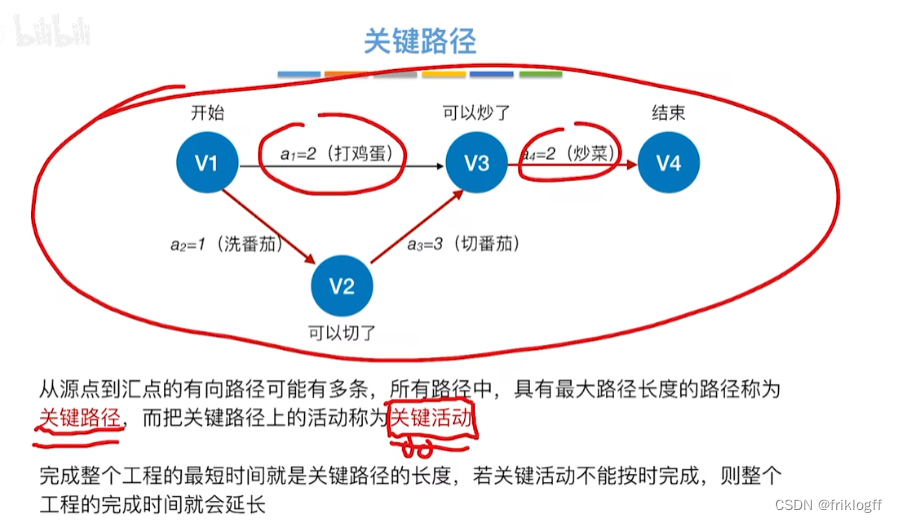
-
概述
-
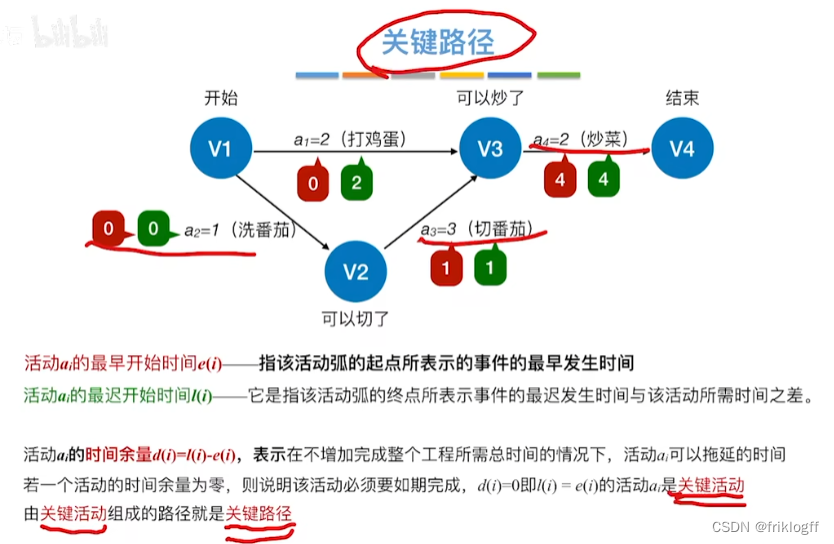
关键路径
- 从源点到汇点的所有路径中,具有最大路径长度的路径
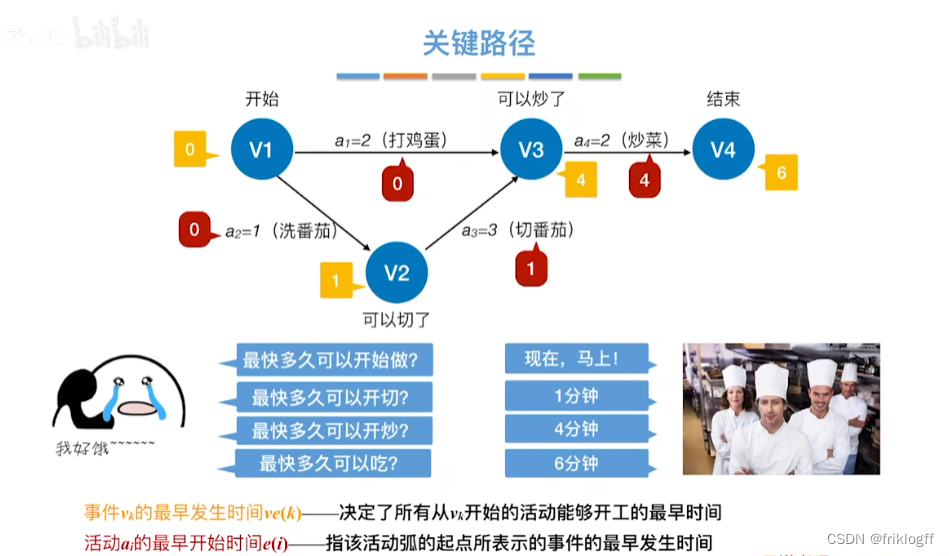
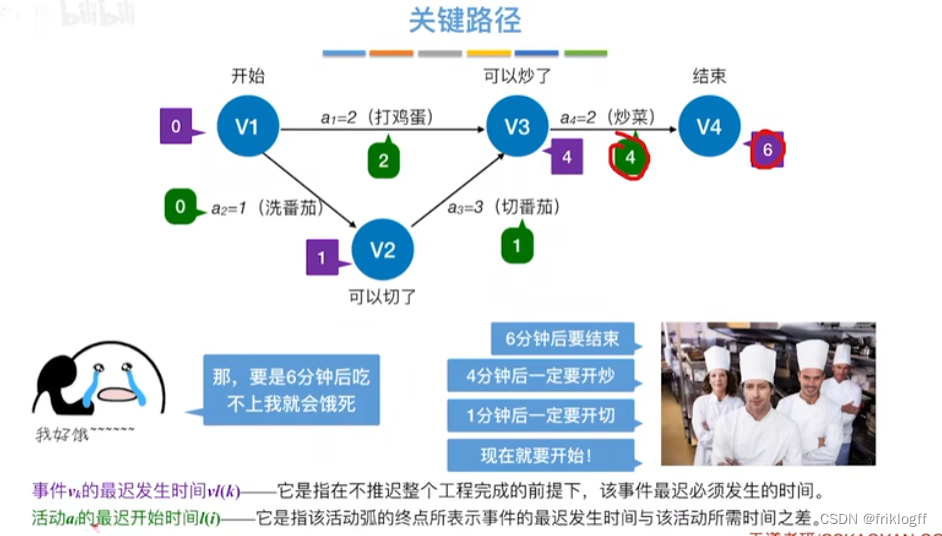
- 从源点到汇点的所有路径中,具有最大路径长度的路径
-
关键活动
- 关键路径上的活动
- 关键路径上的活动
-
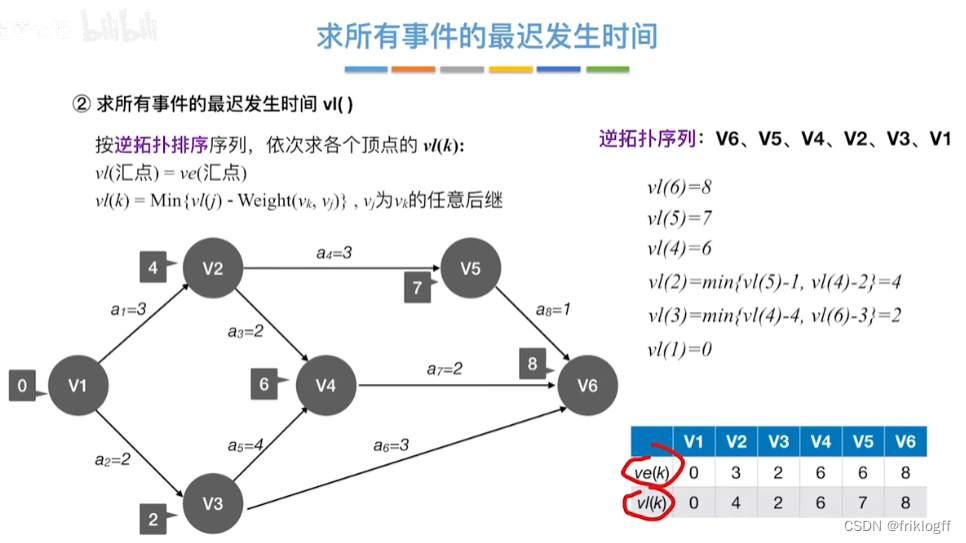
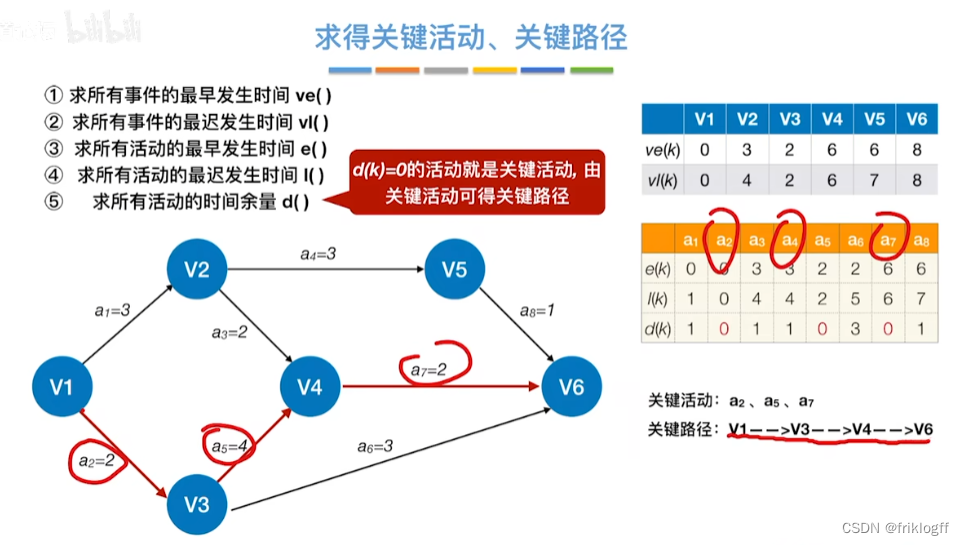
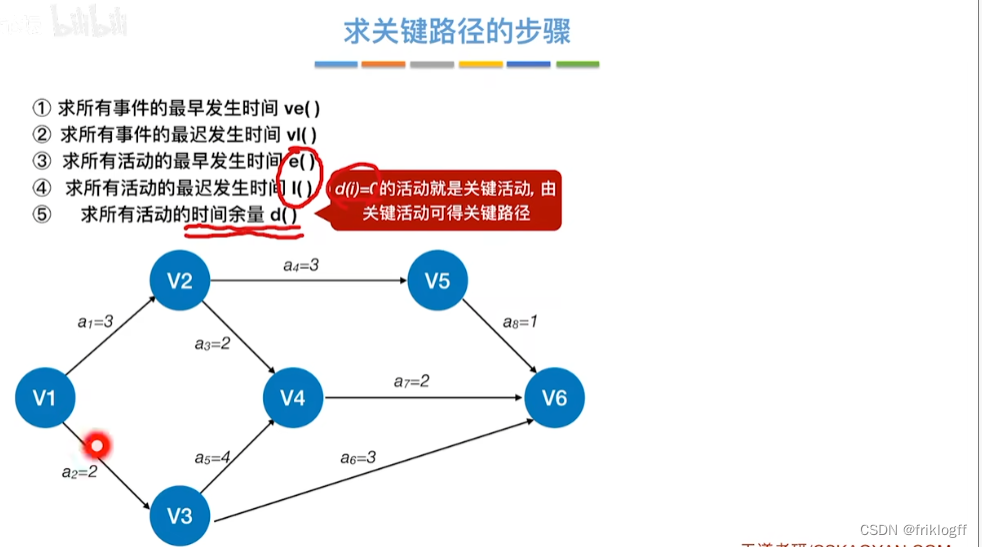
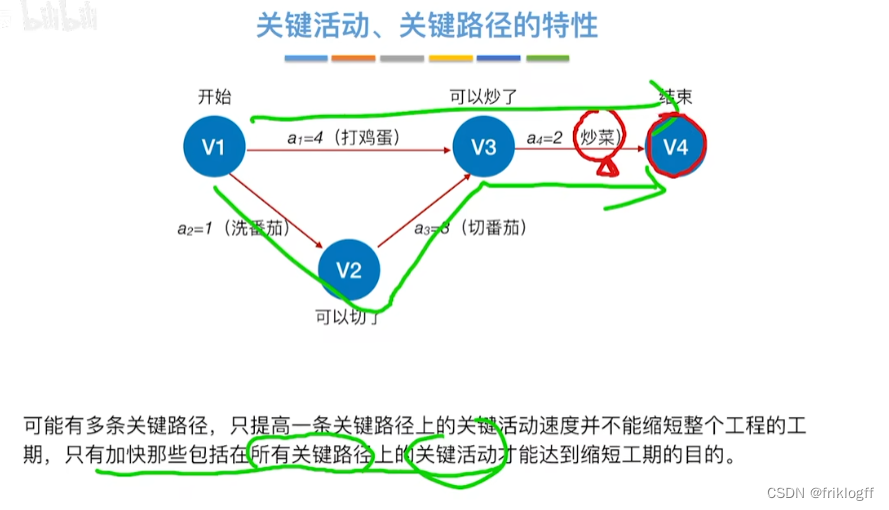
- 过程
| 项目/信息 | V1 | V2 | V3 | V4 | V5 | V6 | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
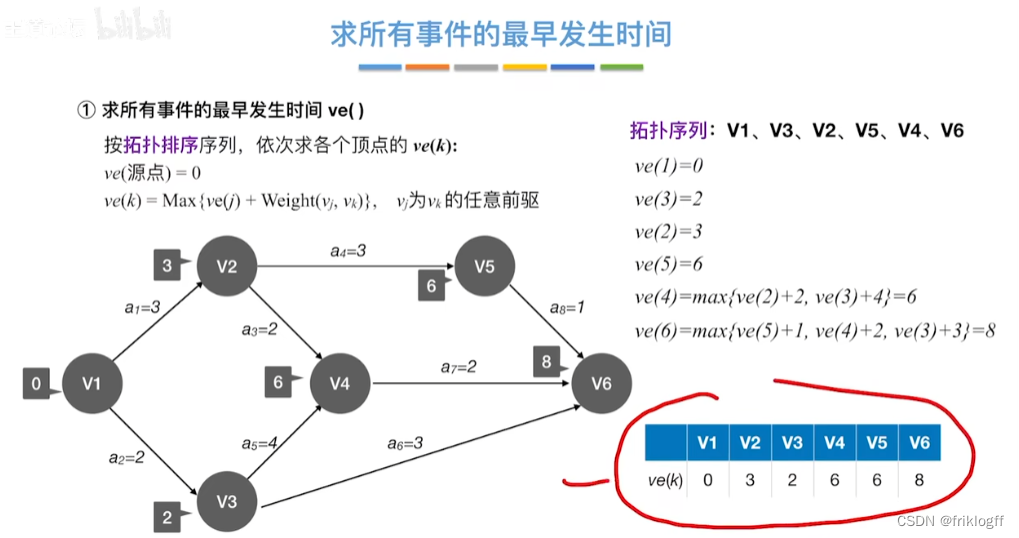
| 求所有事件的最早发生时间ve() | 0 | 3 | 2 | 6 | 6 | 8 | ||||||||
| 求所有事件的最迟发生时间vl() | 0 | 4 | 2 | 6 | 7 | 8 | ||||||||
| 求所有活动的最早发生时间e() | 0 | 0 | 3 | 3 | 2 | 2 | 6 | 6 | ||||||
| 求所有活动的最迟发生时间l() | 1 | 0 | 4 | 4 | 2 | 5 | 6 | 7 | ||||||
| 求所有活动的时间余量d() | 1 | 0 | 1 | 1 | 0 | 3 | 0 | 1 |
- 关键活动(d()=0的活动就是关键活动):a2、a5、a7
- 关键路径:V1—>V3—>V4—>V6
表格一:求所有事件的最早发生时间ve()和最迟发生时间vl()
| 比较项目/存储结构 | V1 | V2 | V3 | V4 | V5 | V6 |
|---|---|---|---|---|---|---|
| 最早发生时间ve(k) | 0 | 3 | 2 | 6 | 6 | 8 |
| 最迟发生时间vl(k) | 0 | 4 | 2 | 6 | 7 | 8 |
表格二:求所有活动的最早发生时间e()、最迟发生时间l()和时间余量d()
| 项目/信息 | a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 |
|---|---|---|---|---|---|---|---|---|
| 最早发生时间e() | 0 | 0 | 3 | 3 | 2 | 2 | 6 | 6 |
| 最迟发生时间l() | 1 | 0 | 4 | 4 | 2 | 5 | 6 | 7 |
| 时间余量d() | 1 | 0 | 1 | 1 | 0 | 3 | 0 | 1 |
关键活动:a2、a5、a7
关键路径:V1—>V3—>V4—>V6
-
注意
-
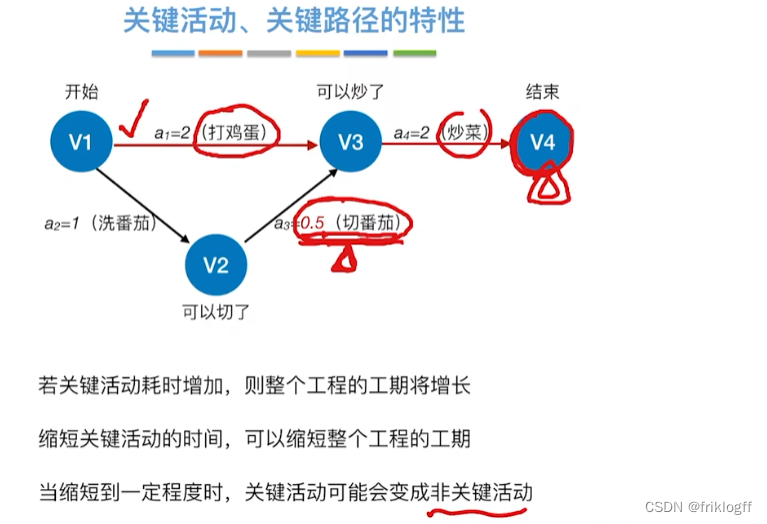
关键路径上的所有活动都是关键活动,是决定整个工程的关键因素,因此可通过加快关键活动来缩短整个工程的工期
-
不能任意缩短关键活动,因为一旦缩短到一定程度,该关键活动可能变成非关键活动
-
网中的关键路径不唯一,只有加快那些包含在所有关键路径上的关键活动才能达到缩短工期的目的
-
若关键活动耗时增加,则整个工程的工期增长
-
小结

代码
图的存储结构
-
邻接矩阵存储
- g[a][b]存储边a->b
-
邻接表存储(数组模拟)
-
// 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点int h[N], e[N], ne[N], idx;// 添加一条边a->bvoid add(int a, int b){e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;}// 初始化idx = 0;memset(h, -1, sizeof h); //在头文件cstring中
-
图的遍历
-
DFS
- 上面的代码思路可以,针对不同题目代码差异大,不列举了
-
BFS
-
queue<int> q; //STL中的队列容器st[1] = true; // 表示1号点已经被遍历过q.push(1);while (q.size()){int t = q.front();q.pop();for (int i = h[t]; i != -1; i = ne[i]){int j = e[i];if (!st[j]){st[j] = true; // 表示点j已经被遍历过q.push(j);}}}
-
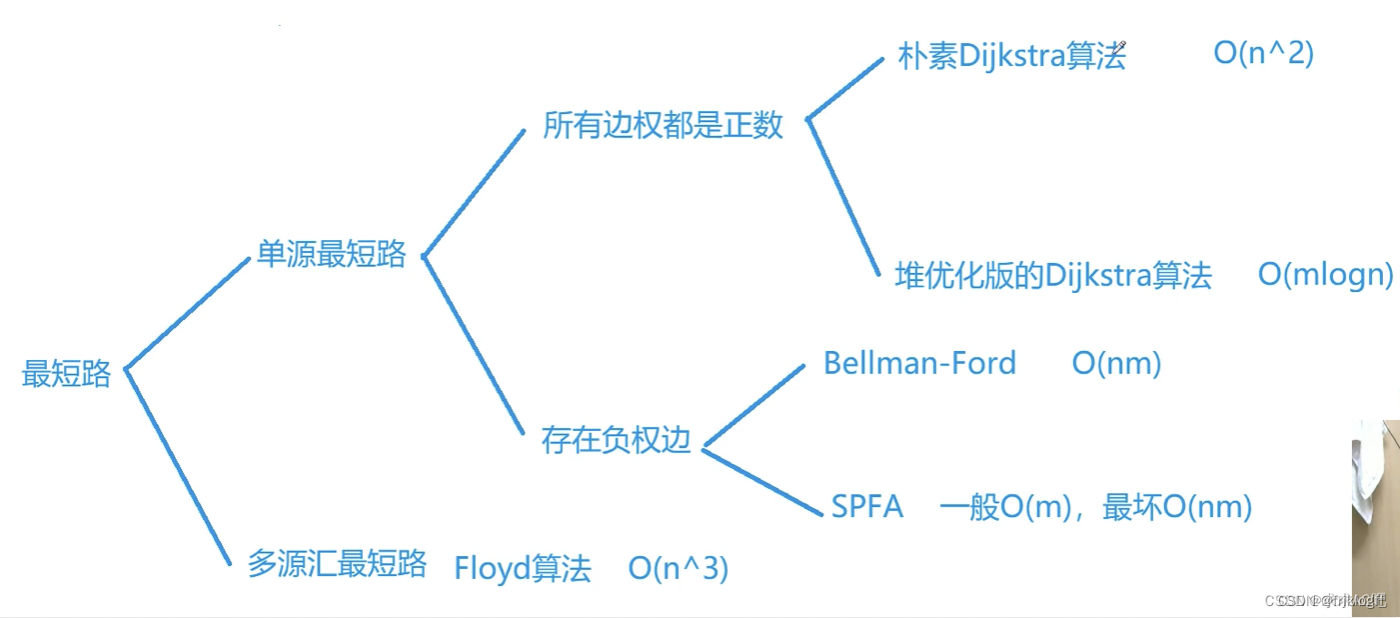
最短路径问题导图
-
-
朴素Dijkstra(适合稠密图,无负权值)
-
思路
-
- 初始化(初始化dist,邻接矩阵)
-
- 循环n-1次,每次找最短dist[t],用t更新其它点的距离
-
-
//初始化,b[]标记是否已经访问,dist[]表示最短路径,path[]表示前驱结点memset(g,0x3f,sizeof g);memset(dist,0x3f,sizeof dist);g[a][b]=min(c,g[a][b]); //如果有重边,需要选小的//Dijkstrabool dijkstra(){dist[1]=0;for(int i=0;i<n-1;i++){int t=-1;//找最小的distfor(int j=1;j<=n;j++){if((t==-1||dist[j]<dist[t])&&!b[j]){t=j;}}//更新已访问的点b[t]=1;//更新该点其它距离for(int j=1;j<=n;j++)dist[j]=min(g[t][j]+dist[t],dist[j]);}if(dist[n]==0x3f3f3f3f) return 0;else return 1;}
-
-
堆优化的Dijkstra(适合稀疏图,无负权值)
-
思路
- 在朴素Dijkstra算法的基础上
初始化(初始化dist,邻接矩阵)
循环n-1次,每次找最短dist[t],用t更新其它点的距离
其中找最短dist[t]需要O(n2),故利用一个堆把该步骤降为O(n)
随之用堆更新的时间复杂度上升为O(mlogn),故适合于稀疏图
- 在朴素Dijkstra算法的基础上
-
-
int dijkstra(){priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>> q;dist[1]=0;q.push({0,1});while(q.size()){pair<int,int> temp=q.top();q.pop();if(st[temp.second]) continue; //若已访问直接跳过,若在下方if语句中判断时间差很多st[temp.second]=1;//更新操作for(int i=h[temp.second];i!=-1;i=ne[i]){int j=e[i];if(dist[j]>temp.first+w[i]){dist[j]=temp.first+w[i];q.push({dist[j],j});}}}if(dist[n]!=0x3f3f3f3f) return dist[n];else return -1;} -
bellman-ford(负权值,若规定k条边最短路径则只能用它,O(nm))
-
思路
- 思路:(很暴力,边的存储仅需要用结构体数组即可)
for n 次
用back数组备份dist,防止串联(访问前几条边改变数据后影响后面的访问,会破坏k条边的条件)
for 所有边 a,b,w
dist[b] = min(dist[b], back[a]+w); //松弛操作
三角不等式:dist[b] <= dist[a]+w
补充:如果执行n次依然更新了路径,说明有n条的最短路径,即有负权边
- 思路:(很暴力,边的存储仅需要用结构体数组即可)
-
struct line{ //定义结构体int a,b,w;}lines[N];void bellman_ford(){dist[1]=0;for(int i=0;i<k;i++){memcpy(back,dist,sizeof dist); //备份防止串联for(int j=0;j<m;j++){if(dist[lines[j].b]>back[lines[j].a]+lines[j].w){//这里用backdist[lines[j].b]=back[lines[j].a]+lines[j].w;}}}if(dist[n]>0x3f3f3f3f/2) printf("impossible");else printf("%d",dist[n]);}
-
-
SPFA(bellman-ford优化,一般O(m),最坏O(nm))
-
思路
- 在bellman-ford的基础上,利用一个队列与广度优先搜索,仅将变小的点加入队列中;
-
补充
- 用一个cnt[]数组维护每个节点的最短路径边数,若边数=n即有负权边。需要考虑图不连通,故需要初始化时把所有点加入队列,且dist都相等即可。
-
void spfa(){q.push(1);dist[1]=0;st[1]=1;while(q.size()){int t=q.front();q.pop();st[t]=0; //SPFA与Dijkstra不同仅在于标记数组用于标记是否重复进去队列而非是否访问过for(int i=h[t];i!=-1;i=ne[i]){int j=e[i];if(dist[j]>dist[t]+w[i]){dist[j]=dist[t]+w[i];if(!st[j]){ //改变后进行判断是否需要加入队列st[j]=1;q.push(j);}}}}if(dist[n]==0x3f3f3f3f) printf("impossible");else printf("%d",dist[n]);}
-
-
Floyd
-
思路
- 三重循环,用邻接矩阵存储
外层循环每个要加入的点,双层循环两个要加入的节点,如果可加入其中且路径边短则更新即可。
- 三重循环,用邻接矩阵存储
-
初始化:
for (int i = 1; i <= n; i ++ )for (int j = 1; j <= n; j ++ )if (i == j) d[i][j] = 0;else d[i][j] = INF;// 算法结束后,d[a][b]表示a到b的最短距离 void floyd() {for (int k = 1; k <= n; k ++ ) //每次要加入的点for (int i = 1; i <= n; i ++ ) //加入点i,j中for (int j = 1; j <= n; j ++ )d[i][j] = min(d[i][j], d[i][k] + d[k][j]); }
-
-
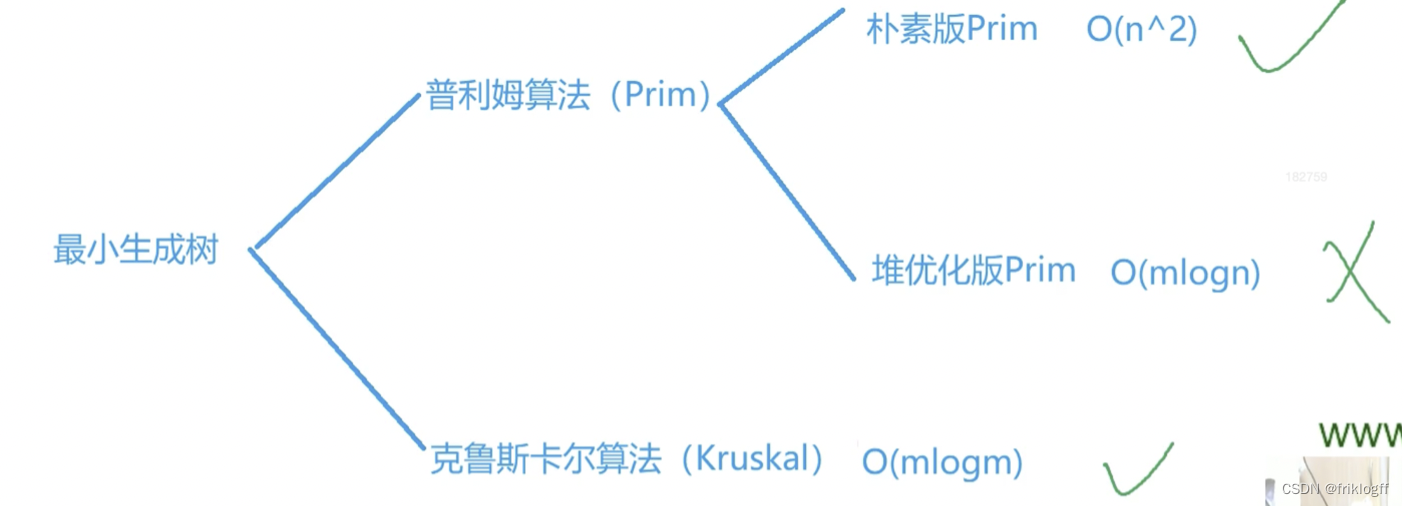
最小生成树与二分图导图
- 朴素Prim算法用于稠密图,优化版Prim和Kruskal算法侧重于稀疏图,由于堆优化代码长,故一般直接用Kruskal算法
-
Prim
-
思路
- 几乎和dijkstra一样,区别在标记数组记录的是进入生成树的节点,dist数组记录的是各节点到生成树的最短路径;
-
void prim(){dist[1]=0;for(int i=0;i<n;i++){int t=-1;for(int j=1;j<=n;j++){if(!st[j]&&(t==-1||dist[t]>dist[j])){t=j;}}st[t]=1;res+=dist[t];for(int j=1;j<=n;j++){if(dist[j]>g[t][j]){dist[j]=g[t][j];}}}}
-
-
Kruskal
-
思路
- 用结构体存边,并排序,从最短的边找起,若两点不在一颗树则连接在一起(并查集思想),直到所有点都用最短的边连在一起
-
sort(lines,lines+m); //边排序 for(int i=0;i<m;i++){ int a=find(lines[i].a),b=find(lines[i].b);if(a!=b){h[b]=a; //若不是一棵树操作res+=lines[i].c;cnt++;} }- 并查集中find函数
-
-
相关文章:
【数据结构】考研真题攻克与重点知识点剖析 - 第 6 篇:图
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

java的基本数据类型
在Java编程语言中,基本数据类型是构成Java程序的基础元素,它们用于存储简单值。Java的基本数据类型可以分为两大类:原始类型(Primitive Types)和引用类型(Reference Types)。原始类型包括整型、…...

0104练习与思考题-算法基础-算法导论第三版
2.3-1 归并示意图 问题:使用图2-4作为模型,说明归并排序再数组 A ( 3 , 41 , 52 , 26 , 38 , 57 , 9 , 49 ) A(3,41,52,26,38,57,9,49) A(3,41,52,26,38,57,9,49)上的操作。图示: tips::有不少在线算法可视化工具(软…...
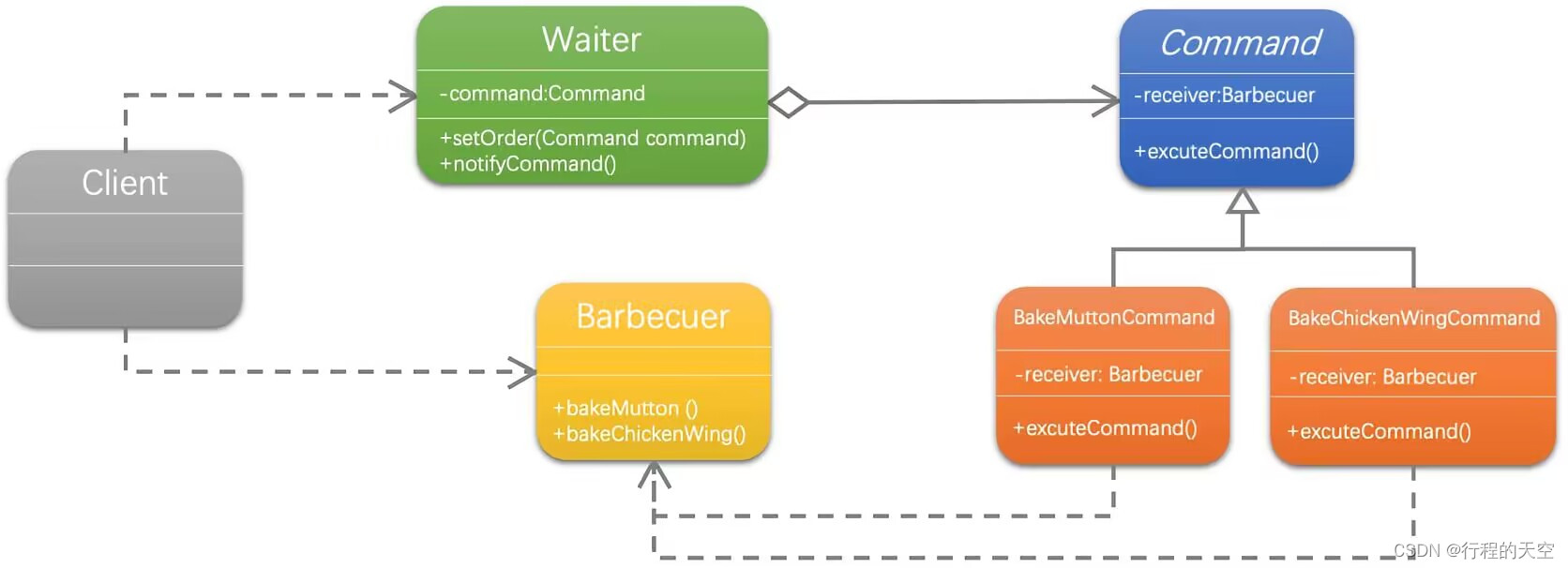
烤羊肉串引来的思考--命令模式
1.1 吃羊肉串! 烧烤摊旁边等着拿肉串的人七嘴八舌地叫开了。场面有些混乱,由于人实在太多,烤羊肉串的老板已经分不清谁是谁,造成分发错误,收钱错误,烤肉质量不过关等。 外面打游击烤羊肉串和这种开门店做烤…...

Python 描述符
文章目录 类型:数据描述符:方法描述符:描述符的要包括以下几点:方法描述符实现缓存 描述符(Descriptor)是 Python 中一个非常强大的特性,它允许我们自定义属性的访问行为。使用描述符,我们可以创建一些特殊的属性,在访问这些属性时执行自定义…...

Go语言创建HTTP服务器
Web服务器可提供网页、Web服务和文件,而Go语言为创建Web服务器提供了强大的支持。 1.通过Hello World Web 服务器宣告您的存在 标准库中的net/http包提供了多种创建HTTP服务器的方法,它还提供了一个基本的路由器。 package mainimport ("net/http" )func helloWo…...

【LeetCode热题100】【栈】柱状图中最大的矩形
题目链接:84. 柱状图中最大的矩形 - 力扣(LeetCode) 要找最大的矩形就是要找以每根柱子为高度往两边延申的边界,要作为柱子的边界就必须高度不能低于该柱子,否则矩形无法同高,也就是需要找出以每根柱子为高…...
谷歌浏览器插件开发速成指南:弹窗
诸神缄默不语-个人CSDN博文目录 本文介绍谷歌浏览器插件开发的入门教程,阅读完本文后应该就能开发一个简单的“hello world”插件,效果是出现写有“Hello Extensions”的弹窗。 作为系列文章的第一篇,本文还希望读者阅读后能够简要了解在此基…...

Lakehouse 大数据概念
“Lakehouse” 是一个相对新的概念,是大数据理论中的一个重要发展方向。它试图结合传统的数据湖(Data Lake)和数据仓库(Data Warehouse)的优点,以创造一种更为灵活和强大的数据管理体系。 在传统的大数据架构中,数据湖用于存储原始、未加工的数据,而数据仓库则用于存储…...
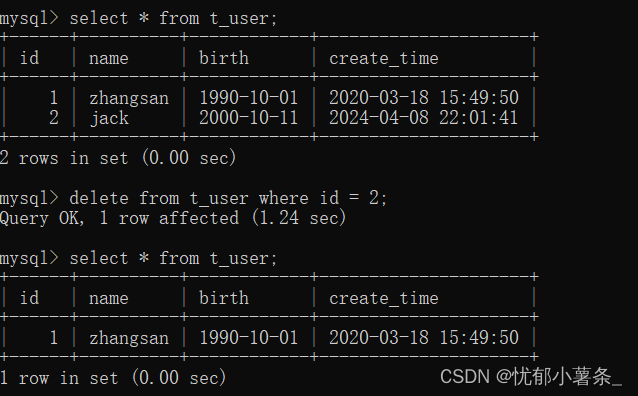
MySQL学习笔记(二)
1、把查询结果中去除重复记录 2、连接查询 从一张表中单独查询,称为单表查询。emp表和dept表联合起来查询数据,从emp表中取员工名字,从dept表中取部门名字,这种跨表查询,多张表联合起来查询数据,被称为连…...

Verilog语法——按位取反“~“和位宽扩展的优先级
前言 先说结论,如下图所示,在Verilog中“~ ”按位取反的优先级是最高的,但是在等式计算时,有时候会遇到位宽扩展,此时需要注意的是位宽扩展的优先级高于“~”。 验证 仿真代码,下面代码验证的是“~”按位取…...
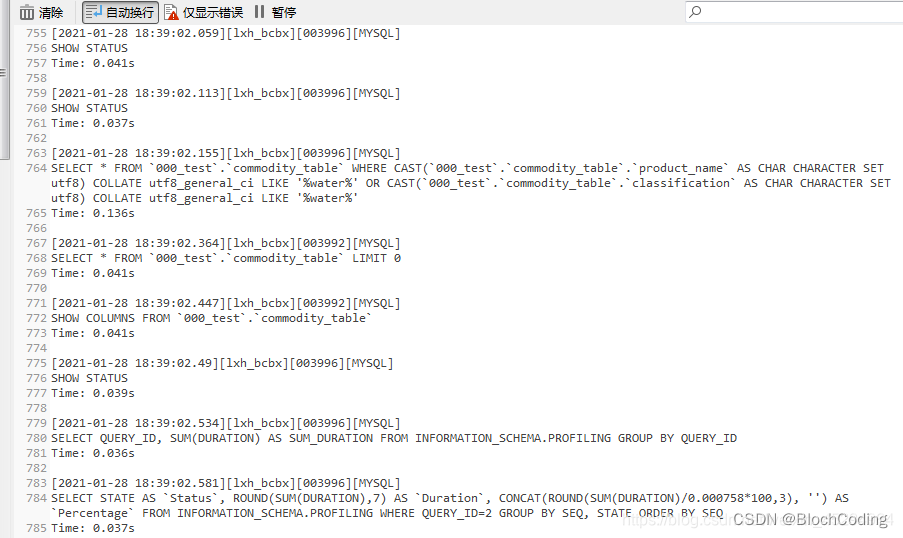
Navicat工具使用
Navicat的本质: 在创立连接时提前拥有了数据库用户名和密码 双击数据库时,相当于建立了一个链接关系 点击运行时,远程执行命令,就像在xshell上操作Linux服务器一样,将图像化操作转换成SQL语句去后台执行 一、打开Navi…...
——mv、rm、which、find)
linux常用指令(一)——mv、rm、which、find
mv命令: 用于查看文件内容 语法:mv 参数1 参数2 参数1,linux路径,表示被移动的文件或文件夹 参数2,linux路径,表示要移动去的地方,如果目标不存在,则进行改名 rm命令:…...
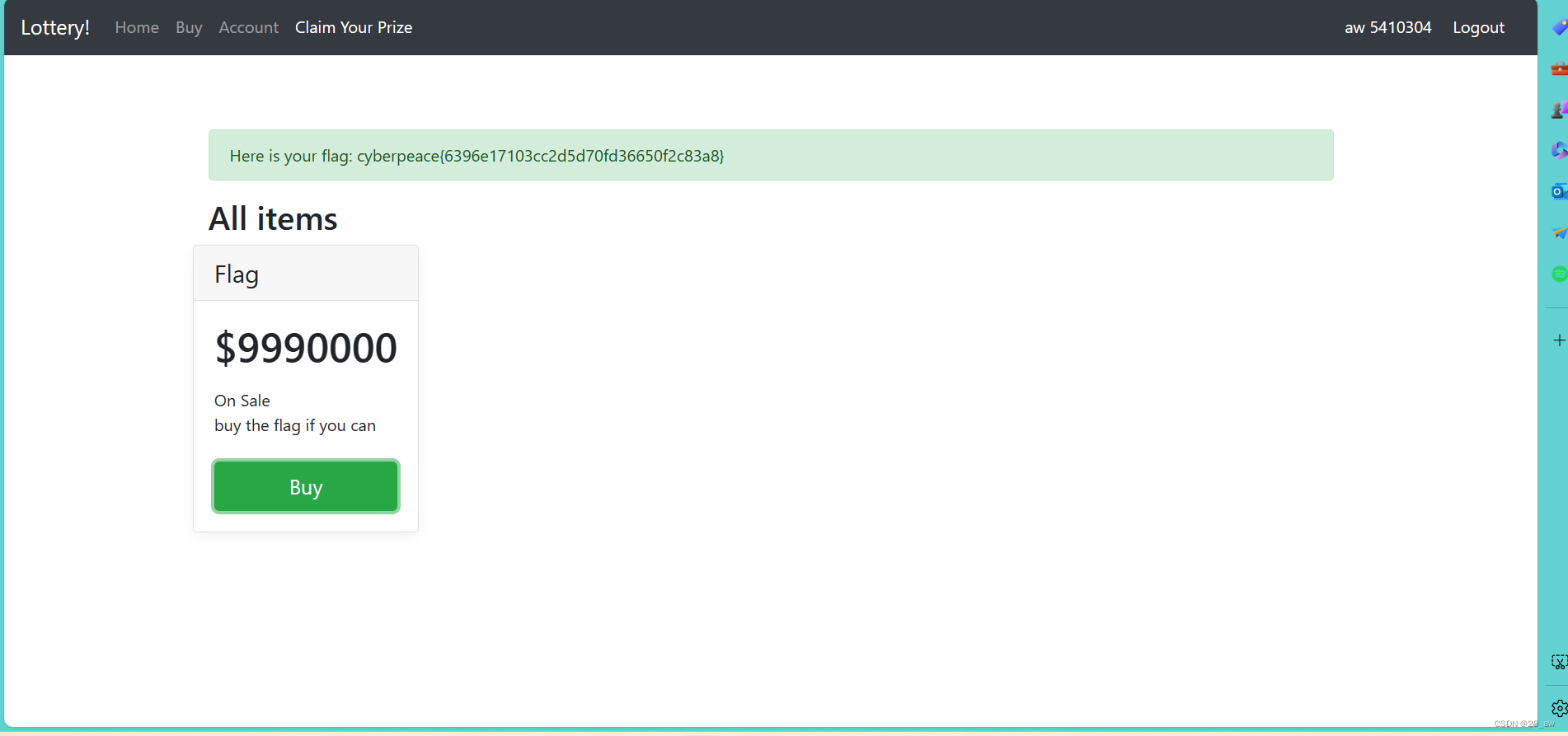
lottery-攻防世界
题目 flag在这里要用钱买,这是个赌博网站。注册个账号,然后输入七位数字,中奖会得到相应奖励。 githacker获取网站源码 ,但是找到了flag文件但是没用。 bp 抓包发现api.php,并且出现我们的输入数字。 根据题目给的附…...

深入理解指针2:数组名理解、一维数组传参本质、二级指针、指针数组和数组指针、函数中指针变量
目录 1、数组名理解 2、一维数组传参本质 3、二级指针 4、指针数组和数组指针 5、函数指针变量 1、数组名理解 首先来看一段代码: int main() {int arr[10] { 1,2,3,4,5,6,7,8,9,10 };printf("%d\n", sizeof(arr));return 0; } 输出的结果是&…...

【C/C++】C语言实现单链表
C语言实现单链表 简单描述代码运行结果 简单描述 用codeblocks编译通过 源码参考连接 https://gitee.com/IUuaena/data-structures-c.git 代码 common.h #ifndef COMMON_H_INCLUDED #define COMMON_H_INCLUDED#define ELEM_TYPE int //!< 链表元素类型/*! brief 返回值类…...
VBA数据库解决方案第九讲:把数据库的内容在工作表中显示
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...
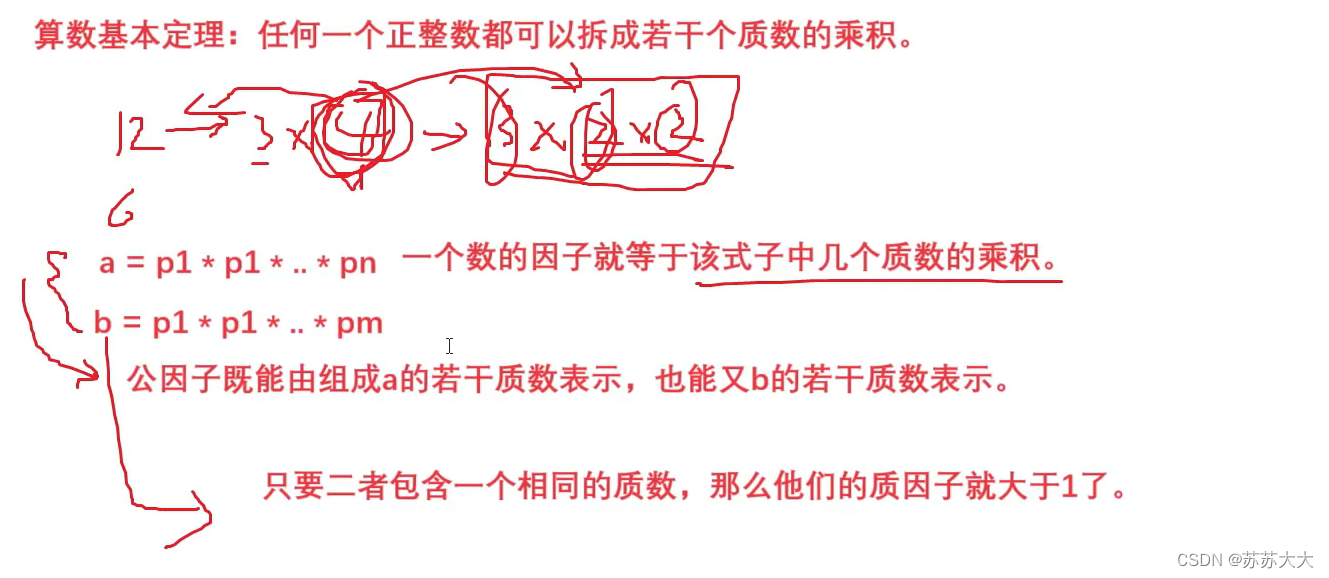
蓝桥杯刷题-12-公因数匹配-数论(分解质因数)不是很理解❓❓
蓝桥杯2023年第十四届省赛真题-公因数匹配 给定 n 个正整数 Ai,请找出两个数 i, j 使得 i < j 且 Ai 和 Aj 存在大于 1 的公因数。 如果存在多组 i, j,请输出 i 最小的那组。如果仍然存在多组 i, j,请输出 i 最小的所有方案中 j 最小的那…...
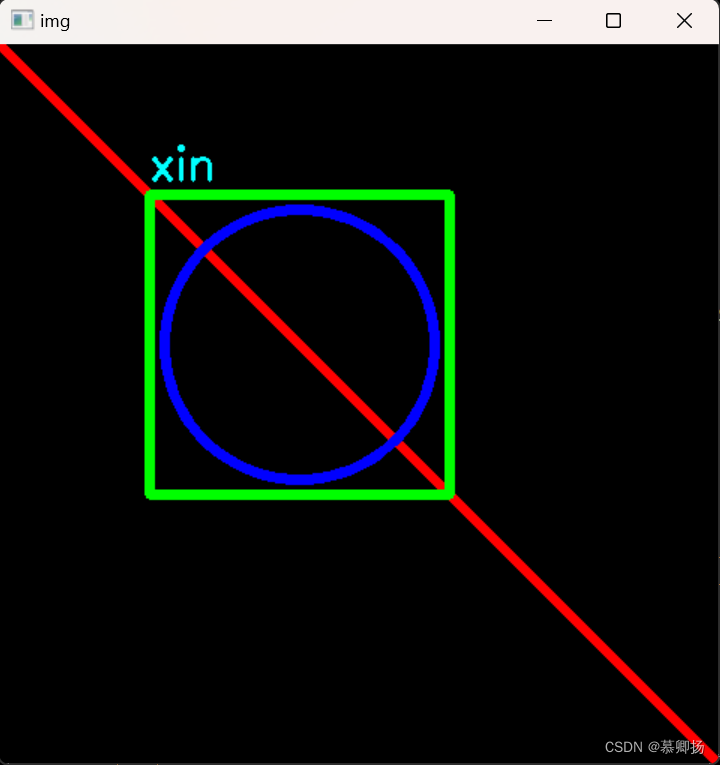
机器视觉学习(十二)—— 绘制图形
目录 一、绘制函数参数说明 1.1 cv2.line()绘制直线 1.2 cv2.rectangle()绘制矩形 1.3 cv2.circle() 绘制圆形 1.4 cv2.ellipse()绘制椭圆 1.5 cv2.polylines()绘制…...

软考信息处理技术员2024年5月报名流程及注意事项
2024年5月软考信息处理技术员报名入口: 中国计算机技术职业资格网(http://www.ruankao.org.cn/) 2024年软考报名时间暂未公布,考试时间上半年为5月25日到28日,下半年考试时间为11月9日到12日。不想错过考试最新消息的…...

【NS-3实战指南】NetAnim可视化调试与网络拓扑分析
1. NetAnim入门:从安装到第一个动画 第一次接触NS-3仿真的人往往会被命令行输出的数字搞得头晕眼花。记得我刚开始做无线网络仿真时,盯着终端里不断跳动的数据包统计数字,完全想象不出节点之间到底是怎么通信的。直到发现了NetAnim这个神器&a…...

【免费下载】 探索语音合成新境界:so-vits-svc-4.1-Stable 资源文件推荐
探索语音合成新境界:so-vits-svc-4.1-Stable 资源文件推荐 【下载地址】so-vits-svc-4.1-Stable资源文件下载 本仓库提供 so-vits-svc-4.1-Stable 资源文件的下载。该资源文件是一个稳定版本的 so-vits-svc 模型,适用于语音合成和相关应用 项目地址: h…...

深入QGIS矢量数据底层:手写WKT字符串添加几何图形,一次搞懂空间数据存储原理
深入QGIS矢量数据底层:手写WKT字符串添加几何图形,一次搞懂空间数据存储原理 当你第一次在QGIS中看到一个点、一条线或一个多边形时,是否好奇过这些图形在计算机中究竟是如何被存储和表达的?本文将带你从最基础的WKT字符串开始&am…...

RT-Thread Studio自定义工程路径踩坑记:解决‘Error retrieving output from the rttconfig server’报错
RT-Thread Studio自定义工程路径踩坑指南:从报错到原理的深度解析 第一次在RT-Thread Studio中尝试将项目放在D盘的自定义文件夹时,那个刺眼的红色报错框让我愣了几秒——"Error retrieving output from the rttconfig server"。控制台里密密麻…...

嵌入式开发实战:SPI、UART、I2C三大硬件接口通信协议详解与CircuitPython应用
1. 项目概述:为什么硬件接口是嵌入式开发的基石如果你玩过单片机或者树莓派,肯定遇到过这样的场景:手里有一块炫酷的LED灯带、一个GPS模块或者一个环境传感器,想让它和你的主控板“说上话”,结果发现连线复杂、代码难调…...

2026年公司文化专题片拍摄公司排行榜:行业深度解析
引言随着企业对品牌传播和文化建设的重视程度不断提升,公司文化专题片成为展示企业形象、传递核心价值观的重要手段。越来越多的企业开始关注如何通过高质量的专题片来提升品牌形象和企业文化影响力。本文将深入分析2026年公司文化专题片拍摄行业的趋势,…...

为什么92%的康复科博士生还没用NotebookLM做系统评价?——2024年最新工具链适配白皮书首发
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在康复医学研究中的范式革命 传统康复医学研究长期受限于多源异构数据整合困难、临床证据转化周期长、跨学科知识对齐成本高等瓶颈。NotebookLM 以“以文献为中心”的可溯源推理架构…...

NotebookLM思维导图生成已进入「语义拓扑时代」:2024Q2最新Benchmark显示其节点关联准确率超越MindNode Pro 41.6%
更多请点击: https://intelliparadigm.com 第一章:NotebookLM思维导图生成已进入「语义拓扑时代」 传统基于关键词共现或规则模板的思维导图生成方式,正被 NotebookLM 的语义理解能力彻底重构。其底层 LLM 模型不再仅识别显式术语关系&#…...

设计师核心能力框架:从思维策略到工程落地的系统化成长路径
1. 项目概述:一个设计师的“内功”修炼场如果你是一名设计师,或者对设计工作感兴趣,那么你一定有过这样的时刻:面对一个设计任务,脑子里有无数想法,但打开软件却不知从何下手;或者看到别人的优秀…...

为什么龙华选了3DGS?详解高斯泼溅、倾斜摄影、点云在治理场景中的优劣
一、行业核心技术科普:三种主流三维建模技术的原理与定位在城市治理与数字孪生领域,倾斜摄影、点云和3D高斯泼溅(3DGS)是三种主流的三维建模技术,它们各有侧重,互为补充。倾斜摄影:大范围实景的…...