LangChain - 文档转换
文章目录
- 一、文档转换器 & 文本拆分器
- 文本拆分器
- 二、开始使用文本拆分器
- 三、按字符进行拆分
- 四、代码分割 (Split code)
- 1、PythonTextSplitter
- 2、JS
- 3、Markdown
- 4、Latex
- 5、HTML
- 6、Solidity
- 五、MarkdownHeaderTextSplitter
- 1、动机
- 2、Use case
- 六、递归按字符分割
- 七、按token 进行分割
- 1、tiktoken
- 2、spaCy
- 3、SentenceTransformers
- 4、NLTK
- 5、Hugging Face tokenizer
本文转载改编自:
https://python.langchain.com.cn/docs/modules/data_connection/document_transformers/
一、文档转换器 & 文本拆分器
一旦加载了文档,您通常会希望对其进行转换,以更好地适应您的应用程序。
最简单的例子是您可能希望将长文档拆分为更小的块,以适应您模型的上下文窗口。
LangChain提供了许多内置的文档转换器,使得拆分、合并、过滤和其他文档操作变得容易。
文本拆分器
当您想要处理大块文本时,有必要将文本拆分为块。
虽然听起来很简单,但这里存在许多 潜在的复杂性。
理想情况下,您希望将 语义相关的文本片段 保持在一起。
"语义相关"的含义可能取决于 文本的类型。本笔记本演示了几种做法。
在高层次上,文本拆分器的工作方式如下:
- 将文本拆分为小的、语义上有意义的块(通常是句子)。
- 将这些小块组合成较大的块,直到达到某个大小(由某个函数测量)。
- 一旦达到该大小,将该块作为自己的文本片段,然后开始创建一个具有一定重叠的新文本块(以保持块之间的上下文)。
这意味着有两个不同的轴可以定制您的文本拆分器:
- 文本如何拆分
- 块大小如何测量
二、开始使用文本拆分器
默认推荐的文本分割器是 RecursiveCharacterTextSplitter。
该文本分割器接受一个字符列表。
它尝试根据第一个字符进行分割来创建块,但如果任何块太大,则继续移动到下一个字符,依此类推。
默认情况下,它尝试进行分割的字符是 ["\n\n", "\n", " ", ""]
除了控制可以进行分割的字符之外,您还可以控制一些其他事项:
length_function:计算块长度的方法。默认只计算字符数,但通常在此处传递一个令牌计数器。chunk_size:块的最大大小(由长度函数测量)。chunk_overlap:块之间的最大重叠。保持一些连续性之间可能有一些重叠(例如使用滑动窗口)。add_start_index:是否在元数据中包含每个块在原始文档中的起始位置。
加载一段长文本
with open('../../state_of_the_union.txt') as f:state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(# Set a really small chunk size, just to show.chunk_size = 100,chunk_overlap = 20,length_function = len,add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
三、按字符进行拆分
这是最简单的方法。它基于字符进行拆分(默认为"\n\n"),并通过字符数量来测量块的长度。
- 文本如何被拆分: 按单个字符拆分。
- 块大小如何被测量: 通过字符数量来测量。
# This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter( separator = "\n\n",chunk_size = 1000,chunk_overlap = 200,length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. ...He met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.' lookup_str='' metadata={} lookup_index=0
如下示例,传递文档的元数据信息。注意,它是和文档一起拆分的。
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas)
print(documents[0])
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. ...From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.' lookup_str='' metadata={'document': 1} lookup_index=0
text_splitter.split_text(state_of_the_union)[0]
'Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. ...From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.'
四、代码分割 (Split code)
CodeTextSplitter 允许您使用多种语言进行代码分割。
导入枚举 Language并指定语言。
from langchain.text_splitter import (RecursiveCharacterTextSplitter,Language,
)
Full list of support languages
[e.value for e in Language]
['cpp','go','java','js','php','proto','python','rst','ruby','rust','scala','swift','markdown','latex','html','sol',]
给定编程语言,你也可以看到 这个语言对应的 separators
RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
['\nclass ', '\ndef ', '\n\tdef ', '\n\n', '\n', ' ', '']
1、PythonTextSplitter
这里是使用 PythonTextSplitter 的示例
PYTHON_CODE = """
def hello_world():print("Hello, World!")# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
[Document(page_content='def hello_world():\n print("Hello, World!")', metadata={}),Document(page_content='# Call the function\nhello_world()', metadata={})]
2、JS
这里是使用 JS 文本分割器的示例
JS_CODE = """
function helloWorld() {console.log("Hello, World!");
}// Call the function
helloWorld();
"""js_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.JS, chunk_size=60, chunk_overlap=0
)
js_docs = js_splitter.create_documents([JS_CODE])
js_docs
[Document(page_content='function helloWorld() {\n console.log("Hello, World!");\n}', metadata={}),Document(page_content='// Call the function\nhelloWorld();', metadata={})]
3、Markdown
这里是使用 Markdown 文本分割器的示例
markdown_text = """# 🦜️🔗 LangChain⚡ Building applications with LLMs through composability ⚡## Quick Install```bashpip install langchain```As an open source project in a rapidly developing field, we are extremely open to contributions.
"""
md_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
md_docs
[Document(page_content='# 🦜️🔗 LangChain', metadata={}),Document(page_content='⚡ Building applications with LLMs through composability ⚡', metadata={}),...Document(page_content='are extremely open to contributions.', metadata={})]
4、Latex
这里是使用 Latex 文本的示例
latex_text = """
\documentclass{article}\begin{document}\maketitle\section{Introduction}
Large language models (LLMs) are a type of machine learning model that can be trained on vast amounts of text data to generate human-like language. In recent years, LLMs have made significant advances in a variety of natural language processing tasks, including language translation, text generation, and sentiment analysis.\subsection{History of LLMs}
The earliest LLMs were developed in the 1980s and 1990s, but they were limited by the amount of data that could be processed and the computational power available at the time. In the past decade, however, advances in hardware and software have made it possible to train LLMs on massive datasets, leading to significant improvements in performance.\subsection{Applications of LLMs}
LLMs have many applications in industry, including chatbots, content creation, and virtual assistants. They can also be used in academia for research in linguistics, psychology, and computational linguistics.\end{document}
"""
latex_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
latex_docs = latex_splitter.create_documents([latex_text])
latex_docs
[Document(page_content='\\documentclass{article}\n\n\x08egin{document}\n\n\\maketitle', metadata={}),Document(page_content='\\section{Introduction}', metadata={}),Document(page_content='Large language models (LLMs) are a type of machine learning', metadata={}),...Document(page_content='psychology, and computational linguistics.', metadata={}),Document(page_content='\\end{document}', metadata={})]
5、HTML
这里是使用 HTML 文本分割器的示例
html_text = """
<!DOCTYPE html>
<html><head><title>🦜️🔗 LangChain</title><style>body {font-family: Arial, sans-serif;}h1 {color: darkblue;}</style></head><body><div><h1>🦜️🔗 LangChain</h1><p>⚡ Building applications with LLMs through composability ⚡</p></div><div>As an open source project in a rapidly developing field, we are extremely open to contributions.</div></body>
</html>
"""
html_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
html_docs = html_splitter.create_documents([html_text])
html_docs
[Document(page_content='<!DOCTYPE html>\n<html>\n <head>', metadata={}),Document(page_content='<title>🦜️🔗 LangChain</title>\n <style>', metadata={}),Document(page_content='body {', metadata={}),Document(page_content='font-family: Arial, sans-serif;', metadata={}),Document(page_content='}\n h1 {', metadata={}),Document(page_content='color: darkblue;\n }', metadata={}),Document(page_content='</style>\n </head>\n <body>\n <div>', metadata={}),Document(page_content='<h1>🦜️🔗 LangChain</h1>', metadata={}),Document(page_content='<p>⚡ Building applications with LLMs through', metadata={}),Document(page_content='composability ⚡</p>', metadata={}),Document(page_content='</div>\n <div>', metadata={}),Document(page_content='As an open source project in a rapidly', metadata={}),Document(page_content='developing field, we are extremely open to contributions.', metadata={}),Document(page_content='</div>\n </body>\n</html>', metadata={})]
6、Solidity
这里是使用 Solidity 文本分割器的示例
SOL_CODE = """
pragma solidity ^0.8.20;
contract HelloWorld {function add(uint a, uint b) pure public returns(uint) {return a + b;}
}
"""sol_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.SOL, chunk_size=128, chunk_overlap=0
)
sol_docs = sol_splitter.create_documents([SOL_CODE])
sol_docs
[Document(page_content='pragma solidity ^0.8.20;', metadata={}),Document(page_content='contract HelloWorld {\n function add(uint a, uint b) pure public returns(uint) {\n return a + b;\n }\n}', metadata={})
]
五、MarkdownHeaderTextSplitter
1、动机
许多聊天或问答应用程序在嵌入和向量存储之前,会先对输入文档进行分割成块。
Pinecone 的这些笔记提供了一些有用的提示:
当嵌入整个段落或文档时,嵌入过程会同时考虑整体上下文和文本中句子和短语之间的关系。这可能会得到更全面的向量表示,捕捉文本的更广泛的含义和主题。
正如上面所述,分块通常旨在将具有共同上下文的文本保持在一起。
在这种情况下,我们可能想要特别尊重文档本身的结构。
例如,一个 Markdown 文件的组织方式是通过标题。
在特定的标题组内创建分块是一个直观的想法。
为了解决这个挑战,我们可以使用 MarkdownHeaderTextSplitter。
它将按照指定的一组标题来分割一个 Markdown 文件。
例如,如果我们想要分割这个 Markdown:
md = '# Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly'
我们可以指定要分割的标题:
[("#", "Header 1"),("##", "Header 2")]
然后根据公共标题进行内容的分组或分割:
{'content': 'Hi this is Jim \nHi this is Joe', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar'}}
{'content': 'Hi this is Molly', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Baz'}}
让我们来看一些下面的示例。
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
for split in md_header_splits:print(split)
{'content': 'Hi this is Jim \nHi this is Joe', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar'}}
{'content': 'Hi this is Lance', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}}
{'content': 'Hi this is Molly', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Baz'}}
在每个 markdown 组中,我们可以应用我们需要的 text splitter。
markdown_document = "# Intro \n\n ## History \n\n Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \n\n Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files. \n\n ## Rise and divergence \n\n As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \n\n additional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n\n #### Standardization \n\n From 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort. \n\n ## Implementations \n\n Implementations of Markdown are available for over a dozen programming languages."headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),
]# MD splits
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)# Char-level splits
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 10
chunk_overlap = 0
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)# Split within each header group
all_splits=[]
all_metadatas=[]
for header_group in md_header_splits:_splits = text_splitter.split_text(header_group['content'])_metadatas = [header_group['metadata'] for _ in _splits]all_splits += _splitsall_metadatas += _metadatas
all_splits[0]
# -> 'Markdown[9'
all_metadatas[0]
# -> {'Header 1': 'Intro', 'Header 2': 'History'}
2、Use case
我们将 MarkdownHeaderTextSplitter 应用到 Notion page 作为测试。详情可见:https://rlancemartin.notion.site/Auto-Evaluation-of-Metadata-Filtering-18502448c85240828f33716740f9574b
这个页面使用 markdown 下载保存到本地。
# Load Notion database as a markdownfile file
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("../Notion_DB_Metadata")
docs = loader.load()
md_file=docs[0].page_content
# Let's create groups based on the section headers
headers_to_split_on = [("###", "Section"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_file)
md_header_splits[3]
{'content': 'We previously introduced [auto-evaluator](https://blog.langchain.dev/auto-evaluator-opportunities/), an open-source tool for grading LLM question-answer chains. Here, we extend auto-evaluator with a [lightweight Streamlit app](https://github.com/langchain-ai/auto-evaluator/tree/main/streamlit) that can connect to any existing Pinecone index. We add the ability to test metadata filtering using `SelfQueryRetriever` as well as some other approaches that we’ve found to be useful, as discussed below. \n[ret_trim.mov](Auto-Evaluation%20of%20Metadata%20Filtering%2018502448c85240828f33716740f9574b/ret_trim.mov)','metadata': {'Section': 'Evaluation'}}
现在,我们将文本拆分到每个组中,并将该组作为元数据保存。
# Define our text splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 500
chunk_overlap = 50
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)# Create splits within each header group
all_splits=[]
all_metadatas=[]
for header_group in md_header_splits:_splits = text_splitter.split_text(header_group['content'])_metadatas = [header_group['metadata'] for _ in _splits]all_splits += _splitsall_metadatas += _metadatas
all_splits[6]
'In these cases, semantic search will look for the concept `episode 53` in the chunks, but instead we simply want to filter the chunks for `episode 53` and then perform semantic search to extract those that best summarize the episode. Metadata filtering does this, so long as we 1) we have a metadata filter for episode number and 2) we can extract the value from the query (e.g., `54` or `252`) that we want to extract. The LangChain `SelfQueryRetriever` does the latter (see'
all_metadatas[6]
{'Section': 'Motivation'}
这使我们能够很好地执行 基于文档结构的 元数据过滤。
让我们先建一个向量库,把这一切结合起来。
! pip install chromadb
# Build vectorstore
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_texts(texts=all_splits,metadatas=all_metadatas,embedding=OpenAIEmbeddings())
我们创建一个 SelfQueryRetriever,可以根据我们定义的元数据进行筛选。
# Create retriever
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo# Define our metadata
metadata_field_info = [AttributeInfo(name="Section",description="Headers of the markdown document that organize the ideas",type="string or list[string]",),
]
document_content_description = "Headers of the markdown document"# Define self query retriver
llm = OpenAI(temperature=0)
sq_retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info, verbose=True)
然后我们可以从 文章的任意部分,获取 chunks。
# Test
question="Summarize the Introduction section of the document"
sq_retriever.get_relevant_documents(question)
query='Introduction' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='Section', value='Introduction') limit=None[Document(page_content='', metadata={'Section': 'Introduction'}),Document(page_content='Q+A systems often use a two-step approach: retrieve relevant text chunks and then synthesize them into an answer. ... Metadata filtering is an alternative approach that pre-filters chunks based on a user-defined criteria in a VectorDB using', metadata={'Section': 'Introduction'}),Document(page_content='on a user-defined criteria in a VectorDB using metadata tags prior to semantic search.', metadata={'Section': 'Introduction'})]
现在,我们可以创建清洗的文档结构的 聊天或Q+A 应用程序。
当然,没有特定元数据过滤的语义搜索,可能对这个简单的文档 相当有效。
但是,对于更复杂或更长的文档,保留文档结构 以进行 元数据过滤的能力 可能会有所帮助。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=sq_retriever)
qa_chain.run(question)
query='Introduction' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='Section', value='Introduction') limit=None'The document discusses different approaches to retrieve relevant text chunks and synthesize them into an answer in Q+A systems.
...
The Retriever-Less option, which uses the Anthropic 100k context window model, is also mentioned as an alternative approach.'
question="Summarize the Testing section of the document"
qa_chain.run(question)
query='Testing' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='Section', value='Testing') limit=None'The Testing section of the document describes how the performance of the SelfQueryRetriever was evaluated using various test cases.
...
Additionally, the document mentions the use of the Kor library for structured data extraction to explicitly specify transformations that the auto-evaluator can use.'
六、递归按字符分割
这个文本分割器 是用于 通用文本的推荐分割器。它通过一个 字符列表进行参数化。
它会按 顺序 尝试使用这些字符进行分割,直到块的大小足够小。
默认列表是 ["\n\n", "\n", " ", ""]。
这样做的效果是尽可能地保持所有段落(然后是句子,然后是单词)在一起,因为它们通常是 在语义上相关的文本片段中 的最强关联部分。
- 文本如何分割:按字符列表。
- 块的大小如何衡量:按字符数。
This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(# Set a really small chunk size, just to show.chunk_size = 100,chunk_overlap = 20,length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' lookup_str='' metadata={} lookup_index=0page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' lookup_str='' metadata={} lookup_index=0
text_splitter.split_text(state_of_the_union)[:2]
['Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and','of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.']
七、按token 进行分割
语言模型有一个token限制。您不应超过token限制。
因此,当您将文本分割成块时,将token的数量进行计数是一个好主意。
有许多分词器可供使用。在计数文本中的token时,应使用 与语言模型 中使用的相同的分词器。
1、tiktoken
tiktoken 是由 OpenAI 创建的高速BPE分词器。
我们可以使用它来估计已使用的token。对于 OpenAI 模型,它可能更准确。
- 文本的分割方式:通过传入的字符进行分割
- 分块大小的衡量标准:使用
tiktoken分词器计数
安装 tiktoken
!pip install tiktoken
# This is a long document we can split up.
with open("../../../state_of_the_union.txt") as f:state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
texts[0]
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. Last year COVID-19 kept us apart. This year we are finally together again. Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. With a duty to one another to the American people to the Constitution.
也可以直接 load 一个 tiktoken splitter
from langchain.text_splitter import TokenTextSplittertext_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
2、spaCy
spaCy is an open-source software library for advanced natural language processing, written in the programming languages Python and Cython.
另一个替代NLTK 的是 spaCy tokenizer.
- How the text is split: by
spaCytokenizer - How the chunk size is measured: by number of characters
!pip install spacy
# This is a long document we can split up.
with open("../../../state_of_the_union.txt") as f:state_of_the_union = f.read()
from langchain.text_splitter import SpacyTextSplittertext_splitter = SpacyTextSplitter(chunk_size=1000)texts = text_splitter.split_text(state_of_the_union)
texts[0]
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman.Members of Congress and the Cabinet.
...From President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.
3、SentenceTransformers
SentenceTransformersTokenTextSplitter 是一个专门用于 sentence-transformer 模型 的文本拆分器。
默认行为是 将文本拆分为 适合您想要使用的 sentence transformer 模型的标记窗口的块。
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
splitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0)
text = "Lorem "count_start_and_stop_tokens = 2
text_token_count = splitter.count_tokens(text=text) - count_start_and_stop_tokens
print(text_token_count) # 2
token_multiplier = splitter.maximum_tokens_per_chunk // text_token_count + 1# `text_to_split` does not fit in a single chunk
text_to_split = text * token_multiplier # 514print(f"tokens in text to split: {splitter.count_tokens(text=text_to_split)}")
tokens in text to split: 514
text_chunks = splitter.split_text(text=text_to_split)print(text_chunks[1]) # lorem
4、NLTK
The Natural Language Toolkit, 或更被知道为 NLTK, 是一套用Python编程语言编写的 用于英语符号和统计自然语言处理(NLP)的库和程序。
在使用 “\n\n” 分割的基础上, 我们使用 NLTK 的 NLTK tokenizers 来分割。
- 文本如何被分割: 使用
NLTKtokenizer. - 块大小如何计算:按 characters 数
# pip install nltk
# This is a long document we can split up.
with open("../../../state_of_the_union.txt") as f:state_of_the_union = f.read()
from langchain.text_splitter import NLTKTextSplittertext_splitter = NLTKTextSplitter(chunk_size=1000)texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman....Groups of citizens blocking tanks with their bodies.
5、Hugging Face tokenizer
Hugging Face 有很多 tokenizers。
我们使用 Hugging Face tokenizer, GPT2TokenizerFast 来计算tokens 中的文本长度。
- 文本如何分割: by character passed in
- 块大小如何计算: 通过
Hugging Facetokenizer计算的 tokens 数量。
from transformers import GPT2TokenizerFast
from langchain.text_splitter import CharacterTextSplittertokenizer = GPT2TokenizerFast.from_pretrained("gpt2")# This is a long document we can split up.
with open("../../../state_of_the_union.txt") as f:state_of_the_union = f.read()text_splitter = CharacterTextSplitter.from_huggingface_tokenizer(tokenizer, chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
texts[0]
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. ...With a duty to one another to the American people to the Constitution.
2024-04-08(一)
相关文章:

LangChain - 文档转换
文章目录 一、文档转换器 & 文本拆分器文本拆分器 二、开始使用文本拆分器三、按字符进行拆分四、代码分割 (Split code)1、PythonTextSplitter2、JS3、Markdown4、Latex5、HTML6、Solidity 五、MarkdownHeaderTextSplitter1、动机2、Use case 六、递归按字符分割七、按tok…...

【C++】STL--list
目录 list的介绍 list的使用 list的构造 list iterator的使用 list capacity list modifiers list的迭代器失效 list模拟实现 list的介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向…...

二. CUDA编程入门-双线性插值计算
目录 前言0. 简述1. 执行一下我们的第十个CUDA程序2. Bilinear interpolation3. 代码分析总结参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 Note:关于 CUDA 加速双线程插值的内容博主…...

实时计算平台设计方案:913-基于100G光口的DSP+FPGA实时计算平台
基于100G光口的DSPFPGA实时计算平台 一、产品概述 基于以太网接口的实时数据智能计算一直应用于互联网、网络安全、大数据交换的场景。以DSPFPGA的方案,体现了基于硬件计算的独特性能,区别于X86GPU的计算方案,保留了高带宽特性&…...

Glide系列-自定义ModuleLoader
在当今快速发展的移动应用领域,图片的高效加载和显示对于提供流畅用户体验至关重要。Glide作为一款强大的图片加载库,已经成为Android开发者的首选工具之一。但是,你有没有遇到过Glide默认不支持的模型类型,或者需要对图片加载过程…...

设计模式——责任链模式13
责任链模式 每个流程或事物处理 像一个链表结构处理。场景由 多层部门审批,问题分级处理等。下面体现的是 不同难度的问题由不同人进行解决。 设计模式,一定要敲代码理解 传递问题实体 /*** author ggbond* date 2024年04月10日 07:48*/ public class…...

Linux云计算之Linux基础3——Linux系统基础part-2
1、终端、shell、文件理论 1、终端 终端(terminal):人和系统交互的必要设备,人机交互最后一个界面(包含独立的输入输出设备) 物理终端(console):直接接入本机器的键盘设备和显示器虚拟终端(tty):通过软件…...
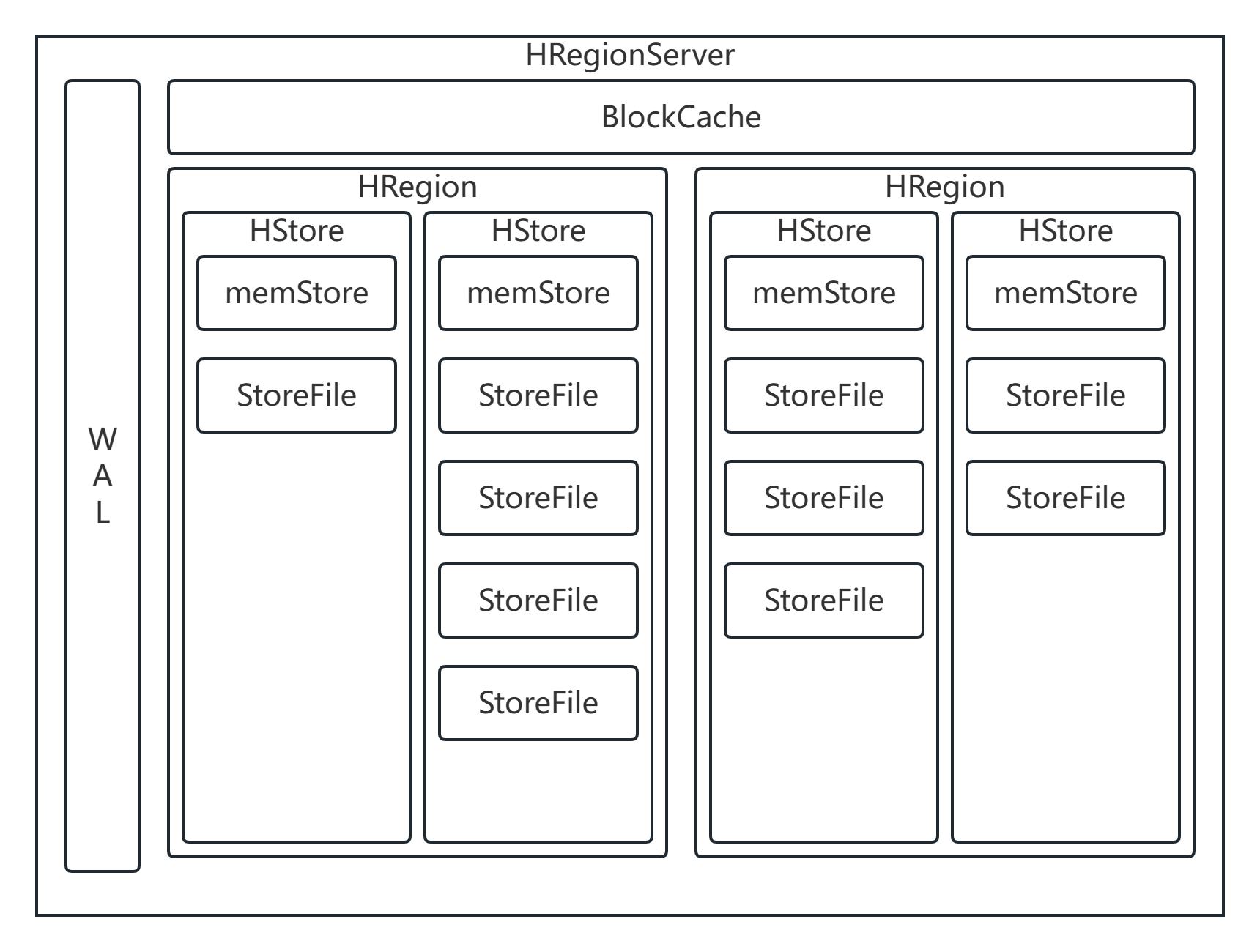
HBase详解(2)
HBase 结构 HRegion 概述 在HBase中,会从行键方向上对表来进行切分,切分出来的每一个结构称之为是一个HRegion 切分之后,每一个HRegion会交给某一个HRegionServer来进行管理。HRegionServer是HBase的从节点,每一个HRegionServ…...
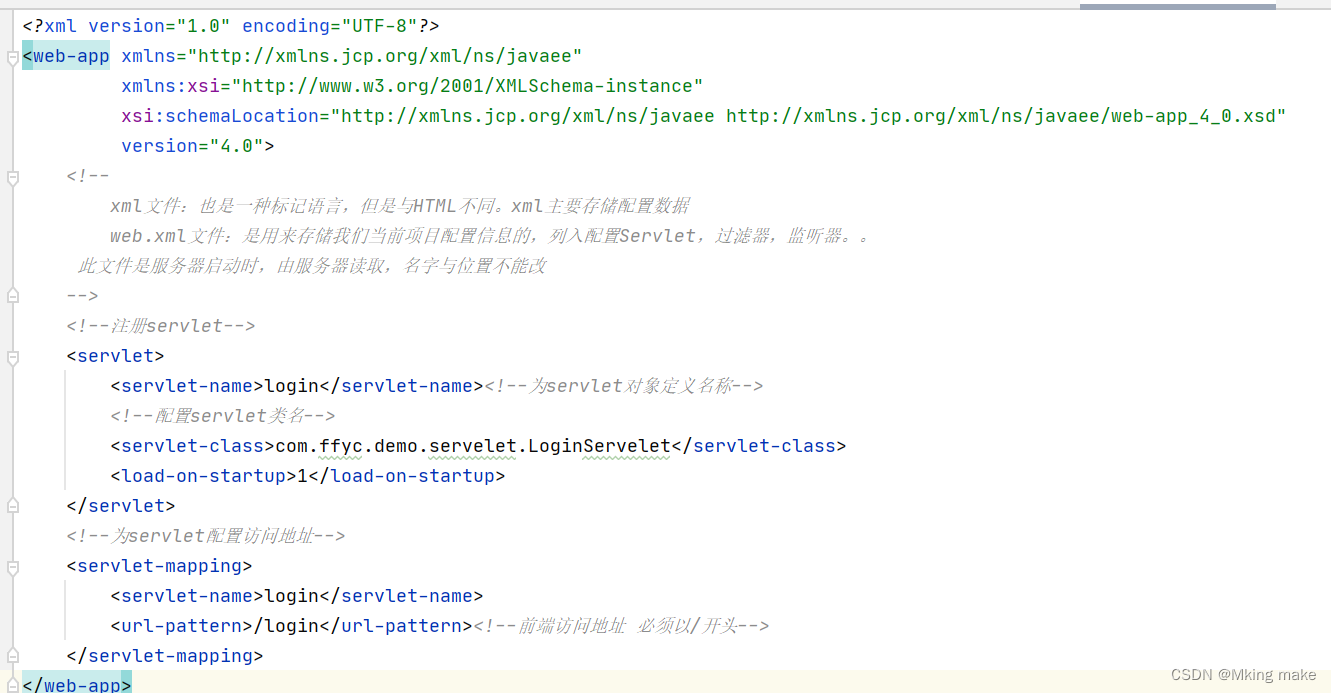
Web后端搭建
目录 一 搭建服务器端 1.1安装服务器软件 1.2检查环境是否配置 1.3安装Tomcat 二 创建并发Web项目 2.1创建一个java项目 三 创建Servlet 前端程序如何才能访问到后端程序呢,这时候我们就需要web服务器来解决:将后端程序部署到服务器中,…...
k8s单节点部署,容器运行时使用containerd
环境 系统 : entOS Linux release 7.9.2009 (CoreIP:192.168.44.177 硬件要求:控制平面最少需要 2c2g 安装前环境准备 如果是集群部署还需要配置时间同步 关闭防火墙 systemctl disable firewalld关闭selinux setenforce 0sed -i s/SELI…...

深入浅出 -- 系统架构之性能优化的核心思维
“在当前的互联网开发模式下,系统访问量日涨、并发暴增、线上瓶颈等各种性能问题纷涌而至,性能优化成为了现时代开发过程中炙手可热的名词,无论是在开发、面试过程中,性能优化都是一个常谈常新的话题”。Java语言作为企业应用中的…...
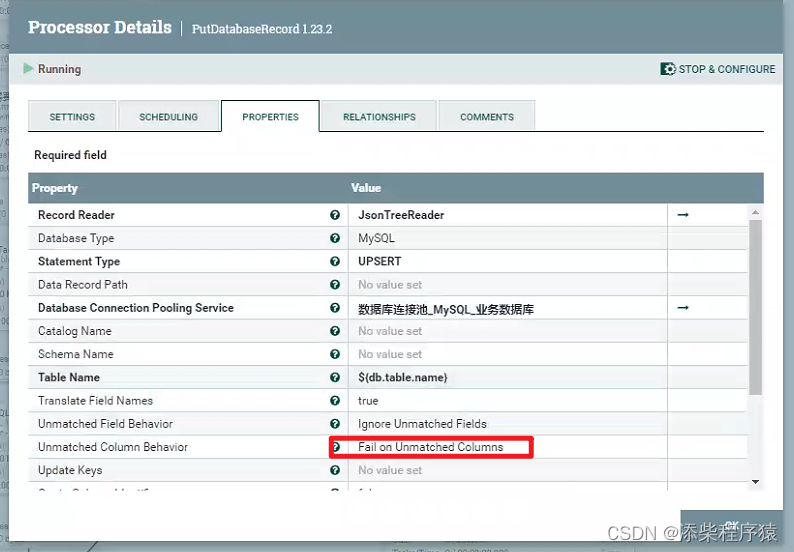
Nifi同步过程中报错create_time字段找不到_实际目标表和源表中没有这个字段---大数据之Nifi工作笔记0066
很奇怪的问题,在使用nifi的时候碰到的,这里是用NIFI,把数据从postgresql中同步到mysql中, 首先postgresql中的源表,中是没有create_time这个字段的,但是同步的过程中报错了. 报错的内容是说,目标表中有个create_time字段,这个字段是必填的,但是传过来的flowfile文件中,的数据没…...

批量删除文件脚本
在工作中我们经常会遇到一些重复性的工作,如批量创建文件,删除文件等等。这种重复性的工作shell脚本往往能给我们带来极大的便利。 将需要删除的文件路径存放在【stt_Files_240410.rpt】随便一个 文档中即可。 下面是一个批量删除文件的一个脚本范例&…...
蓝桥杯物联网竞赛_STM32L071KBU6_我的全部省赛及历年模拟赛源码
我写的省赛及历年模拟赛代码 链接:https://pan.baidu.com/s/1A0N_VUl2YfrTX96g3E8TfQ?pwd9k6o 提取码:9k6o...

微服务和K8S
微服务和Kubernetes(通常简称为K8s)都是现代软件开发和部署中常用的概念和工具。它们有着各自独特的特点和作用: 1. **微服务**: - **定义**:微服务是一种架构设计风格,将应用程序拆分为一组小型、独立…...

Ant Design 表单基础用法综合示例
Ant Design 的表单组件设计得非常出色,极大地简化了表单开发的复杂度,让开发者能够快速构建出功能丰富、交互友好的表单界面。 接下来总结一下 Ant Design 中表单的基本用法。 Form 组件 用于定义整个表单,可以设置表单的布局方式、提交行为等。通常会将表单字段组件嵌套在 F…...

MWeb Pro For Mac v4.5.9 强大的 Markdown 软件中文版
MWeb 是专业的 Markdown 写作、记笔记、静态博客生成软件,目前已支持 Mac,iPad 和 iPhone。MWeb 有以下特色: 软件下载:MWeb Pro For Mac v4.5.9 软件本身: 使用原生的 macOS 技术打造,追求与系统的完美结合…...

Git常用命令详解:掌握版本控制的核心操作
Git作为世界上最流行的分布式版本控制系统,以其强大的分支管理、高效的协同工作能力和完善的版本追溯功能,深受广大开发者喜爱。熟练掌握Git的常用命令是每一位程序员必备的技能。本文将深入解析Git中那些最为基础且实用的命令,助您在日常开发…...

Vue链接跳转地址 href 中有参数带有#
Vue链接跳转地址 href 中有参数带有# A跳转B 带参数backURL 转码一次会被浏览器解码 xxxx?backurlencodeURIComponent(url) 到B页面拿到的query 值取不到 需要对地址转码两次才能取值成功 xxxx?backurlencodeURIComponent(encodeURIComponent(url))...

python 会员信息管理系统2.0
问题介绍 综合案例实现:会员管理系统设计与实现-V3 利用所学习的知识点 ,结合会员管理系统的分析与实现, 了解面向对象开发过程中类内部功能的分析方法,系统讲解 Python语法、控制结构、四种典型序列 ,函数定义以及面向对象语法和模块的应用…...

OpenClaw飞书机器人配置:Qwen3.5-9B多轮对话实战
OpenClaw飞书机器人配置:Qwen3.5-9B多轮对话实战 1. 为什么选择OpenClaw飞书Qwen3.5-9B组合 去年我接手了一个小团队的内部效率优化项目,需要在不增加人力的情况下提升日常事务处理速度。经过几轮技术选型,最终选择了OpenClaw作为自动化核心…...

直播保存新方案:多平台支持的自动录制工具使用指南
直播保存新方案:多平台支持的自动录制工具使用指南 【免费下载链接】DouyinLiveRecorder 可循环值守和多人录制的直播录制软件,支持抖音、TikTok、Youtube、快手、虎牙、斗鱼、B站、小红书、pandatv、sooplive、flextv、popkontv、twitcasting、winktv、…...

深入解析Android驱动开发:从HAL层到多媒体架构实战
第一章 Android驱动开发概述 Android驱动系统采用分层架构设计,主要包含以下层次: Linux内核层 → HAL层 → JNI层 → Framework层 → 应用层其中HAL(Hardware Abstraction Layer)作为硬件与框架的桥梁,通过标准接口实现硬件控制。典型HAL接口定义如下: // hardware/l…...

Building Tools:Blender建筑建模插件终极指南 - 快速生成3D建筑的专业解决方案
Building Tools:Blender建筑建模插件终极指南 - 快速生成3D建筑的专业解决方案 【免费下载链接】building_tools Building generation addon for blender 项目地址: https://gitcode.com/gh_mirrors/bu/building_tools Building Tools是一款专为Blender设计的…...

Ostrakon-VL赋能智能运维:基于卷积神经网络的异常图像检测告警
Ostrakon-VL赋能智能运维:基于卷积神经网络的异常图像检测告警 1. 运维监控的痛点与机遇 IT运维团队每天面对海量监控数据,传统方式依赖人工查看仪表盘和告警日志,效率低下且容易遗漏关键异常。服务器CPU飙红、网络流量突增、磁盘空间告急等…...

WaveTools鸣潮工具箱:游戏辅助工具性能增强与数据分析全攻略
WaveTools鸣潮工具箱:游戏辅助工具性能增强与数据分析全攻略 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools鸣潮工具箱是一款专为《鸣潮》玩家打造的游戏辅助工具,集成性…...

终极pix2pix训练指南:200个epoch完整流程与实战技巧
终极pix2pix训练指南:200个epoch完整流程与实战技巧 【免费下载链接】pix2pix-tensorflow Tensorflow port of Image-to-Image Translation with Conditional Adversarial Nets https://phillipi.github.io/pix2pix/ 项目地址: https://gitcode.com/gh_mirrors/pi…...

PyTorch 2.8镜像企业实操:证券公司研报图表→财经解读短视频流水线
PyTorch 2.8镜像企业实操:证券公司研报图表→财经解读短视频流水线 1. 项目背景与需求分析 在证券行业,分析师每天需要处理大量研报数据,其中包含丰富的图表信息。传统的人工解读方式存在三个痛点: 时效性差:从图表…...

LFM2.5-1.2B-Thinking-GGUF保姆级教程:Windows/Mac/Linux三平台本地部署
LFM2.5-1.2B-Thinking-GGUF保姆级教程:Windows/Mac/Linux三平台本地部署 1. 平台介绍 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的一款轻量级文本生成模型,特别适合在资源有限的设备上快速部署和使用。这个模型采用了GGUF格式,配合llama.c…...

Windows高DPI缩放导致Qt界面崩了?手把手教你用‘高DIP缩放替代’快速修复
Windows高DPI缩放导致Qt界面崩溃?三步搞定“高DPI缩放替代”修复方案 最近几年4K显示器价格越来越亲民,很多用户都升级到了高分辨率屏幕。但随之而来的一个常见问题就是:一些老旧的Qt程序在高分屏上运行时,界面元素变得错乱不堪—…...