Hive的简单学习二
一Hive 库的基本操作
1.1 建库
1.默认路径是/user/hive/warehouse
 例如 我输入命令 create database text1
例如 我输入命令 create database text1
则text1出现在 warehouse目录下

2.指定位置创建数据库
create database text2 location '/bigdata29/bigdata29db'
后面的路径是hdfs的路径

3.最终写法
加上if not exists 可以判断该数据库存不存在
create database if not exists bigdata29_test1 location '/bigdata29/huangdadadb';

1.2 修改数据库
1.一般创建好的数据库都不会去修改数据库,如果要修改数据库也是修改创建的时间
alter database dept set dbproperties('createtime'='20220531');
1.3 数据库详细信息
1.3.1 显示数据库
1.show databases;
1.3.2 可以通过like进行过滤
show databases like 't*';
1.3.3 查看详情
desc database 数据库名;
1.3.4 切换数据库
use 数据库名;
1.3.5 删除数据库
drop database if exists 数据库名;
如果数据库不为空,使用cascade命令进行强制删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists 数据库名 cascade;
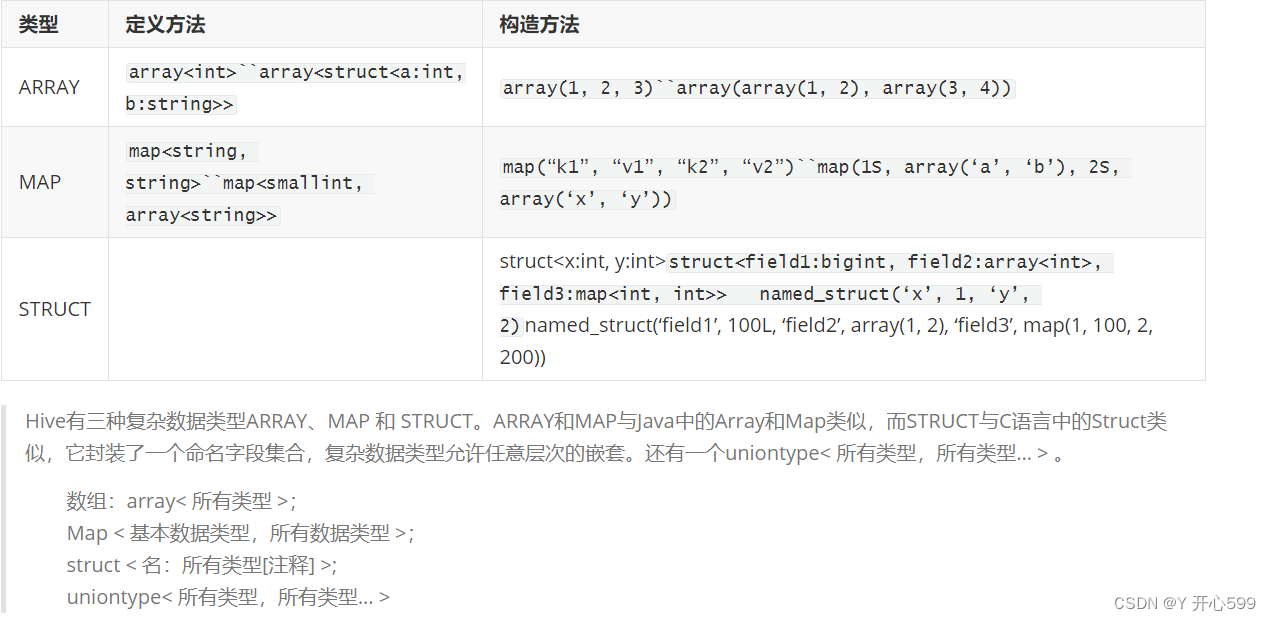
二 Hive的数据类型
2.1 基本数据类型

2.2 复杂数据类型
三 Hive 表的基本操作
3.1 默认建表
1.简单数据
create table IF NOT EXISTS 表名
(
数据名 数据类型
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --> 以逗号做为分隔符
2.复杂数据
create table IF NOT EXISTS t_person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string ,city:string>
)
row format delimited fields terminated by ',' -- 列与列之间的分隔符
collection items terminated by '_' -- 元素与元素之间分隔符
map keys terminated by ':' -- Map数据类型键与值之间的分隔符
lines terminated by '\n'; -- 行与行之间的换行符
3.2 指定存储格式
3.2.1 相关文件格式

平时学习用TextFile,工作使用orc
 3.2.2建表语法
3.2.2建表语法
create table IF NOT EXISTS 表名
(
id bigint,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC -->存储文件的格式
3.3 查询结果作为表
1.表没有的情况下
create table 表名 as 查询语句;
2.有表的情况下 添加数据
insert into 表名 查询语句;
3.4 模仿其他表的结构
create table 表名 like 已经存在的表名;
3.5 显示表
show tables;
show tables like 'u*';
desc t_person;
desc formatted students; // 更加详细
3.6 加载数据
3.6.1 使用hdfs的put或者cp命令
1.将linux文件使用 put的命令放在 hive表对应的HDFS目录下
例如:
hadoop fs -put ./students.csv /bigdata29/bigdata29db/students/

2.如果hdfs中 有数据的文件,那么将这个文件复制一份到 hive表对应的hdfs目录下
例如:
hadoop fs -cp /bigdata29/students.csv /bigdata29/bigdata29db/students/
3.6.2 location 或者是load data
1.location 这个是创建表的时候后面加的数据。(先有数据后有表)
例如 create table IF NOT EXISTS students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/bigdata29/shuju/';
主要保证data目录下只能有一个数据
这个表存储在shuju目录下

2.location 这个是先创建表的时候后面添加数据。(先有表后有数据)
create table IF NOT EXISTS students4(id bigint,name string,age int,gender string,clazz string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/bigdata29/aaa/bbb/ccc';
先在/bigdata29/aaa/bbb/ccc这个目录下创建一个表 再将数据放到这个目录下

3.load data 这个是移动hdfs中文件
先创建一个新表 不加location的话默认在创建数据库的那个目录下
create table IF NOT EXISTS students5
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
再输入 load data inpath '/bigdata29/data/students.csv' into table students5;即可
但是bigdata29/data/students.csv文件没有了
4.load data local 是上传Linux的文件
create table IF NOT EXISTS students6
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
再输入 load data local inpath '/usr/local/soft/bigdata29/students.csv' into table students5;
这里的文件不会消失
into 改成 overwrite就是覆盖
3.6.2 查询语句加载数据
1.表没有的情况下
create table 表名 as 查询语句;
2.有表的情况下 添加数据
insert into 表名 查询语句;
3.6.3普通的插入
insert into 表名 values ('数据');
3.7 修改表
3.7.1 添加列
alter table 表名 add columns (数据名 数据类型);
3.7.2修改列名或者数据类型
alter table 表名 change 之前的数据名 更改过后的数据名 数据类型;
四 内外部表
4.1内部表
1.我们默认创建的就是内部表
2.当设置表路径的时候,如果直接指向一个已有的路径,可以直接去使用文件夹中的数据
当load数据的时候,就会将数据文件存放到表对应的文件夹中
而且数据一旦被load,就不能被修改
我们查询数据也是查询文件中的文件,这些数据最终都会存放到HDFS
当我们删除表的时候,表对应的文件夹会被删除,同时数据也会被删除
4.2外部表
1.创建表的时候加个关键字
create external table 表名
2.一般用的外部表比较多
3.外部表因为是指定其他的hdfs路径的数据加载到表中来,所以hive会认为自己不完全独占这份数据
4.删除hive表的时候,数据仍然保存在hdfs中,不会删除。
五 导出数据
5.1 放入Linux中
1.insert overwrite local directory 'Linux路径' 查询语句;
例如:
insert overwrite local directory '/usr/local/soft/bigdata29/person_data' select * from t_person;
2.按照指定的方式将数据输出到本地
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
5.2 放入hdfs中
1.insert overwrite directory 'hdfs路径' 查询语句;
2.export table t_person to 'hdfs路径';,但是这个路径提前存在
六 Hive的分区
6.1静态分区 SP
借助于物理的文件夹分区,实现快速检索的目的。
一般对于查询比较频繁的列设置为分区列。
分区查询的时候直接把对应分区中所有数据放到对应的文件夹中。
6.1.1 单分区
1.创建表语法:
CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) partitioned by(grade int)
row format delimited fields terminated by ',';
2.加载数据
先数据在Linux创建文件,再上传到hdfs的表目录下
load data local inpath '/usr/local/soft/bigdata29/grade2.txt' into table t_student partition(grade=2);
3.加载数据的时候一定要把分区要确定好,不能不是这个分区的内容加入到这个分区里面
6.1.2 多分区
1.创建表语法
CREATE TABLE IF NOT EXISTS t_teacher (
tno int,
tname string
) partitioned by(grade int,clazz int)
row format delimited fields terminated by ',';
2.加载数据
在Linux创建数据文件,再上传到hdfs的表目录下
load data local inpath '/usr/local/soft/bigdata29/grade22.txt' into table t_teacher partition(grade=2,clazz=2);
3.分区的字段不能少于2个,比如说男生女生就没必要分区了
6.1.3 查看分区
show partitions 表名r;
6.1.4 添加分区
alter table 表名 add partition (字段名);
alter table 表名 add partition (字段名) location '指定数据文件的路径';
例如:
alter table t_teacher add partition (grade=3,clazz=1) location '/user/hive/warehouse/bigdata29.db/t_teacher/grade=3/clazz=1';
6.1.5 删除分区
alter table 表名 drop partition (字段名);
6.2 动态分区
-
动态分区(DP)dynamic partition
-
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
-
详细来说,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
6.2.1 开启动态分区
1.先创建分区表
CREATE TABLE IF NOT EXISTS t_student_d (
sno int,
sname string
) partitioned by (grade int,clazz int)
row format delimited fields terminated by ',';
2.创建原始数据表(外部)
CREATE EXTERNAL TABLE IF NOT EXISTS t_student_e (
sno int,
sname string,
grade int,
clazz int
)
row format delimited fields terminated by ','
location "/bigdata29/teachers";
3.在本地创建文件 然后将数据导入t_student_e表中
4.insert overwrite table t_student_d partition (grade,clazz) select * from t_student_e;
6.3 分区的优缺点
1.优点:
避免全盘扫描,加快查询速度
2.缺点
可能产生大量小文件
数据倾斜问题
七 Hive分桶
7.1 概念
数据分桶的适用场景: 分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式 不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况 分桶是将数据集分解为更容易管理的若干部分的另一种技术。 分桶就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。(都各不相同)
7.2 原理
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
-
bucket num = hash_function(bucketing_column) mod num_buckets
-
列的值做哈希取余 决定数据应该存储到哪个桶
7.3 作用
方便抽样
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便
提高join查询效率
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
7.4 实例
1.先创建数据
2.创建普通的表
create table person
(
id int,
name string,
age int
)
row format delimited
fields terminated by ',';
3.加载数据到普通的表中
4.创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';
这里使用clustered by对表中的列名分桶,后面的4表示分成4个
5.将数据加载到分桶表中
insert into psn_bucket select * from person;
后面是普通表的查询语句
7.5 分桶于分区的区别
1.分区用的是partitioned by 关键字声明的,分桶是clustered by 和into buckets 分成几个桶的关键字声明的
2.分区的在hdfs上面表示的是一个文件夹,分桶表示的是一个文件
3.分区的依据是通过指定分区的字段的值来进行分区的,分桶是指定分桶的字段的哈希值除以桶的个数取余来进行分桶的
八 Idea连接Hive
package com.shujia.jcbc;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class JcbcHive {public static void main(String[] args) throws Exception {//加载驱动Class.forName("org.apache.hive.jdbc.HiveDriver");//创建与hive的连接对象Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/bigdata29");//创建操作hive的对象Statement state = conn.createStatement();ResultSet resultSet = state.executeQuery("select * from emp ");while (resultSet.next()){String empno = resultSet.getString(1);String hiredate = resultSet.getString(2);String sal = resultSet.getString(3);String deptno = resultSet.getString(4);System.out.println(empno+", "+hiredate+", "+sal+", "+deptno);}//释放资源conn.close();}
}
相关文章:
Hive的简单学习二
一Hive 库的基本操作 1.1 建库 1.默认路径是/user/hive/warehouse 例如 我输入命令 create database text1 则text1出现在 warehouse目录下 2.指定位置创建数据库 create database text2 location /bigdata29/bigdata29db 后面的路径是hdfs的路径 3.最终写法 加上if n…...

Qt事件处理机制3-事件函数的分发
Qt开发中,经常重写event函数和具体的事件处理函数,例如mousePressEvent、paintEvent等,那么这些具体的事件处理函数是怎样被调用的呢?答案是由继承自QObject的类中的event函数来处理事件分发。这里以间接继承自QWidget的派生类MyB…...
4月9号总结
java学习 一.steam流 1.介绍 Stream 是 Java 8 中引入的一种处理集合数据的新抽象。它提供了一种高效且便利的方式来处理集合中的元素,支持函数式编程的特性,使得集合操作变得更加简洁和灵活。 2.创建 List和Set可以直接调用接口的steam方法转换为流 …...

Linux生态系统:探索Linux的开源世界
Linux生态系统:探索Linux的开源世界 在前面的博客中,我们深入探讨了Linux的各种技能和技巧,从入门到进阶,再到高手级别。这一路走来,相信大家对Linux已经有了全面的认识和掌握。然而,Linux的魅力远不止于此。今天,我们将进一步探索Linux生态系统,了解Linux在开源世界中的重要地…...

XILINX 10G PCS PMA IP核使用
文章目录 一、设计框图二、模块设计三、IP核配置四、上板验证五、总结 一、设计框图 关于GT高速接口的设计一贯作风,万兆以太网同样如此,只不过这里将复位逻辑和时钟逻辑放到了同一个文件ten_gig_eth_pcs_pma_0_shared_clock_and_reset当中。如果是从第…...
Scrapy框架内存泄漏问题及解决
说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除 作者:zhu6201976 一、问题背景及原因 官方文档:Debugging memory leaks — Scrapy 2.11.1 documentation Scrapy是一款功能强大的网络爬虫框…...

app 创建快捷入口 在手机上面多个icon
activity-alias详解及应用-CSDN博客 Android动态修改应用图标最佳实践 - 简书 AndroidManifest.xml 中 <activity-aliasandroid:name"包名.ui.mine.SecondActivityAlias"android:label"快捷入口"android:icon"mipmap/collection_one"andro…...
【网安小白成长之路】6.pkachu、sql-lbas、upload-lbas靶场搭建
🐮博主syst1m 带你 acquire knowledge! ✨博客首页——syst1m的博客💘 🔞 《网安小白成长之路(我要变成大佬😎!!)》真实小白学习历程,手把手带你一起从入门到入狱🚭 &…...

vue 项目中添加DES加密
vue 项目中添加DES加密 由于现在项目使用http协议,且登录界面是明文传输,项目真正上线后基本的密码传输都很不安全。 决定用前端框架加密后再进行传输,以提高密码传输过程中的安全性。 crypto-js 是一个流行的 JavaScript 加密库࿰…...

【记录问题】如何测试虚拟机已经可以连接网络
如何测试虚拟机已经可以连接网络 要测试虚拟机是否已经连接网络,可以采取以下步骤: 检查虚拟网络编辑器 使用管理员权限打开虚拟网络编辑器,检查NAT方式下的虚拟子网网段。 确保虚拟机的网络设置与虚拟子网网段相匹配。检查虚拟机网络设置 …...

MySQL数据库的详解(1)
DDL(数据库操作) 查询 查询所有数据库:show databases;当前数据库:select database(); 创建 创建数据库:create database [ if not exists] 数据库名 ; 使用 使用数据库:use 数据库名 ; 删除 删除数…...

Python 网络爬虫技巧分享:优化 Selenium 滚动加载网易新闻策略
简介 网络爬虫在数据采集和信息获取方面发挥着重要作用,而滚动加载则是许多网站常用的页面加载方式之一。针对网易新闻这样采用滚动加载的网站,如何优化爬虫策略以提高效率和准确性是一个关键问题。本文将分享如何利用 Python 中的 Selenium 库优化滚动…...

Apache SeaTunnel 社区 3 月月报
各位热爱 SeaTunnel 的小伙伴们,SeaTunnel 社区 3 月月报来啦!这里将记录 SeaTunnel 社区每个月的重要更新,并评选出月度之星,欢迎关注。 SeaTunnel 月度 Merge Stars 感谢以下小伙伴 3 月为 Apache SeaTunnel 做的精彩贡献&…...

ElasticSearch 的 ConstantScoreQuery 的理解
ConstantScoreQuery的定义: A query that wraps another query and simply returns a constant score equal to 1 for every document that matches the query. It therefore simply strips of all scores and always returns 1. 结合DisMaxQueryBuilder可以查找所…...
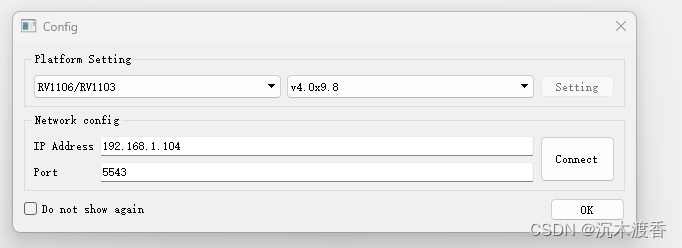
【RV1106的ISP使用记录之一】基础环境搭建
公司缺少ISP工程师,做为图像算法工程师的我这就不就给顶上来了么,也没给发两份工资,唉~ 先写个标题,占一个新坑,记录RK平台的传统ISP工作。 一、基础环境的硬件包括三部分: 1、相机环境,用于采…...
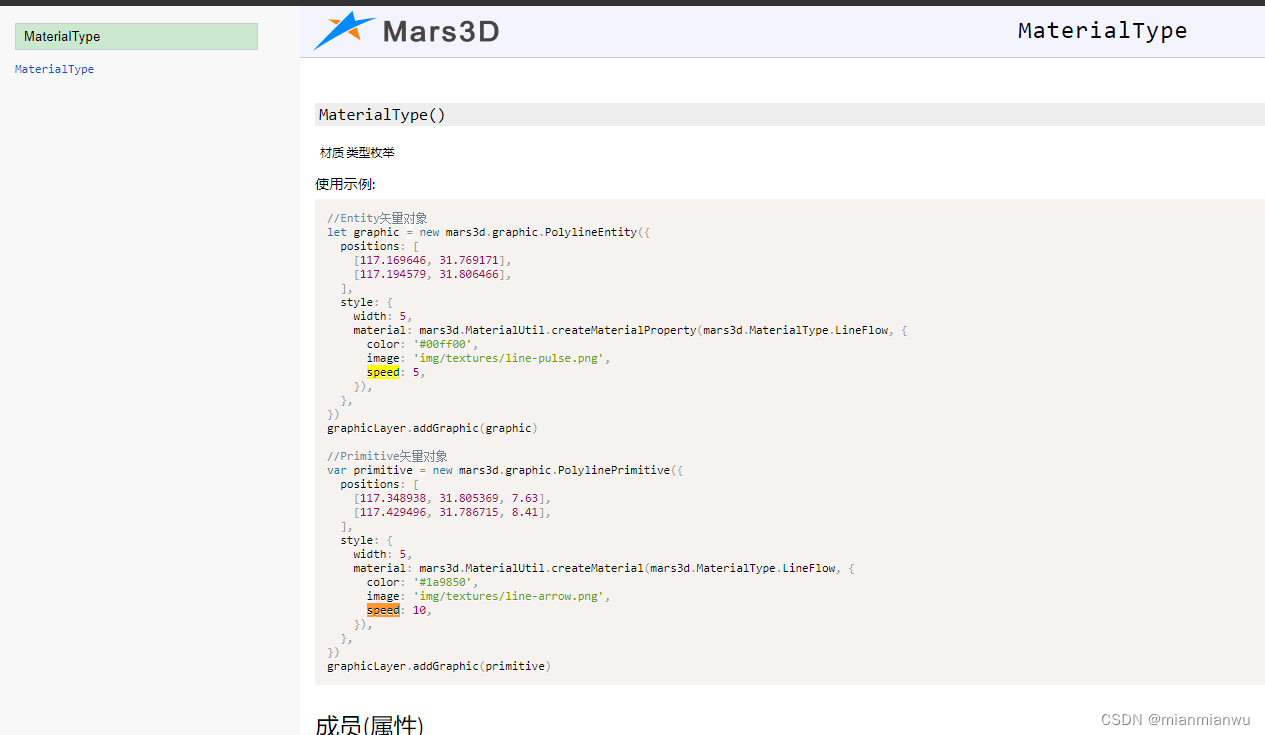
mars3d.MaterialType.Image2修改配置面状:图片2的speed数值实现动画效果说明
摘要: mars3d.MaterialType.Image2修改配置面状:图片2的speed数值实现动画效果说明 前提: 1.在示例中,尝试给mars3d.MaterialType.Image2材质的图片加上speed参数,实现动画效果,但是没有看到流动效果说明…...
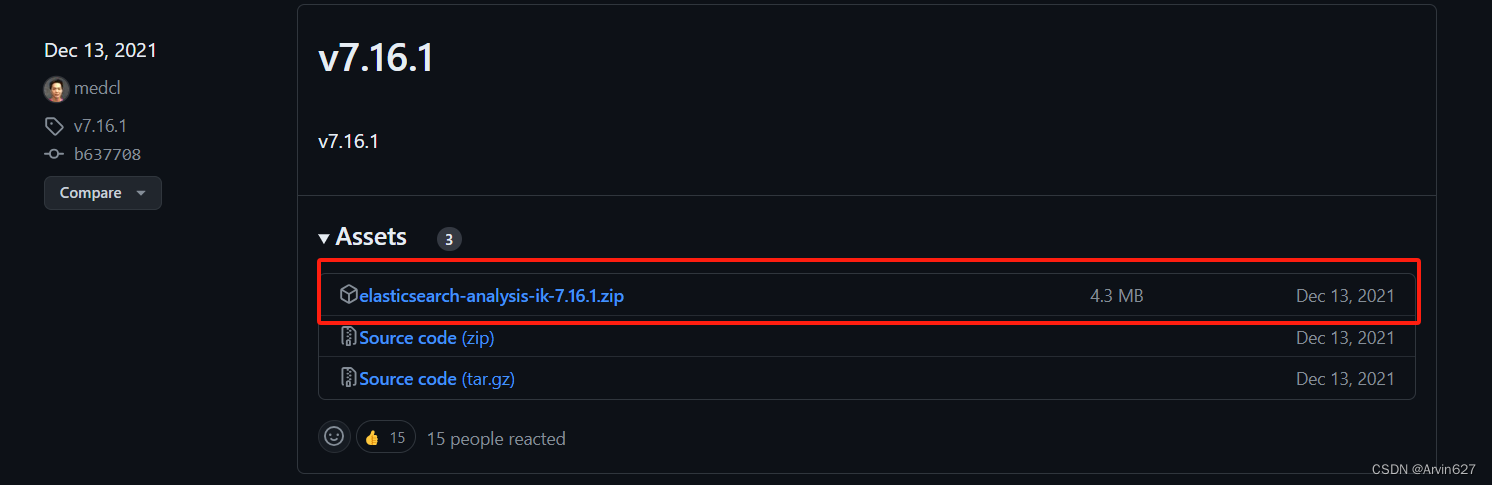
Elasticsearch部署安装
环境准备 Anolis OS 8 Firewall关闭状态,端口自行处理 Elasticsearch:7.16.1(该版本需要jdk11) JDK:11.0.19 JDK # 解压 tar -zxvf jdk-11.0.19_linux-x64_bin.tar.gz# 编辑/etc/profile vim /etc/profile# 加入如下…...
Android零基础入门(一)配置环境和安装Android Studio
闲来无事学一下Android,本人目前java为主,jdk的环境就不赘述了 配置环境 Java JDK5 或 以后版本 Android SDK Java运行时环境(JRE) Android Studio 你可以从 Oracle 的 Java 网站:JDKJava SE下载下载最新版本的 Jav…...

Golang编译优化——消除Copy指令
一、优化概述 以下是Go编译器对某个代码段编译生成的SSA IR摘选,对于Golang SSA IR的介绍我写了文章,但是在犹豫要不要发。 b1:-... Plain → b2 (5)b2: ← b1 b4-v9 (5) Phi <int> v8 v16 (i[int])v22 (8) Phi <int> v7 v14 (r[int])v1…...

Java IO流对象流实操
ATM的io对象流: package com.jsu.atm; import com.jsu.atm.Serializable; public class Account implements Serializable{//私有数据成员private String UserName; // 用户名称private String PassWord; // 用户密码private double RemainMoney; // 用户余额…...

性价比高的AI应用厂家
核心结论: 当前市面上AI应用厂商众多,但真正能做到“高性价比”的,必须同时满足三个条件:功能覆盖企业核心痛点(管理、销售、运营)、落地效果可量化(降本增效有数据支撑)、成本可控&…...

别再只当CANoe/CANape的‘眼睛’了!VN1640A的I/O通道实战:手把手教你采集电压和开关信号
VN1640A硬件接口深度开发:从电压采集到PWM控制的工程实践 在汽车电子测试领域,Vector的VN系列接口设备早已成为行业标准配置。大多数工程师对CAN/LIN通道的应用驾轻就熟,却常常忽略设备上那个不起眼的9针I/O接口——这个被低估的硬件通道实际…...
)
超越‘点亮出图’:深入Sensor AE增益配置的三种模式与实战验证(以SC230AI/OV08A10/IMX335为例)
超越“点亮出图”:深入Sensor AE增益配置的三种模式与实战验证 在嵌入式Camera开发领域,成功点亮Sensor并输出图像仅仅是万里长征的第一步。真正的挑战往往出现在图像质量调优阶段,尤其是自动曝光(AE)与增益配置这一专…...

5G NR物理层实战:从帧结构参数到TB块生成的完整计算解析
1. 5G NR物理层基础:为什么需要计算TB块? 在5G通信系统中,物理层就像快递公司的打包部门,负责把用户数据(比如你刷的视频内容)装进标准化的"包裹"里传输。这个"包裹"的专业名称就是传输…...

基于MCP协议的能源转型智能体:架构、实现与应用场景解析
1. 项目概述:能源转型智能体的“大脑”与“手脚”最近在做一个挺有意思的项目,核心是围绕一个叫apifyforge/energy-transition-intelligence-mcp的智能体展开的。这名字听起来有点拗口,拆开来看,“apifyforge”是发布者࿰…...

避坑指南:R语言做交互效应分析时,你的p for Interaction算对了吗?
R语言交互效应分析:如何避免p值计算中的常见陷阱 在医学统计与流行病学研究中,交互效应分析是探索变量间复杂关系的重要工具。许多研究者在使用R语言进行逻辑回归分析时,常常对交互项的p值计算结果产生疑虑——这个关键指标是否真的反映了变量…...
)
Web安全入门避坑指南:用Pikachu靶场搞懂文件上传的3种Check方式(前端、MIME、getimagesize)
Web安全实战:Pikachu靶场文件上传漏洞攻防全解析 当你第一次接触Web安全时,文件上传功能可能是最令人兴奋又最危险的漏洞之一。想象一下,攻击者仅通过一个看似无害的上传表单就能完全控制你的服务器——这不是电影情节,而是每天都…...

网盘直链下载助手终极指南:3分钟解锁9大网盘满速下载
网盘直链下载助手终极指南:3分钟解锁9大网盘满速下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

htop:Linux系统进程监控与性能分析利器
1. 项目概述:为什么我们需要一个比top更好的工具?如果你在Linux或类Unix系统上做过运维、开发,或者仅仅是好奇过自己的服务器或电脑到底在“忙”些什么,那么top命令几乎是你绕不开的第一个工具。它像系统资源的一个实时仪表盘&…...

维普AI率82%熬夜改一周只降4个点!这款软件几分钟救我一命!
维普AI率82%熬夜改一周只降4个点!这款软件几分钟救我一命! 周一早上送维普看到 82% 那一刻 3 月 17 号周一早上 9 点。导师群:「答辩前再送一次维普看 AIGC 检测,下周一早上群里发达标截图」。我赶紧上传维普「智能检测 4.0」—…...