【Java】JDK1.8 HashMap源码,put源码详细讲解

📝个人主页:哈__
期待您的关注

在Java中,HashMap结构是被经常使用的,在面试当中也是经常会被问到的。这篇文章我给大家分享一下我对于HashMap结构源码的理解。
HashMap的存储与一般的数组不同,HashMap的每一个元素存储的并不是一个值,而是一个引用类型的Node结点,这也就意味着这个Node结点有被扩充的可能,因为这个Node结点可以是一个链表的Head结点,也可以是一棵树的根节点。
HashMap的存储数组叫做table,也可以称作“桶”,试想这样的一个场景:我们在一排放了3个桶,同时我们有4个苹果,如果我们要把所有的苹果放到桶当中,那么必然有一个桶中 的苹果个数>=2。
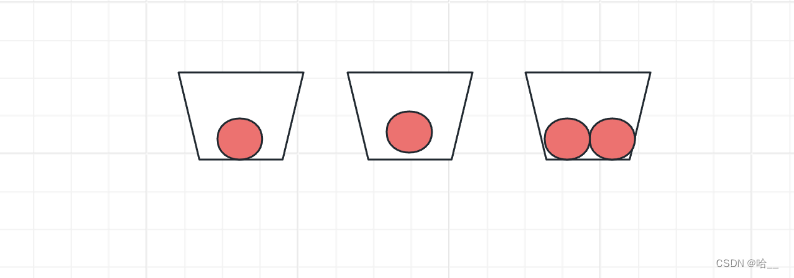
这种情况在我们的HashMap中也会出现,我们的HashMap结构是把很多的数据存放到一个容量达不到元素个数的数组当中,就如同桶和苹果一样。
因此我们的HashMap结果会出现上图所示的一种冲突,我们成为散列冲突,也叫做Hash冲突 。
出现冲突不要怕,解决冲突就是了,我们的一个桶当中可以放两个苹果,自然HashMap的table数组的一个位置也可以存放两个元素。
问题来了,我们现在假设有16个桶,同时间断性的向桶中放苹果,而且还要能够方便我们后续去拿苹果和寻找苹果,那我们这16个桶还够用吗?我们这样子直接把苹果放进桶里,还能够方便我们后续找苹果吗?
行了,解决吧,现在假设你是一位苹果管理员,你该怎么优化一下?你看看这样子行不行,不就是放苹果、找苹果嘛,既然让我来管理,那我希望把苹果平均放到桶当中,每次我放的位置尽量不要和之前的苹果放的位置有冲突,如果桶多的话,你也不能一个一个桶去看吧,所以,我们定义了一个算法,我根据这个苹果的生产ID序列号去寻找对应的桶放进去,如同取余放置一样。这是个不错的思路。但序列号都是有规律的,这样会影响我们的放置,我们希望是一个很随机的结果,因此我们给这个序列号随机变动几个位置后在选择桶。在HashMap中,这样的序列号叫做hashCode值,经过一个扰动函数后,我们的到的扰动的值叫做hash。
如何存放的问题解决了,但苹果一旦多了还是会产生冲突,一个桶里放8个我还能找得到,但是一个桶里放20个,30个苹果,那我就找不到那个序列号的苹果了。
二叉树我们都学过,倘若我们把桶内的苹果以二叉树的方式进行存储,那这样我们在查找的时候是不是就省了很多时间呢?因此HashMap中的table内的一个元素列表长度>8的时候,进行树化操作。但也不是非要进行树化的,毕竟树化也要浪费很多资源。当我们的桶的数量<=64的时候,我们不进行树化操作,我们进行数组扩容,把table扩大2倍,这样的话,我们在放苹果的时候发生冲突的概率就会降低。但如果容量已经达到了64,我们就考虑把链表转为红黑树(也是二叉树)了。
以上的过程不知道你是否理解了没,放苹果的案例和HashMap存储元素的过程相似,现在我们来看代码吧。
一、HashMap中的变量
1.默认容量
HashMap无参构造方法调用时,我们的HashMap数组的初始容量是16。
/*** 默认初始化的容量大小,且必须是2的整数倍*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 162.最大容量
记录了我们HashMap所能存储的最大的元素个数。
/*** 我们的元素数组的最大的容量,如果我们设定的最大容量比这个数还大* 那我们就把容量设定为这个最大的值*/static final int MAXIMUM_CAPACITY = 1 << 30;3.负载因子
负载因子决定了HashMap在存储更多数据时如何扩展其容量。默认情况下,当负载因子达到0.75时,HashMap会进行扩容。这意味着,当HashMap中的元素数量达到数组容量的0.75倍时,数组的大小就会翻倍,以便容纳更多的数据。
为什么选择0.75作为默认的负载因子呢?这并不是随意的选择,而是经过深思熟虑后的优化值。负载因子实际上是一个权衡空间和时间的参数。在理想情况下,如果负载因子为1,这意味着每个索引位置上都有一个键值对存在。然而,当两个或更多的键具有相同的哈希值时,就会发生冲突,这会导致查询效率降低。因此,通过设置一个适当的负载因子,可以平衡键值对的存储效率和查询效率。
通过将负载因子设置为0.75,可以在空间和时间效率之间取得平衡。这意味着,当数组接近其容量时,HashMap会进行扩容,以避免因哈希冲突而导致的性能下降。同时,这个值也避免了因频繁扩容而产生的额外开销。在大多数情况下,0.75的负载因子可以提供较好的性能。
/*** 如果我们并没有自己初始化一个平衡因子,这个就是默认的平衡因子*/static final float DEFAULT_LOAD_FACTOR = 0.75f;4.列表树化的阈值
/*** 当列表的长度超过了8,达到9的时候就会把列表转为红黑树*/static final int TREEIFY_THRESHOLD = 8;5.红黑树转列表的阈值
一个桶里的苹果往外拿了很多,就那么几个苹果我数的清,用不到树了。
/*** 当树中的结点的个数小于6的时候我们就把红黑树转为列表了*/static final int UNTREEIFY_THRESHOLD = 6;6.树化时的最小数组容量
/*** 在我们的列表转为红黑树的时候,如果我们的数组长度(也就是容量)达不到64,那我们就扩充数组* 而不是进行红黑树的转化**/static final int MIN_TREEIFY_CAPACITY = 64;7.元素数组(存放我们插入的数据)
这就是我们的桶。
transient Node<K,V>[] table;8.数组的大小(并非容量,而是实际放了多少个数据结点到table数组中)
/*** 此映射中包含的键值映射数。*/transient int size;这些变量看完了之后,我们在介绍一个结点类Node,我们的元素在存储的时候都是这个类型。
9.Node结点
static class Node<K,V> implements Map.Entry<K,V> {final int hash; //hash值final K key; //keyV value; //valueNode<K,V> next; //记录下一个元素
}10.扩容阈值
当table中的元素个数达到了这个值的时候进行resize操作,并非所有node节点的个数,而是我们的一维table中存放元素的个数(存放的链表和树算一个元素)。
/*** table中存放的元素的个数达到了这个值进行resize操作*/int threshold;二、HashMap的put方法
我们只以无参构造的HashMap为例。
HashMap<String,Integer> map = new HashMap<>();map.put("张三",18);我们看看这个put方法到底干了些什么。
我们点进去这个put方法,发现调用的是putVal方法,这个方法有五个参数,第一个参数传入了一个hash方法,第二个就是我们的key,第三个就是value,而后边的两个是默认的boolean类型的值,我们不看后边的两个。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}hash到底是什么,我们上边其实也讲到过,这是一个扰动函数,意在把我们要插入的这个元素更加随机、均匀的分布到table中。想了解这个过程我们先往下走,到了具体的位置在讲解。
我们看看这个putVal方法。代码倒是挺多的,不过没关系,你就看我写的注释。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {//这里初始化了一个tab用于保存我们最终的结果 还有一个临时的结点pNode<K,V>[] tab; Node<K,V> p; int n, i;//这种写法要弄清,=是赋值,==是判断,如果我们的table还没有初始化的话if ((tab = table) == null || (n = tab.length) == 0)//我们就把这个n记录成我们这个tab初始化后的大小n = (tab = resize()).length;//这里就是进行位置判断的代码了,如果当前遍历的结点是个空的,我们直接把node放到这个桶里if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else { //如果当前位置不为空//定义一个e结点用于遍历Node<K,V> e; K k;//如果这个结点的key和我们插入元素的key相同,那我们把这个e指向这个结点if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//但如果不同,而且这个结点还是个树形结点,我们调用专门的方法遍历树else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//如果不是树,那就是链表了,我们进行链表遍历去插入我们的新元素for (int binCount = 0; ; ++binCount) {//如果我们遍历到的结点已经遍历完了,那我们把元素插入if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//如果达到了树化阈值,那我们进行树化操作//这里注意一下为什么是-1,因为我们从0开始遍历,当我们达到了7说明已经遍历了8次,同时上边进行了一次插入,结点数达到了9if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}//如果当前结点的key就是我们插入的key,我们不做操作,这是e是有指向的if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//如果e不是空,就说明找到了一个key相同的结点,我们进行value的替换if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);//替换后就return了,不对table结构做影响return oldValue;}}//如果我们对table的结构影响了,我们把这个值+1++modCount;//看看把这个值插进去之后,是否达到了扩容阈值,并不是table中元素的长度满了之后才扩容的if (++size > threshold)resize();afterNodeInsertion(evict);return null;} 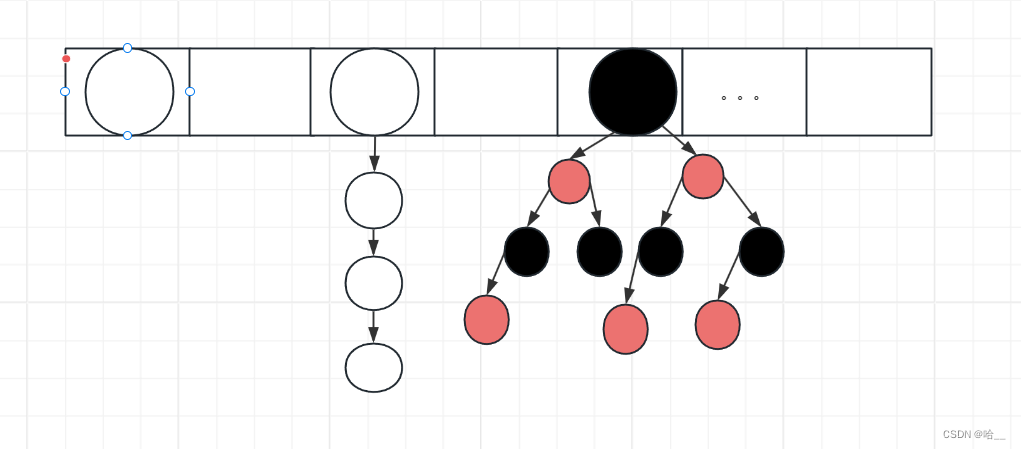
在上方的代码中你看到了这样的代码。这样代码就是判断我们元素放到哪个位置的。我们用桶的容量去和hash值进行与操作。
(p = tab[i = (n - 1) & hash假设当前容量是16,那么你看一下这个与操作的核心部分是什么,n的前28位都是0,与后的结果也是0,所以真正影响元素位置的只有n的最后四位和元素hashcode的最后四位。结果也一定是0~15。
h.hashCode = 1101 0111 1011 1100 0101 1011 1011 1010
n-1 = 0000 0000 0000 0000 0000 0000 0000 1111
那么扰动函数的作用是什么呢。我们上边的与操作只算了元素hashcode的后4位,不够随机,我们想要让hashcode的前16位也要影响最后的结果。所以就有了扰动函数。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}h.hashCode = 1101 0111 1011 1100 0101 1011 1011 1010
h.hashCode >>>16 = 0000 0000 0000 0000 1101 0111 1011 1100
我们取这两个值的与结果,这样我们的hashcode的高位也能扰动我们放的位置。并非单纯的低位和n-1去进行与运算了。
三、resize方法
在上边的代码中有个resize方法的调用,这个方法主要的目的是扩容table。这个resize方法看起来还是非常的恐怖哈。
resize方法解释了为什么数组的容量一定是二的整数倍。
final Node<K,V>[] resize() {//记录一下之前的tableNode<K,V>[] oldTab = table;//算一下之前table的容量int oldCap = (oldTab == null) ? 0 : oldTab.length;//记录一下之前table的扩容阈值int oldThr = threshold;//把新的容量和扩容阈值定义出来int newCap, newThr = 0;//如果已经进行过初始化了if (oldCap > 0) {//如果我们之前的空间大小已经达到了最大容量 -- 很少出现if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}//否则的话 我们新的容量等于旧的容量*2 位移运算else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)//新的扩容阈值也*2newThr = oldThr << 1; // double threshold}//这个先不说了else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;// 这个else重要啊,如果我们没有进行过初始化,那我们就把新容量定位16 新的扩容阈值定为12else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//如果新的扩容阈值等于0 我们要进行处理等于新的容量×负载因子if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//修改我们的扩容阈值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}我们分析一下下边的代码。写了注释的直接看看就好,关于树的我不说了,只说链表。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;//如果我们之前的table不为空的话我们要进行一下元素迁移if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//如果当前结点不为空if ((e = oldTab[j]) != null) {//清空原来的table中的位置,便于垃圾回收oldTab[j] = null;//如果就一个node 把他搬到新的table中if (e.next == null)newTab[e.hash & (newCap - 1)] = e;//如果是树形结点 调用split方法else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//如果是个链表else { // preserve order// 低链表 Node<K,V> loHead = null, loTail = null;//高链表Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;//判断这个结点放到高链表或者低链表中if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}什么是高链表和低链表。在之前我们说到过元素是如何定位的,靠的是hash和数组容量-1的与操作。但如果我们数组容量不减1呢?因为我们的数组容量是2的整数倍,如果不减1,那么就说明只有一个位置为1,其他的全为0(假设容量是16)。
h.hashCode = 1101 0111 1011 1100 0101 1011 1011 1010
n = 0000 0000 0000 0000 0000 0000 0001 0000
如同上方的例子,这个元素到底分到哪里,就看这个元素的hash值的倒数第五位,如果是1,就在高链表,如果是0就在低链表。我们通过这样的方式来把元素分到低链表或者高链表当中。
for循环的最后把我们这个临时的低链表和高链表放到我们新的table中。
最后将新的table返回。
相关文章:
【Java】JDK1.8 HashMap源码,put源码详细讲解
📝个人主页:哈__ 期待您的关注 在Java中,HashMap结构是被经常使用的,在面试当中也是经常会被问到的。这篇文章我给大家分享一下我对于HashMap结构源码的理解。 HashMap的存储与一般的数组不同,HashMap的每一个元素存…...
自定义注解进行数据转换
前言: Java注解是一种元数据机制,可用于方法,字段,类等程序上以提供关于这些元素的额外信息。 以下内容是我自己写的一个小测试的demo,参考该文章进行编写:https://blog.csdn.net/m0_71621983/article/details/1318164…...

React - 你知道在React组件的哪个阶段发送Ajax最合适吗
难度级别:中级及以上 提问概率:65% 如果求职者被问到了这个问题,那么只是单纯的回答在哪个阶段发送Ajax请求恐怕是不够全面的。最好是先详细描述React组件都有哪些生命周期,最后再回过头来点题作答,为什么应该在这个阶段发送Ajax请求。那…...
spa、vue、elementUi
spa (single page application). 动态重写当前页面而非从服务器重新加载整个新页面。使应用程序更像一个桌面应用程序。所有的html、javascript、css通过单个页面检索加载资源。前端页面使用ajax与后端通信。一个项目只有一个html页面。所有的页面跳转都通过路由导航。 vue可用…...

tcp接受命令执行并回显
为了实现循环执行命令并能够多次从TCP客户端接收命令,您需要对上面的代码进行一些修改。下面是一个修改后的示例,它将在接收到新的TCP连接后进入一个循环,不断地读取命令、执行命令,并将结果发送回客户端,直到客户端断…...
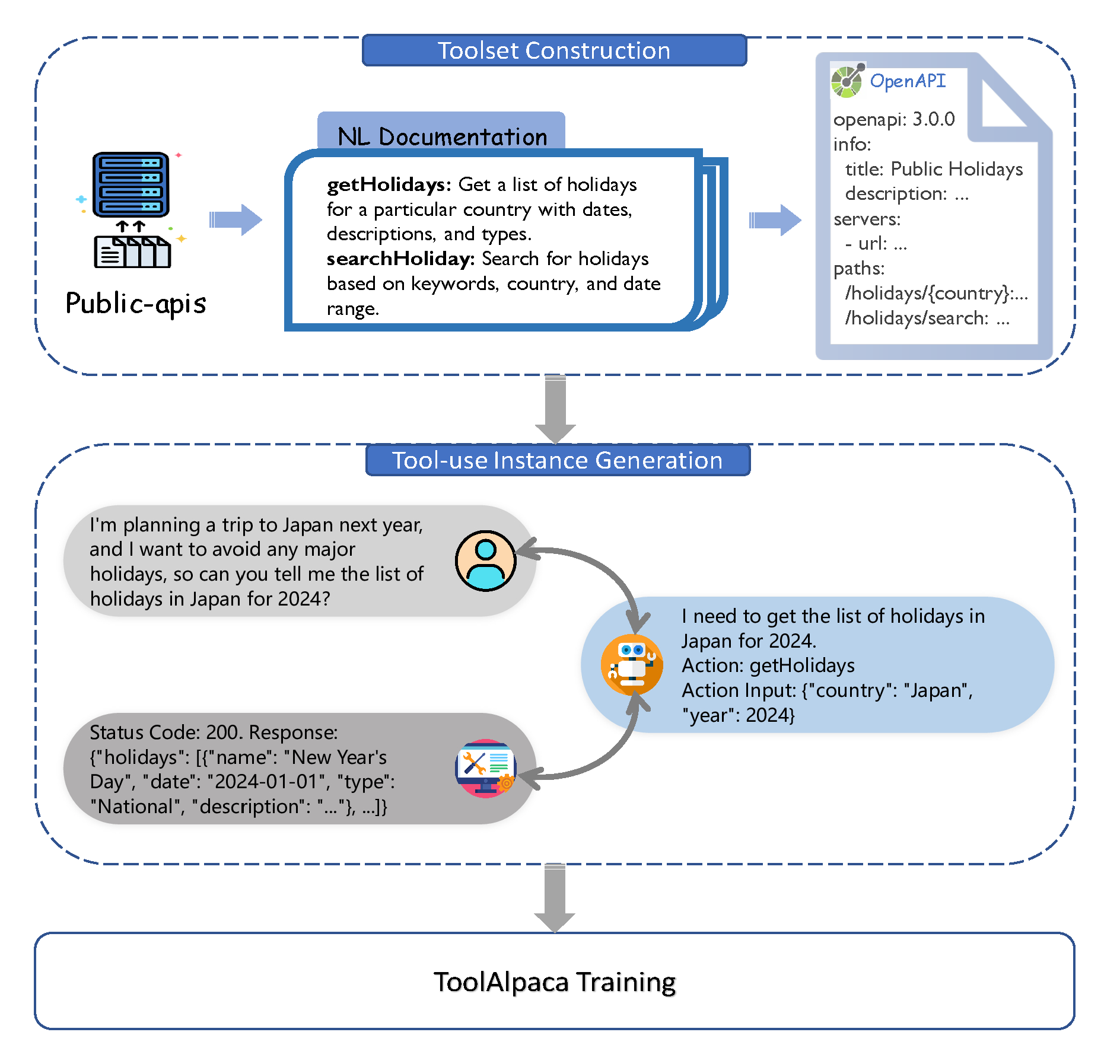
LLMs之ToolAlpaca:ToolAlpaca(通用工具学习框架/工具使用语料库)的简介、安装和使用方法、案例应用之详细攻略
LLMs之ToolAlpaca:ToolAlpaca(通用工具学习框架/工具使用语料库)的简介、安装和使用方法、案例应用之详细攻略 目录 ToolAlpaca的简介 0、《ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases》翻译与解读 1、数据集列表 2…...

TCP/IP协议介绍
TCP/IP协议 先看:程序员必备基础知识-TCP/IP协议详解.(超详细) 太厉害了,终于有人能把TCP/IP协议讲的明明白白了! 面试官:如何理解TCP/IP协议? 一个很全的介绍博客:史上最全的TCP/IP协议原理 对TCP三次握…...

选择排序解读
在计算机科学中,排序算法是一种将数据元素按照某种顺序排列的算法。今天,我们要探讨的是选择排序(Selection Sort),这是一种简单直观的排序方法,通过不断选择剩余元素中的最小(或最大࿰…...

Vue项目自动注入less、sass、scss、stylus全局变量
一、Vue2项目 // vue.config.js const path require(path) module.exports {css: {loaderOptions: {// 给 sass-loader 传递选项sass: {// / 是 src/ 的别名// 所以这里假设有 src/assets/style/var.sass 这个文件// 注意:在 sass-loader v8 中,这个选…...

DXP学习002-PCB编辑器的环境参数及电路板参数相关设置
目录 一,dxp的pcb编辑器环境 1,创建新的PCB设计文档 2,PCB编辑器界面 1)布线工具栏 2)公用工具栏 3)层标签栏 编辑 3,PCB设计面板 1)打开pcb设计面板 4,PCB观…...

Flutter 使用flutter_swiper_null_safety 实现轮播图
目录 引入flutter_swiper_null_safety 在pubspec.yaml文件中dependencies下添加以下依赖 然后执行命令进行下载 实现轮播图 引入flutter_swiper_null_safety 在pubspec.yaml文件中dependencies下添加以下依赖 flutter_swiper_null_safety: ^1.0.2 然后执行命令进行下载 flu…...
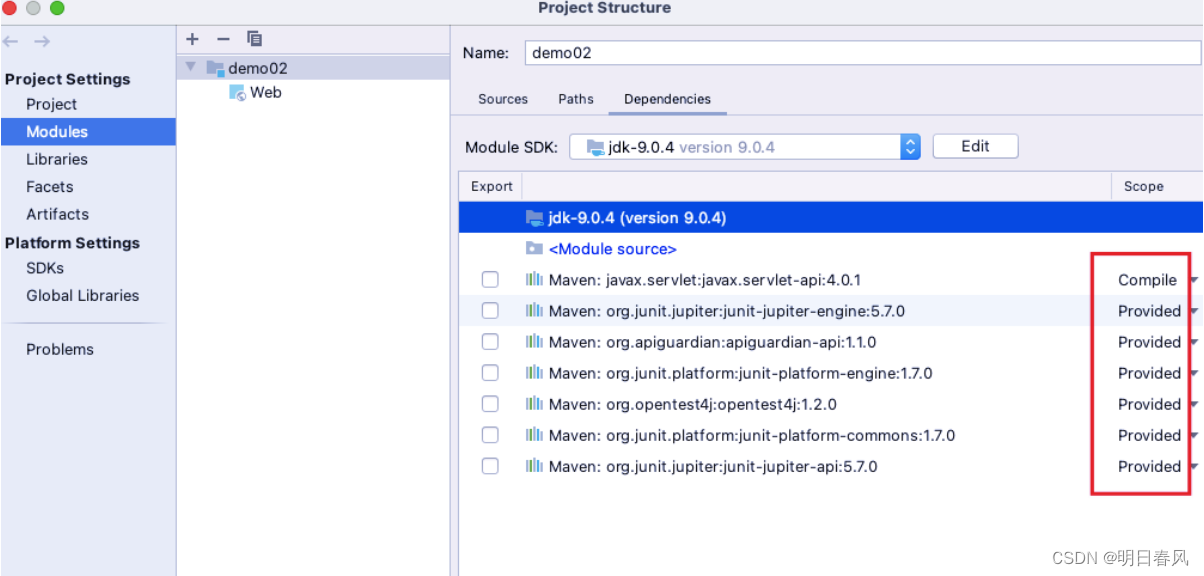
Maven的scope详解
依赖范围介绍 maven 项目不同的阶段引入到classpath中的依赖是不同的,例如,编译时,maven 会将与编译相关的依赖引入classpath中,测试时,maven会将测试相关的的依赖引入到classpath中,运行时,mav…...

如何修复在Deepin系统中因`apt-get autoremove systemd`导致的启动问题
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

LeetCode 每日一题 ---- 【2923. 找到冠军 I】
LeetCode 每日一题 ---- 【2923. 找到冠军 I】 2923.找到冠军I方法一:暴力求解 2923.找到冠军I 方法一:暴力求解 从头遍历一遍二维数组,如果发现 gird[x][y] 1,说明 x 队赢过 y 队,下面我们就只需要子再判断一下是否…...

CMakeLists常用命令
# 设置cmake最低版本 cmake_minimum_required(VERSION 3.2)# project命令用于指定cmake工程的名称,实际上,它还可以指定cmake工程的版本号(VERSION关键字)、 #简短的描述(DESCRIPTION关键字)、主页URL&…...

英语 倒装结构中的主语和助动词,用于强调 inversion
I am used to travelling by air and only on one occasion have I ever felt frightened. 1、翻译为中文:我习惯了乘坐飞机旅行,只有在一次经历中我感到过害怕。 2、分析时态和句子语法是否正确:该句子使用了现在完成时(I am u…...
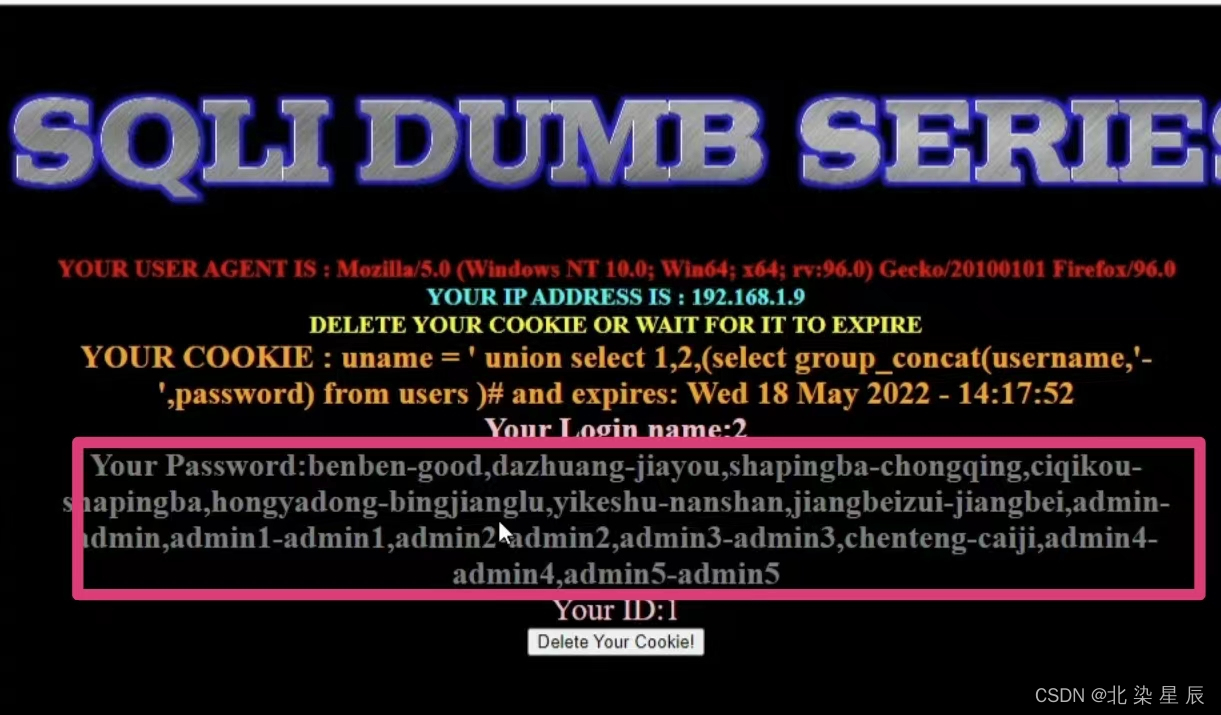
SQL注入---HTTP报头注入
文章目录 目录 文章目录 一.uagent注入 二.refeer注入 三.Cookie注入 前文中提到万能密钥的工作原理,然而万能密钥仅在源代码中没有代码审计,此时才被称之为万能密钥,而代码中有代码审计时需要分以下几种情况讨论 一.uagent注入 先看代码&a…...
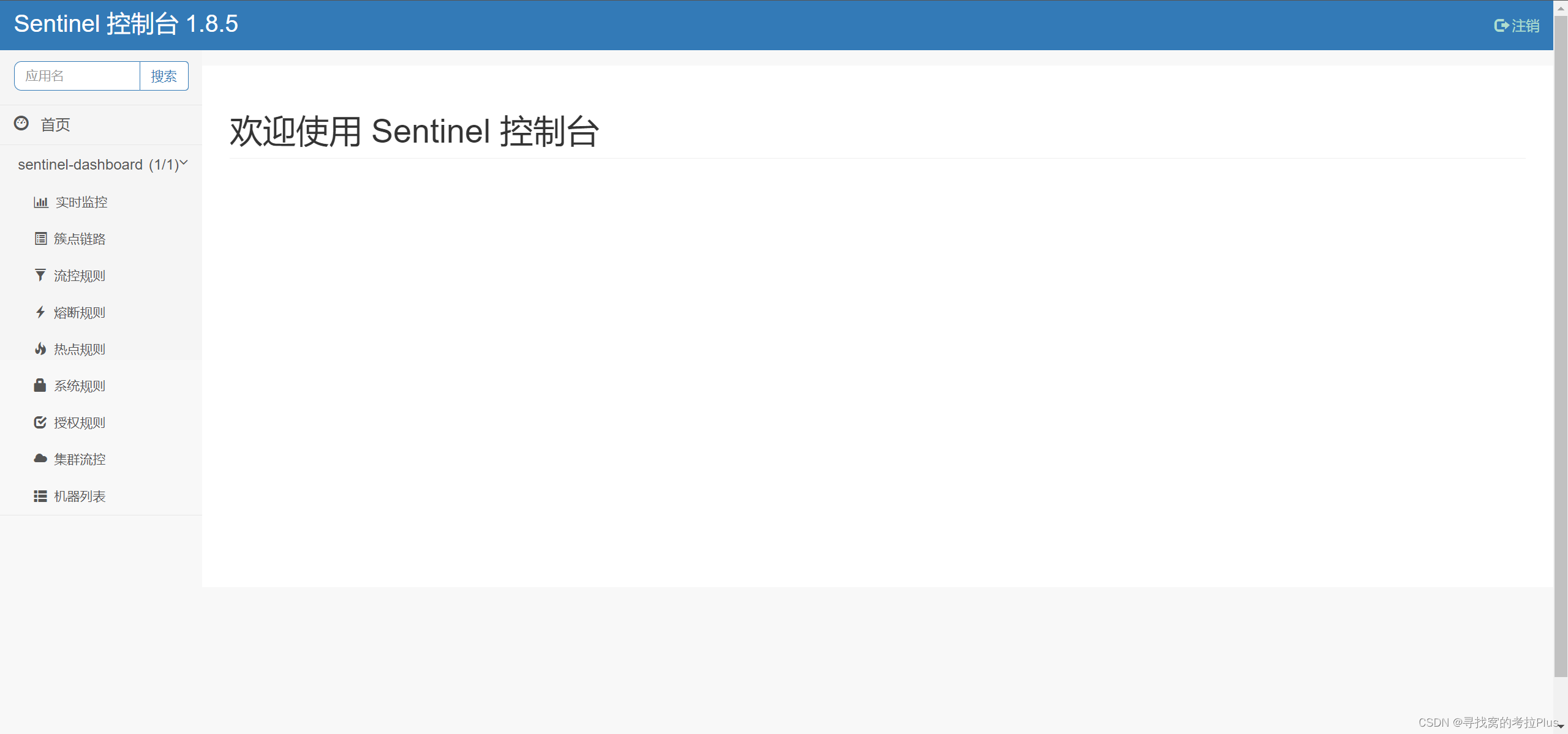
docker安装sentinel
文章目录 前言安装docker指令安装制作docker-compose.yaml文件 查看网站 前言 Sentinel 是阿里巴巴开源的一款轻量级流量控制和熔断降级工具,可用于保护分布式系统中的服务。它可以帮助开发人员解决在分布式架构中面临的流量管理、服务保护、性能优化等问题。 安装…...

达梦的归档日志参数ARCH_RESERVE_TIME测试
达梦的参数ARCH_RESERVE_TIME测试 前面有提到和oracle相比,达梦的归档日志相关参数有个比较特别,可以通过设置它去规定归档日志的保留时间。 ARCH_RESERVE_TIME:归档日志保留时间,单位分钟,取值范围 0~2147483647。只…...
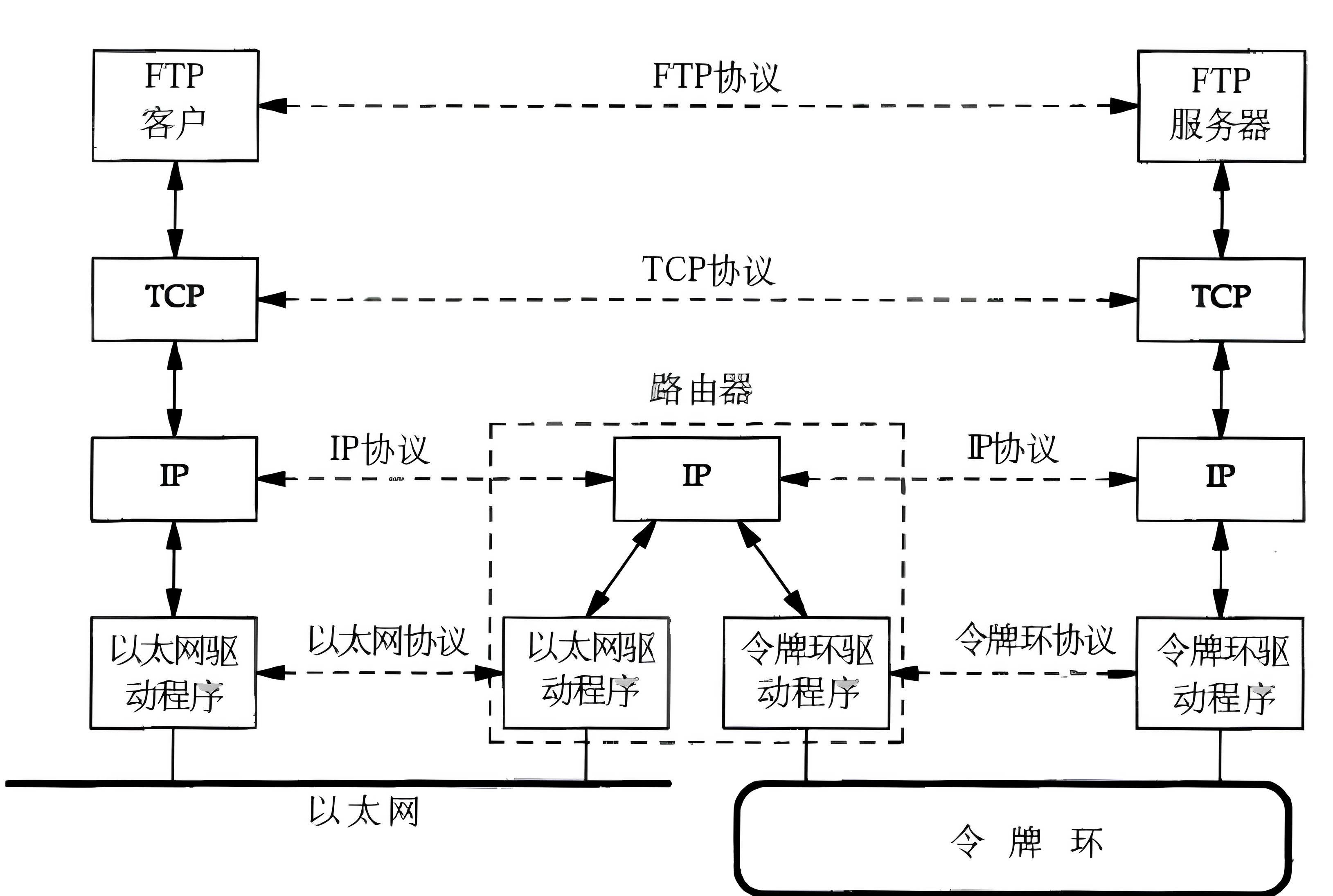
Linux网络 基础概念
目录 背景知识 互联网的发展 局域网和广域网 网络拓扑 网络协议栈 协议的概念 网络协议的分层 网络与操作系统的联系 网络传输的基本流程 IP地址和MAC地址 以太网通信 数据包的封装和分用 跨网段传输 背景知识 互联网的发展 计算机网络是计算机技术和通信技术相…...

终极网盘直链下载助手完整指南:免费解锁八大平台高速下载
终极网盘直链下载助手完整指南:免费解锁八大平台高速下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

Crystal语言Web框架实战:构建高性能API服务的轻量级方案
1. 项目概述:一个轻量级、高性能的Crystal语言Web框架最近在探索一些新兴的编程语言生态时,我注意到了Crystal语言,以及一个名为jvpflum/Crystal的GitHub仓库。乍一看这个标题,可能会让人有些困惑:这究竟是Crystal语言…...

ComfyUI-WanVideoWrapper:一站式AI视频生成插件解决方案
ComfyUI-WanVideoWrapper:一站式AI视频生成插件解决方案 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper ComfyUI-WanVideoWrapper是一个专为ComfyUI设计的视频生成插件包装器&#x…...

黄仁勋CMU演讲:取代你的是会AI的人,所有人同一起跑线,奔跑吧
老黄又当博士了。这是他的第7个荣誉博士学位,而且英特尔CEO陈立武亲自为其授袍。卡内基梅隆大学(CMU)最新一届毕业典礼上,黄仁勋向5800多名毕业生发表演讲。面对AI浪潮的冲击,所有人都在焦虑、都在担心会不会被AI取代&…...

2.2 本地文件读取
本章学习目标: 知道CSV、Excel、JSON三种文件分别怎么读、会遇到什么常见问题理解每种文件格式的“坑”在哪里,以及如何向AI描述解决方案学会用“人话”告诉AI你要做什么,让AI生成代码不需要记住任何函数名或参数,只需要知道“有什…...

在多轮对话应用中体验Taotoken路由策略对响应速度的优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中体验Taotoken路由策略对响应速度的优化 1. 场景与背景 在开发一个需要多轮交互的对话应用时,我们常常…...

5分钟极速指南:免费将Word文档完美转换为LaTeX的终极工具docx2tex
5分钟极速指南:免费将Word文档完美转换为LaTeX的终极工具docx2tex 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 还在为Word文档转换LaTeX格式而烦恼吗?每次手动调整公…...

工程师视角:最低成本脱碳路径与气候解决方案的工程化思维
1. 项目概述:一封关于气候与经济的公开信最近在EE Times上读到一封写给埃隆马斯克的公开信,作者格伦温瑞布提出了一些关于气候变化和联邦预算赤字的想法,挺有意思的。这封信的核心不是空谈环保理念,而是从一个工程师和务实主义者的…...

终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置
终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 还在为复…...

开源情报自动化工具OpenClaw:模块化设计与实战部署指南
1. 项目概述:从“Resolver-TNG/ogas-openclaw”看开源情报自动化最近在开源情报(OSINT)和自动化数据采集的圈子里,一个名为“ogas-openclaw”的项目引起了我的注意。这个项目托管在Resolver-TNG的组织下,名字本身就很有…...