R语言复现:轨迹增长模型发表二区文章 | 潜变量模型系列(2)
培训通知
Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。
案例分享
2022年9月,中国四川大学学者在《Journal of Psychosomatic Research》(二区,IF=4.7)发表题为:"Associations between trajectories of depressive symptoms and rate of cognitive decline among Chinese middle-aged and older adults: An 8-year longitudinal study" 的研究论文。

本公众号回复“ 沙龙 ”即可获得 PPT,数据等资料 |
一、摘要
标题:中国中老年人抑郁症状轨迹与认知能力下降率之间的关系:一项为期8年的纵向研究
目的: 探讨中国中老年人群抑郁症状轨迹与认知能力下降率的关系。
方法: 采用中国健康与退休纵向研究(CHARLS)的人群队列数据。该队列随访8年,并于2011年、2013年、2015年和2018年评估抑郁症状和认知表现。采用基于组的轨迹模型(GBTM)来识别抑郁症状的异质性轨迹。采用线性混合模型(lmm)来检验抑郁症状轨迹与整体认知功能、情景记忆和执行功能下降率之间的关联。
结果:9264名中老年人共分为5个抑郁症状轨迹组:持续低(n = 3206, 34.6%)、持续中(n = 3747, 40.5%)、持续加重(n = 899, 9.7%)、持续减轻(n = 929, 10.0%)、持续加重(n = 483, 5.2%)。抑郁症状加重的个体在整体认知功能和情景记忆方面表现出最快的下降,其次是持续出现重度或中度抑郁症状的参与者。只有在抑郁症状加重的受试者中,执行功能的下降率明显高于抑郁症状持续减轻的受试者。在抑郁症状减轻的个体和抑郁症状持续减轻的个体之间,认知能力下降的比率没有显著差异。
结论:在中国中老年人群中,抑郁症状加重与认知能力下降最严重同时发生,这可能表明,在抑郁症状恶化的个体中,应优先采取旨在缓解认知能力下降的干预措施。
二、研究设计
P(Population)研究对象:参与2011-2018四轮中国健康与退休纵向研究(CHARLS)调查的人群队列数据。
O(Outcome)结局:认知能力下降。
S(Study design)研究类型:队列研究。
三、研究结果
1.人群特征
9264人平均年龄57.8±8.6岁,男性占50.3%。表1显示了每一波调查中抑郁症状、情景记忆和执行功能得分的描述性结果,以及基线协变量。
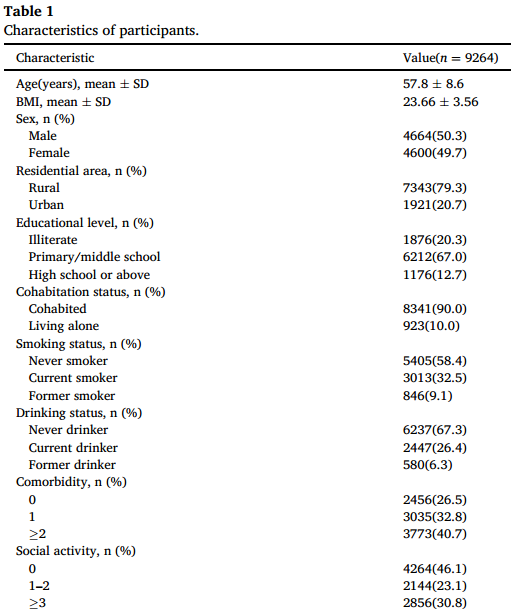
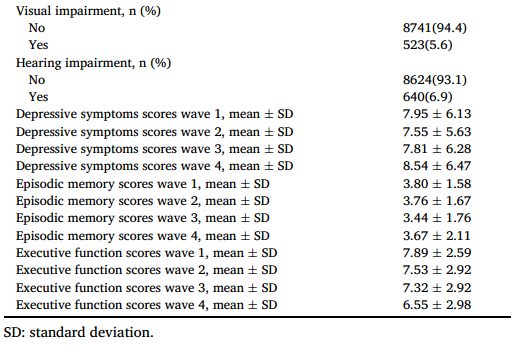
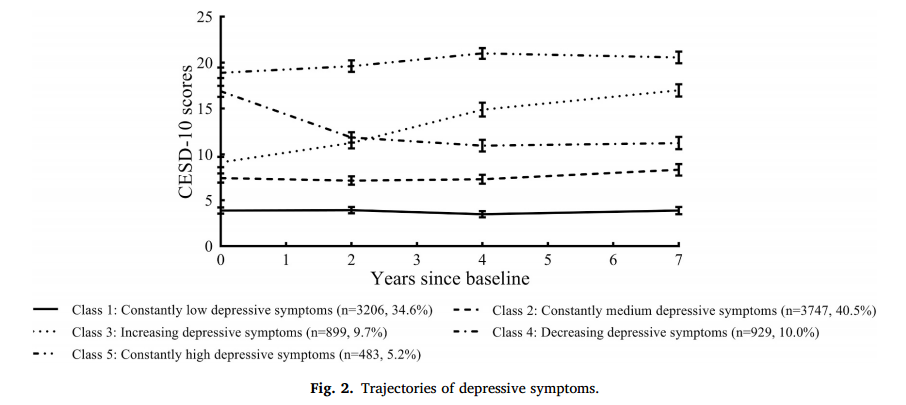
2.抑郁症状的轨迹
逐步建立1至7类的轨迹模型序列,并对其进行比较,以确定表征研究期间抑郁症状动态变化异质性的最佳拟合模型(补充表S1)。这些过程表明,具有5个不同轨迹的模型优于具有较少轨迹的模型。虽然具有6或7个轨迹的模型与BIC和AIC的进一步改善有关,但这些模型产生的一些轨迹的隶属度<5%,平均后验概率<0.7。因此,我们选择了5组抑郁症状轨迹模型(4次立方和1次二次)(表S2)用于后续分析。为了便于解释,我们根据建模的图形模式为不同的抑郁症状轨迹分配了标签(图2):1类,持续的低抑郁症状(n = 3206, 34.6%);第2类,持续中度抑郁症状(n = 3747, 40.5%);第3类,抑郁症状加重(n = 899, 9.7%);第4类,抑郁症状减轻(n = 929, 10.0%);第5类,持续高度抑郁症状(n = 483, 5.2%)。每次就诊时抑郁症状的平均得分和临床相关抑郁症状(csd -10评分≥10)的参与者比例汇总在补充表S3中。
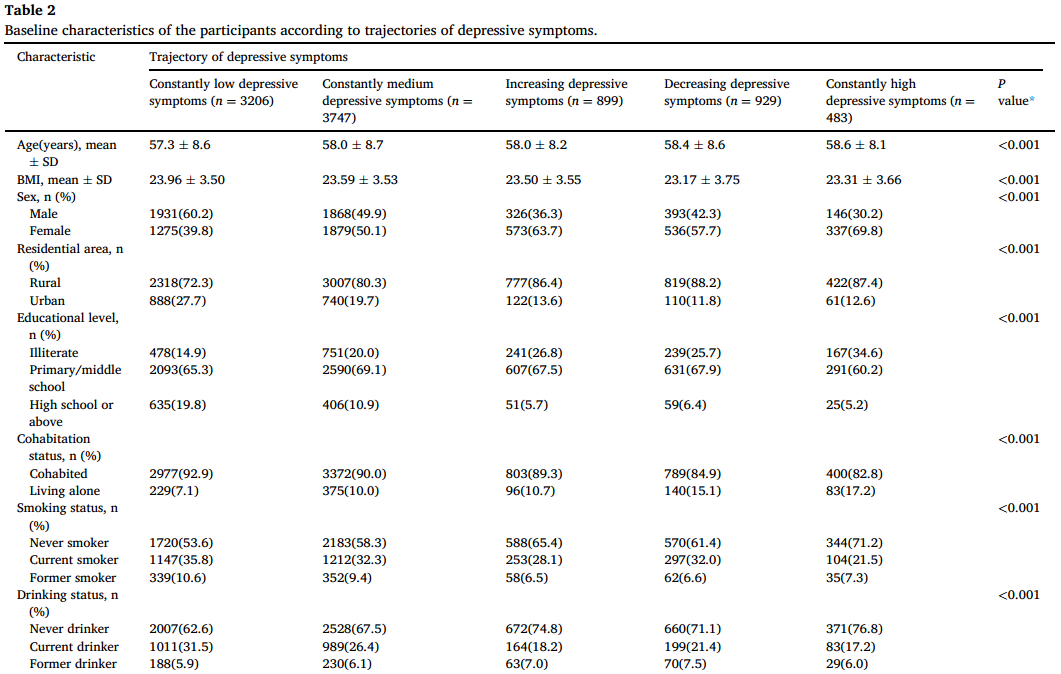
3.轨迹亚种群特征
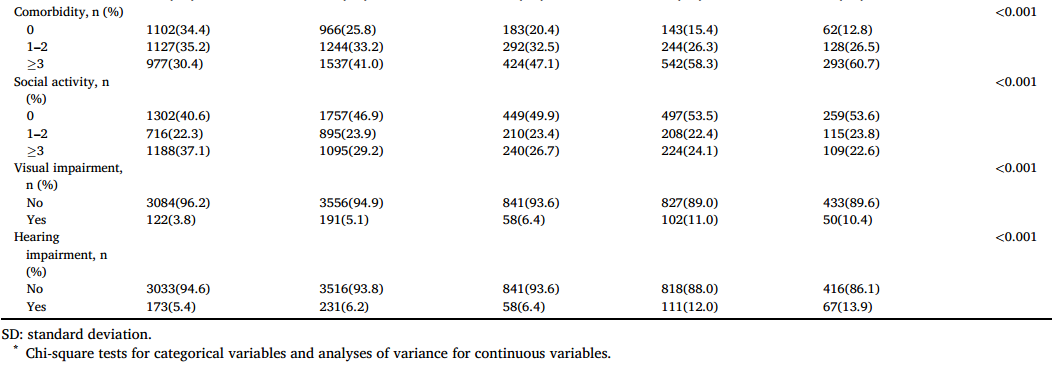
表2显示了每个轨迹组中抑郁症状个体的基线特征。女性参与者更有可能报告抑郁症状持续升高或增加。农村地区的参与者往往表现出抑郁症状的减轻。此外,“持续高抑郁症状”轨迹组的个体往往年龄较大,独居,教育水平较低,有更多的合并症,并有听力障碍。
4.抑郁症状、轨迹和认知能力下降的速度
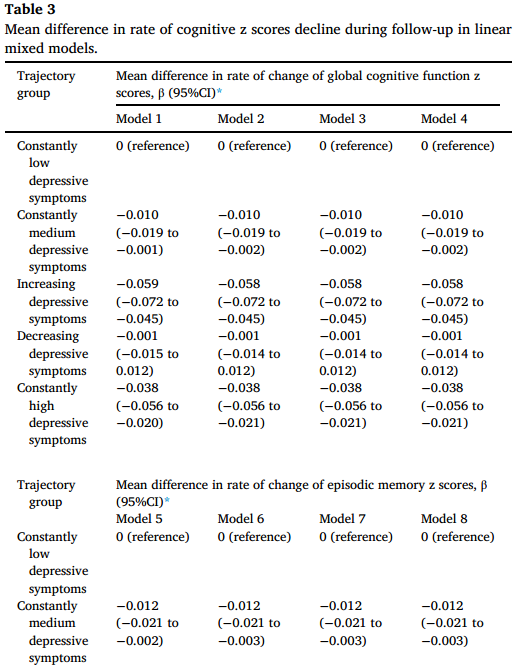
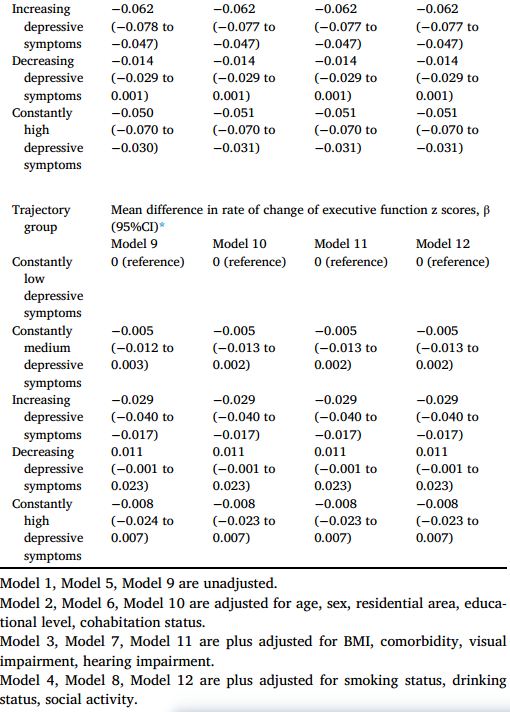
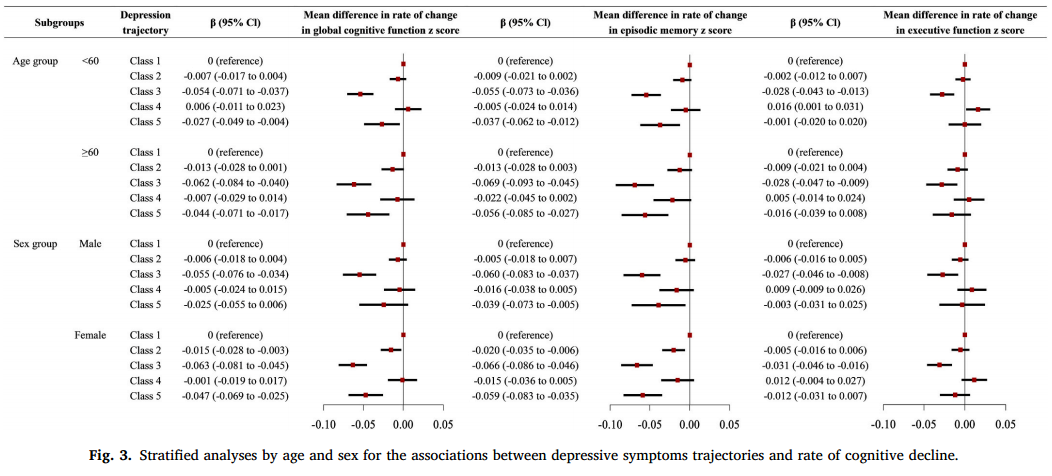
在线性混合模型中,对抑郁症状轨迹和时间相互作用的估计表明,抑郁症状轨迹组的认知z分数下降的平均差异率,如表3所示。在逐步调整协变量的过程中,结果保持稳定。与参照组(持续低抑郁症状)相比,抑郁症状加重的个体在整体认知功能(β =-0.058,95% CI:-0.072至-0.045)和情景记忆(β =-0.062,95% CI:-0.077至-0.047)的z得分下降最快,其次是持续高抑郁症状的参与者(β =-0.038,95% CI:-0.056至-0.021;β =-0.051,95% CI分别为-0.070至-0.031)和持续的中度抑郁症状(β =-0.010,95% CI:-0.019至-0.002;β =-0.012,95% CI分别为-0.021至-0.003)。与抑郁症状持续较低的个体相比,抑郁症状加重的个体在执行功能z分数上的下降速度明显更快(β =- 0.029, 95% CI: -0.040至-0.017)。抑郁症状减轻的个体与抑郁症状持续减轻的良好轨迹组的个体在认知衰退率上没有显著差异。图3显示了抑郁症状轨迹与认知衰退率之间的年龄特异性和性别特异性关联。分层分析的结果与主要分析的结果基本一致。
统计学方法
1.组基轨迹模型
这种方法是有限混合建模的一种特殊形式,它可以根据亚种群在一段时间内属于相似轨迹组的最大概率来区分潜在的、不可直接观察的亚种群。使用最大似然估计过程,该方法允许在模型估计中使用所有可用数据,假设丢失数据的随机性。在本研究中,重复的CESD -10评分被建模为截除正态,抑郁症状的轨迹被建立为自基线以来的年的多项式函数。
基于群的轨迹建模方法需要确定合适数量和形状的潜在轨迹。先验设置最大7个轨迹类别,并拟合1 ~ 7个轨迹类别数量逐渐增大的模型序列。我们同时评估每个轨迹的不同生长参数(线性、二次或三次),以获得描述动态抑郁症状变化的最佳多项式函数形式。比较贝叶斯信息准则(BIC)和赤池信息准则(AIC)选择最优拟合模型,绝对值越低表明模型拟合越好。将个体分配到轨迹组的平均后验概率(APP)高达70%或更高,表明分类准确。此外,为了保证后续分析的准确性,选择每个轨迹组的隶属度大于5%的模型。

2.线性混合效应模型
一旦确定了抑郁症状的不同轨迹,就进行卡方检验和方差分析,以探讨不同轨迹组之间个体特征的差异。为了检验抑郁症状轨迹与认知衰退率之间的关系,我们采用了分离的线性混合模型来计算整体认知功能、情景记忆和执行功能的z分数。按照推荐的程序,模型包括抑郁症状轨迹的隶属度、时间(自基线以来的年份)、时间相互作用的抑郁症状轨迹的隶属度以及上述协变量。我们从未调整的模型开始,通过逐渐加入协变量继续到多变量模型。斜率和截距均拟合为随机效应。还根据年龄和性别群体在不同的模型中进行了分层分析。

3.统计分析软件
使用SAS软件9.4版(SAS Institute, Inc)中的TRAJ插件程序,采用基于组的轨迹建模方法,生成不同访问期间抑郁症状的不同轨迹。
R语言复现
1、变量表
变量名 | 标签 | 变量类型 | 分类变量的编码 |
age | 年龄 | 连续变量 | |
r1mbmi | BMI | 连续变量 | |
gender | 性别 | 2分类 | 0:男性; 1:女性 |
juzhu | 居住地 | 2分类 | 0:农村; 1:城市 |
edu | 教育程度 | 3分类 | 0:文盲; 1:小学/中学;3:高中及以上 |
tongju | 居住状况 | 2分类 | 0:同居; 1:独居 |
somke | 吸烟状况 | 3分类 | 0:从不吸烟者;1:目前吸烟者; 2:曾经吸烟者 |
drink | 饮酒状况 | 3分类 | 0:从不饮酒者;1:目前饮酒者; 2:曾经饮酒者 |
shili | 视觉障碍 | 2分类 | 0:不是; 1:是 |
tingli | 听力障碍 | 2分类 | 0:不是; 1:是 |
comorbidity | 合并症 | 3分类 | 0:0;1:1; 2:≥2 |
social | 社交活动 | 3分类 | 0:0;1:1-2; 2:≥3 |
r1cesd10 | 抑郁评分 | 连续变量 | |
r2cesd10 | 抑郁评分 | 连续变量 | |
r3cesd10 | 抑郁评分 | 连续变量 | |
r4cesd10 | 抑郁评分 | 连续变量 | |
r1tr10 | 情景记忆 | 连续变量 | |
r2tr10 | 情景记忆 | 连续变量 | |
r3tr10 | 情景记忆 | 连续变量 | |
r4tr10 | 情景记忆 | 连续变量 | |
executive | 执行能力 | 连续变量 | |
executive1 | 执行能力 | 连续变量 | |
executive2 | 执行能力 | 连续变量 | |
executive3 | 执行能力 | 连续变量 |
2、安装并加载相关包,导入数据

3、基线特征描述
本次复现基线表格用到了tableone包,这里“myVars”汇总了基线表中的全部变量,其中有部分变量为分类变量,则需要通过“catVars”进行指定,否则分类数据也将以定量数据进行展示。

这里tab2中未指定分组变量,则仅展示各变量的数据分布,此外,“showAllLevels = TRUE”表示展示分类变量所有分类因子的结果,“nonnormal =”指定的定量数据将以偏态分布进行分析,如果所有定量数据都是偏态分布,可以简洁的用“nonnormal = TRUE”来表示。

最后,将基线表结果输出保存在工作空间里,这里我们设置保存为csv格式!
4、数据类型转换

5、组基轨迹模型
首先,建立一个初始模型。

其次,先验设置最大7个轨迹类别,并拟合1 ~ 7个轨迹类别数量逐渐增大的模型序列。

找到最小的BIC值及其对应的模型,查看模型评价参数并建立模型,整合数据集。



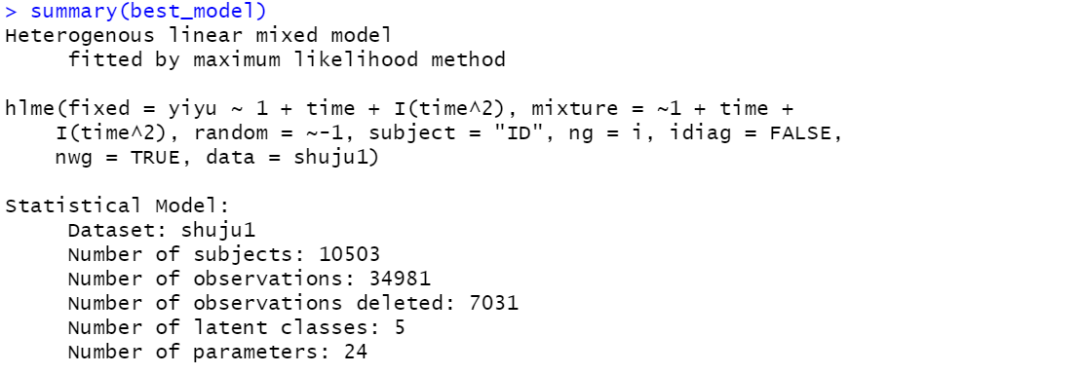
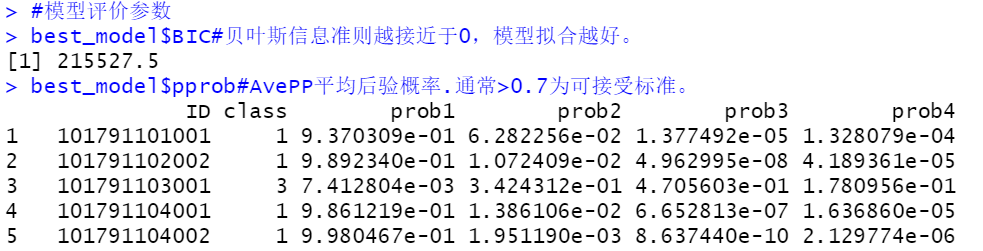

6、线性混合效应模型
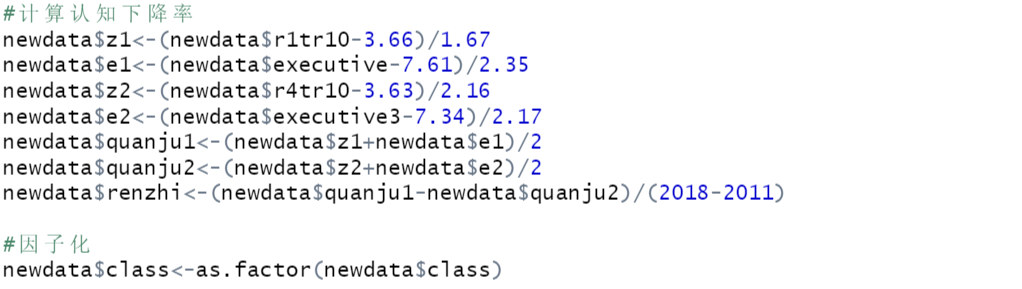
首先,计算认知下降率,并进行因子化。
为了实现不同测试之间的可比性,生成了认知测量的z分数。在实际操作中,每次就诊时的测试分数根据基线时的初始分数进行标准化,方法是减去平均值并除以标准差(SD)。情景记忆和执行功能的z分转换分别进行。每一波的全局认知功能z分是情景记忆z分和执行功能z分的平均值,随后根据基线全局认知功能z分重新标准化。
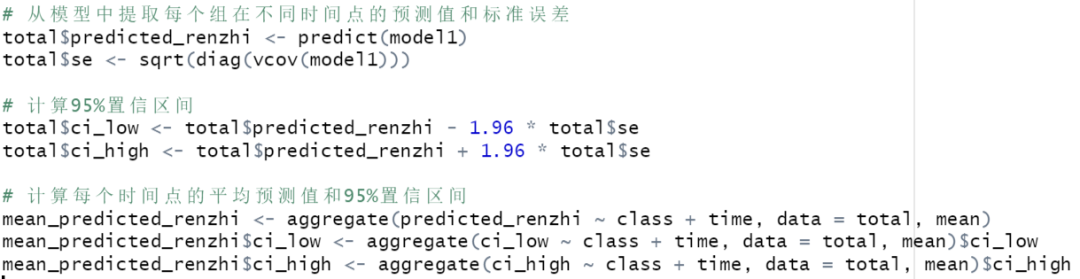
建立未调整模型,通过逐渐加入协变量继续到多变量模型。斜率和截距均拟合为随机效应。

计算每个时间点的平均预测值和95%置信区间。
本公众号回复“ 沙龙 ”即可获得 沙龙PPT,数据等资料 |
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 发文后退款:2024-2025年科研统计课程介绍 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: 课题、论文、毕业数据分析 临床试验设计与分析 、公共数据库挖掘与统计 |
相关文章:
R语言复现:轨迹增长模型发表二区文章 | 潜变量模型系列(2)
培训通知 Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。 案例分享 2022年9月,中国四川大学学者在《Journal of Psychosomatic Research》(二区,I…...

【数据结构】顺序表的实现——动态分配
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:数据结构 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...

3.3.k8s搭建-rancher RKE2
目录 RKE2介绍 k8s集群搭建 搭建k8s集群 下载离线包 部署rke2-server 部署rke2-agent 部署helm 部署rancher RKE2介绍 RKE2,也称为 RKE Government,是 Rancher 的下一代 Kubernetes 发行版。 官网地址:Introduction | RKE2 k8s集群搭…...
CST电磁仿真软件的设置变更与问题【官方教程】
保存结果的Result Navigator 积累的结果一目了然! 用户界面上的Result Navigator 在一个仿真工程中更改变量取值进行仿真分析或者改变设置进行仿真分析时,之前的1DResult会不会消失呢? 1D Result:CST中1D Result指的是Y值取决…...
保研线性代数复习3
一.基底(Basis) 1.什么是生成集(Generating Set)?什么是张成空间(Span)? 存在向量空间V(V,,*),和向量集(xi是所说的列向量ÿ…...

从零开始学Spring Boot系列-集成MyBatis-Plus
在Spring Boot应用开发中,MyBatis-Plus是一个强大且易于使用的MyBatis增强工具,它提供了很多实用的功能,如代码生成器、条件构造器、分页插件等,极大地简化了MyBatis的使用和配置。本篇文章将指导大家如何在Spring Boot项目中集成…...

【云原生篇】k8s之Deployment详解
Kubernetes 的 Deployment 是一种管理声明式更新的资源对象,它允许你描述应用的期望状态,并由 Deployment 控制器自动将当前状态改变为期望状态。Deployment 主要用于无状态应用的部署和扩展,但也可以用于有状态应用。 核心功能 自动化部署…...
linux安装dubboAdmin
1.环境准备: jdk-8u391-linux-x64apache-maven-3.9.6apache-tomcat-8.5.100 2.安装注册中心zookeeper zookeeper的安装看我的另一篇文章,安装完成后保持启动状态 linux安装Zookeeper的详细步骤-CSDN博客 3.安装dubboadmin 源码下载地址:R…...

Android 系统编译 and 应用裁剪
平台应用编译 平台应用demo的Android.mk写法: LOCAL_PATH:= $(call my-dir) include $(CLEAR_VARS)LOCAL_MODULE_TAGS := optional# Only compile source java files in this apk. LOCAL_SRC_FILES := $(call all-java-files-under, src)LOCAL_PACKAGE_NAME := TestLOCAL_CER…...
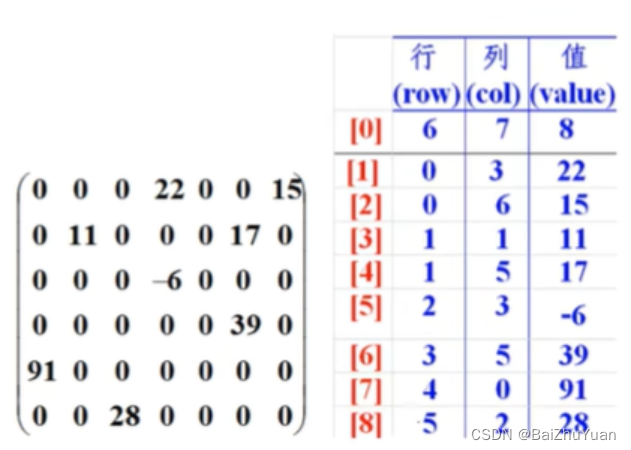
java数组.day16(冒泡排序,稀疏数组)
冒泡排序 冒泡排序无疑是最为出名的排序算法之一,总共有八大排序! 冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。 我们看到嵌套循环,应该立马就可以得出这个算法的时…...
vue+springboot多角色登录
①前端编写 将Homeview修改为manager Manager: <template><div><el-container><!-- 侧边栏 --><el-aside :width"asideWidth" style"min-height: 100vh; background-color: #001529"><div style"h…...

使用 ADB 查找应用名称和活动名称,并启动指定页面
知识点和难题: 查找应用名称和活动名称: 使用 ADB 命令 adb shell dumpsys window | findstr mCurrentFocus 可以查找当前设备上活动的应用名称和活动名称。 保存输出结果: 将命令的输出结果保存到文件中,方便后续使用。 启动指…...

LangChain - 文档转换
文章目录 一、文档转换器 & 文本拆分器文本拆分器 二、开始使用文本拆分器三、按字符进行拆分四、代码分割 (Split code)1、PythonTextSplitter2、JS3、Markdown4、Latex5、HTML6、Solidity 五、MarkdownHeaderTextSplitter1、动机2、Use case 六、递归按字符分割七、按tok…...

【C++】STL--list
目录 list的介绍 list的使用 list的构造 list iterator的使用 list capacity list modifiers list的迭代器失效 list模拟实现 list的介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向…...

二. CUDA编程入门-双线性插值计算
目录 前言0. 简述1. 执行一下我们的第十个CUDA程序2. Bilinear interpolation3. 代码分析总结参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 Note:关于 CUDA 加速双线程插值的内容博主…...

实时计算平台设计方案:913-基于100G光口的DSP+FPGA实时计算平台
基于100G光口的DSPFPGA实时计算平台 一、产品概述 基于以太网接口的实时数据智能计算一直应用于互联网、网络安全、大数据交换的场景。以DSPFPGA的方案,体现了基于硬件计算的独特性能,区别于X86GPU的计算方案,保留了高带宽特性&…...

Glide系列-自定义ModuleLoader
在当今快速发展的移动应用领域,图片的高效加载和显示对于提供流畅用户体验至关重要。Glide作为一款强大的图片加载库,已经成为Android开发者的首选工具之一。但是,你有没有遇到过Glide默认不支持的模型类型,或者需要对图片加载过程…...

设计模式——责任链模式13
责任链模式 每个流程或事物处理 像一个链表结构处理。场景由 多层部门审批,问题分级处理等。下面体现的是 不同难度的问题由不同人进行解决。 设计模式,一定要敲代码理解 传递问题实体 /*** author ggbond* date 2024年04月10日 07:48*/ public class…...

Linux云计算之Linux基础3——Linux系统基础part-2
1、终端、shell、文件理论 1、终端 终端(terminal):人和系统交互的必要设备,人机交互最后一个界面(包含独立的输入输出设备) 物理终端(console):直接接入本机器的键盘设备和显示器虚拟终端(tty):通过软件…...
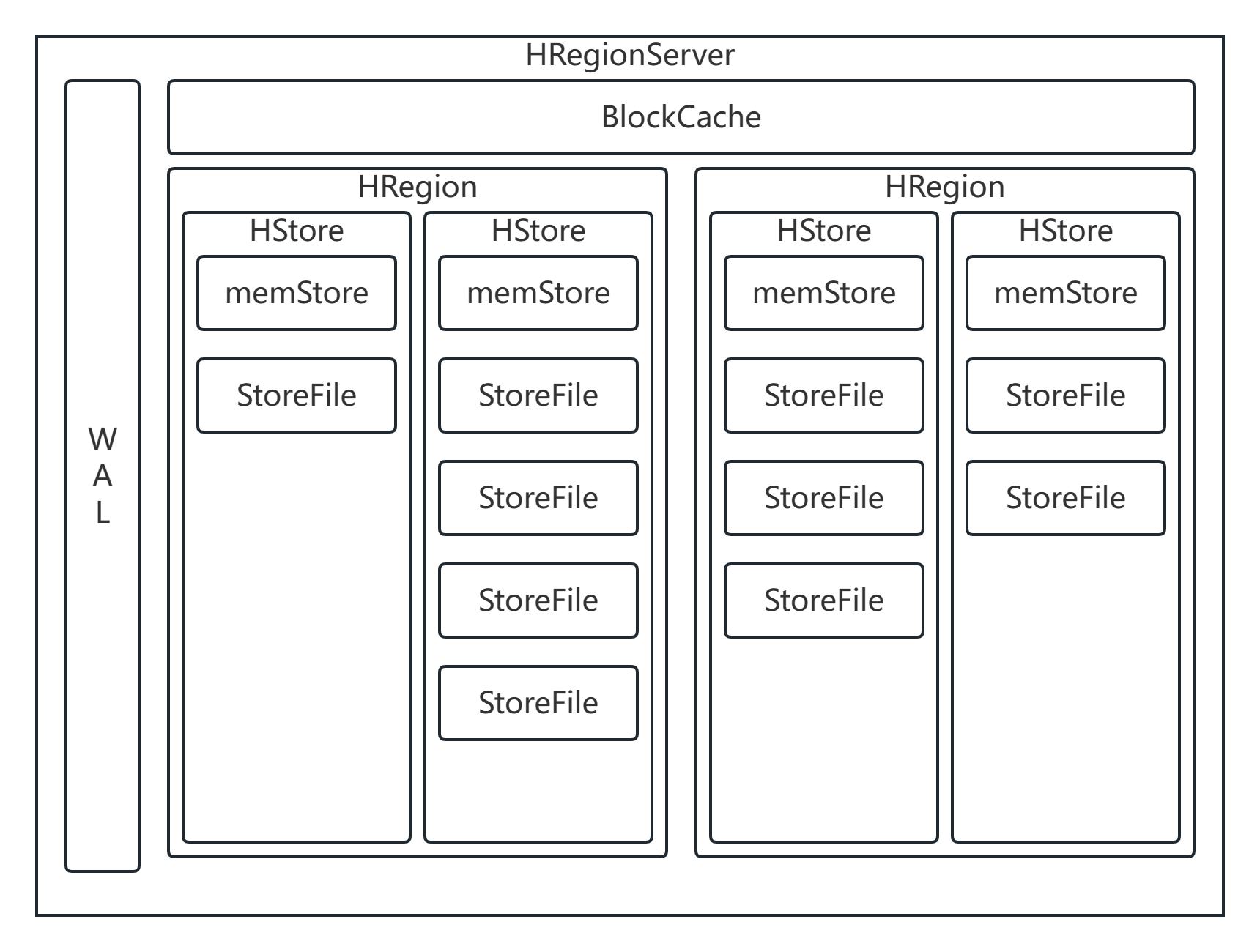
HBase详解(2)
HBase 结构 HRegion 概述 在HBase中,会从行键方向上对表来进行切分,切分出来的每一个结构称之为是一个HRegion 切分之后,每一个HRegion会交给某一个HRegionServer来进行管理。HRegionServer是HBase的从节点,每一个HRegionServ…...
SenseVoice-Small ONNX标点评测:CT-Transformer在不同文本长度下的F1值
SenseVoice-Small ONNX标点评测:CT-Transformer在不同文本长度下的F1值 1. 引言 语音识别技术已经深入到我们工作和生活的方方面面,从手机语音助手到会议纪要自动生成,都离不开它的身影。然而,对于很多开发者和小型团队来说&…...

Anthropic公司内容管理系统配置错误致大模型泄露引市场震荡
配置错误:Claude Mythos大模型意外泄露3月30日,据SiliconAngle报道,Anthropic公司内容管理系统发生配置错误,导致正在测试的新一代大语言模型Claude Mythos意外泄露。官方证实,该模型是公司“迄今为止构建的能力最强的…...

GitHub Copilot 默认启用训练之后 企业安全如何应对
文章目录前言一、这次政策改动,到底改了什么二、为什么企业不能只看“Business 和 Enterprise 不受影响”三、content exclusion 为什么挡不住所有风险四、从 IDE 到 Agent,企业研发边界已经变了五、企业现在就该做的几件事总结前言 GitHub 这次关于 Co…...

原创:黄大年茶思屋难题揭榜第141期|5道核心题精简公开·未获技术反馈求指正
黄大年茶思屋难题揭榜第141期|5道核心题精简公开未获技术反馈求指正 作者:华夏之光永存 摘要 这五道题我们已完整解题并提交黄大年茶思屋难题揭榜,最终被退回,但平台未给出任何具体技术驳回意见、未指明缺陷、未提供修改方向。我们…...

如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统
如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfra…...

5步让Windows 11提速51%:Win11Debloat深度净化指南
5步让Windows 11提速51%:Win11Debloat深度净化指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和改善…...

告别临时表!MySQL8窗口函数优化复杂统计查询的3种典型方案
MySQL8窗口函数实战:3种替代临时表的高效统计方案 在数据分析与报表生成场景中,开发人员经常需要处理复杂的多维度统计需求。传统解决方案往往依赖临时表和多次查询拼接,不仅代码冗长,还存在显著的性能瓶颈。MySQL8引入的窗口函数…...

RTX 3060用户必看:解决nvcc报错‘Unsupported gpu architecture‘的完整指南
RTX 3060显卡CUDA开发实战:彻底解决Unsupported gpu architecture编译错误 当你兴奋地拆开新入手的RTX 3060显卡准备大展拳脚时,却在编译CUDA项目时遭遇了令人沮丧的Unsupported gpu architecture错误。这个看似简单的报错背后,隐藏着CUDA开…...

SolidWorks 与 CATIA 模型转换实战:从本地操作到云端解决方案
1. 为什么需要SolidWorks与CATIA模型转换 在机械设计领域,SolidWorks和CATIA就像两个说着不同语言的工程师。SolidWorks以其直观的操作界面和强大的参数化建模能力,成为中小企业和教育机构的首选工具。而CATIA则凭借在复杂曲面设计和高端制造领域的深厚积…...

只剩马斯克自己!xAI 11个联合创始人跑光了
11位联合创始人三年出清、只剩马斯克一人,xAI这场「天团散伙」背后,藏着AI时代最残酷的人才战争与帝国裂缝。3月28日,Ross Nordeen悄悄摘掉了自己在X平台上的xAI员工认证标识。他发了一张照片——「触碰一些草」。没有长篇告别信,…...