Python爬虫之分布式爬虫
分布式爬虫
1.详情介绍
分布式爬虫是指将一个爬虫任务分解成多个子任务,在多个机器上同时执行,从而加快数据的抓取速度和提高系统的可靠性和容错性的技术。
传统的爬虫是在单台机器上运行,一次只能处理一个URL,而分布式爬虫通过将任务分解成多个子任务,可以同时处理多个URL,从而提高爬取数据的效率。在分布式爬虫中,通常有一个主节点负责任务的调度和管理,其他节点(也称为从节点)负责实际的数据采集和处理。
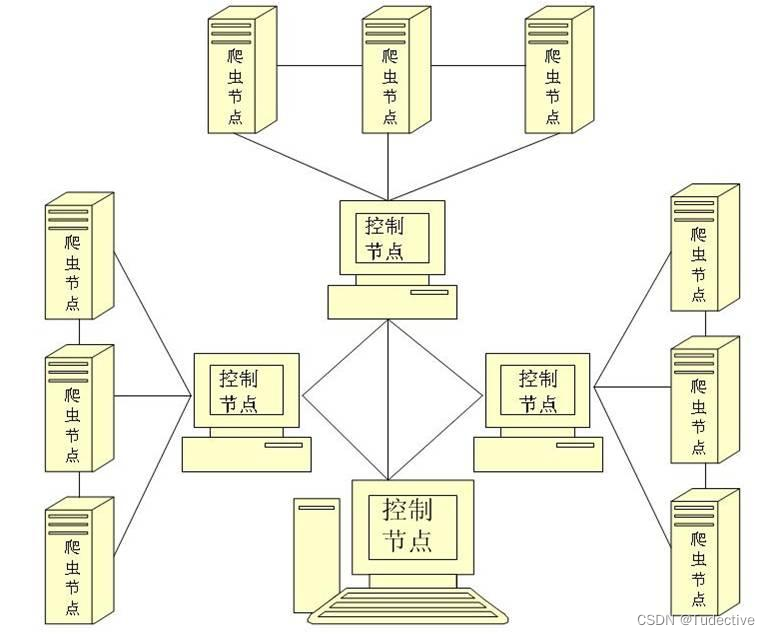
分布式爬虫的好处包括:
| 提高爬取速度 | 通过同时处理多个URL,可以大大加快数据的抓取速度 |
| 提高可靠性和容错性 | 如果某个节点出现故障或者网络中断,其他节点可以继续工作,从而保证任务的完成 |
| 分散资源消耗 | 将任务分布到多个节点上执行,可以分散资源消耗,避免单台机器过载 |
| 扩展性强 | 可以根据需求增加或减少节点数量,从而灵活调整系统的规模 |
分布式爬虫可以应用于各种场景,比如搜索引擎抓取网页数据、大规模数据分析和挖掘等。但是分布式爬虫也面临一些挑战,如数据一致性、网络通信、任务调度等问题,需要合理设计和实施。
2.丰富的工具
分布式爬虫所涉及的工具:
| 分布式任务调度工具 | 用于将任务分发给多个爬虫节点,并协调任务的执行顺序和并发度。常用的工具有Celery、Apache Mesos和Kafka。 |
| 分布式消息队列 | 用于传递任务和数据。爬虫节点通过订阅队列接收任务和发送爬取结果。常用的消息队列有RabbitMQ和Apache Kafka。 |
| 分布式爬虫框架 | 用于构建和管理分布式爬虫。框架提供了任务调度、数据传输和分布式爬取的功能。常用的框架有Scrapy、PySpider和StormCrawler。 |
| 分布式数据库 | 用于存储爬取的数据。分布式数据库提供高可用性和扩展性,可以存储大量的数据,并支持并发读写操作。常用的数据库有MongoDB、Cassandra和HBase。 |
| 分布式存储系统 | 用于存储大量的爬取数据和爬虫代码。分布式存储系统提供高可用性、高吞吐量和容错性。常用的存储系统有Hadoop HDFS、Amazon S3和Google Cloud Storage。 |
| 分布式代理池 | 用于处理反爬虫机制和IP封锁。分布式代理池动态分配代理IP给爬虫节点,以避免被封禁或限制访问。常用的代理池有Scrapy-Proxy、ProxyPool和IPProxyPool。 |
| 分布式解析器 | 用于提取和解析HTML、XML和JSON等数据格式。分布式解析器可以并行解析多个页面,并将数据提供给爬虫节点。常用的解析器有BeautifulSoup、Parsel和Lxml。 |
| 分布式反反爬虫工具 | 用于处理网站的反爬虫机制和封锁策略。分布式反反爬虫工具可以自动处理验证码、动态加载和JS渲染等反爬虫技术。常用的工具有Selenium、Splash和Puppeteer。 |
| 分布式监控和日志工具 | 用于监控爬虫的状态和性能,并记录爬取过程中的日志信息。监控工具可以通过Web界面提供实时监控和报警功能。常用的工具有Prometheus、Grafana和ELK Stack。 |
| 分布式数据处理工具 | 用于对爬取的数据进行清洗、分析和存储。数据处理工具可以进行数据清洗、去重、聚合和转换等操作。常用的工具有Pandas、Spark和Hive。 |
这些工具可以帮助构建一个高效、可靠和可扩展的分布式爬虫系统。根据具体的需求和场景,可以选择适合的工具进行组合和配置。
3.准备工作
scrapy runspider 是 Scrapy 框架提供的一个命令行工具,用于运行指定的 Spider(爬虫)。下面使用 scrapy runspider 的结合Redis实现一个分布式爬虫开始前提:
- 创建一个 Spider 类
首先,你需要创建一个继承自 scrapy.Spider 的 Python 类。这个类定义了你的爬虫的行为和规则。你可以在类中定义起始 URL、提取数据的规则、如何跟踪链接等等。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):# 提取数据的代码pass
- 运行 Spider
要运行这个 Spider,你可以使用以下命令:
scrapy runspider myspider.py
这个命令会在当前目录下启动 Scrapy 进程并运行指定的 Spider。
- 指定输出文件
默认情况下,Scrapy 会将爬取到的数据打印到屏幕上。如果你想将数据保存到文件中,可以使用 -o 参数指定输出文件的路径和格式。例如,将数据保存为 JSON 文件:
scrapy runspider myspider.py -o data.json
- 设置其他选项
你可以在 scrapy runspider 命令后面添加其他选项来配置你的爬虫。常用的选项包括:
-a:传递给 Spider 的参数,例如-a category=books。-s:设置 Scrapy 的设置,例如-s BOT_NAME=mybot。-L:设置日志级别,例如-L INFO。
以上就是使用 scrapy runspider 运行 Spider 的基本教程。你可以根据自己的需要在 Spider 类中添加更多的功能和配置。详细的文档可以在 Scrapy 的官方网站上找到:https://docs.scrapy.org
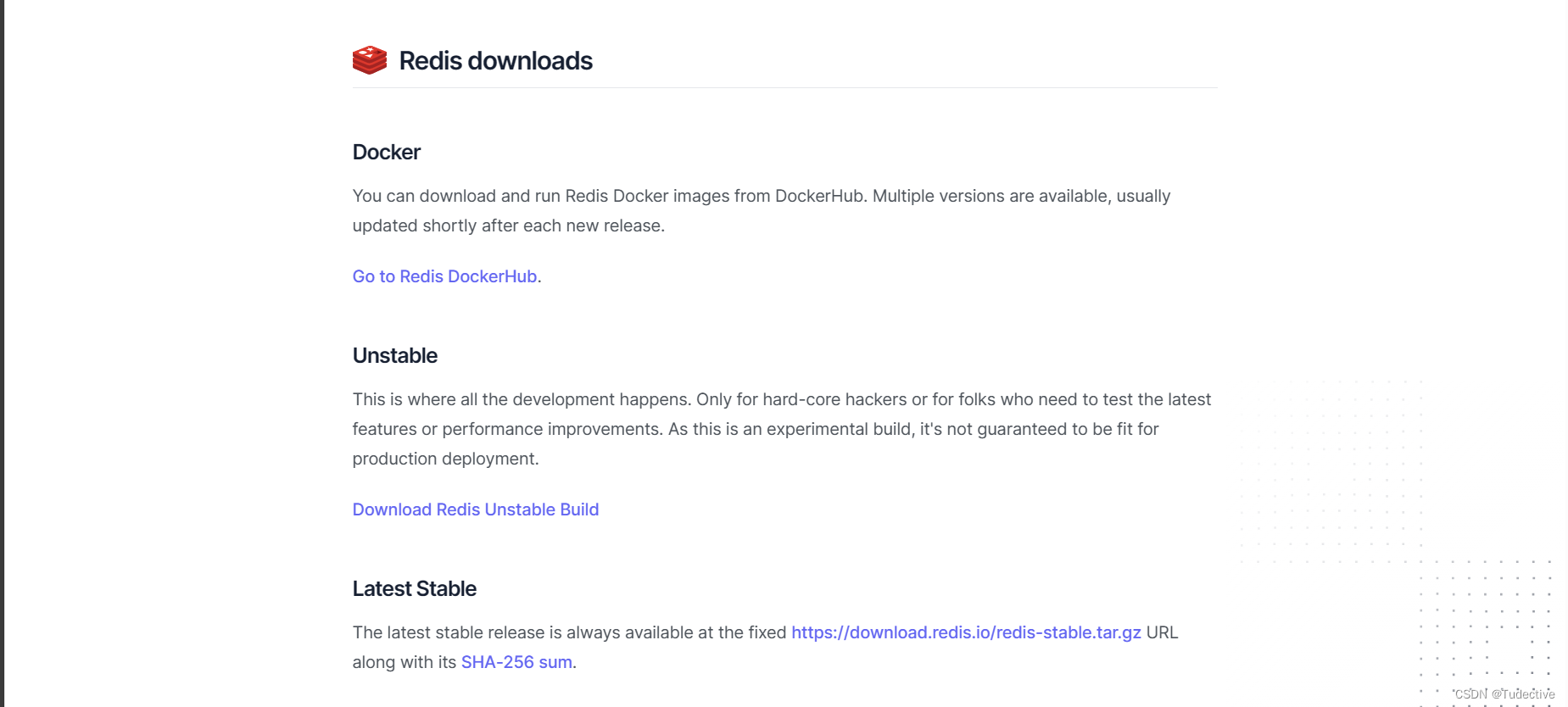
4.redis的下载
要下载Redis,可以按照以下步骤进行操作:
-
打开Redis的官方网站:https://redis.io/.

-
在主页上找到并点击"Download"按钮,或者直接访问https://redis.io/download页面。

-
在下载页面上,可以看到最新版本的Redis以及之前的版本。根据自己的需求选择适合的版本,例如选择最新的稳定版本。点击所选择版本的下载链接,将会跳转到该版本的下载页面。
-
在下载页面上,会列出各种下载选项,根据你的操作系统选择合适的选项。如果你使用Linux,可以下载源代码进行编译安装;如果你使用Windows,可以下载预编译的二进制文件。点击所选择的下载链接,开始下载Redis压缩包。
-
下载完成后,解压缩Redis压缩包到你选择的目录中。

-
进入解压缩后的Redis目录,你会发现一些可执行文件和配置文件。
-
在命令行中进入Redis目录,执行以下命令启动Redis服务。
-
在Linux或Mac上:
$ src/redis-server -
在Windows上:
> redis-server.exe
如果你想修改默认配置文件,可以使用以下命令启动Redis并指定配置文件路径:
-
在Linux或Mac上:
$ src/redis-server /path/to/redis.conf -
在Windows上:
> redis-server.exe C:\path\to\redis.conf
-
-
Redis服务成功启动后,你可以通过Redis客户端连接到Redis服务器进行操作。在命令行中输入以下命令启动Redis客户端:
-
在Linux或Mac上:
$ src/redis-cli -
在Windows上:
> redis-cli.exe
你可以使用各种Redis命令与服务器进行交互。
-
应用案例
1.前言
此案例是通过分布式爬虫对一个新闻问政平台的投诉信息进行爬取,结合分布式爬虫和Redis缓存实现对数据的快速多量的爬取和存储
2.实现步骤
2.1基本项目创建
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from sevenBlood.items import SevenbloodItemclass SevenSpider(CrawlSpider):name = "seven"# allowed_domains = ["www.baidu.com"]# 定义调度器的名称redis_key='sun'rules = (Rule(LinkExtractor(allow=r"id=1&page=\d+"), callback="parse_item", follow=False))2.2获取新闻标题数据
def parse_item(self, response):tr_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for tr in tr_list:new_title = tr.xpath('./span[3]/a/text()').extract_first()print(new_title)item = SevenbloodItem()item['new_title'] = new_titleyield item2.3配置item.py文件
import scrapyclass SevenbloodItem(scrapy.Item):new_title = scrapy.Field()2.4配置setting.py文件
ROBOTSTXT_OBEY = FalseLOG_LEVEL='ERROR'USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"# 指定管道
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline" : 400
}# 指定调度器
#使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#是否允许暂停
SCHEDULER_PERSIST = TrueREDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_ENCODING ="utf-8"2.5Redis设置
在redis的下载安装路径里,点击redis.windows.conf文件
将bind 127.0.0.1进行注释

然后回到redis的下载安装路径里,先点击redis-server.exe启动redis服务

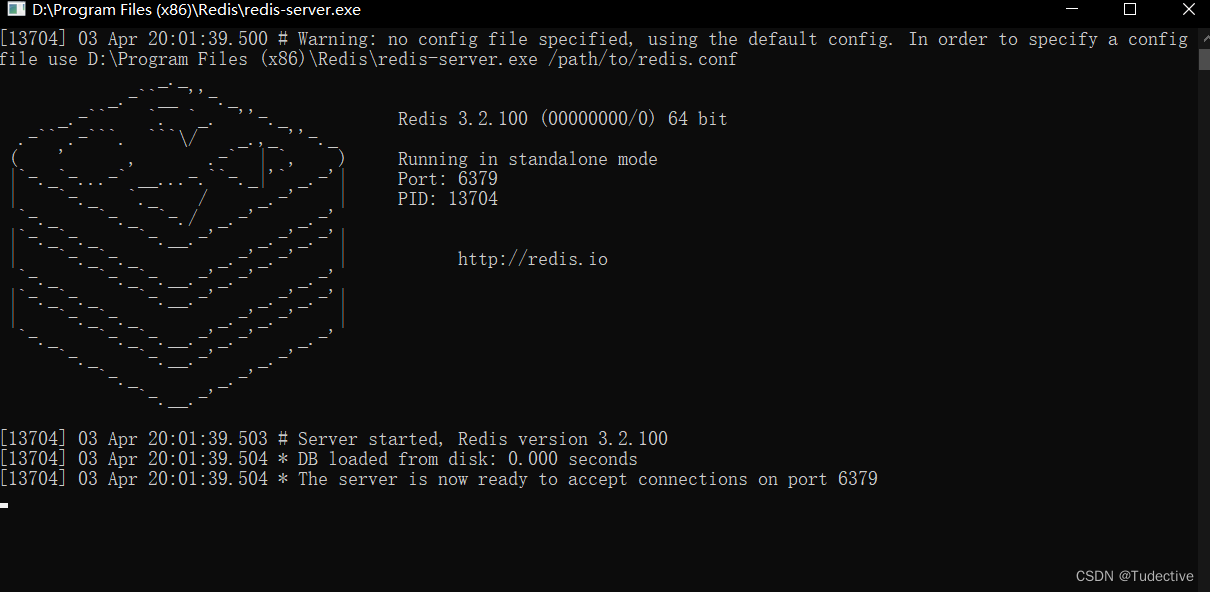 在点击打开redis-cil.exe文件
在点击打开redis-cil.exe文件
2.6项目运行
cmd打开命令行cd切换到项目目录之中,切记需要切换到根目录之中

输入scrapy runspider ‘’项目名‘’.py
然后在redis-cil.exe文件里输入,就成功进行分布式的爬取
lpush ''redis_key'' “爬取网站URL”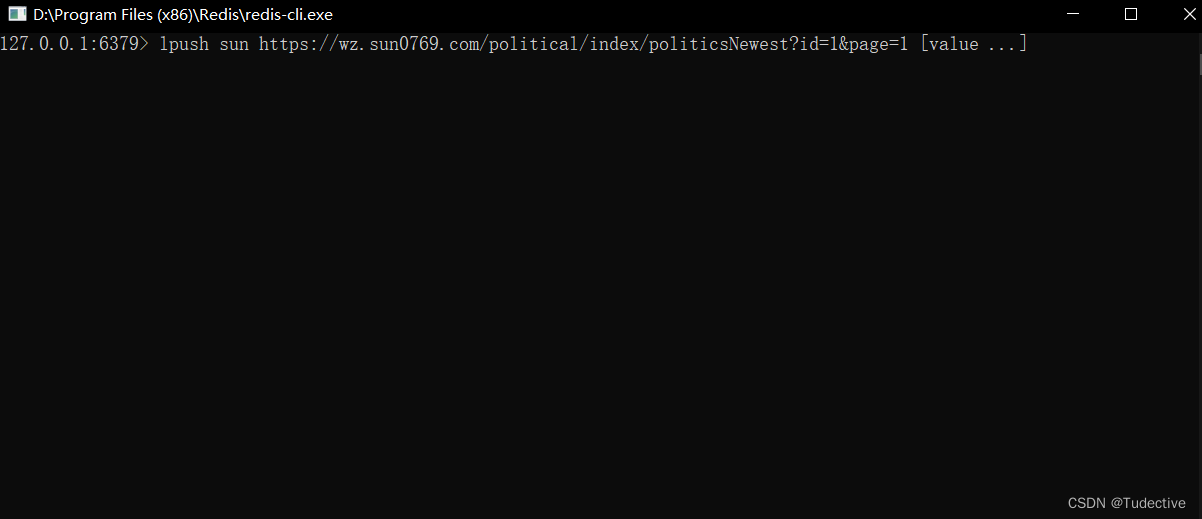
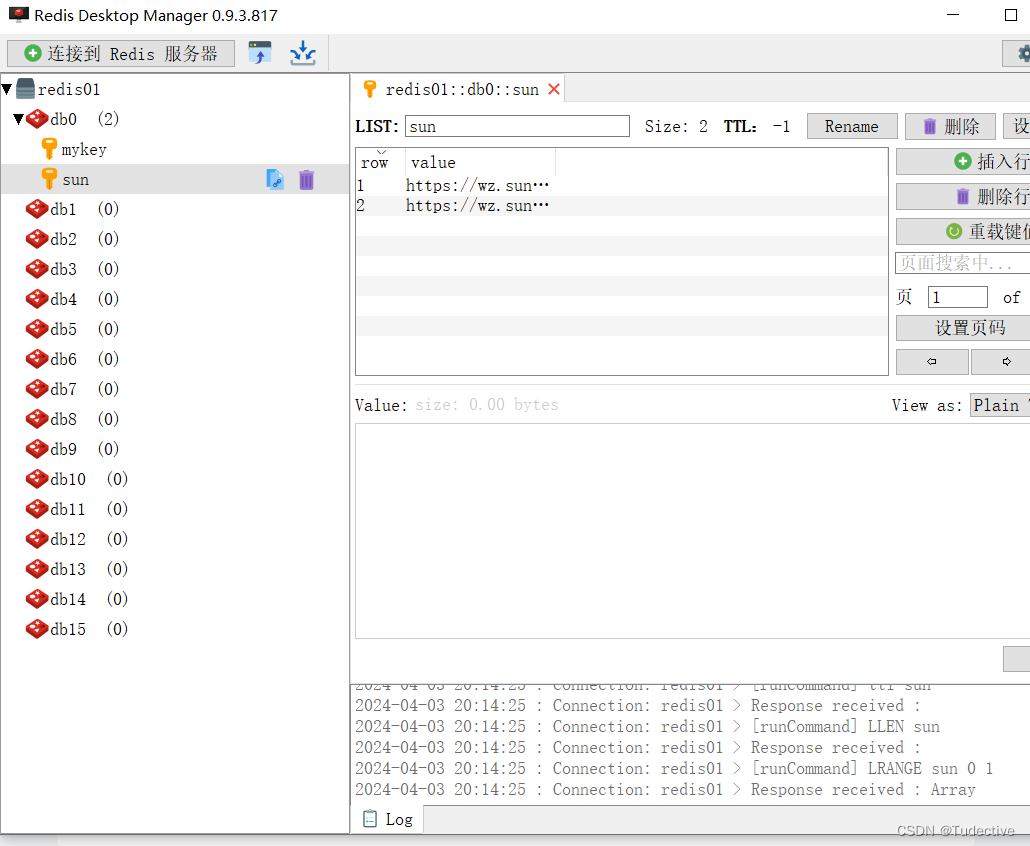
3.数据的查看
使用Redis Desktop Manager 0.9.3.817,对缓存数据进行查看
下载链接:提取码:1631
http:// https://pan.baidu.com/s/1wyELUhOn_rumFecNAS7L0A
相关文章:
Python爬虫之分布式爬虫
分布式爬虫 1.详情介绍 分布式爬虫是指将一个爬虫任务分解成多个子任务,在多个机器上同时执行,从而加快数据的抓取速度和提高系统的可靠性和容错性的技术。 传统的爬虫是在单台机器上运行,一次只能处理一个URL,而分布式爬虫通过将…...

服务器硬件基础知识解析
导言 在当今信息化时代,服务器扮演着至关重要的角色,它们是存储、处理和传输数据的关键设备。本文将介绍服务器硬件的基础知识,包括服务器的组成部分、硬件选型和性能评估等内容,旨在帮助读者更好地理解和应用服务器技术。 服务…...

【芯片设计- RTL 数字逻辑设计入门 1.1 -- Verdi 使用入门介绍 1】
请阅读【芯片设计 RTL 数字逻辑设计扫盲 】 文章目录 Verdi 介绍Verdi 特点和功能Verdi 基本操作Verdi -elab与-dbdir区别-elab 参数介绍-dbdir 参数介绍区别总结Verdi 介绍 Verdi 是由Synopsys公司开发的一款业界领先的自动化电子设计自动化(EDA)工具,主要用于功能验证和调…...
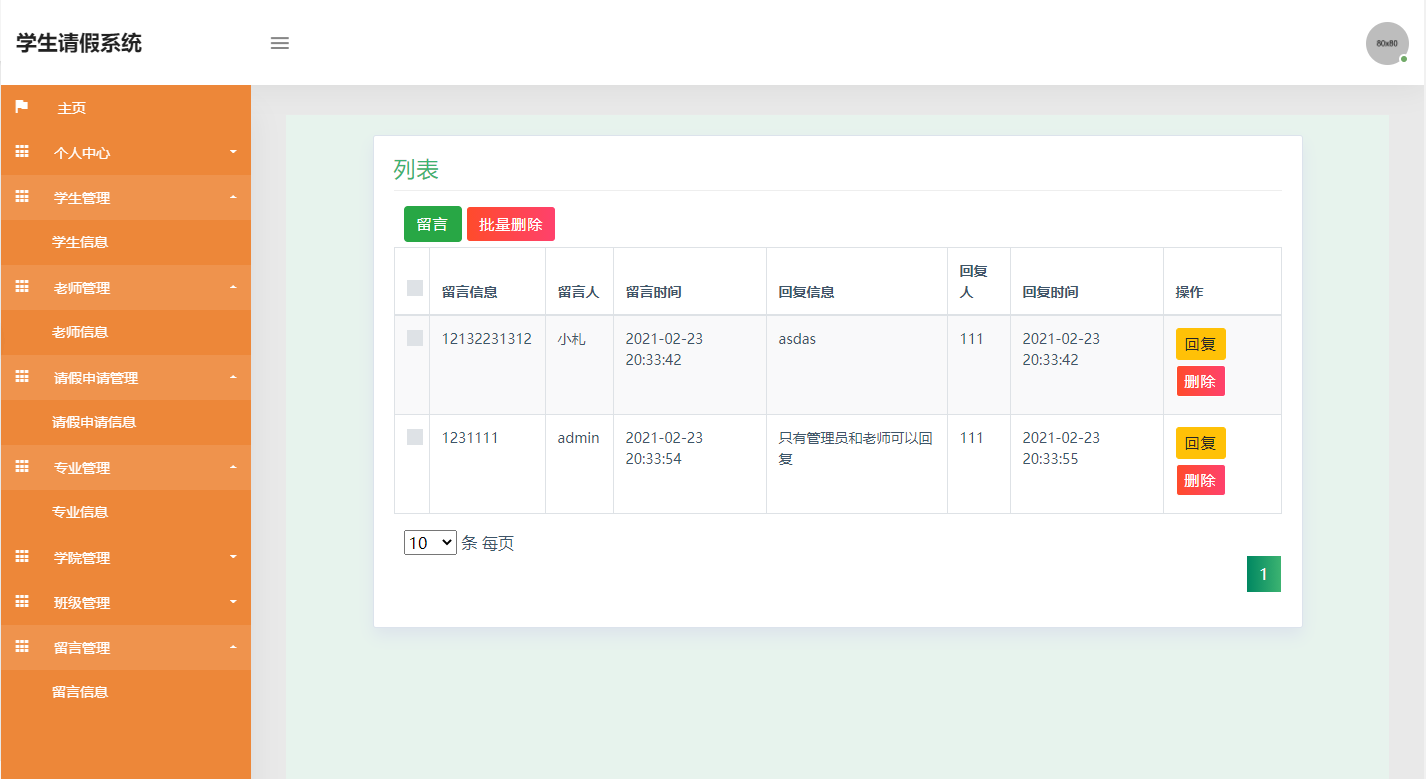
ssm034学生请假系统+jsp
学生请假系统设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本学生请假系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处…...

Leetcode 165. 比较版本号
给你两个版本号 version1 和 version2 ,请你比较它们。 版本号由一个或多个修订号组成,各修订号由一个 ‘.’ 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开…...

LeetCode-279. 完全平方数【广度优先搜索 数学 动态规划】
LeetCode-279. 完全平方数【广度优先搜索 数学 动态规划】 题目描述:解题思路一:Python 动态规划五部曲(完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品…...
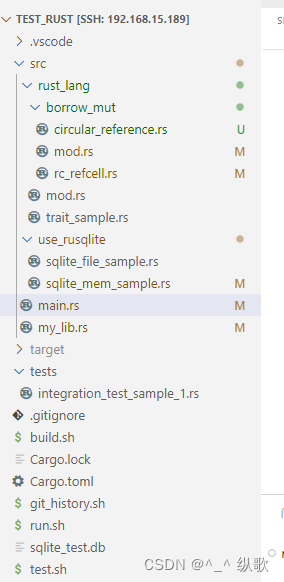
rust项目组织结构和集成测试举例
概述 在学习rust的过程中,当项目结构略微复杂的时候,写集成测试的时候发现总是不能引用项目中的代码,导致编写测试用例失败。查阅了教程,一般举例都很简单。查阅了谷歌和百度以及ai,也没有找到满意的答案。这里记录一…...

软件文档交付清单(直接套用合集)
软件文档交付清单是指在软件开发项目完成后,开发团队需要准备的一份详细清单,用于确保交付的软件产品符合客户需求并达到预期的质量标准。以下是软件文档交付清单中可能包含的一些关键要素 软件开发文档:这包括需求文档、设计文档、测试文档等…...
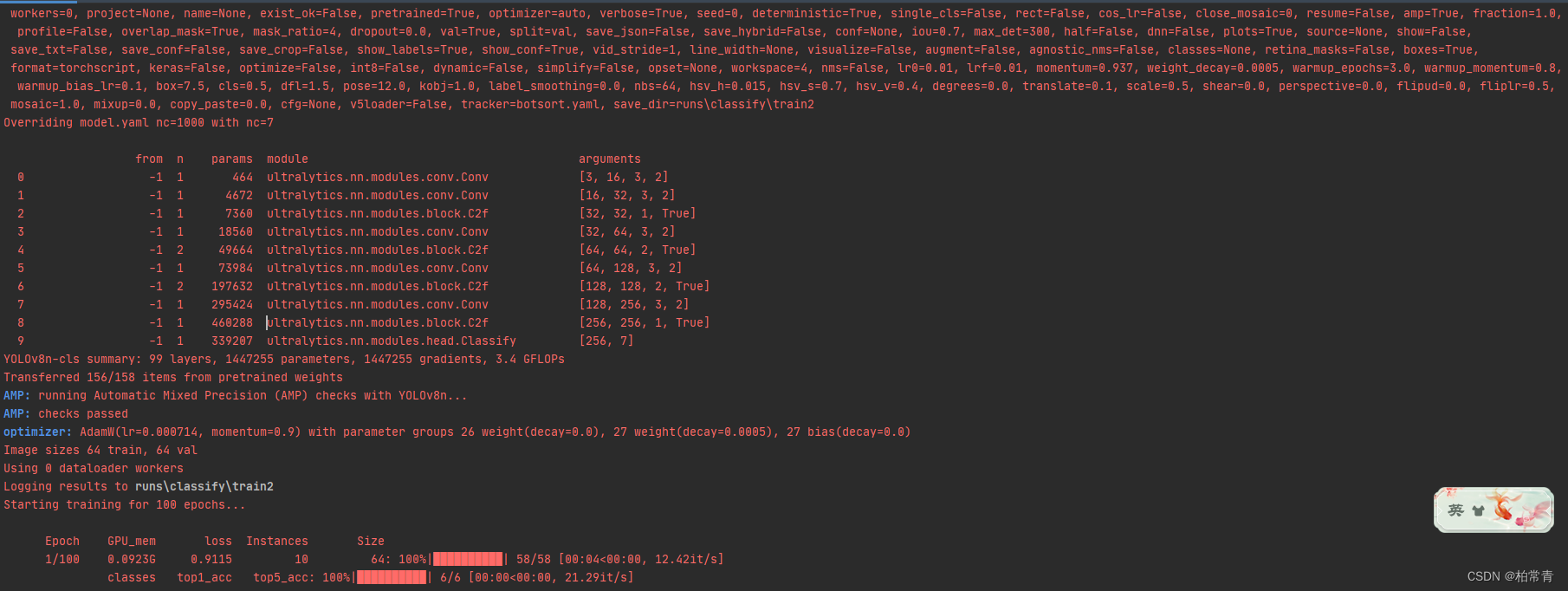
ModuleNotFoundError: No module named ‘ultralytics.utils‘
项目场景he 问题描述 提示:这里简述项目相关背景: model YOLO(modelr./yolov8m-cls.pt) 加载预训练模型时报错。 ModuleNotFoundError: No module named ultralytics.utils warning: bug: 原因分析: 很可能是提前下载的预训练模型出了…...

2024智能计算、大数据应用与信息科学国际会议(ICBDAIS2024)
2024智能计算、大数据应用与信息科学国际会议(ICBDAIS2024) 会议简介 智能计算、大数据应用与信息科学之间存在相互依存、相互促进的关系。智能计算和大数据应用的发展离不开信息科学的支持和推动,而信息科学的发展又需要智能计算和大数据应用的不断拓展和应用。智…...
秋招复习笔记——八股文部分:操作系统
笔试得刷算法题,那面试就离不开八股文,所以特地对着小林coding的图解八股文系列记一下笔记。 这一篇笔记是图解系统的内容。 硬件结构 CPU执行程序 计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备…...

每日一题:C语言经典例题之杨辉三角
题目描述 输出杨辉三角形。 输入 第一行输入一个整数 n (1<n<10)。 输出 输出杨辉三角形的前n行,每个数字占8格左对齐。 样例输入 4 样例输出 1 1 1 1 2 1 1 3 3 1 代码: #inc…...

1. TypeScript: JavaScript 的超集,为大型应用而生
引言 在现代的前端开发领域,JavaScript 无疑是一门极其流行的语言。然而,随着前端项目的日益复杂,JavaScript 本身的一些特性使得维护和扩展大型代码库变得困难。这就是 TypeScript 应运而生的背景。TypeScript 是一种由微软开发的开源语言&…...
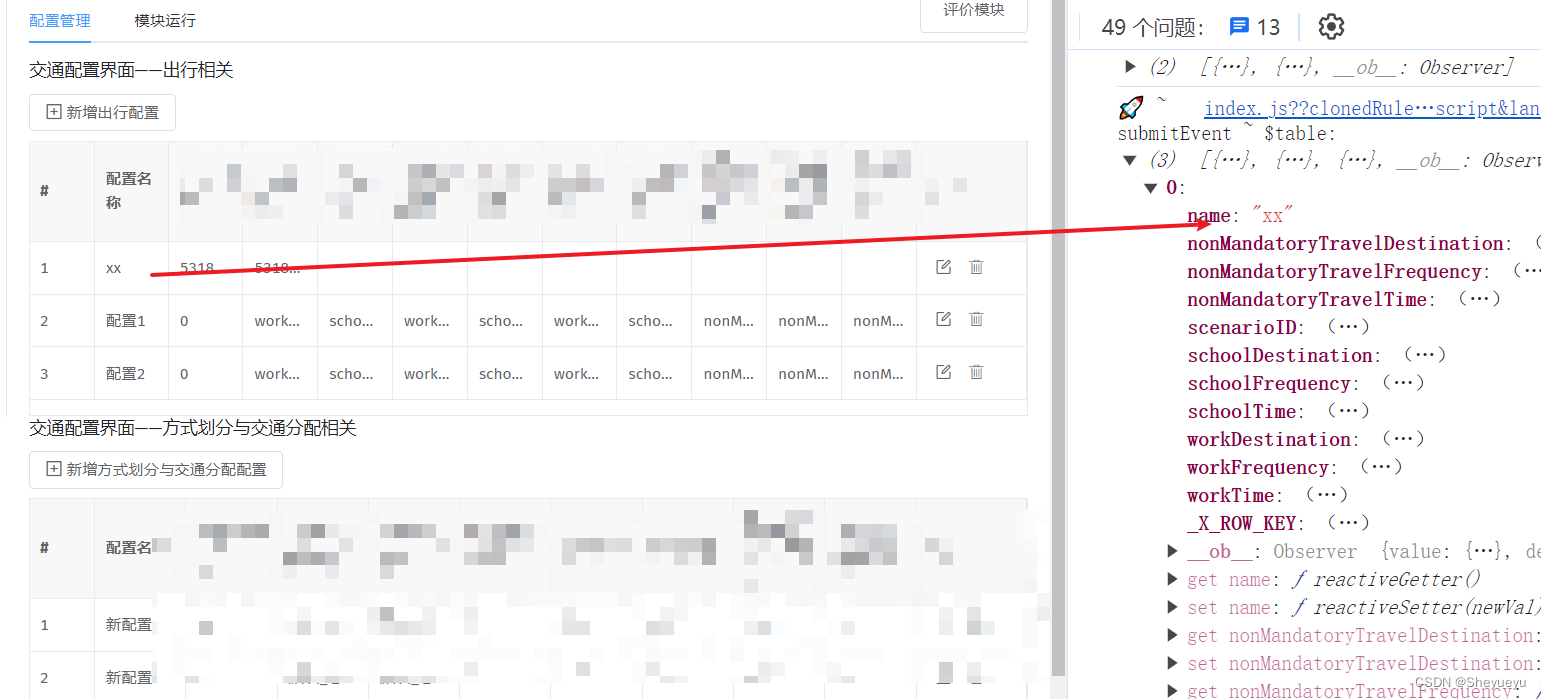
vex-table—— 获取插入或修改数据后的tableData
例子来自vxe-table。在开发过程中发现新增数据后,输出this.tableData,发现数据并没有被修改 想要获取更新的数据方式为 mounted () {const $table this.$refs.xTableconsole.log("🚀 ~ mounted ~ $table:", $table.tableData)},...

通俗易懂地解释Go语言不同版本中垃圾回收机制的演进过程
完整课程请点击以下链接 Go 语言项目开发实战_Go_实战_项目开发_孔令飞_Commit 规范_最佳实践_企业应用代码-极客时间 Go 1.3时代 - 标记清除算法 这就像一个人要打扫房间,首先需要暂停其他活动。然后开始查看房间里的每件物品,对于自己仍需要使用的物品做上记号。查看完毕后…...
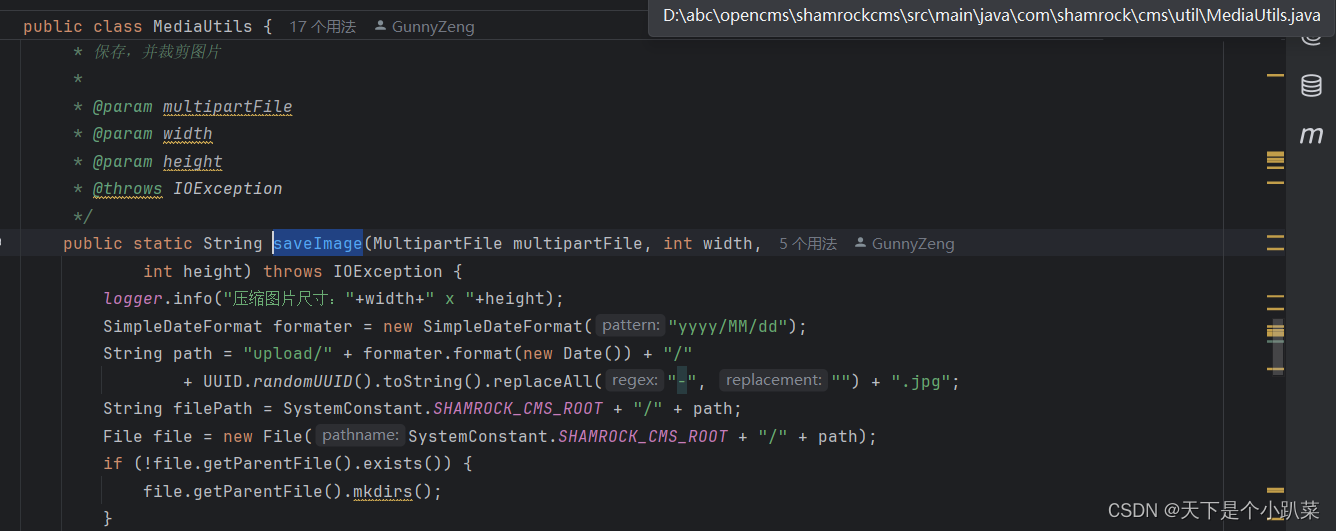
shamrockcms代码审计-啥也没有
shamrockcms 环境搭建 使用阿里源,创建数据库,运行shamrockcms.sql文件,将configure.properties中的jdbc修改为自己本地或者其他ip数据库连接,并且将ueditor.config.json中的master修改为localhost或者其他自己设置的ip 危险组件…...
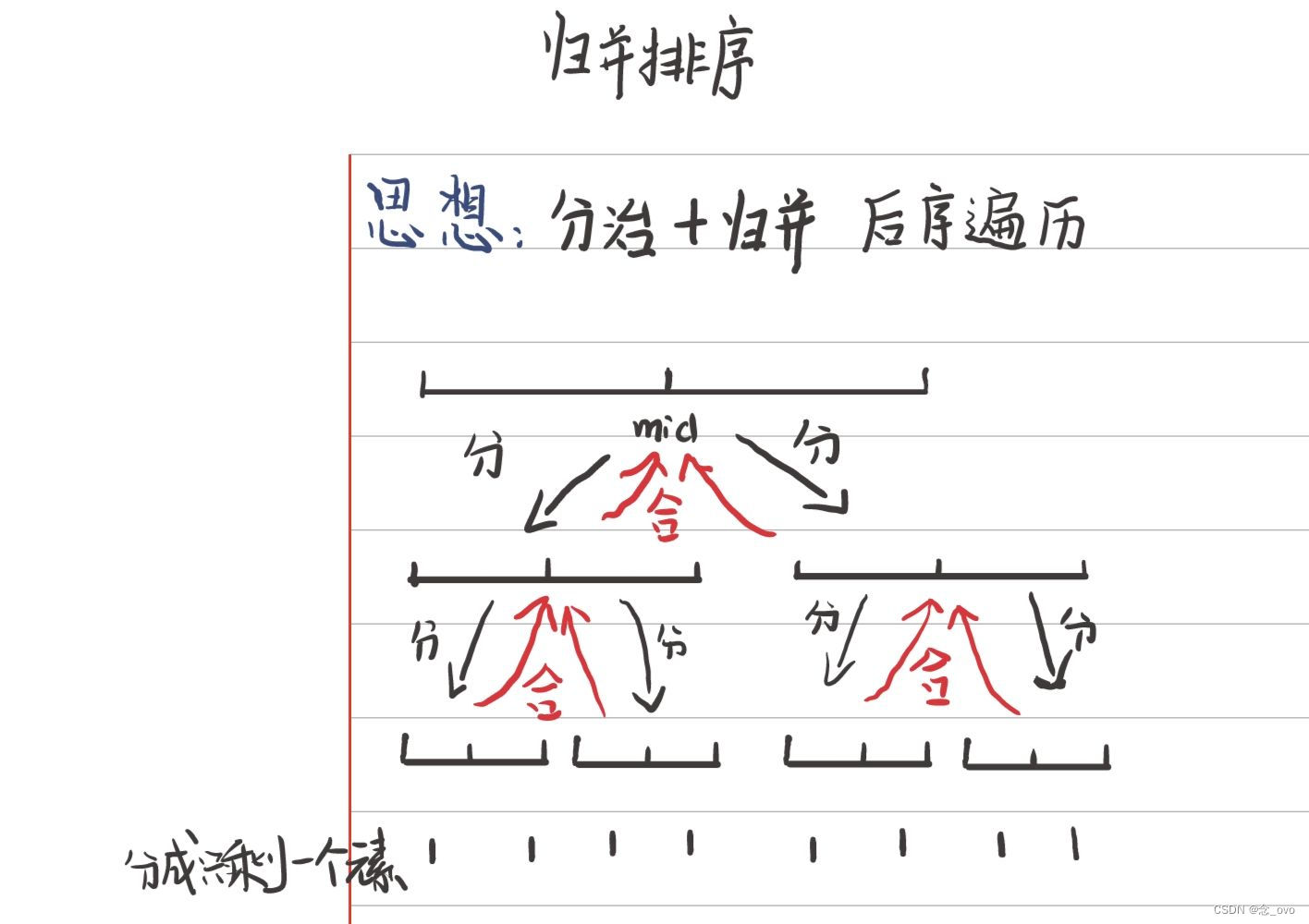
【C++】排序算法 --快速排序与归并排序
目录 颜色分类(数组分三块思想)快速排序归并排序 颜色分类(数组分三块思想) 给定⼀个包含红⾊、⽩⾊和蓝⾊、共 n 个元素的数组 nums ,原地对它们进⾏排序,使得相同颜⾊ 的元素相邻,并按照红⾊、…...
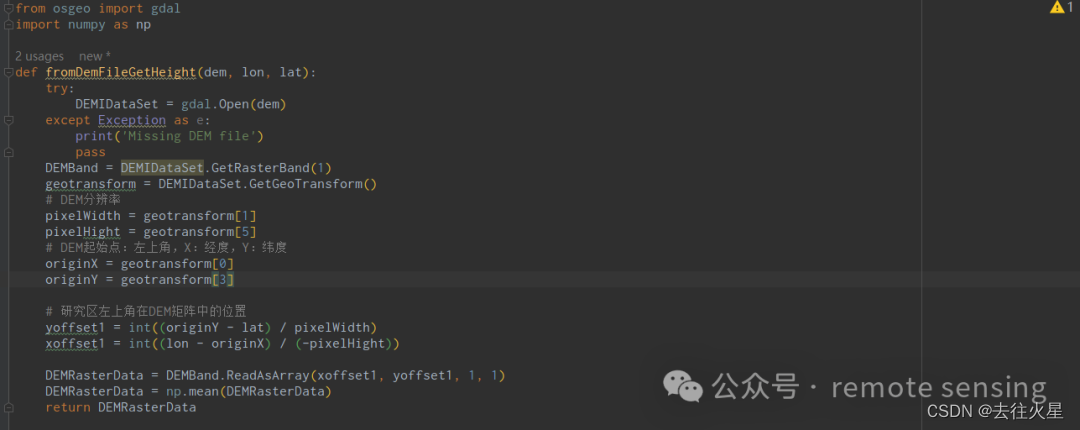
(Python)根据经纬度从数字高程模型(DEM)文件获取高度
基本介绍 在地理信息系统(GIS)和遥感中,数字高程模型(Digital Elevation Model,简称DEM)是一种表示 地表或地形高程信息的重要数据。DEM数据通常以栅格(raster)形式存在࿰…...

【WPF应用41】WPF中的Expander控件详解
Windows Presentation Foundation(WPF)中的Expander控件是一个用于显示详细信息的交互式UI元素。它允许用户通过点击标题来展开或折叠内容区域。Expander控件通常用于在界面上组织内容,提供一种可见/隐藏的功能,以帮助用户专注于当…...

golang变量初始化顺序
顺序: 1.引用的包 2.全局变量 3.init()函数 4.main()函数 package pkgimport "fmt"func init() {fmt.Println("pkg init") }package mainimport ("fmt"_ "gg/pkg" )var v val()func val() int {fmt.Println("func()…...

终极指南:Windows平台APK安装器如何让安卓应用无缝运行
终极指南:Windows平台APK安装器如何让安卓应用无缝运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上运行安卓应用曾经是一个技术难题&am…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

VHD2VL:破解硬件描述语言转换难题的开源解决方案
VHD2VL:破解硬件描述语言转换难题的开源解决方案 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,技术团队常常面临VHDL与Verilog两种硬件描述语言之间的转换挑战。当项目需要跨语言协作、工…...

终极CoreCycler教程:简单三步完成CPU稳定性测试与优化
终极CoreCycler教程:简单三步完成CPU稳定性测试与优化 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换
3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 作为一名3…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...

Arduino nRF52 BLE开发:GATT服务与特征值配置实战详解
1. 项目概述如果你正在用Arduino和nRF52系列芯片(比如nRF52832或nRF52840)做蓝牙低功耗(BLE)开发,那你肯定绕不开GATT(通用属性配置文件)这一关。GATT是BLE通信的“语言规则”,它定义…...