HBase详解(2)
HBase
结构
HRegion
概述
-
在HBase中,会从行键方向上对表来进行切分,切分出来的每一个结构称之为是一个HRegion
-
切分之后,每一个HRegion会交给某一个HRegionServer来进行管理。HRegionServer是HBase的从节点,每一个HRegionServer可以管理多个HRegion
-
如果新建了一个表,那么这个表中只包含1个HRegion
-
在HBase中,因为行键是有序(字典序)的,所以切分出来的每一个HRegion之间的数据是不交叉的,因此HBase可以将接收到的不同的请求分发到不同的HRegionServer来进行处理,从而能够有效的避免请求集中到一个节点上
-
随着运行时间的推移,每一个HRegion中管理的数据都会越来越多,当HRegion管理的数据达到指定大小的时候,会进行分裂,分裂为两个HRegion
-
刚分裂完成之后,两个HRegion还暂时处于同一个HRegionServer上。但是HBase为了节点之间的负载均衡,可能会将其中一个HRegion转移给其他的HRegionServer来进行管理。注意:此时不会发生大量的数据迁移!HBase的数据是存储在HDFS上的,HRegion只是HBase提供的一个用于管理数据的结构!
-
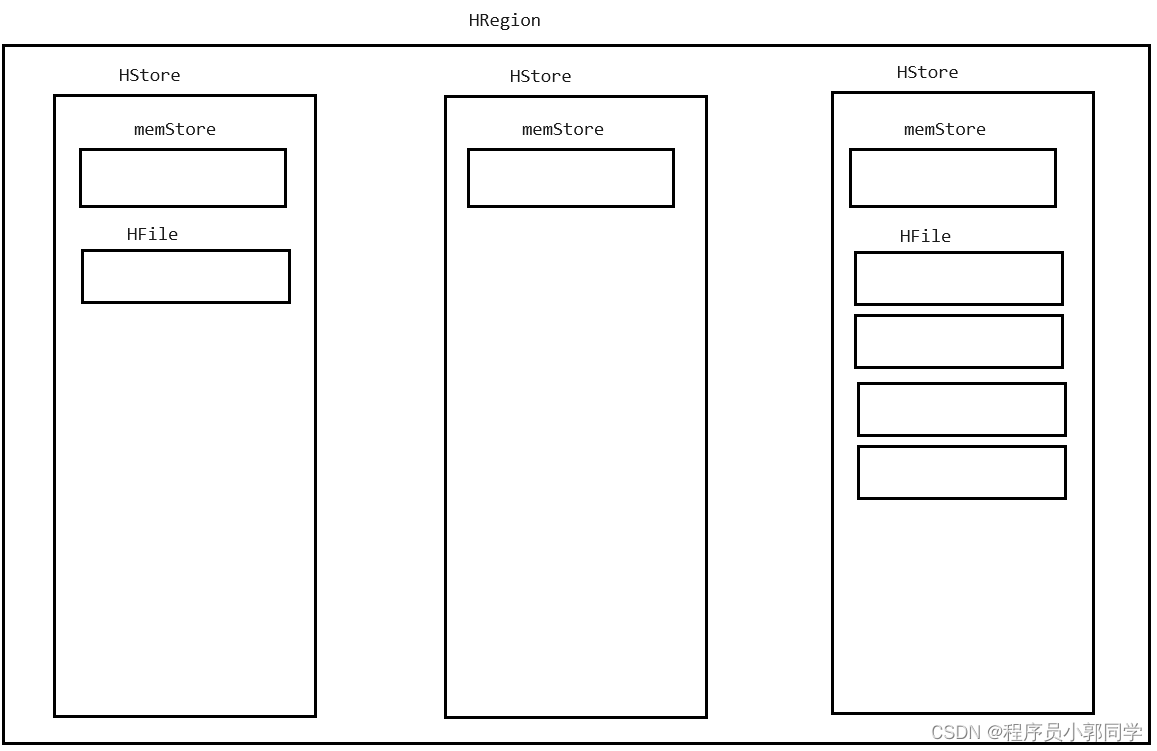
每一个HRegion中,会包含至少1个HStore,可以包含多个HStore。HStore的数量是由列族的数量来决定 - 每一个列队都对应了一个HStore
-
每一个HStore中会包含1个memStore以及0到多个StoreFile/HFile
分裂策略
-
在HBase2.x中,支持7中分裂策略:
ConstantSizeRegionSplitPolicy,IncreasingToUpperBoundRegionSplitPolicy,KeyPrefixRegionSplitPolicy,DelimitedKeyPrefixRegionSplitPolicy,SteppingSplitPolicy,BusyRegionSplitPolicy,DisabledRegionSplitPolicy -
ConstantSizeRegionSplitPolicy:固定大小分裂,默认情况下,这个策略下,当HRegion的大小达到10G的时候,会均分为两个HRegion。可以通过属性hbase.hregion.max.filesize来调节,单位是字节,默认值是10737418240 -
IncreasingToUpperBoundRegionSplitPolicy:HBase1.2及之前版本默认采用的就是这个策略。这个策略的特点:前几次分裂不是固定的数据,而是需要通过计算来获取-
如果HRegion的数量超过了100,那么就按照
hbase.hregion.max.filesize(默认值是10G)大小来分裂 -
如果HRegion的数量在1-100之间,那么按照
min(hbase.hregion.max.filesize, regionCount^3 * initialSize)来计算,其中regionCount表示HRegion的个数,initialSize是HRegion的大小,initialSize的默认值是2 * hbase.hregion.memstreo.flush.size(默认值是134217728B) -
initialSize的值可以通过属性
hbase.increasing.policy.initial.size来指定,单位是字节
-
-
KeyPrefixRegionSplitPolicy:IncreasingToUpperBoundRegionSplitPolicy的子类,在IncreasingToUpperBoundRegionSplitPolicy的基础上,添加了行键的判断,会将行键前缀相同(默认读取行键的前五个字节)的数据拆分到同一个HRegion中。这种分裂策略会导致拆分之后的两个HRegion之间不等大 -
DelimitedKeyPrefixRegionSplitPolicy:例如当行键是video_001、txt_001,log_003等,此时希望行键是以_作为拆分单位,那么此时就需要使用DelimitedKeyPrefixRegionSplitPolicy -
SteppingSplitPolicy:HBase2.X默认使用的就是这个策略-
如果这个表中只有1个HRegion,那么按照
2 * hbase.hregion.memstreo.flush.size来进行分裂 -
如果这个表中HRegion的个数超过1个,那么按照
hbase.hregion.max.filesize来进行分类
-
-
BusyRegionSplitPolicy:这个策略只有在HBase2.x中可以使用,是IncreasingToUpperBoundRegionSplitPolicy的子类-
在
IncreasingToUpperBoundRegionSplitPolicy的基础上,添加了热点策略。热点指的是在一段时间内被频繁访问的数据。如果某一个写数据是热点数据,那么HRegion会将这些数据拆分到同一个HRegion中 -
判断一个HRegion是否是热点的HRegion,计算方式
-
判断条件:
当前时间-上一次检测时间≥hbase.busy.policy.aggWindow,这样做的目的是为了控制后续计算的频率 -
计算请求的被阻塞率:
aggBlockedRate = 一段时间内被阻塞的请求数 / 总的请求数量 -
判断条件:如果
aggBlockedRate > hbase.busy.policy.blockedRequests,且该HRegion的繁忙时间 ≥ hbase.busy.policy.minAge,那么判定这个HRegion就是一个热点HRegion
-
-
hbase.busy.policy.aggWindow的值默认是300000,单位是毫秒,即5min;hbase.busy.policy.blockedRequests的值默认是0.2f;hbase.busy.policy.minAge的默认值是600000,单位是毫秒,即10min -
默认情况下,每隔5min进行一次检测计算,如果该HRegion被频繁访问了10min,且该HRegion的阻塞率超过了20%,那么此时就认为这个HRegion是一个热点HRegion
-
-
DisabledRegionSplitPolicy:禁用分裂策略,禁止HRegion的自动分裂。实际过程中较少使用,除非能够预估数据量
HBase的结构
Zookeeper的作用
-
Zookeeper在HBase中充当了注册中心,即HBase集群中每一个节点启动之后,都会在Zookeeper来注册节点
-
HBase集群启动之后,会在Zookeeper上来注册一个
/hbase节点 -
当Active HMaster启动之后,会自动的在Zookeeper上注册一个临时节点
/hbase/master -
当Backup HMaster启动之后,会自动的在Zookeeper上的
/hbase/backup-masters下来注册临时子节点。例如hadoop02上启动Backup HMaster,那么在Zookeeper上注册的节点/hbase/backup-masters/hadoop02,16000,1712459407965 -
当HRegionServer启动之后,会自动的在Zookeeper上的
/hbase/rs下来注册临时子节点。例如hadoop01上启动HRegionServer,那么在Zookeeper上注册的节点/hbase/rs/hadoop01,16020,1712459960698
HMaster
-
HBase是一个典型的主从结构,主节点是HMaster,从节点是HRegionServer。在HBase中,并不限制HMaster的个数,可以在任意一台安装了HBase的节点上来启动HMaster
hbase-daemon.sh start master
-
因此HBase不限制HMaster的个数,所以理论上而言,HMaster不存在单点故障
-
当HBase集群中存在多个HMaster的时候,此时多个HMaster之间会存在Active和Backup状态
-
为了保证数据的一致性,Active HMaster在接收到请求之后,会将信息同步给其他的Backup HMasters,同步的节点数量越多,效率会越低。也因此,虽然HBase中不限制HMaster的个数 ,但是实际过程中HMaster的数量一般不超过3个(1个Active HMaster + 2个Backup HMaster)
-
Active HMaster会实时监控Zookeeper上
/hbase/backup-masters下的子节点变化,以确定下一次需要将数据同步给哪些节点 -
当Zookeeper发现
/hbase/master节点消失的时候,意味着Active HMaster宕机,那么此时Zookeeper会从/hbase/backup-masters的子节点中挑选一个切换为Active状态 -
HMaster的作用
-
管理HRegionServer,但是不同于NameNode对于DataNode的掌控,HMaster主要是负责HRegion在HRegionServer之间的分布和转移,即HRegion交给HRegionServer来管理,由HMaster决定
-
记录和管理元数据。HBase中的元数据包含:namespace的信息,表信息,列族信息等。也因此,凡是产生元数据的操作(DDL,
create,drop,alter,list,enable,disable等)会经过HMaster,凡是不产生元数据的操作(DML,例如put,append,get,scan,delete,deleteall等)不会经过HMaster
-
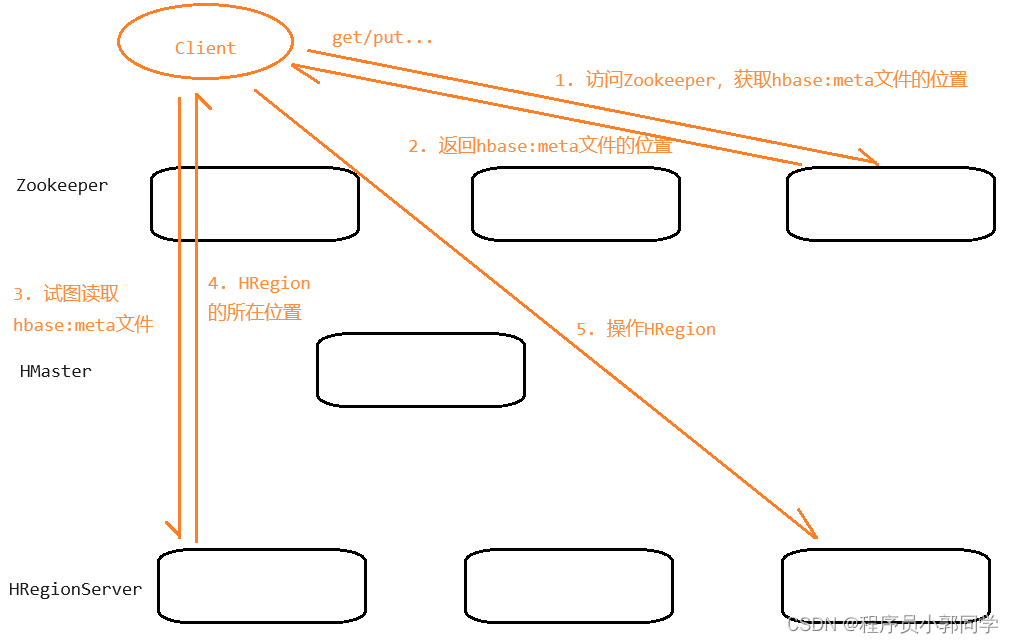
HBase架构的读写流程
-
客户端先访问Zookeeper,从Zookeeper中获取hbase:meta文件的存储位置
-
客户端获取到hbase:meta文件的位置之后,访问HRegionServer,读取hbase:meta文件
-
客户端会从hbase:meta文件中获取到要操作的HRegion所在的位置
-
客户端获取到HRegion的位置之后,会访问对应的HRegionServer,来试着操作这个HRegion
-
注意:HBase为了提高访问效率,还大量的应用了缓存机制
-
在客户端第一次访问Zookeeper之后,会缓存hbase:meta文件的位置,那么后续这个客户端在发起请求的时候,就可以不用访问Zookeeper
-
客户端在获取到HRegion的位置之后,还会缓存这个HRegion的位置,那么后续如果操作的是同一个HRegion,还可以减少对元数据的读取
-
如果这个过程中,发生了内存崩溃或者HRegion的分裂或者转移,会导致缓存失效
-
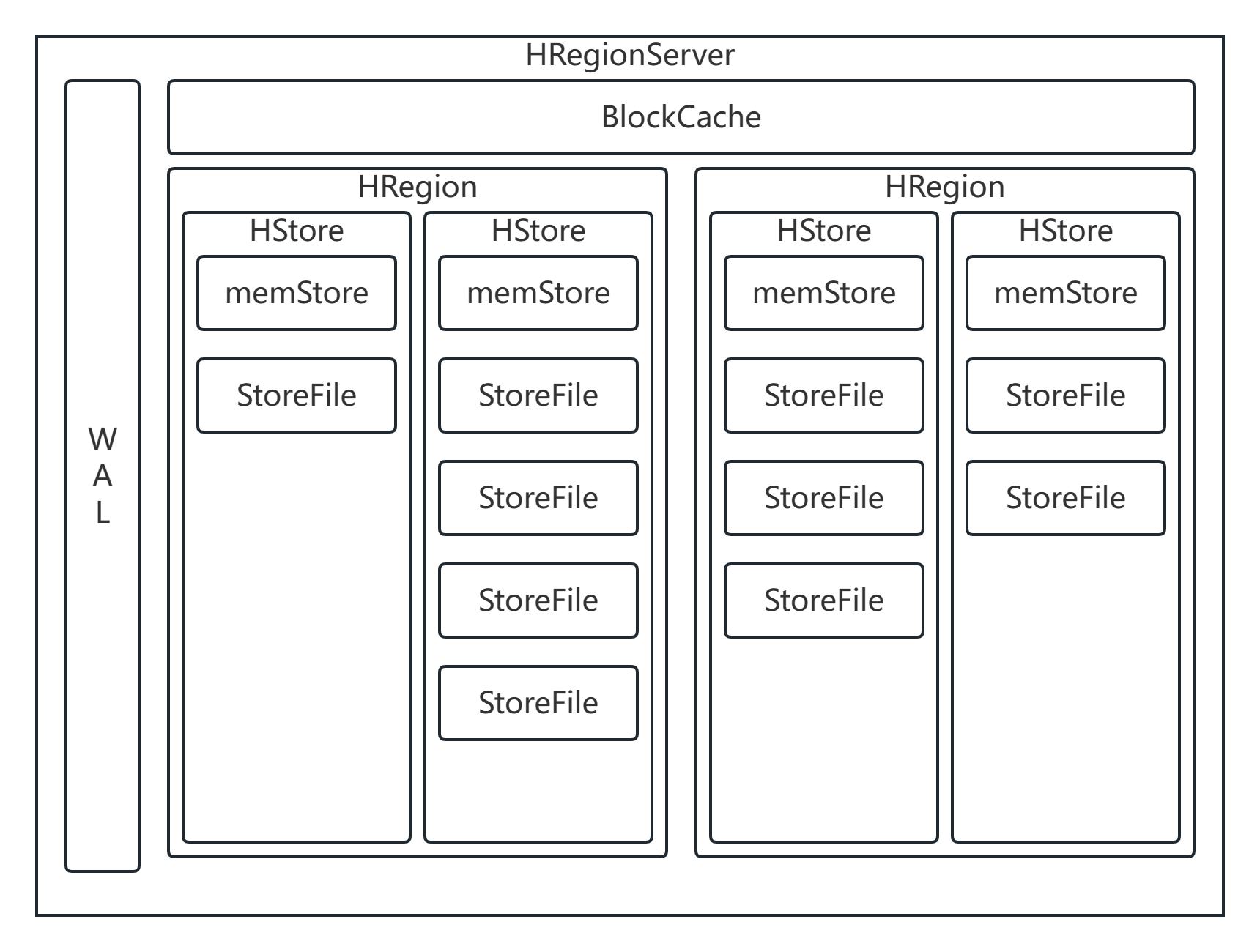
HRegionServer
-
HRegionServer是HBase的从节点,负责管理HRegion。根据官方文档给定,每一个HRegionServer大约可以管理1000个HRegion
-
每一个HRegionServer中包含1到多个WAL,1个BlockCache以及0到多个HRegion
-
WAL(Write Ahead Log):发生在写操作之前的日志,在早期的版本中也称之为HLog
-
WAL类似于HDFS中的edits文件。当HRegionServer接收到写操作之后,会先将这个命令记录到WAL中,然后再将数据更新到对应的HRegion的HStore的memStore中
-
在HBase0.94版本之前,WAL采用的是串行写机制。从HBase0.94开始,引入了NIO中的Channel,从而支持了并行写机制,因此能够提高WAL的写入效率,从而提升HBase的并发量
-
通过WAL机制,能够有效的保证数据不会产生丢失,因为WAL是落地到的磁盘上的,因此会一定程度上降低写入效率。实际过程中,如果能够接收一定程度的数据丢失,那么可以关闭WAL
-
当WAL写满之后,会产生一个新的WAL。单个WAL文件的大小由属性
hbase.regionserver.hlog.blocksize * hbase.regionserver.logroll.multiplier来决定-
早期的时候,
hbase.regionserver.hlog.blocksize的值默认和HDFS的Block等大,从HBase2.5开始,hbase.regionserver.hlog.blocksize的值默认是HDFS Block的2倍大 -
早期的时候,
hbase.regionserver.logroll.multiplier的,默认值是0.95,从HBase2.5开始,hbase.regionserver.logroll.multiplier的值是0.5
-
-
随着运行时间的推移,WAL的数量会越来越多,占用的磁盘会越来越多。因此,当WAL文件的个数超过指定数量的时候,按照时间顺序将产生的比较早的WAL清理掉。早期的时候,WAL的数量由
hbase.regionserver.max.logs来决定,默认值是32;从HBase2.x开始,这个属性被废弃掉,固定值就是32
-
-
BlockCache:数据块缓存
-
本质上就是一个读缓存,维系在内存中。早期的时候,BlockCache的大小是128M,从HBase2.x开始,是通过属性
hfile.block.cache.size来调节,默认值是0.4,即最多占用服务器内存的40% -
需要注意的是,如果
hbase.regionserver.global.memstore.size + hfile.block.cache.size > 0.8,即这个HRegionServer上所有的memStore所占内存之和 + BlockCache占用的内存大小 > 服务器内存 * 0.8,那么HRegionServer就会报错 -
当从HRegionServer来读取数据的时候,数据会先缓存到BlockCache中,然后再返回给客户端;客户端下一次读取的时候,可以直接从BlockCache中获取数据
-
BlockCache在进行缓存的时候,还会采用"局部性"原理。所谓的"局部性"原理本质上就是根据时间或者空间规律来提高猜测的命中率
-
时间局部性:当一条数据被读取之后,HRegionServer会认为这条数据被再次读取的概率要高于其他没有被读取过的数据,那么此时HRegionServer就会将这条数据放入BlockCache中
-
空间局部性:当一条数据被读取之后,HRegionServer会认为与这条数据相邻的数据被读取的概率要高于其他的数据,那么此时HRegionServer会将与这条数据相邻的数据也放入BlockCache中
-
-
BlockCache还采用了LRU(Least Recently Used,最近最少使用)策略。除了LRUBlockCache以外,HBase还支持SlabBlockCache和BucketBlockCache
-
-
HRegion:HBase中分布式存储和管理的基本单位
-
每一个HRegion中包含1个到多个HStore,HStore的数量由列族数量来决定
-
每一个HStore中会包含1个memStore以及0到多个HFile/StoreFile
-
memStore本质上是一个写缓存
-
HStore在接收到数据之后,会将数据临时存储到memStore中
-
memStore是维系在内存中,由属性
hbase.regionserver.memstore.flush.size来决定,默认值是134217728B -
当达到一定条件的时候,HRegionServer会将memStore中的数据进行flush(冲刷)操作,每次冲刷都会产生一个新的HFile
-
HFile最终会以Block形式落地到HDFS上
-
-
memStore的flush条件
-
当某一个memStore被用满之后,这个memStore所在的HRegion中的所有的memStore都会进行冲刷
-
当HRegionServer上,
所有memStore所占内存之和 ≥ java_heapsize * hbase.regionserver.global.memstore.size * hbase.regionserver.global.memstore.upperLimit,按照memStore的大小来依次冲刷,直到不满足上述条件为止。-
java_heapsize:java的堆内存大小 -
hbase.regionserver.global.memstore.size:所有的memStore所能占用的内存比例,默认是0.4 -
hbase.regionserver.global.memstore.upperLimit:上限,默认是0.95 -
假设服务器内存是128G,如果所有的memStore所占内存之和≥128G*0.4*0.95,将memStore从大到小依次冲刷,直到不满足条件为止
-
-
如果WAL的数量达到指定值,由于WAL会被清理掉,所以为了保证数据不丢失,那么会按照时间顺序,将memStore来依次冲刷
-
当距离上一次冲刷达到指定的时间间隔(可以通过属性
hbase.regionserver.optionalflushinterval来指定,单位是毫秒,默认值是3600000)的时候,也会自动的触发memStore的冲刷
-
-
相关文章:
HBase详解(2)
HBase 结构 HRegion 概述 在HBase中,会从行键方向上对表来进行切分,切分出来的每一个结构称之为是一个HRegion 切分之后,每一个HRegion会交给某一个HRegionServer来进行管理。HRegionServer是HBase的从节点,每一个HRegionServ…...
Web后端搭建
目录 一 搭建服务器端 1.1安装服务器软件 1.2检查环境是否配置 1.3安装Tomcat 二 创建并发Web项目 2.1创建一个java项目 三 创建Servlet 前端程序如何才能访问到后端程序呢,这时候我们就需要web服务器来解决:将后端程序部署到服务器中,…...
k8s单节点部署,容器运行时使用containerd
环境 系统 : entOS Linux release 7.9.2009 (CoreIP:192.168.44.177 硬件要求:控制平面最少需要 2c2g 安装前环境准备 如果是集群部署还需要配置时间同步 关闭防火墙 systemctl disable firewalld关闭selinux setenforce 0sed -i s/SELI…...

深入浅出 -- 系统架构之性能优化的核心思维
“在当前的互联网开发模式下,系统访问量日涨、并发暴增、线上瓶颈等各种性能问题纷涌而至,性能优化成为了现时代开发过程中炙手可热的名词,无论是在开发、面试过程中,性能优化都是一个常谈常新的话题”。Java语言作为企业应用中的…...
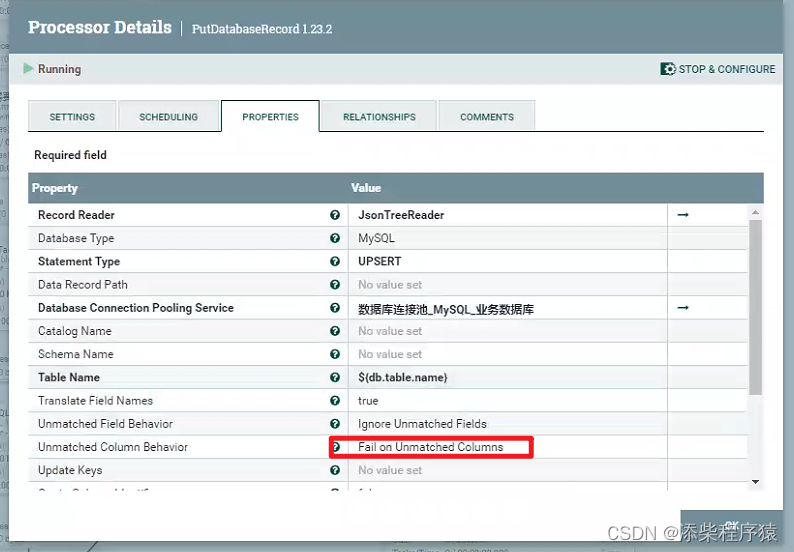
Nifi同步过程中报错create_time字段找不到_实际目标表和源表中没有这个字段---大数据之Nifi工作笔记0066
很奇怪的问题,在使用nifi的时候碰到的,这里是用NIFI,把数据从postgresql中同步到mysql中, 首先postgresql中的源表,中是没有create_time这个字段的,但是同步的过程中报错了. 报错的内容是说,目标表中有个create_time字段,这个字段是必填的,但是传过来的flowfile文件中,的数据没…...

批量删除文件脚本
在工作中我们经常会遇到一些重复性的工作,如批量创建文件,删除文件等等。这种重复性的工作shell脚本往往能给我们带来极大的便利。 将需要删除的文件路径存放在【stt_Files_240410.rpt】随便一个 文档中即可。 下面是一个批量删除文件的一个脚本范例&…...
蓝桥杯物联网竞赛_STM32L071KBU6_我的全部省赛及历年模拟赛源码
我写的省赛及历年模拟赛代码 链接:https://pan.baidu.com/s/1A0N_VUl2YfrTX96g3E8TfQ?pwd9k6o 提取码:9k6o...

微服务和K8S
微服务和Kubernetes(通常简称为K8s)都是现代软件开发和部署中常用的概念和工具。它们有着各自独特的特点和作用: 1. **微服务**: - **定义**:微服务是一种架构设计风格,将应用程序拆分为一组小型、独立…...

Ant Design 表单基础用法综合示例
Ant Design 的表单组件设计得非常出色,极大地简化了表单开发的复杂度,让开发者能够快速构建出功能丰富、交互友好的表单界面。 接下来总结一下 Ant Design 中表单的基本用法。 Form 组件 用于定义整个表单,可以设置表单的布局方式、提交行为等。通常会将表单字段组件嵌套在 F…...

MWeb Pro For Mac v4.5.9 强大的 Markdown 软件中文版
MWeb 是专业的 Markdown 写作、记笔记、静态博客生成软件,目前已支持 Mac,iPad 和 iPhone。MWeb 有以下特色: 软件下载:MWeb Pro For Mac v4.5.9 软件本身: 使用原生的 macOS 技术打造,追求与系统的完美结合…...

Git常用命令详解:掌握版本控制的核心操作
Git作为世界上最流行的分布式版本控制系统,以其强大的分支管理、高效的协同工作能力和完善的版本追溯功能,深受广大开发者喜爱。熟练掌握Git的常用命令是每一位程序员必备的技能。本文将深入解析Git中那些最为基础且实用的命令,助您在日常开发…...

Vue链接跳转地址 href 中有参数带有#
Vue链接跳转地址 href 中有参数带有# A跳转B 带参数backURL 转码一次会被浏览器解码 xxxx?backurlencodeURIComponent(url) 到B页面拿到的query 值取不到 需要对地址转码两次才能取值成功 xxxx?backurlencodeURIComponent(encodeURIComponent(url))...

python 会员信息管理系统2.0
问题介绍 综合案例实现:会员管理系统设计与实现-V3 利用所学习的知识点 ,结合会员管理系统的分析与实现, 了解面向对象开发过程中类内部功能的分析方法,系统讲解 Python语法、控制结构、四种典型序列 ,函数定义以及面向对象语法和模块的应用…...

HTTP的强制缓存和协商缓存
HTTP的强制缓存和协商缓存 HTTP的缓存技术强制缓存ExpiresCache-Control 协商缓存If-Modified-Since和Last-ModifiedIf-None-Match和ETag优先级 可被缓存的请求方法总结 HTTP的缓存技术 当我们进行HTTP请求时,需要将请求报文发送给对端,当服务端收到请求…...
Prometheus-Grafana基础篇安装绘图
首先Prometheus安装 1、下载 https://prometheus.io/download/ 官网路径可以去这儿下载 2、如图: 3.解压: tar -xf prometheus-2.6.1.linux-amd64 cd prometheus-2.6.1.linux-amd64 4.配置文件说明: vim prometheus.yml 5.启动Promethe…...

探索艺术的新领域——3D线上艺术馆如何改变艺术作品的传播方式
在数字化时代的浪潮下,3D线上艺术馆成为艺术家们展示和传播自己作品的新平台。不仅突破了地域和物理空间的限制,还提供了全新的互动体验。 一、无界限的展示空间:艺术家的新展示平台 3D线上艺术馆通过数字化技术,为艺术家提供了一…...
[dvwa] file upload
file upload 0x01 low 直接上传.php 内容写<? eval($_POST[jj]);?> 用antsword连 路径跳两层 0x02 medium 添加了两种验证,格式为图片,大小限制小于1000 上传 POST /learndvwa/vulnerabilities/upload/ HTTP/1.1 Host: dvt.dv Content-Le…...

pygame发射子弹后绘制射线
import pygame import sys import mathpygame.init()screen pygame.display.set_mode((800, 600)) pygame.display.set_caption("Rotate and Shoot Bullets")# 定义子弹类 class Bullet:def __init__(self, x, y, angle):self.x xself.y yself.angle angleself.s…...

逻辑回归都有什么类型
逻辑回归是一种用于解决分类问题的统计学习方法,它基于概率理论,将输入特征与输出类别之间的关系建模为一个概率分布。逻辑回归模型可以用不同的方法来表示,其中包括: 1. **基本逻辑回归模型**:最简单的逻辑回归模型假…...

基于springboot+vue实现的高校宿舍管理系统(界面优美,十分推荐)
一、项目简介 本项目是一套基于springbootvue实现的高校宿舍管理系统设计与实现 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观…...

Packet Tracer实战:交换机基础配置与常见问题排查
1. Packet Tracer与交换机配置入门 第一次接触网络设备配置的朋友可能会觉得交换机是个神秘的黑盒子。其实用Cisco Packet Tracer这个仿真工具,你完全可以在自己的电脑上搭建一个虚拟实验室。我刚开始学习时也是从这个工具入手的,它比真机操作更友好——…...

告别虚拟机!在物理机统信系统上部署FME Desktop的性能调优与存储空间规划指南
告别虚拟机!在物理机统信系统上部署FME Desktop的性能调优与存储空间规划指南 当GIS工程师需要在国产化环境中处理大规模空间数据时,物理机直接部署FME Desktop往往能获得比虚拟机更极致的性能表现。本文将深入探讨在统信UOS专业版物理机环境中ÿ…...
)
QT实战:用QChartView快速打造动态折线图(附完整代码)
QT实战:用QChartView快速打造动态折线图(附完整代码) 在数据可视化领域,动态折线图因其直观展示数据变化趋势的能力,成为监控系统、金融分析、工业控制等场景的标配。QT框架提供的QChartView组件,让开发者能…...

Lingbot-Depth-Pretrain-ViTL-14 实战:Python爬虫获取图像数据并生成深度图
Lingbot-Depth-Pretrain-ViTL-14 实战:Python爬虫获取图像数据并生成深度图 你是不是也遇到过这样的场景:手头有一个很棒的深度估计模型,比如 Lingbot-Depth-Pretrain-ViTL-14,想用它来为自己的项目生成深度图,却发现…...

解决Windows远程桌面连接Ubuntu时xrdp闪退的配置技巧
1. 问题现象与排查思路 最近在帮同事配置Windows远程连接Ubuntu时遇到了一个典型问题:用Windows自带的远程桌面连接工具输入账号密码后,界面闪退无法进入桌面。这种情况在Ubuntu 18.04/20.04/22.04各版本中都可能出现,特别是使用GNOME桌面环…...

简单几步,让AI帮你画瑜伽女孩:雯雯的后宫-造相Z-Image-瑜伽女孩模型使用教程
简单几步,让AI帮你画瑜伽女孩:雯雯的后宫-造相Z-Image-瑜伽女孩模型使用教程 1. 模型介绍:你的专属AI瑜伽画师 想象一下,你只需要用文字描述,就能让AI为你创作出专业级的瑜伽女孩图片。这就是"雯雯的后宫-造相Z…...

终极Bash Infinity代码审查指南:确保Bash框架代码质量的完整检查清单
终极Bash Infinity代码审查指南:确保Bash框架代码质量的完整检查清单 【免费下载链接】bash-oo-framework Bash Infinity is a modern standard library / framework / boilerplate for Bash 项目地址: https://gitcode.com/gh_mirrors/ba/bash-oo-framework …...

Notepad2终极指南:轻量级文本编辑器的完整使用教程
Notepad2终极指南:轻量级文本编辑器的完整使用教程 【免费下载链接】notepad2 Notepad2-zufuliu is a light-weight Scintilla based text editor for Windows with syntax highlighting, code folding, auto-completion and API list for many programming languag…...

VRCX:重新定义VRChat社交管理的智能伴侣工具
VRCX:重新定义VRChat社交管理的智能伴侣工具 【免费下载链接】VRCX Friendship management tool for VRChat 项目地址: https://gitcode.com/GitHub_Trending/vr/VRCX 在虚拟社交平台VRChat的生态中,社交关系管理常常成为用户体验的痛点。传统方式…...

4步打造高效能开源路由器:OpenWrt固件安装指南
4步打造高效能开源路由器:OpenWrt固件安装指南 【免费下载链接】openwrt openwrt编译更新库X86-R2C-R2S-R4S-R5S-N1-小米MI系列等多机型全部适配OTA自动升级 项目地址: https://gitcode.com/GitHub_Trending/openwrt5/openwrt OpenWrt固件安装是提升R5S设备性…...