海山数据库(He3DB)原理剖析:浅析OLAP数据库计算引擎中的统计信息
背景:
统计信息在计算引擎的优化器模块中经常被提及,尤其是在基于成本成本优化(CBO)框架中统计信息发挥着至关重要的作用。CBO旨在通过评估执行查询的可能方法,并选择最有效的执行计划来提高查询性能。而统计信息则提供了关于数据分布、数据倾斜等方面的关键信息,帮助CBO做出最优的决策。无论是传统数据库MySQL、PostgreSQL,还是Hive、Spark计算引擎、Doris、StarRocks 等OLAP引擎,都针对CBO模块做了大量开发工作。而统计信息作为影响CBO决策的最重要因素,计算引擎需要对统计信息的搜集、加工、利用多个阶段进行打磨优化,最终帮助用户业务提供成本最低的执行计划。
本文将会从统计信息的常见来源以及计算引擎如何利用统计信息多个方面着手,综合多个计算引擎的CBO统计信息框架优化案例,浅析计算引擎的CBO统计信息。
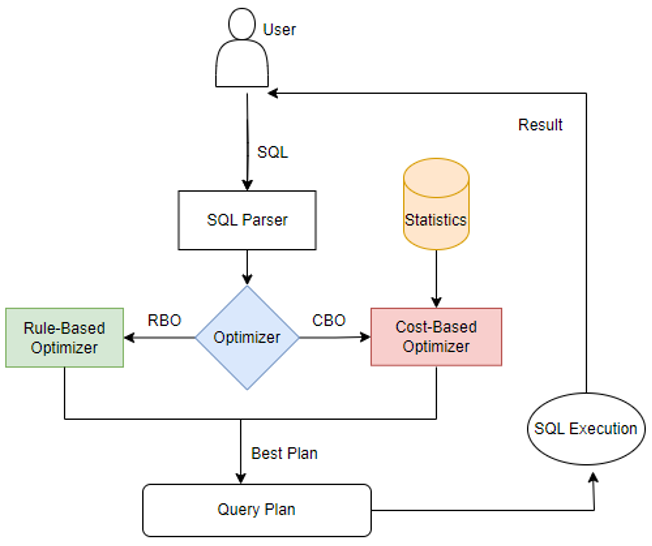
图1 计算引擎的优化器模块
一、统计信息的种类与来源
综合多个计算引擎的统计信息集成情况,可以发现大家获取统计信息手段不尽相同,一种是精准搜集统计信息,一种是采用多种手段对数据进行评估获取统计信息。
常见的基本统计信息类型有min/max/ndv/totalSize/fileNum,各家计算引擎会根据引擎特点继续扩展不同的统计信息,如涉及到数据整体评估的统计信息,MVC(高频非NULL值)、HiSTOGRAM(直方图)等。
1、基本类型统计信息
基本统计类型是相对精准的信息,一般用户analyze语句获取的统计信息多数是这种min/max等基本信息。一般表级别、分区级别、字段级别都会有相应的统计信息。在不同的SQL业务中,计算引擎会根据SQL中的谓词语句、table scan的具体表来分别利用哪种统计信息。
如select count(*) from testtbl; 显然这条语句会用到表级别统计信息,select count(distinct id) from testtbl where date=2024; 这条语句一般就会用到分区date以及字段id的统计信息。
基本类型统计信息一般都是实时获取+定时任务获取。如大数据中Hive每次执行写入任务之后会有线程启动搜集写入数据的基本统计信息,一定程度上保证统计信息实时准确,StarRocks会有定时任务自动执行内表的统计信息搜集。
2、估算类型统计信息
估算类型统计信息一般泛指对数据集的一个整体评估,能够在牺牲一定的准确性的情况下给出数据集的一个分布情况,常见的如MVC。这种统计信息适合对于在大规模数据集下,基本统计信息搜集相对代价较高且基本统计信息缺乏对整体数据集的极端分布(如数据倾斜)的体现,而估算类型的统计信息能够告诉计算引擎数据的分布状况,能够使任务避免数据倾斜等情况。
一般评估数据分布的统计信息都会采用histogram直方图,多数计算引擎根据自身的业务特性实现了不同的直方图。直方图的基本原理是将数据排序后分成若干个bucket桶,并记录每个桶中数据的最大值、最小值、频次出现等信息。常见的直方图有Equal-width Histogram、Equi-height Histogram等。像Doris和StarRocks,均实现了Equi-height Histogram。Equi-width Histogram(等宽直方图)是将数据最大、小值之间的区间等分为N份,每个桶中最大、小值之差都为整体数据最大、小值之差/N,既所谓“等宽”。
Equi-height Histogram(等高直方图),它的桶宽度并不相等,取而代之的是,等高直方图会保证每个桶中数值的频次之和接近总行数的 1/N,就是落入每个桶里的值数量尽量相等。数据数据分布范围比较大时也可以很好的保证误差。各种计算引擎会根据其擅长的业务特性去改进直方图,以尽可能避免直方图落入局部最优的境地,这里不过多详细解释直方图实现原理,大家可以参考直方图的基本原理以及具体计算引擎实现去做细致研究。
一般情况下,估算类型统计信息能够相对准确、相对高效的应用在一些大数据量的表上,尤其是一些数据湖的大表(PB级别),但是一般的估算统计信息实现还是需要对数据做一遍整体扫描,所以多数情况下的实现会判断大小表来决定是否整体数据评估信息搜集还是采样搜集。判断是否整体还是采样搜集各家计算引擎都会有不同的规则,如StarRocks、Doris([Enchancement](statistics) Support sampling collection of statistics by weizhengte · Pull Request #18880 · apache/doris · GitHub)搜集histogram直方图统计信息支持设置最大行数采样、根据比例进行采样;也有的利用统计学方式如伯努利采样PrestoDB(Add reservoir_sample aggregation function by ZacBlanco · Pull Request #21296 · prestodb/presto · GitHub)。
apache datasketches是另一种可用的非常高效的数据分布计算工具, 目前基于apache datasketches算法库实现的直方图统计信息如Hive4.0,草图中实现了各种近似估算方法,很多方法都来源于数据库领域的论文算法。Sketch 结构即「数据草图」结构,主要是为了计算海量的流式数据的概率指标而设计的一种数据结构。
一般占用固定大小的内存,不随着数据量的增加而增大。这种结构通过巧妙地保存或丢弃一些数据的策略,将数据流的信息抽象存储起来,汇总成 Sketch 结构,最终能根据 Sketch 结构还原始数据的分布,实现基数统计、分位数计算等操作。
Spark3.5之后也使用apache datasketches实现了一些估算函数如ndvApache Spark ❤️ Apache DataSketches: New Sketch-Based Approximate Distinct Counting | Databricks Blog ,基于sketch的估算函数能有效加速Spark对大数据集的一些数据分布估算,比如在此之前,统计数据集中的ndv,一般spark用户都会count(distinct),这种计算十分耗时,而且计算结果不会有临时存储,每次都需要重新计算,而datasketch能够利用经过验证的统计学算法,快速的返回计算结果,结果还可以持久化到sketch的存储中,能够大大加速一些统计类型查询。
二、统计信息带来的常见收益
我们常常说统计信息能够加速查询,能够优化执行计划,那么从计算引擎角度来说,统计信息利用最多的地方有哪些呢?这里列举几个关键的点,我们可以从不同的计算引擎中了解统计信息是怎样给用户的业务带来加速。
1、join选择
join能力是考量OLAP引擎的关键指标。如何在复杂的SQL语句中找到优化的join方式是CBO优化要做的事情。分析中常见的hash join,涉及到大小表join,一个关键的因素是怎么判断表的大小,最直接的指标就是表的统计信息,优化器根据表大小,把小表作为build side来构造哈希表放入内存,大表作为probe side,这样可以有效避免数据的shuffle过程,主流的计算引擎都会支持这种高效的join方式。
还有join reorder优化,经常会根据计算过程中生成的临时统计信息对执行计划动态调整,修改join算法,简而言之,join优化的基本要素就是需要有相对准确的统计信息,最直接的统计信息如rowCount判断表大小。计算引擎一般利用这些基础的统计信息再结合一些reorder算法或者自定义的规则,完成join查询的最优执行路径选择。
2、自适应任务执行
Adaptive Query Execution即AQE也是计算引擎高阶优化经常谈到的一个点。AQE执行可以理解为动态CBO,可以根据运行期的一些临时数据的统计信息,动态调整CBO选择的执行路径。典型的一个是Spark AQE,其根据在运行时统计信息(runtime statistics)在查询执行的过程中进行动态(Dynamic)Spark的查询优化,AQE可以Spark运行query stage阶段准确获取统计信息,然后进行CBO优化剩余的stage,可以有效的动态合并Spark shuffle分区,避免join阶段的一些数据倾斜问题。
无独有偶,除了Spark AQE,其他计算引擎也都有很多类似AQE优化。(个人理解AQE优化一般针对中间数据有落盘的计算过程,如上面提到的Spark(shuffle阶段),所以可以推测其他有中间数据可以物化/落盘行为的计算引擎也可以去做这种优化。)。
TrinoDB近年来增强了自身的容错计算能力,即设计了中间shuffle数据落盘的一种计算模式(fte),可以在部分task运行失败时从磁盘中恢复中间执行数据然后重新执行,TrinoDB的这种fte模式很适合使用AQE优化,用于减少运行期启动不必要的task,如Adaptive planning framework in FTE by gaurav8297 · Pull Request #20276 · trinodb/trino · GitHub 就是利用运行期统计信息做一些自适应优化;
PrestoDB虽然没有fte执行模式,但是其曾经也做过一些中间数据物化以提高task容错的开发如[Design] Exchange Materialization · Issue #12387 · prestodb/presto · GitHub ,其思想会把中间数据物化成一个临时表供下游task消费,那么很显然的优化就是获取这个中间表的统计信息来对下游的CBO执行计划做动态自适应调整Initial Support of Adaptive Optimization with Presto Unlimited by pguofb · Pull Request #14675 · prestodb/presto · GitHub。
类似的,Hive3其实就有AQE优化,核心思想缓存中间运行期的统计信息,动态修正CBO执行计划、动态调整分区裁剪优化等[HIVE-17626] Query reoptimization using cached runtime statistics - ASF JIRA 。所以,一旦清楚了AQE思想,每一种计算引擎都可以根据自己运行期的统计信息特点做进一步动态优化,给与业务最好的加速体验。
3、聚合下推优化
计算引擎中的聚合算子如sum、count是相对比较消耗计算资源的操作,常规执行逻辑就是扫描数据的每一行来进行各种加减操作。但是如果已经搜集了存储表的统计信息如rowCount,那么像这种count算子就是一个O(1)的简单元数据操作,计算引擎不需要计算直接返回已经搜集的统计信息即可。
这种聚合下推的优化在各个计算引擎中基本都有实现,尤其是针对底层存储采用Parquet/ORC这种开发式列存的文件格式(如Iceberg的metadata文件就记录了详细的Parquet/ORC统计信息),如Spark利用Iceberg的统计信息,做一些下推的优化操作,如TrinoDB也做了类似的基于统计信息的聚合下推操作优化Add aggregation pushdown support for count using Iceberg Metrics by osscm · Pull Request #15832 · trinodb/trino · GitHub 。
当然,Hadoop之上经典的Hive计算引擎也早就有这种聚合下推优化,比如有些Hive优化参数会控制是否启动MR分布式任务,如参数hive.compute.query.using.stats,该参数开启的情况下,Hive计算引擎会去判断当前表的统计信息rowCount是否最新,如果统计信息最新,则在SQL语句中涉及到count的操作算子直接通过统计信息返回,避免了启动分布式任务去计算。
三、小结
无论是数据库领域还是大数据领域,CBO优化都是非常重要,而统计信息则是作为CBO优化的最关键一环,每一种计算引擎都会根据自身擅长的业务特点进行统计信息的搜集/利用,从而获得最佳的执行计划。如何准确且轻量地获取统计信息,并合理地应用在CBO框架以及其他优化中,是一个非常值得探索的方向。
四、作者介绍
张步涛,中国移动云能力中心数据库产品部-OLAP数据库开发工程师。主要参与OLAP内核研发/湖仓一体研发相关工作。
相关文章:
海山数据库(He3DB)原理剖析:浅析OLAP数据库计算引擎中的统计信息
背景: 统计信息在计算引擎的优化器模块中经常被提及,尤其是在基于成本成本优化(CBO)框架中统计信息发挥着至关重要的作用。CBO旨在通过评估执行查询的可能方法,并选择最有效的执行计划来提高查询性能。而统计信息则提…...
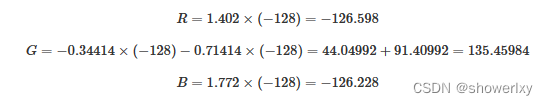
视频图像的两种表示方式YUV与RGB(4)
本篇主要讲YUV与RGB之间的转换,包括YUV444 颜色编码格式 转为 RGB 格式 ,RGB颜色编码格式转为 YUV444 格式。 一、 YUV与RGB之间的转换 YUV与RGB颜色格式之间进行转换时 , 涉及一系列的数学运算 ; YUV 颜色编码格式转为RGB格式的转换公式 取决于 于 YUV …...
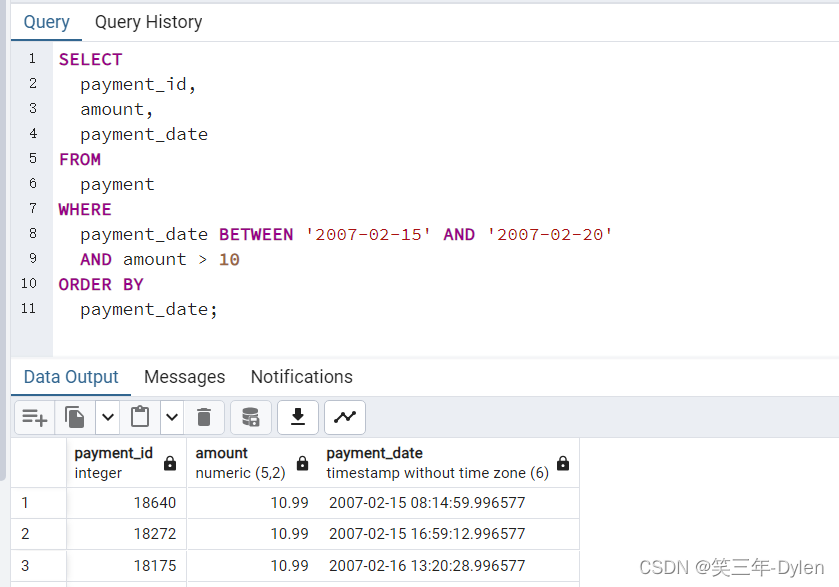
PostgreSQL入门到实战-第十四弹
PostgreSQL入门到实战 PostgreSQL数据过滤(七)官网地址PostgreSQL概述PostgreSQL中BETWEEN 命令理论PostgreSQL中BETWEEN 命令实战更新计划 PostgreSQL数据过滤(七) BETWEEN运算符允许您检查值是否在值的范围内。 官网地址 声明: 由于操作系统, 版本更新等原因, 文章所列内容…...

分布式数据库中间件 Mycat 和 ShardingSphere 对比
Mycat 和 ShardingSphere 都是流行的分布式数据库中间件,都可以用于实现数据分片、读写分离和分布式事务等功能,但它们在设计理念、特点和功能实现上有一些区别 1. 设计理念: Mycat: 基于 MySQL 协议的代理式架构,主要…...
Python实现BOA蝴蝶优化算法优化BP神经网络回归模型(BP神经网络回归算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 蝴蝶优化算法(butterfly optimization algorithm, BOA)是Arora 等人于2019年提出的一种元启发式智能算…...
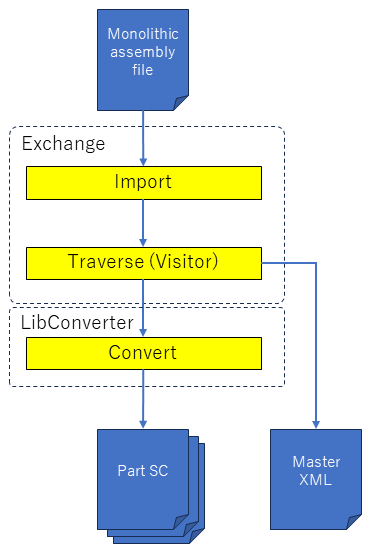
3D Web轻量化引擎HOOPS Commuicator如何从整体装配中创建破碎的装配零件和XML?
前言 虽然可以从某些本机CAD格式(其子组件驻留在单独的文件中,例如CATIA V5、Creo - Pro/E、NX或SolidWorks)创建破碎装配,但无法从整体装配文件(例如IFC、Revit)创建或3DXML。 本文介绍了一个示例&#…...
关于运行阿里云直播Demo pub get 报的错
flutter --version dart --version 如何使用Flutter框架推流_音视频终端 SDK(Apsara Video SDK)-阿里云帮助中心 终端输入 dart pub --trace get --no-precompile 打印详细报错信息 详细咨询chatgpt pub.dev 中已经是最新版本了 项目中已经是最新版本了 最终定位到 终端…...

C语言调用Python
目录 1.直接调用python语句 头文件引用 2.调用无参有参函数 1、调用无参函数 1.建立nopara.py文件 2.使用c语言根据上面流程进行调用 2、调用有参函数 1.建立nopara.py文件 2.使用c语言根据上面流程进行调用 C语言调用python需要我们已经安装好了libpython3的 dev依赖…...

SVN客户端异常问题处理
1、如遇svn服务端异常(所有用户登录不上) (1)登录192.168.**.**服务器,找到E:\仓库所在盘\VisualSVN-GlobalWinAuthz.ini (2)先备份VisualSVN-GlobalWinAuthz.ini文件 (3…...

gin+sse实现离散的消息通知
虽然网上的都是用sse实现将实时消息流不间断的推给前端,但是sse也可以模拟websocket进行突发的消息通知,而不是一直读取数据并返回数据。即服务端保存所有的连接对象,前端管理界面发送正常的http请求,在后端遍历所有的连接对象&am…...
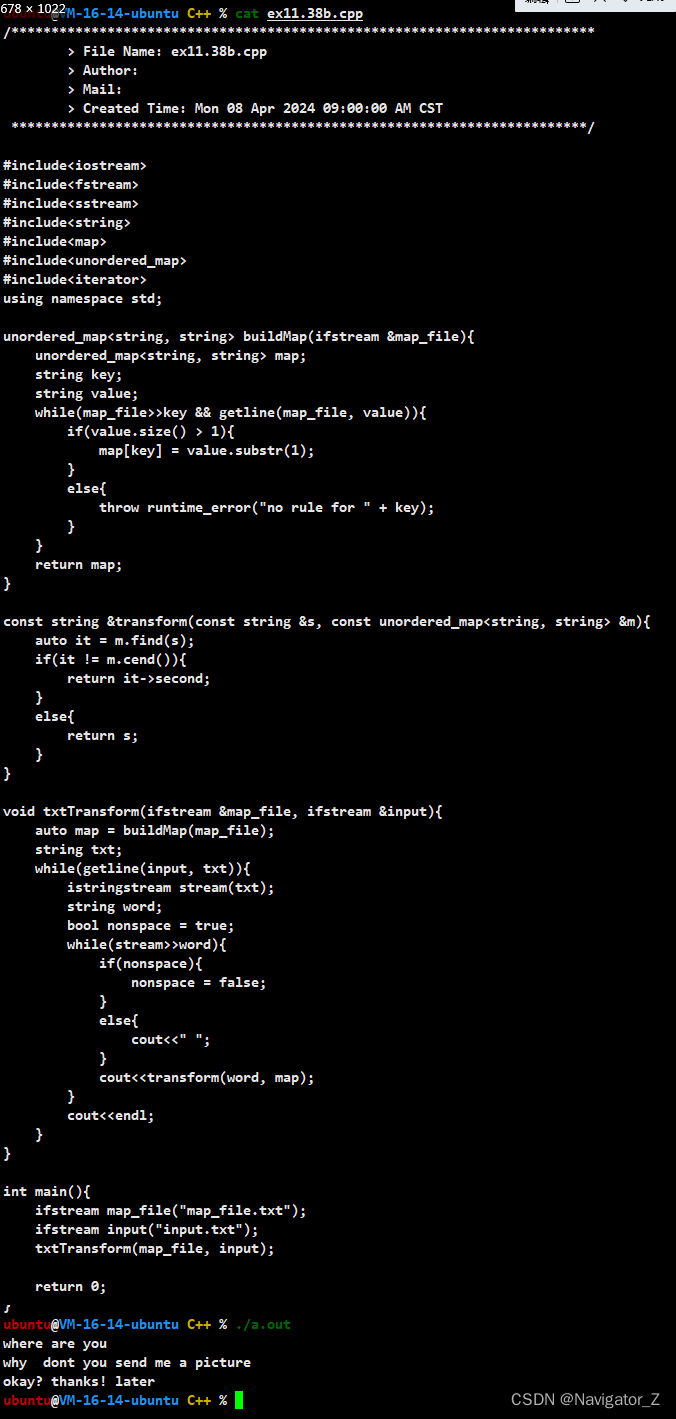
C++ //练习 11.38 用unordered_map重写单词计数程序(参见11.1节,第375页)和单词转换程序(参见11.3.6节,第391页)。
C Primer(第5版) 练习 11.38 练习 11.38 用unordered_map重写单词计数程序(参见11.1节,第375页)和单词转换程序(参见11.3.6节,第391页)。 环境:Linux Ubuntu࿰…...

【示例】MySQL-4类SQL语言-DDL-DML-DQL-DCL
前言 本文主要讲述MySQL中4中SQL语言的使用及各自特点。 SQL语言总共分四类:DDL、DML、DQL、DCL。 SQL-DDL | Data Definition Language 数据定义语言:用来定义/更改数据库对象(数据库、表、字段) 用途 | 操作数据库 # 查询所…...

基于SpringBoot+Vue的果蔬种植销售一体化服务平台(源码+文档+部署+讲解)
一.系统概述 伴随着我国社会的发展,人民生活质量日益提高。于是对果蔬种植销售一体化服务管理进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套果蔬种植销售一体…...

数据结构面试
当然可以!以下是数据结构面试问题及答案整理: **什么是数据结构?** 答:数据结构是指组织和存储数据的方式,它允许高效地访问和操作数据。不同的数据结构有不同的优势和适用场景。常见的基本数据结构包括数组、链表、…...

Linux 上安装 SQLite
SQLite Download Page 从上面的链接中源代码区下载 sqlite-autoconf-*.tar.gz。 历史版本见下连接: https://sqlite.org/chronology.html...
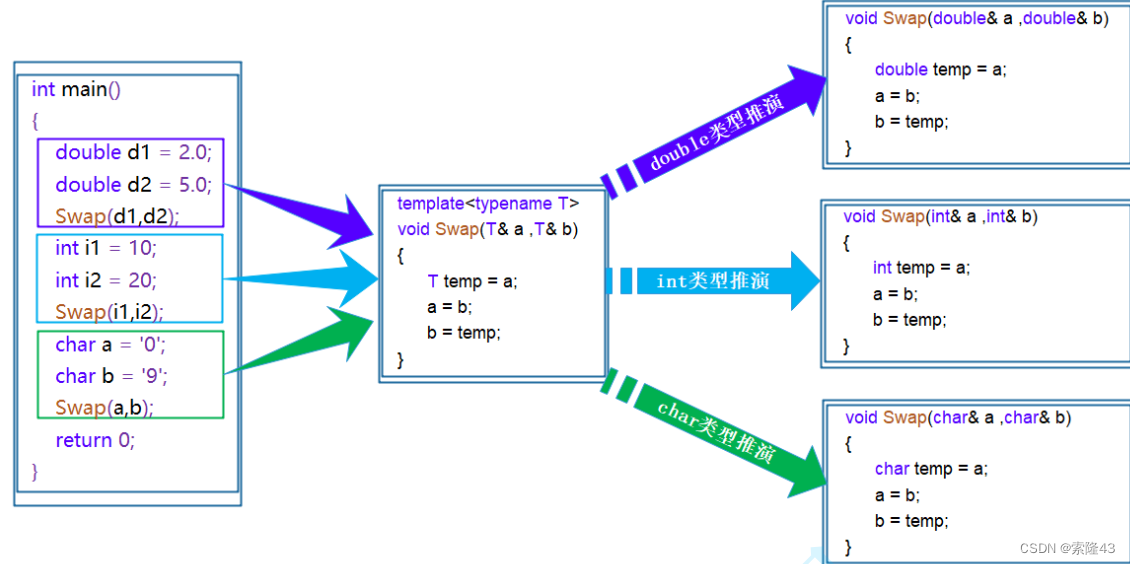
C++模板初阶(个人笔记)
模板初阶 1.泛型编程2.函数模板2.1函数模板的实例化2.2模板参数的匹配规则 3.类模板3.1类模板的实例化 1.泛型编程 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。 //函数重载 //交换函数的逻辑是一致的,…...

如何用Java后端处理JS.XHR请求
Touching searching engine destroies dream to utilize php in tomcat vector.The brave isn’t knocked down,turn its path to java back-end. Java Servlet Bible schematic of interaction between JS front-end and Java back-end Question 如何利用Java…...

分布式锁-redission
5、分布式锁-redission 5.1 分布式锁-redission功能介绍 基于setnx实现的分布式锁存在下面的问题: 重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码…...

C/C++ 自定义头文件,及头文件结构详解
头文件 在之前介绍的大部分C语言语法基础的章节中列举的实例代码部分,都会在源文件的开始的第一行通过#include预处理指令包含进"stdio.h",后面这个".h"后缀名的就是头文件了。而什么是头文件呢? 通俗方式理解头文件 …...

快速列表quicklist
目录 为什么使用快速列表quicklist 对比双向链表 对比压缩列表ziplist quicklist结构 节点结构quicklistNode quicklist 管理ziplist信息的结构quicklistEntry 迭代器结构quicklistIter quicklist的API 1.创建快速列表 2.创建快速列表节点 3.头插quicklistPushHead …...

BilibiliCommentScraper:革新性全量数据采集的技术突破方案
BilibiliCommentScraper:革新性全量数据采集的技术突破方案 【免费下载链接】BilibiliCommentScraper 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCommentScraper 在当今数据驱动决策的时代,高效采集方案与完整数据获取已成为内容分析…...
)
BiLSTM时间序列预测实战:用Python搞定股票价格预测(附完整代码)
BiLSTM金融时间序列预测:从理论到实战的Python完整指南 金融市场如同汹涌的海浪,价格波动背后隐藏着无数投资者的决策与情绪。对于量化分析师和算法交易者而言,准确预测这些波动意味着巨大的商业价值。传统的时间序列分析方法如ARIMA在面对非…...

Artichoke 未来展望:这个创新 Ruby 实现的路线图和愿景 [特殊字符]
Artichoke 未来展望:这个创新 Ruby 实现的路线图和愿景 🚀 【免费下载链接】artichoke 💎 Artichoke is a Ruby made with Rust 项目地址: https://gitcode.com/gh_mirrors/ar/artichoke Artichoke 是一个用 Rust 编写的创新 Ruby 实现…...

FLUX.小红书极致真实V2规模化落地:单节点支持10并发请求,QPS达2.1
FLUX.小红书极致真实V2规模化落地:单节点支持10并发请求,QPS达2.1 1. 项目简介 你是否曾经遇到过这样的困扰:想要生成小红书风格的高质量图片,但要么效果不够真实,要么生成速度太慢,要么显存不够用&#…...

手把手教你用Wireshark抓包分析Opener EIP通信,快速定位ForwardOpen失败原因
深度解析EtherNet/IP通信:用Wireshark诊断ForwardOpen失败的实战指南 当你在MCU上成功移植了Opener协议栈,TCP连接建立正常,却在关键时刻遭遇ForwardOpen失败时,那种挫败感我深有体会。去年在汽车生产线控制系统项目中,…...

3个变革性步骤:用163MusicLyrics彻底解决歌词获取难题
3个变革性步骤:用163MusicLyrics彻底解决歌词获取难题 【免费下载链接】163MusicLyrics Windows 云音乐歌词获取【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 在数字化音乐时代,歌词已不再是简单的文字附…...

s2-pro音色定制实战:为品牌IP打造专属语音形象的全流程方案
s2-pro音色定制实战:为品牌IP打造专属语音形象的全流程方案 1. 为什么品牌需要专属语音形象 在当今数字营销时代,品牌IP的语音形象已经成为品牌识别的重要组成部分。一个独特、一致的语音形象能够: 增强品牌辨识度:让用户一听到…...

[OS] Rate Monotonic Scheduling: Optimizing Real-Time Task Prioritization
1. 速率单调调度:实时系统的优先级管理艺术 想象一下急诊室的医生如何决定救治顺序——心跳停止的患者永远优先于感冒发烧的病人。速率单调调度(Rate Monotonic Scheduling,RMS)就是实时操作系统中的这位"分诊专家"&am…...

DASD-4B-Thinking效果对比:在HumanEval代码生成任务中超越Qwen2.5-7B
DASD-4B-Thinking效果对比:在HumanEval代码生成任务中超越Qwen2.5-7B 1. 为什么这个40亿参数模型值得关注? 你可能已经用过不少大模型,但有没有遇到过这种情况:写一段Python函数时,模型直接给出答案,却跳…...

Buzz字幕长度优化:告别拥挤字幕,提升观看体验的智能解决方案
Buzz字幕长度优化:告别拥挤字幕,提升观看体验的智能解决方案 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Trending/buz/buz…...