AI大模型在自然语言处理中的应用:性能表现和未来趋势
引言
A. AI大模型在自然语言处理中的应用背景简介
近年来,随着深度学习和人工智能技术的快速发展,越来越多的研究人员和企业开始关注应用于自然语言处理的AI大模型。这些模型采用了深层的神经网络结构,具有强大的学习和处理能力,在多项自然语言处理任务中表现出色。AI大模型应用于文本分类、情感分析、机器翻译、问答系统、语义理解、实体识别等方面,有望重新定义自然语言处理的研究和应用。
B. 本文旨在探究AI大模型在自然语言处理中的性能表现和未来趋势
随着AI大模型在自然语言处理领域中的应用逐渐成熟,对其性能表现和未来发展趋势的研究也日益重要。本文旨在分析AI大模型在自然语言处理领域中的应用案例,探究它们在不同任务中的表现和优缺点;再从性能表现的角度出发,分析AI大模型在训练效率、质量控制等方面的挑战与发展空间;最后,展望AI大模型未来的发展趋势,探讨人工智能技术应用于自然语言处理未来可能的发展方向。
II. AI大模型在自然语言处理中的应用案例
随着AI大模型在自然语言处理领域中的应用逐渐成熟,越来越多的研究人员和企业开始关注其在文本分类、命名实体识别、问答系统等方面的应用。以下将介绍几种常见的AI大模型在自然语言处理中的应用案例。
A. 文本分类
文本分类是一种常见的自然语言处理任务,其目标是将输入的文本分为不同的预定义类别。AI大模型在文本分类中的应用可以大大提高预测准确率和泛化能力。
1. BERT模型
BERT(Bidirectional Encoder Representations from Transformers)是Google于2018年9月发布的预训练语言模型。BERT采用Transformer网络架构,通过前馈神经网络对输入的文本进行编码,从而生成一个上下文相关性的表征。BERT模型在多项自然语言处理任务中表现出色,特别是在文本分类方面。
2. GPT-3模型
GPT-3(Generative Pre-trained Transformer 3)是OpenAI于2020年发布的预训练语言模型。该模型采用了极大规模的参数,可以完成许多强大的自然语言处理任务,例如问答、机器翻译和文本生成等。在文本分类方面,GPT-3相对于BERT模型更为灵活,可以通过微调实现优秀的分类效果。
B. 命名实体识别
命名实体识别是指识别出文本中具有特定意义的实体,包括人名、组织机构、地名、时间、日期等。命名实体识别在推荐系统、搜索引擎和自然语言对话等方面具有广泛的应用场景。
1. RoBERTa模型
RoBERTa(Robustly Optimized BERT Approach)是Facebook于2019年发布的预训练语言模型,其用途包括序列分类、目标任务特征提取、文本分类等。在命名实体识别领域,RoBERTa采用了类似BERT的CNN、RNN和自注意力机制等方式,显著提高了预测准确率。
2. ELECTRA模型
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)是Google于2020年发布的预训练语言模型。与RoBERTa相比,ELECTRA通过学习模型的生成过程来替代掉原始输入信息,进一步提高了命名实体识别的准确率和效率。
C. 问答系统
问答系统是一种将自然语言提问和回答自然语言问题相结合的应用程序。其通常需要很好的上下文理解和推理能力。
1. T5模型
T5(Text-to-Text Transfer Transformer)是Google于2019年发布的预训练语言模型。该模型将各种自然语言处理任务表示为一种“文本到文本”的形式,并通过模板填充和条件语言生成等方式,实现多种问答系统的构建。T5模型在问答系统领域具有良好的效果和广泛的适用范围。
2. XLNet模型
XLNet(Generalized Autoregressive Pretraining for Language Understanding)是CMU和谷歌于2019年发布的预训练语言模型。该模型在自注意力机制和掩码等方面进行优化,可以从未标记的文本中学习上下文表示,为构建更复杂的问答系统提供了更强大的基础。
以上是几种常见的AI大模型在自然语言处理领域中的应用案例,这些模型都具有良好的性能表现,在许多关键任务中都取得了优秀的成果。
III. AI大模型在自然语言处理中的性能表现
AI大模型在自然语言处理领域中获得了巨大的成功,但是同时也存在许多挑战和问题。在这一部分,我们将分析AI大模型在处理自然语言时可能存在的性能问题。这些问题包括模型的精度和训练效率、模型的可解释性和质量控制以及模型的可扩展性和通用性。
A. 模型的精度和训练效率
模型的精度和训练效率是AI大模型在自然语言处理中的一个重要挑战之一。虽然AI大模型在很多领域内表现良好,但是训练这些模型需要大量的计算资源和存储资源,尤其是在需要训练具备高精度的大模型时更为明显。
为了解决这个问题,研究人员正在探索一些新的技术,例如迁移学习和增量学习,以便在保持高模型精度的同时减少训练数据和计算资源。这些方法可以在不影响模型精度的情况下降低训练要求,使得研究者和企业能够更容易地利用AI大模型进行自然语言处理任务。
B. 模型的可解释性和质量控制
AI大模型在自然语言处理中表现出来的优异性往往反映了它在难以描述或原始数据范畴组织等纷繁复杂问题的表现。这意味着虽然这些模型可以实现高精度的自然语言处理任务,但是在检查模型中处理文本的方式和生成答案的原因上几乎无法得到解释。这不仅使得AI大模型在解释其处理过程方面受阻,而且使得模型内的错误难以探寻和修正,这是模型真正临终的原因。
为解决这些问题,一些研究人员正在开发新的方法,例如模型可解释性和视觉化技术。这些方法可以帮助解释模型的决策过程,使得研究者和企业可以更理解模型在处理自然语言时的行为,从而改进模型的质量控制。
C. 模型的可扩展性和通用性
AI大模型不仅需要在处理自然语言时具备良好的精度、效率和可解释性,还需要具备良好的可扩展性和通用性。因此,这些模型需要在尽可能少的调整或改变下,必须能够处理语言数据的广泛形式和方法。而且,这些模型还需要提高迁移学习和联邦学习等技术,以便能在处理多方数据时能够维护数据隐私性。
针对这些问题,一些研究者正在开发新的方法,例如基于共享词向量的多语言模型,这些模型可以在多种语言之间共享学习。 同时,为了提高模型的可扩展性和通用性,在开发模型时,需要注意如何在保持高部署效率的同时,积极开发新技术和算法,以增强模型对于多语言和多媒体数据类型的适应能力。
综合上述, AI大模型在自然语言处理中表现出的优越性和挑战性都对未来研究和应用提出了新的要求。在未来,我们有必要做出努力,表面AI大模型的性能和可扩展能力的同时,注意其可解释性和质量控制问题,以实现更加智能、人性化和安全的应用场景。
IV. AI大模型在自然语言处理中的未来趋势
AI大模型是自然语言处理领域最具潜力的技术之一。随着其在自然语言处理任务中的成功,未来研究和发展的趋势也逐渐清晰。以下将介绍AI大模型在自然语言处理中的三个未来发展趋势:结合多模态数据和多语言数据、发展更小的大模型和更大的超大模型、以及推广模型的可解释性和质量控制。
A. 结合多模态数据和多语言数据
多模态数据指的是来自多个源的不同形式的数据,例如图像、音频、视频和文本等。多语言数据指的是来自不同语言的数据。结合多模态数据和多语言数据可以提高自然语言处理的效率和准确性。使用多项数据来源和语言种类可以增加训练样本的数量和多样性,从而提高模型的鲁棒性和泛化性,进一步增强其性能。例如,可以使用语音、视觉、地理信息等与自然语言相结合的技术,解决具有复杂内容和场景条目性的问题,以及针对多语种和多媒体数据的建模和学习,进而引领自然语言处理领域的未来方向。
B. 发展更小的大模型和更大的超大模型
随着AI大模型的发展,过度依赖超大模型以获取更好的性能变得越来越普遍,而这会导致非常高的度偏,及其不适合低计算力设备的部署。因此,未来研究的重点将更多地放在调整模型体系结构和开发更小的大模型上,以实现更高的效率和更强的移动设备支持。同时,还可以探索语言和领域之间的关系,并开发针对不同领域和任务的模型,将自然语言处理与领域特定的解决方案结合起来。
C. 推广模型的可解释性和质量控制
AI大模型在解决自然语言处理问题方面取得了很大进展,但是由于其多层次的神经网络结构以及处理文本的高度抽象方法,使得这些模型内部的工作过程难以解释和掌握。未来,需要注重模型的可解释性和质量控制的问题,使其更透明,更可理解,更可改进。其中,可以通过可视化技术、交互式方法等手段使得人能够更好的理解模型,排除其中存在的错误和隐患,提升自然语言处理的效率和可靠性。
综上所述,AI大模型在自然语言处理领域的未来发展趋势不仅包括结合多模态数据和多语言数据、发展更小的大模型和更大的超大模型、以及推广模型的可解释性和质量控制,还包括其他一系列的技术和方法的实现,这些方法将有助于更好地应对自然语言处理领域中所面临的各种问题,进一步深入挖掘AI大模型在这个领域的巨大潜力。
相关文章:

AI大模型在自然语言处理中的应用:性能表现和未来趋势
引言 A. AI大模型在自然语言处理中的应用背景简介 近年来,随着深度学习和人工智能技术的快速发展,越来越多的研究人员和企业开始关注应用于自然语言处理的AI大模型。这些模型采用了深层的神经网络结构,具有强大的学习和处理能力,…...

三防平板定制服务:亿道信息与个性化生产的紧密结合
在当今数字化时代,个性化定制已经成为了市场的一大趋势,而三防平板定制服务作为其中的一部分,展现了数字化技术与个性化需求之间的紧密结合。这种服务是通过亿道信息所提供的技术支持,为用户提供了满足特定需求的定制化三防平板&a…...

【备战蓝桥杯】2024蓝桥杯赛前突击省一:基础数论篇
2024蓝桥杯赛前突击省一:基础算法模版篇 基础数论算法回顾 判断质数(试除法) 时间复杂度O(sqrt(n)) static int is_prime(int n){if(n<2) return 0;for (int i2;i<n/i;i){if(n%i0) return 0;}return 1; }质因…...

golang es查询的一些操作,has_child,inner_hit,对索引内父子文档的更新
1.因为业务需要查询父文档以及其下子文档,搞了很久才理清楚。 首先还是Inner_hits,inner_hits只能用在nested,has_child,has_parents查询里面 {"query": {"nested": {"path": "comments","query": {"match…...

精准备份:如何自动化单个MySQL数据库的备份过程
自动化备份对于维护数据库的完整性和安全性至关重要。本指南将向您展示如何使用Shell脚本来自动化MySQL数据库的备份过程。 备份脚本内容 首先,这是我们将使用的备份脚本: #!/bin/bash# 完成数据库的定时备份 # 备份路径 BACKUP/data/backup/db # 当前…...
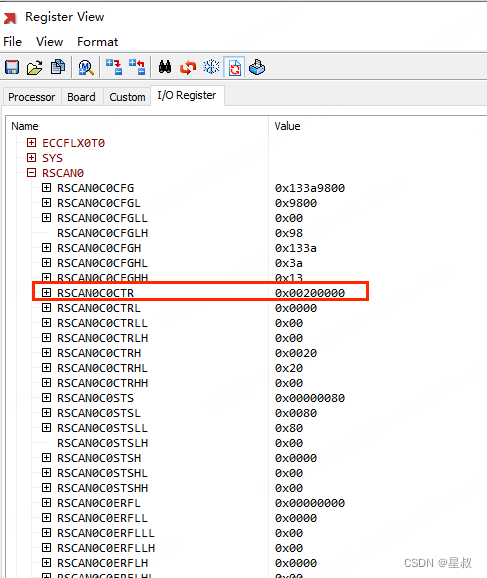
Green Hills 自带的MULTI调试器查看R7芯片寄存器
Green Hills在查看芯片寄存器时需要导入 .grd文件。下面以R7为例,演示一下过程。 首先打开MULTI调试器,如下所示View->Registers: 进入如下界面,选择导入寄存器定义文件.grd: 以当前R7芯片举例(dr7f7013…...
Jupyter Notbook如何安装配置并结合内网穿透实现无公网IP远程连接使用
文章目录 推荐1.前言2.Jupyter Notebook的安装2.1 Jupyter Notebook下载安装2.2 Jupyter Notebook的配置2.3 Cpolar下载安装 3.Cpolar端口设置3.1 Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&am…...
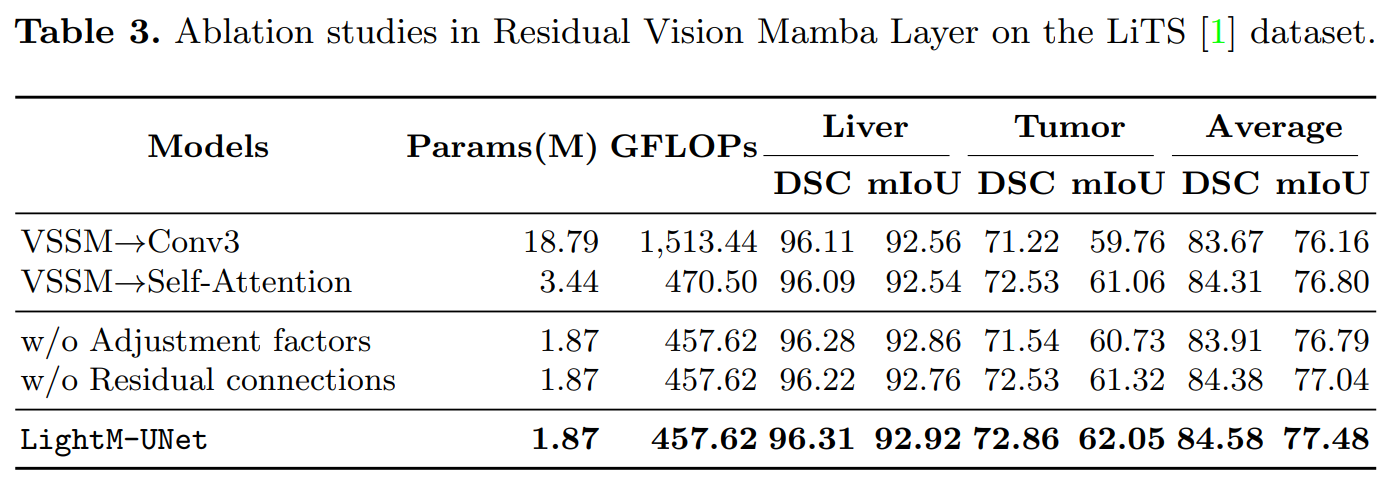
LightM-UNet:Mamba 辅助的轻量级 UNet 用于医学图像分割
文章目录 摘要1 简介2、方法论2.1、架构概述2.2、编码器块2.3、瓶颈块2.4、解码器块 3、实验4、结论 摘要 https://arxiv.org/pdf/2403.05246.pdf UNet及其变体在医学图像分割中得到了广泛应用。然而,这些模型,特别是基于Transformer架构的模型…...
探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言 在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析…...

day16 java object中equals、finalize、
Object类 1.Object类是所有类的父类。 2.一个类如果没有显示继承其它类默认继承Object类equals方法 1.Object中的equals方法 - 用来比较地址值 public boolean equals(Object obj) { return (this obj); } 2.像核心类库中的许多类都重写了equals方法(比如&…...
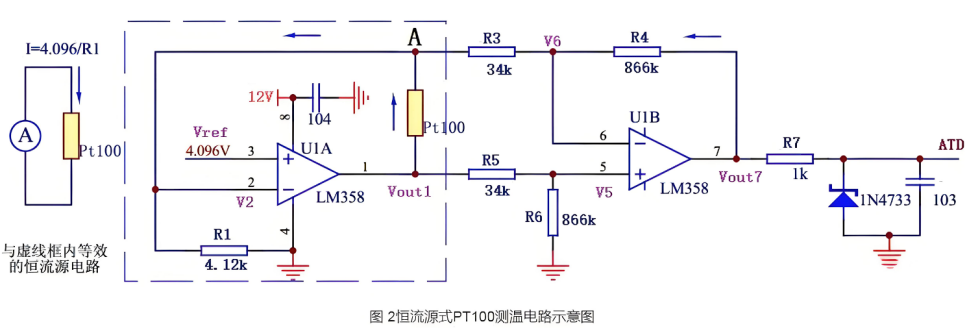
如何应用电桥电路的原理?
电桥电路是一种常用的测量技术,它利用了四个电阻的网络来检测电路的平衡状态。在平衡状态下,电桥的输出电压为零,这种特性使得电桥电路非常适合于精确测量电阻、电感、电容等电气参数,以及用于传感器和测量设备中。以下是电桥电路…...

大话设计模式——24.迭代器模式(Iterator Pattern)
简介 提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部实现。(Java中使用最多的设计模式之一) UML图 应用场景 Java的集合对象:Collection、List、Map、Set等都有迭代器Java ArrayList的迭代器源码 示例 简…...

【数据结构】双向链表 C++
一、什么是双向链表 1、定义 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。 双…...
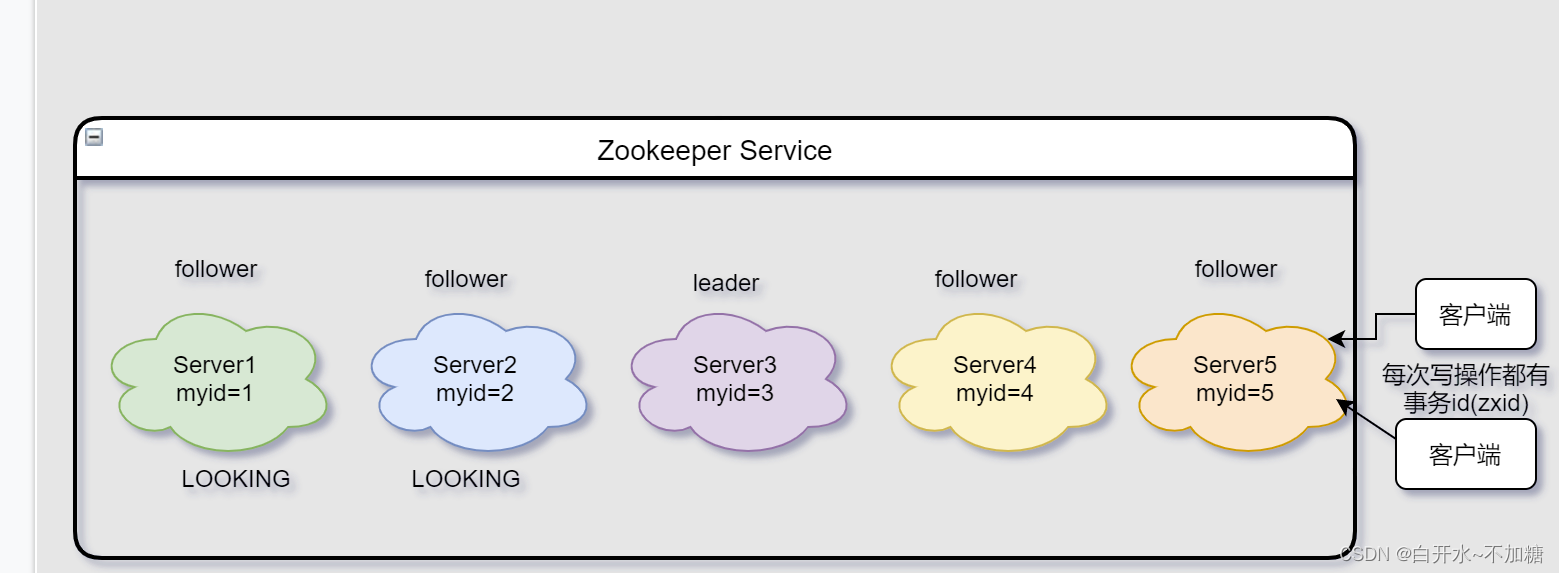
消息队列之-----------------zookeeper机制
目录 一、ZooKeeper是什么 二、ZooKeeper的工作机制 三、ZooKeeper特点 四、ZooKeeper数据结构 五、ZooKeeper应用场景 5.1统一命名服务 5.2统一配置管理 5.3统一集群管理 5.4服务器动态上下线 5.5软负载均衡 六、ZooKeeper的选举机制 6.1第一次启动选举机制 6.2非…...
第十届蓝桥杯大赛个人赛省赛(软件类) CC++ 研究生组2.0
A立方和 #include<iostream> #include<cmath> using namespace std; int main(){int n, t, flag, x;long long ans 0;for(int i 1; i < 2019; i){t i;flag 0;while(t && !flag){x t % 10;if(x 2 || x 0 || x 1 || x 9) flag 1;t / 10;}if(fl…...
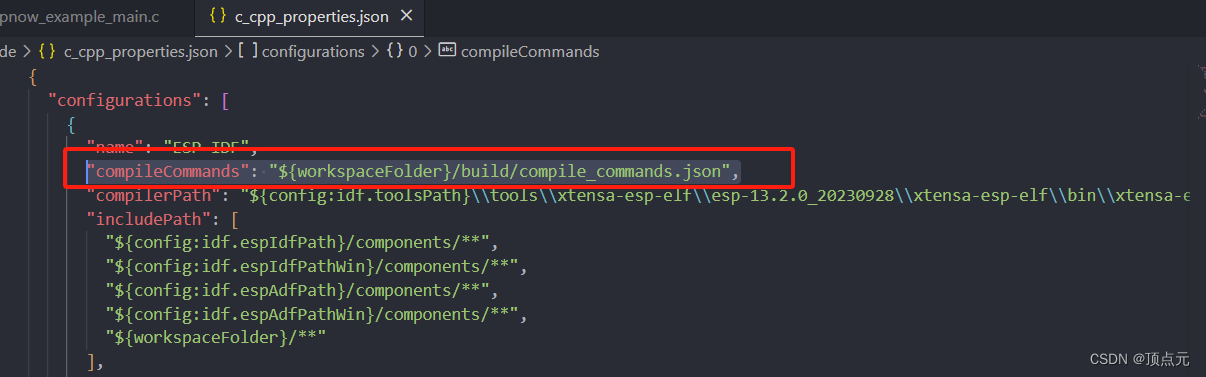
vscode开发ESP32问题记录
vscode 开发ESP32问题记录 1. 解决vscode中的波浪线警告 1. 解决vscode中的波浪线警告 参考链接:https://blog.csdn.net/fucingman/article/details/134404485 首先可以通过vscode 中的IDF插件生成模板工程,这样会自动创建.vscode文件夹中的一些json配…...
R语言复现:轨迹增长模型发表二区文章 | 潜变量模型系列(2)
培训通知 Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。 案例分享 2022年9月,中国四川大学学者在《Journal of Psychosomatic Research》(二区,I…...

【数据结构】顺序表的实现——动态分配
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:数据结构 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...

3.3.k8s搭建-rancher RKE2
目录 RKE2介绍 k8s集群搭建 搭建k8s集群 下载离线包 部署rke2-server 部署rke2-agent 部署helm 部署rancher RKE2介绍 RKE2,也称为 RKE Government,是 Rancher 的下一代 Kubernetes 发行版。 官网地址:Introduction | RKE2 k8s集群搭…...
CST电磁仿真软件的设置变更与问题【官方教程】
保存结果的Result Navigator 积累的结果一目了然! 用户界面上的Result Navigator 在一个仿真工程中更改变量取值进行仿真分析或者改变设置进行仿真分析时,之前的1DResult会不会消失呢? 1D Result:CST中1D Result指的是Y值取决…...

实战调试:段页式内存管理中的首次页故障剖析
1. 段页式内存管理基础概念 段页式内存管理是现代操作系统的核心机制之一,它巧妙结合了分段和分页两种技术的优势。简单来说,就像我们整理衣柜时既按季节(分段)又用收纳盒(分页)来管理衣物。CPU看到的线性地…...

OpenClaw+Qwen3-32B内容创作流:从提纲到公众号发布的自动化
OpenClawQwen3-32B内容创作流:从提纲到公众号发布的自动化 1. 为什么需要自动化内容创作 作为一个技术博主,我每周至少要产出2-3篇深度文章。最痛苦的时刻不是写作本身,而是面对空白文档时的"冷启动"阶段——从选题构思到完成初稿…...

别再到处找免费AI了!用Cherry Studio+OpenRouter,5分钟搞定DeepSeek-R1和Gemini Pro 2.0
高效获取顶级AI模型的实战指南:Cherry Studio与OpenRouter深度整合方案 在探索前沿AI技术时,许多开发者都面临一个共同困境:如何在预算有限的情况下,稳定使用如DeepSeek-R1和Gemini Pro 2.0这样的尖端大语言模型?市面上…...

run-aspnetcore-microservices 购物车微服务:Redis分布式缓存与Grpc同步通信实现
run-aspnetcore-microservices 购物车微服务:Redis分布式缓存与Grpc同步通信实现 【免费下载链接】run-aspnetcore-microservices aspnetrun/run-aspnetcore-microservices: 是一个用于部署和运行 ASP.NET Core 微服务应用程序的开源项目,提供了一个简单…...

granite-4.0-h-350m效果展示:Ollama运行下德语工业标准文档理解案例
granite-4.0-h-350m效果展示:Ollama运行下德语工业标准文档理解案例 1. 模型核心能力概览 Granite-4.0-H-350M是一个轻量级但功能强大的指令模型,专门针对设备部署和研究场景优化。这个350M参数的模型虽然体积小巧,但在多语言理解和指令跟随…...

深入Fast DDS传输层:从UDP、TCP到共享内存,如何为你的ROS2应用选择最佳通信方式?
Fast DDS传输层深度解析:UDP、TCP与共享内存的工程实践指南 在分布式系统架构中,通信中间件的性能直接影响整个系统的响应速度和可靠性。作为ROS 2的默认通信中间件,Fast DDS提供了多种传输协议选择,但如何根据实际场景做出最优决…...

逆向视角看iOS加固:从机器码到伪代码,手把手教你分析加固效果与潜在风险
逆向视角看iOS加固:从机器码到伪代码的深度解析 当你在App Store下载一个应用时,可能不会想到这个看似简单的IPA文件背后隐藏着怎样的技术博弈。作为iOS开发者或安全研究员,我们常常需要从另一个角度思考——不是如何保护自己的应用…...

王者荣耀进阶指南:如何用这个HTML5模拟器测试不同出装对英雄属性的影响
王者荣耀进阶指南:如何用HTML5模拟器优化英雄出装策略 在MOBA游戏的战术体系中,装备选择往往决定着团战的胜负走向。传统依靠经验积累的配装方式存在试错成本高、数据感知模糊等痛点,而现代HTML5技术构建的模拟器为玩家提供了可视化、即时反馈…...

突破设备边界:开源串流解决方案Sunshine革新跨设备游戏共享体验
突破设备边界:开源串流解决方案Sunshine革新跨设备游戏共享体验 【免费下载链接】Sunshine Sunshine: Sunshine是一个自托管的游戏流媒体服务器,支持通过Moonlight在各种设备上进行低延迟的游戏串流。 项目地址: https://gitcode.com/GitHub_Trending/…...
)
全学科适用AI写作辅助网站排行榜(2026 实测推荐)
基于功能完整性、学术适配性、用户反馈及操作便捷性,以下是当前主流AI论文写作工具的实测排名,按综合使用价值从高到低依次呈现,并附上各平台的核心优势与适用人群。🏆 第一梯队:全流程学术解决方案(★★★…...