【SGDR】《SGDR:Stochastic Gradient Descent with Warm Restarts》

arXiv-2016
code: https://github.com/loshchil/SGDR/blob/master/SGDR_WRNs.py
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 5 Experiments
- 5.1 Datasets and Metric
- 5.2 Single-Model Results
- 5.3 Ensemble Results
- 5.4 Experiments on a Dataset of EEG Recordings
- 5.5 Preliminary Experiments on a downsampled ImageNet Dataset
- 6 Conclusion(own) / Future work
1 Background and Motivation
训练深度神经网络的过程可以视为找下面这个方程 min 解的过程

或者用二阶导的形式

然而 inverse Hessian 不好求(【矩阵学习】Jacobian矩阵和Hessian矩阵)
虽然有许多改进的优化方法来尽可能的逼近 inverse Hessian,但是,目前在诸多计算机视觉相关任务数据集上表现最好的方法还是 SGD + momentum
有了实践中比较猛的 optimization techniques 后,The main difficulty in training a DNN is then associated with the scheduling of the learning rate and the amount of L2 weight decay regularization employed.
本文,作者从 learning rate schedule 角度出发,提出了 SGDR 学习率策略,periodically simulate warm restarts of SGD

使得深度学习任务收敛的更快更好
2 Related Work
In applied mathematics, multimodal optimization deals with optimization tasks that involve finding all or most of the multiple (at least locally optimal) solutions of a problem, as opposed to a single best solution.
-
restarts in gradient-free optimization
based on niching methods(见文末总结部分)
-
restarts in gradient-based optimization
《Cyclical Learning Rates for Training Neural Networks》(WACV-2017)
closely-related to our approach in its spirit and formulation but does not focus on restarts
一个 soft restart 一个 hard restart(SGDR)
3 Advantages / Contributions
SGD + warm restart 技术的结合,或者说 warm restart 在 SGD 上的应用
两者均非原创,在一些小数据集(输入分辨率有限)上有提升,泛化性能还可以
速度上比SGD收敛的要快一些,x2 ~x4
4 Method
periodically simulate warm restarts of SGD
SGD with momentum

再加 warm start

蓝色和红色是之前的 step 式 learning rate schedule( A common learning rate schedule is to use a constant learning rate and divide it by a fixed constant in (approximately) regular interval)
其余颜色是作者的 SGDR 伴随不同的参数配置
核心公式

-
η \eta η 是学习率
-
i − t h i-th i−th run
-
T c u r T_{cur} Tcur accounts for how many epochs have been performed since the last restar, T c u r = 0 T_{cur} = 0 Tcur=0 学习率最大,为 η m a x \eta_{max} ηmax, T c u r = T i T_{cur}=T_i Tcur=Ti 时学习率最小为 η m i n \eta_{min} ηmin
-
T i T_i Ti cosine 的一个下降周期对应的 epoch 数或 iteration 数
每次 new start 的时候, η m i n \eta_{min} ηmin 或者 η m a x \eta_{max} ηmax 可调整
让每个周期变得越来越长的话,可以设置 T m u l t T_{mult} Tmult > 1(eg =2, it doubles the maximum number of epochs for every new restart. The main purpose of this doubling is to reach good test error as soon as possible)
code,来自 Cosine Annealing Warm Restart
# 导包
from torch import optim
from torch.optim import lr_scheduler# 定义模型
model, parameters = generate_model(opt)# 定义优化器
if opt.nesterov:dampening = 0
else:dampening = 0.9
optimizer = opt.SGD(parameters, lr=0.1, momentum=0.9, dampening=dampending, weight_decay=1e-3, nesterov=opt.nesterov)# 定义热重启学习率策略
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2, eta_min=0, last_epoch=-1)

5 Experiments
5.1 Datasets and Metric
CIFAR-10:Top1 error
CIFAR-100:Top1 error
a dataset of electroencephalographic (EEG)
downsampled ImageNet(32x32): Top1 and Top5 error
5.2 Single-Model Results

WRN 网络 with depth d and width k
CIFAR10 上 T m u l t i = 1 T_{multi} = 1 Tmulti=1 比较猛
CIFAR100 上 T m u l t i = 2 T_{multi} = 2 Tmulti=2 比较猛

收敛速度快的优势
Since SGDR achieves good performance faster, it may allow us to train larger networks

CIFAR10 上 T m u l t i = 1 T_{multi} = 1 Tmulti=1 比较猛,黑白色
CIFAR100 上 T m u l t i = 2 T_{multi} = 2 Tmulti=2 比较猛
只看收敛效果的话,白色最猛, cosine learning rate
5.3 Ensemble Results
这里是复刻下《SNAPSHOT ENSEMBLES: TRAIN 1, GET M FOR FREE》(ICLR-2017)中的方法




来自 优化器: Snapshots Ensembles 快照集成

具体的实验细节不是很了解,N =16,M=3 表示总共 200 epoch,16个 restart 周期,选出来3个模型平均?还是说跑了 16*200个 epoch,每次run(200epoch)选出来 M 个模型平均?
M = 3,30,70,150
M = 2, 70,150
M = 1 ,150
5.4 Experiments on a Dataset of EEG Recordings

5.5 Preliminary Experiments on a downsampled ImageNet Dataset
our downsampled ImageNet contains exactly the same images from 1000 classes as the original ImageNet but resized with box downsampling to 32 × 32 pixels.


6 Conclusion(own) / Future work
-
实战中 T i T_i Ti 怎么设计比较好,是设置成最大 epoch 吗?还是多 restart 几次, T m u l T_{mul} Tmul 是不是大于 1 比等于 1 效果好?
-
Restart techniques are common in gradient-free optimization to deal with multimodal functions
-
Stochastic subGradient Descent with restarts can achieve a linear convergence rate for a class of non-smooth and non-strongly convex optimization problems
-
Cyclic Learning rate和SGDR-学习率调整策略论文两篇
可以将 SGDR 称为hard restart,因为每次循环开始时学习率都是断崖式增加的,相反,CLR应该称为soft restart

-
理解深度学习中的学习率及多种选择策略
-
什么是ill-conditioning 对SGD有什么影响? - Martin Tan的回答 - 知乎
https://www.zhihu.com/question/56977045/answer/151137770


-
niching
What is niching scheme?
Niching methods:

小生境(Niche):来自于生物学的一个概念,是指特定环境下的一种生存环境,生物在其进化过程中,一般总是与自己相同的物种生活在一起,共同繁衍后代。例如,热带鱼不能在较冷的地带生存,而北极熊也不能在热带生存。把这种思想提炼出来,运用到优化上来的关键操作是:当两个个体的海明距离小于预先指定的某个值(称之为小生境距离)时,惩罚其中适应值较小的个体。
海明距离(Hamming Distance):在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称海明距离。例如,10101和00110从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
相关文章:
【SGDR】《SGDR:Stochastic Gradient Descent with Warm Restarts》
arXiv-2016 code: https://github.com/loshchil/SGDR/blob/master/SGDR_WRNs.py 文章目录 1 Background and Motivation2 Related Work3 Advantages / Contributions4 Method5 Experiments5.1 Datasets and Metric5.2 Single-Model Results5.3 Ensemble Results5.4 Experiment…...

如何将arping以及所有依赖打包安装到另外一台离线ubuntu机器
ubuntu系统下可以使用arping命令检测局域网内一些ip是否冲突,使用方式为: arping xx.xx.xx.xx 在线情况下,可以使用下面命令下载arping,然后使用即可 apt install arping 但是有些情况下机器可能不能上网,这时就需要将…...

mac上如何安装python3
mac上如何安装python3? 安装homebrew 在终端执行命令 /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" 执行完成后,homebrew和pip等工具就自动安装好了。 接下来安装python3.在终端…...

Java 那些诗一般的 数据类型 (下篇)
本篇会加入个人的所谓鱼式疯言 ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接…...

WEB3.0:互联网的下一阶段
随着互联网的发展,WEB3.0时代正在逐步到来。本文将深入探讨WEB3.0的定义、特点、技术应用以及未来展望,为读者带来全新的思考。 一、什么是WEB3.0? WEB3.0可以被理解为互联网发展的下一阶段,是当前WEB2.0的升级版。相较于2.0时代…...
Fastgpt配合chatglm+m3e或ollama+m3e搭建个人知识库
概述: 人工智能大语言模型是近年来人工智能领域的一项重要技术,它的出现标志着自然语言处理领域的重大突破。这些模型利用深度学习和大规模数据训练,能够理解和生成人类语言,为各种应用场景提供了强大的文本处理能力。AI大语言模…...

如何使用选择器精确地控制网页中每一个元素的样式?
1. 基础知识 什么是 CSS 元素选择器 CSS 元素选择器是一种在网页中通过元素类型来应用样式的方法。 简单来说,它就像是一个指挥棒,告诉浏览器哪些 HTML 元素需要应用我们定义的 CSS 样式规则。 为何要使用 CSS 元素选择器 使用元素选择器可以让我们…...

各个微前端框架的优劣浅谈
各个微前端框架都有其独特的优势和劣势,下面我将针对几个主流的微前端框架进行简要的优劣分析: single-spa 优势: 轻量级:single-spa是一个非常轻量级的微前端框架,它主要提供了一个加载和管理微应用的机制,…...
Ansible实战 之Jenkins模块)
自动化运维(二十二)Ansible实战 之Jenkins模块
Ansible提供了一些模块,可以用来与Jenkins进行交互,执行各种操作,如创建任务、触发构建、获取构建结果等。通过使用这些模块,我们可以将Jenkins的配置和管理集成到Ansible的自动化流程中。 以下是一些常用的Ansible Jenkins模块: 1、jenkins_job模块 jenkins_job模块用于创建…...
)
Python数据分析与应用 |第4章 使用pandas进行数据预处理 (实训)
表1-1healthcare-dataset-stroke.xlsx 部分中风患者的基础信息和体检数据 编号性别高血压是否结婚工作类型居住类型体重指数吸烟史中风9046男否是私人城市36.6以前吸烟是51676女否是私营企业农村N/A从不吸烟是31112男否是私人农村32.5从不吸烟...

基于双向长短期神经网络BILSTM的线损率预测,基于gru的线损率预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 BILSTM神经网络 基于双向长短期神经网络BILSTM的线损率预测,基于gru的线损率预测 完整代码:基于双向长短期神经网络BILSTM的线损率预测,基于gru的线损率预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/d…...

智能售货机:引领便捷生活
智能售货机:引领便捷生活 在这个科技迅速进步的时代,便捷已成为生活的必需。智能售货机作为技术与便利完美结合的产物,正逐渐改变我们的购物方式,为都市生活增添新的活力。 智能售货机的主要优势是它的极致便利性。不论是在地铁…...

正向代理和反向代理
正向代理和反向代理是网络中常见的两种代理方式,它们在网络通信中扮演着不同的角色。 正向代理: 正向代理是代理服务器位于客户端和目标服务器之间的一种代理方式。 客户端向代理服务器发送请求,然后代理服务器将请求转发给目标服务器&…...
kimichat使用技巧:用语音对话聊天
kimichat之前是只能用文字聊天的,不过最近推出了语音新功能,也可以用语音畅快的对话聊天了。 这个功能目前支持手机app版本,所以首先要在手机上下载安装kimi智能助手。已经安装的,要点击检查更新,更新到最新的版本。 …...

机器学习-09-图像处理02-PIL+numpy+OpenCV实践
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中图像处理技术。 参考 【人工智能】PythonOpenCV图像处理(一篇全) 一文讲解方向梯度直方图(hog) 【杂谈】计算机视觉在人脸图像领域的十几个大的应用方向&…...
应急响应-战前反制主机HIDSElkeid蜜罐系统HFish
知识点 战前-反制-平台部署其他更多项目: https://github.com/birdhan/SecurityProduct HIDS:主机入侵检测系统,通常会有一个服务器承担服务端角色,其他主机就是客户端角色,客户端加入到服务端的检测范围里ÿ…...

C#:24小时制和12小时制之间的转换
任务描述 本关任务:编写一个程序,利用求余运算完成24小时制和12小时制之间的转换。 注意:要求输入的数字是0到24之间的整数。 测试说明 平台会对你编写的代码进行测试: 测试输入:4 预期输出: 现在是上午4…...
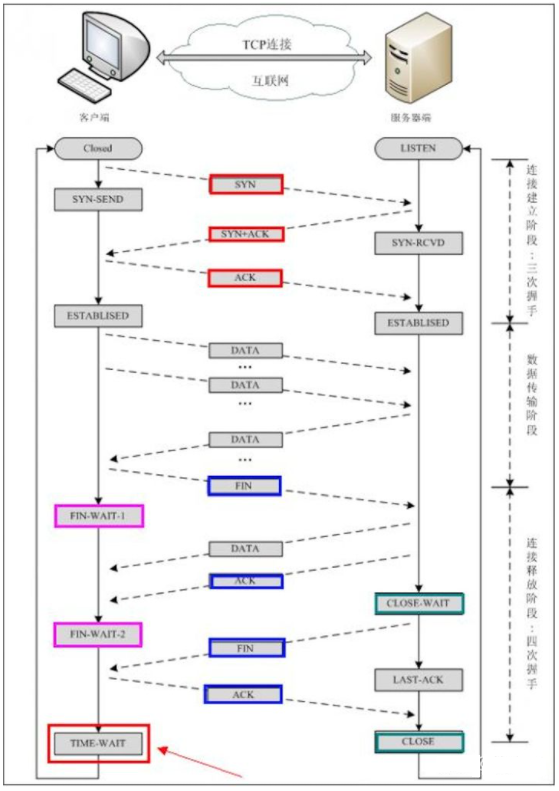
说说TCP为什么需要三次握手和四次挥手?
文章目录 一、三次握手为什么不是两次握手? 二、四次挥手四次挥手原因 三、总结参考文献 一、三次握手 三次握手(Three-way Handshake)其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包 主要作用就是为了确认双方的接收能力和…...
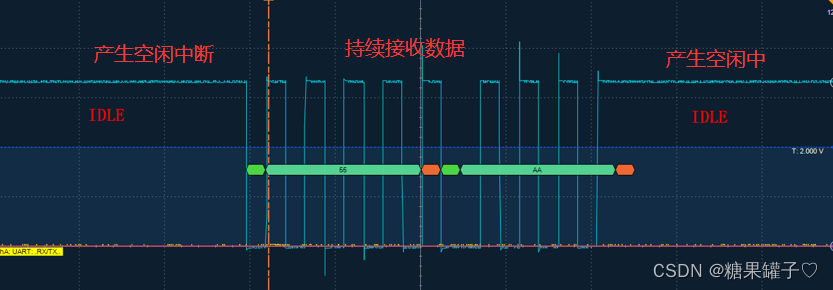
STM32 串口接收定长,不定长数据
本文为大家介绍如何使用 串口 接收定长 和 不定长 的数据。 文章目录 前言一、串口接收定长数据1. 函数介绍2.代码实现 二、串口接收不定长数据1.函数介绍2. 代码实现 三,两者回调函数的区别比较四,空闲中断的介绍总结 前言 一、串口接收定长数据 1. 函…...
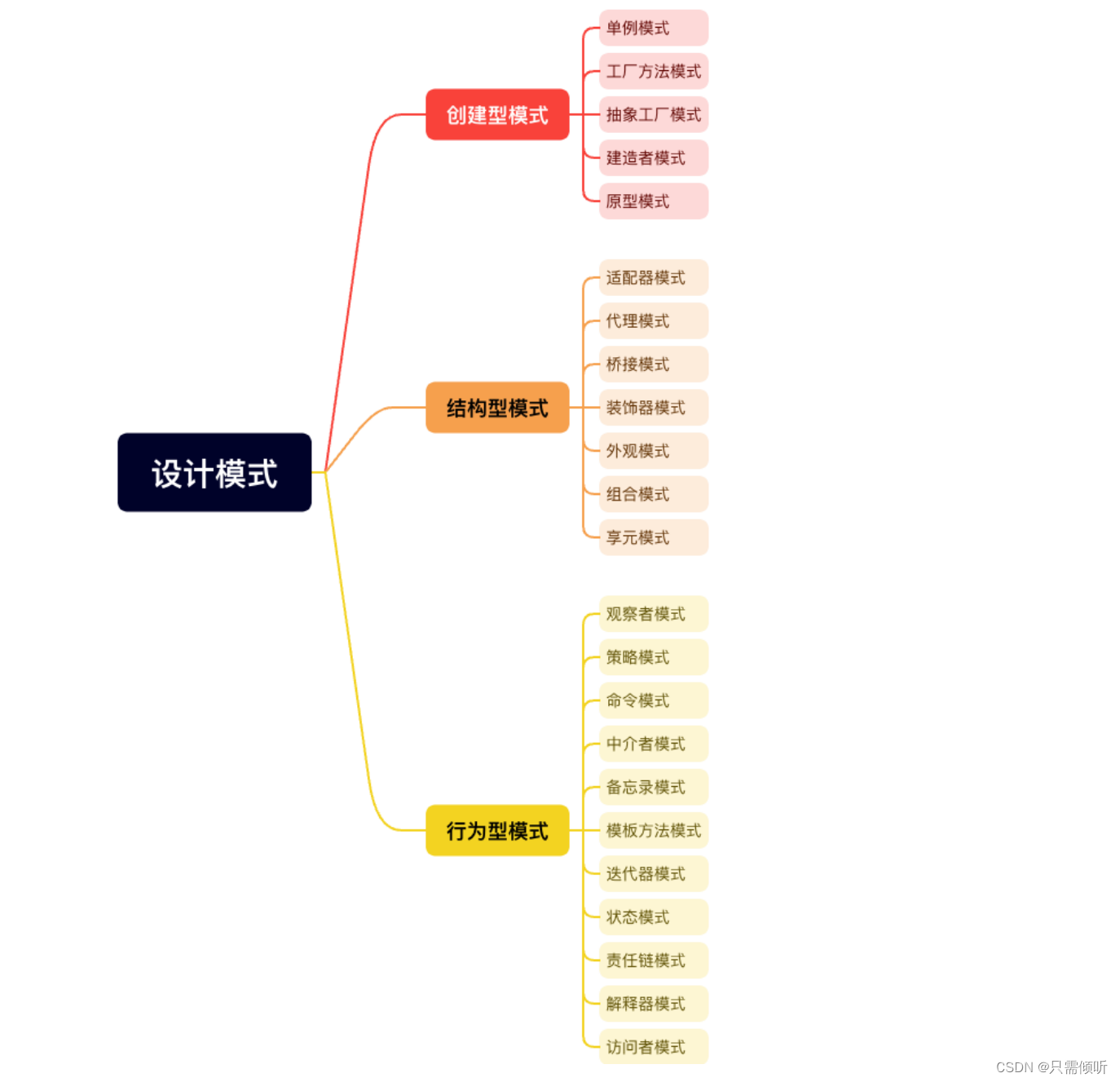
C++设计模式|0.前言
1.什么是设计模式? 简答来说,设计模式就是一套好用的代码经验总结,也就是怎么写好代码的方法论。使用设计模式是为了可重用代码、让代码更容易被他人理解、提高代码的可靠性。 2.设计模式的分类 设计模式可以分为三类:创建型、…...

[Python] Python中自带模块级的单例模式-不需要定义单例类
Python中的单例场景 一般一些需要在模块中全局维护的变量(变量修改范围在模块内);简单方式是构建一个全局变量,然后不符合编码规范:1.线程安全与并发问题;2.测试隔离困难;3.缺乏多实例/多租户支…...

交互式测试与条件有效性:动态数据决策的统计可靠性保障
1. 交互式测试与条件有效性:从理论到实践的深度拆解在数据驱动的决策场景里,比如在线A/B测试、自适应临床试验或者强化学习的策略评估,我们常常面临一个核心矛盾:我们既希望根据不断涌入的数据动态调整分析策略(例如&a…...

完整掌握Stressapptest:高效系统稳定性测试的实用指南
完整掌握Stressapptest:高效系统稳定性测试的实用指南 【免费下载链接】stressapptest Stressful Application Test - userspace memory and IO test 项目地址: https://gitcode.com/gh_mirrors/st/stressapptest Stressful Application Test(简称…...

Nature|619372人循环代谢性状的遗传分析
尽管复杂疾病的全基因组关联研究(GWAS)通常会分析多达100多万人,但分子特征的研究却滞后了。在这里,研究对爱沙尼亚生物库和英国生物库中多达619,372名个体的249个循环代谢特征进行了GWAS荟萃分析。从8,398个趋同于共享基因和通路…...

AI Native 公司构建指南:从 Anthropic 创始人手册到工程实践
【摘要】系统解析 AI Native 公司的本质特征与技术架构,基于 Anthropic 2026 年《创始人行动手册》核心框架,结合 31 家精益 AI 团队的真实案例,提供从想法验证到规模化增长的完整工程落地路径,帮助技术创业者避开 AI 时代特有的创…...

饲料颗粒机生产厂家
行业痛点分析:一场关于“磨损”与“成本”的持久战在饲料加工领域,颗粒机设备的稳定性与耐用性,直接决定了生产线的整体效率与运营成本。然而,长期困扰行业的核心痛点之一,是磨盘与压辊的耐磨性问题。根据行业调研数据…...

FPG平台:行业前景下的战略定位评估
FPG平台:行业前景下的战略定位评估金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG平台经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的…...

Agent开发五层架构详解,AI智能体开发知识点
AI Agent 的五层架构是构建具备自主规划与执行能力的智能代理系统的核心设计范式。 该架构将复杂的智能行为解耦为五个逻辑层次,确保了系统的模块化、可扩展性与可维护性。 以下是对每一层的深度讲解,涵盖其核心概念、应包含的组件以及关键设计要点。 …...
)
CPT 强化学习完整实现(PyTorch 版 - Actor-Critic + CPT)
✅ CPT 强化学习完整实现(PyTorch 版 - Actor-Critic CPT) 以下是生产级友好的实现,适合连续/离散控制任务,结合 Cumulative Prospect Theory 修改优势函数(Advantage)。 推荐配置(默认使用&am…...

明日方舟桌宠Ark-Pets显卡优化配置指南:3步实现流畅桌面动画
明日方舟桌宠Ark-Pets显卡优化配置指南:3步实现流畅桌面动画 【免费下载链接】Ark-Pets Arknights Desktop Pets | 明日方舟桌宠 (ArkPets) 项目地址: https://gitcode.com/gh_mirrors/ar/Ark-Pets Ark-Pets是一款基于《明日方舟》角色模型的桌面宠物软件&am…...