爬虫 新闻网站 以湖南法治报为例(含详细注释) V4.0 升级 自定义可任意个关键词查询、时间段、粗略判断新闻是否和优化营商环境相关,避免自己再一个个判断
目标网站:湖南法治报
爬取目的:为了获取某一地区更全面的在湖南法治报的已发布的和优化营商环境相关的宣传新闻稿,同时也让自己的工作更便捷
环境:Pycharm2021,Python3.10,
安装的包:requests,csv,bs4,datetime
v4.0 版本特点:获取指定时间段的新闻数据,筛选出含有想要查找的的任意个关键词的新闻内容,同时标注新闻是否和优化营商环境相关(粗略判断新闻是否和优化营商环境相关),并存储起来。
1 首先分析网页
(查看数据返回方式,发现网站不用像红网那样设置各种headers了,可以直接爬)
发现在这个页面只有文章标题和发布时间,以及文章链接的信息(当然文章有图片的就还有图片信息)
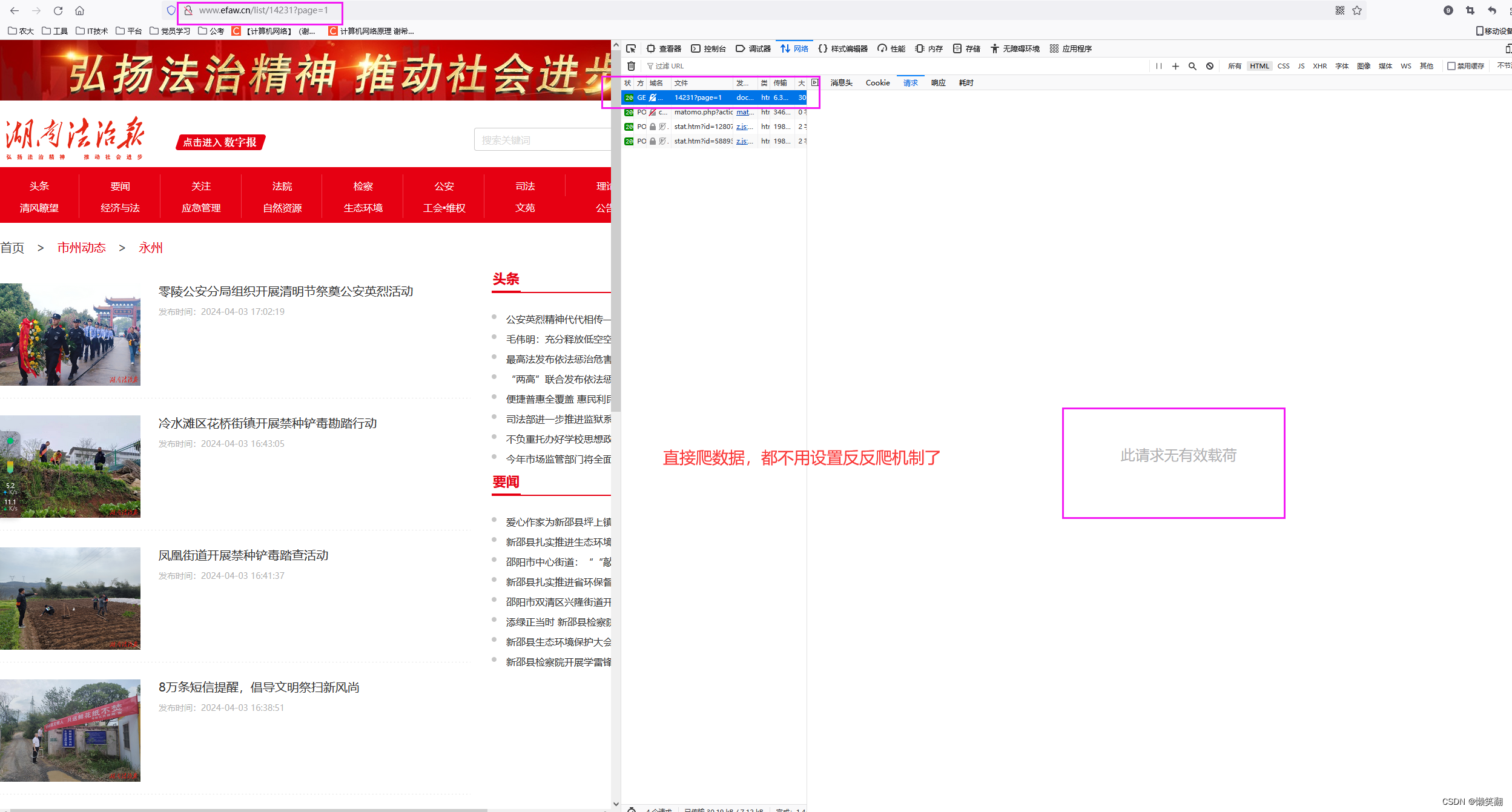

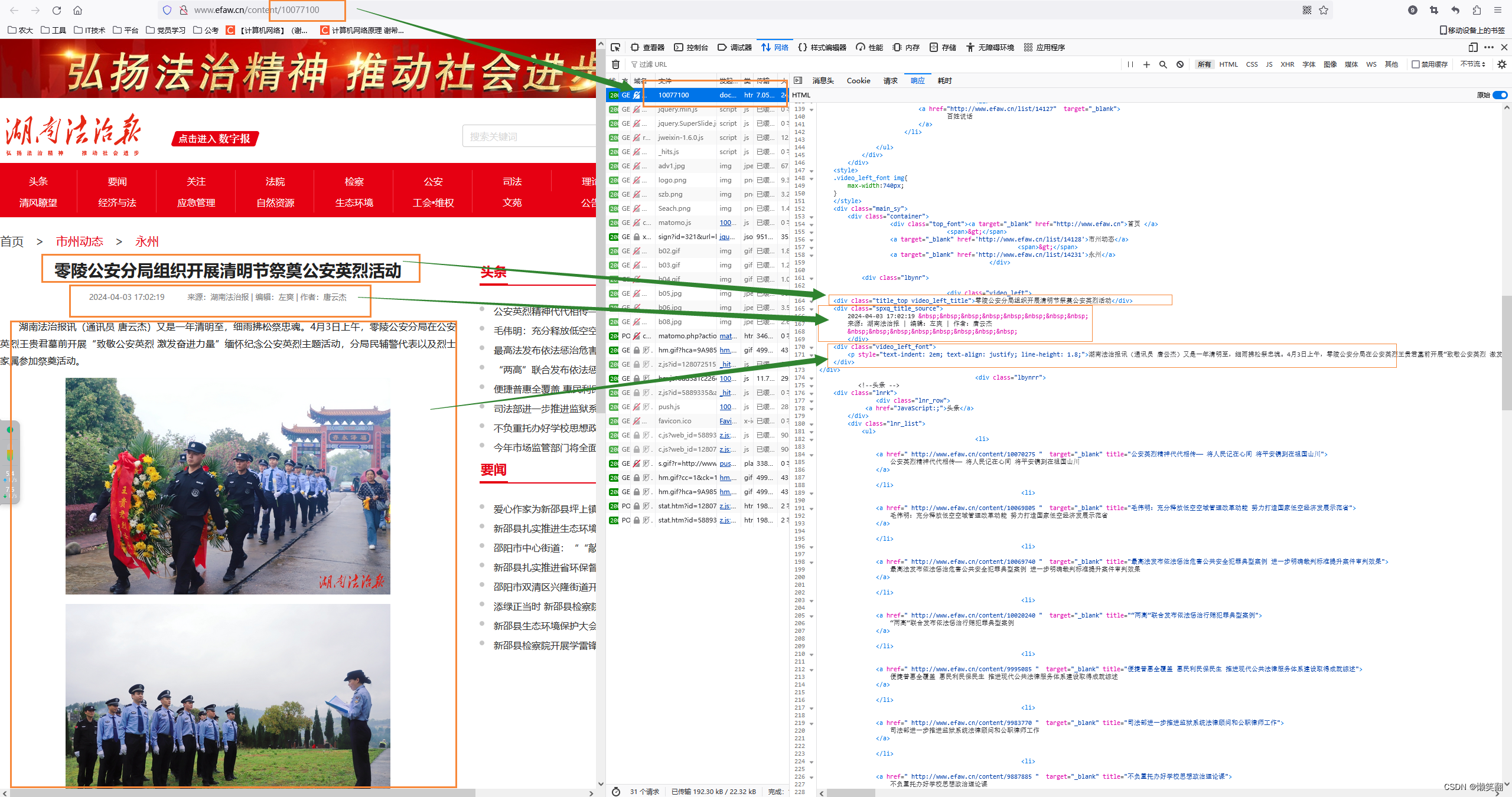
2 再看文章内容页面
(像我就只要文字部分就行了,不需要图片)
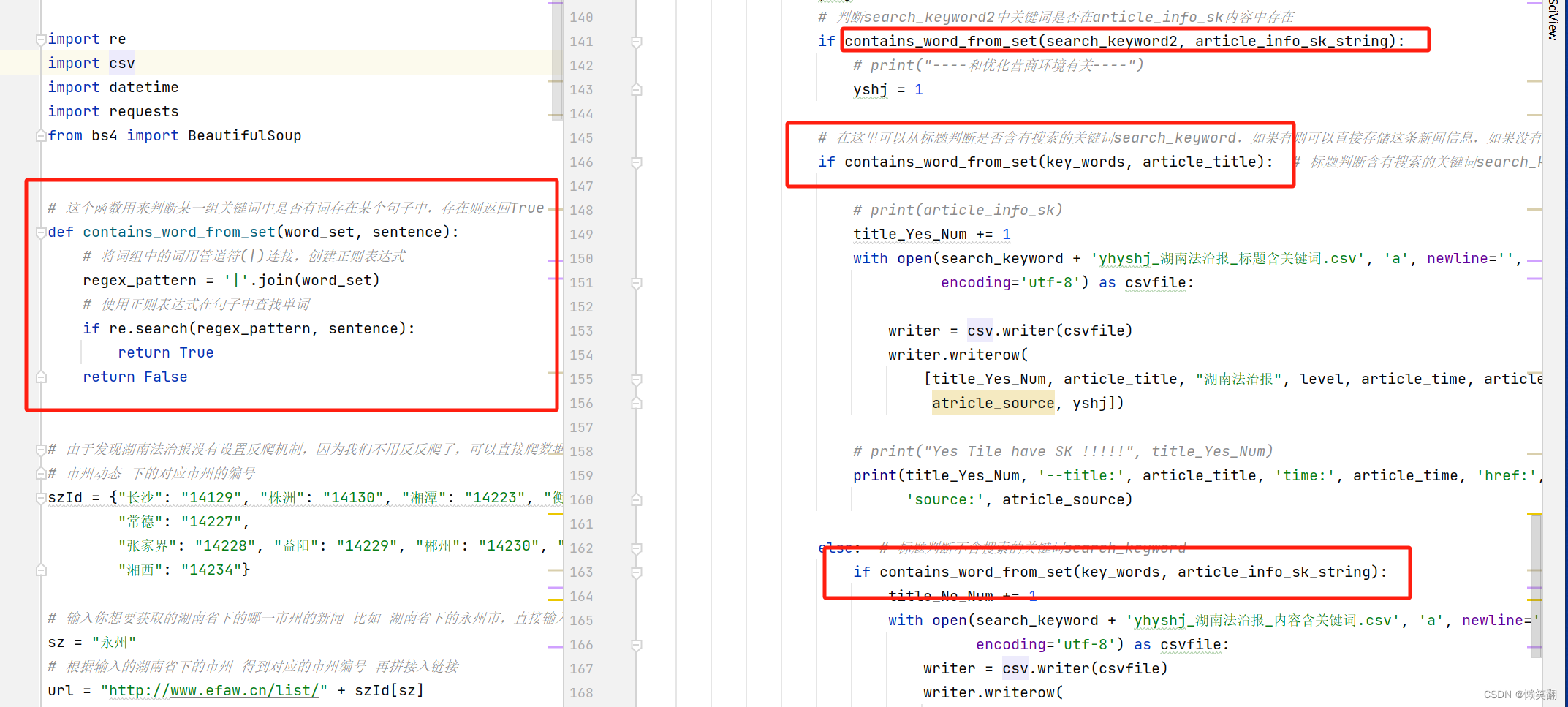
3 和v3对比修改的主要代码:(增加可以多个关键词搜索的方法)
4 运行结果:
5 完整代码,(详细注释)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/4/7 21:05
# @Author : 懒笑翻
# @Site :
# @File : efaw_v4.py
# @Software: PyCharm# v4版本主要是优化搜索,可以任意个关键词,自定义关键词;同时删掉输入,可以直接修改参数,因为每次输入也是头疼,不如直接改参数呢!
# 今天爬取玩数据发现一个问题,就是有一些双牌县下的乡镇的新闻其实是和营商环境相关的,但是因为内容时以他们乡镇直接写的,没提到双牌县**乡镇,因此导致数据被丢弃
# 为了避免上述情况再次出现,于是想了把乡镇的关键词也包含进去
# 双牌县有哪些乡镇:
# 镇:泷泊镇、江村镇、五里牌镇、茶林镇、何家洞镇、麻江镇。
# 乡:塘底乡、上梧江瑶族乡、理家坪乡、五星岭乡、打鼓坪乡。import re
import csv
import datetime
import requests
from bs4 import BeautifulSoup# 这个函数用来判断某一组关键词中是否有词存在某个句子中,存在则返回True
def contains_word_from_set(word_set, sentence):# 将词组中的词用管道符(|)连接,创建正则表达式regex_pattern = '|'.join(word_set)# 使用正则表达式在句子中查找单词if re.search(regex_pattern, sentence):return Truereturn False# 由于发现湖南法治报没有设置反爬机制,因为我们不用反反爬了,可以直接爬数据了
# 市州动态 下的对应市州的编号
szId = {"长沙": "14129", "株洲": "14130", "湘潭": "14223", "衡阳": "14224", "邵阳": "14225", "岳阳": "14226","常德": "14227","张家界": "14228", "益阳": "14229", "郴州": "14230", "永州": "14231", "怀化": "14232", "娄底": "14233","湘西": "14234"}# 输入你想要获取的湖南省下的哪一市州的新闻 比如 湖南省下的永州市,直接输入 永州 即可
sz = "永州"
# 根据输入的湖南省下的市州 得到对应的市州编号 再拼接入链接
url = "http://www.efaw.cn/list/" + szId[sz]
# 输入你想要的关键词 比如 双牌、蓝山、宁远、新田、零陵
search_keyword = '双牌'
# 双牌县下的乡镇
key_words = {'双牌', '泷泊', '江村', '五里牌', '茶林', '何家洞', '麻江', '塘底', '上梧江瑶族', '五星岭', '打鼓坪', '理家坪'}# 二级搜索 优化营商环境 乡村振兴 农业振兴之类的,可以一直加
search_keyword2 = {'优化', '营商', '环境', '春耕', '乡村', '农村', '乡镇', '农业'}
# 自定义需要获取的新闻的时间段
# 开始时间
start_time = '2024 4 1'
start_time = datetime.datetime.strptime(start_time, '%Y %m %d')
# 截止时间
end_time = '2024 4 8'
end_time = datetime.datetime.strptime(end_time, '%Y %m %d')
# 标题就含有关键词的计数器
title_Yes_Num = 0
# 标题不含有关键词但是内容含有关键词的计数器
title_No_Num = 0
# 新闻来源级别
level = "省级"
# 用于计数爬到第几个新闻
count_cc = 0
"""
爬虫思路:
首先最开始是打开要爬取的网站,然后分析怎样获取需要的数据最完整和便捷
一开始看到搜索其实是想直接搜关键词获取新闻的,但是发现通过搜索框获得到新闻数据不如市州动态下的全面,
所以还是打算一条一条新闻比对是否符合自定义关键词
1 首先进入市州动态获取到某市州动态下的所有新闻数据
2 根据具体新闻链接进入新闻页面,获取到新闻信息
"""# # 创建CSV文件并写入头部信息
with open(search_keyword + 'yhyshj_湖南法治报_标题含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源', '优化营商环境相关']) # 根据实际情况定义列名
with open(search_keyword + 'yhyshj_湖南法治报_内容含关键词.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['序号', '新闻名称', '新闻来源', '媒体级别', '发布日期', '原文链接', '来源', '优化营商环境相关']) # 根据实际情况定义列名# http://www.efaw.cn/list/14231?page=1
page = 1
# while page <= 20: # 从这里修改数字以控制要多少页的新闻内容,,page<=20page从1开始一直到20
while page > 0:# 拼接出每一页的urlurl_page = url + "?page=" + str(page) # http://www.efaw.cn/list/14231?page=5html_all = requests.get(url_page)html_all.encoding = 'utf-8'print(page, '页', url_page)if html_all.status_code == 200:soups = BeautifulSoup(html_all.text, 'html.parser')article_info = soups.find_all('ul', class_='list_content')for i in article_info:result_info = i.find_all('div')for art in result_info:article_href = art.a.get('href') # 文章链接article_href = re.sub(r'\s+', '', article_href) # 去除链接中存在的空隔# print(article_href)article_title = art.a.get('title') # 文章标题article_time = art.i.text # 文章发布时间 显示为:发布时间:2024-04-02 10:08:03# 因为只要年月日部分的时间,因此把一些不需要的字符去掉article_time = article_time[2 + article_time.index('间:'):]article_time = article_time[:article_time.index(':') - 3]article_time = article_time.replace('-', '.')article_time_se = datetime.datetime.strptime(article_time, '%Y.%m.%d')count_cc += 1# print('--page', page, 'count_cc', count_cc, '--title:', article_title, 'time:', article_time, 'href:',# article_href)# 现在有个问题怎么退出循环,时间不满足就退出:现在获取到的新闻的时间<开始时间就退出if article_time_se < start_time:page = -1break# 只把时间满足要求的数据才继续下面的操作 并把数据存入表格if start_time <= article_time_se <= end_time:# 从文章内容中获取到来源html_article_info_sk = requests.get(article_href)html_article_info_sk.encoding = 'utf-8'if html_article_info_sk.status_code == 200:soups_sk = BeautifulSoup(html_article_info_sk.text, 'html.parser')# article_info_sk:文章的相关内容,包括标题、发表时间、来源、编辑、作者、文章内容article_info_sk = soups_sk.find_all('div', class_='video_left')# 其实在这里我想获取到具体的来源,这一段因为在新闻详情页面,如果 来源 为 双牌县优化办 ,那么这条新闻就是优化办推过去的spxq_title_source = soups_sk.find('div', class_='spxq_title_source').text# 文章信息来源 显示为: 来源:湖南法治报atricle_source = spxq_title_source[spxq_title_source.index('来源:') + 3:spxq_title_source.index('|')]article_info_sk_string = str(article_info_sk) # 这里要把article_info_sk字符串化,不然无法判断关键词是否在内容中存在# 设立一个标识,默认为0和营商环境无关,1有关yshj = 0# 判断search_keyword2中关键词是否在article_info_sk内容中存在if contains_word_from_set(search_keyword2, article_info_sk_string):# print("----和优化营商环境有关----")yshj = 1# 在这里可以从标题判断是否含有搜索的关键词search_keyword,如果有则可以直接存储这条新闻信息,如果没有则继续查看新闻内容,看是否含有关键词信息if contains_word_from_set(key_words, article_title): # 标题判断含有搜索的关键词search_keyword# print(article_info_sk)title_Yes_Num += 1with open(search_keyword + 'yhyshj_湖南法治报_标题含关键词.csv', 'a', newline='',encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_Yes_Num, article_title, "湖南法治报", level, article_time, article_href,atricle_source, yshj])# print("Yes Tile have SK !!!!!", title_Yes_Num)print(title_Yes_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href,'source:', atricle_source)else: # 标题判断不含搜索的关键词search_keywordif contains_word_from_set(key_words, article_info_sk_string):title_No_Num += 1with open(search_keyword + 'yhyshj_湖南法治报_内容含关键词.csv', 'a', newline='',encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title_No_Num, article_title, "湖南法治报", level, article_time, article_href,atricle_source, yshj])# print("Yes Content have SK !!!!!", article_info_sk)print(title_No_Num, '--title:', article_title, 'time:', article_time, 'href:', article_href,'source:', atricle_source)page += 1print("#### 你获取的关键词", search_keyword, '时间从', start_time, '~', end_time, '的数据已经获取完!')
相关文章:
爬虫 新闻网站 以湖南法治报为例(含详细注释) V4.0 升级 自定义可任意个关键词查询、时间段、粗略判断新闻是否和优化营商环境相关,避免自己再一个个判断
目标网站:湖南法治报 爬取目的:为了获取某一地区更全面的在湖南法治报的已发布的和优化营商环境相关的宣传新闻稿,同时也让自己的工作更便捷 环境:Pycharm2021,Python3.10, 安装的包:requests&a…...

科技云报道:从“奇点”到“大爆炸”,生成式AI开启“十年周期”
科技云报道原创。 世界是复杂的,没有人知道未来会怎样,但如果单纯从技术的角度,我们总是能够沿着技术发展的路径,找到一些主导未来趋势的脉络。 从Sora到Suno,从OpenAI到Copilot、Blackwell,这些热词在大…...

【用户案例】太美医疗基于Apache DolphinScheduler的应用实践
大家好,我叫杨佳豪,来自于太美医疗。今天我为大家分享的是Apache DolphinScheduler在太美医疗的应用实践。今天的分享主要分为四个部分: 使用历程及选择理由稳定性的改造功能定制与自动化部署运维巡检与优化 使用历程及选择理由 公司介绍 …...
权限管理系统【BUG】
1.1.简介 忙里偷闲,学点Java知识。越发觉得世界语言千千万,最核心的还是思想,一味死记硬背只会让人觉得很死板不灵活,嗯~要灵活~ 1.2.问题 permission.js:37 [Vue warn]: Error in render: "TypeError: Cannot read prope…...

【CPA考试】2024注册会计师报名照片尺寸要求解读及手机拍照方法
随着2024年注册会计师考试的临近,众多会计专业人士和学生都开始准备报名参加这一行业的重要考试,报名时间为4月8日至4月30日。报名过程中,一张符合要求的证件照是必不可少的。本文将为您详细解读2024年注册会计师考试报名照片的尺寸要求&…...

高并发环境下的实现与优化策略
在现代互联网应用中,高并发处理能力是衡量系统性能和稳定性的关键指标之一。尤其对于电商、社交、在线支付等业务场景,面对瞬间涌入的大规模用户请求,如何保证系统的稳定性和响应速度,对技术架构设计与优化提出了极高要求。本文将…...

华为海思校园招聘-芯片-数字 IC 方向 题目分享——第二套
华为海思校园招聘-芯片-数字 IC 方向 题目分享(共9套,有答案和解析,答案非官方,未仔细校正,仅供参考)——第二套(共九套,每套四十个选择题) 部分题目分享,完整版获取&am…...
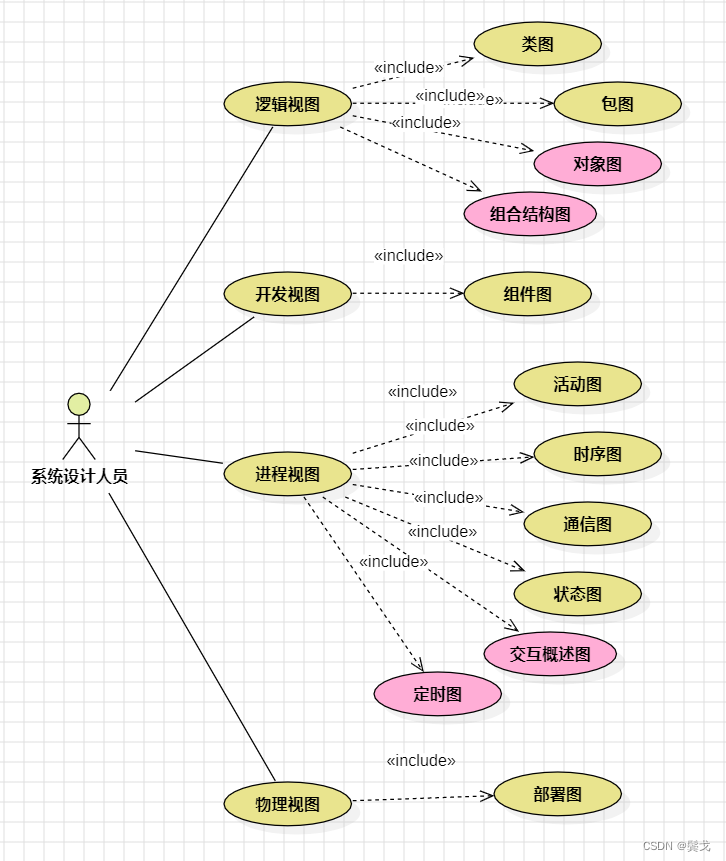
UML2.0在系统设计中的实际使用情况
目前我在系统分析设计过程中主要使用UML2.0来表达,使用StarUML软件做实际设计,操作起来基本很顺手,下面整理一下自己的使用情况。 1. UML2.0之十三张图 UML2.0一共13张图,可以分为两大类:结构图-静态图,行…...

django celery 异步任务 异步存储
环境:win11、python 3.9.2、django 4.2.11、celery 4.4.7、MySQL 8.1、redis 3.0 背景:基于django框架的大量任务实现,并且需要保存数据库 时间:20240409 说明:异步爬取小说,并将其保存到数据库 1、创建…...

apex0.1版本安装踩坑指南
踩了无数坑,发现只需要三行命令就可以成功安装apex0.1. 由于pip命令下只能找到0.9的版本,所以需要git clone的方式安装。 1. git clone https://www.github.com/nvidia/apex 这个命令的意思是下载apex到本地。注意,这里需要稳定的环境…...
)
HTML — 弹性布局(2)
弹性布局的其他属性 1. order 决定弹性项目(flex item)的排列顺序,使用较少,默认为0 。 order 的值可以为任意整数(正整数或负整数均可,也可为0),数值越小越排在前面。 2. align-s…...

MYSQL 8.0版本修改用户密码(知道登录密码)和Sqlyog错误码2058一案
今天准备使用sqlyog连接一下我Linux上面的mysql数据库,然后就报如下错误 有一个简单的办法就是修改密码为password就完事!然后我就开始查找如何修改密码! 如果是需要解决Sqlyog错误码2058的话,执行以下命令,但是注意root对应host是不是loca…...

Linux中磁盘管理
一.磁盘管理的概括和简要说明 磁盘空间的管理,使用硬盘三步: (1)分区: (2)安装文件系统格式化 (3)挂载: 硬盘的分类: (1&#x…...

tailwindcss在manoca在线编辑智能感知
推荐一下monaco-tailwindcss库,它实现在monaco-editor网页在线编辑器中对tailwindcss的智能感知提示,在利用tailwindcss实现html效果布局。非常的方便。 生成CSS...
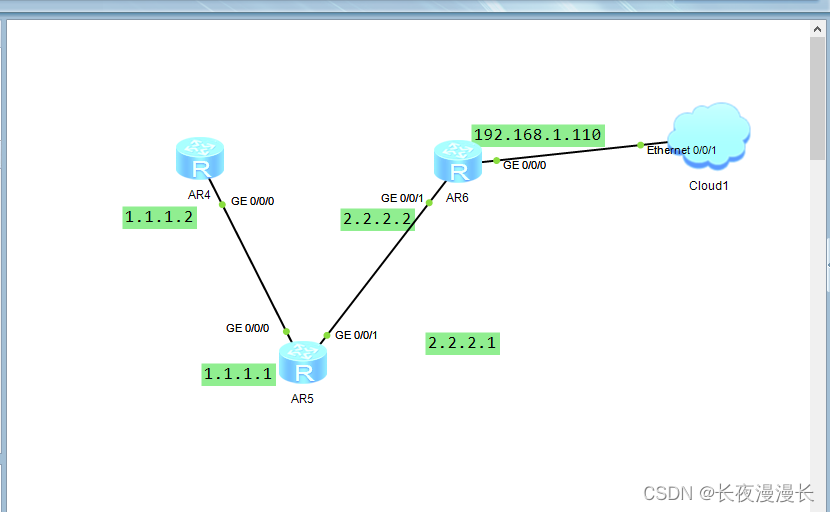
通过本机调试远端路由器非直连路由
实验目的:如图拓扑,通过本机电脑发,telnet调试远程AR4设备。 重点1:通过ospf路由协议配置拓扑网络,知识点:ospf配置路由器协议语法格式,area区域的定义,区域内网络的配置࿰…...

React路由快速入门:Class组件和函数式组件的使用
1. 介绍 在开始学习React路由之前,先了解一下什么是React路由。React Router是一个为React应用程序提供声明式路由的库。它可以帮助您在应用程序中管理不同的URL,并在这些URL上呈现相应的组件。 2. 安装 要在React应用程序中使用React路由,…...
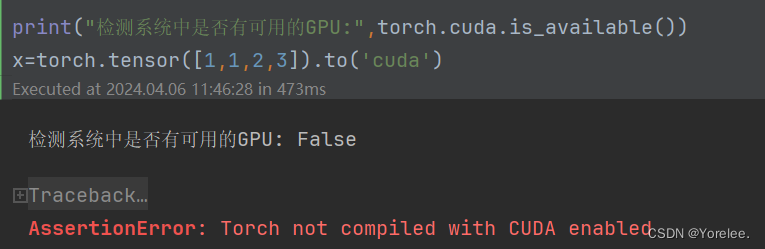
Pytorch数据结构:GPU加速
文章目录 一、GPU加速1. 检查GPU可用性:2. GPU不可用需要具体查看问题3. 指定设备4.将张量和模型转移到GPU5.执行计算:6.将结果转移回CPU 二、转移原理1. 数据和模型的存储2. 数据传输3. 计算执行4. 设备管理5.小结 三、to方法的参数类型 一、GPU加速 .…...

OpenHarmony开发-连接开发板调试应用
在 OpenHarmony 开发过程中,连接开发板进行应用调试是一个关键步骤,只有在真实的硬件环境下,我们才能测试出应用更多的潜在问题,以便后续我们进行优化。本文详细介绍了连接开发板调试 OpenHarmony 应用的操作步骤。 首先…...
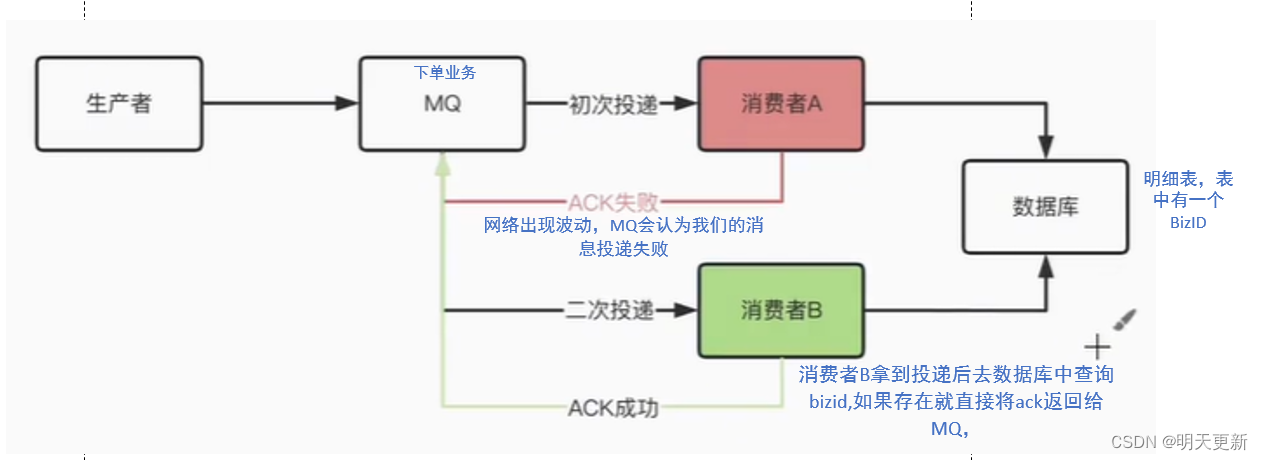
RabbitMQ如何保证消息的幂等性???
在RabbitMQ中,保证消费者的幂等性主要依赖于业务设计和实现,而非RabbitMQ本身提供的一种直接功能。 在基于Spring Boot整合RabbitMQ的场景下,要保证消费者的幂等性,通常需要结合业务逻辑设计以及额外的技术手段来实现。以下是一个…...

【QT】Qt Charts的实际使用中的一些小细节完善如:resetZoom、fitInView
在Qt中, 使用 Qt Charts来创建和操作图表,重置图表缩放状态的功能可以通过调整图表视图的缩放比例来实现。Qt Charts中的QChartView提供了相关的方法来控制图表的缩放和平移。 示例代码,以及如何对此功能进行扩展: #include <…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

人性最残忍的真相是:你越不把自己当回事,别人就越不把你当回事
那个总给别人买贵东西的人,最后都怎么样了? 目录 那个总给别人买贵东西的人,最后都怎么样了? 我们为什么会忍不住过度付出? 真正的爱,从来都不是单方面的牺牲 爱自己,是所有健康关系的前提 昨天刷到一句话,瞬间戳中了我:“永远不要拿自己辛苦钱,去给别人买自己都舍不…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...