Day3-struct类型、列转行、行转列、函数
Hive
数据类型
struct类型
-
struct:结构体,对应了Java中的对象,实际上是将数据以
json形式来进行存储和处理 -
案例
-
原始数据
a tom,19,male amy,18,female b bob,18,male john,18,male c lucy,19,female lily,19,female d henry,18,male david,19,male -
案例
-- 建表 create table groups (group_id string,mem_a struct<name:string, age:int, gender:string>,mem_b struct<name:string, age:int, gender:string> ) row format delimitedfields terminated by ' 'collection items terminated by ','; -- 加载数据 load data local inpath '/opt/hive_data/infos' into table groups; -- 查询数据 select * from groups; -- 获取成员a的信息 select mem_a from groups; -- 获取成员a的名字 select mem_a.name from groups;
-
运算符和函数
概述
-
在Hive中,提供了非常丰富的运算符和函数,用于对数据进行处理和分析。在Hive中,运算符和函数可以归为一类
-
如果需要查看Hive中所有的函数,可以通过
show functions; -
如果想要查看某一个函数的描述,可以使用
-- 简略描述 desc function sum; -- 详细描述 desc function extended sum; -
在Hive中,还允许用户自定义函数
-
在Hive中,函数必须结合其他的关键字来构成语句!
入门案例
-
案例一:给定字符串表示日期,例如’2024-03-25’,从获取年份
-- 方式一:以-拆分字符串,获取数组的第一位,将字符串转化为整数类型 select cast(split('2024-03-25', '-')[0] as int); -- 方式二:正则表达式-捕获组 select cast(regexp_extract('2024-03-25', '(.*)-(.*)-(.*)', 1) as int); -- 方式三:提供了year函数,直接用于提取年份,要求年月日之间必须用-隔开 select year('2024-03-25'); -
案例一:给定字符串表示日期,例如’2024/03/25’,从获取年份
-- 方式一 select cast(split('2024/03/25', '/')[0] as int); -- 方式二 select cast(regexp_extract('2024/03/25', '(.*)/(.*)/(.*)', 1) as int); -- 方式三:先将/替换为-,再利用year函数来提取 select year(regexp_replace('2024/03/25', '/', '-'));
常用函数
nvl函数
-
nvl(v1, v2):判断v1的值是否为null,如果v1的值不是null,那么返回v1,如果v1的值是null,那么返回v2 -
案例
-
原始数据
1 Adair 800 2 David 600 3 Danny 1000 4 Ben 500 5 Grace 6 Cathy 700 7 Kite 8 Will 600 9 Thomas 800 10 Tony 1000 -
案例
-- 建表 create table rewards (id int,name string,reward double ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/rewards' into table rewards; -- 查询数据 select * from rewards; -- 计算每一个人平均发到的奖金是多少 -- avg属于聚合函数,所有的聚合函数在遇到null的时候自动跳过不计算 -- select avg(reward) from rewards; select avg(if(reward is not null, reward, 0.0)) from rewards; -- nvl select avg(nvl(reward, 0)) from rewards;
-
case-when函数
-
类似于Java中的
switch-case结构,是对不同的情况进行选择 -
案例
-
原始数据
1 bob 财务 男 2 bruce 技术 男 3 cindy 技术 女 4 david 财务 男 5 eden 财务 男 6 frank 财务 男 7 grace 技术 女 8 henry 技术 男 9 iran 技术 男 10 jane 财务 女 11 kathy 财务 女 12 lily 技术 女 -
案例
-- 建表 create table employers (id int,name string,department string,gender string ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/employers' into table employers; -- 查询数据 select * from employers; -- 需求:统计每一个部门的男生和女生人数 -- 方式一:sum(if()) select department as `部门`,sum(if(gender = '男', 1, 0)) as `男`,sum(if(gender = '女', 1, 0)) as `女` from employers group by department; -- 方式:sum(case-when) select department as `部门`,sum(case gender when '男' then 1 else 0 end) as `男`,sum(case gender when '女' then 1 else 0 end) as `女` from employers group by department;
-
explode函数
-
explode在使用的时候,需要传入一个数组或者是映射类型的参数。如果传入的是数组,那么会将数组中的每一个元素拆分成单独的一行构成一列数据;如果传入的是映射,那么会将映射的键和值拆分成两列
-
案例:单词统计
-- 创建目录 dfs -mkdir /words -- 将文件复制到这个目录下 dfs -cp /txt/words.txt /words -- 查看数据 dfs -ls /words -- 建表 -- 注意:数据在HDFS上已经存在,所以应该建立外部表 create external table words (line array<string> ) row format delimitedcollection items terminated by ' 'location '/words'; -- 查询数据 select * from words; -- 需求:统计这个文件中每一个单词出现的次数 -- 思路 -- 第一步:先将数组中的元素转成一列 select explode(line) from words; -- 第二步:统计单词出现的次数 -- 基本结构:select x, count(x) from tableName group by x; select w, count(w) from (select explode(line) as w from words ) t1 group by w;
列转行
-
列转行,顾名思义,指的是将一列的数据拆分成多行数据。在列转行的过程中,最重要的函数就是
explode -
案例
-
原始数据
沙丘2 剧情/动作/科幻/冒险 被我弄丢的你 剧情/爱情 堡垒 剧情/悬疑/历史 热辣滚烫 剧情/喜剧 新威龙杀阵 动作/惊悚 周处除三害 动作/犯罪 -
案例
-- 建表 create table movies (name string, -- 电影名kinds array<string> -- 电影类型 ) row format delimitedfields terminated by ' 'collection items terminated by '/'; -- 加载数据 load data local inpath '/opt/hive_data/movies' into table movies; -- 查询数据 select * from movies; -- 需求:查询所有的动作片 -- lateral view function(ex) tableAlias as colAlias -- 列转行,又称之为'炸列' select name, k from movies lateral view explode(kinds) ks as k where k = '动作';
-
-
案例二
-
原始数据
bob 开朗,活泼 打游戏,打篮球 david 开朗,幽默 看电影,打游戏 lucy 大方,开朗 看电影,听音乐 jack 内向,大方 听音乐,打游戏 -
案例
-- 建表 create table persons (name string, -- 姓名characters array<string>, -- 性格hobbies array<string> -- 爱好 ) row format delimitedfields terminated by '\t'collection items terminated by ','; -- 加载数据 load data local inpath '/opt/hive_data/persons' into table persons; -- 查询数据 select * from persons; -- 获取性格开朗且喜欢打游戏的人 select name, c, h from personslateral view explode(characters) cs as clateral view explode(hobbies) hs as h where c = '开朗'and h = '打游戏';
-
行转列
-
行转列,将多行的数据合并成一列
-
案例
select * from students_tmp; -- 将同年级同班级的学生放到一起 -- collect_list和collect_set将数据合并到一个数组中 -- 不同的地方在于,collect_list允许有重复数据,但是collect_set不允许元素重复 -- concat_ws(符号,元素),表示将后边的元素之间用指定的符号进行拼接,拼接成一个字符串 select grade as `年级`,class as `班级`,concat_ws(', ', collect_list(name)) as `学生` from students_tmp group by grade, class;
分类
- 除了窗口函数以外,将其他的函数分为了3类:UDF、UDAF和UDTF函数
- UDF:User Defined Function,用户定义函数,特点是一进一出,即用户输入一行数据会获取到一行结果,例如
year,split,concat_ws,regexp_replace,regexp_extract等 - UDAF:User Defined Aggregation Function,用户定义聚合函数,特点是多进一出,即用户输入多行数据会获取到一行结果,例如
sum,avg,count,max,min,collect_list,collect_set等 - UDTF:User Defined Table-generated Function,用户定义表生成函数,特点是一进多出,即用户输入一行数据能够获取到多行结果,例如
explode,inline、stack等 - 在Hive中,大部分函数都是UDF函数
自定义函数
-
自定义UDF:需要定义一个类,Hive1.x和Hive2.x继承
UDF类,但是Hive3.x,UDF类已经过时,所以需要继承GenericUDF -
自定义UDTF:需要定义一个类,继承
GenericUDTF -
打成jar包,然后上传到HDFS上
-
在Hive中创建函数
-- 基本语法 create function 函数名as '包名.类名'using jar '在HDFS上的存储路径'; -- UDF create function indexOfas 'com.fesco.AuthUDF'using jar 'hdfs://hadoop01:9000/F_Hive-1.0-SNAPSHOT.jar'; -- UDTF create function splitLineas 'com.fesco.AuthUDTF'using jar 'hdfs://hadoop01:9000/F_Hive-1.0-SNAPSHOT.jar';-- 测试 select indexOf('welcome', 'm'); select splitLine('welcome to big data', ' '); -
删除函数
drop function indexOf;
窗口函数
概述
-
窗口函数又称之为开窗函数,用于限定要处理的数据范围
-
基本语法结构
分析函数 over(partition by 字段 order by 字段 [desc/asc] rows between 起始范围 and 结束范围)-
partition by对数据进行分类 -
order by对数据进行排序 -
rows between x and y指定数据的处理范围关键字 解释 preceding 向前 following 向后 unbounded 无边界 current row 当前行 -
示例:假设当前处理的第5行数据
2 preceding and current row:处理前两行到当前行。即处理第3~5行的数据current row and 3 following:处理当前行以及向后3行。即处理第5~8行的数据unbounded preceding and current row:从第一行到当前行current row and unbounded following:从当前行到最后一行
-
分析函数:大致可以分为三组
- 聚合函数,例如
sum,avg等 - 移位函数,包含
lag,lead,ntil - 排序函数,包含
row_number,rank,dense_rank
- 聚合函数,例如
-
案例
-
原始数据
jack,2017-01-01,10 tony,2017-01-02,15 jack,2017-02-03,23 tony,2017-01-04,29 jack,2017-01-05,46 jack,2017-04-06,42 tony,2017-01-07,50 jack,2017-01-08,55 mart,2017-04-08,62 mart,2017-04-09,68 neil,2017-05-10,12 mart,2017-04-11,75 neil,2017-06-12,80 mart,2017-04-13,94 -
建表
-- 建表 create table orders (name string,order_date string,cost int ) row format delimited fields terminated by ','; -- 加载数据 load data local inpath '/opt/hive_data/orders' into table orders; -
需求一:查询每一位顾客的消费明细以及到消费日期为止的总消费金额
-- 思路: -- 1. 拆寻每一位顾客的信息,那么需要按照顾客姓名来分类 -- 2. 按照日期,将订单进行排序 -- 3. 计算总消费金额,所以需要求和 -- 4. 到当前消费日期为止的金额,也就意味着是获取从第一行到当前行的数据来处理 select *,sum(cost) over (partition by name order by order_date rows between unbounded preceding and current row ) as total_cost from orders;
分析函数
- 聚合函数,例如
sum,avg,max,min等 - 移位函数
lag(colName, n):以当前行为基础,来处理第前n行的数据lead(colName, n):以当前行为基础,来处理第后n行的数据ntile(n):要求数据必须有序,将有序的数据依次放入n个桶中,保证每个桶中的数据几乎一致,相差最多不超过1个
- 排序函数
row_number:数据排序之后,按顺序给数据进行编号,即使数据相同,也是给定不同的编号rank:数据排序之后,按顺序给数据进行编号,如果数据相同,则给定相同的序号,会产生空位dense_rank:数据排序之后,按顺序给数据进行编号,如果数据相同,则给定相同的序号,但是不会产生空位
移位函数案例
-
需求二:查询每一位顾客的消费明细以及上一次的消费时间
select *,lag(order_date, 1) over (partition by name order by order_date) as last_order_date from orders; -
需求三:查询最早进店消费的前20%的顾客信息
select * from (select *,ntile(5) over (order by order_date) as nfrom orders ) t1 where n = 1;
排序函数案例
-
原始数据
Bob Chinese 85 Alex Chinese 76 Bill Chinese 78 David Chinese 92 Jack Chinese 69 Lucy Chinese 74 LiLy Chinese 78 Bob Maths 91 Alex Maths 82 Bill Maths 69 David Maths 60 Jack Maths 69 Lucy Maths 71 LiLy Maths 82 Bob English 60 Alex English 62 Bill English 85 David English 85 Jack English 69 Lucy English 78 LiLy English 93 -
案例
-- 建表 create table scores (name string,subject string,score int ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/scores' into table scores; -- 查询数据 select * from scores tablesample (5 rows); -- 按科目对成绩进行降序排序 select *,row_number() over (partition by subject order by score desc) as rn,rank() over (partition by subject order by score desc) as ra,dense_rank() over (partition by subject order by score desc) as dr from scores; -- 获取各科目前三名的信息 select * from (select *, rank() over (partition by subject order by score desc) as n from scores ) t where n <= 3;
补充:正则捕获组
概述
-
在正则表达式中,将
()括起来的部分,称之为捕获组,此时可以将捕获组看作是一个整体 -
在正则表达式中,默认会对捕获组进行编号,编号是从1开始的。编号的计算,是从捕获组左半边括号出现的顺序来依次计算的
例如:(AB(C(D)E)F(G)) 1 AB(C(D)E)F(G) 2 C(D)E 3 D 4 G -
在正则表达式中,可以通过
\n的形式来引用对应编号的捕获组。例如\1表示引用编号为1的捕获组
相关文章:

Day3-struct类型、列转行、行转列、函数
Hive 数据类型 struct类型 struct:结构体,对应了Java中的对象,实际上是将数据以json形式来进行存储和处理 案例 原始数据 a tom,19,male amy,18,female b bob,18,male john,18,male c lucy,19,female lily,19,female d henry,18,male davi…...
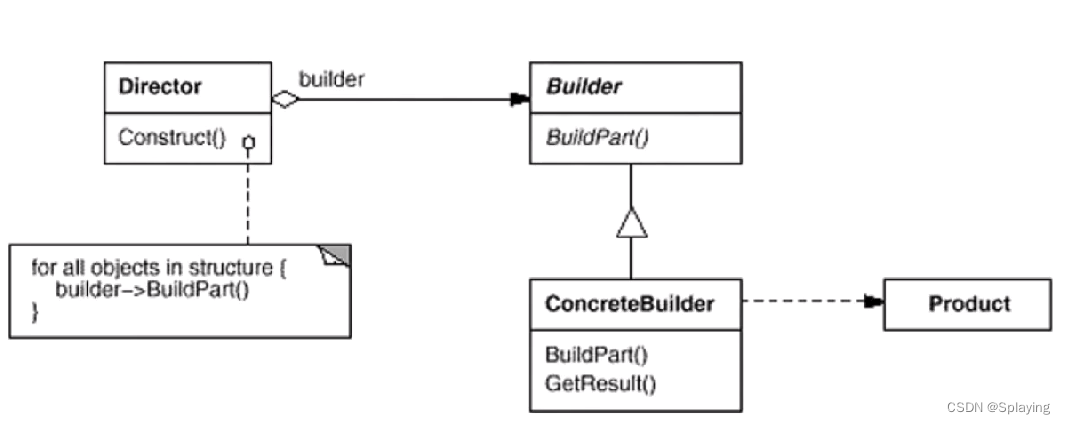
C++设计模式:构建器模式(九)
1、定义与动机 定义:将一个复杂对象的构建与其表示相分离,使得同样的构建过程(稳定)可以创建不同的表示(变化) 动机: 在软件系统中,有时候面临着“一个复杂对象”的创建工作&#x…...

OJ 【难度1】【Python】完美字符串 扫雷 A-B数对 赛前准备 【C】精密计时
完美字符串 题目描述 你可能见过下面这一句英文: "The quick brown fox jumps over the lazy dog." 短短的一句话就包含了所有 2626 个英文字母!因此这句话广泛地用于字体效果的展示。更短的还有: "The five boxing wizards…...

【Tars-go】腾讯微服务框架学习使用01--初始化服务
1 初始INIT-Demo运行 按照官网描述 go get 安装框架依赖 # < go 1.16 go get -u github.com/TarsCloud/TarsGo/tars/tools/tarsgo go get -u github.com/TarsCloud/TarsGo/tars/tools/tars2go # > go 1.16 go install github.com/TarsCloud/TarsGo/tars/tools/tarsgolat…...
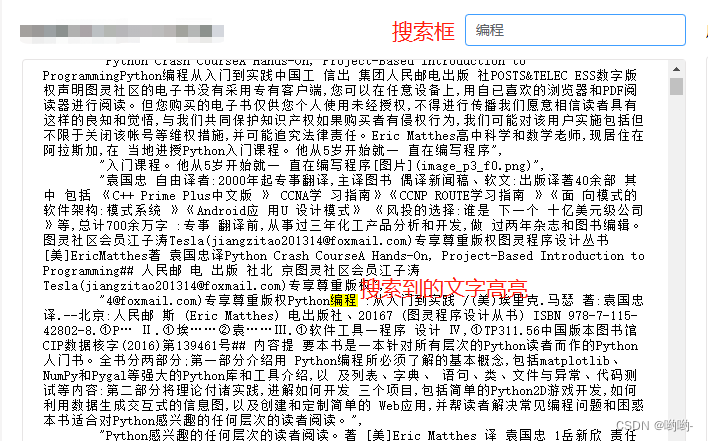
通过pre标签进行json格式化展示,并实现搜索高亮和通过鼠标进行逐个定位的功能
功能说明 实现一个对json进行格式化的功能添加搜索框,回车进行关键词搜索,并对关键词高亮显示搜索到的多个关键词,回车逐一匹配监听json框,如果发生了编辑,需要在退出时提示,在得到用户确认的情况下再退出…...
5分钟了解清楚【osgb】格式的倾斜摄影数据metadata.xml有几种规范
数据格式同样都是osgb,不同软件生产的,建模是参数不一样,还是有很大区别的。尤其在应用阶段。 本文从建模软件、数据组织结构、metadata.xml(投影信息)、应用几个方面进行了经验性总结。不论您是初步开始建模…...

CCIE-10-IPv6-TS
目录 实验条件网络拓朴 环境配置开始Troubleshooting问题1. R25和R22邻居关系没有建立问题2. 去往R25网络的下一跳地址不存在、不可用问题3. 去往目标网络的下一跳地址不存在、不可用 实验条件 网络拓朴 环境配置 在我的资源里可以下载(就在这篇文章的开头也可以下…...
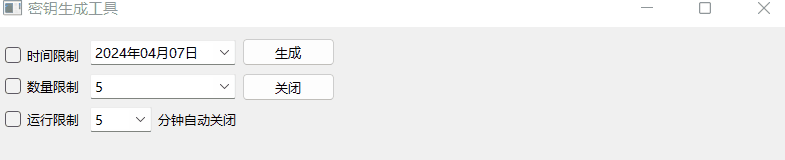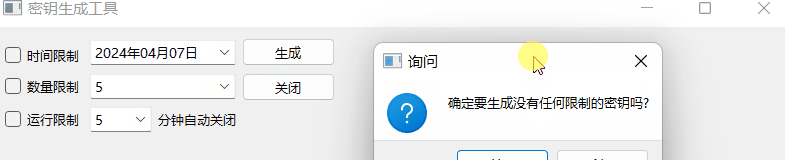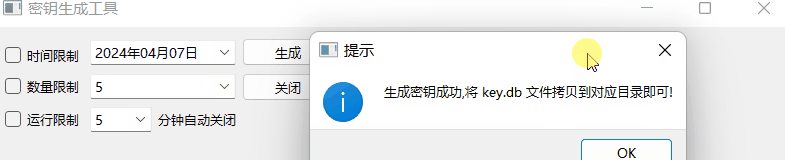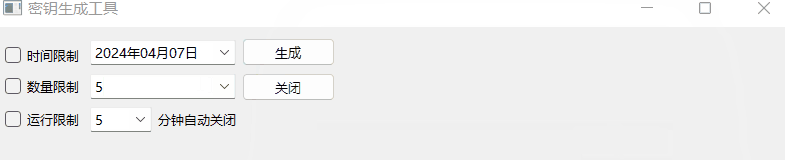
《QT实用小工具·十七》密钥生成工具
1、概述 源码放在文章末尾 该项目主要用于生成密钥,下面是demo演示: 项目部分代码如下: #pragma execution_character_set("utf-8")#include "frmmain.h" #include "ui_frmmain.h" #include "qmessag…...

CSP 比赛经验分享
中国软件专业技术资格(水平)考试( CSP-S )是一项旨在评价软件和信息技术 专业人员专业技术水平的考试。对于参加过 CSP 比赛的人来说,这是一个展示 自己编程能力、逻辑思维和解决问题能力的好机会。下面是一些基于…...

探究“大模型+机器人”的现状和未来
基础模型(Foundation Models)是近年来人工智能领域的重要突破,在自然语言处理和计算机视觉等领域取得了显著成果。将基础模型引入机器人学,有望从感知、决策和控制等方面提升机器人系统的性能,推动机器人学的发展。由斯坦福大学、普林斯顿大学…...

Commitizen:规范化你的 Git 提交信息
简介 在团队协作开发过程中,规范化的 Git 提交信息可以提高代码维护的效率,便于追踪和定位问题。Commitizen 是一个帮助我们规范化 Git 提交信息的工具,它提供了一种交互式的方式来生成符合约定格式的提交信息。 原理 Commitizen 的核心原…...
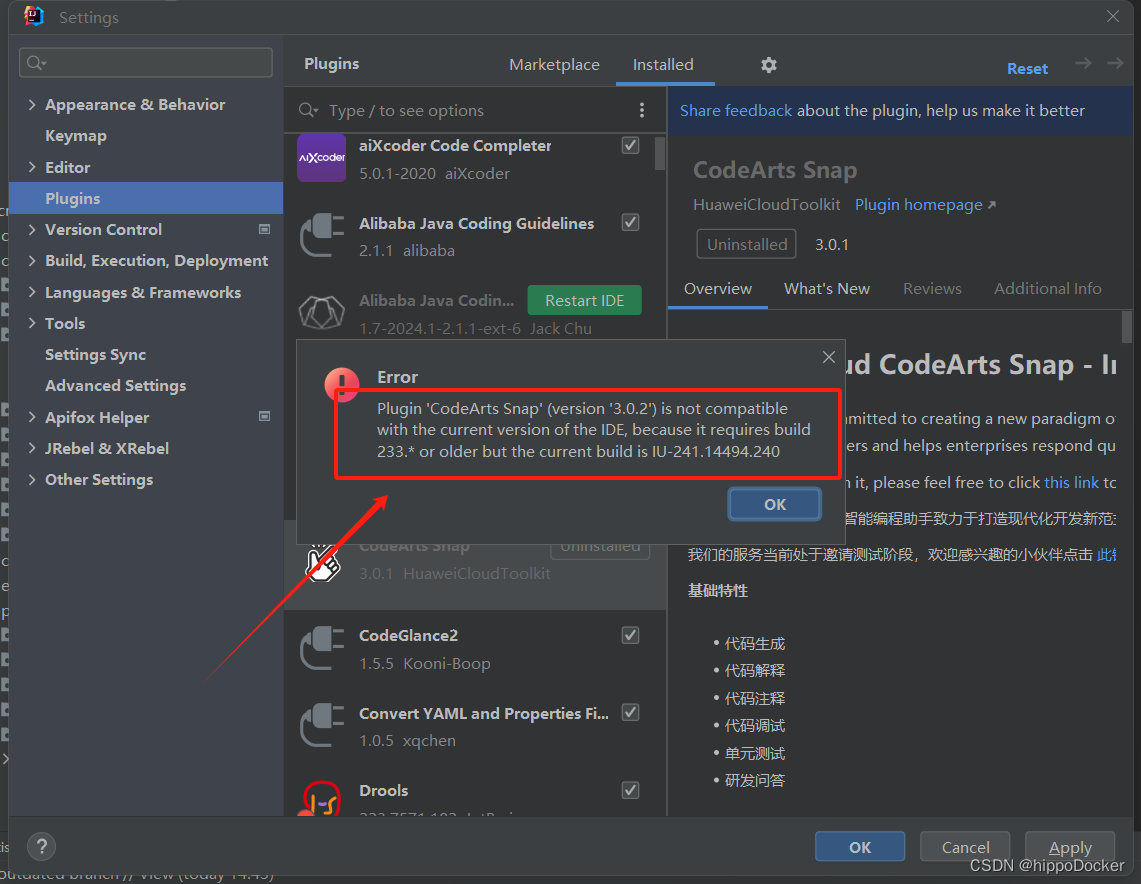
官网下载IDE插件并导入IDE
官网下载IDEA插件并导入IDEA 1. 下载插件2. 导入插件 1. 下载插件 地址:https://plugins.jetbrains.com/plugin/21068-codearts-snap/versions 说明:本次演示以IDEA软件为例 操作: 等待下载完成 2. 导入插件 点击File->setting->Pl…...

三行命令解决Ubuntu Linux联网问题
本博客中Ubuntu版本为23.10.1最新版本,后续发现了很多问题我无法解决,已经下载了另外一个版本22.04,此版本自带网络 一开始我找到官方文档描述可以通过命令行连接到 WiFi 网络:https://cn.linux-console.net/?p10334#google_vig…...

AI大模型在自然语言处理中的应用:性能表现和未来趋势
引言 A. AI大模型在自然语言处理中的应用背景简介 近年来,随着深度学习和人工智能技术的快速发展,越来越多的研究人员和企业开始关注应用于自然语言处理的AI大模型。这些模型采用了深层的神经网络结构,具有强大的学习和处理能力,…...

三防平板定制服务:亿道信息与个性化生产的紧密结合
在当今数字化时代,个性化定制已经成为了市场的一大趋势,而三防平板定制服务作为其中的一部分,展现了数字化技术与个性化需求之间的紧密结合。这种服务是通过亿道信息所提供的技术支持,为用户提供了满足特定需求的定制化三防平板&a…...

【备战蓝桥杯】2024蓝桥杯赛前突击省一:基础数论篇
2024蓝桥杯赛前突击省一:基础算法模版篇 基础数论算法回顾 判断质数(试除法) 时间复杂度O(sqrt(n)) static int is_prime(int n){if(n<2) return 0;for (int i2;i<n/i;i){if(n%i0) return 0;}return 1; }质因…...

golang es查询的一些操作,has_child,inner_hit,对索引内父子文档的更新
1.因为业务需要查询父文档以及其下子文档,搞了很久才理清楚。 首先还是Inner_hits,inner_hits只能用在nested,has_child,has_parents查询里面 {"query": {"nested": {"path": "comments","query": {"match…...

精准备份:如何自动化单个MySQL数据库的备份过程
自动化备份对于维护数据库的完整性和安全性至关重要。本指南将向您展示如何使用Shell脚本来自动化MySQL数据库的备份过程。 备份脚本内容 首先,这是我们将使用的备份脚本: #!/bin/bash# 完成数据库的定时备份 # 备份路径 BACKUP/data/backup/db # 当前…...
Green Hills 自带的MULTI调试器查看R7芯片寄存器
Green Hills在查看芯片寄存器时需要导入 .grd文件。下面以R7为例,演示一下过程。 首先打开MULTI调试器,如下所示View->Registers: 进入如下界面,选择导入寄存器定义文件.grd: 以当前R7芯片举例(dr7f7013…...
Jupyter Notbook如何安装配置并结合内网穿透实现无公网IP远程连接使用
文章目录 推荐1.前言2.Jupyter Notebook的安装2.1 Jupyter Notebook下载安装2.2 Jupyter Notebook的配置2.3 Cpolar下载安装 3.Cpolar端口设置3.1 Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&am…...

基于 SpringBoot 的自助图书借阅管理系统源码讲解
以下是一个基于 SpringBoot 的自助图书借阅管理系统的 核心源码讲解,涵盖用户管理、图书管理、借阅管理、设备对接等关键模块,代码结构清晰,可直接用于学习或二次开发。一、项目结构src/main/java/com/library/ ├── config/ # 配…...

uniapp 如何实现google登录-安卓端
uniapp 如何实现google登录-安卓端 本文只讲解uniapp安卓端如何获取到idToken来实现登录,ios使用uniapp官方方法可以获取 海外app貌似最常用的就是邮箱登录,在app上表现出来最常用的就是谷歌一键登录,或者邮箱加网页验证;google登…...

别再死记硬背DAQmx流程了!LabVIEW数据采集核心逻辑拆解:以USB-6008正弦波实验为例
从设计模式视角重构LabVIEW数据采集:以USB-6008正弦波实验为例 当LabVIEW新手第一次接触DAQmx数据采集时,往往会被"创建任务→添加通道→配置时钟→开始任务→读取数据→清除任务"的固定流程所困扰。这种机械记忆不仅容易遗忘,更难…...

从混淆矩阵到Kappa系数:实战解析土地利用分类精度评估全流程
1. 土地利用分类精度评估入门指南 当你完成了一张精美的土地利用分类图,最常被问到的问题往往是:"这个结果到底有多准?"作为从业多年的GIS分析师,我见过太多人只关注分类过程却忽视精度验证,最后在项目汇报时…...

GoldHEN Cheats Manager:开源工具提升PS4游戏体验的全方位解决方案
GoldHEN Cheats Manager:开源工具提升PS4游戏体验的全方位解决方案 【免费下载链接】GoldHEN_Cheat_Manager GoldHEN Cheats Manager 项目地址: https://gitcode.com/gh_mirrors/go/GoldHEN_Cheat_Manager GoldHEN Cheats Manager是一款专为PlayStation 4打造…...

【电气数据】电力网络充电站定价策略数据集
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

VSCode插件离线安装的隐藏技巧:如何批量安装.vsix文件提升效率
VSCode插件离线批量安装实战指南:企业级效率提升方案 在团队协作或企业内网环境中,开发者常面临VSCode插件安装的困境——无法访问官方市场、重复下载耗时、版本管理混乱。传统单个.vsix文件安装方式在需要部署数十个插件时,效率低下到令人抓…...

别再手动推导了!用Sophus库5分钟搞定机器人SLAM中的位姿插值与扰动更新
别再手动推导了!用Sophus库5分钟搞定机器人SLAM中的位姿插值与扰动更新 在机器人SLAM开发中,你是否曾为手动推导旋转矩阵的插值公式而抓狂?是否在实现位姿扰动更新时被四元数微分弄得晕头转向?今天,我们将用Sophus库彻…...

如何快速掌握单细胞分析:CELLxGENE新手必看的3个实用技巧
如何快速掌握单细胞分析:CELLxGENE新手必看的3个实用技巧 【免费下载链接】cellxgene An interactive explorer for single-cell transcriptomics data 项目地址: https://gitcode.com/gh_mirrors/ce/cellxgene 你是否曾经面对海量的单细胞转录组数据感到无从…...

终极指南:如何快速免费修改艾尔登法环存档
终极指南:如何快速免费修改艾尔登法环存档 【免费下载链接】ER-Save-Editor Elden Ring Save Editor. Compatible with PC and Playstation saves. 项目地址: https://gitcode.com/GitHub_Trending/er/ER-Save-Editor ER-Save-Editor是一款专为《艾尔登法环》…...