Python:如何对FY3D TSHS的数据集进行重投影并输出为TIFF文件以及批量镶嵌插值?
完整代码见 Github:https://github.com/ChaoQiezi/read_fy3d_tshs,由于代码中注释较为详细,因此博客中部分操作一笔带过。
01 FY3D的HDF转TIFF
1.1 数据集说明
FY3D TSHS数据集是二级产品(TSHS即MWTS/MWHS 融合大气温湿度廓线/稳定度指数/位势高度产品);
文件格式为HDF5;
空间分辨率为33KM(星下点);
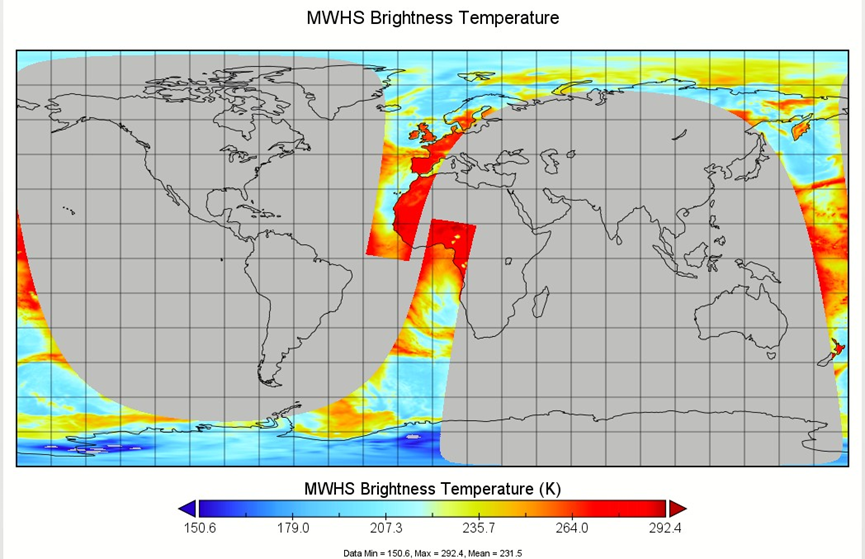
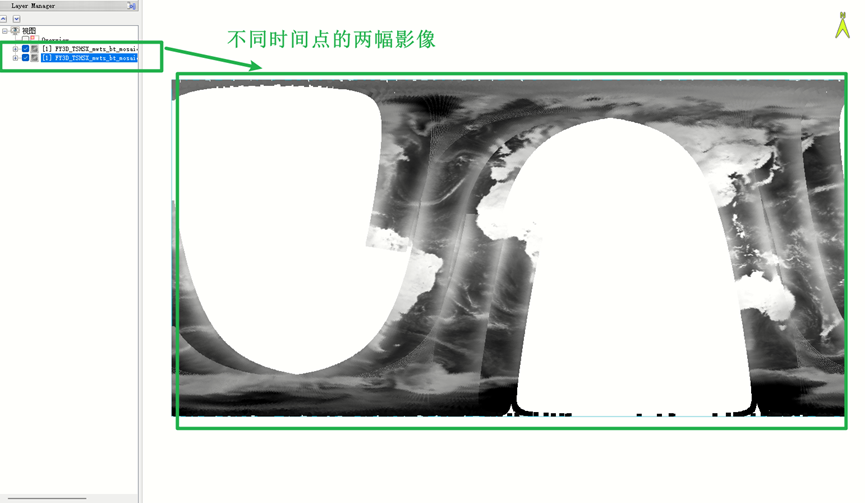
范围为全球区域;(FY3D为极轨卫星,因此对于得到的单个数据集并没有完全覆盖全球区域),类似下方(其余地区均未扫描到):
提取数据涉及的多个数据集:
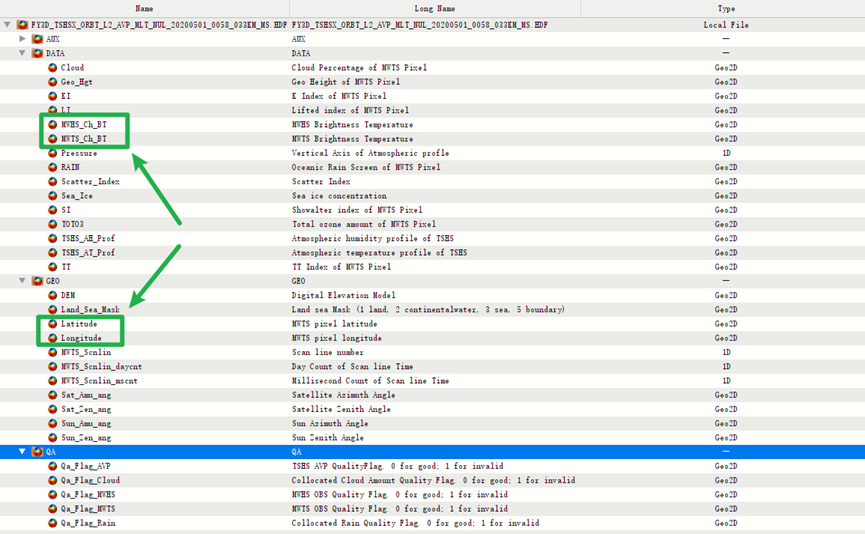
位于DATA/MWHS_Ch_BT和DATA/MWTS_Ch_BT 路径下的两个数据集分别为MWTS 通道亮温和MWHS 通道亮温,这是需要提取的数据集;
另外位于GEO/Latitude 和GEO/Longitude 路径下的两个数据集分别经纬度数据集,用于确定像元的地理位置以便后续进行重投影;
1.1.1 MWTS 通道亮温和MWHS 通道亮温数据集的说明
这是关于数据集的基本属性说明:
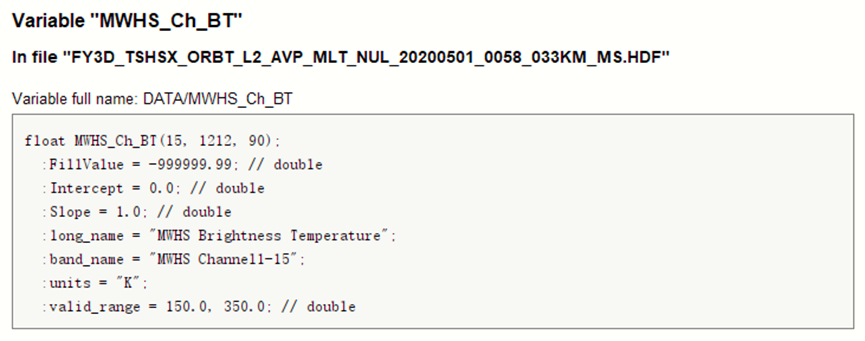
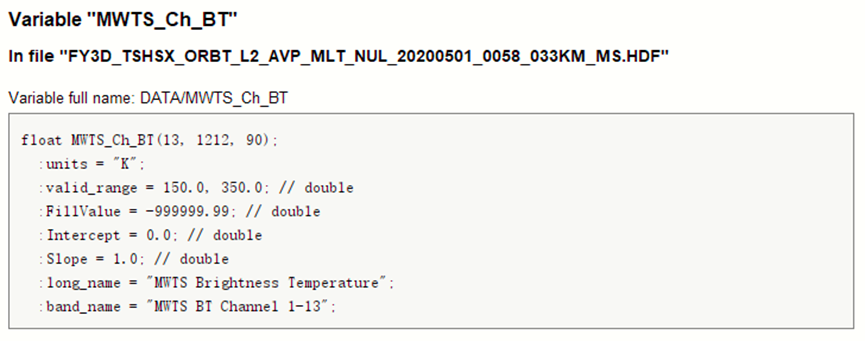
在产品说明书中关于数据集的说明如下:

可以发现,其共有三个维度,譬如MWHS_Ch_BT数据集的Shape为(15, 1212, 90),其表示极轨卫星的传感器15个通道(即波段数)在每条扫描线总共 90 个观测像元的MWHS亮温值,此处扫描线共有1212个。对于MWTS数据集类似格式。(这意味着三个维度中并没有空间上的关系)
1.1.2 经纬度数据集的说明

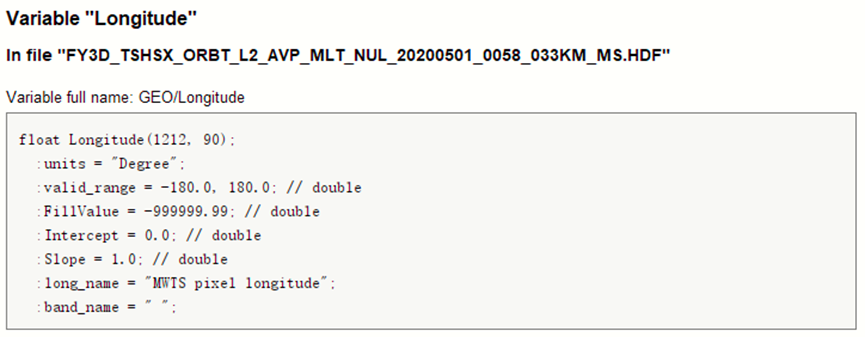
这是官方产品说明对于经纬度数据集的介绍:
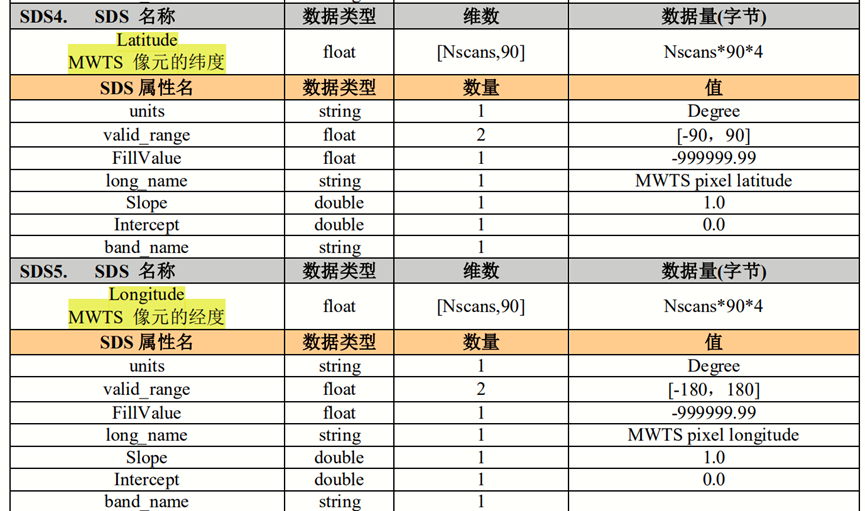
可以发现,经纬度数据集的Shape均为(1212, 90),这正好对应前文提及的两个数据集的所有像元(除去波段数),其表示每条1212条扫描线上的90个观测像元的经纬度。
1.2 读取HDF5文件数据集
def read_h5(hdf_path, ds_path, scale=True):"""读取指定数据集并进行预处理:param hdf_path: 数据集所在HDF文件的绝对路径:param ds_path: 数据集在HDF文件内的路径:return: 返回处理好的数据集"""with h5py.File(hdf_path) as f:# 读取目标数据集属矩阵和相关属性ds = f[ds_path]ds_values = np.float32(ds[:]) # 获取数据集valid_range = ds.attrs['valid_range'] # 获取有效范围slope = ds.attrs['Slope'][0] # 获取斜率(类似scale_factor)intercept = ds.attrs['Intercept'][0] # 获取截距(类似add_offset)""""原始数据集可能存在缩放(可能是为存储空间全部存为整数(需要通过斜率和截距再还原为原来的值,或者是需要进行单位换算甚至物理量的计算例如最常见的DN值转大气层表观反射率等(这多出现于一级产品的辐射定标, 但二级产品可能因为单位换算等也可能出现));如果原始数据集不存在缩放, 那么Slope属性和Intercept属性分别为1和0;这里为了确保所有迭代的HDF文件的数据集均正常得到, 这里依旧进行slope和intercept的读取和计算(尽管可能冗余)"""# 目标数据集的预处理(无效值, 范围限定等)ds_values[(ds_values < valid_range[0]) | (ds_values > valid_range[1])] = np.nanif scale:ds_values = ds_values * slope + intercept # 还原缩放"""Note: 这里之所以选择是否进行缩放, 原因为经纬度数据集中的slope为1, intercept也为1, 但是进行缩放后超出地理范围1°即出现了90.928对于纬度。其它类似, 因此认为这里可能存在问题如果进行缩放, 所以对于经纬度数据集这里不进行缩放"""return ds_values
上述代码用于读取指定HDF5文件的指定数据集的数组/矩阵,scale参数用于是否对数据集进行slope和intercept线性转换。
1.3 重组和重投影
这一部分是整个数据处理的核心。
1.3.1 重组
def reform_ds(ds, lon, lat, reform_range=None):"""重组数组:param ds: 目标数据集(三维):param lon: 对应目标数据集的经度数据集():param lat: 对应目标数据集的纬度数据集(二维):param reform_range: 重组范围, (lon_min, lat_max, lon_max, lat_min), 若无则使用全部数据:return: 以元组形式依次返回: 重组好的目标数据集, 经度数据集, 纬度数据集(均为二维数组)"""# 裁选指定地理范围的数据集if reform_range:lon_min, lat_max, lon_max, lat_min = reform_rangex, y = np.where((lon > lon_min) & (lon < lon_max) & (lat > lat_min) & (lat < lat_max))ds = ds[:, x, y]lon = lon[x, y]lat = lat[x, y]else:ds = ds.reshape(ds.shape[0], -1)lon = lon.flatten()lat = lat.flatten()# 无效值去除(去除地理位置为无效值的元素)valid_pos = ~np.isnan(lat) & ~np.isnan(lon)ds = ds[:, valid_pos]lon = lon[valid_pos]lat = lat[valid_pos]# 重组数组的初始化bands = []for band in ds:reform_ds_size = np.int32(np.sqrt(band.size)) # int向下取整band = band[:reform_ds_size ** 2].reshape(reform_ds_size, reform_ds_size)bands.append(band)else:lon = lon[:reform_ds_size ** 2].reshape(reform_ds_size, reform_ds_size)lat = lat[:reform_ds_size ** 2].reshape(reform_ds_size, reform_ds_size)bands = np.array(bands)return bands, lon, lat
这部分是对原始数据集(此处理中待重组数据集shape为(15, 1212, 90))进行重组。
重组原理即基于经纬度数据集,依据裁剪范围将满足地理范围内的所有有效像元一维化,然后重新reshape为二维数组,数组行列数均为原维度的平方根。
1.3.2 重投影
def data_glt(out_path, src_ds, src_x, src_y, out_res, zoom_scale=6, glt_range=None, windows_size=9):"""基于经纬度数据集对目标数据集进行GLT校正/重投影(WGS84), 并输出为TIFF文件:param out_path: 输出tiff文件的路径:param src_ds: 目标数据集:param src_x: 对应的横轴坐标系(对应地理坐标系的经度数据集):param src_y: 对应的纵轴坐标系(对应地理坐标系的纬度数据集):param out_res: 输出分辨率(单位: 度/°):param zoom_scale::return: None"""if glt_range:# lon_min, lat_max, lon_max, lat_min = -180.0, 90.0, 180.0, -90.0lon_min, lat_max, lon_max, lat_min = glt_rangeelse:lon_min, lat_max, lon_max, lat_min = np.nanmin(src_x), np.nanmax(src_y), \np.nanmax(src_x), np.nanmin(src_y)zoom_lon = zoom(src_x, (zoom_scale, zoom_scale), order=0) # 0为最近邻插值zoom_lat = zoom(src_y, (zoom_scale, zoom_scale), order=0)# # 确保插值结果正常# zoom_lon[(zoom_lon < -180) | (zoom_lon > 180)] = np.nan# zoom_lat[(zoom_lat < -90) | (zoom_lat > 90)] = np.nanglt_cols = np.ceil((lon_max - lon_min) / out_res).astype(int)glt_rows = np.ceil((lat_max - lat_min) / out_res).astype(int)deal_bands = []for src_ds_band in src_ds:glt_ds = np.full((glt_rows, glt_cols), np.nan)glt_lon = np.full((glt_rows, glt_cols), np.nan)glt_lat = np.full((glt_rows, glt_cols), np.nan)geo_x_ix, geo_y_ix = np.floor((zoom_lon - lon_min) / out_res).astype(int), \np.floor((lat_max - zoom_lat) / out_res).astype(int)glt_lon[geo_y_ix, geo_x_ix] = zoom_longlt_lat[geo_y_ix, geo_x_ix] = zoom_latglt_x_ix, glt_y_ix = np.floor((src_x - lon_min) / out_res).astype(int), \np.floor((lat_max - src_y) / out_res).astype(int)glt_ds[glt_y_ix, glt_x_ix] = src_ds_band# write_tiff('H:\\Datasets\\Objects\\ReadFY3D\\Output\\py_lon.tiff', [glt_lon],# [lon_min, out_res, 0, lat_max, 0, -out_res])# write_tiff('H:\\Datasets\\Objects\\ReadFY3D\\Output\\py_lat.tiff', [glt_lat],# [lon_min, out_res, 0, lat_max, 0, -out_res])# # 插值# interpolation_ds = np.full_like(glt_ds, fill_value=np.nan)# jump_size = windows_size // 2# for row_ix in range(jump_size, glt_rows - jump_size):# for col_ix in range(jump_size, glt_cols - jump_size):# if ~np.isnan(glt_ds[row_ix, col_ix]):# interpolation_ds[row_ix, col_ix] = glt_ds[row_ix, col_ix]# continue# # 定义当前窗口的边界# row_start = row_ix - jump_size# row_end = row_ix + jump_size + 1 # +1 因为切片不包含结束索引# col_start = col_ix - jump_size# col_end = col_ix + jump_size + 1# rows, cols = np.ogrid[row_start:row_end, col_start:col_end]# distances = np.sqrt((rows - row_ix) ** 2 + (cols - col_ix) ** 2)# window_ds = glt_ds[(row_ix - jump_size):(row_ix + jump_size + 1),# (col_ix - jump_size):(col_ix + jump_size + 1)]# if np.sum(~np.isnan(window_ds)) == 0:# continue# distances_sort_pos = np.argsort(distances.flatten())# window_ds_sort = window_ds[np.unravel_index(distances_sort_pos, distances.shape)]# interpolation_ds[row_ix, col_ix] = window_ds_sort[~np.isnan(window_ds_sort)][0]deal_bands.append(glt_ds)# print('处理波段: {}'.format(len(deal_bands)))# if len(deal_bands) == 6:# breakwrite_tiff(out_path, deal_bands, [lon_min, out_res, 0, lat_max, 0, -out_res])# write_tiff('H:\\Datasets\\Objects\\ReadFY3D\\Output\\py_underlying.tiff', [interpolation_ds], [lon_min, out_res, 0, lat_max, 0, -out_res])# write_tiff('H:\\Datasets\\Objects\\ReadFY3D\\Output\\py_lon.tiff', [glt_lon], [x_min, out_res, 0, y_max, 0, -out_res])# write_tiff('H:\\Datasets\\Objects\\ReadFY3D\\Output\\py_lat.tiff', [glt_lat], [x_min, out_res, 0, y_max, 0, -out_res])这是对重组后的数组进行重投影,其基本思路就是对经纬度数据集进行zoom (congrid),将其重采样放大譬如此处为原行列数的六倍。
接着再将zoom后的经纬度数据集按照角点信息套入到输出glt数组中,而对重组后的目标数组直接套入,无需进行zoom操作。
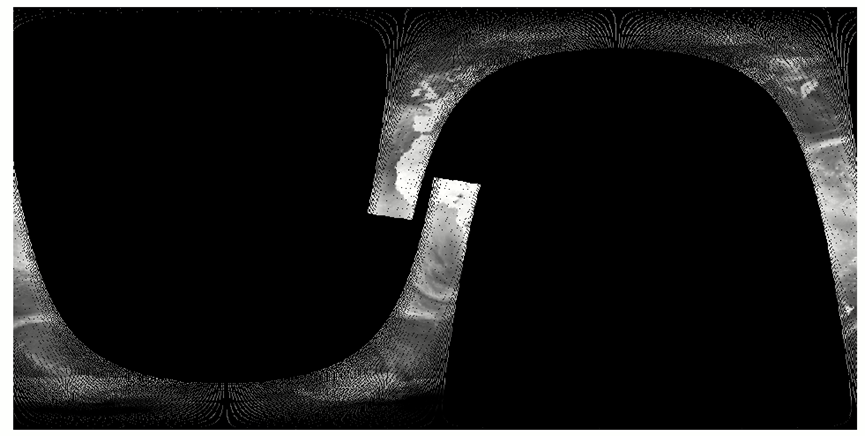
接着对套入的目标数组进行最近邻插值,如果没有进行插值,情况如下:
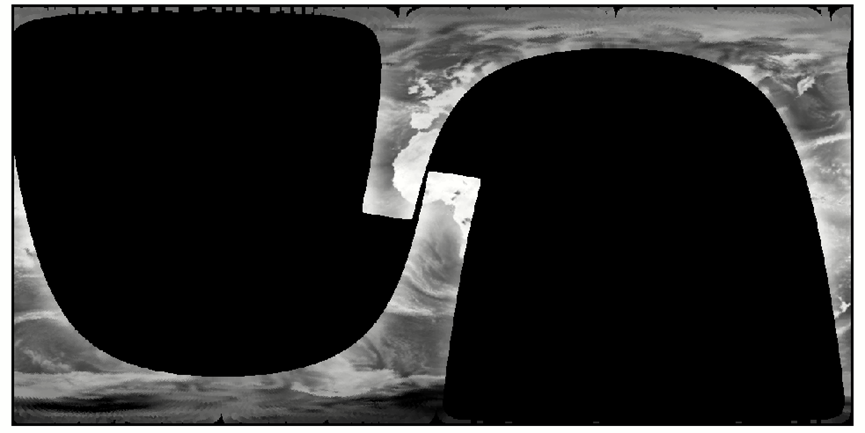
进行最近邻插值后(9*9窗口内的最近有效像元为填充值),结果如下:
但是由于数据集巨大,关于最近邻插值此处进行了注释,将该操作移至后面镶嵌操作之后,数据量大大减少,所花费时间成本也极大降低。
2 镶嵌和最近邻插值
2.1 镶嵌
def img_mosaic(mosaic_paths: list, return_transform: bool = True, mode: str = 'last'):"""该函数用于对列表中的所有TIFF文件进行镶嵌:param mosaic_paths: 多个TIFF文件路径组成的字符串列表:param return_transform: 是否一同返回仿射变换:param mode: 镶嵌模式, 默认是Last(即如果有存在像元重叠, mosaic_paths中靠后影像的像元将覆盖其),可选: last, mean, max, min:return:"""# 获取镶嵌范围x_mins, x_maxs, y_mins, y_maxs = [], [], [], []for mosaic_path in mosaic_paths:ds = gdal.Open(mosaic_path)x_min, x_res, _, y_max, _, y_res_negative = ds.GetGeoTransform()x_size, y_size = ds.RasterXSize, ds.RasterYSizex_mins.append(x_min)x_maxs.append(x_min + x_size * x_res)y_mins.append(y_max+ y_size * y_res_negative)y_maxs.append(y_max)else:y_res = -y_res_negativeband_count = ds.RasterCountds = Nonex_min, x_max, y_min, y_max = min(x_mins), max(x_maxs), min(y_mins), max(y_maxs)# 镶嵌col = ceil((x_max - x_min) / x_res).astype(int)row = ceil((y_max - y_min) / y_res).astype(int)mosaic_imgs = [] # 用于存储各个影像for ix, mosaic_path in enumerate(mosaic_paths):mosaic_img = np.full((band_count, row, col), np.nan) # 初始化ds = gdal.Open(mosaic_path)ds_bands = ds.ReadAsArray()# 计算当前镶嵌范围start_row = floor((y_max - (y_maxs[ix] - x_res / 2)) / y_res).astype(int)start_col = floor(((x_mins[ix] + x_res / 2) - x_min) / x_res).astype(int)end_row = (start_row + ds_bands.shape[1]).astype(int)end_col = (start_col + ds_bands.shape[2]).astype(int)mosaic_img[:, start_row:end_row, start_col:end_col] = ds_bandsmosaic_imgs.append(mosaic_img)# 判断镶嵌模式if mode == 'last':mosaic_img = mosaic_imgs[0].copy()for img in mosaic_imgs:mask = ~np.isnan(img)mosaic_img[mask] = img[mask]elif mode == 'mean':mosaic_imgs = np.asarray(mosaic_imgs)mask = np.isnan(mosaic_imgs)mosaic_img = np.ma.array(mosaic_imgs, mask=mask).mean(axis=0).filled(np.nan)elif mode == 'max':mosaic_imgs = np.asarray(mosaic_imgs)mask = np.isnan(mosaic_imgs)mosaic_img = np.ma.array(mosaic_imgs, mask=mask).max(axis=0).filled(np.nan)elif mode == 'min':mosaic_imgs = np.asarray(mosaic_imgs)mask = np.isnan(mosaic_imgs)mosaic_img = np.ma.array(mosaic_imgs, mask=mask).min(axis=0).filled(np.nan)else:raise ValueError('不支持的镶嵌模式: {}'.format(mode))if return_transform:return mosaic_img, [x_min, x_res, 0, y_max, 0, -y_res]return mosaic_img这里的镶嵌不仅仅可以解决相同地理位置的镶嵌,也可以解决不同地理位置的拼接,拼接方式支持最大最小值计算、均值计算、Last等模式。
思路非常简单,就是将输入的每个数据集重新装入统一地理范围的箱子(数组)中,使所有数组的角点信息一致,然后基于数据集个数这一维度进行Mean、Max、Min等计算,得到镶嵌数组。
2.2 最近邻插值
def window_interp(arr, distances):if np.sum(~np.isnan(arr)) == 0:return np.nan# 距离最近的有效像元arr = arr.flatten()arr_sort = arr[np.argsort(distances)]if np.sum(~np.isnan(arr_sort)) == 0:return np.nanelse:return arr_sort[~np.isnan(arr_sort)][0]
思路与之前一致,不过重构为函数了。
具体代码见项目:https://github.com/ChaoQiezi/read_fy3d_tshs
这是原始数据集:
这是目标结果:


相关文章:
Python:如何对FY3D TSHS的数据集进行重投影并输出为TIFF文件以及批量镶嵌插值?
完整代码见 Github:https://github.com/ChaoQiezi/read_fy3d_tshs,由于代码中注释较为详细,因此博客中部分操作一笔带过。 01 FY3D的HDF转TIFF 1.1 数据集说明 FY3D TSHS数据集是二级产品(TSHS即MWTS/MWHS 融合大气温湿度廓线/稳定度指数/…...
CentOS 镜像下载
CentOS 镜像下载:https://www.centos.org/download/ 选择合适的架构,博主选择x86_64,表示CentOS7 64位系统x86架构,如下: 或者直接访问以下网站下载 清华大学开源软件镜像站:https://mirrors.tuna.tsin…...

yum和配置yum源
yum 以及配置yum 源。 文章目录 一、Linux 软件包管理器yum二、使用yum安装软件三、配置yum源四、yum源仓库五、lrzse 实现linux远端和本地 互传文件 一、Linux 软件包管理器yum (1)什么是yum? yum 是一个软件下载安装管理的一个软件包管理器,它就相当于我们手机…...

jQuery笔记 02
目录 01 jq中预定义动画的使用 02 jq中的自定义动画 03 jq的动画的停止 04 jq节点的增删改 05 属性节点的操作 06 jq中的值和内容的操作 07 jq中宽高的操作 08 jq中坐标的操作 01 jq中预定义动画的使用 jq的预定义动画: 1.显示隐藏动画 显示 : jq对象.show() 不传参数 表…...

基于Java+SpringBoot+Vue文学名著分享系统(源码+文档+部署+讲解)
一.系统概述 随着世界经济信息化、全球化的到来和互联网的飞速发展,推动了各行业的改革。若想达到安全,快捷的目的,就需要拥有信息化的组织和管理模式,建立一套合理、动态的、交互友好的、高效的文学名著分享系统。当前的信息管理…...
C/S医学检验LIS实验室信息管理系统源码 医院LIS源码
LIS系统即实验室信息管理系统。LIS系统能实现临床检验信息化,检验科信息管理自动化。其主要功能是将检验科的实验仪器传出的检验数据经数据分析后,自动生成打印报告,通过网络存储在数据库中,使医生能够通过医生工作站方便、及时地…...
liunx环境变量学习总结
环境变量 在操作系统中,环境变量是一种特殊的变量,它们为运行的进程提供全局配置信息和系统环境设定。本文将介绍如何自定义、删除环境变量,特别是对重要环境变量PATH的管理和定制,以及与环境变量相关的函数使用。 自定义环境变…...
对于Redis,如何根据业务需求配置是否允许远程访问?
1、centos8 Redis安装的配置文件目录在哪里? 在 CentOS 8 中,默认情况下 Redis 的配置文件 redis.conf 通常位于 /etc/ 目录下。确切的完整路径是 /etc/redis.conf。 2、redis如何设置允许远程登录 修改redis.conf文件 # 继承默认注释掉的bind配置 # …...
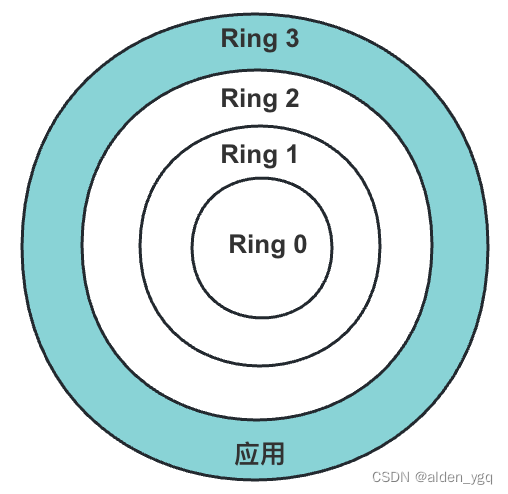
深入分析Linux上下文与上下文切换
Linux 进程运行空间与特权等级 在 Linux 操作系统中,进程的运行空间被划分为内核空间和用户空间,这种划分是为了保护系统的稳定性和安全性。这两个空间对应着 CPU 的特权等级,分别为: Ring 0(内核态)Ring…...

Docker快速上手及常用命令速查
Docker快速上手 安装 在ubuntu上安装docker: sudo apt-get install docker docker -v #查看版本在centos7上安装docker:(docker在YUM源的Extras仓库中) yum install docker systemctl start dockerdocker常用命令速查 #查看docker信息 docker info #查看本地镜…...
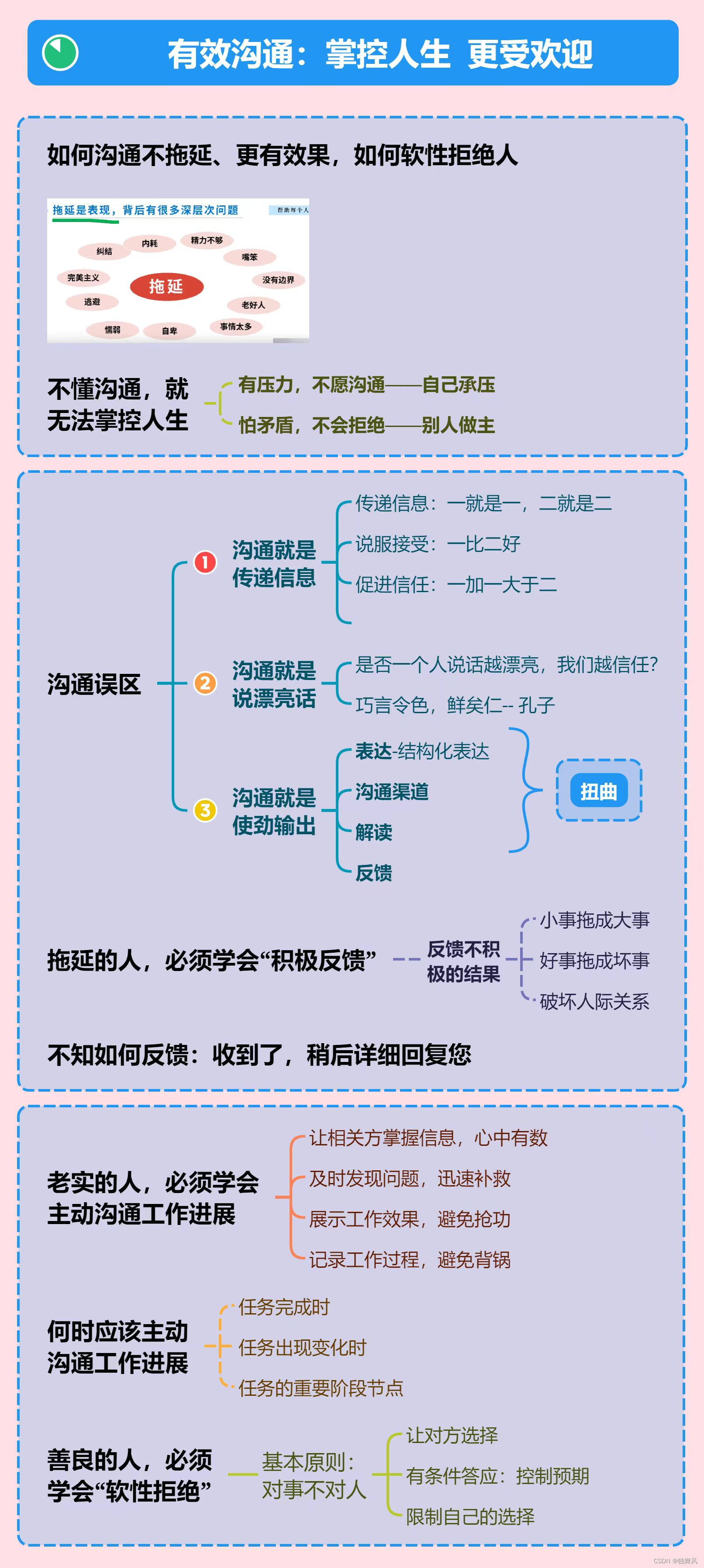
学习笔记:解决拖延
1 解决拖延、减轻压力的关键心态和方法 1.1 要点梳理 拖延是因为自己一直在逃避,重点是要有效突破逃避圈,进入学习圈,扩展成长圈。 毒蛇曲线(见思维导图)中越是临近截止期限,拖延的焦虑越上升࿰…...
第一个Swift程序
要创建第一个Swift项目,请按照以下步骤操作: 打开Xcode。如果您没有安装Xcode,可以在App Store中下载并安装它。在Xcode的欢迎界面上,选择“Create a new Xcode project”(创建新Xcode项目)。在模板选择界面上,选择“App”(应用程序)。在应用模板选择界面上,选择“Si…...

Anthropic Claude 3 加入亚马逊云科技 AI“全家桶”
编辑 | 宋慧 出品 | CSDN AIGC 每天都有新动态发生。最新的消息是亚马逊在 3 月底完成了对 Anthropic 的 40 亿美元投资(也是亚马逊 30 年来最大一笔外部投资),以及 GPT-4 最强对手的 Anthropic Claude 3 已经在亚马逊云科技 Amazon Bedrock…...

学习基于pytorch的VGG图像分类 day3
注:本系列博客在于汇总CSDN的精华帖,类似自用笔记,不做学习交流,方便以后的复习回顾,博文中的引用都注明出处,并点赞收藏原博主. 目录 VGG模型训练 1.导入必要的库 2.主函数部分 2.1使用cpu或gpu 2.2对数据…...

Spring Boot统一功能处理之拦截器
本篇主要介绍Spring Boot的统一功能处理中的拦截器。 目录 一、拦截器的基本使用 二、拦截器实操 三、浅尝源码 初始化DispatcherServerlet 处理请求(doDispatch) 四、适配器模式 一、拦截器的基本使用 在一般的学校或者社区门口,通常会安排几个…...
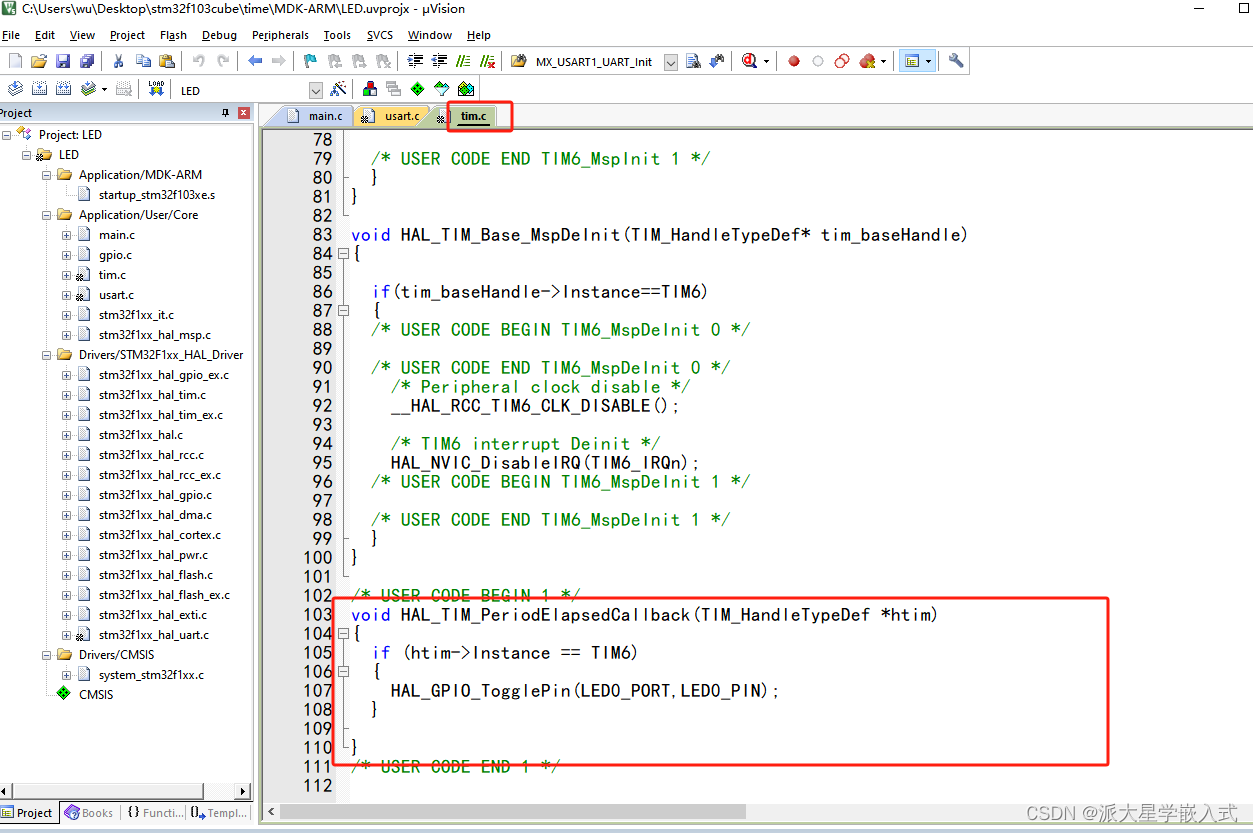
stm32之基本定时器的使用
在上文我们使用到了HAL库的自带的延时函数,HAL_Delay();我们来看一下函数的原型 __weak void HAL_Delay(uint32_t Delay) {uint32_t tickstart HAL_GetTick();uint32_t wait Delay;/* Add a freq to guarantee minimum wait */…...
单片机为什么还在用C语言编程?
单片机产品的成本是非常敏感的。因此对于单片机开发来说,最重要的是在极其有限的ROM和RAM中实现最多产品的功能。或者反过来说,实现相同的产品功能,所需要的ROM和RAM越小越好,在开始前我有一些资料,是我根据网友给的问…...
IO流的基础详解
文件【1】File类: 封装文件/目录的各种信息,对目录/文件进行操作,但是我们不可以获取到文件/目录中的内容。 【2】引入:IO流: I/O : Input/Output的缩写,用于处理设备之间的数据的传输。 【3】…...

实战攻防 | 记一次项目上的任意文件下载
1、开局 开局一个弱口令,正常来讲我们一般是弱口令或者sql,或者未授权 那么这次运气比较好,直接弱口令进去了 直接访问看看有没有功能点,正常做测试我们一定要先找功能点 发现一个文件上传点,不过老规矩,还…...

熔断之神:探寻Hystrix的秘密与实践指南
引言: 在微服务架构中,服务之间的依赖复杂且难以控制,容灾机制成为确保系统稳定性的重要手段。Hystrix作为Netflix开源的断路器实现,提供了一系列强健的容错功能。 Hystrix的核心概念与作用: Hystrix是一个由Netflix开…...

避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析
避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析 在无感FOC驱动开发中,观测器的调试往往是整个项目中最具挑战性的环节。当电机出现抖动、观测角度不准或启动失败时,如何快速定位问题并优化参数,成为工程师们必须…...
详解】学习笔记)
【LangGraph 状态持久化(Checkpoint)详解】学习笔记
目录 什么是状态持久化? 持久化方案对比 内存持久化:MemoryPersistence SQLite 持久化:SqlitePersistence Agent 多轮对话持久化:AgentPersistence get_state 与 get_state_history 详解 总结对比 1. 什么是状态持久化&…...

3步重构你的设计到动画工作流:从Figma到After Effects的无缝转换
3步重构你的设计到动画工作流:从Figma到After Effects的无缝转换 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX 你是否曾为设计到动画的转换过程感到头疼?在Fig…...

该不该现在买房?AI浪潮下,你的房贷是资产还是负债?
该不该现在买房?AI浪潮下,你的房贷是资产还是负债? 开篇:一个普通家庭的决策困境 深夜,东莞某小区的灯光次第熄灭。你刚刚哄睡一岁半的孩子,打开手机看到甲骨文最新一轮裁员的新闻,又瞥了一眼房…...

VTube Studio终极指南:30分钟快速打造专业虚拟主播形象
VTube Studio终极指南:30分钟快速打造专业虚拟主播形象 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 想要开启虚拟主播之旅,却被复杂的技术门槛吓退?VT…...

DSP开发环境搭建实战:从CCSv3.3安装到XDS510仿真器配置全解析
1. CCSv3.3安装全流程详解 第一次接触DSP开发的朋友,安装CCSv3.3这个"老前辈"可能会遇到各种意想不到的问题。我当年在实验室安装时,光是补丁问题就折腾了一整天。下面就把这些年积累的实战经验分享给大家。 首先需要准备的是安装文件。虽然现…...

FPGA并行FIR滤波器设计:50MHz实时信号处理与Verilog实现
1. 项目概述与设计目标在数字信号处理(DSP)的硬件实现领域,FIR(有限长单位冲激响应)滤波器因其绝对稳定性和易于实现线性相位的特性,成为工程师手中的一把“瑞士军刀”。无论是通信系统中的信道均衡、音频处…...

code2prompt:AI编程助手的高效代码上下文生成工具详解
1. 项目概述:从代码到提示词的“翻译官”最近在折腾一些AI辅助编程或者代码分析的工具时,我经常遇到一个头疼的问题:如何把我手头的一大段项目代码,高效、准确地“喂”给像ChatGPT、Claude或者GitHub Copilot这样的AI助手…...

GitHub个人访问令牌实战:告别密码认证,安全推送代码与创建PR
1. 项目概述与核心痛点如果你刚开始接触开源贡献,或者最近在尝试向GitHub推送代码时,大概率会遇到一个令人困惑的拦路虎:在终端执行git push命令后,系统提示你输入用户名和密码。你很自然地输入了登录GitHub网站用的账号密码&…...

基于OpenTelemetry构建企业级可观测性:从设计到生产实践
1. 项目概述:从“黑盒”到“白盒”的工程实践在分布式系统、微服务架构乃至复杂的单体应用开发中,我们常常面临一个共同的困境:系统内部的状态如同一个“黑盒”。当线上服务出现响应缓慢、内存泄漏或偶发性错误时,传统的日志&…...