深度学习八股文
-
Bert旨在通过联合左侧和右侧的上下文,从未标记文本中预训练出一个深度双向表示模型。因此,BERT可以通过增加一个额外的输出层来进行微调,就可以达到为广泛的任务创建State-of-the-arts 模型的效果,比如QA、语言推理任务。Bert的构成:由12层Transformer Encoder构成。bert的基本任务:mask language model 和 next sentence predict,mask language model的遮盖⽅式:选择15%的token进⾏遮盖,再选择其中80%进⾏mask,10%进⾏随机替换,10%不变
- 被随机选择15%的词当中以10%的概率⽤任意词替换去预测正确的词,相当于⽂本纠错任务,为BERT模型赋予了⼀定的⽂本纠错能⼒;
- 被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输⼊不匹配的问题(预训练时候输⼊句⼦当中有mask,⽽finetune时候输⼊是完整⽆缺的句⼦,即为输⼊不匹配问题)。
-
BLEU(Bilingual Evaluation understudy) 是一种流行的机器翻译评价指标,一种基于精度的相似度量方法, 用于分析候选译文和参考译文中n元组共同出现的程度
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation) 一种基于召回率的相似度量方法,和BLEU类似, 无Fmeans 评价功能,主要考察翻译的充分性和忠实性, 无法评价参考译文的流畅度, 其计算的时N元组(Ngram)在参考译文和待测评译文的共现概率.
-
Transformer encoder的组成:self-Attention和feed forward组成 中间穿插残差⽹络;残差⽹络的作⽤:缓解层数加深带来的信息损失,采⽤两个线性变换激活函数为relu,同等层数的前提下残差⽹络也收敛得更快。随着神经网络深度的不断增加,利用sigmoid激活函数来训练被证实不如非平滑、低概率性的ReLU有效,因为ReLU基于输入信号做出门控决策。研究者提出了一种新的非线性激活函数,名为高斯误差线性单元(Gaussian Error Linear Unit)。
- G E L U ( x ) = 0.5 x ( 1 + t a n h ( 2 π ( x + 0.044715 x 3 ) ) ) GELU(x)=0.5x(1+tanh(\sqrt\frac2\pi(x+0.044715x^3))) GELU(x)=0.5x(1+tanh(π2(x+0.044715x3)))
-
GELU与随机正则化有关,因为它是自适应Dropout的修正预期。这表明神经元输出的概率性更高,研究者发现,在计算机视觉、自然语言处理和自动语音识别等任务上,使用GELU激活函数的模型性能与使用RELU或者ELU的模型相当或者超越了它们。
-
import numpy as np import matplotlib.pyplot as plt def gelu_1(x):# 使用numpy实现return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x ** 3))) def gelu_dao(inputs):return ((np.tanh((np.sqrt(2) * (0.044715 * inputs ** 3 + inputs)) / np.sqrt(np.pi)) + ((np.sqrt(2) * inputs * (0.134145 * inputs ** 2 + 1) * ((1 / np.cosh((np.sqrt(2) * (0.044715 * inputs ** 3 + inputs)) / np.sqrt(np.pi))) ** 2)) / np.sqrt(np.pi) + 1))) / 2 def plot_gelu():x1 = np.arange(-8, 8, 0.1)y1 = gelu_1(x1)plt.plot(x1,y1)y2 = gelu_dao(x1)plt.plot(x1, y2)plt.show() if __name__ == '__main__':plot_gelu()
-
-
self-Attetion的组成和作⽤
- 对每⼀个token分别与三个权重矩阵相乘,⽣成q,k,v三个向量,维度是64
- 计算得分,以句⼦中的第⼀个词为例,拿输⼊句⼦中的每个词的 k 去点积 q1,这个分数决定了在编码第⼀个词的过程中有多重视句⼦的其他部分
- 将分数除以键向量维度的平⽅根(根号dk),这可以使梯度更稳定。假设q和k中的向量都服从⾼斯分布,即均值为0,⽅差为1,那可qk点积都的矩阵均值为0,⽅差为dk,此时若直接做softmax,根据公式,分⺟是ex的相加,分⺟较⼤,会导致softmax的梯度变⼩,参数更新困难
- softmax将分数归⼀化,表示每个单词对编码当下位置的贡献
- ⽤v乘softmax分数,希望关注语义上相关的单词,并弱化不相关的词
-
多头机制类似于“多通道”特征抽取,self attention通过attention mask动态编码变⻓序列,解决⻓距离依赖(⽆位置偏差)、可并⾏计算;
- 类似于CNN中通过多通道机制进⾏特征选择;
- Transformer中先通过切头(spilt)再分别进⾏Scaled Dot-Product Attention,可以使进⾏点积计算的维度d不⼤(防⽌梯度消失),同时缩⼩attention mask矩阵。
-
FFN 将每个位置的Multi-Head Attention结果映射到⼀个更⼤维度的特征空间,然后使⽤ReLU引⼊⾮线性进⾏筛选,最后恢复回原始维度。
-
Self-Attention的输出会经过Layer Normalization,为什么选择Layer Normalization⽽不是Batch Normalization?此时,我们应该先对我们的数据形状有个直观的认识,当⼀个batch的数据输⼊模型的时候,⼤⼩为(batch_size, max_len, embedding),其中batch_size为batch的批数,max_len为每⼀批数据的序列最⼤⻓度,embedding则为每⼀个单词或者字的embedding维度⼤⼩。
-
⽽Batch Normalization是对每个Batch的每⼀列做normalization,相当于是对batch⾥相同位置的字或者单词embedding做归⼀化,Layer Normalization是Batch的每⼀⾏做normalization,相当于是对每句话的embedding做归⼀化。显然,LN更加符合我们处理⽂本的直觉。
-
BERT基于“字输⼊”还是“词输⼊”好?如果基于“词输⼊”,会出现OOV(Out Of Vocabulary)问题,会增⼤标签空间,需要利⽤更多语料去学习标签分布来拟合模型。随着Transfomer特征抽取能⼒,分词不再成为必要,词级别的特征学习可以纳⼊为内部特征进⾏表示学习。
-
BERT的词嵌入由符号嵌入(Token Embedding)、片段嵌入(Segmentation Embedding)和位置嵌入(Position Embedding)合成得到,表示为
-
E w o r d = E t o k e n + E s e g + E p o s E_{word}=E_{token}+E_{seg}+E_{pos} Eword=Etoken+Eseg+Epos
-
三个嵌入分量都可以表达为“独热”(one-hot)编码表示输入与嵌入矩阵的乘积形式,即
-
E w o r d = O t o k e n W t o k e n ∣ V ∣ ∗ H + O s e g W s e g ∣ S ∣ ∗ H + O p o s W p o s ∣ P ∣ ∗ H E_{word}= O_{token}W_{token}^{|V|*H} +O_{seg}W_{seg}^{|S|*H} +O_{pos}W_{pos}^{|P|*H} Eword=OtokenWtoken∣V∣∗H+OsegWseg∣S∣∗H+OposWpos∣P∣∗H
-
其中, O t o k e n O_{token} Otoken︰依据符号在词典中位置下标、对输入符号构造的one-hot编码表示; O s e g O_{seg} Oseg∶依据符号在两个序列中隶属标签(更一般的为符号属性)下标、对输入符号构造的one-hot编码表示; O p o s O_{pos} Opos :以符号在句子位置下标、对输入符号构造的one-hot编码表示: W t o k e n ∣ V ∣ ∗ H , W s e g ∣ S ∣ ∗ H , W p o s ∣ P ∣ ∗ H W_{token}^{|V|*H},W_{seg}^{|S|*H},W_{pos}^{|P|*H} Wtoken∣V∣∗H,Wseg∣S∣∗H,Wpos∣P∣∗H分别为其对应的待训练嵌入参数矩阵;|V|、|S|和|P|分别为字典维度、序列个数(更一般的为符号属性)和最大位置数;H为嵌入维度。三个one-hot编码向量与嵌入矩阵相乘,等价于构造三个以one-hot编码向量作为输入,输入维度分别为|V|、|S和|P|,输出维度均为H的全连接网络。求和即为特征融合。
-
-
bert预训练任务的损失函数,两个任务是联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句⼦级别的语义信息。bert的损失函数组成:第⼀部分是来⾃ Mask-LM 的单词级别分类任务;另⼀部分是句⼦级别的分类任务;
-
在第一部分的损失函数中,如果被mask的词集合为M,因为它是一个词典大小V上的多分类问题,所用的损失函数叫做负对数似然函数(且是最小化,等价于最大化对数似然函数),那么具体说来有:
-
L 1 ( θ , θ 1 ) = − ∑ i = 1 M l o g p ( m = m i ∣ θ , θ 1 ) , m i ∈ [ 1 , 2 , . . . , ∣ V ∣ ] L_1(\theta,\theta_1)=-\sum_{i=1}^Mlogp(m=m_i|\theta,\theta_1),m_i\in[1,2,...,|V|] L1(θ,θ1)=−i=1∑Mlogp(m=mi∣θ,θ1),mi∈[1,2,...,∣V∣]
-
在第二部分的损失函数中,在句子预测任务中,也是一个分类问题的损失函数:
-
L 2 ( θ , θ 2 ) = − ∑ j = 1 N l o g p ( n = n i ∣ θ , θ 2 ) , n i ∈ [ i s n e x t , n o t n e x t ] L_2(\theta,\theta_2)=-\sum_{j=1}^Nlogp(n=n_i|\theta,\theta_2),n_i\in[isnext,notnext] L2(θ,θ2)=−j=1∑Nlogp(n=ni∣θ,θ2),ni∈[isnext,notnext]
-
-
自回归与自编码
- 单向特征表示的自回归预训练语言模型,统称为单向模型:ELMO、GPT、ULMFiT、SiATL
- 双向特征表示的自编码预训练语言模型,统称为BERT系列模型:BERT、RoBERTa、ERNIE1.O/ERNIE(THU)
- 双向特征表示的自回归预训练语言模型,XLNet:将自回归LM方向引入双向语言模型方面
- 自回归语言模: 优点∶文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。缺点:只能利用上文或者下文的信息,不能同时利用上文和下文的信息
- 自编码语言模型:优点︰能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文;缺点∶主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的
-
RNN的统—定义为
-
h t = f ( x t , h t − 1 ; θ ) h_t=f(x_t,h_{t-1};\theta) ht=f(xt,ht−1;θ)
-
其中 h t h_t ht是每一步的输出,它由当前输入 x t x_t xt和前一时刻输出 h t − 1 h_{t-1} ht−1共同决定,而 θ \theta θ则是可训练参数。在做最基本的分析时,我们可以假设 h t , h t − 1 , θ h_t , h_{t-1},\theta ht,ht−1,θ都是一维的,这可以让我们获得最直观的理解,并且其结果对高维情形仍有参考价值。要求我们定义的模型有一个比较合理的梯度。我们可以求得:
-
d h t d θ = δ h t δ h t − 1 d h t − 1 δ θ + δ h t δ θ \frac{d~ h_t}{d~ \theta}=\frac{\delta h_t}{\delta h_{t-1}}\frac{d~ h_{t-1}}{\delta \theta} +\frac{\delta h_t}{\delta \theta} d θd ht=δht−1δhtδθd ht−1+δθδht
-
所以步数多了,梯度消失或爆炸几乎都是不可避免的,我们只能对于有限的步数去缓解这个问题。
-
梯度爆炸︰设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。梯度值变得非常大,从而对参数的更新产生巨大影响。这可能会导致模型无法收敛或收敛速度过慢。
-
可能引起梯度爆炸的原因(这其实就是根据反向传播的三个函数链式求导,一个是上一个神经元激活函数,一个是损失函数导数,一个是激活函数导数:
- 如果在神经网络中使用了具有饱和性质(如Sigmoid)的激活函数,并且权重初始化不当,则可能会出现数值上溢问题。当反向传播通过每一层传递时,sigmoid函数在中间区域的斜率很敏感变化很大,最终使得梯度变得异常大。
- 如果权重参数初始化过大,则在前向传播和反向传播过程中都容易造成数值溢出问题。特别是在深层神经网络中,在后面的层级上发生累积效应并放大了初始错误。
- 学习率决定了每次迭代更新参数时所采用的步长大小。如果学习率设置太大,每次更新时参数的变化就会非常剧烈,(即权重变大,数值上溢)可能导致梯度值爆炸。
-
饱和性质的激活函数是指在输入数据较大或较小时,激活函数的导数趋近于0,导致梯度消失或爆炸。这种情况下,神经网络可能会面临训练困难、收敛缓慢等问题。
-
常见的饱和性质的激活函数有Sigmoid函数和双曲正切(Tanh)函数。它们在输入接近极端值时,导数接近于0。对于Sigmoid函数而言,在输入非常大或非常小时,输出值会趋向于1或0,并且导数几乎为0;对于Tanh函数而言,在输入非常大或非常小时,输出值也会趋向于1或-1,并且导数同样几乎为0。
-
ReLU是一种简单但广泛使用的不饱和性质的激活函数。当输入为正时,ReLU将保持原始值作为输出;当输入为负时,则返回零作为输出。ReLU在实践中被证明可以有效地解决梯度消失问题,并提高神经网络模型的训练速度与效果。
-
Leaky ReLU是对ReLU的改进,它在输入为负时不返回零,而是返回一个小的非零值。这样可以避免ReLU中出现的“神经元死亡”问题(即某些神经元永远不会被激活),并且有助于增加模型的表达能力。
-
激活函数 表达式 导数 sigmoid f ( x ) = 1 1 + e x f(x)=\frac{1}{1+e^x} f(x)=1+ex1 f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x)) tanh f ( x ) = e 2 x − 1 e 2 x + 1 f(x)=\frac{e^{2x}-1}{e^{2x}+1} f(x)=e2x+1e2x−1 f ′ ( x ) = 1 − ( f ( x ) ) 2 f'(x)=1-(f(x))^2 f′(x)=1−(f(x))2 Relu f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x) f ′ ( x ) = s g n ( x ) f'(x)=sgn(x) f′(x)=sgn(x) Bnll f ( x ) = l o g ( 1 + e x ) f(x)=log(1+e^x) f(x)=log(1+ex) f ′ ( x ) e x 1 + e x f'(x)\frac{e^x}{1+e^x} f′(x)1+exex Gelu f ( x ) = 0.5 x ( 1 + t a n h ( 2 π ( x + 0.044715 x 3 ) ) ) f(x)=0.5x(1+tanh(\sqrt\frac2\pi(x+0.044715x^3))) f(x)=0.5x(1+tanh(π2(x+0.044715x3))) swish f ( x ) = x ∗ s i g m o i d ( β ∗ x ) f(x)=x*sigmoid(\beta*x) f(x)=x∗sigmoid(β∗x) Leaky relu f ( x ) = { x if x>0 γ ∗ x if x<=0 f(x) = \begin{cases} x&\text{if x>0}\\ \gamma *x &\text{if x<=0}\\ \end{cases} f(x)={xγ∗xif x>0if x<=0 Elu f ( x ) = { x if x>0 α ( e x − 1 ) if x<=0 f(x) = \begin{cases} x&\text{if x>0}\\ \alpha(e^x-1) &\text{if x<=0}\\ \end{cases} f(x)={xα(ex−1)if x>0if x<=0 softmax f ( x ) = e i ∑ j e j f(x)=\frac{e^i}{\sum_je^j} f(x)=∑jejei
-
-
为了解决梯度爆炸问题,可以采取以下措施:
- 权重初始化:合理选择权重的初始化方法,例如使用**Xavier(饱和函数)或He(不饱和函数)**等经典的初始化方法,并避免初始权重过大。
- 激活函数选择:选用具有较小饱和区域并且能够缓解梯度爆炸问题的激活函数(如ReLU、Leaky ReLU)。
- 梯度裁剪:通过限制梯度值的范围来防止其过大。一种常见做法是设置一个阈值,在反向传播过程中对超出阈值范围的梯度进行裁剪。
- 调整学习率:降低学习率可以减轻梯度爆炸现象。可以逐步减小学习率或者使用自适应优化算法(如Adam、Adagrad),使得模型在训练过程中更加稳定。
-
梯度消失是指在深层神经网络中,随着反向传播过程的进行,较早层的权重更新变得非常小或趋近于零,导致这些层对整个网络参数的学习贡献几乎为零。这可能会导致模型无法有效地学习和优化。
-
-
LSTM有输⼊⻔、输出⻔、遗忘⻔
- 遗忘⻔:⽤于决定应丢弃或保留的信息
- 输⼊⻔:⽤于对输⼊信息进⾏过滤,选择性的抛弃⼀些信息,和候选单元状态共同决定当前细胞状态的更新,决定⻓期记忆
- 输出⻔:⽤sigmoid层来确定单元状态的哪个部分将输出出去,ht决定短期记忆
-
batch_size与学习率
-
学习率直接影响模型的收敛状态,batchsize则影响模型的泛化性能,两者又是分子分母的直接关系,相互也可影响。
-
W t + 1 = W t − η 1 b ∑ x ∈ B Δ l ( x , W t ) W_{t+1}=W_t-\eta\frac1b\sum_{x\in\mathcal{B}}\Delta l(x,W_t) Wt+1=Wt−ηb1x∈B∑Δl(x,Wt)
-
大的batchsize减少训练时间,提高稳定性。这是肯定的,同样的epoch数目,大的batchsize需要的迭代数目减少了,所以可以减少训练时间。另一方面,大的batch size梯度的计算更加稳定,因为模型训练曲线会更加平滑。在微调的时候,大的batch size可能会取得更好的结果。
-
-
ROC与AUC
-
ROC要计算FPR和TPR,曲线上的每个点代表不同阈值时的FPR和TPR。在正负样本数量不均衡的时候,比如负样本的数量增加到原来的10倍,那TPR不受影响,FPR的各项也是成比例的增加,并不会有太大的变化。因此,在样本不均衡的情况下,同样ROC曲线仍然能较好地评价分类器的性能,这是ROC的一个优良特性,也是为什么一般ROC曲线使用更多的原因。
-
ROC曲线的横坐标是假阳性率(False Positive Rate),纵坐标是真阳性率(True Positive Rate),相应的还有真阴性率(True Negative Rate)和假阴性率(False Negative Rate)。这四类指标的计算方法如下:
-
假阳性率(FPR):判定为正例却不是真正例的概率,即真负例中判为正例的概率
-
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
-
真阳性率(TPR):判定为正例也是真正例的概率,即真正例中判为正例的概率(也即正例召回率)
-
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
-
假阴性率(FNR):判定为负例却不是真负例的概率,即真正例中判为负例的概率。
-
真阴性率(TNR):判定为负例也是真负例的概率,即真负例中判为负例的概率。
-
预测为真 预测为假 合计 实际为真 true positive false negative TP+FN (Recall,TPR分母) 实际为假 false positive true negative FP+TN (FPR分母) 合计 TP+FP (Precision分母) FN+TN TP+FP+TN+FN -
A c c = T P + T N T P + F P + T N + F N R e c a l l = T P T P + F N = T P R P r e c i s i o n = T P T P + F P Acc=\frac{TP+TN}{TP+FP+TN+FN}\\ Recall=\frac{TP}{TP+FN}=TPR\\ Precision=\frac{TP}{TP+FP} Acc=TP+FP+TN+FNTP+TNRecall=TP+FNTP=TPRPrecision=TP+FPTP
-
-
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。
-
ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)。随着阈值theta增加,TP和FP都减小,TPR和FPR也减小,ROC点向左下移动;而auc就是roc曲线与下方坐标轴围成的面积。
-
A U C = ∑ i ∈ 正样本 R a n k i − M ( 1 + M ) 2 M ∗ N M 为正样本数, N 为负样本数目 AUC=\frac{\sum_{i\in正样本}Rank_i-\frac{M(1+M)}{2}}{M*N}\\ M为正样本数,N为负样本数目 AUC=M∗N∑i∈正样本Ranki−2M(1+M)M为正样本数,N为负样本数目
import numpy as npfrom sklearn.metrics import roc_curvefrom sklearn.metrics import aucdef auc_calculate(labels,preds,n_bins=100):postive_len = sum(labels) #正样本数量(因为正样本都是1)negative_len = len(labels) - postive_len #负样本数量total_case = postive_len * negative_len #正负样本对pos_histogram = [0 for _ in range(n_bins)] neg_histogram = [0 for _ in range(n_bins)]bin_width = 1.0 / n_binsfor i in range(len(labels)):nth_bin = int(preds[i]/bin_width)if labels[i]==1:pos_histogram[nth_bin] += 1else:neg_histogram[nth_bin] += 1accumulated_neg = 0satisfied_pair = 0for i in range(n_bins):satisfied_pair += (pos_histogram[i]*accumulated_neg + pos_histogram[i]*neg_histogram[i]*0.5)accumulated_neg += neg_histogram[i]return satisfied_pair / float(total_case)if __name__ == '__main__':y = np.array([1,0,0,0,1,0,1,0,])pred = np.array([0.9, 0.8, 0.3, 0.1,0.4,0.9,0.66,0.7])fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)print("sklearn:",auc(fpr, tpr))print("验证:",auc_calculate(y,pred))-
AUC即ROC曲线下的面积,AUC越大,说明分类器越可能把正样本排在前面,衡量的是一种排序的性能。AUC的优点:
- AUC衡量的是⼀种排序能⼒,因此特别适合排序类业务;
-
AUC对正负样本均衡并不敏感,在样本不均衡的情况下,也可以做出合理的评估。
- 其他指标⽐如precision,recall,F1,根据区分正负样本阈值的变化会有不同的结果,⽽AUC不需要⼿动设定阈值,是⼀种整体上的衡量⽅法。
-
AUC的缺点:
- 忽略了预测的概率值和模型的拟合优度;
-
AUC反应了太过笼统的信息。⽆法反应召回率、精确率等在实际业务中经常关⼼的指标;
- 它没有给出模型误差的空间分布信息,AUC只关注正负样本之间的排序,并不关⼼正样本内部,或者负样本内部的排序,这样我们也⽆法衡ᰁ样本对于好坏程度的刻画能⼒;
-
-
L1正则化和L2正则化分别适用于什么样的场景:
- 如果需要稀疏性就用l1,因为l1的梯度是1或-1,所以每次更新都稳步向0趋近。l1鲁棒性更强对异常值不敏感。⼀般多⽤l2因为计算⽅便“求导置零解⽅程”,l2只有最好的⼀条预测线⽽l1可能有多个最优解。L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
- L1泛数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。比如向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.线形回归的L1正则化通常称为Lasso回归,它和一般线形回归的区别是在损失函数上增加了一个L1正则化的项,L1正则化的项有一个常数系数alpha来调节损失函数的均方差项和正则化项的权重。可以使一些特征的系数变小,甚至还是一些绝对值较小的系数直接变为0,增强模型的泛化能力。
- 线形回归的L2正则化通常称为Ridge回归,它和一般线形回归的区别是在损失函数上增加了一个L2正则化的项,和Lasso回归的区别是Ridge回归的正则化项是L2范数。Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但和Lasso回归相比,这会使得模型的特征留的特别多,模型解释性差。
-
归⼀化:对不同特征维度的伸缩变换的⽬的是使各个特征维度对⽬标函数的影响权重是⼀致的,即使得那些扁平分布的数据伸缩变换成类圆形。这也就改变了原始数据的⼀个分布。
- 提⾼迭代求解的收敛速度,不归⼀化梯度可能会震荡
- 提⾼迭代求解的精度
-
标准化:对不同特征维度的伸缩变换的⽬的是使得不同度量之间的特征具有可⽐性。同时不改变原始数据的分布。使得不同度量之间的特征具有可⽐性,对⽬标函数的影响体现在⼏何分布上,⽽不是数值上
-
逻辑回归假设数据服从伯努利分布,通过极⼤化似然函数的⽅法,利⽤梯度下降求解参数,来达到将数据⼆分类的⽬的。逻辑回归的第⼆个假设是:样本为正的概率 p = 1 1 + e − θ T x p=\frac{1}{1+e^{-\theta ^{T}x}} p=1+e−θTx1 ,逻辑回归即h(x;θ)=p。伯努利试验是单次随机试验,只有"成功(值为1)"或"失败(值为0)"这两种结果,是由瑞士科学家雅各布**·伯努利(1654 - 1705)提出来的。其概率分布称为伯努利分布**(Bernoulli distribution),也称为两点分布或者0-1分布,是最简单的离散型概率分布。我们记成功概率为p(0≤p≤1),则失败概率为q=1-p。逻辑回归的损失函数就是h(x;θ)的极⼤似然函数
-
L θ ( x ) = ∏ i = 1 m h θ ( x i ; θ ) y i ∗ ( 1 − h θ ( x i ; θ ) ) 1 − y i L_\theta(x)=\prod^m_{i=1}h_{\theta}(x^i;\theta)^{y_i}*(1-h_\theta(x^i;\theta))^{1-y^i} Lθ(x)=i=1∏mhθ(xi;θ)yi∗(1−hθ(xi;θ))1−yi
-
极⼤似然的核⼼思想是如果现有样本可以代表总体,那么极⼤似然估计就是找到⼀组参数使得出现现有样本的可能性最⼤。
-
-
批梯度下降会获得全局最优解,缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且会有很多的冗余计算,显存不友好,导致的结果是当数据量大的时候,每个参数的更新都会很慢。
-
随机梯度下降是以高方差频繁更新,优点是使得sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂。
-
小批量梯度下降结合了sgd和batch gd的优点,每次更新的时候使用n个样本。减少了参数更新的次数,可以达到更加稳定收敛结果,一般在深度学习当中我们采用这种方法。
-
设在特征空间中,位于 x 附近的训练数据中正例所占的比例为 p ,模型在 x 处给出的输出为 y。用cross entropy 作为损失函数,位于 x 附近的这些训练数据,对损失函数的贡献就是:
-
L = − p l o g y − ( 1 − p ) l o g ( 1 − y ) L=-plogy-(1-p)log(1-y) L=−plogy−(1−p)log(1−y)
-
容易算出,使得 L 最小的 y 就等于P,也就是说模型的输出会等于在 x 附近取一个数据,它属于正类的概率。
-
-
SVM本质是在求⽀持向量到超平⾯的⼏何间隔的最⼤值,svm适合解决⼩样本、⾮线性、⾼纬度的问题,核函数:样本集在低维空间线性不可分时,核函数将原始数据映射到⾼维空间,或者增加数据维度,使得样本线性可分。常⽤核函数:
- 线性核:不增加数据维度,⽽是余弦计算内积,提⾼速度
- 多项式核:增加多项式特征,提升数据维度,并计算内积
- ⾼斯核(默认BRF):将样本映射到⽆限维空间,使原来不可分的样本线性可分
-
svm的⽬标函数(硬间隔),有两个⽬标:第⼀个是使间隔最⼤化,第⼆个是使样本正确分类,由此推出⽬标函数:
-
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 y i ( w T x i + b ) > = 1 , i = 1 , 2 , . . . , n \min_{w,b}\frac12||w||^2\\ y_i(w^Tx_i+b)>=1,i=1,2,...,n w,bmin21∣∣w∣∣2yi(wTxi+b)>=1,i=1,2,...,n
-
这是⼀个有约束条件的最优化问题,⽤拉格朗⽇函数来解决
-
min w , b max α = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) \min_{w,b}\max_\alpha=\frac12||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b)) w,bminαmax=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))
-
-
不管直接在原特征空间,还是在映射的⾼维空间,我们都假设样本是线性可分的。虽然理论上我们总能找到⼀个⾼维映射使数据线性可分,但在实际任务中,寻找⼀个合适的核函数核很困难。此外,由于数据通常有噪声存在,⼀味追求数据线性可分可能会使模型陷⼊过拟合,因此,我们放宽对样本的要求,允许少量样本分类错误。这样的想法就意味着对⽬标函数的改变,之前推导的⽬标函数⾥不允许任何错误,并且让间隔最⼤,现在给之前的⽬标函数加上⼀个误差,就相当于允许原先的⽬标出错,引⼊松弛变量 εi≥0,公式变为:
-
min w , b , η 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 n η i \min_{w,b,\eta}\frac12||w||^2+\sum_{i=1}^n\eta_i w,b,ηmin21∣∣w∣∣2+i=1∑nηi
-
那么这个松弛变量怎么计算呢,最开始试图⽤0,1损失去计算,但0,1损失函数并不连续,求最值时求导的时候不好求,所以引⼊合⻚损失(hinge loss):
-
l h i n g e ( z ) = m a x ( 0 , 1 − z ) l_{hinge}(z)=max(0,1-z) lhinge(z)=max(0,1−z)
-
理解起来就是,原先制约条件是保证所有样本分类正确, y i ( w T x i + b ) ≥ 1 y^i (w^Tx_i+b) ≥1 yi(wTxi+b)≥1,现在出现错误的时候,一定是这个式子不被满足了,即 y i ( w T x i + b ) < 1 , 任意 i 错误 y_i (w^T x_i + b)<1,任意 i 错误 yi(wTxi+b)<1,任意i错误,衡量一下错了多少呢?因为左边一定小于1,那就跟 1 比较,因为1是边界,所以用 1 减去 y i ( w T x i + b ) y_i(w^Tx_i+ b) yi(wTxi+b)来衡量错误了多少,所以目标变为(正确分类的话损失为0,错误的话付出代价,但这个代价需要一个控制的因子,引入C>0,惩罚参数,)∶
-
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n m a x ( 0 , 1 − y i ( w T x i + b ) ) \min_{w,b}\frac12||w||^2+C\sum^n_{i=1}max(0,1-y_i(w^Tx_i+b)) w,bmin21∣∣w∣∣2+Ci=1∑nmax(0,1−yi(wTxi+b))
-
可以想象,C越大说明把错误放的越大,说明对错误的容忍度就小,反之亦然。当C无穷大时,就变成一点错误都不能容忍,即变成硬间隔。实际应用时我们要合理选取C,C越小越容易欠拟合,C越大越容易过拟合。
-
-
LR与SVM的相同点:都是有监督的分类算法;如果不考虑核函数,LR和SVM都是线性分类算法。它们的分类决策⾯都是线性的。LR和SVM都是判别式模型。
-
LR与SVM的不同点:本质上是loss函数不同,或者说分类的原理理不不同。SVM是结构⻛险最⼩化(经验+正则),LR则是经验⻛险最⼩化。SVM只考虑分界⾯附近的少数点,⽽LR则考虑所有点。在解决⾮线性问题时,SVM可采⽤核函数的机制,⽽LR通常不采⽤核函数的⽅法。SVM计算复杂,但效果⽐LR好,适合⼩数据集;LR计算简单,适合⼤数据集,可以在线训练。
-
⼀个单词被选作 negative sample 的概率跟它出现的频次有关,出现频次越⾼的单词越容易被选作negative words。在论⽂中作者指出指出对于⼩规模数据集,建议选择 5-20 个 negative words,对于⼤规模数据集选择 2-5个negative words.
-
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆⽂件频率)是⼀种统计⽅法,⽤以评估⼀字词对于⼀个⽂件集或⼀个语料库中的其中⼀份⽂件的重要程度。字词的᯿要性随着它在⽂件中出现的次数成正⽐增加,但同时会随着它在语料库中出现的频率成反⽐下降。TF(Term Frequency, 词频)表示词条在⽂本中出现的频率;IDF(Inverse Document Frequency, 逆⽂件频率)表示关键词的普遍程度
-
jieba分词:依据统计词典(模型中这部分已经具备,也可⾃定义加载)构建统计词典中词的前缀词典。前缀词典构造是将在统计词典中出现的每⼀个词的每⼀个前缀提取出来,统计词频,如果某个前缀词在统计词典中没有出现,词频统计为0。依据前缀词典对输⼊的句⼦进⾏DAG(有向⽆环图)的构造。以每个字所在的位置为键值key,相应划分的末尾位置构成的列表为value。使⽤动态规划的⽅法在DAG上找到⼀条概率最⼤路径,依据此路径进⾏分词。每⼀个词出现的概率等于该词在前缀⾥的词频除以所有词的词频之和。如果词频为0或是不存在,当做词频为1来处理。这⾥会取对数概率,即在每个词概率的基础上取对数,⼀是为了防⽌下溢,⼆后⾯的概率相乘可以变成相加计算。对于未收录词(是指不在统计词典中出现的词),使⽤HMM(隐⻢尔克夫模型)模型,⽤Viterbi(维特⽐)算法找出最可能出现的隐状态序列。
-
感受野(receptive field,RF)也许是CNN中最重要的概念之一,从文献上来看,它应当引起足够的重视。目前所有最好的图像识别方法都是在基于感受野理念来设计模型架构。感受野指的是一个特定的CNN特征(特征图上的某个点)在输入空间所受影响的区域。一个感受野可以用中心位置(center location)和大小(size)来表征。然而,对于一个CNN特征来说,感受野中的每个像素值(pixel)并不是同等重要。一个像素点越接近感受野中心,它对输出特征的计算所起作用越大。这意味着某一个特征不仅仅是受限在输入图片中某个特定的区域(感受野),并且呈指数级聚焦在区域的中心。
-
卷积层(conv)和池化层(pooling)都会影响感受野,而激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填补(padding)没有关系, 计算当层感受野的公式如下:
-
R F i + 1 = R F i + ( k − 1 ) ∗ S i RF_{i+1}=RF_i+(k-1)*S_i RFi+1=RFi+(k−1)∗Si
-
其中, R F i + 1 RF_{i+1} RFi+1 表示当前层的感受野, R F i RF_i RFi 表示上一层的感受野, k 表示卷积核的大小,例如3*3的卷积核,则 k=3 , S i S_i Si 表示之前所有层的步长的乘积(不包括本层)。通常上述公式求取的感受野通常很大,而实际的有效感受野(Effective Receptive Field)往往小于理论感受野,因为输入层中边缘点的使用次数明显比中间点要少,因此作出的贡献不同,所以经过多层的卷积堆叠后,输入层对于特征图点做出的贡献分布呈高斯分布形状。
-
卷积操作的输入与输出尺寸之间的关系如下所示。注意下列除法为
向下取整。 -
H o u t = ⌞ H i n + 2 ∗ p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] ∗ ( k e r n e l [ 0 ] − 1 ) s t r i d e [ 0 ] + 1 ⌟ H_{out}=\llcorner\frac{H_{in}+2*padding[0]-dilation[0]*(kernel[0]-1)}{stride[0]}+1 \lrcorner Hout=└stride[0]Hin+2∗padding[0]−dilation[0]∗(kernel[0]−1)+1┘
-
kernel_size (int or tuple) – 卷积核的大小;
卷积核尺寸,尺寸越大‘感受野’越大,及处理的特征单位越大,同时计算量也越大 -
stride (int or tuple, optional) – 卷积步长(默认为1);
卷积核移动的步数,默认1步,增大步数会忽略局部细节计算,适用于高分辨率的计算提升 -
padding (int, tuple or str, optional) – 输入信号四周的填充,默认填充0。就是填充的意思,通过padding,
可以填充图片的边缘,让图片的边缘的特征得到更充分的计算(不至于被截断) -
dilation (int or tuple, optional) – 卷积核元素之间的间距,默认为1,也就是常规的卷积方式;
-
-
转置卷积,也称为反卷积(deconvlution)和分部卷积(fractionally-strided convolution)。为卷积的逆操作,即把特征的维度压缩,但尺寸放大。注意它 不是真正意义上 的卷积的逆操作。通过反卷积,只能恢复原矩阵的大小,但并不能完全恢复原矩阵的数值。
-
KNN 算法,对未知类别属性的数据集中的每个点依次执⾏以下操作:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最⼩的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最⾼的类别作为当前点的预测分类。
-
决策树的⽣成算法,信息熵越⼤信息的纯度越低。数据的信息熵: − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ l o g 2 ∣ C k ∣ ∣ D ∣ -\sum_{k=1}^{K}\frac{\left | C_{k} \right |}{\left | D \right |}log_{2}\frac{\left | C_{k} \right |}{\left| D \right |} −∑k=1K∣D∣∣Ck∣log2∣D∣∣Ck∣ Ck表示集合D中属于第k类样本的样本⼦集。信息增益=信息熵-条件熵,信息增益是非对称的,用以度量两种概率分布P和Q的差异,从P到Q的信息增益通常不等于从Q到P的信息增益。
-
条件熵: H ( X ∣ Y ) = ∑ x , y p ( x , y ) l o g ( p ( x ∣ y ) ) 条件熵:H(X|Y)=\sum_{x,y}p(x,y)log(p(x|y)) 条件熵:H(X∣Y)=x,y∑p(x,y)log(p(x∣y))
-
信息增益是知道了某个条件后,事件的不确定性下降的程度,知道了某个条件后,原来事件不确定性降低的幅度。
-
-
ID3:根据信息增益分类
- 初始化特征集合和数据集合;
- 计算数据集合信息熵和所有特征的条件熵,选择信息增益最⼤的特征作为当前决策节点;
- 更新数据集合和特征集合(删除上⼀步使⽤的特征,并按照特征值来划分不同分⽀的数据集合);
- 重复 2,3 两步,若⼦集值包含单⼀特征,则为分⽀叶⼦节点。
- ID3 没有剪枝策略,容易过拟合;信息增益准则对可取值数⽬较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;只能⽤于处理离散分布的特征;没有考虑缺失值。
-
C4.5:根据信息增益率划分
- 剪枝策略:预剪枝(在节点划分前来确定是否继续增⻓,及早停⽌增⻓的主要⽅法有)节点内数据样本低于某⼀阈值;所有节点特征都已分裂;节点划分前准确率⽐划分后准确率⾼。预剪枝不仅可以降低过拟合的⻛险⽽且还可以减少训练时间,但另⼀⽅⾯它是基于“贪⼼”策略,会带来⽋拟合⻛险。后剪枝(在已经⽣成的决策树上进⾏剪枝,从⽽得到简化版的剪枝决策树),后剪枝决策树的⽋拟合⻛险很⼩,泛化性能往往优于预剪枝决策树。但同时其训练时间会⼤的多。
- C4.5 采⽤的悲观剪枝⽅法,⽤递归的⽅式从低往上针对每⼀个⾮叶⼦节点,评估⽤⼀个最佳叶⼦节点去代替这课⼦树是否有益。如果剪枝后与剪枝前相⽐其错误率是保持或者下降,则这棵⼦树就可以被替换掉。C4.5 通过训练数据集上的错误分类数量来估算未知样本上的错误率。
- C4.5 只能⽤于分类;C4.5 使⽤的熵模型拥有⼤量耗时的对数运算,连续值还有排序运算;C4.5 在构造树的过程中,对数值属性值需要按照其⼤⼩进⾏排序,从中选择⼀个分割点,所以只适合于能够驻留于内存的数据集,当训练集⼤得⽆法在内存容纳时,程序⽆法运⾏。
- 信息增益率=信息增益/信息熵
-
CART:根据基尼指数分类,越⼩越好
-
G i n i ( D ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − s u m k = 1 K p k 2 Gini(D)=\sum_{k=1}^Kp_k(1-p_k)=1-sum_{k=1}^Kp_k^2 Gini(D)=k=1∑Kpk(1−pk)=1−sumk=1Kpk2
-
pk为Ck表示集合D中属于第k类样本的样本⼦集的概率,CART 在 C4.5 的基础上进⾏了很多提升。
-
C4.5 为多叉树,运算速度慢,CART 为⼆叉树,运算速度快;C4.5 只能分类,CART 既可以分类也可以回归;CART 使⽤ Gini 系数作为变ᰁ的不纯度量,减少了⼤量的对数运算;CART 采⽤代理测试来估计缺失值,⽽ C4.5 以不同概率划分到不同节点中;CART 采⽤“基于代价复杂度剪枝”⽅法进⾏剪枝,⽽ C4.5 采⽤悲观剪枝⽅法。CART 的⼀⼤优势在于:⽆论训练数据集有多失衡,它都可以将其主动消除不需要建模⼈员采取其他操作。
-
-
ID3 C4.5 CART 划分标准 信息增益,偏向特征值多的特征 信息增益率,偏向于特征值⼩的特征 基尼指数,克服 C4.5 需要求 log 的巨⼤计算量,偏向于特征值较多的特征 使⽤场景 只能⽤于分类问题;是多叉树,速度较慢 只能⽤于分类问题;多叉树,速度较慢 可以⽤于分类和回归问题;⼆叉树,计算速度很快 样本数据 只能处理离散数据且缺失值敏感 连续性数据且有多种⽅式处理缺失值;小样本;多次扫描,处理耗时高 连续性数据且有多种⽅式处理缺失值;大数据量 样本特征 层级之间只使⽤⼀次特征 层级之间只使⽤⼀次特征 可多次重复使⽤特征 剪枝策略 没有剪枝策略 悲观剪枝策略来修正树的准确性 通过代价复杂度剪枝 -
bagging,每个基学习器都会对训练集进⾏有放回抽样得到⼦训练集,每个基学习器基于不同⼦训练集进⾏训练,并综合所有基学习器的预测值得到最终的预测结果。Bagging 常⽤的综合⽅法是投票法,票数最多的类别为预测类别。
-
boosting,基模型的训练是有顺序的,每个基模型都会在前⼀个基模型学习的基础上进⾏学习,最终综合所有基模型的预测值产⽣最终的预测结果,⽤的⽐较多的综合⽅式为加权法
-
stacking,并通过训练⼀个元模型来组合它们,然后基于这些弱模型返回的多个预测结果形成新的训练集,通过新的训练集去训练组合模型得到新模型去预测。其中⽤了k-折交叉训练。假设我们想要拟合由 L 个弱学习器组成的 stacking 集成模型。我们必须遵循以下步骤:
- 将训练数据分为两组
- 选择 L 个弱学习器,⽤它们拟合第⼀组数据
- 使 L 个学习器中的每个学习器对第⼆组数据中的观测数据进⾏预测
- 在第⼆组数据上拟合元模型,使⽤弱学习器做出的预测作为输⼊
- 在前⾯的步骤中,我们将数据集⼀分为⼆,因为对⽤于训练弱学习器的数据的预测与元模型的训练不相关。因此,将数据集分成两部分的⼀个明显缺点是,我们只有⼀半的数据⽤于训练基础模型,另⼀半数据⽤于训练元模型。
-
为什么集成学习会好于单个学习器呢?
- 训练样本可能⽆法选择出最好的单个学习器,由于没法选择出最好的学习器,所以⼲脆结合起来⼀起⽤;
- 假设能找到最好的学习器,但由于算法运算的限制⽆法找到最优解,只能找到次优解,采⽤集成学习可以弥补算法的不⾜;
- 可能算法⽆法得到最优解,⽽集成学习能够得到近似解。⽐如说最优解是⼀条对⻆线,⽽单个决策树得到的结果只能是平⾏于坐标轴的,但是集成学习可以去拟合这条对⻆线。
-
Bagging和Stacking中的基模型为强模型(偏差低,⽅差⾼),⽽Boosting中的基模型为弱模型(偏差⾼,⽅差低)。
-
随机森林 = Bagging+CART决策树
- 随机选择样本(放回抽样);
- 随机选择特征;
- 构建决策树;
- 随机森林投票(平均)。
- 随机采样由于引⼊了两种采样⽅法保证了随机性,所以每棵树都是最⼤可能的进⾏⽣⻓就算不剪枝也不会出现过拟合。在数据集上表现良好,相对于其他算法有较⼤的优势;易于并⾏化,在⼤数据集上有很⼤的优势;能够处理⾼维度数据,不⽤做特征选择。
-
Adaboost,前⼀个基本分类器分错的样本会得到加强,加权后的全体样本再次被⽤来训练下⼀个基本分类器。同时,在每⼀轮中加⼊⼀个新的弱分类器,直到达到某个预定的⾜够⼩的错误率或达到预先指定的最⼤迭代次数。
- 初始化训练样本的权值分布,每个样本具有相同权重;
- 训练弱分类器,如果样本分类正确,则在构造下⼀个训练集中,它的权值就会被降低;反之提⾼。⽤更新过的样本集去训练下⼀个分类器;
- 将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加⼤分类误差率⼩的弱分类器的权重,降低分类误差率⼤的弱分类器的权重。
- 分类精度⾼;可以⽤各种回归分类模型来构建弱学习器,⾮常灵活;不容易发⽣过拟合。对异常点敏感,异常点会获得较⾼权重
-
GDBT = Gradient boosting + CART决策树
-
GBDT 由三个概念组成:Regression Decision Tree(即 DT)、Gradient Boosting(即 GB),和 Shrinkage(⼀个重要演变)
-
GBDT 中的树都是回归树;梯度迭代:GBDT 的每⼀步残差计算其实变相地增⼤了被分错样本的权重,⽽对与分对样本的权重趋于 0,这样后⾯的树就能专注于那些被分错的样本;缩减:不直接⽤残差修复误差,⽽是只修复⼀点点,把⼤步切成⼩步。
-
可以⾃动进⾏特征组合,拟合⾮线性数据;可以灵活处理各种类型的数据。对异常点敏感。
-
与Adaboost的对⽐:都是 Boosting 家族成员,使⽤弱分类器;都使⽤前向分布算法;
-
迭代思路不同:Adaboost 是通过提升错分数据点的权重来弥补模型的不⾜(利⽤错分样本),⽽ GBDT 是通过算梯度来弥补模型的不⾜(利⽤残差);损失函数不同:AdaBoost 采⽤的是指数损失,GBDT 使⽤的是绝对损失或者 Huber 损失函数;
-
MSE 和 MAE 各有优点和缺点,那么有没有一种激活函数能同时消除二者的缺点,集合二者的优点呢?答案是有的。Huber Loss 就具备这样的优点,Huber Loss 是对二者的综合,包含了一个超参数 δ。δ 值的大小决定了 Huber Loss 对 MSE 和 MAE 的侧重性,当 |y−f(x)| ≤ δ 时,变为 MSE;当 |y−f(x)| > δ 时,则变成类似于 MAE,因此 Huber Loss 同时具备了 MSE 和 MAE 的优点,减小了对离群点的敏感度问题,实现了处处可导的功能。其公式如下:
-
f ( x ) = { 1 2 ( y − f ( x ) ) 2 if |y−f(x)| ≤ δ δ ∣ y − f ( x ) ∣ − 1 2 δ 2 if |y−f(x)| > δ f(x) = \begin{cases} \frac12(y-f(x))^2 &\text{if |y−f(x)| ≤ δ}\\ δ|y-f(x)|-\frac12δ^2 &\text{if |y−f(x)| > δ}\\ \end{cases} f(x)={21(y−f(x))2δ∣y−f(x)∣−21δ2if |y−f(x)| ≤ δif |y−f(x)| > δ
-
-
XGBoost 是⼤规模并⾏ boosting tree 的⼯具,它是⽬前最快最好的开源 boosting tree ⼯具包
- 精度更⾼:GBDT 只⽤到⼀阶泰勒展开,⽽ XGBoost 对损失函数进⾏了⼆阶泰勒展开。XGBoost 引⼊⼆阶导⼀⽅⾯是为了增加精度,另⼀⽅⾯也是为了能够⾃定义损失函数,⼆阶泰勒展开可以近似⼤ᰁ损失函数;
- 灵活性更强:GBDT 以 CART 作为基分类器,XGBoost 不仅⽀持 CART 还⽀持线性分类器,(使⽤线性分类器的 XGBoost 相当于带 L1 和 L2 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题))。此外,XGBoost ⼯具⽀持⾃定义损失函数,只需函数⽀持⼀阶和⼆阶求导;
- **正则化:**XGBoost 在⽬标函数中加⼊了正则项,⽤于控制模型的复杂度。正则项⾥包含了树的叶⼦节点个数、叶⼦节点权重的 L2 范式。正则项降低了模型的⽅差,使学习出来的模型更加简单,有助于防⽌过拟合;
- Shrinkage(缩减):相当于学习速率。XGBoost 在进⾏完⼀次迭代后,会将叶⼦节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后⾯有更⼤的学习空间;
- 列抽样:XGBoost 借鉴了随机森林的做法,⽀持列抽样,不仅能降低过拟合,还能减少计算;
- 缺失值处理:XGBoost 采⽤的稀疏感知算法极⼤的加快了节点分裂的速度;
- 可以并⾏化操作:块结构可以很好的⽀持并⾏计算。
- 虽然利⽤预排序和近似算法可以降低寻找最佳分裂点的计算ᰁ,但在节点分裂过程中仍需要遍历数据集;预排序过程的空间复杂度过⾼,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
相关文章:

深度学习八股文
Bert旨在通过联合左侧和右侧的上下文,从未标记文本中预训练出一个深度双向表示模型。因此,BERT可以通过增加一个额外的输出层来进行微调,就可以达到为广泛的任务创建State-of-the-arts 模型的效果,比如QA、语言推理任务。Bert的构…...

jquery 自整理
echarts官方:Documentation - Apache ECharts 1、CheckBox复选框 //选中事件(页面点击) $(#operateExit).on(ifChecked, function(){ $(input[name"operateExit"]).val(1); }); //非选中事件ÿ…...

MySQL | 加索引报错
报错信息 1170 - BLOB/TEXT column user_name used in key specification without a key length解决方案 分析 这个错误通常是因为尝试在一个包含BLOB或TEXT类型列的列上创建索引时没有指定键的长度。MySQL要求在使用BLOB或TEXT类型列作为索引键时,必须指定键的长…...

前端:自制年历
详细思路可以看我的另一篇文章《前端:自制月历》,基本思路一致,只是元素布局略有差异 ①获取起始位startnew Date(moment().format(yyyy-01-01)).getDay() ②获取总的格子数numMath.ceil(365/7)*7,这里用365或者366计算结果都是一样的371 …...

9.手写JavaScript大数相加问题
一、核心思想 找到两个字符串中最长的长度,对两个字符串在头位置补0达到相等的长度,相加时注意进位和类型转换,特别考虑当相加到第一位是如果仍然有进位不要忽略。此外,js中允许使用的最大的数字为 console.log("最大数&qu…...
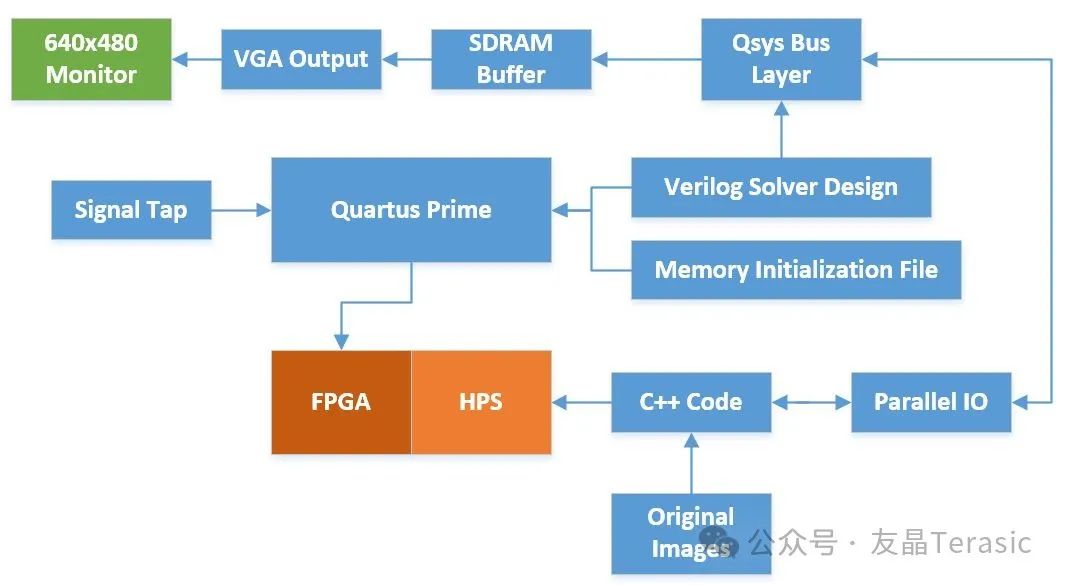
FPGA开源项目分享——基于 DE1-SOC 的 String Art 实现
导语 今天继续康奈尔大学FPGA课程ECE 5760的典型案例分享——基于DE1-SOC的String Art实现。 (更多其他案例请参考网站: Final Projects ECE 5760) 1. 项目概述 项目网址 ECE 5760 Final Project 项目说明 String Art起源于19世纪的数学…...

通过 CLI 和引入的方式使用 React:基础入门
使用React 有两种使用方式,主要有以下几个原因: 灵活性和适应性: 引入的方式可以让开发者在现有的 HTML 页面中快速引入 React,无需设置完整的项目环境。这适合小型或原型项目。 CLI 方式则更适合用于构建大型复杂的 React 应用程序,因为它提供了更完整的项目结构和…...

第三资本:铸就辉煌非凡的资历
第三资本香港有限公司在在金融投资领域一直以专业精神和不懈追求获得良好名声,近几年在国际资本市场上更是写下了辉煌的章节。针对第三资本而言,专业是基本,也是成功的唯一途径。投资总监刘国海解释道:“金融从业者务必深入把握专业能力,对行业现状敏感,重视风险管控,才能在这个…...

基于激光雷达的袋装水泥智能装车系统有哪些优势?
激光雷达技术在水泥机械智能化中发挥着举足轻重的作用,特别在袋装水泥智能装车系统的应用中表现得尤为突出。 由因泰立科技精心打造的基于激光雷达的袋装水泥智能装车系统,不仅大幅缩短了装车码垛的时间,降低了工人的劳动强度,还显…...

实战自动化修改主机名
一、主程序 #!/bin/bash# 设置主机名为node01 set_hostname() {local new_hostname$1echo "正在设置主机名为 $new_hostname ..."# 使用hostnamectl设置主机名hostnamectl set-hostname $new_hostname# 检查主机名是否更改成功if [ "$(hostname)" "…...
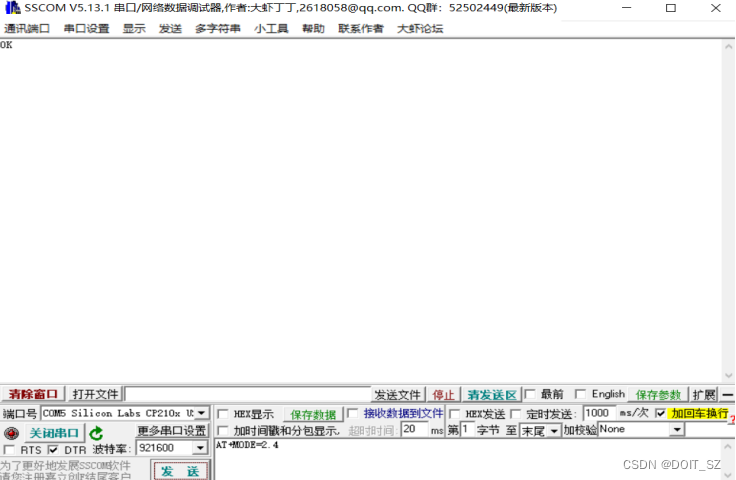
无人机GB42590接收端 +接收端,同时支持2.4G与5.8G双频WIFI模组
严格按照GB42590的协议开发的发射端,通过串口和模块通讯,默认波特率 921600。 http://www.doit.am/首页-深圳四博智联科技有限公司-淘宝网https://shop144145132.taobao.com/?spma230r.7195193.1997079397.2.71f6771dJHT2r0 二、接口文档 单片机和模…...

PVE系统的安装
一.PVE系统的安装 前置准备环境:windows电脑已安装Oracle VM VirtualBox,电脑支持虚拟化,且已经开启,按住ctrl+shift+ESC打开任务管理器查看是否开启,如果被禁用,可进入BIOS开启虚拟化,重启电脑后再进行后续操作。本步骤选用windows10安装VirtualBox,版本为7.0.8。 …...

一辆汽车的节拍时间是怎样的?
节拍时间,又称 takt time,是德语中“节奏”的意思。在汽车制造业中,它指的是按照客户需求和生产计划,生产一辆汽车所需的时间。这个时间是固定的,它决定了生产线上每个工序的操作速度和节奏,是生产线上所有…...
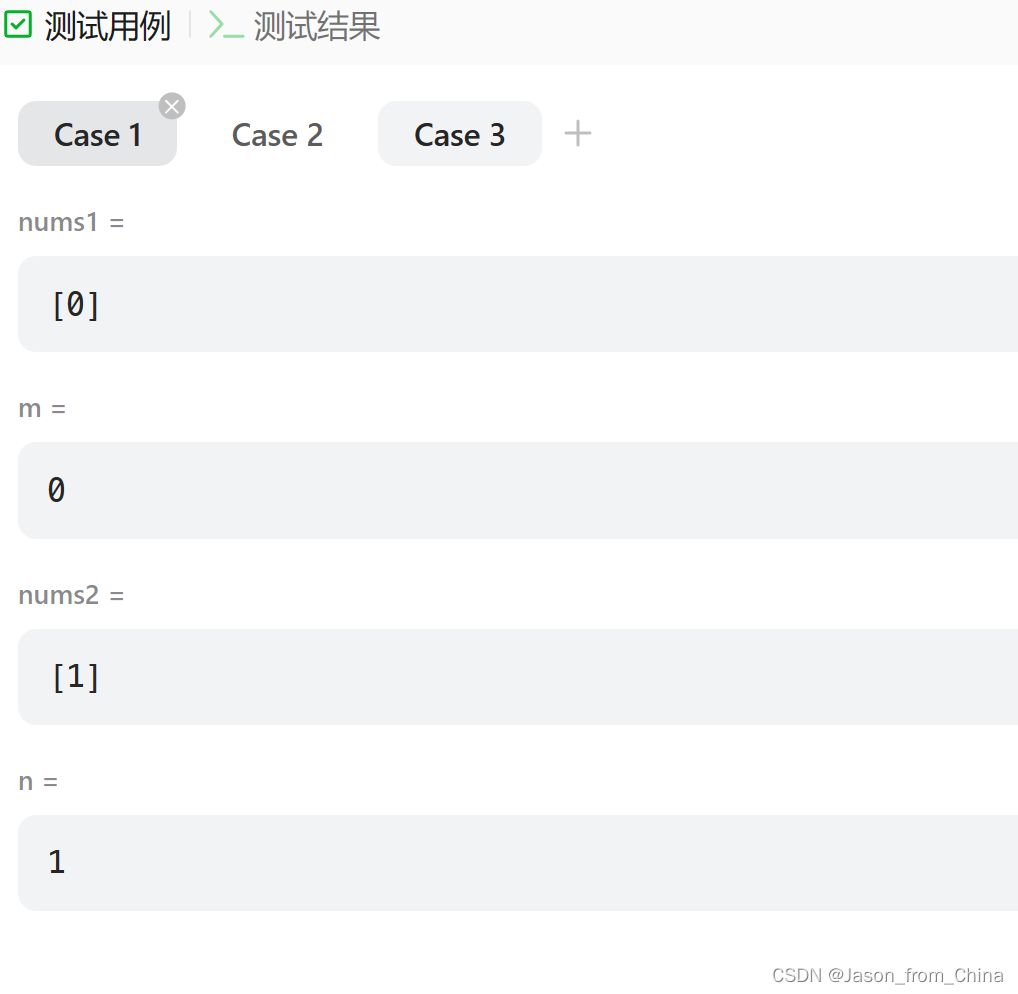
数据结构-合并两个有效数组
题目描述 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,…...
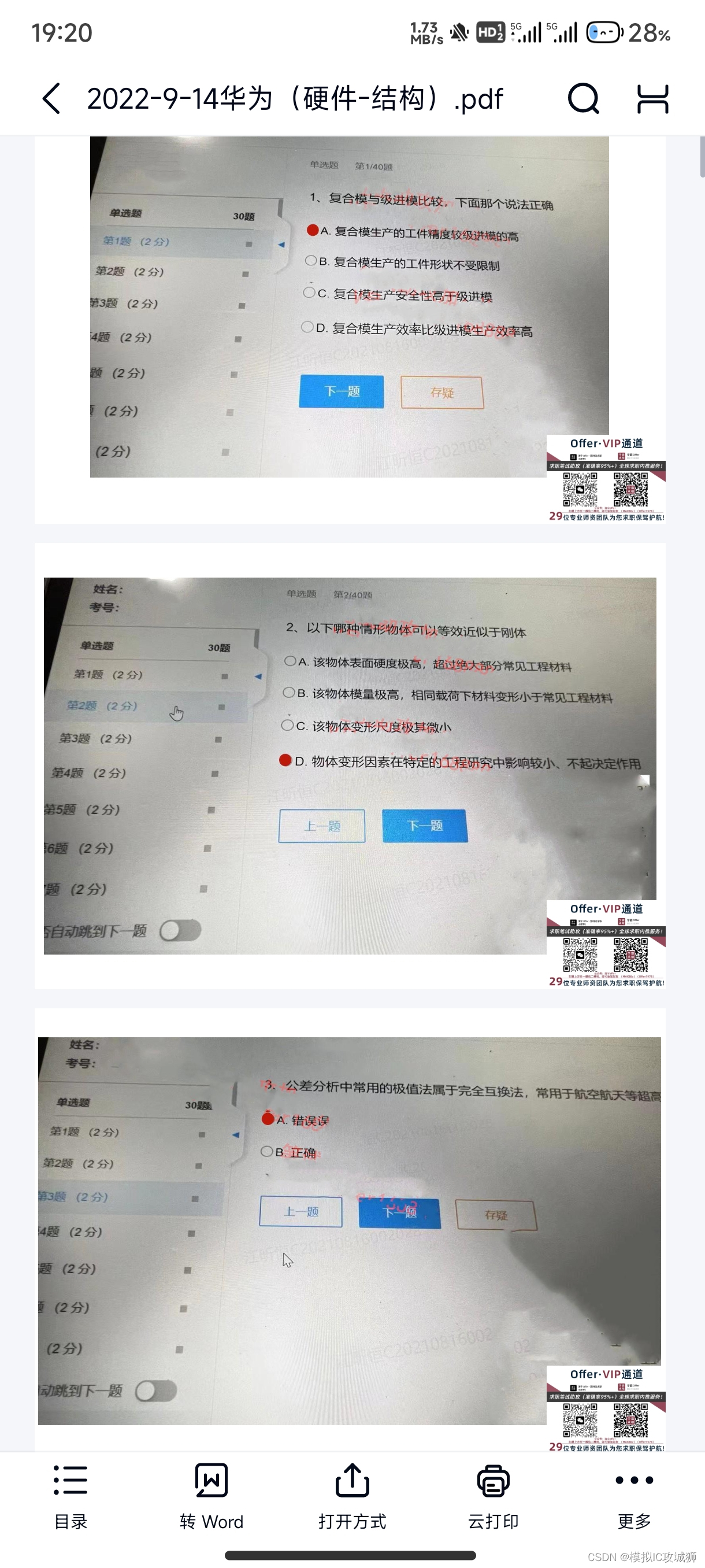
华为2024年校招实习硬件-结构工程师机试题(四套)
华为2024年校招&实习硬件-结构工程师机试题(四套) (共四套)获取(WX: didadidadidida313,加我备注:CSDN 华为硬件结构题目,谢绝白嫖哈) 结构设计工程师,结…...

使用Pandas解决问题:对比两列数据取最大值的五种方法
目录 一、使用max方法 二、使用apply方法结合lambda函数 三、使用np.maximum函数 四、使用clip方法 五、使用where方法结合条件赋值 总结: 在数据处理和分析中,经常需要比较两个或多个列的值,并取其中的最大值。Pandas库作为Python…...

rk3588 安卓13 应用安装黑名单的接口
文章目录 概述一、app应用安装黑名单核心代码二、app应用安装黑名单核心功能分析三、代码实战1.先导入所需要的包2.添加获取黑名单方法3.添加限制黑名单方法4.上层使用PS:查看当前黑名单 总结 概述 在13.0系统rom定制化开发中,客户需求要实现应用安装黑名单功能&am…...

Grafana数据库为MySQL
一、Grafana是一款流行的开源监控和数据可视化平台,它默认使用SQLite作为数据库引擎。然而,对于大型项目或者需要更高性能的场景,我们通常会选择使用MySQL作为Grafana的数据库。在本文中,我将向你介绍如何将Grafana的数据库从SQLi…...
【计算机考研】数据结构都不会,没有思路,怎么办?
基础阶段,并不需要过于专门地练习算法。重点应该放在对各种数据结构原理的深入理解上,也可以说先学会做选择题、应用题。 因为在考试中,大部分的算法题目,尤其是大题,往往可以通过简单的暴力解决方案得到较高的分数。…...

word文档显示异常,mac安装word字体:仿宋gb2312
因为mac没有gb2312字体,windows上word里显示的gb2312字体与排版,在mac上显示为黑体、排版也错乱了,得不到想要打印格式。 需要安装gb2312字体 下载:仿宋GB2312.zip 解压后双击安装得到:仿宋GB2312.ttf 放入word&…...

终极指南:如何用智能工具轻松突破内容访问限制
终极指南:如何用智能工具轻松突破内容访问限制 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 内容访问突破工具是现代数字工作者的必备利器,它能帮助研究人员…...

Graphormer部署案例:中小企业AI药物研发团队低成本GPU算力部署方案
Graphormer部署案例:中小企业AI药物研发团队低成本GPU算力部署方案 1. 项目背景与价值 在药物研发领域,分子属性预测是核心环节之一。传统实验方法成本高昂且周期漫长,而Graphormer作为基于纯Transformer架构的图神经网络,为这一…...
Pixel Aurora Engine效果展示:青蓝+明黄配色系像素画作视觉冲击力解析
Pixel Aurora Engine效果展示:青蓝明黄配色系像素画作视觉冲击力解析 1. 视觉震撼力解析 Pixel Aurora Engine通过精心设计的青蓝明黄配色方案,创造出极具视觉冲击力的像素艺术作品。这种色彩组合源自经典16位游戏的美学理念,但通过现代AI技…...

3分钟上手弹幕盒子:零基础高效制作自定义弹幕的免费工具
3分钟上手弹幕盒子:零基础高效制作自定义弹幕的免费工具 【免费下载链接】danmubox.github.io 弹幕盒子 项目地址: https://gitcode.com/gh_mirrors/da/danmubox.github.io 弹幕盒子是一款专业的在线自定义弹幕生成工具,以轻量化架构设计为核心&a…...

5分钟部署阿里RexUniNLU:Web界面操作,无需编程基础
5分钟部署阿里RexUniNLU:Web界面操作,无需编程基础 1. 认识RexUniNLU:零样本理解的神器 想象一下,你刚接手一个新项目,老板丢给你一堆用户评论,要求你快速分析出大家对产品"屏幕"、"续航&…...

Ubuntu安装中文输入法后无法输入中文----问题分析及解决方法
问题:之前在Ubuntu系统上安装过搜狗输入法,且能正常输入中文。但重启之后无法调出,Shift切换也不管用,依旧是英文原因分析:后台进程(Fcitx)卡死或崩溃了解决方法:重启Fcitx输入法框架…...
李慕婉-仙逆-造相Z-Turbo AI核心原理科普:如何用Transformer理解并生成人类语言
李慕婉-仙逆-造相Z-Turbo AI核心原理科普:如何用Transformer理解并生成人类语言 你有没有想过,当你和“李慕婉-仙逆-造相Z-Turbo”这样的AI模型对话时,它到底是怎么“听懂”你的话,又“想”出那些回答的?它不像我们人…...

DASD-4B-Thinking应用场景:科研人员用Chainlit调用长链思维模型写论文推导
DASD-4B-Thinking应用场景:科研人员用Chainlit调用长链思维模型写论文推导 安全声明:本文仅讨论技术实现与应用,所有内容均符合技术交流规范,不涉及任何敏感或违规内容。 1. 科研写作的新助手:当AI遇到学术研究 作为一…...

Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响
Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响 1. 认识Qwen3.5-2B轻量化多模态模型 Qwen3.5-2B是Qwen3.5系列中的轻量级版本,仅有20亿参数规模。这个模型特别适合在资源有限的设备上运行,比如个人电脑、边缘计算设备等。…...

TD-ACC+实验系统入门指南:手把手教你搭建典型环节模拟电路
TD-ACC实验系统实战手册:从零构建典型环节电路的21个关键细节 第一次接触TD-ACC实验系统时,看着密密麻麻的接口和旋钮,我的手指悬在半空迟迟不敢落下——生怕一个错误的连接就会烧毁昂贵的运算放大器。这种忐忑直到成功捕捉到第一个完美方波信…...