LightM-UNet:Mamba 辅助的轻量级 UNet 用于医学图像分割
文章目录
- 摘要
- 1 简介
- 2、方法论
- 2.1、架构概述
- 2.2、编码器块
- 2.3、瓶颈块
- 2.4、解码器块
- 3、实验
- 4、结论
摘要
https://arxiv.org/pdf/2403.05246.pdf
UNet及其变体在医学图像分割中得到了广泛应用。然而,这些模型,特别是基于Transformer架构的模型,由于参数众多和计算负载大,使得它们不适合用于移动健康应用。最近,以Mamba为代表的状态空间模型(SSMs)已成为CNN和Transformer架构的有力竞争者。在此基础上,我们采用Mamba作为UNet中CNN和Transformer的轻量级替代方案,旨在解决真实医疗环境中计算资源限制带来的挑战。为此,我们引入了轻量级Mamba UNet(LightM-UNet),将Mamba和UNet集成在一个轻量级框架中。具体来说,LightM-UNet以纯Mamba的方式利用残差视觉Mamba层来提取深层语义特征并建模长距离空间依赖关系,具有线性计算复杂度。我们在两个真实世界的2D/3D数据集上进行了大量实验,结果表明LightM-UNet超越了现有最先进的文献方法。特别是与著名的nnU-Net相比,LightM-UNet在显著提高分割性能的同时,参数和计算成本分别降低了116倍和21倍。这凸显了Mamba在促进模型轻量化方面的潜力。我们的代码实现已公开在https://github.com/MrBlankness/LightM-UNet。
关键词:医学图像分割 · 轻量级模型 · 状态空间模型。
1 简介
UNet [16],作为医学图像分割领域一个广为人知的算法,在涉及医学器官和病灶的各种分割任务中得到了广泛应用,涵盖了多种医学图像模态。其对称的U形编解码器架构与整体的跳跃连接为分割模型奠定了基础,催生了一系列基于U形结构的研究工作 [8,15,18]。然而,作为基于卷积神经网络(CNN)的模型,UNet受限于卷积操作的固有局部性,这限制了其理解显式全局和长距离语义信息交互的能力 [2]。一些研究尝试通过采用空洞卷积层 [5]、自注意力机制 [19] 和图像金字塔 [25] 来缓解这一问题。尽管如此,这些方法在建模长距离依赖关系方面仍然存在限制。
为了赋予UNet理解全局信息的能力,最近的研究 [2,7,6] 致力于将Transformer架构 [22] 集成到UNet中,利用自注意力机制将图像视为连续补丁的序列来捕获全局信息。尽管这种方法有效,但基于Transformer的解决方案由于自注意力机制而引入了与图像大小相关的二次复杂度,导致巨大的计算开销,特别是在需要密集预测的任务中,如医学图像分割。这忽视了真实医疗环境中计算约束的重要性,无法满足移动医疗保健分割任务中对低参数和最小计算负载模型的需求 [18]。综上所述,仍有一个未解决的问题:“如何使UNet具备容纳长距离依赖性的能力,同时不增加额外的参数和计算负担?”

最近,状态空间模型(SSMs)在研究者中引起了广泛关注。在经典SSM研究 [10] 奠定的基础上,现代SSM(例如Mamba [4])不仅建立了长距离依赖关系,还展示了与输入大小相关的线性复杂度,这使得Mamba成为UNet轻量化道路上CNN和Transformer的有力竞争对手。一些当代努力,如U-Mamba [14],提出了一个混合CNN-SSM块,将卷积层提取局部特征的能力与SSM捕捉纵向依赖关系的能力相结合。然而,U-Mamba [14] 引入了大量的参数和计算负载(173.53M参数和18,057.20 GFLOPs),这使其在移动医疗环境中部署医学分割任务时面临挑战。因此,本研究中我们介绍了LightM-UNet,一个基于Mamba的轻量级U形分割模型,它在显著减少参数和计算成本的同时实现了最先进的性能(如图1所示)。这项工作的贡献主要有三个方面:
-
我们介绍了LightM-UNet,一个轻量级的UNet和Mamba的融合模型,其参数数量仅为1M。通过在2D和3D真实世界数据集上的验证,LightM-UNet超越了现有的最先进的模型。与著名的nnU-Net [8] 和同期的UMamba [14] 相比,LightM-UNet的参数数量分别减少了116倍和224倍。
-
在技术层面,我们提出了残差视觉Mamba层(RVM层),以纯Mamba的方式从图像中提取深层特征。通过最小化新参数的引入和计算开销,我们进一步利用残差连接和调整因子增强了SSM在视觉图像中建模长距离空间依赖关系的能力。
-
深入来看,与同期将UNet与Mamba整合的努力[14, 23, 17]不同,我们提倡在UNet内部使用Mamba作为CNN和Transformer的轻量级替代品,旨在解决实际医疗环境中计算资源受限所带来的挑战。据我们所知,这是首次将Mamba引入UNet作为轻量化优化策略的创新尝试。
2、方法论
虽然LightM-UNet支持2D和3D版本的医学图像分割,但为了方便起见,本文使用3D版本的LightM-UNet来描述方法论。
2.1、架构概述
所提出的LightM-UNet的整体架构如图2所示。给定一个输入图像 I ∈ R C × H × W × D I \in \mathbb{R}^{C \times H \times W \times D} I∈RC×H×W×D,其中 C , H , W C, H, W C,H,W 和 D D D 分别表示3D医学图像的通道数、高度、宽度和切片数。LightM-UNet首先使用深度可分离卷积(DWConv)层进行浅层特征提取,生成浅层特征图 F S ∈ R 32 × H × W × D F_{S} \in \mathbb{R}^{32 \times H \times W \times D} FS∈R32×H×W×D,其中32表示固定的滤波器数量。随后,LightM-UNet采用三个连续的编码器块从图像中提取深层特征。在每个编码器块之后,特征图的通道数翻倍,而分辨率减半。
因此,在第 l l l个编码器块,LightM-UNet提取深层特征 F D l ∈ R ( 32 × 2 l ) × ( H / 2 l ) × ( W / 2 l ) × ( D / 2 l ) F_{D}^{l} \in \mathbb{R}^{\left(32 \times 2^{l}\right) \times\left(H / 2^{l}\right) \times\left(W / 2^{l}\right) \times\left(D / 2^{l}\right)} FDl∈R(32×2l)×(H/2l)×(W/2l)×(D/2l),其中 l ∈ { 1 , 2 , 3 } l \in\{1,2,3\} l∈{1,2,3}。随后,LightM-UNet采用瓶颈块(Bottleneck Block)来建模长距离空间依赖关系,同时保持特征图的大小不变。之后,LightM-UNet整合三个连续的解码器块用于特征解码和图像分辨率恢复。在每个解码器块之后,特征图的通道数减半,分辨率加倍。最后,最后一个解码器块的输出与原始图像具有相同的分辨率,并包含32个特征通道。LightM-UNet使用深度可分离卷积层将通道数映射到分割目标的数量,并应用SoftMax激活函数生成图像掩码。与UNet的设计一致,LightM-UNet也采用跳跃连接为解码器提供多级别特征图。
2.2、编码器块
为了最小化参数数量和计算成本,LightM-UNet采用仅包含Mamba结构的编码器块来从图像中提取深层特征。具体来说,给定一个特征图 F l ∈ R C ˇ × H ¨ × W ~ × D ˉ F^{l} \in \mathbb{R}^{\check{C} \times \ddot{H} \times \tilde{W} \times \bar{D}} Fl∈RCˇ×H¨×W~×Dˉ,其中 C ˇ = 32 × 2 l \check{C}=32 \times 2^{l} Cˇ=32×2l, H ¨ = H / 2 l \ddot{H}=H / 2^{l} H¨=H/2l, W ~ = W / 2 l \tilde{W}=W / 2^{l} W~=W/2l, D ˉ = D / 2 l \bar{D}=D / 2^{l} Dˉ=D/2l,且 l ∈ { 1 , 2 , 3 } l \in\{1,2,3\} l∈{1,2,3},编码器块首先将特征图展平并转置为形状为 ( L ˘ , C ˇ ) (\breve{L}, \check{C}) (L˘,Cˇ)的张量,其中 L ˘ = H ¨ × W ~ × D ˉ \breve{L}=\ddot{H} \times \tilde{W} \times \bar{D} L˘=H¨×W~×Dˉ。
随后,编码器块利用 N l N_{l} Nl个连续的RVM层来捕获全局信息,并在最后一个RVM层中增加通道数。之后,编码器块将特征图重新整形并转置为形状为 ( C ˇ × 2 , H ¨ , W ~ , D ˉ ) (\check{C} \times 2, \ddot{H}, \tilde{W}, \bar{D}) (Cˇ×2,H¨,W~,Dˉ)的张量,接着进行最大池化操作以减少特征图的分辨率。最终,第 l l l个编码器块输出具有形状 ( C ˇ × 2 , H ¨ / 2 , W ~ / 2 , D ˉ / 2 ) (\check{C} \times 2, \ddot{H} / 2, \tilde{W} / 2, \bar{D} / 2) (Cˇ×2,H¨/2,W~/2,Dˉ/2)的新特征图 F l + 1 F^{l+1} Fl+1。
残差视觉曼巴层(RVM Layer)。LightM-UNet提出了残差视觉曼巴层(RVM Layer),旨在增强原始的SSM块以用于图像的深层语义特征提取。具体来说,LightM-UNet通过先进的残差连接和调整因子进一步提升了SSM的长距离空间建模能力,同时几乎不引入新的参数和计算复杂度。
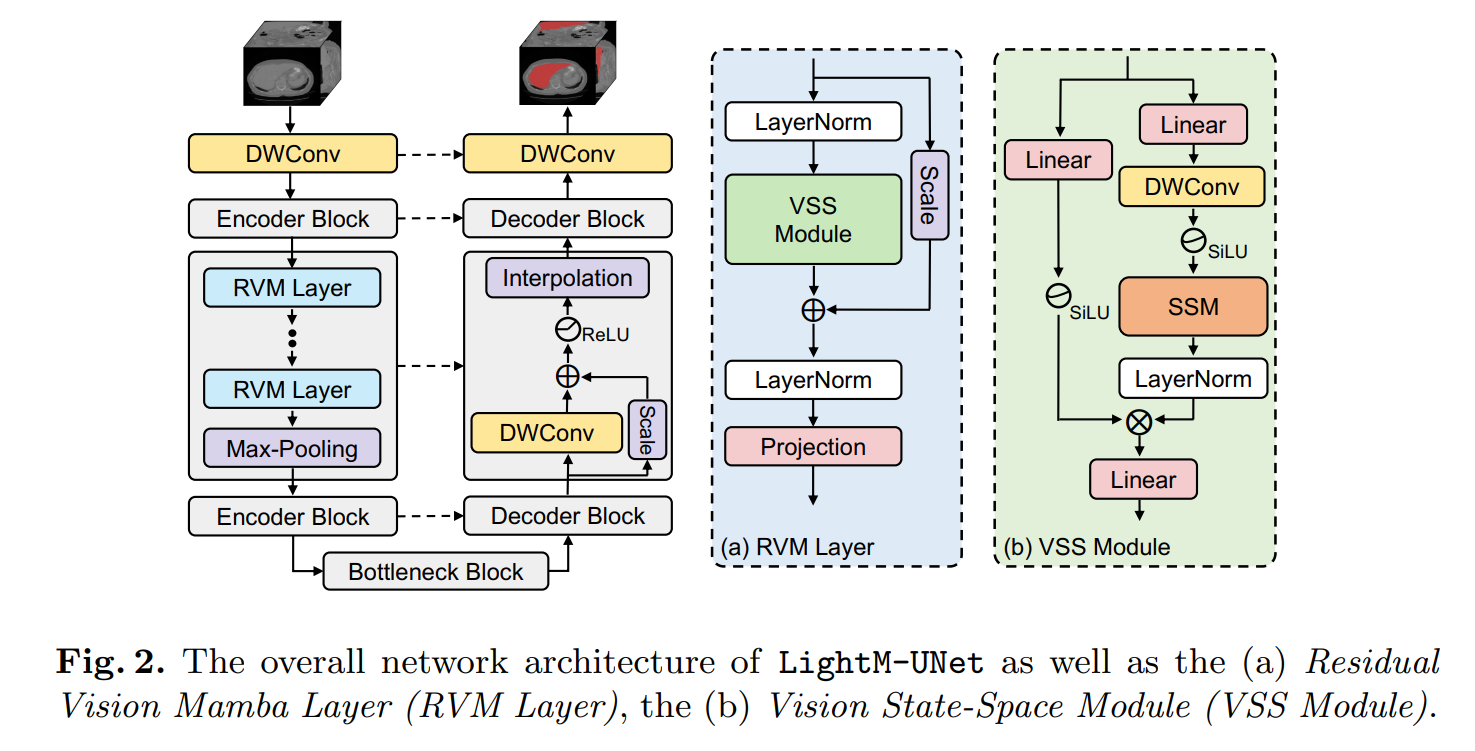
如图2(a)所示,给定输入深层特征 M i n l ∈ R L ˇ × C ˇ M_{i n}^{l} \in \mathbb{R}^{\check{L} \times \check{C}} Minl∈RLˇ×Cˇ,RVM Layer首先应用LayerNorm,然后利用VSSM来捕获空间长距离依赖关系。随后,在残差连接中使用调整因子 s ∈ R C ˇ s \in \mathbb{R}^{\check{C}} s∈RCˇ以提升性能。这一过程可以用数学公式表示如下:
M ~ l = VSSM ( LayerNorm ( M i n l ) ) + s ⋅ M i n l \widetilde{M}^{l}=\operatorname{VSSM}\left(\operatorname{LayerNorm}\left(M_{i n}^{l}\right)\right)+s \cdot M_{i n}^{l} M l=VSSM(LayerNorm(Minl))+s⋅Minl
之后,RVM Layer再次应用LayerNorm对 M ~ l \widetilde{M}^{l} M l进行归一化,并使用一个投影层将 M ~ l \widetilde{M}^{l} M l转换为更深的特征。上述过程可以表述为:
M out l = Projection ( LayerNorm ( M ~ l ) ) M_{\text {out }}^{l}=\operatorname{Projection}\left(\operatorname{LayerNorm}\left(\widetilde{M}^{l}\right)\right) Mout l=Projection(LayerNorm(M l))
视觉状态空间模块(VSS模块)。根据[13]中所述的方法,LightM-UNet引入了视觉状态空间模块(VSS模块,如图2(b)所示),用于进行长距离空间建模。VSS模块将特征 W i n l ∈ R L ˇ × C ˇ W_{i n}^{l} \in \mathbb{R}^{\check{L} \times \check{C}} Winl∈RLˇ×Cˇ作为输入,并将其分为两个并行分支进行处理。
在第一个分支中,VSS模块首先使用线性层将特征通道扩展到 λ × C ˇ \lambda \times \check{C} λ×Cˇ,其中 λ \lambda λ是预定义的通道扩展因子。随后,应用深度可分离卷积(DWConv)、SiLU激活函数[20],再跟随SSM和LayerNorm。在第二个分支中,VSS模块同样使用线性层扩展特征通道到 λ × C ˇ \lambda \times \check{C} λ×Cˇ,然后应用SiLU激活函数。之后,VSS模块使用哈达玛积(Hadamard product)将两个分支的特征进行聚合,并将通道数投影回 C ˇ \check{C} Cˇ,以生成与输入 W i n W_{i n} Win形状相同的输出 W out W_{\text {out }} Wout 。上述过程可以表述为:
W 1 = LayerNorm ( SSM ( SiLU ( DWConv ( Linear ( W in ) ) ) ) ) W 2 = SiLU ( Linear ( W in ) ) W out = Linear ( W 1 ⊙ W 2 ) \begin{array}{c} W_{1}=\operatorname{LayerNorm}\left(\operatorname{SSM}\left(\operatorname{SiLU}\left(\operatorname{DWConv}\left(\operatorname{Linear}\left(W_{\text {in }}\right)\right)\right)\right)\right) \\ W_{2}=\operatorname{SiLU}\left(\operatorname{Linear}\left(W_{\text {in }}\right)\right) \\ W_{\text {out }}=\operatorname{Linear}\left(W_{1} \odot W_{2}\right) \end{array} W1=LayerNorm(SSM(SiLU(DWConv(Linear(Win )))))W2=SiLU(Linear(Win ))Wout =Linear(W1⊙W2)
其中, ⊙ \odot ⊙表示哈达玛积。
2.3、瓶颈块
与Transformer类似,当网络深度过大时,Mamba也会遇到收敛问题[21]。因此,LightM-UNet通过连续使用四个RVM层构建瓶颈块来解决这一问题,以便进一步建模空间长期依赖关系。在这些瓶颈区域中,特征通道数和分辨率保持不变。通过这种设计,LightM-UNet能够在不增加过多计算负担的情况下,提升对图像深层特征的捕捉和提取能力。
2.4、解码器块
LightM-UNet采用解码器块来解码特征图并恢复图像分辨率。具体来说,给定来自跳跃连接的 F D l ∈ R C ˇ × H ˇ × W ˇ × D ˇ F_{D}^{l} \in \mathbb{R}^{\check{C} \times \check{H} \times \check{W} \times \check{D}} FDl∈RCˇ×Hˇ×Wˇ×Dˇ和来自前一块输出的 P i n ∈ R C ˇ × H ˇ × W ˇ × D ˇ P_{i n} \in \mathbb{R}^{\check{C} \times \check{H} \times \check{W} \times \check{D}} Pin∈RCˇ×Hˇ×Wˇ×Dˇ,解码器块首先使用加法操作进行特征融合。随后,它利用深度可分离卷积(DWConv)、残差连接和ReLU激活函数来解码特征图。此外,为了增强解码能力,残差连接中添加了一个调整因子 s ′ s^{\prime} s′。这个过程可以数学表达为:
P out = ReLU ( D W Conv ( P in + F D l ) + s ′ ⋅ ( P in + F D l ) ) P_{\text {out }}=\operatorname{ReLU}\left(D W \operatorname{Conv}\left(P_{\text {in }}+F_{D}^{l}\right)+s^{\prime} \cdot\left(P_{\text {in }}+F_{D}^{l}\right)\right) Pout =ReLU(DWConv(Pin +FDl)+s′⋅(Pin +FDl))
解码器块最终使用双线性插值将预测恢复到原始分辨率。
3、实验
数据集与实验设置。为了评估我们模型的性能,我们选择了两个公开可用的医学图像数据集:包含3D CT图像的LiTs数据集[1]和包含2D X射线图像的Montgomery&Shenzhen数据集[9]。这些数据集在现有的分割研究中得到了广泛应用[12,24],并在此处用于验证LightM-UNet的2D和3D版本的性能。数据被随机划分为训练集、验证集和测试集,比例为7:1:2。
LightM-UNet使用PyTorch框架进行实现,三个编码器块中的RVM层数分别设置为1、2和2。所有实验均在一个Quadro RTX 8000 GPU上进行。我们采用SGD作为优化器,初始学习率设为1e-4。调度器使用的是PolyLRScheduler,共训练了100个周期。此外,损失函数被设计为交叉熵损失和Dice损失的简单组合。
对于LiTs数据集,我们将图像归一化并调整大小为128×128×128,批次大小为2。对于Montgomery&Shenzhen数据集[9],图像被归一化并调整至512×512,批次大小为12。
为了评估LightM-UNet的性能,我们将其与两种基于CNN的分割网络(nnU-Net[8]和SegResNet[15])、两种基于Transformer的网络(UNETR[7]和SwinUNETR[6])以及一种基于Mamba的网络(U-Mamba[14])进行了比较。这些网络在医学图像分割竞赛中常用。此外,我们采用了平均交并比(mIoU)和Dice相似度分数(DSC)作为评估指标。
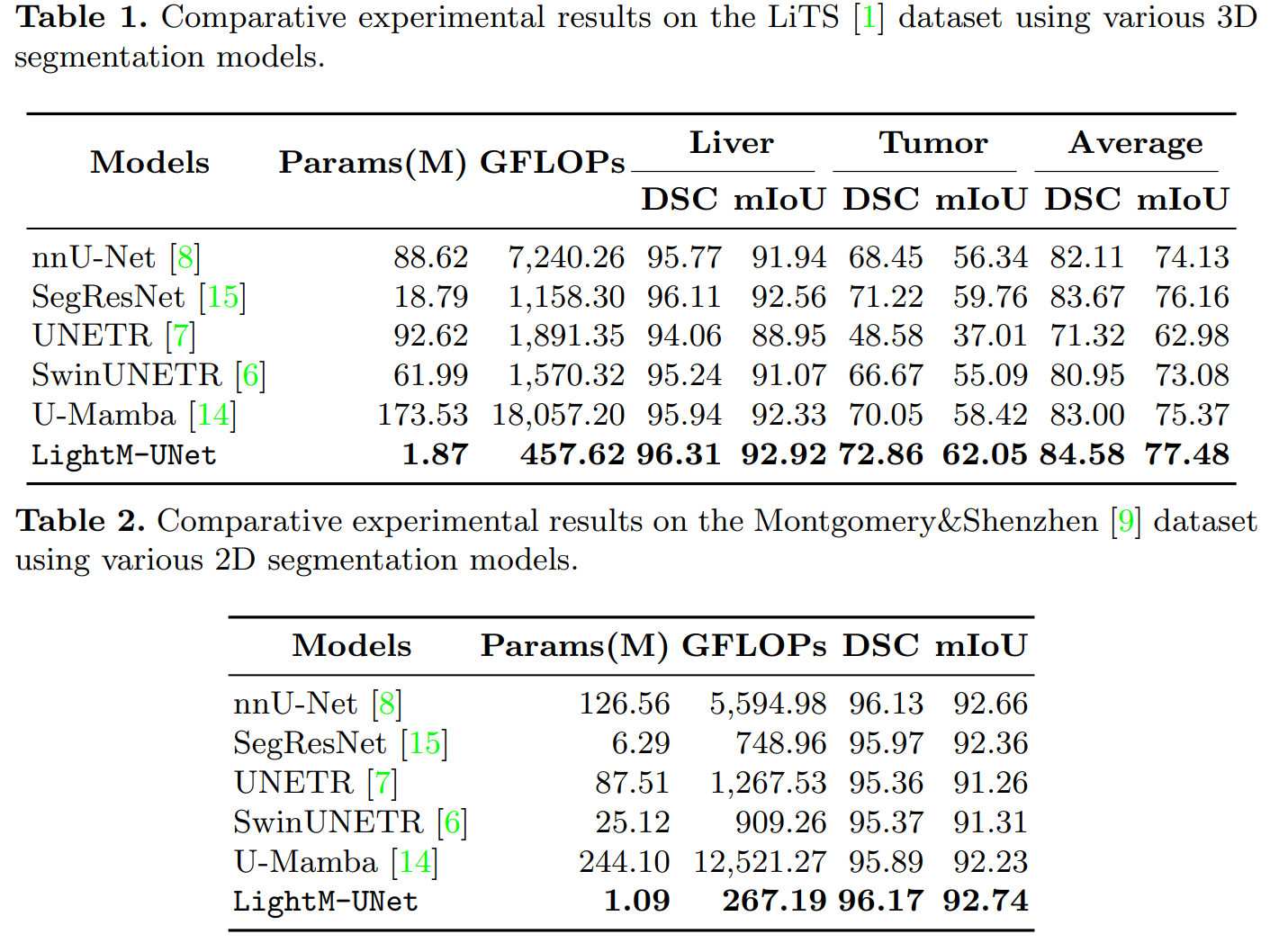
比较结果。表1中呈现的比较实验结果表明,我们的LightM-UNet在LiTS数据集[11]上实现了全面的最先进性能。值得注意的是,与像nnU-Net这样的大型模型相比,LightM-UNet不仅表现出优越的性能,而且参数数量和计算成本分别降低了47.39倍和15.82倍。与同时期的U-Mamba[14]相比,LightM-UNet在平均mIoU方面提高了2.11%。特别是对于常常太小而难以检测到的肿瘤,LightM-UNet实现了3.63%的mIoU提升。重要的是,作为将Mamba融入UNet架构的方法,LightM-UNet相比U-Mamba[14]仅使用了少1.07%的参数和少2.53%的计算资源。
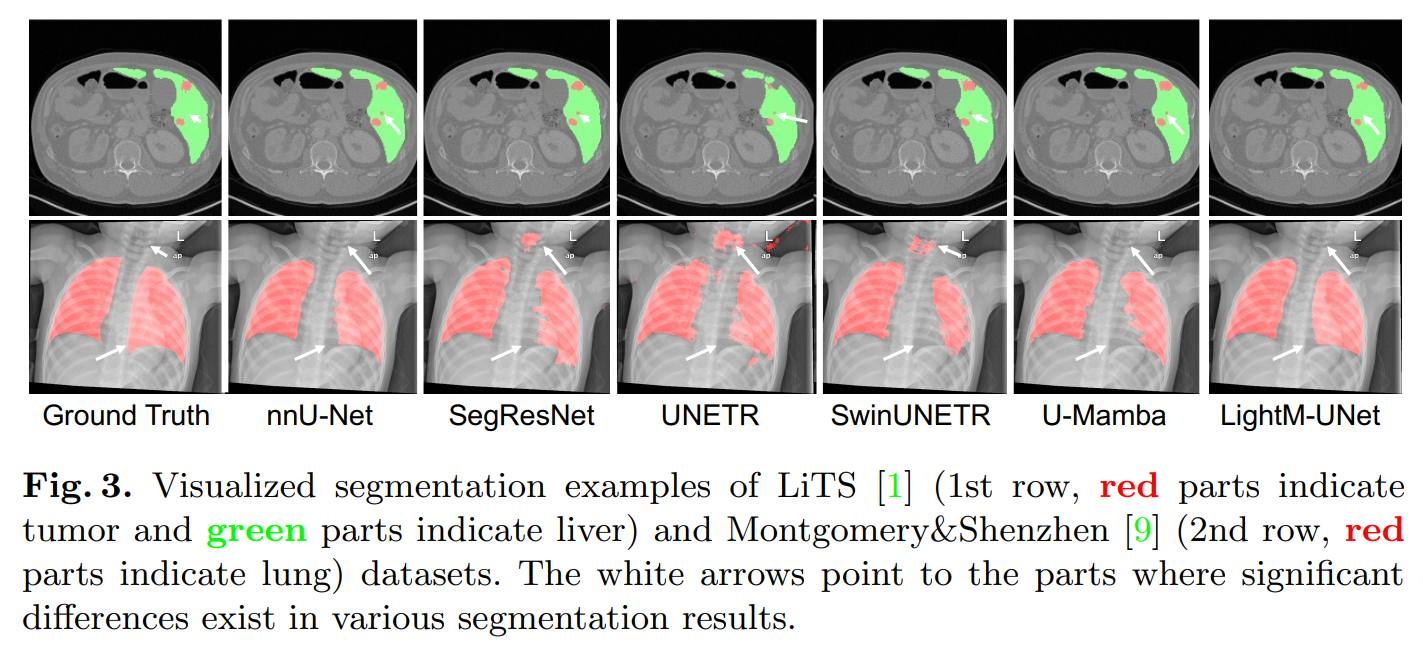
Montgomery&Shenzhen数据集[9]的实验结果总结在表2中。LightM-UNet再次取得了最优性能,并显著超越了其他基于Transformer和Mamba的文献。此外,LightM-UNet以极低的参数计数脱颖而出,仅使用了1.09M参数。这相比nnU-Net[8]和U-Mamba[14]分别减少了99.14%和99.55%的参数。为了更清楚地展示实验结果,请参考图1。图3展示了分割结果示例,说明与其他模型相比,LightM-UNet具有更平滑的分割边缘,并且不会对小物体(如肿瘤)产生错误识别。
消融实验结果。我们进行了广泛的消融实验来验证我们提出模块的有效性。首先,我们在UNet框架内分析了CNN、Transformer和Mamba的性能。具体来说,我们将LightM-UNet中的VSS模块替换为具有3×3内核的卷积操作以代表CNN,并替换为自注意力机制以代表Transformer。考虑到内存限制,对于CNN,我们替换了LightM-UNet中的所有VSS模块;而对于Transformer,我们遵循TransUNet[2]的设计,仅替换了Bottleneck块中的VSS模块。LiTS数据集[1]上的实验结果如表3所示,表明无论是用卷积还是自注意力替换VSSM都会导致性能下降。此外,卷积和自注意力还引入了大量的参数和计算开销。进一步观察发现,基于Transformer和基于VSSM的结果均优于基于卷积的结果,这证明了建模长程依赖性的好处。
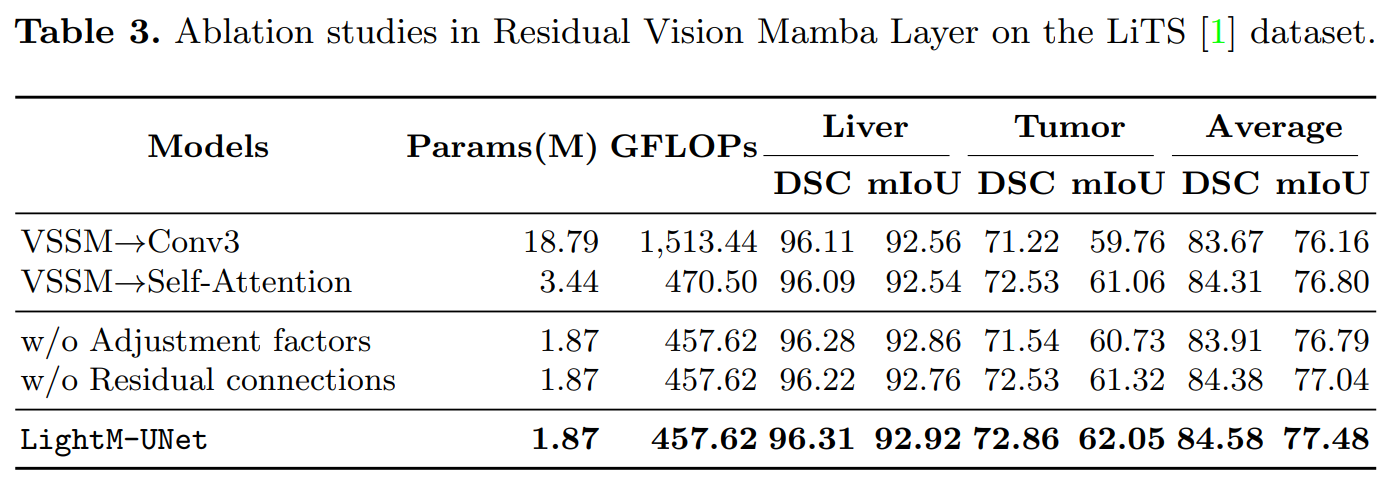
我们进一步移除了RVM层中的调整因子和残差连接。实验结果表明,移除这两个组件后,模型的参数数量和计算开销几乎没有减少,但模型性能却显著下降(mIoU下降了0.44%和0.69%)。这验证了我们的基本原则,即在不增加额外参数和计算开销的情况下提升模型性能。关于Montgomery&Shenzhen数据集[9]的额外消融分析,请参见补充材料。
4、结论
本研究中,我们介绍了LightM-UNet,这是一个基于Mamba的轻量级网络。它在2D和3D分割任务中都取得了最先进的性能,同时仅包含约1M参数,相比最新的基于Transformer的架构,参数减少了99%以上,GFLOPS也显著降低。我们通过一个统一的框架进行了严格的消融研究,验证了我们的方法,这是首次尝试将Mamba作为UNet的轻量级策略。未来的工作将包括设计更轻量级的网络,并在多个器官的更多数据集上进行验证,以促进它们在移动医疗和其他领域的应用。
相关文章:
LightM-UNet:Mamba 辅助的轻量级 UNet 用于医学图像分割
文章目录 摘要1 简介2、方法论2.1、架构概述2.2、编码器块2.3、瓶颈块2.4、解码器块 3、实验4、结论 摘要 https://arxiv.org/pdf/2403.05246.pdf UNet及其变体在医学图像分割中得到了广泛应用。然而,这些模型,特别是基于Transformer架构的模型…...
探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言 在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析…...

day16 java object中equals、finalize、
Object类 1.Object类是所有类的父类。 2.一个类如果没有显示继承其它类默认继承Object类equals方法 1.Object中的equals方法 - 用来比较地址值 public boolean equals(Object obj) { return (this obj); } 2.像核心类库中的许多类都重写了equals方法(比如&…...
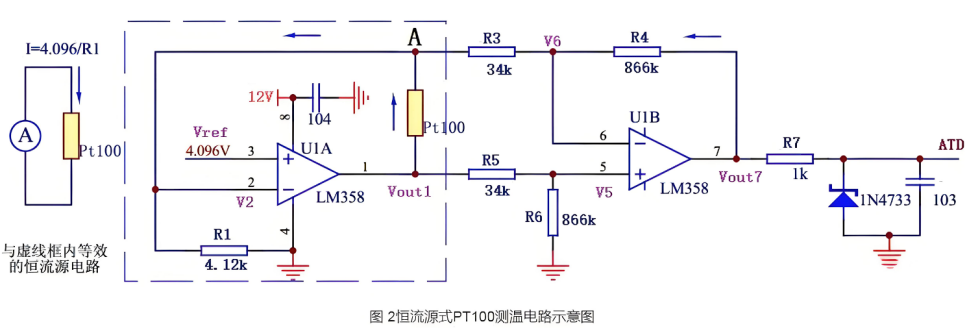
如何应用电桥电路的原理?
电桥电路是一种常用的测量技术,它利用了四个电阻的网络来检测电路的平衡状态。在平衡状态下,电桥的输出电压为零,这种特性使得电桥电路非常适合于精确测量电阻、电感、电容等电气参数,以及用于传感器和测量设备中。以下是电桥电路…...

大话设计模式——24.迭代器模式(Iterator Pattern)
简介 提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部实现。(Java中使用最多的设计模式之一) UML图 应用场景 Java的集合对象:Collection、List、Map、Set等都有迭代器Java ArrayList的迭代器源码 示例 简…...

【数据结构】双向链表 C++
一、什么是双向链表 1、定义 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。 双…...
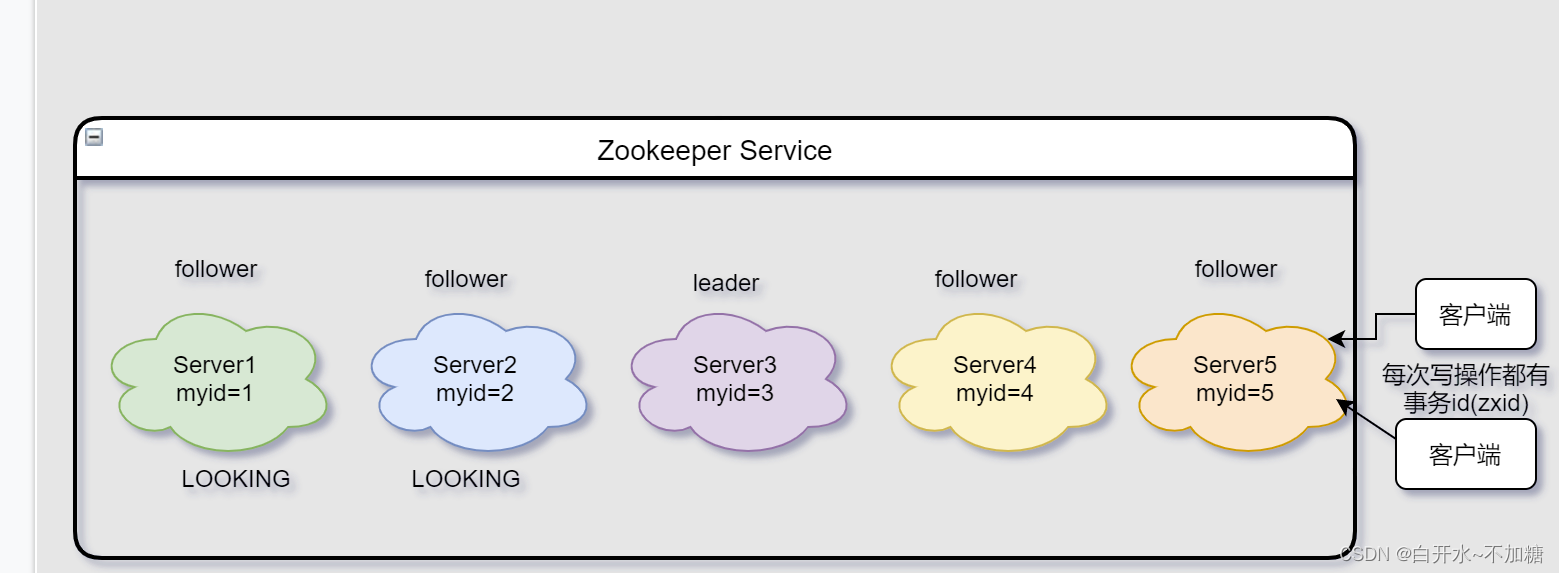
消息队列之-----------------zookeeper机制
目录 一、ZooKeeper是什么 二、ZooKeeper的工作机制 三、ZooKeeper特点 四、ZooKeeper数据结构 五、ZooKeeper应用场景 5.1统一命名服务 5.2统一配置管理 5.3统一集群管理 5.4服务器动态上下线 5.5软负载均衡 六、ZooKeeper的选举机制 6.1第一次启动选举机制 6.2非…...
第十届蓝桥杯大赛个人赛省赛(软件类) CC++ 研究生组2.0
A立方和 #include<iostream> #include<cmath> using namespace std; int main(){int n, t, flag, x;long long ans 0;for(int i 1; i < 2019; i){t i;flag 0;while(t && !flag){x t % 10;if(x 2 || x 0 || x 1 || x 9) flag 1;t / 10;}if(fl…...
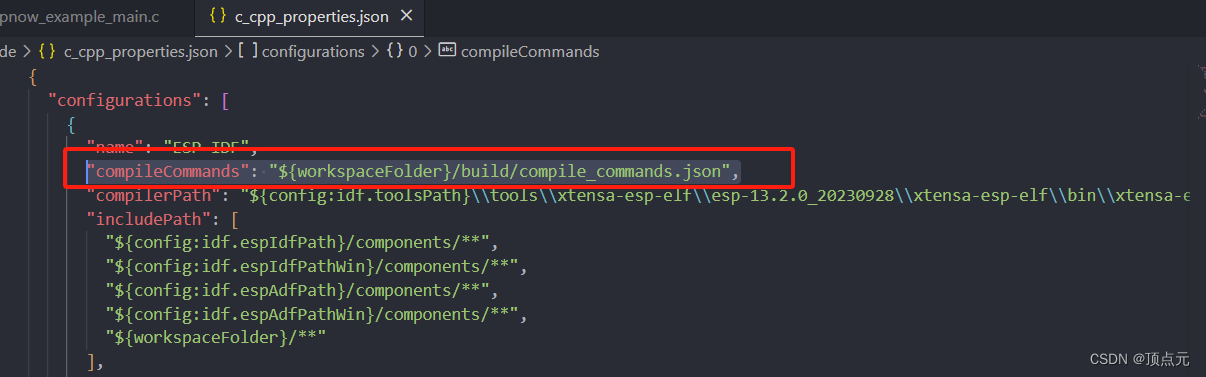
vscode开发ESP32问题记录
vscode 开发ESP32问题记录 1. 解决vscode中的波浪线警告 1. 解决vscode中的波浪线警告 参考链接:https://blog.csdn.net/fucingman/article/details/134404485 首先可以通过vscode 中的IDF插件生成模板工程,这样会自动创建.vscode文件夹中的一些json配…...
R语言复现:轨迹增长模型发表二区文章 | 潜变量模型系列(2)
培训通知 Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。 案例分享 2022年9月,中国四川大学学者在《Journal of Psychosomatic Research》(二区,I…...

【数据结构】顺序表的实现——动态分配
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:数据结构 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...

3.3.k8s搭建-rancher RKE2
目录 RKE2介绍 k8s集群搭建 搭建k8s集群 下载离线包 部署rke2-server 部署rke2-agent 部署helm 部署rancher RKE2介绍 RKE2,也称为 RKE Government,是 Rancher 的下一代 Kubernetes 发行版。 官网地址:Introduction | RKE2 k8s集群搭…...
CST电磁仿真软件的设置变更与问题【官方教程】
保存结果的Result Navigator 积累的结果一目了然! 用户界面上的Result Navigator 在一个仿真工程中更改变量取值进行仿真分析或者改变设置进行仿真分析时,之前的1DResult会不会消失呢? 1D Result:CST中1D Result指的是Y值取决…...
保研线性代数复习3
一.基底(Basis) 1.什么是生成集(Generating Set)?什么是张成空间(Span)? 存在向量空间V(V,,*),和向量集(xi是所说的列向量ÿ…...

从零开始学Spring Boot系列-集成MyBatis-Plus
在Spring Boot应用开发中,MyBatis-Plus是一个强大且易于使用的MyBatis增强工具,它提供了很多实用的功能,如代码生成器、条件构造器、分页插件等,极大地简化了MyBatis的使用和配置。本篇文章将指导大家如何在Spring Boot项目中集成…...

【云原生篇】k8s之Deployment详解
Kubernetes 的 Deployment 是一种管理声明式更新的资源对象,它允许你描述应用的期望状态,并由 Deployment 控制器自动将当前状态改变为期望状态。Deployment 主要用于无状态应用的部署和扩展,但也可以用于有状态应用。 核心功能 自动化部署…...
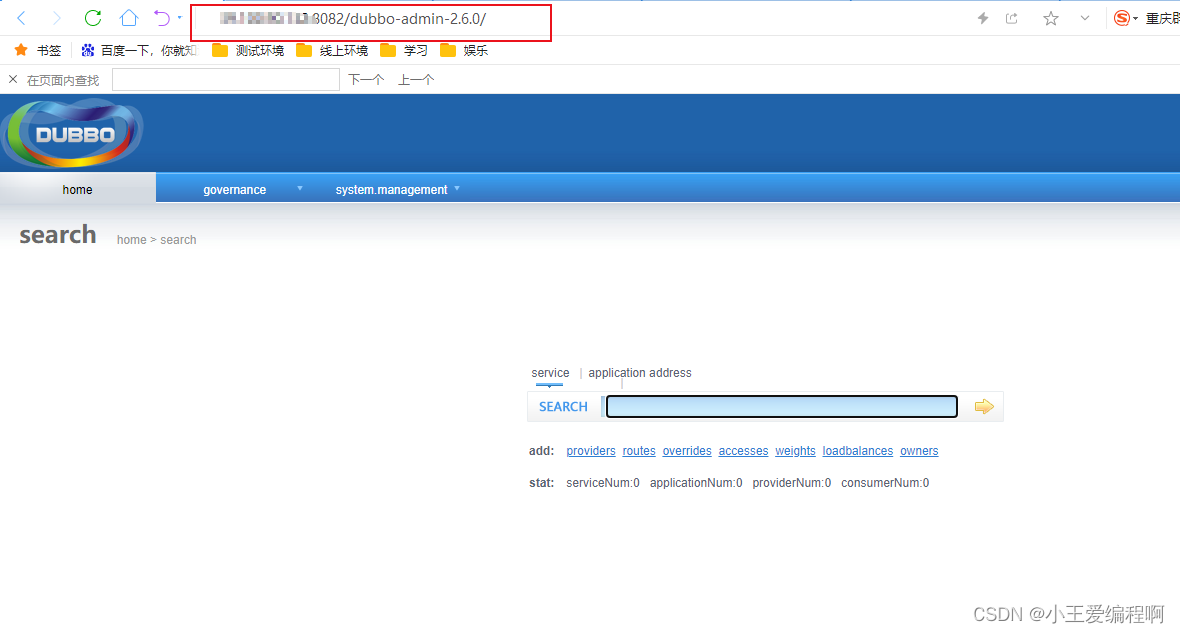
linux安装dubboAdmin
1.环境准备: jdk-8u391-linux-x64apache-maven-3.9.6apache-tomcat-8.5.100 2.安装注册中心zookeeper zookeeper的安装看我的另一篇文章,安装完成后保持启动状态 linux安装Zookeeper的详细步骤-CSDN博客 3.安装dubboadmin 源码下载地址:R…...

Android 系统编译 and 应用裁剪
平台应用编译 平台应用demo的Android.mk写法: LOCAL_PATH:= $(call my-dir) include $(CLEAR_VARS)LOCAL_MODULE_TAGS := optional# Only compile source java files in this apk. LOCAL_SRC_FILES := $(call all-java-files-under, src)LOCAL_PACKAGE_NAME := TestLOCAL_CER…...
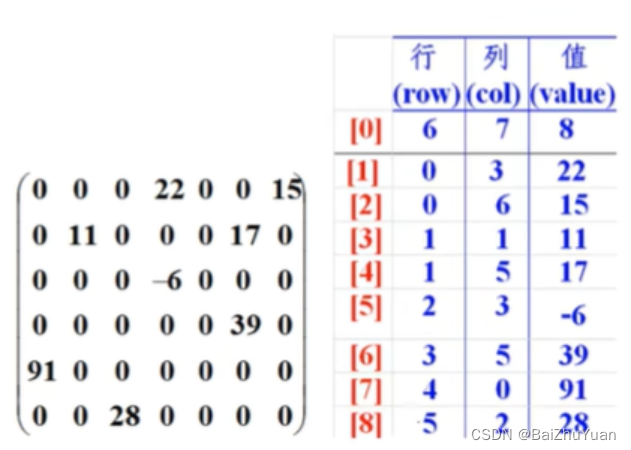
java数组.day16(冒泡排序,稀疏数组)
冒泡排序 冒泡排序无疑是最为出名的排序算法之一,总共有八大排序! 冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。 我们看到嵌套循环,应该立马就可以得出这个算法的时…...
vue+springboot多角色登录
①前端编写 将Homeview修改为manager Manager: <template><div><el-container><!-- 侧边栏 --><el-aside :width"asideWidth" style"min-height: 100vh; background-color: #001529"><div style"h…...

Qwen2.5-72B-GPTQ-Int4开源镜像:Chainlit前端定制化开发入门指南
Qwen2.5-72B-GPTQ-Int4开源镜像:Chainlit前端定制化开发入门指南 想快速搭建一个功能强大、界面美观的AI对话应用吗?今天,我们就来聊聊如何基于Qwen2.5-72B-GPTQ-Int4这个顶级开源大模型,以及Chainlit这个轻量级前端框架…...

深入理解Linux工作队列:从schedule_work到自定义队列的进阶指南
深入理解Linux工作队列:从schedule_work到自定义队列的进阶指南 在Linux内核开发中,工作队列(workqueue)是一种非常重要的异步任务处理机制。它允许开发者将任务推迟执行,从而避免阻塞当前进程或中断上下文。对于需要优…...

360周鸿祎:智能体技术破圈,引领产业全面重构与独角兽机遇
【导语:在2026中关村论坛年会全球独角兽企业大会上,360集团创始人周鸿祎围绕“龙虾”等新一代智能体技术,阐述其带来的产业变革机遇,涉及互联网、软件等多领域重构,有望催生大量独角兽企业。】智能体技术“破圈”&…...

TikTok音乐提取全攻略:3分钟学会用DouK-Downloader分离音频
TikTok音乐提取全攻略:3分钟学会用DouK-Downloader分离音频 【免费下载链接】TikTokDownloader JoeanAmier/TikTokDownloader: 这是一个用于从TikTok下载视频和音频的工具。适合用于需要从TikTok下载视频和音频的场景。特点:易于使用,支持多种…...

企业数字化转型基石:全面认识4A企业架构数据架构方案
数据架构是企业架构中连接业务、应用与技术的桥梁,通过数据资产目录厘清家底,数据标准统一语言,数据模型指导开发,数据分布拉通业务流,从而提升数据质量与运作效率,支撑业务决策与系统建设。 统一语言&…...

10大好用的班组建设系统盘点!助力企业高效开展班组建设
在2026年数字化转型的深水区,班组建设系统已成为企业夯实基层管理、提升执行力的核心引擎。面对市场上琳琅满目的工具,如何筛选出真正好用的班组建设系统,切实助力企业高效开展班组建设,是管理者面临的首要难题。本文深度盘点10大…...

Unity LineRenderer不只是画线:5个实战案例教你做激光、轨迹与魔法特效
Unity LineRenderer实战进阶:从激光瞄准到魔法光束的5种创意实现 在Unity游戏开发中,LineRenderer常被简单地视为"画线工具",但它的潜力远不止于此。当我们将这个组件与物理系统、着色器技术和游戏逻辑相结合时,它能创造…...

Linux文件IO编程实战:用GEC6818开发板上的C程序玩转open/read/write/lseek
Linux文件IO编程实战:GEC6818开发板上的C语言文件操作精要 在嵌入式Linux开发中,文件操作是最基础也是最重要的技能之一。GEC6818作为一款广泛应用于教学和工业场景的开发板,其Linux系统编程能力尤为关键。本文将带你深入理解Linux"一切…...
)
在Ubuntu 22.04上为RK3588编译带RKmpp和RGA的FFmpeg(保姆级避坑指南)
在Ubuntu 22.04上为RK3588编译带RKmpp和RGA的FFmpeg(保姆级避坑指南) RK3588作为Rockchip新一代旗舰SoC,其强大的多媒体处理能力吸引了众多开发者。本文将手把手带你完成FFmpeg的完整编译流程,重点解决环境配置、依赖管理、运行时…...

location-to-phone-number:如何将电话号码转化为商业智能的地理信息平台
location-to-phone-number:如何将电话号码转化为商业智能的地理信息平台 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gi…...