快速列表quicklist
目录
为什么使用快速列表quicklist
对比双向链表
对比压缩列表ziplist
quicklist结构
节点结构quicklistNode
quicklist
管理ziplist信息的结构quicklistEntry
迭代器结构quicklistIter
quicklist的API
1.创建快速列表
2.创建快速列表节点
3.头插quicklistPushHead 和尾插quicklistPushTail
4.特定位置插入元素(不是节点)
5.删除元素
6.查找元素
总结 quicklist的特性
为什么使用快速列表quicklist
在 Redis 的早期设计中,如果列表类型的对象中元素的长度较小或数量比较少的,就采用压缩列表来存储,反之则使用双向链表。
对比双向链表
双向链表便于在链表的两端进行插入和删除操作,在插入节点上复杂度很低,但是它的内存开销比较大,每个节点除了要保存数据之外,还要额外保存两个指针,并且双向链表的各个节点是单独的内存块,地址不连续,容易产生内存碎片。
对比压缩列表ziplist
压缩列表存储在一段连续的内存上,所以存储效率高。但是,它每次变更的时间复杂度都比较高,插入和删除操作需要频繁的申请和释放内存,如果压缩列表长度很长,一次 realloc 可能会导致大批量的数据拷贝。
如何保留ziplist的空间高效性,又能不让其更新复杂度过高?
Redis 在 3.2 版本之后引入了快速列表,列表类型的对象其底层都是由快速列表实现。快速列表是双向链表和压缩列表的混合体,它将双向链表按段切分,每一段都使用压缩列表来紧凑存储,多个压缩列表之间使用双向指针关联起来。
quicklist结构
quicklist是个双端链表,节点结构是quicklistNode,节点的zl字段指向压缩列表。

节点结构quicklistNode
quicklistNode是快速列表的节点。
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *zl; //指向ziplistunsigned int sz; /* ziplist size in bytes */unsigned int count : 16; /* count of items in ziplist */unsigned int encoding : 2; /* RAW==1 or LZF==2 */unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */unsigned int recompress : 1; /* was this node previous compressed? */unsigned int attempted_compress : 1; /* node can't compress; too small */unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;- prev:前驱节点指针。
- next:后驱节点指针。
- zl:数据指针,如果当前节点的数据没有压缩,则指向一个 ziplist 结构,否则指向一个 quicklistLZF 结构。
- sz:表示zl指向的数据总大小。注意,若数据被压缩,其表示压缩前的数据长度大小。
- count:占16bit,表示当前节点的ziplist的entry的个数
- encoding:占2bit,表示当前节点的数据是否被压缩。1表示没有压缩;2是压缩,用的是LZF算法。
- container:是一个预留字段,本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作数据容器,所以叫container)。目前这个值是一个固定的值2,表示使用 ziplist 作为数据容器。
recompress:当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩。extra:其它扩展字段。目前Redis的实现里也没用上。
quicklist
快速列表的结构,从其结构可以看出其是一个链表,保存了头尾节点。
#if UINTPTR_MAX == 0xffffffff
/* 32-bit */
# define QL_FILL_BITS 14
# define QL_COMP_BITS 14
# define QL_BM_BITS 4
#elif UINTPTR_MAX == 0xffffffffffffffff
/* 64-bit */
# define QL_FILL_BITS 16
# define QL_COMP_BITS 16
# define QL_BM_BITS 4 /* we can encode more, but we rather limit the usersince they cause performance degradation. */
#else
# error unknown arch bits count
#endif
//上面的表示:QL_FILL_BITS值在32位机器上是14,64位机器上是16typedef struct quicklist {quicklistNode *head; //头节点quicklistNode *tail; //尾结点unsigned long count; /* total count of all entries in all ziplists */unsigned long len; /* number of quicklistNodes */int fill : QL_FILL_BITS; /* fill factor for individual nodes */unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;//当指定使用lzf压缩算法压缩ziplist的entry节点时,quicklistNode结构的zl成员指向quicklistLZF结构
typedef struct quicklistLZF {//表示被LZF算法压缩后的ziplist的大小unsigned int sz; /* LZF size in bytes*///保存压缩后的ziplist的数组,柔性数组char compressed[];
} quicklistLZF;/* quicklist node encodings */
#define QUICKLIST_NODE_ENCODING_RAW 1
#define QUICKLIST_NODE_ENCODING_LZF 2/* quicklist compression disable */
#define QUICKLIST_NOCOMPRESS 0/* quicklist container formats */
#define QUICKLIST_NODE_CONTAINER_NONE 1
#define QUICKLIST_NODE_CONTAINER_ZIPLIST 2#define quicklistNodeIsCompressed(node) \((node)->encoding == QUICKLIST_NODE_ENCODING_LZF)- count:所有压缩列表的节点数量之和
- len:快速类别的节点数量
- fill:存放
list-max-ziplist-size参数的值,用于设置每个quicklistnode的压缩列表的所有entry的总长度大小。其值默认是-2,表示每个quicklistNode节点的ziplist所占字节数不能超过8kb。若是任意正数:,表示ziplist结构所最多包含的entry个数,最大为215215。 - compress:存放
list-compress-depth参数的值,用于设置压缩深度。快速列表默认的压缩深度为 0,即不压缩。为了支持快速的 push/pop 操作,快速列表的首尾两个节点不压缩,此时压缩深度就是1。若压缩深度为2,表示快速列表的首尾第一个及第二个节点都不压缩。 bookmark_count:占 4 bit,bookmarks数组的长度。bookmarks:这是一个可选字段,快速列表重新分配内存时使用,不使用时不占用空间。
管理ziplist信息的结构quicklistEntry
和压缩列表一样,entry结构在储存时是一连串的内存块,需要将其每个entry节点的信息读取到管理该信息的结构体中,以便操作。
//管理quicklist中quicklistNode节点中ziplist信息的结构
typedef struct quicklistEntry {const quicklist *quicklist; //指向所属的quicklist的指针quicklistNode *node; //指向所属的quicklistNode节点的指针unsigned char *zi; //指向当前ziplist结构的指针unsigned char *value; //查找到的元素如果是字符串,则存在value字段long long longval; //查找到的元素如果是整数,则存在longval字段unsigned int sz; //保存当前元素的长度int offset; //保存查找到的元素距离压缩列表头部/尾部隔了多少个节点
} quicklistEntry;迭代器结构quicklistIter
在Redis的quicklist结构中,实现了自己的迭代器,用于遍历节点。
//quicklist的迭代器结构
typedef struct quicklistIter {const quicklist *quicklist; //指向所属的quicklist的指针quicklistNode *current; //指向当前迭代的quicklist节点的指针unsigned char *zi; //指向当前quicklist节点中迭代的ziplistlong offset; //当前ziplist结构中的偏移量 int direction; //迭代方向
} quicklistIter;quicklist的API
1.创建快速列表
创建快速列表,快速列表的成员变量都使用默认值
/* Create a new quicklist.* Free with quicklistRelease(). */
//创建快速列表,并对各个字段进行初始化
quicklist *quicklistCreate(void) {struct quicklist *quicklist;quicklist = zmalloc(sizeof(*quicklist));quicklist->head = quicklist->tail = NULL;quicklist->len = 0;quicklist->count = 0;quicklist->compress = 0;quicklist->fill = -2;quicklist->bookmark_count = 0;return quicklist;
}创建列表,传入自己设置的参数
//设置压缩深度
#define COMPRESS_MAX ((1 << QL_COMP_BITS)-1)
void quicklistSetCompressDepth(quicklist *quicklist, int compress) {if (compress > COMPRESS_MAX) {compress = COMPRESS_MAX;} else if (compress < 0) {compress = 0;}quicklist->compress = compress;
}//设置压缩列表的大小(成员fill),即是每个压缩列表的总entry的总长度大小
#define FILL_MAX ((1 << (QL_FILL_BITS-1))-1)
void quicklistSetFill(quicklist *quicklist, int fill) {if (fill > FILL_MAX) {fill = FILL_MAX;} else if (fill < -5) {fill = -5;}quicklist->fill = fill;
}//设置快速列表的参数
void quicklistSetOptions(quicklist *quicklist, int fill, int depth) {quicklistSetFill(quicklist, fill);quicklistSetCompressDepth(quicklist, depth);
}//通过一些默认参数创建快速列表,就是调用了前面这些封装好的函数
quicklist *quicklistNew(int fill, int compress) {quicklist *quicklist = quicklistCreate();quicklistSetOptions(quicklist, fill, compress);return quicklist;
}2.创建快速列表节点
REDIS_STATIC quicklistNode *quicklistCreateNode(void) {quicklistNode *node;node = zmalloc(sizeof(*node));node->zl = NULL;node->count = 0;node->sz = 0;node->next = node->prev = NULL;node->encoding = QUICKLIST_NODE_ENCODING_RAW; //默认不压缩node->container = QUICKLIST_NODE_CONTAINER_ZIPLIST; //默认使用压缩列表结构来存数据node->recompress = 0;return node;
}3.头插quicklistPushHead 和尾插quicklistPushTail
/* 头部插入* 如果在已存在节点插入,返回0* 如果是在新的头结点插入,返回1 */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {quicklistNode *orig_head = quicklist->head;//判断头节点的空间是否足够容纳要添加的元素if (likely(_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {quicklist->head->zl =ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD); // 在头结点对应的ziplist中插入 quicklistNodeUpdateSz(quicklist->head);} else { // 否则新建一个头结点,然后插入数据 quicklistNode *node = quicklistCreateNode();node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);quicklistNodeUpdateSz(node);//新增元素添加进这个新的快速列表节点里_quicklistInsertNodeBefore(quicklist, quicklist->head, node);}quicklist->count++;quicklist->head->count++;return (orig_head != quicklist->head);
}/* 尾部插入。* 如果在已存在节点插入,返回0* 如果是在新的头结点插入,返回1 */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {quicklistNode *orig_tail = quicklist->tail;if (likely(_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {quicklist->tail->zl =ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);quicklistNodeUpdateSz(quicklist->tail);} else {quicklistNode *node = quicklistCreateNode();node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);quicklistNodeUpdateSz(node);_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);}quicklist->count++;quicklist->tail->count++;return (orig_tail != quicklist->tail);
}头插和尾插都是先调用了_quicklistNodeAllowInsert来判断能否在当前头/尾节点插入。如果能插入就直接插入到对应的ziplist中,否则就需要新建一个新节点再进行操作。
前面讲解过的quicklist结构的fill字段,其实_quicklistNodeAllowInsert就是根据fill的值来判断是否已经超过最大容量的。
其中使用到函数_quicklistInsertNodeBefore 和 _quicklistInsertNodeBefore,这两个就是在指定位置插入元素。
4.特定位置插入元素(不是节点)
注意:我们使用Redis,接触到的快速列表插入的都是插入元素,不是插入快速列表的节点。
插入元素会使用到结构体quicklistEntry。
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz) {_quicklistInsert(quicklist, entry, value, sz, 0);
}void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz) {_quicklistInsert(quicklist, entry, value, sz, 1);
}/* 在一个已经存在的entry前面或者后面插入一个新的entry * 如果after==1表示插入到后面,否则是插入到前面 */
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz, int after) {int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;int fill = quicklist->fill;//1. 获取插入位置的quicklist的节点,通过entry的node字段quicklistNode *node = entry->node;quicklistNode *new_node = NULL;assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) *///2. 该节点不存在,也只有当快速列表的头或尾节点存在才会进入这个if条件if (!node) {/* we have no reference node, so let's create only node in the list */D("No node given!");new_node = quicklistCreateNode();//将添加的元素插入快速列表节点对应的压缩列表的节点头部new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);__quicklistInsertNode(quicklist, NULL, new_node, after);new_node->count++;quicklist->count++;return;}//3. 判断node节点对应的压缩列表是否能够容纳得下要添加的元素,即node节点是否已满if (!_quicklistNodeAllowInsert(node, fill, sz)) {D("Current node is full with count %d with requested fill %lu",node->count, fill);//表示当前节点的数量已满full = 1;}//4. 判断是否需要是在尾部添加if (after && (entry->offset == node->count)) {//表示在尾部添加at_tail = 1;if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {D("Next node is full too.");//表示下一quicklistNode的ziplist的entry已满了full_next = 1;}}//5.判断是否在头部添加if (!after && (entry->offset == 0)) {D("At Head");at_head = 1;if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) {D("Prev node is full too.");//表示前一节点已满full_prev = 1;}}//未完待续..........,后面再讲解
}- 1.通过通过entry的node字段获取插入位置的quicklist的节点
- 2.判断该节点是否存在,若不存在,就创建节点,并创建ziplist,插入该元素到ziplist
- 3.判断node节点对应的压缩列表是否能够容纳得下要添加的元素,即node节点是否已满,用来设置变量full
- 4.判断是否在该quicklistNode的ziplist的尾部添加,并判断该quicklistNode的下一节点的ziplist是否已满
- 5.判断是否在该quicklistNode的ziplist的头部添加,并判断该quicklistNode的前驱节点的ziplist是否已满
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz, int after) {//........................................../* Now determine where and how to insert the new element */if (!full && after) {//6. 当前节点的zipList不满,并且是在当前位置的后面插入D("Not full, inserting after current position.");quicklistDecompressNodeForUse(node); //当前节点解压缩//entry->zi是ziplist的一个entry,返回entry->zi的下一个ziplist的entryunsigned char *next = ziplistNext(node->zl, entry->zi);if (next == NULL) {node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);} else {node->zl = ziplistInsert(node->zl, next, value, sz);}node->count++;quicklistNodeUpdateSz(node);//添加完元素后再根据node->recompress判断是否对压缩列表进行压缩quicklistRecompressOnly(quicklist, node);} else if (!full && !after) {//7. 当前节点的ziplist不满,在当前entry的前面插入D("Not full, inserting before current position.");quicklistDecompressNodeForUse(node);node->zl = ziplistInsert(node->zl, entry->zi, value, sz);node->count++;quicklistNodeUpdateSz(node);quicklistRecompressOnly(quicklist, node);} else if (full && at_tail && node->next && !full_next && after) {/* If we are: at tail, next has free space, and inserting after:* - insert entry at head of next node. *///8. D("Full and tail, but next isn't full; inserting next node head");new_node = node->next;quicklistDecompressNodeForUse(new_node);new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD);new_node->count++;quicklistNodeUpdateSz(new_node);quicklistRecompressOnly(quicklist, new_node);} else if (full && at_head && node->prev && !full_prev && !after) {/* If we are: at head, previous has free space, and inserting before:* - insert entry at tail of previous node. *///9. D("Full and head, but prev isn't full, inserting prev node tail");new_node = node->prev;quicklistDecompressNodeForUse(new_node);new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);new_node->count++;quicklistNodeUpdateSz(new_node);quicklistRecompressOnly(quicklist, new_node);} else if (full && ((at_tail && node->next && full_next && after) ||(at_head && node->prev && full_prev && !after))) {/* If we are: full, and our prev/next is full, then:* - create new node and attach to quicklist *///10. D("\tprovisioning new node...");new_node = quicklistCreateNode();new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);new_node->count++;quicklistNodeUpdateSz(new_node);__quicklistInsertNode(quicklist, node, new_node, after);} else if (full) {/* else, node is full we need to split it. *//* covers both after and !after cases */D("\tsplitting node...");//11quicklistDecompressNodeForUse(node);new_node = _quicklistSplitNode(node, entry->offset, after);new_node->zl = ziplistPush(new_node->zl, value, sz,after ? ZIPLIST_HEAD : ZIPLIST_TAIL);new_node->count++;quicklistNodeUpdateSz(new_node);__quicklistInsertNode(quicklist, node, new_node, after);_quicklistMergeNodes(quicklist, node);}quicklist->count++;
}这部分主要是分了几种情况来插入:
- 6.当前节点的ziplist没满,并在当前entry的后面插入
- 7.当前节点的ziplist没满,并在当前entry的前面插入
- 8.当前节点的ziplist已满、要添加在尾部、并且后移节点是存在的、后一节点的ziplist没满,那就添加到后一节点对应的ziplist的第一个entry的前面
- 9.当前节点的ziplist已满、要添加在头部、并且前一节点存在、前一节点的ziplist没满,就添加到前一节点的ziplist的尾部。
- 10.当前节点的ziplist已满、插入的位置是在头/尾的、并且当前节点的前/后节点的ziplist已满,则需要创建新的quicklistNode来存放要放的元素。
- 11.当前节点的ziplist已满,但是插入的位置不在两端的,则要从插入位置把当前节点分裂成两个节点
5.删除元素
快速列表删除元素有两个函数 quicklistDelEntry 和 quicklistDelRange,分别是删除单个元素和删除某个区间的元素。
删除元素使用到了迭代器结构quicklistIter,需要更新迭代器对应的节点等信息。
/* Delete one element represented by 'entry'*/
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {quicklistNode *prev = entry->node->prev;quicklistNode *next = entry->node->next;//删除元素,返回值 deleted_node 表示当前节点是否要删除。1表示该节点已删除int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,entry->node, &entry->zi);/* after delete, the zi is now invalid for any future usage. */iter->zi = NULL;/* If current node is deleted, we must update iterator node and offset. */if (deleted_node) {if (iter->direction == AL_START_HEAD) {iter->current = next;iter->offset = 0;} else if (iter->direction == AL_START_TAIL) {iter->current = prev;iter->offset = -1;}}
}REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,unsigned char **p) {int gone = 0;//删除 node 节点对应的压缩列表 p 位置的entry,返回新的zipListnode->zl = ziplistDelete(node->zl, p);node->count--;if (node->count == 0) {gone = 1;__quicklistDelNode(quicklist, node);//当前节点的ziplist的entry个数为0,就删除该节点} else {quicklistNodeUpdateSz(node); //更新该节点的ziplist的总长度大小}quicklist->count--;/* If we deleted the node, the original node is no longer valid */return gone ? 1 : 0;
}6.查找元素
Redis中没有提供直接查找元素的API。查找元素是通过遍历查找的,这就需要通过上面所讲的迭代器quicklistIter。
quicklistIter *iter = quicklistGetIterator(ql, AL_START_HEAD);
quicklistEntry entry;
int i = 0;
while (quicklistNext(iter, &entry)) { //获取迭代器中的下一个元素//比较当前的压缩列表节点存储的元素与所要查找的是否相同if (quicklistCompare(entry.zi, (unsigned char *)"bar", 3)) {//进行一些操作...........}i++;
}总结 quicklist的特性
- 其是一个节点为ziplist的双端链表
- 节点采用了ziplist,解决了传统链表的内存占用和易产生内存碎片问题
- 对比单个ziplist,quicklist使用了多个ziplist,那每个ziplist的entry个数就可以控制的比较小,解决了连续空间申请效率和ziplist变更的时间复杂度过于大的问题
- 中间节点可以压缩,进一步节省了内存
相关文章:
快速列表quicklist
目录 为什么使用快速列表quicklist 对比双向链表 对比压缩列表ziplist quicklist结构 节点结构quicklistNode quicklist 管理ziplist信息的结构quicklistEntry 迭代器结构quicklistIter quicklist的API 1.创建快速列表 2.创建快速列表节点 3.头插quicklistPushHead …...
《MATLAB科研绘图与学术图表绘制从入门到精通》
解锁MATLAB科研绘图魅力,让数据可视化成为你的科研利器! 1.零基础快速入门:软件操作实战案例图文、代码结合讲解,从入门到精通快速高效。 2.多种科研绘图方法:科研绘图基础变量图形极坐标图形3D图形地理信息可视化等&a…...

Day3-struct类型、列转行、行转列、函数
Hive 数据类型 struct类型 struct:结构体,对应了Java中的对象,实际上是将数据以json形式来进行存储和处理 案例 原始数据 a tom,19,male amy,18,female b bob,18,male john,18,male c lucy,19,female lily,19,female d henry,18,male davi…...
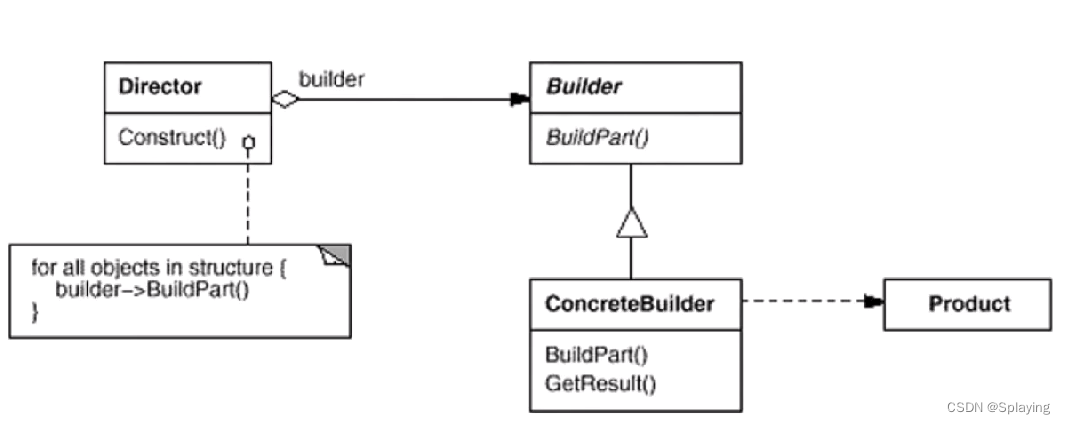
C++设计模式:构建器模式(九)
1、定义与动机 定义:将一个复杂对象的构建与其表示相分离,使得同样的构建过程(稳定)可以创建不同的表示(变化) 动机: 在软件系统中,有时候面临着“一个复杂对象”的创建工作&#x…...

OJ 【难度1】【Python】完美字符串 扫雷 A-B数对 赛前准备 【C】精密计时
完美字符串 题目描述 你可能见过下面这一句英文: "The quick brown fox jumps over the lazy dog." 短短的一句话就包含了所有 2626 个英文字母!因此这句话广泛地用于字体效果的展示。更短的还有: "The five boxing wizards…...

【Tars-go】腾讯微服务框架学习使用01--初始化服务
1 初始INIT-Demo运行 按照官网描述 go get 安装框架依赖 # < go 1.16 go get -u github.com/TarsCloud/TarsGo/tars/tools/tarsgo go get -u github.com/TarsCloud/TarsGo/tars/tools/tars2go # > go 1.16 go install github.com/TarsCloud/TarsGo/tars/tools/tarsgolat…...
通过pre标签进行json格式化展示,并实现搜索高亮和通过鼠标进行逐个定位的功能
功能说明 实现一个对json进行格式化的功能添加搜索框,回车进行关键词搜索,并对关键词高亮显示搜索到的多个关键词,回车逐一匹配监听json框,如果发生了编辑,需要在退出时提示,在得到用户确认的情况下再退出…...
5分钟了解清楚【osgb】格式的倾斜摄影数据metadata.xml有几种规范
数据格式同样都是osgb,不同软件生产的,建模是参数不一样,还是有很大区别的。尤其在应用阶段。 本文从建模软件、数据组织结构、metadata.xml(投影信息)、应用几个方面进行了经验性总结。不论您是初步开始建模…...

CCIE-10-IPv6-TS
目录 实验条件网络拓朴 环境配置开始Troubleshooting问题1. R25和R22邻居关系没有建立问题2. 去往R25网络的下一跳地址不存在、不可用问题3. 去往目标网络的下一跳地址不存在、不可用 实验条件 网络拓朴 环境配置 在我的资源里可以下载(就在这篇文章的开头也可以下…...
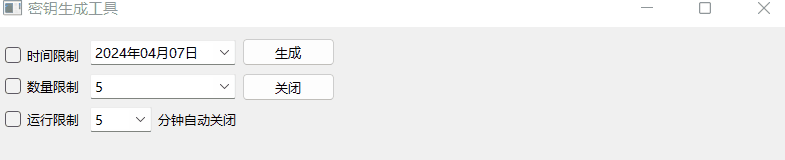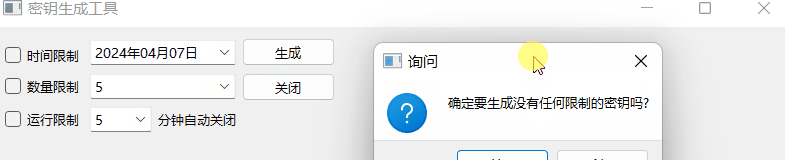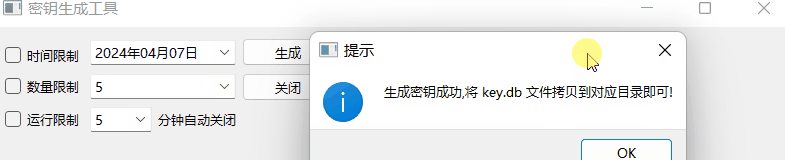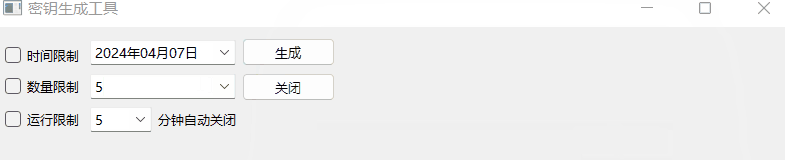
《QT实用小工具·十七》密钥生成工具
1、概述 源码放在文章末尾 该项目主要用于生成密钥,下面是demo演示: 项目部分代码如下: #pragma execution_character_set("utf-8")#include "frmmain.h" #include "ui_frmmain.h" #include "qmessag…...

CSP 比赛经验分享
中国软件专业技术资格(水平)考试( CSP-S )是一项旨在评价软件和信息技术 专业人员专业技术水平的考试。对于参加过 CSP 比赛的人来说,这是一个展示 自己编程能力、逻辑思维和解决问题能力的好机会。下面是一些基于…...

探究“大模型+机器人”的现状和未来
基础模型(Foundation Models)是近年来人工智能领域的重要突破,在自然语言处理和计算机视觉等领域取得了显著成果。将基础模型引入机器人学,有望从感知、决策和控制等方面提升机器人系统的性能,推动机器人学的发展。由斯坦福大学、普林斯顿大学…...

Commitizen:规范化你的 Git 提交信息
简介 在团队协作开发过程中,规范化的 Git 提交信息可以提高代码维护的效率,便于追踪和定位问题。Commitizen 是一个帮助我们规范化 Git 提交信息的工具,它提供了一种交互式的方式来生成符合约定格式的提交信息。 原理 Commitizen 的核心原…...
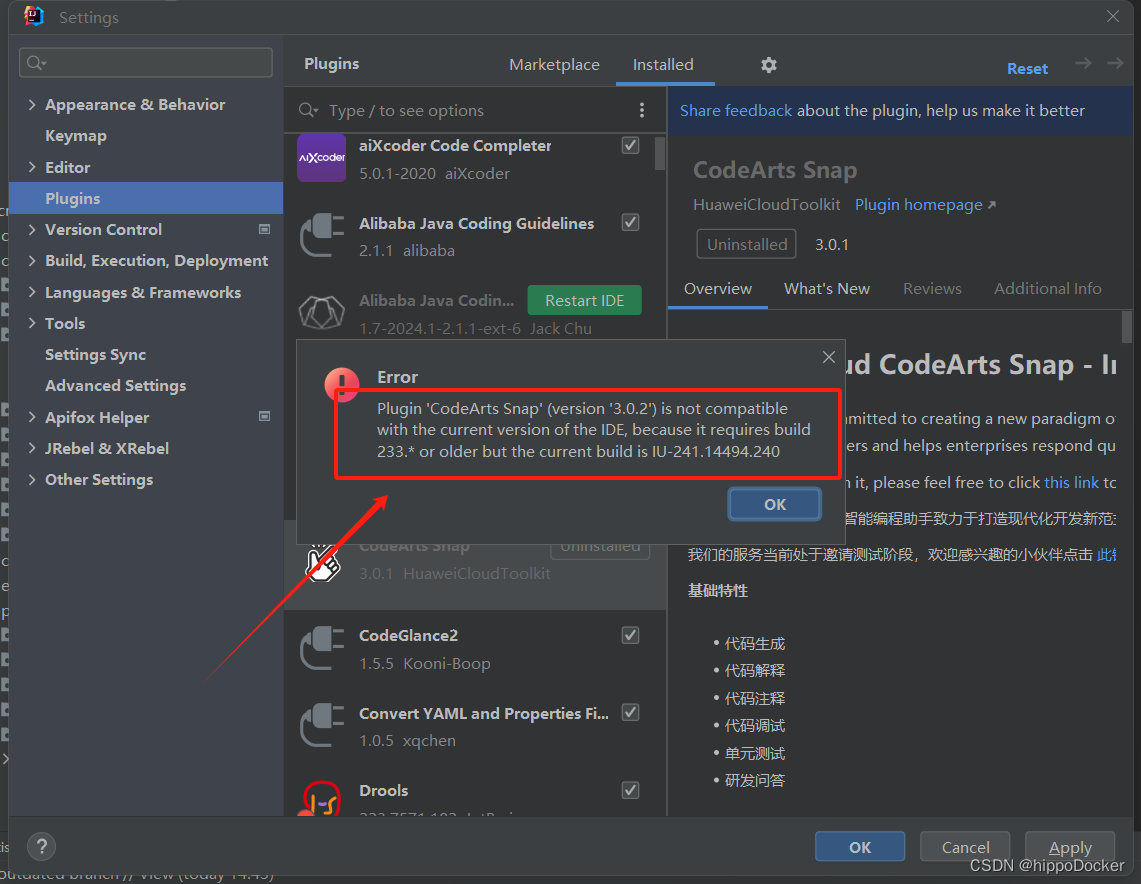
官网下载IDE插件并导入IDE
官网下载IDEA插件并导入IDEA 1. 下载插件2. 导入插件 1. 下载插件 地址:https://plugins.jetbrains.com/plugin/21068-codearts-snap/versions 说明:本次演示以IDEA软件为例 操作: 等待下载完成 2. 导入插件 点击File->setting->Pl…...

三行命令解决Ubuntu Linux联网问题
本博客中Ubuntu版本为23.10.1最新版本,后续发现了很多问题我无法解决,已经下载了另外一个版本22.04,此版本自带网络 一开始我找到官方文档描述可以通过命令行连接到 WiFi 网络:https://cn.linux-console.net/?p10334#google_vig…...

AI大模型在自然语言处理中的应用:性能表现和未来趋势
引言 A. AI大模型在自然语言处理中的应用背景简介 近年来,随着深度学习和人工智能技术的快速发展,越来越多的研究人员和企业开始关注应用于自然语言处理的AI大模型。这些模型采用了深层的神经网络结构,具有强大的学习和处理能力,…...

三防平板定制服务:亿道信息与个性化生产的紧密结合
在当今数字化时代,个性化定制已经成为了市场的一大趋势,而三防平板定制服务作为其中的一部分,展现了数字化技术与个性化需求之间的紧密结合。这种服务是通过亿道信息所提供的技术支持,为用户提供了满足特定需求的定制化三防平板&a…...

【备战蓝桥杯】2024蓝桥杯赛前突击省一:基础数论篇
2024蓝桥杯赛前突击省一:基础算法模版篇 基础数论算法回顾 判断质数(试除法) 时间复杂度O(sqrt(n)) static int is_prime(int n){if(n<2) return 0;for (int i2;i<n/i;i){if(n%i0) return 0;}return 1; }质因…...

golang es查询的一些操作,has_child,inner_hit,对索引内父子文档的更新
1.因为业务需要查询父文档以及其下子文档,搞了很久才理清楚。 首先还是Inner_hits,inner_hits只能用在nested,has_child,has_parents查询里面 {"query": {"nested": {"path": "comments","query": {"match…...

精准备份:如何自动化单个MySQL数据库的备份过程
自动化备份对于维护数据库的完整性和安全性至关重要。本指南将向您展示如何使用Shell脚本来自动化MySQL数据库的备份过程。 备份脚本内容 首先,这是我们将使用的备份脚本: #!/bin/bash# 完成数据库的定时备份 # 备份路径 BACKUP/data/backup/db # 当前…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...
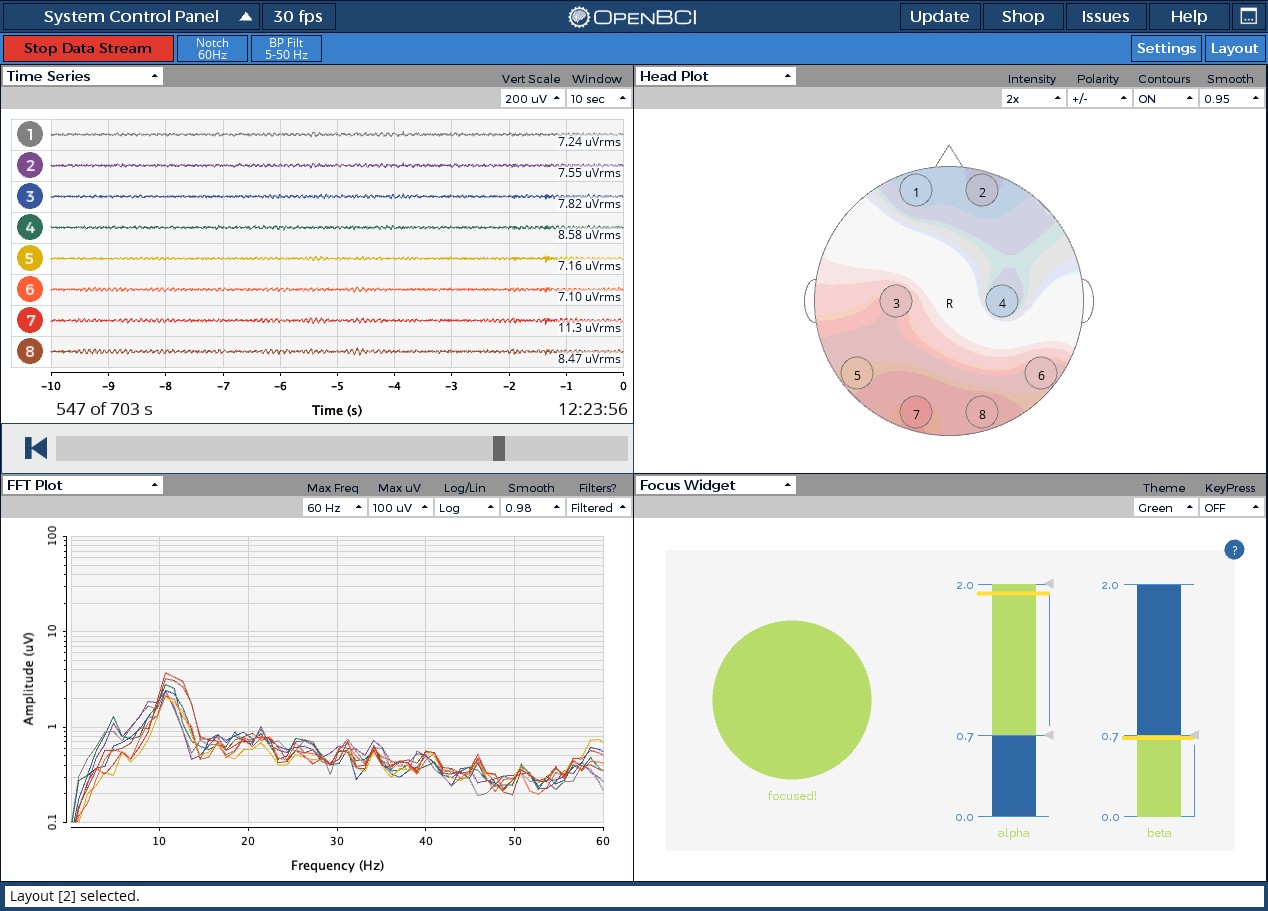
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...
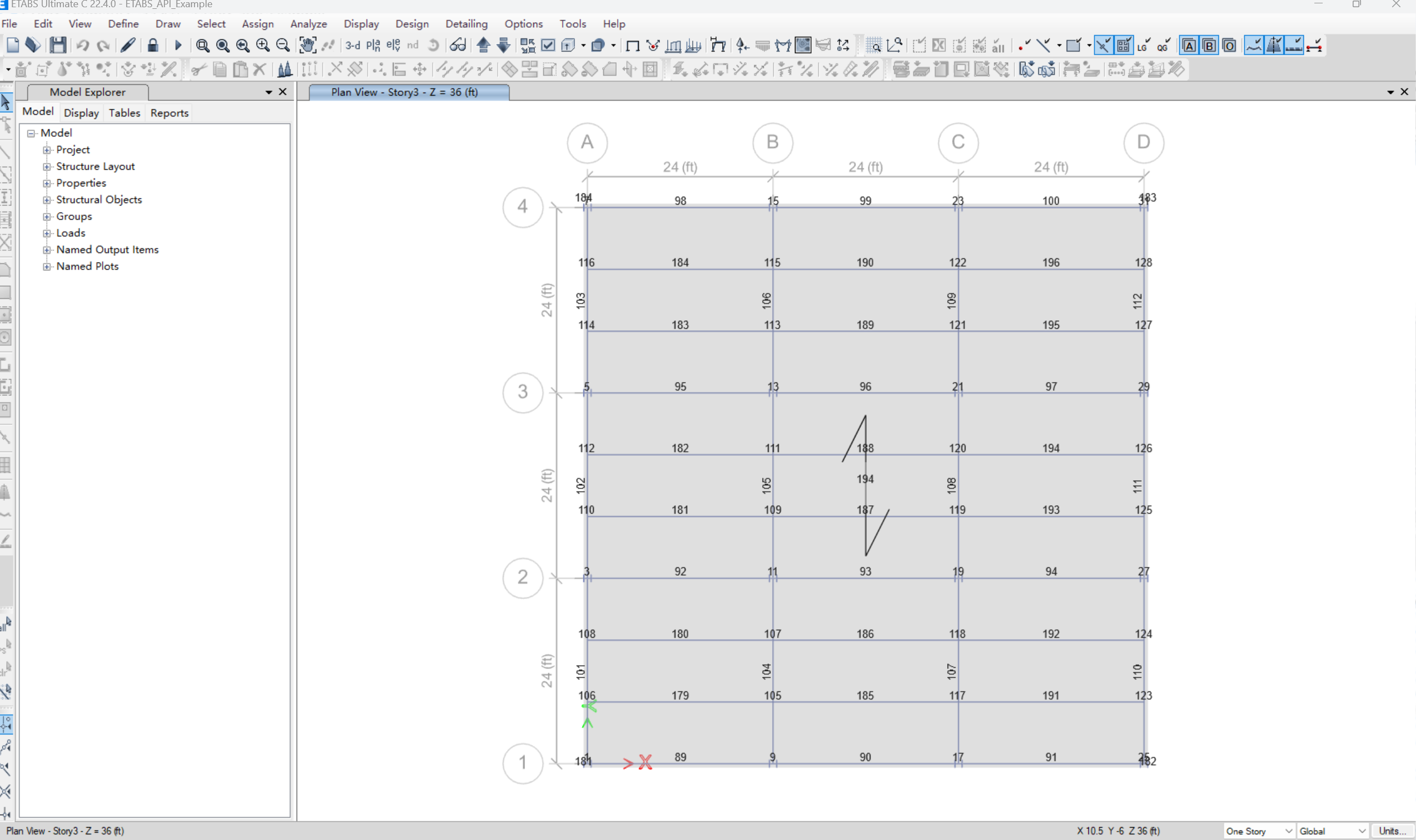
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...
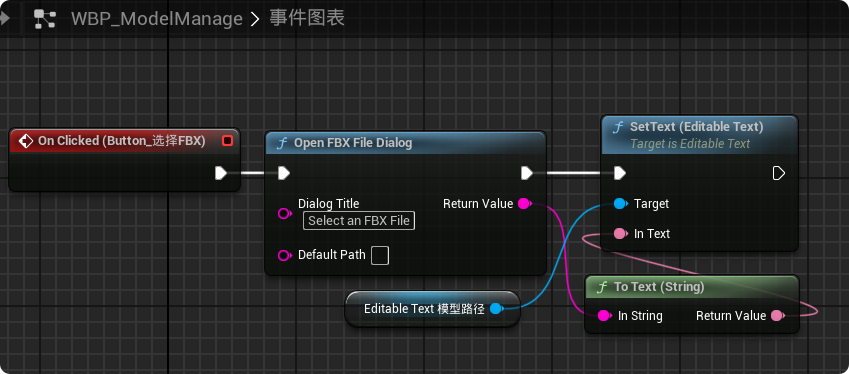
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...
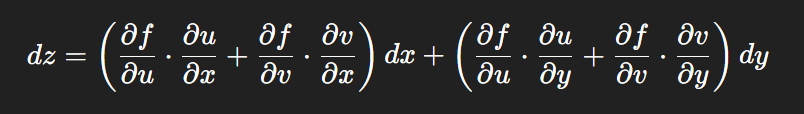
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...
GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比Grap…...