二. CUDA编程入门-双线性插值计算
目录
- 前言
- 0. 简述
- 1. 执行一下我们的第十个CUDA程序
- 2. Bilinear interpolation
- 3. 代码分析
- 总结
- 参考
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
Note:关于 CUDA 加速双线程插值的内容博主之前有简单记录过,感兴趣的可以看看 YOLOv5推理详解及预处理高性能实现
本次课程我们来学习课程第二章—CUDA 编程入门,一起来学习双线性插值的计算
课程大纲可以看下面的思维导图

0. 简述
本小节目标:理解如何使用 cuda 进行 opencv 的图像处理的加速,理解双线性插值进行图像大小调整的算法流程
这节我们来讲第二章第 5 小节,双线性插值的计算,这个小节的案例更偏实际应用,大家在利用 TensorRT 做模型部署的时候会考虑将输入的图片统一缩放到同一尺寸大小,如果我们直接使用 OpenCV 的 resize 函数其实效率并不高,那我们这个小节就要学习如何利用 CUDA 的高并发行特性对双线性插值进行加速
1. 执行一下我们的第十个CUDA程序
源代码获取地址:https://github.com/kalfazed/tensorrt_starter
这节课的案例代码是 2.10-bilinear-interpolation,如下所示:

这个小节的案例代码核心是 preprocess.cpp 和 preprocess.cu 两个文件,preprocess.cpp 中是 bilinear resize 和 opencv 实现以及 bilinear resize 的 CUDA 接口实现,如下图所示:

而 preprocess.cu 则是利用 CUDA 核函数来实现双线程插值,如下所示:
__global__ void resize_bilinear_BGR2RGB_kernel(uint8_t* tar, uint8_t* src, int tarW, int tarH, int srcW, int srcH, float scaled_w, float scaled_h)
{// bilinear interpolation -- resized之后的图tar上的坐标int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;// bilinear interpolation -- 计算x,y映射到原图时最近的4个坐标int src_y1 = floor((y + 0.5) * scaled_h - 0.5);int src_x1 = floor((x + 0.5) * scaled_w - 0.5);int src_y2 = src_y1 + 1;int src_x2 = src_x1 + 1;if (src_y1 < 0 || src_x1 < 0 || src_y1 > srcH || src_x1 > srcW) {// bilinear interpolation -- 对于越界的坐标不进行计算} else {// bilinear interpolation -- 计算原图上的坐标(浮点类型)在0~1之间的值float th = ((y + 0.5) * scaled_h - 0.5) - src_y1;float tw = ((x + 0.5) * scaled_w - 0.5) - src_x1;// bilinear interpolation -- 计算面积(这里建议自己手画一张图来理解一下)float a1_1 = (1.0 - tw) * (1.0 - th); //右下float a1_2 = tw * (1.0 - th); //左下float a2_1 = (1.0 - tw) * th; //右上float a2_2 = tw * th; //左上// bilinear interpolation -- 计算4个坐标所对应的索引int srcIdx1_1 = (src_y1 * srcW + src_x1) * 3; //左上int srcIdx1_2 = (src_y1 * srcW + src_x2) * 3; //右上int srcIdx2_1 = (src_y2 * srcW + src_x1) * 3; //左下int srcIdx2_2 = (src_y2 * srcW + src_x2) * 3; //右下// bilinear interpolation -- 计算resized之后的图的索引int tarIdx = (y * tarW + x) * 3;// bilinear interpolation -- 实现bilinear interpolation的resize + BGR2RGBtar[tarIdx + 0] = round(a1_1 * src[srcIdx1_1 + 2] + a1_2 * src[srcIdx1_2 + 2] +a2_1 * src[srcIdx2_1 + 2] +a2_2 * src[srcIdx2_2 + 2]);tar[tarIdx + 1] = round(a1_1 * src[srcIdx1_1 + 1] + a1_2 * src[srcIdx1_2 + 1] +a2_1 * src[srcIdx2_1 + 1] +a2_2 * src[srcIdx2_2 + 1]);tar[tarIdx + 2] = round(a1_1 * src[srcIdx1_1 + 0] + a1_2 * src[srcIdx1_2 + 0] +a2_1 * src[srcIdx2_1 + 0] +a2_2 * src[srcIdx2_2 + 0]);}
}
preprocess.cu 中使用了多个核函数来实现双线性插值,插值效果对比如下图所示:

resized_bilinear_gpu 是一个普通的双线性插值,它将图片缩放到对应的尺寸且不做填充,resized_bilinear_letterbox_gpu 则是保证缩放后图片的长宽比保持一致多余部分填充,resized_bilinear_letterbox_center_gpu 则是将 letterbox 后的图片进行居中,一般来说我们在分类模型的预处理中使用 resized_bilinear_gpu 较多,而在检测模型的预处理中使用 resized_bilinear_letterbox_center_gpu 较多
本节案例执行效果如下:

我们可以看到不同双线性插值实现的时间对比,一共有 5 个数据,第一个是 CPU 上双线性插值的执行时间大概是 1.18ms,其次是 GPU 上最近邻插值的执行时间大概是 0.021ms,接着是 GPU 上双线性插值的时间大概是 0.037ms,最后两个是双线性插值-letterbox 的执行时间大概是 0.018ms,相比于 CPU 上的执行时间大概可以加速 60 倍,这个还是比较夸张的,大家可以自己更改 kernel 核函数的一些参数看下实际效果
2. Bilinear interpolation
在代码分析之前我们有必要聊下 Bilinear interpolation 双线性插值,那双线性插值到底是什么呢?它其实是一种对图像进行缩小/放大的计算方法,也是 opencv 默认的 resize 方式

以上图为例来讲解,现在我们这里有一张 1000x600 分辨率的狐狸图片,我们需要将它缩小到 256x256 分辨率,我们怎么来实现呢?那其实这里是有一个映射关系存在的(具体推导大家可以参考 here),也就是说对于目标图像 dst 上任意像素点我们都可以通过映射关系找到它在源图像 src 上的位置,从而将源图像上的像素点填充到目标图像上,如下图所示:

但是这里存在一个问题,那就是目标图像通过映射关系到源图像上时的位置坐标不一定是整数,这也就是意味着我们没有办法直接获取到对应位置的像素值,这个时候我们就可以利用插值算法来取像素,如下图所示:

现在假设我们目标图像 dst 的 (100,100) 处要填充的像素值映射回源图像 src 时的位置是 (200.14,100.11),由于映射回源图时的位置坐标是浮点数导致我们没有办法直接获取像素值,但是我们可以得到距离它最近的周围四个点的像素值即 (200,100)、(200,101)、(201,100) 以及 (201,101)
它们四个点的像素值是已知的,那中间红色点 (200.14,100.11) 像素值该怎么求呢?我们可以通过加权平均的方式来求取即
d s t [ 100 , 100 ] = s r c [ 100 , 200 ] × a 11 + s r c [ 101 , 200 ] × a 10 + s r c [ 100 , 201 ] × a 01 + s r c [ 101 , 201 ] × a 00 dst[100,100] = src[100,200]\times a11 + src[101,200]\times a10 + src[100,201] \times a01 + src[101,201] \times a00 dst[100,100]=src[100,200]×a11+src[101,200]×a10+src[100,201]×a01+src[101,201]×a00
这个其实就是双线性插值的过程,通过未知像素点周围的四个像素来进行加权求和得到最终的像素,那依此类推最近邻插值是怎么做的呢?那通过名字我们就可以知道这个插值方式其实就是选取距离未知像素点最近的那个像素点的像素值,最近邻插值计算速度相较于双线性插值要快但图像质量相较于双线性插值要差
如果我们想要缩放后的图像仍然保持相同的长宽比,我们需要保证图像的宽和高的缩放比一致,最终的缩放因子 s c a l e = m i n ( t a r _ w s r c _ w , t a r _ h s r c _ h ) scale = min(\frac{tar\_w}{src\_w}, \frac{tar\_h}{src\_h}) scale=min(src_wtar_w,src_htar_h) 最终实现的效果如下图所示:

一般来说在进行缩放以后我们还希望图像居中,所以还需要让图像的中心坐标 shift 一定的像素,如下图所示:

shift 代码如下:
// bilinear interpolation -- 计算原图在目标图中的x, y方向上的偏移量
y = y - int(srcH / (scaled_h * 2)) + int(tarH / 2);
x = x - int(srcW / (scaled_w * 2)) + int(tarW / 2);
在代码中我们让图像的中心点坐标平移到最上面之后再移动到整个目标图像的中心,那其实以上的各种缩放、平移变换我们其实可以直接通过一个仿射变换矩阵解决,这个我们在 YOLOv5推理详解及预处理高性能实现 中有提到过,大家感兴趣的可以看看
利用 CUDA 来实现双线性插值其实还有其它的好处,由于 CUDA 中我们是启动多个线程处理一张图像,每个线程处理一个像素是像素级别的处理,因此很容易实现 BGR2RGB、减均值除标准差等操作,也就是说我们可以通过一个核函数把图像预处理操作全都给做了,这个我们在之后 affine_transformation(仿射变换)的案例再讲解
3. 代码分析
OK,下面我们一起来看下代码,先从 main.cpp 开始,代码如下
#include <stdio.h>
#include <cuda_runtime.h>
#include <iostream>#include "utils.hpp"
#include "timer.hpp"
#include "preprocess.hpp"using namespace std;int main(){Timer timer;string file_path = "data/deer.png";string output_prefix = "results/";string output_path = "";cv::Mat input = cv::imread(file_path);int tar_h = 500;int tar_w = 250;int tactis;cv::Mat resizedInput_cpu;cv::Mat resizedInput_gpu;/* * bilinear interpolation resize的CPU/GPU速度比较* 由于CPU端做完预处理之后,进入如果有DNN也需要将数据传送到device上,* 所以这里为了让测速公平,仅对下面的部分进行测速:** - host端* cv::resize的bilinear interpolation* normalization进行归一化处理* BGR2RGB来实现通道调换** - device端* bilinear interpolation + normalization + BGR2RGB的自定义核函数** 由于这个章节仅是初步CUDA学习,大家在自己构建推理模型的时候可以将这些地方进行封装来写的好看点,* 在这里代码我们更关注实现的逻辑部分** tatics 列表* 0: 最近邻差值缩放 + 全图填充* 1: 双线性差值缩放 + 全图填充* 2: 双线性差值缩放 + 填充(letter box)* 3: 双线性差值缩放 + 填充(letter box) + 平移居中* */resizedInput_cpu = preprocess_cpu(input, tar_h, tar_w, timer, tactis);output_path = output_prefix + getPrefix(file_path) + "_resized_bilinear_cpu.png";cv::cvtColor(resizedInput_cpu, resizedInput_cpu, cv::COLOR_RGB2BGR);cv::imwrite(output_path, resizedInput_cpu);tactis = 0;resizedInput_gpu = preprocess_gpu(input, tar_h, tar_w, timer, tactis);output_path = output_prefix + getPrefix(file_path) + "_resized_nearest_gpu.png";cv::cvtColor(resizedInput_cpu, resizedInput_cpu, cv::COLOR_RGB2BGR);cv::imwrite(output_path, resizedInput_gpu);tactis = 1;resizedInput_gpu = preprocess_gpu(input, tar_h, tar_w, timer, tactis);output_path = output_prefix + getPrefix(file_path) + "_resized_bilinear_gpu.png";cv::cvtColor(resizedInput_cpu, resizedInput_cpu, cv::COLOR_RGB2BGR);cv::imwrite(output_path, resizedInput_gpu);tactis = 2;resizedInput_gpu = preprocess_gpu(input, tar_h, tar_w, timer, tactis);output_path = output_prefix + getPrefix(file_path) + "_resized_bilinear_letterbox_gpu.png";cv::cvtColor(resizedInput_cpu, resizedInput_cpu, cv::COLOR_RGB2BGR);cv::imwrite(output_path, resizedInput_gpu);tactis = 3;resizedInput_gpu = preprocess_gpu(input, tar_h, tar_w, timer, tactis);output_path = output_prefix + getPrefix(file_path) + "_resized_bilinear_letterbox_center_gpu.png";cv::cvtColor(resizedInput_cpu, resizedInput_cpu, cv::COLOR_RGB2BGR);cv::imwrite(output_path, resizedInput_gpu);return 0;
}
这段代码主要实现了一个用于图像处理的程序,旨在比较CPU和GPU在进行双线性插值图像缩放时的性能。代码通过分别使用CPU和GPU来处理同一图像,并将处理结果保存下来,以便于性能比较。下面是对代码的简单分析:(from chatGPT)
主函数(main)定义:
- 初始化一个
Timer类的实例,用于测量代码执行时间。 - 定义了几个字符串变量来指定输入文件的路径、输出文件的前缀和完整输出路径。
- 读取指定路径的图像文件到
cv::Mat类型的变量input中,这里使用的是 OpenCV 库的imread函数。 - 定义了目标高度
tar_h和目标宽度tar_w变量,以及tactis变量用于指定缩放策略。
图像处理逻辑:
- 对输入图像使用 CPU 进行预处理,包括调整大小、归一化和通道转换。处理后的图像保存在
resizedInput_cpu中。 - 使用
cv::cvtColor函数将处理后的图像从 RGB 转换为 BGR 格式,这通常是因为 OpenCV 默认使用 BGR 颜色空间。 - 使用
cv::imwrite函数将处理后的图像写入到文件系统中。 - 通过变化
tactis的值,分别使用 GPU 进行不同的预处理操作,并保存不同的输出文件。预处理包括最近邻缩放、双线性缩放、带填充的双线性缩放等。
接着我们来看下 preprocess.cpp,代码如下:
#include "preprocess.hpp"
#include "opencv2/opencv.hpp"
#include "utils.hpp"
#include "timer.hpp"// 根据比例进行缩放 (CPU版本)
cv::Mat preprocess_cpu(cv::Mat &src, const int &tar_h, const int &tar_w, Timer timer, int tactis) {cv::Mat tar;int height = src.rows;int width = src.cols;float dim = std::max(height, width);int resizeH = ((height / dim) * tar_h);int resizeW = ((width / dim) * tar_w);int xOffSet = (tar_w - resizeW) / 2;int yOffSet = (tar_h - resizeH) / 2;resizeW = tar_w;resizeH = tar_h;timer.start_cpu();/*BGR2RGB*/cv::cvtColor(src, src, cv::COLOR_BGR2RGB);/*Resize*/cv::resize(src, tar, cv::Size(resizeW, resizeH), 0, 0, cv::INTER_LINEAR);timer.stop_cpu();timer.duration_cpu<Timer::ms>("Resize(bilinear) in cpu takes:");return tar;
}// 根据比例进行缩放 (GPU版本)
cv::Mat preprocess_gpu(cv::Mat &h_src, const int& tar_h, const int& tar_w, Timer timer, int tactis)
{uint8_t* d_tar = nullptr;uint8_t* d_src = nullptr;cv::Mat h_tar(cv::Size(tar_w, tar_h), CV_8UC3);int height = h_src.rows;int width = h_src.cols;int chan = 3;int src_size = height * width * chan;int tar_size = tar_h * tar_w * chan;// 分配device上的src和tar的内存CUDA_CHECK(cudaMalloc(&d_src, src_size));CUDA_CHECK(cudaMalloc(&d_tar, tar_size));// 将数据拷贝到device上CUDA_CHECK(cudaMemcpy(d_src, h_src.data, src_size, cudaMemcpyHostToDevice));timer.start_gpu();// device上处理resize, BGR2RGB的核函数resize_bilinear_gpu(d_tar, d_src, tar_w, tar_h, width, height, tactis);// host和device进行同步处理CUDA_CHECK(cudaDeviceSynchronize());timer.stop_gpu();switch (tactis) {case 0: timer.duration_gpu("Resize(nearest) in gpu takes:"); break;case 1: timer.duration_gpu("Resize(bilinear) in gpu takes:"); break;case 2: timer.duration_gpu("Resize(bilinear-letterbox) in gpu takes:"); break;case 3: timer.duration_gpu("Resize(bilinear-letterbox-center) in gpu takes:"); break;default: break;}// 将结果返回给host上CUDA_CHECK(cudaMemcpy(h_tar.data, d_tar, tar_size, cudaMemcpyDeviceToHost));CUDA_CHECK(cudaFree(d_src));CUDA_CHECK(cudaFree(d_tar));return h_tar;
}
这段代码提供了两个函数 preprocess_cpu 和 preprocess_gpu,用于图像预处理,包括缩放和颜色空间转换,分别在 CPU 和 GPU 上执行。下面是对这两个函数的详细分析:(from chatGPT)
CPU 版本预处理 (preprocess_cpu)
- 函数参数:接收一个源图像(
cv::Mat &src)、目标高度(const int &tar_h)、目标宽度(const int &tar_w)、一个Timer实例和一个操作策略(int tactis)作为参数。返回处理后的图像。 - 缩放逻辑:
- 首先,计算原图像的高度和宽度比例,然后根据目标高宽比例调整图像大小,确保图像不会因缩放而失真。
- 使用
cv::resize函数进行双线性缩放(cv::INTER_LINEAR),将图像缩放到目标大小。
- 颜色空间转换:使用
cv::cvtColor将图像从 BGR 转换为 RGB 格式。 - 计时功能:通过
Timer类实例的start_cpu和stop_cpu方法测量缩放操作的耗时,并通过duration_cpu方法打印耗时信息。
GPU 版本预处理 (preprocess_gpu)
- 函数参数:与 CPU 版本类似,但是处理过程在 GPU 上执行。
- 内存分配与拷贝:
- 使用
cudaMalloc在 GPU 上为源图像和目标图像分配内存。 - 通过
cudaMemcpy将源图像数据从主机复制到 GPU。
- 使用
- GPU处理:
- 调用一个自定义的核函数
resize_bilinear_gpu进行图像的缩放和颜色空间转换,具体实现细节没有在此代码段中展示,但可以推断该函数根据tactis参数选择不同的缩放策略。 - 使用
cudaDeviceSynchronize确保 GPU 上的所有操作都完成。
- 调用一个自定义的核函数
- 计时与结果获取:
- 使用
Timer类实例的start_gpu和stop_gpu方法测量 GPU 操作的耗时。 - 根据
tactis参数的不同,打印出对应的耗时信息。 - 最后,使用
cudaMemcpy将处理后的图像数据从 GPU 复制回主机。
- 使用
- 资源释放:使用
cudaFree释放 GPU 上分配的内存。
总结
这两个函数展示了在 CPU 和 GPU 上进行图像预处理的不同方法,包括颜色空间转换和图像缩放。GPU 版本需要显式管理内存(包括分配和释放),并且利用 CUDA 提供的 API 执行数据传输和同步。这种处理方式能够利用 GPU 的并行处理能力,加速图像处理任务,特别是在处理大量数据或进行复杂运算时。
最后我们看下核心代码 preprocess.cu,如下所示:
#include "cuda_runtime_api.h"
#include "stdio.h"
#include <iostream>#include "utils.hpp"__global__ void resize_nearest_BGR2RGB_kernel(uint8_t* tar, uint8_t* src, int tarW, int tarH, int srcW, int srcH,float scaled_w, float scaled_h)
{// nearest neighbour -- resized之后的图tar上的坐标int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;// nearest neighbour -- 计算最近坐标int src_y = round((float)y * scaled_h);int src_x = round((float)x * scaled_w);if (src_x < 0 || src_y < 0 || src_x > srcW || src_y > srcH) {// nearest neighbour -- 对于越界的部分,不进行计算} else {// nearest neighbour -- 计算tar中对应坐标的索引int tarIdx = (y * tarW + x) * 3;// nearest neighbour -- 计算src中最近邻坐标的索引int srcIdx = (src_y * srcW + src_x) * 3;// nearest neighbour -- 实现nearest beighbour的resize + BGR2RGBtar[tarIdx + 0] = src[srcIdx + 2];tar[tarIdx + 1] = src[srcIdx + 1];tar[tarIdx + 2] = src[srcIdx + 0];}
}__global__ void resize_bilinear_BGR2RGB_kernel(uint8_t* tar, uint8_t* src, int tarW, int tarH, int srcW, int srcH, float scaled_w, float scaled_h)
{// bilinear interpolation -- resized之后的图tar上的坐标int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;// bilinear interpolation -- 计算x,y映射到原图时最近的4个坐标int src_y1 = floor((y + 0.5) * scaled_h - 0.5);int src_x1 = floor((x + 0.5) * scaled_w - 0.5);int src_y2 = src_y1 + 1;int src_x2 = src_x1 + 1;if (src_y1 < 0 || src_x1 < 0 || src_y1 > srcH || src_x1 > srcW) {// bilinear interpolation -- 对于越界的坐标不进行计算} else {// bilinear interpolation -- 计算原图上的坐标(浮点类型)在0~1之间的值float th = ((y + 0.5) * scaled_h - 0.5) - src_y1;float tw = ((x + 0.5) * scaled_w - 0.5) - src_x1;// bilinear interpolation -- 计算面积(这里建议自己手画一张图来理解一下)float a1_1 = (1.0 - tw) * (1.0 - th); //右下float a1_2 = tw * (1.0 - th); //左下float a2_1 = (1.0 - tw) * th; //右上float a2_2 = tw * th; //左上// bilinear interpolation -- 计算4个坐标所对应的索引int srcIdx1_1 = (src_y1 * srcW + src_x1) * 3; //左上int srcIdx1_2 = (src_y1 * srcW + src_x2) * 3; //右上int srcIdx2_1 = (src_y2 * srcW + src_x1) * 3; //左下int srcIdx2_2 = (src_y2 * srcW + src_x2) * 3; //右下// bilinear interpolation -- 计算resized之后的图的索引int tarIdx = (y * tarW + x) * 3;// bilinear interpolation -- 实现bilinear interpolation的resize + BGR2RGBtar[tarIdx + 0] = round(a1_1 * src[srcIdx1_1 + 2] + a1_2 * src[srcIdx1_2 + 2] +a2_1 * src[srcIdx2_1 + 2] +a2_2 * src[srcIdx2_2 + 2]);tar[tarIdx + 1] = round(a1_1 * src[srcIdx1_1 + 1] + a1_2 * src[srcIdx1_2 + 1] +a2_1 * src[srcIdx2_1 + 1] +a2_2 * src[srcIdx2_2 + 1]);tar[tarIdx + 2] = round(a1_1 * src[srcIdx1_1 + 0] + a1_2 * src[srcIdx1_2 + 0] +a2_1 * src[srcIdx2_1 + 0] +a2_2 * src[srcIdx2_2 + 0]);}
}__global__ void resize_bilinear_BGR2RGB_shift_kernel(uint8_t* tar, uint8_t* src, int tarW, int tarH, int srcW, int srcH, float scaled_w, float scaled_h)
{// resized之后的图tar上的坐标int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;// bilinear interpolation -- 计算x,y映射到原图时最近的4个坐标int src_y1 = floor((y + 0.5) * scaled_h - 0.5);int src_x1 = floor((x + 0.5) * scaled_w - 0.5);int src_y2 = src_y1 + 1;int src_x2 = src_x1 + 1;if (src_y1 < 0 || src_x1 < 0 || src_y1 > srcH || src_x1 > srcW) {// bilinear interpolation -- 对于越界的坐标不进行计算} else {// bilinear interpolation -- 计算原图上的坐标(浮点类型)在0~1之间的值float th = ((y + 0.5) * scaled_h - 0.5) - src_y1;float tw = ((x + 0.5) * scaled_w - 0.5) - src_x1;// bilinear interpolation -- 计算面积(这里建议自己手画一张图来理解一下)float a1_1 = (1.0 - tw) * (1.0 - th); //右下float a1_2 = tw * (1.0 - th); //左下float a2_1 = (1.0 - tw) * th; //右上float a2_2 = tw * th; //左上// bilinear interpolation -- 计算4个坐标所对应的索引int srcIdx1_1 = (src_y1 * srcW + src_x1) * 3; //左上int srcIdx1_2 = (src_y1 * srcW + src_x2) * 3; //右上int srcIdx2_1 = (src_y2 * srcW + src_x1) * 3; //左下int srcIdx2_2 = (src_y2 * srcW + src_x2) * 3; //右下// bilinear interpolation -- 计算原图在目标图中的x, y方向上的偏移量y = y - int(srcH / (scaled_h * 2)) + int(tarH / 2);x = x - int(srcW / (scaled_w * 2)) + int(tarW / 2);// bilinear interpolation -- 计算resized之后的图的索引int tarIdx = (y * tarW + x) * 3;// bilinear interpolation -- 实现bilinear interpolation + BGR2RGBtar[tarIdx + 0] = round(a1_1 * src[srcIdx1_1 + 2] + a1_2 * src[srcIdx1_2 + 2] +a2_1 * src[srcIdx2_1 + 2] +a2_2 * src[srcIdx2_2 + 2]);tar[tarIdx + 1] = round(a1_1 * src[srcIdx1_1 + 1] + a1_2 * src[srcIdx1_2 + 1] +a2_1 * src[srcIdx2_1 + 1] +a2_2 * src[srcIdx2_2 + 1]);tar[tarIdx + 2] = round(a1_1 * src[srcIdx1_1 + 0] + a1_2 * src[srcIdx1_2 + 0] +a2_1 * src[srcIdx2_1 + 0] +a2_2 * src[srcIdx2_2 + 0]);}
}/*这里面的所有函数都实现了kernel fusion。这样可以减少kernel launch所产生的overhead如果使用了shared memory的话,就可以减少分配shared memory所产生的overhead以及内部线程同步的overhead。(这个案例没有使用shared memory)CUDA编程中有一些cuda runtime api是implicit synchronize(隐式同步)的,比如cudaMalloc, cudaMallocHost,以及shared memory的分配。高效的CUDA编程需要意识这些implicit synchronize以及其他会产生overhead的地方。比如使用内存复用的方法,让cuda分配完一次memory就一直使用它这里建议大家把我写的每一个kernel都拆开成不同的kernel来分别计算e.g. resize kernel + BGR2RGB kernel + shift kernel 之后用nsight去比较融合与不融合的差别在哪里。去体会一下fusion的好处
*/void resize_bilinear_gpu(uint8_t* d_tar, uint8_t* d_src, int tarW, int tarH, int srcW, int srcH, int tactis)
{dim3 dimBlock(16, 16, 1);dim3 dimGrid(tarW / 16 + 1, tarH / 16 + 1, 1);//scaled resizefloat scaled_h = (float)srcH / tarH;float scaled_w = (float)srcW / tarW;float scale = (scaled_h > scaled_w ? scaled_h : scaled_w);if (tactis > 1) {scaled_h = scale;scaled_w = scale;}switch (tactis) {case 0:resize_nearest_BGR2RGB_kernel <<<dimGrid, dimBlock>>> (d_tar, d_src, tarW, tarH, srcW, srcH, scaled_w, scaled_h);break;case 1:resize_bilinear_BGR2RGB_kernel <<<dimGrid, dimBlock>>> (d_tar, d_src, tarW, tarH, srcW, srcH, scaled_w, scaled_h);break;case 2:resize_bilinear_BGR2RGB_kernel <<<dimGrid, dimBlock>>> (d_tar, d_src, tarW, tarH, srcW, srcH, scaled_w, scaled_h);break;case 3:resize_bilinear_BGR2RGB_shift_kernel <<<dimGrid, dimBlock>>> (d_tar, d_src, tarW, tarH, srcW, srcH, scaled_w, scaled_h);break;default:break;}
}
这段代码定义了 GPU 上执行的核心图像处理函数,特别是用于图像缩放和颜色空间转换的 CUDA 核函数。这些函数设计来在 CUDA 架构上高效地处理图像数据。代码中包含了三种核心操作:最近邻插值、双线性插值、以及双线性插值加平移居中。下面详细分析这些组成部分:(from chatGPT)
CUDA 核函数解析
1. 最近邻插值+颜色转换(resize_nearest_BGR2RGB_kernel)
- 功能:对图像进行最近邻插值缩放,并将颜色空间从 BGR 转换为 RGB。
- 参数:包括目标图像和源图像的指针、目标和源图像的宽高、以及缩放因子。
- 实现细节:
- 计算每个线程应该处理的目标图像上的像素位置(
x,y)。 - 使用缩放因子将目标像素位置映射回源图像上的最近像素。
- 如果计算出的源像素位置在源图像范围内,进行颜色值的复制和转换,否则不处理越界的部分。
- 实现了 kernel fusion,即在同一个 CUDA 核函数中完成了缩放和颜色空间转换,减少了内存访问次数。
- 计算每个线程应该处理的目标图像上的像素位置(
2. 双线性插值+颜色转换(resize_bilinear_BGR2RGB_kernel)
- 功能:使用双线性插值对图像进行缩放,同时将颜色空间从BGR转换为RGB。
- 参数:同上。
- 实现细节:
- 计算目标图像上每个像素点对应源图像上的四个近邻像素点位置。
- 根据四个近邻像素点的颜色值和相对位置,使用双线性插值公式计算目标像素点的颜色值。
- 在复制和计算颜色值时,同时完成颜色空间的转换。
- 这种方法可以得到比最近邻插值更平滑的缩放效果。
3. 双线性插值+颜色转换+平移居中(resize_bilinear_BGR2RGB_shift_kernel)
- 功能:在双线性插值和颜色转换的基础上,添加了平移操作以使缩放后的图像在目标空间中居中。
- 参数:同上。
- 实现细节:
- 首先进行双线性插值和颜色转换。
- 在将计算得到的颜色值写入目标图像之前,计算目标像素点经过居中处理后的新位置。
- 如果新位置在目标图像范围内,则将颜色值写入新位置;否则,该像素点不进行处理。
综合函数 resize_bilinear_gpu
- 功能:根据
tactis参数的值选择执行上述中的一个CUDA核函数。 - 实现细节:
- 使用
dim3类型定义了CUDA核函数的网格和块尺寸,确保足够的线程覆盖整个图像。 - 计算缩放因子,如果
tactis大于 1,则使用相同的缩放因子,确保图像在缩放时保持比例。 - 根据
tactis值选择相应的 CUDA 核函数执行,其中包括最近邻插值、双线性插值,以及双线性插值加平移居中。
- 使用
总结
这段代码高效地利用 CUDA 进行图像处理,通过并行计算加速了图像缩放和颜色空间转换的操作。代码中的 kernel fusion 技术减少了内存访问次数,提高了处理效率。
OK,以上就是对 2.10-bilinear-interpolation 案例代码的简单分析,最后我们执行下看下输出结果,如下图所示:

其实图片分辨率越大加速比其实越明显,大家可以尝试下不同分辨率的图片看看
总结
本次课程我们主要讲解了双线性插值算法以及如何通过 CUDA 高并发的特性来对其加速,这个核函数的实现大家需要掌握,因为这是我们在 TensorRT 模型部署中非常常见的。博主之前有相关笔记记录过双线性插值因此这里就简单过一下,大家感兴趣的可以多看看案例代码分析分析
OK,以上就是第 5 小节有关双线性插值的全部内容了,下节我们进入第三章—TensorR基础入门的学习,敬请期待😄
参考
- YOLOv5推理详解及预处理高性能实现
相关文章:
二. CUDA编程入门-双线性插值计算
目录 前言0. 简述1. 执行一下我们的第十个CUDA程序2. Bilinear interpolation3. 代码分析总结参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 Note:关于 CUDA 加速双线程插值的内容博主…...

实时计算平台设计方案:913-基于100G光口的DSP+FPGA实时计算平台
基于100G光口的DSPFPGA实时计算平台 一、产品概述 基于以太网接口的实时数据智能计算一直应用于互联网、网络安全、大数据交换的场景。以DSPFPGA的方案,体现了基于硬件计算的独特性能,区别于X86GPU的计算方案,保留了高带宽特性&…...

Glide系列-自定义ModuleLoader
在当今快速发展的移动应用领域,图片的高效加载和显示对于提供流畅用户体验至关重要。Glide作为一款强大的图片加载库,已经成为Android开发者的首选工具之一。但是,你有没有遇到过Glide默认不支持的模型类型,或者需要对图片加载过程…...

设计模式——责任链模式13
责任链模式 每个流程或事物处理 像一个链表结构处理。场景由 多层部门审批,问题分级处理等。下面体现的是 不同难度的问题由不同人进行解决。 设计模式,一定要敲代码理解 传递问题实体 /*** author ggbond* date 2024年04月10日 07:48*/ public class…...

Linux云计算之Linux基础3——Linux系统基础part-2
1、终端、shell、文件理论 1、终端 终端(terminal):人和系统交互的必要设备,人机交互最后一个界面(包含独立的输入输出设备) 物理终端(console):直接接入本机器的键盘设备和显示器虚拟终端(tty):通过软件…...
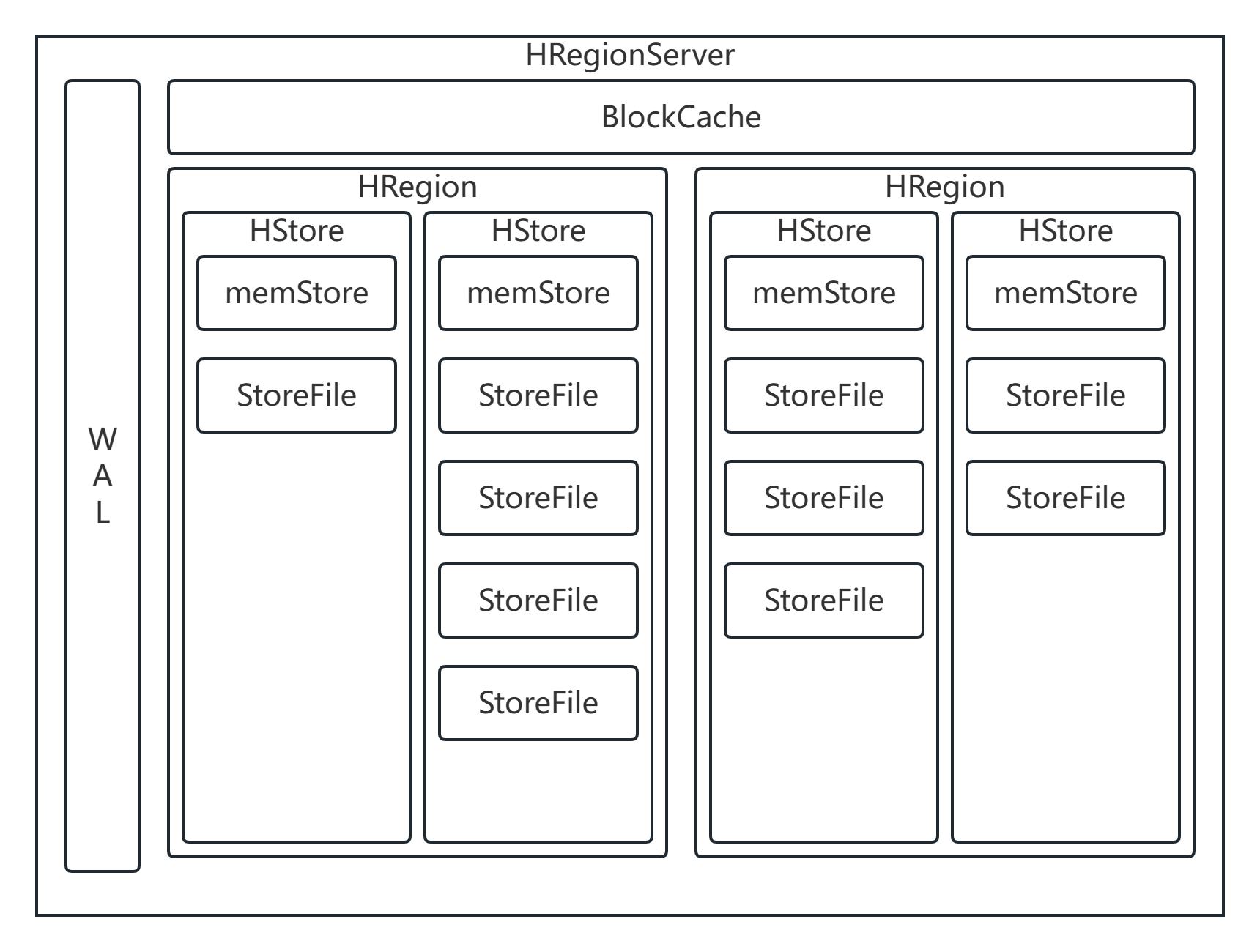
HBase详解(2)
HBase 结构 HRegion 概述 在HBase中,会从行键方向上对表来进行切分,切分出来的每一个结构称之为是一个HRegion 切分之后,每一个HRegion会交给某一个HRegionServer来进行管理。HRegionServer是HBase的从节点,每一个HRegionServ…...
Web后端搭建
目录 一 搭建服务器端 1.1安装服务器软件 1.2检查环境是否配置 1.3安装Tomcat 二 创建并发Web项目 2.1创建一个java项目 三 创建Servlet 前端程序如何才能访问到后端程序呢,这时候我们就需要web服务器来解决:将后端程序部署到服务器中,…...
k8s单节点部署,容器运行时使用containerd
环境 系统 : entOS Linux release 7.9.2009 (CoreIP:192.168.44.177 硬件要求:控制平面最少需要 2c2g 安装前环境准备 如果是集群部署还需要配置时间同步 关闭防火墙 systemctl disable firewalld关闭selinux setenforce 0sed -i s/SELI…...

深入浅出 -- 系统架构之性能优化的核心思维
“在当前的互联网开发模式下,系统访问量日涨、并发暴增、线上瓶颈等各种性能问题纷涌而至,性能优化成为了现时代开发过程中炙手可热的名词,无论是在开发、面试过程中,性能优化都是一个常谈常新的话题”。Java语言作为企业应用中的…...
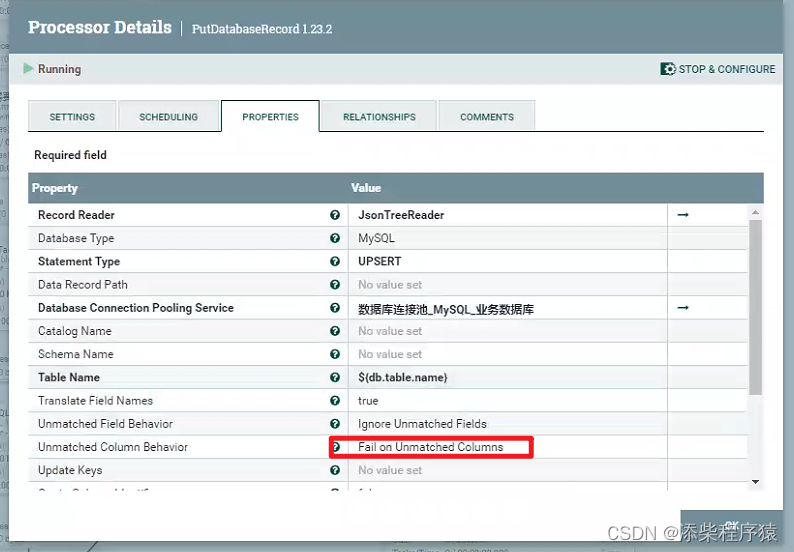
Nifi同步过程中报错create_time字段找不到_实际目标表和源表中没有这个字段---大数据之Nifi工作笔记0066
很奇怪的问题,在使用nifi的时候碰到的,这里是用NIFI,把数据从postgresql中同步到mysql中, 首先postgresql中的源表,中是没有create_time这个字段的,但是同步的过程中报错了. 报错的内容是说,目标表中有个create_time字段,这个字段是必填的,但是传过来的flowfile文件中,的数据没…...

批量删除文件脚本
在工作中我们经常会遇到一些重复性的工作,如批量创建文件,删除文件等等。这种重复性的工作shell脚本往往能给我们带来极大的便利。 将需要删除的文件路径存放在【stt_Files_240410.rpt】随便一个 文档中即可。 下面是一个批量删除文件的一个脚本范例&…...
蓝桥杯物联网竞赛_STM32L071KBU6_我的全部省赛及历年模拟赛源码
我写的省赛及历年模拟赛代码 链接:https://pan.baidu.com/s/1A0N_VUl2YfrTX96g3E8TfQ?pwd9k6o 提取码:9k6o...

微服务和K8S
微服务和Kubernetes(通常简称为K8s)都是现代软件开发和部署中常用的概念和工具。它们有着各自独特的特点和作用: 1. **微服务**: - **定义**:微服务是一种架构设计风格,将应用程序拆分为一组小型、独立…...

Ant Design 表单基础用法综合示例
Ant Design 的表单组件设计得非常出色,极大地简化了表单开发的复杂度,让开发者能够快速构建出功能丰富、交互友好的表单界面。 接下来总结一下 Ant Design 中表单的基本用法。 Form 组件 用于定义整个表单,可以设置表单的布局方式、提交行为等。通常会将表单字段组件嵌套在 F…...

MWeb Pro For Mac v4.5.9 强大的 Markdown 软件中文版
MWeb 是专业的 Markdown 写作、记笔记、静态博客生成软件,目前已支持 Mac,iPad 和 iPhone。MWeb 有以下特色: 软件下载:MWeb Pro For Mac v4.5.9 软件本身: 使用原生的 macOS 技术打造,追求与系统的完美结合…...

Git常用命令详解:掌握版本控制的核心操作
Git作为世界上最流行的分布式版本控制系统,以其强大的分支管理、高效的协同工作能力和完善的版本追溯功能,深受广大开发者喜爱。熟练掌握Git的常用命令是每一位程序员必备的技能。本文将深入解析Git中那些最为基础且实用的命令,助您在日常开发…...

Vue链接跳转地址 href 中有参数带有#
Vue链接跳转地址 href 中有参数带有# A跳转B 带参数backURL 转码一次会被浏览器解码 xxxx?backurlencodeURIComponent(url) 到B页面拿到的query 值取不到 需要对地址转码两次才能取值成功 xxxx?backurlencodeURIComponent(encodeURIComponent(url))...

python 会员信息管理系统2.0
问题介绍 综合案例实现:会员管理系统设计与实现-V3 利用所学习的知识点 ,结合会员管理系统的分析与实现, 了解面向对象开发过程中类内部功能的分析方法,系统讲解 Python语法、控制结构、四种典型序列 ,函数定义以及面向对象语法和模块的应用…...

HTTP的强制缓存和协商缓存
HTTP的强制缓存和协商缓存 HTTP的缓存技术强制缓存ExpiresCache-Control 协商缓存If-Modified-Since和Last-ModifiedIf-None-Match和ETag优先级 可被缓存的请求方法总结 HTTP的缓存技术 当我们进行HTTP请求时,需要将请求报文发送给对端,当服务端收到请求…...
Prometheus-Grafana基础篇安装绘图
首先Prometheus安装 1、下载 https://prometheus.io/download/ 官网路径可以去这儿下载 2、如图: 3.解压: tar -xf prometheus-2.6.1.linux-amd64 cd prometheus-2.6.1.linux-amd64 4.配置文件说明: vim prometheus.yml 5.启动Promethe…...

告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块
告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块 开发涉及钱包集成的DApp时,最让人头疼的就是那些重复性的基础代码。每次新项目都要重新写一遍连接钱包、处理授权、监听网络切换的逻辑,不仅浪费时间,还容易引入安全…...

AI推动SEO关键词优化的全新策略与实践明晰
在当前数字营销环境中,AI技术为SEO关键词优化带来了前所未有的变革。它通过自动化的数据分析与挖掘工具,能够帮助企业更准确地识别用户需求与搜索趋势。通过AI的支持,关键词挖掘变得更加高效和精准,企业可以快速获取相关关键词并优…...

Ostrakon-VL-8B打通企业数据流:与内部CRM系统集成实现智能客户分析
Ostrakon-VL-8B打通企业数据流:与内部CRM系统集成实现智能客户分析 你有没有遇到过这样的情况?销售团队抱怨客户画像太模糊,营销活动像在“盲人摸象”,投入了大量资源,转化率却总是不尽如人意。传统的客户关系管理&am…...

千问3.5-2B快速部署:Docker镜像一键run,7860端口自动监听,无需端口映射配置
千问3.5-2B快速部署:Docker镜像一键run,7860端口自动监听,无需端口映射配置 1. 千问3.5-2B模型介绍 千问3.5-2B是Qwen系列的小型视觉语言模型,它能够同时理解图片和生成文本。这个模型特别适合需要结合视觉和语言理解的任务场景…...

Z-Image-GGUF模型量化与压缩教程:在低显存GPU上运行大模型
Z-Image-GGUF模型量化与压缩教程:在低显存GPU上运行大模型 想用AI生成图片,但一看模型大小和显存要求就头疼?手头只有一张8GB显存的消费级显卡,是不是就只能和那些功能强大的图像生成模型说再见了? 别急着放弃。今天…...

zynq7020 u-boot 外设配置实战指南
1. Zynq7020 U-Boot外设配置概述 在嵌入式系统开发中,U-Boot作为系统启动加载器扮演着关键角色。对于Xilinx Zynq-7020平台来说,正确配置U-Boot外设是确保系统正常启动和运行的基础。本文将重点介绍网口、QSPI Flash和eMMC这三个核心外设的配置方法。 为…...
)
Pyspark环境搭建及案例(Windows)
Windows环境下开发pyspark程序 一、环境准备:Anaconda Python 虚拟环境 1. 安装 Anaconda(推荐) 下载地址:https://www.anaconda.com/products/distribution 安装时选择“Add Anaconda to PATH”会更方便。 2、新建虚拟环境 使…...

颠覆中文字体困境:思源宋体CN 7字重开源方案深度解析
颠覆中文字体困境:思源宋体CN 7字重开源方案深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 价值主张:破解中文字体的"三重枷锁" 在数字设计…...

GLM-4.1V-9B-Base部署教程:NVIDIA驱动版本兼容性验证与降级方案
GLM-4.1V-9B-Base部署教程:NVIDIA驱动版本兼容性验证与降级方案 1. 模型概述 GLM-4.1V-9B-Base是智谱开源的一款视觉多模态理解模型,专注于图像内容识别与分析任务。该模型具备以下核心能力: 图片内容描述与场景理解图像主体识别与定位颜色…...

XHS-Downloader:构建高效采集流程的无水印内容批量管理方案
XHS-Downloader:构建高效采集流程的无水印内容批量管理方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...