人工智能分类算法概述
文章目录
- 人工智能主要分类算法
- 决策树
- 随机森林
- 逻辑回归
- K-均值
- 总结
人工智能主要分类算法
人工智能分类算法是用于将数据划分为不同类别的算法。这些算法通过学习数据的特征和模式,将输入数据映射到相应的类别。分类算法在人工智能中具有广泛的应用,如图像识别、语音识别、文本分类等。以下是几种常见的人工智能分类算法的详细讲解过程:
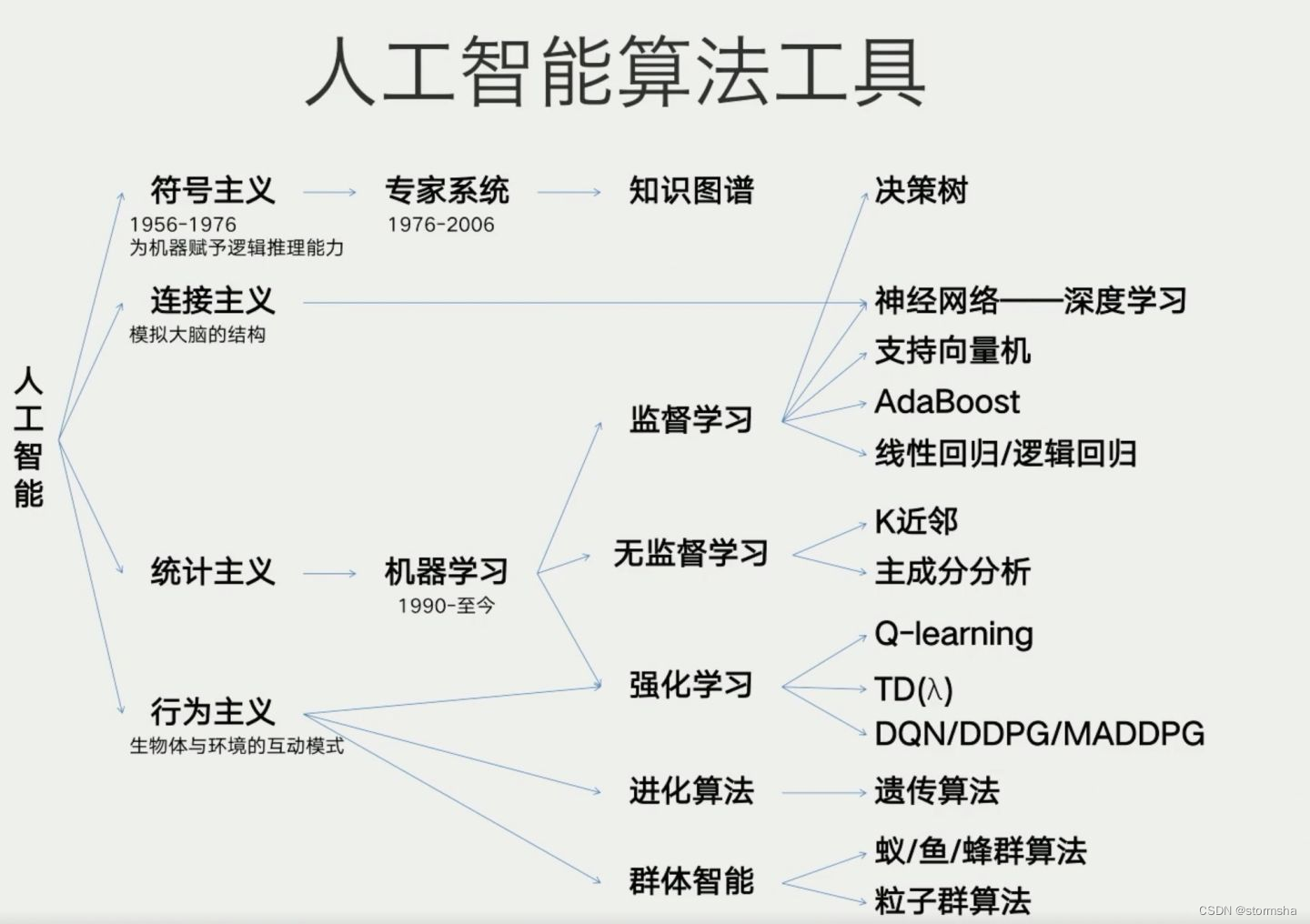
决策树
决策树是一种基于树形结构的分类算法。它通过一系列的问题来判断数据应该被分为哪一类。每个节点代表一个问题,根据问题的答案,数据被分为两类,并继续向下遍历直到到达叶节点。决策树的构建过程是根据已有数据学习出来的,当新的数据投入时,就可以根据这棵树上的问题,将数据划分到合适的叶子上。如下图是一个决策树的简单示意图

如下python实现的决策树代码示例:
import numpy as np
from sklearn.tree import DecisionTreeClassifier# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])# 创建决策树分类器
clf = DecisionTreeClassifier()# 训练决策树分类器
clf.fit(X, y)# 使用决策树分类器进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个决策树分类器对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
随机森林
随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。随机森林通过建立几个模型组合的方式来解决单一预测问题。它的构建过程包括以下几个步骤:首先,从训练用例中以有放回抽样的方式,取样形成一个训练集,并用未抽到的用例作预测,评估其误差;然后,根据特征数目,计算其最佳的分裂方式;最后,重复上述步骤,构建另外一棵棵决策树,直到达到预定数目的一群决策树为止,即构建好了随机森林。
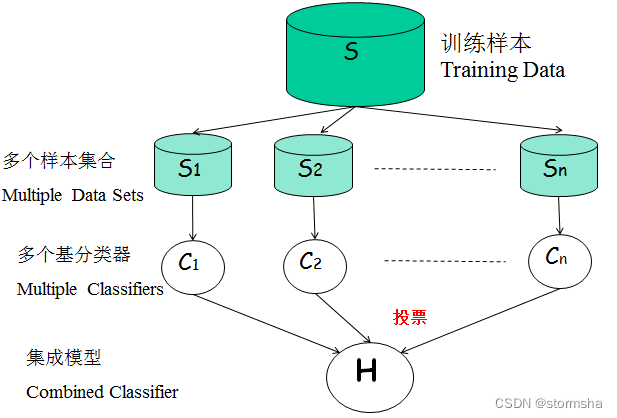
以下是一个使用Python实现随机森林的示例代码:
import numpy as np
from sklearn.ensemble import RandomForestClassifier# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])# 创建随机森林分类器
clf = RandomForestClassifier()# 训练随机森林分类器
clf.fit(X, y)# 使用随机森林分类器进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个随机森林分类器对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
逻辑回归
逻辑回归是一种常用的监督分类算法。它通过使用逻辑函数估计概率来测量因变量和自变量之间的关系。如果预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。这个模型需要满足两个条件大于等于0,小于等于1。大于等于0的模型可以选择绝对值,平方值,这里用指数函数,一定大于0。再做一下变形,就得到了logisticregression模型。
以下是一个使用Python实现逻辑回归的示例代码:
import numpy as np
from sklearn.linear_model import LogisticRegression# 创建数据集
X = np.array([[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]])
y = np.array([0, 1, 0, 1])# 创建逻辑回归模型
clf = LogisticRegression()# 训练逻辑回归模型
clf.fit(X, y)# 使用逻辑回归模型进行预测
predictions = clf.predict(X)
print(predictions)
在上述代码中,我们首先导入了NumPy和Scikit-Learn库。然后,我们创建了一个包含3个特征和4个样本的数据集,并使用NumPy将其转换为一个数组。接下来,我们创建了一个逻辑回归模型对象,并使用fit()方法对其进行训练。最后,我们使用predict()方法对数据集进行预测,并将预测结果打印出来。
K-均值
K-均值是一种聚类算法,它通过对数据集进行分类来聚类。K-均值用于无监督学习,因此,我们只需使用训练数据X,以及我们想要识别的聚类数量K。K-均值的基本过程是:首先,随机选择K个初始聚类中心;然后,将每个数据点分配到离它最近的聚类中心所在的类别;接着,重新计算每个类别的聚类中心;最后,重复以上步骤直到聚类中心不再发生变化或达到预设的最大迭代次数。

以下是一个使用Python实现K-均值聚类算法的示例代码:
import numpy as npdef k_means(data, k):# 数据标准化data = (data - np.mean(data, axis=0)) / np.std(data, axis=0)# 随机选择k个质心centers = np.random.choice(data, size=(k, data.shape[1]), replace=False)# 迭代聚类while True:# 将每个样本分配给最近的质心labels = np.argmin(np.sum((data[:, None, :] - centers) ** 2, axis=-1), axis=1)# 更新质心new_centers = np.array([data[labels == i].mean(axis=0) for i in range(k)])# 如果质心没有变化,则停止迭代if np.allclose(centers, new_centers, atol=1e-4):breakcenters = new_centersreturn labels, centers# 测试代码
data = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
k = 2
labels, centers = k_means(data, k)
print("Labels:", labels)
print("Centers:", centers)
在上述代码中,我们首先导入了NumPy库,然后定义了一个k_means函数来执行K-均值聚类算法。该函数接受两个参数:data表示要聚类的数据,k表示要聚类的类别数。函数首先对数据进行标准化处理,然后随机选择k个质心作为初始聚类中心。接下来,函数进入一个循环,在每次循环中,将每个样本分配给最近的质心,然后更新质心。如果质心没有变化,则停止迭代。最后,函数返回聚类结果和最终的质心。
在测试代码中,我们创建了一个包含5个样本的数据集,每个样本包含两个特征。然后,我们使用k_means函数对数据集进行聚类,并将聚类结果和最终的质心打印出来。
总结
以上就是几种常见的人工智能分类算法的详细讲解过程。这些算法在人工智能的研究和应用中都有着广泛的应用。
相关文章:
人工智能分类算法概述
文章目录 人工智能主要分类算法决策树随机森林逻辑回归K-均值 总结 人工智能主要分类算法 人工智能分类算法是用于将数据划分为不同类别的算法。这些算法通过学习数据的特征和模式,将输入数据映射到相应的类别。分类算法在人工智能中具有广泛的应用,如图…...

理解 Golang 变量在内存分配中的规则
为什么有些变量在堆中分配、有些却在栈中分配? 我们先看来栈和堆的特点: 简单总结就是: 栈:函数局部变量,小数据 堆:大的局部变量,函数内部产生逃逸的变量,动态分配的数据&#x…...
《QT实用小工具·二十四》各种数学和数据的坐标演示图
1、概述 源码放在文章末尾 该项目实现了各种数学和数据的坐标演示图,下面是demo演示: 项目部分代码如下: #ifndef FRMMAIN_H #define FRMMAIN_H#include <QWidget> class QAbstractButton;namespace Ui { class frmMain; }class fr…...
)
【S32K3 MCAL配置】-3.1-CANFD配置-经典CAN切换CANFD(基于MCAL+FreeRTOS)
"><--返回「Autosar_MCAL高阶配置」专栏主页--> 目录(共5页精讲,基于评估板: NXP S32K312EVB-Q172,手把手教你S32K3从入门到精通) 实现的架构:基于MCAL层 前期准备工作:...
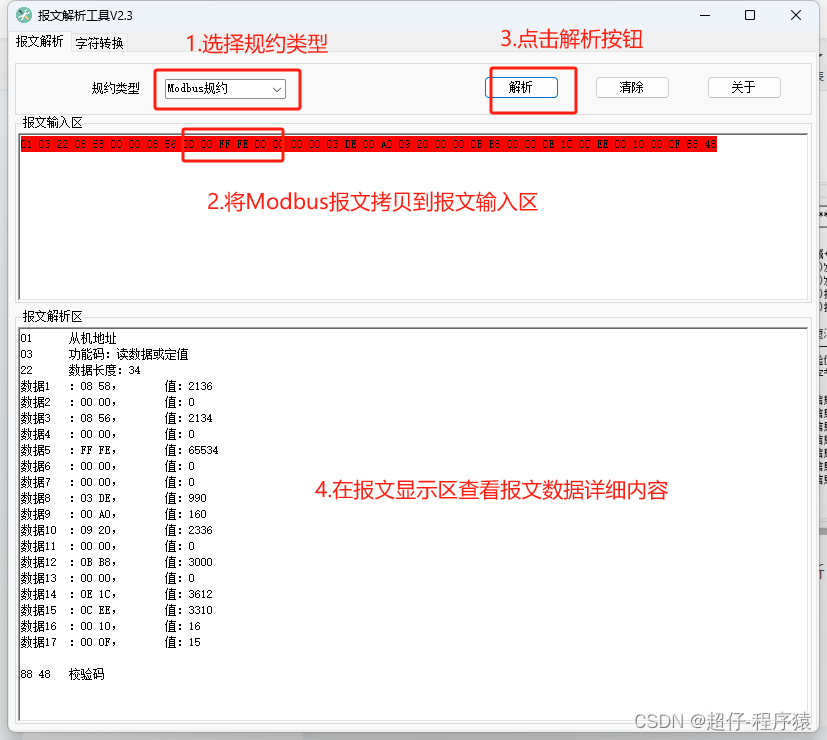
IEC101、IEC103、IEC104、Modbus报文解析工具
一、概述 国际电工委员会第57技术委员会(IEC TC57)1995年出版IEC 60870-5-101后,得到了广泛的应用。为适应网络传输,2000年IEC TC57又出版了IEC 60870-5-104:2000《远东设备及系统 第5-104部分:传输规约-采…...

node res.end返回json格式数据
使用 Node.js 内置 http 模块的createServer()方法创建一个新的HTTP服务器并返回json数据,代码如下: const http require(http);const hostname 127.0.0.1; const port 3000;const data [{ name: 测试1号, index: 0 },{ name: 测试2号, index: 1 },…...
产品开发流程
产品开发流程 时间:2024年04月10日 作者:小蒋聊技术 邮箱:wei_wei10163.com 微信:wei_wei10 产品开发流程_小蒋聊技术_免费在线阅读收听下载 - 喜马拉雅欢迎收听小蒋聊技术的类最新章节声音“产品开发流程”。时间:…...

Python蓝桥杯赛前总结
1.进制转换 (1) 2进制转换为其他进制 # 2转10 int(n, 2) # 2转8 oct(int(n, 2)) # 2转16 hex(int(n, 2)) (2) 8进制转换为其他进制 #8转10 int(n, 8) #8转2 bin(int(n, 8)) #8转16 hex(int(n, 8)) (3) 10进制转换为其他进制 #10转2 bin(n) #10转8 oct(n) #10转16 hex(n) …...

20240326-1-KNN面试题
KNN面试题 1.简述一下KNN算法的原理 KNN算法利用训练数据集对特征向量空间进行划分。KNN算法的核心思想是在一个含未知样本的空间,可以根据样本最近的k个样本的数据类型来确定未知样本的数据类型。 该算法涉及的3个主要因素是:k值选择,距离度…...

【论文速读】| MASTERKEY:大语言模型聊天机器人的自动化越狱
本次分享论文为:MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots 基本信息 原文作者:Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, Yang Liu 作者单位:南洋理工…...

jvm运行情况预估
相关系统 jvm优化原则-CSDN博客 执行下面指令 jstat gc -pid 能计算出一些关键数据,有了这些数据,先给JVM参数一些的初始的,比堆内存大小、年轻代大小 、Eden和Srivivor的比例,老年代的大小,大对象的阈值,…...
Day105:代码审计-PHP原生开发篇SQL注入数据库监控正则搜索文件定位静态分析
目录 代码审计-学前须知 Bluecms-CNVD-1Day-常规注入审计分析 emlog-CNVD-1Day-常规注入审计分析 emlog-CNVD-1Day-2次注入审计分析 知识点: 1、PHP审计-原生态开发-SQL注入&语句监控 2、PHP审计-原生态开发-SQL注入&正则搜索 3、PHP审计-原生态开发-SQ…...
Python:如何对FY3D TSHS的数据集进行重投影并输出为TIFF文件以及批量镶嵌插值?
完整代码见 Github:https://github.com/ChaoQiezi/read_fy3d_tshs,由于代码中注释较为详细,因此博客中部分操作一笔带过。 01 FY3D的HDF转TIFF 1.1 数据集说明 FY3D TSHS数据集是二级产品(TSHS即MWTS/MWHS 融合大气温湿度廓线/稳定度指数/…...
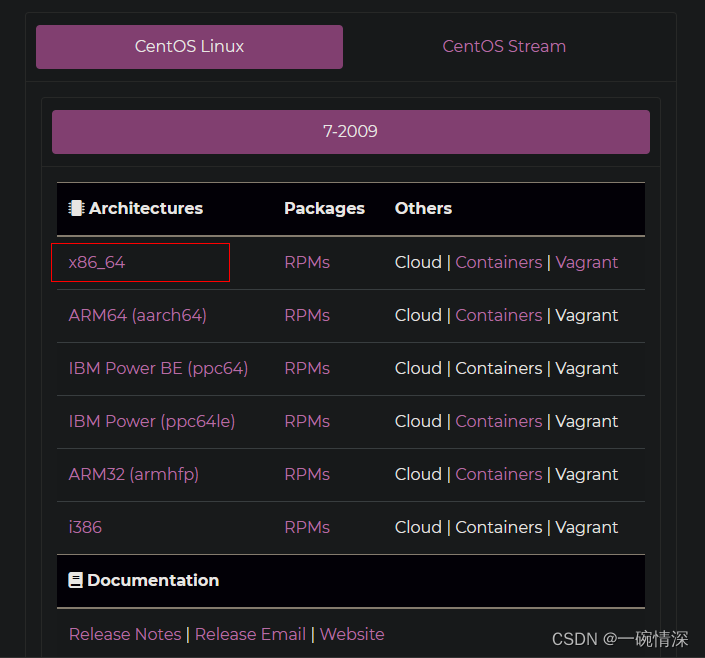
CentOS 镜像下载
CentOS 镜像下载:https://www.centos.org/download/ 选择合适的架构,博主选择x86_64,表示CentOS7 64位系统x86架构,如下: 或者直接访问以下网站下载 清华大学开源软件镜像站:https://mirrors.tuna.tsin…...

yum和配置yum源
yum 以及配置yum 源。 文章目录 一、Linux 软件包管理器yum二、使用yum安装软件三、配置yum源四、yum源仓库五、lrzse 实现linux远端和本地 互传文件 一、Linux 软件包管理器yum (1)什么是yum? yum 是一个软件下载安装管理的一个软件包管理器,它就相当于我们手机…...

jQuery笔记 02
目录 01 jq中预定义动画的使用 02 jq中的自定义动画 03 jq的动画的停止 04 jq节点的增删改 05 属性节点的操作 06 jq中的值和内容的操作 07 jq中宽高的操作 08 jq中坐标的操作 01 jq中预定义动画的使用 jq的预定义动画: 1.显示隐藏动画 显示 : jq对象.show() 不传参数 表…...

基于Java+SpringBoot+Vue文学名著分享系统(源码+文档+部署+讲解)
一.系统概述 随着世界经济信息化、全球化的到来和互联网的飞速发展,推动了各行业的改革。若想达到安全,快捷的目的,就需要拥有信息化的组织和管理模式,建立一套合理、动态的、交互友好的、高效的文学名著分享系统。当前的信息管理…...
C/S医学检验LIS实验室信息管理系统源码 医院LIS源码
LIS系统即实验室信息管理系统。LIS系统能实现临床检验信息化,检验科信息管理自动化。其主要功能是将检验科的实验仪器传出的检验数据经数据分析后,自动生成打印报告,通过网络存储在数据库中,使医生能够通过医生工作站方便、及时地…...
liunx环境变量学习总结
环境变量 在操作系统中,环境变量是一种特殊的变量,它们为运行的进程提供全局配置信息和系统环境设定。本文将介绍如何自定义、删除环境变量,特别是对重要环境变量PATH的管理和定制,以及与环境变量相关的函数使用。 自定义环境变…...
对于Redis,如何根据业务需求配置是否允许远程访问?
1、centos8 Redis安装的配置文件目录在哪里? 在 CentOS 8 中,默认情况下 Redis 的配置文件 redis.conf 通常位于 /etc/ 目录下。确切的完整路径是 /etc/redis.conf。 2、redis如何设置允许远程登录 修改redis.conf文件 # 继承默认注释掉的bind配置 # …...

Claude代码生成Token预算管理实战:成本控制与智能优化策略
1. 项目概述与核心价值最近在折腾大模型应用开发,特别是围绕Claude这类顶尖的代码生成模型时,一个绕不开的痛点就是成本控制。模型调用是按Token计费的,而一个复杂的代码生成任务,动辄消耗成千上万个Token,账单不知不觉…...

利用Taotoken用量看板精细化管理团队API消耗
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken用量看板精细化管理团队API消耗 对于依赖大模型API进行开发的团队而言,清晰、透明地掌握资源消耗情况是成…...

BEAGLE库终极指南:如何快速实现高性能系统发育分析
BEAGLE库终极指南:如何快速实现高性能系统发育分析 【免费下载链接】beagle-lib general purpose library for evaluating the likelihood of sequence evolution on trees 项目地址: https://gitcode.com/gh_mirrors/be/beagle-lib 你是否在系统发育分析中遇…...

Polymarket套利机器人:DeFi预测市场的自动化交易策略与实现
1. 项目概述:一个捕捉Polymarket预测市场套利机会的自动化交易机器人 最近在DeFi和预测市场领域,Polymarket这个基于Polygon链的平台热度持续攀升。它本质上是一个事件预测市场,用户可以就各类现实世界事件(比如“某球队能否赢得冠…...

ENSP实战:从Console到AAA,详解交换机安全登录的进阶配置
1. 从零开始:认识交换机登录安全的基本面 第一次接触企业级交换机时,很多新手都会被各种登录方式搞得晕头转向。我刚开始做网络运维时,就曾经因为没设置好登录认证,导致测试环境的交换机被隔壁团队的同事误操作重启。今天我们就从…...

STM32的RTC掉电还能走时?深入聊聊后备域和纽扣电池那点事
STM32的RTC掉电还能走时?深入聊聊后备域和纽扣电池那点事 当你在深夜调试STM32的RTC功能时,是否曾好奇过这个小巧的实时时钟为何能在主电源断开后依然精准走时?这背后隐藏着STM32芯片设计中一个精妙的电源管理机制——后备域(Back…...

Anthropic 百万行代码库的官方最佳实践
随着AI 编程智能体的越来越深入到日常工作,相信你也遇到了大型项目和和小型代码库完全不同的场景。正好最近也是在做大型项目的重构开发,刷到这篇来自 Anthropic 官方的文章。系统梳理了 Claude Code 在大规模代码库中的运作机制、Harness 架构的七个扩展…...

qmc-decoder:专业QMC音频文件解密转换工具
qmc-decoder:专业QMC音频文件解密转换工具 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder qmc-decoder是一款高效、专业的QMC音频文件解密转换工具,…...

Linly中文大模型本地部署指南:从选型到实战优化
1. 项目概述:一个面向中文场景的“小而美”语言模型最近在折腾本地部署大语言模型的朋友,可能都绕不开一个名字:Linly。这个由深圳大学计算机视觉研究所(CVI-SZU)开源的项目,在中文社区里热度一直不低。它不…...

Proxima向量检索库:硬件优化与量化技术实战解析
1. 项目概述:一个为现代开发者打造的“近邻”代码库 最近在GitHub上看到一个挺有意思的项目,叫“Zen4-bit/Proxima”。乍一看这个标题,可能会有点摸不着头脑。“Zen4-bit”像是一个用户名或者某种架构的代号,而“Proxima”则让人联…...