个人博客项目笔记_05
1. ThreadLocal内存泄漏
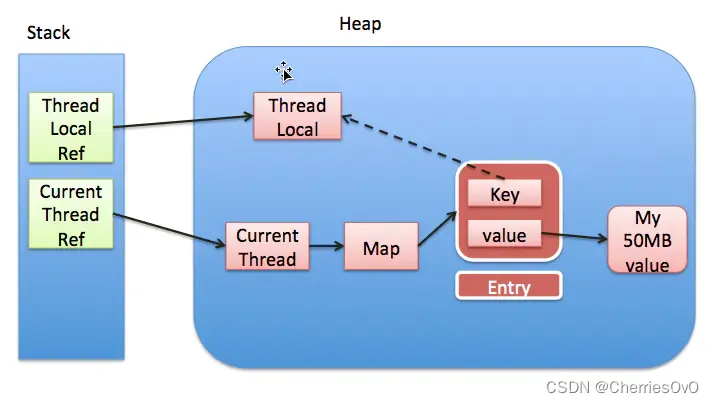
ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。
内存泄漏通常发生在以下情况下:
- 线程池场景下的 ThreadLocal 使用不当: 在使用线程池时,如果线程被重用而没有正确清理 ThreadLocal 中的数据,那么下次使用这个线程时,它可能会携带上一次执行任务所遗留的数据,从而导致数据累积并消耗内存。
- 长时间运行的应用中未清理 ThreadLocal 数据: 在一些长时间运行的应用中,比如 Web 应用,可能会创建很多 ThreadLocal 实例并存储大量数据。如果这些数据在使用完后没有及时清理,就会导致内存泄漏问题。
- 没有使用
remove()方法清理 ThreadLocal 数据: 在使用完 ThreadLocal 存储的数据后,如果没有调用remove()方法清理数据,就会导致数据长时间存在于 ThreadLocal 中,从而可能引发内存泄漏。
实线代表强引用,虚线代表弱引用
每一个Thread维护一个ThreadLocalMap, key为使用弱引用的ThreadLocal实例,value为线程变量的副本。
强引用,使用最普遍的引用,一个对象具有强引用,不会被垃圾回收器回收。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不回收这种对象。
如果想取消强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样可以使JVM在合适的时间就会回收该对象。
弱引用,JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。
2. 文章详情
2.1 接口说明
接口url:/articles/view/{id}
请求方式:POST
请求参数:
| 参数名称 | 参数类型 | 说明 |
|---|---|---|
| id | long | 文章id(路径参数) |
返回数据:
{"success": true,"code": 200,"msg": "success","data": "token"
}
2.2 涉及到的表
CREATE TABLE `blog`.`ms_article_body` (`id` bigint(0) NOT NULL AUTO_INCREMENT,`content` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL,`content_html` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL,`article_id` bigint(0) NOT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `article_id`(`article_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 38 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
package com.cherriesovo.blog.dao.pojo;import lombok.Data;@Data
public class ArticleBody { //文章详情表private Long id;private String content;private String contentHtml;private Long articleId;
}
#文章分类
CREATE TABLE `blog`.`ms_category` (`id` bigint(0) NOT NULL AUTO_INCREMENT,`avatar` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,`category_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,`description` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
package com.cherriesovo.blog.dao.pojo;import lombok.Data;@Data
public class Category {private Long id;private String avatar;private String categoryName;private String description;
}
2.3 Controller
//json数据进行交互
@RestController
@RequestMapping("articles")
public class ArticleController {/** 通过id获取文章* */@PostMapping("view/{id}")//@PathVariable("id") 注解用于将 URL 中的 {id} 赋值给 articleId 参数。public Result findArticleById(@PathVariable("id") Long articleId) { return articleService.findArticleById(articleId);}
}2.4 Service
ArticleVo findArticleById(Long id);
public interface ArticleService {//查看文章详情Result findArticleById(Long articleId);
}package com.cherriesovo.blog.vo;import lombok.Data;import java.util.List;@Data
public class ArticleVo {private Long id;private String title;private String summary;private int commentCounts;private int viewCounts;private int weight;/*** 创建时间*/private String createDate;private String author;private ArticleBodyVo body;private List<TagVo> tags;private CategoryVo category;}
@Service
public class ArticleServiceImpl implements ArticleService {@Autowiredprivate ArticleMapper articleMapper;@Autowiredprivate TagService tagService;@Autowiredprivate SysUserService sysUserService;@Autowiredprivate CategoryService categoryService;public ArticleVo copy(Article article,boolean isAuthor,boolean isBody,boolean isTags,boolean isCategory){ArticleVo articleVo = new ArticleVo();BeanUtils.copyProperties(article, articleVo);articleVo.setCreateDate(new DateTime(article.getCreateDate()).toString("yyyy-MM-dd HH:mm"));//并不是所有的接口都需要标签,作者信息if(isTags){Long articleId = article.getId();articleVo.setTags(tagService.findTagsByArticleId(articleId));}if(isAuthor){Long authorId = article.getAuthorId();//getNickname()用于获取某个对象或实体的昵称或别名articleVo.setAuthor(sysUserService.findUserById(authorId).getNickname());}if (isBody){Long bodyId = article.getBodyId();articleVo.setBody(findArticleBodyById(bodyId));}if (isCategory){Long categoryId = article.getCategoryId();articleVo.setCategory(categoryService.findCategoryById(categoryId));}return articleVo;}private List<ArticleVo> copyList(List<Article> records,boolean isAuthor,boolean isBody,boolean isTags) {List<ArticleVo> articleVoList = new ArrayList<>();for (Article article : records) {ArticleVo articleVo = copy(article,isAuthor,false,isTags,false);articleVoList.add(articleVo);}return articleVoList;}private List<ArticleVo> copyList(List<Article> records,boolean isAuthor,boolean isBody,boolean isTags,boolean isCategory) {List<ArticleVo> articleVoList = new ArrayList<>();for (Article article : records) {ArticleVo articleVo = copy(article,isAuthor,isBody,isTags,isCategory);articleVoList.add(articleVo);}return articleVoList;}@Autowiredprivate ArticleBodyMapper articleBodyMapper;private ArticleBodyVo findArticleBodyById(Long bodyId) {ArticleBody articleBody = articleBodyMapper.selectById(bodyId);ArticleBodyVo articleBodyVo = new ArticleBodyVo();articleBodyVo.setContent(articleBody.getContent());//setContent()是articleBodyVo的set方法return articleBodyVo;}@Overridepublic List<ArticleVo> listArticlesPage(PageParams pageParams) {// 分页查询article数据库表QueryWrapper<Article> queryWrapper = new QueryWrapper<>();Page<Article> page = new Page<>(pageParams.getPage(),pageParams.getPageSize());Page<Article> articlePage = articleMapper.selectPage(page, queryWrapper);List<ArticleVo> articleVoList = copyList(articlePage.getRecords(),true,false,true);return articleVoList;}@Overridepublic Result hotArticle(int limit) {LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.orderByDesc(Article::getViewCounts); //根据浏览量倒序queryWrapper.select(Article::getId,Article::getTitle);queryWrapper.last("limit " + limit);//select id,title from article order by view_counts desc limit 5List<Article> articles = articleMapper.selectList(queryWrapper);return Result.success(copyList(articles,false,false,false));}@Overridepublic Result newArticles(int limit) {LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.orderByDesc(Article::getCreateDate);queryWrapper.select(Article::getId,Article::getTitle);queryWrapper.last("limit "+limit);//select id,title from article order by create_date desc limit 5List<Article> articles = articleMapper.selectList(queryWrapper);return Result.success(copyList(articles,false,false,false));}@Overridepublic Result listArchives() {List<Archives> archivesList = articleMapper.listArchives();return Result.success(archivesList);}@Overridepublic Result findArticleById(Long articleId) {/** 1、根据id查询文章信息* 2、根据bodyId和categoryId去做关联查询* */Article article = this.articleMapper.selectById(articleId);ArticleVo articleVo = copy(article, true, true, true,true);return Result.success(articleVo);}
}
package com.cherriesovo.blog.vo;import lombok.Data;@Data
public class CategoryVo {private Long id;private String avatar;private String categoryName;
}
package com.cherriesovo.blog.vo;import lombok.Data;@Data
public class ArticleBodyVo {private String content;
}package com.cherriesovo.blog.service;import com.cherriesovo.blog.vo.CategoryVo;import java.util.List;public interface CategoryService {CategoryVo findCategoryById(Long categoryId);
}@Service
public class CategoryServiceImpl implements CategoryService {@Autowiredprivate CategoryMapper categoryMapper;@Overridepublic CategoryVo findCategoryById(Long categoryId) {Category category = categoryMapper.selectById(categoryId);CategoryVo categoryVo = new CategoryVo();BeanUtils.copyProperties(category,categoryVo);return categoryVo;}
}
package com.cherriesovo.blog.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.cherriesovo.blog.dao.pojo.ArticleBody;public interface ArticleBodyMapper extends BaseMapper<ArticleBody> {
}package com.cherriesovo.blog.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.cherriesovo.blog.dao.pojo.Category;public interface CategoryMapper extends BaseMapper<Category> {
}2.5 测试
3. 使用线程池 更新阅读次数
3.1 线程池配置
taskExecutor是一个线程池对象,在这段代码中通过@Bean("taskExecutor")注解定义并配置了一个线程池,并将其命名为 “taskExecutor”。asyncServiceExecutor()方法是一个Bean方法,用于创建并配置一个线程池,并以taskExecutor作为 Bean 的名称。ThreadPoolTaskExecutor是 Spring 框架提供的一个实现了Executor接口的线程池- 在方法中创建了一个
ThreadPoolTaskExecutor实例executor,并对其进行了一系列配置:
setCorePoolSize(5): 设置核心线程数为 5,即线程池在空闲时会保持 5 个核心线程。setMaxPoolSize(20): 设置最大线程数为 20,即线程池中允许的最大线程数量。setQueueCapacity(Integer.MAX_VALUE): 配置队列大小为整数的最大值,即任务队列的最大容量。setKeepAliveSeconds(60): 设置线程活跃时间为 60 秒,即线程在空闲超过该时间后会被销毁。setThreadNamePrefix("CherriesOvO博客项目"): 设置线程名称的前缀为 “CherriesOvO博客项目”。setWaitForTasksToCompleteOnShutdown(true): 设置在关闭线程池时等待所有任务结束。initialize(): 执行线程池的初始化。- 最后,将配置好的线程池返回为一个
ExecutorBean,供其他组件使用。
package com.cherriesovo.blog.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.Executor;@Configuration
@EnableAsync //开启多线程
public class ThreadPoolConfig {@Bean("taskExecutor")public Executor asyncServiceExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();// 设置核心线程数executor.setCorePoolSize(5);// 设置最大线程数executor.setMaxPoolSize(20);//配置队列大小executor.setQueueCapacity(Integer.MAX_VALUE);// 设置线程活跃时间(秒)executor.setKeepAliveSeconds(60);// 设置默认线程名称executor.setThreadNamePrefix("CherriesOvO博客项目");// 设置等待所有任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown(true);//执行初始化executor.initialize();return executor;}
}
3.1 使用
通过
@Async("taskExecutor")注解,该方法标记为异步执行,并指定了使用名为 “taskExecutor” 的线程池。
articleMapper.update(articleUpdate, updateWrapper)是一个 MyBatis-Plus 中的更新操作,用于更新数据库中的文章记录。
update方法接受两个参数:
articleUpdate:表示需要更新的文章对象,其中包含了新的阅读量。updateWrapper:表示更新条件,即确定哪些文章需要被更新的条件。这段代码通过
Thread.sleep(5000)方法在当前线程中休眠了5秒钟。这样做的目的是为了模拟一个耗时操作,以展示在异步线程中执行的任务不会影响到主线程的执行。
package com.cherriesovo.blog.service;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.cherriesovo.blog.dao.mapper.ArticleMapper;
import com.cherriesovo.blog.dao.pojo.Article;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;@Component
public class ThreadService {//期望此操作在线程池中执行,不会影响原有的主线程@Async("taskExecutor")public void updateArticleViewCount(ArticleMapper articleMapper, Article article){int viewCounts = article.getViewCounts();Article articleUpdate = new Article();articleUpdate.setViewCounts(viewCounts + 1);LambdaQueryWrapper<Article> updateWrapper = new LambdaQueryWrapper<>();updateWrapper.eq(Article::getId,article.getId());//设置一个 为了在多线程环境下 线程安全updateWrapper.eq(Article::getViewCounts,article.getViewCounts());//update article set view_count=? where view_count=? and id=?articleMapper.update(articleUpdate,updateWrapper);try {//睡眠5秒 证明不会影响主线程的使用,5秒后数据才会出现Thread.sleep(5000);
// System.out.println("更新完成了");} catch (InterruptedException e) {e.printStackTrace();}}
}@Service
public class ArticleServiceImpl implements ArticleService {@Autowiredprivate ThreadService threadService;@Overridepublic Result findArticleById(Long articleId) {/** 1、根据id查询文章信息* 2、根据bodyId和categoryId去做关联查询* */Article article = this.articleMapper.selectById(articleId);ArticleVo articleVo = copy(article, true, true, true,true);//查看完文章了,新增阅读数,有没有问题?//查看完文章之后,本应该直接返回数据了,这时候做了一个更新操作,更新时加写锁,阻塞其他读操作,性能比较低//更新增加此时接口的耗时,如果一旦更新出问题,不能影响查看文章的操作//线程池 可以把更新操作扔到线程池中去执行,和主线程就不相关了threadService.updateArticleViewCount(articleMapper,article);return Result.success(articleVo);}
}3.3 测试
- 2、根据bodyId和categoryId去做关联查询
* */
Article article = this.articleMapper.selectById(articleId);
ArticleVo articleVo = copy(article, true, true, true,true);
//查看完文章了,新增阅读数,有没有问题?
//查看完文章之后,本应该直接返回数据了,这时候做了一个更新操作,更新时加写锁,阻塞其他读操作,性能比较低
//更新增加此时接口的耗时,如果一旦更新出问题,不能影响查看文章的操作
//线程池 可以把更新操作扔到线程池中去执行,和主线程就不相关了
threadService.updateArticleViewCount(articleMapper,article);
return Result.success(articleVo);
}
}
## 3.3 测试睡眠 ThredService中的方法 5秒,不会影响主线程的使用,即文章详情会很快的显示出来,不受影响
相关文章:
个人博客项目笔记_05
1. ThreadLocal内存泄漏 ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。 内存泄漏通常发生在以下情况下: 线程池场景下的 ThreadL…...
)
基础知识点全覆盖(1)
Python基础知识点 1.基本语句 1.注释 方便阅读和调试代码注释的方法有行注释和块注释 1.行注释 行注释以 **# **开头 # 这是单行注释2.块注释 块注释以多个 #、三单引号或三双引号(注意: 基于英文输入状态下的标点符号) # 类 # 似 # 于 # 多 # 行 # 效 # 果 这就是多行注释…...

异常处理java
在Java中,异常处理可以使用"throws"关键字或者"try-catch"语句。这两种方法有不同的用途和适用场景。 "throws"关键字: 在方法声明中使用"throws"关键字,表示该方法可能会抛出异常,但是并不立即处理…...

个人博客项目_09
1. 归档文章列表 1.1 接口说明 接口url:/articles 请求方式:POST 请求参数: 参数名称参数类型说明yearstring年monthstring月 返回数据: {"success": true, "code": 200, "msg": "succ…...
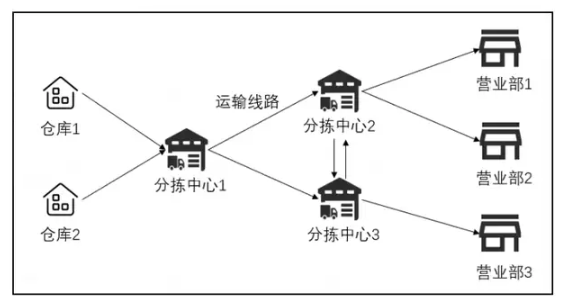
【2024年MathorCup数模竞赛】C题赛题与解题思路
2024年MathorCup数模竞赛C题 题目 物流网络分拣中心货量预测及人员排班背景求解问题 解题思路问题一问题二问题三问题四 本次竞赛的C题是对物流网络分拣中心的货量预测及人员排班问题进行规划。整个问题可以分为两个部分,一是对时间序列进行预测,二是对人…...

蓝桥杯省赛冲刺(3)广度优先搜索
广度优先搜索(Breadth-First Search, BFS)是一种在图或树等非线性数据结构中遍历节点的算法,它从起始节点开始,按层级逐步向外扩展,即先访问离起始节点最近的节点,再访问这些节点的邻居,然后是邻…...

网页内容生成图片,这18般武艺你会几种呢?
前言 关于【SSD系列】: 前端一些有意思的内容,旨在3-10分钟里, 500-1000字,有所获,又不为所累。 网页截图,windows内置了快捷命令和软件,chrome开发者工具也能一键截图,html2canva…...

pytest的时候输出一个F后面跟很多绿色的点解读
使用pytest来测试pyramid和kotti项目,在kotti项目测试的时候,输出一个F后面跟很多绿色的点,是什么意思呢? 原来在使用pytest进行测试时,输出中的“F”代表一个失败的测试(Failed),而…...

算法打卡day33
今日任务: 1)509. 斐波那契数 2)70. 爬楼梯 3)746.使用最小花费爬楼梯 509. 斐波那契数 题目链接:509. 斐波那契数 - 力扣(LeetCode) 斐波那契数,通常用 F(n) 表示,形成…...
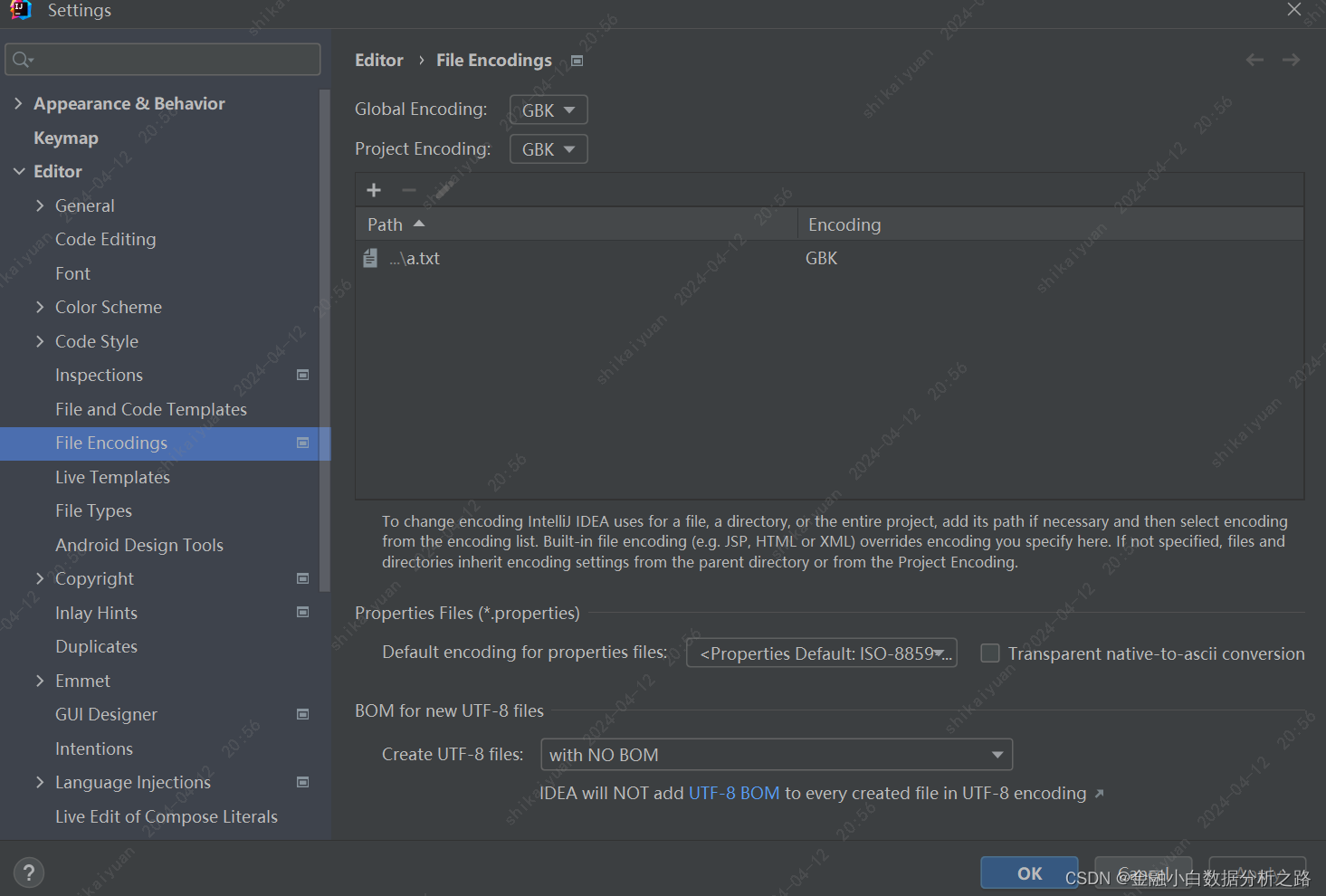
《疯狂java讲义》Java AWT图形化编程中文显示
《疯狂java讲义》第六版第十一章AWT中文没有办法显示问题解决 VM Options设置为-Dfile.encodinggbk 需要增加变量 或者这边直接设置gbk 此外如果用swing 就不会产生这个问题了。...

Python3 标准库,API文档链接
一、标准库 即当你安装python3 后就自己携带的一些已经提供好的工具模块,工具类,可以专门用来某一类相关问题,达到辅助日常工作或者个人想法的一些成品库 类似的 C ,Java 等等也都有自己的标准库和使用文档 常见的一些: os 模块…...
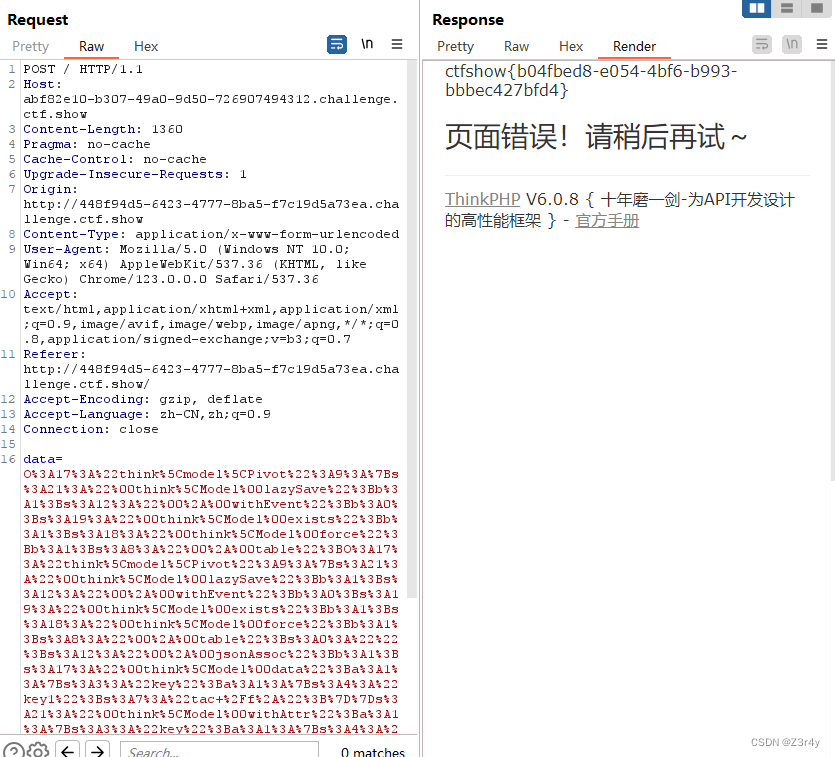
【Web】CTFSHOW-ThinkPHP5-6反序列化刷题记录(全)
目录 web611 web612 web613-622 web623 web624-626 纯记录exp,链子不作赘述 web611 具体分析: ThinkPHP-Vuln/ThinkPHP5/ThinkPHP5.1.X反序列化利用链.md at master Mochazz/ThinkPHP-Vuln GitHub 题目直接给了反序列化入口 exp: <?ph…...

AR智能眼镜方案_MTK平台安卓主板芯片|光学解决方案
AR眼镜作为一种引人注目的创新产品,其芯片、显示屏和光学方案是决定整机成本和性能的关键因素。在这篇文章中,我们将探讨AR眼镜的关键技术,并介绍一种高性能的AR眼镜方案,旨在为用户带来卓越的体验。 AR眼镜的芯片选型至关重要。一…...
Android网络抓包--Charles
一、Android抓包方式 对Https降级进行抓包,降级成Http使用抓包工具对Https进行抓包 二、常用的抓包工具 wireshark:侧重于TCP、UDP传输层,HTTP/HTTPS也能抓包,但不能解密HTTPS报文。比较复杂fiddler:支持HTTP/HTTPS…...
)
【LeetCode热题100】238. 除自身以外数组的乘积(数组)
一.题目要求 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 **不要使用除法,**且在…...
《哈迪斯》自带的Lua解释器是哪个版本?
玩过《哈迪斯》(英文名:Hades)吗?最近在研究怎么给这款游戏做MOD,想把它的振动体验升级到更高品质的RichTap。N站下载了一些别人做的MOD,发现很多都基于相同的格式,均是对游戏.sjon文件或.lua文…...

Java内存泄漏内存溢出
1.定义 OOM内存溢出是指应用程序尝试使用更多内存资源,而系统无足够的内存,导致程序崩溃。 内存泄漏是指应用程序中分配的内存未能被正确释放,导致系统中的可用内存逐渐减少。 2.内存泄漏的原因 可能包括对象引用未被释放、缓存未被清理等。 …...

【springboot】项目启动时打印全部接口方法
方法:在你springboot项目的基础上,创建下面的类: package com.llq.wahaha.listener;import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.ApplicationContext; import org.springframework…...

单例19c RMAN数据迁移方案
一、环境说明 源库 目标库 IP 192.168.37.200 192.168.37.202 系统版本 RedHat 7.9 RedHat 7.9 数据库版本 19.3.0.0.0 19.3.0.0.0 SID beg beg hostname beg rman 数据量 1353M 说明:源库已经创建数据库实例,并且存在用户kk和他创建的表空间…...
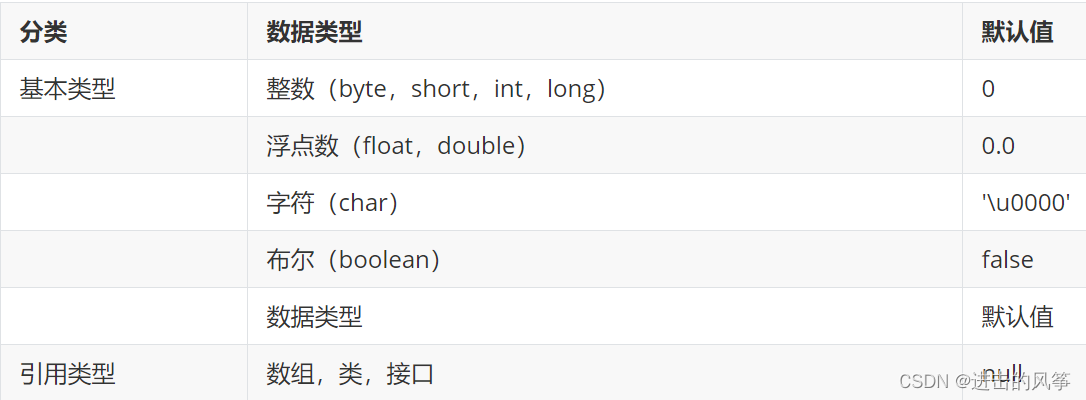
05—面向对象(上)
一、面向对象编程 1、类和对象 (1)什么是类 类是一类具有相同特性的事物的抽象描述,是一组相关属性和行为的集合。 属性:就是该事物的状态信息。行为:就是在你这个程序中,该状态信息要做什么操作&#x…...

观察taotoken用量看板如何清晰呈现各模型token消耗
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察taotoken用量看板如何清晰呈现各模型token消耗 对于使用大模型API的开发者或团队管理者而言,成本的可观测性与可控…...

3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖
3分钟掌握完全离线的实时语音转文字:TMSpeech让你彻底告别云端依赖 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字时代,语音转文字已成为现代办公和学习的高效助手,但你是…...

TextInputLayout实战:从属性解析到自定义样式进阶
1. TextInputLayout基础入门:从零开始掌握Material输入框 第一次接触TextInputLayout时,我被它丝滑的浮动提示动画惊艳到了。相比传统的EditText,这个Material Design组件确实能让表单界面瞬间提升好几个档次。记得去年做登录页面重构时&…...

终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置
终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 还在为复…...

JPlag代码抄袭检测:17种编程语言的智能原创守护者
JPlag代码抄袭检测:17种编程语言的智能原创守护者 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在数字化教…...

3分钟掌握Windows安装APK:告别复杂模拟器的终极方案
3分钟掌握Windows安装APK:告别复杂模拟器的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经遇到过这样的场景?同事发来一个实…...

Java开发者集成OpenAI API:社区SDK核心设计与生产实践
1. 项目概述:一个面向Java开发者的OpenAI API集成利器如果你是一名Java后端开发者,最近被ChatGPT、DALLE这些AI能力深深吸引,想在自家的Spring Boot应用里快速集成智能对话、文本生成或者图像创作功能,那你大概率已经搜过“OpenAI…...

UniversalUnityDemosaics:Unity游戏马赛克去除全攻略
UniversalUnityDemosaics:Unity游戏马赛克去除全攻略 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...

在ubuntu上使用nodejs通过taotoken统一调用多模型api
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上使用 Node.js 通过 Taotoken 统一调用多模型 API 基础教程类,指导 Ubuntu 上的 Node.js 开发者如何利用 T…...

管式土壤墒情监测站:深埋地下测湿度,云端上报助灌溉
管式土壤墒情监测站采用土壤介电常数检测原理,结合专业数学模型算法,搭配独创螺旋式测量电极结构开展高精度土壤含水率监测。土壤介电常数与土壤含水量存在稳定且精准的对应关系,设备通过传感器高频感知土层介电参数变化,经内置算…...