学习基于pytorch的VGG图像分类 day3
注:本系列博客在于汇总CSDN的精华帖,类似自用笔记,不做学习交流,方便以后的复习回顾,博文中的引用都注明出处,并点赞收藏原博主.
目录
VGG模型训练
1.导入必要的库
2.主函数部分
2.1使用cpu或gpu
2.2对数据进行预处理
2.3 训练集部分
2.4索引与标签
2.5创建数据加载器
2.6验证集部分
2.7模型的初始化
2.8训练部分
2.9评估验证部分
2.10主函数入口
小结
VGG模型训练
1.导入必要的库
导入所需的库,以及导入自定义的VGG模型模版
import os
import sys
import json import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm from model import vgg # 导入自定义的VGG模型模块 2.主函数部分
def main(): 2.1使用cpu或gpu
# 检查是否有可用的CUDA设备,如果有则使用GPU,否则使用CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("using {} device.".format(device)) 2.2对数据进行预处理
# 定义数据预处理操作,包括随机裁剪、随机水平翻转、转为Tensor格式、标准化 data_transform = { "train": transforms.Compose([ transforms.RandomResizedCrop(224), # 随机裁剪为224x224大小 transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.ToTensor(), # 将PIL Image或ndarray转换为torch.FloatTensor,并归一化到[0.0, 1.0] transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理,减均值除标准差 ]), "val": transforms.Compose([ transforms.Resize((224, 224)), # 调整图片大小到224x224 transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 标准化处理 }2.3 训练集部分
读取脚本的路径,构建一个图像数据的跟路径(用条件判断断言路径是否存在,不存在进行报错)加载训练数据集
# 获取当前脚本的绝对路径 current_file_dir = os.path.dirname(os.path.abspath(__file__)) # 构建图像数据的根路径 image_root = os.path.join(current_file_dir, "image_path") train_dir = os.path.join(image_root, "train") # 训练集目录 # 确保训练集目录存在 assert os.path.exists(train_dir), "{} path does not exist.".format(train_dir) # 使用torchvision.datasets的ImageFolder类加载训练数据集,它假设每个子文件夹的名称是其对应的类别 train_dataset = datasets.ImageFolder(root=train_dir, transform=data_transform["train"]) # 定义保存类别标签与索引对应关系的json文件路径 image_path = os.path.join(image_root) # 计算训练集样本数量 train_num = len(train_dataset) 2.4索引与标签
# 获取类别标签与索引的对应关系 flower_list = train_dataset.class_to_idx # 反转字典,将索引映射到类别标签 cla_dict = {val: key for key, val in flower_list.items()} # 将类别索引到标签的映射关系写入json文件 json_str = json.dumps(cla_dict, indent=4) # 使用json库将字典转化为格式化字符串 with open('class_indices.json', 'w') as json_file: 2.5创建数据加载器
定义每个数据加载器使用的工作进程数量,若自身内存不够,可以小一点!!!
# 定义每个数据加载器使用的工作进程数量 batch_size = 32nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 取CPU核心数, batch_size(如果大于1)和8中的最小值 print('Using {} dataloader workers every process'.format(nw)) # 打印每个进程使用的数据加载器工作进程数 # 创建训练集数据加载器 train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw) 2.6验证集部分
道理同训练集。
# 验证集目录 val_dir = os.path.join(image_path, "val") # 验证集文件夹路径 # 检查验证集目录是否存在 assert os.path.exists(val_dir), "{} path does not exist.".format(val_dir) # 加载验证数据集 validate_dataset = datasets.ImageFolder(root=val_dir, transform=data_transform["val"]) # 获取验证集样本数量 val_num = len(validate_dataset) # 创建验证集数据加载器 validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=nw) # 打印训练集和验证集的样本数量 print("using {} images for training, {} images for validation.".format(train_num, val_num))2.7模型的初始化
对模型各个参数进行初始化,确定分类个数,训练轮数,最佳准确率,学习率
# 初始化模型 model_name = "vgg16" net = vgg(model_name=model_name, num_classes = 4, init_weights=True) # 创建VGG16模型,类别数为4,并初始化权重 net.to(device) # 将模型转移到指定的设备上(CPU或GPU) # 定义损失函数和优化器 loss_function = nn.CrossEntropyLoss() # 交叉熵损失函数,用于分类问题 optimizer = optim.Adam(net.parameters(), lr=0.0001) # 使用Adam优化器,学习率为0.0001 # 设置训练轮数 epochs = 60# 初始化最佳准确率 best_acc = 0.0 # 设置模型保存路径 save_path = './{}Net.pth'.format(model_name) # 计算训练步骤数 train_steps = len(train_loader)2.8训练部分
训练及展示进度
# 开始训练循环 for epoch in range(epochs): # 将模型设置为训练模式 net.train() # 初始化运行损失 running_loss = 0.0 # 使用tqdm库创建进度条,用于显示训练进度 train_bar = tqdm(train_loader, file=sys.stdout) # 开始每个epoch的训练步骤循环 for step, data in enumerate(train_bar): # 从数据加载器中获取图像和标签 images, labels = data # 梯度清零 optimizer.zero_grad() # 前向传播,计算输出 outputs = net(images.to(device)) # 计算损失 loss = loss_function(outputs, labels.to(device)) # 反向传播,计算梯度 loss.backward() # 更新模型参数 optimizer.step() # 更新运行损失(这部分代码在原始代码中被省略了,通常需要用于记录或展示) # 将当前损失值添加到运行损失中 running_loss += loss.item() # 打印训练过程中的统计信息 # 格式化字符串,显示当前epoch、总epoch数和当前损失值 train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) 2.9评估验证部分
# 验证模型性能 net.eval() # 将模型设置为评估模式 acc = 0.0 # 初始化累积的正确预测数量 with torch.no_grad(): # 不计算梯度,节省计算资源 val_bar = tqdm(validate_loader, file=sys.stdout) # 创建验证集的进度条 for val_data in val_bar: # 遍历验证集数据 val_images, val_labels = val_data # 获取图像和标签 outputs = net(val_images.to(device)) # 前向传播,获取模型输出 predict_y = torch.max(outputs, dim=1)[1] # 获取预测类别 # 计算预测正确的数量,并累加到acc中 acc += torch.eq(predict_y, val_labels.to(device)).sum().item() # 计算验证集的准确率 val_accurate = acc / val_num # 打印当前epoch的训练损失和验证准确率 print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate)) # 如果当前验证准确率高于最佳准确率,则更新最佳准确率并保存模型状态 if val_accurate > best_acc: best_acc = val_accurate torch.save(net.state_dict(), save_path) # 保存模型权重到指定路径 print('Finished Training') # 训练完成,打印提示信息 2.10主函数入口
# 主函数入口
if __name__ == '__main__': main() # 调用main函数,开始训练过程小结
1.对内存不够的情况要降低batch_size的值,否则模型无法训练
2.在构建路径后,一定要用条件判断断言路径是否存在(这是一个好习惯)
3.在模型训练时最好实时更新数据(可以更加直观的体现)
相关文章:

学习基于pytorch的VGG图像分类 day3
注:本系列博客在于汇总CSDN的精华帖,类似自用笔记,不做学习交流,方便以后的复习回顾,博文中的引用都注明出处,并点赞收藏原博主. 目录 VGG模型训练 1.导入必要的库 2.主函数部分 2.1使用cpu或gpu 2.2对数据…...

Spring Boot统一功能处理之拦截器
本篇主要介绍Spring Boot的统一功能处理中的拦截器。 目录 一、拦截器的基本使用 二、拦截器实操 三、浅尝源码 初始化DispatcherServerlet 处理请求(doDispatch) 四、适配器模式 一、拦截器的基本使用 在一般的学校或者社区门口,通常会安排几个…...
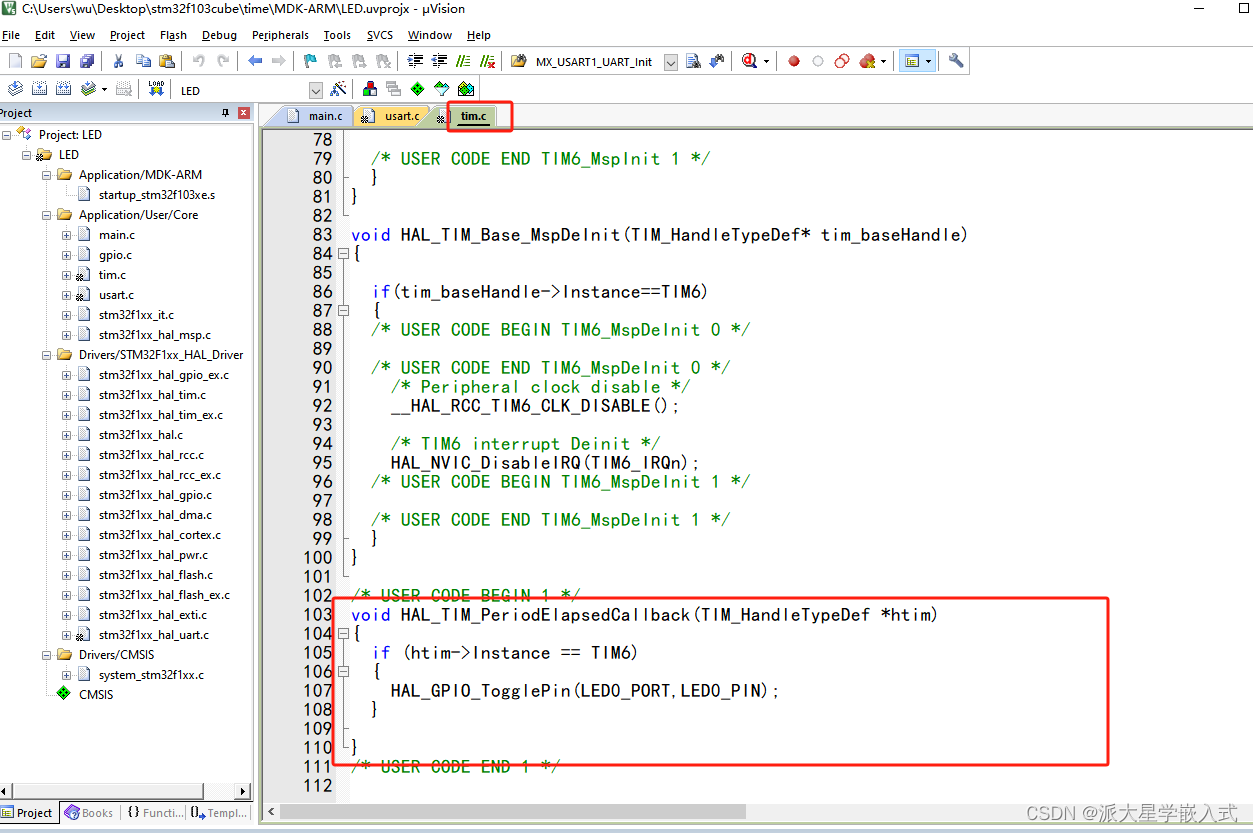
stm32之基本定时器的使用
在上文我们使用到了HAL库的自带的延时函数,HAL_Delay();我们来看一下函数的原型 __weak void HAL_Delay(uint32_t Delay) {uint32_t tickstart HAL_GetTick();uint32_t wait Delay;/* Add a freq to guarantee minimum wait */…...
单片机为什么还在用C语言编程?
单片机产品的成本是非常敏感的。因此对于单片机开发来说,最重要的是在极其有限的ROM和RAM中实现最多产品的功能。或者反过来说,实现相同的产品功能,所需要的ROM和RAM越小越好,在开始前我有一些资料,是我根据网友给的问…...
IO流的基础详解
文件【1】File类: 封装文件/目录的各种信息,对目录/文件进行操作,但是我们不可以获取到文件/目录中的内容。 【2】引入:IO流: I/O : Input/Output的缩写,用于处理设备之间的数据的传输。 【3】…...

实战攻防 | 记一次项目上的任意文件下载
1、开局 开局一个弱口令,正常来讲我们一般是弱口令或者sql,或者未授权 那么这次运气比较好,直接弱口令进去了 直接访问看看有没有功能点,正常做测试我们一定要先找功能点 发现一个文件上传点,不过老规矩,还…...

熔断之神:探寻Hystrix的秘密与实践指南
引言: 在微服务架构中,服务之间的依赖复杂且难以控制,容灾机制成为确保系统稳定性的重要手段。Hystrix作为Netflix开源的断路器实现,提供了一系列强健的容错功能。 Hystrix的核心概念与作用: Hystrix是一个由Netflix开…...

Web功能测试测试点总结!
web测试就是基于BS架构的软件产品的测试,通俗点来说就是web网站的测试。 一 、界面检查 当我们进入一个页面时,首先应该检查title,页面排版(即页面的展示),而不是马上进入字段校验页面面包屑导航是否正确当前位置是否可见 您的位…...
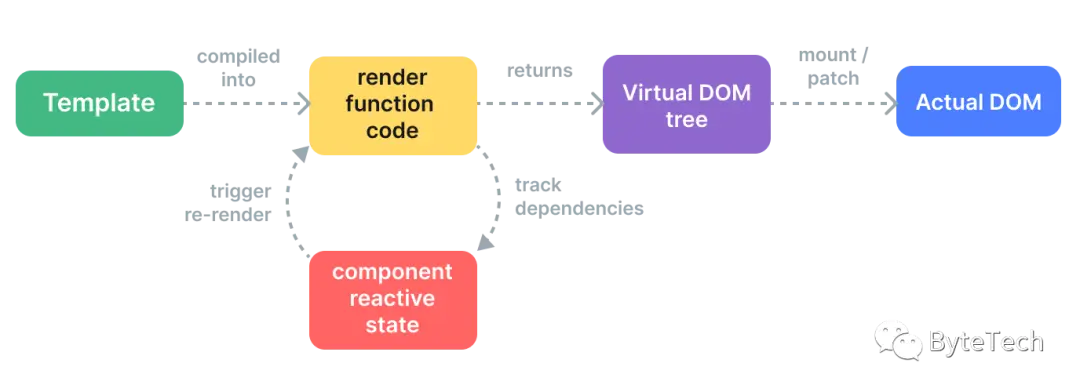
关于vue3的简单学习
Vue 3 简介 Vue 3 是一个流行的开源Java框架,用于构建用户界面和单页面应用。它带来了许多新特性和改进,包括更好的性能、更小的打包大小、更好的Type支持、全新的组合式 API,以及一些新的内置组件。 一. Vue 3 的新特性 Vue 3引入了许多新…...
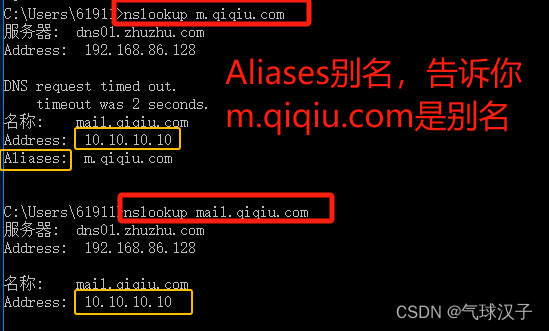
windows server 2019 -DNS服务器搭建
前面是有关DNS的相关理论知识,懂了的可以直接跳到第五点。 说明一下:作为服务器ip最好固定下来,以DNS服务器为例子,如果客户机的填写DNS信息的之后,服务器的ip如果变动了的话,客户机都得跟着改,…...

使用 XCTest 进行 iOS UI 自动化测试
使用 XCTest 进行 iOS UI 自动化测试是一种有效的方法,可以帮助你验证应用界面的行为和功能。以下是使用 XCTest 进行 iOS UI 自动化测试的基本步骤: 设置项目: 确保你的 Xcode 项目已经包含了 XCTest 测试目标。在测试目标中创建一个新的测试类…...

【Python】FANUC机器人OPC UA通信并记录数据
目录 引言机器人仿真环境准备代码实现1. 导入库2. 设置参数3. 日志配置4. OPC UA通信5. 备份旧CSV文件6. 主函数 总结 引言 OPC UA(Open Platform Communications Unified Architecture)是一种跨平台的、开放的数据交换标准,常用于工业自动化…...

Linux 中断处理
一、基本概念 1、中断及中断上下文 中断是一种由硬件设备产生的信号,不同设备产生的中断通过中断号来区分。CPU在接收到中断信号后,根据中断号执行对应的中断处理程序(Interrupt Service Routine) 内核对异常和中断的处理类似&a…...

人大金昌netcore适配,调用oracle模式下存储过程\包,返回参数游标
using KdbndpConnection conn new KdbndpConnection("Host192.168.133.221;Port54321;Databasedb1;Poolingtrue;User IDsystem;Password123");conn.Open();//存储过程调用也是类似using var cmd conn.CreateCommand();cmd.CommandText "模式.包名称.存储过程…...

pandas常用的一些操作
EXCLE操作 读取Excel data1 pd.read_excel(excle_dir) 读Excel取跳过前几行: data1 pd.read_excel(excle_dir,skiprows1) 获取总行数 data1.shape[0] 获取总列数 data1.shape[1] 指定某列数据类型 data1 pd.read_excel("C:数据导入.xlsx",dtype…...
【鸿蒙开发】系统组件Row
Row组件 Row沿水平方向布局容器 接口: Row(value?:{space?: number | string }) 参数: 参数名 参数类型 必填 参数描述 space string | number 否 横向布局元素间距。 从API version 9开始,space为负数或者justifyContent设置为…...

Hadoop和zookeeper集群相关执行脚本(未完,持续更新中~)
1、Hadoop集群查看状态 搭建Hadoop数据集群时,按以下路径操作即可生成脚本 [test_1analysis01 bin]$ pwd /home/test_1/hadoop/bin [test_01analysis01 bin]$ vim jpsall #!/bin/bash for host in analysis01 analysis02 analysis03 do echo $host s…...
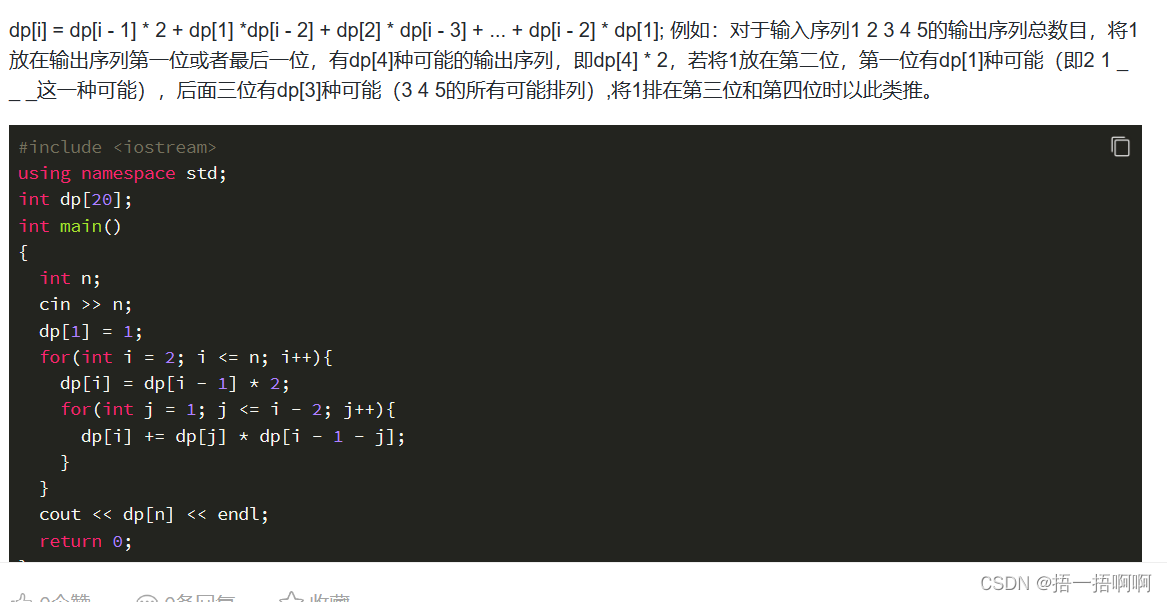
蓝桥杯算法题:栈(Stack)
这道题考的是递推动态规划,可能不是很难,不过这是自己第一次靠自己想出状态转移方程,所以纪念一下: 要做这些题目,首先要把题目中会出现什么状态给找出来,然后想想他们的状态可以通过什么操作转移…...
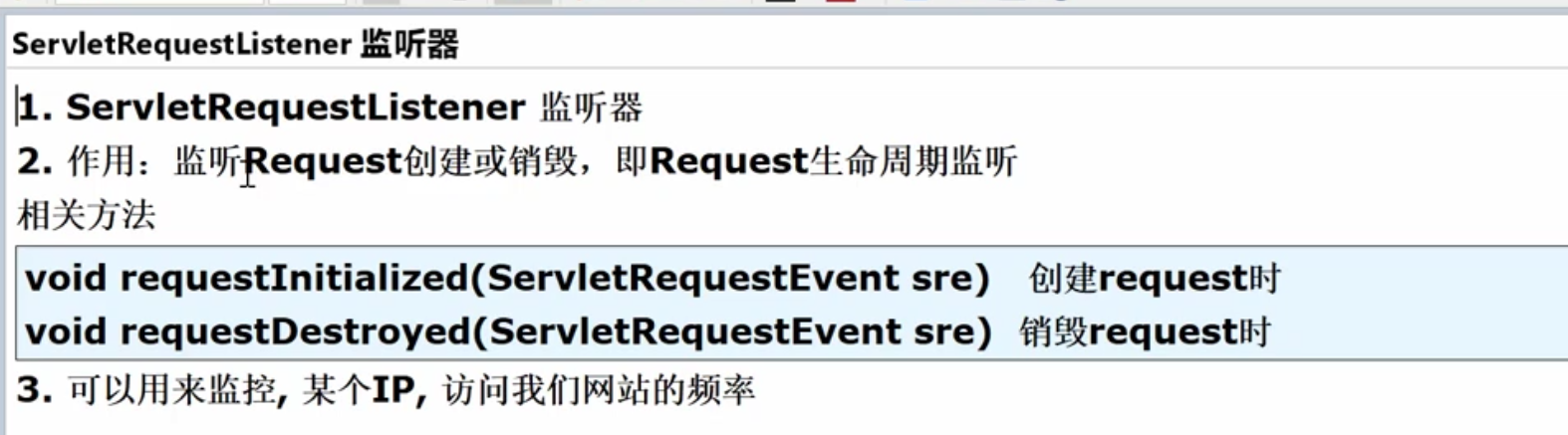
JavaWeb-监听器
文章目录 1.基本介绍2.ServletContextListener1.基本介绍2.创建maven项目,导入依赖3.代码演示1.实现ServletContextListener接口2.配置web.xml3.结果 3.ServletContextAttributeListener监听器1.基本介绍2.代码实例1.ServletContextAttributeListener.java2.配置web…...

系统架构设计基础知识
一. 系统架构概述系统架构的定义 系统架构(System Architecture)是系统的一种整体的高层次的结构表示,是系统的骨架和根基,支撑和链接各个部分,包括构件、连接件、约束规范以及指导这些内容设计与演化的原理࿰…...
城市规划师实战:如何用TransCad+四阶段法,为你的新区规划提供交通量支撑?
城市规划师实战:TransCad与四阶段法在新区交通规划中的深度应用 1. 从理论到实践:四阶段法的核心逻辑 在Z新城规划项目中,我们面临的核心挑战是如何科学预测未来15年的交通需求。四阶段法作为交通规划领域的经典方法论,其价值在于…...

智能定时任务管理:用自然语言替代Crontab,TickGPTick项目实践
1. 项目概述:一个能“听懂”你需求的定时任务管理器最近在折腾一个自动化脚本项目时,我又一次陷入了“定时任务”的泥潭。相信很多开发者都有同感:写个脚本容易,但想让它定时、可靠、有状态地跑起来,总得和 crontab、s…...

Verilog行为级建模:从initial/always到阻塞非阻塞赋值的核心语法解析
1. 项目概述:从“连线”到“行为”的思维跃迁刚接触数字电路设计的朋友,可能都是从画原理图、连逻辑门开始的。但当你面对一个需要处理复杂时序、包含状态机或者有算法逻辑的模块时,光靠门级网表来描述,那工程量简直让人头皮发麻。…...
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题 计算机视觉领域正经历一场由Transformer架构引领的革命。从最初的图像分类任务到如今的复杂场景理解,Transformer以其强大的全局建模能力不断刷新着各项基准。而在天气…...
)
别再被CUDA版本搞懵了!PyTorch环境配置保姆级避坑指南(含conda与本地安装对比)
深度学习环境配置终极指南:PyTorch与CUDA版本匹配的实战解决方案 1. 理解CUDA与PyTorch版本冲突的本质 当你第一次在终端看到"RuntimeError: The detected CUDA version mismatches the version that was used to compile PyTorch"这个错误时,…...

AI智能体配置管理实战:基于agent-config-manager的解决方案
1. 项目概述与核心价值最近在折腾一个多智能体协作的项目,发现配置文件的管理简直是个灾难。每个智能体(Agent)都有自己的一堆参数:API密钥、模型选择、系统提示词、温度值、最大token数……更别提不同环境(开发、测试…...

基于大语言模型的强化学习奖励函数自动生成:text2reward项目实践指南
1. 项目概述:从文本指令到强化学习奖励的桥梁最近在折腾强化学习项目时,一个老问题又冒出来了:怎么设计一个既精确又高效的奖励函数?传统方法要么是工程师凭经验手写一堆规则,复杂场景下容易顾此失彼;要么依…...

基于MCP协议的AI工具调用服务器:omega-point-convergence-mcp实战指南
1. 项目概述与核心价值最近在折腾AI智能体开发,特别是想让它们能更“主动”地去获取和处理外部信息时,一个绕不开的话题就是工具调用。传统的API集成方式,每个新工具都得写一遍对接代码,调试起来繁琐不说,维护成本也高…...
)
别再死记硬背了!用Python手把手带你画一棵哈夫曼树(附完整代码)
用Python动态构建哈夫曼树:从理论到可视化的完整实践指南 在计算机科学中,数据压缩是一个永恒的话题。想象一下,当你需要传输大量数据时,如何用最少的比特数表示最多的信息?这就是哈夫曼编码要解决的问题。传统的教科书…...

基于LangBot框架快速构建智能对话机器人:从工具集成到RAG应用实战
1. 项目概述:一个能“听懂人话”的智能对话机器人如果你正在寻找一个能快速搭建、高度定制,并且能真正理解你意图的智能对话机器人,那么langbot-app/LangBot这个项目绝对值得你花时间深入研究。它不是一个简单的聊天接口封装,而是…...