探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言
在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析它们的功能特点、优势以及适用场景,以助开发者选择最适合自己项目需求的工具。
2、Jsoup
2.1、简介
Jsoup 是一款 Java 编写的开源 HTML 解析器,它提供了一套丰富的 API,用于解析、操作和清理 HTML 文档。Jsoup 能够从网页中提取数据,并且广泛应用于网络爬虫、数据挖掘和自动化测试等领域。
Jsoup 官方网站
2.2、特性
- 轻量级:Jsoup 作为一个轻量级的库,不需要额外的服务器或复杂的配置即可使用。
- 解析能力:能够从 HTML 文件、字符串或 URL 中解析文档,并提取数据。
- 强大的选择器:支持 CSS 选择器和正则表达式,使得数据提取更加灵活和高效。
- 易于使用:API 设计直观,易于上手,适合初学者和有经验的开发者。
- 处理异常:能够处理 HTML 文档中的异常情况,如不完整的标签等。
2.3、优点
- 易学易用:Jsoup 的 API 设计简单直观,学习成本低。
- 灵活性:支持多种数据提取方式,适应不同的数据抽取需求。
- 社区支持:作为一个成熟的开源项目,Jsoup 拥有活跃的社区,方便获取帮助和资源。
2.4、缺点
- 不支持 JavaScript:无法直接处理 JavaScript 动态加载的内容。
- 性能限制:对于大型或复杂的 HTML 文档,解析速度可能不如其他专业的解析工具。
- 安全风险:如果不正确使用,可能会引入跨站脚本攻击(XSS)等安全问题。
2.5、使用场景
- 静态网页爬取:适用于从不需要执行 JavaScript 的静态网页中提取信息。
- 数据提取:从网页中提取链接、图片、文本等数据。
- 自动化测试:在 Web 应用程序的自动化测试中,用于模拟用户操作和验证页面内容。
- 内容清洗:清理 HTML 文档,移除不需要的元素或属性,确保输出的 HTML 是安全和干净的。
2.6、注意事项
- JavaScript 渲染:Jsoup 不执行 JavaScript,因此无法直接从依赖 JavaScript 动态生成的内容中提取数据。
- 编码问题:在处理非标准编码的 HTML 文档时,可能需要手动设置字符编码。
- 异常处理:虽然 Jsoup 能够处理一些异常情况,但对于某些复杂的 HTML 结构,可能需要额外的处理逻辑。
2.7、示例代码
如果你使用的是 Maven,可以在 pom.xml 文件中添加以下依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.17.2</version> <!-- 请使用最新版本 -->
</dependency>
以下是一个简单的 Jsoup 示例代码,演示了如何抓取百度首页上的热门搜索新闻:
public class JsoupExample {public static void main(String[] args) {// 目标网页 URLString url = "https://www.baidu.com";try {// 连接到网页并获取文档对象Document doc = Jsoup.connect(url).get();// 获取百度首页热搜Elements hotSearchList = doc.selectXpath("//*[@id=\"hotsearch-content-wrapper\"]/li");System.out.println("今日百度热搜:");// 遍历所有热搜新闻for (Element hotSearch : hotSearchList) {Elements newsMetaList = hotSearch.selectXpath(".//span");for (Element newsMeta : newsMetaList) {System.out.print(newsMeta.text() + " ");}System.out.print("\n");}} catch (Exception e) {e.printStackTrace();}}
}
运行结果截图如下:
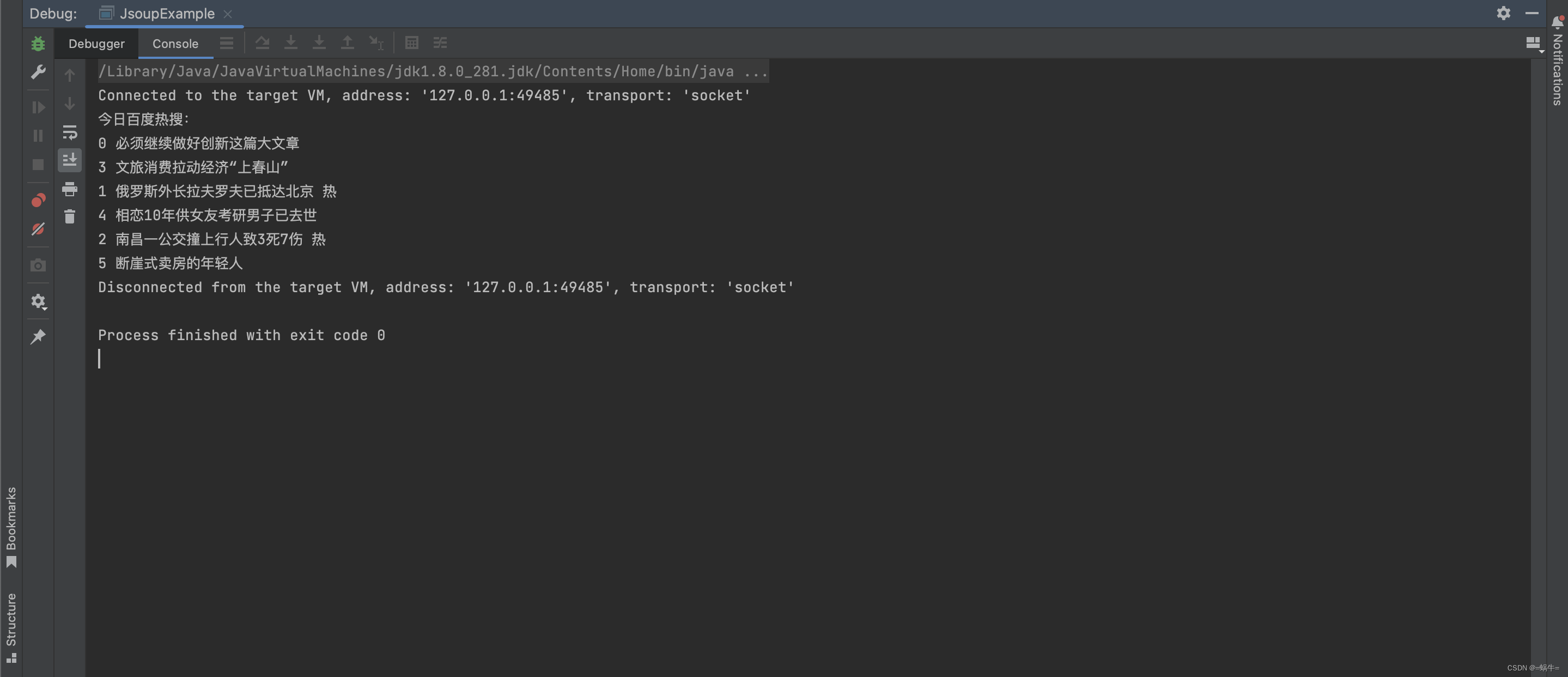
Jsoup 主要用于静态网页的内容抓取,对于使用 Vue.js 等现代 JavaScript 框架构建的动态网站,其直接获取页面内容的能力受限。由于 Vue.js 等框架通过 JavaScript 动态生成页面内容,Jsoup 无法执行相应的脚本,因此可能无法获取到完整的、动态渲染的数据。
因此,使用 Jsoup 爬取这类网站时,通常只能获取到初始的、不包含动态数据的HTML结构。结果如下:
<!doctype html>
<html><head><meta charset="utf-8"></head><body><div id="app"></div></body>
</html>
3、HtmlUnit
3.1、简介
HtmlUnit 是一个用 Java 编写的无界面浏览器,它模拟 HTML 文档并提供了一系列 API,允许开发者以编程方式与网页进行交互。这个工具可以用于自动化测试、网络爬虫以及自动化网页交互等场景。HtmlUnit 支持 JavaScript(通过 Mozilla Rhino 引擎),并且能够处理 AJAX 功能,使得它能够与现代的动态网页进行交互。
HtmlUnit 官方网站
HtmlUnit GitHub
3.2、特性
- 无界面:HtmlUnit 不需要图形用户界面,可以在服务器或后台环境中运行。
- 支持 JavaScript:内置 Rhino JavaScript 引擎,可以执行 JavaScript 代码,处理 AJAX 请求。
- 模拟浏览器行为:可以模拟用户在浏览器中的操作,如点击、表单提交等。
- 多浏览器模拟:可以模拟多种浏览器,如 Chrome、Firefox、Internet Explorer 等。
- 丰富的 API:提供了丰富的 API 来操作网页元素,如获取、设置属性、执行事件等。
3.3、优点
- 易用性:HtmlUnit 的 API 设计简单直观,易于上手和使用。
- 跨平台:作为无界面浏览器,HtmlUnit 可以在任何支持Java的平台上运行。
- 社区支持:作为一个成熟的开源项目,HtmlUnit 拥有活跃的社区,可以方便地获取帮助和资源。
3.4、缺点
- 性能:由于 HtmlUnit 需要解释 JavaScript,对于复杂的 JavaScript 操作,性能可能不如真实浏览器。
- 兼容性:虽然支持多种浏览器特性,但仍有可能遇到一些网页在 HtmlUnit 中无法正确渲染或表现的问题。
- 更新维护:随着 Web 技术的发展,HtmlUnit 需要不断更新以支持新的Web标准和特性,这可能导致版本间的不兼容问题。
3.5、使用场景
- 自动化测试:用于 Web 应用程序的功能测试,模拟用户操作验证应用程序的行为。
- 网络爬虫:抓取网站数据,提取信息,适用于数据分析、数据挖掘等。
- Web 自动化:自动化执行 Web 相关的任务,如登录、下载文件、填写并提交表单等。
3.6、注意事项
- CSS 和 JavaScript 支持:HtmlUnit 对 CSS 和 JavaScript 的支持可能不如真实浏览器完美,有时候需要禁用 CSS 和 JavaScript 来避免潜在的问题。
- 异常处理:在处理 JavaScript 错误时,可以通过设置来防止测试因脚本错误而失败。
- 版本兼容性:使用 HtmlUnit 时,需要注意库的版本与依赖的其他库的兼容性,以及与目标网站的 JavaScript 和 CSS 的兼容性。
3.7、示例代码
如果你使用的是 Maven,可以在 pom.xml 文件中添加以下依赖
<!-- https://mvnrepository.com/artifact/org.htmlunit/htmlunit -->
<dependency><groupId>org.htmlunit</groupId><artifactId>htmlunit</artifactId><version>4.0.0</version> <!-- 请使用最新版本 -->
</dependency>
以下是一个简单的 HtmlUnit 示例代码,演示了如何抓取百度首页上的热门搜索新闻:
public class HtmlUnitExample {public static void main(String[] args) {// 目标网页 URLString url = "https://www.baidu.com";WebClient webClient = getWebClient();try {// 打开网页HtmlPage page = webClient.getPage(url);// 获取网页标题String title = page.getTitleText();System.out.println("网页标题: " + title);// 获取百度首页热搜List<DomElement> hotSearchList = page.getByXPath("//*[@id=\"hotsearch-content-wrapper\"]/li");System.out.println("今日百度热搜:");// 遍历所有热搜新闻for (DomElement hotSearch : hotSearchList){List<DomElement> newsMetaList = hotSearch.getByXPath(".//span");for (DomElement newsMeta : newsMetaList) {System.out.print(newsMeta.asNormalizedText() + " ");}System.out.print("\n");}} catch (Exception e) {e.printStackTrace();} finally {// 关闭WebClient,释放资源webClient.close();}}/*** <h2>获取一个 Web 模拟浏览器客户端</h2>*/public static WebClient getWebClient(){// 浏览器设置WebClient webClient = new WebClient(BrowserVersion.CHROME);// ajaxwebClient.setAjaxController(new NicelyResynchronizingAjaxController());// 支持jswebClient.getOptions().setJavaScriptEnabled(true);// 忽略js错误webClient.getOptions().setThrowExceptionOnScriptError(false);// 忽略css错误webClient.setCssErrorHandler(new SilentCssErrorHandler());// 不执行CSS渲染webClient.getOptions().setCssEnabled(false);// 超时时间webClient.getOptions().setTimeout(3000);// 允许重定向webClient.getOptions().setRedirectEnabled(true);// 允许cookiewebClient.getCookieManager().setCookiesEnabled(true);return webClient;}
}
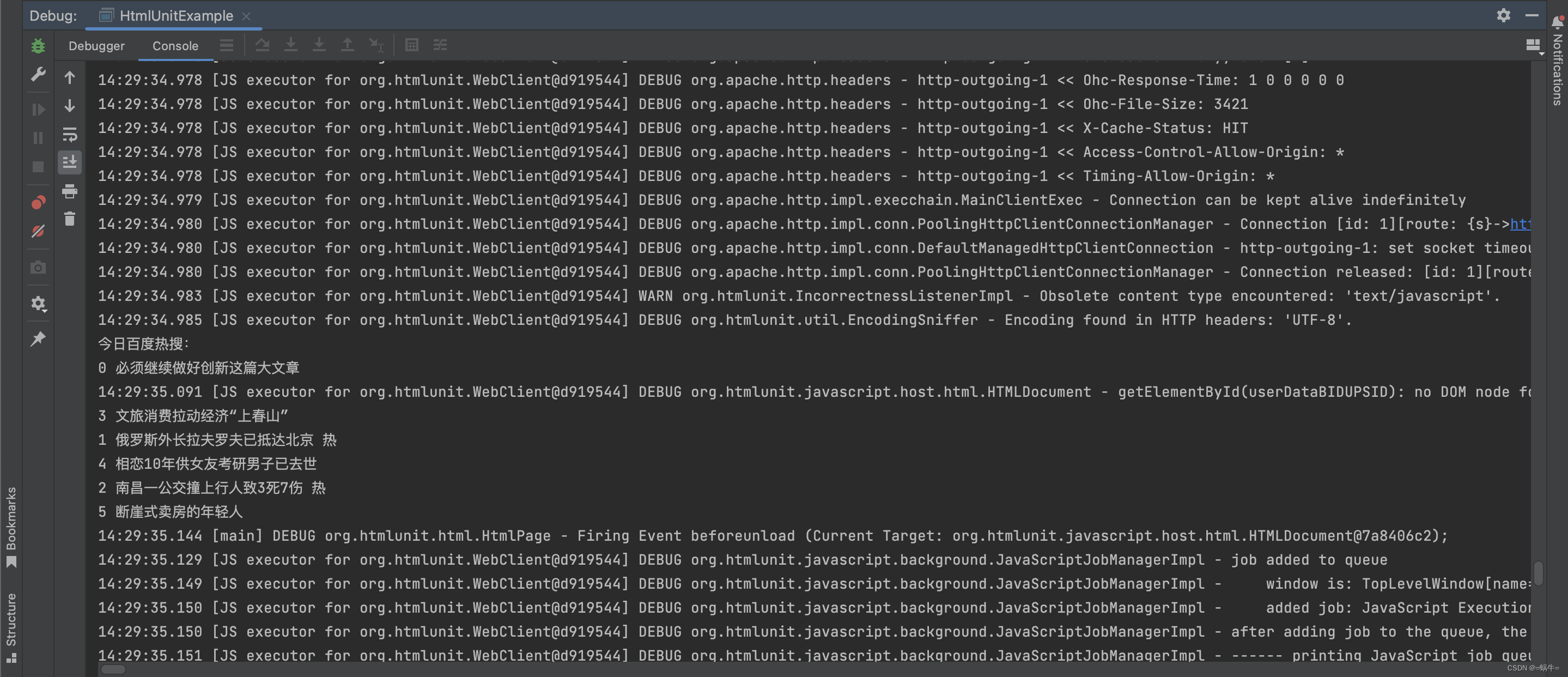
运行结果截图如下:
4、WebMagic
4.1、简介
WebMagic 是一个简单灵活的 Java 爬虫框架。基于 WebMagic,你可以快速开发出一个高效、易维护的爬虫。
WebMagic 官方网站
WebMagic 总体架构图如下:

4.2、特性
- 简洁的 API:WebMagic 提供了简单直观的 API,使得开发者可以快速编写爬虫程序。
- 强大的抽取能力:支持多种数据抽取方式,包括 XPath、正则表达式等,方便从网页中提取所需数据。
- 多线程处理:WebMagic 内部采用多线程进行页面抓取,提高了爬取效率。
- 自动重试机制:在请求失败时,WebMagic 能够自动重试,增强了爬虫的稳定性。
- 灵活的数据处理:允许开发者自定义数据处理逻辑,可以将数据存储到数据库、文件或进行其他处理。
- Site 对象:封装了目标网站的一些基本信息,如编码、重试次数、抓取间隔等,方便配置和调整。
4.3、优点
- 易学易用:WebMagic 的 API 设计简单,学习成本低,适合初学者快速上手。
- 高效稳定:内置多线程处理和自动重试机制,提高了爬虫的效率和稳定性。
- 灵活性:支持自定义数据处理,可以轻松应对不同的数据存储和处理需求。
4.4、缺点
- 社区支持:相比于其他流行的爬虫框架,WebMagic 的社区可能相对较小,资源和支持可能有限。
- 更新维护:Web 技术不断发展,WebMagic 需要不断更新以适应新的网页结构和反爬策略,可能存在一定的维护成本。
- JavaScript 渲染:WebMagic 在处理 JavaScript 动态渲染的页面时可能存在局限,对于复杂的 JavaScript 操作可能需要额外的处理。
4.5、使用场景
- 数据抓取:适用于抓取网站信息,如新闻、博客、商品数据等。
- 网站监控:可以用来监控目标网站的更新,及时获取最新内容。
- 数据分析:抓取的数据可以直接用于数据分析、市场研究等领域。
4.6、注意事项
- 遵守 robots.txt:在使用 WebMagic 进行爬虫开发时,应遵守目标网站的 robots.txt 文件规定,尊重网站的爬虫策略。
- 合理设置抓取间隔:为了避免对目标网站造成过大压力,应设置合理的抓取间隔和重试次数。
- 异常处理:网络请求可能会失败,需要在代码中进行适当的异常处理。
4.7、示例代码
如果你使用的是 Maven,可以在 pom.xml 文件中添加以下依赖
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-core -->
<!-- WebMagic是一个简单灵活的爬虫框架,其核心部分(webmagic-core)是一个精简的、模块化的爬虫实现。 -->
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.9.0</version>
</dependency><!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-extension -->
<!-- WebMagic的扩展模块(webmagic-extension)为使用者提供了更方便的编写爬虫的工具,包括注解格式定义爬虫、JSON、分布式等支持。 -->
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>0.9.0</version>
</dependency><!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-selenium -->
<!-- WebMagic 是一个基于 Java 的开源网络爬虫框架,而 Selenium 是一个用于自动化 Web 浏览器的工具。 -->
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-selenium</artifactId><version>0.9.0</version>
</dependency>以下是一个简单的 WebMagic 示例代码,演示了如何抓取百度首页上的热门搜索新闻:
1、自定义下载器
WebMagic-Selenium 是 WebMagic 爬虫框架的一个扩展,它结合了 WebMagic 的爬虫能力和 Selenium 的浏览器自动化功能。这种结合使得 WebMagic-Selenium 能够处理那些需要执行 JavaScript 或模拟用户交互才能获取完整信息的动态网页。
通过使用 WebMagic-Selenium,开发者可以利用 WebMagic 的简洁 API 来定义爬虫的抓取逻辑,同时使用 Selenium 来处理那些需要复杂交互的网页。例如,可以模拟用户的登录过程、处理弹出窗口、执行复杂的表单提交等操作。
WebMagic 默认使用了 Apache HttpClient 作为下载工具。
/*** <h1>自定义下载器</h1>* Downloader 负责从互联网上下载页面,以便后续处理。* WebMagic 默认使用了Apache HttpClient作为下载工具。* */
public class WNDownloader implements Downloader {// 声明驱动private RemoteWebDriver driver;@Overridepublic Page download(Request request, Task task) {// 第一个参数是使用哪种浏览器驱动,第二个参数是浏览器驱动的地址System.setProperty("webdriver.chrome.driver","/Users/yaoshuaizhou/Downloads/chromedriver-mac-arm64/chromedriver");// 创建浏览器参数对象ChromeOptions chromeOptions = new ChromeOptions();// 设置为 无界面浏览器 模式,若是不想看到浏览器打开,就可以配置此项// chromeOptions.addArguments("--headless");chromeOptions.addArguments("--window-size=1440,1080"); // 设置浏览器窗口打开大小this.driver = new ChromeDriver(chromeOptions); // 创建驱动driver.get(request.getUrl()); // 第一次打开url,跳转到登录页try {Thread.sleep(3000); // 等待打开浏览器// 获取从process返回的site携带的cookies,填充后第二次打开urlSite site = task.getSite();if (site.getCookies() != null) {// for (Map.Entry cookieEntry : site.getCookies()
//
// .entrySet()) {
//
// Cookie cookie = new Cookie(cookieEntry.getKey(),
//
// cookieEntry.getValue());
//
// driver.manage().addCookie(cookie);
//
// }// 添加对应domain的cookie后,第二次打开urldriver.get(request.getUrl());}Thread.sleep(2000);// 需要滚动到页面的底部,获取完整的数据driver.executeScript("window.scrollTo(0, document.body.scrollHeight - 1000)");Thread.sleep(2000); // 等待滚动完成// 获取页面,打包成Page对象,传给PageProcessor 实现类Page page = createPage(request.getUrl(), driver.getPageSource());driver.close(); // 看需要是否关闭浏览器return page;} catch (InterruptedException e) {throw new RuntimeException(e);}}@Overridepublic void setThread(int i) {}//构建page返回对象private Page createPage(String url, String content) {Page page = new Page();page.setRawText(content);page.setUrl(new PlainText(url));page.setRequest(new Request(url));page.setDownloadSuccess(true);return page;}
}
2、自定义页面解析器
/*** <h1>自定义页面解析器</h1>* PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。* WebMagic 使用 Jsoup 作为 HTML 解析工具,并基于其开发了解析 XPath 的工具 Xsoup。* */
public class WNPageProcessor implements PageProcessor {private Site site = Site.me().setCharset("UTF-8") // 设置编码.setSleepTime(1) // 抓取间隔时间.setTimeOut(1000 * 10) // 超时时间.setRetrySleepTime(3000) // 重试时间.setRetryTimes(3).addHeader("CSDN", "woniu").addHeader("Content-Type", "application/json;charset=UTF-8");@Overridepublic void process(Page page) {Html html = page.getHtml();List<Selectable> hotSearchList = html.xpath("//*[@id=\"hotsearch-content-wrapper\"]/li").nodes();System.out.println("今日百度热搜:");// 遍历所有热搜新闻for (Selectable hotSearch : hotSearchList){List<Selectable> newsMetaList = hotSearch.xpath("//span/text()").nodes();for (Selectable newsMeta : newsMetaList) {System.out.print(newsMeta.get() + " ");}System.out.print("\n");}// 存储,可以传递到 WNPipelinepage.putField("woniu", "我是CSDN");}@Overridepublic Site getSite() {return site;}
}
3、自定义结果处理器
/*** <h1>自定义结果处理器</h1>* Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。* WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。* Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。* 对于一类需求一般只需编写一个Pipeline。* */
public class WNPipeline implements Pipeline {@Overridepublic void process(ResultItems resultItems, Task task) {// 获取封装好的数据String woniu = resultItems.get("woniu");System.out.println("WNPageProcessor 传递结果:" + woniu);}
}
4、单元测试
public class WebMagicExample {public static void main(String[] args) {// 目标网页 URLString url = "https://www.baidu.com";Spider.create(new WNPageProcessor()) // 创建爬虫,并指定PageProcessor.addUrl(url) // 添加需要爬取的URL.setDownloader(new WNDownloader()) // 设置 Downloader,一个 Spider 只能有个一个 Downloader.addPipeline(new WNPipeline()) // 添加一个 Pipeline,一个 Spider 可以有多个 Pipeline.thread(5) // 开启5个线程抓取.start(); // 开始爬取,设置最多在10分钟内停止}
}
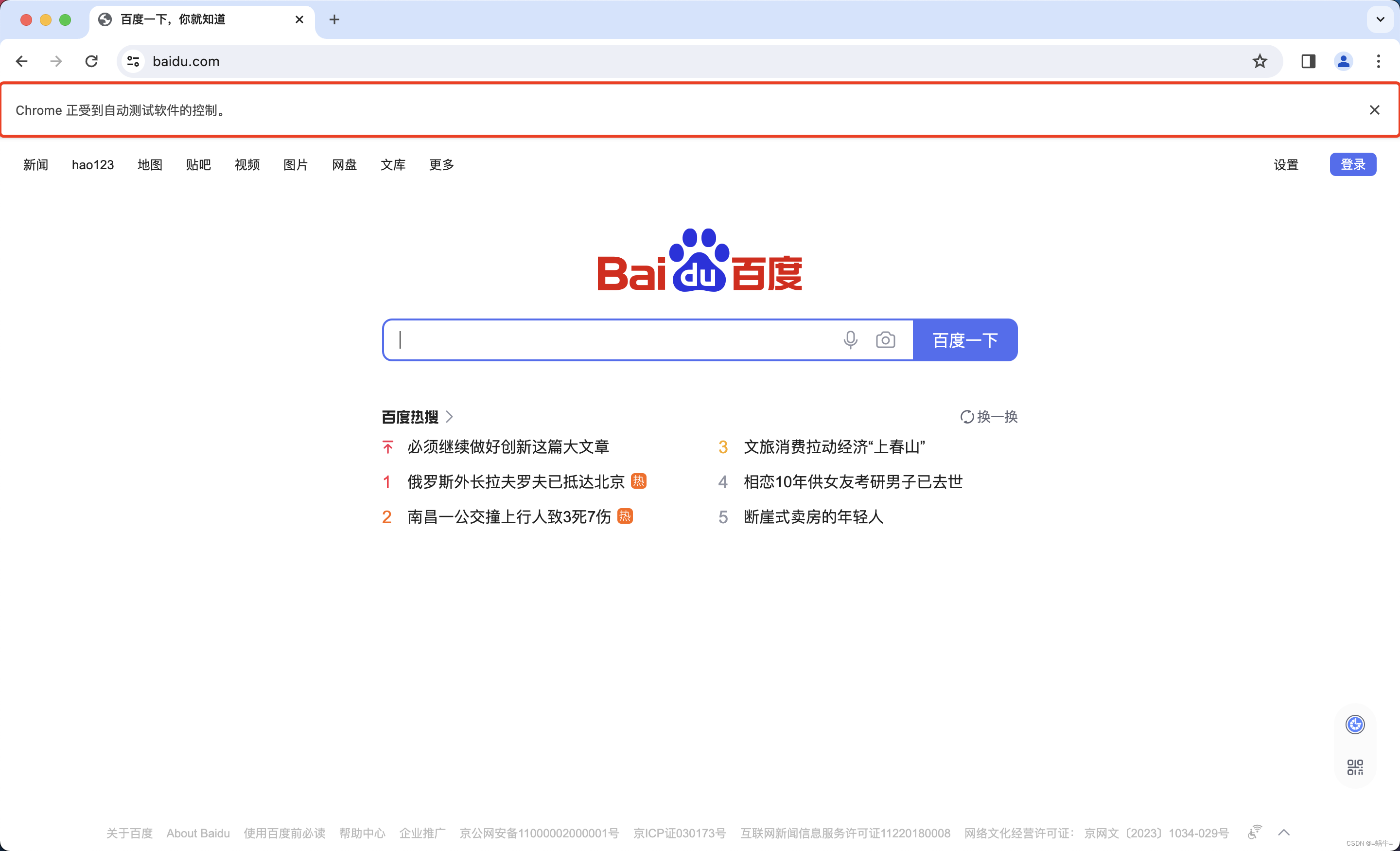
Selenium 可以配置为两种模式运行:有界面(headed)和无界面(headless)。
在默认情况下,Selenium WebDriver 会启动一个完整的浏览器窗口,用户可以直观地看到浏览器中的操作和页面变化,这对于测试和调试非常有用。如下图:
要启动无界面模式,需要在 Selenium 的浏览器配置中添加相应的参数。例如,在 Java 中使用ChromeDriver 时,可以通过以下代码启动无界面模式:
// 创建浏览器参数对象
ChromeOptions chromeOptions = new ChromeOptions();// 设置为无界面浏览器模式,若是不想看到浏览器打开,就可以配置此项
chromeOptions.addArguments("--headless");
这段代码会启动一个没有图形界面的 Chrome 浏览器,并打开指定的网址。在无界面模式下,所有的 Selenium 操作都会正常执行,但不会有任何视觉反馈。
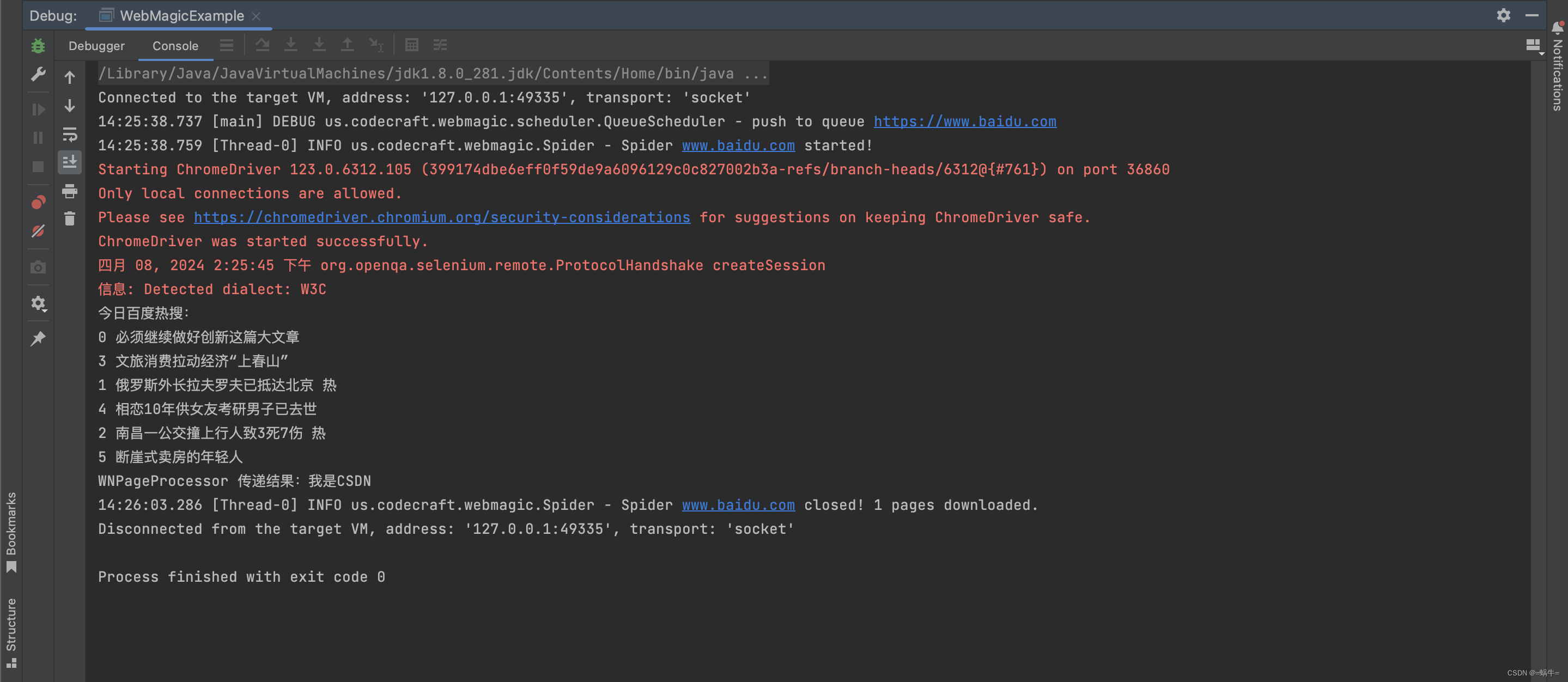
运行结果截图如下:
5、知识库
5.1、Chrome 浏览器查找 html 元素中的 XPath 路径
在谷歌 Chrome 浏览器中查找 HTML 元素的 XPath 路径,可以通过以下步骤进行:
5.1.1、打开开发者工具
使用快捷键 Ctrl + Shift + I 或 F12 打开 Chrome 的开发者工具,或者在页面上右键点击,选择“检查”来打开。
5.1.2、切换到Elements面板
在开发者工具中,默认选中的是 “元素(Elements)” 面板,这里可以查看页面的 DOM 结构。
5.1.3、选择目标元素
使用鼠标点击页面上的目标元素,或者使用开发者工具中的选择器工具(点击左上角的小箭头图标后,鼠标变为一个箭头状)来选择页面上的元素。
5.1.4、复制 XPath 路径
在元素(Elements)面板中,选中目标元素后,右键点击该元素的代码行,在弹出的菜单中选择“复制” > “复制 XPath”来复制 XPath 路径。如果想要复制完整的 XPath 路径(从根节点开始),可以选择“复制” > “复制完整 XPath”。
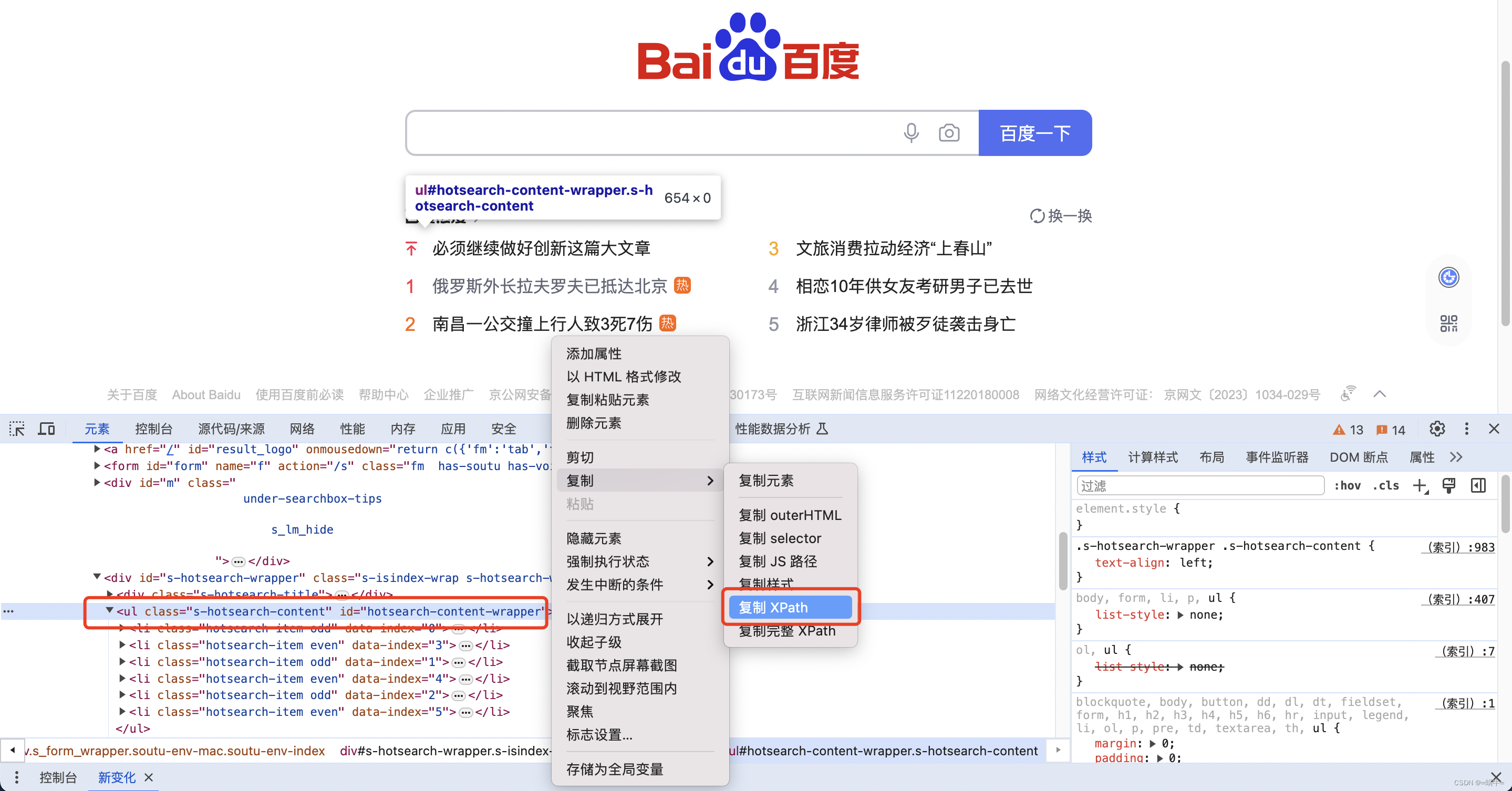
5.1.5、验证 XPath 路径
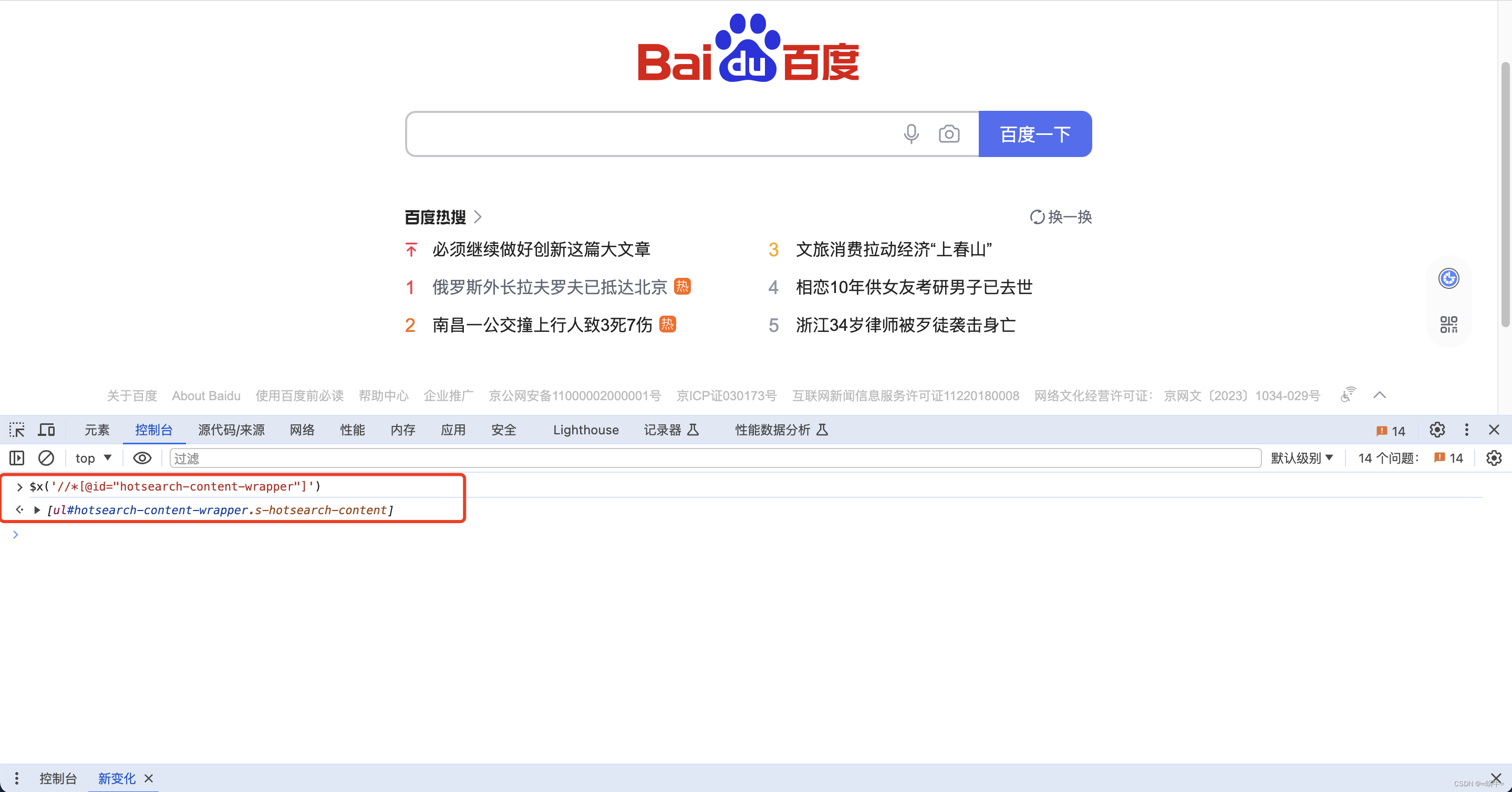
在开发者工具的控制台(Console)面板中,可以使用 XPath 表达式来验证路径是否正确。例如,输入$x(‘//XPath 表达式’)并回车,如果路径正确,控制台会输出匹配的元素数量
示例:$x(‘//*[@id=“hotsearch-content-wrapper”]’),如下图:
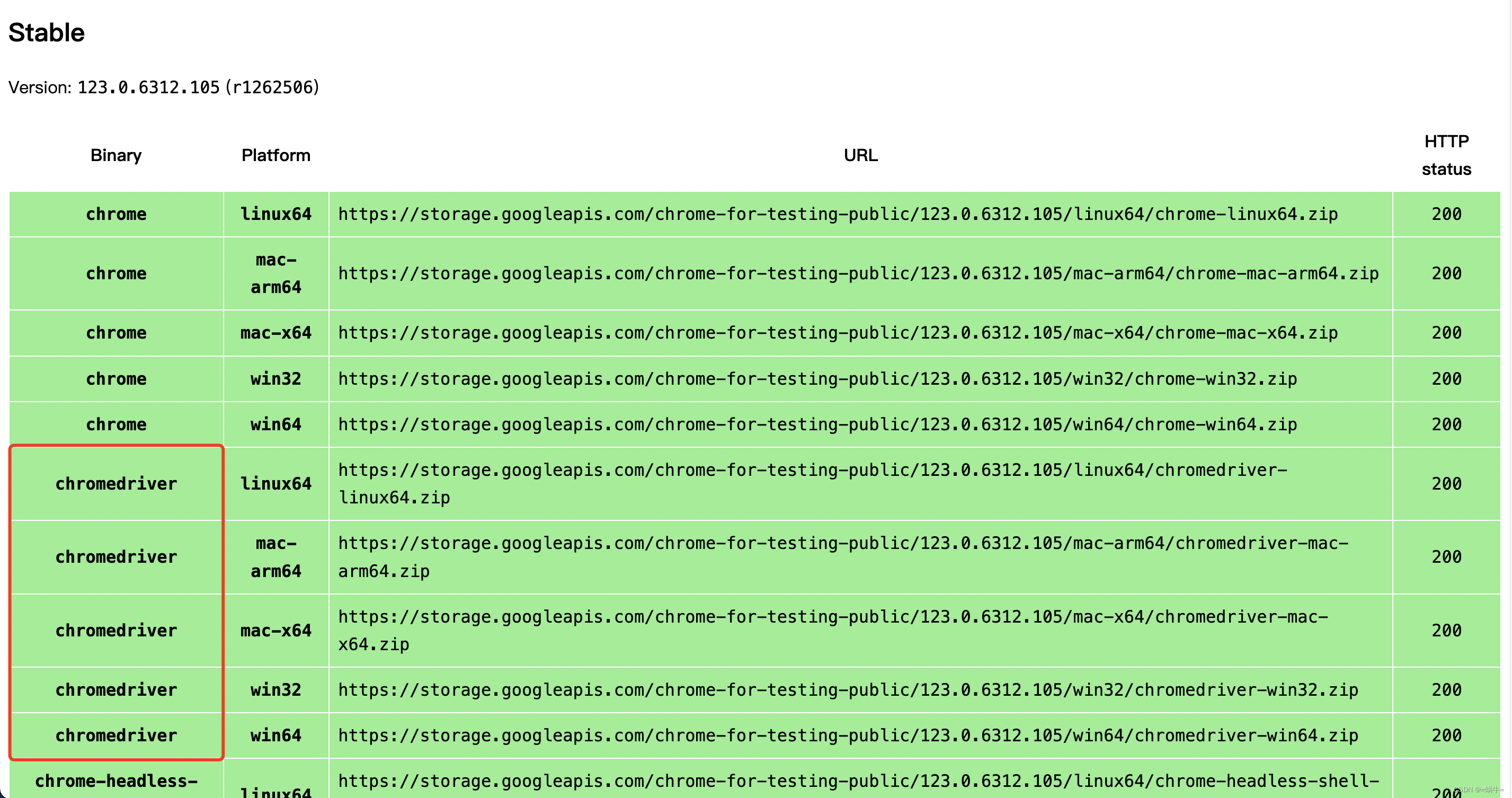
5.2、ChromeDriver 下载
ChromeDriver 下载地址,请根据您使用的操作系统下载相应的 ChromeDriver 版本。
6、总结
Jsoup 主要用于抓取和解析静态 HTML 页面,它不执行 JavaScript,因此对于依赖 JavaScript动态加载内容的网站可能无法获取完整的页面信息。而 HtmlUnit 和 WebMagic 则具备处理动态网页的能力。
HtmlUnit 是一个无头浏览器,它可以执行 JavaScript 代码,从而允许用户与动态内容进行交互,获取通过 JavaScript 动态加载的数据。这使得 HtmlUnit 非常适合抓取那些需要执行脚本才能显示完整内容的网站。
WebMagic 作为一个爬虫框架,它不仅支持静态页面的抓取,也能够通过内置的或自定义的处理器来处理动态内容。WebMagic 的多线程和分布式特性使其在大规模数据抓取方面表现出色,尤其适合于处理复杂的动态网站。
因此,在选择工具时,如果目标网站主要是静态内容,Jsoup 可能是一个简单且高效的选择。而如果网站包含大量的动态内容,HtmlUnit 和 WebMagic 将更能满足需求。
综上所述,Jsoup、HtmlUnit 和 WebMagic 各有千秋,它们分别适用于不同的网页抓取场景。通过合理选择和应用这些工具,开发者可以大幅提升工作效率,优化项目质量,从而在网络爬虫的开发之旅中取得成功。无论您的项目需求如何,这三款工具都能为您提供强大的支持,助您轻松应对网络数据抓取的挑战。
本文教程到此结束,祝愿小伙伴们在编程之旅中能够愉快地探索、学习、成长!
相关文章:
探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言 在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析…...

day16 java object中equals、finalize、
Object类 1.Object类是所有类的父类。 2.一个类如果没有显示继承其它类默认继承Object类equals方法 1.Object中的equals方法 - 用来比较地址值 public boolean equals(Object obj) { return (this obj); } 2.像核心类库中的许多类都重写了equals方法(比如&…...
如何应用电桥电路的原理?
电桥电路是一种常用的测量技术,它利用了四个电阻的网络来检测电路的平衡状态。在平衡状态下,电桥的输出电压为零,这种特性使得电桥电路非常适合于精确测量电阻、电感、电容等电气参数,以及用于传感器和测量设备中。以下是电桥电路…...

大话设计模式——24.迭代器模式(Iterator Pattern)
简介 提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部实现。(Java中使用最多的设计模式之一) UML图 应用场景 Java的集合对象:Collection、List、Map、Set等都有迭代器Java ArrayList的迭代器源码 示例 简…...

【数据结构】双向链表 C++
一、什么是双向链表 1、定义 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。 双…...
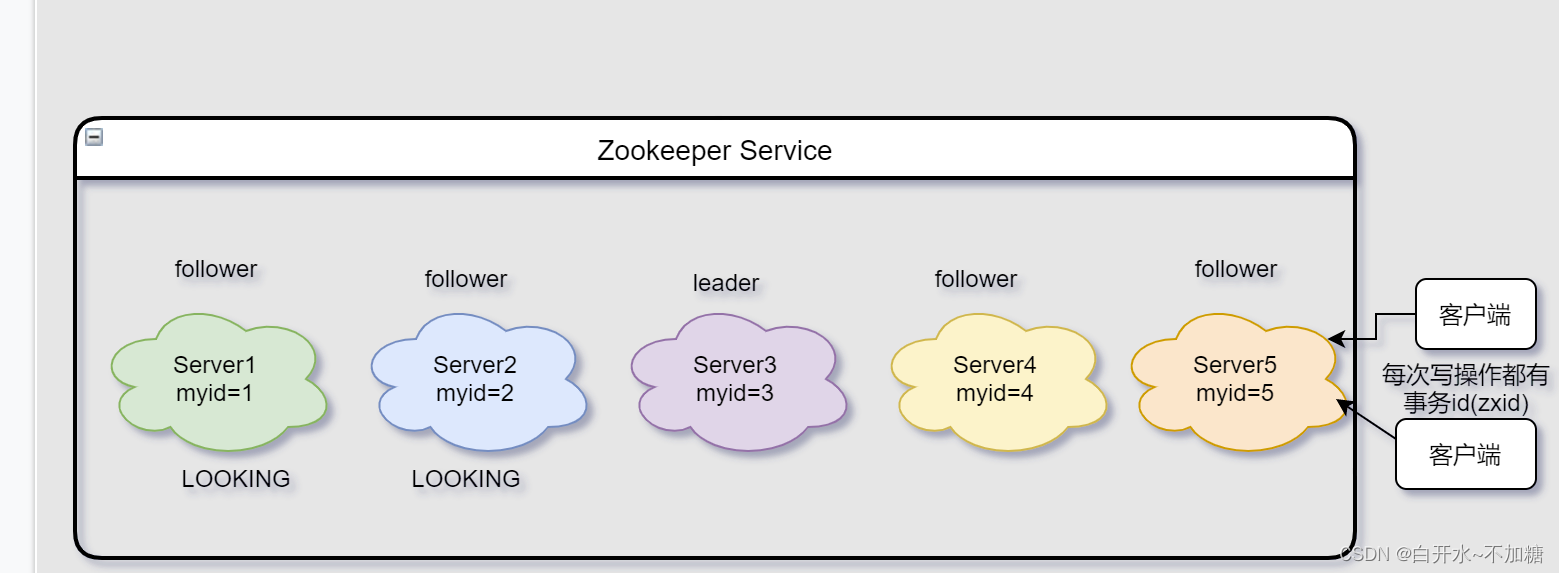
消息队列之-----------------zookeeper机制
目录 一、ZooKeeper是什么 二、ZooKeeper的工作机制 三、ZooKeeper特点 四、ZooKeeper数据结构 五、ZooKeeper应用场景 5.1统一命名服务 5.2统一配置管理 5.3统一集群管理 5.4服务器动态上下线 5.5软负载均衡 六、ZooKeeper的选举机制 6.1第一次启动选举机制 6.2非…...
第十届蓝桥杯大赛个人赛省赛(软件类) CC++ 研究生组2.0
A立方和 #include<iostream> #include<cmath> using namespace std; int main(){int n, t, flag, x;long long ans 0;for(int i 1; i < 2019; i){t i;flag 0;while(t && !flag){x t % 10;if(x 2 || x 0 || x 1 || x 9) flag 1;t / 10;}if(fl…...
vscode开发ESP32问题记录
vscode 开发ESP32问题记录 1. 解决vscode中的波浪线警告 1. 解决vscode中的波浪线警告 参考链接:https://blog.csdn.net/fucingman/article/details/134404485 首先可以通过vscode 中的IDF插件生成模板工程,这样会自动创建.vscode文件夹中的一些json配…...
R语言复现:轨迹增长模型发表二区文章 | 潜变量模型系列(2)
培训通知 Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。 案例分享 2022年9月,中国四川大学学者在《Journal of Psychosomatic Research》(二区,I…...

【数据结构】顺序表的实现——动态分配
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:数据结构 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...

3.3.k8s搭建-rancher RKE2
目录 RKE2介绍 k8s集群搭建 搭建k8s集群 下载离线包 部署rke2-server 部署rke2-agent 部署helm 部署rancher RKE2介绍 RKE2,也称为 RKE Government,是 Rancher 的下一代 Kubernetes 发行版。 官网地址:Introduction | RKE2 k8s集群搭…...
CST电磁仿真软件的设置变更与问题【官方教程】
保存结果的Result Navigator 积累的结果一目了然! 用户界面上的Result Navigator 在一个仿真工程中更改变量取值进行仿真分析或者改变设置进行仿真分析时,之前的1DResult会不会消失呢? 1D Result:CST中1D Result指的是Y值取决…...
保研线性代数复习3
一.基底(Basis) 1.什么是生成集(Generating Set)?什么是张成空间(Span)? 存在向量空间V(V,,*),和向量集(xi是所说的列向量ÿ…...

从零开始学Spring Boot系列-集成MyBatis-Plus
在Spring Boot应用开发中,MyBatis-Plus是一个强大且易于使用的MyBatis增强工具,它提供了很多实用的功能,如代码生成器、条件构造器、分页插件等,极大地简化了MyBatis的使用和配置。本篇文章将指导大家如何在Spring Boot项目中集成…...

【云原生篇】k8s之Deployment详解
Kubernetes 的 Deployment 是一种管理声明式更新的资源对象,它允许你描述应用的期望状态,并由 Deployment 控制器自动将当前状态改变为期望状态。Deployment 主要用于无状态应用的部署和扩展,但也可以用于有状态应用。 核心功能 自动化部署…...
linux安装dubboAdmin
1.环境准备: jdk-8u391-linux-x64apache-maven-3.9.6apache-tomcat-8.5.100 2.安装注册中心zookeeper zookeeper的安装看我的另一篇文章,安装完成后保持启动状态 linux安装Zookeeper的详细步骤-CSDN博客 3.安装dubboadmin 源码下载地址:R…...

Android 系统编译 and 应用裁剪
平台应用编译 平台应用demo的Android.mk写法: LOCAL_PATH:= $(call my-dir) include $(CLEAR_VARS)LOCAL_MODULE_TAGS := optional# Only compile source java files in this apk. LOCAL_SRC_FILES := $(call all-java-files-under, src)LOCAL_PACKAGE_NAME := TestLOCAL_CER…...
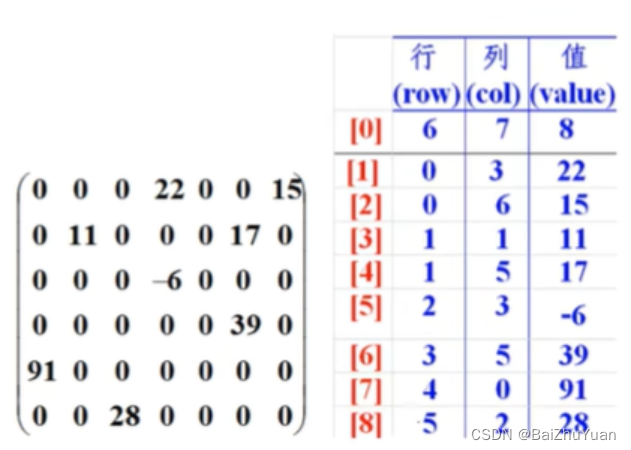
java数组.day16(冒泡排序,稀疏数组)
冒泡排序 冒泡排序无疑是最为出名的排序算法之一,总共有八大排序! 冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。 我们看到嵌套循环,应该立马就可以得出这个算法的时…...
vue+springboot多角色登录
①前端编写 将Homeview修改为manager Manager: <template><div><el-container><!-- 侧边栏 --><el-aside :width"asideWidth" style"min-height: 100vh; background-color: #001529"><div style"h…...

使用 ADB 查找应用名称和活动名称,并启动指定页面
知识点和难题: 查找应用名称和活动名称: 使用 ADB 命令 adb shell dumpsys window | findstr mCurrentFocus 可以查找当前设备上活动的应用名称和活动名称。 保存输出结果: 将命令的输出结果保存到文件中,方便后续使用。 启动指…...

STM32F103红外循迹避障小车实战:从Proteus仿真到实物调试全解析
1. STM32F103与红外循迹避障小车入门指南 第一次接触STM32F103做红外循迹避障小车时,我和很多初学者一样,以为照着网上的例程就能轻松搞定。但真正动手后发现,从仿真到实物调试的每个环节都可能遇到意想不到的问题。这个小车看似简单…...

如何高效获取Twitter社交数据:学术研究的实战指南
如何高效获取Twitter社交数据:学术研究的实战指南 【免费下载链接】getting-started-with-the-twitter-api-v2-for-academic-research A course on getting started with the Twitter API v2 for academic research 项目地址: https://gitcode.com/gh_mirrors/ge/…...

DDD 领域驱动设计实战:从理论到代码
DDD 领域驱动设计实战:从理论到代码别叫我大神,叫我 Alex 就好。DDD 不是银弹,但它是处理复杂业务逻辑的利器。一、DDD 核心概念 1.1 分层架构 ┌─────────────────────────────────────────┐ │ …...

别再重装OriginPro了!遇到盗版弹窗,试试这个修改Hosts文件的永久方案
彻底解决OriginPro授权验证问题的技术指南 引言:为何传统方法无法根治授权问题 许多科研工作者和数据分析师都曾遇到过这样的困扰:明明已经安装了正版OriginPro软件,却频繁遭遇"盗版提示"弹窗。更令人沮丧的是,重装系统…...

OpCore Simplify:自动化OpenCore EFI配置的革命性工具
OpCore Simplify:自动化OpenCore EFI配置的革命性工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore Simplify是一款专为Hackinto…...

终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络
终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络 【免费下载链接】lorawan-server Compact server for private LoRaWAN networks 项目地址: https://gitcode.com/gh_mirrors/lo/lorawan-server 你是否想拥有一个完全可控的LoRaWAN物联网平台&…...

解决RK3588安装OpenCV时libjasper-dev缺失问题:Ubuntu20.04特殊源配置教程
RK3588平台OpenCV安装困境:深度解析libjasper-dev缺失问题与多维度解决方案 在RK3588平台上部署计算机视觉应用时,OpenCV作为核心依赖库的安装过程往往成为开发者的第一个"拦路虎"。特别是在Ubuntu 20.04环境下,当执行标准的sudo a…...
)
告别Postman!用Kettle直接处理钉钉API的POST请求(含MySQL连接jar包缺失解决方案)
告别Postman!用Kettle直接处理钉钉API的POST请求(含MySQL连接jar包缺失解决方案) 在数据集成领域,Kettle(现称Pentaho Data Integration)一直以其强大的ETL能力著称。但许多开发者可能不知道,这…...

Z-Image Turbo与Vue3前端框架集成实战
Z-Image Turbo与Vue3前端框架集成实战 本文详细介绍了如何在Vue3项目中集成Z-Image Turbo图像生成API,通过WebSocket实现实时图像生成功能,并提供完整的组件封装方案。 1. 引言 前端开发者经常面临一个挑战:如何在Web应用中集成强大的AI图像…...

高效实用的Notepad2文本编辑器:从入门到精通的全方位指南
高效实用的Notepad2文本编辑器:从入门到精通的全方位指南 【免费下载链接】notepad2 Notepad2-zufuliu is a light-weight Scintilla based text editor for Windows with syntax highlighting, code folding, auto-completion and API list for many programming l…...